 Vasiliki Folia1,2
Vasiliki Folia1,2 Karl Magnus Petersson1,2,3*
Karl Magnus Petersson1,2,3*- 1Neurobiology of Language, Max Planck Institute for Psycholinguistics, Nijmegen, Netherlands
- 2Neurocognition of Language, Donders Institute for Brain, Cognition and Behaviour, Radboud University Nijmegen, Nijmegen, Netherlands
- 3Cognitive Neuroscience Research Group, Department of Psychology, Institute of Biotechnology and Bioengineering, Centre for Molecular and Structural Biomedicine (CBME), Universidade do Algarve, Faro, Portugal
In this event-related fMRI study we investigated the effect of 5 days of implicit acquisition on preference classification by means of an artificial grammar learning (AGL) paradigm based on the structural mere-exposure effect and preference classification using a simple right-linear unification grammar. This allowed us to investigate implicit AGL in a proper learning design by including baseline measurements prior to grammar exposure. After 5 days of implicit acquisition, the fMRI results showed activations in a network of brain regions including the inferior frontal (centered on BA 44/45) and the medial prefrontal regions (centered on BA 8/32). Importantly, and central to this study, the inclusion of a naive preference fMRI baseline measurement allowed us to conclude that these fMRI findings were the intrinsic outcomes of the learning process itself and not a reflection of a preexisting functionality recruited during classification, independent of acquisition. Support for the implicit nature of the knowledge utilized during preference classification on day 5 come from the fact that the basal ganglia, associated with implicit procedural learning, were activated during classification, while the medial temporal lobe system, associated with explicit declarative memory, was consistently deactivated. Thus, preference classification in combination with structural mere-exposure can be used to investigate structural sequence processing (syntax) in unsupervised AGL paradigms with proper learning designs.
Introduction
Artificial grammar learning (AGL) is commonly used to probe implicit sequence learning (Reber, 1967; Seger, 1994; Stadler and Frensch, 1998). In the standard AGL paradigm, participants are exposed to example sequences that are generated from a finite set of rules, a grammar, which specify non-overt (non-marked) sequence regularities. After exposure, participants classify new sequences as grammatical or not (grammaticality instruction). Participants that perform robustly above chance are said to have acquired relevant knowledge related to the grammar and their classification performance shows that they are able to generalize and use the acquired knowledge effectively in a new situation. Although AGL is often used to probe incidental implicit learning, most functional neuroimaging (and some recent behavioral) research has used explicit instructions in combination with the grammaticality classification task. In these experiments, the participants are informed about the existence of a grammar before acquisition (i.e., before exposure to grammatical items) and are explicitly instructed to identify the underlying rules by, for example, trial-and-error or other explicit problem solving strategies, in combination with performance feedback during acquisition and sometimes during classification. Participants in these studies are therefore explicitly guided in their learning toward what is relevant to learn and what is not (e.g., Fletcher et al., 1999; Strange et al., 2001; Opitz and Friederici, 2003; reviewed in Petersson et al., 2004; and more recently, Bahlmann et al., 2008, 2009; reviewed in Petersson et al., 2010). For example, in the studies by Opitz and Friederici (2003, 2007); Opitz and Kotz (2012), the participants were instructed to extract the underlying rules during training, while feedback was provided on each trial during testing. In contrast, implicit AGL studies avoid using explicit instructions for the acquisition session(s) and do not providing any sort of performance feedback, although the grammaticality instruction presupposes (at the time of classification) that the participants are informed about the existence of an underlying grammar.
A central aspect of implicit learning, the mere-exposure effect (Zajonc, 1968; see also Reber, 1967), is the observation that participants that have been exposed to stimuli show an enhanced preference for these compared to novel stimuli. The mere-exposure effect has been investigated with positron emission tomography and abstract visual stimuli (Japanese ideograms) and resulted in a right inferior frontal activation including Brodmann's area (BA) 44 (Elliott and Dolan, 1998). In contrast to this surface-based mere-exposure effect, the structural mere-exposure effect is based on an underlying rule-system for stimulus generation and is characterized by the tendency to prefer new stimuli that conform to the rule-system, independent of surface structure (Gordon and Holyoak, 1983; Zizak and Reber, 2004). In implicit AGL paradigms, the structural mere-exposure effect provides a sensitive indirect measure of grammatical knowledge (Zizak and Reber, 2004). Preference classification, in combination with a structural mere-exposure design, can therefore be used to investigate syntactic (structural) processing in unsupervised AGL paradigms. One difference between this type of paradigm and explicit AGL paradigms is that in the former, both the acquisition and classification phases are implicit and there is no reference to any previous acquisition episode made (Shanks and St. John, 1994). Because of this, it is never necessary to inform the participants about the existence of a generative grammar or any other aspect of the paradigm and the preference classification instruction minimizes the potential that participants develop and/or use deliberate explicit strategies (e.g., problem solving). In addition, from the subject's point of view there is no correct or incorrect response and the motivation to use explicit strategies is therefore further minimized during the experiment. More importantly from the point of view of functional neuroimaging is the fact that this paradigm allows us to acquire a naive classification baseline, both in terms of a proper behavioral preference classification baseline and a corresponding fMRI baseline in within-subject designs. This paradigm has been investigated behaviorally and we have shown in several experiments that participants classify robustly well-above chance on regular as well as non-regular grammars (Folia et al., 2008; Forkstam et al., 2008; Uddén et al., 2012). However, the learning paradigm has not been investigated with functional neuroimaging methods. Previous fMRI studies of implicit AGL (structural mere-exposure and grammaticality instruction) have shown that the grammaticality effect engages inferior frontal regions, centered on BA 44 and 45, and medial prefrontal region, centered on BA 8 and 32, as well as the basal ganglia (Petersson et al., 2004, 2010; Forkstam et al., 2006), while the medial temporal lobe memory system is deactivated (Petersson et al., 2010). This raises the question whether these findings reflect intrinsic outcomes of the learning process itself or whether they reflect a preexisting functionality that is recruited during classification. In this study, we address this issue by investigating the neural correlates of incidental structured sequence learning by means of a multi-day implicit AGL paradigm based on preference classification in a structural mere-exposure design. On the first day, before the first acquisition session, we acquired event-related fMRI data in order to establish a naive preference baseline by asking the participants to indicate whether they liked or disliked sequences based to their immediate intuitive impression (i.e., guessing based on “gut-feeling”). Participants were then exposed to grammatical sequences once a day, for 5 days, during a short-term memory cover task in which the participants were presented with (grammatical) sequences on a computer screen and immediately retyped the sequences on a keyboard without performance feedback. On the last day, participants were again asked to indicate whether they liked or disliked new sequences based to their immediate intuitive impression while event-related fMRI data was acquired.
Materials and Methods
Here, we briefly outline the stimulus material and the experimental procedures used in the current study since these are closely related to those described in Forkstam et al. (2006).
Participants
Thirty-two healthy right-handed Dutch university students were recruited for the study (50% females, age range: 19–27 years). None of the subjects used any medication, had a history of drug abuse, head trauma, neurological or psychiatric illness, or a family history of neurological or psychiatric illness. All subjects had normal or corrected-to-normal vision. Approval from the local medical ethics committee was obtained and written informed consent was obtained from all participants according to the Declaration of Helsinki.
Stimulus Material
We used a simple right-linear unification grammar (Figure 1) to generate 569 grammatical (G) sequences, with a sequence length ranging from 5 to 12. For each item we calculated the frequency distribution of 2 and 3 letter chunks for both terminal and complete sequence positions. In this way, we derived a local subsequence familiarity measure termed associative chunk strength (ACS) for each item (Knowlton and Squire, 1996; Meulemans and Van der Linden, 1997; Forkstam et al., 2006, 2008). Local subsequence familiarity, or ACS, is an associative measure that quantifies the superficial resemblance between classification and acquisition sequences. To generate the acquisition set, we randomly selected (in an iterative way) 100 sequences that were representative of the full sequence set in terms of ACS. In the next step, we derived the non-grammatical (NG) sequences from the pool of non-selected G sequences by switching letters in two non-terminal positions. The NG sequences matched the G sequences in terms of terminal and complete sequence ACS. Finally, we randomly selected two sets of 60 sequences each from the remaining G sequences to serve as classification sets. Thus, each classification set consisted of 30 strings of each string type, in other words: 25% high ACS grammatical (HG), 25% low ACS grammatical (LG), 25% high ACS non-grammatical (HNG), and 25% low ACS non-grammatical (LNG). The sequences of high ACS contained subsequences that appeared frequently in the acquisition set, while sequences of low ACS contained subsequences with a low frequency in the acquisition set. See Appendix for a specification and example of the construction of the stimulus material.
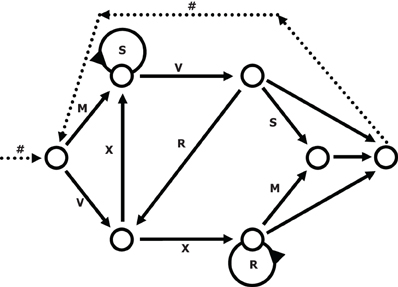
Figure 1. The transition graph representation of the grammar used in the experiment (cf., Reber, 1967).
Experimental Procedures
The experiment extended over 5 days, including 2 fMRI sessions. On the first day participants had to undergo a preference classification task in the scanner (baseline classification) before any exposure to grammatical sequences during the first acquisition session. On day 2–4, the subjects participated in one behavioral implicit acquisition session each day. On the last (5th) day of the experiment, the subjects underwent a last acquisition session and were then engaged in preference classification during fMRI data acquisition.
Acquisition
During acquisition, subjects were presented with the 100 acquisition sequences (new randomized order for each acquisition session). Each sequence was centrally presented letter-by-letter on a computer screen (3–7 s corresponding to 5–12 terminal symbols; 300 ms presentation, 300 ms inter-symbol-interval) using Presentation (nbs.neuro-bs.com). The subjects were instructed to retype the sequence on a keyboard. No performance feedback was provided and only grammatical sequences were presented. The acquisition session lasted approximately 20–40 min each day for 5 consecutive days.
Classification
The classification sequences were organized in a 2 × 2 factorial design with the factors grammaticality status (grammatical/non-grammatical) and local subsequence familiarity (high/low ACS). During the fMRI naive baseline classification on the first day, the participants were presented with letter sequences which they had never seen before (letter-by-letter; 300 ms presentation, 300 ms inter-symbol-interval) and which would not be used during acquisition. They were instructed to indicate, based on their immediate intuitive impression whether they liked or disliked the sequences presented. On the last day of the experiment, subjects underwent an identical preference classification session with novel sequences. The classification sequences were presented via an LCD-projector on semi-transparent screen that the subject comfortably viewed through a mirror mounted on the head-coil. The classification sessions were split in two parts in order to balance response finger within subjects (subjects indicated their classification decision by pushing the corresponding response key with their left/right index finger). After a 1 s pre-stimulus period, the sequences were presented sequentially, letter-by-letter (300 ms presentation, 300 ms inter-symbol-interval), followed by a 3 s response window. A sensorimotor decision baseline task was also included in the fMRI experiment. All conditions, including the sensorimotor decision baseline, were presented in a randomized order during the acquisition of fMRI data both on day 1 and 5. This sensorimotor baseline included sequences of either P or L (e.g., PPPPP or LLLLLLLL), matched to the classification set for sequence length, and presented in the same fashion as the classification sequences. The participants were instructed to respond by pressing the right or left index finger, respectively.
Data Acquisition and Analysis
MR Data Acquisition
Whole head T2*-weighted functional echo planar, blood oxygenation level dependent (EPI-BOLD) fMRI data were acquired with a SIEMENS Avanto 1.5T scanner using an ascending slice acquisition sequence (volume TR = 2.6 s, TE = 40 ms, 90° flip-angle, 33 axial slices, slice-matrix size = 64 × 64, slice thickness = 3 mm, slice gap = 0.5 mm, FOV = 224 mm, isotropic voxel size = 3.5 × 3.5 × 3.5 mm3) in a randomized event related fashion. For the structural MR image volume, a high-resolution T1-weighted magnetization-prepared rapid gradient-echo pulse sequence was used (MP-RAGE; volume TR = 2250 ms, TE = 3.93 ms, 15° flip-angle, 176 axial slices, slice-matrix size = 256 × 256, slice thickness = 1 mm, field of view = 256 mm, isotropic voxel-size = 1.0 × 1.0 × 1.0 mm3).
fMRI Data Preprocessing and Statistical Analysis
We used the SPM software for image preprocessing and statistical analysis (Friston et al., 2007). The EPI-BOLD volumes were realigned to correct for subject movement and corrected for differences in slice acquisition time. The subject-mean EPI-BOLD images were subsequently spatially normalized to the functional EPI template provided by SPM. The normalization transformations were generated from the subject-mean EPI-BOLD volumes and applied to the corresponding functional volumes. The functional EPI-BOLD volumes were transformed into the MNI space, an approximate Talairach space (Talairach and Tournoux, 1988), defined by the SPM template, and spatially filtered with an isotropic 3D spatial Gaussian filter kernel (FWHM = 10 mm). The fMRI data were analyzed statistically, using the general linear model framework and statistical parametric mapping, in a two-step mixed-effects summary-statistics procedure (Friston et al., 2007). We included the realignment parameters for movement artifact correction and a temporal high-pass filter (cycle cut-off at 128 s) to account for various low-frequency effects.
At the first-level, the linear models for the single-subject analyses included explanatory regressors that modeled the sequence presentation period, starting from the violation position in the HNG and LNG conditions and their correct counterparts in the HG and LG conditions. This was done separately for correct and incorrect responses. The initial part of the sequences, before the first critical violation position, was also modeled separately, as was the baseline and the inter-sequence-interval. The explanatory variables were temporally convolved with the canonical hemodynamic response function provided by SPM. At the second-level, we generated single-subject contrast images for the correctly classified HG, LG, HNG, and LNG sequences relative to the sensorimotor decision baseline. These were analyzed in a random-effects repeated-measures ANOVA under an unequal between-conditions variance assumption and with non-sphericity correction for correlated measures. Statistical inference was based on the cluster-size test-statistic from the relevant second-level SPM[T] maps, thresholded at P = 0.005 (uncorrected). Only clusters significant at P < 0.05 family-wise error (FWE) corrected for multiple dependent comparisons, based on smooth random field theory (Adler, 1981; Adler and Taylor, 2007) are described. In addition, we list the coordinates of local maxima and their corresponding P-values corrected for the false discovery rate (Genovese et al., 2002) for descriptive purposes.
Results
Classification Performance
Some of the behavioral results have been reported in Folia et al. (2008) and are briefly summarized here for convenience. The classification performance (hit rates) on day 1 was at chance level [mean ± standard deviation = 50 ± 7% correct, T(31) = 0.42, P = 0.67] and increased significantly above chance after 5 days of implicit acquisition [65 ± 14% correct, T(31) = 5.7, P < 0.001]. Standard signal detection analysis confirmed a robust d-prime effect in discriminating between grammatical (G) and non-grammatical (NG) sequences one day 5 (d-prime: 0.94) but not on day 1 [d-prime: 0.006; day 5 vs. day 1: T(31) = 4.91, P < 0.001]. No significant response bias was found (beta-value: day 1 = 1.02; day 5 = 1.02; all P > 0.6). Moreover, participants did not discriminate between high and low ACS sequences (d-prime: day 1 = 0.15; day 5 = 0.22; all P > 0.66). This suggests that there is no difference in the ability to discriminate sequences based on local subsequence familiarity. No significant response bias was found (beta-value: day 1 = 1.02; day 5 = 1.01; all P > 0.6).
Concerning the endorsement rate (i.e., items preferred independent of actual grammaticality status), a repeated-measures ANOVA showed that both grammaticality status and ACS influenced preference classification on day 5, but not on day 1 [grammaticality day 1: F(1, 31) = 0.00, P = 0.95, η2p = 0.00; ACS day 1: F(1, 31) = 2.3, P = 0.14, η2p = 0.06; interaction grammaticality and ACS on day 1: F(1, 31) = 2.3, P = 0.13, η2p = 0.07; Table 1, Figures 2, 3]. There was no effects of grammaticality status for either high or low ACS sequences on day 1 [HG vs. HNG: F(1, 31) = 0.42, P = 0.52, η2p = 0.01; LG vs. LNG: F(1, 31) = 0.65, P = 0.43, η2p = 0.02]. In contrast, on day 5, the endorsement rate was significantly affected by the grammaticality status [F(1, 31) = 31.7, P < 0.001, η2p = 0.50], local subsequence familiarity [F(1, 31) = 15.4, P < 0.001, η2p = 0.33], while the interaction between grammaticality and ACS was non-significant [F(1, 31) = 3.8, P > 0.05, η2p = 0.11]; this was also the case for sequences with high and low subsequence familiarity, respectively, [HG vs. HNG: F(1, 31) = 34, P < 0.001, η2p = 0.52; LG vs. LNG: F(1, 31) = 24, P < 0.001, η2p = 0.44]. During each classification session (day 1/5) the subjects were asked to rate their level of attention (VAS ratings, four times evenly distributed over each session). There was no significant attention difference between days (day 1: 7.9, SD = 1.07; day 5: 7.9, SD = 1.12).
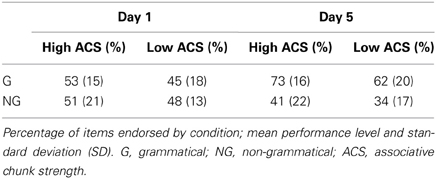
Table 1. Endorsement rates over grammaticality and local subsequence familiarity (ACS) for day 1 and day 5.
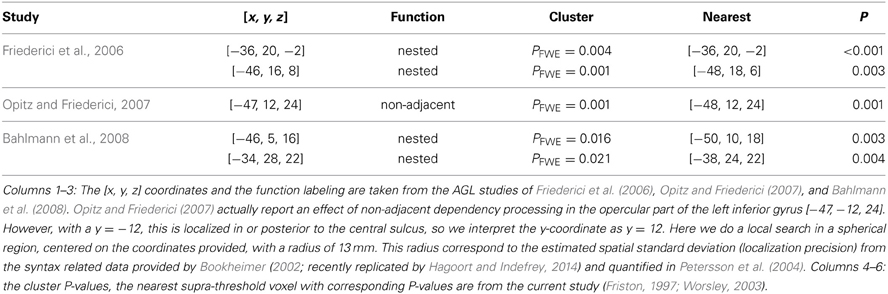
Table 2. Overlap between the activated clusters in the listed studies and the clusters that we found activated in the left inferior frontal region related to the learning effect (Figure 7).
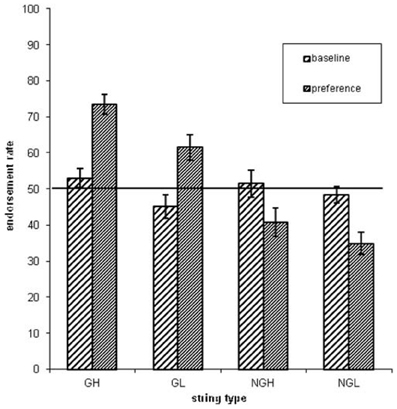
Figure 2. The endorsement rates as a function of grammaticality status (G = grammatical sequences, NG = non-grammatical sequences) and associative chunk strength (H = high ACS sequences, L = low ACS sequences). Error bars correspond to standard error of the mean.
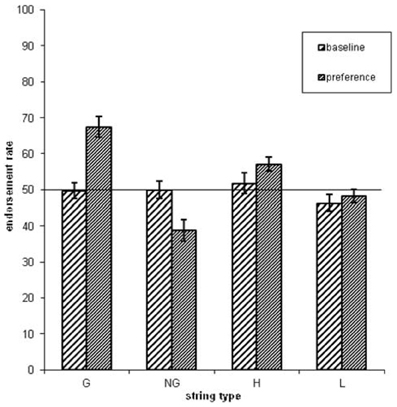
Figure 3. The endorsement rates as a function of grammaticality status and associative chunk strength (G = grammatical, NG = non-grammatical, H = high ACS, L = low ACS sequences). Error bars correspond to standard error of the mean.
fMRI Results
Some of the fMRI results were summarily described in Folia et al. (2011), in particular, the overlap between grammaticality- and preference classification on day 5 was tested and reported. Here we report the fMRI results from the complete learning design experiment described in the current study. When compared to the sensorimotor decision baseline, preference classification activated a set of regions (PFWE < 0.001) previously found to be involved in grammaticality classification (Petersson et al., 2004, 2010; Forkstam et al., 2006), including the inferior and middle frontal regions bilaterally and the anterior cingulate cortex (all clusters PFWE < 0.001). Bilateral posterior activations included the inferior parietal, the posterior cingulate, and the occipital cortex. Moreover, the basal ganglia (caudate/putamen/globus pallidus) were activated during classification (relative the sensorimotor decision baseline; Figure 4) and this increased over the 5 days of implicit acquisition (cluster PFWE = 0.012; [x, y, z] = [−24, −6, −4], PFDR = 0.012, small-volume correction). In contrast, the medial temporal lobes were deactivated (right cluster PFWE < 0.001; [30, −24, −16], PFDR = 0.007; left cluster PFWE < 0.001; [−30, −28, −12], PFDR = 0.001; Figure 5). These effects extended along most of the medial temporal lobe axis, bilaterally.
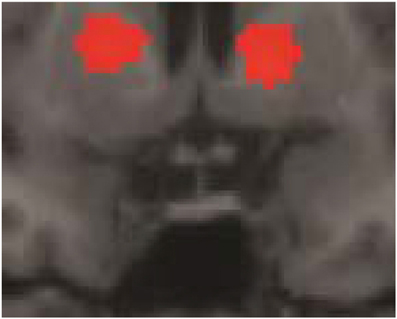
Figure 4. Basal ganglia activations. Preference classification vs. sensorimotor decision baseline on day 5. The effect was present but smaller on day 1 (day 5 vs. day 1; cluster PFWE = 0.012; [x, y, z] = [−24, −6, −4], PFDR = 0.012, small-volume correction).
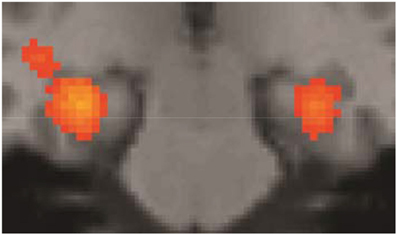
Figure 5. Medial temporal lobe deactivations. Sensorimotor decision baseline vs. preference classification on day 5 (all clusters PFWE < 0.001). These effects were very similar on day 1.
On day 1, as expected, we found no significant main effects or interactions for naïve preference classification, except an initial bias activations in the right superior-inferior parietal region (BA 7/40; G > NG, PFWE = 0.002) and an interaction in the right posterior cingulate cortex (BA 23/31; [HNG—HG] > [LNG—LG], PFWE = 0.001). Importantly, these initial bias effects reversed and disappeared with repeated implicit exposure to grammatical sequences. After 5 days, preference classification resulted in several significant brain activations (Figure 6, Table 3).
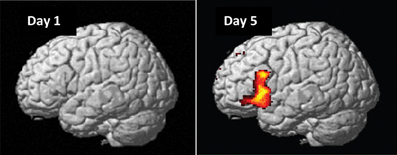
Figure 6. Grammaticality effect during preference classification. Brain regions engaged by artificial syntactic anomalies (NG > G). Day 1: No significant effect in the left hemisphere (PFWE > 0.50). Day 5: Significant activation in the inferior frontal (left and right: PFWE < 0.001) and medial prefrontal (PFWE < 0.001; not shown) regions.
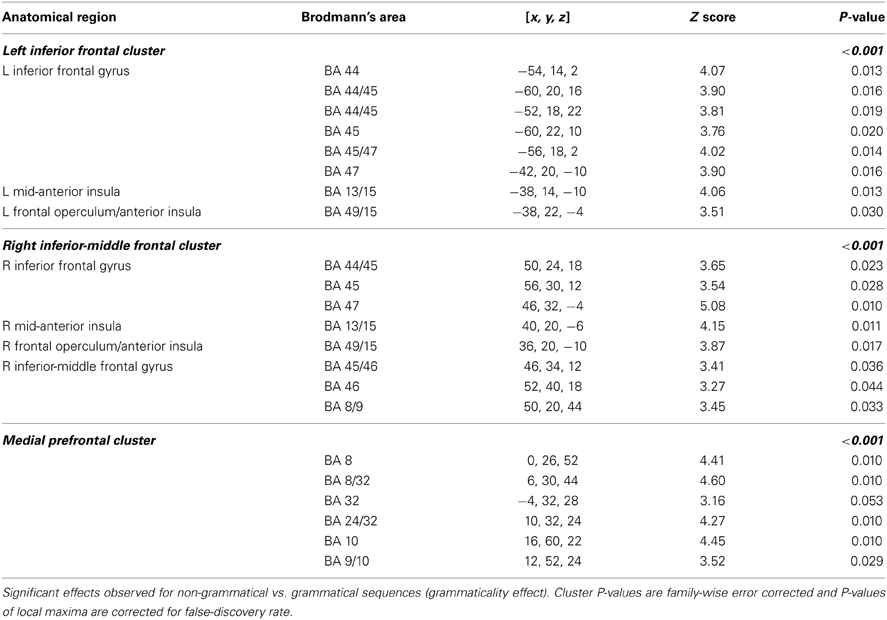
Table 3. Preference classification Day 5.
In particular, artificial syntactic anomalies (grammaticality effect, NG > G) engaged the left inferior and right inferior-middle frontal gyri (left and right cluster PFWE < 0.001) centered on Broca's region (BA 44/45), extending into BA 47 and the right middle frontal gyrus (BA 46) as well as the frontal operculum/anterior insula. Additional activations were found in the medial prefrontal regions (BA 8/32; cluster PFWE < 0.001), while no significant activations were observed in the reverse contrast (G > NG; cluster PFWE > 0.54). We found no significant effect of local subsequence familiarity (all clusters PFWE > 0.98) and no significant interactions (all clusters PFWE > 0.83), consistent with our previous behavioral findings.
The central result of this study is that all the artificial syntax processing effects observed on day 5 resulted from the exposure to grammatical items generated from the underlying grammar during the 5 days of implicit acquisition (Figure 7, Table 4). In particular, for the day 5 vs. day 1 comparison of the NG vs. G effect, we found the same set of brain regions that was observed on day 5, including the inferior frontal (BA 44/45; cluster PFWE < 0.001) and medial prefrontal region (BA 8/32; cluster PFWE < 0.001; Figure 7, Table 4). In addition, we confirmed that the initial bias activation observed in the right superior-inferior parietal region on day 1 had disappeared (BA 7/40; cluster PFWE = 0.021). No other learning effects reached significance (all clusters PFWE > 0.90).
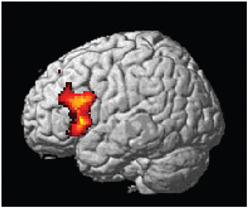
Figure 7. Learning effect with respect to grammaticality status. Comparing the grammaticality effect (NG > G) during preference classification on day 5 and day 1 yielded significant effects in the inferior frontal (left and right: PFWE < 0.001), the medial prefrontal (PFWE < 0.001; not shown) regions.
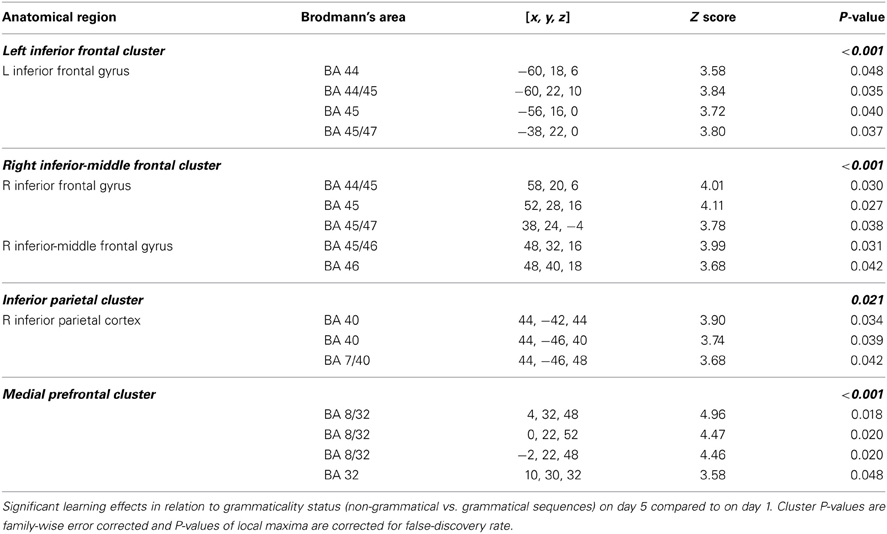
Table 4. Implicit learning effects.
Discussion
In the present event-related fMRI study we investigated the effect of 5 days of implicit acquisition on preference classification by means of an AGL paradigm based on the structural mere-exposure effect using a simple right-linear unification grammar. This is the first fMRI study to investigate implicit AGL with preference classification in a proper learning design (i.e., including baseline measurements prior to grammar exposure). The main fMRI findings are consistent with previous grammaticality classification results (Petersson et al., 2004, 2010; Forkstam et al., 2006; Folia et al., 2011). Importantly, and central to this study, we show that the preference classification results are the outcome of the underlying implicit learning process. More specifically, after 5 days of implicit acquisition, the fMRI results showed activations in a network of brain regions including the inferior frontal regions (centered on BA 44/45) and the medial prefrontal region (centered on BA 8/32; Figure 6, Table 3). The inclusion of a naive preference classification fMRI baseline measurement in a learning design (Petersson et al., 1999a,b) allow us to conclude that the fMRI findings are the intrinsic outcomes of the learning process itself and not a reflection of a preexisting functionality that is recruited during classification, independent of acquisition (Figure 7, Table 4). Moreover, the presence of initial bias activations observed during the naive preference classification (e.g., right superior inferior parietal region) emphasizes the importance of including fMRI baseline measurements in learning designs. Similar initial bias effects are sometimes observed in behavioral data (Forkstam et al., 2008), although not in the present data, which can thus, be less sensitive in this respect compared to fMRI. Behavioral results (Forkstam et al., 2008) suggest that the presence of right hemisphere activation on the first day, during naive classification, might be related to an initial attempt by the participants to subjectively classify the sequences based on spurious surface features attributed to a prior participant bias. Importantly, these bias activations reversed with repeated exposure to grammatical sequences and were not observed on the last day of the experiment. Nevertheless, this emphasizes the importance of including naive fMRI baseline measurements in order to properly characterize the learning related effects (Petersson et al., 1999a,b).
At the behavioral level, participants incidentally learned relevant aspects associated with the underlying grammar and were able to successfully generalize to new sequences after 5 days of implicit acquisition. In contrast, the classification performance was at chance-level for the naive preference classification. The learning effect with respect to superficial local subsequence familiarity, although significant, was smaller (ACS: η2p = 0.33; compared to grammaticality status: η2p = 0.50). This finding was more pronounced in the fMRI results, which showed no significant learning effect of ACS. In contrast, the effect of grammaticality status, resulting from 5 days of implicit acquisition, was highly significant. Additional support for the implicit nature of the knowledge utilized during preference classification on day 5 come from the fact that the basal ganglia (Figure 4) were activated during classification. This is perhaps not surprising, given the massive nature of the recurrent connectivity between the frontal neocortex and the basal ganglia (i.e., fronto-striatal loops). It is hard to imagine fully functioning prefrontal regions without normally functioning basal ganglia and there is evidence that the basal ganglia are involved in rule-processing (e.g., Packard and Knowlton, 2002; Ullman, 2004; Forkstam and Petersson, 2005; Teichmann et al., 2005, 2008). In contrast, the medial temporal lobe memory system was consistently deactivated in this study. The medial temporal lobes are associated with explicit declarative memory (Squire, 1992; cf., Petersson et al., 1997, 1999a), while the basal ganglia have been related to implicit learning and the procedural memory system (Seger, 1994; Packard and Knowlton, 2002; Ullman, 2004; Forkstam and Petersson, 2005). However, the implicit procedural memory system (related to the basal ganglia) and the explicit declarative memory system (related to the medial temporal lobes) are not necessarily always engaged in opposition. The experimental evidence suggests a more complex picture where these two memory systems can interact both in a competitive and a cooperative, non-competitive manner (Devan and White, 1999; Voermans et al., 2004; Brown et al., 2012). However, the interpretation of this state of affairs is not well-understood, except perhaps, to suggest that several neural learning mechanisms can be recruited depending on the type of information processing the brain engages in, in any particular context. The results of the present study, as well as grammaticality classification fMRI studies based on implicit AGL (Forkstam et al., 2006; Petersson et al., 2010), show strong activation and deactivation of the basal ganglia and the medial temporal lobes, respectively.
The sequential presentation mode used in this study entails on-line processing memory (i.e., something roughly akin to a “working memory”). We often use sequential instead of whole sequence presentation in order to model the sequential nature of language input/output. This aspect of the experimental paradigm is very unlikely to affect the reported results or their interpretation. First, the demand for on-line processing memory in the preference classification task is the same for all sequence types (matched for length; and grammatical/non-grammatical sequences matched for ACS). In the case of grammaticality classification, it might be the case that there is a tendency that the non-grammatical sequences require somewhat less processing memory compared to grammatical sequences, since the participants could in principle stop processing the non-grammatical items as soon as they judge them non-grammatical. However, this would not explain the observed frontal activation increases observed for non-grammatical compared to grammatical items during grammaticality classification (Petersson et al., 2004, 2010; Forkstam et al., 2006). Second, Petersson et al. (2004) used whole sequence presentation in a grammaticality classification task and reported virtually identical results as found in the present study after 5 days of implicit acquisition. Therefore, the presentation mode of the stimulus items (whole/sequential) seems to be of little consequence for the fMRI results.
The Inferior Frontal Region, AGL, and Other Cognitive Domains
Human languages are characterized by “design features” (Hockett, 1963, 1987; including discreteness, arbitrariness, productivity, and the duality of patterning) and somehow these characteristics arise from the properties of the human brain, how it develops and learns in interaction with its environment. One of the difficulties with acquiring a language is related to the fact that the internal mental structures that represent linguistic information are not expressed in the surface form of the language (i.e., the utterance). This suggests that humans are equipped with learning mechanisms which shape the acquired language into a discrete and recursively organized system when the relevant communicative context is present. With respect to syntax, these learning mechanisms are to a large extent implicit in nature and despite much progress it is still not well-understood how humans acquire their native language skills (Folia et al., 2010, 2011; Reber, 2011).
AGL was originally implemented in order to investigate implicit learning mechanisms shared with natural language acquisition (Reber, 1967). The neurobiology of implicit sequence learning, assessed with AGL, has been investigated by means of functional neuroimaging (Petersson et al., 2004; Forkstam et al., 2006), brain stimulation (Udden et al., 2008; de Vries et al., 2010), and has consistently shown that Broca's region (BA 44/45), in addition to other brain regions, is involved. In addition, the breakdown of syntax processing in agrammatic aphasia and in patients with lesions in the inferior frontal region is associated with impairments in AGL (Christiansen et al., 2010; Opitz and Kotz, 2012) and individual variability in implicit sequence learning correlates with language processing (Conway and Pisoni, 2008; Misyak et al., 2010). Taken together, this supports the idea that AGL taps into implicit learning/processes that are shared with aspects of natural syntax acquisition and processing.
In this study we used an implicit AGL paradigm, based on preference classification and the structural mere-exposure effect. One difference between this type of paradigm and explicit AGL paradigms that have been used lately is that in the former, both the acquisition and classification phases are implicit and no reference to any previous acquisition episode made. Because of this, it is never necessary to inform the participants about the existence of an underlying grammar or any other aspect of the paradigm and from the subject's perspective there is no correct or incorrect response. In several functional neuroimaging studies, explicit paradigms have been used (e.g., Friederici et al., 2006; Opitz and Friederici, 2007; Bahlmann et al., 2008, 2009; reviewed in Petersson et al., 2010). For example, in the studies by Opitz and Friederici (2003, 2007); Opitz and Kotz (2012), the participants were instructed to extract the underlying rules during training, while feedback was provided on each trial during testing. Moreover, while the artificial language used by Opitz and Friederici (2003) is finite (Figure 1, p. 1731), in the modified version (Opitz and Friederici, 2007; Opitz and Kotz, 2012), they introduce a “complementizer” in a way that yields a right-branching regular language (Figure 1, p. 586, Opitz and Friederici, 2007; note also that both conditions depicted correspond to hierarchical phrase structures). It is worth noting in this context, that regular grammars can generate non-adjacent (long-distance) dependencies (cf., e.g., Pullum and Scholz, 2010; see also Pullum and Scholz, 2009, and in particular the supporting on-line material of Petersson and Hagoort, 2012, for simple examples). We emphasize that the use of a particular grammar in AGL does not ensure that the participants acquire, or use, this during testing, instead of using, for example, a different and perhaps simpler way of representing the knowledge acquired (de Vries et al., 2011, 2012). Finally, it should be noted that the representational structures that function during explicit decision-making are not the same as those that hold the knowledge of the structure that is used to make those decisions. Here, we have used the notions “implicit” and “implicit learning” in their classical sense, which entails a lack of meta-cognitive knowledge/judgment and in particular the absence of any stated use of explicit “problem solving” strategies. For example, when we speak we are clearly aware of the fact that we produce sentences, but we have no explicit knowledge or insight into how this is actually carried out.
It is unlikely that explicit selection or any other form of explicit decision making can explain our findings in any relevant sense for another reason. In the preference classification task, there is as much “decision making” going on whether the participant likes or dislikes an item. Moreover, the sensorimotor baseline of this study included an explicit decision component and the fact that we find the same inferior frontal activations centered on Broca's region (BA 44/45) in both preference and grammaticality classification, suggests to us, that the observed activation reflects neural processing related to implicit knowledge. We note that the unification grammar framework offers an alternative perspective on selection and control in this context. In this picture, it is the syntactic features of lexical items that exert control over the integration process via a general integration mechanism, which is already in place, for unifying structured representations (cf., Vosse and Kempen, 2000; Jackendoff, 2002; Petersson et al., 2005). Thus, control is implicitly distributed over a long-term memory representation, the mental lexicon, in terms of the control features that govern the integration process based on what is allowed (or not) to merge.
It is uncontroversial that participants have acquired some relevant knowledge associated with the underlying grammar, if they, for example, discriminate new grammatical from non-grammatical items in a reliable manner. However, this does not necessarily imply that the participants process the sequences according to the rules of the grammar and the empirical findings rarely support such claims in any strong sense (cf., Petersson et al., 2010; Petersson and Hagoort, 2012, for a discussion).
For example, sometimes it appears as if claims are made that different subregions of Broca's region are specifically related to different types of grammars or the processing of, for example, nested non-adjacent dependencies. In this study we used a simple right-linear unification grammar and in Table 2 we specify the overlap between the learning effects observed in the left inferior frontal region in this study (Figure 7) and the activated clusters reported in some of the studies previously reviewed. The outcome of this comparison suggests that the left inferior frontal region (BA 44/45) is significantly related to implicit AGL and artificial syntax processing, independent of the fact that the simple right-linear unification grammar we investigated does not involve nested center-embedded non-adjacent dependencies or dependencies introduced by syntactic displacement (i.e., syntactic movement). These findings are similar to corresponding findings reported in Petersson et al. (2010) for the grammaticality instruction. Thus, in the context of artificial syntax processing, and more generally language processing, the left inferior frontal region is unlikely to be specific to the processing of or nested center-embedded structures or non-adjacent dependencies introduced by syntactic movement. Instead, these results, in conjunction with previous functional neuroimaging results, suggest that the left inferior frontal region is a generic on-line structured sequence processor that unifies information from various sources in an incremental and recursive manner (for a discussion see Petersson et al., 2010; Petersson and Hagoort, 2012).
Several previous studies have suggested that the left inferior frontal region has a broader role in cognition than just language processing (Marcus et al., 2003; Petersson et al., 2004; Hagoort, 2005), including action recognition and movement preparation (e.g., Thoenissen et al., 2002; Hamzei et al., 2003), musical syntax (e.g., Maess et al., 2001; Koelsch et al., 2002; for a review see Patel, 2003), lexical and sub-lexical processing (Sahin et al., 2009), working memory (Price, 2010), and visuo-spatial sequence processing (Bahlmann et al., 2009). Thus, a growing body of evidence from functional neuroimaging suggests that the processing of structural sequence relations in several cognitive domains overlap in the inferior frontal regions, including language, music and artificial grammars/languages. This suggests a framework for the left inferior frontal region in which incremental recursive (i.e., state-dependent) integration of various sources of linguistic information (e.g., phonological, syntactic, semantic/pragmatic) operate interactively in parallel via interfaces (cf., e.g., Jackendoff, 2007). Moreover, other brain regions have been related to the processing of natural language syntax, including the left inferior parietal region, the left superior and middle temporal regions as well as right hemisphere, largely homotopic, regions (e.g., Snijders et al., 2009, 2010; Segaert et al., 2012; for reviews see Bookheimer, 2002; Price, 2010; Friederici, 2012; Hagoort and Indefrey, 2014). Finally, none of these regions seem uniquely related to syntax processing (Petersson et al., 2004; Petersson and Hagoort, 2012). It is therefore not unreasonable to suggest that artificial and natural syntax processing, and more generally language processing, is dependent on a functional network of interacting brain regions (Friederici, 2012; Petersson and Hagoort, 2012), none perhaps which is uniquely involved in syntax processing only. This conclusion appears to hold for higher cognitive functions more generally (Ingvar and Petersson, 2000; Petersson et al., 2009).
Acquisition of Structured Sequence Knowledge
The acquisition of language is a complex learning task which is governed by constraints derived from the properties of the developing human brain. The current lack of knowledge concerning the actual mechanisms involved during infancy makes it difficult to determine the relative contributions of innate- and acquired knowledge in language acquisition (Folia et al., 2010, 2011; Petersson and Hagoort, 2012). On the traditional Chomskyan view, disputed by many (for a recent example, see Reber, 2011; for a discussion see Petersson and Hagoort, 2012), the input underdetermines the linguistic knowledge of the adult language capacity. Thus, the acquisition of a grammar is not only based on an analysis of the linguistic input, but depends on an innate structure (i.e., the “language acquisition device”) that guides the acquisition process (Jackendoff, 2002, 2007). In this context, it is of interest to note that Folia et al. (2011) reported behavioral and corresponding activation differences in Broca's region (BA 44/45), in an implicit AGL grammaticality classification paradigm, which depended on the genotype related to the CNTNAP2 gene, a gene controlled by the transcription factor FOXP2.
In the following, we briefly discuss work on the acquisition of structured sequence knowledge (for reviews see Gomez and Gerken, 2000; Folia et al., 2010), which seem relevant to the current study. Uddén et al. (2009, 2012) investigated implicit acquisition of nested- and crossed non-adjacent dependencies (corresponding to context-free and context-sensitive grammars, respectively), while controlling for local subsequence familiarity, in an implicit learning paradigm based on structural mere-exposure in a paradigm very similar to the current study. Given the difficulty reported by some researchers in getting participants to acquire non-adjacent dependencies, the repeated exposure to grammatical items over 9 days used by Uddén et al. (2009, 2012) was likely important. In particular, this provides exposure and presumably time for both the necessary abstraction and knowledge consolidation processes to take place. There is some experimental evidence suggesting that this is important for improved performance in implicit AGL. For example, sleep has been shown to have a significant effect on grammaticality classification after implicit AGL (Nieuwenhuis et al., 2013), and to promote abstraction processes after AGL in infants (Gomez et al., 2006). Uddén et al. (2009, 2012) found that, while the subjects implicitly acquired knowledge about the non-regular nested structures, the acquisition of non-regular dependencies were harder compared to regular dependencies in the underlying grammar. Participants in these studies also acquired sensitivity to a context-sensitive agreement structure that generated non-adjacent crossed dependencies, but found the agreement violations harder to reject than category violations (Uddén et al., 2009, 2012). Interestingly, in an ERP study by Friederici et al. (2011), they reported that 4-months-old infants developed sensitivity to a simple non-adjacent AXB-dependency structure, perhaps suggesting that the negative results in 12-months-old reported by Gomez and Maye (2005) might be due to a lack of sensitivity. The ability to develop sensitivity to both adjacent and non-adjacent dependencies from early infancy suggests that innate implicit learning mechanism(s) are present already in the new born. Friederici et al. (2011) reported that the grammaticality effect (NG vs. G) yielded a late centro-parietal positivity and in a parallel experiment on adults, the same paradigm yielded a P600 (Mueller et al., 2009), which often reflects processes related to syntax (Hagoort et al., 1993).
Conclusion
We conclude that preference classification, in combination with a structural mere-exposure design, can be used to investigate structural (syntax) processing in unsupervised AGL paradigms with event-related fMRI in proper learning designs. The main findings suggest that a network of brain regions, including the inferior frontal (centered on BA 44/45) and the medial prefrontal regions (centered on BA 8/32), are activated as the intrinsic result of an implicit learning process. Support for the implicit nature of the knowledge utilized during preference classification come from the fact that the basal ganglia were activated during classification, while the medial temporal lobe memory system was consistently deactivated.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by Max Planck Institute for Psycholinguistics, Donders Institute for Brain, Cognition and Behaviour, Fundação para a Ciência e Tecnologia (PTDC/PSI-PCO/110734/2009; IBB/CBME, LA, FEDER/POCI 2010; PEst-OE/EQB/LA0023/2013), Vetenskapsrådet, The Swedish Dyslexia Foundation. We thank Christian Forkstam for help with the stimulus material and the experimental set-up.
References
Bahlmann, J., Schubotz, R. I., and Friederici, A. D. (2008). Hierarchical artificial grammar processing engages Broca's area. Neuroimage 42, 525–534. doi: 10.1016/j.neuroimage.2008.04.249
Bahlmann, J., Schubotz, R. I., Mueller, J. L., Koester, D., and Friederici, A. D. (2009). Neural circuits of hierarchical visuo-spatial sequence processing. Brain Res. 1298, 161–170. doi: 10.1016/j.brainres.2009.08.017
Bookheimer, S. (2002). Functional MRI of language: New approaches to understanding the cortical organization of semantic processing. Annu. Rev. Neurosci. 25, 151–188. doi: 10.1146/annurev.neuro.25.112701.142946
Brown, T. I., Ross, R. S., Tobyne, S. M., and Stern, C. E. (2012). Cooperative interactions between hippocampal and striatal systems support flexible navigation. Neuroimage 60, 1316–1330. doi: 10.1016/j.neuroimage.2012.01.046
Christiansen, M. H., Kelly, M. L., Shillcock, R., and Greenfield, K. (2010). Impaired artificial grammar learning in agrammatism. Cognition 116, 382–393. doi: 10.1016/j.cognition.2010.05.015
Conway, C. N., and Pisoni, D. B. (2008). Neurocognitive basis of implicit learning of sequential structure and its relation to language processing. Ann. N.Y. Acad. Sci. 1145, 113–131. doi: 10.1196/annals.1416.009
Devan, B. D., and White, N. M. (1999). Parallel information processing in the dorsal striatum: relation to hippocampal function. J. Neurosci. 19, 2789–2798.
de Vries, M. H., Barth, A. R. C., Maiworm, S., Knecht, S., Zwitserlood, P., and Flöel, A. (2010). Electrical stimulation of Broca's area enhances implicit learning of an artificial grammar. J. Cogn. Neurosci. 22, 2427–2436. doi: 10.1162/jocn.2009.21385
de Vries, M. H., Christiansen, M. H., and Petersson, K. M. (2011). Learning recursion: multiple nested and crossed dependencies. Biolinguistics 5, 10–35.
de Vries, M. H., Petersson, K. M., Geukes, S., Zwitserlood, P., and Christiansen, M. H. (2012). Processing multiple non-adjacent dependencies: evidence from sequence learning. Philos. Trans. R. Soc. Lond. B Biol. Sci. 367, 2065–2076. doi: 10.1098/rstb.2011.0414
Elliott, R., and Dolan, R. J. (1998). Neural response during preference and memory judgments for subliminally presented stimuli: a functional neuroimaging study. J. Neurosci. 18, 4697–4704.
Fletcher, P., Büchel, C., Josephs, O., Friston, K., and Dolan, R. (1999). Learning-related neuronal responses in prefrontal cortex. Cereb. Cortex 9, 168–178. doi: 10.1093/cercor/9.2.168
Folia, V., Forkstam, C., Ingvar, M., Hagoort, P., and Petersson, K. M. (2011). Implicit artificial syntax processing: genes, preference, and bounded recursion. Biolinguistics 5, 105–132.
Folia, V., Uddén, J., De Vries, M., Forkstam, C., and Petersson, K. M. (2010). Artificial language learning in adults and children. Lang. Learn. 60, 188–220. doi: 10.1111/j.1467-9922.2010.00606.x
Folia, V., Uddén, J., Forkstam, C., Ingvar, M., Hagoort, P., and Petersson, K. M. (2008). Implicit learning and dyslexia. Ann. N.Y. Acad. Sci. 1145, 132–150. doi: 10.1196/annals.1416.012
Forkstam, C., Elwér, Å., Ingvar, M., and Petersson, K. M. (2008). Instruction effects in implicit artificial grammar learning: a preference for grammaticality. Brain Res. 1221, 80–92. doi: 10.1016/j.brainres.2008.05.005
Forkstam, C., Hagoort, P., Fernandez, G., Ingvar, M., and Petersson, K. M. (2006). Neural correlates of artificial syntactic structure classification. Neuroimage 32, 956–967. doi: 10.1016/j.neuroimage.2006.03.057
Forkstam, C., and Petersson, K. M. (2005). Towards an explicit account of implicit learning. Curr. Opin. Neurol. 18, 435–441. doi: 10.1097/01.wco.0000171951.82995.c4
Friederici, A. D., Bahlmann, J., Heim, S., Schubotz, R. I., and Anwander, A. (2006). The brain differentiates human and non-human grammars: Functional localization and structural connectivity. Proc. Natl. Acad. Sci. U.S.A. 103, 2458–2463. doi: 10.1073/pnas.0509389103
Friederici, A. D., Mueller, J. L., and Oberecker, R. (2011). Precursors to natural grammar learning: Preliminary evidence from 4-month-old infants. PLoS ONE 6:e17920. doi: 10.1371/journal.pone.0017920
Friederici, A. D. (2012). The cortical language circuit: from auditory perception to sentence comprehension. Trends Cogn. Sci. 16, 262–268. doi: 10.1016/j.tics.2012.04.001
Friston, K. J. (1997). Testing for anatomically specified regional effects. Hum. Brain Mapp. 5, 133–136.
Friston, K. J., Ashburner, J. T., Kiebel, S. J., Nichols, T. E., and Penny, W. D. (eds.). (2007). Statistical Parametric Mapping: The Analysis of Functional Brain Images. San Diego, CA: Academic Press. doi: 10.1002/(SICI)1097-0193(1997)5:2<133::AID-HBM7>3.0.CO;2-4
Genovese, C. L., Lazar, N. A., and Nichols, T. (2002). Thresholding of statistical maps in functional neuroimaging using the false discovery rate. Neuroimage 15, 870–878. doi: 10.1006/nimg.2001.1037
Gomez, R. L., Bootzin, R. R., and Nadel, L. (2006). Naps promote abstraction in language-learning infants. Psychol. Sci. 17, 670–674. doi: 10.1111/j.1467-9280.2006.01764.x
Gomez, R. L., and Gerken, L. (2000). Infant artificial language learning and language acquisition. Trends Cogn. Sci. 4, 178–186. doi: 10.1016/S1364-6613(00)01467-4
Gomez, R. L., and Maye, J. (2005). The developmental trajectory of nonadjacent dependency learning. Infancy 7, 183–206. doi: 10.1207/s15327078in0702_4
Gordon, P. C., and Holyoak, K. J. (1983). Implicit learning and generalization of the mere exposure effect. J. Pers. Soc. Psychol. 45, 492–450. doi: 10.1037/0022-3514.45.3.492
Hagoort, P., Brown, C. M., and Groothusen, J. (1993). The syntactic positive shift (SPS) as an ERP measure of syntactic processing. Lang. Cogn. Process. 8, 439–483. doi: 10.1080/01690969308407585
Hagoort, P. (2005). On Broca, brain, and binding: A new framework. Trends Cogn. Sci. 9, 416–423. doi: 10.1016/j.tics.2005.07.004
Hagoort, P., and Indefrey, P. (2014). The neurobiology of language beyond single words. Annu. Rev. Neurosci. 37. doi: 10.1146/annurev-neuro-071013-013847
Hamzei, F., Rijntjes, M., Dettmers, C., Glauche, V., Weiller, C., and Buchel, C. (2003). The human action recognition system and its relationship to Broca's area: an fMRI study. Neuroimage 19, 637–644. doi: 10.1016/S1053-8119(03)00087-9
Hockett, C. F. (1963). “The problem of universals in language,” in Universals of Language, ed J. H. Greenberg (Cambridge, MA: MIT Press), 1–29.
Hockett, C. F. (1987). Refurbishing our Foundations: Elementary Linguistics from an Advanced Point of View. Philadelphia, PA: John Benjamins. doi: 10.1075/cilt.56
Ingvar, M., and Petersson, K. M. (2000). “Functional maps—cortical networks,” in Brain Mapping: The Systems, ed J. C. Mazziotta (San Diego, CA: Academic Press), 111–140. doi: 10.1016/B978-012692545-6/50006-4
Jackendoff, R. (2002). Foundations of Language: Brain, Meaning, Grammar, Evolution. Oxford: Oxford University Press. doi: 10.1093/acprof:oso/9780198270126.001.0001
Jackendoff, R. (2007). A parallel Architecture perspective on language processing. Brain Res. 1146, 2–22. doi: 10.1016/j.brainres.2006.08.111
Knowlton, B. J., and Squire, L. R. (1996). Artificial grammar learning depends on implicit acquisition of both abstract and exemplar-specific information. J. Exp. Psychol. Learn. Mem. Cogn. 22, 169–181. doi: 10.1037/0278-7393.22.1.169
Koelsch, S., Gunter, T. C., von Cramon, D. Y., Zysset, S., Lohmann, G., and Friederici, A. D. (2002). Bach speaks: A cortical “language-network” serves the processing of music. NeuroImage 17, 956–966. doi: 10.1006/nimg.2002.1154
Maess, B., Koelsch, S., Gunter, T. C., and Friederici, A. D. (2001). Musical syntax is processed in Broca's area: A MEG study. Nat. Neurosci. 4, 540–545. doi: 10.1038/87502
Marcus, G. F., Vouloumanos, A., and Sag, I. A. (2003). Does Broca's play by the rules? Nat. Neurosci. 6, 651–652. doi: 10.1038/nn0703-651
Meulemans, T., and Van der Linden, M. (1997). Associative chunk strength in artificial grammar learning. J. Exp. Psychol. Learn. Mem. Cogn. 23, 1007–1028. doi: 10.1037/0278-7393.23.4.1007
Misyak, J. B., Christiansen, M. H., and Tomblin, J. B. (2010). On-line individual differences in statistical learning predict language processing. Front. Psychol. 1:31. doi: 10.3389/fpsyg.2010.00031
Mueller, J. L., Oberecker, R., and Friederici, A. D. (2009). Syntactic learning by mere exposure – An ERP study in adult learners. BMC Neurosci. 10:89. doi: 10.1186/1471-2202-10-89
Nieuwenhuis, I. L. C., Folia, V., Forkstam, C., Jensen, O., and Petersson, K. M. (2013). Sleep promotes the extraction of grammatical rules. PLoS ONE 8:e65046. doi: 10.1371/journal.pone.0065046
Opitz, B., and Friederici, A. D. (2003). Interactions of the hippocampal system and the prefrontal cortex in learning language-like rules. Neuroimage 19, 1730–1737. doi: 10.1016/S1053-8119(03)00170-8
Opitz, B., and Friederici, A. D. (2007). Neural basis of processing sequential and hierarchical syntactic structures. Hum. Brain Mapp. 28, 585–592. doi: 10.1002/hbm.20287
Opitz, B., and Kotz, S. D. (2012). Ventral premotor cortex lesions disrupt learning of sequential grammatical structures. Cortex 48, 664–673. doi: 10.1016/j.cortex.2011.02.013
Packard, M. G., and Knowlton, B. J. (2002). Learning and memory functions of the basal ganglia. Annu. Rev. Neurosci. 25, 563–593. doi: 10.1146/annurev.neuro.25.112701.142937
Patel, A. D. (2003). Language, music, syntax and the brain. Nat. Neurosci. 6, 674–681. doi: 10.1038/nn1082
Petersson, K. M., Elfgren, C., and Ingvar, M. (1997). A dynamic role of the medial temporal lobe during retrieval of declarative memory in man. Neuroimage 6, 1–11. doi: 10.1006/nimg.1997.0276
Petersson, K. M., Elfgren, C., and Ingvar, M. (1999a). Dynamic changes in the functional anatomy of the human brain during recall of abstract designs related to practice. Neuropsychologia 37, 567–587. doi: 10.1016/S0028-3932(98)00152-3
Petersson, K. M., Elfgren, C., and Ingvar, M. (1999b). Learning related effects and functional neuroimaging. Hum. Brain Mapp. 7, 234–243. doi: 10.1002/(SICI)1097-0193(1999)7:4<234::AID-HBM2>3.0.CO;2-O
Petersson, K. M., Folia, V., and Hagoort, P. (2010). What artificial grammar learning reveals about the neurobiology of syntax. Brain Lang. 120, 83–95. doi: 10.1016/j.bandl.2010.08.003
Petersson, K. M., Forkstam, C., and Ingvar, M. (2004). Artificial syntactic violations activate Broca's region. Cogn. Sci. 28, 383–407. doi: 10.1016/j.cogsci.2003.12.003
Petersson, K. M., Grenholm, P., and Forkstam, C. (2005). Artificial grammar learning and neural networks. Proc. Cogn. Sci. Soc. 2005, 1726–1731.
Petersson, K. M., and Hagoort, P. (2012). The neurobiology of syntax: beyond string-sets. Philos. Trans. R. Soc. Lond. B Biol. Sci. 367, 1971–1883. doi: 10.1098/rstb.2012.0101
Petersson, K. M., Ingvar, M., and Reis, A. (2009). “Language and literacy from a cognitive neuroscience perspective,” in Cambridge handbook of literacy, eds D. Olsen, and N. Torrance (Cambridge: Cambridge University Press), 152–181.
Price, C. J. (2010). The anatomy of language: a review of 100 fMRI studies published in 2009. Ann. N.Y. Acad. Sci. 1191, 62–88. doi: 10.1111/j.1749-6632.2010.05444.x
Pullum, G. K., and Scholz, B. C. (2009). For universals (but not finite-state learning) visit the zoo. Behav. Brain Sci. 32, 466–467. doi: 10.1017/S0140525X09990732
Pullum, G. K., and Scholz, B. C. (2010). “Recursion and the infinitude claim,” in Recursion in human language, ed H. van der Hulst (Berlin: Mouton de Gruyter), 113–138.
Reber, A. S. (1967). Implicit learning of artificial grammars. J. Verbal Learn. Verbal Behav. 6, 855–863. doi: 10.1016/S0022-5371(67)80149-X
Reber, A. S. (2011). “An epitaph for grammar,” in Implicit and Explicit Language Learning, eds C. Sanz and R. P. Loew (Washington, DC: Georgetown University Press), 23–34.
Sahin, N. T., Pinker, S., Cash, S. S., Schomer, D., and Halgren, E. (2009). Sequential processing of lexical, grammatical, and phonological information within Broca's area. Science 326, 445–449. doi: 10.1126/science.1174481
Segaert, K., Menenti, L., Weber, K., Petersson, K. M., and Hagoort, P. (2012). Shared syntax in language production and language comprehension—an fMRI study. Cereb. Cortex 22, 1662–1670. doi: 10.1093/cercor/bhr249
Seger, C. A. (1994). Implicit learning. Psychol. Bull. 115, 163–196. doi: 10.1037/0033-2909.115.2.163
Shanks, D. R., and St. John, M. F. (1994). Characteristics of dissociable human learning systems. Behav. Brain Sci. 17, 367–447. doi: 10.1017/S0140525X00035032
Snijders, T., Petersson, K. M., and Hagoort, P. (2010). Effective connectivity of cortical and subcortical regions during unification of sentence structure. Neuroimage 52, 1633–1644. doi: 10.1016/j.neuroimage.2010.05.035
Snijders, T. M., Vosse, T., Kempen, G., Van Berkum, J. A., Petersson, K. M., and Hagoort, P. (2009). Retrieval and unification in sentence comprehension: an fMRI study using word-category ambiguity. Cereb. Cortex 19, 1493–1503. doi: 10.1093/cercor/bhn187
Squire, L. (1992). Memory and the hippocampus: a synthesis from findings with rats, monkeys, and humans. Psychol. Rev. 99, 195–231. doi: 10.1037/0033-295X.99.2.195
Strange, B. A., Henson, R. N. A., Friston, K. J., and Dolan, R. J. (2001). Anterior prefrontal cortex mediates rule learning in humans. Cereb. Cortex 11, 1040–1046. doi: 10.1093/cercor/11.11.1040
Talairach, J., and Tournoux, P. (1988). Co-planar Stereotaxic Atlas of the Human Brain: 3-Dimensional Proportional System—an Approach to Cerebral Imaging. New York, NY: Thieme Medical Publishers.
Teichmann, M., Dupoux, E., Cesaro, P., and Bachoud-Levi, A.-C. (2008). The role of the striatum in sentence processing: evidence from a priming study in early stages of Huntington's disease. Neuropsychologia 46, 174–185. doi: 10.1016/j.neuropsychologia.2007.07.022
Teichmann, M., Dupoux, E., Kouider, S., Brugières, P., Boissé, M. F., Baudic, S., et al. (2005). The role of the striatum in rule application: the model of Huntington's disease at early stage. Brain 128, 1155–67. doi: 10.1093/brain/awh472
Thoenissen, D., Zilles, K., and Toni, I. (2002). Differential involvement of parietal and precentral regions in movement preparation and motor intention. J. Neurosci. 22, 9024–9034.
Uddén, J., Araújo, S., Forkstam, C., Ingvar, M., Hagoort, P., and Petersson, K. M. (2009). “A matter of time: implicit acquisition of recursive sequence structures,” in Proceedings of the Thirty-First Annual Conference of the Cognitive Science Society (Amsterdam, MA: Vrije Universiteit), 2444–2449.
Udden, J., Folia, V., Forkstam, F., Ingvar, M., Fernandez, G., Overeem, S., et al. (2008). The inferior frontal cortex in artificial syntax processing: An rTMS study. Brain Res. 1224, 69–78. doi: 10.1016/j.brainres.2008.05.070
Uddén, J., Ingvar, M., Hagoort, P., and Petersson, K. M. (2012). Implicit acquisition of grammars with crossed and nested non-adjacent dependencies: investigating the push-down stack model. Cogn. Sci. 36, 1078–1101. doi: 10.1111/j.1551-6709.2012.01235.x
Ullman, M. T. (2004). Contributions of memory circuits to language: the declarative/procedural model. Cognition 92, 231–270. doi: 10.1016/j.cognition.2003.10.008
Voermans, N. C., Petersson, K. M., Daudey, L., Weber, B., van Spaendonck, K. P., Kremer, H. P. H., et al. (2004). Interaction between the human hippocampus and caudate nucleus during route recognition. Neuron 43, 427–435. doi: 10.1016/j.neuron.2004.07.009
Vosse, T., and Kempen, G. (2000). Syntactic structure assembly in human parsing: a computational model based on competitive inhibition and a lexicalist grammar. Cognition 75, 105–143. doi: 10.1016/S0010-0277(00)00063-9
Worsley, K. J. (2003). “Developments in random field theory,” in Human Brain Function, (2nd Edn.), eds R. S. J. Frackowiak, K. J. Friston, C. Frith, R. Dolan, C. Price, S. Zeki, J. Ashburner, and W. Penny (San Diego, CA: Academic Press), 881–886.
Zajonc, R. B. (1968). Attitudinal effects of mere exposure. J. Pers. Soc. Psychol. 9(pt 2), 1–27. doi: 10.1037/h0025848
Zizak, D. M., and Reber, A. S. (2004). Implicit preferences: the role(s) of familiarity in the structural mere exposure effect. Conscious. Cogn. 13, 336–362. doi: 10.1016/j.concog.2003.12.003
Appendix
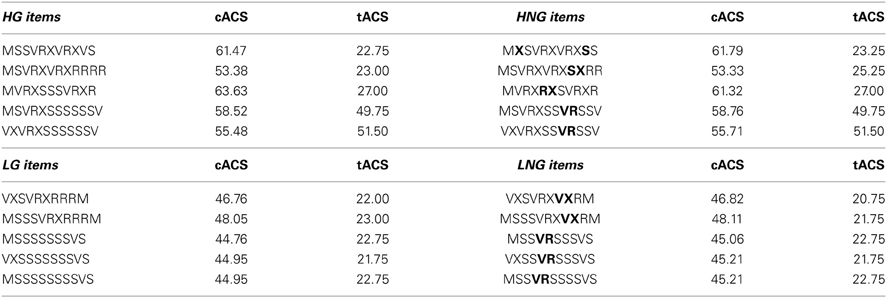
Example of the stimulus material used in the present experiment. HG, high grammatical; HNG, high non-grammatical; LG, low grammatical; LNG, low non-grammatical; cACS, frequency distribution of 2 and 3 letter chunks for complete sequence position (in relation to the acquisition stimuli); tACS, frequency distribution of 2 and 3 letter chunks for terminal sequence position. The non-grammatical (NG) items were derived from the grammatical (G) sequences, by switching letters in two non-terminal positions (in bold). The NG sequences matched the G sequences in terms of terminal and complete sequence ACS. This was accomplished by generating all possible NG sequences for each G sequence, and selecting the NG sequence that was most equal in ACS to the G sequence. Each letter sequence is decomposed into 2 and 3 letter chunks, their frequency for complete and terminal position in the learning sequences are calculated. Example of the calculation of the complete sequence position (cACS): MSSVRXVRXVS is decomposed in the bigrams MS (40), SS (59), SV (87), VR (97), RX (97), XV (50), VR (97), RX (97), XV (50), VS (16). The frequencies in the learning sequences of these bigrams are shown in parenthesis. The sequence was also decomposed in the trigrams, MSS (27), SSV (59), SVR (75), VRX (97), RXV (37), XVR (41), VRX (97), RXV (37), XVS (8). The cACS of this item was calculated by averaging its different bigram and trigram frequencies. The obtained cACS is 61.47 indicates a relatively high mean high frequency of 2 and 3 letter chunks in relation to the acquisition stimuli.
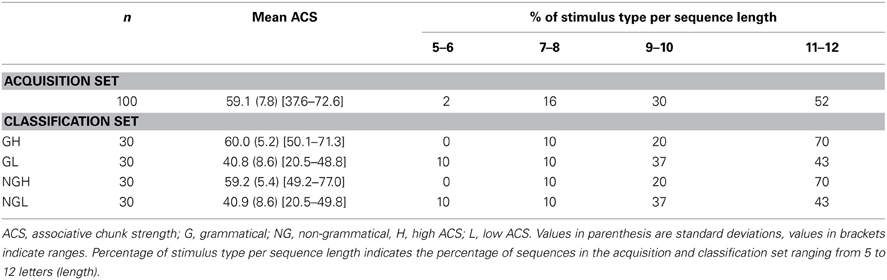
Table A1. Characteristics of the stimulus material used in the present experiment.
Keywords: fMRI, artificial syntax, implicit learning, artificial grammar learning, inferior frontal gyrus, structural mere-exposure, preference classification
Citation: Folia V and Petersson KM (2014) Implicit structured sequence learning: an fMRI study of the structural mere-exposure effect. Front. Psychol. 5:41. doi: 10.3389/fpsyg.2014.00041
Received: 23 August 2013; Accepted: 13 January 2014;
Published online: 04 February 2014.
Edited by:
Vinciane Gaillard, Université Libre de Bruxelles, BelgiumReviewed by:
Carol Seger, Colorado State University, USAArthur S. Reber, Brooklyn College of the City University of New York, USA
Copyright © 2014 Folia and Petersson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Karl Magnus Petersson, Max Planck Institute for Psycholinguistics, PO. Box 310, 6500 AH Nijmegen, Netherlands e-mail:a2FybC1tYWdudXMucGV0ZXJzc29uQG1waS5ubA==