 Magda L. Dumitru
Magda L. Dumitru- 1Department of Cognitive Science, Macquarie University, Sydney, NSW, Australia
- 2University of York, York, UK
- 3University of Connecticut, Storrs, CT, USA
We investigated whether the size and number of objects mentioned in digit-word expressions influenced participants’ performance in covert numerosity estimations (i.e., property probability ratings). Participants read descriptions of big or small animals standing in short, medium, and long rows (e.g., There are 8 elephants/ants in a row) and subsequently estimated the probability that a health statement about them was true (e.g., All elephants/ants are healthy). Statements about large animals scored lower than statements about small animals, confirming classical findings that humans perceive groups of large objects as being more numerous than groups of small objects (Binet, 1890) and suggesting that object size effects in covert numerosity estimations are particularly robust. Also, statements about longer rows scored lower than statements about shorter rows (cf. Sears, 1983) but no interaction between factors obtained, suggesting that quantity information is not fully retrieved in digit—word expressions or that their values are processed separately.
Introduction
People usually count concrete objects and living things and would rather speak of “8 baskets” or of “8 elephants” than simply of “8,” for instance. Despite their frequency, these complex numerical expressions composed of a digit followed by a word referring to a concrete object have been overlooked in current research on numerical cognition. The present study is the first to investigate whether word representations impact digit values to yield combined numerosity estimations. We are particularly interested in how robust these effects are as well as in whether the two magnitudes, for digits and for words, have distinct or shared conceptual and cortical representations when processed together.
Current behavioral and neural evidence suggests that numerical abilities are flexible and depend on context, habit, and cortical development (e.g., Dehaene, 1992; Lipton and Spelke, 2003; Siegler and Opfer, 2003; Cantlon et al., 2006). Moreover, numerical abilities are common across sensory modalities (cf. Walsh, 2003) and generate interaction and interference effects with space, time, size, and luminance (e.g., Pinel et al., 2004; Cohen Kadosh et al., 2007; Conson et al., 2008). Recent research investigating the common basis of numerical values and object size (i.e., Gabay et al., 2013) has confirmed that size-congruency effects are distinct from response-initiation effects triggered by the primary motor cortex (cf. Cohen Kadosh et al., 2007) and are truly conceptual in nature. Gabay et al. (2013) used equally-sized images of small and large animals in a parity-judgment task and reported that, in conditions where response conflict effects were controlled for, images of small animals primed small numbers whereas images of large animals primed large numbers.
These findings led us to hypothesize that, when processing complex numerical expressions such as “8 elephants” or “8 ants,” the size of the objects to which the nouns refer would exert a certain influence on people’s combined numerosity estimations that is, on their concluding that both expressions refer to eight objects. So, for example, we expect that even numerate adults might unduly estimate that rows of large objects (e.g., 8 elephants) contain more members than rows of small objects (e.g., 8 ants), whereby they would be tempted to combine the two magnitude types, for digits and for objects. Indeed, numerosity estimations of concrete objects vary with object size such that groups of small objects are judged to be less numerous than groups of large objects (cf. Binet, 1890). We therefore anticipate that merely mentioning a group of objects would evoke their combined size, which in turn would affect the overall numerosity estimations of digit-word expressions.
Language instantly evokes object properties including object size (Rubinsten and Henik, 2002; Setti et al., 2009; Sellaro et al., 2015), as predicted by theories of embodied and grounded cognition (Barsalou, 2008). These theories hold that people evoke multimodal perceptual simulations during online language processing based on their experience with concrete situations. Therefore, since language expressions are grounded in situations where people routinely use them, merely reading about an object is likely to evoke a full array of related experiences that gives instant access to associated perceptual and cognitive processes. Furthermore, results from brain imaging studies indicate that the same regions become active when objects are presented in pictorial form or when they are mentioned by language (e.g., Chao et al., 1999; Just et al., 2010). Research has also found that the retrieval of number magnitude is a spontaneous process similar to automatic language processing (Paivio, 1971; Barsalou, 2008) such that numbers are rapidly assigned approximate representations prior to further refinement in specific cortical areas (e.g., Tzelgov et al., 1992).
Among the studies devoted to investigating language-evoked object size, we recall the evidence reported in Rubinsten and Henik (2002), who used a Stroop-like paradigm to show that, in physical-comparison tasks (i.e., estimating which font size is larger) as well as in conceptual-comparison tasks (i.e., estimating which real-life animal is larger), judgments were faster for congruent animal names (e.g., “lion” written in large font or “ant” written in small font) than for incongruent names (e.g., “lion” written in small font or “ant” written in large font). Similar evidence was provided by Setti et al. (2009) who used an indirect task (i.e., category decision) asking participants to decide whether two objects evoked by a prime word and by a target word belonged to the same category. People responded faster to targets following same-size primes (e.g., “elephant” following “giraffe”) than to targets following different-size primes (e.g., “hare” following “giraffe”).
In our study, we used an indirect task (i.e., property probability ratings) to explore the hypothesis that object size affects numerosity estimations in digit-word expressions. We relied on a well-established finding that people tend to evaluate single entities more positively than groups (i.e., the “person-positivity bias hypothesis” cf. Sears, 1983), which results in lower probability ratings for a particular property as groups grow larger. For example, when participants are presented with the information “There are 8 elephants in a row” or “There are 156 elephants in a row” and subsequently rate the probability that the statement “All elephants are healthy” is true, their scores should be lower for the statement about 156 elephants than for the about 8 elephants. We further predict that participants will rate small animals’ health higher than large animals’ health (e.g., “All ants are healthy” following “There are 8 ants in a row” would score higher than “All elephants are healthy” following “There are 8 elephants in a row”). In other words, adults might consider rows composed of large animals as being more numerous than rows composed of the same number of small animals and thus think of animals in “long” rows as being less healthy than animals in “short” rows. Object size effects may occur despite people’s ability to instantly recover the representation of the digit “8” in “8 ants” and “8 elephants,” for instance, because they are also able to rapidly evoke the size of the animals mentioned.
Our covert task (i.e., object-property probability ratings) taps into the later stages of combined magnitude processing hence obtaining significant effects of word-evoked object size on numerosity estimations would indicate that object-size effects are particularly robust. To further preclude confounds relating to whether size affects digit magnitude in virtue of the form of the statement rather than in virtue of the way that sentence fragments combine (i.e., jointly or independently), we varied the quantifier type to suggest aggregate (i.e., “All elephants are healthy”) as well as discrete numerosities (i.e., “Each elephant is healthy”).
Materials and Methods
Subjects
Fifty-two native English speakers volunteered for an online study in return for course credit.
Stimuli
Stimuli were 36 sentences of which half included small animals (e.g., bats, mice, crabs) and half included large animals (e.g., tigers, bears, wolves), as determined from a previous rating study summarized in Table 1. Average ratings were calculated based on individual size ratings (N = 22) of 100 items from two categories (animals and vegetables). Participants rated the size of each item presented individually in a scale from “0” (“not very big”) to “10” (“very big”). We then selected 36 items (i.e., names of small and large animals) from the rating study such that large animals received ratings at least twice as high as small animals and were also matched for frequency and length. Each sentence was followed by a statement about the health of the animals mentioned, as explained below. We constructed two lists (Latin square design) such that all participants saw each number once, paired with a small animal in the first list and with a large animal in the second list. In each list, half of the animals were small and the other half were large. Numbers ran from 3 to 8 in short rows, from 43 and 95 in medium rows, and from 1269 to 8421 in long rows. Both the numerosity study and the preliminary rating study were conducted in accordance with the ethics requirements of the University of York and followed relevant regulatory standards.
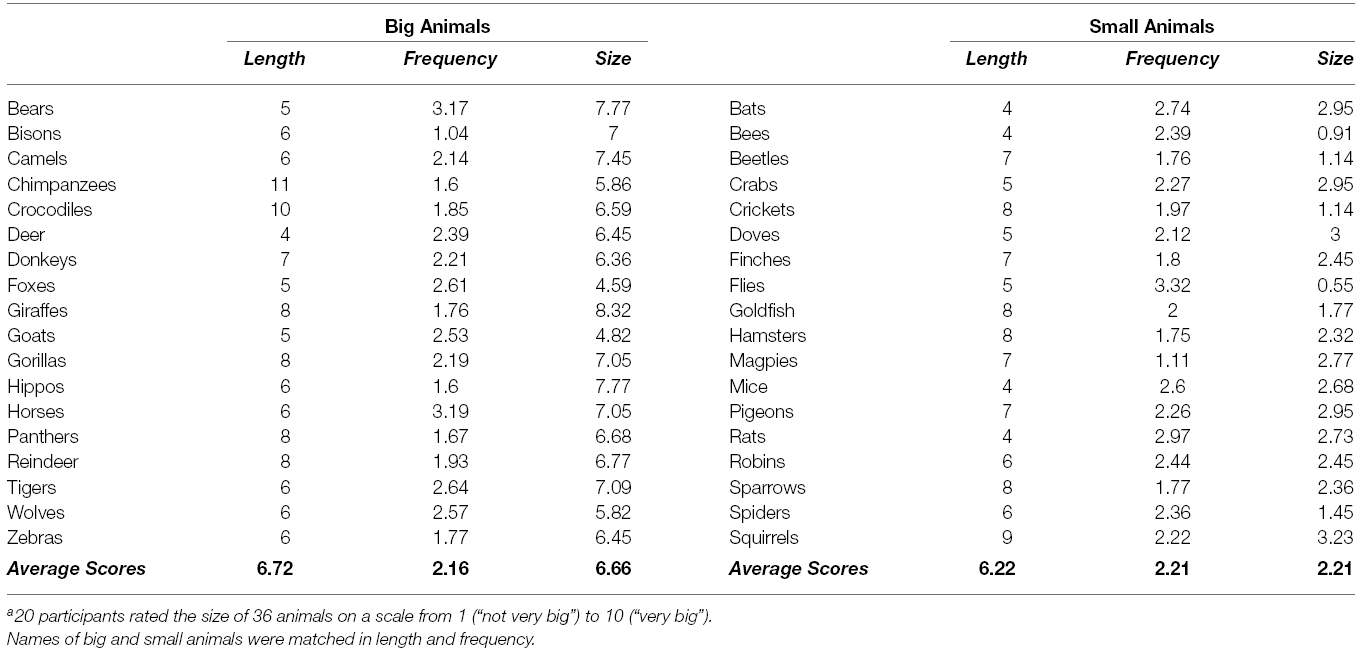
Table 1. Animal names in all stimuli statements used in the experimental studya.
Design and Procedure
The experiment followed a 2 (Size: Small vs. Large animals) × 3 (Row-length: Short vs. Medium vs. Long) fully factorial design. We also introduced “quantifier” as a between-subjects factor such that half of the participants read statements containing the quantifier all and the other half read statements containing the quantifier each. On a typical trial, participants read a description (e.g., There are 3 crocodiles in a row) followed by a statement (e.g., All crocodiles are healthy or Each crocodile is healthy), which they rated on a scale from 0 (“not very likely”) to 10 (“very likely”), as seen in Figure 1.
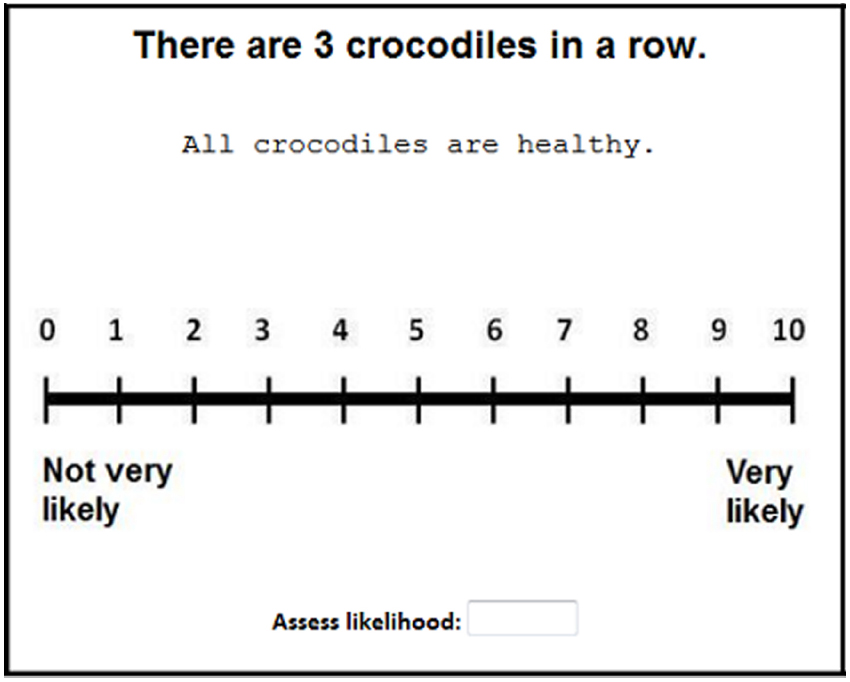
Figure 1. Example stimulus in our study. In each trial, participants read a description (e.g., There are 3 crocodiles in a row) followed by a statement (e.g., All crocodiles are healthy), whose likelihood they rated on a scale from 0 (not very likely) to 10 (very likely). In half of the trials, the statement contained a different quantifier (e.g., Each crocodile is healthy).
Results
Figure 2 summarizes the average likelihood scores across conditions. A 2 (Size: Small vs. Large animal) × 3 (Row-length: Short vs. Medium vs. Long) ANOVA revealed a main effect of size, F(1, 50) = 6.62, p = 0.013, = 0.117, and a main effect of row-length, F(2, 100) = 173.76, p < 0.001, = 0.777, but no interaction between factors, F(2, 100) = 2.06, p = 0.132, suggesting that group size as well as word-evoked object size influence property-probability ratings and thereby covert numerosity estimations.
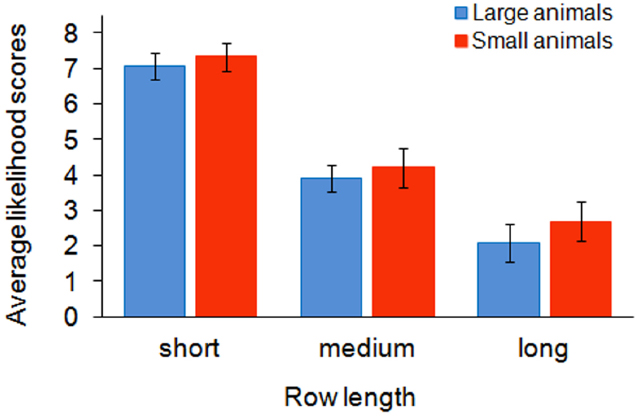
Figure 2. Mean likelihood judgments and 95% CIs for statements (e.g., All elephants are healthy) following descriptions of short, medium, and long rows of animals (e.g., There are 8/ 156/ 2600 elephants in a row). Rows of small animals were perceived as less numerous than rows of large animals, hence higher scores obtained for the former than for the latter.
We also calculated Cohen’s d for each row-length condition separately and found a sizeable difference between the effect size in the long-row condition and the effect size in the short- and medium-row conditions, namely a value of 0.311 for long rows, a value of 0.183 for short rows, a value of 0.123 for medium rows, suggesting the existence of a qualitative distinction between small and medium groups comprising at most tens of individuals on the one hand, and very large groups comprising thousands of individuals on the other hand.
Importantly, we found no effect of quantifier type, F(1, 50) = 0.189, p = 0.665, suggesting that magnitude estimations were not dependent on whether the quantifiers accompanying animal names prompted participants to view the groups (i.e., rows of animals) as aggregates (i.e., the quantifier “all”) or as discrete sums of individuals (i.e., the quantifier “each”).
Discussion
We provided evidence that word-evoked object size impacts numerosity estimations in a covert task where participants rated the probability that several objects (i.e., 8 elephants) mentioned in a previous statement are healthy. We obtained a main effect of object size such that participants rated health statements about large animals lower than health statements about small animals, thereby confirming previous findings that language evokes object size, which in turn impacts number processing (Rubinsten and Henik, 2002; Setti et al., 2009; Gabay et al., 2013; Sellaro et al., 2015). Unsurprisingly (cf. Sears, 1983), we also obtained a main effect of group size such that health statements about long rows of animals scored lower than statements about medium rows, which in turn scored lower than statements about short rows.
Interestingly, we observed no interaction between factors, which might suggest that quantity information is not fully retrieved in digit—word combinations or that digit and word magnitudes are processed separately at some level. Indeed, current evidence suggests that de-composition may occur for expressions containing same-type magnitude values, in particular for two-digit combinations (e.g., Nuerk et al., 2001) such that each digit is processed separately. Unfortunately, a decomposition account of same or different magnitude types runs counter previous evidence (i.e., size congruency effects in reaction-time studies) supporting a shared magnitude code across quantity dimensions. Nevertheless, the predictions of the decomposition account and of the size-congruency principle could be reconciled if we examined more closely the particularities of our task and associated cognitive processes.
Most notably, the effect of object size is robust but small that is, numerical estimations of digit—word expressions are largely determined by digit values, which are subsequently modulated by the size of a single object rather than by the combined size of a group whose cardinality matches the digit value. In other words, the plural form on the noun in “8 ants” does nothing to influence overall numerosity estimations, which suggests that language processing constraints might be responsible for the lack of interaction between object number and object size. In particular, linearity requires that items in a string be processed one by one in the order in which they are mentioned and is thus compatible with the so-called “anchoring bias” (cf. Tversky and Kahneman, 1974), which is a general-cognitive tendency toward grounding upcoming information into information already acquired. In digit-word expressions, the information provided by digit representations serves to anchor subsequent information provided by word representations, with lasting effects. In particular, our covert numerosity task (i.e., property probability ratings) explored the late combination stages of word-evoked object size and overall numerosity estimations rather than early behavioral reactions in item-by-item processing, as was the case in previous studies. The linearity constraint is likely to be responsible for the incomplete retrieval of quantity information. It is a matter for further research to confirm this hypothesis as well as whether full magnitude retrieval might be obtained for languages with a different word order, namely for languages where digits follow object names.
Let us now briefly consider the score differences between the short and medium row conditions on the one hand and the large row condition on the other hand, which were rather sizeable in the absence of a significant interaction between object number and object size. We believe that these findings too are amenable to task properties, in particular to the stimuli used (i.e., digit magnitudes). Unlike previous studies where small numbers ran from 1 to 10 and large numbers would not surpass 100, our study included extremely large values (i.e., thousands) in the long-row category, which people might find less familiar or more difficult to grasp. The qualitative properties of very large magnitudes are likely to result from the comprehension effort they require, which might help explain why score differences between small and large animals were greatest in effortful trials (i.e., in the “long row” condition). By comparison, the tasks used in previous behavioral and neuro–cognitive studies reporting significant object size effects strongly evoked motor control and were thus inherently effortful. Importantly, effortful processing depends on participants’ goals hence specific cortical areas are recruited for handling the response types required. These findings suggest that the mapping between number magnitude and action representation is rather flexible (Koch and Prinz, 2005; Koch and Rumiati, 2006; Wenke and Frensch, 2005). Indeed, as shown in Fias et al. (2001) and in Lammertyn et al. (2002), effects of Spatial-Numerical Association Response Code (SNARC – e.g., Dehaene et al., 1993) were obtained only when participants judged the orientation of a digit, but not when they judged the color of the digit, arguably because the processing of numbers as well as orientation relies on regions of the parietal cortex, which belongs to the dorsal stream, while color processing relies mainly on regions of the inferior temporal cortex, which belongs to the ventral stream (Zeki et al., 1999). Since particular tasks involve different magnitude representations in the ventral and dorsal pathways, the extent of their neural overlap determines the interaction between numbers and action as well as between numbers and space (e.g., Badets et al., 2007).
In the present study, the object size effect as well as the qualitative difference between small and medium groups on the one hand and large groups on the other hand might stem from a basic tendency toward translating different magnitude types onto each other as well as from an instant appraisal of the effort required for manipulating the objects, as predicted by theories of embodied cognition (Barsalou, 2008), thus engaging specific cortical pathways. It remains an issue for future research to carefully determine the relevance of the manipulability hypothesis (e.g., Moretto and Di Pellegrino, 2008; Badets and Pesenti, 2010, 2011; Ranzini et al., 2011) for the processing of digit-word expressions by varying response type and/or object affordability (e.g., manipulable vs. non-manipulable).
Numerate adults’ susceptibility to object-size biases also remains to be investigated in future research. Whereas it is widely acknowledged that the number sense is influenced by maturation levels, which generate differences in cortical activity between children and adults (Dehaene et al., 2003; Cantlon et al., 2006; Hyde et al., 2010), the extent to which maturation levels reflect expertise levels is largely unknown. The existence of correlations between maturation and expertise levels might help explain why children’s ability to discriminate numerosities and their capacity to map numbers onto distinct numerosities are not perfected before adolescence, once they have been exposed to a full range of numerical information (e.g., Lipton and Spelke, 2003). We believe that, in our study, adults’ numeracy expertise has prevented them from unduly concluding that the result of counting 8 elephants would be very different from the result of counting 8 ants, thus yielding only small effects of object size and no interaction between number and size. In other words, though object size exerted only a limited influence on adults’ numerosity estimations, it might have a greater impact on children and adults who lack extensive expertise with numerical calculations (e.g., tribal populations). The results of our study suggest that words can readily evoke object properties, which numerate adults factor in when making overt property likelihood judgments and thereby covert numerosity estimations.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Badets, A., Andres, M., Di Luca, S., and Pesenti, M. (2007). Number magnitude potentiates action judgments. Exp. Brain Res. 180, 525–534. doi: 10.1007/s00221-007-0870-y
Badets, A., and Pesenti, M. (2010). Creating number semantics through finger movement perception. Cognition 115, 46–53. doi: 10.1016/j.cognition.2009.11.007
Badets, A., and Pesenti, M. (2011). Finger-number interaction: an ideomotor account. Exp. Psychol. 58, 287–292. doi: 10.1027/1618-3169/a000095
Barsalou, L. W. (2008). Grounded cognition. Annu. Rev. Psychol. 59, 617–645. doi: 10.1146/annurev.psych.59.103006.093639
Binet, A. (1890). La perception des longueurs et des nombres chez quelques petits enfants. Revue Philosophique France L’Étranger 30, 68–81.
Cantlon, J. F., Brannon, E. M., Carter, E. J., and Pelphrey, K. A. (2006). Functional imaging of numerical processing in adults and 4-y-old children. PLoS Biol. 4:e125. doi: 10.1371/journal.pbio.0040125
Chao, L. L., Haxby, J. V., and Martin, A. (1999). Attribute-based neural substrates in temporal cortex for perceiving and knowing about objects. Nat. Neurosci. 2, 913–919. doi: 10.1038/13217
Cohen Kadosh, R., Cohen Kadosh, K., Linden, D. E. J., Gevers, W., Berger, A., and Henik, A. (2007). The brain locus of interaction between number and size: a combined functional magnetic resonance imaging and event related potential study. J. Cogn. Neurosci. 19, 957–970. doi: 10.1162/jocn.2007.19.6.957
Conson, M., Cinque, F., Barbarulo, A. M., and Trojano, L. (2008). A common processing system for duration, order and spatial information: evidence from a time estimation task. Exp. Brain Res. 187, 267–274. doi: 10.1007/s00221-008-1300-5
Dehaene, S. (1992). Varieties of numerical abilities. Cognition 44, 1–42. doi: 10.1016/0010-0277(92)90049-N
Dehaene, S., Bossini, S., and Giraux, P. (1993). The mental representation of parity and number magnitude. J. Exp. Psychol. Gen. 122, 371–393. doi: 10.1037/0096-3445.122.3.371
Dehaene, S., Piazza, M., Pinel, P., and Cohen, L. (2003). Three parietal circuits for number processing. Cogn. Neuropsychol. 20, 487–506. doi: 10.1080/02643290244000239
Fias, W., Lauwereyns, J., and Lammertyn, J. (2001). Irrelevant digits affect feature-based attention depending on the overlap of neural circuits. Cogn. Brain Res. 12, 415–423. doi: 10.1016/S0926-6410(01)00078-7
Gabay, S., Leibovich, T., Henik, A., and Gronau, N. (2013). Size before numbers: conceptual size primes numerical value. Cognition 129, 18–23. doi: 10.1016/j.cognition.2013.06.001
Hyde, D. C., Boas, D. A., Blair, C., and Carey, S. (2010). Near-infrared spectroscopy shows right parietal specialization for number in pre-verbal infants. Neuroimage 53, 647–652. doi: 10.1016/j.neuroimage.2010.06.030
Just, M. A., Cherkassky, V. L., Aryal, S., and Mitchell, T. M. (2010). A neurosemantic theory of concrete noun representation based on the underlying brain codes. PLoS ONE 5:e8622. doi: 10.1371/journal.pone.0008622
Koch, I., and Prinz, W. (2005). Response preparation and code overlap in dual tasks. Mem. Cogn. 33, 1085–1095. doi: 10.3758/BF03193215
Koch, I., and Rumiati, R. I. (2006). Task-set inertia and memory-consolidation bottleneck in dual tasks. Psychol. Res. 70, 448–458. doi: 10.1007/s00426-005-0020-8
Lammertyn, J., Fias, W., and Lauwereyns, J. (2002). Semantic influences on feature based attention due to overlap of neural circuits. Cortex 38, 878–882. doi: 10.1016/S0010-9452(08)70061-3
Lipton, J., and Spelke, E. (2003). Origins of number sense: large-number discrimination in human infants. Psychol. Sci. 14, 396–401. doi: 10.1111/1467-9280.01453
Moretto, G., and Di Pellegrino, G. (2008). Grasping numbers. Exp. Psychol. 188, 505–515. doi: 10.1007/s00221-008-1386-9
Nuerk, H. C., Weger, U., and Willmes, K. (2001). Decade breaks in the mental number line? Putting the tens and units back in different bins. Cognition 82, B25–B33. doi: 10.1016/S0010-0277(01)00142-1
Pinel, P., Piazza, M., Le Bihan, D., and Dehaene, S. (2004). Distributed and overlapping cerebral representations of number, size, and luminance during comparative judgments. Neuron 41, 983–993. doi: 10.1016/S0896-6273(04)00107-2
Ranzini, M., Lugli, L., Anelli, F., Carbone, R., Nicoletti, R., and Borghi, A. M. (2011). Graspable objects shape number processing. Front. Hum. Neurosci. 5:147. doi: 10.3389/fnhum.2011.00147
Sears, D. O. (1983). The person-positivity bias. J. Pers. Soc. Psychol. 44, 233–250. doi: 10.1037/0022-3514.44.2.233
Sellaro, R., Treccani, B., Job, R., and Cubelli, R. (2015). Spatial coding of object typical size: evidence for a SNARC-like effect. Psychol. Res. [Epub ahead of print].
Setti, A., Caramelli, N., and Borghi, A. M. (2009). Conceptual information about size of objects in nouns. Eur. J. Cogn. Psychol. 21, 1022–1044. doi: 10.1080/09541440802469499
Siegler, R. S., and Opfer, J. E. (2003). The development of numerical estimation: evidence for multiple representations of numerical quantity. Psychol. Sci. 14, 237–243. doi: 10.1111/1467-9280.02438
Tversky, A., and Kahneman, D. (1974). Judgment under uncertainty: heuristics and biases. Science 185, 1124–1131. doi: 10.1126/science.185.4157.1124
Tzelgov, J., Meyer, J., and Henik, A. (1992). Automatic and intentional processing of numerical information. J. Exp. Psychol. Learn. Mem. Cogn. 18, 166–179. doi: 10.1037/0278-7393.18.1.166
Walsh, V. (2003). A theory of magnitude: common cortical metrics of time, space, and quantity. Trends Cogn. Sci. 7, 483–488. doi: 10.1016/j.tics.2003.09.002
Wenke, D., and Frensch, P. A. (2005). The influence of task instruction on action coding: constraint setting or direct coding. J. Exp. Psychol. Hum. Percept. Perform. 31, 803–819. doi: 10.1037/0096-1523.31.4.803
Keywords: numerosity estimation, digit—word expression, numerical cognition, embodied cognition
Citation: Dumitru ML and Joergensen GH (2015) Effects of word-evoked object size on covert numerosity estimations. Front. Psychol. 6:876. doi: 10.3389/fpsyg.2015.00876
Received: 13 April 2015; Accepted: 13 June 2015;
Published: 03 July 2015.
Edited by:
Roberta Sellaro, Leiden University, NetherlandsReviewed by:
Anna M. Borghi, University of Bologna and Institute of Cognitive Sciences and Technologies, ItalyShai Gabay, University of Haifa, Israel
Copyright © 2015 Dumitru and Joergensen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Magda L. Dumitru, Department of Cognitive Science, Macquarie University, 16 University Avenue, Sydney, NSW 2109, Australia,bWFnZGEuZHVtaXRydUBnbWFpbC5jb20=