 Giorgio Arcara1
Giorgio Arcara1 Graziano Lacaita2
Graziano Lacaita2 Elisa Mattaloni3 Laura Passarini4
Elisa Mattaloni3 Laura Passarini4 Sara Mondini1,5
Sara Mondini1,5 Paola Benincà2
Paola Benincà2 Carlo Semenza4,6*
Carlo Semenza4,6*- 1 Dipartimento di Psicologia Generale, Università di Padova, Padova, Italy
- 2 Dipartimento di Linguistica, Università di Padova, Padova, Italy
- 3 Dipartimento di Psicologia, Università di Trieste, Trieste, Italy
- 4 IRCCS Ospedale S. Camillo, Lido di Venezia, Venezia, Italy
- 5 Casa di Cura Figlie di San Camillo, Cremona, Italy
- 6 Dipartimento di Neuroscienze, Università di Padova, Padova, Italy
The present study is the first neuropsychological investigation into the problem of the mental representation and processing of irreversible binomials (IBs), i.e., word pairs linked by a conjunction (e.g., “hit and run,” “dead or alive”). In order to test their lexical status, the phenomenon of neglect dyslexia is explored. People with left-sided neglect dyslexia show a clear lexical effect: they can read IBs better (i.e., by dropping the leftmost words less frequently) when their components are presented in their correct order. This may be taken as an indication that they treat these constructions as lexical, not decomposable, elements. This finding therefore constitutes strong evidence that IBs tend to be stored in the mental lexicon as a whole and that this whole form is preferably addressed in the retrieval process.
Introduction
Our language faculties allow us to produce and understand a potentially infinite set of word combinations (Chomsky, 1965). However, this does not necessarily imply that the normal usage of language always occurs via a full parsing of whatever linguistic information we are presented with. There are indeed word sequences that, because of some peculiar characteristics, are likely to be stored as a whole. Some examples are collocations, i.e., expressions of multiple words which commonly co-occur in a given order (e.g., “at the end of,” “in relation to”), idioms, i.e., word phrases that have a meaning different from their literal meaning (e.g., “to kick the bucket,” “to spill the beans”), compounds, i.e., words made up by other existing words (e.g., “black hole,” “pickpocket”), and irreversible binomials (IBs), i.e., word pairs linked by a conjunction (e.g., “hit and run,” “dead or alive”).
There are two main reasons why our mental lexicon could store word sequences: frequency of usage (Bybee, 2007), and the opaque relationship between the meaning of the single words and the meaning of whole structures, when the meaning of the whole sequence cannot be derived analytically by the meaning of the constitutive elements (Libben, 1998).
The present study focuses on IBs, which are complex linguistic constructions found in both Romance and Germanic languages. In Italian and in English, as well as in other languages, IBs usually consist of two words conjoined by a copulative or disjunctive conjunction (e.g., “bianco e nero,” black and white; “ora o mai più,” now or never), in some cases accompanied by one or more prepositions (e.g., “in fretta e furia,” in a rush, lit. in rush and fury; Malkiel, 1959; Masini, 2006). The two constituents must belong to the same lexical class.
As the adjective irreversible suggests, the order of the elements in an IB cannot be reversed. The Italian sentences in Figure 1 can be used as examples.

Figure 1. (A) Example of irreversible binomial. (B) A corresponding non-binomial sequence.
In Figure 1A the IB “acqua e sapone” (lit. water and soap) shows an idiomatic, non-compositional meaning. The reversed order is unacceptable.
In Figure 1B the same sequence “acqua e sapone” becomes completely different because of its referential, non-idiomatic, meaning (water and soap), and the order can be freely reversed.
For IBs (as for all other idiomatic word sequences) it is logically necessary that the information about the whole sequence meaning is stored somewhere in the long-term memory. In light of this consideration, a crucial issue concerns how this information is stored and accessed. Evidence related to multi-word sequence representation and processing mainly comes from studies of idioms (e.g., “to cry over spilled milk”) and compounds (e.g., “black hole”).
The “lexical” models, which were initially proposed for idiom processing, postulated that idioms are stored in the mental lexicon as multi-words sequences and can be retrieved as such (Bobrow and Bell, 1973). On the other hand, according to “non-lexical” theories, idioms are represented as configurations of lexical items but whole-sequence representations are not stored in the mental lexicon. For example, according to the Configuration Hypothesis (Cacciari and Tabossi, 1988), an idiom initially undergoes a word-by-word processing (just as a non-idiomatic sentence) and the idiomatic meaning is retrieved only when enough information is accumulated to identify the word sequence as an idiom. According to the hybrid model of idiom representation (Sprenger et al., 2006) idioms are not treated as unitary lexical items at the word form level, but at a higher level of representation (i.e., superlemma, Sprenger et al., 2006). Recent findings on idiom processing seem to support non-lexical models, since there is evidence that syntactic analysis occurs also after the idiomatic expression is recognized (Peterson et al., 2001).
Theories on the representation and processing of compound words mainly derive from the theories on morphologically complex words. Traditionally two competing classes of theories about the representation of complex words have been proposed: the “full-listing” theories (Butterworth, 1983; Bybee, 1995) and the “decomposition” or “full parsing” theories (Taft and Forster, 1976; Libben et al., 1999; McKinnon et al., 2003; Taft, 2004). After an initial debate about these opposing theories, a compromise known as “dual-route” theories, has gained ground. There are several variants of “dual-route” theories, but all of them share the claim that words can be either stored as a whole or be decomposed into their morphological constituents (Caramazza et al., 1988; Sandra, 1990; Zwitserlood, 1994; Baayen et al., 1997; Isel et al., 2003). Different types of complex words can be processed preferentially via one route rather than another. For example, very frequently used items and, in the particular case of compounds, opaque ones, can be stored and processed more efficiently in their full form. In contrast, less frequent items and transparent compounds can be preferably subject to decomposition. Compounds have largely been studied using different experimental paradigms, such as lexical decision (e.g., Juhasz et al., 2003; Duñabeitia et al., 2007) or priming (e.g., Jarema et al., 1999), with different experimental techniques such as recording eye movements (e.g., Juhasz et al., 2003; Inhoff et al., 2008; Kuperman et al., 2008), or ERPs (e.g., Koester et al., 2004; Koester et al., 2007; El Yagoubi et al., 2008), and with patients who have brain lesions (for recent reviews see Chiarelli et al., 2007; Semenza and Mondini, 2010; Semenza et al., 2011b). The large majority of these studies converge in suggesting that compounds are decomposed at an early stage of their processing, regardless of their transparency. However, the evidence of early parsing often does not exclude the role of a whole-word form. Indeed, recent results suggest that together with compound parsing, whole-word forms may affect early processing, and that multiple sources of information are taken into account in compound processing (Kuperman et al., 2008).
To our knowledge no previous study has ever investigated the mental representation of IBs. One study (Siyanova-Chanturia et al., 2011) focused on non-idiomatic “reversible binomials,” word phrases composed of two words and a conjunction. Whereas the word order in IBs is fixed, in reversible binomials it is not, and reversing the order of constituents does not change the overall meaning of the word pair (e.g., “groom and bride,” “bride and groom”). However, one word order is usually preferred to the other, and occurs more frequently (Masini, 2006). In their study, Siyanova-Chanturia et al. (2011) investigated the effects of several psycholinguistic variables on different eye movement measures. Their main findings were about the effects of binomial frequency, indicating that a whole-sequence representation of reversible binomials affects reading.
The data presented in the relevant literature point to two opposite hypotheses. According to theories on idioms, a whole-sequence representation would play a significant role only in the later stages of processing (e.g., Cacciari and Tabossi, 1988; Sprenger et al., 2006). In contrast, recent theories on compounds (e.g., Kuperman et al., 2008) suggest an early influence of representation of both constituents and whole words. The very recent study of Siyanova-Chanturia et al. (2011) on reversible binomials supports this latter hypothesis in that only a frequency effect of the whole binomial (and not of single words) was found.
The present study is the first neuropsychological investigation concerning the problem of the mental representation and processing of IBs (preliminary data on a lesser number of participants have been presented at the Academy of Aphasia conference held in Athens in 2010, see Arcara et al., 2010). In order to test the lexical status of IBs, the phenomenon of neglect dyslexia is exploited. Reading IBs in terms of neglect dyslexia may indeed contribute to understanding if and when a whole representation can be accessed during lexical processing.
Neglect dyslexia is a deficit that commonly follows right hemisphere damage: it is characterized by an impairment in reading of letters, words, or strings of words located in the contra-lesional (i.e., left) visual space. Errors produced in word reading are often omissions and substitutions of the leftmost portion of the word or of the string of words. The literature on neglect dyslexia suggests that errors may be influenced by the lexical status of the target. The nature of stored lexical knowledge seems to partially compensate for attentional problems (Arduino et al., 2002). More conspicuous components of a word, such as, for instance, the head of a compound, seem more resistant to the deficit (Semenza et al., 2011a). A similar investigation related to IBs is thus conducted here.
Materials and Methods
Thirty participants with left neglect were recruited for the present research. All patients were Italian native speakers who showed signs of neglect dyslexia for the left side of the visual space as a consequence of a right hemisphere lesion. They were recruited, for the most part, through the I.R.C.C.S1 Ospedale S. Camillo, Lido di Venezia (Italy) and a few participants were tested in their homes. Neglect was assessed through the Behavioral Inattention Test (BIT). Table 1 reports descriptive data about participants. The location of the bulk of the lesions is reported as the best approximation allowed by available neuroimaging data (CT scans or MRI).
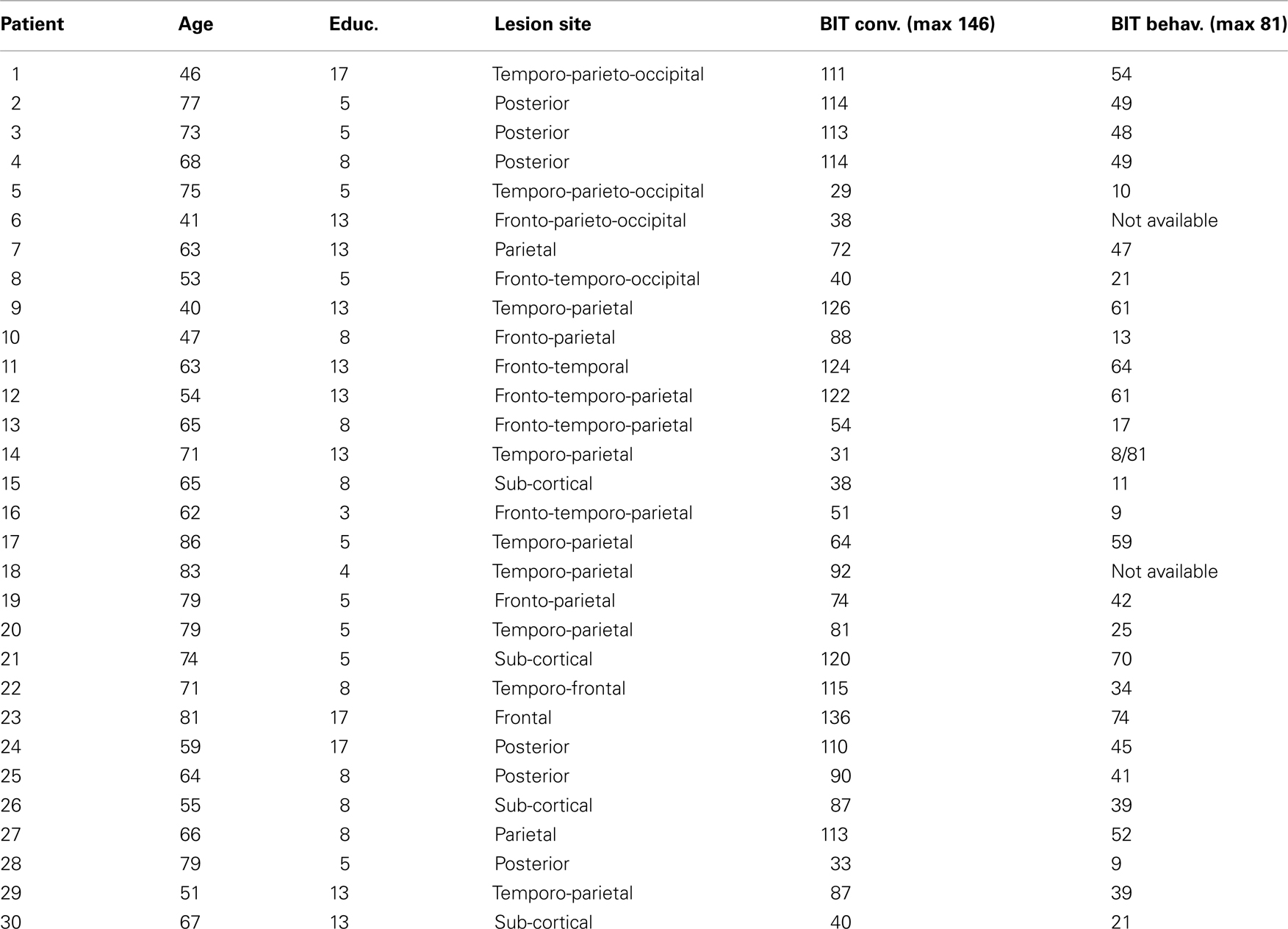
Table 1. Age, years of education (Educ.), lesion site and performance on BIT conventional (BIT conv.), and BIT behavioral (BIT behav.) for each patient.
Stimuli
Each patient was asked to read a total of 108 stimuli aloud. The set of stimuli included 36 IBs (e.g., “botta e risposta,” sparring matches, lit. hit and answer). All IBs used in the experiment were composed of two content words (henceforth, constituents) connected by a linking element. Constituents of IBs were mostly nouns, or, in few cases, adjectives or adverbs.
The experiment also included two different types of control stimuli: (1) 36 reversed binomials (RBs) in which the order of the content words of the binomials was reversed (e.g., “*risposta e botta,” answer and hit); (2) 36 non-binomials (NBs), verbal sequences of two words in which the first constituent of a binomial was replaced with a random word (e.g., “pugno e risposta,” punch and answer) and the second constituent was kept. NBs were included to control the possibility of guessing the first component of an IB, while relying only on the second one. All the stimulus variables considered are listed in Table 2. Length was calculated as the total number of letters composing the stimulus. Frequency was calculated as the number of occurrences in a corpus of written Italian (http://dev.sslmit.unibo.it/corpora/corpora.php). The neighborhood size of a word was calculated as the total number of words that could be formed by replacing one letter of a target word. The in-between category (IB, RB, and NB) differences were investigated by means of separate ANOVAs. The length of the first content words was significantly different among the categories [F(2, 105) = 5.78, p < 0.005]. Post hoc analyses showed that the length of the first constituent (LENGTH_FIRST) was longer in RBs and NBs than in IBs (all ps < 0.01). A significant difference was also found in the length of the second constituent, [F(2, 105) = 5.60, p < 0.005]. Post hoc analysis showed that second constituents (LENGTH_SECOND) were shorter in RBs compared to IBs and NBs.
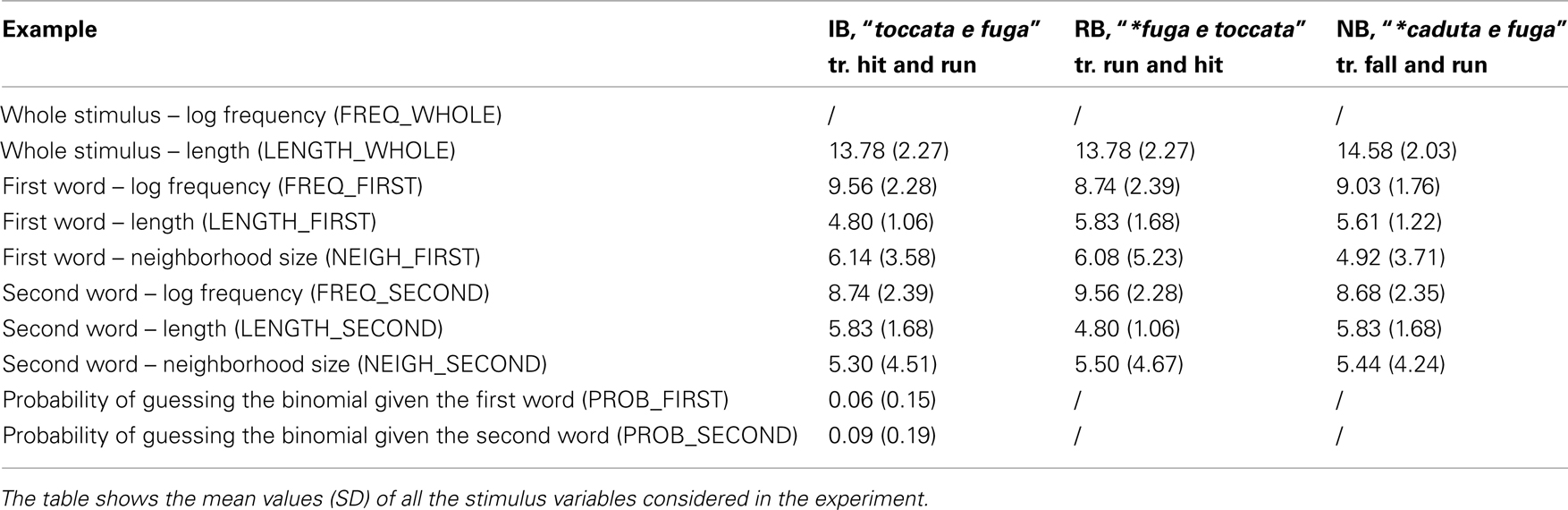
Table 2. Stimulus variables.
The characteristics of experimental stimuli were further explored by means of separate t-tests, conducted for each stimulus type and each psycholinguistic variable, contrasting the properties of the first and the second constituents. These analyses showed that the frequency of the first constituent of IBs was significantly higher than the frequency of the second constituent of IBs [t(35) = 3.01, p < 0.005]. These results, however, are not surprising: frequency seems to contribute to determining the order of the constituents within a binomial with a preference for highest frequency words in the first position (Fenk-Oczlon, 1989). The length of content words in IBs was also different [t(49) = −3.73, p < 0.001]. This difference can be systematically observed in binomials (Jespersen, 1905) and seems to reflect rhythmic preferences.
To further rule out the possibility that the performance of experimental participants is related to a simple guessing strategy, the probability of guessing the whole binomial when only part of the information on the stimulus is available was considered. Two different probabilities were computed, only for IBs: the probability of guessing the whole binomial given the first word (PROB_FIRST) and the probability of guessing the whole binomial when the second word was given (PROB_SECOND). Assuming that the frequency of a given stimulus in a corpus is a good estimation of the probability of encountering that stimulus, these two probabilities can be calculated as the ratio of two frequencies: the frequency of the whole stimulus and the frequency of the first (or the second) word of the binomial. Thus, PROB_FIRST = (FREQ_WHOLE/FREQ_FIRST) and PROB_SECOND = (FREQ_WHOLE/FREQ_SECOND). This probability of guessing was statistically different [t(49) = −2.91, p < 0.01] indicating that, although both probabilities are low, there may be a slight advantage in guessing the whole binomial when the second word is available.
Procedure
Stimuli were presented to all patients in random order. Each stimulus was displayed singularly in the middle of a computer screen. The distance from the computer screen was 50/60 cm. On the horizontal plane, the stimuli subtended 16–22°. Participants were asked to read each word aloud with no time limit. The examiner had the possibility to manually switch to the following stimulus once the stimulus was read by the participant. The first response was collected. Only “neglect” errors, i.e., those connected with the leftmost part of the stimulus (i.e., identified as the region including the first constituent and linking element) were included in the analysis.
Data Analysis
People affected by neglect dyslexia made a total of 934 erroneous responses out of 2295 total valid responses (29% of errors). Ten responses were excluded from the analysis because the error (or the errors) fell only within the rightmost part of the stimulus. Errors were classified according to two variables: error type (omission or substitution), and error position (first constituent, linking element, second constituent). Errors were classified as omissions if a whole constituent of the stimulus was dropped (e.g., “fuga,” escape, in place of “toccata e fuga,” hit and run, lit. touch and escape), or if a fragment of the constituent was dropped (e.g., “*cata e fuga,” in place of “toccata e fuga”). Errors were classified as substitutions if a whole word (or a word fragment) was substituted with another word or with another word fragment (e.g., “venti e mari,” winds and seas, in place of the RB “monti e mari,” mountains and seas).
Table 3 shows a summary of omissions and substitution frequency, with reference to error positions and types of stimuli. In this table, all errors committed by the participants are listed. Each erroneous response (of the 934 collected) could include more than one error. For example, the response “vegeto” (alive) in place of “vivo e vegeto” (alive and kicking, lit. living and alive), included two errors (omission of the first constituent and omission of the linking element), but this was considered in the statistical analysis as a single erroneous response.
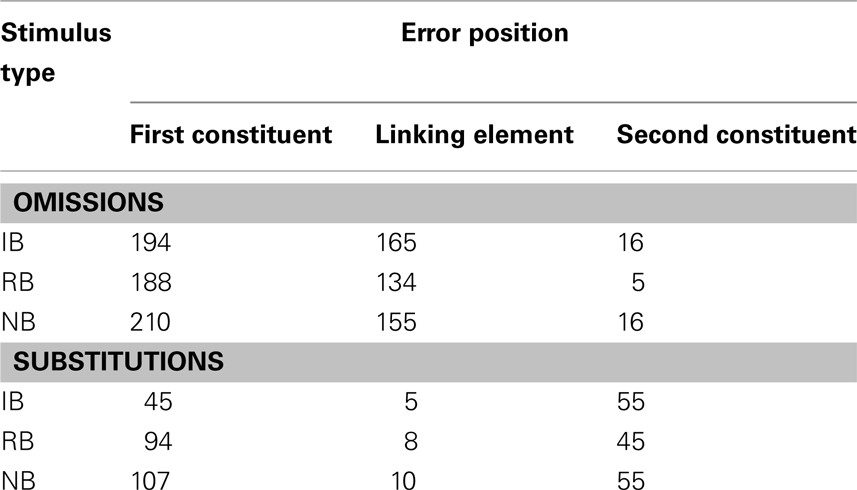
Table 3. Number of omissions and substitutions according to stimulus type and error position.
An inspection of Table 3 shows that the errors made by the neglect dyslexic patients consisted mostly of omissions of the first constituent or of the first preposition (if present). The largest difference in categories was in the number of substitutions of the first constituents (Table 3). In this case the number of errors in RBs and NBs was almost twice the number of errors in IBs.
Statistical analysis was carried out on the overall erroneous responses (rather than separately for each error type), in order to achieve the best statistical power available. Data were analyzed using mixed models (Baayen, 2008; Baayen et al., 2008). There are many advantages in using these statistical models in language studies. Firstly, they can deal with the problem of the language-as-fixed-effect fallacy (Clark, 1973) by including both subjects and stimuli as random variables. This inclusion avoids the results of this statistical model being influenced by the performance of just a few subjects or the performance of just a few stimuli. This is particularly relevant to studies with pathological participants, which may show a high degree of inter-subject variability in the performance. A further advantage is that mixed models, as regression models, take into account the influence of several covariates (included as fixed effects). Including the properties of the stimuli (i.e., frequency, length, neighborhood size) as covariates in this experiment means that the effectiveness of their influence on the reading performance of neglect dyslexic patients can be assessed.
In the present study the random effects were the stimuli and the subjects (codified as categorical variables), while the fixed effects were the stimulus type (TYPE: a factor with three levels, NB, RB, and IB) and all the variables listed in Table 2 (inserted as covariates). The dependent variable (the reading accuracy of the whole binomial) was codified in terms of dichotomous responses (correct vs. incorrect), and a logit mixed model was employed (Jaeger, 2008). The dependent variable is the probability of correctly reading the stimulus. This probability is expressed in logits (see Jaeger, 2008). Positive values indicate a predicted probability higher than 50%, negative values indicate a predicted probability lower than 50% and a value of 0 indicates a predicted probability of exactly 50%. The effect of every significant predictor is independent and the relationship between the predictors is additive. That is, the prediction for the probability of correct reading is the sum of the effects of all significant variables.
Since some variables (i.e., FREQ_WHOLE, PROB_COND1, PROB_COND2) are meaningless for RBs and NBs, two separate analyses were run on the data. In the first analysis (all stimuli analysis) the model was fit on the stimuli of all categories (IB, RB, and NB), ignoring the variables FREQ_WHOLE, PROB_FIRST, and PROB_SECOND. In the second analysis (IB analysis) a model was fit only on IBs, and all of the variables listed in Table 2 were considered. Special attention was paid to the issue of multicollinearity, the correlation among predictors in the analysis (Baayen et al., 2006). Before running the analysis we checked if the set of predictors showed a potentially harmful multicollinearity. If this issue was present, we “residualized” the original measures in order to obtain uncorrelated predictors (see the Appendix). Tables reporting predictor correlations before and after residualization are presented in the Section “Appendix.”
In both the all stimuli analysis and the IB analysis, the model that best fits the data was selected by backward elimination. Non-significant variables were excluded from the model one at a time, starting with the variables with the lowest |z|. For the categorical variables, no effect was excluded if it belonged to a factor in which at least one level had a p < 0.05. Before excluding a variable from the model, a further check was made: a likelihood ratio test was carried out and if the presence of the variable was irrelevant in improving the goodness-of-fit of the model, the variable was definitively removed.
All analyses were performed using R software (R Development Core Team, 2011). For generalized mixed effect models, we used the R package lme4 (Bates et al., 2011) and the package languageR (Baayen, 2011).
Results
All Stimuli Analysis
The model fit on all stimuli included the following fixed effects: TYPE, LENGTH_FIRST, LENGTH_SECOND. The significant random variables were stimulus and subject, whose inclusion as random variables improved the goodness-of-fit of the model. Details of significant effects are listed in Tables 4 and 5. The first parameter of the model is the Intercept, a default prediction for stimuli of type NB with all covariates set to 0. The coefficients associated with TYPE = RB and TYPE = IB indicate the adjustment to the Intercept that needs to be made when the stimuli are respectively, RBs and IBs. The coefficients of covariates indicate the slopes of the effects of each covariate. In order to obtain a meaningful prediction all effects have to be considered.
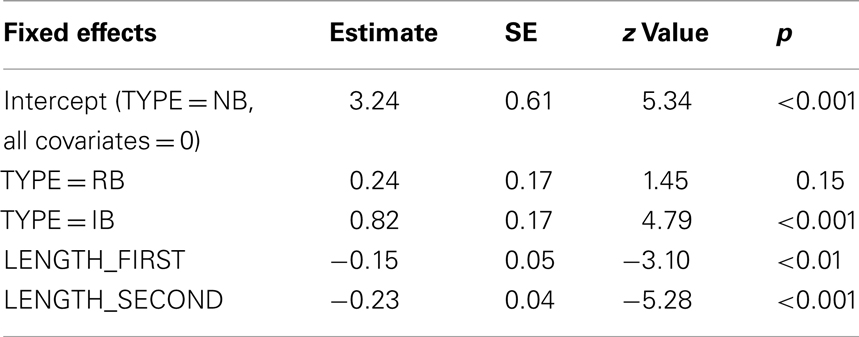
Table 4. Fixed effects of the model fit on all stimuli.

Table 5. Random effects of the model fit on all stimuli.
According to this model, there is a significant higher probability of correct reading IBs compared to RBs and NBs, while there is no significant difference between RBs and NBs2. The probability of obtaining a correct reading was influenced by the length of both the first and second constituents of the stimulus: the longer the constituents of the binomial, the more likely that an error will be committed, with a slightly larger effect of the length of the second constituent (LENGTH_SECOND) compared to the length of the first one (LENGTH_FIRST). Figure 2 shows the plots of the significant effects of all stimuli analysis. Only the variables listed in Table 4 were statistically significant.
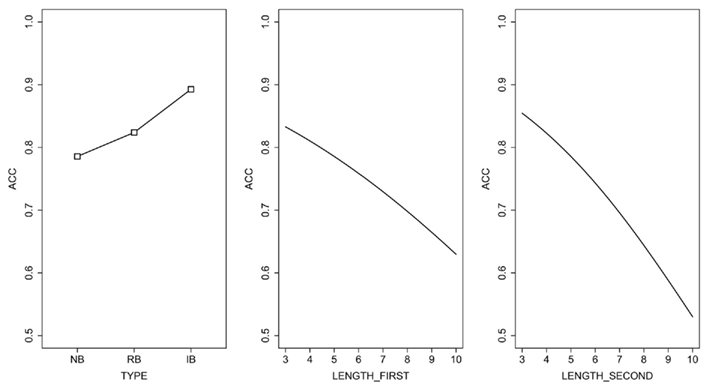
Figure 2. Partial effects of model fit on all stimuli. The plots are shown for the reference level of factor and adjusted for the median value for the covariates in the model. The y-axis denotes the predicted reading accuracy (ACC), expressed as proportion of items correctly read.
Table 5 reports random effects. The variances indicate that there is a substantial amount of inter-subject variability compared to the inter-stimulus variability. Importantly, the significance of the fixed effects in the mixed models indicates that the predictors are significant even taking into account both these sources of variability. As indices of goodness-of-fit we calculated index of concordance C and Somers’ D. The index of concordance C takes the value 0.5 when the model makes random predictions, and the value 1 when the predictions are perfect. When it takes a value above 0.8, then the model shows an effective predictive ability (Baayen, 2008). Somers’ D is a rank correlation between predicted probabilities and observed responses. Both indices of goodness-of-fit (C = 0.93; Somers’ D = 0.86) indicate that the model explains the observed data satisfactorily.
IB Analysis
Given the intrinsic relationship between frequencies and conditional probabilities (PROB_FIRST and PROB_SECOND are calculated as ratio of FREQ_WHOLE, to FREQ_FIRST and FREQ_SECOND), the effects of these variables were investigated by fitting two separate models. The backfitting procedure on both models led to the same final model, which included only the following significant fixed effect: LENGTH_SECOND (see Table 6). The significant random variables were stimulus and Subject (see Table 7). The effect of LENGTH_SECOND indicates that, as the length of the second constituent increases the probability of correctly reading, the IB decreases. Table 7 of random effects shows that there is considerable inter-subject variability. All the other variables were not significant. Indices of goodness-of-fit (C = 0.94; Somers’ D = 0.89) indicate that the model fits well the observed data.
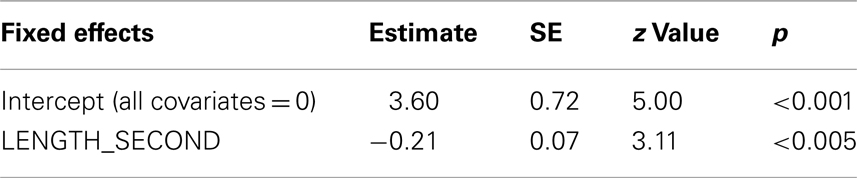
Table 6. Fixed effects of model fit only on IB.

Table 7. Random effects of model fit only on IB.
Figure 3 illustrates the effect of LENGTH_SECOND in the model fit only on IBs.
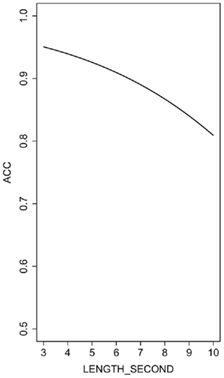
Figure 3. Significant effect of model fit on IBs. The y-axis denotes the predicted reading accuracy (ACC), expressed as proportion of items correctly read.
Discussion
People with left-sided neglect dyslexia demonstrate a clear lexical effect. They can read IBs better when components are presented in their correct order. This may be taken as an indication that they treat IBs as lexical, not decomposable, elements. This finding is therefore a strong evidence that IBs tend to be stored in the mental lexicon as a whole and that this whole form is preferably addressed in the retrieval process. Even though it should be possible to activate each constituent of an IB singularly, this experiment shows the primacy of the lexicality of whole binomials in terms of their processing (examples of recent results supporting whole-sequence representation and processing are given in Tremblay and Baayen, 2010; Siyanova-Chanturia et al., 2011; Tremblay et al., 2011). It is unlikely that the observable advantages of IBs are related to a guessing strategy which may be adopted by patients with neglect dyslexia. Only once did a patient produce an IB in place of the corresponding NB (e.g., the NB “caduta e fuga,” fall and run, read as the IB “toccata e fuga,” hit and run). Secondly, no significant effect of the probability of guessing the IBs giving the second constituent was found (no significant effect of PROB_SECOND). Thus, it is unlikely that patients used the available information on the rightmost part of the stimulus to guess what the neglected part was.
The difference between IBs and RBs supports the conclusion of the effect of a whole-sequence representation. Both IBs and RBs include the same words but arranged in a different order (e.g., “toccata e fuga,” tr. hit and run and “fuga e toccata,” tr. run and hit). The only difference between these two conditions is the order of constituents. The advantages of IBs cannot be explained, but assuming that a whole-binomial representation affects the early stages of word processing, which may be impaired in patients with neglect dyslexia (Vallar et al., 2010). The advantages of IB reading may also be explained in terms of frequency: IBs in the correct order are obviously more frequent then RBs and NBs. However, when considering only IBs, we did not find any effect of frequency (the probability of reading correctly IBs is not related to their frequency) suggesting that it is not the frequency that mainly determines if an IB is stored as a whole, but its lexical status.
Side effects of constituent length were also found. The effects of word length are commonly found in many studies on neglect dyslexia patients (see the review by Vallar et al., 2010). In the present study, the analysis of all stimuli shows that, as the length of both the first and the second constituent increases, reading accuracy decreases. The lengths of the first and second constituents could affect the stimulus processing in different ways. In the case of the first constituent, the longer it is, the more it falls on the neglected side. It is more difficult to interpret the effect of the length of the second constituent. We can speculate that, the longer it is, the more it may capture the attention of neglect patients on the right (Vallar et al., 2010), further compromising their reading performance of the left portion.
In the analysis restricted to IBs, only an effect of the second constituent length was found. As its length increases, reading performance decreases. Again, the effect of attentional capture could explain this result. The absence of an effect of first constituent length only on IBs supports the importance of a whole-sequence representation in the analysis. In fact, if the attention of neglect patients is captured by the second constituent, then the first one is more often dropped (see the difference in the proportion of omissions and substitutions of the first constituent in IBs, Table 3), but if the patient directs his/her attention also toward the leftmost part of the stimulus, then the whole sequence can be retrieved (hence, the first constituent length plays no role).
These findings extend our knowledge of the phenomena which occur as part of the syndrome of neglect dyslexia, showing the extent to which stored lexical knowledge interferes with defective visuo-spatial processing and partially compensates for attentional problems. The lexical effects in neglect dyslexia demonstrated so far are typically exemplified by the word superiority effect (a proportion of such patients read better words than non-words, Sieroff et al., 1988; Behrmann et al., 1990; Brunn and Farah, 1991). Another finding in neglect dyslexia is that non-words consisting of a real root and a real affix are easier to read than when they contain neither of these constituents (Arduino et al., 2002). Moreover, words with more orthographic neighbors are more difficult to read than words with few orthographic neighbors (Riddoch et al., 1990; Arguin and Bub, 1997). A similar effect has not been so far described for strings of words. The present findings thus underline the pervasiveness of lexical effects in neglect dyslexia and highlight the nature of this deficit. Orthographic information is easier to process when related to salient lexical items. Thus, words presented in the context of an IB would require a relatively lighter processing load. They would benefit from top-down facilitation (see Lavie, 1995; Brand-D’Abrescia and Lavie, 2007 for theories about the role of attention in word recognition) with respect to when they are presented in the reverse order or when they have no established relation to each other in the lexicon. Strings of words with no order relation to each other appear instead to be more prone to attention lapses. As suggested by effects obtained from substitution errors, probably the strongest competition is from distracters. The lexical effects of neglect dyslexia can be interpreted (Arduino et al., 2002) as supporting “late selection” views of attentional processing (Deutsch and Deutsch, 1963; Behrmann et al., 1991; Umiltà, 2001). They suggest that spatial attentional components, the impairment of which leads to neglect dyslexia, also operate at a later stage of processing, after the information presented in the unattended visual area has undergone higher-level analyses, including lexical and semantic processing.
In reference to theories of lexical representations, the performance of neglect patients in reading IBs suggests that a whole-binomial representation is stored at the level of the input orthographic lexicon (Vallar et al., 2010). In reference to the theory by Levelt and collaborators (Levelt et al., 1999; Sprenger et al., 2006), IB reading can imply the activation of a whole-sequence representation being already at a peripheral input level, i.e., the word form level. We cannot exclude the possibility that these effects are also related to an activation of semantic representations. However, the modulation of the attentional deficit, shown here in analogy with other lexical effects in neglect dyslexia, seems to suggest that the representation of the whole sequence is stored at the level of the input orthographic lexicon.
These results are in line with theories that assume the possibility of an early influence of the whole-sequence representation in lexical processing. A recent mathematical model that embraces such view is the probabilistic model of information sources (PROMISE) (Kuperman et al., 2008). According to the PROMISE model, several probabilistic sources of information are taken into account in morphological processing. Among these sources, one is the whole-word probability. Even if this model has been introduced for morphologically complex words (as compounds) it could also be valid for explaining IB processing. Indeed, increasing evidence supports models that take into account word sequence probabilities in reading (e.g., McDonald and Shillcock, 2003). It is more difficult to integrate the current results with the major established views of idiom processing (Cacciari and Tabossi, 1988; Sprenger et al., 2006), which advocate that a whole-idiom representation should play a role only in later stages of processing or be represented at a superlemma level (hence, not in the word form, but at a supralexical level). However, it is possible to conciliate the present results with these theories by assuming as follows: since IBs are small constructions with poor syntactic information, they are more likely to be stored in the input orthographic lexicon as a whole (as compounds) in comparison to idiomatic sentences.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This study was supported by grants from the University of Padova and from MIUR to Carlo Semenza.
Footnotes
- ^Istituto di Ricovero e Clinica a Carattere Scientifico, tr. Institute of Hospitalization and Care with Scientific Orientation.
- ^To support these claims about the statistical differences between IB, RB, and NB a further model was fit with RB as reference level. When RB is the reference level, there was a significant difference between RB and IB and again no difference between RB and NB. The change of reference level did not influence the effects of LENGTH_FIRST and LENGTH_SECOND, which remained significant.
References
Arcara, G., Lacaita, G., Mattaloni, E., Mondini, S., Benincà, P., and Semenza, C. (2010). Irreversible binomials: evidence from neglect dyslexia. Procedia Soc. Behav. Sci. 6, 20–21.
Arduino, L., Burani, C., and Vallar, G. (2002). Lexical effects in left neglect dyslexia: a study in Italian patient. Cogn. Neuropsychol. 19, 421–444.
Arguin, M., and Bub, D. (1997). Lexical constraints on reading accuracy in neglect dyslexia. Cogn. Neuropsychol. 14, 765–800.
Baayen, R. H. (2008). Analyzing Linguistic Data. A Practical Introduction to Statistics. Cambridge: Cambridge University Press.
Baayen, R. H. (2011). languageR: Data Sets and Functions With “Analyzing Linguistic Data: A Practical Introduction to statistics”. R package version 1.2. Available at: http://CRAN.R-project.org/package=languageR
Baayen, R. H., Davidson, D. J., and Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412.
Baayen, R. H., Dijkstra, T., and Schreuder, R. (1997). Singulars and plurals in Dutch: evidence for a parallel dual-route model. J. Mem. Lang. 37, 94–117.
Baayen, R. H., Feldman, L. B., and Schreuder, R. (2006). Morphological influences on the recognition of monosyllabic monomorphemic words. J. Mem. Lang. 55, 290–313.
Bates, D., Maechler, M., and Bolker, B. (2011). lme4: Linear Mixed-Effects Models Using S4 Classes. R package version 0.999375-39. Available at: http://CRAN.R-project.org/package=lme4
Behrmann, M., Moscovitch, M., Black, S. E., and Mozer, M. (1990). Perceptual and conceptual mechanisms in neglect dyslexia. Brain 113, 1163–1183.
Behrmann, M., Moscovitch, M., and Mozer, M. C. (1991). Directing attention to words and nonwords in normal subjects and in a computational model: implications for neglect dyslexia. Cogn. Neuropsychol. 8, 213–248.
Bobrow, S. A., and Bell, S. M. (1973). On catching on to idiomatic expressions. Mem. Cognit. 1, 343–346.
Brand-D’Abrescia, M., and Lavie, N. (2007). Distractor effects during processing of words under load. Psychon. Bull. Rev. 14, 1153–1157.
Brunn, J. L., and Farah, M. J. (1991). The relation between spatial attention and reading: evidence from the neglect syndrome. Cogn. Neuropsychol. 8, 59–75.
Butterworth, B. (1983). “Lexical representation,” in Language Production, Vol. 2, ed. B. Butterworth (London: Academic Press), 257–294.
Bybee, J. L. (2007). From usage to grammar: the mind’s response to repetition. Language 82, 711–733.
Caramazza, A., Laudanna, A., and Romani, C. (1988). Lexical access and inflectional morphology. Cognition 28, 297–332.
Chiarelli, V., Menichelli, A., and Semenza, C. (2007). Naming compounds in Alzheimer’s disease. Ment. Lex. 2, 259–269.
Clark, H. H. (1973). The language-as-fixed-effect fallacy: a critique of language statistics in psychological research. J. Verbal Learn. Verbal Behav. 12, 335–359.
Deutsch, J. A., and Deutsch, D. (1963). Attention: some theoretical considerations. Psychol. Rev. 70, 80–90.
Duñabeitia, J. A., Perea, M., and Carreiras, M. (2007). The role of the frequency of constituents in compound words: evidence from Basque and Spanish. Psychon. Bull. Rev. 14, 1171–1176.
El Yagoubi, R. Y., Chiarelli, V., Mondini, S., Perrone, G., Danieli, D., and Semenza, C. (2008). Neural correlates of Italian compounds and potential impact of headedness effect: an ERP study. Cogn. Neuropsychol. 25, 559–581.
Inhoff, A. W., Starr, M. S., Solomon, M., and Placke, L. (2008). Eye movements during the reading of compound words and the influence of lexeme meaning. Mem. Cognit. 36, 675–687.
Isel, F., Gunter, T. C., and Friederici, A. D. (2003). Prosody-assisted head driven access to spoken German compounds. J. Exp. Psychol. Learn. Mem. Cogn. 29, 277–288.
Jaeger, T. F. (2008). Categorical data analysis: away from ANOVAs (transformation or not) and towards logit mixed models. J. Mem. Lang. 59, 434–446.
Jarema, G., Busson, C., Nikolova, R., Tsapkini, K., and Libben, G. (1999). Processing compounds: a cross-linguistic study. Brain Lang. 68, 362–369.
Juhasz, B. J., Starr, M. S., Inhoff, A. W., and Placke, L. (2003). The effects of morphology on the processing of compound words: evidence from naming, lexical decisions and eye fixations. Br. J. Psychol. 94, 223–244.
Koester, D., Gunter, T. C., and Wagner, S. (2007). The morphosyntactic decomposition and semantic composition of German compound words investigated by ERPs. Brain Lang. 102, 64–79.
Koester, D., Gunter, T. C., Wagner, S., and Friederici, A. D. (2004). Morphosyntax, prosody, and linking elements: the auditory processing of German nominal compounds. J. Cogn. Neurosci. 16, 1647–1668.
Kuperman, V., Bertram, R., and Baayen, R. H. (2008). Morphological dynamics in compound processing. Lang. Cogn. Process. 23, 1089–1132.
Lavie, N. (1995). Perceptual load as a necessary condition for selective attention. J. Exp. Psychol. Hum. Percept. Perform. 21, 451–468.
Levelt, W. J. M., Roelofs, A., and Meyer, A. S. (1999). A theory of lexical access in speech production. Behav. Brain Sci. 22, 1–75.
Libben, G. (1998). Semantic transparency in the processing of compounds: consequences for representation, processing and impairment. Brain Lang. 61, 30–44.
Libben, G., Derwing, B. L., and de Almeida, R. G. (1999). Ambiguous novel compounds and models of morphological parsing. Brain Lang. 68, 378–386.
Masini, F. (2006). Binomial constructions: inheritance, specification and subregularities. Lingue Linguaggio 2, 207–232.
McDonald, S. A., and Shillcock, R. C. (2003). Eye movements reveal the on-line computation of lexical probabilities during reading. Psychol. Sci. 14, 648–652.
McKinnon, R., Allen, M., and Osterhout, L. (2003). Morphological decomposition involving non productive morphemes: ERP evidence. Neuroreport 14, 883–886.
Peterson, R. R., Burgess, C., Dell, G. S., and Eberhard, K. L. (2001). Dissociation between syntactic and semantic processing during idiom comprehension. J. Exp. Psychol. Learn. Mem. Cogn. 90, 227–234.
R Development Core Team. (2011). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Riddoch, J., Humphreys, G., Cleton, P., and Fery, P. (1990). Interaction of attentional and lexical processes in neglect dyslexia. Cogn. Neuropsychol. 7, 479–517.
Sandra, D. (1990). On the representation and processing of compound words: automatic access to constituent morphemes does not occur. Q. J. Exp. Psychol. (Hove) 42, 529–567.
Semenza, C., Arcara, G., Facchini, S., Meneghello, F., Ferraro, M., Passarini, L., Pilosio, C., Vigato, G., and Mondini, S. (2011a). Reading compounds in neglect dyslexia: the headedness effect. Neuropsychologia 49, 3116–3120.
Semenza, C., De Pellegrin, S., Battel, I., Garzon, M., Meneghello, F., and Chiarelli, V. (2011b). Compounds in different aphasia categories: a study on picture naming. J. Clin. Exp. Neuropsychol. 33, 1099–1107.
Semenza, C., and Mondini, S. (2010). Compound words in neuropsychology. Linguistische Berichte 17, 331–348.
Sieroff, E., Pollatsek, A., and Posner, M. (1988). Recognition of visual letter strings following injury to the posterior visual spatial attention system. Cogn. Neuropsychol. 5, 427–449.
Siyanova-Chanturia, A., Conklin, K., and van Heuven, W. J. B. (2011). Seeing a phrase “time and again” matters: the role of phrasal frequency in the processing of multiword sequences. J. Exp. Psychol. Learn. Mem. Cogn. 37, 776–784.
Sprenger, S. A., Levelt, W. J., and Kempen, G. (2006). Lexical access during the production of idiomatic phrases. J. Mem. Lang. 54, 161–184.
Taft, M. (2004). Morphological decomposition and the reverse base frequency effect. Q. J. Exp. Psychol. (Hove) 57, 745–765.
Taft, M., and Forster, K. I. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. J. Verbal Learn. Verbal Behav. 15, 607–620.
Tremblay, A., Derwing, B., Libben, G., and Westbury, C. (2011). Processing advantages of lexical bundles: evidence from self-paced reading and sentence recall tasks. Lang. Learn. 61, 569–613.
Tremblay, A., and Baayen, H. (2010). “Holistic processing of regular four-word sequences: a behavioral and ERP study of the effects of structure, frequency and probability on immediate free recall,” in Perspectives on Formulaic Language: Acquisition and Communication, ed. D. Wood (London: The Continuum International Publishing Group), 151–173.
Umiltà, C. (2001). “Mechanisms of attention” in The Handbook of Cognitive Neuropsychology, ed. B. Rapp (New York: Psychology Press), 135–158.
Vallar, G., Burani, C., and Arduino, L. S. (2010). Neglect dyslexia: a review of the neuropsychological literature. Exp. Brain Res. 206, 219–235.
Zwitserlood, P. (1994). The role of semantic transparency in the processing and representation of Dutch compounds. Lang. Cogn. Process. 9, 341–368.
Appendix
Table A1 shows the initial correlations of predictors considered in all stimuli analysis. A potential harmful correlation between FREQ_FIRST and FREQ_SECOND (0.57) was removed residualizing FREQ_FIRST on FREQ_SECOND. The residuals of a linear model with FREQ_FIRST as dependent variable, and FREQ_SECOND as predictor, were used to build the new variable RESID_FREQ_FIRST. This new variable was highly correlated with the original variable and poorly correlated with FREQ_SECOND. The “condition number” of the new set of predictors, that is an index of multicollinearity, was 22 (below the cut-off of 30, which indicates a potential harmful multicollinearity). Table A2 shows the correlations of predictors included in all stimuli analysis after residualization.

Table A1. Correlation matrix of predictors utilized in all stimuli analysis before residualization (values indicate pairwise Pearson correlations).

Table A2. Correlation matrix of predictors used in all stimuli analysis after residualization (values indicate pairwise Pearson correlations).
Table A3 shows the initial correlations of predictors considered in IB analysis. In IB analysis, two separate sets of predictors were considered: one with the frequencies (FREQ_WHOLE, FREQ_FIRST, and FREQ_SECOND) and another with the probabilities of guessing the IBs (PROB_FIRST, PROB_SECOND). Frequencies and probabilities were not considered together because they are intrinsically related (PROB_FIRST and PROB_SECOND are calculated as ratio between FREQ_WHOLE and FREQ_FIRST and as ratio of FREQ_WHOLE and FREQ_SECOND, respectively). In the set with the frequencies, two potential harmful correlations were detected: one between FREQ_FIRST and FREQ_SECOND and the other between FREQ_WHOLE and FREQ_SECOND. RESID_FREQ_FIRST and RESID_FREQ_WHOLE were created from residuals of the linear models with FREQ_SECOND as predictor and with FREQ_FIRST and FREQ_WHOLE as dependent variables. These new variables were highly correlated with the original variables and poorly correlated with FREQ_SECOND. The condition number of the new set of predictors was 25 (below the cut-off of 30). In the set with the probabilities, the potential harmful correlation between PROB_FIRST and PROB_SECOND was removed residualizing PROB_FIRST on PROB_SECOND. The new variable RESID_PROB_FIRST was highly correlated with PROB_FIRST and poorly correlated with PROB_SECOND. The condition number of this set of predictors was 18, below the cut-off of 30. Table A4 shows the correlations of predictors included in IB analysis after residualization.
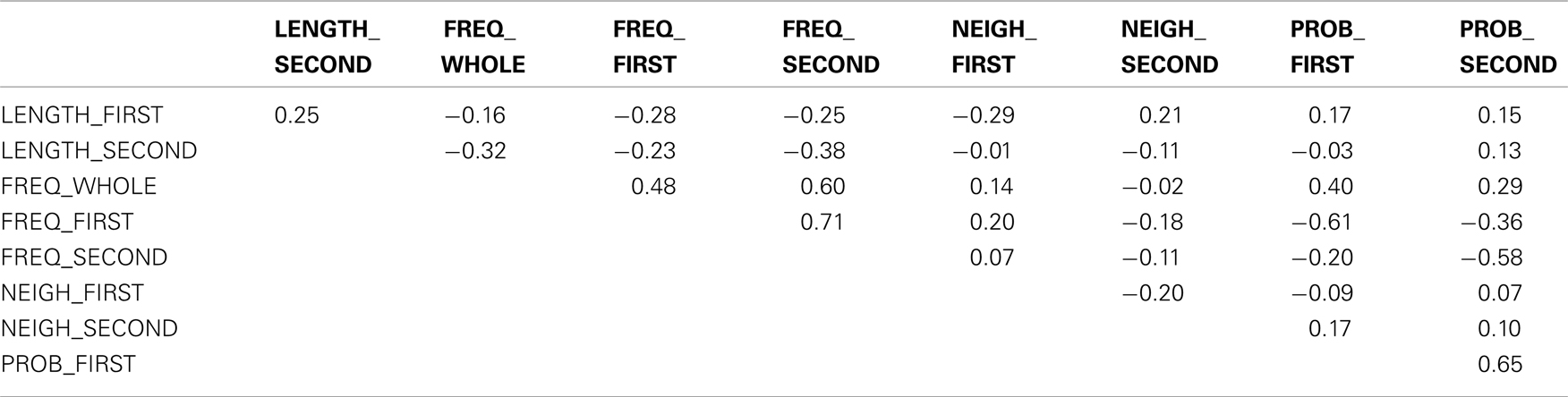
Table A3. Correlation matrix of predictors used in IB analysis before residualization (values indicate pairwise Pearson correlations).
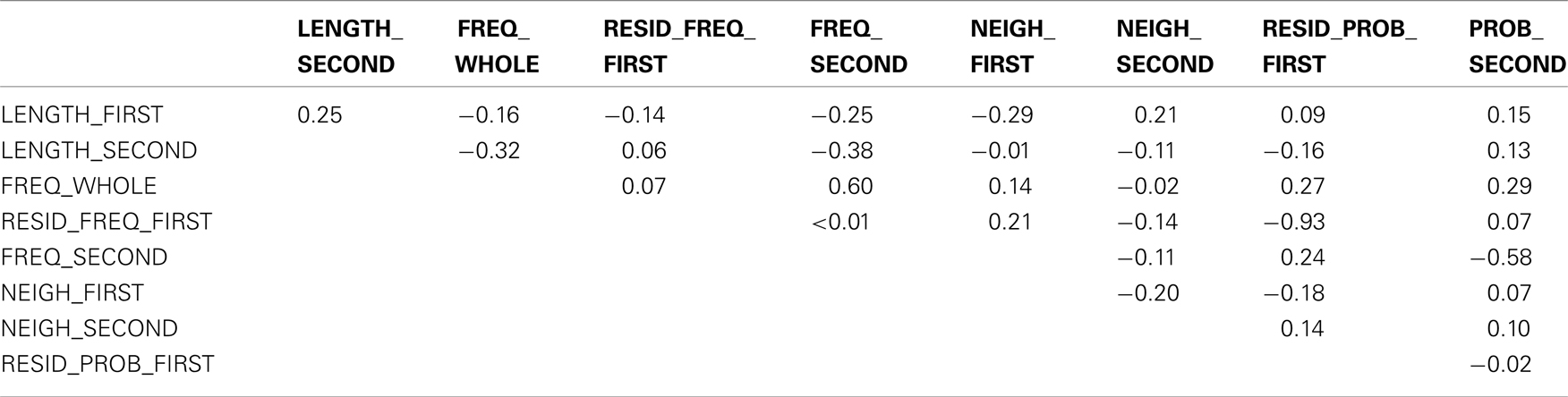
Table A4. Correlation matrix of predictors used in IB analysis after residualization (values indicate pairwise Pearson correlations).
Keywords: irreversible binomials, neglect dyslexia, neglect syndrome, lexical retrieval, neuropsychology, neurolinguistics
Citation: Arcara G, Lacaita G, Mattaloni E, Passarini L, Mondini S, Benincà P and Semenza C (2012) Is “hit and run” a single word? The processing of irreversible binomials in neglect dyslexia. Front. Psychology 3:11. doi: 10.3389/fpsyg.2012.00011
Received: 29 September 2011;
Accepted: 10 January 2012;
Published online: 03 February 2012.
Edited by:
Marcela Pena, Catholic University of Chile, ChileReviewed by:
Jon Andoni Duñabeitia, Basque Center on Cognition, Brain and Language, SpainDirk Koester, Bielefeld University, Germany
Copyright: © 2012 Arcara, Lacaita, Mattaloni, Passarini, Mondini, Benincà and Semenza. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Carlo Semenza, Dipartimento di Neuroscienze, Università di Padova, via Giustiniani 5, 35128 Padova, Italy. e-mail:Y2FybG8uc2VtZW56YUB1bmlwZC5pdA==