Abstract
Is agency a straightforward and universal feature of human experience? Or is the construction of agency (including attention to and memory for people involved in events) guided by patterns in culture? In this paper we focus on one aspect of cultural experience: patterns in language. We examined English and Japanese speakers’ descriptions of intentional and accidental events. English and Japanese speakers described intentional events similarly, using mostly agentive language (e.g., “She broke the vase”). However, when it came to accidental events English speakers used more agentive language than did Japanese speakers. We then tested whether these different patterns found in language may also manifest in cross-cultural differences in attention and memory. Results from a non-linguistic memory task showed that English and Japanese speakers remembered the agents of intentional events equally well. However, English speakers remembered the agents of accidents better than did Japanese speakers, as predicted from patterns in language. Further, directly manipulating agency in language during another laboratory task changed people’s eye-witness memory, confirming a possible causal role for language. Patterns in one’s linguistic environment may promote and support how people instantiate agency in context.
Introduction
Throughout life, we act on the world around us. We move and shake things, we build and break things. And we make many inferences about actions and outcomes, deciding who to blame for what. Mundane, everyday life may lead us to think that causal agency is a natural, straightforward, and universal feature of human experience. Is it?
Consider this scenario: A forklift operator is maneuvering his heavy load toward its destination in a crowded warehouse, and as he squeezes around a tight turn, the nearest shelf collapses and millions of dollars worth of fine crystal comes crashing to the floor. Was the operator, the tight turn, the rickety shelf, or the fragile crystal the cause? Was collapsing, falling, or shattering the effect?
Previous work in the psychology of agency has revealed that “causal agent” is a context-dependent construct, with both physical and social context playing important roles. For example, in visual cognition, the perception of physical causality is easily altered by minor changes in context. In one set of studies, Scholl and Nakayama (2002) showed people videos of an event that could be seen either as a ball knocking into another ball thereby launching it into motion (a launch) or as a ball passing another stationary ball (a pass). They discovered that the visual context in which people perceived this ambiguous event mattered. When paired with even a momentary glimpse of another launch event in the visual environment, the event now looked like a clear launch. That is, whether a moving object is seen as a causal agent – in the identical physical presentation – depends on the surrounding visual context.
Social context also plays an important role. Societies across the world instantiate different concepts of the self, with East Asian societies emphasizing interdependent ways of being and Western societies emphasizing more independent notions of self (e.g., Markus and Kitayama, 1991, 2004). Compared to people in interdependent societies, people in independent societies are more likely to select a single proximal cause for an event (e.g., Chiu et al., 2000; Choi et al., 2003), are less aware of distal consequences of events (e.g., Maddux and Yuki, 2006), are more susceptible to correspondence bias (e.g., Choi et al., 1999), and are more motivated by personal choice (e.g., Iyengar and Lepper, 1999). The role that individuals play in events may depend on notions of agency that are culture-specific (e.g., Morris et al., 2001). What it means to be an “agent” does not appear to be a stable, universal property of events in the world. What people see and believe to be an agent is constructed in context.
In this paper we ask whether habitual patterns of speaking in one's linguistic community, as well as patterns in one's immediate linguistic context, might also be included among the set of cues for constructing notions of agency. In particular, we examine the role of language in shaping attention to and memory for individuals involved in events (potential agents).
In language, one finds pervasive and systematic ways of construing and interpreting the world. Patterns in everyday descriptions (e.g., whether someone says “He shattered the crystal” or “The crystal shattered”) may serve as pervasive and powerful cues to agency. Previous work has demonstrated that such differences in linguistic framing can indeed serve as cues to agency and carry serious consequences for how much we blame and punish others (Fausey and Boroditsky, in press a). For example, English speakers who read a report about Justin Timberlake and Janet Jackson's wardrobe malfunction containing the agentive expression “tore the bodice” not only blamed Timberlake more, but also levied 53% more in fines for the offense than those who read the non-agentive “the bodice tore.” The linguistic framing had a big effect on blame and punishment even when people watched a video of the event and were able to witness the tearing with their own eyes. In this paper, we explore the role of such patterns in language in shaping attention to and memory for individuals involved in events.
A role for language?
We talk about the events of our days, often discussing who did what to whom. We talk to our children, we update our bosses, we negotiate with friends and colleagues. We learn from other people's stories. A huge proportion of what we know about the world comes to us through the medium of language. Human language use is exquisitely structured and systematic, and as a result our conversations carry many regularities in how we communicate “what happened.” Could patterns in language help shape whether we construe someone as being the agent of an event and whether we attend to and remember who was involved?
The influence of language on cognition and behavior has been demonstrated in many domains. For example, linguistic framing or labeling changes how people perceive emotion (e.g., Barrett et al., 2007), represent objects (e.g., Lupyan, 2008) and remember events (e.g., Loftus and Palmer, 1974; Gentner and Loftus, 1979; Billman and Krych, 1998). Further, people are sensitive to how often certain expressions are used within their linguistic community (Saffran et al., 1996; Landauer and Dumais, 1997; Gahl and Garnsey, 2004) and speakers of different languages talk about events differently (e.g., Gentner and Goldin-Meadow, 2003). Language directs attention (e.g., Reali et al., 2006; Richardson and Matlock, 2007) and through repeated use may guide habitual event construals (e.g., Slobin, 1996).
Indeed, research in the tradition of linguistic relativity has suggested that habitual ways of talking influence how people think about colors (e.g., Roberson and Hanley, 2007; Winawer et al., 2007), space (e.g., Levinson et al., 2002), objects (e.g., Lucy, 1992; Imai and Gentner, 1997; Boroditsky et al., 2003; Dilkina et al., 2007) and events (Slobin, 1996, 2003; Finkbeiner et al., 2002; Gennari et al., 2002; Oh, 2003; Papafragou et al., 2008; Wolff et al., 2009; Trueswell and Papafragou, 2010).
Could language also play a role in how people construct agency and attend to and remember the potential agents of events? In this paper, we identify cross-linguistic differences in how English and Japanese speakers describe the same events, and find that there are corresponding cross-linguistic differences in eye-witness memory.
Agentivity in language
You see someone accidentally brush against a flower vase and the vase ends up in pieces on the floor. When asked about what happened, you might say, “She broke the vase.” In English, agentive descriptions like this are typical and appropriate even for clearly accidental events. By contrast, non-agentive language often sounds evasive (e.g., Reagan's famous “mistakes were made” in the 1987 State of the Union Address).
Linguistic analyses suggest that in other languages, non-agentive expressions are more frequent and are used to distinguish accidental from intentional actions (Slobin and Bocaz, 1988; Maldonado, 1992; Martinez, 2000; Dorfman, 2004; Filipovic, 2007). For example, some analyses have suggested that the frequency of non-agentive expressions may be higher in Japanese than in English (e.g., Teramura, 1976; Choi, 2009).
In Japanese, two different verbs are often used for the transitive and intransitive description of the same action. These two verbs often share the same stem. One example is waru/wareru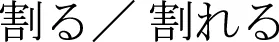 (to break). An agentive use would be
(to break). An agentive use would be  (Tamago-wo watta/(I) broke (the) egg). A non-agentive use would be
(Tamago-wo watta/(I) broke (the) egg). A non-agentive use would be  (Tamago-ga wareta/(The) egg broke). Other verbs in Japanese have the same form for both transitive and intransitive uses, and the presence of the particle “ga” attached to the affected object marks the non-agentive expression. One example is hiraku
(Tamago-ga wareta/(The) egg broke). Other verbs in Japanese have the same form for both transitive and intransitive uses, and the presence of the particle “ga” attached to the affected object marks the non-agentive expression. One example is hiraku (to open). An agentive use would be
(to open). An agentive use would be  (Kare-ga DOA-wo hiraita/He opened (the) door) and a non-agentive use would be
(Kare-ga DOA-wo hiraita/He opened (the) door) and a non-agentive use would be  (DOA-ga hiraita/(The) door opened).
(DOA-ga hiraita/(The) door opened).
Verbs are thought to be especially salient in Japanese and typical verb forms in Japanese may differ from typical verb forms in English. For example, Teramura (1976) noted that even when an event involves someone who could be described as a causal agent (e.g., “He dropped the pen”), it is often more natural in Japanese to describe such events using non-agentive expressions like “PEN-ga ochiteshimatta” (“(The) pen dropped, unfortunately”), or even sentences that include only a verb like “ochiteshimatta” (“dropped, unfortunately”). Also, when describing certain kinds of causal events (such as when there is a delay between the cause and outcome, or when an agent is not visually depicted but may be inferred), Japanese speakers are less likely to use transitive expressions compared to speakers of other languages (Bohnemeyer et al., 2010; Choi, 2009). Further, evidence from patterns of language acquisition suggests that early verb use in English may be more transitive than early verb use in Japanese, likely due to different adult input (e.g., Nomura and Shirai, 1997; Fukuda, 2005; Tsujimura, 2006).
Verbs may be especially salient in Japanese because nouns and pronouns in Japanese are often optional and inferred from context (e.g., Fernald and Morikawa, 1993). The form of the verb may therefore be a potent cue for how to frame an event. Might such differences in event descriptions lead people to construe and remember causal events differently?
The plan of the paper
In this paper we focus on one aspect of culture: the typical patterns in linguistic event descriptions within a community. In Study 1, we compare English and Japanese descriptions of the same causal events. We find that English and Japanese descriptions are equally agentive when it comes to talking about intentional events, but differ for accidents: in the case of accidental events Japanese descriptions are less agentive than are English descriptions. In Study 2, we ask whether these patterns in linguistic descriptions may also manifest in patterns of eye-witness memory. We find that English and Japanese speakers remember the agents of intentional events equally well, but in the case of accidental events English speakers are more likely to remember the individuals potentially construable as agents than are Japanese speakers. (Note: Our two groups of participants are native English-speaking residents of the USA, and native Japanese-speaking residents of Japan, as described in more detail in the methods. Because our studies focus on the dimension of language, for brevity we refer to our participants as English speakers and Japanese speakers.)
In Study 3, we ask whether patterns in one's local linguistic context can help shift attention toward or away from individuals who might be construed as agents. We take inspiration from previous work in social psychology that has used short-term linguistic manipulations to instantiate different models of construing events in the world (for example, research on self-theories by Dweck and colleagues, e.g., Chiu et al., 1997). Before testing English speakers on their memory for the individuals involved in events (as in the previous study), we exposed them to either a set of agentive or non-agentive linguistic expressions (that were unrelated to the events that they would later need to remember). We reasoned that hearing many non-agentive expressions (e.g., “The toast burned,” “The necklace unfastened”) should draw people's attention away from agents, while hearing agentive expressions (e.g., “He burned the toast,” “He unfastened the necklace”) should put attention squarely on agents. We find that manipulating the local linguistic environment in this way can indeed shift attention with respect to agency: English speakers remembered the individuals involved in causal events better when they were primed with unrelated agentive than with unrelated non-agentive expressions.
Study 1
In Study 1, English and Japanese speakers watched videos of intentional and accidental events and provided descriptions of these events.
Method
Participants
Fifty-eight English speakers (mean age = 33.38 years) and 22 Japanese speakers (mean age = 23.59 years) participated. English speakers completed the study via Amazon's Mechanical Turk service (mturk.com) and Japanese speakers were recruited from a community sample in Tokyo, Japan.
Participants were selected to be functionally monolingual. All participants reported that the target language was their native language. English speakers reported learning only English before age 12. Exposure to English in Japan is almost inevitable, including in school before age 12. Thus, we selected Japanese speakers based on their self-rated proficiency speaking and understanding English. Using a 5-point scale in which 5 indicated “native-like,” Japanese speakers who rated themselves as 3 or lower for an English proficiency measure were included1.
Materials
Participants read instructions in either English or Japanese. Instructions in the two languages were developed simultaneously and verified by an independent Japanese-English bilingual.
Videos of intentional and accidental versions of 16 unique events were used (Table 1). In all events, a man physically interacted with an object. The man's reaction differed between the intentional and accidental versions of the event. For example, in the intentional version of the pencil breaking event, a man who was seated at a desk picked up a pencil, deliberately broke it in half and looked satisfied. In the accidental version of this event, a man was writing, and while writing the pencil broke in half. In this case, the man showed a startle response and threw his hands up in surprise. Thus, the accidental events were characterized by a “whoops!” reaction such as a startle response, surprised facial expressions and/or surprised hand gestures. Videos of eight events (both intentional and accidental versions) featured an actor in a black shirt and videos of another eight events (both intentional and accidental versions) featured a different actor in a white shirt.
Table 1
| Action | Intentional | Accidental |
|---|---|---|
| Crumple can | Crumples can on floor by stepping on it | Turns to walk and crumples can on floor by stepping on it |
| Knock box | Faces table, knocks box off table | While gesturing, knocks box off table, reaches to grab it |
| Knock cups | Faces cup tower, swipes, knocks down tower | Faces cup tower, reaches for a cup, knocks down tower |
| Close book | Reading book, then turns head, closes book | Reading book, then turns to look at something, closes book |
| Rip paper | Sits at table, rips page from notebook | Sits at table, turns page in notebook and rips it |
| Turn off light | Using hand, hits switch and turns off light | By leaning against wall, hits switch and turns off light |
| Spill rice | Pours rice into a measuring cup | While pouring rice into a measuring cup, spills rice |
| Crack egg | Takes egg from carton, cracks it against bowl | As picking up egg from carton, cracks it against bowl |
| Close drawer | Sits at desk with open drawer, closes with knee | Turning toward desk with open drawer, closes with knee |
| Pop balloon | Pops balloon using tack | Reaches to put tack in container, pops balloon during reach |
| Open umbrella | Stands with closed umbrella, then opens it | Stands with closed umbrella, jumps back as opens it |
| Open door | By turning doorknob, opens door | By leaning too hard against door, opens it and stumbles |
| Drop keys | Drops keys onto table | Attempts to put keys on table, but drops them on floor |
| Break pencil | Sits at table, breaks pencil in half | Sits at table, breaks pencil in half while writing |
| Stick sticker | Places nametag sticker on shirt | Flops arm onto table without looking, then sticker is on arm |
| Release balloon | Sits among balloons, releases one that is untied | Sits among balloons, releases one, reaches to grab it |
Causal event stimuli.
Videos in this study featured Japanese actors. In cross-cultural research about attention to human agents, one necessarily confronts potential challenges in interpreting patterns due to possible cross-race recognition effects (e.g., Malpass and Kravitz, 1969) – in many cases, either the exact stimuli or the “same race” status is held constant across the two groups, but not both at the same time. In the current studies, the nature of the interaction design mitigates against these concerns because all participants attempt to describe (and in Study 2, remember) two kinds of events (intentional and accidental) and it is the relationship between these two kinds of events within each community that is of interest.
Procedure
Participants watched 16 videos and were asked to provide a linguistic description for each video. In each description trial, participants viewed a video and then answered the question “What happened?” (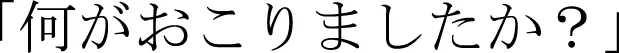 ). Participants typed their responses at their own pace and received no feedback.
). Participants typed their responses at their own pace and received no feedback.
Each video showed a different event; half featured the actor in black and half the actor in white, half were intentional actions and half accidental. Whether an event was presented in its intentional or accidental version was counterbalanced across participants. Videos were presented in random order.
Results
Descriptions were coded as agentive if the sentence described the change-of-state event using a transitive expression. A canonical agentive description would be “He popped the balloon.” Descriptions were coded as non-agentive if the change-of-state event was described intransitively. A canonical non-agentive description would be “The balloon popped.” In Japanese, non-agentive descriptions were characterized by an intransitive verb as well as the particle “ga” with the affected object (e.g., 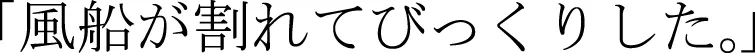 , Balloon-ga popped-intransitive was surprised). Some non-agentive descriptions took the form “Someone was doing X and then Y happened,” in which the agent was linguistically separated from a change-of-state event that was described intransitively.
, Balloon-ga popped-intransitive was surprised). Some non-agentive descriptions took the form “Someone was doing X and then Y happened,” in which the agent was linguistically separated from a change-of-state event that was described intransitively.
Across all participants, 6.33% of descriptions did not describe the event and were excluded from analyses. All descriptions were coded by two independent raters, with high point-to-point reliability (99.14% English, 97.44% Japanese). Disagreements were resolved upon discussion2.
Results are shown in Figures 1 and 2A. Intentional events were described equally agentively by both English and Japanese speakers [English M = 97.12, SE = 0.75; Japanese M = 97.00, SE = 1.21, t(76) = 0.09, n.s.]. Accidental events, on the other hand, were more often described agentively by English speakers than by Japanese speakers [English M = 69.24, SE = 2.62; Japanese M = 51.69, SE = 4.49, t(76) = 3.48, p = 0.001, d = 0.88].
Figure 1

Distributions of causal event descriptions in English and Japanese. (A) Intentional, (B) accidental, (C) difference (Intentional minus Accidental). Histograms (with proportion of the sample on the y-axis) of the proportion of agentive language use in each language community are plotted.
Figure 2

Describing and remembering agents in English and Japanese. (A) Causal event descriptions, with the mean proportion of agentive descriptions plotted on the y-axis, (B) causal agent memory, with mean proportion correct plotted on the y-axis. Error bars are ±1 SEM.
To compare how strongly speakers distinguished between intentional and accidental events in their descriptions, we computed a difference score for each participant as the proportion of intentional events described using agentive language minus the proportion of accidental events described using agentive language. This distinction was more pronounced for Japanese speakers (M = 45.31, SE = 4.28) than for English speakers (M = 27.89, SE = 2.62), t(76) = 3.51, p = 0.001, d = 0.88. This cross-linguistic difference was also consistent across events, as revealed by comparing the difference scores for each event in English and in Japanese, paired t(15) = 2.96, p = 0.013.
Discussion
English and Japanese speakers described intentional events similarly but differed in their descriptions of accidental events. This pattern in language suggests a specific prediction: If English speakers are more likely than Japanese speakers to describe accidents agentively, might they also pay more attention to and be more likely to remember the individuals involved in accidental events? The patterns in language predict no differences between the two groups for intentional events, but more attention to potential agents for English speakers in the case of accidental events.
Previous work has examined the role of linguistic framing in eye-witness memory within a language by presenting participants with different descriptions of the same event, for example varying the vividness of verbs, and measuring effects on memory (e.g., Loftus and Palmer, 1974; Gentner and Loftus, 1979). The studies here extend this work to the cross-linguistic domain and examine memory for agents. Instead of giving participants different descriptions of the same event, we ask whether speakers of two different languages that would typically describe an event differently would naturally pay attention to, encode, and remember different aspects of the same event. That is, are members of different culturo-linguistic communities habitually operating in different framing conditions as a function of the patterns in language?
Habitual linguistic framing may be a powerful mechanism by which cultural values are propagated. In Study 2, we test for whether patterns in language are also evident in patterns in memory. Importantly, we test for cross-cultural differences in memory for causal events in a task where participants are not asked to describe the events at any time before or during the memory task. Establishing that there are similar patterns in linguistic and non-linguistic behavior is a necessary first step in developing any theory about habitual framing effects. The next step, of course, would be to show that language itself may play a causal role, which is addressed in Study 3.
Study 2
Method
Participants
Sixty-two English speakers (Stanford University; Mean age = 19.29 years) and 70 Japanese speakers (Keio University, Jochi University, Tokyo Kogyo University, Surugadai Law School, in Tokyo, Japan; Mean age = 20.94 years) received course credit or were paid for their participation. Participants were selected to be under 25 years old to ensure a homogenous sample for memory performance. All participants were monolingual, by the same criteria used in Study 1. None of the participants had taken part in Study 1.
General design
Participants read instructions in either English or Japanese. All participants completed two tasks, first an Object-orientation memory task and then an Agent memory task. The first task was designed to allow participants to acclimate to laboratory memory tasks and also to serve as a measure of memory performance that is unrelated to eye-witness memory. The second task was designed to test for differences in non-linguistic eye-witness memory (memory for the agents of events) between English and Japanese speakers. The two tasks were non-linguistic measures of memory – participants never described any of the images or events during these two tasks, nor were they provided with any linguistic descriptions.
Object-orientation memory
During encoding, participants saw pictures of 15 objects presented on a computer screen one at a time for two seconds each (images courtesy of Michael J. Tarr, Brown University, http://www.tarrlab.org/). Each object appeared in one of three possible orientations, counterbalanced across participants. Participants were instructed to pay attention to the images and were told that their memory would be tested.
After the encoding phase, participants were given a brief distracter task (counting the number of white squares on a grid of black and white squares), followed by the memory test. For the memory test, participants were shown the three possible orientations of each object and asked to indicate which one they had seen previously.
Agent memory
Video materials
For the encoding phase, the same videos were used as in Study 1. For the test phase, we used an additional set of videos showing all the same events but with actions performed by a new, third actor. The same silent videos served as stimuli for both English and Japanese speakers.
Encoding
During the encoding phase, participants viewed 16 videos, each showing a different event (half featured the actor in white and half the actor in black, half were intentional actions and half accidental). Whether an event was presented in its intentional or accidental version was counterbalanced across participants. Videos were presented in one of two pseudo-random orders that ensured that no more than three videos of the same agent or the same intention appeared in a row.
Participants were instructed to pay attention to the videos and were told that their memory would be tested, but were not given any further clues. After viewing all 16 videos (once each, with a 1200 ms pause between videos), participants were instructed to count to 10 as a brief distracter task.
Test
Test trials consisted of a probe video followed by still photos of the two agents from the encoding phase. In the probe videos, a third actor appeared as the agent of the same events participants saw during encoding. For example, if a participant had seen the “accidental balloon popping” event during encoding, they would see this same event acted by the new agent in the test phase. After each probe video, participants were asked, “Who did it the first time?” (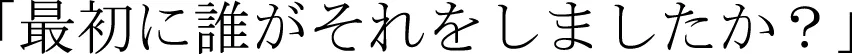 )4 and responded by pressing a key associated with the side of the screen of either the white-shirt man or the black-shirt man. Participants were tested only on the events they had seen during encoding, presented in a different pseudo-random order from the encoding phase, and received no feedback.
)4 and responded by pressing a key associated with the side of the screen of either the white-shirt man or the black-shirt man. Participants were tested only on the events they had seen during encoding, presented in a different pseudo-random order from the encoding phase, and received no feedback.
Results: eye-witness memory in english and japanese
Eleven participants were excluded from analyses for one of the following reasons: (a) chance performance on the object-orientation memory task (three Japanese), (b) a z-score greater than |2| (relative to language group) on the Memory Difference Score (Intentional Memory minus Accidental Memory) (four English, four Japanese). The Memory Difference Score was the analysis of interest in this study, and we wanted to be sure that outliers did not drive any observed cross-linguistic differences.
Results are shown in Figure 2B5. Intentional agents were remembered well by both English (M = 71.55, SE = 2.57) and Japanese (M = 70.44, SE = 2.32) speakers, t(119) = 0.32, n.s. However, as predicted, accidental agents were better remembered by English speakers (M = 73.06, SE = 2.42) than by Japanese speakers (M = 66.07, SE = 2.67), t(119) = 1.93, p = 0.028, d = 0.35. As predicted by patterns in language, the distinction between memory for individuals involved in intentional and accidental events was more pronounced for Japanese speakers (M = 4.37, SE = 2.06) than for English speakers (M = −1.51, SE = 1.97), t(119) = 2.05, p = 0.02, d = 0.37. This difference remains robust when participants’ memory performance on the object-orientation task is added as a covariate in the analysis (p = 0.023) ensuring that this observed cross-linguistic difference in agent memory is not simply due to more general differences in memory performance. Importantly, the agent memory task itself serves as the crucial control that guards against concerns about overall memory differences between the two groups: English and Japanese speakers remembered intentional agents equally well. They only differed in their memory for individuals involved in accidental events.
Discussion
In Studies 1 and 2, English speakers and Japanese speakers used agentive expressions to talk about intentional events and remembered intentional agents equally well. When it came to accidents, however, cross-cultural differences in both linguistic descriptions and eye-witness memory were observed. English speakers described accidents using more agentive language than Japanese speakers did and also remembered the individuals involved in accidents better than Japanese speakers did. Importantly, these memory patterns were observed in a non-linguistic memory task: participants were not asked to describe events, nor were the events described for them at any point before or during the memory task.
Cross-cultural differences in memory patterns were localized to a particular kind of event (accidents). Given other findings about cross-cultural differences in attention (e.g., Masuda and Nisbett, 2001), other patterns of results might have been predicted. For example, global differences in Japanese and English speakers’ attention – such as relative attention to context versus focal objects – might have led to overall lower memory for causal agents in Japanese speakers compared to English speakers. Cross-linguistic differences in noun and pronoun use (with lower frequency in Japanese compared to English) might also have resulted in overall lower agent memory in Japanese speakers. Instead, we found evidence for memory differences only for those events in which patterns of action descriptions also differed. Thus, this study may help refine our understanding of cross-cultural differences in attention to events and suggests that patterns in verb use may be one mechanism that drives these differences.
The findings of Studies 1 and 2 raise an important question: Can patterns in language per se shape people's attention to agents? There are many differences between the life experiences of English and Japanese speakers beyond the languages that they speak, so it is possible that other extra-linguistic cultural differences created the memory difference we observed in the previous study. For example, it is possible that members of some cultural groups learn to not gawk at others in embarrassing or unfortunate circumstances (of which accidents would be a good example). If one group of participants diverted their attention when they saw an accident in order to be polite, this could also explain the pattern of results in Study 2. Are patterns in language indeed among the causal factors that can create the kinds of differences in eye-witness memory that we observed in Study 2?
It seems likely that language and other extra-linguistic aspects of culture work in concert to instantiate and maintain habits of thought. One approach to testing for the role of language is to look across cultures to find other linguistic systems that contrast in agentive language use and test if correspondences in eye-witness memory emerge. We have conducted one such set of studies comparing English and Spanish speakers on the same description and eye-witness memory tasks described here (Fausey and Boroditsky, in press b). Spanish descriptions of accidental events tend to be less agentive than English descriptions, and Spanish speakers correspondingly remember the individuals involved in accidents less well than do English speakers, replicating the pattern of differences we see between English and Japanese. Of course, these results do not in any way rule out or diminish the potential contributions of other non-linguistic aspects of culture. But they do at least help confirm that when patterns in language differ, there are corresponding differences in cognition. The directions of causation, however, remain an open question. Do different cultural ways of thinking lead to different patterns in languages, or the other way around, or both?
To more directly test whether patterns in language per se can cause people to pay more or less attention to agents, we conducted a third study. Previous work in social psychology has used short-term linguistic manipulations to instantiate different modes of thinking. For example, Chiu et al. (1997) identified a set of important behavioral differences that stem from differences in people's implicit self-theories, and then demonstrated that explicitly manipulating such self-theories can change behavior.
We apply this logic to the current set of questions to determine whether exposure to agentive or non-agentive language can indeed encourage different patterns in eye-witness memory for individuals involved in events. Before testing English speakers on their memory for events (as in the previous study), we exposed them to either a set of agentive or non-agentive linguistic expressions (that were unrelated to the events that they would later need to remember). We reasoned that hearing many non-agentive expressions (e.g., “The toast burned,” “The necklace unfastened”) should draw people's attention away from agents, while hearing agentive expressions (e.g., “He burned the toast,” “He unfastened the necklace”) should direct attention toward agents.
Study 3
In Study 3, we exposed English speakers to either agentive or non-agentive language in a separate task before they completed an agent memory task.
Presumably, any “chronic” influence of language on attention and memory results from a combination of many shorter-term episodes of linguistic descriptions of events. It is therefore useful to examine the role of a relatively “temporary” manipulation of the language environment. This study is one step toward establishing a more direct link between agentivity in language and eye-witness memory. If patterns in one's linguistic environment can bias eye-witness memory, then directly manipulating the frequency of agentive expressions in the local linguistic environment should modulate English speakers’ memory for agents.
Method
Participants
Sixty-five English speakers (33 agentive prime, 32 non-agentive prime) participated. Inclusion criteria were the same as in the previous studies.
General design
Participants completed three tasks: first the same object-orientation memory task as in Study 2, then the linguistic priming task described below, and finally the same agent memory task as in Study 2 (except with Caucasian actors; see Fausey and Boroditsky, in press b, for specific event stimuli). The procedure was identical to the cross-linguistic eye-witness memory paradigm except for the inserted linguistic priming task.
Linguistic priming task
Participants in each condition listened to 24 sentences, either all agentive (e.g., He burned the toast) or all non-agentive (e.g., The toast burned) (Table 2). As participants heard each sentence, two related images (e.g., a piece of bread and a burned piece of bread) were presented on a computer screen. The participants’ task was to click on the image described by the sentence (e.g., the burned bread). The same response was correct regardless of priming condition. Stimuli were presented in random order. All sentences were recorded by a female native English speaker and were played to participants via computer speakers. Importantly, no verbs that could describe actions in the agent memory task were used in the priming task.
Table 2
| Agentive | Non-agentive |
|---|---|
| He wore out the shoe. | The shoe wore out. |
| He shrunk the shirt. | The shirt shrunk. |
| He ignited the grill. | The grill ignited. |
| He unfastened the necklace. | The necklace unfastened. |
| He crashed the car. | The car crashed. |
| He squirted the ketchup. | The ketchup squirted. |
| He cooked the chicken. | The chicken cooked. |
| He dried the flowers. | The flowers dried. |
| He burned the toast. | The toast burned. |
| He bent the clip. | The clip bent. |
| He started up the computer. | The computer started up. |
| He loosened the hinge. | The hinge loosened. |
| He unbuttoned the jeans. | The jeans unbuttoned. |
| He scattered the cards. | The cards scattered. |
| He shut down the laptop. | The laptop shut down. |
| He splattered the paint. | The paint splattered. |
| He melted the ice cream. | The ice cream melted. |
| He boiled the water. | The water boiled. |
| He unwound the yoyo. | The yoyo unwound. |
| He straightened the slinky. | The slinky straightened. |
| He lowered the chair. | The chair lowered. |
| He crumbled the cookie. | The cookie crumbled. |
| He unfolded the lawn chair. | The lawn chair unfolded. |
| He blew out the match. | The match blew out. |
Prime sentences (English speakers).
After completing these trials, participants were given a surprise recall test and asked to write down as many sentences as they could remember6. They then continued on to complete the agent memory task. The priming manipulation was designed to change the overall frequency of agentive versus non-agentive expressions in the participants’ linguistic environment and to produce a “main effect” of linguistic environment: exposure to agentive language should lead people to have better overall memory for agents than exposure to non-agentive language.
Results
Five participants were excluded from analyses for one of the following reasons: (a) chance performance on the object-orientation memory task (1 agentive, 2 non-agentive), (b) ungrammatical or infelicitous language use (1 agentive, 1 non-agentive).
As predicted, participants primed with agentive language showed better memory for agents (M = 78.02, SE = 2.93) than those primed with non-agentive language (M = 70.69, SE = 3.07), t(58) = 1.73, p < 0.05 (one-tailed), d = 0.45 (Figure 3). This was not simply a function of the non-agentive group being worse at memory overall. Participants in the two conditions remembered object-orientation equally well (agentive M = 71.40, SE = 2.38; non-agentive M = 75.63, SE = 2.50), t(58) = 1.23, n.s. There was no main effect of event type or interaction of prime by event type. The effect of prime condition on memory was also reliable across items, t(15) = 3.04, p < 0.01.
Figure 3

Remembering agents after agentive or non-agentive linguistic primes. Mean proportion correct is plotted on the y-axis. Error bars are ±1 SEM.
Discussion
It appears that the local linguistic environment can influence how well people remember who did what: English speakers who were exposed to agentive language in the priming task remembered agents better than those who were exposed to non-agentive language. This was true even though the particular verbs used in the priming task were unrelated to the actions that participants observed in the agent memory task. This result confirms a possible causal role for the linguistic environment in guiding eye-witness memory.
General Discussion
Results from three studies demonstrate that our eye-witness memories for even such momentary events as popping a balloon or breaking a pencil may be susceptible to influence from patterns in culture. In particular, we find that patterns in the language use of two cultural groups predict patterns in eye-witness memory in the two groups. Further, manipulating the local linguistic environment created the predicted shift in eye-witness memory, lending support to a causal role for language.
How important are the cross-cultural differences we find? One way to compose an answer is quantitatively: the effect sizes are in the typical range for eye-witness identification research and qualify as small to medium in terms of Cohen's d. The difference in memory for accidental events between the two groups is 7% (this constitutes 14% of the effective measurement range). Of course, the importance of any difference one might observe depends on what is at stake. If a US presidential election were won by 7% of the vote, such a difference would be considered a landslide. In this case, the results are important because the measure is eye-witness memory, a measure that in the real-world can make the difference between life in prison and getting away with murder, between being falsely accused or exonerated. Further, attention to and memory for who did what is one of the ingredients of the construct of agency, a construct of paramount importance in human cognition and motivation.
It is important to note that remembering individuals involved in accidental events is not inherently a good or a bad thing to do. Placing attention on individuals involved in accidents may improve memory for those individuals, but it may also undermine memory for other details of the situation or context and may invite undue punishment (or undue reward in the case of positive accidental outcomes) on those who were not acting intentionally. Research demonstrating differences does not license us to place a value on any given cognitive skill. Such attributions of value necessarily depend on culturally and situationally relevant goals and can only be constructed with respect to cultural and social context.
One interesting feature of these findings is that cross-cultural differences in eye-witness memory were observed even in a non-linguistic task, one that did not linguistically frame the events for participants and did not require participants to talk about the events. Previous studies on the role of language in event cognition have found cross-linguistic differences in how people encode and reason about motion events (e.g., Finkbeiner et al., 2002; Gennari et al., 2002; Oh, 2003; Slobin, 2003; Papafragou et al., 2008; Trueswell and Papafragou, 2010), though some find such differences only when people are explicitly instructed to describe the events during the task (e.g., Gennari et al., 2002; Papafragou et al., 2008). The influence of patterns in language may cut deeper for causal events because observers must integrate both physical and social cues in order to construe what happened. That is, causal events may require more cognitive construal than motion events and therefore be especially susceptible to linguistic and other cultural influences. Given the critical role of eye-witness memory performance in many settings (e.g., criminal trials), it is important to uncover under which circumstances cultural experience guides how people encode and remember events.
Interrelationships between language and other aspects of culture
Influences of language and culture are sometimes pitted against each other as competing forces. For example, one might ask “Are the effects we're observing here effects of language or culture?” We find this formulation of the question to be ill-formed. Language is one part of culture. That is, language and culture are not competitors, they have a subset-superset relationship. Further, language and other aspects of culture do not act in isolation, they mutually influence and reinforce each other.
Languages, of course, are cultural creations: they are incredibly intricate and structured tools that we shape and hone to suit our needs. Building a culturally-important pattern into a linguistic system is a terrific way to ensure its longevity across generations, ensure universal distribution within the culture, and provide a constant cognitive support system for maintaining the cultural value in the moment.
Language is good for preserving cultural values in the long term because while the structures of language are constantly changing, they change relatively slowly: it is rare to see sudden large-scale shifts like the abolition of a canonical word order or the resurgence of archaic grammatical cases. Maintaining a culturally-important feature in language use is a good way to ensure its longevity. Further, language ensures universal distribution because learning to speak one's language is a non-optional part of growing up to be a full-fledged participant in a culture. This ensures that any cultural value manifest in language will receive universal distribution within the culture.
Finally, language acts as a constant maintenance and cognitive support system because communicating with language (and in some cases talking to ourselves) is a pervasive and ubiquitous part of human experience. If a cultural norm becomes enshrined in noun morphology, for example, then that norm will necessarily be instantiated and reinforced whenever a noun is used. Because we use language to talk about so much of our experience, cultural influences through language could end up having pervasive effects throughout the cognitive system.
One attractive aspect of studying culture through the lens of language is that because language use is richly structured, it is possible to make precise measurements of patterns in language use, and make specific falsifiable predictions for potential cross-cultural differences. For example, in the case explored in this paper, the patterns in language use observed in Study 1 predict different memory patterns for intentional and accidental events, and this prediction is indeed borne out in the eye-witness memory data in Study 2.
Such patterns in language and thought can emerge over time through iterative mutual influences of linguistic and extra-linguistic forces that support and reinforce each other. For example, as demonstrated in Study 3, hearing non-agentive language leads to poorer memory for who was involved in events. And if people remember less about who was involved, they will in turn be less likely to talk about them, reinforcing and strengthening the pattern in language, and so on.
Alternatively, the process could start because of a visual norm that diverts people's attention away from individuals involved in accidents (perhaps because it is deemed impolite to look at people in embarrassing or unfortunate circumstances). This would in turn lead to worse eye-witness memory for potential agents, and may manifest in norms in language use. Not mentioning the potential agent could be the linguistic version of “looking away” when describing an event. If this linguistic “looking away” pattern becomes customary, the practice of “looking away” could spread not only to events that we ourselves witness (and could physically look away from), but to all events we hear about or retell to others. This linguistic norm would support, reinforce, preserve and distribute the visual “looking away” norm. The results of Study 3 suggest that local patterns of “looking away” in one's linguistic environment can indeed shift patterns in subsequent memory for individuals involved in events.
Of course, not all cultural norms need be reflected in language, and not all features of language need to be tied to other cultural norms. Languages may develop features to satisfy a variety of other communicative and cognitive constraints, and many changes over time may simply be a function of non-directed drift. Features that develop in the language system guided by these other constraints could also start off a chain of events in cultural change, shifting attentional patterns and becoming integrated into other extra-linguistic behavioral norms according to the same mechanisms as described above. Of course, not all features of languages may have measurable cognitive consequences. Understanding when patterns in language will yield effects on thinking and when they will not is the next frontier for this area of research.
Future directions
Blame and punishment
Beyond differences in eye-witness memory, previous work in English has shown that alternations between agentive and non-agentive descriptions can have important consequences for how much we blame and punish others (Fausey and Boroditsky, in press a). Whether cross-linguistic differences in event descriptions lead to corresponding differences in blame and punishment is an open question for future research.
First-person versus observed agency
A further interesting question for future research is whether similar patterns emerge for events experienced from a first-person perspective. In this paper, we examined patterns of description and eye-witness memory for observed events. How do people talk about and remember accidents in which they themselves were a potential agent?
Classic social psychological findings suggest that people more readily attribute blame to intrinsic “person” factors for events that they observe but to extrinsic “situation” factors for events that they experience (e.g., Jones and Nisbett, 1972). On this account, people might talk about their own accidents less agentively than they would talk about other people's accidents. Would both English and Japanese speakers be more likely to focus on the situation of first-person events, using less agentive language to describe them and remembering less about their own actions compared to situational details? If so, cross-cultural variation may remain, just with lower levels of agentive language and memory overall than in the current studies.
However, the very distinction between observed and experienced events may vary across cultures. Some evidence suggests that this distinction may be less pronounced in interdependent cultures compared to independent cultures. For example, the actor-observer effect described above appears to be attenuated in East Asians compared to Americans (e.g., Choi and Nisbett, 1998; Choi et al., 1999). Further, when recalling events in which they were involved, Americans “view” the event (in their mind's eye) from the first-person perspective but East Asians view it from a third-person perspective (e.g., Cohen and Gunz, 2002). That is, East Asians “observe” (themselves) even in experienced events. Thus, first-person perspective events might reduce the agentivity of English speakers’ descriptions and memory but not that of Japanese speakers.
The role of culturo-linguistic context
Much evidence from cross-national comparisons as well as from priming studies has demonstrated that cultural context can influence a wide range of behaviors (see Oyserman and Lee, 2008, for one review). An additional source of evidence comes from research showing that bicultural individuals can behave more like members of one culture or another, depending on which culture is cued in the testing context. For example, bicultural individuals in Hong Kong were more likely to attribute outcomes to situational causes after seeing Chinese icons than after seeing American icons (e.g., Hong et al., 2000). In addition to extra-linguistic cultural cues, linguistic context can also guide how bicultural bilinguals behave. For example, linguistic context can bias what bilinguals recall from events in their own lives as well as from general semantic information they have learned (e.g., Marian and Neisser, 2000; Marian and Fausey, 2006; Marian and Kaushanskaya, 2007). Language can even influence one's perceived personality, with bilinguals displaying different personality profiles depending on the language in which they are queried (e.g., Ramírez-Esparza et al., 2006).
Importantly, research with bicultural bilinguals has revealed that linguistic and other cultural cues may be fundamentally related. To take one example, the narrative style of Russian-English bilinguals who reported autobiographical memories depended on what language they used. When speaking in Russian, they recounted events in a more collectivistic way, but when speaking in English their stories were more individualistic (e.g., Marian and Kaushanskaya, 2004; see also Wang et al., 2010). That is, embedded within the linguistic narratives were cultural values. Findings like these, along with the results reported in this paper, highlight the mutual influence and support between linguistic and extra-linguistic aspects of culture. It appears that language and other aspects of culture work in concert to establish and maintain habits of thought.
Conclusion
Results of three experiments suggest that our eye-witness memories for events are influenced by patterns in culture. Such cultural differences may be instantiated and supported by patterns in the languages we speak. We find that speakers of different languages remember different things about the same events. Whether or not one is likely to remember who did what appears to pattern with how such events are normally described in one's language community as well as on the patterns in one's local linguistic environment.
Statements
Acknowledgments
We thank T. Korenaga, J. Otomo, and S. Seki (acting talent), M. Gutierrez, G. Jenkins, N. Saji, and H. Tily (help with data collection), and A. Toskos Dils (help with programming). We especially thank Dr. Mutsumi Imai for lending use of her lab space in Tokyo, Japan. This research was funded by an NSF Graduate Research Fellowship to CMF and NSF Grant No. 0608514 to LB.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1.^Data from four additional participants who failed to meet the language background criteria were not analyzed.
2.^Two participants (both English) were excluded from subsequent analyses because over a third of their descriptions did not describe the event.
3.^All conclusions are also supported by non-parametric analyses (Mann–Whitney U-test and Wilcoxon Signed Ranks).
4.^45 participants received this wording; 25 participants received the wording 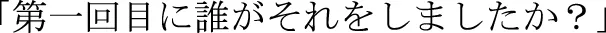 We used the second phrasing after discussions with several native Japanese speakers revealed differing opinions about the best translation for the English question. Question wording did not interact with patterns of memory for intentional versus accidental agents and so data were pooled.
We used the second phrasing after discussions with several native Japanese speakers revealed differing opinions about the best translation for the English question. Question wording did not interact with patterns of memory for intentional versus accidental agents and so data were pooled.
5.^Results from Study 1 motivate directed predictions and so one-tailed planned contrasts are reported.
6.^Participants recalled about half of the prime sentences that they had heard. The amount recalled did not differ for those primed with agentive language (M = 41.53, SE = 1.65) and those primed with non-agentive language (M = 45.83, SE = 2.24), t(58) = 1.56, n.s.
References
1
BarrettL. F.LindquistK.GendronM. (2007). Language as a context for emotion perception. Trends Cogn. Sci. (Regul. Ed.)11, 327–332.
2
BillmanD.KrychM. (1998). “Path and manner verbs in action: effects of “skipping” or “exiting” on event memory,” in Proceedings of the 20th annual meeting of the Cognitive Science Society. Mahwah, NJ: Lawrence Erlbaum Associates.
3
BohnemeyerJ.EnfieldN.EssegbeyJ.KitaS. (2010). “The macro-event property: the segmentation of causal chains,” in Event Representation in Language and Cognition, eds BohnemeyerJ.PedersonE. (Cambridge: Cambridge University Press), 43–67.
4
BoroditskyL.SchmidtL.PhillipsW. (2003). “Sex, syntax, and semantics,” in Language in Mind: Advances in the Study of Language and Thought, eds GentnerD.Goldin-MeadowS. (Cambridge, MA: MIT Press), 61–79.
5
ChiuC.HongY.DweckC. S. (1997). Lay dispositionism and implicit theories of personality. J. Pers. Soc. Psychol.73, 19–30.10.1037/0022-3514.73.1.19
6
ChiuC.MorrisM. W.HongY.MenonT. (2000). Motivated cultural cognition: the impact of implicit cultural theories on dispositional attribution varies as a function of need for closure. J. Pers. Soc. Psychol.78, 247–259.10.1037/0022-3514.78.2.247
7
ChoiS. (2009). “Typological differences in syntactic expressions of path and causation,” in Routes to Language: Studies in Honor of Melissa Bowerman, ed. GathercoleV. (Mahwah, NJ: Lawrence Erlbaum Associates), 169–194.
8
ChoiI.DalalR.Kim-PrietoC.ParkH. (2003). Culture and judgment of causal relevance. J. Pers. Soc. Psychol.84, 46–59.10.1037/0022-3514.84.1.46
9
ChoiI.NisbettR. E. (1998). Situational salience and cultural differences in the correspondence bias and in the actor-observer bias. Pers. Soc. Psychol. Bull.24, 949–960.10.1177/0146167298249003
10
ChoiI.NisbettR. E.NorenzayanA. (1999). Causal attribution across cultures: variation and universality. Psychol. Bull.125, 47–63.10.1037/0033-2909.125.1.47
11
CohenD.GunzA. (2002). As seen by the other…: perspectives on the self in the memories and emotional perceptions of easterners and westerners. Psychol. Sci.13, 55–59.10.1111/1467-9280.00409
12
DilkinaK.McClellandJ. L.BoroditskyL. (2007). “How language affects thought in a connectionist model,” in Proceedings of the 29th Annual Meeting of the Cognitive Science Society. Mahwah, NJ: Lawrence Erlbaum Associates.
13
DorfmanA. (2004). “Footnotes to a double life,” in The Genius of Language, ed. LesserW. (New York: Random House), 206–217.
14
FauseyC. M.BoroditskyL. (in press-a). Subtle linguistic cues influence perceived blame and financial liability. Psychon. Bull. Rev.
15
FauseyC. M.BoroditskyL. (in press-b). Whodunnit? Cross-linguistic differences in eye-witness memory. Psychon. Bull. Rev.
16
FernaldA.MorikawaH. (1993). Common themes and cultural variations in Japanese and American mothers’ speech to infants. Child Dev.64, 637–656.10.2307/1131208
17
FilipovicL. (2007). Language as a witness: insights from cognitive linguistics. Int. J. Speech Lang. Law14, 245–267.
18
FinkbeinerM.NicolJ.GrethD.NakamuraK. (2002). The role of language in memory for actions. J. Psycholinguist. Res.31, 447–457.10.1023/A:1021204802485
19
FukudaS. (2005). “Transitivity bias and the acquisition of verbs with transitivity alternation in English and Japanese,”Paper Presented at the SDSU LSA Spring Colloquium, San Diego.
20
GahlS.GarnseyS. (2004). Knowledge of grammar, knowledge of usage: syntactic probabilities affect pronunciation variation. Language,80, 748–775.10.1353/lan.2004.0185
21
GennariS. P.SlomanS. A.MaltB. C.FitchW. T. (2002). Motion events in language and cognition. Cognition,83, 49–79.10.1016/S0010-0277(01)00166-4
22
GentnerD.Goldin-MeadowS. (2003). Language in Mind: Advances in the Study of Language and Thought. Cambridge, MA: MIT Press.
23
GentnerD.LoftusE. F. (1979). Integration of verbal and visual information as evidenced by distortions in picture memory. Am. J. Psychol.92, 363–375.10.2307/1421930
24
HongY.MorrisM. W.ChiuC.Benet-MartínezV. (2000). Multicultural minds: a dynamic constructivist approach to culture and cognition. Am. Psychol., 55, 709–720.10.1037/0003-066X.55.7.709
25
ImaiM.GentnerD. (1997). A cross-linguistic study of early word meaning: universal ontology and linguistic influence. Cognition, 62, 169–200.10.1016/S0010-0277(96)00784-6
26
IyengarS. S.LepperM. R. (1999). Rethinking the value of choice: a cultural perspective on intrinsic motivation. J. Pers. Soc. Psychol.76, 349–366.10.1037/0022-3514.76.3.349
27
JonesE. E.NisbettR. E. (1972). “The actor and the observer: divergent perceptions of the causes of the behavior,” in Attribution: Perceiving the Causes of Behavior, eds JonesE. E.KanouseD. E.KelleyH. H.NisbettR. E.ValinsS.WeinerB. (Morristown, NJ: General Learning Press), 79–94.
28
LandauerT. K.DumaisS. T. (1997). A solution to Plato's problem: the latent semantic analysis theory of acquisition, induction, and representations of knowledge. Psychol. Rev.104, 211–240.10.1037/0033-295X.104.2.211
29
LevinsonS. C.KitaS.HaunD.RaschB. (2002). Returning the tables: language affects spatial reasoning. Cognition,84, 155–188.10.1016/S0010-0277(02)00045-8
30
LoftusE. F.PalmerJ. C. (1974). Reconstruction of automobile destruction: an example of the interaction between language and memory. J. Verbal Learn. Verbal Behav.13, 585–589.10.1016/S0022-5371(74)80011-3
31
LucyJ. A. (1992). Grammatical Categories and Cognition: A Case Study of the Linguistic Relativity Hypothesis. Cambridge: Cambridge University Press.
32
LupyanG. (2008). From chair to “chair”: a representational shift account of object labeling effects on memory. J. Exp. Psychol. Gen.137, 348–369.10.1037/0096-3445.137.2.348
33
MadduxW. W.YukiM. (2006). The “ripple effect”: cultural differences in perceptions of the consequences of events. Pers. Soc. Psychol. Bull.32, 669–683.10.1177/0146167205283840
34
MaldonadoR. (1992). Middle voice: The Case of Spanish se. Dissertation Abstracts International, 53(07), 2351A. (UMI No. 9235939).
35
MalpassR. S.KravitzJ. (1969). Recognition for faces of own and other race. J. Pers. Soc. Psychol.13, 330–334.10.1037/h0028434
36
MarianV.FauseyC. M. (2006). Language-dependent memory in bilingual learning. Appl. Cogn. Psychol.20, 1025–1047.10.1002/acp.1242
37
MarianV.KaushanskayaM. (2004). Self-construal and emotion in bicultural bilinguals. J. Mem. Lang.51, 190–201.10.1016/j.jml.2004.04.003
38
MarianV.KaushanskayaM. (2007). Language context guides memory content. Psychon. Bull. Rev.14, 925–933.
39
MarianV.NeisserU. (2000). Language-dependent recall of autobiographical memories. J. Exp. Psychol. Gen.129, 361–368.10.1037/0096-3445.129.3.361
40
MarkusH.KitayamaS. (1991). Culture and the self: implications for cognition, emotion, and motivation. Psychol. Rev.98, 224–253.10.1037/0033-295X.98.2.224
41
MarkusH. R.KitayamaS. (2004). “Models of agency: sociocultural diversity in the construction of action,” in The 49th Annual Nebraska Symposium on Motivation: Cross-cultural Differences in Perspectives on Self, eds Murphy-BermanV.BermanJ. (Lincoln: University of Nebraska Press), 1–57.
42
MartinezI. (2000). The Effects of Language on Children's Understanding of Agency and Causation. Dissertation Abstracts International, 61(10), 3976A. (UMI No. 9990936).
43
MasudaT.NisbettR. E. (2001). Attending holistically vs. analytically: comparing the context sensitivity of Japanese and Americans. J. Pers. Soc. Psychol.81, 922–934.10.1037/0022-3514.81.5.922
44
MorrisM. W.MenonT.AmesD. R. (2001). Culturally conferred conceptions of agency: a key to social perception of persons, groups and other actors. J. Pers. Soc. Psychol. Rev.5, 169–182.10.1207/S15327957PSPR0502_7
45
NomuraM.ShiraiY. (1997). “Overextension of intransitive verbs in the acquisition of Japanese,” in Proceedings of the 28th annual Child Language Research Forum, ed. ClarkE. V. (Stanford, CA: CSLI), 233–242.
46
OhK. (2003). Language, Cognition, and Development: Motion Events in English and Korean. Dissertation Abstracts International, 64(09), 4655B. (UMI No. 3105326).
47
OysermanD.LeeS. W. S. (2008). Does culture influence what and how we think? Effects of priming individualism and collectivism. Psychol. Bull.134, 311–342.10.1037/0033-2909.134.2.311
48
PapafragouA.HulbertJ.TrueswellJ. (2008). Does language guide event perception? Evidence from eye movements. Cognition,108, 155–184.10.1016/j.cognition.2008.02.007
49
Ramírez-EsparzaN.GoslingS. D.Benet-MartínezV.PotterJ. P.PennebakerJ. W. (2006). Do bilinguals have two personalities? A special case of cultural frame switching. J. Res. Pers.40, 99–120.10.1016/j.jrp.2004.09.001
50
RealiF.SpiveyM.TylerM.TerranovaJ. (2006). Inefficient conjunction search made efficient by concurrent spoken delivery of target identity. Percept. Psychophys.68, 959–974.
51
RichardsonD. C.MatlockT. (2007). The integration of figurative language and static depictions: an eye movement study of fictive motion. Cognition.102, 129–138.10.1016/j.cognition.2005.12.004
52
RobersonD.HanleyJ. R. (2007). Color categories vary with language after all. Curr. Biol.17, 605–606.10.1016/j.cub.2007.05.057
53
SaffranJ. R.AslinR. N.NewportE. L. (1996). Statistical learning by 8-month-old infants. Science274, 1926–1928.10.1126/science.274.5294.1926
54
SchollB. J.NakayamaK. (2002). Causal capture: contextual effects on the perception of collision events. Psychol. Sci.13, 493–498.10.1111/1467-9280.00487
55
SlobinD. I. (1996). From “thought and language” to “thinking for speaking”. In Rethinking Linguistic Relativity, eds GumperzJ. J.LevinsonS. C. (Cambridge: Cambridge University Press), 70–96.
56
SlobinD. I. (2003). “Language and thought online: cognitive consequences of linguistic relativity,” in Language in Mind: Advances in the Study of Language and Thought, eds GentnerD.Goldin-MeadowS. (Cambridge, MA: MIT Press), 157–191.
57
SlobinD. I.BocazA. (1988). Learning to talk about movement through time and space: the development of narrative abilities in Spanish and English. Lenguas Modernas,15, 5–24.
58
TeramuraH. (1976). Naru'hyoogen to ‘suru’ hyoogen: nichiei ‘tai’ hyoogen no hikaku. Nihongoto Nihongo Kyooiku Mojihyoogenhen, National Language Center.
59
TrueswellJ. C.PapafragouA. (2010). Perceiving and remembering events cross-linguistically: evidence from dual-task paradigms. J. Mem. Lang.63, 64–82.10.1016/j.jml.2010.02.006
60
TsujimuraN. (2006). “Why not all verbs are learned equally: the intransitive bias in Japanese,” in The Acquisition of Verbs and their Grammar: The Effect of Particular Languages, eds. GagarinaN.GülzowI. (Dordrecht: Springer), 105–122.
61
WangQ.ShaoY.LiY. J. (2010). “My way or mom's way?” the bilingual and bicultural self in Hong Kong Chinese children and adolescents. Child Dev.81, 555–567.10.1111/j.1467-8624.2009.01415.x
62
WinawerJ.WitthoftN.FrankM.WuL.WadeA.BoroditskyL. (2007). The Russian blues reveal effects of language on color discrimination. Proc. Natl. Acad. Sci. U.S.A.104, 7780–7785.10.1073/pnas.0701644104
63
WolffP.JeonG.LiY. (2009). Causers in English, Korean and Chinese and the individuation of events. Lang. Cogn. 1, 165–194.
Summary
Keywords
culture, language, eye-witness memory, events, causality, agents, accident
Citation
Fausey CM, Long BL, Inamori A and Boroditsky L (2010) Constructing Agency: The Role of Language. Front. Psychology 1:162. doi: 10.3389/fpsyg.2010.00162
Received
07 August 2010
Accepted
12 September 2010
Published
15 October 2010
Volume
1 - 2010
Edited by
Heejung Kim, University of California at Santa Barbara, USA
Reviewed by
Joan Chiao, Northwestern University, USA; Eric D. Knowles, University of California at Irvine, USA
Copyright
© 2010 Fausey, Long, Inamori and Boroditsky.
This is an open-access article subject to an exclusive license agreement between the authors and the Frontiers Research Foundation, which permits unrestricted use, distribution, and reproduction in any medium, provided the original authors and source are credited.
*Correspondence: Caitlin M. Fausey, Department of Psychological and Brain Sciences, Indiana University, 1101 E. 10th Street, Bloomington, IN 47405, USA e-mail: cfausey@indiana.edu
This article was submitted to Frontiers in Cultural Psychology, a specialty of Frontiers in Psychology.
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.