



- 1Institut de Recherche en Sciences Psychologiques, Université catholique de Louvain, Louvain-la-Neuve, Belgium
- 2Institute of Neuroscience, Université catholique de Louvain, Bruxelles, Belgium
Numerosity, length, and duration processing may share a common functional mechanism situated within the parietal cortex. A strong parallelism between the processing of these three magnitudes has been revealed by similar behavioral signatures (e.g., Weber–Fechner's law, the distance effect) and reciprocal interference effects. Here, we extend the behavioral evidence for a common magnitude processing mechanism by exploring whether the under- and overestimation patterns observed during numerical perception and production tasks are also present in length and duration perception and production. In a first experiment, participants had to perform two estimation tasks (i.e., perception and production) on three magnitudes (i.e., numerosities, lengths, and durations). The results demonstrate similar patterns for the three magnitudes: underestimation was observed in all perception tasks, whereas overestimation was found in all production tasks. A second experiment ensured that this pattern of under- and over-estimation was not solely generated by the mere process of perceiving or producing something. Participants were required to estimate the alphabetical position of a letter (i.e., perception task) or to produce the letter corresponding to a given position (i.e., production task). No under- or overestimation were observed in this experiment, which suggests that the process of perceiving or producing something alone cannot explain the systematic pattern of estimation observed on magnitudes. Together, these findings strengthen the idea that magnitude estimations share a common metric system, requiring similar mechanisms and/or representations.
Introduction
Number, space and time are fundamental properties of the environment constantly used by humans and animals to adapt and regulate their behavior to the external world. The idea of a unique functional mechanism supporting magnitude processing was primary developed for numerosity and duration in the Accumulator model (Meck and Church, 1983) and later extended by A Theory Of Magnitude (ATOM; Walsh, 2003; Bueti and Walsh, 2009). This model proposes the existence of a generalized magnitude processing system that would underlie the representation of numerosity, space and time through a common metric system controlled by areas of the parietal cortices. Three series of arguments support this idea.
At the neurofunctional level, brain areas located along the right intraparietal sulcus (IPS) are involved in numerosity, length, and duration discrimination. The involvement of these areas has been highlighted in neuroimaging (e.g., Pinel et al., 2004; Cohen Kadosh et al., 2005; Bueti and Walsh, 2009; Dormal and Pesenti, 2009; Dormal et al., 2012b), TMS (e.g., Bjoertomt et al., 2002; Alexander et al., 2005; Dormal et al., 2012a; Hayashi et al., 2013) and monkey electrophysiological (e.g., Leon and Shadlen, 2003; Nieder and Miller, 2003; Roitman et al., 2007; Tudusciuc and Nieder, 2007) studies.
At the developmental level, several studies have shown that discriminating numerosities, surface areas and durations leads to similar patterns of performance in babies (see respectively, Xu and Spelke, 2000; Brannon et al., 2006; van Marle and Wynn, 2006; for a review, see Feigenson, 2007): 6-month old infants are able to discriminate the numerosity, the duration or the size of one or several visual or auditory presented elements with a 1:2 ratio, but they fail to discriminate them with a 2:3 ratio. By 9 or 10 months, the precision of the representations improves, and infants develop the ability to discriminate durations and numerosities with a 2:3 ratio (Lipton and Spelke, 2003; Brannon et al., 2007). These studies therefore suggest that the discrimination of magnitude improves with development in a similar way for different magnitudes.
Finally, at the behavioral level, various similarities have been reported between the discrimination of numerosities, lengths, and durations. First, discriminating all three magnitudes obey Weber–Fechner's law (Stevens and Greenbaum, 1966; Teghtsoonian and Teghtsoonian, 1978), according to which the increase in stimulus intensity required to produce a noticeable increase of sensation is a constant function of the intensity of this stimulus1 (Fechner, 1860). Second, the behavioral signatures of the distance and size effects typically encountered in numerical judgments also appear when comparing other magnitudes. The distance effect refers to the observation that the ability to discriminate two numbers increases as the numerical distance between them increases (Moyer and Landauer, 1967; Buckley and Gillman, 1974). The size effect reflects the fact that, at equal numerical distance, the discrimination of two numbers decreases as their numerical size increases (Restle, 1970; van Oeffelen and Vos, 1982). Both effects are present in most judgments of quantifiable physical dimensions such as line lengths (e.g., Henmon, 1906; Johnson, 1939; Fias et al., 2003; Dormal and Pesenti, 2007), duration of sequences (e.g., Droit-Volet et al., 2004), physical size of geometric forms (e.g., Fulbright et al., 2003), and physical size of numerical symbols (e.g., Pinel et al., 2004; Cohen Kadosh et al., 2005; Kaufmann et al., 2005; Tang et al., 2006). Third, professional musicians, known to outperform non-musicians in temporal discrimination tasks, showed evidence of improved abilities also in spatial and numerical discrimination (Agrillo and Piffer, 2012). Fourth, several studies have investigated the influence of concurrent cognitive or motor tasks on numerosity, length, and duration processing. For example, the transient distortions in both space and time occurring after saccadic eye movements (i.e., compression of perceived magnitude of spatial separations and temporal intervals to approximately half of their true value; Morrone et al., 2005; Burr and Morrone, 2006) have recently also been reported during a numerosity perception task (Burr et al., 2010; Binda et al., 2011). The bisection of time, number and length were affected in a similar way by a click-train procedure (i.e., the presentation of a train of auditory clicks during a bisection judgment; Droit-Volet, 2010). Behavioral interactions between various quantifiable dimensions during estimation processing were also reported in interference paradigms exploring the influence of an irrelevant magnitude on the judgment of another magnitude (for a review, see Dormal and Pesenti, 2012). Whereas bidirectional interference effects were consistently observed between numerosity and space (e.g., Dormal and Pesenti, 2007; de Hevia and Spelke, 2009), the numerical cues influenced duration perception and reproduction but not the reverse (e.g., Dormal et al., 2006; Xuan et al., 2007; Agrillo et al., 2010; Chang et al., 2011; Vicario, 2011; but see Javadi and Aichelburg, 2012). Finally, a mutual interference was reported between time and space (e.g., Casasanto and Boroditsky, 2008). All these results suggest the existence of a continuum of automaticity, in which numerosity processing takes place more or less automatically, followed by length processing and then duration processing (Dormal and Pesenti, 2013).
Together, these behavioral similarity and interference results, and the common activation areas support Walsh's (2003) proposal of a generalized magnitude processing underlying the representation of numerosity, space, and duration. However, asymmetric interference results between numerical and temporal dimensions (Droit-Volet et al., 2004; Dormal et al., 2006; Agrillo et al., 2010) and the absence of numerical learning transfer to the discrimination of length (DeWind and Brannon, 2012) did not support the idea of a fully common magnitudes processing. Moreover, recent TMS and neuropsychological studies have revealed the presence of a double dissociation between numerosity and duration processing (Dormal et al., 2008, 2012c; Cappelletti et al., 2009, 2011). Two brain-damaged patients showed specific deficits in either numerical or duration processing (Cappelletti et al., 2009, 2011), while left parietal stimulation disrupted only numerosity processing in healthy participants (whereas duration processing was not impaired; Dormal et al., 2008). Finally, impairments in duration processing were observed both in elderly healthy adults and in patients suffering from early Parkinson's disease, whereas both groups performed correctly in a numerosity comparison task (Dormal et al., 2012c). These results suggest the coexistence of common and partially independent, rather than fully shared magnitude mechanisms and/or representations (Cappelletti et al., 2011; Dormal and Pesenti, 2012).
To explore the characteristics of the accuracy estimation profile observed during numerosity, length, and duration, perception and production tasks were used jointly for the first time in order to highlight similarities and differences in estimation processes. In perception tasks, non-symbolic stimuli, such as collections of dots, are presented to participants who have to estimate their numerosity by providing symbolic outputs, such as verbal or Arabic numerals. Conversely, in production tasks, participants produce non-symbolic numerosities (e.g., collection of dots or sequences of sounds) corresponding to symbolic stimuli (e.g., Arabic digits or verbal numerals). A specific pattern of behavioral results has been revealed in the literature on numerical cognition. While numerosities are systematically underestimated in perception tasks (Kaufman et al., 1949; Bevan and Turner, 1964; Krueger, 1972; Mandler and Shebo, 1982; Castronovo and Seron, 2007; Crollen et al., 2011), they are systematically overestimated in production tasks (Whalen et al., 1999; Cordes et al., 2001; Castronovo and Seron, 2007; Crollen et al., 2011; Crollen and Seron, 2012).
The present study was conducted to assess whether other magnitudes, such as length or duration, share or not a common metric system with numerosity, by determining whether under- and overestimation are also observed during length and duration perception and production tasks. In order to directly compare the performance patterns, Experiment 1 required each participant to perform both perception and production judgments on numerosity, length, and duration. If numerical, spatial and temporal estimations rely on a common mechanism and/or involve a common representation, the participants should underestimate these three magnitudes in the perception tasks, while a general overestimation should be observed in the production tasks. Dissimilarities in the performance patterns during the estimation of the three magnitudes would imply several core mechanisms using different metrics. To control whether those under- or overestimation patterns could be due to specific magnitude mechanisms and not to non-specific task requirement (perceiving or producing a stimulus), Experiment 2 was conducted with the same tasks but using unquantifiable material (i.e., letters).
Experiment 1
Method
Participants
Sixteen volunteers (5 males, 1 left-handed, mean age: 19.50 ± 0.97) took part in this experiment. They all had normal or corrected-to-normal vision and were unaware of the purpose of the study. All the procedures were non-invasive and were performed in accordance with the ethical standards laid down in the 1964 Helsinki Declaration.
Stimuli, tasks, and general procedure
The participants had to perform two tasks (i.e., perception and production) on three magnitudes (i.e., numerosity, length, and duration), giving a total of six different conditions (Figure 1). The whole experiment lasted about 60 min and was divided into two sessions taking place on two different days. The three perception conditions were always performed during the first session, and the three production conditions during the second one. This procedure was adopted in order to prevent participants from being aware of the different values used for the perception tasks as the same values were explicitly presented in the production tasks. The order of magnitude processing within the first session was counterbalanced across participants and kept constant for the second session within participants.
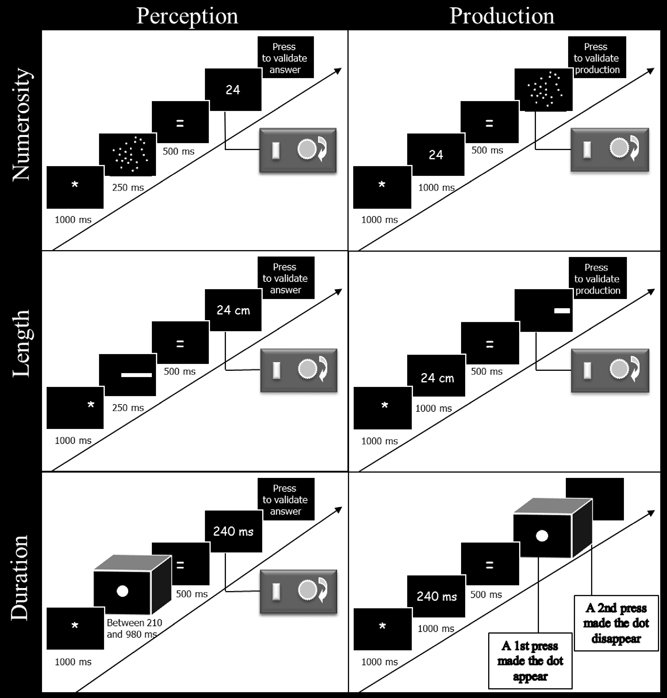
Figure 1. Schematic representation of the time course of events used in the perception and production tasks for numerosity, length, and duration. In the perception tasks, the participants had to estimate the numerosity, length, or duration of the stimuli by turning the potentiometer after the sign “=” had been displayed. In the production tasks, they had to produce a stimulus with a numerosity, length, or duration corresponding to the given value, by using the potentiometer after the sign “=” had been displayed. Responses were validated by pressing a button on the response box.
The presentation procedure and the number of trials were identical in the six conditions. Each condition was composed of 3 blocks of 24 experimental trials, with every target values presented twice. Ten training trials were presented before the experimental trials in order to familiarize the participants with the tasks, and were not analyzed. The stimuli were projected on a screen measuring 1.65 m wide and 1.20 m high. This methodological choice was made to ensure that the participants could not use their knowledge of computer screen size to infer their answer and to allow a similar potential variability in the answers of the participants across the different dimensions. The participants sat 95 cm from the screen in a dark room. Stimulus presentation and data collection were controlled by a PC computer connected to a data projector and using a customized E-prime 2 program (Schneider et al., 2002).
The same range of values was used in the different conditions (21, 24, 28, 32, 37, 42, 49, 56, 64, 74, 85, 98 dots or cm for numerosity and length, respectively; 210, 240, 280, 320, 370, 420, 490, 560, 640, 740, 850, 980 ms for duration). These figures were chosen by applying a ratio between two consecutive values ranging from 0.85 to 0.93, as this ratio corresponds to the discrimination threshold in adults (Halberda and Feigenson, 2008). For numerosity, the range started at 21, as previous studies have shown that estimation is usually accurate for values below 20 (Indow and Ida, 1977; Krueger, 1982, 1984). Durations less than one second were presented to avoid explicit counting strategies. Lengths smaller than 1 m were chosen to reduce the use of perceptual cues such as the distance separating the target stimulus and the edge of the screen.
Perception conditions
Numerosity. The participants had to estimate the numerosity of various visual arrays of white dots displayed on a black background. In order to control low-level continuous perceptive variables (Dehaene et al., 2005), two different arrays of dots were created: an extensive and an intensive sets. In the extensive set, the sum of the area of all the dots (i.e., the luminance) on the screen was kept constant across numerosities. As a consequence, the size of the dots decreased while the density of the array increased as numerosity increased. In the intensive set, the size of the dots and the density of the array were kept constant. Therefore, the luminance and the total occupied area increased with increasing numerosity.
Each trial began with the presentation of the sign “*” for 1000 ms. Then, an array of dots was flashed on the screen for a duration of 250 ms followed by the sign “=” (500 ms). After the sign “=,” the Arabic numeral “1” was presented, indicating to the participants that they had to give their estimation. To give their answers, participants had to turn a potentiometer on a response box (Mejias et al., 2012) to go through the Arabic numeral sequence. The potentiometer allowed the display of all the values between 1 and 255 (by jump of one unit every 1.4° of angular rotation). To validate their answers, the participants pressed a button on the response box.
Length. The participants had to estimate the length (in cm) of horizontal rectangles. The rectangles were white, measured 4.5 cm in height and were presented on a black background. To avoid estimations based only on the distance from the edge of the screen, the rectangle occupied two different positions on the screen: on the left, where the rectangle began 10 cm from the left edge of the screen; or on the right, where the end of the rectangle was at 10 cm from the right edge of the screen. The sign “*” appeared either on the left or the right of the screen for 1000 ms for each trial, to warn the participant on which part of the screen the rectangle would be presented. Afterwards, a rectangle was displayed on the same side as the sign “*” for a duration of 250 ms, followed by the sign “=” centrally presented for 500 ms followed by the Arabic numeral “1.” This Arabic numeral indicated to the participants that they had to give their response by using the potentiometer (jump of one unit every 1.4° of angular rotation; the letters “cm” appeared next to the Arabic numerals). To validate their answers, the participants pressed a button on the response box.
Duration. The participants had to estimate the duration of presentation of a dot. The trials started with the central presentation of the sign “*” (1000 ms). Then a white dot, 16 cm in diameter, was displayed on a black background in the center of the screen for a given duration (i.e., between 210 and 980 ms; see above for detailed values). After stimulus offset, the sign “=” appeared (500 ms), followed by the Arabic numeral “10” that indicated to the participants that they had to produce their answer by turning the potentiometer (the letters “ms” appeared next to the Arabic numerals). In this task, the use of the potentiometer induced a jump of 10 units every 1.4° of angular rotation and allowed the responses to range from 10 to 2550 ms. To validate their answers, the participants pressed a button on the response box.
Production conditions
Numerosity. The participants had to produce an array of dots corresponding to the numerosity of a target Arabic numeral. Each trial started with the sign “*” presented for 1000 ms, followed by an Arabic numeral also presented for 1000 ms in the center of the screen. This Arabic numeral indicated the number of dots to produce. The sign “=” was then displayed on the screen for 500 ms followed by a single dot which indicated to the participants that they had to start their production by turning the potentiometer (with a jump of one dot for every 1.4° of angular rotation). The response box allowed the participants to produce all the numerosities ranging from 1 to 254. In a random way, half of the array of dots produced by the participants belonged to the intensive set while the other half belonged to the extensive set (see above for details). Finally, the participants pressed a button on the response box to validate their answers.
Length. The participants had to produce a rectangle of a given length. Each trial started with the sign “*” presented for 1000 ms followed by an Arabic number for 1000 ms. The Arabic number indicated the length (in cm) of the rectangle to produce. Afterwards, the sign “=” appeared for 500 ms followed by a rectangle of 0.5 cm length which was displayed for half of the trials on the left of the screen (the start of the rectangle was 10 cm from the left edge of the screen; the rectangle was therefore generated from left to right), and, for the other half of the trials, on the right of the screen (the end of the rectangle was at 10 cm from the right edge of the screen; the rectangle was therefore generated from right to left). The participants had to turn the potentiometer to the right to increase or to the left to decrease the length of the rectangle (jump of 0.65 cm for every 1.4° of angular rotation). The maximum length of the rectangle that could be produced was 165 cm. To validate their answers, participants pressed a button on the response box.
Duration. The participants had to produce time intervals. Each trial started with the sign “*” presented for 1000 ms, followed by an Arabic number for 1000 ms indicating the duration (ms) of the time interval to produce. Afterwards, the sign “=” was displayed on the screen for 500 ms, followed by an empty screen. In order to produce the time interval, participants had to press the button of the response box twice. The first press produced a central dot of 16 cm of diameter and indicated the beginning of the time interval; the second press made the dot disappearing and finished the production of the time interval. There was no time limit for the interval production.
Data analyses
For each target value and in every condition, any response which fell 2 or more standard deviations (SD) above the mean individual response was excluded from the analyses. As the mean estimates and their standard deviations were not normally distributed, logarithmic transformations were applied to the data before the following statistical analyses were carried out.
Firstly, to determine whether performance obeyed Weber–Fechner's law, linear mixed models (LMM) with magnitude (i.e., numerosity in the numerical estimation, length in the length estimation, and duration in the temporal estimation) as a fixed effect and participants as a random effect were conducted for perception and production conditions on log(mean) and log(SD).
Secondly, a mean error rate (ER) for each condition was calculated as follows: ER = [(participant's response—target value)/target value]*100. An ER of zero indicates accurate estimation, a negative ER indicates underestimation, and a positive ER indicates overestimation. The mean ER for each task and magnitude was then submitted to t-tests with a test value of 0 to determine the presence of significant under- or overestimation. In order to directly compare the three magnitudes, an ANOVA was carried out on the mean ER with condition (perception vs. production) and magnitude (numerosity, length vs. duration) as within-subject variables.
Results
Linear mixed models on separate magnitudes
Numerosity. For the perception condition, the results of the LMM showed that the log of the mean estimates increased with target numerosity, F(11, 180) = 83.12, p < 0.001, as did the log of the standard deviation, F(11, 180) = 17.80, p < 0.001, suggesting that the numerosity estimations obeyed Weber–Fechner's law; Figure 2A. For the production condition, the log of the mean estimates and the log of the standard deviation increased with target numerosity, F(11, 180) = 70.13, p < 0.001 for log(mean); F(11, 179) = 19.57, p < 0.001 for log(SD), Figure 2B.
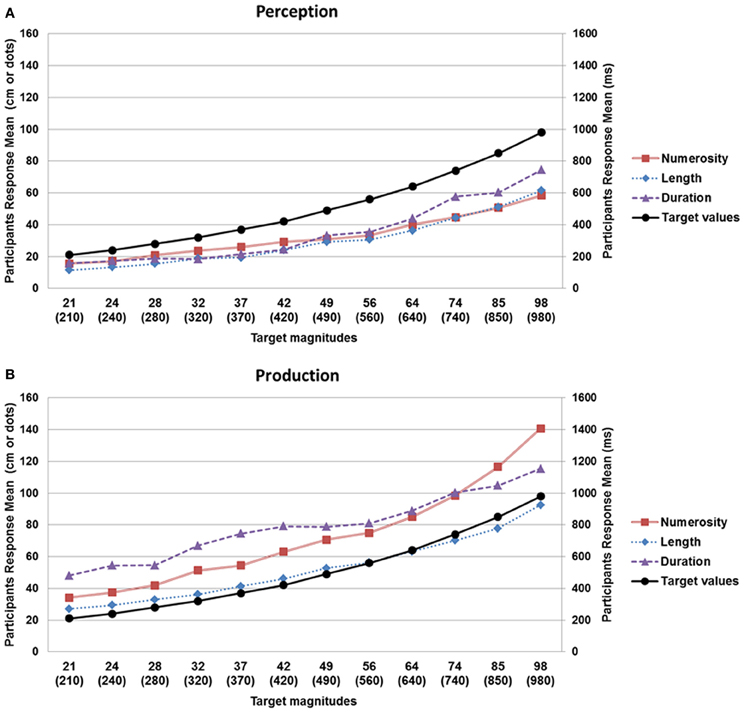
Figure 2. Mean estimation values observed in the perception (A) and production (B) tasks as a function of target value (black line: target values; red line: numerosity; blue line: lenght; mauve line: duration). The left vertical axis shows the estimated values for numerosity and length (in number of dots and cm, respectively) while the right axis corresponds to the values for duration (in ms). On the horizontal axis, the first row corresponds to numerosity (number of dots) or length (cm), while the values in brackets on the second line indicate duration (ms). As shown in the upper graph, a systematic underestimation was observed in the perception tasks, whereas an overestimation was present in the production tasks (lower graph), for the three magnitudes.
Length. For the perception condition, the log of the mean estimates and the log of the standard deviation increased with target value, F(11, 180) = 69.15, p < 0.001 for log(mean); F(11, 178) = 4.66, p < 0.001 for log(SD); Figure 2A. For the production condition, the log of the mean estimates and the log of the standard deviation were also found to increase with target value, F(11, 180) = 121.39, p < 0.001 for log(mean); F(11, 180) = 9.55, p < 0.001 for log(SD), suggesting that participants' production judgments obeyed Weber–Fechner's law; Figure 2B.
Duration. For the perception condition, the results of the LMM showed that participants' judgments obeyed Weber–Fechner's law: the log of the mean estimates increased with duration, F(11, 180) = 12.61, p < 0.001; the log of the standard deviation also increased with duration, F(11, 180) = 8.25, p < 0.001; Figure 2A. For the production condition, the log of the mean estimates and the log of the standard deviation also increased with target value, F(11, 180) = 9.23, p < 0.001 for log(mean); F(11, 180) = 2.65, p < 0.01 for log(SD); Figure 2B.
Comparison across magnitudes
In the perception conditions, a significant underestimation was observed for each magnitude as confirmed by the results of t-tests with the test value of 0; mean ER rates for numerosity: −32.4 ± 10.5%; t(15) = −12.574, p < 0.0012 ; for length: −42.2 ± 12.9%; t(15) = −13.037, p < 0.001; and for duration: −30.6 ± 31.8%; t(15) = −3.846, p < 0.003; Figure 3. Similarly, in the production conditions, all the t-tests were significant, indicating the presence of overestimation in each magnitude; mean ER rates for numerosity: 47.82 ± 29.3%; t(15) = 6.521, p < 0.0013 ; for length: 7.5 ± 14.5%; t(15) = 2.081, p < 0.05; and for duration: 77.1 ± 61.7%; t(15) = 4.996, p < 0.001; Figure 3.
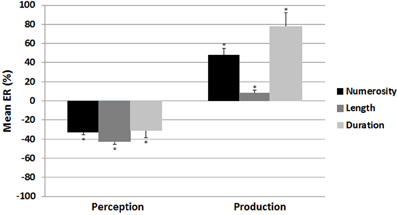
Figure 3. Mean error rate as a function of condition (perception vs. production) and magnitude (numerosity, length, vs. duration) in Experiment 1. A significant underestimation was observed in the perception tasks, whereas a significant overestimation was observed in the production tasks, for the three magnitudes. Error bars denote Standard Error of the Mean (SEM); asterisks indicate significant differences compared to 0.
The ANOVA performed on the mean ER with condition and magnitude as within subject-variables demonstrated a significant main effect of magnitude, F(2, 30) = 23.9 p < 0.001: a significant difference was found between numerosity and length [t(15) = 6.53, p < 0.01] and between length and duration [t(15) = 6.31, p < 0.01], while the remaining comparison was not significant (p > 0.1). A main effect of condition, F(1, 15) = 66.7 p < 0.001, indicated that the ER for the perception tasks (M = −35.3 ± 12.74) was lower than the ER for the production tasks (M = 44.1 ± 30.1). Since the interaction between condition and magnitude was also significant, F(2, 30) = 6.675, p < 0.005, separate ANOVAs were conducted for perception and production conditions with magnitude as the within-subject variable. In the perception condition, no significant effect of magnitude was revealed, F(2, 30) = 1.728, ns, suggesting that the underestimation rates were equivalent for the three magnitudes. In the production condition, a significant main effect of magnitude was observed, F(2, 30) = 16.094, p < 0.001. The mean overestimation ER for length was smaller than that for numerosity or duration (all p-values < 0.001), that did not differ from each other (p > 0.1).
Discussion of Experiment 1
For all magnitudes and tasks, both the means and the standard deviations of the magnitude judgments increased with target value, and the variability in the participants responses was always proportional to the mean for a given target (i.e., the average magnitude of the error increased in proportion to the target), reflecting the scalar property (i.e., the signature of Weber–Fechner's law) already described in various magnitudes estimation tasks (e.g., Stevens, 1957; Meck and Church, 1983; Logie and Baddeley, 1987; Moyer and Landauer, 1967; Whalen et al., 1999).
Under- and over-estimation were observed during numerosity perception and production tasks, respectively, in line with the error pattern observed in previous studies on numerosity processing (e.g., Whalen et al., 1999; Cordes et al., 2001; Castronovo and Seron, 2007; Crollen et al., 2011; Crollen and Seron, 2012). These results were observed here in the particular condition of stimuli presentation on a large screen, suggesting that under- and over-estimation of numerosity occur whatever the conditions of presentation. Interestingly, this characteristic pattern is observed for the first time here in the estimation of length and duration. Participants' answers were indeed systematically underestimated in the three perception conditions, whatever the magnitude to process. Conversely, overestimation occurred whenever numerosity, length, or duration had to be produced. These findings clearly support the idea of a common metric system underlying the processing of numerosity, length, and duration (Walsh, 2003), and suggest that this common metric system could involve at least partially common mechanisms and/or representations. However, one cannot rule out the possibility that it is the processes of perceiving and/or producing something per se that cause the under- and overestimation, irrespective of the materials estimated. By using similar tasks (i.e., perception and production) but with an unquantifiable material (i.e., letters of the alphabet), Experiment 2 was specially designed to address this issue.
Experiment 2
Method
Participants
A total of 16 volunteers (8 males, mean age: 29 ± 7 years) participated after they gave their informed consent. They all had normal or corrected-to-normal vision, were unaware of the purpose of the study and had not participated in Experiment 1. All the procedures were non-invasive and were performed in accordance with the ethical standards laid down in the 1964 Helsinki Declaration.
Stimuli, tasks and procedure
As in Experiment 1, participants had to perform two tasks (i.e., perception and production), but with letters of the alphabet. The same letters were used in the two tasks; the first four and last four letters of the alphabet were not used as their positions could be overlearned, hence too easy to perceive/produce. Seven consonants and 4 vowels were chosen among the 18 remaining letters (i.e., E, F, H, I, K, N, O, R, T, U, V). Each task was composed of 1 block of 44 experimental trials with every letter presented four times. Stimulus presentation and data collection were controlled by a Dell laptop using a customized E-prime 2 program (Schneider et al., 2002) and equipped with a 15.6″ HD screen. The viewing distance was approximately 50 cm. The participant always began with the perception task; the whole session lasted about 15 minutes. The instructions of both perception and production tasks clearly mentioned to the participants that they had to estimate their answer and could not use counting strategies.
In the perception task, participants were required to give the alphabetical position of a letter (e.g., “F” is “6”). Each trial began with the presentation of the sign “*” for 1000 ms. Then, a letter was displayed on the screen for a duration of 1000 ms followed by the sign “=” (500 ms) indicating to the participants that they had to give their estimation. Participants were asked to answer aloud as fast and accurately as possible. We did not use the potentiometer in this task in order to avoid the use of a counting strategy that would probably have taken place if the letters had passed by one after the other. Response accuracy was monitored on-line by the experimenter. The next trial started immediately after the validation of the response by the experimenter (i.e., by pressing the space bar).
In the production condition, participants were asked to produce the letter corresponding to a given number (e.g., “6” is “F”). The presentation procedure was similar to the perception task, except that an Arabic number (corresponding to one of the positions of the 11 letters) was displayed on the screen.
Data analyses
The same data transformation and analyses as in Experiment 1 were applied.
Results
For the perception task, the results of the LMM showed that the log of the mean estimates increased with the alphabetical position of the letter, F(10, 165) = 252.5, p < 0.001, while it was not the case for the log of the standard deviation, F(10, 165) = 1.2, ns. For the production task, both the log of the mean estimates and the log of the standard deviation increased significantly with the alphabetical position, F(10, 165) = 470.3, p < 0.001 for log(mean); F(10, 165) = 4.6, p < 0.001 for log(SD); Figure 4.
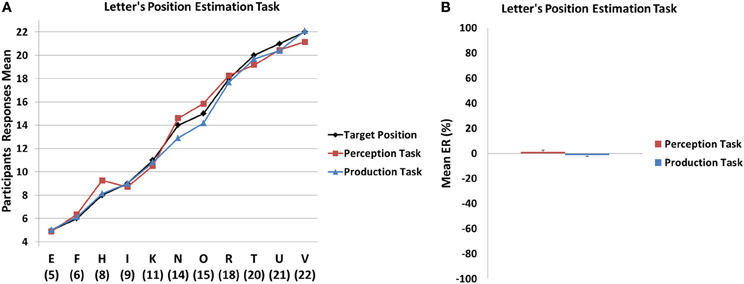
Figure 4. (A) Mean estimation values observed in the Letter position perception and production tasks as a function of target values. (B) Mean error rate for the Letter position estimation tasks as a function of condition (perception vs. production). No systematic under- or over-estimation were observed in the perception and production tasks. Error bars denote Standard Error of the Mean (SEM).
The mean ER did not significantly differ from zero in the perception [M = 1.25 ± 5.2; t(15) = 0.95, p > 0.3] and production [M = −1.49 ± 3.9; t(15) = −1.5, p > 0.1] conditions, suggesting that the participants did not systematically under- or overestimate the position of the letters. Moreover, the direct comparison of the two tasks revealed that the mean ER from the perception and the production did not significantly differ from each other [t(15) = 1.3, p > 0.2]. Finally, in order to assess global accuracy, the mean absolute ER was also calculated and, in both perception (M = 12.6 ± 5.61) and production (M = 9.09 ± 3.98) conditions, these values were significantly different from 0 (all p < 0.001).
Discussion of Experiment 2
In contrast to Experiment 1, perceiving and producing an unquantifiable ordered sequence does not lead to systematic under- and over-estimation, respectively. These data therefore suggest that the mere process of perceiving or producing is not sufficient to explain the systematic under- and overestimation patterns observed in Experiment 1.
General Discussion and Conclusions
Previous research on numerical cognition has demonstrated that the estimation of numerosity induces either under- or overestimation as a function of task (i.e., perception or production; Castronovo and Seron, 2007; Crollen et al., 2011). Several classical behavioral effects have been reported consistently in numerosity, length, and duration processing (for a recent review, see Dormal and Pesenti, 2012). In order to extend these behavioral data and determine whether numerosity, length, and duration processing involve the same mechanisms, we examined the profile of the error estimation during perception and production judgments of numerosities, lengths, and durations.
In Experiment 1, the pattern of under- and overestimation previously observed during perception and production of numerosity (e.g., Whalen et al., 1999; Cordes et al., 2001; Castronovo and Seron, 2007; Crollen et al., 2011) was extended to the processing of length and duration. Indeed, participants underestimated the length of visually presented horizontal rectangles and the duration of temporal intervals in perception tasks, whereas a systematic overestimation was observed when participants had to produce the length of horizontal rectangles or time intervals. These under- and overestimation patterns were not found in Experiment 2 in which participants had to perceive or produce the alphabetical position of letters, showing that it is not the processes of perceiving or producing something per se that cause under- or overestimation. Importantly, the absence of systematic under- and overestimation cannot be accounted by the fact that these perception and production tasks were too easy as demonstrated by the presence of a significant error rates. Together, these findings support the idea that a common metric system, requiring similar mechanisms and/or representations is shared by all the processing of magnitudes (Walsh, 2003; Bueti and Walsh, 2009).
The scalar variability principle predicts imprecise performances, with the average magnitude of the error increasing in proportion to the target (e.g., Meck and Church, 1983). However, this principle cannot explain why these errors correspond to a systematic under- (i.e., negative errors mean) and overestimation (i.e., positive errors mean) in perception and production tasks, respectively. How can this specific pattern of under- and overestimation be accounted for? Underestimation error could arise from a noisy mapping between the objective stimulus magnitude and its mental counterparts (Stevens, 1956; Stevens and Harris, 1962). Consequently, when participants have to produce a quantity, they overestimate their production to compensate their erroneous perception. Overestimation error could also correspond to scalar memory error, which is well documented in the psychophysics of duration memory (Gibbon et al., 1984; Cordes et al., 2001). In the numerical domain, it has been suggested that these opposed patterns of performance could be due to transcoding activities taking place between two differently scaled representations of numerical quantity (Whalen et al., 1999; Castronovo and Seron, 2007; Crollen et al., 2011): a non-symbolic representation assumed to be logarithmically compressed (Dehaene, 2003) on the one hand, and a symbolic numerical representation assumed to be more linear and precise (e.g., Verguts and Fias, 2004; Piazza et al., 2007) on the other hand. According to this bi-directional mapping hypothesis, the participants underestimate numerosities in perception tasks because the symbolic magnitude activated as the output is always smaller than its initial non-symbolic representation. Conversely, in production tasks, participants overestimate numerosities because the non-symbolic output is always larger than the symbolic input. This representational dichotomy has also been highlighted in a recent model, tested through a computational experiment, by postulating the existence of a summation coding (i.e., non-symbolic inputs activate a portion of the mental number line that includes the units smaller than and equal to the target quantities) and a place coding (i.e., symbolic inputs activate their corresponding units and their smaller and larger neighboring units with gradually decreasing strength as a function of distance) system for the processing of numerical magnitude (Verguts and Fias, 2004). These two representation systems are sustained by different cerebral areas (Santens et al., 2010) and do not share the same degree of precision: symbolic magnitudes are represented by sharper (i.e., less variable around the target value) tuning curves than non-symbolic numerosities (Verguts and Fias, 2004; Piazza et al., 2007). In the three perception tasks, the participants had to use symbolic numerical value to realize their estimation of non-symbolic inputs' magnitude; and conversely, participants had to produce non-symbolic outputs corresponding to their estimation of the inputs' magnitude in the production tasks. The systematic distortion found in our results might therefore be due to a general noisy bi-directional mapping between the two types of representations.
Although processing numerosity, length, and duration present some similarities (e.g., global under- and overestimation), the mean overestimation error was significantly smaller in the length production task than in the production of the other two magnitudes, suggesting that participants were more precise in their estimations of length. This observation of better length performance might be accounted for by the fact that humans are confronted to the spatial magnitude earlier and more frequently than to the other magnitudes. Indeed, babies are able to move and use objects in their peripersonal space at a very early stage in their understanding of distance (Piaget and Inhelder, 1948). Although a precise representation of these three magnitudes emerged by 8–9 months of age (e.g., Brannon et al., 2007; Lourenco and Longo, 2010), space may have a basic role as the primary grounding of the general magnitude system (Lourenco and Longo, 2010). Moreover, through geometrical lessons and life experience, it is possible that adults have built a more precise representation of some particular lengths (e.g., 1 m (or 1 yard) corresponding to a step, or 30 cm (1 foot) corresponding to a classic ruler). Finally, despite several methodological precautions (e.g., the use of a large screen of 1.65 x 1.20 m, variation of the presentation position of the rectangle), the participants may have been able to use some spatial cues or strategies to perform better in the length production task. For example, they may have used the lateral edges or the middle of the screen (i.e., corresponding to their position) to guide their length productions, whereas such screen-guided calibrations could probably not occur in the perception task since the lengths were only presented for 250 ms. However, it is worth noting that, even though the length-production performance was better, length was, like the other two magnitudes, generally overestimated.
To conclude, in Experiment 1, under- and overestimation were observed in perception and production tasks, respectively, for numerosity, length, and duration. As the results of Experiment 2 demonstrate that perceiving and producing per se were not sufficient to induce this pattern of under- and overestimation, the present findings support the idea of a common metric system underlying the processing of numerosity, length, and duration (Walsh, 2003).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This study was supported by grant FSR 2011 ADi/DB/1058.2011 from the Fonds Spéciaux de Recherche of the Université catholique de Louvain (Belgium). Stéphane Grade is a research fellow, Virginie Crollen and Valérie Dormal are post-doctoral researchers and Mauro Pesenti is a research associate at the National Fund for Scientific Research (Belgium). The authors are grateful to Xavier De Fays and Sandrine Mejias for their help in material construction and data collection.
Footnotes
- ^Weber–Fechner's law states that Δ l/l = k, where l corresponds to the stimulus intensity and k is a constant.
- ^Note that this analysis was also carried out separately for extensive and intensive sets and a significant difference from 0 was found in each condition (extensive: M = −37.33 ± 2.74%; t (15) = −13.63, p < 0.001; and intensive: M= −28.30 ± 2.90%; t (15)= −9.76, p < 0.001).
- ^Similar differences from 0 were observed for the extensive (M = 62.73 ± 8.62%; t(15) = 7.27, p < 0.001) and intensive (M = 34.47 ± 7.54%; t(15)= 4.57, p < 0.001) sets of dots.
References
Agrillo, C., and Piffer, L. (2012). Musicians outperform nonmusicians in magnitude estimation: evidence of a common processing mechanism for time, space and numbers. Q. J. Exp. Psychol. 65, 2321–2332. doi: 10.1080/17470218.2012.680895
Agrillo, C., Ranpura, A., and Butterworth, B. (2010). Time and numerosity estimation are independent: behavioral evidence for two different systems using a conflict paradigm. Cogn. Neurosci. 1, 96–101. doi: 10.1080/17588921003632537
Alexander, I., Cowey, A., and Walsh, V. (2005). The right parietal cortex and time perception: back to Critchley and the Zeitraffer phenomenon. Cogn. Neuropsychol. 22, 306–315. doi: 10.1080/02643290442000356
Bevan, W., and Turner, E. (1964). Assimilation and contrast in the estimation of number. J. Exp. Psychol. 67, 458–462. doi: 10.1037/h0041141
Binda, P., Morrone, C., Ross, J., and Burr, D. (2011). Underestimation of perceived number at the time of saccades. Vision Res. 51, 34–42. doi: 10.1016/j.visres.2010.09.028
Bjoertomt, O., Cowey, A., and Walsh, V. (2002). Spatial neglect in near and far space investigated by repetitive transcranial magnetic stimulation. Brain 125, 2012–2022. doi: 10.1093/brain/awf211
Brannon, E. M., Lutz, D., and Cordes, S. (2006). The development of area discrimination and its implication for number representation in infancy. Dev. Sci. 9, 59–64. doi: 10.1111/j.1467-7687.2006.00530.x
Brannon, E. M., Suanda, U., and Libertus, K. (2007). Temporal discrimination increases in precision over development and parallels the development of numerosity. Dev. Sci. 10, 770–777. doi: 10.1111/j.1467-7687.2007.00635.x
Buckley, P. B., and Gillman, C. B. (1974). Comparison of digit and dot patterns. J. Exp. Psychol. 103, 1131–1136. doi: 10.1037/h0037361
Bueti, D., and Walsh, V. (2009). The parietal cortex and the representation of time, space, number and other magnitudes. Philos. Trans. R. Soc. B 364, 1831–1840. doi: 10.1098/rstb.2009.0028
Burr, D., and Morrone, C. (2006). Time perception: space–time in the brain. Curr. Biol. 16, R171–R173. doi: 10.1016/j.cub.2006.02.038
Burr, D. C., Ross, J., Binda, P., and Morrone, M. C. (2010). Saccades compress space, time and number. Trends Cogn. Sci. 14, 528–533. doi: 10.1016/j.tics.2010.09.005
Cappelletti, M., Freeman, E. D., and Cipollotti, L. (2009). Dissociations and interactions between time, numerosity and space processing. Neuropsychologia 47, 2732–2748. doi: 10.1016/j.neuropsychologia.2009.05.024
Cappelletti, M., Freeman, E. D., and Cipollotti, L. (2011). Numbers and time doubly dissociate. Neuropsychologia 49, 3078–3092. doi: 10.1016/j.neuropsychologia.2011.07.014
Casasanto, D., and Boroditsky, L. (2008). Time in the mind: using space to think about time. Cognition 106, 579–593. doi: 10.1016/j.cognition.2007.03.004
Castronovo, J., and Seron, X. (2007). Numerical estimation in blind subjects: evidence of the impact of blindness and its following experience. J. Exp. Psychol. Hum. Percept. Perform. 33, 1089–1106. doi: 10.1037/0096-1523.33.5.1089
Chang, A., Tzeng, O., Hung, D., and Wu, D. (2011). Big time is not always long: numerical magnitude automatically affects time reproduction. Psychol. Sci. 22, 1567–1573. doi: 10.1177/0956797611418837
Cohen Kadosh, R., Henik, A., Rubinsten, O., Mohr, H., Dori, H., Van de Ven, V., et al. (2005). Are numbers special? The comparison systems of the human brain investigated by fMRI. Neuropsychologia 43, 1238–1248. doi: 10.1016/j.neuropsychologia.2004.12.017
Cordes, S., Gelman, R., Gallistel, C. R., and Whalen, J. (2001). Variability signatures distinguish verbal from non-verbal counting for both large and small numbers. Psychon. Bull. Rev. 8, 698–707. doi: 10.3758/BF03196206
Crollen, V., Castronovo, J., and Seron, X. (2011). Under- and over-estimation: a bi-directional mapping process between symbolic and non-symbolic representations of number? Exp. Psychol. 58, 39–49. doi: 10.1027/1618-3169/a000064
Crollen, V., and Seron, X. (2012). Over-estimation in numerosity estimation tasks: more than an attentional bias? Acta Psychol. 140, 246–251. doi: 10.1016/j.actpsy.2012.05.003
Dehaene, S. (2003). The neural basis of the Weber-Fechner law: a logarithmic mental number line. Trends Cogn. Sci. 7, 145–147. doi: 10.1016/S1364-6613(03)00055-X
Dehaene, S., Izard, V., and Piazza, M. (2005). Control Over Non- Numerical Parameters in Numerosity Experiments. Unpublished Technical Note. Cognitive Neuroimaging Unit, INSERM-CEA. Paris, France. Available online at: www.unicog.org
de Hevia, M. D., and Spelke, E. S. (2009). Spontaneous mapping of number and space in adults and young children. Cognition 110, 198–207. doi: 10.1016/j.cognition.2008.11.003
DeWind, N. K., and Brannon, E. M. (2012). Malleability of the approximate number system; effects of feedback and training. Front. Hum. Neurosci. 6:68 doi: 10.3389/fnhum.2012.00068
Dormal, V., Andres, M., and Pesenti, M. (2008). Dissociation of numerosity and duration processing in the left intraparietal sulcus: a transcranial magnetic stimulation study. Cortex 44, 462–469. doi: 10.1016/j.cortex.2007.08.011
Dormal, V., Andres, M., and Pesenti, M. (2012a). Contribution of the right intraparietal sulcus to numerosity and length processing: an fMRI-guided TMS study. Cortex 48, 623–629. doi: 10.1016/j.cortex.2011.05.019
Dormal, V., Dormal, G., Joassin, F., and Pesenti, M. (2012b). A common right fronto-parietal network for numerosity and duration processing: An fMRI study. Hum. Brain Mapp. 33, 1490–1501. doi: 10.1002/hbm.21300
Dormal, V., Grade, S., Mormont, E., and Pesenti, M. (2012c). Dissociation between numerosity and duration processing in aging and early Parkinson's disease. Neuropsychologia 50, 2365–2370. doi: 10.1016/j.neuropsychologia.2012.06.006
Dormal, V., and Pesenti, M. (2007). Numerosity-length interference: a Stroop experiment. Exp. Psychol. 54, 1–9.
Dormal, V., and Pesenti, M. (2009). Common and specific contributions of the intraparietal sulci to numerosity and length processing. Hum. Brain Mapp. 30, 2466–3476. doi: 10.1002/hbm.20677
Dormal, V., and Pesenti, M. (2012). “Processing magnitudes within the parietal cortex,” in Horizons in Neuroscience Research, Vol. 8. eds A. Costa and E. Villalba (New York, NY: Nova Science Publishers), 107–140.
Dormal, V., and Pesenti, M. (2013). Processing numerosity, length and duration in a three-dimensional Stroop-like task: towards a gradient of processing automaticity? Psychol. Res. 77, 116–127. doi: 10.1007/s00426-012-0414-3
Dormal, V., Seron, X., and Pesenti, M. (2006). Numerosity-duration interference: a Stroop experiment. Acta Psychol. 121, 109–124. doi: 10.1016/j.actpsy.2005.06.003
Droit-Volet, S. (2010). Speeding up a master clock common to time, number and length? Behav. Process. 85, 126–134. doi: 10.1016/j.beproc.2010.06.017
Droit-Volet, S., Tourret, S., and Wearden, J. (2004). Perception of the duration of auditory and visual stimuli in children and adults. Q. J. Exp. Psychol. A 57, 797–818. doi: 10.1080/02724980343000495
Fechner, G. T. (1860). Elemente der psychophysik, breitkopf und härtel. Leipzig: Breitkopf und Härtel (reprinted by Thoemmes Press, 1999).
Feigenson, L. (2007). The equality of quantity. Trends Cogn. Sci. 11, 185–187. doi: 10.1016/j.tics.2007.01.006
Fias, W., Lammertyn, J., Reynvoet, B., Dupont, P., and Orban, G. A. (2003). Parietal representation of symbolic and non-symbolic magnitude. J. Cogn. Neurosci. 15, 47–56. doi: 10.1162/089892903321107819
Fulbright, R., Manson, C., Skudlarski, P., Lacadie, C. M., and Gore, C. L. J. (2003). Quantity determination and the distance effect with letters, numbers and shapes: a functional MR imaging study of number processing. Am. J. Neuroradiol. 23, 197–200.
Gibbon, J., Church, R. M., and Meck, W. H. (1984). “Scalar timing in memory,” in Timing and Time Perception, Vol. 423, eds J. Gibbon and L. Allan (New York, NY: New York Academy of Sciences), 52–77. doi: 10.1111/j.1749-6632.1984.tb23417.x
Halberda, J., and Feigenson, L. (2008). Developmental change in the acuity of the “Number Sense”: the approximate number system in 3-, 4-, 5-, 6-year-olds and adults. Dev. Psychol. 44, 1457–1465. doi: 10.1037/a0012682
Hayashi, M. J., Kanai, R., Tanabe, H. C., Yoshida, Y., Carlson, S., Walsh, V., et al., (2013). Interaction of numerosity and time in prefrontal and parietal cortex. J. Neurosci. 33, 883–893. doi: 10.1523/JNEUROSCI.6257-11.2013
Henmon, V. A. C. (1906). The time of perception as a measure of differences in sensation. Arch. Philos. Psychol. Sci. Method 8, 5–75.
Indow, T., and Ida, M. (1977). Scaling of dot numerosity. Percept. Psychophys. 22, 265–276. doi: 10.3758/BF03199689
Javadi, A. H., and Aichelburg, C. (2012). When time and numerosity interfere: the longer the more, and the more the longer. PLoS ONE 7:e41496. doi: 10.1371/journal.pone.0041496
Kaufman, L., Lord, M. W., Reese, T. W., and Volkmann, J. (1949). The discrimination of visual number. Am. J. Psychol. 62, 498–525. doi: 10.2307/1418556
Kaufmann, L., Koppelstaetter, F., Delazer, M., Siedentopf, C., Rhomberg, P., Golaszewski, S., et al. (2005). Neural correlates of distance and congruity effects in a numerical Stroop task: an event related fMRI study. Neuroimage 25, 888–898. doi: 10.1016/j.neuroimage.2004.12.041
Krueger, L. E. (1982). Single judgments of numerosity. Percept. Psychophys. 31, 175–182. doi: 10.3758/BF03206218
Krueger, L. E. (1984). Perceived numerosity: a comparison of magnitude production, magnitude estimation, and discrimination judgments. Percept. Psychophys. 35, 536–542. doi: 10.3758/BF03205949
Leon, M. I., and Shadlen, M. N. (2003). Representation of time by neurons in the posterior parietal cortex of the macaque. Neuron 38, 317–327. doi: 10.1016/S0896-6273(03)00185-5
Lipton, J. S., and Spelke, E. S. (2003). Origins of number sense: large number discrimination in human infants. Psychol. Sci. 14, 396–401. doi: 10.1111/1467-9280.01453
Logie, R. H., and Baddeley, A. D. (1987). Cognitive processes in counting. J. Exp. Psychol. Learn. Mem. Cogn. 13, 310–326. doi: 10.1037/0278-7393.13.2.310
Lourenco, S. F., and Longo, M. R. (2010). General magnitude representation in human infants. Psychol. Sci. 21, 873–881. doi: 10.1177/0956797610370158
Mandler, G., and Shebo, B. J. (1982). Subitizing: an analysis of its component processes. J. Exp. Psychol. Gen. 111, 1–22. doi: 10.1037/0096-3445.111.1.1
Meck, W. H., and Church, R. M. (1983). A mode control model of counting and timing processes. J. Exp. Psychol. Anim. Behav. Process 9, 320–334. doi: 10.1037/0097-7403.9.3.320
Mejias, S., Mussolin, C., Rousselle, L., Grégoire, J., and Noel, M. P. (2012). Numerical and nonnumerical estimation in children with and without mathematical learning disabilities. Child Neuropsychol. 18, 550–575. doi: 10.1080/09297049.2011.625355
Morrone, M. C., Ross, J., and Burr, D. (2005). Saccadic eye movements cause compression of time as well as space. Nat. Neurosci. 8, 950–954. doi: 10.1038/nn1488
Moyer, R. S., and Landauer, T. K. (1967). The time required for judgements of numerical inequality. Nature 215, 1519–1520. doi: 10.1038/2151519a0
Nieder, A., and Miller, E. K. (2003). Coding of cognitive magnitude: compressed scaling of numerical information in the primate prefrontal cortex. Neuron 37, 149–157. doi: 10.1016/S0896-6273(02)01144-3
Piaget, J., and Inhelder, B. (1948). The child's Conception of Space. London: Routledge and Kegan Paul.
Piazza, M., Pinel, P., Le Bihan, D., and Dehaene, S. (2007). A magnitude code common to numerosities and number symbols in human intraparietal cortex. Neuron 53, 293–305. doi: 10.1016/j.neuron.2006.11.022
Pinel, P., Piazza, M., Le Bihan, D., and Dehaene, S. (2004). Distributed and overlapping cerebral representation of number, size, and luminance during comparative judgments. Neuron 41, 983–993. doi: 10.1016/S0896-6273(04)00107-2
Restle, F. (1970). Speed of adding and comparing numbers. J. Exp. Psychol. 83, 274–278. doi: 10.1037/h0028573
Roitman, J. D., Brannon, E. M., and Platt, M. L. (2007). Monotonic coding of numerosity in macaque lateral intraparietal area. PLoS Biol. 5:e208. doi: 10.1371/journal.pbio.0050208
Santens, S., Roggeman, C., Fias, W., and Verguts, T. (2010). Number processing pathways in human parietal cortex. Cereb. Cortex 20, 77–88. doi: 10.1093/cercor/bhp080
Schneider, W., Eschman, A., and Zuccolotto, A. (2002). E-Prime User's Guide. Pittsburgh, PA: Psychology Software Tools.
Stevens, S. (1956). The direct estimation of sensory magnitudes-Loudness. Am. J. Psychol. 69, 1–25. doi: 10.2307/1418112
Stevens, S. S., and Greenbaum, H. (1966). Regression effect in psychophysical judgment. Percept. Psychophys. 1, 439–446.
Stevens, S., and Harris, J. R. (1962). The scaling of subjective roughness and smoothness. J. Exp. Psychol. 64, 489–494. doi: 10.1037/h0042621
Tang, Y., Zhang, W., Chen, K., Feng, S., Ji, Y., Shen, J., et al. (2006). Arithmetic processing in the brain shaped by cultures. Proc. Natl. Acad. Sci. U.S.A. 103, 10775–10780. doi: 10.1073/pnas.0604416103
Teghtsoonian, R., and Teghtsoonian, M. (1978). Range and regression effects in magnitude scaling. Percept. Psychophys. 24, 305–314. doi: 10.3758/BF03204247
Tudusciuc, O., and Nieder, A. (2007). Neuronal population coding of continuous and discrete quantity in the primate posterior parietal cortex. Proc. Natl. Acad. Sci. U.S.A. 104, 14513–14518. doi: 10.1073/pnas.0705495104
van Marle, K., and Wynn, K. (2006). Six-month-old infants use analog magnitudes to represent duration. Dev. Sci. 9, 41–49. doi: 10.1111/j.1467-7687.2006.00508.x
van Oeffelen, M. P., and Vos, P. G. (1982). A probabilistic model for the discrimination of visual number. Percept. Psychophys. 32, 163–170. doi: 10.3758/BF03204275
Verguts, T., and Fias, W. (2004). Representation of number in animals and humans: a neural model. J. Cogn. Neurosci. 16, 1493–1504. doi: 10.1162/0898929042568497
Vicario, C. M. (2011). Perceiving numbers affects the subjective temporal midpoint. Perception 40, 23–29. doi: 10.1068/p6800
Walsh, V. (2003). A theory of magnitude: common cortical metrics of time, space and quantity. Trends Cogn. Sci. 7, 483–488. doi: 10.1016/j.tics.2003.09.002
Whalen, J., Gallistel, C. R., and Gelman, R. (1999). Nonverbal counting in humans: the psychophysics of number representation. Psychol. Sci. 10, 130–137. doi: 10.1111/1467-9280.00120
Xu, F., and Spelke, E. (2000). Large number discrimination in 6-month-old infants. Cognition 74, 1–11. doi: 10.1016/S0010-0277(99)00066-9
Keywords: magnitude processing, numerosity, length, duration, estimation
Citation: Crollen V, Grade S, Pesenti M and Dormal V (2013) A common metric magnitude system for the perception and production of numerosity, length, and duration. Front. Psychol. 4:449. doi: 10.3389/fpsyg.2013.00449
Received: 10 April 2013; Paper pending published: 08 May 2013;
Accepted: 28 June 2013; Published online: 22 July 2013.
Edited by:
Carmelo Mario Vicario, University of Queensland, ItalyReviewed by:
Christian Agrillo, University of Padova, ItalyZaira Cattaneo, University of Milano-Bicocca, Italy
Copyright © 2013 Crollen, Grade, Pesenti and Dormal. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and subject to any copyright notices concerning any third-party graphics etc.
*Correspondence: Valérie Dormal, Centre de Neuroscience Système et Cognition, Institut de Recherche en Sciences Psychologiques, Université Catholique de Louvain, Place Cardinal Mercier, 10, B-1348 Louvain-la-Neuve, Belgium e-mail:dmFsZXJpZS5kb3JtYWxAdWNsb3V2YWluLmJl