 Lisianne Hoch1
Lisianne Hoch1- 1 Lyon Neuroscience Research Center, CNRS UMR5292, INSERM U1028, Université Lyon1, Lyon, France
- 2 Laboratoire d’Etude de l’Apprentissage et du Développement, CNRS-UMR 5022, Université de Bourgogne, Dijon, France
Recent research has suggested that music and language processing share neural resources, leading to new hypotheses about interference in the simultaneous processing of these two structures. The present study investigated the effect of a musical chord’s tonal function on syntactic processing (Experiment 1) and semantic processing (Experiment 2) using a cross-modal paradigm and controlling for acoustic differences. Participants read sentences and performed a lexical decision task on the last word, which was, syntactically or semantically, expected or unexpected. The simultaneously presented (task-irrelevant) musical sequences ended on either an expected tonic or a less-expected subdominant chord. Experiment 1 revealed interactive effects between music-syntactic and linguistic-syntactic processing. Experiment 2 showed only main effects of both music-syntactic and linguistic-semantic expectations. An additional analysis over the two experiments revealed that linguistic violations interacted with musical violations, though not differently as a function of the type of linguistic violations. The present findings were discussed in light of currently available data on the processing of music as well as of syntax and semantics in language, leading to the hypothesis that resources might be shared for structural integration processes and sequencing.
Introduction
Music and language are rule-governed systems. The rules, which organize events (e.g., chords, words) structurally over time, define syntactic principles. Acculturated listeners and speakers have implicit knowledge of musical and linguistic syntax, allowing them to develop expectations about future musical and linguistic events (Besson and Schön, 2003; Patel, 2008). Such structural similarities have encouraged investigations about the domain-specificity or generality of music and language processing.
Evidence of independence between music and language processing mainly comes from neuropsychological studies revealing a double dissociation between music and language deficits for brain-damaged patients (Basso and Capitani, 1985; Peretz et al., 1994, 1997). While few behavioral and neurophysiological studies have reported independent processes (Besson et al., 1998; Bonnel et al., 2001), several behavioral and neurophysiological studies have reported dependent processes for music and language (Patel et al., 1998; Bigand et al., 2001; Koelsch et al., 2001, 2002, 2005; Maess et al., 2001; Tillmann et al., 2003; Poulin-Charronnat et al., 2005; Steinbeis and Koelsch, 2008; Fedorenko et al., 2009; Slevc et al., 2009). Behavioral studies have shown, for example, that musical structures influence syllable (Bigand et al., 2001) and word (Poulin-Charronnat et al., 2005) processing in vocal music. Event-related potential (ERP) studies have shown that (1) the late positivity P600, which reflects syntactic integration, is not language-specific but can be elicited by music-syntactic violations (Patel et al., 1998), and (2) music-syntactic violations can elicit an early right anterior negativity (ERAN), which is comparable to the left-lateralized (early) anterior negativity (i.e., (E)LAN) elicited by linguistic-syntactic violations (Koelsch et al., 2001). In addition, functional imaging data have revealed that cortical areas involved in linguistic processing (e.g., Broca’s area) are also involved in music processing (Maess et al., 2001; Koelsch et al., 2002; Tillmann et al., 2003). Based on these data, Patel (2003) proposed the “shared syntactic integration resource hypothesis” (SSIRH): Music and language share neural resources for processes linked to the structural integration of events (i.e., processing of structural relations between events (chords/words) in working memory). In contrast, the musical and linguistic representations would be stored in distinct neural networks and can be selectively damaged, thus reconciling the double dissociations that had been observed in patients (Basso and Capitani, 1985; Peretz et al., 1994, 1997).
The SSIRH predicts that “tasks which combine linguistic and musical syntactic integration will show interference between the two” (Patel, 2003, p. 679). This hypothesis has been initially supported by ERP studies showing interactive influences between the simultaneous processing of music-syntactic and linguistic-syntactic structures (Koelsch et al., 2005; Steinbeis and Koelsch, 2008). Using a cross-modal paradigm, visually presented sentences were synchronized with auditorily presented chord sequences. As in previous studies investigating either language processing (e.g., Gunter et al., 2000) or music processing (e.g., Koelsch et al., 2001), syntactically incorrect words elicited a LAN, while music-syntactically unexpected chords (i.e., Neapolitan chords containing out-of-key tones) elicited an ERAN. Most importantly, linguistic and musical syntax interacted: A music-syntactically unexpected chord reduced the amplitude of the LAN while a linguistic-syntactically unexpected word reduced the amplitude of the ERAN. Recently (and in parallel to our present study), a behavioral study measuring reading-times in a self-paced reading paradigm reported cross-modal interactive influences of music-syntactic violations on syntactic complexity processing in garden-path sentences (Slevc et al., 2009). Reading-times showed enhanced garden-path effects (i.e., longer reading-times for syntactically unexpected words) when sentences were presented simultaneously with music-syntactically unexpected, out-of-key chords (compared to expected in-key chords).
These cross-modal experiments used strong musical expectancy violations and introduced unexpected, out-of-key chords or chords with out-of-key tones that created acoustic violations with the preceding context (thus creating a confound with the music-syntactic violation). However, previous research investigating music perception has promoted the need for controlled musical materials with the aim to disentangle the influence of acoustic deviance from that of music-syntactic processing (Tekman and Bharucha, 1998; Bigand et al., 2003, 2006; Koelsch et al., 2007). In particular, musical context effects can be due to knowledge-driven processes (referred to as cognitive priming) or sensory-driven processes (i.e., sensory priming). The former result from the activation of listeners’ knowledge of Western musical syntax, the later from the difference in acoustic overlap between prime and target (i.e., harmonic spectra, tone repetition vs. novelty). Out-of-key tones do not only create an expectancy violation based on listeners’ tonal knowledge and musical-syntax processing, but create sensory dissonance with the other context tones as well (Terhardt, 1984). These perceptual changes define unexpected events as sensory deviants. The use of unexpected events with out-of-key tones does not allow distinguishing whether context effects are due to violations of musical structures or to violations of sensory features. Relatively subtle tonal manipulations (such as comparing target chords belonging to the same context key, i.e., tonic vs. subdominant) avoid creating any contextual dissonance and thus allow focusing on cognitive priming and musical structure processing.
This kind of experimental control is also relevant for the investigation of interactions between music and language processing, notably to be able to study interactions only due to music-syntactic processing (and not due to acoustic deviance processing). Our Experiment 1 investigated the interaction between simultaneous music-syntactic and linguistic-syntactic processing with more subtle music-syntactic violations than those previously used. For this aim, the music-syntactic manipulation used the in-key subdominant chord as the unexpected chord and the in-key tonic chord as the expected chord. With this musical material, previous studies have shown faster and more accurate processing for the expected tonic chord than for the less-expected subdominant chord (referred to as the tonal function effect). Originally, this tonal function effect was observed with tasks that focused on a perceptual feature of the target chord (e.g., consonance/dissonance judgment, Bigand et al., 2003). More recently, the tonal function effect was observed with tasks that focused on a simultaneously presented linguistic feature, such as sung, spoken, and visual syllables (Bigand et al., 2001; Escoffier and Tillmann, 2008; Hoch and Tillmann, 2010, respectively). The effect of tonal function on syllable processing suggests that listeners process musical structures, even when these structures are task-irrelevant.
In a cross-modal paradigm (i.e., task-relevant visual information presented with a musical background), Escoffier and Tillmann (2008) compared target chord processing in tonal sequences (ending with an expected tonic or a less-expected subdominant chord) and in tonally neutral sequences (i.e., baseline sequences). The comparison to neutral baseline sequences followed a rationale previously used in psycholinguistics to study costs and benefits of contextual expectations (e.g., Jonides and Mack, 1984). In contrast to the tonal sequences (ending on tonic vs. subdominant), which install a tonal center and evoke expectations for the tonic in particular, the baseline sequences do not install a tonal center and thus do not guide listeners’ tonal expectations. In Escoffier and Tillmann (2008), the processing of the visual event was faster for the tonic condition than for the baseline condition, but was not slowed down in the subdominant condition, which did not differ from the baseline condition. This comparison to baseline thus suggests that the cross-modal influence of the tonal function on the visual processing is not due to a general distraction or attentional shift (due to the unexpected subdominant), but rather to a benefit of processing thanks to the expected tonic chord.
Our Experiment 1 used a cross-modal paradigm: Sentences were presented visually in synchrony with auditorily presented task-irrelevant chord sequences, which ended on an expected tonic chord or a less-expected subdominant chord. Participants performed a lexical decision task on the final word, which was syntactically expected or unexpected. If previously reported interactive influences between music-syntactic and linguistic-syntactic processing were not due to the acoustic violation created by the strong music-syntactic violation (i.e., out-of-key chords or tones, Koelsch et al., 2005; Steinbeis and Koelsch, 2008), then Experiment 1 should reveal an interaction: The linguistic-syntactic expectancy effect should be modulated by the tonal function of the final chord and the tonal function effect (i.e., the musical expectancy effect) should be modulated by the linguistic-syntactic expectancy. Based on the previously reported tonic facilitation in a cross-modal paradigm (Escoffier and Tillmann, 2008), interfering processes between music-syntactic and linguistic-syntactic processing should be reflected in a reduced or vanished tonic facilitation when simultaneously presented with a syntactically unexpected word. Such interfering processes between music-syntactic and linguistic-syntactic processing would support the hypothesis of shared structural and temporal integration resources, as formulated for syntax in the SSIRH (Patel, 2003).
Experiment 1: Syntactic Expectancy and Musical Expectancy
Method
Participants
Thirty-two students from the University of Lyon (M ± SD = 22 ± 2.83 years) participated in Experiment 1. Number of years of formal musical practice ranged from 0 to 12 (3.72 ± 4.11 years; Mdn = 2 years). All participants gave informed consent, and none of the participants reported to have an auditory impairment.
Materials
Musical material. Twelve eight-chord sequences from Bigand et al. (2001) were used; half ended on the expected tonic chord and the other half on the less-expected subdominant chord. The inter-chord distance was set to zero. The first seven chords sounded for 625 ms each (thus a stimulus onset asynchrony of 625 ms), and the final chord sounded for 850 ms (due to the timbre’s resonance). Sequences were generated with Cubase 5.1 (Steinberg) and Grand Piano sound samples using Halion software sampler (Steinberg).
Linguistic material. In 24 French sentences of eight syllables (Appendix), the final word of each sentence defined the target, which was monosyllabic and syntactically expected. Aiming for semantically expected target-words, the syntactically expected sentences were constructed on the basis of a pretest. In the pretest, the targets were given as the appropriate final word by at least 60% of the participants (students from the University of Lyon that did not participate in Experiment 1) in a free-completion task. The syntactic expectancy manipulation consisted of a gender violation (also named morphosyntactic violation, see Gunter et al., 2000): The target word was either syntactically expected or unexpected relative to the preceding article (e.g., “Le méchant chien dort dans la[fem.]niche[fem.] / The nasty dog is sleeping in the[fem.] kennel [fem.]” vs. “Le méchant chien dort dans le[masc.] niche[fem.] / The nasty dog is sleeping in the[masc.] kennel [fem.],” see Appendix). This manipulation was applied to all 24 sentences, leading to 48 experimental sentences.
Pseudo-words were constructed from target-words by altering one letter [e.g., “puche” instead of “poche” (pocket)]. This modification changed only one phoneme and did not violate orthographic or phonological rules of French. None of the pseudo-words were pseudo-homonyms in French.
Each sentence was visually presented, syllable-by-syllable, on the center of the screen. For polysyllabic words, a dash was presented at the end of the syllable to indicate that the word continued on the next screen. The syllable-by-syllable presentation allowed reading at a comfortable pace using the chords’ stimulus onset asynchrony of 625 ms. The first seven syllables of each sentence were presented in white (380 ms followed by an inter-syllable-interval of 245 ms), and the target was displayed in red up to the participant’s response, with a timeout of 1200 ms.
Audio-visual presentation. The onset of each syllable was synchronized with the onset of each chord so that the target word (or pseudo-word) was synchronized with the onset of the final chord. The 96 sentences (i.e., the 48 sentences ending on either a word or a pseudo-word) were presented with a musical sequence ending on either a tonic or a subdominant chord. The resulting 192 trials were presented in pseudorandom order, where the presentation of the same sentence was separated by at least four other sentences and consecutive presentations of each experimental condition were limited to five repetitions. A different pseudorandom order was created for each participant. The experiment was run with the PsyScope Software (Cohen et al., 1993).
Procedure
Participants were informed that sentences containing eight syllables were presented syllable-by-syllable on successive screens with music in the background. Their task was to read the sentences and to decide as quickly and accurately as possible whether the last element was a word or a pseudo-word (i.e., lexical decision task). Before the presentation of the first syllable, a fixation cross appeared in the center of the screen. Participants were first trained in the lexical decision task with eight isolated words and pseudo-words that was followed by training with four sentences accompanied by chord sequences. Error feedback was given in the training and experimental phases. A 250-ms noise mask followed each trial to diminish the trace of the preceding musical sequence in the sensory memory buffer and thus its influence on the processing of the following musical sequence (as, for example, in Bigand et al., 2003; Escoffier and Tillmann, 2008).
Results
The mean accuracy was 94 and 97% for words and pseudo-words, respectively. The means of correct response times (RTs) were 588 ms (range: 455–826 ms) and 643 ms (range: 495–829 ms) for words and pseudo-words, respectively. Correct RTs were individually normalized with a mean of 0 and a SD of 1, providing z-scores. For words1, percentages of correct responses (Table 1) and normalized RTs (Figure 1) were, respectively, analyzed by two 2 × 2 ANOVAs with syntactic expectancy (expected, unexpected) and tonal function (tonic, subdominant) as within-participant factors and either participants (F1) or target-words (F2) as a random variable.
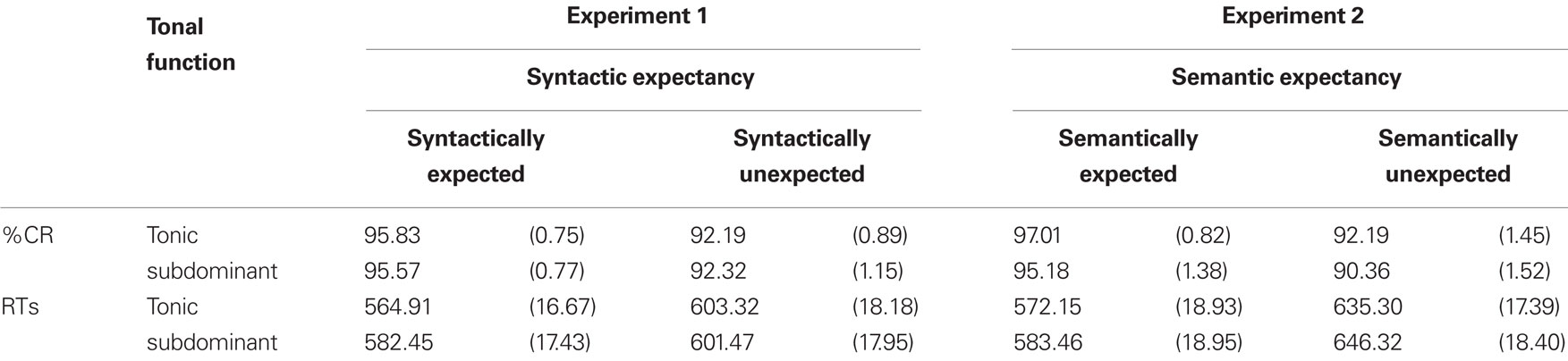
Table 1. Percentages of correct responses (%CR) and correct response times (RTs, raw latencies in ms) presented as a function of Linguistic Expectancies (Syntactic for Experiment 1 and Semantic for Experiment 2) and Tonal Function (Tonic, Subdominant). SE are indicated in brackets.
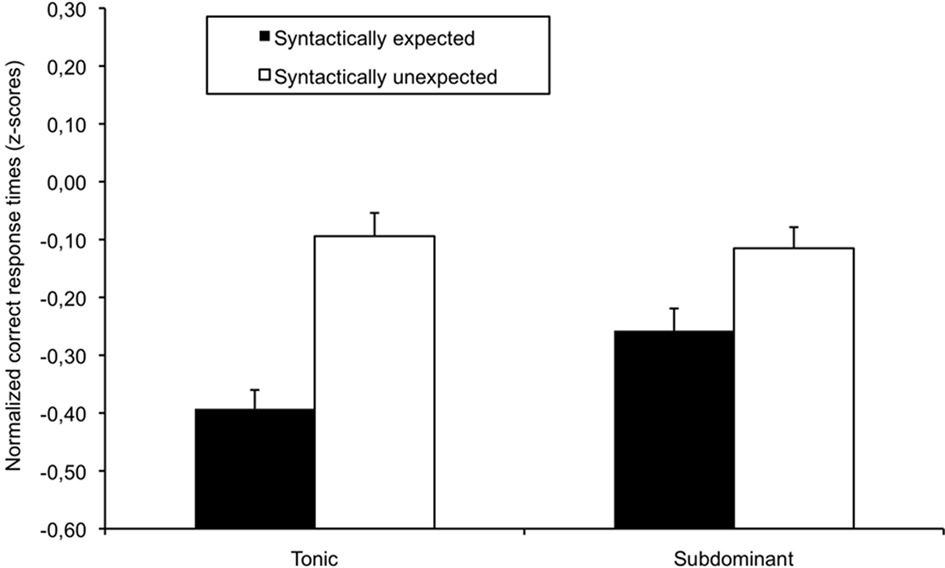
Figure 1. Normalized correct response times (z-scores) for words presented as a function of syntactic expectancy (expected, unexpected) and tonal function (tonic, subdominant) for Experiment 1. Error bars indicate between-participants SE.
For correct responses and normalized RTs, the main effect of syntactic expectancy was significant, F1(1, 31) = 27.99, p < 0.001, MSE = 13.61, F2(1, 23) = 12.68, p < 0.005, MSE = 28.87, and F1(1, 31) = 57.68, p < 0.001, MSE = 0.03, F2(1, 23) = 39.52, p < 0.001, MSE = 0.03, respectively. Expected words were processed more accurately and faster than syntactically unexpected words. For the normalized RTs, the two-way interaction between syntactic expectancy and tonal function was significant, F1(1, 31) = 6.25, p < 0.05, MSE = 0.03, F2(1, 23) = 8.95, p < 0.01, MSE = 0.02. For expected words, a musical expectancy effect was observed: Processing was faster when the target word was presented with a tonic rather than with a subdominant chord F1(1, 31) = 6.12, p < 0.05, MSE = 0.05, F2(1, 23) = 5.59, p < 0.05, MSE = 0.03. For syntactically unexpected words, this tonic facilitation was not observed (F1 and F2 < 1). In addition, the syntactic expectancy effect was decreased when the target word was presented together with a subdominant chord, F1(1, 31) = 10.78, p < 0.005, MSE = 0.03, F2(1, 23) = 8.71, p < 0.01, MSE = 0.02, rather than with a tonic chord, F1(1, 31) = 50.96, p < 0.001, MSE = 0.03, F2(1, 23) = 38.84, p < 0.001, MSE = 0.03.
Discussion
In Experiment 1, expected words were processed faster and more accurately than syntactically unexpected words, reflecting the influence of morphosyntactic expectancies (see Colé and Segui, 1994; Friederici et al., 1998; Gunter et al., 2000, for similar results). This syntactic expectancy effect was modulated by the tonal function of simultaneously presented chords: It was reduced for words presented with a less-expected subdominant chord compared to an expected tonic chord. The present interaction also revealed that the musical expectancy effect was observed only for the expected words, but not for the syntactically unexpected words. The expected words showed a tonic facilitation as previously observed for sung, spoken and visual syllables (Bigand et al., 2001; Escoffier and Tillmann, 2008; Hoch and Tillmann, 2010, respectively) and for expected words in sung sentences (Poulin-Charronnat et al., 2005). In contrast, syntactically unexpected words did not show the tonic facilitation. Escoffier and Tillmann (2008) had shown that in a cross-modal paradigm the relative facilitation between tonic and subdominant chords was due to a benefit of the tonic, rather than to a cost of the subdominant. Given that this facilitation requires the processing of musical structures and tonal functions, the interference observed here with the processing of the unexpected word suggests that musical structure and linguistic syntax processing tap into the same processing resources, thus hindering the otherwise observed tonic benefit.
In contrast to the findings of Experiment 1 that were observed with morphosyntactic agreement manipulations (see also Koelsch et al., 2005; Steinbeis and Koelsch, 2008), Slevc et al. (2009) have reported a different type of interactive pattern between music-syntactic and linguistic-syntactic processing using a syntactic garden-path manipulation(see also Fedorenko et al., 2009, with object-extracted sentences): Self-paced reading-times were slower for target-words in syntactic garden-path sentences compared to simple sentences, but this effect was greater when presented with an unexpected out-of-key chord (107 ms) than with an expected in-key chord (31 ms). This comparison suggests that the type of linguistic-syntactic manipulation might lead to different interactive patterns with music-syntactic processing. Slevc et al. (2009) and our Experiment 1 also differed in the type of music-syntactic violation tested (i.e., unexpected musical events that were out-of-key vs. in-key). This difference might also influence the type of interactive pattern observed, notably with an additional cost due to strong musical violations that include acoustic violations. This hypothesis would need to be tested in an experimental paradigm that also integrates a baseline condition. However, it is worth noting that in Slevc et al. (2009), the expected words did not show the typically observed musical expectancy effect (i.e., faster processing for the expected tonic chord, e.g., Bharucha and Stoeckig, 1986): Reading-times of expected words were faster with unexpected out-of-key chords (i.e., 606 ms) than with expected in-key chords (i.e., 639 ms, see Slevc et al., 2009 for a discussion).
Despite differences in interactive data patterns between our Experiment 1 and the study by Slevc et al. (2009), overall findings showed interactive influences between simultaneous music-syntactic and linguistic-syntactic processing, thus suggesting shared processing resources for musical-syntax and linguistic syntax, as proposed by the SSIRH (Patel, 2003).
Experiment 2: Semantic Expectancy and Musical Expectancy
To further investigate whether shared resources between music and language processing are restricted to linguistic-syntactic processing or extend to linguistic-semantic processing, previous studies have investigated the simultaneous processing of musical syntax and linguistic semantics (Koelsch et al., 2005; Steinbeis and Koelsch, 2008; Slevc et al., 2009; see also Poulin-Charronnat et al., 2005). In contrast to the consistently observed interactive influences between the simultaneous processing of syntactic structures in music and language, these studies have revealed mixed data patterns. With a cross-modal presentation, the processing of a linguistic-semantic violation was not influenced by the simultaneous processing of a music-syntactic violation (i.e., out-of-key chords or tones, Koelsch et al., 2005; Slevc et al., 2009). However, when participants were required to perform a dual-task on language (visually presented) and music (auditorily presented), interactive influences were observed between music processing and semantic processing (Steinbeis and Koelsch, 2008). A similar interactive pattern was observed for vocal music and the use of more subtle musical expectancy violations in a behavioral priming paradigm (Poulin-Charronnat et al., 2005): The musical expectancy effect (i.e., faster processing for expected tonic chords than for less-expected subdominant chords) was observed only for semantically expected words but vanished for semantically unexpected words. This interaction also revealed that tonal function modulated semantic processing: The semantic expectancy effect (i.e., faster processing for semantically expected words than for unexpected words) was reduced for words sung on the less-expected subdominant chord compared to words sung on the expected tonic chord. In contrast to the studies that did not report interactive influences between musical and semantic structures (Koelsch et al., 2005; Slevc et al., 2009), the interactive influences reported by Steinbeis and Koelsch (2008) and Poulin-Charronnat et al. (2005) suggest the extension of shared resources from syntactic structures to semantic structures.
In view of the previous studies, which revealed mixed data patterns using various materials and tasks, Experiment 2 investigated simultaneous linguistic-semantic and music-syntactic processing with the musical materials and the linguistic task of Experiment 1. The musical and linguistic materials and the linguistic task were comparable to Poulin-Charronnat et al. (2005), but here used in a cross-modal presentation. As in Experiment 1, Experiment 2 used music-syntactic manipulation without acoustic confound, thus contrasting with all the previous studies using a cross-modal presentation (Koelsch et al., 2005; Steinbeis and Koelsch, 2008; Slevc et al., 2009): Chord sequences ended on either the expected tonic or the less-expected subdominant chord. For the language manipulation, the final word of the sentence was semantically expected or unexpected (as in all the previous studies). Thus, Experiment 2 investigated whether previously observed interactive influences between music and semantic processing (Poulin-Charronnat et al., 2005; Steinbeis and Koelsch, 2008) extends to a cross-modal presentation with subtle musical expectancy violations and with a task focusing on language only. If previously reported interactive influences between music-syntactic and linguistic-semantic processing were not due to the experimental task and/or the form of presentation of the materials (i.e., vocal music in Poulin-Charronnat et al., 2005, and dual-task paradigm in Steinbeis and Koelsch, 2008), then in Experiment 2, the linguistic-semantic expectancy effect should be modulated by the tonal function of the final chord, and the tonal function effect (i.e., the musical expectancy effect) should be modulated by the linguistic-semantic expectancy.
Method
Participants
Thirty-two students from the University of Lyon (M ± SD = 21 ± 2.38 years) participated in Experiment 2. The number of years of formal musical practice ranged from 0 to 14 (2.78 ± 4.32 years; Mdn = 0). This mean level of musical practice did not differ significantly from that of the participants in Experiment 1 [t(31) = 0.90, p = 0.38]. All participants gave informed consent. None of the participants had declared to have an auditory impairment, and none participated in Experiment 1.
Materials and procedure
The musical sequences and the sentences ending on syntactically expected words of Experiment 1 were used. These syntactically expected words were also semantically expected, and they had been chosen, as described in Experiment 1, based on a free-completion test. Sentences were then matched by pair so that the semantically expected target word of one sentence defined the semantically unexpected target word of another sentence (and vice versa), resulting in 24 sentences ending on a semantically expected word and 24 sentences ending on a semantically unexpected word [e.g., “Le mé-chant chien dort dans la niche (vs. tente)”/“The nasty dog is sleeping in thekennel (vs. tent)”]. These combinations of semantically unexpected target-words were pretested (with 29 new participants, students of the University of Lyon). The semantically unexpected word was never chosen as an appropriate ending among multiple choices (including expected/unexpected words and fillers), except by two participants for one sentence (sentence 22, see Appendix). The procedure was as described for Experiment 1.
Results
The mean accuracy was 94% and 95% for target-words and pseudo-words, respectively. The means of correct RTs were 608 ms (range, 447–879 ms) and 656 ms (range, 533–880 ms) for words and pseudo-words, respectively. As for Experiment 1, correct RTs were individually normalized with a mean of 0 and a SD of 1, providing z-scores (see footnote 1). For words, percentages of correct responses (Table 1) and normalized RTs (Figure 2) were, respectively, analyzed by two 2 × 2 ANOVAs with semantic expectancy (expected, unexpected) and tonal function (tonic, subdominant) as within-participant factors and either participants (F1) or target-words (F2) as random variables.
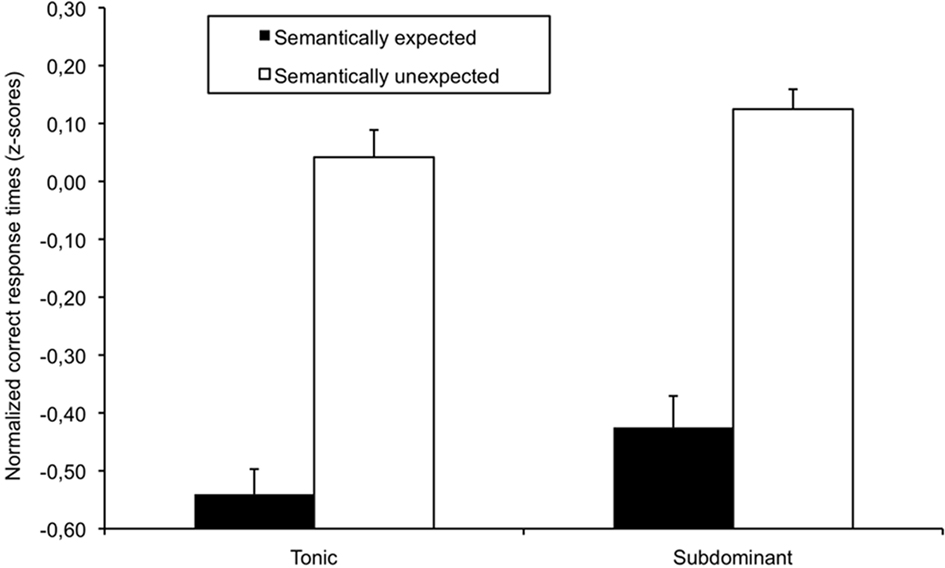
Figure 2. Normalized correct response times (z-scores) for words presented as a function of semantic expectancy (expected, unexpected) and tonal function (tonic, subdominant) for Experiment 2. Error bars indicate between-participants SE.
For correct responses and normalized RTs, the main effect of semantic expectancy was significant, F1(1, 31) = 20.98, p < 0.001, MSE = 35.40, F2(1, 23) = 22.31, p < 0.001, MSE = 24.30, and F1(1, 31) = 127.88, p < 0.001, MSE = 0.08, F2(1, 23) = 91.44, p < 0.001, MSE = 0.09, respectively: Expected words were processed more accurately and faster than semantically unexpected words. The main effect of tonal function was significant for normalized RTs, F1(1, 31) = 6.05, p < 0.05, MSE = 0.05, F2(1, 23) = 7.71, p < 0.05, MSE = 0.03, and marginally significant for correct responses, F1(1, 31) = 3.28, p = 0.08, MSE = 32.41, F2(1, 23) = 3.70, p = 0.07, MSE = 20.02, target word processing was more accurate and faster when presented in synchrony with a tonic chord than with a subdominant chord. The two-way interaction between semantic expectancy and tonal function was not significant [F1(1, 31) = 0.21, p = 0.65, MSE = 0.04; F2(1, 23) = 0.83, p = 0.37, MSE = 0.03 for normalized RTs; and F1(1, 31) = 0.000, p = 1.00, MSE = 12.88, F2(1,23) = 0.005, p = 0.94, MSE = 19.00 for percentages of correct responses].
Discussion
Experiment 2 replicated the well-known semantic priming effect (see McNamara, 2005 for a review), with semantically expected words being processed faster and more accurately than unexpected words. In addition, a main effect of tonal function was observed with faster and more accurate processing of words presented in synchrony with an expected tonic chord than with a less-expected subdominant chord. The facilitated visual word processing when simultaneously presented with a tonic chord confirmed the previously described tonic facilitation, as observed for sung, spoken, and visual syllables (Bigand et al., 2001; Escoffier and Tillmann, 2008; Hoch and Tillmann, 2010).
Experiment 2 did not reveal interactive influences between linguistic-semantic and music-syntactic processing. The semantic priming effect did not modulate the musical expectancy effect nor was it modulated by the musical expectancy effect. The absence of interactive influence is consistent with some of the previous data observed with stronger musical expectancy violations (Koelsch et al., 2005; Slevc et al., 2009). As previously argued, it might suggest independent resources between music-syntactic and linguistic-semantic processing (see however the General Discussion here below).
Further insight can be provided by the comparison of the various data patterns of previous experimental studies that used similar materials, but differed in material presentation or tasks. In contrast to the data of Experiment 2, the data by Poulin-Charronnat et al. (2005) suggested shared resources for music and semantic processing: They revealed interactive influences with similar materials and tasks as in Experiment 2, but presented as vocal music. The data by Steinbeis and Koelsch (2008) also suggested shared resources with the observation of interactive influences for the same materials and cross-modal presentation as in Koelsch et al. (2005), but using a dual-task (instead of a single task leading to a data pattern suggesting independent influences). Taken together, these findings suggest that the presentation form of the experimental material (as separate information streams in a cross-modal paradigm or combined in one information stream as in vocal music) and the attentional level required for the processing of each material type (in single vs. dual-tasks) influence whether interactive data patterns are observed between simultaneous music and semantic processing. In particular, interactive patterns might be observed for semantics when the tonal function is part of the task-relevant information stream(s).
It is worth noting that in contrast to the chord material used in the previously cited studies, behavioral and ERPs for sung melodies suggested independent processing of music and semantic expectancy violations (Besson et al., 1998; Bonnel et al., 2001). However, even for this melodic material, (1) a reduction of the N400 for semantically unexpected words sung on an unexpected tone can be noticed in the reported ERPs (see Besson et al., 1998, Figure 2, p. 496, but not significant), and (2) these studies (Besson et al., 1998; Bonnel et al., 2001) used two explicit tasks (i.e., semantic and musical coherence judgments) that might lead participants to separately analyze musical and linguistic information, thus weakening interactive influences.
General Discussion
Our study manipulated the tonal function of chords together with either syntactic or semantic structures in a cross-modal paradigm. Experiment 1 revealed interactive influences between music-syntactic and linguistic-syntactic processing. The effect of linguistic-syntactic expectancy was reduced when the target word was simultaneously presented with a less-expected subdominant chord, and there was no effect of musical expectancy for syntactically unexpected words. This outcome extends interactive influences previously observed with strong violations of musical expectancies (Koelsch et al., 2005; Steinbeis and Koelsch, 2008; Fedorenko et al., 2009; Slevc et al., 2009) to more subtle violations of musical expectancies. By contrast, Experiment 2 did not reveal interactive influences between music-syntactic and linguistic-semantic processing: Only main effects of tonal function and semantic expectancy were observed. The absence of interactive influences is in agreement with some of the previous studies investigating music-syntactic and linguistic-semantic processing (Koelsch et al., 2005; Slevc et al., 2009), but differs from the interactive influences consistently observed for music-syntactic and linguistic-syntactic processing (Experiment 1; Koelsch et al., 2005; Slevc et al., 2009).
Overall, the findings of our two cross-modal experiments can be interpreted as new support for the SSIRH (Patel, 2003), notably by revealing interactive influences between music-syntactic and linguistic-syntactic processing, but not between music-syntactic and linguistic-semantic processing. More importantly, the controlled construction of our musical material allowed focusing on the influence of musical structure processing, notably by excluding that the observed interference was due to acoustic deviance processing (thus going beyond previous studies using out-of-key events, e.g., Koelsch et al., 2005; Steinbeis and Koelsch, 2008). In particular here, the influence of the musical structures was based on the tonic facilitation (rather than on a subdominant cost), as suggested by previous research including a neutral baseline condition (Escoffier and Tillmann, 2008).
In the following, we propose to discuss our study together with the currently available data on simultaneous musical and linguistic (syntactic or semantic) structure processing, revealing the need for future studies and suggesting an extension of the SSIRH. Simultaneous music and syntactic processing has consistently shown interactive influences (Koelsch et al., 2005; Steinbeis and Koelsch, 2008; Slevc et al., 2009; Fedorenko et al., 2009; Experiment 1), while simultaneous music and semantic processing has either shown interactive influences or not (Poulin-Charronnat et al., 2005; Steinbeis and Koelsch, 2008 vs. Koelsch et al., 2005; Slevc et al., 2009; Experiment 2). To further investigate simultaneous musical and linguistic structure processing (notably as a function of the type of linguistic expectancies, syntax vs. semantics), we ran an additional analysis combining Experiments 1 and 2: This combined analysis revealed a two-way interaction between musical and linguistic expectancy effects, but this interaction was not significantly modulated by the type of linguistic manipulation (syntactic or semantic)2. Interestingly, even though the interaction was not significant in Experiment 2, the effect sizes suggested a similar interactive pattern as in Experiment 1: The influence of tonal function was stronger for expected words (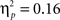 and
and 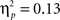 for syntax in Experiment 1, and for semantics in Experiment 2, respectively) than for unexpected words (
for syntax in Experiment 1, and for semantics in Experiment 2, respectively) than for unexpected words (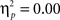 and
and 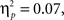 for syntax and semantics, respectively). It is worth noting that also in Slevc et al. (2009), the mean RT data for semantics mirrored this interactive pattern (see also Poulin-Charronnat et al., 2005), even if not significantly: The mean reading-times of semantically expected and unexpected words differed more strongly when the simultaneously presented chord was the expected in-key chord (i.e., 71 ms) than when it was the unexpected out-of-key chord (i.e., 38 ms, see Slevc et al., 2009, Table 1, p. 377).
for syntax and semantics, respectively). It is worth noting that also in Slevc et al. (2009), the mean RT data for semantics mirrored this interactive pattern (see also Poulin-Charronnat et al., 2005), even if not significantly: The mean reading-times of semantically expected and unexpected words differed more strongly when the simultaneously presented chord was the expected in-key chord (i.e., 71 ms) than when it was the unexpected out-of-key chord (i.e., 38 ms, see Slevc et al., 2009, Table 1, p. 377).
Beyond the influence of the presentation form and the experimental task (see Discussion of Experiment 2), the rather unstable data pattern for music and semantic processing, which is observed over the currently available studies, might have been based on the type of semantic violation that has been used in all the cited studies, and that contrasts to the expectancy violations applied to syntax. The challenge to aim for comparable violation types and to equate the levels of processing difficulty between the to-be-compared materials is not only encountered by research investigating language and music, but is also well-known in research investigating linguistic syntax and semantics (e.g., Friederici et al., 1993, 2003). In studies investigating language and music processing, up to now, the syntactic expectancy violations consisted of syntactic errors (e.g., gender violations, Koelsch et al., 2005; Steinbeis and Koelsch, 2008; Experiment 1) or syntactic complex sentences (Fedorenko et al., 2009; Slevc et al., 2009), while the semantic expectancy violations consisted of correct, but low-cloze probability words (Koelsch et al., 2005; Poulin-Charronnat et al., 2005; Steinbeis and Koelsch, 2008; Slevc et al., 2009; Experiment 2). This comparison thus points to the potential influence of the strength of the structure manipulations, and it raises the question whether the use of stronger semantic violations (semantic errors, semantically implausible words) or semantically more complex structures might produce more consistent interference with simultaneous music processing. The underlying hypothesis would be that, as previously suggested by Steinbeis and Koelsch (2008), neural resources might be shared for the processing of structure violation and the integration of unexpected events for both musical structures and linguistic-semantic structures. As phrased by Slevc et al. (2009), music and language processing might share “resources for a more general type of processing (e.g., for a process of integrating new information into any type of evolving representation),” p. 375).
Research in music cognition and psycholinguistics has suggested that both music and language processing require integrative processes. Each incoming event needs to be integrated on-line into an updated mental representation of the global context, notably to form a coherent and meaningful representation (Friederici, 2001; Jackendoff, 2002; Patel, 2003, 2008; Hagoort, 2005; Tillmann, 2005). For language, structural integration of information over time is necessary for both syntactic and semantic processing (Gibson, 1998; Friederici, 2001; Jackendoff, 2002; Hagoort, 2005). At the sentence level, readers or listeners need to integrate newly incoming information to update their mental representation, and create a coherent and meaningful situational model (e.g., van Dijk and Kintsch, 1983; Kintsch, 1988). This research in music and language cognition, taken together with the observation of interactive influences between music and syntactic processing and between music and semantic processing (at least in some of the studies), led us to propose that structural integration resources might be the key concept of shared resources in the processing of music, syntax, and semantics. The SSIRH might thus be extended from syntactic to more general structural integration resources. This hypothesis of shared structural integration resources needs to be further investigated by testing (1) stronger semantic expectancy violations (e.g., semantically implausible words) or sentences with more complex semantic structures (e.g., semantic garden-path sentences, role assignment violations), which require more complex processes such as a reanalysis and a reinterpretation of the previous information, and (2) predictions for interactive influences beyond music and linguistic structure processing, notably for the simultaneous processing of other structured materials, such as arithmetic, movies, dance, or action sequences (see also Jackendoff, 2009)3. This hypothesis integrates in research revealing the role of inferior frontal cortex (in particular, Broca’s area and its right-hemisphere homolog) not only in language processing for syntax and semantics (e.g., Kotz et al., 2002), but also in the processing of musical structures (e.g., Maess et al., 2001; Tillmann et al., 2003) and artificial grammar structures (Petersson et al., 2004, 2010) as well as sequential manipulation and structuring of notes, syllables, visuo-spatial materials or action sequences (e.g., Gelfand and Bookheimer, 2003; Tettamanti and Weniger, 2006) and the perception and production of temporal sequences (Schubotz et al., 2000; Coull, 2004). Converging evidence has been provided by patient studies (in particular Broca aphasics), showing deficits in language processing as well as musical structure processing (Patel et al., 2008), artificial grammar learning (Christiansen et al., 2010) and the perception of human action (Fazio et al., 2009). As developed by Petersson et al. (2010), the inferior frontal cortex (centered on BA 44 and 45) might thus be a main candidate for the encoding and subsequent processing of discrete elements presented in a sequence, thus providing domain-general neural resources for on-line sequence processing that requires the structural integration of events in an incremental and recursive manner.
Conclusion
Recent research has investigated the hypothesis of neural resources shared between music and language processing, in particular differentiating syntax and semantics of the language material. While musical structure processing interacted consistently with linguistic syntax processing, the data patterns observed for musical-syntax and linguistic-semantics were less clear, showing either interactive patterns or not. Our study tested the simultaneous processing of musical syntax with either linguistic syntax (Experiment 1) or semantics (Experiment 2) and the observed data pattern is in agreement with these previous findings. A closer analysis of material, violation types as well as experimental tasks suggests the extended hypothesis of shared structural integration resources that goes beyond syntactic integration. This extended hypothesis now requires future research to further investigate not only music and language processing, but also the behavioral and neural correlates of the simultaneous processing of other material types that require structural and temporal integration (such as action, for example).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Thanks to Pierre Sereau for help in preparing and running pre-tests. This research was supported by the grant ANR-09-BLAN-0310.
Footnotes
- ^Analyses for pseudo-words are reported here for completion. For Experiments 1 and 2, respectively, percentages of correct responses and normalized RTs were analyzed by 2 × 2 ANOVAs with linguistic expectancy and tonal function as within-participant factors. No significant effects were observed, except a main effect of linguistic expectancy in Experiment 1. Pseudo-words that matched expected words were processed faster than pseudo-words that matched syntactically unexpected ones, F1(1, 31) = 4.49, p < 0.05, MSE = 0.04, F2(1, 23) = 6.53, p < 0.05, MSE = 0.02.
- ^The two-way interaction between musical and linguistic expectancy manipulation was significant, F1(1, 62) = 4.01, p < 0.05, MSE = 0.04, but the three-way interaction integrating also the type of linguistic manipulation (syntactic or semantic) was not significant: F(1,62) = 1.73, p = 0.19, MSE = 0.04.
- ^These predictions have been started to be tested in recent works (see Sammler et al., 2010 for action; Hoch and Tillmann, submitted, for maths).
References
Basso, A., and Capitani, E. (1985). Spared musical abilities in a conductor with global aphasia and ideomotor apraxia. J. Neurol. Neurosurg. Psychiatr. 48, 407–412.
Besson, M., Faïta, F., Peretz, I., Bonnel, A. M., and Requin, J. (1998). Singing in the brain: independence of lyrics and tunes. Psychol. Sci. 9, 494–498.
Besson, M., and Schön, D. (2003). “Comparison between music and language,” in The Cognitive Neuroscience of Music, eds I. Peretz and R. Zatorre (Oxford: Oxford University Press), 269–293.
Bharucha, J. J., and Stoeckig, K. (1986). Reaction time and musical expectancy: priming of chord. J. Exp. Psychol. Hum. Percept. Perform. 12, 403–410.
Bigand, E., Poulin, B., Tillmann, B., Madurell, F., and D’Adamo, D. (2003). Sensory versus cognitive components in harmonic priming. J. Exp. Psychol. Hum. Percept. Perform. 29, 159–171.
Bigand, E., Tillmann, B., and Poulin-Charronnat, B. (2006). A module for syntactic processing in music? Trends Cogn. Sci. (Regul. Ed.) 10, 195–196.
Bigand, E., Tillmann, B., Poulin, B., D’Adamo, D. A., and Madurell, F. (2001). The effect of harmonic context on phoneme monitoring in vocal music. Cognition 81, B11–B20.
Bonnel, A. M., Faïta, F., Peretz, I., and Besson, M. (2001). Divided attention between lyrics and tunes of operatic songs: evidence for independent processing. Percept. Psychophys. 63, 1201–1213.
Christiansen, M. H., Kelly, M. L., Shillcock, R. C., and Greenfield, K. (2010). Impaired artificial grammar learning in agrammatism. Cognition 116, 382–393.
Cohen, J., MacWhinney, B., Flatt, M., and Provost, J. (1993). Psyscope: an interactive graphic system for designing and controlling experiments in the psychology laboratory using Macintosh computers. Behav. Res. Methods Instrum. Comput. 25, 257–271.
Colé, P., and Segui, J. (1994). Grammatical incongruency and vocabulary types. Mem. Cognit. 22, 387–394.
Coull, J. T. (2004). fMRI studies of temporal attention: allocating attention within, or towards, time. Brain Res. Cogn. Brain Res. 21, 216–226.
Escoffier, N., and Tillmann, B. (2008). The tonal function of a task-irrelevant chord modulates speed of visual processing. Cognition 107, 1070–1080.
Fazio, P., Cantagallo, A., Craighero, L., D’Ausilio, A., Roy, A. C., Pozzo, T., Calzolari, F., Granieri, E., and Fadiga, L. (2009). Encoding of human action in Broca’s area. Brain 132, 1980–1988.
Fedorenko, E., Patel, A. D., Casasanto, D., Winawer, J., and Gibson, E. (2009). Structural integration in language and music: evidence for a shared system. Mem. Cognit. 37, 1–9.
Friederici, A. D. (2001). “The neural basis of sentence processing: a neurocognitive model,” in Towards a New Functional Anatomy of Language Cognition, eds G. Hickok and D. Poeppel (special issue).
Friederici, A. D., Pfeifer, E., and Hahne, A. (1993). Event-related brain potentials during natural speech processing: effects of semantic, morphological and syntactic violations. Brain Res. Cogn. Brain Res. 1, 183–192.
Friederici, A. D., Rüschemeyer, S.-A., Hahne, A., and Fiebach, C. J. (2003). The role of left inferior frontal and superior temporal cortex in sentence comprehension: localizing syntactic and semantic processes. Cereb. Cortex 13, 170–177.
Friederici, A. D., Schriefers, H., and Lindenberger, U. (1998). Differential age effects on semantic and syntactic priming. Int. J. Behav. Dev. 22, 813–845.
Gelfand, J. R., and Bookheimer, S. Y. (2003). Dissociating neural mechanisms of temporal sequencing and processing phonemes. Neuron 38, 831–842.
Gunter, T. C., Friederici, A. D., and Schriefers, H. (2000). Syntactic gender and semantic expectancy: ERPs reveal early autonomy and late interaction. J. Cogn. Neurosci. 12, 556–568.
Hagoort, P. (2005). On Broca, brain, and binding: a new framework. Trends Cogn. Sci. (Regul. Ed.) 9, 416–423.
Hoch, L., and Tillmann, B. (2010). Laterality effects for musical structure processing: a dichotic listening study. Neuropsychology 24, 661–666.
Jackendoff, R. (2002). Foundations of Language: Brain, Meaning, Grammar, Evolution. New York: Oxford University Press.
Jackendoff, R. (2009). Parallels and nonparallels between language and music. Music Percept. 26, 195–204.
Jonides, J., and Mack, R. (1984). On the cost and benefit of cost and benefit. Psychol. Bull. 96, 29–44.
Kintsch, W. (1988). The role of knowledge in discourse comprehension: a construction-integration model. Psychol. Rev. 95, 163–182.
Koelsch, S., Gunter, T. C., Schröger, E., Tervaniemi, M., Sammler, D., and Friederici, A. D. (2001). Differentiating ERAN and MMN: an ERP study. Neuroreport 12, 1385–1389.
Koelsch, S., Gunter, T. C., von Cramon, D. Y., Zysset, S., Lohmann, G., and Friederici, A. D. (2002). Bach speaks: a cortical “language-network” serves the processing of music. Neuroimage 17, 956–966.
Koelsch, S., Gunter, T. C., Wittfoth, M., and Sammler, D. (2005). Interaction between syntax processing in language and in music: an ERP study. J. Cogn. Neurosci. 17, 1565–1577.
Koelsch, S., Jentschke, S., Sammler, D., and Mietchen, D. (2007). Untangling syntactic and sensory processing: an ERP study of music perception. Psychophysiology 44, 476–490.
Kotz, S. A., Cappa, S. F., von Cramon, D. Y., and Friederici, A. D. (2002). Modulation of the lexical–semantic network by auditory semantic priming: an event-related functional MRI study. Neuroimage 17, 1761–1772.
Maess, B., Koelsch, S., Gunter, T. C., and Friederici, A. D. (2001). Musical syntax is processed in Broca’s area: an MEG study. Nat. Neurosci. 4, 540–544.
McNamara, T. P. (2005). Semantic priming: Perspectives from memory and word recognition. Sussex: Psychology Press.
Patel, A. D., Gibson, E., Ratner, J., Besson, M., and Holcomb, P. J. (1998). Processing syntactic relations in language and music: an event-related potential study. J. Cogn. Neurosci. 10, 71–733.
Patel, A. D., Iversen, J. R., Wassenaar, M., and Hagoort, P. (2008). Musical syntactic processing in agrammatic Broca’s aphasia. Aphasiology 22, 776–789.
Peretz, I., Belleville, S., and Fontaine, S. (1997). Dissociation entre musique et langage après atteinte cérébrale: un nouveau cas d’amusie sans aphasie. Can. J. Exp. Psychol. 51, 354–367.
Peretz, I., Kolinsky, R., Tramo, M., Labrecque, R., Hublet, C., Demeurisse, G., and Belleville, S. (1994). Functional dissociations following bilateral lesions of auditory cortex. Brain 117, 1283–1301.
Petersson, K. M., Folia, V., and Hagoort, P. (2010). What artificial grammar learning reveals about the neurobiology of syntax. Brain Lang. [Epub ahead of print].
Petersson, K. M., Forkstam, C., and Ingvar, M. (2004). Artifical syntactic violations activate Broca’s region. Cogn. Sci. 28, 383–407.
Poulin-Charronnat, B., Bigand, E., Madurell, F., and Peereman, R. (2005). Musical structure modulates semantic priming in vocal music. Cognition 94, B67–B78.
Sammler, D., Harding, E. E., D’Ausilio, A., Fadiga, L., and Koelsch, S. (2010). “Music and action: do they share neural resources?” in 11th International Conference of Music Perception and Cognition, eds S. M. Demorest, S. J. Morrison, and P. S. Campbell (Seattle, WA: Causal Productions), 87.
Schubotz, R. I., Friederici, A. D., and von Cramon, D. Y. (2000). Time perception and motor timing: a common cortical and subcortical basis revealed by fMRI. Neuroimage 11, 1–12.
Slevc, L. R., Rosenberg, J. C., and Patel, A. D. (2009). Making psycholinguistics musical: self-paced reading time evidence for shared processing of linguistic and musical syntax. Psychon. Bull. Rev. 16, 374–381.
Steinbeis, N., and Koelsch, S. (2008). Shared neural resources between music and language indicate semantic processing of musical tension-resolution patterns. Cereb. Cortex 18, 1169–1178.
Tekman, H. G., and Bharucha, J. J. (1998). Implicit knowledge versus psychoacoustic in priming of chords. J. Exp. Psychol. Hum. Percept. Perform. 24, 252–260.
Terhardt, E. (1984). The concept of musical consonance: a link between music and psychoacoustics. Music Percept. 1, 276–295.
Tettamanti, M., and Weniger, D. (2006). Broca’s area: a supramodal hierarchical processor? Cortex 42, 491–494.
Tillmann, B. (2005). Implicit investigations of tonal knowledge in nonmusicians listeners. Ann. N. Y. Acad. Sci. 1060, 1–11.
Keywords: musical expectancy, semantic expectancy, syntactic expectancy, structural integration, cross-modal interactions
Citation: Hoch L, Poulin-Charronnat B and Tillmann B (2011) The influence of task-irrelevant music on language processing: syntactic and semantic structures. Front. Psychology 2:112. doi: 10.3389/fpsyg.2011.00112
Received: 14 February 2011; Accepted: 13 May 2011;
Published online: 06 June 2011.
Edited by:
Lutz Jäncke, University of Zurich, SwitzerlandReviewed by:
Eckart Altenmüller, University of Music and Drama Hannover, GermanyAntoine Shahin, The Ohio State University, USA
Patrick Wong, Northwestern University, USA
Copyright: © 2011 Hoch, Poulin-Charronnat and Tillmann. This is an open-access article subject to a non-exclusive license between the authors and Frontiers Media SA, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and other Frontiers conditions are complied with.
*Correspondence: Barbara Tillmann, Team Auditory Cognition and Psychoacoustics, Lyon Neuroscience Research Center, 50 Avenue Tony Garnier, F-69366 Lyon Cedex 07, France. e-mail:YnRpbGxtYW5uQG9sZmFjLnVuaXYtbHlvbjEuZnI=