 Joan Guàrdia-Olmos1,2*
Joan Guàrdia-Olmos1,2* Maribel Peró-Cebollero1
Maribel Peró-Cebollero1 Daniel Zarabozo-Hurtado3
Daniel Zarabozo-Hurtado3 Andrés A. González-Garrido3
Andrés A. González-Garrido3 Esteve Gudayol-Ferré4
Esteve Gudayol-Ferré4- 1Facultat de Psicologia, Institut de Recerca en Cognició, Cervell i Conducta, Universitat de Barcelona, Barcelona, Spain
- 2Department of Methodology of Behavioral Sciences, School of Psychology, University of Barcelona, Barcelona, Spain
- 3Instituto de Neurociencias, Universidad de Guadalajara, Guadalajara, Mexico
- 4Universidad Michoacana de San Nicolás de Hidalgo, Morelia, Mexico
The study of orthographic errors in a transparent language like Spanish is an important topic in relation to writing acquisition. The development of neuroimaging techniques, particularly functional magnetic resonance imaging (fMRI), has enabled the study of such relationships between brain areas. The main objective of the present study was to explore the patterns of effective connectivity by processing pseudohomophone orthographic errors among subjects with high and low spelling skills. Two groups of 12 Mexican subjects each, matched by age, were formed based on their results in a series of ad hoc spelling-related out-scanner tests: a high spelling skills (HSSs) group and a low spelling skills (LSSs) group. During the f MRI session, two experimental tasks were applied (spelling recognition task and visuoperceptual recognition task). Regions of Interest and their signal values were obtained for both tasks. Based on these values, structural equation models (SEMs) were obtained for each group of spelling competence (HSS and LSS) and task through maximum likelihood estimation, and the model with the best fit was chosen in each case. Likewise, dynamic causal models (DCMs) were estimated for all the conditions across tasks and groups. The HSS group’s SEM results suggest that, in the spelling recognition task, the right middle temporal gyrus, and, to a lesser extent, the left parahippocampal gyrus receive most of the significant effects, whereas the DCM results in the visuoperceptual recognition task show less complex effects, but still congruent with the previous results, with an important role in several areas. In general, these results are consistent with the major findings in partial studies about linguistic activities but they are the first analyses of statistical effective brain connectivity in transparent languages.
Introduction
Reading is a cognitive process that requires visually identifying written elements and their respective phonological association to form meaning. In recent years, the study of reading under a neurocognitive perspective has focused on reading disabilities, mainly accuracy and speed (Wolf et al., 2000; Leinonen et al., 2001; Torppa et al., 2007; Nation, 2008), as well as on their possible origin and their respective brain functioning. From an anatomical-functional perspective, the development of the skills needed to process the information of the orthographic structure, phonology and meaning of words, involves activating the participation of several brain regions, mainly cortical, thus forming what some authors have called a specialized system for reading (Berninger and Richards, 2002).
Some authors like Perfetti and Bolger (2004) or Hills et al. (2005) have proposed three main anatomical regions involved in this reading system: occipital-temporal, temporal-parietal, and inferior frontal. The first of them, which includes the fusiform and lingual gyruses, has been related to the structural or morphological (orthographic) analysis of words. Activations have been reported in the left hemisphere’s fusiform gyrus when faced with the presentation of words in tasks demanding relatively simple manipulation or processing, such as visual priming (Devlin et al., 2006; Glezer et al., 2009), lexical decision (Cohen et al., 2002; Dehaene et al., 2002), or structure-based word decision (Binder et al., 2006; Kronbichler et al., 2008). This region has also been called visual word form area or VWFA (Cohen et al., 2000).
It has been proposed that the activation patterns of these three regions of the reading system are different between good and deficient readers, such as dyslexics (Fiez and Petersen, 1998; Shaiwitz et al., 1998). Deficient readers present fewer activations of occipital-temporal and temporal-parietal regions (Shaiwitz et al., 2002) and more activations of the inferior frontal regions (Temple et al., 2001). This pattern has been interpreted as a compensatory mechanism (Shaiwitz et al., 2006), although other authors have also proposed the existence of bilateral activations in these three regions with the same purpose (Gebauer et al., 2012).
Fu et al. (2006) found statistically significant estimates when comparing the visual word recognition task’s difficulty and pointed out that areas such as the precuneus, the anterior cingulate cortex, and the left middle frontal gyrus are functionally connected to one another. Additionally they pointed out that areas such as the left inferior frontal gyrus, the left middle temporal gyrus, and the right middle areas also present statistically significant connections according to task difficulty. In a paper on reading competences, Levy et al. (2009) showed functional connectivity models which included areas such as the left middle occipital gyrus, the left occipital-temporal junction, the left parietal cortex, and the left inferior frontal gyrus. Dick et al. (2010) – by using structural equation models (SEMs) – found statistically significant connectivity patterns involving the inferior frontal gyrus (pars triangularis/pars opercularis/ventral premotor), the supramarginal gyrus, the posterior superior temporal, the anterior superior temporal, the posterior superior temporal sulcus, the posterior middle temporal gyrus, the fusiform gyrus, and the visual, striate, and extrastriate cortex. In adition Vitali et al. (2010) – in a two-case study – yields a regular connectivity structure focused basically on significant effects between areas such as the inferior frontal gyrus, the middle temporal gyrus, and the inferior parietal lobule. Taken together, these papers suggest some regularity in the areas involved in this type of tasks (Taylor et al., 2010).
However, the vast majority of the previously mentioned studies have been conducted on shallow orthographies. Some authors argue that the consistency of different orthographies is a factor that may directly influence the processing of reading (Davies et al., 2007). Orthographic consistency and its corresponding instructional regime could lead to the adoption of different reading strategies across languages based on visual or whole word recognition in shallow orthographies, and on phonological recognition in transparent ones (Wimmer and Goswami, 1994). These concepts are consistent with different reading models, such as the DRC (Coltheart et al., 2001), on which anatomical (Allen et al., 2009) and functional (Fiebach et al., 2002) representations were studied.
Spanish is considered a language with a regular orthography, such as Dutch, Italian, and German, due to its high grapheme–phoneme correspondence for reading; however, for writing, some phonemes may be mapped onto two or three different letters. This is particularly true in Mexican Spanish, given that – in addition to the matches between a phoneme and several graphemes of standard Spanish – other sounds are also equivalent. For example, the phoneme /s/ matches the graphemes “c,” “s,” and “z”; the phoneme /x/ matches “x,” “g,” and “j” the phoneme /j/ matches “y” and “ll”; and the phoneme /b/ matches “b” and “v.” Moreover, Mexican Spanish comprises a great percentage of words originating from the country’s various indigenous languages – now completely integrated into Spanish – many of which involve these types of phonemes and spelling not based on orthographic rules (arbitrary). Because of all this, Mexican Spanish is probably the transparent language where speakers might make the most mistakes when writing pseudohomophones (words with an orthographic error and the same phonology as the correct one), or in the visual recognition of a pseudohomophone as a valid word while reading.
Although these mistakes do not compromise reading comprehension in normal persons in a meaningful way, they do cause the speakers of Mexican Spanish to make numerous pseudohomophone spelling mistakes, something observable in the general population (Gómez-Velázquez et al., 2013a).
The study by González-Garrido et al. (2014) suggests that the electrophysiological correlates of orthographic error processing have shown that adults with low orthographic abilities have problems in detecting orthographic rules violations, which could indicate weak representations in the orthographic lexicon, or a difficulty in automatically accessing such representations. According to Bahr et al. (2012), the proper development of an orthographic lexicon could lead to an adequate processing of phonology, orthography and morphology at the level of visual word recognition. In addition, few works exist on effective connectivity in visual word recognition tasks using SEM or Dynamic Causal Model (DCM). The paper by Kiebel et al. (2007) yields statistically significant connections in this type of task in areas like the left primary auditory cortex, the right primary auditory cortex, the left superior temporal gyrus, the right superior temporal gyrus, and the right inferior frontal gyrus. An innovative aspect of this paper is that, in order to estimate those effects, the authors used DCM estimation techniques based on assumptions somewhat different from those of SEM.
The main objective of the present study was to explore the possible differences in effective connectivity among subjects with high and low spelling orthographic abilities while processing pseudohomophone orthographic errors by using visual word recognition tasks. Another goal of this study is to compare SEM and DCM models given that they entail different approaches to connectivity models and each one reports on different processes to model the brain activities under the Bold signal paradigm.
Materials and Methods
Participants
Twenty-four young adults (age M = 21.83 years, SD = 5.02, 10 women) participated in the experiment. They were all right-handed in agreement with the Edinburgh handedness inventory (Oldfield, 1971), with normal or corrected view, and none presented a history of neurological illness or learning disorder. They all signed an informed consent and received economic compensation for their participation, in accordance with the permission and recommendations of the Ethical Committee of the Instituto de Neurociencias of the University of Guadalajara, Mexico.
Prior to the fMRI registrations, five tasks were applied to all the participants intended to assess their handling of homophone spelling in Spanish words (b-v, c-s-z, g-j, ll-y, h-no h) in four different contexts: completing words, dictation (words and text), error detection in a text, and free composition. The tasks used to discriminate the subjects’ performances had yielded an adequate reliability value (α = 0.833) and a very high discrimination capacity in order to distinguish between groups with different orthographic skills (t = 11.608; p < 0.001) in a previous study, complementary to the current one, with a general sample of 827 subjects (Gómez-Velázquez et al., 2013b).
Out of this large sample, 12 subjects with low spelling skills (LSSs group, 10th percentile) and another 12 with high spelling skills (HSSs group, 90th percentile) were selected to form this study’s sample.
Stimuli and Procedure
Throughout two experimental tasks, the subjects were exposed to 80 Spanish words, 60 out of which were spelled correctly. Also, 20 words contained a homophone orthographic error [e.g., sapato (incorrect) instead of zapato (correct), the Spanish word for ‘shoe’].
In the first task (blocks A and B, spelling recognition task), the participants were required to indicate whether the word was written correctly or else contained a pseudohomophone orthographic error. In block A, 50% of the words were written correctly and the remaining 50% contained an orthographic error. In block B, 100% of the words were written correctly. In the second task (blocks C and D, visuoperceptual recognition task) the participants were instructed to answer whether the word displayed contained the vowel “i” or not. In block C, 50% of the words were written correctly and 50% contained a pseudohomophone orthographic error. In block D, 100% of the words were written correctly. We should bear in mind, however, that the participants did not have that information, neither in block B nor D.
Both the stimuli and the interval between them were 1 s long. In order to present them, a block design was used: the stimuli were divided into eight blocks of 10 stimuli each and presented pseudo-randomly. The stimuli were presented in an Arial 60 font and were typed in white on a black background with a 300 pixel-per-inch resolution.
Both the words spelled correctly and those with an orthographic error had a high or low frequency according to a frequency dictionary widely used in studies involving words in Spanish (Sebastián et al., 2000).
The total number of stimuli from both categories (words spelled correctly and incorrectly) was divided in half to be presented in both experimental tasks. In each task, four rest blocks were presented with a center fixation dot during which the subjects were not supposed to conduct any activity; the change of color in the fixation dot told the subjects they were about to start watching words and executing answers. Likewise, four activation blocks were presented in each task with ten stimuli each: two of them with words spelled correctly and incorrectly (50–50%), and two blocks only with words spelled correctly.
The participants gave their answer to each stimulus through one out of two buttons, following the requirement of the two experimental tasks: spelling recognition, where they had to decide, as quickly as possible, whether the word presented was spelled correctly or incorrectly (Figure 1, A and B blocks); and visuoperceptual recognition, where they had to decide, also quickly, whether the words presented contained the vowel ‘i’ or not (Figure 1, C and D blocks). The complete design of both tasks can be observed in Figure 1.
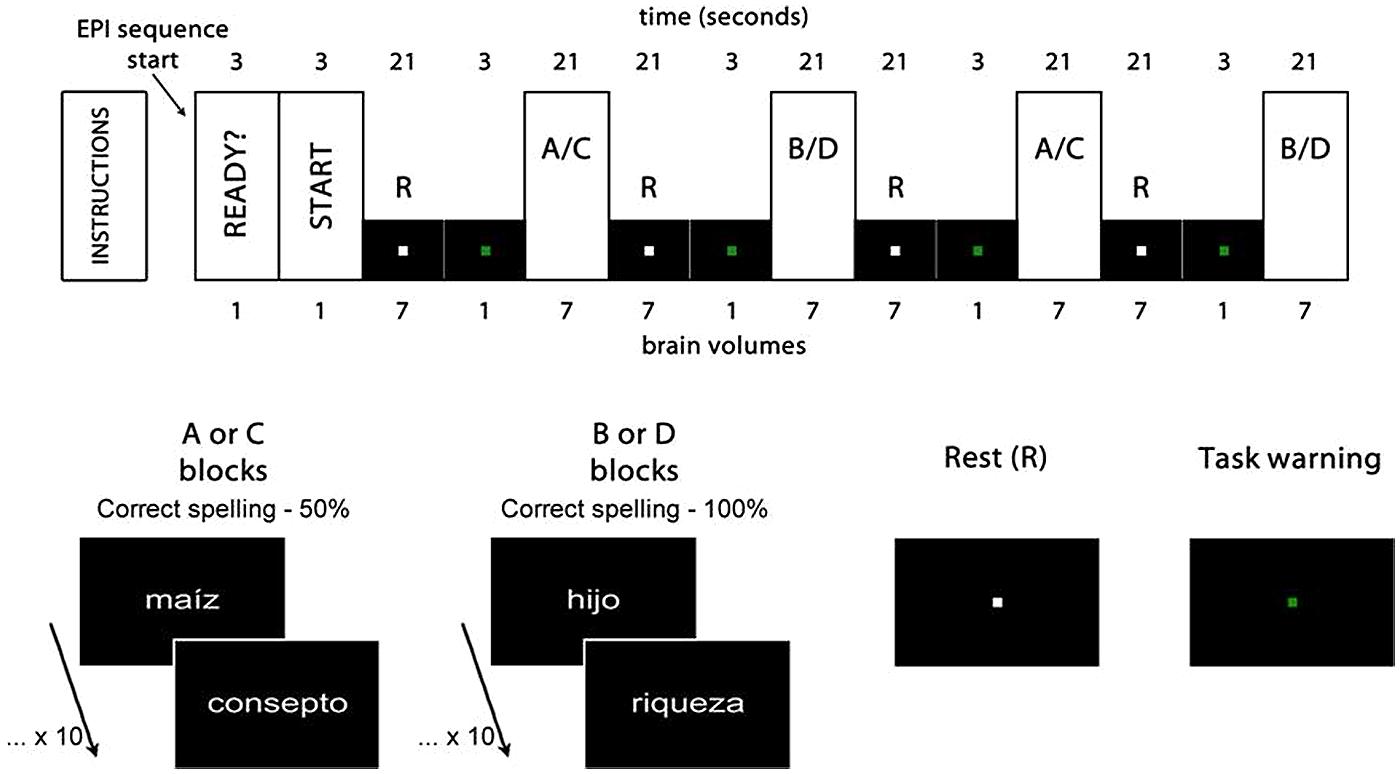
FIGURE 1. Experimental design. Rest (R) and activation (A, B, C, and D) blocks. The first two brain volumes were eliminated from the analysis, as well as the four task warning volumes. Maíz (corn), hijo (son) and riqueza (wealth) are examples of words spelled correctly. Consepto (concept) is an example of a word spelled incorrectly, with an s instead of a c, thus generating a homophone error.
Image Acquisition Through Magnetic Resonance Imaging
We used a GE Signa Excite HDxT 1.5 Tesla (GE Medical Systems, Milwaukee, WI, USA) and an 8-channel head coil. For each experimental task, we obtained 32 4-mm thick adjacent axial cuts. We used an echo planar pulse sequence with a Repetition Time of 3 s, echo time of 60 ms, 26-cm FOV, and a 64 × 64 matrix. The voxel size used was 4.06 × 4.06 × 4 mm. From each experimental task, a total of 62 brain volumes were obtained. For reasons of image acquisition time and experimental design, six brain volumes per task were discarded, thus leaving a total of 56 to be analyzed later on (according Figure 1).
The pre-process and the statistical analysis of the images were conducted using the SPM8 computer package (http://www.fil.ion.ucl.ac.uk/spm/software/spm8/). The images were realigned spatially, readjusted to the voxel size, and normalized according to the MNI reference – Montreal Neurological Institute – and Talairach coordinates.
For the smoothing, a Kernel Gaussian filter three times the voxel size was used on the x, y, and z axes. Based on the analysis of each group in each task, regions of interest (ROIs) were formed by means of the MarsBar software (Brett et al., 2002), and therefore the selection of ROIs was data driven. All the models – SEM and DCM – for the study of effective connectivity were data driven. To conduct this analysis, we previously carried out four first-level analyses (Zarabozo-Hurtado et al., under revision), differentiating groups and tasks, in fact one first level analysis was done for HSS group and spelling recognition task comparing the activation between the blocks A and B, the same analysis was done for the LSS group, and the same structure was repeated for the visuoperceptual recognition task (first level HSS group comparing C and D Blocks and first level LSS group comparing C and D Blocks).
Structural Equation Models and Dynamic Causal Models Approach
There are several statistical conditions involved in the use of SEM to estimate connectivity. Basically, they concern the SEM properties as regards the linear model, and the conditions of range and order that the Path Analysis models must follow. In fact, generating a factorial structure to obtain a score by ROI based on the voxels defined would be, ultimately, a peculiar application of the dimension reduction or, in SEM terms, of a measurement model. Accordingly, it is more than debatable that effective connectivity estimation follows a Path Analysis model strictly.
Regardless of these rather conceptual considerations, several papers have shown the limitations of this technique, which can be summarized in the following aspects. Firstly, SEMs do not allow us to easily analyze the self-impact effects, that is, the βii effects where a specific ROI shows an effect on itself. This type of effect does not comply with the condition of order and compromises the estimation. Secondly, we should remember that non-recursive models are difficult to estimate and, in the case at hand, they are inevitable effects for a reasonable approach to functional connectivity. This type of condition has been formulated differently in papers on connectivity (Horwitz et al., 1999; Gonçalves and Hall, 2003; Astolfi et al., 2004, among many others). Additionally, some statistical questions arise, in the sense that the ROI selection usually conducted in SEM may generate some bias in the parameter estimation.
Consequently, papers like those by Erickson et al. (2005), Caclin and Fonlupt (2006), or Marrelec et al. (2006, 2007) show us how the estimation of correlation between ROI values is not bias-free depending on the number of brain volumes involved in the analysis and on the number of ROIs selected. Accordingly, the estimations of partial correlations or the results with estimation techniques that reduce collinearity effects are not necessarily similar to those obtained with maximum likelihood (ML) estimations.
In addition, an effect exists that has received little attention based on the assumption of variance homogeneity between ROIs which can only be solved by standardizing the values, but which is not assumable from the onset (Charlton et al., 2008). Even the definition of ROI itself is only a somewhat paradoxical effect which is not necessarily constant through the subjects. Accordingly, the selection of a number of ROIs within a group of subjects involves an essential variability of significance and activations (Marco et al., 2009). That is to say, ROIs with significant effects in one subject do not necessarily present activations in another or with the same intensity if the activation is repeated.
Such is the case between groups (Kim and Horwitz, 2009) and between experimental conditions, which entails a difficult situation to manage in statistical terms. Despite these comments, effective connectivity models based on SEMs have proven useful for their verification, and many are the papers which can be considered as good praxis from a statistical point of view (Rowe, 2010; Carballedo et al., 2011; Karunanayaka et al., 2011; Inman et al., 2012), in addition to the modifications and extensions generated (Chen et al., 2011), or the use of Extended Unified SEMs (Gates et al., 2011).
The choice of DCM models seems an interesting alternative to the SEM models, given that their statistical properties make them somewhat more malleable. Generally speaking, they are more tolerant with reciprocal effects, with βii effects, and they incorporate the direct effects from the stimuli in the activations of specific ROIs. Additionally, the incorporation of the B matrix into the general model allows us to establish the mediating effects of the experimental conditions on the direct effects between ROIs. Indeed, the DCM-derived general model can be summarized as follows:
where t is continuous time, Zt is the neuronal activity, ut(j) is the j input at time t, A,Bj, and C are the connectivity matrices, A = Intrinsic connections, B = Modulatory Connections, and C = External Connections.
Therefore, as mentioned above, not specifying the C matrix involves that, given certain conditions – that is, yi = zi and ζ = Cut –, the expression [1] becomes a general SEM expression, i.e., the popular yt = βyt + ζt, in LISREL terminology. Consequently, the advantage of using DCM over SEM is based on the idea of defining the impact of External Connections within the model, which in SEM complicates estimation.
On the other hand, DCM is strictly linked to ROIs presenting statistically significant activations. In general, the fundamental condition of applying DCM lies on the situation of subject-model specificity when fitting models to specific subjects under defined experimental conditions.
This question has not been overlooked. In fact, several choices of parameter estimation have been generated for it. Penny et al. (2009), Marreiros et al. (2010), or Friston et al. (2012) are examples of possible DCM approaches to different scenarios of complexity.
It has also been discussed that using DCM entails difficulty given that it only analyzes activated ROIs, and therefore, it overlooks other sources of variation. However, some proposals have tried to generate alternatives to this possible bias effect (Wolff et al., 2010), including the inevitable Bayesian estimations effect (Patel et al., 2006). These should be taken into account to a greater extent than they are currently, since they would solve certain matters concerning the classic statistical significance used nowadays or the study of DCM in seeded or unseeded resting situations for a wider study of ROIs.
According to the recommendations by Stephan et al. (2010), we are interested in inferring neurophysiological mechanisms in terms of the statistical inference effect (excitatory or inhibitory impact) using the information derived from the SEM models as a prior. We are focusing on determining the task’s impact causal effect, with group distinction according to the effective connectivity between statistically significant ROIs in a first-level analysis of the comparison of blocks in each task. This analysis is conducted separately in each group.
Despite the limited empirical evidence in this field (using orthographic tasks in Spanish-speaking populations) we expected the DCM models to be different for the two groups considered, that is, more complex in the A–B task for the LSS group than for the HSS group. In contrast, for the C–D task, we expected the models fitted in the HSS group to be more complex than those in the LSS group because the former had to complete both tasks (spelling and visuoperceptual recognition).
In any case, Saur et al. (2010) – in an auditory comprehension task – find a statistically significant effect in several ROIs, which is very similar to what our data and results show. Despite that, our objective has no strict anatomical support. As is usual in many other connectivity models, little evidence exists about the anatomic viability of the DCM results.
Results
Behavioral
A multivariate analysis of the variance (MANOVA) was conducted by using orthographic competence (High or Low) as a factor between the two groups and the four programmed blocks as an intra-group factor (A, B, C, and D), defining the subjects’ ages as a covariant to extract the components caused by that factor and the following dependent variables: the number of correct answers given in each block, and the simple reaction time in each subject’s answer to the 20 tries in each experimental condition.
Clearly significant was the interaction between Group and Blocks concerning the number of correct answers (F = 5.017; p = 0.010; η2 = 0.442). The HSS group presents better performance in both spelling recognition tasks blocks than the LSS group, whereas performance is similar for both groups in the visuoperceptual recognition task. Also for the reaction time, the interaction between the Group and the Blocks was statistically significant (F = 25.554; p < 0.001; η2 = 0.801).
Finally, the main effect linked to the group effect for the reaction time (F = 13.367; p = 0.001; η2 = 0.389) was also statistically significant. The HSS group was faster than the LSS group in both blocks of the spelling recognition tasks but, in the visuoperceptual recognition task, the HSS group was slower in block C than the LSS group, and the opposite effect in block D.
Neither the effect of age as a covariant nor its interaction with the block or the group of belonging turned out statistically significant. To prevent the possible “double dipping” effect described by Kriegeskorte et al. (2009), all contrasts were made by orthogonal coefficients so that the effects were not overestimated and, likewise, the significances of this phase were carried out under the false discovery rate (FDR) criteria with p < 0.001. A more detailed display of these results may be consulted in a previous analysis in (Zarabozo-Hurtado et al., under revision). Table 1 presents a brief statistical description (mean and SD) of the behavioral results for an analysis of the aforementioned performance of the different groups.

TABLE 1. Descriptive statistical results, mean and standard deviation (SD) for the number of correct answers and the reaction time for each experimental condition.
We conducted an analysis of the SPM algorithm’s linear model (Friston et al., 2007). All the analyses were conducted for each group and task comparing the two blocks in each task. For each group we worked with the average image of each subject obtained in the first-level analysis. The first-level analysis through multiple comparisons with complete factorial ANOVA differentiated by groups and tasks – with a final FDR of α = 0.001 – showed that the statistically significant activations appeared bilaterally, mainly in two large groupings located in the inferior temporal gyrus, predominantly in the left hemisphere, and in the middle temporal gyrus, predominantly in the right hemisphere. In the LSS group, we also spotted activations in the right hemisphere’s supramarginal gyrus and in the middle portion of the frontal gyrus in the left hemisphere. Likewise, this group presented activations in subcortical regions such as the cerebellum, the parahippocampal gyrus, and the anterior cingulate region, all of them in the left hemisphere. Conversely, the group analysis of HSS unveils activation in a small grouping located in the right hemisphere’s pre-central gyrus. The exact location of these activations can be seen in Table 2 (Zarabozo-Hurtado et al., under revision) and are represented in Figures 2A,B and 3.
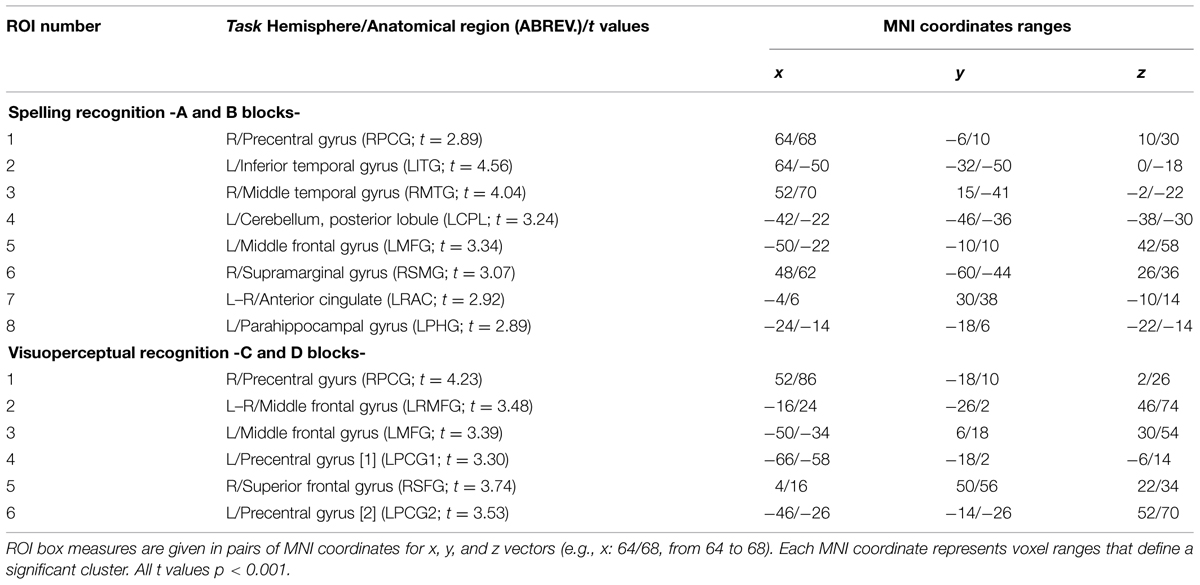
TABLE 2. Definition of Regions of interest (ROI) from activations by group and task.
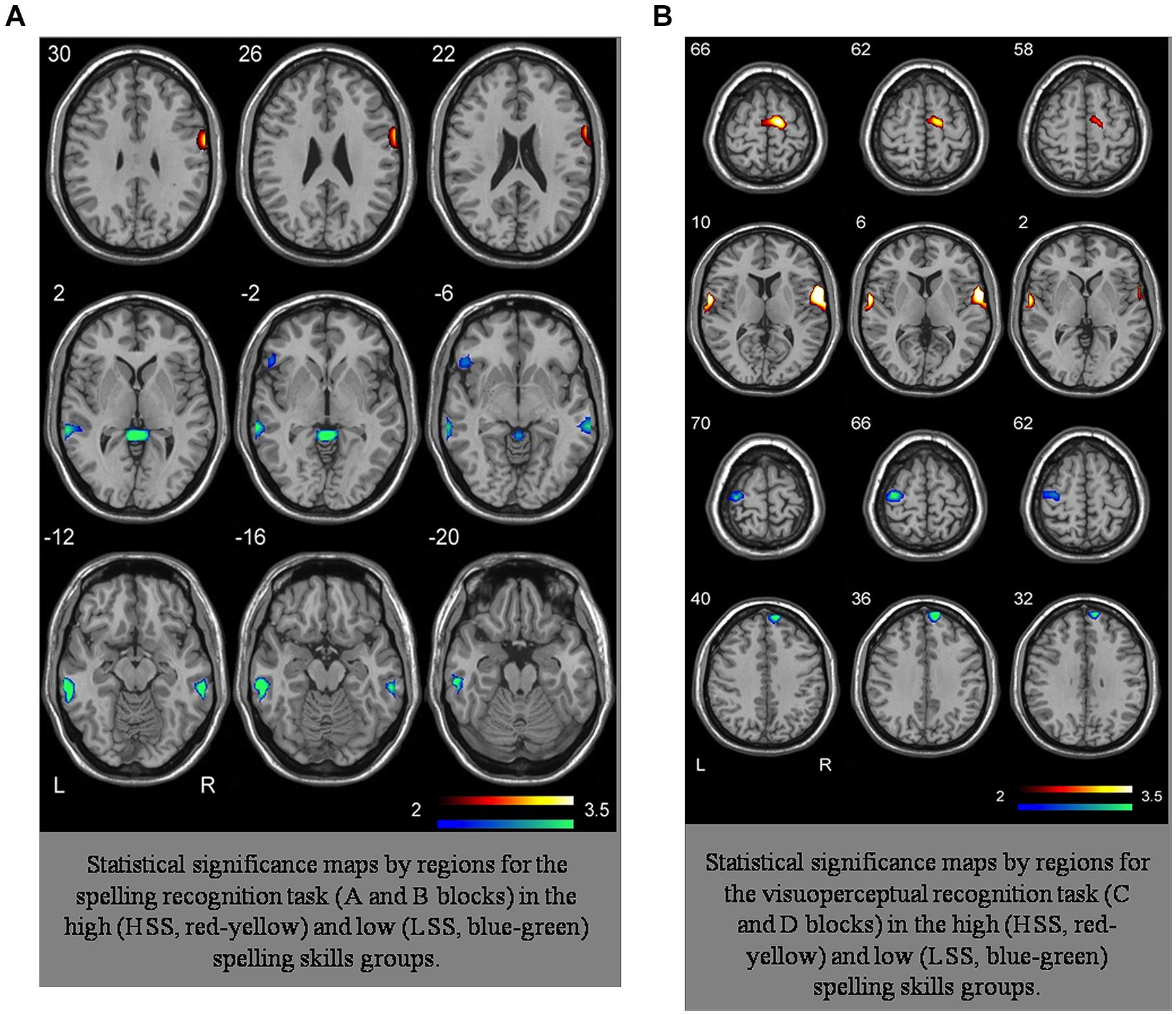
FIGURE 2. (A) Representation of activation loci in A–B tasks HSS group and LSS group. (B) Representation of activation loci in C–D tasks HSS group and LSS group.
The extraction of ROIs was data driven. We selected the most significant signal values for each region by defining an area of 5 mm and conducting a Component Principal Analysis to extract the ROI. For each cluster we presented the t value for each group, first the HSS group and then the LSS group. In all the cases, we obtained p < 0.00001 after Bonferroni correction. The minimum number of voxels per significant cluster was 22.
Based on the results above and consequently following a data-driven strategy, we extracted the ROIs values for the four first-level analyses conducted through MarsBar by defining, for each significant area, a 5-mm volume around the most statistically significant voxel for each significant cluster. We used a threshold = 3, and obtained the value derived from the first component of the principal component analysis (PCA). Thus we generated the resulting score in a standardized scale with a mean = 100. In all the cases, the percentage of variance explained by the first component ranged between 84.5 and 92.1%, which guaranteed the first component’s reliability. Likewise, we estimated, for each task and group, Pearson’s product-moment correlations matrix in order to begin the parameter estimation. Table 3 displays the values of the correlations estimated between the previously defined ROIs.
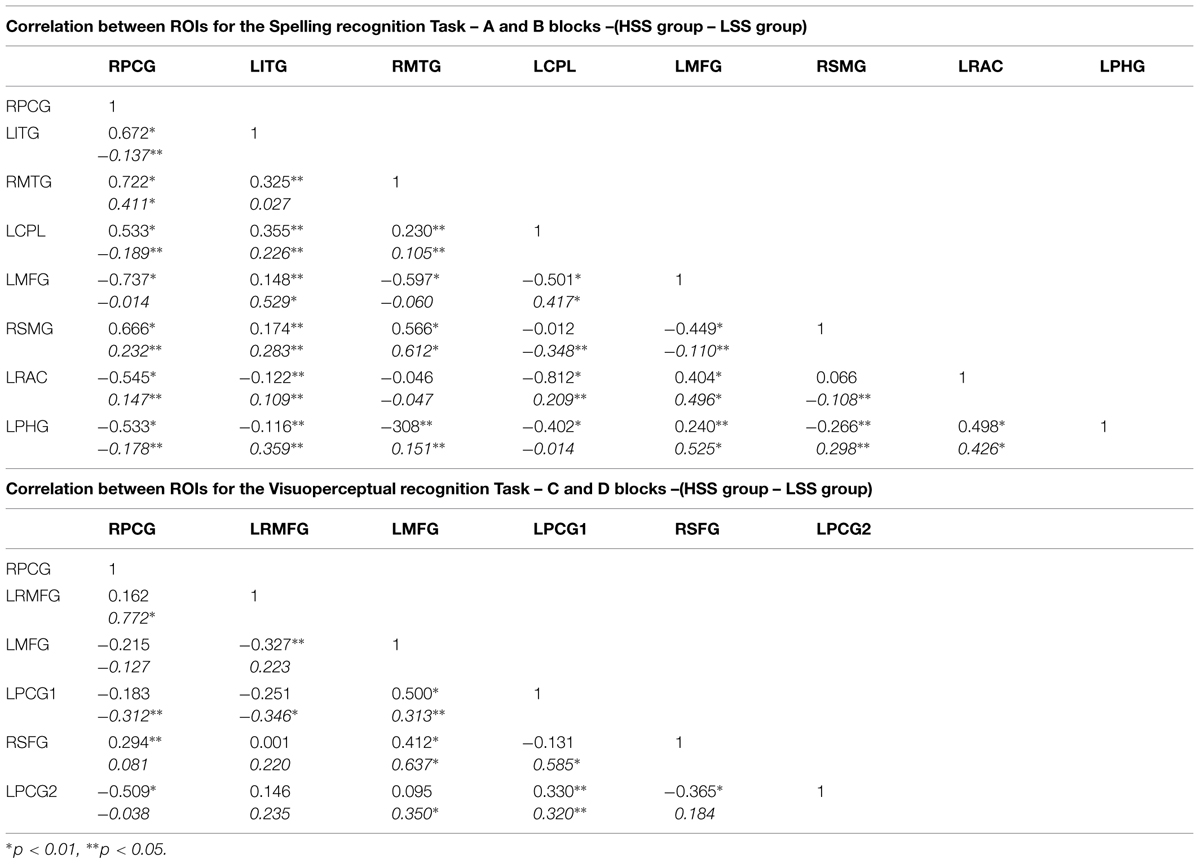
TABLE 3. Correlation matrix between ROIs for the AB task (spelling recognition) and for the CD task (visuoperceptual recognition) for the two competence groups (High or Low).
ROIs for the Spelling Recognition Task
RPCG (Right Precentral Gyrus), LITG (Left Inferior Temporal Gyrus), RMTG (Right Middle Temporal Gyrus), LCPL (Left Cerebellum Posterior Lobule), LMFG (Left Middle Frontal Gyurs), RSMG (Right Supramarginal Gyrus), LRAC (Left–Right Anterior Cingulate), LPHG (Left Parahippocampal Gyrus).
ROIs for the Visuoperceptual Recognition Task
RPCG (Right Precentral Gyrus), LRMFG (Left–Right Middle Frontal Gyrus), LMFG (Left Middle Frontal Gyrus), LPCG1 (Left Precentral Gyrus 1), RSFG (Right Superior Frontal Gyrus), LPCG2 (Left Precentral Gyrus 2).
Structural Equation Model Estimation
In order to estimate effective connectivity, each correlation matrix was submitted to the procedure described by Inman et al. (2012) in order to obtain the best possible model regarding fit. To achieve that, we opted for a conventional ML estimation based on the previous correlations; we set unrestricted parameter estimation and adopted the usual assumptions of SEM. In this case, they had been adapted to the Path Analysis’ characteristics, given the lack of latent variables. Therefore, we assumed that E(Yi) = 0 and Var(Yi) = 1. In consequence, all the variables were reduced and normalized and E(ζiζj) = E(Yiζj) = 0; the structural errors are not correlated between themselves or between the observed variables. For these calculations, we used the Mplus software bootstrap estimation and simulation routines for the standard errors, and we analyzed each possible effect combination with regard to the null model. Additionally we also analyzed, in each case, the values of the indexes of fit and the results of Akaike’s criteria (AIC), and the Bayesian information criteria (BIC).
The results of the models with the best fit are summarized in Table 4. To select them, we eliminated those models which turned out unidentified, those which did not converge in the estimation process, and those whose solution presented incorrect fits. Specifically, we discarded those whose p value associated to the χ2 fit test was below 0.10. Additionally, we also discarded those whose values in the Tucker Lewis index (TLI), comparative fit index (CFI), goodness of fit index (GFI), and adjusted goodness of fit index (AGFI) which were not over.95. Lastly, we also discarded those whose standardized mean residuals (SMRs) values were not below 0.10.
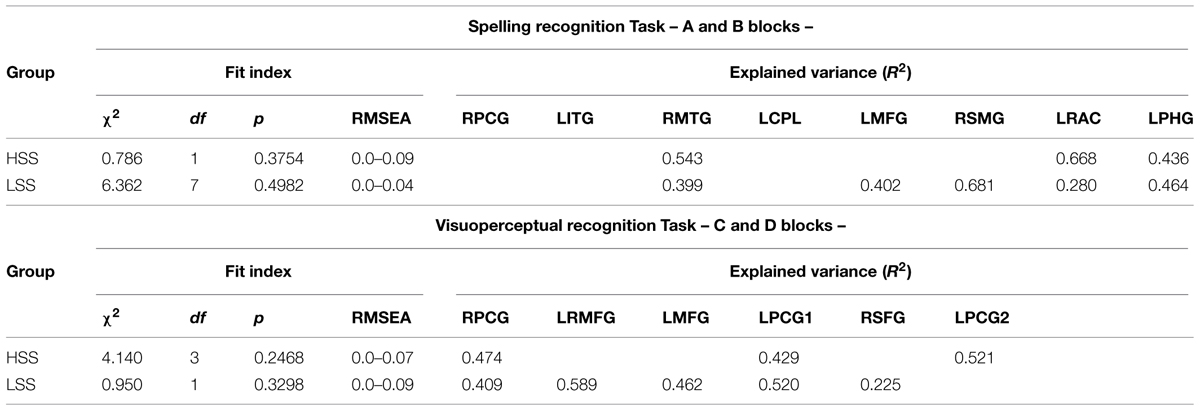
TABLE 4. Fit index for the best models under SEM approach for each task and groups.
Out of all the models complying with the above criteria, we selected, for each condition, those offering the best fit and the highest value in the determination coefficient (R2) estimated for each endogenous variable.
ROIs for the Spelling Recognition Task
RPCG (Right Precentral Gyrus), LITG (Left Inferior Temporal Gyrus), RMTG (Right Middle Temporal Gyrus), LCPL (Left Cerebellum Posterior Lobule), LMFG (Left Middle Frontal Gyurs), RSMG (Right Supramarginal Gyrus), LRAC (Left–Right Anterior Cingulate), LPHG (Left Parahippocampal Gyrus).
ROIs for the Visuoperceptual Recognition Task
RPCG (Right Precentral Gyrus), LRMFG (Left–Right Middle Frontal Gyrus), LMFG (Left Middle Frontal Gyrus), LPCG1 (Left Precentral Gyrus 1), RSFG (Right Superior Frontal Gyrus), LPCG2 (Left Precentral Gyrus 2).
Finally, the path diagrams for each model representing the standardized parameters ML estimation are shown in the Figure 3.
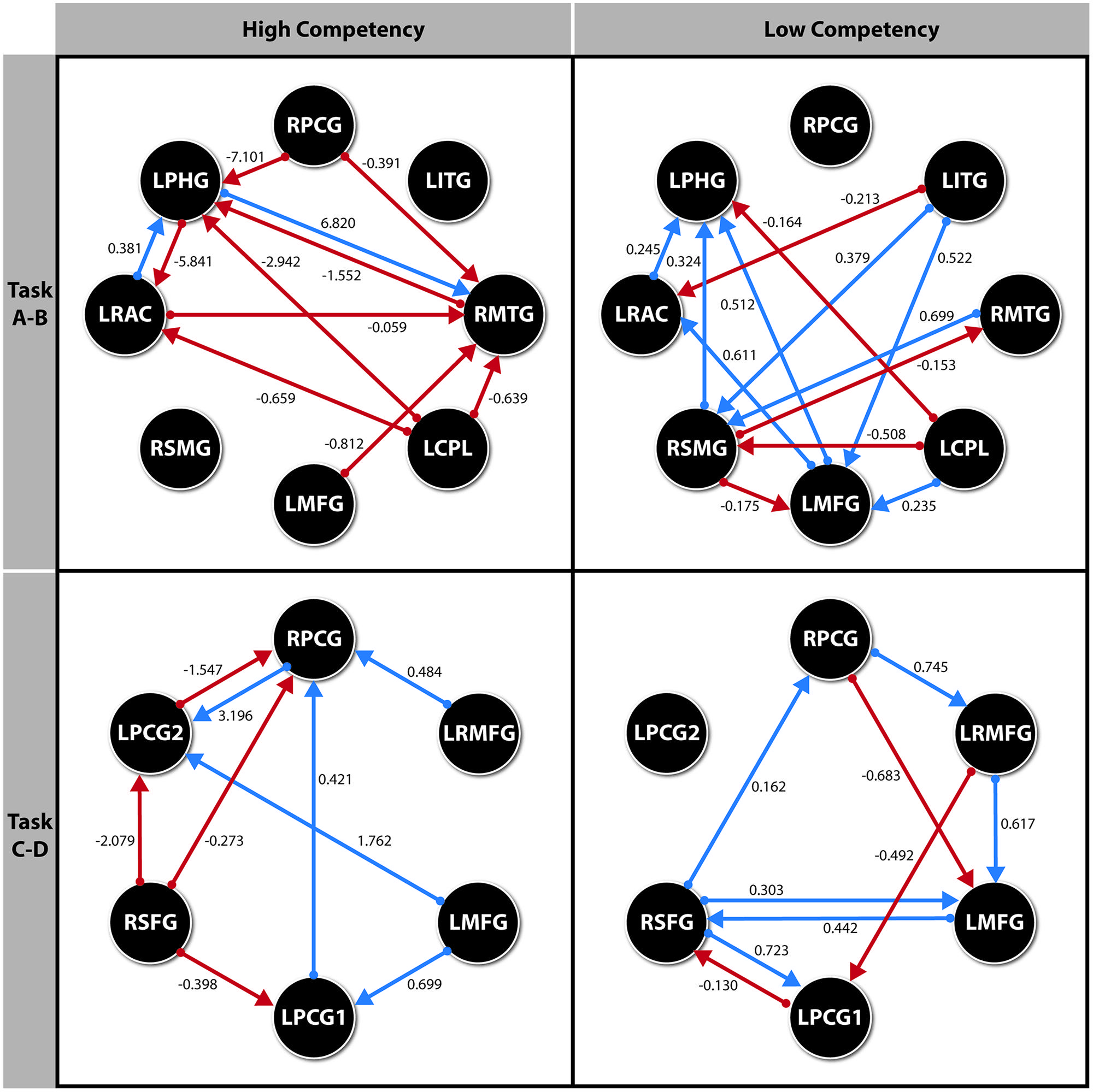
FIGURE 3. Path diagram for each model with the parameter values for each significant direct effect. All effects p < 0.05. ROI’s for Spelling recognition Task. RPCG (Right Precentral Gyrus), LITG (Left Inferior Temporal Gyrus), RMTG (Right Middle Temporal Gyrus), LCPL (Left Cerebellum Posterior Lobule), LMFG (Left Middle Frontal Gyurs), RSMG (Right Supramarginal Gyrus), LRAC (Left–Right Anterior Cingulate), LPHG (Left Parahippocampal Gyrus). ROI’s for Visuoperceptual recognition Task. RPCG (Right Precentral Gyrus), LRMFG (Left–Right Middle Frontal Gyrus), LMFG (Left Middle Frontal Gyrus), LPCG1 (Left Precentral Gyrus 1), RSFG (Right Superior Frontal Gyrus), LPCG2 (Left Precentral Gyrus 2).
As we can observe in Figure 2, the complexity of the connectivity network is more complex in the LSS group than in the HSS group for the spelling recognition task (AB blocks). In the LSS, 13 paths (seven with positive effect) were defined among the eight ROIs analyzed but in fact the RPCG ROI is not connected to the rest of ROIs. 11 paths (three of them with positive effect) were defined in the HSS group among the ROIs, but in fact the RSMG ROI is not connected to the rest of ROIs.
As for the HSS group, only three ROIs received connections from the other ROIs (right parietal gyrus, LRAC, and RMTG), whereas in the LSS group, five ROIs received connections from the other ROIs involved in the system (right parietal gyrus, LRAC, RMTG, LMFG and RSMG).
For the visuoperceptual recognition task the complexity of the connectivity network is similar in both groups. Eleven paths were defined for both, but the connectivity structure is different: in the LSS group, all the ROIs involved in the connectivity network receive connections from at least one of the other ROIs of the system.
Dynamic Causal Modeling
This paper analyzes the DCM models in each of the two groups of orthographic competence (High and Low) in the two tasks presented: A–B (spelling recognition task), and C–D (visuoperceptual recognition task). Therefore, four DCM models were generated based on the average values of each group’s twelve subjects under every condition.
However, the analysis of the results obtained by SEM indicate that, in the case of the subjects with high orthographic competence when solving the A–B task, their levels of significance are of little statistical intensity, except for the ROI defined by the right pre-central gyrus (Zarabozo-Hurtado et al., under revision).
Thus being the case, and in light of the presence of only one statistically relevant ROI, we decided to discard the DCM model for this group and task, so that, ultimately, the remaining three models were studied with several significant ROIs. To do this, we followed the recommended steps by Stephan et al. (2010) in order to guarantee the definition of space and the causal effects in the parameter structure inference, using an optimal Bayesian parameter averaging and defining fixed effects, as usual.
The estimations of the three remaining DCM models are displayed in Figure 4. As we can see the connectivity network for the visuoperceptual recognition task is more complex in the HSS group than in the LSS group. In the HSS group, four ROIs are involved in the system and interconnected to each other. Instead, for the LSS group, only two interconnected ROIs are involved in the system.
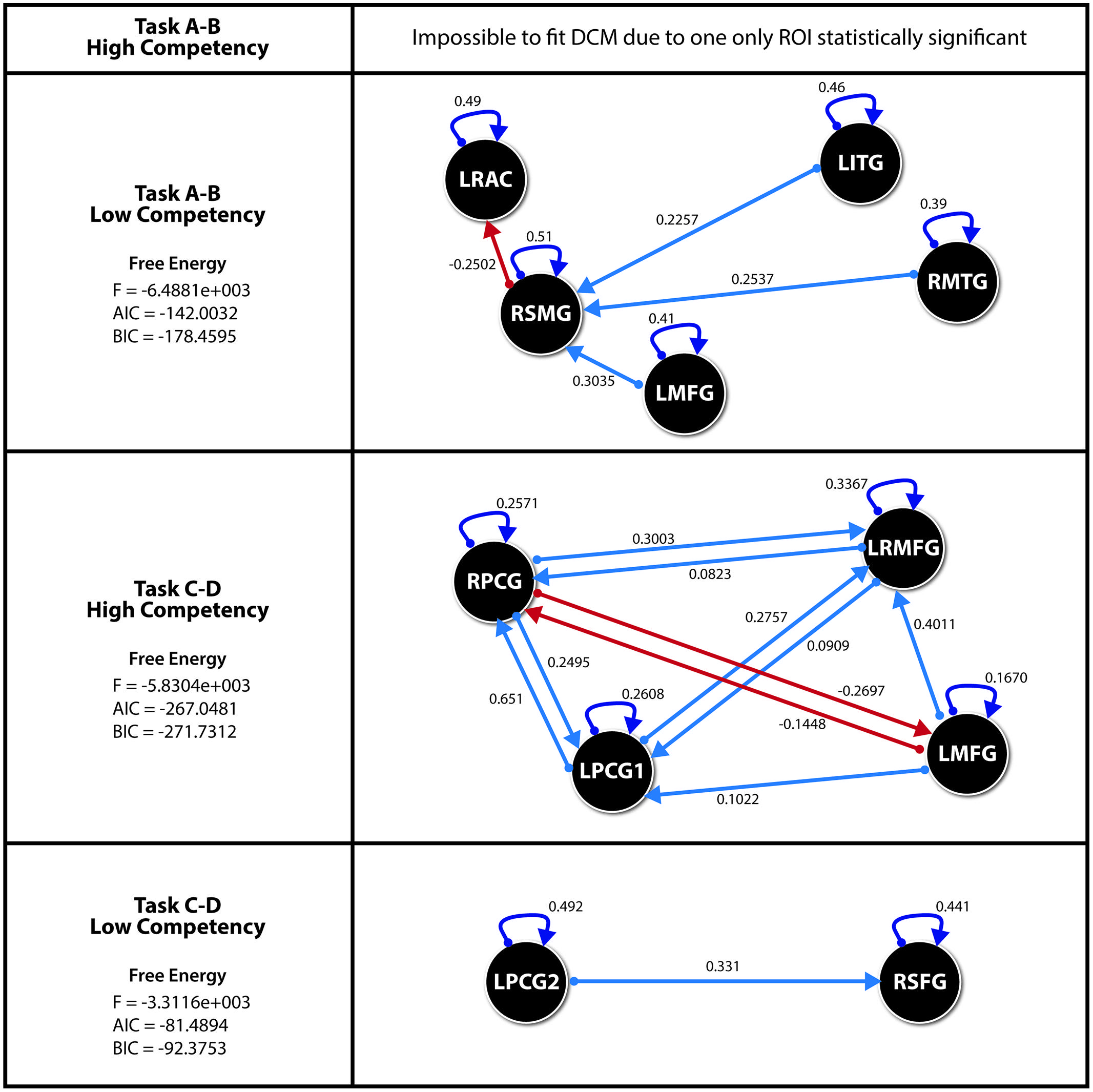
FIGURE 4. Effects for each DCM with the parameter values for each significant direct effect. All effects p < 0.05. ROI’s for Spelling recognition Task. LITG (Left Inferior Temporal Gyrus), RMTG (Right Middle Temporal Gyrus), LMFG (Left Middle Frontal Gyurs), RSMG (Right Supramarginal Gyrus), LRAC (Left–Right Anterior Cingulate). ROI’s for Visuoperceptual recognition Task. RPCG (Right Precentral Gyrus), LRMFG (Left–Right Middle Frontal Gyrus), LMFG (Left Middle Frontal Gyrus), LPCG1 (Left Precentral Gyrus 1), RSFG (Right Superior Frontal Gyrus), LPCG2 (Left Precentral Gyrus 2). Akaike information criteria (AIC), Bayesian information criteria (BIC).
It is also important to mention than the ROIs involved are different in both groups.
Discussion and Conclusion
We studied the possible differences in detecting homophone orthographic errors in the neurobiological substrate by using two approaches: analyzing the effective connectivity model estimated through SEM and DCM. In order to study this phenomenon, two tasks were used: a spelling recognition task, and a visuoperceptual recognition task. These were applied to two groups of subjects, one with HSS, and another with LSS (Zarabozo-Hurtado et al., under revision).
According to the results while performing the spelling recognition task, the LSS group showed poorer behavioral performance (fewer correct answers and higher reaction times) as compared to the HSS group. Given that the early stages of the reading process involve encoding and orthographical-phonological conversion, these data suggest that, globally, this cognitive process is different in the LSS and HSS groups.
The SEM results of the HSS group suggest that, in the spelling recognition task, two brain areas are involved in the majority of significant effects: the RMTG, and, to a lesser extent, the LPHG. In the LSS group, however, the majority of significant effects are received in the LPHG, and, to a lesser extent, the RSMG. The latter anatomical region has been reported in different studies under transparent orthographies as visual to a phonological encoder (Wimmer et al., 2010; Gebauer et al., 2012).
In this sense, we should mention that the LSS group probably presents activations in the supramarginal gyrus as a compensatory mechanism, since these subjects do not present the temporal-occipital activations shown by the HSS group and which are usually observed in reading tasks in healthy persons. For us this means that the LSS subjects must use this compensatory mechanism to access other later reading processes. This is a consistent result in papers studying reading in transparent languages and, in this sense, our results are similar to those in Booth et al. (2002, 2004) and Gebauer et al. (2012).
We should point out that such compensatory mechanism in readers of transparent orthographies is observed rather generally in persons with reading deficiencies, as shown by the recent meta-analyses by Maisog et al. (2008) and Richlan et al. (2009).
Additionally, the intensity of these effects both in the most active brain areas during the task and in the rest of ROIs is much less intense in the LSS group than in the HSS group. In the spelling recognition task, the connectivity model is very different between the HSS and the LSS groups. On the one hand, in the former, the ROI receiving the most significant effects is the LPHG, whereas for the LSS group, it is the LMFG. Once again, the most intense effects appear in the HSS group, while they are much more diffuse in the LSS group.
Along with the behavioral data, and given that the early stages of the reading process involve encoding and orthographical-phonological conversion, these data suggest that, globally, we can conclude that the effective connectivity pattern during the spelling recognition task is different between HSS and LSS subjects. The behavioral performance data, which shows that the LSS group performed worse in the task than the HSS group, all of it suggests that the reading process is globally different between the HSS and LSS groups. This had already been proposed in previous neuroimaging studies (Georgiewa et al., 2002; Landi et al., 2010; Wimmer et al., 2010).
In addition, in a broader sense, our results agree with those of Pugh et al. (2000), a study in which they used phonological processing tasks, orthographic processing tasks, and tasks combining both cognitive processes. Their results suggest that dyslexic subjects showed a weaker connectivity pattern than the pattern shown by normal subjects when they solved the task implying both phonological and orthographic decisions.
The DCM results of our study show an effective connectivity pattern quite different from the SEM connectivity pattern. Firstly, in the spelling recognition task in the HSS group, for whom the task is easier due to their probable visual word processing expertise, the DCM model was not estimated due to the fact that only one ROI presented statistically significant activations.
Conversely, in the LSS group, we found significant connectivity patterns between the LMFG, the RMTG, and the LITG toward the RSFG. However, as was the case in the effective connectivity analysis through SEM, the intensity of these effects as well as the intensity of each ROI’s self-activation with itself is small.
These data suggest again that, in both groups, reading is a globally different process in terms of brain activation. The impossibility to estimate DCM in the HSS group is due to the fact that only one ROI reaches statistical activation and in consequence it is impossible to estimate connectivity models.
This situation means that – for this group – there are a smaller number of activated clusters that can explain a statistical model. Strictly speaking, there are no other statistical effects other than the self-correlation effects for this specific ROI. It might be thought that the subjects with high skills found so little difficulty in the spelling task that they did not need special connectivity networks to meet the demand. This would be consistent with some previous results by Zarabozo-Hurtado et al. (under revision) showing similar effects in the estimation of simple effects. The lack of papers on connectivity in this type of task for this specific population prevents us from delving further into the discussion of this aspect.
Conversely, in the LSS group, the DCM pattern is more complex than in the HSS group. In fact, these results are congruent with those found by Saur et al. (2010).
Some studies suggest that individuals with reading problems present a series of compensatory mechanisms at brain level when facing the complexity it means for them to execute this cognitive task (Sandak et al., 2004; Gebauer et al., 2012). These data support our results. The DCM results of the visuoperceptual recognition task show that, in the LSS group, there is only one significant effect of the left pre-central gyrus toward the RSFG. The group of good readers, instead, presents a more complex effective connectivity pattern, where the precentral gyrus of both hemispheres receives the majority of the effects, although they are of low intensity. This could represent that the HSS group is consistently mapping between orthography and phonology, even though orthographic recognition was not requested in this task.
The fact that it is the subjects from the HSS group presenting the more complex DCM model, however, is not as surprising as it might seem. The execution of a relatively simple task, such as finding a letter in a word, which was executed correctly by the low-spelling skills group, might be affected by the automatization of the orthographic processing of words, where the presence of orthographic errors increases the task’s difficulty only for those subjects who have developed a specialization in recognizing orthographic patterns, like the HSS group had.
However, in adults with low orthographic abilities, an orthographic violation is not automatically processed, probably due to weaker orthographic representations in long term memory or to a poorer development of the orthographic lexicon. In other words, the subjects from the HSS group, in the C-D pair of blocks (visuoperceptual recognition task) would be conducting two tasks at once: vowel detection, as requested, and, involuntarily or automatically, orthographic mapping.
Despite the above comments in relation to HSS group, it is important to bear in mind the small sample size used to estimate the statistical effects. There are several DCM models estimated with small sample sizes, but there is not enough evidence about the effects of sample size on the connectivity modelization process (Benetti et al., 2009; Sato et al., 2009; Rowe, 2010).
Our paper presents some limitations that need to be discussed. The main limitation, in our opinion, is the fact that the subjects were selected among students in the senior year of high school and, in light of their reading performance, some subjects from the LSS group might have been dyslexic but, as far as we know, none of them had been diagnosed previously. In other words, some of the participants from this group might have suffered from a relatively mild form of dyslexia that would have been compensated by their own means allowing them to reach the senior year. On the other hand, no measurement or estimation instrument was applied to them for intellect, which might have also influenced their performance in this study’s tasks.
Nonetheless, these limitations need to be clarified. Firstly, the orthographic abilities tests used to form the groups were very thorough, which allowed us to form the HSS and LSS groups with wide knowledge of the subjects’ reading performance at the moment of inclusion in the study, and it also allowed us to have much intra-group homogeneity as regards their current reading skills. Additionally, the fact that all the subjects, both HSS and LSS, were students from the same degree of high school makes it unlikely that there were great differences in the general intellectual functioning of both groups, which makes our results hardly questionable in this sense.
We would also like to note that, to conduct this study, a 1.5T scanner was used with a TR of 3. There is a possibility that, with a 3T scanner, the DCM model could be estimated for the HSS group in the spelling recognition task. However, our data suggest that, in that case, our results would point in the same direction, that is, a very simple DCM model in the HSS group when compared to the LSS group, thus suggesting that the task is easy for these subjects. Still, even if these conditions are not ideal for connectivity studies, recent studies on effective connectivity have used similar equipment to the one used in the present study (Hildebrant et al., 2013).
Another limitation of our study is the sample size we selected, which may be considered rather small. However, this should be seen as a relative limitation. The criteria to confirm the groups were strict, and the method of assignment to the groups, following the extreme values technique, allowed us to maximize the possible differences. This made data interpretation rather clear in terms of brain activation despite the relatively small sample size (Friston, 1998, 2012; Logothetis, 2002). Apart from the sample size, the regularity of the effects and the activations found in the intra-group effects guarantee the homogeneity of the sampling and the correct application of the experimental procedure. In any case, it might be important to dedicate some efforts through simulation procedures to estimate the impact and effect of the sample size on the estimation of models for connectivity, SEM and DCM.
Our paper also has some strengths that deserve comment. The most remarkable one is that this is, to our knowledge, the first paper exploring the effective connectivity model, estimated through SEM, and the efficient connectivity model, estimated through DCM, in a visual recognition task of homophone errors in Spanish, while at the same time controlling the subjects’ level of orthographic competence and, consequently, separating those with a high level from those with a low level of competence. As has been commented above, this type of error is characteristic of transparent languages, especially of the variety of Spanish spoken in different parts of Latin America. In this sense, our results are particularly interesting, given that this type of orthographic errors is characteristic and very usual of transparent languages, where reading as a cognitive function has some distinctive features.
More studies should be analyzed to see whether the activation patterns observed in this study are found when facing detection tasks of other types of orthographic errors, or, on the contrary, homophone error detection activates a pattern in good and bad readers somewhat different from other types of errors. In the future, we should obtain more detailed information about brain activities in order to analyze more statistically complex models like Farràs et al. (under revision) suggest.
To conclude, we can say that taken globally, the analyses of the connectivity of the tasks under study through SEM and through DCM present some similarities. The first one is that both the SEM and the DCM models show distinctive connectivity patterns between the HSS and LSS groups. Likewise, both types of analyses suggest patterns with effective connectivity in one case (SEM) and the other (DCM) that are much clearer and with more intense effects in the case of the HSS group as compared to the LSS group. This is much clearer, obviously, in the case of the visuoperceptual recognition task.
Nonetheless, they also present important differences. The DCM models are very different between both groups under study, for the spelling and visuoperceptual recognition tasks. In fact, the DCM models probably reflect somewhat better what happens with the behavioral conduct of the tasks under study. A clear interaction effect was revealed between group and task, so that the HSS group conducted the spelling recognition task more efficiently than the LSS group. Likewise, as we commented above, in the visuoperceptual recognition task, the effective connectivity pattern was more complex in the HSS group than in the LSS group. However, it was due to the fact that the subjects who are good readers probably carry out both tasks at the same time, whereas the LSS subjects would only carry out the visuoperceptual vowel recognition task, their reading being much less automatized than that of the good readers.
Furthermore, we consider it important to remark that it is essential to continue with this research line. It might be interesting to analyze the ROIs that emerge when we request the subjects to conduct an automatic process by differentiating HSS and LSS groups, like the Stroop task. Another important line to continue is the analysis of people who have in fact a real orthographic problem, for example working with dyslexic persons as compared to persons with good competences in orthography.
Finally, these data point in two complementary directions for future research. Firstly, we should approach the estimation of connectivity models when faced with these tasks or similar ones with samples from the same populations but with a larger amount of ROIs, not just the ones generated from data-driven approaches. Instead, more theoretical models should be analyzed and their possibilities of empirical and statistical evidence evaluated for viability. Secondly, we must work in a more structured way on the analysis of limitations and possible improvements of the statistical models we use to estimate connectivity since they involve a special conception of the way connectivity works and it entails a specific way to understand that complex reality.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This study was supported by the Grup de Recerca en Tècniques Estadístiques Avançades Aplicades a la Psicologia (GTEAAP) members of the Generalitat de Catalunya’s 2014 SGR 326 Consolidated Research Group (GRC) and was made possible by the PSI2013-41400-P project of Ministerio de Economia y Competitividad of Spanish Government.
References
Allen, P. A., Smith, A. F., Lien, M. C., Kaut, K. P., and Canfield, A. (2009). A multistream model of visual word recognition. Atten. Percept. Psychophys. 71, 281–296. doi: 10.3758/APP.71.2.281
Astolfi, L., Cincotti, F., Mattia, D., Salinari, S., Babiloni, C., Basilisco, A., et al. (2004). Estimations of the effective and functional human cortical connectivity with structural equation modeling and directed transfer function applied to high-resolution EEG. Magn. Reson. Imaging 22, 1457–1470. doi: 10.1016/j.mri.2004.10.006
Bahr, R. H., Silliman, E. R., Berninger, V. W., and Dow, M. (2012). Linguistic pattern analysis of misspellings of typically developing writers in grades 1 to 9. J. Speech Lang. Hear. Res. 55, 1587–1599. doi: 10.1044/1092-4388(2012/10-0335)
Benetti, S., Mechelli, A., Picchioni, M., Broome, M., Williams, S., and McGuire, P. (2009). Functional integration between the posterior hippocampus and prefrontal cortex is impaired in both first episode schizophrenia and the at risk mental state. Brain 132, 2426–2436. doi: 10.1093/brain/awp098
Berninger, V., and Richards, T. (2002). “Building a reading brain neurologically,” in Brain Literacy for Educators and Psychologists, eds V. Berninger and T. Richards (San Diego: Elsevier), 111–167.
Binder, J. R., Medler, D. A., Westbury, C. F., Liebenthal, E., and Buchanan, L. (2006). Tuning of the human left fusiform gyrus to sublexical orthographic structure. Neuroimage 33, 739–748. doi: 10.1016/j.neuroimage.2006.06.053
Brett, M., Anton, J. L., Valabregue, R., and Poline, J. B. (2002). “Region of interest analysis using an SPM toolbox [abstract],” in Proceedings of the Presented at the 8th International Conference on Functional Mapping of the Human Brain, June 2-6, 2002, Sendai.
Booth, J., Burnman, D., Meyer, J., Gitelman, D., Parrish, T., and Mesulam, M. (2002). Functional anatomy of intra- and cross-modal lexical tasks. Neuroimage 16, 7–22. doi: 10.1006/nimg.2002.1081
Booth, J., Burnman, D., Meyer, J., Gitelman, D., Parrish, T., and Mesulam, M. (2004). Development of brain mechanisms for processing orthographic and phonologic representations. J. Cogn. Neurosci. 16, 1234–1249. doi: 10.1162/0898929041920496
Caclin, A., and Fonlupt, P. (2006). Effect of initial fMRI data modeling on the connectivity reported between brain areas. Neuroimage 33, 515–521. doi: 10.1016/j.neuroimage.2006.07.019
Carballedo, A., Scheuerecker, J., Meisenzahl, E., Schoepf, V., Bokde, A., Möller, H., et al. (2011). Functional connectivity of emotional processing in depression. J. Affect. Disord. 134, 272–279. doi: 10.1016/j.jad.2011.06.021
Charlton, R. A., Landau, S., Schiavone, F., Barrick, T. R., Clark, C. A., Markus, H. S., et al. (2008). A structural equation modeling investigation of age-related variance in executive function and DTI measured white matter damage. Neurobiol. Aging 29, 1547–1555. doi: 10.1016/j.neurobiolaging.2007.03.017
Chen, G., Glen, D. R., Saad, Z. S., Hamilton, J. P., Thomason, M. E., Gotlib, I. H., et al. (2011). Vector autoregressive, structural equation modeling, and their synthesis in neuroimaging data analysis. Comput. Biol. Med. 41, 1142–1155. doi: 10.1016/j.compbiomed.2011.09.004
Cohen, L., Dehaene, S., Naccache, L., Lehéricy, S., Dehaene-Lambertz, G., Hénaff, M. A., et al. (2000). The visual word form area. Spatial and temporal characterization on an initial stage of reading in normal subjects and posterior split-brain patients. Brain 123, 291–307. doi: 10.1093/brain/123.2.291
Cohen, L., Lehéricy, S., Chochon, F., Lemer, C., Rivaud, S., and Dehaene, S. (2002). Language-specific tuning of visual cortex? Functional properties of the visual word forma area. Brain 125, 1054–1069. doi: 10.1093/brain/awf094
Coltheart, M., Rastle, K., Perry, C., Langdon, R., and Ziegler, J. (2001). DRC: a dual route cascaded model of visual word recognition and reading aloud. Psychol. Rev. 108, 204–256. doi: 10.1037/0033-295X.108.1.204
Davies, R., Cuetos, F., and González-Seijas, R. M. (2007). Reading development and dyslexia in a transparent orthography: a survey of Spanish children. Ann. Dyslexia 57, 179–198. doi: 10.1007/s11881-007-0010-1
Dehaene, S., Le Clec’H, G., Poline, J. B., LeBihan, D., and Cohen, L. (2002). The visual word form area: a prelexical representation of visual words in the fusiform gyrus. Neuroreport 13, 321–325. doi: 10.1097/00001756-200203040-00015
Devlin, J. T., Jamison, H. L., Gonnerman, L. M., and Matthews, P. M. (2006). The role of the posterior fusiform gyrus in reading. J. Cogn. Neurosci. 18, 911–922. doi: 10.1162/jocn.2006.18.6.911
Dick, A. S., Solodkin, A., and Small, S. L. (2010). Neural development of netwoks for audiovisual speech comprehension. Brain Lang. 114, 101–114. doi: 10.1016/j.bandl.2009.08.005
Erickson, K. I., Ringo Ho, M., Colcombe, S. J., and Kramer, A. F. (2005). A structural equation modeling analysis of attentional control: an event-related fMRI study. Cogn. Brain Res. 22, 349–357. doi: 10.1016/j.cogbrainres.2004.09.004
Fiebach, C. J., Friederici, A. D., Müller, K., and von Cramon, D. Y. (2002). fMRI evidence for dual routes to the mental lexicon in visual word recognition. J. Cogn. Neurosci. 14, 11–23. doi: 10.1162/089892902317205285
Fiez, J. A., and Petersen, S. E. (1998). Neuroimaging studies of word reading. Proc. Natl. Acad. Sci. U.S.A. 95, 914–921. doi: 10.1073/pnas.95.3.914
Friston, K. J. (1998). Imaging neuroscience: principles or maps? Proc. Natl. Acad. Sci. U.S.A. 95, 796–802. doi: 10.1073/pnas.95.3.796
Friston, K. (2012). Ten ironic rules for non-statistical reviewers. Neuroimage 61, 1300–1310. doi: 10.1016/j.neuroimage.2012.04.018
Friston, K. J., Ashburner, J. T., Kiebel, S. J., Nichols, T. E., and Penny, W. D. (2007). Statistical Parametric Mapping. The Analysis of Functional Brain Image. London: Elsevier.
Friston, K. J., Bastos, A., Litvak, V., Stephan, K. E., Fries, P., and Moran, R. J. (2012). DCM for complex-valued data: cross-spectra, coherence and phase-delays. Neuroimage 59, 439–455. doi: 10.1016/j.neuroimage.2011.07.048
Fu, C., McIntosh, A. R., Kim, J., Chau, W., Bullmore, E. T., Williams, S. C. R., et al. (2006). Modulation of effective connectivity by cognitive demand in phonological verbal fluency. Neuroimage 30, 266–271. doi: 10.1016/j.neuroimage.2005.09.035
Gates, K. M., Molenaar, P. C. M., Hillary, F., and Slobpounov, S. (2011). Extendend unified SEM approach for modeling event-related fMRI data. Neuroimage 54, 1151–1158. doi: 10.1016/j.neuroimage.2010.08.051
Gebauer, D., Enzinger, C., Kronbichler, M., Schurz, M., Reishofer, G., Koschutnig, K., et al. (2012). Distinct patterns of brain function in children with isolated spelling impairment: new insights. Neuropsychologia 50, 1353–1361. doi: 10.1016/j.neuropsychologia.2012.02.020
Georgiewa, P., Rzanny, R., Gaser, C., Gerhard, U. J., Vieweg, U., Freesmeyer, D., et al. (2002). Phonological processing in dyslexic children: a study combining functional neuroimaging and event related potentials. Neurosci. Lett. 318, 5–8. doi: 10.1016/S0304-3940(01)02236-4
Glezer, L. S., Jiang, X., and Riesenhuber, M. (2009). Evidence for highly selective neuronal tuning to whole words in the “visual word form area”. Neuron 62, 199–204. doi: 10.1016/j.neuron.2009.03.017
Gómez-Velázquez, F. R., González-Garrido, A. A., and Vega-Gutiérrez, O. L. (2013a). Naming abilities and orthographic recognition during childhood an event-related brain potentials study. Int. J. Psychol. Stud. 5, 55–68. doi: 10.5539/ijps.v5n1p55
Gómez-Velázquez, F. R., González-Garrido, A. A., Guàrdia-Olmos, J., Peró-Cebollero, M., Zarabozo-Hurtado, D., and Zarabozo, D. (2013b). Evaluación del conocimiento ortográfico en adultos jóvenes y su relación con la lectura [Orthographic knowledge evaluation in young adults and its relationship with reading]. Rev. Neurol. Neuropsiquiatría y Neurociencias 14, 40–67.
Gonçalves, M. S., and Hall, D. A. (2003). Connectivity analysis with structural equation modeling: an example of the effects of voxel selection. Neuroimage 20, 1455–1467. doi: 10.1016/S1053-8119(03)00394-X
González-Garrido, A. A., Gómez-Velázquez, F. R., and Rodríguez-Santillán, E. (2014). The orthographic recognition in late adolescents: an assessment through event-related brain potentials. Clin. EEG Neurosci. 45, 113–121. doi: 10.1177/1550059413489975
Hildebrant, H., Dumontheil, I., Blakemore, S. J., and Rosier, J. P. (2013). Dynamic causal modelling of effective connectivity during perspective taking in a communicative task. Neuroimage 76, 116–124. doi: 10.1016/j.neuroimage.2013.02.072
Hills, A. E., Newhart, M., Heidler, J., Barker, P., Herskovits, E., and Degaonkar, M. (2005). The roles of the “visual word form area” in reading. Neuroimage 24, 548–559. doi: 10.1016/j.neuroimage.2004.08.026
Horwitz, B., Tagamets, M. A., and McIntosh, A. R. (1999). Neural modeling, functional brain imaging and cognition. Trends Cogn. Sci. 3, 91–98. doi: 10.1016/S1364-6613(99)01282-6
Inman, C. S., James, G. A., Hamann, S., Rajendra, J. K., Pagnoni, G., and Butler, A. J. (2012). Altered resting-state effective connectivity of fronto-parietal motor control systems on the primary motor network following stroke. Neuroimage 59, 227–237. doi: 10.1016/j.neuroimage.2011.07.083
Karunanayaka, P., Schmithorst, V. J., Vannest, J., Szaflarski, J. R., Plante, E., and Holland, S. K. (2011). A linear structural equation model for covert verb generation based on independent component analysis of fMRI data from children and adolescents. Front. Sys. Neurosci. 5:29. doi: 10.3389/fnsys.2011.00029
Kiebel, S. J., Garrido, M. I., and Friston, K. J. (2007). Dynamic causal modelling of evoked potentials: a reproducibility study. Neuroimage 36, 332–345. doi: 10.1016/j.neuroimage.2007.02.046
Kim, J., and Horwitz, B. (2009). How well does structural equation modeling reveal abnormal brain anatomical connections? An fMRI simulation study. Neuroimage 45, 1190–1198. doi: 10.1016/j.neuroimage.2009.01.006
Kriegeskorte, N., Simmons, W. K., Bellgowan, P., and Baker, C. I. (2009). Circular analysis in systems neuroscience – the dangers of doubledipping. Nat. Neurosci. 12, 535–540. doi: 10.1038/nn.2303
Kronbichler, M., Klackl, J., Richlan, F., Schurz, M., Staffen, W., Ladurner, G., et al. (2008). On the functional neuroanatomy of visual word processing: effects of case and letter deviance. J. Cogn. Neurosci. 21, 222–229. doi: 10.1162/jocn.2009.21002
Landi, N., Mencl, W. E., Frost, S. J., Sandak, R., and Pugh, K. R. (2010). An fMRI study of multimodal semantic and phonological processing in reading disabled adolescents. Annals Dyslexia 60, 102–121. doi: 10.1007/s11881-009-0029-6
Leinonen, S., Müller, K., Leppänen, P. H. T., Aro, M., Ahonen, T., and Lyytinen, H. (2001). Heterogeneity in adult dyslexic readers: relating processing skills to the speed and accuracy of oral text reading. Read. Writ. Interdiscip. J. 14, 265–296. doi: 10.1023/A:1011117620895
Levy, J., Pernet, C., Treserras, S., Boulanouar, K., Aubry, F., Démobet, J. F., et al. (2009). Testing for the dual-route cascade reading model in the brain: an fMRI effective connectivity account of an efficient reading style. PLoS ONE 4:e6675. doi: 10.1371/journal.pone.0006675
Logothetis, N. K. (2002). The neural basis of the blood-oxygen-level-dependent functional magnetic resonance imaging signal. Philos. Trans. R. Soc. Lond. B Biol. Sci. 357, 1003–1037. doi: 10.1098/rstb.2002.1114
Marco, G., Devauchelle, B., and Berquin, P. (2009). Brain functional modeling, what do we measure with fMRI data?. Neurosci. Res. 64, 12–19. doi: 10.1016/j.neures.2009.01.015
Marreiros, A. C., Kiebel, S. J., and Friston, K. (2010). A dynamic causal model study of neuronal population dynamics. Neuroimage 51, 91–101. doi: 10.1016/j.neuroimage.2010.01.098
Marrelec, G., Horwitz, B., Kim, J., Pélégrini, M., Benali, H., and Doyon, J. (2007). Using partial correlation to enhance structural equation modeling of functional MRI data. Magn. Reson. Imaging 25, 1181–1189. doi: 10.1016/j.mri.2007.02.012
Marrelec, G., Krainik, A., Duffau, H., Pélégrini, M., Lehéracy, S., Doyon, J., et al. (2006). Partial correlation for functional brain interactivity investigation in functional MRI. Neuroimage 32, 228–237. doi: 10.1016/j.neuroimage.2005.12.057
Maisog, J. M., Einbinder, E. R., Flowers, D. L., Turkeltaub, P. E., and Eden, G. F. (2008). A meta-analysis of functionalneuroimagingstudies of dyslexia. Ann. N. Y. Acad. Sci. 1145, 237–259. doi: 10.1196/annals.1416.024
Nation, K. (2008). Learning to read words. Q. J. Exp. Psychol. 61, 1121–1133. doi: 10.1080/17470210802034603
Oldfield, R. C. (1971). The assessment and analysis of handedness: the edinburgh inventory. Neuropsychologia 9, 97–113. doi: 10.1016/0028-3932(71)90067-4
Patel, R. S., DuBois Bowman, F., and Rilling, J. K. (2006). A bayesian approach to determining connectivity of the human brain. Hum. Brain Mapp. 27, 267–276. doi: 10.1002/hbm.20182
Penny, W. D., Litvak, V., Fuentemilla, L., Duzel, E., and Friston, K. (2009). Dynamic causal modeling for phase coupling. J. Neurosci. Methods 183, 19–30. doi: 10.1016/j.jneumeth.2009.06.029
Perfetti, C. A., and Bolger, D. J. (2004). The brain might read that way. Sci. Stud. Read. 8, 293–304. doi: 10.1207/s1532799xssr0803_7
Pugh, K. R., Mencl, W. E., Shaywitz, B. A., Shaywitz, S. E., Fulbright, R. K., Constable, R. T., et al. (2000). The angular gyrus in developmental dyslexia: task-specific differences in functional connectivity within posterior cortex. Psychol. Sci. 11, 51–56. doi: 10.1111/1467-9280.00214
Richlan, F., Kronbichler, M., and andWimmer, H. (2009). Functional abnormalities in the dyslexic brain: a quantitative meta-analysis of neuroimaging studies. Hum. Brain Mapp. 30, 3299–3308. doi: 10.1002/hbm.20752
Rowe, J. B. (2010). Connectivity analysis is essential to understand neurological disorders. Front. Sys. Neurosci. 4:144. doi: 10.3389/fnsys.2010.00144
Sandak, R., Mencl, W. E., Frost, S. J., and Pugh, K. R. (2004). The neurobiological basis of skilled and impaired reading: recent findings and new directions. Sci. Stud. Read. 8, 273–292. doi: 10.1207/s1532799xssr0803_6
Sato, J. R., Takahashi, D. Y., Arcuri, S. M., Semeshina, K., Morettin, P. A., and Baccalá, L. A. (2009). Frequency domain connectivity identification: an application of partial directed coherence in fMRI. Hum. Brain Mapp. 30, 452–461. doi: 10.1002/hbm.20513
Saur, D., Schelter, B., Schnell, S., Kratochvil, D., Küpper, H., Kellmeyer, P., et al. (2010). Combining functional and anatomical connectivity reveals brain networks for auditory language comphrehension. Neuroimage 49, 3187–3197. doi: 10.1016/j.neuroimage.2009.11.009
Sebastián, N., Martí, M. A., Carreiras, M. F., and Cuetos, F. (2000). LEXESP. Léxico Informatizado Del Español [LEXESP: Spanish Computerized Lexicon]. Barcelona: Edicions de la Universitat de Barcelona.
Shaiwitz, B. A., Lyon, G. R., and Shaiwitz, S. E. (2006). The role of functional magnetic resonance imaging in understanding reading and dyslexia. Dev. Neuropsychol. 30, 613–632. doi: 10.1207/s15326942dn3001_5
Shaiwitz, B. A., Shaywitz, S. E., Pugh, K. R., Mencl, W. E., Fulbright, R. K., Skudlarski, P., et al. (2002). Disruption of posterior brain systems for reading in children with developmental dyslexia. Biol. Psychiatry 52, 101–110. doi: 10.1016/S0006-3223(02)01365-3
Shaiwitz, S. E., Shaywitz, B. A., Pugh, K. R., Fulbright, R. K., Constable, R. T., Mencl, W. E., et al. (1998). Functional disruption in the organization of the brain for reading in dyslexia. Proc. Natl. Acad. Sci. U.S.A. 95, 2636–2641. doi: 10.1073/pnas.95.5.2636
Stephan, K. E., Penny, W. D, Moran, R. J., den Ouden, H. E. M., Daunizeau, J., and Friston, K. J. (2010). Ten simple rules for dynamic causal modeling. Neuroimage 49, 3099–3109. doi: 10.1016/j.neuroimage.2009.11.015
Taylor, J. G., Krause, B., Shah, N. J., Horwitz, B., and Mueller-Gaertner, H. W. (2010). On the relation between brain images and brain neural networks. Hum. Brain Mapp. 9, 165–182. doi: 10.1002/(SICI)1097-0193(200003)9:3<165::AID-HBM5>3.0.CO;2-P
Temple, E., Poldrack, R. A., Salidis, J., Deutsch, G. K., Tallal, P., Merzenich, M. M., et al. (2001). Disrupted neural responses to phonological and orthographic processing in dyslexic children: an fMRI study. Neuroreport 12, 299–307. doi: 10.1097/00001756-200102120-00024
Torppa, M., Tolvanen, A., Poikkeus, A. M., Eklund, K., Laukkanen, M. K., Leskinen, E., et al. (2007). Reading development subtypes and their early characteristics. Annals Dyslexia 57, 3–32. doi: 10.1007/s11881-007-0003-0
Vitali, P., Tettamanti, M., Abutalebi, J., Ansaldo, A. I., Perani, D., Cappa, S. F., et al. (2010). Generalization of the effects of phonological training for anomia using structural equation modeling: a multiple single-case-study. Neurocase 16, 93–105. doi: 10.1080/13554790903329117
Wimmer, H., and Goswami, U. (1994). The influence of orthographic consistency on reading development: word recognition in English and German children. Cognition 51, 91–103. doi: 10.1016/0010-0277(94)90010-8
Wimmer, H., Schurz, M., Sturm, D., Richlan, F., Klackl, J., Kronbichler, M., et al. (2010). A dual-route perspective on poor reading in a regular orthography: an fMRI study. Cortex 46, 1284–1298. doi: 10.1016/j.cortex.2010.06.004
Wolf, M., Bowers, P. G., and Biddle, K. (2000). Naming-speed processes, timing, and reading: a conceptual review. J. Learn. Disabil. 33, 387–407. doi: 10.1177/002221940003300409
Keywords: fMRI, orthography, homophone errors, reading, structural equation models, dynamic causal modeling
Citation: Guàrdia-Olmos J, Peró-Cebollero M, Zarabozo-Hurtado D, González-Garrido AA and Gudayol-Ferré E (2015) Effective connectivity of visual word recognition and homophone orthographic errors. Front. Psychol. 6:640. doi: 10.3389/fpsyg.2015.00640
Received: 23 January 2015; Accepted: 01 May 2015;
Published online: 20 May 2015.
Edited by:
Jason W. Osborne, University of Louisville, USAReviewed by:
Mercedes Atienza, Universidad Pablo de Olavide, SpainJames T. Townsend, Indiana University, USA
Rodrigo Ramos-Zúñiga, University of Guadalajara, Mexico
Copyright © 2015 Guàrdia-Olmos, Peró-Cebollero, Zarabozo-Hurtado, González-Garrido and Gudayol-Ferré. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Joan Guàrdia-Olmos, Department of Methodology of Behavioral Sciences, School of Psychology, University of Barcelona, Passeig de la Vall d’Hebron 171, 08035 Barcelona, Spain,amd1YXJkaWFAdWIuZWR1