 Roberta M. DiDonato
Roberta M. DiDonato Aimée M. Surprenant
Aimée M. Surprenant- 1Cognitive Aging and Memory Lab, Department of Psychology, Memorial University of Newfoundland, St. John's, NL, Canada
- 2Speech Language Pathology, Medicine Department, Eastern Health, St. John's, NL, Canada
Communication success under adverse conditions requires efficient and effective recruitment of both bottom-up (sensori-perceptual) and top-down (cognitive-linguistic) resources to decode the intended auditory-verbal message. Employing these limited capacity resources has been shown to vary across the lifespan, with evidence indicating that younger adults out-perform older adults for both comprehension and memory of the message. This study examined how sources of interference arising from the speaker (message spoken with conversational vs. clear speech technique), the listener (hearing-listening and cognitive-linguistic factors), and the environment (in competing speech babble noise vs. quiet) interact and influence learning and memory performance using more ecologically valid methods than has been done previously. The results suggest that when older adults listened to complex medical prescription instructions with “clear speech,” (presented at audible levels through insertion earphones) their learning efficiency, immediate, and delayed memory performance improved relative to their performance when they listened with a normal conversational speech rate (presented at audible levels in sound field). This better learning and memory performance for clear speech listening was maintained even in the presence of speech babble noise. The finding that there was the largest learning-practice effect on 2nd trial performance in the conversational speech when the clear speech listening condition was first is suggestive of greater experience-dependent perceptual learning or adaptation to the speaker's speech and voice pattern in clear speech. This suggests that experience-dependent perceptual learning plays a role in facilitating the language processing and comprehension of a message and subsequent memory encoding.
Introduction
Adverse listening conditions that may hinder communication success arise from multiple sources. They may arise from within the speaker (imprecise articulation or accented speech), within the listener (hearing loss or cognitive-linguistic compromise) and/or within the environment (degraded transmission of the communication signal from telecommunication systems) (Mattys et al., 2009, 2012; Mattys and Wiget, 2011). By examining how speaker, listener and environmental sources of interference interact and influence language understanding and communication success, those factors or mechanisms that may also hinder or facilitate learning and memory performance can be identified (McCoy et al., 2005). This could have many practical impacts. First, those components that are most amenable to intervention could be improved in order to affect functional performance of activities of daily living that require communication and memory of important instructions (IADLs). Second, understanding them will advance our knowledge of how age-related changes in sensory-perceptual abilities influence cognitive decline in the older adult and may provide opportunities for prevention.
The primary purpose of this study was to accomplish the following goals: (1) to examine whether a specific type of auditory enhancement, a message spoken with clear speech technique, relative to normal conversational speech results in better learning efficiency, immediate, and delayed memory performance (Bradlow et al., 2003); (2) to investigate whether a distractor (e.g., speech babble noise) decreases learning and memory performance similarly in both the conversational and clear speech listening conditions; and (3) to determine how individual differences in hearing-listening and cognitive-linguistic factors contribute to memory performance. Three sources that contribute to adverse listening conditions were examined: those that arise within the speaker (conversation vs. clear speech), the listener (hearing-listening or cognitive linguistic functioning) and the environment (noise vs. quiet). Further, due to the nature of the design, learning-practice effects were also considered in this study. Specifically it was important to determine if memory performance was influenced as a result of practice with the experimental tasks, specifically for the role of experience-dependent perceptional learning or adaptation to the speaker (Peelle and Wingfield, 2005).
A secondary purpose was to examine this in an ecologically valid manner that captures real-life listening, language comprehension, and memory performance that is pragmatically relevant for many older adults. One motivation to use ecologically valid methods and tasks is to generalize these findings to more typical communication scenarios that require dual-tasking such as learning a task while listening to instructions (Schaefer, 2014). Additionally, as Gilbert et al. (2014) suggested, enhanced speech intelligibility with ecologically valid methods is necessary for examining how speech perception and processing in more naturalistic communicative scenarios influences listening effort and memory in older adults. Another motivation is to address the criticism of cognitive-aging research that uses methods and tasks that are more relevant to university students and less relevant to older adults, particularly when comparing the groups' performance. The criticism is that the older adults' poorer performance could be attributed to reasons unrelated to cognitive-aging decline (older adults view tasks to be patently artificial and therefore are less motivated to perform) (Craik and Bialystok, 2006).
Age-related hearing loss (ARHL) can be defined as a combination of auditory perceptual and auditory processing deficits. These age-related changes in auditory perception and processing have been demonstrated to occur as early as middle age (e.g., 40–57 years old) (Working Group on Speech Understanding and Aging and the Committee on Hearing, Bioacoustics and Biomechanics (CHABA), 1988; Helfer and Vargo, 2009; Wambacq et al., 2009). The etiology of ARHL can be attributed to a combination of the auditory stressors that are acquired throughout the life span (e.g., trauma, noise, and otologic diseases) together with genetically controlled aging processes (CHABA, 1988). Older adults with clinically normal audiograms demonstrate less dynamic temporal processing abilities as compared to younger adults with normal hearing (Konkle et al., 1977; Gordon-Salant and Fitzgibbons, 1993). Additionally, a mixed-type hearing loss is also consistent with this definition of ARHL. Therefore, a broader definition of ARHL beyond the audiogram (high frequency sensori-neural hearing loss) was considered for this study, one that incorporates these other aspects of hearing-listening changes that interfere with signal processing for speech understanding (Anderson et al., 2011, 2012; John et al., 2012).
There is evidence that as we age, particularly around the 6th decade of life, our listening abilities are less precise and less efficient compared to younger adults in the 2nd to 3rd decades of life (CHABA, 1988). These age-related hearing-listening changes distort and degrade the stimuli (Rosen, 1992; Gordon-Salant and Fitzgibbons, 1993). These listening difficulties arise from at least three general areas: decreased audibility particularly in the high frequencies disrupting consonant discrimination (Humes, 2008), slowed temporal processing or adaptation (Peelle and Wingfield, 2005) interference with experience-dependent perceptual learning of the speaker's voice and speech pattern, and difficulty segmenting the target from a competing message (e.g., listening in noise). The listening-in-noise difficulty evident in the older adult arises from both domain-specific processes (such as auditory stream segregation) and domain-general cognitive-linguistic processes (such as attention, task switching, inhibition, and monitoring capacity) (Anderson et al., 2012, 2013; Humes et al., 2012; Amichetti et al., 2013).
Furthermore, several studies have shown that even mild hearing loss that has no measurable effect on speech understanding in quiet listening conditions can have substantial effects in noisy or other adverse conditions for both discriminating words (CHABA, 1988), and memory for words recognized (Rabbitt, 1990; Pichora-Fuller et al., 1995; Mattys et al., 2009, 2012; Ng et al., 2013).
The ability to understand spoken language is necessary for functional performance of instructional activities of daily living (IALDs) (e.g., use of medical instructions for medical adherence). Fundamental to comprehension and learning of an auditory-verbal message are sufficiently intact auditory perceptual-processing abilities and cognitive-linguistic functioning. These bottom-up (auditory perceptual-processing) and top-down (cognitive-linguistic) processes need to be efficiently recruited to effectively decode the message for communication success. Both implicit and explicit recruitment of these limited-capacity resources (Kahneman, 1973), perhaps as compensation (Bäckman and Dixon, 1992; Rönnberg et al., 2010; Wild et al., 2012) have been demonstrated to promote ease of language understanding in sub-optimal or adverse communication scenarios.
Rönnberg et al. (2008) used a working memory model for Ease of Language Understanding (ELU) to explain how perceptual processes interact with cognitive processes for understanding. They proposed that it is the relative fidelity of the speech message that allows for the ease or automaticity of the match between the upstream sub-lexical features (phonology) and the target in the lexicon. Thus, when the fidelity is optimal, the match with the target occurs, at the exclusion of other competing targets in the lexicon, more rapidly and automatically due to implicit processes. When the fidelity of the message is low or suboptimal, the automatic matching processes of the sub-lexical features to the target in the lexicon is unsuccessful, resulting in a mismatch. The ELU model suggests that controlled processes are then required such that the sub-lexical, lexical, and semantic and conceptual representations from long-term memory are needed to further decode the speech signal. The match then occurs by way of explicit processes (Rönnberg et al., 2008, 2013). Thus, the re-allocation of explicit cognitive-linguistic resources for decoding of the speech signal results in fewer resources available for the learning and recall of the materials heard. Under optimal listening conditions fewer explicit resources are needed for comprehension, presumably because the perceptual features more closely match the listener's sub-lexical and lexical features in long-term memory. Optimizing the fidelity of the spoken message allows for more rapid and automatic-implicit perceptual learning of the speaker (Rudner et al., 2009) and more cognitive-linguistic resources will be available for comprehension, learning, and recall of the message (Wingfield et al., 1985, 1999, 2006; Wingfield and Ducharme, 1999).
One method to optimize the listening situation is to increase the fidelity of the speech message by using a style of speaking that increases the speech intelligibility. The “clear speech technique” is one in which the talker is instructed to produce the speech as if speaking to someone who is either hearing impaired or to one who is not a native speaker of the language (Ferguson and Kewley-Port, 2007). These were the instructions provided to the male speaker who produced the stimuli for our study. This “clear speech” technique resulted in an average speaking rate of 145 syllables per minute (spm). Relative to the original-conversational rate of the vignettes (192.5 spm), the clear speech rate was on the slower end of the normal speech rate (Goldman-Eisler, 1968); consistent with other studies that use this technique (Ferguson, 2012).
In addition to a slower rate of speech, other acoustic dimensions change by using the “clear speech” technique. The acoustic characteristics that give clear speech its intelligibility benefit are increased duration of vowels, longer and more frequent pauses, a larger consonant-vowel ratio, increased size of vowel space, decreased alveolar flapping, increased stop-plosive release, more variable voice fundamental frequency (F0), and greater variability in vocal intensity (Bradlow et al., 2003; Ferguson and Kewley-Port, 2007).
Although the use of clear speech has been demonstrated to enhance intelligibility of word and sentence discrimination in younger and older adults with and without hearing loss (Picheny et al., 1985; Ferguson, 2012) less is understood regarding its role for facilitating memory encoding. Gilbert et al. (2014) investigated intelligibility and recognition memory in noise for conversational and clear speech recorded in quiet and in response to the environmental noise (noise adapted speech-NAS) in young normal hearing adults. Results demonstrated that improved intelligibility for clear relative to conversational speech in noise improved recognition memory and that the NAS speech further enhanced intelligibility and recognition memory. Gilbert et al. (2014) concluded that naturalistic methods that simulate real-world communicative conditions for enhancing speech intelligibility have a role in improving speech recognition, comprehension, and memory performance in younger adults and may improve memory abilities for older adults.
Both sensory deficits (such as hearing loss) and cognitive impairments (such as memory difficulties) increase as a function of age and are highly correlated (Baltes and Lindenberger, 1997). In a comprehensive review of the literature, Schneider and Pichora-Fuller (2000) discussed a number of ways in which these sensory and cognitive declines could be related. They suggested that poor memory performance could be partially attributed to unclear and/or distorted perceptual information delivered to the cognitive/memory processes; the so-called “information-degradation hypothesis” (Schneider and Pichora-Fuller, 2000). In addition, several researchers (Rabbitt, 1968, 1990; Surprenant, 1999, 2007; Wingfield et al., 2005, 2006; Stewart and Wingfield, 2009; Tun et al., 2009; Baldwin and Ash, 2011) have argued that perceptual effort has an effect on cognitive resources with concomitant influences on memory performance. This is often referred to as the “effortfulness hypothesis.”
According to the effortfulness hypothesis, if listening effort for decoding the verbal message comes at the cost of cognitive resources that would otherwise be shared with the secondary task of encoding information into memory, then decreasing listening effort should result in improved learning and memory performance. Further, those individuals with greater capacity in hearing-listening and cognitive–linguistic abilities would theoretically have more resources (Kahneman, 1973) to share between the two tasks (Rabbitt, 1968, 1990). Therefore, in order to determine how these bottom up and top down resources contributed to memory performance it was first necessary to examine the participant's unique abilities in hearing-listening and cognitive-linguistic functioning. Then, how these individual variables (hearing and cognition abilities) contribute to the memory performance by listening condition (conversational and clear) and by group (Quiet and Noise) can be examined.
In this study, we recruited older adults with a range from normal-to-moderately impaired hearing-listening abilities. They listened to medical instructions either in quiet or in the presence of background babble. Half of the sentences were presented in conversational speech and half in clear speech. The listeners were asked to repeat the stimuli as precisely as they could after each trial of listening. After a filled delay they were asked to recall all the information that they heard. We examined learning efficiency defined as the averaged amount of the stimuli repeated over the four trials to learn; immediate memory as the total of items repeated immediately; and the delayed memory as the total of items recalled after a delay period. We compared learning and memory performance within subjects for the two listening conditions (clear and conversational) and between subjects for the competition (quiet and noise). In addition, we measured the individual's hearing-listening and cognitive-linguistic abilities to determine how these unique characteristics may have influenced the delayed memory performance in the two listening conditions for the two groups.
For theoretical and practical reasons, we examined how quickly the participant was able to learn the passages, how much they discriminated for immediate repetition and how much of the message they encoded for later free-recall. Theoretically, the question is whether these learning and memory processes in older adults are differentially affected by the change in listening condition. The intention is to identify the dissociable memory processing components that potentially contribute to a decline in memory for older adults (Salthouse, 2010).
Zacks et al. (2000) summarized the theoretical orientations in memory and aging and described three areas that differentiate the younger from the older adult; limited resources, processing speed, and inhibitory control.
Older adults are more limited in essential resources or self-initiated processing both at encoding and retrieval (Hasher and Zacks, 1979; Light, 1991; Craik et al., 1995). Relative to younger adults, older adults are more negatively affected by free-recall tasks, which require a higher degree of self-initiated processes. For the present study, the type of memory task chosen was free-recall. If the experimental manipulation to enhance the auditory stimuli improves the older adult's free-recall performance relative to conversational speech it will suggest that the age differences in free-recall, consistently reported by other authors (Salthouse, 2010), may be partially attributed to the effort in listening which consumes those same resources.
Older adults process information slower than younger adults (Park et al., 1996; Salthouse, 1996; Verhaeghen and Salthouse, 1997). According to Salthouse (1996) in situations in which time is restricted, the time required for the memory processes to rehearse or elaborately encode may be compromised by earlier processes, consuming the total time available to perform the task.
In relation to the present study, auditory enhancement (clear speech), which facilitates more timely and automatic processes for auditory perception and processing of the message, should free up time for those memory processes. In this way the auditory enhancements may facilitate faster perceptual learning or adaptation to the speaker's pattern. A larger learning effect (better learning or memory performance on 2nd trial of a task) indicates that the more automatic and timely auditory processing of the message for comprehension has allowed for more time available to rehearse or elaborately encode information for later recall. If learning effects differ by listening condition for the older adults, this finding suggests that some of the age-related slowing may be attributed to differences in perceptual learning of the speaker's pattern.
Older adults have less inhibitory control particularly for attention to the relevant contents of working memory. The increased mental clutter due to poorer inhibitory control increases the likelihood for sources of interference, both at encoding and retrieval (Hasher and Zacks, 1988; Zacks and Hasher, 1994, 1997; Hasher et al., 1999). In relation to the present study, the older adult with ARHL may experience an increase in mental clutter from the perceptual and lexical processing loads (Mattys and Scharenborg, 2014). Inhibiting this “noise” and maintaining attention to the task for both comprehension of the message and encoding into memory requires greater inhibitory control (or executive function) and working memory capacity for successful performance. In this way, the individual's executive control, working memory, and short-term memory is taxed more in adverse listening conditions relative to easier listening. Relevant to this study, those individuals with strengths in inhibitory control and working memory capacity should demonstrate better learning and memory performance, particularly for adverse listening conditions in which these resources are strained.
Both the ELU and the effortfulness hypotheses were considered for this study. According to the effortfulness hypothesis first described by Rabbitt (1968) and subsequently others (Tun et al., 2002, 2009; McCoy et al., 2005), while listening to typically spoken messages in degraded conditions, cognitive-linguistic resources are re-allocated for deciphering the message. This re-allocation of resources comes at the cost of those same resources for learning and memory encoding (Kahneman, 1973). The stimuli here were constructed in such a way as to optimize the auditory processing of the verbal message. The expectation is that the enhanced stimuli “clear speech technique” will mitigate those aspects of age-related hearing that interfere with communication success by reducing the perceptual, lexical, and cognitive loads (Mattys et al., 2012). In so doing, enhanced listening will free up those resources that are required for elaborate encoding for learning and remembering the passages.
Similarly, according to the ELU (Rönnberg et al., 2008), if the match between the stimuli and the long-term representation of the target in memory is automatic, then fewer explicit resources will be required for understanding the message. If we can enhance the clarity of the speech by using a style of speaking that promotes an intelligibility benefit, these same explicit cognitive-linguistic resources should become available for perceptual learning, comprehension, and elaborate encoding for later recall. Both of these hypotheses suggest that easier auditory processing of the message results in easier learning and recall. Also the suggestion is that resources for listening, learning, and remembering processes are limited and must be shared or re-allocated as needed (Gilbert et al., 2014).
If the hypotheses are confirmed, there should be a main effect of listening condition: Relative to conversational speech, enhanced listening will result in more efficient learning and better immediate and delayed memory performance. If the irrelevant speech-babble noise further interferes with processing of the targeted message then there will be a main effect of speech babble noise and an interaction of listening condition and group (Quiet vs. Noise). If found, the difference in memory performance between the two groups could be attributed to either energetic masking (Heinrich et al., 2008) of the stimuli, the noise covers up part of the sub-lexical acoustic information of the target; and/or a distractor effect, the noise distracts the listener's attention from the target (Lavie and DeFockert, 2003; Lavie, 2005; Mattys et al., 2009). In both scenarios, re-allocation of explicit cognitive-linguistic resources are required to “fill in” for what was missed to understand the message, while inhibiting the to-be-ignored background and maintaining focus for processing of the ongoing message.
Materials and Methods
Participants
Ethics clearance was obtained from Memorial University's Interdisciplinary Committee on Ethics in Human Research (ICEHR) in accordance with the Tri-Council Policy Statement on Ethical Conduct involving Humans. Inclusion criteria: community dwelling-healthy older adults 55+ years old. Exclusion criteria: known medical events that may affect cognition (e.g., cardiovascular event, neurological event, or disease), failed cognitive screening, insufficient corrected vision for performing the experiment, and hearing loss that exceeded the capacity of the speakers (90 dBA). To determine the sample size required to detect a small effect size we used G*Power 3.1 (Faul et al., 2007) (Input: Effect size f = 0.26 α error probability = 0.05, Power (1-β error probability) = 0.95, Number of groups = 2, Number of measurements = 3, Correlations among repeated measures (learning efficiency, immediate, and delayed memory) = 0.5, Non-sphericity correction ε = 1. Output: Non-centrality parameter λ = 16.22, Critical F = 3.17, Numerator df = 2.0, Denominator df = 76.0). This suggested a total sample size of 40 participants. We over-recruited by 20% (e.g., 48 participants recruited) to account for attrition.
Forty-eight older adults were recruited to participate and were randomly assigned to either the Quiet (n = 24, 14 females) or Noise (n = 24, 12 females) group. This was accomplished by first generating a counterbalanced and randomized list for the two groups and the eight different orders for completing the experiment, then the participant was allocated to the pre-randomized group/order condition sequentially. Three participants wore hearing aids, two in the Quiet, and one in the Noise group. (See Table 1 for demographic, hearing and cognitive characteristics means and standard deviations; see Figure 1 for audiogram data.) Participants received $10 an hour for their participation.
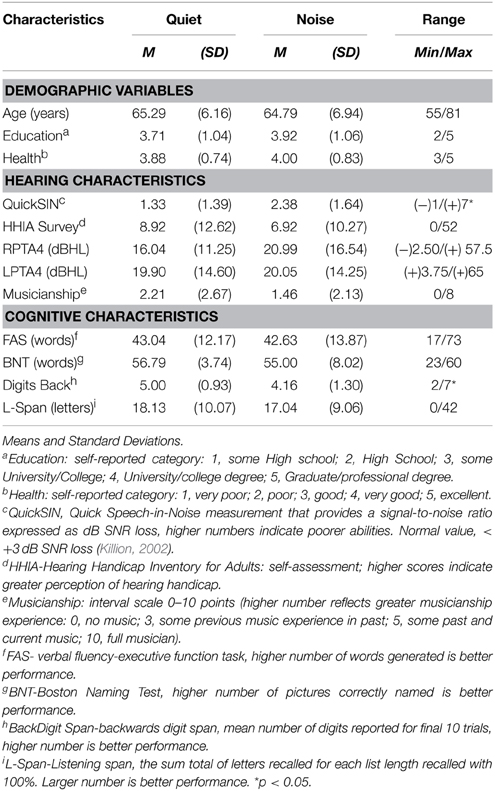
Table 1. Demographics, Hearing, and Cognitive Characteristics.
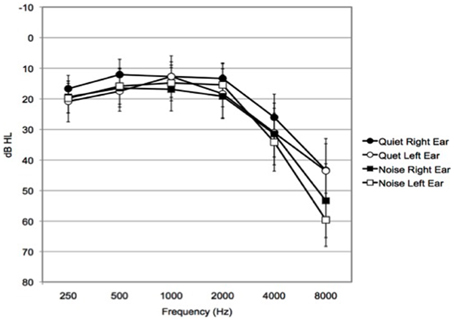
Figure 1. Mean audiogram profile. Hearing thresholds of all participants in this study. Mean audiogram profile of Quiet group right ear and Quiet group left ear (n = 24), Noise group right ear and Noise group left ear (n = 24). Bars represent 95% confidence intervals.
Preliminary Measures
The purpose of these measures was to determine if an individual should be excluded from the study. No participant was excluded from the experiment based on the measures of vision, hearing, or the cognitive screening (e.g., passing score is >23) (Crum et al., 1993) the scores ranged from 27 to 30 on the Mini-Mental Status Examination (MMSE) (Folstein et al., 1975).
The following hearing-listening and cognitive-linguistic measures were obtained for all participants, the rationale for these measures and the standardized methods used are described in greater detail elsewhere (DiDonato, 2014).
Hearing-Listening Measures
Audiometric tests were conducted in a single-walled sound attenuated chamber using a Grason Stadler Instruments Audiometer (GSI-61), Telephonics TDH50P headphones, E.a.r.Tone™ 3A insert earphones and free-field speakers calibrated to specification (American National Standards Institute ANSI, 2004). Standardized procedures with the TDH50P headphones were used to obtain pure-tone hearing thresholds for right (R) and left (L) ear. Pure tone average (PTA4) is the average of 0.5, 1, 2, and 4 kHz in dB HL (Katz, 1978). PTA4 was the metric used to indicate degree of auditory acuity deficit consistent with the WHO definition (PTA4 greater than 25 dB HL) (World Health Organization Prevention of Blindness and Deafness (PBD) Program, 2014). Speech Reception Threshold (SRT) is the threshold in dB at which one can repeat a closed set of words with 50% consistency (Newby, 1979). The Phonetically balanced (PB) max-most comfortable loudness level (PB max-MCL) is the intensity level measured in decibels in Hearing Level (dB HL), for which the participants achieved the highest accuracy for repeating phonetically-balanced (PB) word lists (Newby, 1979). The SRT and PB max-MCL were used to calculate the sensation level in which participants experienced the stimuli.
The Quick Speech-In-Noise test (QuickSIN): Etymotic Research, Elk Grove, IL; (Killion et al., 2004) is a standardized assessment of the ability to repeat/recall sentences from a target speaker (a female voice) in the presence of multi-talker babble at various levels of speech-in-noise ratios (SNRs). The target sentences were routed through the GSI-61 audiometer's external channel at 70 dB HL via the free-field speaker (Killion, 2002). The score is the signal-to-noise ratio (SNR), in decibels (dB), in which the listener recognizes the speech target correctly with 50% accuracy. A score of +7 dB SNR loss on the QuickSIN indicates that the individual needs the signal to be 7 dB louder than the competing speech noise in order to identify the sentences with 50% accuracy. Higher values reflect poorer listening-in-noise ability. The Hearing Handicap Inventory for Adults HHIA (Newman et al., 1991) is a standardized and normed self-assessment used clinically to determine the individual's self-perception of the degree to which they experience a handicap due to hearing loss (adapted from Hearing Handicap Inventory for the Elderly, HHIE (Ventry and Weinstein, 1982). The questions reflect both the social/situational and emotional consequences of hearing loss. The individual's response is yes (4 points), sometimes (2 points), or no (0 points). The score is the sum total of all the responses. A higher value reflects a greater perception of hearing handicap.
A musicianship score was calculated based on the responses to the demographic questionnaire regarding musical experience. The demographic questionnaire also included questions regarding age, education, occupation, health, medication use, and language(s) spoken (see Appendix A in supplementary Material). The musicianship classification score created for this study was an interval scale in which a higher value reflected more experience with music. Participants answered questions regarding exposure to music, age of onset of formal training, duration in years of musical performance, and the extent to which they were engaged in musical practice (e.g., hours/days per week). These questions were consistent with other studies that examine musical training and its relationship with auditory perceptual and processing abilities in behavioral and electrophysiological studies (Kraus and Chandrasekaran, 2010; Zendel and Alain, 2012, 2013). A composite score was calculated so that participants had a musicianship score from 0 to 10. A minimum score of 0 reflected no early music education, no formal lessons, and no instrumental or vocal performance presently or in the past. Maximum score of 10 reflected those who identify themselves as a musician (not necessarily professionally), started music education by 10 years of age or younger, had been musically active throughout their lifetime, had performed 12 years or greater, and those who currently perform on average at a minimum of 6 h weekly.
Cognitive-Linguistic Measures
Listening span (L-span) is a working memory (WM) task that is similar to the reading span measure (Daneman and Carpenter, 1980). The rationale for using a WM span task in this study was that this type of span task is highly predictive for complex cognitive behaviors across domains such as understanding spoken language and reading comprehension (Just and Carpenter, 1992; St Clair-Thompson and Sykes, 2010). Participants heard a sentence and had to indicate whether the last word in the sentence was predictable or not predictable (mouse-click on the respective boxes on the computer screen). At the same time that they heard the sentence, they saw a letter on the computer screen. They were instructed to attend to the letters presented and after a series of sentences and letters, were cued to recreate the letter sequence in order. The sum total of all the list lengths, which were correctly recalled, is the score. Higher scores reflect better working memory. Backward digit span (Wechsler, 1981) is a task that correlates with other measures of cognitive function such as working memory capacity, but not so strongly that it measures the same construct (Conway et al., 2005; St Clair-Thompson, 2010). Participants heard lists of digits and recreated them in reverse order. The score reflects the mean number of digits recreated in reverse order for the final 10 trials. Boston Naming Test (BNT) is a subtest of the Boston Diagnostic Aphasia Examination (Kaplan et al., 2001). The BNT is a standardized and normed confrontation picture-naming task. Participants name 60 line drawings, 1 point for each correctly named item. The BNT has been found to have good internal consistency and high reliability (Goodglass et al., 2001). Verbal fluency measure (FAS) correlates with other metrics that measure executive function. Scores reflect the individual's cognitive flexibility, inhibition and response generation (Mueller and Dollaghan, 2013). Participants generate as many words as possible beginning with the letter “F,” “A,” and “S,” given 1 min for each letter. The score is the total number of words generated.
Comparing Groups on Demographic, Hearing, and Cognitive Measures
There were no differences on demographic, hearing, and cognitive measures between the competition groups (Quiet/Noise) by ANOVA or Mann-Whitney U-tests (where appropriate) (smallest p > 0.23) except on the QuickSIN, F(1, 47) = 5.65, p = 0.02, and Backward digit span, F(1, 38) = 5.36, p = 0.03. The Quiet group demonstrated better listening-in-noise abilities, MQuiet = 1.33 dB, SD = 1.39 dB, compared to the Noise group MNoise = 2.38 dB, SD = 1.64 dB. The Quiet group demonstrated longer backward digit span values (MQuiet = 5.00, SD = 0.93), compared to the Noise group (MNoise = 4.16, SD = 1.30). Due to an error in the program there were nine backward digits scores that had been incorrectly calculated (5 Quiet, 4 Noise); these values were not entered in the analysis for this measure. (Table 1).
There were unexpected a priori differences between the groups. If differences exist between the two competition groups for the learning and memory performance in the two listening conditions, these variables must be considered and understood in terms of their impact. The Quiet group's better listening-in-noise and short-term memory abilities could result in better learning and memory performance for the two listening conditions independent of the lack of noise (i.e., erroneously concluding that the noise interfered with performance). However, no main effect of group or interaction would suggest that these differences did not influence the result.
The Auditory-Verbal Stimuli
Fictionalized medical prescription vignettes were created. The vignettes were thematic in nature and described the multiple steps needed to use specific medical prescriptions (see Appendix B in Supplementary Material for the two vignettes: medipatch and puffer-inhaler and training item). These vignettes were matched on many linguistic and non-linguistic aspects of speech to equate them as much as possible on the complexity of the stimuli, while at the same time maintaining their ecological validity (see Table 2). Both sets of prescription instructions comprised 10 sentences, with 37 critical units (CU) to report. The 37 CU were the content words within each phrase that carried the most important salient meaning for the practical purpose of using these fictional medications. Critical units may be a single word, compound word, or multiple words (e.g., breathe out, out of reach). The distribution of the CU throughout the vignette was arranged so that each third of the vignettes had similar numbers and distribution of items to recall. The two vignettes were spoken at their original-conversational rate, 192.5 (spm) and then these same vignettes were spoken using a slower hyper-articulated “clear speech” technique, (145 spm) (Baker and Bradlow, 2009).
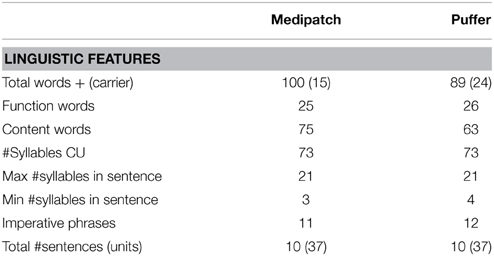
Table 2. Linguistic aspects of the vignettes.
The clear speech and the conversational speech vignettes in this experiment were subjected to acoustic analysis using Praat version 5.3.63 (Boersma and Weenink, 2014). Similar to Bradlow et al. (2003), total sentence duration, total number of pauses, average pause duration, F0 mean (Hz), F0 range (Hz), and the average vowel space range in F1 (mels) and F2 (mels) were examined. To calculate the vowel space in mels, the frequency (Hz) was converted to the perceptually motivated mel scale according to the equation by Fant (1973). Similar to Bradlow et al. (2003), when the speaker used a “clear speech” technique there was an increase in the overall duration, the number of pauses, a change in F0 mean and range, and increase in vowel space relative to when the conversational style speech technique was used. Thus, the clear speech vignettes reflect a temporal-spectral enhancement relative to the conversational speech vignettes (see Table 3 for the characteristics of each vignette; Figure 2 for Praat waveform). Avid Pro-tools 8.0.5 was used to manipulate the original sound files to ensure that the recordings were equated for loudness [root mean squared (RMS) amplitude] throughout the passages.
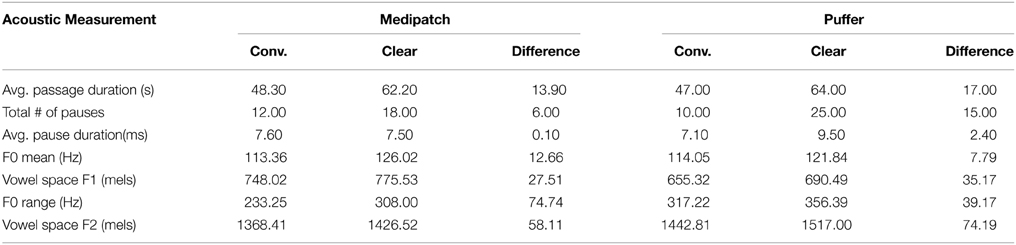
Table 3. Acoustic Characteristics of Conversational (Conv.) and Clear speech.

Figure 2. The Praat waveforms: Two listening conditions. The waveforms depict the phrase “wash your hands” from the medipatch vignette. The two listening conditions: (A) 0.97 s, original format, conversational speech technique (196 spm); (B) 1.24 s, spoken with clear speech technique (152 spm). Note in clear speech, the temporal-spectral enhancement can be appreciated by the increased durations of the vowels and increased amplitudes of the waveform.
Research Design
There was one between-subjects variable, competition (Quiet vs. Noise) and two within-subjects variables, listening condition (conversational vs. clear speech), and time of memory recall (immediate vs. delayed). This study used a modification of the learn-relearn paradigm (Keisler and Willingham, 2007). Participants listened to, immediately repeated what they had heard (immediate memory), and learned the vignettes as precisely as they could over a series of trials (learning efficiency). They then recalled the vignettes after the completion of 20 min of interference/filler tasks (delayed memory). The participants completed the study in two sessions on two separate days. In the first session they completed the vision screening, audiometric tests and the listening span (L-span). In the second session they completed the experiment as well as the other measures of hearing-listening and cognitive-linguistic abilities (included in the interference/filler task sets A and B).
Each participant listened to two passages (medipatch and puffer), one spoken with conversational and one in clear speech listening conditions, and all preliminary measures and filler/interference tasks (set A and set B). This resulted in eight different combinations of order conditions. The order in which participants performed the listening conditions, passages, or tasks (set A and B) was counterbalanced and participants were randomly assigned to one of the order conditions. An example of one of the orders is EmA/DpB. Figure 3 illustrates the procedures for the second session, when the participant performed the experiment in two listening conditions. In this example, the participant experienced the relatively Enhanced listening condition first (clear speech through insertion ear phones) with the medipatch passage, completed the interference/filler tasks set A. At completion of the timer the participant then returned to the sound booth to recall the medipatch passage. There was a 5-min break (/) between the first and second listening condition. Then the participant experienced the second listening condition, the relatively Degraded listening condition (conversational speech through the speaker in sound field) with the puffer-inhaler passage, completed the interference/filler task set B. Again at completion of the timer the participant returned to the sound booth to recall the puffer-inhaler passage.
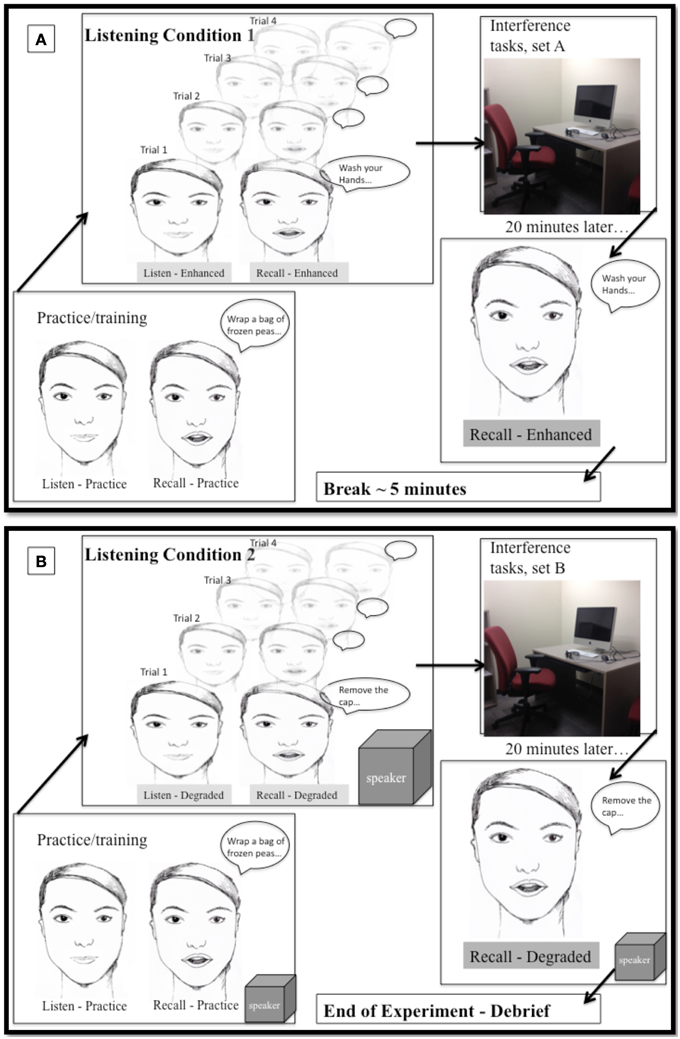
Figure 3. Illustration of procedures for experiment (second session). (A) Top panel: Listening condition 1, enhanced (clear speech), via insertion earphones. Participant instructed and practice session. Trials of listening and recall × 4. Move to experiment room for 20 min of interference/filler tasks (set A). Move back to sound booth for delayed recall. Five min break. (B) Lower panel: Listening condition 2, degraded (conversational speech) via speaker. Participant re-instructed and practice session repeated. Trials of listening and recall × 4. Move to experiment room for 20 min of interference/filler tasks (set B). Move back to sound booth for delayed recall, end of experiment, debriefing.
Filler/interference tasks. The tasks had two purposes: (1) to provide a delay between listening and delayed recall and a filler activity; and (2) to assess participants on various cognitive and linguistic measures that were later used in the correlation analyses to examine the individual differences in relationship to memory performance. The tasks within each set were administered in the same order. Set A included the (FAS), the backward digit span task, the Philadelphia naming test items 1–87 (Roach et al., 1996), and a demographic questionnaire. Set B included the Philadelphia naming test items 88–175, the BNT, the MMSE, and the HHIA.
There were three dependent measures that were obtained for the two listening conditions as follows: Learning efficiency was operationally defined as the mean number of CU learned per trial, calculated using the total sum of the number of CU reported at each of the four trials of learning divided by the number of trials (4). In this way there was a single value for the learning efficiency during the conversational listening, and a single value for the learning efficiency during the clear condition. Immediate memory was operationally defined as the sum total of the CU that had been reported during any of the learning trials for that listening condition, to the maximum of a possible total of 37 units (e.g., 1st trial (15) reported CU, plus 2nd trial (5) new CU, plus 3rd trial (3) new CU, plus 4th trial (1) new additional units = 24 CU recalled immediately for that listening condition). Delayed memory was operationally defined as the total number of reported CU after the filler tasks for that listening condition, to the maximum of 37 CU.
Instructions
Participants were informed of the experimental tasks with a written script (see Appendix C in Supplementary Material) that was read aloud to them, while they read along. Answers to questions and redirections to the written instructions were provided prior to and during the training/practice item. They were instructed that they would have multiple trials (4) to learn each vignette and to repeat all that they had heard and remembered after each trial of listening. Participants were instructed that gist reporting was acceptable but were encouraged to use as close to verbatim as possible. The participants were not under any time constraint. Responses were spoken aloud and the responses were audio-recorded. Each trial of listening and then recall of the vignette was recorded into GarageBand '11 on a Macintosh computer for later transcription and off-line scoring. A single research assistant blinded to the listening condition/competition group coded the data.
A training item was created so that participants could understand the nature of the task with feedback provided during the training task, and to confirm that the intensity level determined during the audiometric testing as PB max-MCL was comfortably loud but not too loud. After completion of the training/practice the participant was reminded to perform the experiment as they had just done during the training.
Presentation of the Auditory Condition
The stimuli were routed from a MacBook Pro computer via Apogee One, a studio quality USB music interface, to the auxiliary channels of the GSI-61 to the transducers (insert earphones or free-field speaker). The intensity level was set at each individual participant's PB max-MCL obtained during the audiometric testing. This individualized audibility level is consistent with an intensity level that reflects their best performance for discriminating and repeating a list of open-set words in quiet in a sound attenuated chamber.
Despite the advantage of using MCL in dB HL (see DiDonato, 2014), the actual sensation levels or hearing levels for the presentation of the stimuli may have varied by group. Therefore, the sensation level that the participants experienced was calculated for all participants in each group by subtracting the Speech Reception Threshold in dB from the MCL in dB HL, which indicates the sensation level in dB SL. There were no differences between the competition groups (Quiet/Noise) by ANOVA for the sensation level presentation, F(1, 47) = 2.98, p = 0.09 or for the MCL in dB HL, F(1, 47) = 0.96, p = 0.33 (see Table 4).
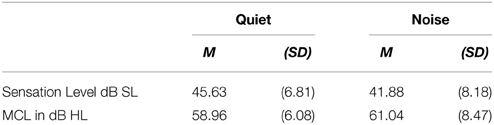
Table 4. Intensity level of stimuli presentation.
Conversational Speech Listening Condition
The conversational speech was presented binaurally via a free-field speaker calibrated to a 1 kHz tone. Participants who wore hearing aids did so for this listening condition only. The free-field presentation was used for this listening condition to mimic listening in natural listening environments. All participants were seated and positioned 1 meter distance and 0 degree azimuth to the speaker. The Noise group. The conversational speech vignette and competing speech babble noise at +5 dB SNR were routed to the speaker. The Quiet group. The conversational speech vignette was routed to the speaker in quiet.
Clear Speech Listening Condition
The clear speech stimuli were presented binaurally via disposable 3A E.A.R.tone™ insert earphones. This was intended to further enhance listening by providing optimized signal-to-noise (SNR) benefit. This was done to simulate enhancements for listening by optimizing SNR benefit easily captured in the natural environment (i.e., heard with either a personal FM system, head phones, or through a looped hearing aid). The reality of an SNR benefit of the stimuli in Quiet with the insert earphones in an anechoic sound-attenuated chamber would be much less but perhaps not zero. Additionally, since the clear speech signal and the noise were transduced via the insert earphones simultaneously the SNR benefit would have been nullified for the Noise group. The Noise group. The clear speech vignette and competing speech babble noise at +5 dB SNR were presented simultaneously to the insert earphones binaurally. The Quiet group. The clear speech vignette was presented without speech babble noise to the insert earphones binaurally.
Results
To determine the consistency and accuracy of the coding of the participant sound files, one research assistant, blinded to the listening condition, coded all the participant files and then re-coded 21% of the total of the files randomly selected from the experiment. Intra-rater reliabilities for coding of blinded scoring were assessed using intra-class correlation coefficient (ICC) with a two-way mixed effects model and absolute agreement type (Shrout and Fleiss, 1979). The ICC for single measures for the reported-recalled CU for each trial was 0.98. An ICC value between 0.75 and 1.00 is considered excellent (Hallgren, 2012). The high ICC intra-rater reliabilities suggests that minimal amount of measurement error was introduced by the coding of the participants' sound files (Cicchetti, 1994).
Order of Experiment Effects
There were eight different orders in which the participants completed the experiment. To determine whether the order of the experiment affected the participant's performance, a series of mixed design ANOVAs were conducted. The learning efficiency, immediate memory, and delayed memory scores were analyzed, with a 2 (listening condition: conversational vs. clear) × 2 (listen order: conversational first vs. clear first) × 2 (passage order: medipatch first vs. puffer first) × 2 (interference/filler task set order: Set A first vs. Set B first) mixed factors ANOVA, with listening condition as a within-subjects factor, and the three order variables as between-subjects factors. This was conducted for each of the dependent variables separately (see Table 5 for all F and p-values).
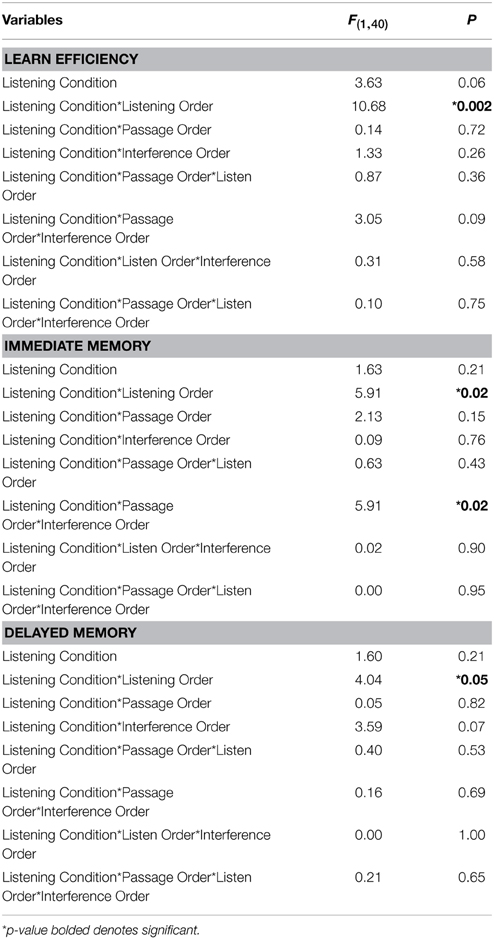
Table 5. Order of Experimental Effects and Interactions.
Listening Condition Order and Listening Condition Interactions
There was an interaction between listening condition order (conversational-clear vs. clear-conversational) and listening condition on learning efficiency, F(1, 40) = 10.68, p = 0.002, on immediate memory, F(1, 40) = 5.91, p = 0.02, and on delayed memory, F(1, 40) = 4.04, p = 0.05. This interaction is as follows: Performance was always better for the subgroups who experienced the listening condition as their second listening task compared to the subgroups who experienced that same listening condition as their first listening task (Figure 4).
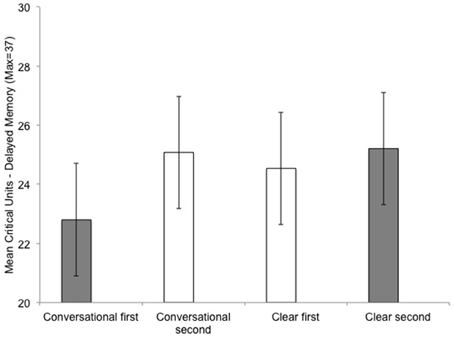
Figure 4. Comparing learning effects with listening condition (conversational and clear speech) on delayed memory performance for the Quiet/Noise groups combined. First/second indicates the order in which the participant performed that experimental listening condition. The color of the bars differentiates the between-subject listening order in which they experienced the listening condition: Gray bars represent the subgroup of participants who listened in conversation first/clear second; white bars represent the subgroup of participants who listened in clear first/conversation second. Error bars are the standard error of the mean.
Learning efficiency was better for second vs. first listening condition in both the conversational listening condition, Mfirst-conversational = 19.66, SD = 5.81, Msecond-conversational = 21.94, SD = 5.40; and the clear listening condition, Mfirst-clear = 21.03, SD = 6.75, Msecond-clear = 23.09, SD = 5.73.
Immediate memory performance was better for second vs. first listening condition in the conversational listening condition, Mfirst-conversational = 28.79, SD = 5.38, Msecond-conversational = 30.42, SD = 4.51; and the clear listening condition, Mfirst-clear = 29.63, SD = 5.79, Msecond-clear = 31.33, SD = 4.43.
Delayed memory was better for second vs. first listening condition in the conversational listening condition, Mfirst-conversational = 22.83, SD = 5.85, Msecond-conversational = 25.08, SD = 6.01; and the clear listening condition, Mfirst-clear = 24.54, SD = 6.73, Msecond-clear = 25.21, SD = 6.38.
This reflects general learning-practice effects, which were greater for the conversational (heard clear first) compared to the clear (heard conversational first) condition.
Post-hoc paired samples t-test (Bonferroni correction, alpha = 0.025) revealed that listening-order influenced the dependent variables differentially for the listening conditions. Conversational-1st order resulted in a significant difference in the two speech styles; for learning efficiency, t(23) = 3.60, p = 0.002; immediate memory, t(23) = 2.49, p = 0.021; and marginally significant for delayed memory, t(23) = 1.90, p = 0.07. However, clear-1st order resulted in no difference in performance for listening conditions for the dependent variables, (all values for t < 1, p > 0.34). For example, when comparing the within-subject differences between the two speech styles (conversational vs. clear), there is a much smaller and non-significant differences when clear speech is heard first, where the difference between the two speech styles are significantly greater when conversational speech is heard first. Figure 4 illustrates this difference for Delayed memory performance, gray bars represent the subgroup Clear second (25.21) − Conversational 1st (22.8) = 2.41; compared to the white bars, the subgroup Clear first (25.54) − Conversational 2nd (25.08) = 0.54. This larger and significant difference between the within-subject variable (conversational vs. clear listening condition) for the Conversational-1st is evident in both learning efficiency performance, 3.43 units, compared to Clear 1st a non-significant difference of 0.91; as well for the immediate memory performance, Conversational-1st, 2.54 units, compared to Clear 1st a non-significant difference of 0.79.
As a result of these interactions between listening-order and listening condition, listening order was entered as a covariate for further hypothesis testing of learning efficiency, immediate, and delayed memory performance between the Quiet and Noise groups in the conversational and clear listening conditions.
Passage, Interference/Filler Task, and Listening Condition Interactions
There was no effect of order or interactions for passage (e.g., medipatch vs. puffer) or interference/filler task set on Learning efficiency or Delayed memory performance (see Table 5 for F and p-values). However, there was a 3-way interaction among passage (medipatch-puffer), interference/filler task (set A or B), and listening condition on immediate memory performance, F(1, 40) = 5.91, p = 0.02.
The three-way interaction indicated that for the conversational speech listening conditions, those in the puffer passage with the interference task set A, immediately recalled more units, Mconversational/puffer-set A = 32.75, SD = 3.47, than the other 3 passage × interference task combinations, Mconversational/puffer-set B = 28.50, SD = 5.33, Mconversational/medi-set A = 27.67, SD = 5.69, Mconversational/medi-set B = 29.50, SD = 4.10; this was not the case in clear speech listening, the four subgroups are more similar, Mclear/puffer-set A = 31.17, SD = 4.11, Mclear/puffer-set B = 29.83, SD = 6.42, Mclear/medi-set A = 31.42, SD = 5.11, Mclear/medi-set B = 29.50, SD = 5.21.
As a result of the interactions noted above, listening condition order, passage order, and interference task order, were entered as covariates for further hypothesis testing for the differences of immediate memory between the groups (Quiet and Noise) in the conversational and clear listening conditions.
Listening Condition, Competition, and Interaction Effects on Learning and Memory Performance
Learning efficiency, immediate memory and delayed memory scores were analyzed with a 2 (competition: Quiet, Noise) × 2 (listening condition: conversation, clear speech) mixed design ANOVA in which listening condition was entered as the repeated measure within-subject variable and competition was a between-subject variable.
Effects of Listening Condition for Learning Efficiency, Immediate and Delayed Memory
There were main effects of listening condition on learning efficiency, F(1, 45) = 13.48, p = 0.001, on immediate memory, F(1, 43) = 6.35, p = 0.02, and on delayed memory, F(1, 45) = 5.51, p = 0.02. The clear speech listening enhancements improved learning efficiency on average by 1.26 CU learned per trial and improved immediate and delayed recall on average by approximately 1 critical unit (see Table 6).
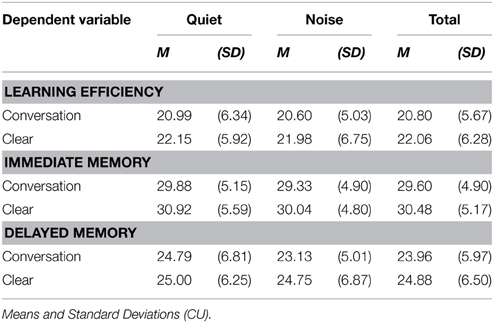
Table 6. Quiet and Noise groups for Learning Efficiency, Immediate, and Delayed Memory performance in conversational and clear listening conditions.
Effect of the Competition: Speech Babble Noise vs. Quiet
There were no main effects of the between-subject variable (competition: noise vs. quiet) on learning efficiency, immediate memory or delayed memory (all values for F < 1, p > 0.57).
Interaction Effects of Listening Condition and Competition
There were no significant interactions of listening condition by competition for learning efficiency, immediate memory or delayed memory (all values for F < 1, p > 0.33). The Quiet and the Noise groups were similarly affected by the “clear” speech enhancement to the listening condition.
Delayed Memory Performance and the Relationship with Hearing-Listening and Cognitive-Linguistic Abilities
Correlation analyses were conducted to further explore the unique contribution of the individual's hearing-listening and cognitive-linguistic abilities on delayed memory performance in the conversational and clear speech listening conditions for the two groups (Quiet and Noise) separately. The rationale to conduct this analysis for only the delayed memory performance variable was based on the following. First, all three dependent variables showed similar patterns: the clear speech technique relative to the conversational listening condition resulted in better performance for learning efficiency, immediate, and delayed memory performances (approximately one additional critical unit reported). Second, these dependent variables were significantly and highly correlated with each other (see Table 7 for correlation matrix of the dependent variables). Finally, important for the ecological validity of this study, the delayed memory variable was the metric that would support functional memory performance relevant to medical adherence.
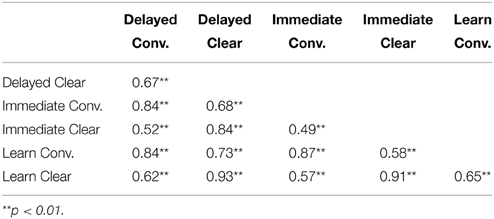
Table 7. Correlations between dependent variables for conversational (conv.) and clear listening.
The variables that reflected the hearing-listening ability as it relates to ARHL included in this analysis were LPTA4 and RPTA4, QuickSIN scores, the Hearing Handicap Inventory for Adults (HHIA), and musicianship score. The variables that reflected the cognitive-linguistic characteristics included in this analysis were as follows: auditory working memory as measured by L-span, executive function measured by verbal fluency task (FAS), lexical ability as measured by the word retrieval-picture naming task (BNT), and immediate memory as measured by the backwards digit span (Digits Back). The memory measures that were included in these correlation analyses were the delayed memory performance in the conversational and in the clear listening condition. These relationships were examined separately for the Quiet and the Noise groups.
Hearing-Listening Abilities and Delayed Memory Performance
There were no correlations for LPTA4 and RPTA4; HHIA, QuickSIN, and Musicianship scores with delayed memory in the conversational and clear listening conditions in either the Quiet group or the Noise group when these groups are examined separately (see Tables 8, 9, 10).
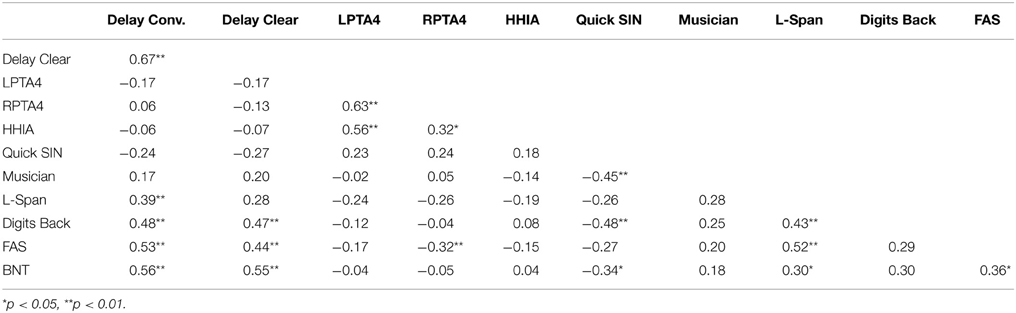
Table 8. Correlation analysis between delayed memory performance in the conversational (conv.) and clear listening conditions and hearing and cognitive abilities–Both groups.
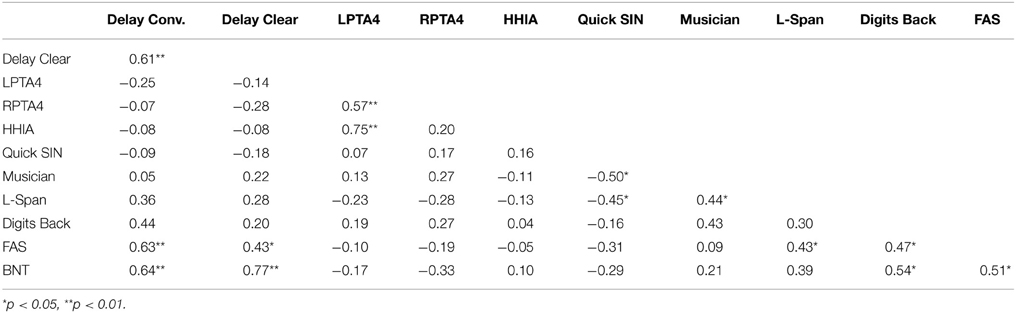
Table 9. Correlation analysis between delayed memory performance in the conversational (conv.) and clear listening conditions and hearing and cognitive abilities–Quiet group.
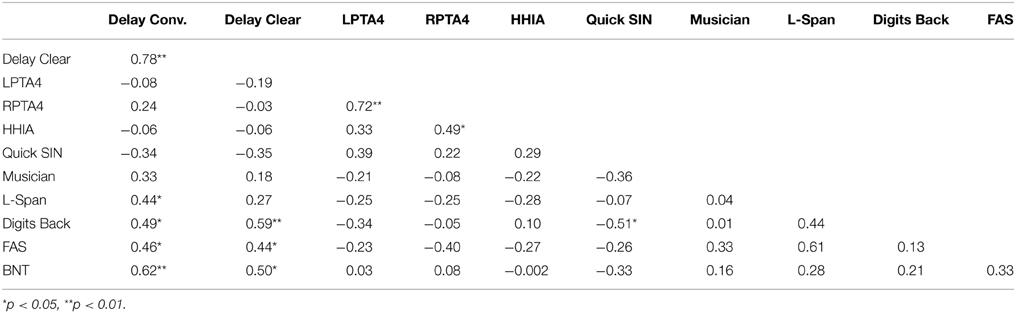
Table 10. Correlation analysis between delayed memory performance in the conversational (conv.) and clear listening conditions and hearing and cognitive abilities–Noise group.
However, when the entire sample was analyzed there were significant correlations with LPTA4, r = 0.56, p < 0.001; and with RPTA4, r = 0.32, p = 0.03 and self-perception of hearing handicap (HHIA); and a significant positive correlation of musicianship and listening-in-noise ability, (QuickSIN), r = − 0.45, p = 0.001. Higher musicianship scores correlated with lower QuickSIN scores or better listening-in noise abilities. This is consistent with studies that examine the relationship of degree of musicianship and perception of speech-in-noise (Parbery-Clark et al., 2009, 2012). Those with more musical training, for longer periods of time, starting at a younger age, demonstrate superior temporal processing, which supports better listening-in-noise abilities (Kraus and Chandrasekaran, 2010; Zendel and Alain, 2013). When considering the operationalized values of effect size as recommended by Cohen (1992), in which correlations >0.1 are considered small, >0.3 are considered medium, and >0.5 are considered large effect sizes. The above significant values ranged from medium to large effect sizes.
Although these hearing-listening abilities were not significantly related to delayed memory for the two listening conditions, generally the direction of the weak relationship of ARHL and memory performance was in the expected negative direction. As well, the hearing-listening measures did correlate with each other in the expected ways. For example, there were large effect sizes for the relationship between left and right acuity deficits and perception of hearing handicap (Newman et al., 1991), and a medium-large effect size of the relationship of musicianship and listening-in-noise abilities.
Cognitive-Linguistic Abilities and Delayed Memory Performance
L-span: working memory ability and delayed memory performance
There was a significant positive correlation for the L-span scores and delayed memory for the Noise group in the conversational, r = 0.44, p = 0.03, but not in the clear, r = 0.27, p = 0.20, listening condition. There were no significant correlations for the L-span scores and delayed memory performance for the Quiet group for the conversational, r = 0.36, p = 0.08, and for the clear, r = 0.28, p = 0.18 listening condition. The magnitude of the effect decreased when the listening condition was more favorable as in the clear speech without the competing noise, in which it became non-significant.
Backward digit spans: short-term memory ability and delayed memory performance
In view of the fact that there were missing backward digit span scores, which most likely reflected poorer values, these results should be considered with some caution. There were significant positive correlations for the backward digit span scores and delayed memory for the Noise group in the conversational, r = 0.49, p = 0.03, and for the clear, r = 0.59, p = 0.006, listening condition. There were no significant correlations for the backward digit span scores and delayed memory performance for the Quiet group for either the conversational, r = 0.44, p = 0.06, or the clear, r = 0.20, p = 0.41, listening conditions.
When the entire sample was examined, there were significant positive correlations between backward digits spans and memory performance for both the conversational, r = 0.49, p = 0.002, and the clear, r = 0.47, p = 0.003, listening conditions. The magnitude of the effect became smaller when the listening condition was more favorable as in the clear listening or without competing noise.
FAS: Executive function ability and delayed memory performance
There were positive correlations of the FAS scores and delayed memory for the Noise group in the conversational, r = 0.46, p = 0.02, and for the clear, r = 0.44, p = 0.03, listening condition. There were positive correlations of the FAS scores and delayed memory for the Quiet group in the conversational, r = 0.63, p = 0.001, and the clear listening, r = 0.43, p = 0.04. The magnitude of the effect became smaller when the listening condition was more favorable in the clear speech listening condition. However, it is interesting to note that the magnitude of the relationship of executive function and delayed memory was the greatest in the Quiet group in the conversational listening condition, which is an unexpected finding that will be considered in more detail below.
Boston Naming Test (BNT): Lexical ability (naming/verbal fluency) and delayed memory performance
There were positive correlations for the BNT scores and delayed memory for the Noise group in the conversational, r = 0.62, p = 0.001, and the clear, r = 0.50, p = 0.01, listening condition. There were correlations for the BNT scores and delayed memory for the Quiet group in the conversational, r = 0.64, p = 0.001, and the clear, r = 0.77, p < 0.001, listening condition. The magnitude of the effect became greater when the listening condition was most favorable, that is in the clear speech listening condition without competing noise.
Summary of cognitive-linguistic abilities and delayed memory performance in the conversational and clear listening for the Quiet and Noise groups
When the entire sample was analyzed, as well as when the two groups (Quiet and Noise) were analyzed separately, there were medium to large effects of the cognitive-linguistic measures on delayed memory for the conversational and clear speech listening conditions. The magnitude of these effects generally became smaller when the listening condition was more favorable as in the Quiet group or in the clear speech enhancement (Tables 8–10).
Discussion
The purpose of this study was to examine how auditory perception and processing of a relatively enhanced speech message (clear vs. conversational speech) affected perceptual learning efficiency, immediate, and delayed memory performance in older adults with varying levels of hearing-listening abilities. This was examined with ecologically valid methods to assess how the older adult's learning and memory performance is influenced based on real-life listening scenarios, with relevant materials and with enhancements that could be reasonably achieved.
Ultimately the research question proposed was whether ease of perceptual processing (ELU hypothesis Rönnberg et al., 2008) or effortless listening (effortfulness hypothesis, Rabbitt, 1968) mitigates the distortions from ARHL in quiet and noisy listening and promotes better learning and memory. The clear speech relative to conversational speech in this study promoted intelligibility similar to other studies that examined speech perception in younger and older adults (Ferguson, 2012). The slower rate, increased pauses, and acoustic changes (increased vowel space, F0 mean and range) enhanced the temporal-spectral aspects of the stimuli such that it was more similar to how the younger adult perceives speech compared to how the older adult typically perceives speech. Relative to younger adults with normal hearing, older adults with normal audiograms have been found to demonstrate less stable and less precise temporal processing of specific speech cues such as timing, frequency, and harmonics which interferes with speech discrimination (Anderson et al., 2012). These auditory temporal-spectral processes are necessary for discrimination of phonemes, morphemes and the regularities in the speaker's voice and speech pattern (Rosen, 1992). The stability of the acoustic information allows one to detect the regularities of the input over time. Optimal auditory perceptual ability allows one to temporally process and perceptually learn and adapt to the variability of the speaker, even within a single conversation (Mattys et al., 2012). The speech was optimized in this way to provide the older adult with the psycho-acoustic perception of speech more similar to how the younger adult experiences the stimuli (audible, slower, more distinctive).
The expectation was that clear speech would ease or decrease the effort for the experience-dependent perceptual learning of the auditory-verbal message, such that the older adult can adapt to the speaker's speech and voice pattern more efficiently, and stay attendant to the linguistic processing of the targeted message. As Salthouse (2010) states, “the most convincing evidence that the causes of a phenomenon are understood are results establishing that the phenomenon can be manipulated through interventions” (p. 157). Indeed this was the intent of the current study. Since learning and memory performance improved due to the behavioral intervention (listening enhancements) that manipulated those specific factors that were theoretically hypothesized to cause the phenomenon of poorer learning/memory performance, then these results support the hypothesis.
There are both theoretical and practical implications of these findings. Broadly defined, ARHL in older adults may indeed be contributing to age-related cognitive memory decline. Optimizing listening scenarios may significantly influence the functional performance of the older adult for IADLs.
Strengths in cognitive-linguistic abilities were positively associated with delayed memory performance with the magnitude of this effect greater in the relatively adverse listening (conversational speech). Larger effect sizes for cognitive-linguistic abilities on delayed memory performance in conversational vs. clear speech in a within-subject design suggests that indeed fewer explicit cognitive resources were required for deciphering the message in the enhanced listening.
These results are consistent with both the ELU and the effortfulness hypotheses in that making the speech audible and clearer enhanced learning and memory performance in older adults. Thus, the results of this study shed light on how sensory perception and processing declines in the older adult affect the implicit experience-dependent perceptual learning processes. This disruption to the perceptual learning processes then has cascading effects on higher-level cognitive-memory processes, delayed memory performance.
Learning-Practice Effects: Order of Listening Condition and Delayed Memory Performance
The significant interactions between the order of the presentation of the listening condition (conversational-clear vs. clear-conversational) and listening condition on learning efficiency, immediate and delayed memory performance in this study, are consistent with the extant literature describing a learning-practice effect and the related learning curve. A practice or learning effect is described as more positive scores (e.g., faster, more accurate, higher consistency, more efficient) with experience of task over subsequent trials of the same type of task or test. This learning-practice effect and the classic s-shaped learning curve (progress plotted on the y axis as a function of time/trials on the x axis) has been described to occur on the simplest perceptual-motor tasks as well as complex cognitive tasks (Ritter and Schooler, 2001). It is evident in educational testing, clinical neuropsychological tests, and in research with test-retest experimental designs (Hausknect et al., 2006). Learning effects may be affected by familiarity with task, decreased anxiety with repeated trials, and employment of strategies learned and transferred to the subsequent trials (Ritter et al., 2004).
The design and methods employed in this study were conducted in such a way that these learning-practice effects were anticipated (participants randomly assigned to the counterbalanced order of the variables), investigated (order effects examined); and controlled for in the analyses (entered listening-order as covariate).
Learning-Practice Effect Benefit on Delayed Memory Performance
Pure listening condition effects (i.e., without learning-practice effects) can be appreciated by examining the subgroups' (N = 24) first listening conditions (conversation first vs. clear first). Delayed memory performance is similarly improved in clear vs. conversation in quiet (+1.5 units) and noise (+1.92 units). This supports the statistical finding of the clear speech enhancement improving delayed memory performance in quiet and noise conditions. (Figure 4).
A learning effect benefit is defined as previous experience with the task or test improving performance compared to no previous experience. It is quantified as the difference in delayed memory performance between the subgroups who had that listening condition as their second condition and the subgroups who had that same listening condition first (i.e., no prior experience with doing the experiment). For example, for delayed recall Clear 2nd − Clear 1st = +0.67; Conversational 2nd − Conversational 1st = +2.25. The reported interaction is that the learning effect benefit is differentially influenced by which listening condition was first. The benefit of experiencing the experiment first with conversational speech only increased the clear speech performance over the “pure listening condition effect” by +0.67. Where the benefit of experiencing the experiment first with clear speech increased the conversational speech performance over the “pure listening condition effect” by +2.25. In this way, conversational speech listening as the first listening condition provided less of a learning-practice effect benefit.
The learning-practice effect may be attributable to the fact that this subgroup of participants who had the second listening task as the conversational speech listening condition had the benefit of learning how to do the task first in their first listening condition (i.e., clear listening condition). They were able to perceptually learn and adapt to the speaker's voice and speech characteristics more easily after that first clear listening condition. Further, the finding that the magnitude of the relationship of executive function and delayed memory performance was the greatest in the Quiet group in the conversational listening condition indicates that strengths in this cognitive ability contributed to successful performance perhaps as compensation (Bäckman and Dixon, 1992; Wild et al., 2012).
These results suggest the following: (1) The “clear” speech relative to conversational speech promotes an additional perceptual learning of the speaker's voice and speech pattern, this increases the overall learning benefit even in the noise conditions, perhaps by the high perceptual load mitigating the distractor effect of the noise. (2) Conversational speech heard with ARHL decreases the learning-practice benefit, with learning-practice benefits becoming much smaller relative to the clear speech style.
Implications
In summary, the results showed that when older adults listened to complex medical prescription instructions with “clear speech,” (presented at audible levels through insertion earphones) their learning efficiency, immediate, and delayed memory performance improved relative to their performance when they listened with a normal conversational speech rate (presented at audible levels in sound field). This better learning and memory performance for clear speech listening was maintained even in the Noise group. When the speech was manipulated so that it was sufficiently discriminable in that it could be easily segregated into meaningful units (the clear speech technique), the presence of the irrelevant distractor - speech babble noise did not differentially affect memory performance. There was a weakly associated negative relationship between ARHL and delayed memory performance in this experiment. There were medium to large positive associations between delayed memory performance and working memory, executive control and lexical abilities; however, the magnitude of these effects were larger in the conversational listening compared to the clear listening condition. This finding indicates that explicit cognitive-linguistic abilities are correlated with delayed memory performance more so in sub-optimal or adverse listening conditions. It appears that those with strengths in cognitive-linguistic abilities are able to more efficiently compensate by re-allocating resources for discrimination and comprehension of the auditory-verbal message and still have sufficient resources for the secondary task of encoding the message in memory for later recall.
Further, these results suggest that the sources of interference (speaker, listener, and environment) may interact as follows. The auditory-verbal stimuli in the conversational speech relative to clear speech listening create a demand for more cognitive-linguistic resources to achieve successful decoding of the message. As a result, the listener's limited-capacity resources are re-allocated such that fewer resources are available for learning and encoding for later recall (effortfulness hypothesis). In addition, the finding that learning-practice effects were largest when clear speech was heard first, in both quiet (+3.25) and noise (+1.25), supports the hypothesis that a high perceptual load decreases the distractor effect, where a high perceptual load spoken with conversational style does not (Lavie, 2005). Perhaps then when older adults listen to conversational speech rate that is further degraded by ARHL (listener source of interference), the high perceptual load does not mitigate the distractor effect (environment issues - ambient noise/reverberation/babble), which then interferes with the on-line processing of the acoustic message. Results suggest that it is this environmental issue-the distraction (even milliseconds) from the online auditory temporal-spectral processing of the message that then requires those explicit cognitive-linguistic resources to decode the message, so that fewer resources are available for encoding for later recall.
Although the data showed a main effect of listening condition (conversational and clear) on learning and memory performance, the expectation was that the competition groups (Noise vs. Quiet) would be differentially affected by the listening condition resulting in an interaction of group with listening condition. This was not found, most likely because the noise was a between group variable and there were large variances in performance within the groups. However, an interaction of listening condition order with listening condition for the subgroups of 1st vs. 2nd listening conditions was evident reflecting a perceptual learning effect or adaptation of those who listened first in the clear speech.
In addition, the expectation was that the age-related auditory acuity deficit would be more strongly correlated with learning and memory performance for the two listening conditions. The expectation was that there would be a large negative effect of hearing-listening abilities, on learning and memory performance, with the magnitude of that effect being larger in the conversational compared to the clear listening condition (as a result of the signal). Perhaps the ARHL acuity deficit was completely corrected for by presenting the stimuli at the individual's MCL. If the presentation level was set at a fixed absolute hearing level (70 dB HL) this may have then resulted in the expected negative associations of greater ARHL and poorer delayed memory performance. It also could be because the groups' PTA4 reflected normal-to-moderate hearing loss at the higher frequencies. Use of MCL presentation level for a group of older adults with more severe, precipitously-sloping high-frequency hearing loss, would not have corrected for the hearing loss as completely. Perhaps then these ARHL factors would have negatively associated with delayed memory performance.
It is probable that once the stimuli were sufficiently audible, the level of temporal-spectral degrading did not reach a threshold or tipping point in which the added distortion from ARHL interacts with the processing of the message for successful recognition and comprehension. Instead it is the cognitive-linguistic abilities that are recruited as a compensatory process for successful recognition and encoding for later recall (Bäckman and Dixon, 1992; Wild et al., 2012). The cognitive-linguistic scores significantly correlating with delayed memory performance with greater magnitudes in the conversational listening condition support this compensatory role of cognitive-linguistic abilities for adverse listening (Rudner et al., 2009).
Yet still the relative temporal-spectral manipulation of these two listening conditions might not have resulted in the conversational speech being sufficiently degraded. The temporal-spectral degrading of more typically produced conversational speech may not have been captured by this speaker's rendition. Since he was instructed to use articulation, rate and prosody for optimal clarity even for the original-conversation recording, and as a professionally trained singer and speaker, his normal conversational style is most likely comparable to citation-style speech. As Lam et al. (2012) demonstrated the instructions given to the speaker for the production of the passages affects the acoustic aspects and the intelligibility benefit (Krause and Braida, 2004, 2009; Lam et al., 2012). Citation–style speech production has been demonstrated to provide a larger intelligibility benefit than typically produced conversational speech and potentially only slightly less so from “clear speech technique” (Ferguson and Kewley-Port, 2007).
Nonetheless, enhancing the message by using a “clear speech” technique resulted in better learning and memory performance in two groups of older adults matched for age and ARHL. Additionally, the clear speech technique compared to conversational style speech reduced the negative impact that the competing noise had on learning and memory. Third, the finding that there was the largest learning effect on conversational speech as the second-listening condition after the clear speech listening condition was the first-listening condition of the experiment suggests greater perceptual learning or adaptation to the speaker's speech and voice pattern. This suggests that experience-dependent perceptual learning plays a role in facilitating or interfering with language processing and comprehension of a message and subsequent memory encoding.
Limitations and Future Directions
Ecologically valid methods and stimuli are preferred for understanding complex human behaviors in the context of real life, particularly for applicability and generalizability. However, there are inherent limitations such as fewer controls of latent variables, which may confound the results. For example, relevance, familiarity, and the subjective and objective importance of instructions can influence memory performance for older adults when processing larger quantities of information (Friedman et al., 2015). The vignettes in this study were developed to be intentionally relevant, important and generally familiar (medical-patch, puffer-inhaler). However, these variables were not actively manipulated in this study. Since relevance, importance and familiarity may interact with the listening conditions, future studies should consider manipulating and/or actively controlling for these variables. It is possible that these variables influence learning and memory more so in adverse listening conditions.
Another concern was the interaction between passage order, and listening condition order on immediate memory. It is possible that one passage may have lent itself to be spoken more “clearly” than another. In the future, experiments should use a more controlled method to spectrally and temporally enhance the stimuli such as a time-expansion technique (Tun, 1998; Peelle and Wingfield, 2005). Also, to examine whether a more substantial manipulation of the temporal-spectral aspect of the stimuli interacts with ARHL, either more typically spoken conversational speech or a time-compressed technique could be employed. Additionally, using the competition as a within subject variable instead of as a between subject variable will capture the degree to which the ARHL interacts with the noise and further increases listening effort for language processing and comprehension of the message. Finally, by using a more controlled enhancement such as expanded speech in quiet this manipulation would more closely resemble the experience that the younger adult has when listening. Then younger and older participant group's learning and memory performance could be compared in the two listening conditions (time-compressed with noise and time-expanded in quiet). Those aspects that mimic ARHL should then result in poorer learning and memory performance, and those that mimic younger listening should result in better learning and memory performance for both groups. With a within-subject research design one can then examine the relationships of hearing-listening factors and cognitive-linguistic characteristics on the learning and memory performance during the two listening conditions.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was funded by the Newfoundland and Labrador Healthy Aging Research Program, Doctoral Dissertation Award (2012), Doctoral Research Grant (2011); and the Canadian Institutes of Health Research Gold award (2011).
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fpsyg.2015.00778/abstract
References
American National Standards Institute. (2004). Specification for Audiometers. ANSI S3.6-2004, ANSI. Melville, NY: Acoustical Society of America (ASA).
Amichetti, N. M., Stanley, R. S., White, A. G., and Wingfield, A. (2013). Monitoring the capacity of working memory: executive control and effects of listening effort. Mem. Cognit. 41, 839–849. doi: 10.3758/s13421-013-0302-0
Anderson, S., Parbery-Clark, A., White-Schwoch, T., and Kraus, N. (2012). Aging affects neural precision of speech encoding. J. Neurosci. 32, 14156–14164. doi: 10.1523/JNEUROSCI.2176-12.2012
Anderson, S., Parbery-Clark, A., Yi, H., and Kraus, N. (2011). A neural basis of speech-in-noise perception in older adults. Ear Hear. 32, 750–757. doi: 10.1097/AUD.0b013e31822229d3
Anderson, S., White-Schwoch, T., Parbery-Clark, A., and Kraus, N. (2013). A dynamic auditory-cognitive system supports speech-in-noise perception in older adults. Hear. Res. 300, 18–32. doi: 10.1016/j.heares.2013.03.006
Bäckman, L., and Dixon, R. A. (1992). Psychological compensation: a theoretical framework. Psychol. Bull. 112, 259–283. doi: 10.1037/0033-2909.112.2.259
Baker, R. E., and Bradlow, A. R. (2009). Variability in word duration as a function of probability, speech style, and prosody. Lang. Speech 52, 391–413. doi: 10.1177/0023830909336575
Baldwin, C. L., and Ash, I. K. (2011). Impact of sensory acuity on auditory working memory span in young and older adults. Psychol. Aging 26, 85–91. doi: 10.1037/a0020360
Baltes, P. B., and Lindenberger, U. (1997). Emergence of a powerful connection between sensory and cognitive functions across the adult life span: a new window to the study of cognitive aging. Psychol. Aging 12, 12–21. doi: 10.1037/0882-7974.12.1.12
Boersma, P., and Weenink, D. (2014). Praat: Doing Phonetics by Computer Version 5.3.63. University of Amsterdam, Amsterdam. Available online at: http://www.praat.org/
Bradlow, A., Kraus, N., and Hayes, E. (2003). Speaking clearly for children with learning disabilities: sentence perception in noise. J. Speech Lang. Hear. Res. 46, 80–97. doi: 10.1044/1092-4388(2003/007)
Cicchetti, D. V. (1994). Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychol. Assess. 6, 284–290. doi: 10.1037/1040-3590.6.4.284
Conway, A. R. A., Kane, M. J., Bunting, M. F., Hambrick, D. Z., Wilhelm, O., and Engle, R. W. (2005). Working memory span tasks: a methodological review and user's guide. Psychon. Bull. Rev. 12, 769–786. doi: 10.3758/BF03196772
Craik, F. I. M., Anderson, N. D., Kerr, S. S., and Li, K. Z. H. (1995). “Memory changes in normal ageing,” in Handbook of Memory Disorders, eds A. D. Baddeley, B. A. Wilson, and F. N. Watts (New York, NY: Wiley), 211–241.
Craik, F. I. M., and Bialystok, E. (2006). Planning and task management in older adults: cooking breakfast. Mem. Cognit. 34, 1236–1249. doi: 10.3758/BF03193268
Crum, R. M., Anthony, J. C., Bassett, S. S., and Folstein, M. F. (1993). Population-based norms for the mini-mental state examination by age and educational level. J. Am. Med. Assoc. 269, 2386–2391. doi: 10.1001/jama.1993.03500180078038
Daneman, M., and Carpenter, P. A. (1980). Individual differences in working memory and reading. J. Verbal Learning Verbal Behav. 19, 450. doi: 10.1016/S0022-5371(80)90312-6
DiDonato, R. (2014). Effortful and Effortless Listening: How Age-Related Hearing Loss and Cognitive Abilities Interact and Influence Memory Performance in Older Adults. Ph.D. thesis, Memorial University of Newfoundland.
Faul, F., Erdfelder, E., Lang, A.-G., and Buchner, A. (2007). G*Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods 39, 175–191. doi: 10.3758/BF03193146
Ferguson, S. H. (2012). Talker differences in clear and conversational speech: vowel intelligibility for older adults with hearing loss. J. Speech Lang. Hear. Res. 55, 779–790. doi: 10.1044/1092-4388(2011/10-0342)
Ferguson, S. H., and Kewley-Port, D. (2007). Talker differences in clear and conversational speech: acoustic characteristics of vowels. J. Speech Lang. Hear. Res. 50, 1241–1255. doi: 10.1044/1092-4388(2007/087)
Folstein, M. F., Folstein, S. E., and McHugh, P. R. (1975). Mini-mental state: a practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 12, 189–198. doi: 10.1016/0022-3956(75)90026-6
Friedman, M. C., McGilliray, S., Murayama, K., and Castel, A. D. (2015). Memory for medication side effects in younger and older adults: the role of subjective and objective importance. Mem. Cognit. 43, 206–215 doi: 10.3758/s13421-014-0476-0
Gilbert, R. C., Chandrasekaran, B., and Smiljanic, R. (2014). Recognition memory in noise for speech of varying intelligibility. J. Acoust. Soc. Am. 135, 389–399. doi: 10.1121/1.4838975
Goldman-Eisler, F. (1968). Psycholinguistics: Experiments in Spontaneous Speech. New York, NY: Academic Press.
Goodglass, H., Kaplan, E., and Barresi, B. (2001). The Assessment of Aphasia and Related Disorders, 4th Edn. Baltimore, MD: Lippincott Williams and Wilkins.
Gordon-Salant, S., and Fitzgibbons, P. J. (1993). Temporal factors and speech recognition performance in young and elderly listeners. J. Speech Lang. Hear. Res. 36, 1276–1285. doi: 10.1044/jshr.3606.1276
Hallgren, K. A. (2012). Computing inter-rater reliability for observational data: an overview and tutorial. Tutor. Quant. Methods Psychol. 8, 23–34. Available online at: http://www.tqmp.org/RegularArticles/vol08-1/p023/p023.pdf
Hasher, L., and Zacks, R. T. (1979). Automatic and effortful processes in memory. J. Exp. Psychol. 108, 356–388. doi: 10.1037/0096-3445.108.3.356
Hasher, L., and Zacks, R. T. (1988). “Working memory, comprehension, and aging: a review and a new view,” in The Psychology of Learning and Motivation: Advances in Research and Theory, Vol. 22, ed G. H. Bower (San Diego, CA: Academic Press), 193–225.
Hasher, L., Zacks, R. T., and May, C. P. (1999). “Inhibitory control, circadian arousal, and age,” in Attention and Performance XVII: Cognitive Regulation of Performance: Interaction of Theory and Application, eds D. Gopher and A. Koriat (Cambridge, MA: The MIT Press), 653–675. Available online at: http://www.psych.utoronto.ca/users/hasherlab/abstracts/hasher_zacks_may99.htm
Hausknect, J. P., Halpert, J. A., DiPaolo, N. T., and Moriarty, G. M. O. (2006). Retesting in selection: a meta-analysis of coaching and practice effects for tests of cognitive ability. J. Appl. Psychol. 92, 373–385. doi: 10.1037/0021-9010.92.2.373
Heinrich, A., Schneider, B. A., and Craik, F. I. M. (2008). Investigating the influence of continuous babble on auditory short-term memory performance. Q. J. Exp. Psychol. 61, 735–751. doi: 10.1080/17470210701402372
Helfer, L. S., and Vargo, M. (2009). Speech recognition and temporal processing in middle-aged women. J. Am. Acad. Audiol. 20, 264–271. doi: 10.3766/jaaa.20.4.6
Humes, L. E. (2008). Aging and speech communication: peripheral, central-auditory, and cognitive factors affecting the speech-understanding problems of older adults. ASHA Lead. 13, 10–33. doi: 10.1044/leader.FTR1.13052008.10
Humes, L. E., Dubno, J. R., Gordon-Salant, S., Lister, J. J., Cacace, A. T., Cruickshanks, K. J., et al. (2012). Central presbycusis: a review and evaluation of the evidence. J. Am. Acad. Audiol. 23, 635–666. doi: 10.3766/jaaa.23.8.5
John, A. B., Hall, J. W., and Kreisman, B. M. (2012). Effects of advancing age and hearing loss on gaps-in-noise test performance. Am. J. Audiol. 21, 242–250. doi: 10.1044/1059-0889(2012/11-0023)
Just, M. A., and Carpenter, P. A. (1992). A capacity theory of comprehension: individual difference in working memory. Psychol. Rev. 99:122. doi: 10.1037/0033-295X.99.1.122
Kaplan, E., Goodglass, H., and Weintraub, S. (2001). Boston Naming Test, 2nd Edn. Austin, TX: Pro-ed.
Katz, J. (ed.). (1978). Handbook of Clinical Audiology, 2nd Edn. Baltimore, MD: Williams and Wilkins.
Keisler, A., and Willingham, D. T. (2007). Non-declarative sequence learning does not show savings in relearning. Hum. Mov. Sci. 26, 247–256. doi: 10.1016/j.humov.2007.01.003
Killion, M. (2002). New thinking on hearing in noise: a generalized articulation index. Semin. Hear. 23, 57. doi: 10.1055/s-2002-24976
Killion, M., Niquette, P., Gudmundsen, G. I., Revit, L., and Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 116, 2395–2405. doi: 10.1121/1.1784440
Konkle, D. F., Beasley, D. S., and Bess, F. H. (1977). Intelligibility of time-altered speech in relation to chronological aging. J. Speech Lang. Hear. Res. 20, 108–115. doi: 10.1044/jshr.2001.108
Kraus, N., and Chandrasekaran, B. (2010). Music training for the development of auditory skills. Nat. Rev. Neurosci. 11, 599–605. doi: 10.1038/nrn2882
Krause, J., and Braida, L. (2004). Acoustic properties of naturally produced clear speech at normal speaking rates. J. Acoust. Soc. Am. 115, 362–378. doi: 10.1121/1.1635842
Krause, J., and Braida, L. (2009). Evaluating the role of spectral and envelop characteristics in the intelligibility advantage of clear speech. J. Acoust. Soc. Am. 125, 3346–3357. doi: 10.1121/1.3097491
Lam, J., Tjaden, K., and Wilding, G. (2012). Acoustics of clear speech: effect of instruction. J. Speech Lang. Hear. Res. 55, 1807–1821. doi: 10.1044/1092-4388(2012/11-0154)
Lavie, N. (2005). Distracted and confused?: selective attention under load. Trends Cogn. Sci. 9, 75. doi: 10.1016/j.tics.2004.12.004
Lavie, N., and DeFockert, J. W. (2003). Contrasting effects of sensory limits and capacity limits in visual selective attention. Percept. Psychophys. 65, 202. doi: 10.3758/BF03194795
Light, L. L. (1991). Memory and aging: four hypotheses in search of data. Annu. Rev. Psychol. 42, 333. doi: 10.1146/annurev.ps.42.020191.002001
Mattys, S. L., Brooks, J., and Cooke, M. (2009). Recognizing speech under a processing load: dissociating energetic from informational factors. Cogn. Psychol. 59, 203–243. doi: 10.1016/j.cogpsych.2009.04.001
Mattys, S. L., Davis, M. H., Bradlow, A. R., and Scott, S. K. (2012). Speech recognition in adverse conditions: a review. Lang. Cogn. Process. 27, 953–978. doi: 10.1080/01690965.2012.705006
Mattys, S. L., and Scharenborg, O. (2014). Phoneme categorization and discrimination in younger and older adults: a comparative analysis of perceptual, lexical and attentional factors. Psychol. Aging 29, 150–162. doi: 10.1037/a0035387
Mattys, S. L., and Wiget, L. (2011). Effects of cognitive load on speech recognition. J. Mem. Lang. 65, 145–160. doi: 10.1016/j.jml.2011.04.004
McCoy, S., Tun, P., Cox, L., Colangelo, M., Stewart, R., and Wingfield, A. (2005). Hearing loss and perceptual effort: downstream effects on older adults' memory for speech. Q. J. Exp. Psychol. A 58, 22–33. doi: 10.1080/02724980443000151
Mueller, J. A., and Dollaghan, C. (2013). A systematic review of assessments for identifying executive function impairments in adults with acquired brain injury. J. Speech Lang. Hear. Res. 56, 1051–1064. doi: 10.1044/1092-4388(2012/12-0147)
Newman, C. W., Weinstein, B. E., Jacobson, G., and Hug, G. (1991). Test-retest reliability of the hearing handicap inventory for adults. Ear Hear. 12, 355–357. doi: 10.1097/00003446-199110000-00009
Ng, E. H. N., Rudner, M., Lunner, T., Pedersen, M. S., and Rönnberg, J. (2013). Effects of noise and working memory capacity on memory processing of speech for hearing-aid users. Int. J. Audiol. 52, 433–441. doi: 10.3109/14992027.2013.776181
Parbery-Clark, A., Anderson, S., Hittner, E., and Kraus, N. (2012). Musical experience offsets age-related delays in neural timing. Neurobiol. Aging 33, 1483–1481. doi: 10.1016/j.neurobiolaging.2011.12.015
Parbery-Clark, A., Skoe, E., Lam, C., and Kraus, N. (2009). Musician enhancement for speech in noise. Ear Hear. 30, 653–661. doi: 10.1097/AUD.0b013e3181b412e9
Park, D. C., Smith, A. D., Lautenschlager, G., Earles, J. L., Frieske, D., Zwahr, M., et al. (1996). Mediators of long-term memory performance across the life span. Psychol. Aging 11, 621–637. doi: 10.1037/0882-7974.11.4.621
Peelle, J., and Wingfield, A. (2005). Dissociations in perceptual learning revealed by adult age differences in adaptation to time-compressed speech. J. Exp. Psychol. 31:1315. doi: 10.1037/0096-1523.31.6.1315
Picheny, M. A., Durlach, N. I., and Braida, L. D. (1985). Speaking clearly for the hard of hearing I. Intelligibility differences between clear and conversational speech. J. Speech Lang. Hear. Res. 28, 96–103. doi: 10.1044/jshr.2801.96
Pichora-Fuller, K., Schneider, B., and Daneman, M. (1995). How young and old adults listen to and remember speech in noise. J. Acoust. Soc. Am. 97, 593. doi: 10.1121/1.412282
Rabbitt, P. (1968). Channel-capacity, intelligibility and immediate memory. Q. J. Exp. Psychol. 20, 241–248. doi: 10.1080/14640746808400158
Rabbitt, P. (1990). Mild hearing loss can cause apparent memory failures which increase with age and reduce with IQ. Acta Otolaryngol. Suppl. 111, 167–175. doi: 10.3109/00016489109127274
Ritter, F. E., Reifers, A., Klein, L. C., Quigley, K., and Schoelles, M. (2004). “Using cognitive modeling to study behavior moderators: pre-task appraisal and anxiety,” in Human Factors and Ergonomics Society Annual Meeting Proceedings (Santa Monica, CA: Human Factors and Ergonomics Society), 48, 2121–2125. doi: 10.1177/154193120404801709
Ritter, F. E., and Schooler, L. J. (2001). “The learning curve,” in International Encyclopedia of the Social and Behavioral Sciences, eds W. Kintch, N. Smelser, and P. Baltes (Amsterdam: Pergamon), 8602–8605. doi: 10.1016/B0-08-043076-7/01480-7
Roach, A., Schwartz, M. R., Martin, N., Grewal, R. S., and Brecher, A. (1996). The Philadelphia naming test: scoring and rationale. Clin. Aphasiol. 24, 121–133.
Rönnberg, J., Lunner, T., Zekveld, A., Sörqvist, P., Danielsson, H., Lyxell, B., et al. (2013). The ease of language understanding (ELU) model: theoretical, empirical, and clinical advances. Front. Syst. Neurosci. 7:31. doi: 10.3389/fnsys.2013.00031
Rönnberg, J., Rudner, M., Foo, C., and Lunner, T. (2008). Cognition counts: a working memory system for ease of language understanding (ELU). Int. J. Audiol. 47, S99-S105. doi: 10.1080/14992020802301167
Rönnberg, J., Rudner, M., Lunner, T., and Zekveld, A. (2010). When cognition kicks in: working memory and speech understanding in noise. Noise Health 49, 263–269. doi: 10.4103/1463-1741.70505
Rosen, S. (1992). “Temporal information in speech: acoustic, auditory and linguistic aspects,” in Philosophical Transactions of the Royal Society of London Series B: Biological Sciences, Vol. 336, eds R. P. Carlyon, C. J. Darwin, and I. J. Russell (New York, NY: Clarendon Press/Oxford University Press), 367–373.
Rudner, M., Foo, C., Rönnberg, J., and Lunner, T. (2009). Cognition and aided speech recognition in noise: specific role for cognitive factors following nine-weeks experience with adjusted compression settings in hearing aids. Scand. J. Psychol. 50, 405–418. doi: 10.1111/j.1467-9450.2009.00745.x
Salthouse, T., A (2010). Major Issues in Cognitive Aging. Oxford; New York, NY: Oxford University Press.
Salthouse, T. A. (1996). The processing-speed theory of adult age differences in cognition. Psychol. Rev. 103, 403–428. doi: 10.1037/0033-295X.103.3.403
Schaefer, S. (2014). The ecological approach to cognitive-motor dual-tasking: findings on the effects of expertise and age. Front. Psychol. 5:1167. doi: 10.3389/fpsyg.2014.01167
Schneider, B., and Pichora-Fuller, K. (2000). “Implications of perceptual deterioration for cognitive aging research,” in The Handbook of Aging and Cognition, 2nd Edn. eds F. I. M. Craik, and T. Salthouse (Mahwah, NJ: Lawrence Erlbaum Associates, Inc.), 155.
Shrout, P. E., and Fleiss, J. L. (1979). Intraclass correlations: uses in assessing rater reliability. Psychol. Bull. 86, 420–428. doi: 10.1037/0033-2909.86.2.420
St Clair-Thompson, H. L. (2010). Backwards digit recall: a measure of short-term memory or working memory? Eur. J. Cogn. Psychol. 22, 286–296. doi: 10.1080/09541440902771299
St Clair-Thompson, H., and Sykes, S. (2010). Scoring methods and the predictive ability of working memory tasks. Behav. Res. Methods 42, 969–975. doi: 10.3758/BRM.42.4.969
Stewart, R., and Wingfield, A. (2009). Hearing loss and cognitive effort in older adults' report accuracy for verbal materials. J. Am. Acad. Audiol. 20, 147–154. doi: 10.3766/jaaa.20.2.7
Surprenant, A. (1999). The effect of noise on memory for spoken syllables. Int. J. Psychol. 34, 328–333. doi: 10.1080/002075999399648
Surprenant, A. (2007). Effects of noise on identification and serial recall of nonsense syllables in older and younger adults. Neuropsychol. Dev. Cogn. B Aging Neuropsychol. Cogn. 14, 126–143. doi: 10.1080/13825580701217710
Tun, P. A. (1998). Fast noisy speech: age differences in processing rapid speech with background noise. Psychol. Aging 13, 424–434. doi: 10.1037/0882-7974.13.3.424
Tun, P. A., O'Kane, G., and Wingfield, A. (2002). Distraction by competing speech in young and older adult listeners. Psychol. Aging 17, 453–467. doi: 10.1037/0882-7974.17.3.453
Tun, P., McCoy, S., and Wingfield, A. (2009). Aging, hearing acuity, and the attentional cost of effortful listening. Psychol. Aging 24, 761. doi: 10.1037/a0014802
Ventry, I., and Weinstein, B. E. (1982). The hearing handicap inventory for the elderly: a new tool. Ear Hear. 3, 128–134. doi: 10.1097/00003446-198205000-00006
Verhaeghen, P., and Salthouse, T. A. (1997). Meta-analyses of age–cognition relations in adulthood: estimates of linear and nonlinear age effects and structural models. Psychol. Bull. 122, 231–249. doi: 10.1037/0033-2909.122.3.231
Wambacq, I. J. A., Koehnke, J., Besing, J., Romei, L. L., DePierro, A., and Cooper, D. (2009). Processing interaural cues in sound segregation by young and middle-aged brains. J. Am. Acad. Audiol. 20, 453–458. doi: 10.3766/jaaa.20.7.6
Wechsler, D. (1981). Wechsler Adult Intelligence Scale Revised. San Antonio, TX: The Psychological Corporation.
Wild, C., Yusuf, A., Wilson, D., Peelle, J., Davis, M., and Johnsrude, I. (2012). Effortful listening: the processing of degraded speech depends critically on attention. J. Neurosci. 32, 14010–14021. doi: 10.1523/JNEUROSCI.1528-12.2012
Wingfield, A., and Ducharme, J. L. (1999). Effects of age and passage difficulty on listening-rate preferences for time-altered speech. J. Gerontol. B Psychol. Sci. Soc. Sci. 54B, P199–P202. doi: 10.1093/geronb/54B.3.P199
Wingfield, A., McCoy, S. L., Peelle, J. E., Tun, P. A., and Cox, L. C. (2006). Effects of adult aging and hearing loss on comprehension of rapid speech varying in syntactic complexity. J. Am. Acad. Audiol. 17, 487–497. doi: 10.3766/jaaa.17.7.4
Wingfield, A., Poon, L. W., Lombardi, L., and Lowe, D. (1985). Speed of processing in normal aging: effects of speech rate, linguistic structure, and processing time. J. Gerontol. 40, 579–585. doi: 10.1093/geronj/40.5.579
Wingfield, A., Tun, P. A., Koh, C. K., and Rosen, M. J. (1999). Regaining lost time: adult aging and the effect of time restoration on recall of time-compressed speech. Psychol. Aging 14, 380–389. doi: 10.1037/0882-7974.14.3.380
Wingfield, A., Tun, P. A., and McCoy, S. L. (2005). Hearing loss in older adulthood: what it is and how it interacts with cognitive performance. Curr. Dir. Psychol. Sci. 14, 144–148. doi: 10.1111/j.0963-7214.2005.00356.x
Working Group on Speech Understanding and Aging and the Committee on Hearing, Bioacoustics and Biomechanics (CHABA). (1988). Speech understanding and aging. J. Acoust. Soc. Am. 83, 859–895. doi: 10.1121/1.395965
World Health Organization Prevention of Blindness and Deafness (PBD) Program. (2014). Prevention of Deafness and Hearing Impaired Grades of Hearing Impairment. Available online at: http://www.who.int/pbd/deafness/hearing_impairment_grades/en/index.html (Accessed January 06, 2014).
Zacks, R. T., and Hasher, L. (1994). “Directed ignoring: inhibitory regulation of working memory,” in Inhibitory Processes in Attention, Memory, and Language, eds D. Dagenbach and T. H. Carr (San Diego, CA: Academic Press), 241–264.
Zacks, R. T., and Hasher, L. (1997). Cognitive gerontology and attentional inhibition: a reply to Burke and McDowd. J. Gerontol. B Psychol. Sci. Soc. Sci. 52, 274–284. doi: 10.1093/geronb/52B.6.P274
Zacks, R. T., Hasher, L., and Li, K. Z. H. (2000). “Human memory,” in The Handbook of Aging and Cognition, 2nd Edn., eds F. I. M. Craik, and T. A. Salthouse (Mahwah, NJ: Lawrence Erlbaum Associates), 293–357.
Zendel, B. R., and Alain, C. (2012). Musicians experience less age-related decline in central auditory processing. Psychol. Aging 27, 410–417. doi: 10.1037/a0024816
Keywords: memory, hearing loss, aging, auditory processing, comprehension
Citation: DiDonato RM and Surprenant AM (2015) Relatively effortless listening promotes understanding and recall of medical instructions in older adults. Front. Psychol. 6:778. doi: 10.3389/fpsyg.2015.00778
Received: 26 January 2015; Accepted: 25 May 2015;
Published: 09 June 2015.
Edited by:
Mary Rudner, Linköping University, SwedenReviewed by:
Helen Henshaw, University of Nottingham, UKElaine Hoi Ning Ng, Linköping University, Sweden
Copyright © 2015 DiDonato and Surprenant. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Roberta M. DiDonato, Cognitive Aging and Memory Lab, Department of Psychology, Memorial University of Newfoundland, 230 Elizabeth Ave., St. John's, NL A1B 3X9, Canada,cm1kMzA4QG11bi5jYQ==