 Franco Delogu1*
Franco Delogu1* Tanja C. W. Nijboer1,2,3 and Albert Postma1,2
Tanja C. W. Nijboer1,2,3 and Albert Postma1,2
- 1 Department of Experimental Psychology, Helmholtz Institute, Utrecht University, Utrecht, Netherlands
- 2 Department of Neurology, Rudolf Magnus Institute of Neuroscience, University Medical Center, Utrecht, Netherlands
- 3 Rudolf Magnus Institute of Neuroscience and Center of Excellence for Rehabilitation Medicine, University Medical Center Utrecht and Rehabilitation Center De Hoogstraat, Utrecht, Netherlands
Information about where and when events happen seem naturally linked to each other, but only few studies have investigated whether and how they are associated in working memory. We tested whether the location of items and their temporal order are jointly or independently encoded. We also verified if spatio-temporal binding is influenced by the sensory modality of items. Participants were requested to memorize the location and/or the serial order of five items (environmental sounds or pictures sequentially presented from five different locations). Next, they were asked to recall either the item location or their order of presentation within the sequence. Attention during encoding was manipulated by contrasting blocks of trials in which participants were requested to encode only one feature to blocks of trials where they had to encode both features. Results show an interesting interaction between task and attention. Accuracy in serial order recall was affected by the simultaneous encoding of item location, whereas the recall of item location was unaffected by the concurrent encoding of the serial order of items. This asymmetric influence of attention on the two tasks was similar for the auditory and visual modality. Together, these data indicate that item location is processed in a relatively automatic fashion, whereas maintaining serial order is more demanding in terms of attention. The remarkably analogous results for auditory and visual memory performance, suggest that the binding of serial order and location in working memory is not modality-dependent, and may involve common intersensory mechanisms.
Introduction
There is ample evidence that different types of information can be associated into integrated multi-dimensional representations in working memory (see Zimmer et al., 2006 for a review). Such integrated representations are ensured by processes of binding, which allow the integration of separate features in correct combinations (Treisman, 1999).Evidence of multi-dimensional binding has had a significant impact on working memory models. A major example is represented by Baddeley’s classic working memory model, which has been revised to include an additional component (i.e. the episodic buffer) responsible for integrating different information in short-time multi-dimensional representations (Baddeley, 2000).
Binding processes can involve various categories of stimulus features and take place in different sensory modalities. However, until now some features and modalities have been examined more extensively than others. Specifically, while feature–feature binding (see for example the seminal works of Treisman, 1999; Luck and Vogel, 1997) and feature–location binding (see, among others, Prabhakaran et al., 2000) have been extensively investigated, less attention has been devoted to explore the mechanisms of binding between the serial order and the location of items. Regarding sensory modalities, most binding studies focused on vision and much less attention has been devoted to the other modalities. In the current study, we focused on serial order–location binding in auditory as well as visual working memory, in order to fully investigate the (dis-)similarities in spatio-temporal binding processes in vision versus audition.
A crucial research question in working memory binding is about the automaticity of feature association. In other words, is overt attention crucial to encode a specific feature, or is it automatically encoded when processing other dimensions of the stimuli? Previous studies in feature-to-location binding have demonstrated that when encoding the identity of the item, we also process its location (Ellis, 1990; Andrade and Meudell, 1993; Köhler et al., 2001). Recently, opposite effects have been reported in the auditory modality by Maybery et al. (2009). They observed that a task irrelevant variation in the identity of the stimuli can affect the recall of auditory locations. They argued that this difference between modalities depends on the fact that location is a crucial feature for vision, whereas it is a subordinate dimension in audition. Few studies specifically focused on the automaticity of serial order–location binding (Dutta and Nairne, 1993; van Asselen et al., 2006). Results so far indicated that the intention to memorize one feature is important for feature encoding. For example, Dutta and Nairne (1993) found a mutual interference between spatial and temporal information. In their study, participants selectively attended either to spatial or temporal information during a speeded classification task, while ignoring irrelevant variations along the other dimension. They demonstrated that whereas participants can selectively ignore temporal or spatial variations when no recall of the irrelevant dimension is required, they suffer interference when information from both dimensions must be remembered (Dutta and Nairne, 1993). Similar results were found by van Asselen and colleagues. They asked participants to recall either the exact serial order, or the exact individual positions of sequentially presented visual items. In order to investigate the automaticity of spatio-temporal integration, they manipulated attention toward each one of the two dimensions by biasing the expectancy of attending either to a spatial or to a temporal task across different blocks of trials. In two “pure” blocks, participants were exclusively presented with temporal or spatial trials. In two “mixed” blocks, they were presented with the majority of trials (80%) within one dimension (temporal or spatial), and the remaining trials (20%) within the alternative dimension. Higher accuracy was obtained in expected tasks than in the less expected task, both in the spatial and the temporal domains. The authors concluded that attention plays an important role during the encoding of both the spatial and the temporal dimension of visual objects (van Asselen et al., 2006).
In all the above-mentioned order–location binding studies, the existence of bi-directional associations of features is assumed. However, evidence of asymmetric associations has also been observed, in which the encoding of one feature obligatorily implicates the encoding of a second feature, whereas the encoding of the second feature does not imply the encoding of the first one (Jiang et al., 2000; Olson and Marshuetz, 2005; Maybery et al., 2009). In a study conducted in our laboratory, we recently demonstrated asymmetric costs of feature binding in the recall of location and order in the auditory modality (Delogu et al., submitted for publication). In two experiments, participants were presented with sequences of five environmental sounds originating from five different locations in space with the instruction to memorize their location, their serial order, or both. Participants were then asked to recall either sound position or serial order. Results showed that attention in encoding has a stronger effect on the serial order than on the position task. We concluded that, in auditory working memory, serial order, and position are not automatically integrated in a multi-dimensional representation. Moreover, such asymmetric effects of attention lead to the idea that one of the two features is primary and more automatically encoded per se, while the other feature is subordinate and/or more demanding in terms of attention. In the specific case of serial order–location binding, our recent findings suggest that in spatio-temporal binding, a primary role is played by item location in auditory working memory. In fact, our results indicated that dual encoding only impairs temporal recall, but not spatial recall (Delogu et al., submitted for publication). By contrast, in van Asselen’s study with visual stimuli, dual encoding impaired both temporal and spatial recall, and no asymmetric effects of attention were found. Such differences in spatio-temporal binding between the visual and the auditory domain can be due to an authentic modality effect, or to the mere effect of the different experimental procedures and designs adopted in the two studies. A direct intermodal comparison is needed to disentangle the two alternative explanations.
In the current study, we used a within-subject design to directly test the interactions between item modality (i.e. audition versus vision) and the attention in encoding (dual versus single encoding) in serial order–location binding. We presented participants with two blocks of trials that were either exclusively serial or exclusively spatial, and with a third block of trials in which the expectations of recalling the serial and the spatial dimensions were equal. With respect to the latter block, it was reasoned that, as participants did not know which of the two alternative tasks they were going to perform, they were forced to maintain both the serial order and the spatial location of items in their memory.
Materials and Methods
Participants
Twenty-four students from Utrecht University [mean age: 21.3 (SD = 3.14), 15 females] participated in the experiment in exchange for course credits or a small amount of money. All participants reported normal hearing and sight, and they were all right handed. Informed consent was obtained from all subjects.
Apparatus
In the auditory condition, five loudspeakers were placed inside a circular soundproofed room used to present the auditory sequences (see the top-left part of Figure 1). They were positioned 45° apart from each other in azimuth, at angles of −90°, −45°, 0°, +45°, +90° (0° corresponds to the position faced by the participant). The loudspeakers were placed at about the head height of the seated participant (1.25 m above the ground), at a distance of 1.35 m from the participant’s head. A sixth loudspeaker (hereafter test loudspeaker) was positioned behind the participant (180° angle), at the same height as the other five speakers and 1.35 m behind the participant’s head. Sound absorbing materials were arranged on the walls in order to minimize sound wave reflection. All sounds were presented with an average loudness of 70 dB. A response box was placed in a table in front of the participant for providing responses to stimuli presentation. The position of the keys on the response box was arranged in an ergonomic way in order to reduce muscular tension and fatigue. A 24-channel audio card (MOTU 24 i/o) controlled by a custom script written in MATLAB (The Mathworks, MA, USA) was used for sound presentation. A chinrest was used to prevent head movements during listening.
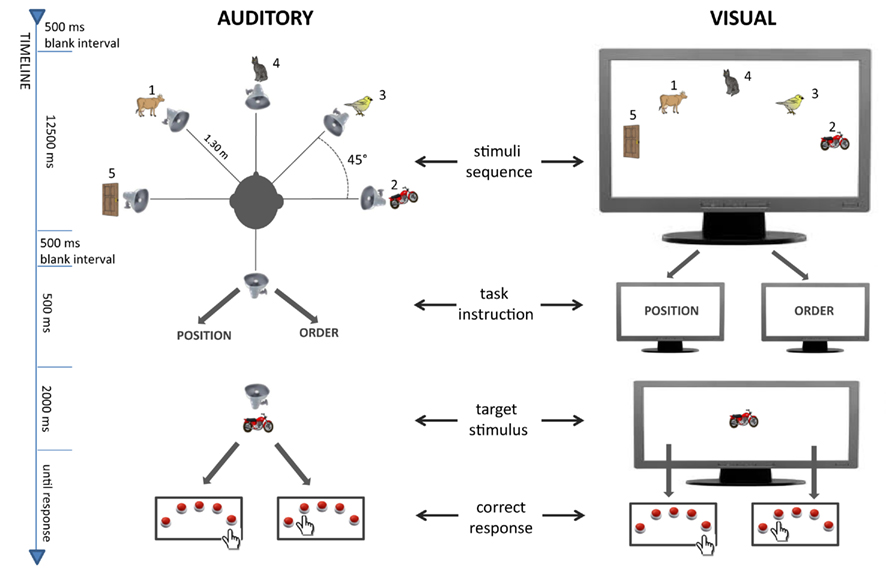
Figure 1. Sequence of events in the auditory and visual trials.
In the visual condition, five positions in a screen were used to present the visual stimuli (see Figure 1, top-right). The visual angle between two subsequent positions was about 7° apart from each other. The screen was placed at about the head height of the seated participant (1.25 m above the ground), at a distance of 1 m from the participant’s head. The same response box used in the auditory condition was also used in the visual condition.
Stimuli and Tasks
Forty environmental sounds and 40 pictures were used in the study. In order to make visual and auditory presentations as comparable as possible, the semantic category of auditory and visual stimuli were matched (e.g. sound of the telephone and image of a telephone) whenever possible. For images that did not have an immediate sound correspondence and for sounds with no immediate pictorial representation, we selected pictures and sounds which were correctly named by the 100% of the participants in a pilot study.
The auditory stimuli were sounds of human beings (e.g. baby crying, person coughing), animals (e.g. cat meowing, bird chirping), and inanimate objects (e.g. car engine, telephone ring) selected from a wider set of environmental sounds described in a previous study (Delogu et al., 2009). All stimuli were edited to a duration of 2 s. Sounds were presented in sequences of five sounds, each of them originating from a different loudspeaker. All the sequences contained a semi-random selection of items, with the limitation that a sound which was presented in the last and in the second-to-last sequence could not be presented in the following sequence.
Visual stimuli included pictures of human beings, animals, and objects selected from the database described in Rossion and Pourtois (2004). All stimuli were included in sequences of five pictures and presented on screen for 2 s.
In both the visual and auditory condition, the experiment included three different blocks of trials: two blocks of 10 sequences each (single encoding), in which participants had to perform only one task (either the location memory or the temporal order task) throughout the entire block; one block of 20 sequences each (dual encoding), in which the participants were requested to perform the location memory task in the 50% of trials and the temporal order judgment in the remaining 50%. When attending the mixed block trial, participants did not know if they were going to perform a spatial or a serial order task. Consequently, they had to encode and maintain both types of information.
Procedure
Participants were first trained to use the five keys to indicate either the position (with the leftmost key indicating the leftmost position and the rightmost key indicating the rightmost position), or to indicate its serial order (with the leftmost key corresponding to the first sound/picture in the sequence and the rightmost key corresponding to the last sound/picture in the sequence). Before starting the experiment, they also performed an auditory localization task in which they were asked to indicate the position of a series of 100 sounds randomly originating from one of the five speakers. Results of the sound localization task showed high accuracy (mean 96%, SD: 3%), indicating a sufficient Azimuthal separation between auditory sources.
Before each block of trials, instructions were given indicating which task the participants were about to perform during the block (i.e. serial order, spatial location, or both). In the dual encoding block, before starting, participants were explicitly told that they could be asked to recall either the position or the order of the items. As participants were told which feature they would have to recall only after the presentation of the stimuli sequence, they were forced to pay attention to both features during the sequence presentation in order to optimize recall performance. For each learning sequence, participants triggered the presentation by pressing a key on the response box. After the learning sequence, the instruction word (either “ORDER” or “POSITION”) indicating which feature they had to recall was presented for 500 ms from the test loudspeaker in the auditory condition and in the middle of the screen in the visual condition. Then all stimuli of the learning sequence were presented again, one by one in a random order, from the test loudspeaker or in the middle of the screen. After each test item, they recalled either the location or the serial order of the item in the learning sequence (see Figure 1). Participants could respond to target items both while items were still displayed and after their presentation. The experiment lasted approximately 1 h. The order of presentation of the visual and the auditory blocks, as well the order of the three blocks within each of the two modalities, was counterbalanced between participants.
Analysis
A three-factor repeated measure ANOVA analysis with the variables task (location versus order), encoding (single versus dual), and modality (auditory versus visual) was performed on the mean percentage of correct responses. For post-hoc analyses, Bonferroni correction was applied to pairwise comparisons.
Two participants were excluded from final analysis because their accuracy in one of the experimental blocks was under the group average of more than 2 SD.
Results
The main effects of the factors task, modality, and encoding as well as the interactions between these factors are reported in Table 1.
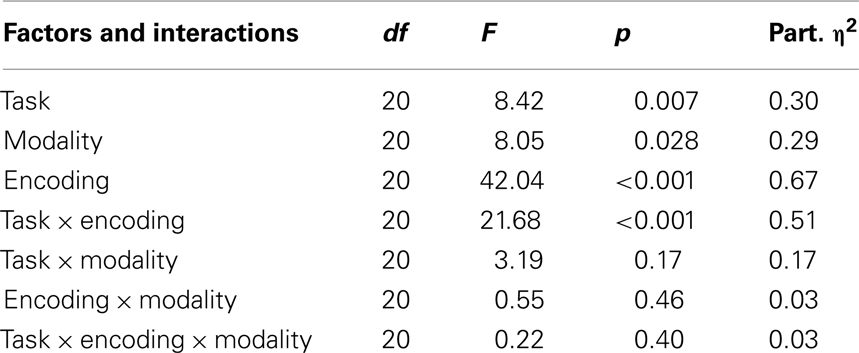
Table 1. Summary of all the ANOVA effects.
A significant main effect of task indicates that the overall across-modalities accuracy in the serial order task (77.6%) was higher compared to accuracy in the location task (72.5%). A significant main effect of modality was also found, which shows that the overall accuracy was higher in the visual condition (78%) than in the auditory condition (72%). Encoding also yielded a main effect, with higher accuracy in the single encoding trials compared to the dual-encoding trials.
One of the crucial comparisons of our investigation is the two-factor interaction between task and encoding, This interaction was significant, demonstrating that the effects of attention are significantly higher for the temporal than for the spatial task. Pairwise comparison showed that the influence of attention was significant only for the serial order task. Specifically, while serial order recall is more accurate after dual than after single encoding both in the auditory condition, t(20) = 5.89, p < 0.001 and in visual condition, t(20) = 6.69, p < 0.001, location recall does not differ after dual and single encoding neither in the auditory condition, t(20) = 1.67, p = 0.44 nor in visual condition, t(20) = 5.89, p = 0.36.
The two-factor interaction between task and modality and the interaction between modality and encoding were both not significant. The three-factor interaction between task, encoding, and modality was also not significant, indicating that the different influence of attention in the spatial and temporal tasks is not modulated by the modality of the stimuli. Accuracy in all conditions is displayed in Figure 2.
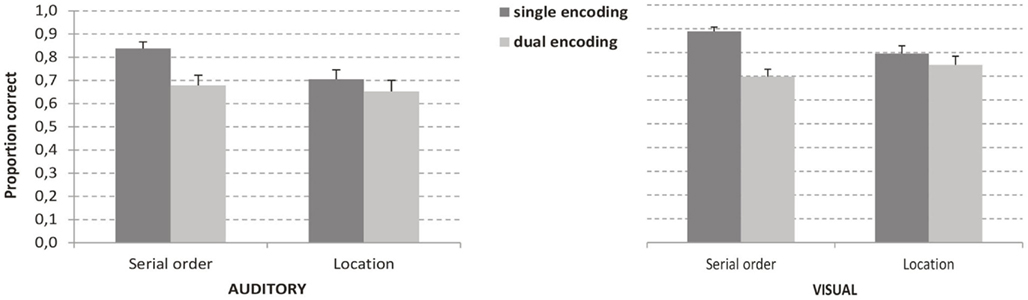
Figure 2. Accuracy in the serial order and location tasks in the two modalities as a function of the encoding condition. Error bars represent SE.
Discussion
The aim of the current study was to investigate how spatial and serial order features are encoded, both in isolation and under dual encoding conditions, in auditory and visual working memory. We presented sequences of five auditory or visual stimuli originating from five different locations in space, and we asked participants to recall either the position or the serial order of items. Attentional focus during encoding was manipulated by contrasting blocks of trials containing only spatial or temporal trials to mixed blocks containing the same amount of spatial and temporal trials.
Regarding feature processing per se, we found that spatial information is more difficult to recall than serial order information. Such difference could be due to different rehearsal mechanisms for serial order and spatial information. We suggest that whereas serial order recall is achieved by mere item rehearsal, location recall is not guaranteed by item identity maintenance. In fact, whereas serial order maintenance is likely to be a mere byproduct of stimuli identity rehearsal (Gmeindl et al., 2011b), location maintenance cannot be accomplished by simply rehearsing item identity and it needs specific spatial additional processing. Concerning the format in which items were rehearsed, it is possible to argue that sounds and pictures were recoded in a verbal format. To establish the influence of verbal recoding in our experiment, an articulatory suppression (AS) condition could have been included. However, for two reasons we decided not to include AS in the experimental design. Firstly, the required tasks already were rather demanding, especially in the dual encoding condition. Therefore, we reasoned that an additional requirement could cause an extreme drop of accuracy and weaken the effects in analysis. Secondly, we argued that the inclusion of AS could cause a greater impairment in the serial order task, since AS has a greater effect on serial order than on spatial encoding (see Dent and Smyth, 2005).
Another possible source of differentiation between the accuracy in the two tasks could be the response method. It is in fact possible that the response device could have caused some benefits for spatial processing. This is because the response buttons were arranged in a horizontal fashion, similarly to item positions, while having a less direct analogy to item serial order. However, considering the higher accuracy in the serial task than in the spatial task, we can assume that serial recall was not severely impaired by the position of the response buttons. By contrast, we think that the use of different spatial configurations for response buttons, for example a spatial arrangement orthogonal to item position, could cause a substantial impairment in spatial recall, which could compromise the emergence of the effects we wanted to scrutinize. Moreover, the use of alternative response devices, like laser pointing, eye tracking or verbal response recording, would have all implied some advantages and raised new problems, but we do not think that they would change the substance of the findings.
Interestingly, an analogous pattern of differences between spatial and temporal tasks was found in the two modalities. This result suggests that, in spite of the obvious perceptual differences between auditory and visual stimuli processing, it could be that the same mechanisms are used in both modalities to maintain serial order (see Depoorter and Vandierendonck, 2009) and location (see Lehnert and Zimmer, 2006) respectively. Concerning memory for item location in particular, previous results suggested that spatial memory is not bound to a specific sensory modality. For example, Baddeley and Lieberman (1980) found that a visuo-spatial main task was impaired by an auditory–spatial secondary task. More recently, Martinkauppi et al. (2000) found a neural substantiation of these findings using imaging techniques. Their data indicated that a common neural network in the human cortex was activated by both auditory and visual stimuli during a working memory task.
Concerning the overall effect of attention, our data showed that participants were more accurate when encoding only the target dimension than when also encoding the second dimension. This suggests that, both in vision and in audition, the integration of serial order and location in working memory is not automatic. This result is consistent with previous findings in both the visual (Dutta and Nairne, 1993; van Asselen et al., 2006) and the auditory (Delogu et al., submitted) domain.
More interestingly, we found that the influence of attention critically depends on the feature to be recalled. In fact, the concurrent encoding of the alternative feature selectively impairs serial order, but does not interfere with item position. As tolerance toward concurrent processing is interpreted as a sign of automaticity (Ellis, 1990; Andrade and Meudell, 1993), we infer that, in dual encoding contexts, spatial encoding is more automatic than serial order encoding. This result confirms, and extends to vision, what we recently found in the auditory modality (Delogu et al., submitted). It is important to underline that the asymmetric influence of attention on the two tasks is remarkably analogous in the two sensory modalities. The absence of modality effects leads to the consideration that some mechanisms of working memory do not depend on the modality of the input, but are more related to the feature to be processed and recalled (e.g., spatial, serial, identity, or an association of any of them). In particular, the evidence that the dual encoding influence on serial order recall is not dependent on item modality is consistent with previous studies demonstrating the existence of a modality-independent representation of order information in working memory (Jones et al., 1995; Depoorter and Vandierendonck, 2009).
Why is location more resistant to interference than serial order? We may speculate that it depends on different rehearsal mechanisms of spatial and serial information in WM. In serial order rehearsal, which requires remembering the correct sequence of items, the memory of the serial order of each single item is strictly linked with the memory of the other elements in the sequence. In this context, a constant attentional control of item order during rehearsal could be crucial. By contrast, in spatial rehearsal, in which the location of each single item is not linked with the memory of other items’ location, maintenance of item location in space could be configurational and not sequential. In this context, a constant attentional control could be less critical for spatial rehearsal, and the encoding of a concurrent feature can be attained without weakening spatial processing. This interpretation is consistent with the notion that the maintenance of dynamic, sequential information is more demanding in terms of attention than static information. In fact, the former draws directly on the central executive, while the latter relies on it to a lesser extent, and only to refresh the image (Logie, 1995; Logie and van der Meulen, 2009).
However, since items are sequentially presented also in the location task, an alternative interpretation is possible. The asymmetric role of attention could be due to the fact that location of the sequence of items, encoded serially, is also rehearsed in a serial fashion, by using the same serial order of the items as in encoding. This way, in dual encoding conditions, when serial order has to be memorized too, there is no impairment in spatial recall. This account is inconsistent with a recent study by Gmeindl et al. (2011b). They found that removing serial order requirements from a location memory task improves spatial performance. They suggested that the position of multiple, serially presented items is not rehearsed serially, but it is simultaneously represented as multi-location configurations (Gmeindl et al., 2011a; see also Jiang et al., 2000).The different results can be caused by the different tasks involved in our and in Gmeindl’s study. Whereas their spatial task required recalling the position of identical squares flashing among distracters (similarly to a Corsi block test, De Renzi and Nichelli, 1975), in our spatial task participants were asked to recall the position of five different meaningful items in five fixed locations (object location memory task). Therefore, it is plausible that object location memory tasks, in which both item identity and position are relevant for the task, requires serial rehearsal. On the other hand, pure spatial tasks, in which only location but not item identity is relevant, can be achieved through a configurational, multi-location rehearsal.
Our findings are also in partial contrast with the findings of van Asselen et al. (2006), who found that not only the serial order task, but also the spatial task is impaired when attention to the target feature is reduced. This contrasting result is likely due to the fact that while we used a dual encoding condition in which the expectation of recall was equally divided between the target and the concurrent feature, they used an unbalanced attentional condition in which the expectation of recalling the target feature was extremely low (20% of the probability of occurrence). This interpretation is supported by the results of our previous study (Delogu et al., submitted) which included an unbalanced attentional condition analogous to the one in van Asselen’s study. In such unbalanced attentional condition, we also obtained a significant impairment in the spatial recall. The comparison between these different studies suggests an attentional threshold model for spatial working memory: as long as a certain amount of attention is allocated to spatial encoding, spatial recall is not influenced by attention. Only when there is an extreme drop in attentional allocation (i.e., in the 20% conditions of van Asselen et al., 2006; Delogu et al., submitted) spatial recall is impaired.
Conclusion
This study presents a direct comparison of auditory and visual modalities in the mechanisms of binding between spatial and serial order information.
Although overall accuracy in our experiment was higher in vision than in audition, the effects of attention on the two tasks were not modulated by the sensory modality of the input. We concluded that spatio-temporal binding is not automatic, it is task dependent, and it is not modality dependent.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was supported by the grant 254446 from the IEF Marie Curie Actions to Franco Delogu and by the grant 451-10-013 from the Netherlands Organization for Scientific Research (NWO) to Tanja C. W. Nijboer.
References
Andrade, J., and Meudell, P. (1993). Is spatial information encoded automatically? Q. J. Exp. Psychol. 46A, 365–375.
Baddeley, A. D. (2000). The episodic buffer: a new component of working memory? Trends Cogn. Sci. 4, 417–423.
Baddeley, A. D., and Lieberman, K. (1980). “Spatial working memory,” in Attention and Performance VIII, ed. R. S. Nickerson (Hillsdale, NJ: Erlbaum), 521–539.
Delogu, F., Raffone, A., and Olivetti, M. (2009). Semantic encoding in working memory: is there a (multi)modality effect? Memory 17, 655–663.
Dent, K., and Smyth, M. M. (2005). Verbal coding and the storage of form-position associations in visual-spatial short-term memory. Acta Psychol. 120, 113–140.
Depoorter, A., and Vandierendonck, A. (2009). Evidence for modality-independent order coding in working memory. Q. J. Exp. Psychol. 62, 531–549.
De Renzi, E., and Nichelli, P. (1975). Verbal and non-verbal short-term memory impairment following hemispheric damage. Cortex 11, 341–354.
Dutta, A., and Nairne, J. S. (1993). The separability of space and time: dimensional interaction in the memory trace. Mem. Cognit. 21, 440–448.
Ellis, N. R. (1990). Is memory for spatial location automatically encoded? Mem. Cognit. 18, 584–592.
Gmeindl, L., Nelson, J. K., Wiggin, T., and Reuter-Lorenz, P. A. (2011a). Configural representations in spatial working memory: modulation by perceptual segregation and voluntary attention. Atten. Percept. Psychophys. 73, 2130–2142.
Gmeindl, L., Walsh, M., and Courtney, S. M. (2011b). Binding serial order to representations in working memory: a spatial/verbal dissociation. Mem. Cognit. 39, 37–46.
Jiang, Y., Olson, I. R., and Chun, M. M. (2000). Organization of visual short term memory. J. Exp. Psychol. Learn. Mem. Cogn. 26, 683–702.
Jones, D. M., Farrand, P., Stuart, G., and Morris, N. (1995). Functional equivalence of verbal and spatial information in serial short-term memory. J. Exp. Psychol. Learn. Mem. Cogn., 21, 1008–1018.
Köhler, S., Moscovitch, M., and Melo, B. (2001). Episodic memory for object location versus episodic memory for object identity: do they rely on distinct encoding processes? Mem. Cognit. 29, 948–959.
Lehnert, G., and Zimmer, H. D. (2006). Auditory and visual spatial working memory. Mem. Cognit. 34, 1080–1090.
Logie, R. H., and van der Meulen, M. (2009). “Fragmenting and integrating visuo-spatial working memory,” in Representing the Visual World in Memory, ed. J. R. Brockmole (Hove: Psychology Press), 1–32.
Luck, S. J., and Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature 390, 279–281.
Martinkauppi, S., Rama, P., Aronen, H. J., Korvenoja, A., and Carlson, S. (2000). Working memory of auditory localization. Cereb. Cortex 10, 889–898.
Maybery, M. T., Clissa, P. J., Parmentier, F. B. R., Leung, D., Harsa, G., Fox, A. M., and Jones, D. M. (2009). Binding of verbal and spatial features in auditory working memory. J. Mem. Lang. 61, 112–133.
Olson, I. R., and Marshuetz, C. (2005). Remembering “what” brings along “where” in visual working memory. Percept. Psychophys. 67, 185–194.
Prabhakaran, V., Narayanan, K., Zhao, Z., and Gabrieli, J. D. (2000). Integration of diverse information in working memory within the frontal lobe. Nat. Neurosci. 3, 85–90.
Rossion, B., and Pourtois, G. (2004). Revisiting Snodgrass and Vanderwart’s object set: the role of surface detail in basic-level object recognition. Perception 33, 217–236.
Treisman, A. (1999). “Feature binding, attention and object perception,” in Attention, Space and Action, eds. G. W. Humphreys, J. Duncan, and A. Treisman (Oxford: Oxford University Press), 91–111.
Keywords: automatic encoding, attention, localization, serial order, environmental sound
Citation: Delogu F, Nijboer TCW and Postma A (2012) Binding “when” and “where” impairs temporal, but not spatial recall in auditory and visual working memory. Front. Psychology 3:62. doi: 10.3389/fpsyg.2012.00062
Received: 31 December 2011; Accepted: 18 February 2012;
Published online: 07 March 2012.
Edited by:
Snehlata Jaswal, Indian Institute of Technology Ropar, IndiaReviewed by:
Eric Postma, Tilburg University, NetherlandsLouise Brown, Nottingham Trent University, UK
Copyright: © 2012 Delogu, Nijboer and Postma. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Franco Delogu, Department of Experimental Psychology, Utrecht University, Heidelberglaan 2, 3584 CS Utrecht, Netherlands. e-mail:Zi5kZWxvZ3VAdXUubmw=