
 Wolfgang Mann1,2
Wolfgang Mann1,2
- 1 Department of Language and Communication Science, City University London, London, UK
- 2 Deafness, Cognition and Language Research Centre, University College London, London, UK
A commentary on
Looking for an explanation for low sign span: is order involved?
by Gozzi, M., Geraci, C., Cecchetto, C., Perugini, M., and Papagno, C. (2010). J. Deaf Stud. Deaf Educ. 16, 101–107.
“Working memory, deafness and sign language,” in The Handbook of Deaf Studies, Language and Education
by Hall, M., and Bavelier, D. (2010). 458–472.
The higher short-term memory (STM) capacity for spoken language compared to signed language is well-documented: speakers have a digit span of 7 ± 2, signers only 5 ± 1 (see Hall and Bavelier, 2010, for a review). A consensus has been developing that speech is “special” in supporting the temporal sequencing of linguistic information, giving spoken-language users a serial recall advantage (e.g., Bavelier et al., 2008; Conway et al., 2009). The “speech supports temporal sequencing” hypothesis predicts that the difference between signed and spoken languages should disappear in tasks that do not require recall of a sequence of signs. However, recent data from a non-sign repetition task do not support this prediction.
We created a sign language equivalent of the non-word repetition task, a task widely used to investigate phonological STM in speakers. Test items were phonotactically plausible but meaningless signs, manipulated for complexity of handshape and movement (Mann et al., 2010). Importantly, serial recall was not involved in this task. At most, a non-sign contained a change from one handshape to another or from one location to another (or both). We tested 91 deaf children aged 3–11 years, divided into three age-bands. All had early and continued regular exposure to BSL, comprehension skills within the normal range (as measured by the BSL Receptive Skills Test; Herman et al., 1999), normal nonverbal cognitive development and no identified special educational need additional to deafness. The task proved to be surprisingly difficult, with low scores across the age groups in comparison to results from non-word repetition studies of hearing, English-speaking children of equivalent ages, including those for whom English is an additional language (Figure 1).
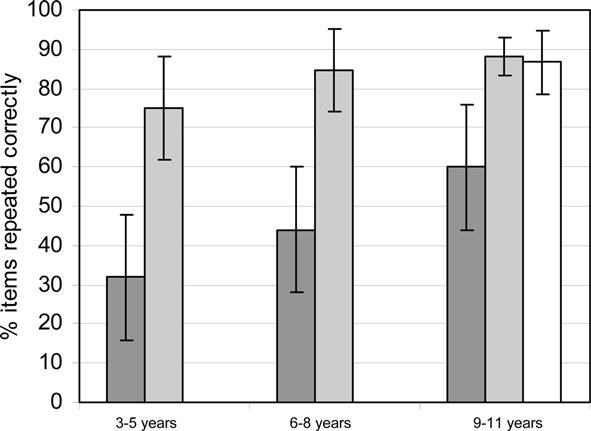
Figure 1. Comparison between performance on the non-sign repetition test and studies of non-word repetition in English. Bars show SD.  Non-sign repetition, Mann et al., 2010;
Non-sign repetition, Mann et al., 2010;  Non-word repetition, native English speakers; • At age 3–5 years: Roy and Chiat, 2004. Age: 3 years; • At age 6–8 years: Gathercole and Baddeley, 1990. Age: 6–7; • At age 9–11 years: Archibald and Gathercole, 2006. Age: 7–11, mean 9;
Non-word repetition, native English speakers; • At age 3–5 years: Roy and Chiat, 2004. Age: 3 years; • At age 6–8 years: Gathercole and Baddeley, 1990. Age: 6–7; • At age 9–11 years: Archibald and Gathercole, 2006. Age: 7–11, mean 9;  Non-word repetition, children with English as an additional language; • At age 9–11 years: Kohnert et al., 2006. Age: 7–13, mean 9.
Non-word repetition, children with English as an additional language; • At age 9–11 years: Kohnert et al., 2006. Age: 7–13, mean 9.
Generally, signs are of longer average duration than words, so we measured the duration of a selection of 3 and 4 syllable non-words used in a new non-word repetition study (Marshall et al., 2011). Duration for non-words ranged from 0.97 to 1.36 s and non-signs were slightly longer, with a mean duration of 1.31 s for phonologically simple and 1.35 s for phonologically complex non-signs (overall range 1–1.84 s). Is it possible that non-signs are more difficult to repeat because of these differences in temporal duration? After all, hearing children are less successful at repeating longer non-words (for a review, see Gathercole, 2006). For hearing children, STM capacity increases rapidly throughout childhood, and at the age of 3 years it is already equal to about 3 digits (Chi, 1977). Yet, in non-sign and non-word repetition tasks, stimuli are presented singly and not in a span, so there is no new material to block rehearsal, and our stimuli do not exceed the estimated 2 s of available time capacity in STM (Baddeley et al., 1975). Rather than duration, we argue that the way in which phonological material is structured is likely to be a more important limiting factor in repetition.
The “speech supports temporal processing” view has recently been modified by Hall and Bavelier (2010), who argue that the advantage for speech arises from speakers being more likely to rely on the temporal chunking of units and on articulatory rehearsal. Under this more nuanced view, they might predict that the repetition of non-signs would be disadvantaged relative to the repetition of non-words because the latter benefit from the chunking of temporally adjacent units. However, in a direct comparison between serial recall and non-word repetition Archibald and Gathercole (2007) found that there was a role for phonology in explaining individual differences in non-word repetition accuracy above and beyond the impact of serial recall. We suggest therefore that STM differences between signed and spoken languages are not due solely to the advantages offered by temporal chunking, but also to differences in phonological structure. Here we speculate as to what those differences might be.
Gozzi et al. (2011) propose a “same store, bigger units” explanation, according to which “signs are ultimately more difficult to retain because they are phonologically heavier than words” (p. 6). They suggest that signed material is “heavier” because even the simplest syllable requires the signer to process information about the four formational parameters of a sign, namely handshape, orientation, movement, and location. In contrast, they argue, a spoken-language syllable can consist of just a single vowel (for example, the spoken forms of the English words “eye” and “oh!”).
That may be the case, but in non-words the amount of phonological material to be remembered is considerably larger than just a vowel. However, there are formational constraints on the construction of spoken syllables: from the inventory of sounds that a language allows its words to be built from, only a subset of those sounds can occur in word-initial, middle, and final positions. In contrast, it is not clear that there are equivalent limits on the permutations of handshape, orientation, movement and location within signs. While there are well-formedness constraints on signs in terms of how many parameters can be combined (e.g., one specified handshape or location change) there do not appear to be restrictions, for example, on which handshapes can occur with which locations (Orfanidou et al., 2010). As a result, signers have to be prepared to encounter many possible combinations of each formational parameter while processing novel signs, rather than following predictive routes. Furthermore, with respect to the phonological features that make up phonemes and sign parameters, signed languages have arguably around twice as many features as spoken languages (Sandler, 2008).
We speculate that these differences in structural organization between signed and spoken phonology mean that signers, when faced with an unfamiliar sign, have to monitor a larger repertoire of parameter values and parameter combinations. One way of construing “phonological heaviness” is in terms of there being more “degrees of freedom” in the phonological composition of a sign. Having fewer limits on what to expect in terms of the linguistic input’s phonological form imposes a greater STM load. Thinking in terms of “degrees of freedom” also makes predictions for non-word repetition in spoken languages. Speakers of languages with larger inventories of segments, syllable types, and metrical patterns (and therefore arguably less predictability in terms of how segments are sequenced and where stress falls) might repeat non-words less accurately than speakers of languages with smaller inventories, all other characteristics (e.g., syllable number) being equal.
The “degrees of freedom” hypothesis needs fleshing out, but it has promise in helping us to understand why modality differences in STM exist, and why STM deals particularly effectively with speech.
Acknowledgments
Chloë R. Marshall is funded by a Leverhulme Trust Early Career Fellowship, Wolfgang Mann by a City University London Research Fellowship, and Gary Morgan by the Economic and Social Research Council of Great Britain (Grant 620-28-600 Deafness, Cognition and Language Research Centre).
References
Archibald, L., and Gathercole, S. (2006). Non-word repetition: a comparison of tests. J. Speech Lang. Hear. Res. 49, 970–983.
Archibald, L., and Gathercole, S. (2007). Non-word repetition in specific language impairment: more than a phonological short-term memory deficit. Psychon. Bull. Rev. 14, 919–924.
Baddeley, A., Thomson, N., and Buchanan, M. (1975). Word length and the structure of short term memory. J. Verbal Learn. Verbal Behav. 14, 575–589.
Bavelier, D., Newport, E., Hall, M., Supalla, T. S., and Boutla, M. (2008). Ordered short-term memory differs in signers and speakers: implications for models of short-term memory. Cognition 107, 433–459.
Conway, C., Pisoni, D., and Kronenberger, W. (2009). The importance of sound for cognitive sequencing abilities: the auditory scaffolding hypothesis. Curr. Dir. Psychol. Sci. 18, 275–279.
Gathercole, S. (2006). Non-word repetition and learning: the nature of the relationship. Appl. Psycholinguist. 27, 513–543.
Gathercole, S., and Baddeley, A. (1990). Phonological memory deficits in language disordered children: is there a causal connection? J. Mem. Lang. 29, 336–360.
Gozzi, M., Geraci, C., Cecchetto, C., Perugini, M., and Papagno, C. (2011). Looking for an explanation for low sign span: is order involved? J. Deaf Stud. Deaf Educ. 16, 101–107.
Hall, M., and Bavelier, D. (2010). “Working memory, deafness and sign language,” in The Handbook of Deaf Studies, Language and Education, Vol. 2, eds M. Marschark and P. E. Spencer (Oxford: Oxford University Press), 458–472.
Herman, R., Holmes, S., and Woll, B. (1999). Assessing British Sign Language Development: Receptive Skills Test. Gloucestershire: Forest Bookshop.
Kohnert, K., Windsor, J., and Yim, D. (2006). Do language-based processing tasks separate children with primary language impairment from typical bilinguals? Learn. Disabil. Res. Pract. 21, 19–29.
Mann, W., Marshall, C. R., Mason, K., and Morgan, G. (2010). The acquisition of sign language: the impact of phonetic complexity on phonology. Lang. Learn. Dev. 6, 60–86.
Marshall, C. R., Payne, H., and Williams, D. (2011). “Non-word repetition as a tool for investigating disorders that are comorbid with SLI,” in European Child Language Disorders Workshop, Thessaloniki, Greece.
Orfanidou, E., Adam, R., Morgan, G., and McQueen, J. M. (2010). Segmentation in signed and spoken language: different modalities, same segmentation procedures. J. Mem. Lang. 62, 272–283.
Citation: Marshall CR, Mann W and Morgan G (2011) Short-term memory in signed languages: not just a disadvantage for serial recall. Front. Psychology 2:102. doi: 10.3389/fpsyg.2011.00102
Received: 21 December 2010;
Accepted: 09 May 2011;
Published online: 18 May 2011.
Copyright: © 2011 Marshall, Mann and Morgan. This is an open-access article subject to a non-exclusive license between the authors and Frontiers Media SA, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and other Frontiers conditions are complied with.
*Correspondence: e-mail:Y2hsb2UubWFyc2hhbGwuMUBjaXR5LmFjLnVr