


- 1 Max Planck Institute for Psycholinguistics, Nijmegen, Netherlands
- 2 School of Psychology, University of Birmingham, Birmingham, UK
Many contemporary texts include shortcuts, such as cu or phones4u. The aim of this study was to investigate how the meanings of shortcuts are retrieved. A primed lexical decision paradigm was used with shortcuts and the corresponding words as primes. The target word was associatively related to the meaning of the whole prime (cu/see you – goodbye), to a component of the prime (cu/see you – look), or unrelated to the prime. In Experiment 1, primes were presented for 57 ms. For both word and shortcut primes, responses were faster to targets preceded by whole-related than by unrelated primes. No priming from component-related primes was found. In Experiment 2, the prime duration was 1000 ms. The priming effect seen in Experiment 1 was replicated. Additionally, there was priming from component-related word primes, but not from component-related shortcut primes. These results indicate that the meanings of shortcuts can be retrieved without translating them first into corresponding words.
Introduction
Over the past two decades, the English language has undergone substantial change due to the introduction and rapid spread of SMS shortcuts, such as gr8, cu, or phones4u. Shortcuts are used not only in emails and text messages but also in commercials, poetry, and sometimes even in spoken communication (e.g., lol). There are prizes awarded for the best SMS message (e.g., the Golden Thumb; Crystal, 2008), and the 2010 exam for the General Certificate of Secondary Education (GCSE) in English language in the UK included a component assessing the knowledge of shortcuts (http://www.telegraph.co.uk/education/secondaryeducation/6574393/GCSE English-exams-to-include-questions-on-text-messaging.html).
The popularity of shortcuts suggests that both writers and readers find them easy and perhaps fun to use. If readers had great difficulty constructing or remembering the meanings of shortcuts such as phones4u, brand names and advertising would quickly change. Surprisingly, there appear to be no empirical studies on the ease of writing shortcuts, and only a few studies on the ease of reading them. These studies will be reviewed below. There are a number of studies on the processing of conventional acronyms, such as BBC, some which will also be described below. Conventional acronyms, much like SMS shortcuts, often violate the orthographic conventions of the language (e.g., the rule that only the first letter of word can be capitalized). However, many acronyms are well established in the language (see Izura and Playfoot, in press, for norms for British English), whereas shortcuts tend to be “newcomers.” Moreover, conventional acronyms are used in spoken and written language, whereas the use of shortcuts is largely confined to written texts. As will be explained below, Brysbaert et al. (2009) showed that the processing of acronyms is quite similar to the processing of regular words. The present study investigated whether this was also true for shortcuts.
As noted there are only a handful of studies on the processing of SMS shortcuts: Perea et al. (2009) showed that sentences that consisted almost exclusively of SMS language were read much more slowly than conventionally written sentences. Convergent evidence comes from an EEG study by Berger and Coch (2010), who showed that the N400 effect (i.e., larger EEG amplitudes to semantically incongruent than to congruent sentence-final words in a time window approximately 400 ms after the onset of the critical stimulus) peaked later and was more extended when participants read texted English than when they read standard English. However, in an eye movement study where shortcuts were used sparingly in the sentences, Ganushchak et al. (in press) found longer first-fixation and first-run gaze durations for shortcuts than the word equivalents, but no differences in second-run gaze durations and total fixation durations. This suggests that shortcuts caused some difficulty in the early stages of word recognition but were subsequently integrated into the sentence context as easily as conventionally written words. This suggests that shortcuts are harder to recognize, but that, once recognized, they are integrated into the sentence context as easily as ordinary words. Additional evidence supporting this view comes from an event related potentials (ERP) study by Ganushchak et al. (2010a). Here a lexical decision task was used. Participants were asked to categorize conventional words as words and both shortcuts and pseudo-shortcuts as non-words. Earlier ERP studies on visual word recognition had shown that visual features activate letter representations about 150 ms after the onset of word presentation (Holcomb and Grainger, 2006; Barber and Kutas, 2007). After about 250 ms, a phonological code is activated and a whole-word representation is accessed (Holcomb and Grainger, 2006; Barber and Kutas, 2007). Finally, between 250 and 400 ms after the word onset, lexical access takes place, as indexed by the N400 component (Kutas and van Petten, 1994; Kutas and Federmeier, 2000). Ganushchak et al. (2010a) found that ERP responses for SMS shortcuts did not differ from those of pseudo-shortcuts until about 270 ms after stimulus onset. However, shortcuts and pseudo-shortcuts significantly differed from each other in the N400 window, suggesting that shortcuts, but not pseudo-shortcuts, activate stored lexical representations. Taken together, the studies reviewed here suggest that shortcuts differ from words primarily in the earliest, but not so much in later processing steps.
Turning to conventional acronyms, Besner et al. (1984) showed that acronyms were processed like words and were part of the mental lexicon in spite of their often atypical orthography. Besner et al. (1984) asked participants to identify target letters in acronyms and meaningless letter strings. A typical finding in this task is that participants are faster to react to the targets when they appear in words than in pseudo-words. Besner et al. (1984) showed that the same was true for acronyms: Participants identified the target letters significantly faster in acronyms than in letter strings (see also Coltheart, 1978; Laszlo and Federmeier, 2007a). Subsequently, Slattery et al. (2006) showed that acronyms were phonologically encoded, with the phonological code being a sequence of letter names. Slattery et al. (2006) tracked the participants’ eye movements while they were silently reading sentences containing acronyms (e.g., FBI agent). The acronyms were preceded by a determiner that was consistent with the phonological code of the acronym (e.g., an FBI agent) or inconsistent (a FBI agent). The first-fixation durations were shorter for phonologically consistent than for inconsistent pairings, which demonstrates that the acronyms were phonologically encoded (for related evidence see Izura and Playfoot, in press).
Furthermore, Laszlo and Federmeier(2007b, 2008) showed that the processing of words and acronyms engaged closely related processes of semantic access. They recorded ERP while participants read words, familiar acronyms, and illegal letter strings and focused on repetition priming and its effect on the N400 component. Typically the N400 component for words decreases when words are repeated (e.g., Deacon et al., 2004). No such repetition effect is observed for illegal letter strings (e.g., Rugg and Nagy, 1987). Laszlo and Federmeier(2007b, 2008) found significant repetition priming effects for words and acronyms, but not for illegal letter strings, suggesting that the processing of words and acronyms engage similar processes of semantic access.
The study most closely related to the present work was conducted by Brysbaert et al. (2009). In a masked priming experiment, they replicated the standard finding that participants were faster to decide that a target (e.g., ERROR) was a word rather than a pseudo-word when it was preceded by a briefly presented associatively related prime (MISTAKE) than by an unrelated prime (see also Neely, 1991; Kouider and Dehaene, 2007; Van den Bussche et al., 2009). Importantly, a priming effect of the same magnitude was found when targets were preceded by related vs. unrelated acronyms (e.g., MUSIC preceded by MTV vs. CNN). Furthermore, the priming effect was independent of the case in which primes were presented. For instance, mtv and mTv primed MUSIC to the same extent as MTV. Given the short time allowed for the processing of the primes, the meanings of the acronyms must have been accessed directly, rather than via recoding into the full forms. Therefore, Brysbaert and colleagues concluded that, “acronyms like BBC are part of the mental lexicon” (cf. Brysbaert et al., 2009, p. 7).
The main goal of the present project was to determine whether parallel results to those obtained by Brysbaert et al. (2009) for acronyms would be obtained for shortcuts, which would imply that both forms of abbreviations are represented in the mental lexicon and retrieved in similar ways.
To elaborate on what this might entail: in many models of the mental lexicon, words are represented at three levels: a form level that represents their phonological and orthographic properties, a conceptual level, and a lemma level that links form representations with conceptual representations (e.g., Baayen et al., 1997; Taft, 2003). One possibility is that conceptual representations of shortcuts are activated via representations of the full forms they stand for. Thus, the reader of the shortcut lol might first activate the orthographic and/or phonological form of the phrase laugh out loud and then the associated lemma and meaning. One would expect this to take somewhat longer than accessing the meaning of laugh out loud from the traditional spelling (see also Brysbaert, 1995). Alternatively and especially for highly familiar shortcuts, readers may have acquired links from the orthographic forms of the shortcuts to the associated lemmas, bypassing access to the full form. Note that the lemma of a shortcut may or may not be shared with the full form given that the usage and meanings of lol might be a little different from the meanings of laugh out loud. In other words, the meaning of a shortcut such as lol might initially be learned by associating the letter string lol with the full form laugh out loud (rather than, for instance, love our leader), but once the link between the orthographic surface form and the meaning of the shortcut is well established, the activation of the orthographic or phonological form of the full form may not be needed anymore when the shortcut is processed.
Experiment 1 of the present study used a similar paradigm to the one used by Brysbaert et al. (2009) to investigate the priming effects of shortcuts and the corresponding words on the same word targets. Two types of shortcuts were presented: simple shortcuts replacing single words (gr8 for great) and complex shortcuts replacing phrases (cu for see you). The target word was associatively related to the meaning of the whole prime (cu/see you – goodbye), related to a component of the prime (cu/see you – look), or unrelated to the prime and any of its components. The primes were presented for 57 ms and preceded by a pattern mask. Masked prime presentation is often used to limit the time available for prime processing and to minimize the strategic use of the primes (Forster, 1998). In addition to trials featuring word targets, there were trials featuring pseudo-word targets. As in the study by Brysbaert et al. (2009), participants were asked to categorize the targets as words or pseudo-words as quickly as possible.
We predicted that the related simple and the whole-related word primes (great for the target good and see you for the target goodbye) should facilitate the responses to the targets. Such associative priming effects might arise at the lexical level, via spread of activation between lemmas, or at a conceptual level, via spread of activation among related concepts (see Collins and Loftus, 1975; Ratcliff and McKoon, 1994; Burgess, 1998; Chwilla et al., 2000; Lucas, 2000; Hutchison, 2003). If the lemmas and meanings of shortcuts can be retrieved directly from their orthographic forms, without recoding into full forms, then simple and whole-related shortcut primes (gr8 for the target good and cu for the target goodbye) should also facilitate responses to the targets. Component-related word primes (see you for the target look) might prime the targets, but component-related shortcut primes (cu for the target look) should not do so. In other words, cu should not prime look if c is not linked to see. In contrast, if lexical access to shortcuts is mediated through their full forms, there should be no priming from any shortcut primes, because there is no time to access the full form in the masked condition.
Experiment 1: Masked Priming
Methods
Participants
Twenty-four students of the University of Birmingham (23 female) took part in the experiment (average age: 19.1 years, SD = 0.9 years). All participants were right-handed native speakers of English and had normal or corrected-to-normal vision. Participants gave written informed consent prior to participating in the study. Participants received course credits for their participation. Three female participants reported to be able to read the primes. Their data were excluded from the analysis.
Materials and design
The experimental stimuli consisted of 60 word targets and 60 pseudo-word targets. Pseudo-words were selected from the English Lexicon Project, a data base including naming and lexical decision latencies for over 40,000 words and over 40,000 pseudo-words collected from 1200 participants (Balota et al., 2007). The pseudo-words were matched to the target words in length (on average 5.5 characters, SD = 1.8, ranging from 3 to 12 characters) and number of syllables (on average 1.5 characters, SD = 0.6, ranging from 1 to 3 syllables). Twenty of the targets appeared in the simple-short conditions (see Appendix). They were combined with four primes: a related shortcut (e.g., 2day for now), a related word (today), an unrelated shortcut (ppl), and an unrelated word (people). Twenty further targets were combined in the same way with complex whole-related shortcuts and their word equivalents. As there were not many complex shortcuts, pairs of targets with related meanings were combined with the same set of primes. For instance, the targets gift and present were both combined with the primes 4u and for you in the related conditions and with the primes cu and see you in the unrelated conditions. The remaining 20 targets were combined with component-related primes. Again, pairs of targets were coupled with the same primes. Moreover, these primes were the same as those used in the complex whole-related conditions. For instance, the targets myself and self were combined with the same primes as the targets gift and present, namely 4u, four you, cu and see you (see Table 1 for the prime characteristics).

Table 1. Prime characteristics: average length of the prime (number of characters, SDs in parentheses).
The related pairs were selected based on a pre-test questionnaire in which 24 undergraduate students of the University of Birmingham were presented with a list of 63 familiar shortcuts. They were asked to write down the first associate that came to mind. From that list, the 30 shortcuts (20 simple and 10 complex shortcuts) with the most frequent associates were chosen (simple: association strength 23%; SD = 0.1; complex whole-related: association strength 22%; SD = 0.2). The component-related pairs were selected from the University of South Florida Association Norms (Nelson et al., 1998), which lists semantic association ratings for English word pairs (associate strength: 19%; SD = 0.2). There were no significant differences between the item groups (all ts < 2).
The following conditions were used: (1) targets related to simple shortcuts and their spelled-out equivalents (gr8/great – good); (2) targets related to whole complex shortcuts and their spelled-out equivalents (cu/see you – goodbye); (3) targets related to a component of the complex shortcuts and spelled-out equivalents (cu/see you – look). There were no component-related pairs involving the simple primes because they only replaced a single word. Unrelated prime target pairs were created by re-combing primes and targets into semantically unrelated pairs.
Four lists of prime target pairs were created so that no list contained the same target twice. Primes were repeated within lists but never in the same condition. Each list contained 120 targets (60 words and 60 pseudo-words, 20 items per condition). Each participant saw only one of these lists.
Procedure
Participants were tested individually. The experiment was controlled by the software package E-prime 1.2. Stimuli were presented using a Samsung SyncMaster 753s monitor. The refresh rate was 75 Hz, and the screen resolution was 1024 × 760 pixels. The participants’ responses were recorded using a keyboard.
All stimuli were presented in black-on-white in the center of the computer screen. Primes were presented in Courier New font (12 points). The targets were presented in Courier New font (20 points). Primes and targets were presented in lower-case letters. This was done because in SMS/online chat using capital letters is emotionally loaded (e.g., might indicate annoying, anger, excitement; Crystal, 2008) and would therefore add additional semantics to the shortcuts that is not present for the words.
Each trial started with the presentation of a fixation cross in the center of the computer screen for the duration of 500 ms. Next a forward mask was presented for 300 ms. The mask consisted of 20 number signs (#) and had the same font and size as the primes. Then the prime was presented for 57 ms, immediately followed by the target that remained on the screen until a response was given or a maximum of 3 s. A blank screen was presented for 1800 ms between trials.
Participants were asked to press the “m”-key of a keyboard when the target was a word and the “z”-key when it was a pseudo-word. They were instructed to respond as fast and as accurately as possible. They were told that each target was preceded by a string of number signs. The primes were not mentioned in the instructions. After the experiment, all participants were asked whether they had been aware of the primes. In addition, they completed a questionnaire, indicating how often (never, once a year, once a month, once a week, every 2 days, once a day, or several times a day) they read and wrote each of the shortcuts used in the experiment and then wrote down its meaning. Finally, they indicated for all prime target pairs they had seen how strongly related the members of the pair were, using a 5-point scale (1 – not at all related; 5 – highly related).
Data analysis
Mean reaction times to word targets were submitted to mixed-effects model analyses (Brysbaert, 2007; Baayen et al., 2008; Quené and van den Bergh, 2008) using SPSS software. The analyses were run on non-aggregated data and the degrees of freedom were derived from the total number of trials (Brysbaert, 2007; Baayen et al., 2008; Quené and van den Bergh, 2008). Participants and Targets were treated as random factors, Relatedness (related vs. unrelated) and Prime Type (shortcut vs. word) as fixed factors. Separate analyses were run for targets with simple primes, whole-related complex primes, and component-related complex primes. Prior to analysis, reaction times below 300 ms or above 1500 ms (1.3% of the data) were eliminated and the remaining reaction times were transformed to their logarithmic values to remove the intrinsic positive skew and non-normality of the distribution (Keene, 1995; Limpert et al., 2001; Quené and van den Bergh, 2008).
Results
The participants’ modal response in the questionnaire was that they read and wrote the shortcuts once a week. On average, there were 3.2 low-frequency shortcuts (SD = 0.7) per participant (shortcuts used “never” or “once a year”) and 3.6 high-frequency shortcuts (SD = 0.8) per participant (shortcuts used “once a day” or “several times a day”). For each participant, any shortcuts were removed from the analysis for which they did not provide the expected meaning [on average 0.48 shortcuts (SD = 0.97) per participant]. Furthermore, for each participant any related prime target pairs were removed that the participant rated as unrelated [on average 2.09 pairs (SD = 1.11) per participant]. This left on average 18 trials per condition and participant for the analyses. The error rates for words and non-words were low (2.5 and 2.1%, respectively) and no error analysis was conducted.
Simple primes
There was a main effect of Relatedness [F(1, 346) = 4.98; p = 0.02; see Figure 1], with participants being 28 ms faster to decide that a target was a word when it was preceded by a related prime than when it was preceded by an unrelated prime. There was no effect of Prime Type [F(1, 346) = 1.09; p = 0.30] and no interaction between Relatedness and Prime Type (F < 1).
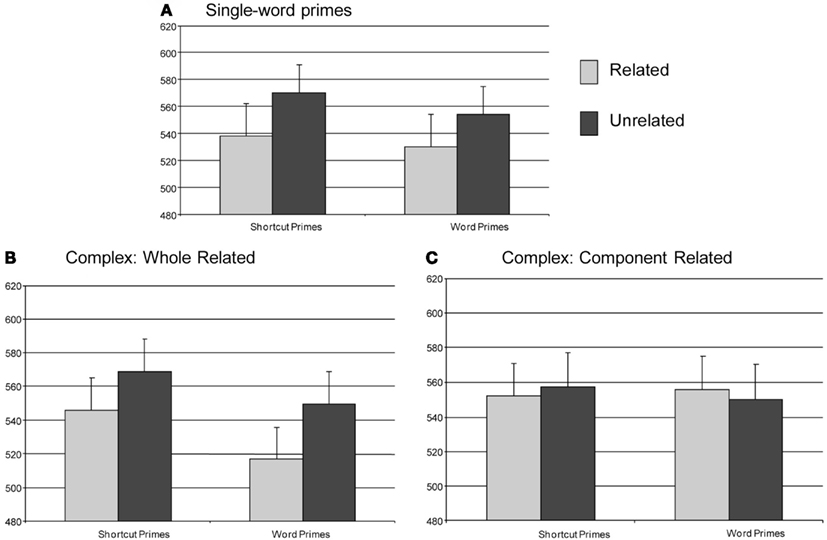
Figure 1. Results of Experiment 1: mean reaction times (ms) as a function of Relatedness and Prime Type for single-word primes (A), whole-related complex primes (B) and component-related complex primes (C). Error bars show the SE.
Complex whole-related primes
There was a main effect of Relatedness [F(1, 356) = 4.53; p = 0.03; see Figure 1], with participants being 28 ms faster to decide that a target was a word when it was preceded by a related prime than when it was preceded by an unrelated prime. Furthermore, there was a main effect of Prime Type [F(1, 356) = 4.79; p = 0.03]: Participants were 24 ms faster to decide that a target was a word when it was preceded by a word prime than by a shortcut prime. The interaction between Relatedness and Prime Type was not significant (F < 1).
Complex component-related primes
Neither of the main effects (Relatedness or Prime Type) nor their interaction was significant (all Fs < 1).
Discussion
Participants were faster to decide that a target was a word when it was preceded by an associatively related prime than when it was preceded by an unrelated prime. This effect was independent of whether the prime was a word or a shortcut, and it was obtained for simple primes (e.g., gr8/great – good) as well as for whole-related complex primes (e.g., cu/see you – goodbye; see Figure 1). In other words, the related shortcuts primed the targets as much as the full forms. This suggests that shortcuts were not first translated into their corresponding full forms, but that they activated associated lemmas and meanings just like full forms.
Lexical decisions were faster after word than shortcut primes. It has been proposed that in the lexical decision task, the decision is based on global lexical activity, which is the summed activity in the mental lexicon (Paap and Johansen, 1994; Grainger and Jacobs, 1996; Coltheart et al., 2001). One might argue that lexical activity is higher when the prime is a real word than when it is a shortcut because shortcuts are less frequent and have fewer orthographic neighbors that they might activate compared to words (see Laszlo and Federmeier, 2011). This account predicts that non-word decision should be slower after word than shortcut primes, as was observed [simple words: 674 ms, SD = 193 ms; simple shortcuts: 660 ms, SD = 170 ms; complex words: 674 ms; SD = 177 ms; complex shortcuts: 653 ms; SD = 181 ms; F(1, 1,047) = 4.49; p = 0.03].
In contrast to simple primes (e.g., gr8/great – good) and whole-related complex primes (e.g., cu/see you – goodbye), component-related primes did not yield any priming (e.g., cu/see you – look), regardless of their spelling. This was most likely due to the short prime duration, which was sufficient for the meaning of the prime as a whole to be activated, but did not lead to the activation of the meanings of the components. To test this hypothesis, a second experiment was conducted where the prime duration was extended to 1000 ms. For the simple primes and whole-related complex primes, we expected to replicate the effects of Experiment 1. Additionally, we expected to find a significant priming effect from component-related word primes. If the meaning of shortcuts is indeed retrieved from their form representations without translation into full forms, then no priming of component-related shortcut primes should be seen.
Experiment 2. Overt Priming
Methods
Participants
Twenty-two students of the University of Birmingham (21 female) took part in the experiment (average age: 19.5 years, SD = 0.9). Participants gave written informed consent prior to participating in the study. All participants were right-handed native speakers of English and had normal or corrected-to-normal vision. They received course credits for their participation.
Materials and design
The same materials and design were used as in Experiment 1.
Procedure
The same procedure as in Experiment 1 was used, except for an altered structure of the trials. Each trial started with a fixation cross for 500 ms. Next the prime was presented for 1000 ms. This was followed by a blank screen for 500 ms and the target which was shown until a response was given, up to a maximum of 3 s.
Results
As in Experiment 1, the modal response in the questionnaire was that participants read and wrote the shortcuts once a week, with on average 2.1 low-frequency shortcuts (SD = 1.2) and 2.5 high-frequency shortcuts (SD = 1.3) per participant. The questionnaire data were used to exclude shortcuts participants did not know [on average 0.45 shortcuts (SD = 0.80) per participant] and related prime target pairs that they rated as being unrelated [on average 2.05 pairs (SD = 1.09) per participant]. The error rates for words and pseudo-words were very low (2.2 and 2.1%, respectively) and no error analysis was conducted. As for Experiment 1, reaction times below 300 ms and above 1500 ms (1.6% of the data) were excluded from the analyses, leaving on average 18 trials per condition.
Simple primes
There was a main effect of Relatedness [F(1, 345) = 4.75; p = 0.03; see Figure 2], with participants being 33 ms faster to decide that a target was a word when it was preceded by a related prime than when it was preceded by an unrelated prime. There was no effect of Prime Type and no interaction between Relatedness and Prime Type (both Fs < 1).
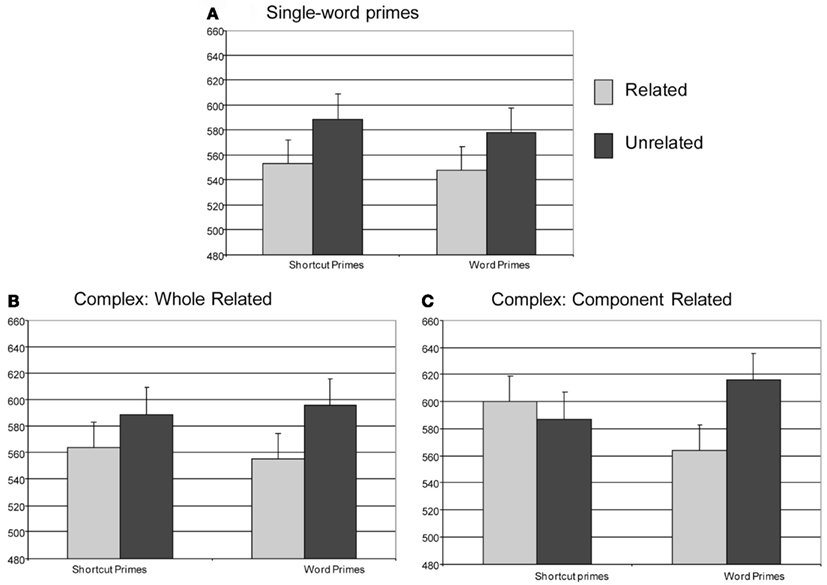
Figure 2. Results of Experiment 2: mean reaction times (ms) as a function of Relatedness and Prime Type for single-word primes (A), whole-related complex primes (B) and component-related complex primes (C). Error bars show the SE.
Complex whole-related primes
There was a main effect of Relatedness [F(1, 356) = 6.43; p = 0.01; see Figure 2], with participants being 33 ms faster to decide that a target was a word when it was preceded by a related prime than when it was preceded by an unrelated prime. There was no effect of Prime Type and no interaction between Relatedness and Prime Type (both Fs < 1).
Complex component-related primes
The main effects of Relatedness and Prime Type were not significant [F(1, 369) = 1.50; p = 0.22; F < 1, respectively]. However, there was a significant interaction between these factors [F(1, 371) = 4.63; p = 0.03; see Figure 2]. Follow-up analyses revealed that there was a significant 52-ms priming effect from word primes [F(1, 164) = 6.54; p = 0.01], but there was no priming from shortcut primes (F < 1). In other words, the 17-ms difference favoring the unrelated shortcut condition was not significant.
Discussion
As in Experiment 1, priming effects were obtained from simple primes and whole-related complex word and shortcut primes. Additionally, there was a significant priming effect from component-related word primes (e.g., see you), which had not been seen in Experiment 1. Thus, with extended prime duration and clear visibility of the primes, the meaning of the individual words (e.g., see and you) in the prime phrases became sufficiently activated to affect the processing of the targets (e.g., look). By contrast, component-related shortcut primes (e.g., cu) did not facilitate target processing associated with a component of the prime (e.g., cu – look), which suggests that the corresponding full word forms (see you) were not retrieved even when there was plenty of time to do so.
In Experiment 2, the main effect of Prime Type (word vs. shortcut) seen in Experiment 1 was not replicated. This is probably due to the altered temporal structure of the trials. The primes now began 1.5 s before the targets, and primes and targets were separated by a 500-ms blank interval. This time interval may have been sufficient for the global lexical activation elicited by shortcuts to reach similar levels to that of words and therefore no effect of Prime Type on speed of the participants’ responses to the targets was seen.
General Discussion
The goal of the present study was to investigate how readers access the meaning of shortcuts, specifically, whether lexical access is necessarily mediated by access to representations of the corresponding full forms, or whether shortcuts could be accessed directly from their orthographic representations, as Brysbaert et al. (2009) have argued for conventionalized acronyms. To that end, semantic priming effects of simple (gr8/great – good), whole-related (cu/see you – goodbye), and component-related shortcut primes (cu/see you – look) were compared to the priming effects of the corresponding word primes, either presenting masked (Experiment 1) or overt primes (Experiment 2)1.
In both experiments, simple and whole-related shortcut primes had equivalent effects to the corresponding word primes. The fact that these primes yielded facilitation in the masked priming experiment, where the time allowed for prime processing was severely limited, demonstrates that these types of shortcuts can rapidly activate their associated meanings, just like words. In the masked priming experiment, component-related primes did not facilitate the responses to the targets, regardless of their spelling. In the overt priming experiment, only the word primes but not the shortcut primes yielded component-related facilitation. It is quite remarkable that even in Experiment 2, when there was plenty of processing time, the meanings of the components of complex shortcut primes were not activated. Together, these results suggest that shortcuts need not necessarily be recoded into words but that participants had acquired direct access to the representations of shortcuts.
Note that the issue of whether or not accessing the meaning of a shortcuts requires access to the corresponding full form is different from the issue of whether or not shortcuts activate phonological representations. The current data do not speak to the latter issue. Thus, it may or may not be the case that the shortcuts spk activates the phonological form [spi:k], and it may or may not be the case that the shortcut cu activates the phonological form [si: ju:], which happens to be homophonous to the phonological form of the corresponding set of words “see you.” This issue could be addressed in further research (see also Perea et al., 2009). However, the current data do suggest that participants reading lol probably did not activate the full phonological representation [lA:f aUt laUd] of the corresponding full form. In future experiments, it would be interesting to investigate whether there is rapid access to the meaning of shortcuts via their phonological representations (e.g., by comparing two types of shortcuts: phonological ones like cu and true acronyms like lol).
The difference in the results seen for component-related word primes in the two experiments needs further explanation. The fact that the multiple-word phrases presented in the present experiment have shortcut equivalents indicates that these phrases are frequently used (though there might be exceptions, e.g., laugh out loud, where shortcuts overtake the spoken full forms in frequency). These phrases are probably processed in much the same way as clichés (e.g., conquer the world) and decompositional idioms (e.g., pop the question). Such lexicalized phrases can have their own lemma representations (e.g., Sprenger et al., 2006), which can be activated before the meanings of the component words (e.g., Tabossi and Zardon, 1993, 1995). Similarly, the present results imply that the meanings of the phrases used in the complex prime condition were activated before the meanings of the component words. In the masked priming experiment, the meanings of the component words were not activated quickly enough to affect the responses to the targets. In the overt priming experiment, the meaning of the whole phrase as well as the meanings of the individual words within the phrase were activated, resulting in significant priming effects for both component-related and whole-related word primes.
The present results suggest that readers can retrieve the meanings of familiar shortcuts without prior access to the corresponding full forms. This is in line with conclusions by Perea et al. (2009) and Brysbaert et al. (2009). Brysbaert et al. (2009) found priming effects of similar size from words and acronyms and concluded that everyday acronyms could directly access their meaning. The current study leads to the same conclusion with respect to shortcuts. Therefore, it appears that shortcuts and acronyms are represented in the mental lexicon and retrieved in very similar ways, even though acronyms are used in spoken and written language, while shortcuts are rarely found in spoken language. The processing of both acronyms and shortcuts appears to be very similar to the processing of regular words.
Of course, direct access is not the only way of processing shortcuts. Most readers probably know which full forms common shortcuts are derived from (e.g., that cu is derived from see you). Thus for some shortcuts direct and mediated access might occur in parallel. This proposal is related to dual-route models proposed elsewhere in psycholinguistics, for instance for reading aloud (for discussion see Frost, 1998; Coltheart et al., 2001) and for the processing of morphologically complex words (e.g., Baayen and Schreuder, 1999, 2000). The relative efficiency of the two routes is likely to depend on a number of variables. One would, for instance, expect the direct route to be stronger for very familiar than for unfamiliar shortcuts and, of course, non-existent for novel shortcuts, for which the reader has to construct the meaning from the components2. Task demands may also affect the relative importance of the two routes (see also Macizo and Bajo, 2006). For instance, Ganushchak et al. (2010b) presented shortcuts and pseudo-shortcuts with embedded digits (e.g., 4u vs. 4y) as primes in a parity judgment task, where participants had to decide whether displays showed even or odd numbers of dots. The results demonstrated that the number concepts associated with the digits in shortcut and pseudo-shortcut primes were briefly activated, implying that both types of primes were decomposed into their components. The number concepts in existing shortcuts, but not in pseudo-shortcuts, were quickly deactivated, presumably due to inhibition arising from the activation of the meanings of the whole shortcuts. In line with the present findings, these results demonstrate that shortcuts quickly activate their meaning, but contrary to the present findings, they also imply that the meanings of the components of the shortcuts are activated as well. A possible reason for the difference in the results of the two studies is that the number concepts were directly relevant to the parity judgment task, but not to the lexical decision task used in the present study.
In sum, together with previous findings, the present results imply that familiar shortcuts, much like conventional acronyms, can be accessed directly, even though mediated access is possible. Nevertheless shortcuts are generally read more slowly than traditional words. In spite of appearing frequently in certain types of text, most shortcuts are probably still encountered less frequently than their corresponding full forms, and this may affect the efficiency of both the direct and the mediated route to their meanings. It will be interesting to see whether eventually the increasing usage of shortcuts in everyday language will close the gap to regular words so that shortcuts become just like any other words of the language.
Author Note
This research was supported by a Dutch Organization for Scientific Research (NWO) grant (no. 446-07-027) to L. Y. Ganushchak. Research reported in the current manuscript was conducted in accord with APA standards for ethical treatment of participants and with the approval of the ethical committee in the School of Psychology at the University of Birmingham. The authors thank Emma Palmer and Eva Nielsen for their help in collecting data.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
- ^In both experiments most participants were women, reflecting the fact that the large majority of the undergraduates in the School of Psychology at the University of Birmingham are female. It seems unlikely that young men would process shortcuts differently from young women, but this should be assessed in further research.
- ^In an exploratory analysis, Frequency (low and high) was added as a crossed-fixed factor into the model. The analysis was run only for simple shortcuts, since all complex shortcuts had high or moderate frequency. For the masked priming experiment, the analysis showed a significant interaction between Relatedness and Frequency [F(1, 166) = 3.25; p = 0.04]. For the low-frequency shortcuts there was no difference between the related (542 ms; SD = 130 ms) and unrelated conditions (544 ms; SD = 136 ms; F < 1). For the high-frequency shortcuts, however, participants were 128 ms faster deciding that target was a word when it was preceded by a related (499 ms; SD = 182 ms) shortcut than by an unrelated shortcut [627 ms; SD = 156 ms; F(1, 21) = 10.75; p = 0.003]. No such interaction was found in the overt priming task, possibly because in the overt priming task there was more time available to process prime, so any initial difficulties of processing of low-frequency shortcuts was overcome by the time response was given.
References
Baayen, R. H., Davidson, D. J., and Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412.
Baayen, R. H., Dijkstra, T., and Schreuder, R. (1997). Singulars and plurals in Dutch: evidence for a parallel dual-route model. J. Mem. Lang. 37, 94–117.
Baayen, R. H., and Schreuder, R. (1999). War and peace: morphemes and full forms in a noninteractive activation parallel dual-route model. Brain Lang. 68, 27–32.
Baayen, R. H., and Schreuder, R. (2000). Towards a psycholinguistic computational model for morphological parsing. Philos. Trans. Math. Phys. Eng. Sci. 358, 1281–1293.
Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson, G. B., and Treiman, R. (2007). The English Lexicon Project. Behav. Res. Methods 39, 445–459.
Barber, H. A., and Kutas, M. (2007). Interplay between computational models and cognitive electrophysiology in visual word recognition. Brain Res. Rev. 53, 98–123.
Berger, N. I., and Coch, D. (2010). Do u txt? Event-related potentials to semantic anomalies in standard and texted English. Brain Lang. 113, 135–148.
Besner, D., Davelaar, E., Alcott, D., and Parry, P. (1984). “Wholistic reading of alphabetic print: evidence from the FDM and the FBI,” in Orthographies and Reading: Perspectives from Cognitive Psychology, Neuropsychology and Linguistics, ed. L. Henderson (Hillsdale, NJ: Lawrence Erlbaum Associates), 121–135.
Brysbaert, M. (1995). Arabic number reading: on the nature of the numerical scale and the origin of phonological recoding. J. Exp. Psychol. Gen. 124, 434–452.
Brysbaert, M. (2007). The Language-As-Fixed-Effect-Fallacy: Some Simple SPSS Solutions to a Complex Problem. London: Royal Holloway, University of London.
Brysbaert, M., Speybroeck, S., and Vanderelst, D. (2009). Is there room for the BBC in the mental lexicon? On the recognition of acronyms. Q. J. Exp. Psychol. 1, 1–11.
Burgess, C. (1998). From simple associations to the building blocks of language: modeling meaning in memory with the HAL model. Behav. Res. Methods Instrum. Comput. 30, 188–198.
Chwilla, D. J., Kolk, H. H. J., and Mulder, G. (2000). Mediated priming in the lexical decision task: evidence from event-related potentials and reaction time. J. Mem. Lang. 42, 314–341.
Collins, A., and Loftus, E. (1975). A spreading activation theory of semantic processing. Psychol. Rev. 82, 407–428.
Coltheart, M. (1978). “Lexical access in simple reading tasks,” in Strategies of Information Processing, ed. G. Underwood (London: Academic Press), 151–216.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., and Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychol. Rev. 108, 204–256.
Deacon, D., Dynowska, A., Ritter, W., and Grose-Fifer, J. (2004). Repetition and semantic priming of nonwords: implications for theories of N400 and word recognition. Psychophysiology 4, 60–74.
Frost, R. (1998). Towards a strong phonological theory of visual word recognition: true issues and false trails. Psychol. Bull. 123, 71–99.
Ganushchak, L. Y., Krott, A., and Meyer, A. S. (2010a). Electroencephalographic responses to SMS shortcuts. Brain Res. 1348, 120–127.
Ganushchak, L. Y., Krott, A., and Meyer, A. S. (2010b). Is it a letter? Is it a number? Processing of numbers within SMS shortcuts. Psychon. Bull. Rev. 17, 101–105.
Ganushchak, L. Y., Krott, A., Frisson, S., and Meyer, A. S. (in press). Processing words and SMS shortcuts in sentential contexts: an eye movement study. Appl. Psycholinguist.
Grainger, J., and Jacobs, A. M. (1996). Orthographic processing in visual word recognition: a multiple read-out model. Psychol. Rev. 103, 518–565.
Holcomb, P. J., and Grainger, J. (2006). On the time course of visual word recognition: an event-related potential investigation using masked repetition priming. J. Cogn. Neurosci. 18, 1631–1643.
Hutchison, K. A. (2003). Is semantic priming due to association strength or feature overlap? A microanalytic review. Psychon. Bull. Rev.10, 785–813.
Izura, C., and Playfoot, D. (in press). A normative study of acronyms and acronym naming. Behav. Res. Methods.
Kouider, S., and Dehaene, S. (2007). Levels of processing during nonconscious perception: a critical review of visual masking. Philos. Trans. R.Soc. B 362, 857–875.
Kutas, M., and Federmeier, K. D. (2000). Electrophysiology reveals semantic memory use in language comprehension. Trends Cogn. Sci.(Regul. Ed.) 4, 463–470.
Kutas, M., and van Petten, C. (1994). “Psycholinguistics electrified II (1994-2005),” in Handbook of Psycholinguistics, 2nd Edn, eds M. A. Gernsbacher, and M. Traxler (New York: Elsevier Press), 659–724.
Laszlo, S., and Federmeier, K. D. (2007a). The acronym superiority effect. Psychon. Bull. Rev. 14, 1158–1163.
Laszlo, S., and Federmeier, K. D. (2007b). Better the DVL you know: acronyms reveal the contribution of familiarity to single word reading. Psychol. Sci. 18, 122–126.
Laszlo, S., and Federmeier, K. D. (2008). Minding the PS, queues, and PXQs: Uniformity of semantic processing across multiple stimulus types. Psychophysiology, 45, 458–466.
Laszlo, S., and Federmeier, K. D. (2011). The N400 as a snapshot of interactive processing: evidence from regression analyses of orthographic neighbour and lexical associate effects. Psychophysiology 48, 176–186.
Limpert, E., Stahel, W. A., and Abbt, M. (2001). Lognormal distributions across the science: keys and clues. Bioscience 51, 341–352.
Lucas, M. (2000). Semantic priming without association: a meta-analytic review. Psychon. Bull. Rev. 7, 618–630.
Macizo, P., and Bajo, M. T. (2006). Reading for repetition and reading for translation: do they involve the same processes? Cognition 99, 1–34.
Neely, J. H. (1991). “Semantic priming effects in visual word recognition: a selective review of current findings and theories,” in Basic Processes in Reading: Visual Word Recognition, eds D. Besner, and G. Humphreys (Hillsdale, NJ: Erlbaum), 264–336.
Nelson, D. L., McEvoy, C. L., and Schreiber, T. A. (1998). The University of South Florida Word Association, Rhyme, and Word Fragment Norms. Available at: http://www.usf.edu/FreeAssociation/
Paap, K. R., and Johansen, L. S. (1994). The case of the vanishing frequency effect: a retest of the verification model. J. Exp. Psychol. Hum. Percept. Perform. 20, 1129–1157.
Perea, M., Acha, J., and Carreiras, M. (2009). Eye movements when reading text messaging (txt msgng). Q. J. Exp. Psychol. 62, 1560–1567.
Quené, H., and van den Bergh, H. (2008). Examples of mixed-effects modeling with crossed random effects and with binomial data. J. Mem. Lang. 59, 413–425.
Ratcliff, R., and McKoon, G. (1994). Retrieving information from memory: spreading-activation theories versus compound-cue theories. Psychol. Rev. 95, 385–408.
Rugg, M. D., and Nagy, M. E. (1987). Lexical contribution to nonword-repetition effects: evidence from event-related potentials. Mem. Cognit. 15, 473–481.
Slattery, T. J., Pollatsek, A., and Rayner, K. (2006). The time course of phonological and orthographic processing of acronyms in reading: evidence from eye movement. Psychon. Bull. Rev. 13, 412–417.
Sprenger, S. A., Levelt, W. J. M., and Kempen, G. (2006). Lexical access during the production of idiomatic phrases. J. Mem. Lang. 54, 161–184.
Tabossi, P., and Zardon, F. (1993). “The activation of idiomatic meaning in spoken language comprehension,” in Idioms: Processing, Structure, and Interpretation, eds C. Cacciari, and P. Tabossi (Hillsdale, NJ: Erlbaum), 145–162.
Tabossi, P., and Zardon, F. (1995). “The activation of idiomatic meaning,” in Idioms: Structural and Psychological Perspectives, eds M. Everaert, E.-J. van der Linden, A. Schenk, and R. Schreuder (Hillsdale, NJ: Erlbaum), 273–282.
Taft, M. (2003). “Morphological representation as a correlation between form and meaning,” in Reading Complex Words: Cross-Language Studies, eds E. M. H. Assink, and D. Sandra (New York, NJ: Kluwer Academic), 113–137.
Appendix
Materials
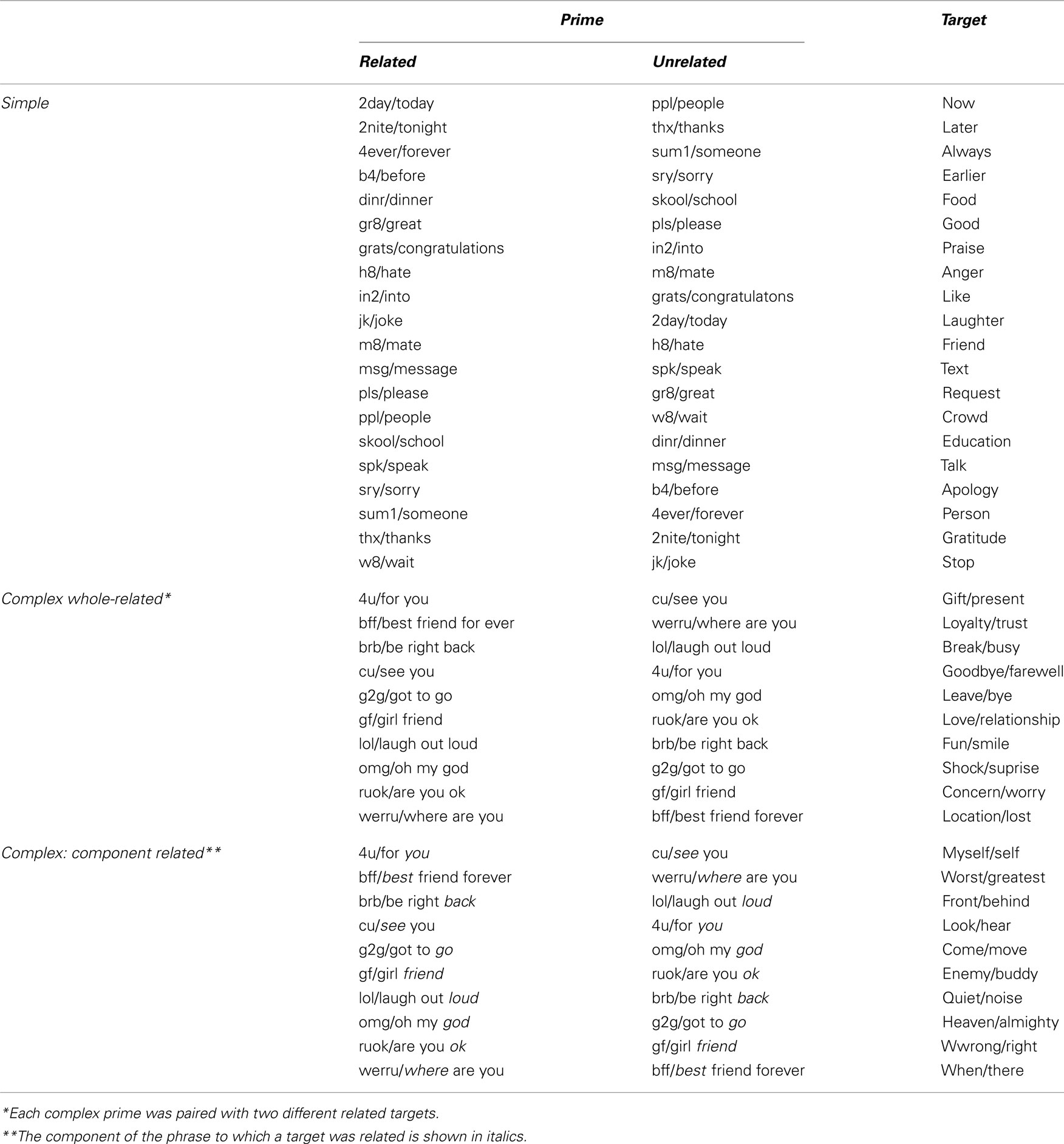
Table A1. Related and unrelated word and shortcut prime-target pairs.
Keywords: SMS shortcuts, lexical representations, priming
Citation: Ganushchak LY, Krott A and Meyer AS (2012) From gr8 to great: lexical access to SMS shortcuts. Front. Psychology 3:150. doi: 10.3389/fpsyg.2012.00150
Received: 26 March 2012; Paper pending published: 14 April 2012;
Accepted: 26 April 2012; Published online: 23 May 2012.
Edited by:
Marc Brysbaert, Ghent University, BelgiumCopyright: © 2012 Ganushchak, Krott and Meyer. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Lesya Y. Ganushchak, Max Planck Institute for Psycholinguistics, 6500 AH Nijmegen, Netherlands. e-mail:bGVzeWEuZ2FudXNoY2hha0BtcGkubmw=