 Arthur Wingfield
Arthur Wingfield- Volen National Center for Complex Systems, Brandeis University, Waltham, MA, USA
The comprehension of spoken language has been characterized by a number of “local” theories that have focused on specific aspects of the task: models of word recognition, models of selective attention, accounts of thematic role assignment at the sentence level, and so forth. The ease of language understanding (ELU) model (Rönnberg et al., 2013) stands as one of the few attempts to offer a fully encompassing framework for language understanding. In this paper we discuss interactions between perceptual, linguistic, and cognitive factors in spoken language understanding. Central to our presentation is an examination of aspects of the ELU model that apply especially to spoken language comprehension in adult aging, where speed of processing, working memory capacity, and hearing acuity are often compromised. We discuss, in relation to the ELU model, conceptions of working memory and its capacity limitations, the use of linguistic context to aid in speech recognition and the importance of inhibitory control, and language comprehension at the sentence level. Throughout this paper we offer a constructive look at the ELU model; where it is strong and where there are gaps to be filled.
Introduction
Raymond Carhart has been credited with coining the term “audiology” (an interesting mix of Latin and Greek roots), and offering the first formal course with that name at Northwestern University in 1946. In its early beginnings the issue of cognition played no role in research or teaching on hearing loss. In Newby’s (1958) then-classic text in audiology, for example, the focus was squarely on peripheral hearing loss; any issues related to the pathways from the brain stem to and including the cortex was cited as the domain of neurology (Newby, 1958, pp. 53–55). Indeed, beyond supplying a definition of presbycusis as an age-related hearing loss, adult aging received no additional attention.
It is now well recognized that older adults’ success in speech recognition, especially under difficult listening conditions, will be affected by cognitive factors: either in a positive way through support from linguistic context, or in a negative way where performance can be constrained by limitations in working memory and executive resources (van Rooij and Plomp, 1992; Humes, 1996; Gordon-Salant and Fitzgibbons, 1997; Wingfield and Tun, 2001; Pichora-Fuller, 2003). Just as audiology has begun to recognize that cognitive factors may play a role in performance, so cognitive psychologists engaged in research on language comprehension in older adults are beginning to recognize that the full picture of language comprehension cannot be understood without attending to the auditory declines that are common in normal aging. The joining of these two areas of expertise has seen a dramatic increase, giving rise to such terms as “cognitive hearing science” (Arlinger et al., 2009) and “ cognitive audiology ” (Jerger, cited in Fabry, 2011, p. 20). The introduction of these terms reflects an increasing emphasis on the importance of taking into account how cognitive processes interact with hearing acuity in communicative behavior and remediation strategies to deal with hearing loss.
The broad sweep of issues underlying sensory-cognitive interactions in the perception and comprehension of speech raises the need for a unifying framework to guide present and near-future research. The Ease of Language Understanding (ELU) model (Rönnberg, 2003; Rönnberg et al., 2008, 2013) stands as such attempt. In this article we examine aspects of the ELU model that apply especially to spoken language comprehension in adult aging, where speed of processing (Salthouse, 1996), working memory capacity (Salthouse, 1994), and hearing acuity (Lethbridge-Ceijku et al., 2004) are often compromised. Throughout, we hope to offer a constructive look at the ELU model; where it is strong and where there are gaps to be filled. In so doing we use this discussion as a vehicle to examine interactions of perceptual, linguistic, and cognitive factors in spoken language understanding.
The ELU Model: A Brief Summary
The ELU model has developed from its original version (Rönnberg, 2003) to the more inclusive model as it is presented today (Rönnberg et al., 2013). The 2003 paper presents a basic framework along with a formulation to capture four parameters of spoken language understanding: (1) accuracy and features of syllable representations; (2) the speed of access to long-term memory (LTM); (3) the level of mismatch between the stimulus input and the corresponding phonology represented in the mental lexicon; and (4) the processing efficacy and storage capacity of working memory. This initial model assumed an interaction between the quality of the sensory input, information available in LTM, and the utilization of working memory. Together these would determine the ease with which language can be comprehended under difficult listening conditions. An important element in this initial presentation was a model assumption that phonological and lexical access are automatic (implicit) as long as no mismatch occurs between the sensory input and stored lexical representations. When a mismatch occurs processing becomes explicit, represented by employment of supportive context and engagement of working memory resources. This early foundation thus assumed a fundamental division between implicit and explicit components in speech understanding.
The 2013 version (Rönnberg et al., 2013) became more nuanced and more specific. In the former case it was now argued that implicit and explicit processing may operate on the interaction of phonology and semantics in parallel. As such, long-term memory (LTM) can be used either explicitly (a slow process) or implicitly (a rapid process) for understanding a spoken message. There was also an increasing attempt to say how working memory capacity relates to attention, short-term storage, inhibition, episodic LTM, and listening effort. In addition, the model in 2013 distinguishes between types of LTM (episodic and semantic) and how and when these memory systems are accessed at different stages of understanding. Rönnberg et al.’s (2008) version implied a solely feed-forward system, with the rapid and automatic multimodal binding of phonology taking place in an episodic buffer through implicit processing that matches inputs with stored representations in the mental lexicon. The 2013 version now recognizes the involvement of continuous feedback with both predictive and post-dictive (backward) feedback loops. This latter presumption is necessary given findings such as, for example, the demonstration that the perception of sub-lexical sounds are influenced by top-down word knowledge (Samuels, 2001).
Finally, in Rönnberg et al. (2013) the ELU model has been broadened to include multimodal integration in the form of visual information from seeing a talker’s articulatory movements, processed in a modality-general limited capacity working memory system. In this latter regard there is certainly ample evidence for multimodal integration beginning with Sumby and Pollack’s (1954) demonstration that people perceive speech in noise better when they can see the speaker’s face. Access to such visual information can also be advantageous for older adults (Sommers et al., 2005; Feld and Sommers, 2009). With these recent revisions, the ELU model sets up a new line of predictions. Many of these predictions relate to the effects of different signal qualities, the type and modality of the inputs (hearing, vision, and sign language), and the relationship of working memory capacity to different encoding operations and other memory systems.
Although the ELU model has become more inclusive, there are aspects of language processing that remain underrepresented in model. We address several of these issues below. In so doing we place special emphasis on spoken language understanding by older adults following typical age-related changes in cognitive efficiency and hearing acuity. As we shall see, the cognitive literature, upon the ELU model should rely, remains unsettled on many critical issues. These issues also form a part of our discussion.
Conceptions and Control Functions in Working Memory and its Capacity
As we have noted above, working memory plays a central role in the ELU model, where it is seen as carrying a number of cognitive functions relevant to language understanding. Most conceptions of working memory in the cognitive literature have in one way or another postulated a trade-off between processing and storage, whether conceived in terms of a shared general resource (Just and Carpenter, 1992; Carpenter et al., 1994), or a limited-capacity central executive (Baddeley, 1996; Logie, 2011). Mechanisms that have been proposed to underlie the limited capacity of working memory have included time-based models in which switching attention from processing to storage or updating and refreshing the memory trace are constrained by the time parameters of these processes (Barrouillet et al., 2004, 2012). In this latter regard descriptions of working memory and executive function begin to merge, with these terms often used along with the even more general term, “resources” (often, without distinction, referred to as attentional resources, processing resources, or cognitive resources).
A model that focuses on language understanding under adverse listening conditions would benefit greatly if it could rest on settled conceptions of working memory and executive function in the general cognitive literature. As yet such a simple consensus has yet to emerge. It might be helpful to adopt McCabe et al.’s (2010) characterization of working memory as focusing on the ability to store and manipulate information, and executive function as focusing on goal-directed behavior, monitoring and updating performance, set shifting, and inhibition (cf. Hasher and Zacks, 1988; Hasher et al., 1991; Cowan, 1999; Engle, 2002; Fisk and Sharp, 2004; Bopp and Verhaeghen, 2005; Logie, 2011), albeit with each containing elements of the other and all of these abilities associated with activity in prefrontal cortex (McCabe et al., 2010).
In its current version the ELU model cites the importance of inhibition and executive function in speech processing, but the relationship between these functions and working memory are as yet not clearly articulated within the model (Rönnberg et al., 2013, p. 10). The challenge in doing so is highlighted in McCabe et al. (2010) who report a strong correlation between tests of working memory capacity and those purported to test executive functioning (r = 0.97), with only processing speed showing independence. Although there is agreement that working memory capacity is limited, and more limited in older relative to younger adults (Salthouse, 1994, 1996; Salthouse et al., 2003), there is no uniform agreement within the cognitive aging literature on the mechanisms that underlie this limitation.
Our own view is closely aligned with the postulate that working memory capacity is determined by how well one can focus attention (Engle et al., 1999; Engle and Kane, 2004). A case in point is Cowan’s (1999) Embedded-Process model that sees working memory as an activated subset of information within LTM. The source of the well-known capacity limitation in working memory is seen as due to the limited capacity of attentional focus that operates on the activated areas within LTM (Cowan, 1999). As such, the capacity of working memory arises from both a time limit on activation of items in memory, unless refreshed, and a limit on attentional capacity in terms of the number of items that can be concurrently activated (Cowan, 2005). What we describe here is a process-based view of working memory and working memory capacity that allows concurrent activation of representationally distributed information, a potential mechanistic account for the modality-general aspects of working memory postulated in the ELU model.
Control Functions in Working Memory
The emphasis in the ELU model is on communication, which sets it apart from many extant models of speech recognition and language understanding that focus more narrowly on specific processes and in many cases do not address how the systems operate under adverse listening conditions. Considerable research has shown that the perceptual effort attendant to poor listening conditions has a negative impact on recall of speech materials (Rabbitt, 1968, 1991; Pichora-Fuller et al., 1995; Surprenant, 1999, 2007; Wingfield et al., 2005) and comprehension of sentences that express their meaning with non-canonical word orders typical of syntactically complex speech, with this latter effect compounded by effects of age, hearing acuity, and rapid speech rates (Wingfield et al., 2006).
In the ELU model the degree of effort engendered by task difficulty affects the degree to which explicit processing will be engaged. Among such explicit processes must be an ability to monitor the ongoing capacity of working memory as speech arrives in real time. Figure 1 shows data taken from our laboratory in which we probed the effect of listening effort on the ability to monitor the capacity of working memory as speech is arriving in real time. For this purpose we used an interruption-and-recall (IAR) paradigm in which participants listen to a string of recorded words with instructions to interrupt the input when they believe they have heard the maximum number of words that will allow for perfect recall of what has been heard. Germaine to our present interests, the word-lists were presented at one of two sound levels: at 25 dB SL to represent listening ease, and 10 dB SL to represent effortful listening. The participants were young adults with age-normal hearing (Amichetti et al., 2013, Experiment 2).
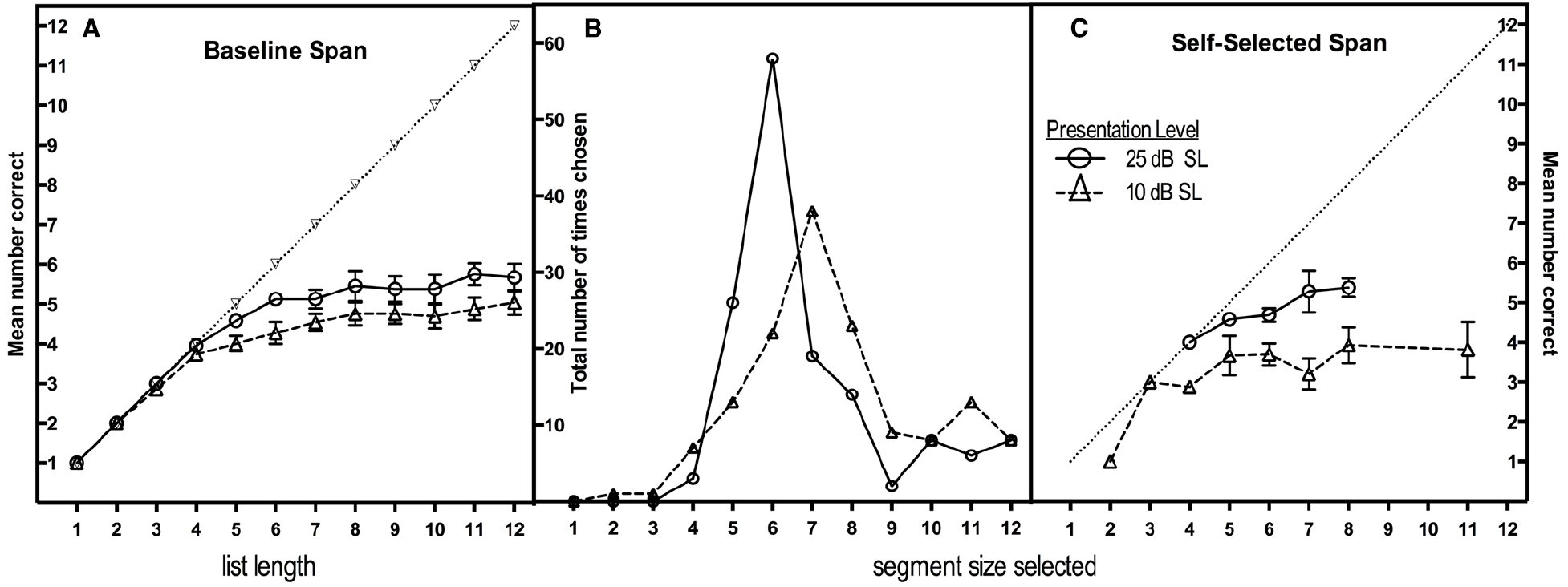
Figure 1. Mean number of words correctly recalled as a function of the number of words presented (baseline span) for words presented at either 25 dB SL or 10 dB SL (A); the distribution of segment sizes selected in the interruption-and-recall (IAR) condition at the two sound levels (B); and the number of words recalled as a function of the number of words selected in the IAR condition at the two presentation levels (C). Error bars in left and right panels represent one standard error. (From Figure 2 in Amichetti et al., 2013, Copyright 2013 by the Psychonomic Society. Reprinted with permission.)
Figure 1A shows the mean number of words correctly recalled in a simple baseline span task in which listeners heard lists varying in length from one to 12 items for immediate recall. It can be seen that for list lengths of up to three words recall is at ceiling, and at near-ceiling for a four-item list length at both intensity levels, thus confirming the audibility of the stimuli at the two sound levels. Beyond a four-item list, additional stimulus items yield progressively smaller recall gains that never peak beyond means of 5.8 items for the 25-dB SL lists and 4.3 items for the 10-dB SL lists. This small but significant difference affirms the above-cited negative effect of effortful listening on recall.
Figures 1B,C are of greater interest as they show what happened when participants heard supra-span lists with instructions to interrupt the word-lists with a keypress when they believed they had heard the maximum number of words that they could recall with perfect accuracy. The middle panel shows the distribution of segment sizes participants selected for recall for the 25-dB SL and 10-dB SL presentation levels in this IAR condition. One can see a shift in the peaks of the two distributions, from a modal self-selected segment length of six words for lists at the louder 25-dB SL level, to seven words, at the 10-dB SL level. Specifically, at 25 dB SL the modal segment size of six words was close to the mean for accurate item recall of 5.8 words in the baseline span condition at that sound level shown in the left panel, suggesting a good ability to calibrate segment size selections with actual memory span. By contrast, in the effortful listening condition, listeners appeared to lose this close calibration. That is, a reduced memory span for accurate recall of 4.3 words for 10 dB SL lists in the baseline condition was not accompanied by listeners adaptively taking shorter segment sizes for recall in the IAR condition.
The right panel shows the number of words recalled in the IAR conditions for list lengths that had more than 10 examples on which to base a mean. The dual-task nature of the IAR condition (the listener must make continuous capacity judgments while holding what has been heard to that point in memory) reflects a greater cognitive load than in baseline span task. As would be expected if listening effort draws on already strained resources in the IAR task, while for the 25-dB SL presentations the IAR-produced spans are similar to baseline spans at 25 dB SL, recall accuracy for the IAR spans at the more effortful 10 dB SL level were reduced relative to the corresponding baseline span presented at 10 dB SL.
As we have noted, the ELU model asserts that a degraded (perceptually effortful) signal leads to a shift from automatic to controlled processing with an engagement of working memory resources. We show with the above data that this control itself may be affected by the necessity to process a low-quality signal. In part the lower sound level may have slowed the stimulus encoding, resulting in an overlap in time in which the cognitive system is concurrently conducting perceptual and encoding operations on one stimulus as another is arriving (Miller and Wingfield, 2010; Piquado et al., 2010). It is also possible that a reduced stimulus intensity may truncate the duration of an already rapidly fading echoic trace (Baldwin, 2007; Baldwin and Ash, 2011).
This control function in working memory may be obscured in natural speech if listeners are allowed to periodically interrupt a spoken narrative to give themselves time to process what they have heard before the arrival of yet more information. In this case both young and older adults tend to interrupt the speech input at major linguistic clauses and sentence boundaries rather than after a set number of words (Wingfield and Lindfield, 1995; Piquado et al., 2012; see also Wingfield et al., 1999; Fallon et al., 2006). Importantly, such findings are indicative of listeners’ access to syntactic and semantic knowledge as the speech is being heard, and hence being involved in very early stage processing. We will address the implications of early access in several places in the following discussion.
The Implicit versus Explicit Distinction
Fundamental to the ELU model is the position that when speech quality is good, with a clear match between acoustic input and its corresponding phonological representation in LTM, lexical recognition will be automatic (“implicit”). That is, lexical access will be rapid, resource-free, and will not require access to top-down information such as linguistic or semantic context. When the input quality is poor, whether due to external factors such as background noise, or internal factors such as hearing loss or a distorted phonological representation in LTM consequent to a long-term hearing impairment, the degraded information can be supplemented by linguistic or real-world knowledge, a process that requires explicit or “effortful conscious processing” (Mishra et al., 2013, p. 2).
Use of the terms implicit and explicit processing in the ELU model resonate with the early (LaBerge and Samuels, 1974; Shiffrin and Schneider, 1977), but still often used distinction in the cognitive literature between automatic versus controlled processes. In the context of speech perception, automatic processes emphasize bottom-up, stimulus-driven processing that is rapid, obligatory, and demanding few if any resources. By contrast, controlled processes tend to be top-down, voluntary, and to one degree or another resource-demanding (Pashler et al., 2001). They are also assumed to require some level of awareness (LaBerge and Samuels, 1974; Posner and Snyder, 1975; Shiffrin and Schneider, 1977; Flores d’Arcais, 1987). All of these attributes fit squarely with the characterization of implicit and explicit processing as represented in the ELU model.
Although early-stage perception is often considered to be automatic, arguments have been offered for cognitive and attentional control operating at the earliest stages of input processing of speech (Nusbaum and Magnuson, 1997; Heald and Nusbaum, 2014). It should also be recognized that a system that appears to be resource-free could require resources but not those shared with other processes. This exact position was taken by Caplan and Waters (1999) who argued that on-line syntactic operations are conducted by sentence-specific resources not measured by traditional working memory tasks such as the Daneman and Carpenter (1980) readings span task or its several variants. They suggest that the appearance of effects working memory limitations on sentence processing represent post-interpretive processes rather than on initial syntactic parsing. Our present focus, however, is the specific assertion in the ELU model that when there is degraded input perceptual operations will shift from automatic to controlled processing, with the latter increasing the drain on working memory resources (Rönnberg et al., 2013).
Proposals of binary, either-or process distinctions have been a hallmark of early theory development in cognitive psychology such as distinctions drawn between semantic versus episodic memory (Tulving, 1972), procedural versus non-procedural learning (Squire, 1994), implicit versus explicit memory in reference to priming studies (Schacter, 1987), and so forth. In each case subsequent studies have shown none of these proposed distinctions to be process pure. In a similar way, the distinction between automatic (implicit) versus controlled (explicit) processes can best be seen as two ends of a continuum and a matter of degree rather than the sharp contrast current in the ELU model.
Although drawing a distinction between implicit and explicit processes, Rönnberg et al. (2013) note that the extent to which explicit or implicit processing may be employed can vary over the course of a single task, with the ratio changing from moment to moment during a conversation depending on signal quality and speech content (see also Rönnberg et al., 2010).
It is the case that the automatic versus controlled distinction retains descriptive utility (Birnboim, 2003; Schneider and Chen, 2003), but only insofar as one thinks of some operations being potentially “more automatic” than others in a relative or graded sense (Chun et al., 2011).
The Match versus Mismatch Distinction
The match versus mismatch distinction highlighted in the ELU model may be accepted as an idealized principle, although such a distinction should be treated with caution. This is so because there is rarely a perfect match between a phonological input and the phonological representation of an item in the mental lexicon. This is due to the variability in the way words and their sub-lexical elements are articulated from speaker to speaker, and effects of syllabic context within a single speaker (Liberman et al., 1967; Mullennix et al., 1989).
At the more cognitive level, analyses of natural speech show that speakers tend spontaneously to employ a functional adaptation in their production. That is, we tend to articulate more clearly words that cannot be easily inferred from context, and to articulate less clearly those that can (Hunnicutt, 1985; Lindblom et al., 1992). It is not assumed that these dynamic adjustments are consciously applied by the speaker, any more than we assume that listeners are necessarily consciously aware of using acoustic and linguistic context in their perceptual operations.
Because of this functional adaptation, what one might call an articulatory principle of least effort, words are often under-articulated when they can be predicted from the context, and many words would be unintelligible were it not for the phonemic and linguistic context in which they are ordinarily heard (Lieberman, 1963; Pollack and Pickett, 1963; Grosjean, 1985; Wingfield et al., 1994). Because of this variability perfect-match template matching models of perception must be an ineffective account of perceptual identification. To the extent that the ELU model presumes a perfect or near perfect match between phonological inputs and stored counterparts in LTM as the default condition with natural speech, this would be out of tune with these data. It should be noted that although the early Rönnberg (2003) formulation implied a stark contrast between a perfect match versus one that requires top-down support, the current model version sees word recognition in terms of a threshold function affected by phonological and semantic attributes (Rönnberg et al., 2013). This question relates to broader issues in the role of linguistic context in speech recognition and comprehension.
The Role of Context
A common view in speech recognition is that questions related to effects of context should be framed in terms of top-down effects operating on initially stimulus-driven perceptual processes. The ELU model is in general accord with this principle, although an apparently conflicting observation appears in the suggestion in Rönnberg et al. (2013) that if a sentence context is sufficiently predictive, a target word might be activated even with minimal phonological input (Rönnberg et al., 2013). This presumption, although consistent with everyday experience, would not seem to follow at first look from the precepts of the ELU model. It would follow, however, from a number of extant models of word recognition.
Most models of word recognition, to include the ELU model, assume a reciprocal balance between bottom-up information determined by the clarity of the speech signal and top-down information supplied by a system of linguistic knowledge (e.g., Morton, 1969, 1979; McClelland and Elman, 1986; Marslen-Wilson, 1987). It is the compensatory availability of preserved linguistic knowledge and the procedural rules for its use that accounts for the general effectiveness of speech comprehension in adult aging in spite of cognitive and sensory declines (Wingfield et al., 1991; Pichora-Fuller et al., 1995; Wingfield and Stine-Morrow, 2000; Pichora-Fuller, 2003). Although these principles are embodied within the broad outlines of the ELU model, questions remain as to whether context comes into play before, during, or after the acoustic representation of a word unfolds in time.
A model that assumes that context activates lexical possibilities before a stimulus word is heard was embodied in one of the earliest interactive models: the so-called “logogen” model that also went through a period of development (Morton, 1964a,b, 1969, 1979). Morton postulated a “dictionary” of “units” (later re-named “logogens”), with each unit corresponding to a word represented in LTM. When the level of activation of a logogen exceeds a critical level, the unit “fires,” and the corresponding word is available as a response.
In this model each unit has a resting potential, or base level of activation, determined by the relative frequency with which the unit has fired in the past. This is reflected behaviorally in the word frequency effect, in which words that have a high frequency of occurrence in the language are recognized faster or with less stimulus information than low-frequency words (Howes, 1957; Grosjean, 1980). Following the firing of a unit its resting level of activation increases sharply, resulting in recency or repetition priming, and then decays slowly. Through direct connections with other units, the activation of any given unit adds to the level of activation of all associated units, whether this association is semantic, categorical, or based on shared attributes.
In operation, a sensory input would be coded in terms of the presence of detected phonological features, the presence of which would simultaneously increase the level of activation of all units sharing these phonological features. Thus, the unit sharing the greatest number of features with the presented stimulus would receive the greatest increase in its level of activation. It can be seen from this formulation that the amount of stimulus information required for a unit to exceed its critical level and “fire,” would be lower either when there is already a high level of residual activation (the word frequency effect), when the level of activation has been temporarily raised by a recent firing of the unit (recency priming), or by the firing of an associated unit or units (an effect of context).
Within the Logogen model, a highly constraining linguistic or environmental context that increases the likelihood of occurrence of a stimulus word will increase the level of activation of that item in the mental lexicon, thus priming the entry even before the stimulus is actually encountered. The higher the level of activation, the less stimulus information will be required for recognition of the target word. Activation due to contextual expectancy would thus override units’ initial resting potentials initially determined by their relative frequency of occurrence in the language, and hence, their likelihood of re-occurrence. A constraining linguistic or environmental context would also override other factors known to affect the intelligibility of individual words, such as the detrimental effect of a large number of words that share initial or overall phonology with the target word (cf. Tyler, 1984; Wayland et al., 1989; Wingfield et al., 1997; Luce and Pisoni, 1998). These general principles have been embodied in a number of models, to include TRACE, a computational model in which the above factors, operating in parallel, can be implemented by transient weighting factors (McClelland and Elman, 1986).
A correlate of Morton’s model is that if the level of activation of a lexical unit is sufficiently raised due to a high probability of it being encountered, a lexical unit may “fire” in the absence of objective stimulus information. It can be seen that Morton’s logogen model and others like it offer a mechanistic account noted by Rönnberg et al. (2013) that if a sentence context is sufficiently predictive, a target word might be activated even with minimal phonological input. This principle of an inverse relationship between the a priori probability of a word and the amount of phonological information needed for its recognition is a well established finding in the literature for both spoken and written words and for both young and older adults (Black, 1952; Bruce, 1958; Morton, 1964a,b; Cohen and Faulkner, 1983; Madden, 1988). It should be pointed out, of course, that the more likely scenario following the same principle is the misidentification of an indistinct word as a word with a similar sound that is a closer fit to a semantic context (Rogers et al., 2012). Either case, however, would necessitate a closer look within the ELU model at whether context raises lexical activation before (Morton, 1969), during (Marslen-Wilson and Zwitserlood, 1989), or after (Swinney, 1979) the word unfolds in time.
In contrast with models that assume that linguistic context raises target activation even prior to acoustic input, we have seen that a basic tenet of the ELU model is that an acoustically clear stimulus with a correspondingly rich mental representation results in automatic (implicit) lexical access; a rapid, obligatory, resource-free process. In the model context comes into play only when poor stimulus quality does not allow an immediate match at which point context “kicks in.” The process being described is suggestive of early modular models of lexical access such as Forster’s (1976; 1981) argument for autonomous lexical access: a self-contained modular system, with restricted access to information. Such an “informationally encapsulated” (context-free) process fit within Fodor’s (1983) broader argument for modularity within cognitive domains and processes.
The positive influence of a constraining sentence context or other sources of semantic priming on the accuracy or speed of lexical access (e.g., Holcomb and Neville, 1990) appears as inconsistent with the postulate of a context-impenetrable modular view of lexical access. This issue is not easily settled in spite of a history of creative experiments intended to determine whether the facilitation observed with a constraining sentence context reflect a true access effect (cf., Swinney, 1979; Seidenberg et al., 1982, 1984; Stanovich and West, 1983).
The issue is whether the well-documented effects of expectancy on ease of lexical access, and especially the suggestion that a sufficiently strong expectation can activate a lexical entry in the absence of sensory input, is most compatible with a pre-lexical (e.g., Morton, 1969) or a post-lexical (e.g., Forster, 1981) effect. Our reading of the ELU model appears to favor both positions, an issue that would need to be reconciled as the model develops in detail.
Before leaving this issue, we might also suggest that a complete model for word recognition should include not only the level of activation of a lexical entry as determined by contextual expectancy and the goodness of fit with the stimulus, but also on the individual’s acceptance criterion level. This flexible criterion level would be determined by such factors as the priority given to speed versus accuracy (Wagenmakers et al., 2008) or the reward for a correct recognition versus the negative consequences of making an erroneous identification (Green and Swets, 1966). This position thus adds motivational state to the quality of the sensory input and the sensory capacities of the listener.
Age and Inhibition in Word Recognition: The Role of Working Memory
Benichov et al. (2012) examined ease of recognition of sentence-final words heard in noise with participants aged 19–89 years, with levels of hearing acuity ranging from normal hearing to mild-to-moderate hearing loss. Regression analyses showed that hearing acuity, although a predictor of the signal to noise ratio necessary to correctly recognize a word in the absence of a constraining linguistic context, dropped away as a significant contributor to recognition of sentence-final words by the time the linguistic context was strongly predictive. By contrast, a cognitive composite of individuals’ episodic memory, working memory, and processing speed accounted for a significant amount of the variance in word recognition for words heard in a neutral context and for all degrees of contextual constraint examined. (The contextual probability of the target words was taken from published “cloze” norms, which report the percentage of participants who give particular words when asked to complete sentence stems with the final word missing.)
One likely candidate for the role that working memory capacity may play in word recognition was revealed in a study by Lash et al. (2013) who examined effects of age, hearing acuity, and expectations for the occurrence of a word based on a linguistic context. Importantly, the study also examined the effects of competition from other words that might also fit the semantic contexts. Lash et al. (2013) used the technique of word-onset gating, in which a listener is presented with an increasing amount of a word’s onset duration until the word can be correctly identified (Grosjean, 1980, 1996). When a linguistic context is absent, word recognition is affected by the number of words that share the initial sounds with the target word (Tyler, 1984; Wayland et al., 1989), further limited by words that share syllabic stress (Wingfield et al., 1997; Lindfield et al., 1999; see also Wingfield et al., 1990).
A major focus of the Lash et al. (2013) study was the effect of a linguistic context on word recognition that, as we have previously indicated, will override such factors as word frequency or the number (“density”) of phonological competitors as determinants of word recognition. A critical feature of published cloze norms (e.g., Lahar et al., 2004), however, is that when participants have been asked to complete sentence stems, also reported is the full range of responses given by each of the participants, and the number of participants giving these alternative responses. These data allow one to estimate not only the expectancy of a sentence-final word based on the transitional probability of that word in the sentence context, but also the uncertainty (entropy) implied by the number, and probability distribution, of alternative responses that also might be implied by the context. Lash et al. (2013) found that while both young and older adults’ word recognition benefitted from a sentence context that increased word expectancy, a differentially negative effect of the presence of strong competitor responses was found for older adults independent of hearing acuity.
This latter finding is consistent with Sommers and Danielson’s (1999) proposition that older adults have greater difficulty than their young adult counterparts in inhibiting non-target responses. In Sommers and Danielson’s (1999) case the competition came from the presence of a larger number of phonological “neighbors” of target words. The present case differed only in that response competition came from the distribution of words that also shared a contextual fit with a semantic context. Such results would be expected from arguments that older adults have a general inhibition deficit (Hasher and Zacks, 1988), that in this case, would interfere with word recognition.
A subsequent study by Lash and Wingfield (2014) directly examined working memory capacity and effectiveness of inhibition in word recognition as would be predicted from observations present in the current version of the ELU model. This study was based on the finding that gradually increasing the clarity of a stimulus until it can be correctly identified retards its recognition relative to when a stimulus is presented just once, even at a level of clarity below that needed for recognition using an ascending presentation. This finding, observed originally for degraded visual stimuli, has been interpreted as reflecting the negative effect of interference from incorrect identification hypotheses formed during the incremental presentations that would not be present with a single presentation (Bruner and Potter, 1964; Snodgrass and Hirshman, 1991; Luo and Snodgrass, 1994).
Lash and Wingfield (2014) conducted an analogous study for spoken words using word-onset gating with older adults (M = 75 years) with good hearing acuity (PTA < 25 dB HL) and an age-matched group with a mild-to-moderate hearing loss. A group of young adults with normal hearing acuity was also included for comparison. For each individual we determined the word-onset gate size that allowed the participant to recognize correctly 40 to 60% of target words when they were presented successively with increasing onset durations (an ascending presentation). We also determined for each individual the recognition accuracy level for comparable words presented just once (a fixed presentation) with the same gate size that yielded the 40 to 60% correct recognition with an ascending presentation. The size of the interference effect from ascending presentations would be indexed by the difference between word identification rates under the two presentation conditions. The question was whether individual differences in working memory capacity might predict one’s ability to inhibit interference from false identification hypotheses presumed to be formed in the course of the incrementally larger and larger word onset durations represented in the ascending presentation condition (e.g., Snodgrass and Hirshman, 1991; Luo and Snodgrass, 1994).
As might be expected from age and inhibition arguments, the older adults in the study showed a larger interference effect from ascending presentations than the young adults. Germaine to our present question, a follow-up regression analysis revealed that participants’ reading spans, taken as a measure of working memory capacity (Daneman and Carpenter, 1980; McCabe et al., 2010), contributed significantly to the size of the interference effect (see Lash and Wingfield, 2014, for full details). The reading span test, which we discuss in a subsequent section, was used rather than a listening span version (e.g., Wingfield et al., 1988) to avoid a potential confound with hearing acuity.
This effect of working memory span on the effectiveness of inhibition can be illustrated most clearly in Figure 2 in which we have taken data from Lash and Wingfield (2014) and have plotted the percentage of correct identifications for the same gate size when words were presented in the fixed versus the ascending presentation conditions separated by participants’ working memory span. A participant was considered to have a high working memory span (left panel) if they scored greater than one standard deviation above the mean for their age cohort determined by McCabe et al. (2010), or a low span if they did not (right panel). These data are based on a subset of participants from Lash and Wingfield (2014) where high and low span participants within each participant group were equal in number and matched for age.
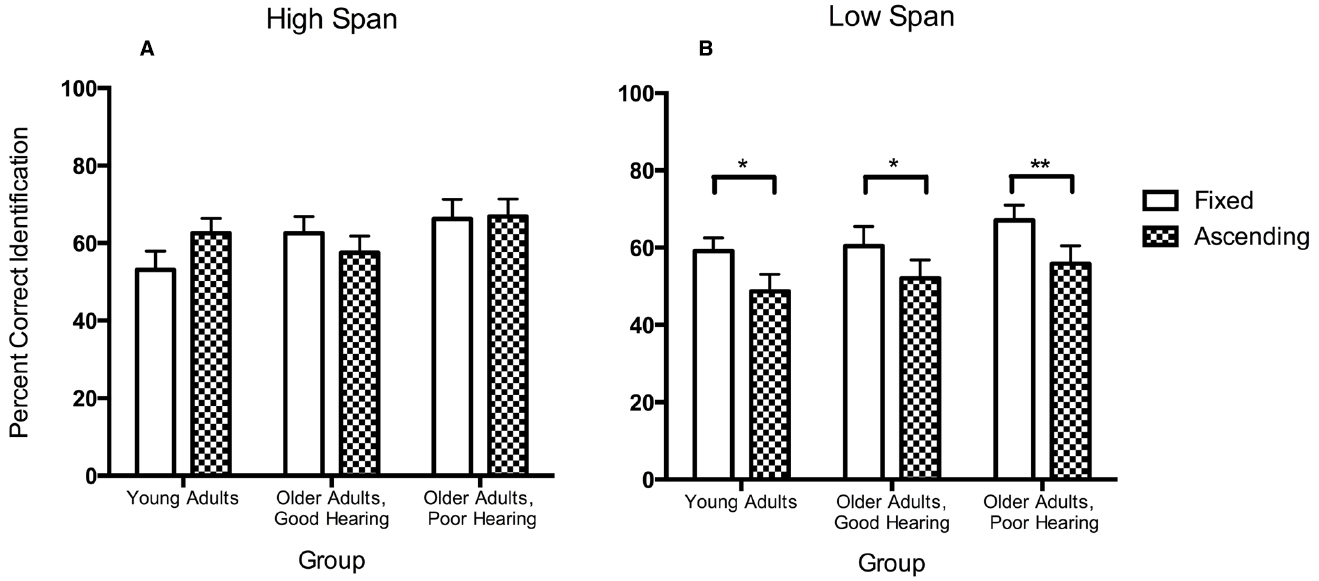
Figure 2. Percentage of words correctly identified with the same onset gate size when stimuli were presented under fixed versus ascending procedures for young adults with age-normal hearing acuity and older adults with good hearing acuity or a mild-to-moderate hearing loss. Panel (A) shows participants with high working memory spans. Panel (B) shows these data for participants with lower working memory spans. Error bars represent one standard error. (Data from Lash and Wingfield, 2014, Psychology and Aging, Viol. 29.) *p < 0.05, **p < 0.01.
Although for the high span participants some variability appears in the difference between identification scores for the fixed versus ascending presentation conditions, especially for the young adults, none of these differences reached significance. By contrast, the lower span participants in each of the three participant groups consistently show a significant interference effect even after adjusting for differences in baseline recognition accuracy.
These data can thus be taken to offer empirical support for the suggestion in Rönnberg et al. (2013) that working memory capacity may affect the efficiency of inhibitory processes (see also Sörqvist et al., 2012). It should be noted, however, that a relationship between working memory capacity and effectiveness of inhibition leaves open the direction of causality. Indeed, an influential argument has been made that it is a failure of the ability to inhibit off-target interference that may determine the size of one’s working memory capacity (Hasher and Zacks, 1988; Hasher et al., 1991). We will have more to say on this topic in the following section.
Input Challenge at the Sentence Level: Deep versus Shallow Processing
A premise of the ELU model is that a perceptual mismatch due to a poor quality stimulus causes a shift from implicit (automatic) to explicit (controlled) processing where support from linguistic or environmental context are brought into play through involvement of working memory. As outlined in the model, this shift will slow processing but hopefully lead to a successful solution. Because syntactic resolution of a sentence is arguably a precursor to determination of sentence meaning, this would imply that, when speech quality is poor, listeners will engage in an especially detailed and explicit syntactic analysis. Rönnberg et al. (2013), however, offer a qualification: when placed under time pressure, and if the listener is willing to accept the gist of the message, such a close analysis might not take place (Rönnberg et al., 2013, p. 10).
There is no doubt that this latter point is true, both intuitively and empirically. We would suggest, however, that in natural language comprehension such gist processing may be the rule rather than the exception. This would be so since in listening to spoken discourse one is almost always under time pressure due to the rapidity of natural speech and the transient nature of the speech signal. Ordinary speech rates average between 140 to 180 words per minute, and can often reach 210 words per minute as, for example, with a radio of TV newsreader working from a prepared script (Stine et al., 1990).
Although in many cases a complete syntactic analysis may be conducted as a precursor to determining a sentence meaning, there is considerable evidence that listeners often, perhaps more often, take processing short-cuts, sampling key words and using plausibility to understand the meaning of an utterance. Because we live in a plausible world this strategy will in most cases yield rapid and successful comprehension, albeit with comprehension errors should one encounter a sentence with an unexpected or implausible meaning.
Analyses of everyday discourse show that most of our sentences, when they are in fact grammatical, tend to have meaning expressed in a relatively simple noun-verb-noun canonical word order with the first word representing the agent or source of the action (Goldman-Eisler, 1968). Thus, so long as the syntax is represented by canonical word order and the meaning of a sentence is plausible, a gist analysis will most often yield a correct understanding. This strategy goes unnoticed because it invariably works; it is revealed, however, when comprehension fails. In such cases listeners “mishear” a sentence as if it were sensible, such as the sentence, “The teenager that the miniskirt wore horrified the mother” (Stromswold et al., 1996). Examination of individuals’ comprehension of such sentences have shown that comprehension errors frequently occur, suggesting the absence of a full syntactic analysis of a sentence input in favor of sampling key words, assuming that the word order represents the meaning in a canonical form, and that the semantic relations being expressed in the sentence are plausible (Fillenbaum, 1974; Sanford and Sturt, 2002).
Ferreira (2003) has formalized these notions, suggesting that heuristic short-cuts may be taken by all listeners, by-passing a full syntactic analysis but instead using word-order and plausibility as a rapid first-pass comprehension strategy (Ferreira et al., 2002; Ferreira, 2003; Ferreira and Patson, 2007). As Ferreira et al. (2002) have argued, it should not be assumed that all relevant information from a detailed and time-consuming lexical and syntactic analysis will be used in everyday comprehension. Sanford and Sturt (2002), from the perspective of computational linguistics, come to a similar conclusion. That is, to use Ferreira and Patson’s (2007) words, sentence processing is as often as not conducted at a level of analysis that is “good enough” for comprehension. As we have argued above, this processing strategy will yield the right answer more often than not. It is consistent with the slowed processing and limited working memory capacity of older adults that Christianson et al. (2006) have argued that a “good enough” processing heuristic may be even more common in the elderly.
Working Memory and Language Comprehension
There are a variety of working memory measures in the literature designed to capture operational capacity. Important among them is the reading span task introduced by Daneman and Carpenter (1980), that focuses more specifically on verbal working memory (Carpenter et al., 1994). It is a version of this reading span task that serves as the preferred measure of working memory in the ELU-related studies conducted by the Rönnberg group.
The reading span (or listening span) task requires the listener to read (or listen to) a series of sentences and, to insure the sentences are being comprehended, to state after each sentence whether it is true or false, or in some variants, whether the meaning of the sentence is plausible or implausible. After a set of sentences is finished the reader (or listener) must recall the final word of each sentence, or he or she receives a signal to recall either the last word or the first word of each of the sentences. The span is taken as the number of sentences that allow accurate recall of the final, or the first or final words depending on the version (cf. Daneman and Carpenter, 1980; Rönnberg et al., 1989; Waters and Caplan, 1996; McCabe et al., 2010). As previously noted, the reading span, as opposed to a listening span version, is preferable when speech is involved in order to avoid a confound with hearing acuity or stimulus clarity.
We earlier cited the claim by Caplan and Waters (1999), based on their work and the work of others, that working memory, at least as tested with the reading span task of Daneman and Carpenter (1980) and its variants, does not constrain, or by inference carry, on-line sentence comprehension. In contrast, the well-known meta-analysis by Daneman and Merikle (1996) showed reading span scores to reliably predict performance on a number of language comprehension and language memory tasks.
In addition to mixed findings in experimental studies relating reading spans to efficacy in language comprehension (see, the review in Wingfield et al., 1998) there is a similar case for the ability of working memory span as measured by reading span, as a predictor of perception of speech in noise or with reduced hearing acuity (cf. Akeroyd, 2008; Schoof and Rosen, 2014; Füllgrabe et al., 2015).
It is possible that the mixed findings in studies using the reading span as a measure of verbal working memory may lie in the intentional complexity of the reading span task itself, with this complexity allowing task demands or nuances of the instructions to affect the sensitivity of the span scores across different experiments. When one considers the reading span task it can be seen that there is an opportunity for a trade-off on the part of the reader or listener between recalling the sentence-final or sentence-initial words versus processing efficiency on the sentence comprehension component of the task. Indeed, individual differences in strategy use and session-to-session variability has been shown to occur in even less complex memory tasks (e.g., Logie et al., 1996).
Waters and Caplan (1996) recognized that the reading span task, because it involves both storage and processing components, is a better measure of working memory than a simple span test that has only a storage component. The task also has face validity as both the reading span task and language comprehension require temporary storage of verbal material along with ongoing syntactic and semantic computations. As Waters and Caplan note, this complexity of the Daneman and Carpenter (1980) reading span task focuses solely on the storage component of the task (recalling the sentence final words as the span measure) but not the efficiency with which the sentence comprehension component is conducted. To overcome this limitation they suggest a more valid measure might be represented by an index that takes into account sentence comprehension accuracy, the number of sentence final words that can be recalled, and as a measure of efficiency at sentence processing, response times to the sentence judgments. Represented as a z-score they show this composite measure to have better test-retest reliability than the original Daneman and Carpenter (1980) span test.
An additional criticism of the Daneman and Carpenter (1980) span test is that participants always know in advance that they will be asked to recall the last word of each of the sentences. That knowledge might lead to development of processing strategies by the participant. To overcome this issue Rönnberg et al. (1989) developed a span task that uses a post-cueing method in which the participant reads the stimulus sentences without knowing in advance whether they will be asked to recall the first or the final word of each sentence. This instruction is given after a sentence set has been presented.
In these regards, we suggest that a large-scale meta-analysis of studies compare and contrast findings using extant variations of the reading span task. Such an analysis should include relative strengths in terms of test-retest reliability where available.
The above discussion has focused more on the reading span as a measure of working memory capacity than on the memory systems that may be involved in speech comprehension at the sentence level. On the one hand, our discussion of “good enough” sentence processing suggests that an abstract representation of sentence meaning is formed as a sentence is being heard. On the other hand, our ability to “replay” the sensory input to retroactively repair an initial misanalysis of a garden-path sentence implies the support of a briefly sustained veridical trace of the input.
This apparent paradox was recognized by Potter (1993; Potter and Lombardi, 1990), who proposed that as a sentence is heard, both a verbatim trace of the spoken input and a semantic abstraction are concurrently formed and briefly stored in memory. Depending on the momentary needs of the listener or complexity of the speech materials, the individual might rely more or less heavily on the transient verbatim trace, whether this is thought of as a phonological, articulatory, or echoic store. In everyday listening the default mode may be reliance on the abstracted semantic trace for constructing narrative coherence, with the concurrently available verbatim trace accessible for a brief period if needed for specific task requirements or if access to the original input is needed in order to rescue an initial processing error. In the case of understanding meaningful speech, such a model might account at least in part for many of the paradoxes outlined above.
Resource-Limited versus Data-Limited Processes
In performing a complex cognitive task one would expect that, at least to some limit, the level of performance will improve with the amount of effort (resources) given to that task. This refers to a task that is “resource-limited”: the upper limits on performance will be set only by the amount of resources one is willing, or able, to apply to it (Norman and Bobrow, 1975). In cases of degraded input, performance can often be improved with additional effort. There are other cases where the stimuli are of such poor quality that no amount of effort or allocation of resources will improve the level of performance. In such cases, when the upper limit on performance is determined by the limited quality of the stimulus, the task can be referred to as data-limited (Norman and Bobrow, 1975). Most tasks, even ones with a poor quality stimulus, are resource-limited up to some point where one’s performance is limited only by the amount of resources one is willing to devote to it. It is only beyond this point that one can say that the task is data-limited. Although questions have arisen about distinguishing between a data-limited transition and possible constraints of a ceiling effect (Norman and Bobrow, 1975; Kantowitz and Knight, 1976). Norman and Brobrow’s(1975) conceptualization is a descriptively important one.
Within the context of what Norman and Bobrow (1975) would call the resource-limited range, one can describe three “zones” of listening conditions: (1) effortless listening, where working memory resources are not drained by perceptual processing demands, (2) effortful but successful listening where errors will occur unless resources can be reallocated from other tasks, and (3) effortful but error-prone listening which is not yet data-limited, but where there are insufficient or non-optimally allocated resources (see Schneider and Pichora-Fuller, 2000; Pichora-Fuller, 2003, for discussions). Poor-hearing older adults would reach these points of effortful listening with higher sound levels than those with better hearing, and they would be reached sooner for more complex speech materials than simpler materials.
Although traditionally theorists have focused on just one direction of activity, whether on limited resources constraining perceptual effectiveness (Kahneman, 1973; de Fockert et al., 2001; Lavie et al., 2004) or perceptual effort reducing higher-level cognitive effectiveness (Rabbitt, 1968, 1991; Dickinson and Rabbitt, 1991; Murphy et al., 2000) one can postulate a single interactive dynamic which may operate in both directions: limited resources may impede successful perception when the quality of the sensory information requires perceptual effort for success, while successful perception in the context of a degraded stimulus or a hearing loss may draw on resources that might otherwise be available for downstream cognitive operations. These notions fit acceptably within the ELU model and it is hoped that they are more fully developed in future versions of the model.
Conclusion
The ELU model can fairly be represented as a work in progress with many gaps to be filled. The model nevertheless serves as a useful framework for thinking critically about language understanding, especially under difficult listening conditions. That is, a model has value not only when it answers all of our questions, accounts for extant data, and makes specific predictions for experiments yet to be conducted. A model also has value when close scrutiny highlights what we know and what we do not know; the broader the sweep of the model the more this is likely to be so.
Our goal in this discussion has been to point to places in the model where there are gaps that are yet to be filled and where the model could be productively expanded. In doing so we acknowledge that the ELU model represents a unique attempt to formulate a unifying framework to describe sensory-cognitive interactions especially under difficult listening conditions.
An important feature in the development of the ELU model has been a shared focus both on theory and on the practical implications of cognitive resources in remediation in the case of hearing loss (e.g., Rudner and Lunner, 2013). The effectiveness of the rapid development of sophisticated signal processing algorithms, whether in traditional hearing aids or in cochlear implants, must take into account the cognitive supports and cognitive constraints of the user, especially, we suggest, in the case of the older listener. The integrative approach of the ELU model offers an ideally suited framework on which to carry continued research on this critical interaction.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Our work is supported by NIH grant R01 AG019714 from the National Institute on Aging (AW). We also acknowledge support from training grant T32 AG000204 (NMA and AL) and support from the W.M. Keck Foundation.
References
Akeroyd, M. A. (2008). Are individual differences in speech perception related to individual differences in cognitive ability? A survey of twenty experimental studies with normal and hearing impaired adults. Int. J. Audiol. 47, S53–S71. doi: 10.1080/14992020802301142
Amichetti, N. M., Stanley, R. S., White, A. G., and Wingfield, A. (2013). Monitoring the capacity of working memory: executive control and effects of listening effort. Mem. Cogn. 41, 839–849. doi: 10.3758/s13421-013-0302-0
Arlinger, S., Lunner, T., Lyxell, B., and Pichora-Fuller, M. K. (2009). The emergence of cognitive hearing science. Scand. J. Psychol. 50, 371–384. doi: 10.1111/j.1467-9450.2009.00753.x
Baddeley, A. D. (1996). “The concept of working memory,” in Models of Short-Term Memory, ed. S. Gathercole (Hove: Psychology Press), 1–28.
Baldwin, C. L. (2007). Cognitive implications of facilitating echoic persistence. Mem. Cogn. 35, 774–780. doi: 10.3758/BF03193314
Baldwin, C. L., and Ash, I. K. (2011). Impact of sensory acuity on auditory working memory span in young and older adults. Psychol. Aging 26, 85–91. doi: 10.1037/a0020360
Barrouillet, P., Bernardin, S., and Camos, V. (2004). Time constraints and resource sharing in adults’ working memory spans. J. Exp. Psychol. Gen. 133, 83–100. doi: 10.1037/0096-3445.133.1.83
Barrouillet, P., De Paepe, A., and Langerock, N. (2012). Time causes forgetting from working memory. Psychon. Bull. Rev. 19, 87–92. doi: 10.3758/s13423-011-0192-8
Benichov, J., Cox, L. C., Tun, P. A., and Wingfield, A. (2012). Word recognition within a linguistic context: effects of age, hearing acuity, verbal ability and cognitive function. Ear Hear. 33, 250–256. doi: 10.1097/AUD.0b013e31822f680f
Birnboim, S. (2003). The automatic and controlled information-processing dissociation: is it still relevant? Neuropsychol. Rev. 13, 19–31. doi: 10.1023/A:1022348506064
Black, J. W. (1952). Accompaniments of word intelligibility. J. Speech Hear. Disord. 17, 409–418. doi: 10.1044/jshd.1704.409
Bopp, K. L., and Verhaeghen, P. (2005). Aging and verbal memory span: a meta-analysis. J. Gerontol. Psychol. Sci. 60B, P223–P233. doi: 10.1093/geronb/60.5.p223
Bruce, D. J. (1958). The effects of listeners’ anticipation on the intelligibility of heard speech. Lang. Speech 1, 79–97.
Bruner, J. S., and Potter, M. C. (1964). Interference in visual recognition. Science 144, 424–425. doi: 10.1126/science.144.3617.424
Caplan, D., and Waters, G. S. (1999). Verbal working memory and sentence comprehension. Behav. Brain Sci. 22, 77–126. doi: 10.1017/S0140525X99001788
Carpenter, P. A., Miyake, A., and Just, M. A. (1994). “Working memory constraints in comprehension: evidence from individual differences, aphasia, and aging,” in ed. Handbook of Psycholinguistics, ed. M. Gernsbacher (San Diego, CA: Academic Press), 1075–1122.
Christianson, K., Williams, C. C., Zacks, R. T., and Ferreira, S. (2006). Younger and older adults’ “good enough” interpretations of garden path sentences. Discourse Process. 42, 205–238. doi: 10.1207/s15326950dp4202_6
Chun, M. M., Golomb, J. D., and Turk-Browne, N. B. (2011). A taxonomy of external and internal attention. Annu. Rev. Psychol. 62, 73–101. doi: 10.1146/annurev.psych.093008.100427
Cohen, G., and Faulkner, D. (1983). Word recognition: age differences in contextual facilitation effects. Br. J. Psychol. 74, 239–251. doi: 10.1111/j.2044-8295.1983.tb01860.x
Cowan, N. (1999). “An embedded-process model of working memory,” in Models of Working Memory: Mechanisms of Active Maintenance and Executive Control, eds A. Miyake and P. Shah (Cambridge: Cambridge University Press), 62–101.
Cowan, N. (2005). “Working memory capacity limits in a theoretical context,” in Human Learning and Memory: Advances in Theory and Application: The 4th Tsukuba International Conference on Memory, eds C. Izawa and N. Ohta (Mahwah, NJ: Erlbaum), 155–175.
Daneman, M., and Carpenter, P. A. (1980). Individual differences in working memory and reading. J. Verbal Learning Verbal Behav. 19, 450–466. doi: 10.1016/S0022-5371(80)90312-6
Daneman, M., and Merikle, P. M. (1996). Working memory and language comprehension: a meta-analysis. Psychon. Bull. Rev. 3, 422–433. doi: 10.3758/BF03214546
de Fockert, W., de, Rees, G., Frith, C. D., and Lavie, N. (2001). The role of working memory in visual selective attention. Science 291, 1803–1806. doi: 10.1126/science.1056496
Dickinson, C. V. M., and Rabbitt, P. M. A. (1991). Simulated visual impairment: effects on text comprehension and reading speed. Clin. Vis. Sci. 6, 301–308.
Engle, R. (2002). Working memory as executive attention. Curr. Dir. Psychol. Sci. 11, 19–23. doi: 10.1111/1467-8721.00160
Engle, R. W., and Kane, M. J. (2004). Executive attention, working memory capacity, and a two-factor theory of cognitive control. Psychol. Learn. Motiv. 44, 145–199. doi: 10.1016/S0079-7421(03)44005-X
Engle, R. W., Tuholski, S. W., Laughlin, J. E., and Conway, R. A. (1999). Working memory, short-term memory, and general fluid intelligence: a latent-variable approach. J. Exp. Psychol. Gen. 128, 309–331. doi: 10.1037/0096-3445.128.3.309
Fallon, M., Peelle, J. E., and Wingfield, A. (2006). Spoken sentence processing in young and older adults modulated by task demands: evidence from self-paced listening. J. Genrontol. Psychol. Sci. 61B, P310–P317. doi: 10.1093/geronb/61.1.p10
Feld, J., and Sommers, M. S. (2009). Lipreading, processing speed, and working memory in younger and older adults. J. Speech Lang. Hear. Res. 52, 1555–1565. doi: 10.1044/1092-4388(2009/08-0137)
Ferreira, F. (2003). The misinterpretation of noncanonical sentences. Cogn. Psychol. 47, 164–203. doi: 10.1016/S0010-0285(03)00005-7
Ferreira, F., Bailey, K. G. D., and Ferraro, V. (2002). Good-enough representations in language comprehension. Curr. Dir. Psychol. Sci. 11, 11–15. doi: 10.1111/1467-8721.00158
Ferreira, F., and Patson, N. (2007). The ‘good enough’ approach to language comprehension. Lang. Linguist. Compass 1, 71–83. doi: 10.1111/j.1749-818X.2007.00007.x
Fillenbaum, S. (1974). Pragmatic normalization: further results for some conjunctive and disjunctive sentences. J. Exp. Psychol. 102, 574–578. doi: 10.1037/h0036092
Fisk, J. E., and Sharp, C. A. (2004). Age-related impairment in executive functioning: updating, inhibition, shifting, and access. J. Clin. Exp. Neuropsychol. 26, 874–890. doi: 10.1080/13803390490510680
Flores d’Arcais, G. B. (1987). “Automatic processes in language comprehension,” in Perspectives in Cognitive Neuropsychology, eds G. Denes, C. Semenza, P. Bisiacchi, and E. Andreewsky (Hillsdale, NJ: Erlbaum), 91–114.
Forster, K. J. (1976). “Accessing the mental lexicon,” in New Approaches to Language Mechanisms, eds R. J. Wales and E. Walker (Amsterdam: North-Holland).
Forster, K. J. (1981). Priming and the effects of sentence and lexical contexts on naming time: evidence for autonomous lexical processing. Q. J. Exp. Psychol. 33, 465–495. doi: 10.1080/14640748108400804
Füllgrabe, C., Moore, B. C. J., and Stone, M. A. (2015). Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition. Front. Aging Neurosci. 6:347.doi: 10.3389/fnagi.2014.00347
Goldman-Eisler, F. G. (1968). Psycholinguistics: Experiments in Spontaneous Speech. New York, NY: Academic Press.
Gordon-Salant, S., and Fitzgibbons, P. J. (1997). Selected cognitive factors and speech recognition performance among young and elderly listeners. J. Speech Lang. Hear. Res. 40, 423–431. doi: 10.1044/jslhr.4002.423
Green, D. M., and Swets, J. A. (1966). Signal Detection Theory and Psychophysics. New York, NY: Wiley.
Grosjean, F. (1980). Spoken word recognition processes and the gating paradigm. Percept. Psychophys. 28, 267–283. doi: 10.3758/BF03204386
Grosjean, F. (1985). The recognition of words after their acoustic offset: evidence and implications. Percept. Psychophys. 38, 299–310. doi: 10.3758/BF03207159
Hasher, L., Stoltzfus, E. R., Zacks, R. T., and Rypma, B. R. (1991). Age and inhibition. J. Exp. Psychol. Learn. Mem. Cogn. 17, 163–169. doi: 10.1037/0278-7393.17.1.163
Hasher, L., and Zacks, R. T. (1988). “Working memory, comprehension, and aging: a review and a new view,” in The Psychology of Learning and Motivation: Advances in Research and Theory, Vol. 22, ed. G. H. Bower (San Diego, CA: Academic Press), 193–225.
Heald, S. L. M., and Nusbaum, H. C. (2014). Speech perception as an active cognitive process. Front. Syst. Neurosci. 8:35. doi: 10.3389/fnsys.2014.00035
Holcomb, P. J., and Neville, H. J. (1990). Auditory and visual semantic priming in lexical decision: a comparison using event-related brain potentials. Lang. Cogn. Process. 5, 281–312. doi: 10.1080/01690969008407065
Howes, D. (1957). On the relation between the intelligibility and frequency of occurrence of English words. J. Acoust. Soc. Am. 29, 296–305. doi: 10.1121/1.1908862
Hunnicutt, S. (1985). Intelligibility versus redundancy—conditions of dependency. Lang. Speech 28, 47–56.
Just, M. A., and Carpenter, P. A. (1992). A capacity theory of comprehension: individual differences in working memory. Psychol. Rev. 99, 122–149. doi: 10.1037/0033-295X.99.1.122
Kantowitz, B. H., and Knight, J. L. (1976). On experimenter limited processes. Psychol. Rev. 83, 502–507. doi: 10.1037/0033-295X.83.6.502
LaBerge, D., and Samuels, S. J. (1974). Toward a theory of automatic information processing in reading. Cogn. Psychol. 6, 293–323. doi: 10.1016/0010-0285(74)90015-2
Lahar, C. J., Tun, P. A., and Wingfield, A. (2004). Sentence-final word completion norms for young, middle-aged, and older adults. J. Gerontol. B Psychol. Sci. Soc. Sci. 59, P7–P10. doi: 10.1093/geronb/59.1.p7
Lash, A., Rogers, C. S., Zoller, A., and Wingfield, A. (2013). Expectation and entropy in spoken word recognition: effects of age and hearing acuity. Exp. Aging Res. 39, 235–253. doi: 10.1080/0361073X.2013.779175
Lash, A., and Wingfield, A. (2014). A Bruner-Potter effect in audition? Spoken word recognition in adult aging. Psychol. Aging 29, 907–912. doi: 10.1037/a0037829
Lavie, N., Hirst, A., de Fockert, J. W., and Viding, E. (2004). Load theory of selective attention and cognitive control. J. Exp. Psychol. Gen. 133, 339–354. doi: 10.1037/0096-3445.133.3.339
Lethbridge-Ceijku, M., Schiller, J. S., and Brernadel, L. (2004). Summary health statistics for U.S. adults: National Health Interview Survey. Vital Health Stat. 10, 1–151.
Liberman, A. M., Cooper, F. S., Shankweiler, D. P., and Studdert-Kennedy, M. (1967). Perception of the speech code. Psychol. Rev. 74, 431–461. doi: 10.1037/h0020279
Lieberman, P. (1963). Some effects of semantic and grammatical context on the production and perception of speech. Lang. Speech 6, 172–187.
Lindblom, B., Brownlee, S., Davis, B., and Moon, S. J. (1992). Speech transforms. Speech Commun. 11, 357–368. doi: 10.1016/0167-6393(92)90041-5
Lindfield, K. C., Wingfield, A., and Goodglass, H. (1999). The contribution of prosody to spoken word recognition. Appl. Psycholinguist. 20, 395–405. doi: 10.1017/S0142716499003045
Logie, R. H. (2011). The functional organization and capacity of working memory. Curr. Dir. Psychol. Sci. 20, 240–245. doi: 10.1177/0963721411415340
Logie, R. H., Della Sala, S., Laiacona, M., Chalmers, P., and Wynn, V. (1996). Group aggregates and individual reliability: the case of verbal short-term memory. Mem. Cogn. 24, 305–321. doi: 10.3758/BF03213295
Luce, P. A., and Pisoni, D. B. (1998). Recognizing spoken words: the neighborhood activation model. Ear Hear. 19, 1–36. doi: 10.1097/00003446-199802000-00001
Luo, C. R., and Snodgrass, J. G. (1994). Competitive activation model of perceptual interference in picture and word identification. J. Exp. Psychol. Hum. Percept. Perform. 20, 50. doi: 10.1037/0096-1523.20.1.50
Madden, D. J. (1988). Adult age differences in the effects of sentence context and stimulus degradation during visual word recognition. Psychol. Aging 3, 167–172. doi: 10.1037/0882-7974.3.2.167
Marslen-Wilson, W. D. (1987). Functional parallelism in spoken word recognition. Cognition 25, 71–102. doi: 10.1016/0010-0277(87)90005-9
Marslen-Wilson, W. D., and Zwitserlood, P. (1989). Accessing spoken words: the importance of word onsets. J. Exp. Psychol. Hum. Percept. Perform. 15, 576–585. doi: 10.1037/0096-1523.15.3.576
McCabe, D. P., Roediger, H. L., McDaniel, M. A., Balota, D. A., and Hambrick, D. Z. (2010). The relationship between working memory capacity and executive functioning: evidence for a common executive attention construct. Neuropsychology 24, 222–243. doi: 10.1037/a0017619
McClelland, J. L., and Elman, J. L. (1986). The TRACE model of speech recognition. Cogn. Psychol. 18, 1–86. doi: 10.1016/0010-0285(86)90015-0
Miller, P., and Wingfield, A. (2010). Distinct effects of perceptual quality on auditory word recognition, memory formation and recall in a neural model of sequential memory. Front. Syst. Neurosci. 4:14. doi: 10.3389/fnsys.2010.00014
Mishra, S., Lunnrer, T., Stenfelt, S., Rönnberg, J., and Rudner, M. (2013). Seeing the talker’s face supports executive processing of speech in steady state noise. Front. Syst. Neurosci. 7:96. doi: 10.3389/fnsys.2013.00096/full
Morton, J. (1964a). A preliminary functional model for language behavior. Int. Audiol. 3, 1–9. doi: 10.3109/05384916409074089
Morton, J. (1969). Interaction of information in word recognition. Psychol. Rev. 76, 165–178. doi: 10.1037/h0027366
Morton, J. (1979). “Facilitation in word recognition: experiments causing change in the logogen model,” in Processing Visual Language, eds P. A. Kolers, M. E. Wrolstad, and H. Bouma (New York: Plenum Press), 259–268.
Mullennix, J. W., Pisoni, D. B., and Martin, C. S. (1989). Some effects of talker variability on spoken word recognition. J. Acous. Soc. Am. 85, 365–378. doi: 10.1121/1.397688
Murphy, D. R., Craik, F. I. M., Li, K. Z. H., and Schneider, B. A. (2000). Comparing the effects of aging and background noise on short-term memory performance. Psychol. Aging 15, 323–334. doi: 10.1037/0882-7974.15.2.323
Norman, D. A., and Bobrow, D. G. (1975). On data-limited and resource-limited processes. Cogn. Psychol. 7, 44–64. doi: 10.1016/0010-0285(75)90004-3
Nusbaum, H., and Magnuson, J. (1997). “Talker normalization: phonetic constancy as a cognitive process,” in Talker Variability and Speech Processing, K. A. Johnson and J. W. Mullennix (New York, NY: Academic Press), 109–132.
Pashler, H., Johnston, J. C., and Ruthruff, E. (2001). Attention and performance. Annu. Rev. Psychol. 52, 629–651. doi: 10.1146/annurev.psych.52.1.629
Pichora-Fuller, M. K. (2003). Cognitive aging and auditory information processing. Int. J. Audiol. 42, 2S26–2S32. doi: 10.3109/14992020309074641
Pichora-Fuller, M. K., Schneider, B. A., and Daneman, M. (1995). How young and old adults listen to and remember speech in noise. J. Acoust. Soc. Am. 97, 593–607. doi: 10.1121/1.412282
Piquado, T., Benichov, J. I., Brownell, H., and Wingfied, A. (2012). The hidden effect of hearing acuity on speech recall, and compensatory effects of self-paced listening. Int. J. Audiol. 51, 576–583. doi: 10.3109/14992027.2012.684403
Piquado, T., Cousins, K. A. Q., Wingfield, A., and Miller, P. (2010). Effects of degraded sensory input on memory for speech: behavioral data and a test of biologically constrained computational models. Brain Res. 1365, 48–65. doi: 10.1016/j.brainres.2010.09.070
Pollack, I., and Pickett, J. M. (1963). The intelligibility of excerpts from conversation. Lang. Speech 6, 165–171.
Posner, M. I., and Snyder, C. R. R. (1975). “Attention and cognitive control,” in Information Processing and Cognition: The Loyola Symposium, ed. R. Solso (Hillsdale, NJ: Erlbaum), 205–223.
Potter, M. C. (1993). Very short-term conceptual memory. Mem. Cogn. 21, 156–161. doi: 10.3758/BF03202727
Potter, M. C., and Lombardi, L. (1990). Regeneration in the short-term recall of sentences. J. Mem. Lang. 29, 633–654. doi: 10.1016/0749-596X(90)90042-X
Rabbitt, P. (1968). Channel capacity, intelligibility, and immediate memory. Q. J. Exp. Psychol. 20, 241–248. doi: 10.1080/14640746808400158
Rabbitt, P. (1991). Mild hearing loss can cause apparent memory failures which increase with age and reduce with IQ. Acta Otolaryngol. 476, 167–176. doi: 10.3109/00016489109127274
Rogers, C. S., Jacoby, L. L., and Sommers, M. S. (2012). Frequent false hearing by older adults: the role of age differences in metacognition. Psychol. Aging 27, 33–45. doi: 10.1037/a0026231
Rönnberg, J. (2003). Cognition in the hearing impaired and deaf as a bridge between signal and dialogue: a framework and a model. Int. J. Audiol. 42, S68–S76. doi: 10.3109/14992020309074626
Rönnberg, J., Rudner, M., Lunner, T., and Zekveld, A. A. (2010). When cognition kicks in: Working memory and speech understanding in noise. Noise Health 12, 263.
Rönnberg, J., Lunner, T., Zekveld, A., Sörqvist, P., Danielsson, H., Lyxell, B., et al. (2013). The Ease of Language Understanding (ELU) model: theoretical, empirical, and clinical advances. Front. Syst. Neurosci. 7:31. doi: 10.3389/fnsys.2013.00031
Rönnberg, J., Lyxell, B., Arlinger, S., and Kinnefors, C. (1989). Visual evoked potentials: relation to adult speechreading and cognitive function. J. Speech Hear. Lang. Res. 32, 725–735. doi: 10.1044/jshr.3204.725
Rönnberg, J., Rudner, M., Foo, C., and Lunner, T. (2008). Cognition counts: a working memory system for ease of language understanding (ELU). Int. J. Audiol. 47, S171–S177. doi: 10.1080/14992020802301167
Rudner, M., and Lunner, T. (2013). Cognitive spare capacity as a window on hearing aid benefit. Semin. Hear. 34, 298–307. doi: 10.1055/s-0033-1356642
Salthouse, T. A. (1994). The aging of working memory. Neuropsychology 8, 535–543. doi: 10.1037/0894-4105.8.4.535
Salthouse, T. A. (1996). The processing-speed theory of adult age differences in cognition. Psychol. Rev. 103, 403–428. doi: 10.1037/0033-295X.103.3.403
Salthouse, T. A., Atkinson, T. M., and Berish, D. E. (2003). Executive functioning as a potential mediator of age-related cognitive decline in normal adults. J. Exp. Psychol. Gen. 132, 566–594. doi: 10.1037/0096-3445.132.4.566
Samuels, A. G. (2001). Knowing a word affects the fundamental perception of the sounds within it. Psychol. Sci. 12, 348–351. doi: 10.1111/1467-9280.00364
Sanford, A. J., and Sturt, P. (2002). Depth of processing in language comprehension: not noticing the evidence. Trends Cogn. Sci. 6, 382–386. doi: 10.1016/S1364-6613(02)01958-7
Schacter, D. L. (1987). Implicit memory: history and current status. J. Exp. Psychol. Learn. Mem. Cogn. 13, 501–518. doi: 10.1037/0278-7393.13.3.501
Schneider, B. A., and Pichora-Fuller, M. K. (2000). “Implications of perceptual deterioration for cognitive aging research,” in Handbook of Aging and Cognition, 2nd Edn, eds F. I. M. Craik and T. A. Salthouse (Mahwah, NJ.: Erlbaum), 155–219.
Schneider, W., and Chen, J. M. (2003). Controlled and automatic processing: behavior, theory, and biological mechanisms. Cogn. Sci. 27, 525–559. doi: 10.1207/s15516709cog2703_8
Schoof, T., and Rosen, S. (2014). The role of auditory and cognitive factors in understanding speech in noise by normal-hearing older listeners. Front. Aging Neurosci. 6:307. doi: 10.3389/fnagi.2014.00307
Seidenberg, M. S., Tannenhaus, M. K., Leiman, J. M., and Bienkowski, M. (1982). Automatic access of the meanings of ambiguous words in context: some limitations of knowledge-based processing. Cogn. Psychol. 14, 489–537. doi: 10.1016/0010-0285(82)90017-2
Seidenberg, M. S., Waters, G. S., Sanders, M., and Langer, P. (1984). Pre- and post-lexical loci of contextual effects on word recognition. Mem. Cogn. 12, 315–328. doi: 10.3758/BF03198291
Shiffrin, R. M., and Schneider, W. (1977). Controlled and automatic human information processing: II. Perceptual learning, automatic attending, and a general theory. Psychol. Rev. 84, 155–171. doi: 10.1037/0033-295X.84.2.127
Snodgrass, J. G., and Hirshman, E. (1991). Theoretical explorations of the Bruner-Potter 1964 interference effect. J. Mem. Lang. 30, 273–293. doi: 10.1016/0749-596X(91)90037-K
Sommers, M. S., and Danielson, S. M. (1999). Inhibitory processes and spoken word recognition in young and older adults: the interaction of lexical competition and semantic context. Psychol. Aging 14, 458–472. doi: 10.1037/0882-7974.14.3.458
Sommers, M. S., Spehar, B., and Tye-Murray, N. (2005). Auditory visual speech perception and visual enhancement in normal-hearing younger and older adults. Ear Hear. 26, 263–275. doi: 10.1097/00003446-200506000-00003
Sörqvist, P., Stenfelt, S., and Rönnberg, J. (2012). Working memory capacity and visual-verbal cognitive load modulate auditory-sensory gating in the brainstem: toward a unified view of attention. J. Cogn. Neurosci. 24, 2147–2154. doi: 10.1162/jocn_a_00275
Squire, L. R. (1994). “Declarative and nondeclarative memory: multiple brain systems supporting learning and memory,” in Memory Systems, eds D. L. Schacter and E. Tulving (Cambridge, MA: MIT Press), 203–232.
Stanovich, K. E., and West, R. F. (1983). On priming by sentence context. J. Exp. Psychol. Gen. 112, 1–36. doi: 10.1037/0096-3445.112.1.1
Stine, E. A. L., Wingfield, A., and Myers, S. D. (1990). Age differences in processing information from television news: the effects of bisensory augmentation. J. Gerontol. Psychol. Sci. 45, 1–8. doi: 10.1093/geronj/45.1.P1
Stromswold, K., Caplan, D., Alpert, N., and Rauch, S. (1996). Localization of syntactic comprehension by positron emission tomography. Brain Lang. 52, 452–473. doi: 10.1006/brln.1996.0024
Sumby, W., and Pollack, I. (1954). Visual contribution to speech intelligibility in noise. J. Acoust. Soc. Am. 26, 212–215. doi: 10.1121/1.1907309
Surprenant, A. M. (1999). The effect of noise on memory for spoken syllables. Int. J. Psychol. 34, 328–333. doi: 10.1080/002075999399648
Surprenant, A. M. (2007). Effects of noise on identification and serial recall of nonsense syllables in older and younger adults. Aging Neuropsychol. Cogn. 14, 126–143. doi: 10.1080/13825580701217710
Swinney, D. A. (1979). Lexical access during sentence comprehension: (Re)consideration of context effects. J. Verbal Learn. Verbal Behav. 18, 645–659. doi: 10.1016/S0022-5371(79)90355-4
Tulving, E. (1972). “Episodic and semantic memory,” in Organization of Memory, eds E. Tulving and W. Donaldson (New York, NY: Academic Press), 381–403.
Tyler, L. K. (1984). The structure of the initial cohort: evidence from gating. Percept. Psychophys. 36, 417–427. doi: 10.3758/BF03207496
van Rooij, J. C. G. M., and Plomp, R. (1992). Auditive and cognitive factors in speech perception by elderly listeners: III. Additional data and final discussion. J. Acoust. Soc. Am. 91, 1028–1033. doi: 10.1121/1.402628
Wagenmakers, E-J., Ratcliff, R., Gomez, P., and McKoon, G. (2008). A diffusion model account of criterion shifts in the lexical decision task. J. Mem. Lang. 58, 140–159. doi: 10.1016/j.jml.2007.04.006
Waters, G., and Caplan, D. (1996). The measurement of verbal working memory capacity and its relation to reading comprehension. Q. J. Exp. Psychol. 49A, 51–79. doi: 10.1080/713755607
Wayland, S. C., Wingfield, A., and Goodglass, H. (1989). Recognition of isolated words: the dynamics of cohort reduction. Appl. Psycholinguist. 10, 475–487. doi: 10.1017/S0142716400009048
Wingfield, A., Aberdeen, J. S., and Stine, E. A. L. (1991). Word onset gating and linguistic context in spoken word recognition by young and elderly adults. J. Gerontol. Psychol. Sci. 46, P127–P129. doi: 10.1093/geronj/46.3.p127
Wingfield, A., Alexander, A. H., and Cavigelli, S. (1994). Does memory constrain utilization of top-down information in spoken word recognition? Evidence from normal aging. Lang. Speech 37, 221–235.
Wingfield, A., Goodglass, H., and Lindfield, K. C. (1997). Word recognition from acoustic onsets and acoustic offsets: effects of cohort size and syllabic stress. Appl. Psycholinguist. 18, 85–100. doi: 10.1017/S0142716400009887
Wingfield, A., Goodglass, H., and Smith, K. L. (1990). Effects of word-onset cuing on picture naming in aphasia: a reconsideration. Brain Lang. 39, 373–390. doi: 10.1016/0093-934X(90)90146-8
Wingfield, A., and Lindfield, K. C. (1995). Multiple memory systems in the processing of speech: evidence from aging. Exp. Aging Res. 21, 101–121. doi: 10.1080/03610739508254272
Wingfield, A., McCoy, S. L., Peelle, J. E., Tun, P. A., and Cox, L. C. (2006). Effects of adult aging and hearing loss on comprehension of rapid speech varying in syntactic complexity. J. Am. Acad. Audiol. 17, 487–497. doi: 10.3766/jaaa.17.7.4
Wingfield, A., Stine, E. L., Lahar, C. J., and Aberdeen, J. S. (1988). Does the capacity of working memory change with age? Exp. Aging Res. 14, 103–107. doi: 10.1080/03610738808259731
Wingfield, A., and Stine-Morrow, E. A. L. (2000). “Language and speech,” in Handbook of Aging and Cognition, 2nd Edn, eds F. I. M. Craik and T. A. Salthouse (Mahwah, NJ: Erlbaum), 359–416.
Wingfield, A., and Tun, P. A. (2001). Spoken language comprehension in older adults: interactions between sensory and cognitive change in normal aging. Semin. Hear. 22, 287–301. doi: 10.1055/s-2001-15632
Wingfield, A., Tun, P. A., Koh, C. K., and Rosen, M. J. (1999). Regaining lost time: adult aging and the effect of time restoration on recall of time-compressed speech. Psychol. Aging 14, 380–389. doi: 10.1037/0882-7974.14.3.380
Wingfield, A., Tun, P. A., and McCoy, S. L. (2005). Hearing loss in older adulthood: what it is and how it interacts with cognitive performance. Curr. Dir. Psychol. Sci. 14, 144–148. doi: 10.1111/j.0963-7214.2005.00356.x
Keywords: speech recognition, working memory, inhibition, sentence comprehension, ELU model
Citation: Wingfield A, Amichetti NM and Lash A (2015) Cognitive aging and hearing acuity: modeling spoken language comprehension. Front. Psychol. 6:684. doi: 10.3389/fpsyg.2015.00684
Received: 06 March 2015; Accepted: 10 May 2015;
Published: 11 June 2015.
Edited by:
Mary Rudner, Linköping University, SwedenReviewed by:
Steve Majerus, Université de Liège, BelgiumJerker Rönnberg, Linköping University, Sweden
Copyright © 2015 Wingfield, Amichetti and Lash. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Arthur Wingfield, Volen National Center for Complex Systems, Brandeis University, 415 South Street, Waltham, MA 02454, USA,d2luZ2ZpZWxkQGJyYW5kZWlzLmVkdQ==