

- Department of Psychology, Goldsmiths, University of London, London, UK
Congenital amusia is a lifelong disorder whereby individuals have pervasive difficulties in perceiving and producing music. In contrast, typical individuals display a sophisticated understanding of musical structure, even in the absence of musical training. Previous research has shown that they acquire this knowledge implicitly, through exposure to music’s statistical regularities. The present study tested the hypothesis that congenital amusia may result from a failure to internalize statistical regularities – specifically, lower-order transitional probabilities. To explore the specificity of any potential deficits to the musical domain, learning was examined with both tonal and linguistic material. Participants were exposed to structured tonal and linguistic sequences and, in a subsequent test phase, were required to identify items which had been heard in the exposure phase, as distinct from foils comprising elements that had been present during exposure, but presented in a different temporal order. Amusic and control individuals showed comparable learning, for both tonal and linguistic material, even when the tonal stream included pitch intervals around one semitone. However analysis of binary confidence ratings revealed that amusic individuals have less confidence in their abilities and that their performance in learning tasks may not be contingent on explicit knowledge formation or level of awareness to the degree shown in typical individuals. The current findings suggest that the difficulties amusic individuals have with real-world music cannot be accounted for by an inability to internalize lower-order statistical regularities but may arise from other factors.
Introduction
Research into developmental disorders seeks to explain why basic abilities that are acquired effortlessly by most humans prove difficult for others. The capacity to perceive music is one such example. While the ability to make sense of music is recognized as a fundamental human trait (Blacking, 1995), an estimated 4% of the population have pervasive and lifelong difficulties in this domain (Kalmus and Fry, 1980). Such individuals cannot discriminate between different melodies, recognize music that should be familiar to them without the aid of lyrics, detect anomalous pitches in familiar and unfamiliar melodies or judge dissonance in musical excerpts (Ayotte et al., 2002; Peretz et al., 2003). The presence of this disorder, termed “congenital amusia,” is typically ascertained using a diagnostic tool known as the Montreal battery for the evaluation of amusia (MBEA: Peretz et al., 2003) and cannot be explained by peripheral hearing problems or general cognitive deficits (Ayotte et al., 2002; Peretz et al., 2002).
The lack of facility these individuals have with music urges us to consider how the more typical human capacity to perceive music comes about. Music is composed of a small set of elements which combine to form complex hierarchical structures (Lerdahl and Jackendoff, 1983; Bod, 2002). Despite this level of complexity, it appears that almost all humans possess knowledge of musical structure (Bigand and Poulin-Charronnat, 2006). In individuals without musical training, such knowledge is implicit and cannot be verbalized, but studies which probe listeners’ musical expectations find that non-musicians are just as sensitive as formally trained musicians to many aspects of musical structure (Cuddy and Badertscher, 1987; Hebert, Peretz and Gagnon, 1995; Schellenberg, 1996; Honing and Ladinig, 2009; Marmel and Tillmann, 2009). Importantly, listeners acquire this knowledge in an incidental manner and without any awareness of their doing so, in a process commonly referred to as “implicit learning” (Reber, 1992).
A growing body of work suggests that the implicit learning of the musical knowledge that is possessed by most listeners is acquired via the internalization of statistical regularities (Smith et al., 1994; Tillmann et al., 2000; Tillmann and McAdams, 2004; Jonaitis and Saffran, 2009), which confers sensitivity to several aspects of musical structure that can be demonstrated across a range of musical tasks. These include making subjective ratings on goodness of fit, melodic expectation, and goodness of completion (Krumhansl and Keil, 1982; Cuddy and Badertscher, 1987; Schmuckler, 1989; Brown et al., 1994; Toiviainen and Krumhansl, 2003) as well as demonstrating sensitivity to musical tensions and relaxations in sequences of chords (Bigand et al., 1996; Bigand and Parncutt, 1999).
One paradigm, originating in the language acquisition literature, has been particularly influential in demonstrating the ability of listeners to compute the statistical properties of their auditory environment. Saffran et al. (1996) demonstrated that adult listeners exposed to a nonsense speech language comprised of tri-syllabic units (which, from now on, will be referred to as “words,” following Saffran et al., 1996) were able to discover boundaries between these words by computing the transitional probabilities between adjacent syllables. The authors showed that even though the speech stream was continuous, with no temporal cues between adjacent words, listeners in a later test phase were able to successfully discriminate between words in the language they had been exposed to versus foils containing the same syllables, which were arranged in a different order (so called “non-words”). In a separate experiment, the authors demonstrated that listeners were also able to discriminate between words and foils in which either the first or third syllable in a word from the language had been substituted with a different syllable (so called “part-words”). Importantly for the present research, in an analogous study using tonal sequences, the authors reported that the learning mechanism by which listeners carried out this sequence segmentation was not confined to linguistic materials. Saffran et al. (1999) presented participants with a continuous tone stream comprised of tone-triplet units (which the authors termed “tone words”) made up of musical notes from the octave above middle C. They showed that after 21 min of exposure, listeners were able to distinguish the tone words they had been exposed to from both non-word and part-word foils. While this paradigm focuses on transitional probabilities between adjacent tone elements, other paradigms have also examined listeners’ sensitivity to transitional probabilities within sequences of harmonic elements (Jonaitis and Saffran, 2009), pitch intervals (Saffran and Griepentrog, 2001), and timbral elements (Tillmann and McAdams, 2004), the statistical learning of non-adjacent dependencies in tonal stimuli (Creel et al., 2004; Kuhn and Dienes, 2005; Gebhart et al., 2009), and the facilitative effect of musical information on language learning (Schön et al., 2008). Taken together, results from these studies show that listeners require only a limited amount of exposure to internalize the statistical properties of a completely novel musical system.
Evidence that musical competencies arise largely from implicit learning of regularities in our musical environment suggests at least two testable hypotheses concerning the nature of musical deficits in congenital amusia. One hypothesis may be that such individuals lack the learning mechanism that permits internalization of regularities from a structured sound stream. The disproportionate difficulties seen with music, as opposed to language, would predict that a faulty learning mechanism would be restricted to tonal, rather than linguistic material. A second hypothesis may be that the learning mechanism is intact, but a difficulty in detection and/or discrimination of small pitch changes is the limiting factor in building up knowledge of musical structure.
The present study addressed these hypotheses, by testing a group of amusic and control participants on their ability to internalize the regularities present in structured linguistic and tonal materials, given equal amounts of exposure. Following the paradigm used by Saffran et al. (1996, 1999) our participants were exposed to streams made up of words comprised of either syllables or tones. Critically, only the statistical properties within the stream served as a reliable cue as to the location of word boundaries. In a subsequent test phase, participants were then required to demonstrate their knowledge of these word boundaries, by distinguishing between words they had heard in the exposure phase and non-words, which were comprised of identical syllables or tones that were arranged in a different temporal order. Two types of tonal material were used. In the first, intervals within the tone sequence exceeded psychophysically measured thresholds across the amusic group (“supra-threshold” condition) while in the second (“sub-threshold” condition) intervals within the tone sequence were smaller, including a semitone. According to the literature, many amusics have difficulty with the detection and/or discrimination of pitch direction around this level (Foxton et al., 2004; Hyde and Peretz, 2004; Liu et al., 2010).
If general learning mechanisms are compromised, we would predict inferior learning across all conditions in the amusic group. If learning mechanisms are compromised for tonal material only, we would predict inferior learning for both tonal conditions in the amusic group but equivalent learning across both groups with the linguistic material. Finally, if learning mechanisms are intact, for both linguistic and tonal material, but the learning of amusics is limited by a poor sensitivity to pitch change, we would predict equivalent learning in both groups for the linguistic material and for the supra-threshold tonal condition, but inferior learning for the sub-threshold tonal condition.
In addition to recording accuracy rates for the above tasks, we also collected binary confidence judgments on a trial-to-trial basis for the sub-threshold tonal condition. Recent studies have suggested that amusia may be a disorder of awareness, rather than perception, i.e., such individuals can represent pitch changes adequately, but these do not reach conscious awareness, resulting in poor performance on tests which probe musical perception explicitly (Peretz et al., 2009; Hyde et al., 2011). Such a hypothesis would predict that even if amusics and controls show comparable learning, as indicated by equivalent accuracy in identifying words they had been previously exposed to, individuals with amusia may show a bias toward reporting low confidence compared to control individuals.
Materials and Methods
Participants
A total of 24 participants (12 amusic, 12 control) took part in this study. All participants were recruited via an online assessment based on the scale and rhythm subtest of the MBEA (Peretz et al., 2003)1. Each participant took the online test twice and if they consistently achieved a score of 22/30 or less, they were invited to come in to the lab where assessment could take place under controlled conditions. Each participant was administered four MBEA sub-tests (scale, contour, interval, and rhythm sub-tests) in a sound-attenuated booth in order to confirm the presence or absence of amusia. Previous research had shown that amusia is characterized by poor perception in the pitch-based sub-tests of the MBEA (scale, contour, interval) while only half of them typically show a deficit in the rhythm test (Peretz et al., 2003). Thus we calculated a composite score for the three pitch-based sub-tests, using 65 out of 90 as a cut off score, whereby individuals were classified as amusic if their composite score fell below this value (Peretz et al., 2003; Liu et al., 2010). The amusic and control sample were matched on age, gender, score on the national adult reading test (NART: Nelson and Willison, 1991), Digit span (Weschler adult intelligence scale, WAIS: Wechsler, 1997), number of years of formal education and number of years of musical education. In addition, two pitch threshold tasks were conducted. A pitch change detection task and a pitch direction discrimination task, both employing a two-alternative forced-choice AXB adaptive tracking procedure with pure tones, were used to assess thresholds for the detection of a simple pitch change and the discrimination of pitch direction respectively (see Liu et al., 2010 for further details). Table 1 provides background information on the two groups, while Table 2 provides mean scores on the MBEA sub-tests and pitch thresholds. In addition to performing significantly worse on four sub-tests of the MBEA, the current cohort of amusic individuals differed significantly in their thresholds for the discrimination of pitch direction (Controls: M = 0.18, SD = 0.08, Range = 0.09–0.33; Amusics: M = 1.05, SD = 1.07, Range = 0.10–2.97). However the two groups did not differ significantly in thresholds for the detection of a pitch change with only one amusic individual having a threshold above one semitone (Controls: M = 0.15, SD = 0.06, Range = 0.08–0.26; Amusics: M = 0.27, SD = 0.33, Range = 0.07–1.29).
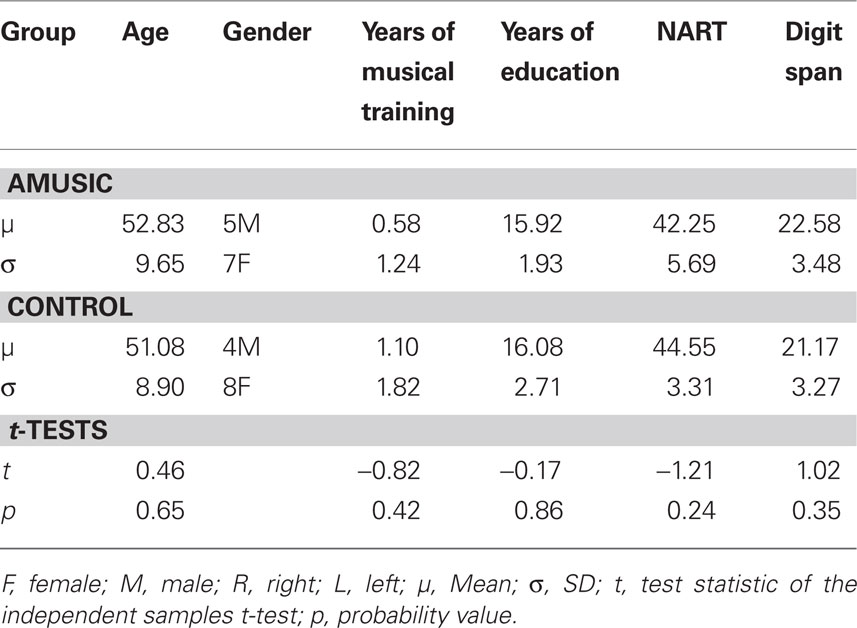
Table 1. Amusic and control participant characteristics; summary of the two groups in terms of their mean age, gender, years of musical training, and education, NART and total digit span (forward and backward).
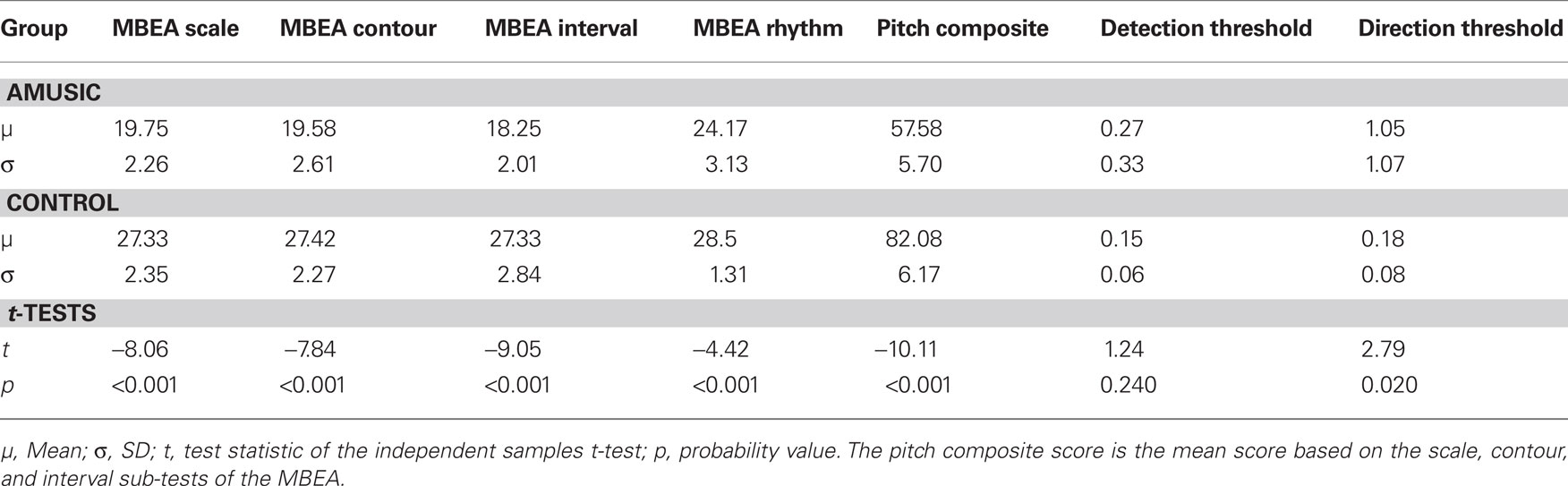
Table 2. Mean scores of the amusic and control groups on sub-tests of the Montreal Battery for the evaluation of amusia (MBEA). A pitch composite score below the cut off of 65 out of 90 was considered to be diagnostic of amusia.
Stimuli
Stimuli for the three conditions (linguistic, supra-threshold tonal, and sub-threshold tonal conditions) were based on those used by Saffran et al. (1996, 1999). The linguistic sequences were created from 11 syllables obtained by pairing the consonants p, t, b, and d with the vowels a, i, and u. Syllabic sounds were excised from the recorded speech of a native English speaker who was required to read aloud a string of words in which the required syllables were inserted. All pitch information was subsequently removed from the syllable sounds using Praat software (Boersma, 2001). Subsequently, the syllable sounds were stretched or compressed (as necessary) to a fixed duration of 280 ms using Audacity software2.
Figure 1 shows the frequencies used in both tonal conditions. Following Saffran et al. (1999), the sub-threshold sequences were constructed from eleven tones drawn from the chromatic scale beginning at C4 (261.3 Hz). As in Saffran et al. (1999), all the tones from C4 to B4 were used, excluding A#. The supra-threshold sequences were constructed from a novel scale with unfamiliar interval sizes, obtained by dividing the two-octave span from C4 (261.3 Hz) into 11 evenly log-spaced divisions. Thus, the 11 tones in the sub-threshold condition were generated using the formula: Frequency (Hz) = 261.63*2^ n/12, with n referring to the number of steps along the chromatic scale (0–9, 11) while the 11 tones in the supra-threshold condition followed the formula: Frequency (Hz) = 261.63*4^ n/11, where n is the number of equal sized steps along the new scale (0–10). Consequently, the tones used in the sub-threshold tonal condition were 261.63, 277.18, 293.66, 311.13, 329.63, 349.23, 369.99, 392.00, 415.30, 440, and 493.88 Hz while those used in the supra-threshold tonal condition were 261.63, 296.77, 336.63, 381.84, 433.13, 491.31, 557.29, 632.14, 717.05, 813.36, and 922.60 Hz. All tones were sine tones generated in Matlab3 with a duration of 330 ms and an envelope rise and fall time of 10 ms on either side.
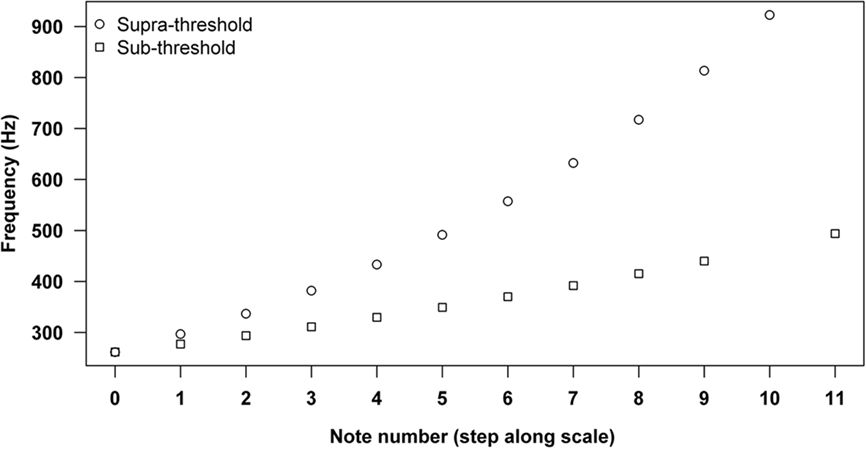
Figure 1. Frequency of tones used in the sub-threshold and supra-threshold tonal conditions. Note numbers 0–9 and 11 in the sub-threshold condition correspond to C4 to A4 and B4 while note numbers 0–10 in the supra-threshold condition correspond to tones from a novel scale obtained by dividing the two-octave span from C4 (261.3 Hz) into 11 evenly log-spaced divisions.
Language construction
For all conditions (linguistic, supra-threshold tonal, sub-threshold tonal), two languages analogous in statistical structure were prepared to ensure that any potential learning could not be accounted for by idiosyncratic aspects of one language in particular. Both languages were comprised of the same elements that had been arranged to make different words, and differed only in the transitional probabilities between elements of the words (see Saffran et al., 1999 for further details). For half the participants of each group, language 1 was used in the listening phase, and words from language 2 were used as the non-word foils during the test phase, while the opposite was the case for the remaining participants.
Each language comprised six words. In language 1 of the linguistic condition, the six words used were babupu, bupada, dutaba, patubi, pidabu, and tutibu while in language 2, they were batida, bitada, dutupi, tipuba, tipabu, and tapuba. In the sub-threshold tonal condition, language 1 comprised of six tone words taken from the chromatic scale beginning at C4; ADB, DFE, GG#A, FCF#, D#ED, and CC#D whilst language 2 comprised of a different set of six tone words from the chromatic scale beginning at C4; AC#E, F#G#E, GCD#, C#BA, C#FD, G#BA. To create tone words that were analogous in structure across the two tonal conditions, words in the supra-threshold condition were created by substituting frequencies in the sub-threshold words with frequencies from the novel scale that corresponded in terms of the number of steps from C4. Tone words in the two conditions were identical in pattern and differed only in the actual frequencies, and consequently the size of interval occurring between adjacent tones (Figure 2).
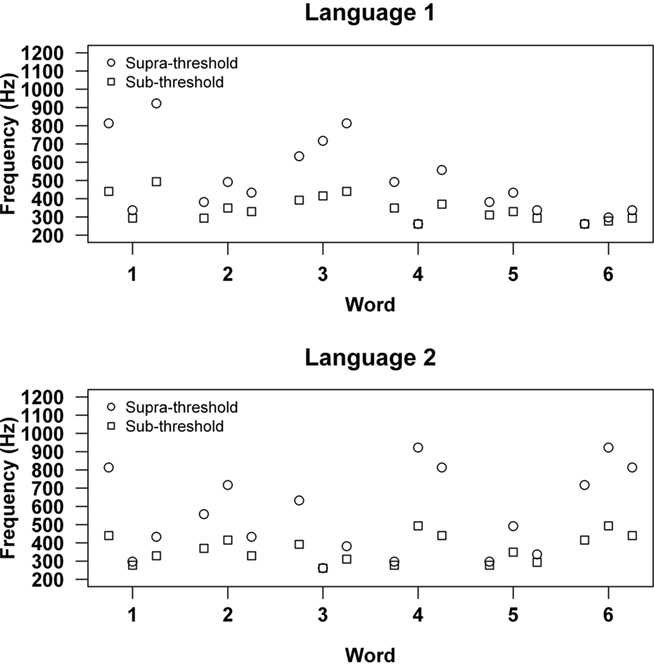
Figure 2. Tone words used in language 1 and language 2 for the sub-threshold and supra-threshold tonal conditions. For the sub-threshold conditions, these correspond to ADB, DFE, GG#A, FCF#, D#ED, and CC#D in language 1 and AC#E, F#G#E, GCD#, C#BA, C#FD, G#BA in language 2. For the supra-threshold conditions, these correspond to tone-triplets composed using a novel scale obtained by dividing the two-octave span from C4 (261.3 Hz) into 11 evenly log-spaced divisions.
Sequence concatenation
To create each sequence, the six words from the given language were concatenated in random order to create six different blocks containing 18 words each. Concatenation adhered to two strict conditions; that a word could not follow itself and that there were no silent gaps between words. The six blocks created in this way were then further concatenated to create sequences consisting of 432 words (72 tokens of each word). As the sequences in the tonal conditions consisted of units with a duration of 330 ms, these lasted approximately 7 min. The sequences in the linguistic condition, consisting of syllable sounds of 280 ms length, were approximately 6 min long.
Procedure
Participants gave written consent to participate in the experiments, which were approved by the Ethics Committee at Goldsmiths, University of London. All experiments were conducted in a sound-attenuated booth. Sounds for the listening and test phase were presented through an external sound card (Edirol UA-4FX USB Audio Capture) at a fixed intensity level of 73 dB using Sennheiser headphones HD 202. Programs for stimulus presentation and the collection of data were written in Matlab4.
As languages in the sub-threshold and supra-threshold tonal conditions comprised analogous words (but over a different frequency range), it was important to eliminate any potential carryover effects between the conditions. This was achieved by splitting each group in two such that one half of each group was exposed to language 1 of the linguistic condition, language 2 of the supra-threshold tonal condition and language 1 of the sub-threshold tonal condition while the other half of each group was exposed to language 2 of the linguistic condition, language 1 of the supra-threshold tonal condition and language 2 of the sub-threshold condition.
To avoid fatigue effects, testing took place over two sessions. In the first session, participants were run on the supra-threshold tonal condition and on the linguistic condition. The order in which the conditions were presented to participants was counterbalanced for both the amusic and control groups. The linguistic and tonal conditions were separated by a period in which participants carried out a completely unrelated task. The second testing session was carried out on a different day on average 7 months later. In these sessions, participants were run on the sub-threshold tonal condition only.
Exposure lasted approximately 21 min in total for the tonal conditions and 18 min for the linguistic condition. Instructions for all three conditions were identical for the listening phase. Participants were told that they would hear a stream of sounds. They were asked to avoid analyzing the stream but also to refrain from blocking out the sounds as they would be tested on what they had heard afterward. They were then presented with three blocks of one of the sound sequences described previously with the opportunity for a short break between blocks.
Immediately after the exposure phase, the testing phase commenced, starting with three practice trials. Participants were then presented with 36 trials. Each trial comprised two words; one of which they had heard during exposure and another which had the same constituent parts, but which had not appeared in combination during the exposure phase. For all three conditions, the 36 trials were created by exhaustively pairing the six words from both languages such that on each trial participants exposed to opposing languages were expected to select opposing items. Within a trial, words were presented with a 750-ms inter-stimulus interval and there was an inter-trial interval of 5 s during which the participant was required to make their response.
On each trial of the test phase for the conditions run in the first session (the linguistic condition and the supra-threshold tonal condition), the participant’s task was to indicate, using the computer keyboard, which word (the first or the second) in the pair they had heard during the exposure phase. In the second session (the sub-threshold tonal condition), participants were additionally required to indicate whether or not they were confident about their decision by responding “confident” or “not confident” immediately after. As this condition required participants to make two responses (compared to one in the previous conditions), responses in this session were entered into the computer by the experimenter so as to avoid inputting error. Two different random orders of the test trials were generated for each condition and following Saffran et al. (1999) each participant was randomly assigned to one of the two different random orders in each condition.
Results
Evidence of Learning: Performance during the Test Phase
Figure 3 shows scores for all individuals, by group, across all three conditions. As shown in Table 3, single-sample t-tests (all two-tailed) revealed an overall performance that was significantly greater than chance for both groups across all conditions. Independent sample t-tests revealed no significant differences between the scores of individuals assigned to alternative orders of the test trials in any of the three conditions (all p > 0.05) so data were treated similarly regardless of this factor.
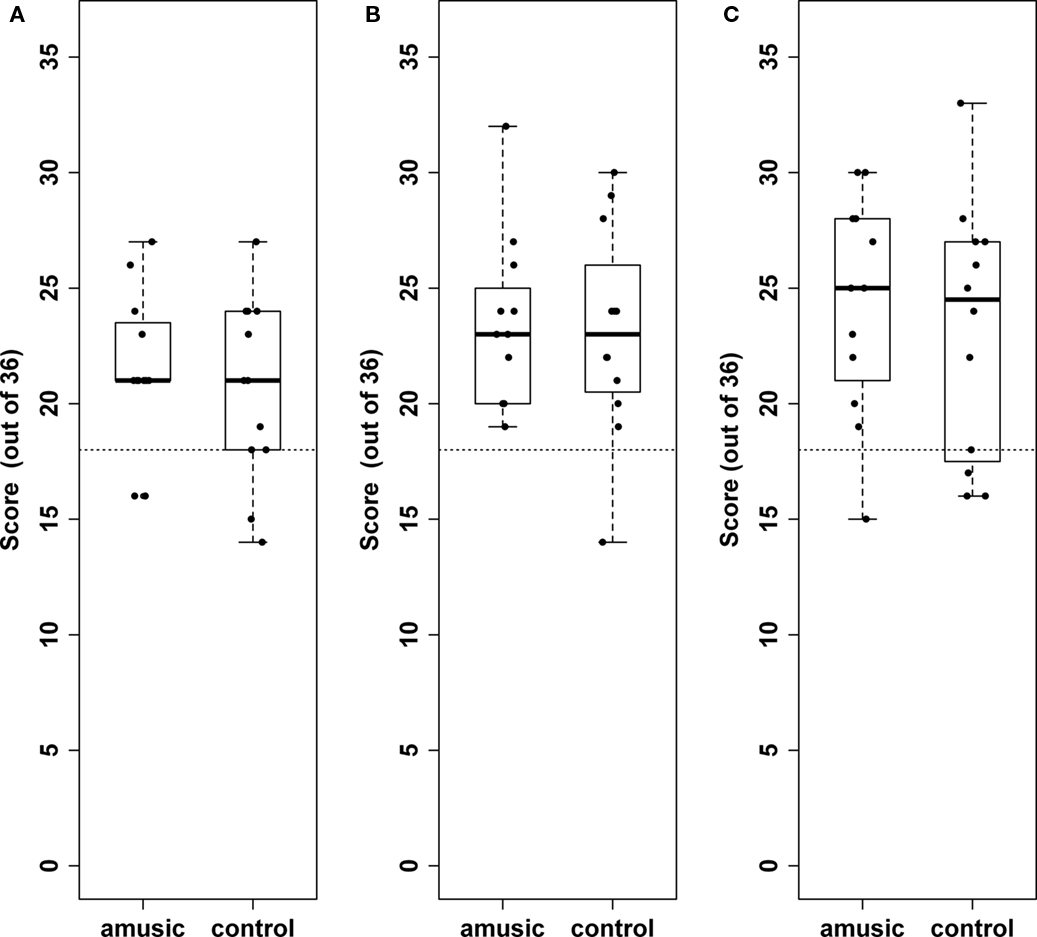
Figure 3. Boxplots showing performance on the linguistic (A) supra-threshold tonal (B) and sub-threshold tonal (C) conditions for amusic and control participants. Black dots represent an individual. Median performance is represented by the solid black bar. Chance performance is represented by the dotted line.
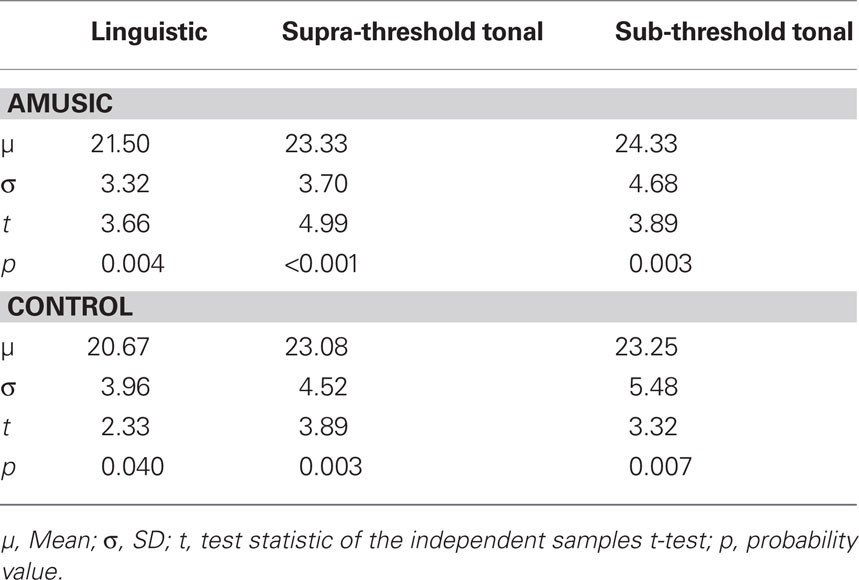
Table 3. Means, SD, and results for one sample t-tests (df = 11) against chance performance for amusic and control individuals across all three conditions.
Individual participants’ data were entered into a preliminary 2 × 2 × 3 split plot ANOVA with condition (linguistic, supra-threshold tonal, sub-threshold tonal) as a within subject factor and group (amusic, control) and language set (one, two) as between subject factors. The aim of this initial analysis was to observe any effect of the set of languages to which participants were allocated. There were no significant main effects of language set, group, or condition [Language set: F(1, 20) = 0.03, MSe = 5.69, p = 0.87, Group: F(1, 20) = 0.55, MSe = 5.69, p = 0.47; Condition: F(2, 40) = 2.48, MSe = 19.69, p = 0.10], nor were there any significant interactions (all p > 0.05).
Given that performance was not differentially affected according to the precise set of languages a participant had been allocated to, scores were collapsed across this factor to increase the power of the main analysis. A 2 × 3 split plot ANOVA with group (amusic versus control) as a between-subjects factor and condition (linguistic, supra-threshold, sub-threshold) as a within-subjects factor was carried out in order to re-assess the main effects of group and condition. No difference was found between control and amusic subjects: F(1, 22) = 0.60, MSe = 5.19, p = 0.45, or across conditions: F(2, 44) = 2.39, MSe = 20.4, p = 0.10, nor was there a significant interaction between group and condition, suggesting that both groups performed equally well on all conditions: F(2, 44) = 0.05, MSe = 20.4, p = 0.95.
Having employed a within-subjects design in the current study, further analysis investigated the possibility that repeated testing on the same individuals may have resulted in order effects during the first session, where the linguistic condition and the supra-threshold tonal condition conditions were carried within an hour of each other. However, an independent samples t-test indicated that participants who carried out the linguistic condition first did not perform any better in the supra-threshold tonal condition (M = 22.92) compared with those who carried out the supra-threshold tonal condition first [M = 23.50, t(22) = −0.035, p = 0.73].
Finally, of key interest was whether participants’ performance on the two tonal conditions could be accounted for by psychophysically measured pitch detection and pitch discrimination thresholds. Results from correlation analyses with each of the groups treated separately (Table 4), showed no significant relationship between learning and perceptual thresholds.
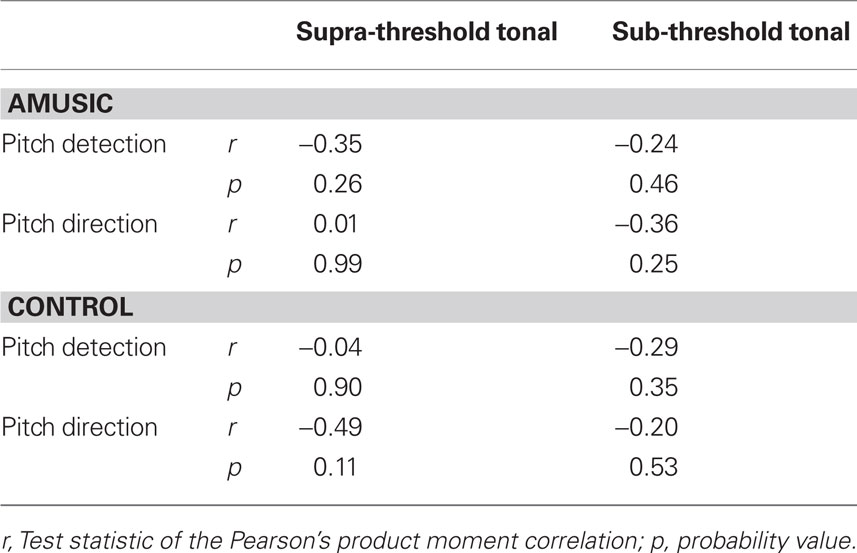
Table 4. Results of Pearson correlations (df = 10) between the overall performance of both groups in the two conditions and psychophysically measured pitch direction and discrimination thresholds.
Confidence Judgments
The next stage of analysis evaluated the degree to which participants’ confidence in their performance predicted their accuracy in the test phase of the sub-threshold task, as well as the overall bias in confidence responses reported by the two groups. Analysis of the confidence ratings given on a trial-by-trial basis was carried out using Signal Detection Theory (Green and Swets, 1966). Following previous studies employing these methods, a “hit” was considered to be a correct response with high confidence, whereas a “false alarm” was an incorrect response with high confidence (Kunimoto et al., 2001; Tunney and Shanks, 2003). Using hit and false alarm rates, computed by expressing the number of hits and false alarms as a proportion of correct and incorrect responses respectively, two key variables were extracted for each participant: their “awareness” or ability to judge whether a correct or an incorrect response had been made (the discriminability index, d′) and their tendency to favor one response (“confident” versus “not confident”) over the other (the response bias, c). The former, d′, was computed as d′ = z (hit rate) − z (false alarm rate), while the latter, c, was computed as c = −0.5 [z (hit rate) + z (false alarm rate)] (Macmillan and Creelman, 2001). A higher d′ denotes greater awareness compared with a lower one and a d′ value significantly greater than zero indicates presence of explicit knowledge. A negative value c denotes a liberal response bias (more likely to report “confident”), and a positive c value denotes a conservative response bias (less likely to report “confident”).
Table 5 shows means and SD of the hit rates, false alarm rates, d′ and c for both groups. Although the control group had a higher mean d′, an independent sample t-test revealed no difference between the groups in their ability to discriminate correct responses from incorrect ones [t(22) = −0.40, p = 0.70]. Further, neither group had a mean d′ significantly greater than zero [amusics: t(11) = 0.74, p = 0.48; controls: t(11) = 1.61, p = 0.14] suggesting that knowledge acquired was largely implicit and failed to reach full conscious awareness in both groups (Tunney and Shanks, 2003; Dienes and Scott, 2005). The next analysis examined whether there were any differences in response biases (c) between the two groups using an independent samples t-test. This revealed that the amusic group exhibited significantly greater conservatism than the control group when judging their performance [t(22) = 3.15, p < 0.01]. In order words, amusic individuals were less likely than controls to give a “confident” response.
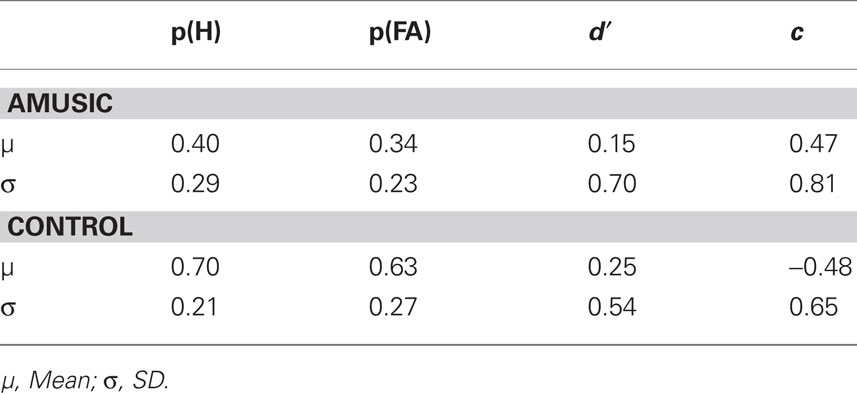
Table 5. Mean hit rates, false alarm rates, and d′ and c values for amusic and control participants.
Finally, using correlation analyses, it was investigated whether either awareness level (d′) or the response bias (c) predicted participants performance, as defined by the number of correct responses out of 36 in the test phase. No relationship was seen between the response bias and performance in either the amusic (r = −0.46, p = 0.13) or the control group (r = −0.07, p = 0.84). However, results shown in Figure 4 revealed that while controls who had a greater level of awareness were also more accurate in the test phase (r = 0.62, p = 0.03), there was no such relationship in the amusic group (r = 0.27, p = 0.40).
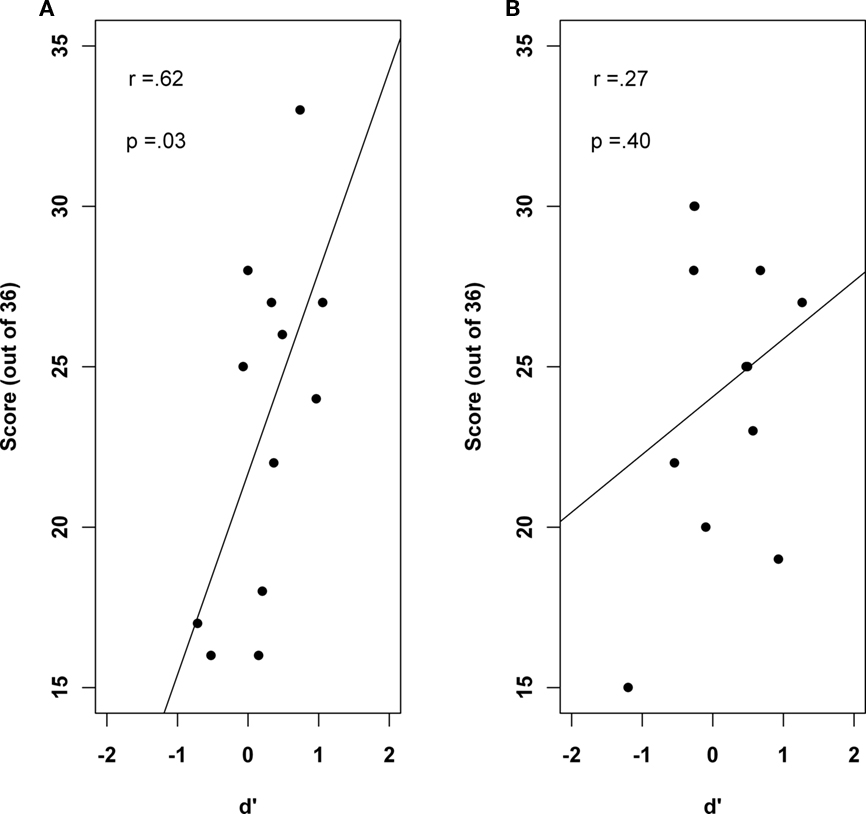
Figure 4. Scatter plot showing the significant correlation between d′ and performance for the control group (A) and the null correlation in the amusic group (B).
Discussion
The facility that typical individuals have in perceiving music is built upon long term schematic knowledge gained incidentally over a life-time of exposure to the statistical properties of one’s own musical culture (Tillmann et al., 2000). Individuals who exhibit pervasive and lifelong difficulties with music may lack such knowledge, either due to inadequate learning mechanisms, or intact learning mechanisms, which are rendered less effective owing to an insensitivity to small pitch changes. The present study aimed to distinguish between these possibilities, as well as to consider the possibility that any potential learning deficits were specific to music, rather than manifested more generally across the auditory domain.
A cohort of amusic individuals and matched controls were given equal opportunity to learn the regularities present within novel tonal and linguistic materials. In all conditions, participants were exposed to structured sequences made up of discrete “words” (tri-syllabic or tone-triplets) that were concatenated in such a manner that the only cues to where words began and ended were the transitional probabilities between adjacent syllables and tones. Following an exposure phase, participants heard pairs of words and identified which word had been present in the exposure phase. Two tonal conditions were used, spanning one and two-octaves respectively, in order to determine whether the use of small intervals could explain any potential lack of learning in the amusic group. Evidence of learning was seen across all three conditions, and equivalently for amusic individuals and controls. Interestingly neither the manipulation of pitch range (and thus interval size), nor the degree of familiarity with the tonal materials (the supra-threshold was constructed using a novel scale) had any effect on the degree of learning, for either group, and measured pitch thresholds did not correlate with the degree of learning shown by either group.
The finding of intact learning for the tonal and linguistic material suggests that difficulties in real-world music perception are unlikely to be explained in terms of a faulty learning mechanism. However, the current study has used non-word foils to assess learning in the test phase and it is possible that the use of part-word foils, which differ by just one syllable or tone, and therefore constitute a more difficult discrimination task in the test phase, would reveal more subtle deficits. Another issue worthy of consideration is that the current design involved multiple testing on the same individuals. While the use of a within-subjects design was deemed more suitable than a between-subjects design (where any observed differences across conditions could not be accounted for solely by the nature of the materials) its use resulted in a scenario whereby participants were no longer naïve to the task demands following the first experiment. It was unlikely that any transfer effects could occur between the first and second sessions, which were carried out several months apart, however we addressed the issue of repeated testing in the first session by counterbalancing the order in which individuals undertook the linguistic and supra-threshold tonal conditions. Post hoc analysis of the scores of individuals assigned to one or the other condition first verified the absence of any order effects.
The finding that learning was equivalently good for both tonal conditions is particularly striking, since previous studies have suggested that an insensitivity to pitch may lie at the heart of the disorder (Peretz et al., 2002; Foxton et al., 2004; Hyde and Peretz, 2004). The theory holds that, owing to the prevalence of small intervals in Western music (Dowling and Harwood, 1986; Vos and Troost, 1989), an insensitivity to such small intervals would have downstream effects for the acquisition of higher-order music features such as contour (Stewart et al., 2006) and the assimilation of musical scales which is central to the tonal encoding of pitch (Peretz and Hyde, 2003).
In the current cohort, only one amusic individual had a pitch detection threshold greater than a semitone. This might seem surprising given the common notion amusia arises from a fine-grained pitch discrimination problem (Hyde and Peretz, 2004). However a close examination of the literature suggests a mixed picture regarding the issue of pitch sensitivity in amusia (see Stewart, 2011). For instance, in one of the first studies to report fundamental pitch discrimination deficits in a cohort of amusic individuals, participants were required to monitor a sequence of five monotonic piano notes for a possible change in pitch at the fourth note (Hyde and Peretz, 2004). The authors reported that whilst controls were able to detect pitch intervals as small as a quarter of a semitone, amusic individuals were unable to detect a pitch change of a semitone or less. However, results from other studies have suggested that while pitch change detection is indeed worse in amusic individuals, their thresholds may be reduced to below a semitone when perception is assessed using alternative tasks. For instance, Foxton et al. (2004) and Tillmann et al. (2009) presented two pairs of sounds, one of which consisted of identical tones and the other of two tones of different frequencies, and required participants to indicate which of the two pairs differed in pitch. In a more recent study (Liu et al., 2010), participants were required to indicate whether the first or last tone in a series of three tones contained a pitch glide. The forced-choice nature of these tasks makes them “criterion-free” (Kershaw, 1985; Macmillan and Creelman, 2001) which eliminates the effect of any bias amusic individuals may have toward favoring a more conservative “no change” response. Interestingly, results from these latter studies suggest that even though thresholds for the detection of a pitch change tend to be normal when assessed using forced-choice methods, thresholds for the discrimination of pitch direction are not, with a sizeable subgroup of amusic individuals possessing thresholds of a semitone or more.
This mixed picture regarding pitch thresholds in amusia suggests that performance is highly dependent on the way in which knowledge is probed. Neuro-imaging studies have demonstrated that individuals with amusia unconsciously process pitch deviations which they are unable to report explicitly (Peretz et al., 2009; Hyde et al., 2011). Measuring electrical brain activity using EEG, Peretz et al. (2009) reported that amusic individuals, showed evidence of an early right lateralized negative brain response to notes in melodies from the MBEA which had been mistuned by a quarter of a tone. Importantly, these same amusic individuals demonstrated no awareness of the incongruous mistuned notes in an equivalent behavioral task. Further to this evidence of intact processing in the auditory cortex, a recent fMRI study further confirmed that the brains of amusic individuals are sensitive to extremely fine pitch changes with activation in both the left and right auditory cortices increasing as a function of increasing pitch distance (Hyde et al., 2011). Although experimental studies in which participants are exposed to artificial grammars provide evidence that implicit learning often gives way to explicit awareness after sufficient exposure (Shanks and St. John, 1994), the confidence ratings collected in the present study indicated that neither the control nor the amusic group were able to acquire full explicit knowledge of the sequences’ structure. The finding of normal learning, as measured via largely implicit knowledge corroborates these previous studies, which suggest a level of unconscious knowledge in amusia that is in stark contrast to the explicit knowledge required for successful performance in musical perception tasks such as the MBEA (Peretz et al., 2009).
Analysis of response biases revealed that individuals with amusia were less confident about their performance, though no less accurate than controls. While the groups did not differ from each other in terms of how aware they were of their performance, a striking positive association was observed between awareness and performance in the control group that was not observed in the amusic group. The presence of this relationship in controls is not surprising as increasing awareness indicates an increasing tendency toward explicit knowledge acquisition and it is reasonable for performance in a learning task to correlate with levels of awareness (when unconscious) or explicit knowledge (when conscious). In contrast, the absence of this association in the amusic sample suggests a degree of dissociation whereby the level of awareness demonstrated by an individual does not predict their performance. What this finding suggests is that, in contrast to controls for whom performance in learning tasks may be largely contingent on awareness (Shanks and St. John, 1994), at least some individuals with amusia are able to perform well in the absence of any ability to discriminate when they are making a correct response from when they are making an incorrect one.
A dissociation between performance and explicit knowledge of performance has been frequently reported in the neuropsychological literature, for instance with amnesic patients who often show preserved memory in priming tasks while lacking any explicit memory for the same information (Graf et al., 1984; Knowlton et al., 1992; Reber et al., 2003). Such a dissociation has also been reported by Tillmann et al. (2007) in an individual with acquired amusia, as well as in a group of individuals with congenital amusia (unpublished data), who demonstrate implicit knowledge of musical structure in a harmonic priming task. However, attempts to disentangle the nature of implicit and explicit processing in individuals with congenital amusia suggest that their difficulties may not simply be attributed to a lack of confidence or awareness. In contrast to studies suggesting that amusic individuals possess intact musical knowledge but can not explicitly report it, results from other studies that use indirect tasks and electrophysiological methods (in which neither attention nor knowledge declaration is required) have provided evidence that their deficits include a genuine insensitivity to pitch change (Pfeuty and Peretz, 2010) and tonal aspects of musical structure (Peretz et al., 2009). The failure of control individuals to acquire explicit knowledge in the current task makes it impossible to fully address the question of the extent to which amusic individuals are able to acquire explicit knowledge through incidental listening but the approach of collecting confidence ratings seems promising and future studies using tasks in which controls reliably acquire explicit knowledge may help to resolve this.
Two other possibilities may be considered to explain why amusic individuals have such difficulties in perceiving music, despite showing intact learning for statistical regularities in tonal material. While exposure time was equated across groups in the present study, it could be argued that amusic individuals have had insufficient exposure to real-world music. This seems unlikely, given that young children are able to show knowledge of musical structure despite relatively limited exposure to musical material (Krumhansl and Keil, 1982; Trainor and Trehub, 1994), at least compared with a life-time of incidental exposure in adult amusics. In addition, several amusics have been reported to have engaged in protracted attempts to learn music and to have grown up in a musically enculturated environment (Ayotte et al., 2002; Stewart, 2008). More plausible is the possibility that the internalization of statistical regularities from real-world music may be more complex compared with the first-order transitional probabilities used in the present study. Higher-order transitional probabilities or relational probabilities between non-adjacent tones (Creel et al., 2004; Gebhart et al., 2009) may be more relevant to the acquisition of knowledge required to support an understanding of melodic and harmonic structure compared with the simple first-order transitional probabilities used in the present study (Tillmann et al., 2000; Jonaitis and Saffran, 2009). Future studies might assess the ability of amusic individuals to internalize the rules guiding more complex musical grammars (Loui et al., 2010; Rohrmeier et al., 2011) though it should be borne in mind that performance on artificial grammar learning tasks simulating more complex musical systems may be limited by the short-term memory deficits shown by many individuals with congenital amusia (Gosselin et al., 2009; Williamson and Stewart, 2010; Williamson et al., 2010).
Conclusion
In sum, the present study has provided evidence that while individuals with amusia may possess some of the fundamental mechanisms required to build knowledge of musical structure, they lack confidence in their ability and display different patterns of awareness compared with typical individuals. The striking ability of the current cohort to internalize statistical regularities based on a tonal sequence of intervals including the semitone, urges a reconsideration of the view that amusia may emerge owing to an insensitivity to small pitch changes (Peretz and Hyde, 2003). Whether the difficulties that amusic individuals show with real music can be related to a failure to internalize higher-order regularities remains to be investigated. Results from future studies investigating the state of higher-order learning mechanisms and the types of knowledge acquired, will have a critical bearing on the extent to which the condition may be considered a disorder of awareness, rather than perception.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This study was supported by a grant to Lauren Stewart from the Economic and Social Research council (ESRC; RES-061-25-0155) and a joint studentship awarded to Diana Omigie by the ESRC and the Medical Research council (MRC). We would like to thank all the participants for their continued assistance in our studies of amusia, and for their insights.
Footnotes
References
Ayotte, J., Peretz, I., and Hyde, K. L. (2002). Congenital amusia: a group study of adults afflicted with a music-specific disorder. Brain 125, 238–251.
Bigand, E., and Parncutt, R. (1999). Perceiving musical tension in long chord sequences. Psychol. Res. 62, 237–254.
Bigand, E., Parncutt, R., and Lerdahl, F. (1996). Perception of musical tension in short chord sequences: the influence of harmonic function, sensory dissonance, horizontal motion, and musical training. Percept. Psychophys. 58, 125–141.
Bigand, E., and Poulin-Charronnat, B. (2006). Are we “experienced listeners?” A review of the musical capacities that do not depend on formal musical training. Cognition 100, 100–130.
Bod, R. (2002). A unified model of structural organization in language and music. J. Artif. Intell. Res. 17, 289–308.
Brown, H., Butler, D., and Jones, M. R. (1994). Musical and temporal influences on key discovery. Music Percept. 11, 371–407.
Creel, S., Newport, E., and Aslin, R. (2004). Distant melodies: statistical learning of nonadjacent dependencies in tone sequences. J. Exp. Psychol. Learn. Mem. Cogn. 30, 1119–1130.
Cuddy, L. L., and Badertscher, B. (1987). Recovery of the tonal hierarchy-some comparisons across age and levels of musical experience. Percept. Psychophys. 41, 609–620.
Dienes, Z., and Scott, R. (2005). Measuring unconscious knowledge: distinguishing structural knowledge and judgment knowledge. Psychol. Res. 69, 338–351.
Foxton, J. M., Dean, J. L., Gee, R., Peretz, I., and Griffiths, T. D. (2004). Characterization of deficits in pitch perception underlying “tone deafness.” Brain 127, 801–810.
Gebhart, A., Newport, E., and Aslin, R. (2009). Statistical learning of adjacent and nonadjacent dependencies among nonlinguistic sounds. Psychon. Bull. Rev. 16, 486–490.
Gosselin, N., Jolicoeur, P., and Peretz, I. (2009). Impaired memory for pitch in congenital amusia. Ann. N. Y. Acad. Sci. 1169, 270–272.
Graf, P., Squire, L. R., and Mandler, G. (1984). The information that amnesic patients do not forget. J. Exp. Psychol. Learn. Mem. Cogn. 10, 164–178.
Hebert, S., Peretz, I., and Gagnon, L. (1995). Perceiving the tonal ending of tune excerpts: the roles of pre-existing representation and musical expertise. Can. J. Exp. Psychol. 49, 193–209.
Honing, H., and Ladinig, O. (2009). Exposure influences expressive timing judgments in music. J. Exp. Psychol. Hum. Learn. 35, 281–288.
Hyde, K. L., and Peretz, I. (2004). Brains that are out of tune but in time. Psychol. Sci. 15, 356–360.
Hyde, K. L., Zatorre, R., and Peretz, I. (2011). Functional MRI evidence of an abnormal neural network for pitch processing in congenital amusia. Cereb. Cortex 21, 292–299.
Jonaitis, E. M., and Saffran, J. R. (2009). Learning harmony: the role of serial statistics. Cogn. Sci. 33, 951–968.
Kalmus, H., and Fry, D. B. (1980). On tune deafness (dysmelodia) – frequency, development, genetics and musical background. Ann. Hum. Genet. 43, 369–382.
Kershaw, C. D. (1985). Statistical properties of staircase estimates from two interval forced choice experiments. Br. J. Math. Stat. Psychol. 38, 35–43.
Knowlton, B. J., Ramus, S. J., and Squire, L. R. (1992). Intact artificial grammar learning in amnesia – dissociation of classification learning and explicit memory for specific instances. Psychol. Sci. 3, 172–179.
Krumhansl, C. L., and Keil, F. C. (1982). Acquisition of the hierarchy of tonal functions in music. Mem. Cognit. 10, 243–251.
Kuhn, G., and Dienes, Z. (2005). Implicit learning of nonlocal musical rules: implicitly learning more than chunks. J. Exp. Psychol. Learn. Mem. Cogn. 31, 1417–1432.
Kunimoto, C., Miller, J., and Pashler, H. (2001). Confidence and accuracy of near-threshold discrimination responses. Conscious. Cogn. 10, 294–340.
Lerdahl, F., and Jackendoff, R. (1983). A Generative Theory of Tonal Music. Cambridge, MA: MIT Press.
Liu, F., Patel, A. D., Fourcin, A., and Stewart, L. (2010). Intonation processing in congenital amusia: discrimination, identification and imitation. Brain 133, 1682–1693.
Loui, P., Wessel, D. L., and Kam, C. L. H. (2010). Humans rapidly learn grammatical structure in a new musical scale. Music Percept. 27, 377–388.
Macmillan, N. A., and Creelman, C. D. (2001). Detection Theory: A User’s Guide. Cambridge: Cambridge University Press.
Nelson, H. E., and Willison, J. (1991). National Adult Reading Test Manual, 2nd Edn. Windsor: NFER-Nelson.
Peretz, I., Ayotte, J., Zatorre, R. J., Mehler, J., Ahad, P., Penhune, V. B., and Jutras, B. (2002). Congenital amusia: a disorder of fine-grained pitch discrimination. Neuron 33, 185–191.
Peretz, I., Brattico, E., Jarvenpaa, M., and Tervaniemi, M. (2009). The amusic brain: in tune, out of key, and unaware. Brain 132, 1277–1286.
Peretz, I., Champod, A. S., and Hyde, K. L. (2003). Varieties of musical disorders. The Montreal battery of evaluation of amusia. Ann. N. Y. Acad. Sci. 999, 58–75.
Peretz, I., and Hyde, K. L. (2003). What is specific to music processing? Insights from congenital amusia. Trends Cogn. Sci. 7, 362–367.
Pfeuty, M., and Peretz, I. (2010). Abnormal pitch-time interference in congenital amusia: evidence from an implicit test. Atten. Percept. Psychophys. 72, 763–744.
Reber, A. S. (1992). The cognitive unconscious – an evolutionary perspective. Conscious. Cogn. 1, 93–133.
Reber, P. J., Martinez, L. A., and Weintraub, S. (2003). Artificial grammar learning in Alzheimer’s disease. Cogn. Affect. Behav. Neurosci. 3, 145–153.
Rohrmeier, M., Rebuschat, P., and Cross, I. (2011). Incidental and online learning of melodic structure. Conscious. Cogn. 20, 214–222.
Saffran, J., Johnson, E., Aslin, R., and Newport, E. (1999). Statistical learning of tone sequences by human infants and adults. Cognition 70, 27–52.
Saffran, J. R., and Griepentrog, G. J. (2001). Absolute pitch in infant auditory learning: evidence for developmental reorganization. Dev. Psychol. 37, 74–85.
Saffran, J. R., Newport, E. L., and Aslin, R. N. (1996). Word segmentation: the role of distributional cues. J. Mem. Lang. 35, 606–621.
Schellenberg, E. G. (1996). Expectancy in melody: tests of the implication-realisation model. Cognition 58, 75–125.
Schmuckler, M. A. (1989). Expectation in music – investigation of melodic and harmonic processes. Music Percept. 7, 109–150.
Schön, D., Boyer, M., Moreno, S., Besson, M., Peretz, I., and Kolinsky, R. (2008). Songs as an aid for language acquisition. Cognition 106, 975–983.
Shanks, D. R., and St. John, M. F. (1994). Characteristics of dissociable human learning systems. Behav. Brain Sci. 17, 367–4470.
Smith, J. D., Nelson, D. G. K., Grohshkopf, L. A., and Appleton, T. (1994). What child is this – what interval was that – familiar tunes and music perception in novice listeners. Cognition 52, 23–54.
Stewart, L. (2008). Fractionating the musical mind: insights from congenital amusia. Curr. Opin. Neurobiol. 18, 127–130.
Stewart, L., von Kriegstein, K., Warren, J. D., and Griffiths, T. D. (2006). Music and the brain: disorders of musical listening. Brain 129, 2533–2553.
Tillmann, B., Bharucha, J. J., and Bigand, E. (2000). Implicit learning of tonality: a self-organizing approach. Psychol. Rev. 107, 885–913.
Tillmann, B., and McAdams, S. (2004). Implicit learning of musical timbre sequences: statistical regularities confronted with acoustical (dis)similarities. J. Exp. Psychol. Learn. Mem. Cogn. 30, 1131–1142.
Tillmann, B., Peretz, I., Bigand, E., and Gosselin, N. (2007). Harmonic priming in an amusic patient: the power of implicit tasks. Cogn. Neuropsychol. 24, 603–622.
Tillmann, B., Schulze, K., and Foxton, J. M. (2009). Congenital amusia: a short-term memory deficit for non-verbal, but not verbal sounds. Brain Cogn. 71, 259–264.
Toiviainen, P., and Krumhansl, C. L. (2003). Measuring and modeling real-time responses to music: the dynamics of tonality induction. Perception 32, 741–766.
Trainor, L. J., and Trehub, S. E. (1994). Key membership and implied harmony in western tonal music: developmental perspectives. Percept. Psychophys. 56, 125–132.
Tunney, R. J., and Shanks, D. R. (2003). Subjective measures of awareness and implicit cognition. Mem. Cognit. 31, 1060–1071.
Vos, P. G., and Troost, J. M. (1989). Ascending and descending melodic intervals – statistical findings and their perceptual relevance. Music Percept. 6, 383–396.
Wechsler, D. (1997). Wechsler Adult Intelligence Scale-III (WAIS-III). San Antonio, TX: The Psychological Cooperation.
Williamson, V. J., McDonald, C., Deutsch, D., Griffiths, T. D., and Stewart, L. (2010). Faster decline of pitch memory over time in congenital amusia. Adv. Cogn. Psychol. 6, 15–22.
Keywords: congenital amusia, statistical learning, implicit learning
Citation: Omigie D and Stewart L (2011) Preserved statistical learning of tonal and linguistic material in congenital amusia. Front. Psychology 2:109. doi: 10.3389/fpsyg.2011.00109
Received: 14 February 2011; Accepted: 13 May 2011;
Published online: 03 June 2011.
Edited by:
Lutz Jäncke, University of Zurich, SwitzerlandReviewed by:
Barbara Tillmann, Centre National de La Recherche Scientifique, FranceIsabelle Peretz, Université de Montréal, Canada
Copyright: © 2011 Omigie and Stewart. This is an open-access article subject to a non-exclusive license between the authors and Frontiers Media SA, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and other Frontiers conditions are complied with.
*Correspondence: Lauren Stewart, Department of Psychology, Goldsmiths, University of London, New Cross, London SE14 6NW, UK. e-mail:bC5zdGV3YXJ0QGdvbGQuYWMudWs=