

- 1 Department for Nonlinear Dynamics, Max Planck Institute for Dynamics and Self-Organization, Göttingen, Germany
- 2 Center for the Study of Human Cognition, Department of Psychology, University of Oslo, Oslo, Norway
In this paper three experiments and corresponding model simulations are reported that investigate the priming of famous name recognition in order to explore the structure of the part of the semantic system dealing with people. Consistent with empirical findings, novel computational simulations using Burton et al.’s interactive activation and competition model point to a conceptual distinction between how priming is initiated in single- and double-familiarity tasks, indicating that priming should be weaker or non-existent for the single-familiarity task. Experiment 1 demonstrates that, within a double-familiarity framework using famous names, categorical, and associative priming are reliable effects. Pushing the model to the limit, it predicts that pairs of celebrities who are neither associatively nor categorically related but who share single biographical features, both died in a car crash for example, should prime each other. Experiment 2 investigated this in a double-familiarity task but the effect was not observed. We therefore simulated and realized a pairwise learning task that was conceptually similar to the double-familiarity-decision task but allowed to strengthen the underlying connections. Priming based on a single biographical feature could be found both in simulations and the experiment. The effect was not due to visual or name similarity which were controlled for and participants did not report using the biographical links between the people to learn the pairs. The results are interpreted to lend further support to structural models of the memory for persons. Furthermore, the results are consistent with the idea that episodic features known about people are stored in semantic memory and are automatically activated when encountering that person.
1 Introduction
There has been a long-standing controversy in the scientific literature that revolves around the question of whether memory for people has an associative or a hierarchically organized categorical structure. For the semantic system dealing with objects, a network-like structure as proposed by Collins and Quillian (1969) is a largely accepted model. These networks are supposed to be organized along categorical lines such that superordinates are connected to subordinates. For the semantic representation of people, some researchers have expressed doubts that it is organized in that way. Rather, it has been suggested that it is organized along associative lines, such that there may be a direct link between two persons (Young et al., 1994; Barry et al., 1998).
The main empirical workhorses for the investigation of semantic memory are priming paradigms which vary the subject’s “degree of preparedness” over the course of the experiment. One class of priming effects is known generically as semantic priming. It was in the domain of word recognition that semantic priming was first reported (Meyer and Schvaneveldt, 1971), and referred to the finding that related word pairs, for example bread–butter, were more quickly recognized than unrelated word pairs. In person identification, semantic priming thus refers to the phenomenon that seeing one person (be it their face or name, for example) can affect the speed of recognition of another related person. First reported by Bruce (1983) and Bruce and Valentine (1986) for face recognition, the effect was demonstrated for closely associated pairs of people, for example John Lennon–Paul McCartney: seeing one sped up recognition of the other compared to control conditions where either unrelated famous or unknown faces were presented first. The effect crosses domains in that seeing for example Paul Simon’s face speeds up the recognition of Art Garfunkel’s name (Young et al., 1988). This result and Rhodes and Tremewan’s (1993) finding that name–face and face–face semantic priming effects are similar in terms of signal detection sensitivity, demonstrated that these effects are unlikely to be due to mechanisms at the perceptual level. Rather they are taken to be due to spreading activation between representations in semantic memory.
The finding that the sequential or simultaneous presentation of two associated people may result in an acceleration in responding (associative priming; Bruce, 1983) is in support for both, the categorical and the associative point of view. While associative priming is distinguished by the fact that it is based on close associations between two people who are often thought of together, perhaps seen together, and are predictive of each other, in the sense that given one name, one can generate the other, categorical priming is based on a purely incidental sharing of the same category, for example the singers Ricky Martin and Eminem, or the politicians Nicolas Sarkozy and Sarah Palin. Some studies have questioned the existence of such categorical priming effects (Young et al., 1994; Barry et al., 1998) and suggested that only people that are closely associated will be linked together in semantic memory. However, there is accumulating evidence that pairs of faces that came from the same occupational category result in shorter response times (Brennen and Bruce, 1991; Carson and Burton, 2001; Darling and Valentine, 2005; Stone and Valentine, 2007; Stone, 2008; Wiese and Schweinberger, 2008, 2011; Darling et al., 2010).
The most influential categorical model is the interactive activation and competition (IAC) model of person identification that has been introduced by Burton et al. (1990) and extended, among others, by Burton (1994), Brédart et al. (1995), and Burton et al. (1999). These authors suggested and implemented a connectionist architecture as developed by McClelland and Rumelhart (1990) that consists of pools of mutually inhibitory nodes representing the content of semantic memory (see Figure 1 for a graphical representation). The pools are organized hierarchically, such that the flow of information is restricted. The model does not attempt to include the computationally complex perceptual process of recognizing a face, i.e., to match a given retinal image to the corresponding representation stored in long-term memory (but see Burton et al., 1999). Instead, the model’s entry point are the face recognition units (FRU), a perceptual stage where the activation of a unit represents a match between the visual input and the stored structural description of a specific person’s face. Similarly, name recognition units (NRU) are perceptual units for names. Nodes from these pools converge at the person identity nodes (PIN) that are an abstract representation of the amount of evidence there is for a given person (independent of whether the evidence was received from a face, a name, visually, auditory, or any other perceptual pathway).
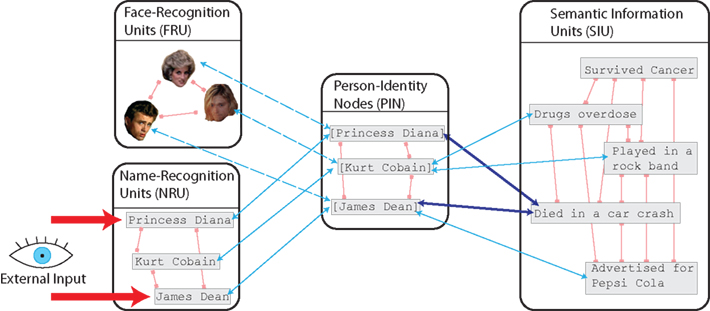
Figure 1. Interactive activation and competition (IAC) model. Red lines are inhibitory connections, blue arrows are excitatory. Note that access to the semantic information is routed exclusively via the PINs.
That means, each unit within the FRU and the NRU pools is connected bidirectionally with a unit in the pool of PINs: for instance, Ole Gunnar Solskjær’s FRU and NRU are connected with his PIN unit. In the model, suprathreshold activation at the PIN allows a familiarity decision to a person to be taken. They also present the exclusive pathway to the semantic information units (SIU). Each SIU represents a biographical characteristic of a person, i.e., a single piece of semantic information that is known to the observer. Typical examples quoted in the literature are, e.g., an SIU for “French,” for “comedian,” or for “prime minister.” Each known fact about a particular person is represented by a bidirectional link between that person’s PIN and a SIU. Thus the semantic information is not directly linked to the representation of a persons face, but is always accessed via the abstract, modality-independent PINs.
As shown for example by Burton et al. (1999), this simple architecture is very well-suited to account for a large range of empirical phenomena related to person recognition. These include identity priming, associative and categorical priming, the fan-effect, and distinctiveness effects. Associative and categorical priming, for example, are emergent features of the architecture’s dynamics. The mechanism for both types of priming is as follows: when the face of a person from a related pair is seen, say Brad Pitt, his FRU is activated, which activates his PIN, allowing a familiarity decision to be taken. Relevant SIUs, for example actor, American, are simultaneously being activated in a cascade fashion. As they are activated, each SIU will begin to activate all PINs connected to it, i.e., all PINs connected to “American” and all PINs connected to “actor.” Thus when Angelina Jolie’s or Tom Cruise’s face is presented shortly afterward, the corresponding PIN has a non-zero activation level because of the shared semantics and will be recognized more quickly than if Brad Pitt had not just been presented. Note that in this model priming is modality-independent because it is predicted to be equivalent whether the prime and target are faces, names or any other key to identity.
The SIUs represent the semantic information known by the observer about a given individual. The exact nature of the SIUs, however, has not been clearly specified, i.e., it is unclear whether these units correspond to single biographical incidents such as “died in a car accident,” or whether only stronger, category-like information such as “is a comedian” or “is American” are stored at that level (Brédart et al., 1995). Still, an assumption of the model is that all connections between PINs and SIUs are of equal strength. This is a potentially vulnerable point in the model, as it does not allow one to model how memory traces of different strengths are encoded which is obviously the case in real-life representations of people. Nevertheless, the assumption of equal connection-strengths is a necessary characteristic of the model because it reduces the degrees of freedom and prevents the model from overfitting.
The only way to represent memories of variable strengths while retaining the assumption of equal connection weights, is to model memory strength in terms of a different number of SIUs for memories of different strengths (for example “comedian” would not be modeled by a single SIU but would rather activate a large number of more basic SIUs, such as “tells jokes,” “is quick-witted,” or “performs in front of an audience”). These “basic” SIUs however would still have the same weight1. This view is similar to that expressed by Brédart et al. (1995). In their extension of the IAC model, these authors clustered related semantic information into groups according to categorical similarity.
In the following, we will investigate the structure of memory for people in a series of three experiments. We base our experimental efforts on an implementation of the IAC model of person identification from which we derive concrete predictions. The paper is therefore organized as follows: In the next section, we introduce our computational implementation and derive predictions for Experiments 1 and 2 that are subsequently presented. The results from these studies provoke a change in our paradigm for which we present a model before discussing Experiment 3.
2 The Computational Model
Burton et al.’s (1990) IAC model has had great influence in the literature on the organization of person-related semantic knowledge. This is due to the fact that in spite of its simplicity it is able to account for many of the observed effects. Another useful aspect is that the model is implemented as a coupled non-linear system and can thus be used to make quantitative predictions when adapted to specific paradigms.
However, this potential is not exploited by most studies because, instead of using a concrete computational implementation, the model is often used to derive predictions only in a heuristic manner. These studies operate by trying to envisage what the dynamic model would do when subjected to the specific manipulations in the novel paradigm. However, given the complexity of the dynamics in the network-like structure, it is often very hard or near-impossible to predict how it would behave under novel circumstances. Important side-effects are easily overlooked that can counteract the presumed processes and lead to different behavior of the model.
We illustrate this argument by way of an example: By conceptually elaborating on the IAC model, one might be tempted to think that any number of shared SIUs will invariably result in a semantic priming effect in a primed familiarity task. We show below that this is not true in general: Depending on the connectivity of the network, as well as the nature of the employed task, there is a critical number of SIUs that need to be shared in order for semantic priming to emerge. This effect is hard to derive from a heuristic use of Burton et al.’s model. However, when looking at a concrete implementation of the IAC model, the finding emerges quite naturally, as we will show in the next sections. We therefore argue that it is crucial to test predictions in an implementation of the model similarly to how we test predictions empirically.
Furthermore, previous simulations typically used small networks with very simple connectivity (Burton et al., 1990). Studies using such networks do not allow to derive predictions about the behavior of the model in general, i.e., when a more complex connectivity is employed since the network’s behavior can change drastically with the structure. In our simulations, we choose a statistical approach to derive predictions from the model: We randomly draw samples from the population of possible networks and calculate population statistics across these samples. This approach allows us to generalize to arbitrary connectivity. Our view is that the investigation of simple versions of network models is worthwhile for understanding the mechanisms that produce a specific effect. However, it is also of importance to generalize these ideas to more complex instances of the same model in order to show that it is not an artifact of the simplified version of the model.
Our simulations are therefore based on random networks and we present statistical data that are acquired by submitting the same task to many different such networks. We use medium-sized networks and keep its size as well as the expected number of excitatory connections constant, only randomizing the actual connectivity. This is unavoidable, because all major parameters depend on the size and approximate number of connections and have to be fine-tuned for different sizes (see Table A1 and Appendix for details on the simulations).
3 Simulations 1 and 2
3.1 Semantic Priming in a Familiarity-Decision Task
The semantic priming effect as observed in the familiarity-decision task (for example, Bruce and Valentine, 1986) is, in terms of the IAC model, based on activation spreading from the externally activated PIN (for example by visual presentation via FRUs or NRUs) to the connected SIUs which, in turn, propagate the activity to other PINs sharing the same nodes. Conceptually, a single shared SIU could be enough to elicit an activation in another PIN. This is true for simplified networks that have very few SIUs and a simple excitatory connectivity between PINs and SIUs where it is possible to find a semantic priming effect even for a single shared SIU. However, this does not hold for larger networks with more complex connectivity. We argue that it is a strength when a prediction of the model is independent of the network’s size and connectivity because it allows us to conclude about a class of models rather than a single realization.
In a first experiment with the model, we investigated whether the semantic priming effect reported in previous simulations was present in our model. We therefore excited an arbitrary NRU from the network and observe whether any semantic priming could be observed. Semantic priming depends on self-sustained activity propagating from shared SIUs to related PINs. Therefore, we counted the number of above-zero activations after switching off the external activity and letting the network settle to an equilibrium. All above-zero activations in the PIN pool result in some amount of semantic priming when subsequently subjected to external input and we therefore did not consider the absolute values of the above-zero activations (though the higher the above-zero activity, the stronger the priming effect is going to be).
Figure 2 plots the number of primed nodes as a function of the maximum number of SIUs shared by the activated and any other PIN. Only PINs that receive some activation via SIU-connections from the externally stimulated target PIN will produce a difference in reaction time in a succeeding trial. Hence, a minimum number of four shared SIUs was necessary to produce a semantic priming effect in our medium-sized model. We conclude, that there is a critical number of shared SIUs that is necessary to elicit above-zero activation and therefore semantic priming effects in the associated PINs. This number could not be changed by adjusting the global model parameters (e.g., coupling strength, decay constant; see Table A2 in Appendix), i.e., it is not an artifact of a specific choice of these parameters. Rather, it is an effect inherent to the considered model.
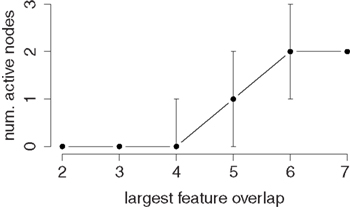
Figure 2. Number of PINs with above-zero activation after external input to a target PIN as a function of maximum SIU-overlap of the target and any other PIN. The plot shows the median over 10 different random networks along with the first and fourth quantile.
In general, there is only a small range of settings for the global parameters in which the model exhibits reasonable behavior: Only when the parameters are within a certain regime can semantic priming be observed at all without producing unstable network responses. Within this regime, the discussed critical number of shared nodes was constant. This critical number is dependent on the connectivity and the number of nodes in the network.
Technically, the effect that there is a critical number of shared SIUs can be explained as follows: The semantic priming effect relies on the rather delicate balance between external and internal excitation and inhibition. Stimulating PIN 1 that has only a single shared SIU with PIN 2 will result in some activation passing via the shared SIU-link. However, there is strong competition in the PIN pool and the activity of PIN 1 will actually inhibit PIN 2 (and so will other incidental PIN 1 → SIU → PIN 3 links). Thus, depending on the connectivity and size of the network there will be a different number of SIUs that need to be shared between PIN 1 and 2 to produce semantic priming.
Also in larger networks, as the number of connected SIUs is increased, so does the overlap with PINs other than the one investigated. This overlap in turn will increase the activity in the PINs leading to increased inhibition that will suppress the activity coming from the weakly coupled few-feature-overlap SIU. By way of example, presentation of Brad Pitt will activate related PINs (say Jennifer Aniston and Angelina Jolie) and this activation will inhibit associations that are of a more subtle nature like Tom Cruise.
We conclude that whether categorical priming takes place in a single-familiarity-decision task depends on whether the number of SIUs activated via the shared category will exceed the necessary critical number or not. In principle, this will depend on properties of the network’s connectivity, e.g., exclusiveness (i.e., are there many PINs that share the SIUs in the network?) and typicality (i.e., there will be more shared connections between two actors that are typical). Empirical investigations that have focused on priming effects in single-familiarity-decision tasks that are based on a smaller set of shared nodes, i.e., categorical priming studies (Young et al., 1994; Barry et al., 1998; Stone, 2008; Wiese and Schweinberger, 2011) have had mixed success in finding a significant main effect of the same category.
Along these lines, our simulation results fit remarkably well with a recent finding by Stone (2008): These authors showed that the presence of closely associated pairs in the trial-sequence will prevent the more subtle categorical priming effect from occurring, an effect that they explained by different levels of processing triggered by the presence of highly associated pairs. The previous simulation can explain this effect without requiring the assumption of different processing mechanisms: It attributes this effect to increased inhibition when strongly associated pairs have been activated in the past that is due to residual activation from the previous presentations. Consider again the presentation of Brad Pitt and Angelina Jolie as a prime–probe pair. According to the IAC model, all other actors will be inhibited because of the dominant activation of the two associated PINs. Hence, when an actor is presented in the next prime, activation will take longer, potentially leading to a reduced priming effect. In contrast, using only categorical prime–probe pairs, the weaker activations will spread to all actors, leading to a facilitation for the next categorical prime and a potential increase of the priming effect. It is therefore not necessary to assume additional mechanisms (like level of processing, for example) but one can account for Stone’s (2008) effect purely within the basic IAC-framework.
We conclude that it will be difficult to detect subtle semantic priming effects with a single-familiarity-decision task. We therefore consider a paradigm that provides a better chance to observe semantic priming when there are a lower number of shared features. Studies using a double-familiarity task were able to demonstrate reliable semantic priming effects in the study of objects (Lupker, 1988), words (Fischler, 1977), and faces (Brennen and Bruce, 1991). The double-familiarity task is distinguished from the usual familiarity task by the fact that two words, objects or faces are presented simultaneously. Participants are required to respond with “familiar” only when both are familiar. The literature showing stable priming effects in this task led us to presume that it was more suited for the investigation of semantic priming effects that are based on a lower number of shared semantics. We therefore investigated priming effects in this task within our implementation.
3.2 Semantic Priming in a Double-Familiarity Decision
In contrast to the single-familiarity-decision task, the priming effect in a double-familiarity task is not based on persisting activation from a previous presentation of a related person. Rather, the two linked persons are both activated thus receiving reciprocal feedback. We hypothesize that the priming effect should therefore be less dependent of the number of shared features: Because the external input, when applied to two nodes at once, is strong enough to elicit the secondary path via the SIU between the two PINs, recognition of both persons should be facilitated. Also, the priming effect would supposedly vary in magnitude with the number of shared nodes, where a larger overlap would produce stronger priming effects because the “bandwidth” is increased (similar to the situation in the single-familiarity-decision task).
We investigated this hypothesis in a model-experiment. To simulate the requirements of the double-familiarity task, we simultaneously activated two random NRUs that shared a number of SIUs (the priming condition) or two NRUs that did not share any SIU (the control condition). We measured the model’s “reaction time” which we define to be the crossing of a threshold at the PIN level and calculate priming effects as the difference between a priming and a control condition. The model RT was chosen as the dependent variable in this simulation in order to investigate the magnitude of the priming effects as compared to the previous simulation in which only the existence of priming was of interest. When there are few shared SIUs, the situation corresponds to categorical priming and when there are many, it corresponds to associative priming.
Figure 3 plots the result of this experiment. Obviously, increasing the number of overlapping SIUs results in a decrease in reaction time, a priming effect. Already the single-feature overlap turns out to be significant in a one-way ANOVA, F(1,38) = 23.98, p < 0.001 and so do, of course, priming effects with more shared features.
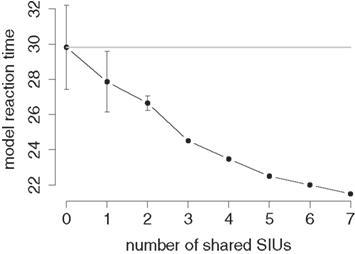
Figure 3. Model reaction time for a familiarity decision in a double-familiarity task as a function of shared features between the two presented names. The plot shows the mean value and SD over 20 different random networks. The gray line marks the control condition with zero-feature-overlap.
3.3 Conclusion
Based on the simulation results, we conclude that it should in principle be possible to produce priming based on very few (and even a single) overlapping biographical features in a double-familiarity task. As such, the double-familiarity task does not simply imply “twice the amount of priming” but rather there are different mechanisms underlying the single- and double-familiarity tasks. Note however, that this distinction is not an artificially introduced one (like the underlying mechanisms for identity and semantic priming within the IAC-model, for example) but that it emerges naturally within the model, when only the mode of stimulation is changed. The model in the two reported simulations was exactly the same (apart from the randomness of the network’s connectivity, of course) and the only difference was, whether a single or two NRUs were stimulated at once. The double-familiarity task has therefore conceptually superior potential to measure subtle priming effects.
In the following experiment, we will investigate semantic priming based on few overlapping features (categorical) and many overlapping features (associative priming) within a double-familiarity task.
4 Experiment 1
As pointed out by Carson and Burton (2001), because in Burton et al.’s model associative priming arises due to shared semantic properties, priming between members of the same occupational category is expected. Associative and categorical priming from this point of view are based on exactly the same process (namely shared semantic information) differing only in the number of units involved in the process. While associative priming is conceived to involve a large number of shared SIUs, their number would be considerably less for categorical pairs and a less strong priming effect is expected. This interpretation fits nicely with Carson and Burton (2001) observation that in Young et al. (1994) and Barry et al. (1998) and other failures to find categorical (and non-associative) priming the non-significant trend was invariably in the expected direction. This led them to speculate that the categorical effect was a weaker version of the associative one. To back this up, they demonstrated that if a target was primed by four (rather than one) categorical primes then reliable priming was obtained, on analyses by participants and by items.
Stable priming effects of categorically related pairs of persons have also been shown in a famous/non-famous classification task using primes that were subliminally presented (Stone and Valentine, 2007). Wiese and Schweinberger (2011) implemented a standard single-familiarity-decision task and reduced the possibility of strategic behavior (e.g., expectancy) by using sandwich-masked primes. Using that approach, a categorical priming effect did emerge in a single-familiarity paradigm. Other recent studies adapted the release from proactive interference (RPI) paradigm (Gardiner et al., 1972) for faces that were categorically related (Darling and Valentine, 2005; Darling et al., 2010). RPI manifests as an advantage in memory performance in list-learning tasks, when the learned items change the category from which they were drawn. The decline in performance when many trials from the same category are presented is argued to be due to persisting activation in the category-specific SIUs which leads to interference during recall. The change of the active category therefore provides a release from this interference, leading to improved performance. In their studies, Darling and Valentine (2005) and Darling et al. (2010) could show that a stable RPI effect emerges for categorically related names.
In Experiment 1, we investigated priming based on (a) shared category and (b) strong association in a double-familiarity task using famous names as stimuli. By implementing both categorical and associative priming in a single experiment we are able to assess the relative strength of the effects. Previous studies that applied the double-familiarity task used images of faces of famous persons as stimuli. While there is no particular reason to believe that the presentation of names instead of faces should influence the observed priming effects, it is still worthwhile to check that this is actually the case. Experiment One can therefore also be seen as a replication and extension of Brennen and Bruce (1991) using a different stimulus-modality.
4.1 Method
4.1.1 Participants
Fifty undergraduate students were recruited from the University of Tromsø campus. Their average age was 24 (range 20–37, SD = 3.7), and the 18 women and 7 men were randomly assigned to each subgroup (see Design). They received no reward for taking part in the experiment. All ratings were performed by students from the Social Sciences Faculty, mainly the Department of Psychology, within the same age range as the eventual participants, also with a majority of women.
4.1.2 Stimuli
For this experiment we wished to obtain pairs of celebrities that shared an increasing amount of semantic information. In addition, we wanted to keep other factors as constant as possible between the conditions. This led us to the approach of finding pairs of strongly related pairs that could also be recombined to produce pairs that were only categorically related. We chose celebrities from different categories that appear together, for example Michael Douglas–Catherine Zeta-Jones, Kate Winslet–Leonardo Di Caprio and should thus share a large number of semantic information. We then recombined them in a way that they were apparently unrelated, e.g., Michael Douglas–Leonardo Di Caprio, Kate Winslet–Catherine Zeta-Jones but were of the same profession such that they still shared a number of common semantics (see Table A3 in Appendix for a list).
In order to achieve this, a list was generated of 47 related pairs of celebrities likely to be known to our participant population. A further 26 pairs of people, some of whom were weakly related and some of whom were unrelated, were mixed in with the closely related pairs. Nine people rated the strength of relatedness within these pairs by answering the question: “How related are the people in each of these pairs, on a scale of 1–7, where 1 means completely unrelated and 7 means the most tight relationship imaginable.” They were also asked to indicate when they did not know a celebrity.
Twenty-nine pairs fulfilled the criteria of being known by at least 7 of the 9 raters, and where the mean rated strength of relatedness was over 5.5. Two more lists were made, each with one name from each of these 29 related pairs. Sixteen people – eight per list – who did not take part in the previous phase were asked to write down as many people as possible that each celebrity made them think of, and to indicate when a name was not familiar to them. These participants generated a mean of 3.4 names per person. In addition to the criterion of mean associative relatedness, the pairs that were used in the experiment were those where (a) at least 14 of the participants who saw each name in the stimulus preparation procedures described above knew both of the celebrities, and (b) where at least two pairs from the same occupational category passed the first two criteria and could be recombined into two related pairs without strong association, i.e., that were never generated in the free association procedure above. This gave a total of 36 celebrities that could be combined into 18 associatively or categorically related pairs.
The stimuli pairs in the Unrelated condition were obtained by combining the stimuli in the related conditions, so that they did not share association or category. There were two conditions for the negative trials: one with one famous name and an unfamous name, and one with two unfamous names.
4.1.3 Design
This was a mixed design. The within-subjects factor was Priming, with the levels of Related and Unrelated. The between-subject factor was Relatedness Type where one group of participants saw Associatively related pairs in the Related condition, and the other group saw Categorically related pairs. Twenty-five participants were randomly allocated to the Associative condition and 25 to the Categorical condition. Each participant performed 18 familiarity judgments to related trials and 18 to unrelated trials, where the required response was affirmative, and 36 trials containing unfamiliar names, to which the correct response was negative. The conditions were presented in a different random order for each participant, with the constraints that no more than three from the same condition could be presented consecutively, and no more than four trials requiring the same response could be presented consecutively. Across the experiment, both groups of participants made familiarity judgments to the same names, just arranged in different pairs in the Related condition.
4.1.4 Procedure
The experiment was controlled with ERTS software on a color monitor. Participants were tested individually, and instructed that on each trial two names would be presented, one above the other. Their task was to press “Yes” if both names were those of famous people, and “No” otherwise. Stimuli were presented until a response was forthcoming, and the inter-trial interval was 1000 ms. There were 20 warm-up trials not used in the analysis, where 10 contained one or two unfamous names, and 10 contained 2 famous people’s names, of whom 3 were related (associatively or categorically, according to condition) and 7 were unrelated. None of the famous names were also included in the experiment proper. No explicit reference was made to the possibility that some of the people may be related to each other.
4.2 Results
The number of errors and the mean response time for correct responses were computed for the Related and Unrelated conditions, and are shown in Table 1. The error data were entered into a two-way ANOVA with the factors of Relatedness Type and Priming. There was a main effect of Priming, F(1,48) = 7.4, p < 0.05, no main effect of Relatedness Type F(1,48) < 1, qualified by a significant interaction, F(1,48) = 6.1, p < 0.05. T-tests showed that the Associative group had fewer errors in the Related condition than in the Unrelated, t(24) = 3.0, p < 0.05, but that there was no difference for the Categorical group, t(24) < 1.

Table 1. The mean response times in milliseconds for correct responses (SD in brackets), and error rates in Experiment 2.
The mean correct response times were entered into a two-way ANOVA with the same factors, where there was a significant main effect of Priming, F(1,48) = 30.2, p < 0.001, but no main effect of Relatedness Type, F(1,48) < 1 nor an interaction, F(1,48) = 2.2, p > 0.1. In other words, the response time advantage of the Related condition over the Unrelated appears to be as strong for the Categorical condition as for the Associative. A two-way ANOVA was also performed with items as random factor, and correct response times as dependent variable. There were two between-items factors of Priming and Relatedness Type. There was a significant main effect of Priming, F(1,34) = 21.1, p < 0.001, and a marginal one of Relatedness Type, F(1,34) = 3.6, p = 0.066, because participants in the Categorical group recognized the names slightly more quickly than participants in the Associative group, but again no interaction between the two factors, F(1,34) = 1.02, ns. An independent samples two-tailed t-test for the Categorical items showed a difference between the Related and Unrelated conditions, t(34) = 2.4, p < 0.05.
Finally, we compared negative trials in which participants were required to give “unfamiliar” judgments with unrelated trials (in which a “familiar” decision was correct). In two-tailed paired t-tests, Negative trials were slower both for the associative group, t(23) = 5.95, p < 0.001 and for the categorical group, t(23) = 4.61, p < 0.001.
4.3 Discussion
When investigating associative and categorical priming within the same experimental framework, we found reliable priming effects with associatively as well as with categorically related pairs using famous names as stimuli. Brennen and Bruce (1991) showed categorical priming of face recognition on a double-familiarity task and Carson and Burton (2001) showed categorical priming of name recognition using multiple primes. Experiment 1 bridges the gap between these results by revealing categorical priming of name recognition using a double-familiarity task. The data is in accordance with structural models of the semantic memory for persons postulating a pool of shared semantics, including category.
However, there is an alternative explanation for these results that is not based on spreading activation but rather on strategic matching processes. It has been suggested that a late semantic matching process may bias the response in favor of one of the response alternatives in binary decision tasks (Neely et al., 1989). This matching process has been suggested to function as a plausibility or coherence check. In the double-familiarity task, if the participant detects a semantic connection, both names must be familiar because else a semantic overlap could not have been detected. Therefore, there is a perfect contingency between semantic match and familiarity and a bias in favor of familiar-decisions would be helpful. On the other hand, however, a familiarity decision does not necessarily imply a semantic match meaning that an “unfamiliar” bias in case of no detected match could be counter-productive. If a matching process was responsible for our effects, we would therefore expect that unrelated trials (in which a familiar-decision had to be given) should be slower compared to negative trials (where the unfamiliar-bias is in the correct direction) because in the unrelated trials, two names that are familiar contradict the result from the matching process. Our results show that this is not the case: Negative trials are slower compared to positive trials and we therefore conclude that matching processes can be excluded as an alternative explanation.
Since the same celebrities were used to investigate associative priming between participants in the same experiment, we can make a statement about the relative size of the effects. Although numerically bigger, the priming effect was not statistically larger for the associative pairs than the categorical, either by items or by participants. Our simulations showed a correlation between priming effect and number of overlapping features. However, when considering Figure 3, the curve asymptotically approaches a fixed value. The lack of an effect between a strong and even stronger overlap of SIUs (categorical vs. associative) could therefore be attributed to the fact that categorical relation is already too strong for the additional association to make a difference (because a strong difference has only a weak effect in terms of RT for higher values of number of shared SIUs). Relating these considerations back to the data on hand and assuming that categorical and associative priming are based on the same mechanisms (Carson and Burton, 2001), it might just be the case that the additional overlap in semantics for the associative pairs was not strong enough to elicit a significantly larger effect.
When pushing the assumption that both categorical and associative priming differ only in the number of shared semantics to the limit, the question appears whether a single common semantic feature is sufficient to produce priming.
5 Experiment 2
In all work carried out so far in person identification, priming due to the relationship between two people has relied on relatively stable aspects of the peoples’ lives, the essence of the identity of the person. For example Barack Obama and Joe Biden are associated because they work in the same Democrat administration. Laurel and Hardy are so closely related that it is unclear what the meaning of one would be independently of the other. Similarly for categorically related pairs, the profession is normally why people are connected, for example Tom Cruise and Mel Gibson are related by both being actors, which is absolutely central to why they are known. So, in the case of both associative and categorical priming the overlap between related items is in terms of the essence of who the person is.
However, some pairs of people are related for reasons not pertaining to the essence of who they are, but more incidental, random or trivial things, sometimes deriving from single episodes. For instance, Princess Diana and James Dean, who did not have the same profession and lived in different eras, both died in car crashes; boxer Evander Holyfield and painter Vincent van Gogh both lost a part of their ear at some point, and both Nobel Prize Laureate Thomas Mann and “King of Pop” Michael Jackson were accused of pedophilia. Note that in none of these cases does the titbit of information define the people: they are principally known for other reasons. In addition, it will be hard to think of any additional feature to relate the two persons to one another and any observed priming effect could therefore be attributed to that shared biographical information.
Experiment 2 investigates this issue by implementing a corresponding experiment where we attempted to isolate a single shared biographical feature that could in principle correspond to an isolated SIU in the IAC model. In continuation of the previous distinction of “associative” and “categorical” priming and for clarity of exposition, we tentatively call this putative effect “biographical” priming.
Previous experimental work that focused on related questions has been conducted by McNeill and Burton (2002). In two experiments they compared the effect of associative primes to two types of unrelated primes: one where the prime and target had the same nationality and one where they had different nationalities. On a familiarity task and on a nationality categorization task, for faces and for names, the associative primes speeded processing, and there was no difference between the two Unrelated conditions, suggesting that a difference on a single biographical feature is not enough to give rise to priming in the standard familiarity-judgment paradigms. The lack of an effect in their experiment can be interpreted in the framework of our simulations: In single-familiarity-decision tasks, a critical number of shared features must be present for priming to emerge. Also, the lack of a difference may be due to the fact that the different unrelated conditions were not matched for (dis-)similarity, i.e., it was not shown that if one disregards the nationality, the two conditions were then equally unrelated.
In a recent experiment, Darling and Valentine(2005, Experiment 4) investigated whether similarity in an ad hoc category was enough to elicit release from proactive inhibition. They defined persons to be related when both did their job in a sitting (or standing) position and did not observe an RPI effect, both in a cued and an uncued condition. This can not quite be interpreted to correspond to what we referred to as biographical priming because the ad hoc categorizing principle is probably not stored in semantic memory.
In summary, associative priming has been operationally defined for people who are predictive of each other. In practice, this procedure gives rise to pairs of people who (1) are closely associated together, (2) who are talked about in the same breath, and (3) who are seen together. The pairs to be used in Experiment 1 to detect biographical priming have none of these properties. This priming is neither associative nor categorical. Members of each pair share one concept or trait or feature which (a) does not define them, (b) became associated with them after they became famous, and (c) is not predictive of their occupational category. Experiment 1 investigates whether these non-associative and non-categorical links produce priming on a double name familiarity-decision task.
5.1 Method
5.1.1 Participants
Twenty undergraduates from the University of Tromsø volunteered to take part in this experiment. Eleven were female and nine were male. Mean age was 26.1 years (SD = 7). Ratings were done by participants from the same university within a similar age range and a majority of women.
5.1.2 Stimuli
Four lists of pairs of names were used in this experiment. One list comprised 12 pairs of names of celebrities who were related non-categorically and non-associatively by virtue of sharing a single piece of biographical information. A pilot study was conducted in which 10 participants were asked if they were familiar with both celebrities in the pair, and if they could identify the link between them. Only pairs where over 60% of the pilot participants could identify the link were included in the experiment. A second list comprised the 12 pairs comprised of the same exemplars as the first list, but with the pairs re-arranged such that there was no relationship (categorical, associative, or biographical) between the pairs. Pairs were included only if a set of 10 additional pilot participants failed to think of any link between the items. The negative items were created where only one of the stimulus items was a famous person; the non-famous names were plausible Norwegian or American English names; there were 24 such pairs. Responses to these items were not analyzed in this experiment.
5.1.3 Design
The independent variable studied here was Relatedness: On trials where both names were famous, the people were either Related by a single biographical feature, or they were Unrelated. The negative items were only included in the experiment in order to provide trials on which participants could answer “no.” No analysis of these items was conducted.
5.1.4 Procedure
Participants were tested individually using a program written using ERTS software. Each trial began with a fixation point, presented in the center of the screen and accompanied by a warning tone, presented for 500 ms. A pair of names was then presented on the screen, either side of the center point. Half of these pairs were negative items containing non-famous names, one-quarter were from the related list and the remainder from the unrelated list. This display was visible for 2500 ms. Participants were instructed to respond by pressing “z” in the case of both names being those of famous people, and “m” if both names were not those of celebrities (i.e., only one or no celebrities). Participants were asked to respond as quickly and accurately as possible. The names display cleared after 2500 ms and there was a further 2500 ms inter-trial interval where participants were still able to respond. The next trial began immediately.
5.2 Results
Median correct response times were taken for each participant, removing all RTs below 200 ms and over 3000 ms. The mean for the Related condition was 1227 ms (SD = 187), and for the Unrelated condition was 1232 ms (SD = 309). A t-test showed no significant difference, t(18) = −0.13, p > 0.1. Additionally, error rates were subjected to the same analyses. Error rate in the Related condition was 10.09 (SD = 13.49) and 10.53 (SD = 16.63) in the Unrelated condition. The corresponding t-test yielded an insignificant result, t(18) = −0.29, p > 0.1.
5.3 Discussion
In Experiment 2 there was no evidence of biographical priming in a double-familiarity-decision task even though we concluded from the model that it should be observable in principle. There are several possible reasons for the lack of an effect. First the effect of the single shared biographical feature might not have been strong enough to be detectable in the double-familiarity paradigm. Variability in studies on famous persons is rather strong because of the different degrees of exposure that participants have to celebrities. Furthermore, it is likely that not all participants had a representation of the linking feature in their semantic memory and that the general knowledge surrounding this particular information differs vastly.
Thus, we argue that in order to observe biographical priming, it is necessary to increase the experiment’s sensitivity. Hypothetically, this can be achieved by (a) an even more sensitive procedure, (b) decreasing other sources of variance (by using a more homogeneous population of participants or stimuli, for example), or (c) strengthening the links between the two PINs and their shared SIU. In Experiment 3, we opted for the third of these approaches. Before discussing this experiment, we inspect this idea more closely in the framework of our computational model.
6 Simulation 3: Biographical Priming in a Pair-Learning Task
We argue that it should in principle be possible to observe priming based on a single overlapping SIU in a double-familiarity task and attribute our failure to do so in Experiment 2 to the experimental procedure that was not sensitive enough to measure the effect. We therefore propose to increase the strength of the connectivity between the single feature and its associated person representations by a learning mechanism. The idea is to strengthen any PIN1 → SIU → PIN2 links by repeatedly showing two names together and requiring participants to learn to associate them. We argue, that the error rate while retrieving this association will be affected by whether the two persons share a semantic feature or not.
Technically, we implement this idea in the framework of the IAC model using a technique similar to the one employed by Burton (1994) where new faces were learned using a Hebb-like link-updating rule. We realized the model-equivalent of a pair-learning and cued-recall task: We activated two distinct NRUs that shared or did not share SIUs and adapted all synaptic weights between all pools according to the Hebb rule (see the Appendix for details of the simulation). This is the equivalent of pairwise name- or face-learning. Note, that in order to compare retrieval performance of unrelated and related pairs, the model had to contain means of learning to associate two previously unrelated persons. We employed the same mechanism used in Burton (1994): We created a random, fixed network that corresponds to the current semantic memory of a person. In addition, we added a number of “spare” SIUs, that were weakly (and randomly) coupled to the PINs. In the unrelated condition, one of these spare nodes was eventually going to be converted to act as the active link between the two presented persons.
After the learning phase, we activated only one of the two learned names and observed how the activity in the system behaved. This is a straight-forward implementation of a cued-recall task, where participants, given one name of the pair, have to retrieve the associated other name. In a behavioral experiment, we observed error rates (see Experiment 3) and we argue that the signal-to-noise ratio (SNR) at the PIN level (as defined in Eq. 2, see Appendix) is an adequate modeling equivalent, because it is related to the likelihood of retrieving the correct name in the presence of spurious activity (the noise). The higher the SNR, the better the two persons can be distinguished from the activity of all other PINs and the higher the accuracy of responding. While the results in terms of the SNR are not directly comparable to that of the previous simulation using reaction times as the dependent variable, it reflects the requirements of the empirical learning paradigm under investigation.
The plot in Figure 4 shows the long-term behavior of the SNR for the case of unrelated pairs (control condition) and one and four SIU-overlap. Clearly, the more nodes that were shared initially, the higher the SNR after a sufficiently long training phase. Also, the slope of the three curves increases with number of overlapping features, indicating that this difference will continue to grow with further learning steps. A 3 (shared features: 0, 1, 4) × 30 (learn-steps) within-subject (within-net) ANOVA showed a main effect for shared features, F(5,20) = 3.44, p < 0.05, a main effect for learning, F(29,116) = 33.87, p < 0.001, and an interaction, F(145,580) = 3.59, p < 0.001. This indicates that the network is able to learn associations and that there is a difference in learning speed depending on the number of initially overlapping features. A one-way ANOVA with number of overlapping features as between-subject (between-net) factor on SNRs after the 30th learning step was significant, F(5,24) = 3.13, p < 0.05.
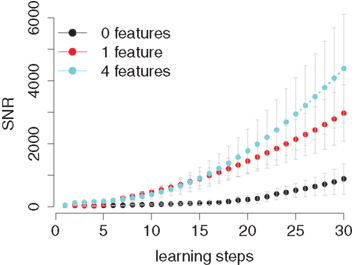
Figure 4. Signal-to-noise ratio (SNR) as a function of learning step and initial overlap in the pool of SIUs. Each plotted point contains data from five random networks and five repetitions with each network/overlap condition. The error-bars show the Standard Error of the Mean (SEM).
We conclude that our model was able to successfully establish a new associative connection between two previously unrelated PINs (via a “spare” SIU-link). In addition, the formation of the association was faster when one or several SIUs were previously shared. The long-term behavior of the SNR across learning steps indicates also that this difference will persist even after the associations are learned sufficiently. These conclusions are in favor of our objective to tease out the priming effects via a link-strengthening mechanism. Therefore, in Experiment Three we implemented this theoretical result in a behavioral experiment using a paired learning paradigm.
7 Experiment 3
In Experiment 3, we investigated biographical priming in a learning-based paradigm. The main rationale for using this approach was to strengthen the supposedly existing link connecting two persons via incidentally shared biographical information. Because it was not detectable with a double-familiarity task in Experiment 2, we opted for a task in which the corresponding links would be strengthened. Based on the results from our simulations in the previous section, we implemented the discussed mechanism using a pairwise association-learning and cued-recall task, arguing that any semantic connections between persons would manifest in better learning/recall performance.
7.1 Method
7.1.1 Participants
Fifty-five people from the undergraduate and postgraduate population of the University of Tromsø were recruited in the preparation of the pairs of celebrities. Their average age was 25 years, and 34 were women, and they received no remuneration. Ninety-nine people were recruited from the same population to rate the pairs for similarity, 79 of whom were women, and the overall average age was 23 years. Twenty-two people, also from the same population, were recruited for the experiment proper, their average age was 24 years and 14 of them were women. The experimental group received a scratch card worth around two EUR for taking part.
7.1.2 Stimuli
The experimenters generated a list of 43 pairs of celebrities linked by a biographical feature and not from the same occupational category or in any standard way associated to each other. Then 50 participants were tested individually and for each pair were asked to say what the unique link was. For cases where they indicated that they could not generate the link themselves, the experimenter told them the link, and the participant had to say whether or not they could confirm the link, i.e., whether they now remembered it. In this way 14 of the original pairs passed the criteria of at least 40 of the 50 participants either generating or recognizing the link within the pair, e.g., Princess Diana–James Dean (died in a car crash), Gianni Versace–Olof Palme (murdered with a gun). See Table A5 in Appendix for all pairs and their linking features.
To create the counterbalancing factor, these pairs were divided into two subgroups of seven related pairs. Within each group, the seven pairs were then shuffled to create seven unrelated pairs. Five people were recruited and challenged to try to find links between the unrelated pairs. Initially some spurious links were found but after a couple of reshuffles, the strongest links remaining were of the type “both are famous,” “both like money,” “both have been interviewed by the same man.” In other words, the Unrelated pairs were neither associatively nor categorically related, and nor did they share consensual central biographical features.
Notwithstanding the fact that within each pair the celebrities came from different professional categories and that even the celebrities in the related pairs were not at all predictive of each other in the way that associative pairs are, we wished to establish how similar these people within the pairs were in other ways. It is conceivable for example that people may be judged as similar, not due to shared occupational category, but more to a vague compatibility due to, for instance, how rich or “provincial” or charming or happy they are perceived to be. In order to take account of this sort of personal similarity a further ratings procedure was undertaken. Two lists were made, each containing seven biographically related pairs and seven unrelated pairs, with each celebrity appearing in the related condition in one list and the unrelated in the other. The pairs were presented in a random order on a sheet of paper. The instructions said that the pairs should be rated according to the similarity of what the celebrities do and what they are known for, and how alike they are in what they meant to the rater, with 1 as minimum and 7 as maximum.
The same lists were also used for ratings of two other types of similarity within the pairs: Name similarity and visual similarity. The instructions for the name similarity ratings were to rate how similar the two names in each pair sounded, on a scale from 1 (meaning “completely unlike”) to 7 (meaning “extremely similar-sounding”). They were explicitly told to try to ignore what they knew about the people themselves and to only focus on the names. The visual similarity instructions asked participants to rate how physically alike the celebrities were, and told them to try to ignore similarity “due to profession, for example,” on the same seven-point scale. All three sheets had a box to tick in the case of not knowing a celebrity. A total of 99 people participated in these procedures: 31 rated semantic similarity, 37 rated name similarity, and 31 rated visual similarity.
In addition to the biographically related pairs, a set of pairs containing visually similar people was compiled. The types of visual similarity included physiognomic similarity, similar hairdos, similar glasses and similarly protruding ears. Seven such pairs and seven visually dissimilar pairs were included as fillers in the experiment in order to avoid ceiling effects in the learning of the biographical pairs.
7.1.3 Design
There were two factors in this experiment: a within-subjects factor of Biographical Priming, with the levels of Related and Unrelated, and a between-subject factor of Subgroup. The latter ensured that for any participant each celebrity appeared in only one condition, and that all celebrities appeared equally often in the Related and Unrelated conditions across the experiment. The dependent variable was the number of errors made during the learning procedure.
7.1.4 Procedure
Participants were tested individually in a quiet lab and the experiment was run on a PC using ERTS software. They were instructed to try to remember the pairs of names that would be presented. After two runs through each pair, they would have to try to recall one name when given the other. Fourteen biographically related pairs (seven related and seven unrelated) and 14 visual pairs (seven related and seven unrelated) were presented in the same random order to all participants. On each trial a cross was presented on the screen for 750 ms, followed by the pair of names for 5 s, and with an inter-trial interval of 2 s (see Figure 5). A different random order was used for the second presentation. Then the test phase of the experiment began, with one name being presented on the screen, and the participant had to recall the person’s “partner.” The response was recorded by a research assistant, blind to the hypotheses of the experiment. For commission and omission errors, the correct name was provided by the experimenter. Each of the 28 names in biographically related pairs and the 28 names in visual pairs was presented five times, in a different random order for each participant (with the constraints that names from the same pair could not be presented consecutively and no more than 2 names from the same condition could be presented consecutively). The experiment was terminated in cases where the participant made no errors for any pair for three consecutive presentations.
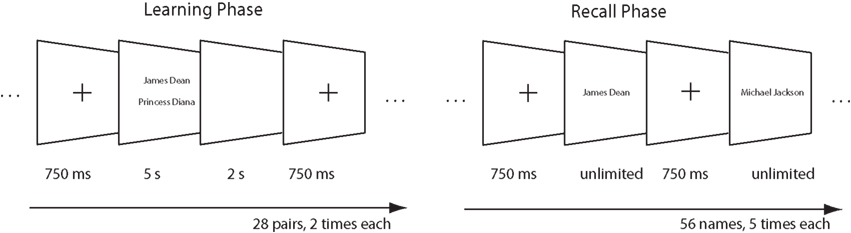
Figure 5. Experimental procedure in Experiment 3.
After the test phase was over, participants were first asked to indicate whether any of the celebrities were not known to them, and then to introspect on how they had learned each of the pairs. Then they were presented with each visual and biographical pair one by one, both the related and unrelated, and asked to say what the two people had in common. Then participants were debriefed and thanked.
7.2 Results
There were eight occasions on which a participant reported not knowing a celebrity – four in the Related condition and four in the Unrelated – and these data were discarded. For the remaining cells, the mean number of errors during learning made by each participant for each pair in the Related condition was 2.1 (SD = 2.0), and for the Unrelated condition was 3.6 (SD = 2.1). A two-way analysis of variance with the factors of Biographical Priming and Subgroup showed a main effect of Biographical Priming, F(1,18) = 12.9, p < 0.005, but none of Subgroup, F(1,18) < 1. The interaction was not significant either, F(1,18) = 3.0, ns. Parenthetically, we note that the same pattern was obtained for the visual pairs: the mean number of errors was 2.1 (SD = 2.0) for Related and 3.8 (SD = 2.1) for Unrelated. A two-way ANOVA showed a main effect of Relatedness, F(1,18) = 24.1, p < 0.005, but neither a main effect of Subgroup nor an interaction, F(1,18) < 1, and F(1,18) = 2.6, ns.
A two-way ANOVA was also performed with items as random factor. Both factors (Biographical Priming and Subgroup) were between-items factors, and of the three sources of variance only Biographical Priming was significant, F(1,12) = 16.1, p < 0.005; Subgroup: F(1,12) < 1; Interaction: F(1,12) = 2.7, ns. The biographical priming was thus significant by participants and by items.
Pearson correlations were used to investigate associations between the number of errors made for the 28 pairs (the 14 related pairs and the 14 unrelated pairs), the mean obtained for each pair from the three similarity ratings procedures, and Biographical condition (Related or Unrelated). The number of errors made correlated negatively with all three ratings, but only significantly so for personal similarity, Personal: r = −0.42,p < 0.05; Name: r = −0.20, ns; Visual: r = −0.24, ns. For Biographical condition, Visual similarity also showed a significant association, Personal: r = −0.81, p < 0.001; Name: r = −0.31, ns; Visual: r = −0.38, p < 0.05. Personal and Name similarity correlated significantly with each other r = 0.42, p < 0.05, but no other correlation between ratings was significant.
The high correlation between rated Personal similarity and Biographical condition raises the possibility that the significant main effect of biographical priming found on the ANOVA was due to personal relatedness rather than to the single shared biographical feature. A multiple regression was carried out with the mean number of errors per pair as the dependent variable, and the independent variables of rated personal similarity, name similarity, visual similarity, Subgroup, and Biographical condition. This gave a significant model, F(5,22) = 3.01, p < 0.05, with an adjusted r2 of 0.27. The only significant independent variable used in the model was Biographical condition, β = 0.79, t = 2.8, p < 0.05; Personal similarity: β = 0.24, t = 0.80, ns; Name similarity: β = −0.06, t = 0.33, ns; Visual similarity: β = 0.002, t = 0.01, ns; Subgroup: β = −0.06, t = −0.33, ns. This suggests that the factor of Biographical condition is directly related to the number of errors made, and that the correlation between personal similarity and errors only emerges because of the former’s correlation with Biographical condition.
As described in the Procedure section, participants were asked to tell the experimenter how they had learned the pairs. Just under half the participants reported looking for similarities between the names or visual appearance to aid them in the task. Despite this, of course, visual similarity did not correlate significantly with number of errors. Five participants reported looking for common semantic features, but no participant came up with an observation regarding the links via a single biographical feature.
7.3 Discussion
As predicted by the simulations, participants made fewer errors when learning to associate pairs of celebrities related by a single biographical feature than unrelated pairs. This indicates that the biographical link present for these pairs eased learning to associate the two persons. In addition, the result was shown not to be due to visual similarity or name similarity or ratings of how similar the people in the pairs were.
This “biographical priming”-effect can best be explained by the notion of spreading activation through semantically related memory representations: The pairwise learning procedure strengthened the PIN → SIU → PIN links producing a stronger and less-error prone association manifested in lower error rates. Notably, the found effect is incompatible with associative accounts of memory-organization for people. In order to complete the experimental task, participants had to form associations between two previously unrelated persons, i.e., in terms of Barry et al.’s (1998) model, an associative bond had to be created. If this process is as claimed independent of the semantics, there is no reason to believe that bonds should be more efficiently created when the persons shared a single semantic feature.
Our experimental setup bears some similarity to the re-learning savings reported in a prosopagnostic patient: When the patient had to learn a name of a person that could not be identified overtly, the patient performed better when the name was the true name of the face (de Haan et al., 1987). Participants in our experiment behaved not unlike this patient, showing an advantage in a learning task due to links in the semantic system of which they were unaware. In addition, face–name priming effects similar to healthy subjects were reported for the patient (de Haan et al., 1987) which strengthens our argument that the learning and priming paradigms test the same underlying structure.
8 General Discussion
The experiments and simulations in this paper elaborated on several aspects of the semantic system dealing with knowledge of people. In the first part of the paper, we showed both conceptually and empirically that the double-familiarity task is a much more sensitive experimental paradigm than the commonly used single-familiarity task to investigate subtle semantic priming effects. Experiment 1 showed stable categorical and associative priming which were, in fact, statistically indistinguishable (although the associate priming effect was numerically bigger). Given these results ensuring the paradigm’s sensitivity, we concluded that it should in principle be possible to observe a priming effect that is based only on incidental and peripheral information.
However, we failed to find this “biographical priming” effect with a simple double-familiarity task in Experiment 2 which led us to strengthen the underlying semantic connectivity to reveal the predicted effect. Simulation results were promising because stable differences in terms of SNR during cued retrieval persisted even after all associations had been well-learned. Consistent with these considerations, we were able to find a biographically related effect on error rates in a pairwise learning and recall task in Experiment 3. The effect emerged despite the fact that participants were largely unable to pinpoint the key links within the related pairs, and reported using other strategies to learn to associate the celebrities’ names.
This type of priming is a conceptually intriguing effect because it is distinct from both associative and categorical priming: It is not based on general compatibility between the pairs of people, but more specifically can be traced to single semantic features that they share. We are thus able to go beyond previous research that could show that categorical relations are represented in semantic memory: Even isolated features that are common for two persons lead to a facilitation in learning. Strictly speaking, we cannot conclude that this effect is due to shared storage of semantic information. Barry et al. (1998) argued that semantic information is stored redundantly with each identity and that implicit access to this information can create a link between similar semantics. The same argument holds for results from studies on categorical priming. Still, a spreading activation-like mechanism is necessary to account for the unconscious formation of between-person links and assuming a shared semantic storage seems to be the most natural explanation for the found effects: If the biographical detail is stored in a shared memory storage and activation flows between a person’s representation and the associated semantic information, the facilitation can be explained by simple link-strengthening.
Biographical priming as reported in this study has not been detected earlier. Previous attempts failed to find evidence for a shared storage of biographical features (Darling and Valentine, 2005): While these authors were able to demonstrate stable RPI-effects for categorically related persons, they did not find an effect for persons sharing a biographical feature (nationality) if they were not previously cued to attend to that feature. A potential explanation for the divergent findings is based on the distinctiveness of the shared biographical feature. While the same nationality is shared by many other people, there are much fewer that, e.g., lost part of their ear. In the IAC model, the more PINs activated by a shared SIU, the stronger the inhibition in the pool, leading essentially to a weaker SIU-based activation of the nodes. It would be interesting to compare the differences of our approach and the RPI-paradigm in a computational model in order to investigate this distinctiveness-based effect in more detail.
In the spirit of Caramazza and Shelton’s (1998) domain-specific theory of semantic memory, several case studies have recently reported circumscribed deficits of semantic knowledge about people, e.g., Kay and Hanley (1999) or Miceli et al. (2000), and one a preservation (Kay and Hanley, 2002). Showing priming on a biographical priming task with such a patient with a preservation of knowledge about people (for example using a non-verbal matching variant of the task used here) would demonstrate preserved semantic knowledge beyond the levels of categories, to specific details one knows about a person. Conversely, patients with a deficit in semantic knowledge about people would be expected to show no biographical priming.
When Stanhope and Cohen (1993) used a learning paradigm to test Burton et al.’s model, Bruce et al. (1994) argued that their “steady-state” model could not be tested by acquisition experiments. While we would agree with this in general, the prediction we are testing arises directly from the structure of current IAC models, and so tests them “in principle.” Assuming the validity of the IAC model, our experiment does not modify the underlying network in memory. Rather, we opted to strengthen the assumed linkage in order to be able to observe the subtle biographical priming effect. We argue that this approach is compatible with the IAC model because we exclusively applied modeling strategies that have previously been used in the IAC model’s framework: The link-strengthening mechanism is essentially the same as the one used in Burton et al.’s (1990) initial paper for explaining the identity-priming effect. The mechanism used to enable the model to acquire new associations has been used in the context of the IAC model to account for the learning of new faces (Burton, 1994).
More speculatively, we could interpret our results as consistent with the idea that categories are not represented per se but that categorical priming effects are rather based on the spreading activation through a large number of such biographical details. This idea is in line with classical studies on typicality (Rosch, 1975) showing that typical items of a category are faster categorized than untypical ones: Typical items share more features (SIUs in terms of the IAC model) and thus reach threshold faster when activated. From this viewpoint, both the associative and categorical priming effect would really be biographical priming with different numbers of overlapping features. This has interesting consequences for how semantic priming effects should be modulated by, e.g., typicality (typical actors will share more features with other typical actors) or semantic distinctiveness (persons that have a lot of unshared SIUs would be processed faster than those having a lot of SIUs shared with many other people).
The IAC model implies that association between people is always via a semantic link. This might seem to conflict with intuition when considering pairwise learning paradigms in which participants are directly ask to associate a given pair of people. In our implementation, the association was created via spare SIUs. In reality, this would correspond to crafting a unique semantic link that connects the pair. When arguing, that SIUs are episodic in nature, SIUs of the sort “I have seen Princess Diana and Michael Jackson together in an experiment at the Psychology Department” can be assumed to be created for completely unrelated persons. Stone (2008) took a similar perspective, when arguing that close associates are related via a particularly strong node in the SIU-pool. This consideration makes explicit the question about what is actually stored in a single SIU.
Our proposal above to have isolated a feature corresponding to a single SIU in Burton et al.’s (1990) IAC model is a simplification to increase clarity of exposition: Obviously, the strength of individual memory representations will depend on the personal experiences to which any particular participant has been exposed. Thinking along these lines, a natural question to emerge is: If all associations are made up of shared semantics, what is the basic “primitive” or the elementary semantic unit? Or in terms of the IAC model, what content is stored in an SIU? In our experiments, we presented pairs of people for whom we claimed that they shared a specific feature, like “died in a car accident,” but note that here we could just as well have written “died in an accident” or “died an unnatural death.”
The question of the level at which memory representations are distinct (and thus should be regarded as an SIU) is at a level where we have to think about the neural implementation of semantic memory: Is a memory representation split into more basic units or are facts stored in clusters such that more similar ones are closer together, forming a hierarchy of “categories”? Obviously, we cannot answer these questions using purely behavioral measures. However, we like to think about SIUs as an abstraction: The assumption of distinct SIUs is merely a crude model for the real situation and does not need to have a physical equivalent. So rather than directly assuming distinct nodes for “died in a car crash” and “died an unnatural death,” we think about semantic memory as a flexible system that is able to map similar facts to one another such that the activity can spread.
In summary, we accumulated empirical evidence for the idea that single features and episodes are stored in a shared pool giving rise to between-person priming effects based on only incidentally shared information. These results are consistent with IAC models of person recognition, which we could show using computational simulations.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The first author acknowledges financial support by the Göttingen Graduate School for Neurosciences and Molecular Biosciences (GGNB) and the German Ministry for Education and Science (BMBF) via the Center for Computational Neuroscience (BCCN) Göttingen (Grant No. 01GQ0432). The authors would also like to thank Hecke Schrobsdorff, Torunn Bjørkum, Serge Brédart, Kari Hveem, Terje Lier, Ine Myrland, Fredrik Pedersen, Iris Søderholm, Live Sørensen, and Turid Tveraabak for discussion and help with the experiments, and the Norwegian Research Council for a travel stipend to the second author.
Footnote
- ^Varying the number of involved SIUs is not identical to changing the connection strengths between PINs and SIUs. A larger number of active SIUs implies stronger inhibitory activity within the SIU pool. This side-effect could potentially lead to different effects from directly increasing connection weights.
References
Barry, C., Johnston, R. A., and Scanlan, L. C. (1998). Are faces ‘special’ objects? Associative and semantic priming of face and object recognition and naming. Q. J. Exp. Psychol. 51, 853–882.
Brédart, S., Valentine, T., Calder, A., and Gassi, L. (1995). An interactive activation model of face naming. Q. J. Exp. Psychol. 48, 466–486.
Brennen, T., and Bruce, V. (1991). Context effects in the processing of familiar faces. Psychol. Res. 53, 296–304.
Bruce, V., Burton, A., and Walker, S. (1994). Testing the models? New data and commentary on Stanhope and Cohen (1993). Br. J. Psychol. 85, 335–349.
Bruce, V., and Valentine, T. (1986). Semantic priming of familiar faces. Q. J. Exp. Psychol. 38, 125–150.
Burton, A. M. (1994). Learning new faces in an interactive activation and competition model. Vis. Cogn. 1, 313–348.
Burton, A. M., Bruce, V., and Hancock, P. J. (1999). From pixels to people: a model of familiar face recognition. Cogn. Sci. 23, 1–31.
Burton, A. M., Bruce, V., and Johnston, R. A. (1990). Understanding face recognition with an interactive activation and competition model. Br. J. Psychol. 81, 361–380.
Caramazza, A., and Shelton, J. R. (1998). Domain-specific knowledge systems in the brain the animate-inanimate distinction. J. Cogn. Neurosci. 10, 1–34.
Carson, D. R., and Burton, A. M. (2001). Semantic priming of person recognition: categorical priming may be a weaker form of the associative priming effect. Q. J. Exp. Psychol. 1155–1179.
Collins, A., and Quillian, M. (1969). Retrieval time from semantic memory. J. Verbal Learn. Verbal Behav. 8, 240–247.
Darling, S., Martin, D., and Macrae, C. N. (2010). Categorical proactive interference effects occur for faces. Eur. J. Cogn. Psychol. 22, 1001–1009.
Darling, S., and Valentine, T. (2005). The categorical structure of semantic memory for famous people: a new approach using release from proactive interference. Cognition 96, 35–65.
de Haan, E. H. F., Young, A., and Newcombe, F. (1987). Face recognition without awareness. Cogn. Neuropsychol. 4, 385–415.
Fischler, I. (1977). Semantic facilitation without association in a lexical decision task. Mem. Cognit. 5, 335–339.
Gardiner, J., Craik, F., and Birtwistle, J. (1972). Retrieval cues and release from proactive inhibition. J. Verbal Learn. Verbal Behav. 11, 778–783.
Kay, J., and Hanley, J. R. (1999). Person-specific knowledge and knowledge of biological categories. Cogn. Neuropsychol. 16, 171–180.
Kay, J., and Hanley, J. R. (2002). Preservation of memory for people in semantic memory disorder: further category-specific semantic dissociation. Cogn. Neuropsychol. 19, 113–133.
Lupker, S. (1988). Picture naming: an investigation of the nature of categorical priming. J. Exp. Psychol. Learn. Mem. Cogn. 14, 444–455.
McClelland, J., and Rumelhart, D. E. (1990). Explorations in Parallel Distributed Processing: A Handbook of Models, Programs, and Exercises. Boston, MA: MIT Press.
McNeill, A., and Burton, A. M. (2002). The locus of semantic priming effects in person recognition. Q. J. Exp. Psychol. 55, 1141–1156.
Meyer, D., and Schvaneveldt, R. (1971). Facilitation in recognizing pairs of words: evidence of a dependence between retrieval operations. J. Exp. Psychol. Learn. Mem. Cogn. 90, 227–234.
Miceli, G., Capasso, R., Daniele, A., Esposito, T., Magarelli, M., and Tomaiuolo, F. (2000). Selective deficit for people’s names following left temporal damage: an impairment of domain-specific conceptual knowledge. Cogn. Neuropsychol. 17, 489–516.
Neely, J. H., Keefe, D. E., and Ross, K. L. (1989). Semantic priming in the lexical decision task: roles of prospective prime-generated expectancies and retrospective semantic matching. J. Exp. Psychol. Learn. Mem. Cogn. 15, 1003–1019.
R Development Core Team. (2010). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Rhodes, G., and Tremewan, T. (1993). The Simon then Garfunkel effect: semantic priming, sensitivity, and the modularity of face recognition. Cogn. Psychol. 25, 147–187.
Rosch, E. (1975). Cognitive representations of semantic categories. J. Exp. Psychol. Gen. 104, 192–233.
Stanhope, N., and Cohen, G. (1993). Retrieval of proper names: testing the models. Br. J. Psychol. 84, 51–65.
Stone, A. (2008). Categorical priming of famous person recognition: a hitherto overlooked methodological factor can resolve a long-standing debate. Cognition 108, 874–880.
Stone, A., and Valentine, T. (2007). The categorical structure of knowledge for famous people (and a novel application of centre-surround theory). Cognition 104, 535–564.
Wiese, H., and Schweinberger, S. R. (2008). Event-related potentials indicate different processes to mediate categorical and associative priming in person recognition. J. Exp. Psychol. Learn. Mem. Cogn. 34, 1246–1263.
Wiese, H., and Schweinberger, S. R. (2011). Accessing semantic person knowledge: temporal dynamics of nonstrategic categorical and associative priming. J. Cogn. Neurosci. 23, 447–459.
Keywords: interactive activation and competition model, person recognition, semantic priming, face recognition, biographical priming
Citation: Ihrke M and Brennen T (2011) Sharing one biographical detail elicits priming between famous names: empirical and computational approaches. Front. Psychology 2:75. doi: 10.3389/fpsyg.2011.00075
Received: 25 February 2011;
Paper pending published: 16 March 2011;
Accepted: 08 April 2011;
Published online: 06 May 2011.
Edited by:
Andreas B. Eder, University of Wuerzburg, GermanyCopyright: © 2011 Ihrke and Brennen. This is an open-access article subject to a non-exclusive license between the authors and Frontiers Media SA, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and other Frontiers conditions are complied with.
*Correspondence: Matthias Ihrke, Department for Nonlinear Dynamics, Max Planck Institute for Dynamics and Self-Organization, Bunsenstrasse 10, 37075 Göttingen, Germany. e-mail:aWhya2VAbmxkLmRzLm1wZy5kZQ==