 Mathieu Andrieux
Mathieu Andrieux Luc Proteau
Luc Proteau- Département de kinésiologie, Université de Montréal, Montréal, QC, Canada
Observation aids motor skill learning. When multiple models or different levels of performance are observed, does learning improve when the observer is informed of the performance quality prior to each observation trial or after each trial? We used a knock-down barrier task and asked participants to learn a new relative timing pattern that differed from that naturally emerging from the task constraints (Blandin et al., 1999). Following a physical execution pre-test, the participants observed two models demonstrating different levels of performance and were either informed of this performance prior to or after each observation trial. The results of the physical execution retention tests of the two experiments reported in the present study indicated that informing the observers of the demonstration quality they were about to see aided learning more than when this information was provided after each observation trial. Our results suggest that providing advanced information concerning the quality of the observation may help participants detect errors in the model's performance, which is something that novice participants have difficulty doing, and then learn from these observations.
Introduction
You are an avid golfer and you want to learn a new shot. How would you proceed? There is a fair chance that you will observe someone (live, on video, on Youtube, etc.) who knows how to perform this shot, and you will try to understand what to do and how to do it. Research clearly indicates that this learning strategy is successful because observation has been shown to promote the learning of a wide variety of motor skills (see McCullagh et al., 1989; Hodges et al., 2007; Vogt and Thomaschke, 2007; Ste-Marie et al., 2012; Lago-Rodríguez et al., 2014, for reviews on observational learning). This is because observation has much commonality with physical practice, which is the first determinant of motor skill learning. Specifically, it has been demonstrated that variables, such as the amount of practice (Carroll and Bandura, 1990; Blandin, 1994), the frequency of knowledge of results ([KR], Badets and Blandin, 2004, 2005; Badets et al., 2006), and the practice schedule (Blandin et al., 1994; Wright et al., 1997), affect learning via observational practice and physical practice in similar ways. These data led to the proposition that observation and physical practice use very similar processes. This proposition is supported by the results of neuroimaging studies that showed that an ensemble of neural structures (including the premotor cortex, the inferior parietal lobule, the superior temporal sulcus, the supplementary motor area, the cingulate gyrus, and the cerebellum), also called the “action observation network” (AON) (Kilner et al., 2009; Oosterhof et al., 2010), is activated both when individuals perform a given motor task and when they observe others performing that same motor task (Grafton et al., 1997; Buccino et al., 2001; Gallese et al., 2002; Cisek and Kalaska, 2004; Frey and Gerry, 2006; Cross et al., 2009; Dushanova and Donoghue, 2010; Rizzolatti and Fogassi, 2014; Rizzolatti et al., 2014).
Observation favors motor skill learning, but who should you observe to learn that new golf shot? An expert who masters the shot presumably will help you develop a reference of what to do and how to do it, but should you observe someone like you who is learning that shot and who presumably gives you a better chance of detecting and learning from errors or changes in strategy? Research has shown that observing both a skilled model (Martens et al., 1976; McCullagh et al., 1989; Lee et al., 1994; Al-Abood et al., 2001; Heyes and Foster, 2002; Hodges et al., 2003; Bird and Heyes, 2005) and a novice model leads to significant learning (Lee and White, 1990; McCullagh and Caird, 1990; Pollock and Lee, 1992; McCullagh and Meyer, 1997; Black and Wright, 2000; Buchanan et al., 2008; Buchanan and Dean, 2010; Hayes et al., 2010). However, recent results from our laboratory showed that observational learning of a new motor skill is improved following observation of both novice and expert models rather than either a novice or an expert model alone (Rohbanfard and Proteau, 2011; Andrieux and Proteau, 2013, 2014). We believe that this “variable” observation format leads to not only the development of a good movement representation (expert observation) but also the development of efficient processes for error detection and correction (novice observation).
In the present study, the question of interest is a simple but important one. When using a variable schedule of observation, will learning be better when the observers are informed beforehand of the “quality” of the performance they are about to see or will it be better when the observers are left to evaluate the performances before receiving feedback. Informing the observers of what they are about to see may enable them to select whether they will observe to imitate or rather observe to detect error, or weaknesses in the model's performance, which might facilitate the development of these processes. Alternatively, having the participants evaluate the performance quality they observed may activate more elaborate cognitive processes than when this information is fed forward (e.g., error detection and recognition, or evaluation of alternative strategy), thus resulting in better learning of the task.
The task that we chose required the participants to change the relative timing pattern that naturally emerged from the task constraints (Collier and Wright, 1995; Blandin et al., 1999) to a new, imposed pattern of relative timing. This is similar to changing one's tempo when executing a serve in tennis or a drive in golf (Rohbanfard and Proteau, 2011). The participants observed two models demonstrating a wide variety of performances. In one group, observers were informed before each trial of the quality level (expert, advanced, intermediate, novice, or beginner performance) of what they were about to see, whereas a second group of observers was provided the same information only after each observation trial was completed.
Experiment 1
Methods
Participants
Ninety right-handed students (45 males and 45 females; mean age = 20.5 years; SD = 0.9 years) from the Département de kinésiologie at the Université de Montréal participated in this experiment. The participants were naive to the purpose of the study and had no prior experience with the task, and all participants were self-declared as being right-handed. None of the participants reported neurological disorders, and all had normal or corrected-to-normal vision. The participants completed and signed individual consent forms before participation. The Health Sciences Research Ethics Committee of the Université de Montréal approved this experiment.
Apparatus and Task
The apparatus was similar to that used by Rohbanfard and Proteau (2011). As illustrated in Figure 1, it consisted of a wooden base (45 × 54 cm), three wooden barriers (11 × 8 cm), and a starting button embedded in a target (11 × 8 cm). The distance between the starting button and the first barrier was 15 cm. The distances of the remaining three segments of the task were 32, 18, and 29 cm, respectively. The barriers were placed perpendicular to the wooden base at the beginning of each trial, yielding a closed microswitch circuit. All of the microswitches were connected to a computer via the I/O port of an A–D converter (National Instruments, Austin, Texas, USA), and a millisecond timer was used to record both the total movement time (TMT) and the time required to complete each segment of the task (intermediate times, ITs).
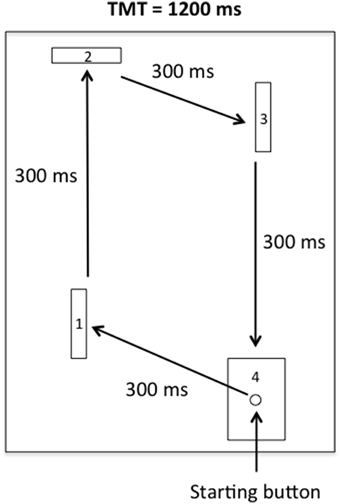
Figure 1. Sketch of the apparatus. Participants had to leave the starting button and hit the first, second, and third barriers in a clockwise motion before finally reaching the target.
For the physical practice trials (see below), the participants sat close to the starting position in front of the apparatus. Then, from the starting button, the participants were asked to successively knock down the first, second, and third barriers (thus releasing the microswitches) and finally hit the target in a clockwise motion as illustrated in Figure 1. Each segment of the task had to be completed in an IT of 300 ms, for a TMT of 1200 ms. The movement pattern, ITs, and TMT were illustrated on a poster located directly in front of the apparatus during all of the experimental phases.
Experimental Phases and Procedure
The participants were randomly assigned to one of the three groups, each consisting of 30 participants (15 females per group): control (C), feedforward KR and observation (FW), and observation and feedback KR (FB). All groups performed four experimental phases, spread over 2 successive days.
All participants received verbal instructions regarding TMT and ITs before the first experimental phase. The first experimental phase was a pre-test, in which all participants performed 20 physical practice trials without knowledge of the results (KR) on the TMT and the ITs.
The second phase was an acquisition phase and consisted of 60 observation trials for the participants in the two observation groups (FW and FB). These participants individually watched a video presentation of two models physically performing the experimental task. For each observation trial, KR concerning the model's performance (both TMT and ITs) was presented in ms (see Figure 1) either before the demonstration for the FW group or after the demonstration for the FB group. The model was changed every five trials (i.e., model 1: trials 1–5 and model 2: trials 6–10, and so on), for a total of 30 trials performed by one model and 30 trials performed by the other model. For both the FW and FB groups, the two models, who participated in previous work from our laboratory, were chosen because for both models, we had six video clips that illustrated performances in each one of five subcategories. Thus, the participants in the FW and FB groups could not associate one particular model with either a better or a poorer performance. An expert performance corresponded to a root mean square error (RMSE; see data analysis section for computation details) ranging between 0 and 15 ms; advanced, intermediate, novice, and beginner performances corresponded to RMSEs of 30–45 ms, 60–75 ms, 90–105 ms and 120+ ms, respectively. The participants in the FW and FB groups were informed of the model's performance in ms; they were also informed of the level of performance to which it referred. The resulting 30 trials of each model (five levels of performance × six repetitions) were randomized so that the five levels of performance were presented once into each set of five trials. To avoid physical imitation of the sequence, which could interfere with the observational processes, we asked the participants in the FW and FB groups to keep their hands on their thighs during the acquisition phase and to not reproduce the movements while watching the model(s). It was the Experimenter's main task to ensure that the participants complied with these instructions. The participants' overt behavior suggests that they did. Finally, participants of the control group did not physically practice or observe anything during this phase. Instead, they read a provided newspaper or magazine for the same duration as the observation for the other groups (approximately 10 min).
The third and fourth experimental phases were 10-min and 24-h retention phases. In each phase, all participants physically performed 20 trials with no KR. The participants were asked to complete each segment of the task in 300 ms, for a TMT of 1200 ms.
Data Analysis
The data from the pre-test and the two retention phases were regrouped into blocks of five trials. For each successive block of five trials (i.e., trials 1–5, 6–10, etc.), we computed the absolute value of each participant's constant error (|CE|, the constant error indicates whether a participant undershot [negative value] or overshot [positive value] the total movement time) and variable error of the total movement time (VE or within-participant variability) to determine the accuracy and consistency of TMT, respectively. For intermediate times, we computed a RMSE, which indicates how much each participant deviated from the prescribed relative timing pattern in a single score. For each trial,
where ITi represents the intermediate time for segment “i,” and target represents the goal movement time for each segment of the task (i.e., 300 ms).
Because the data were not normally distributed (RMSE and time data are positively skewed), each dependent variable underwent a logarithmic transformation (ln). The transformed data for each dependent variable were independently submitted to an ANOVA contrasting three groups (C, FW, and FB) × three phases (pre-test, 10-min retention, 24-h retention) × four blocks of trials (1–5, 6–10, 11–15, and 16–20), with repeated measures on the last two factors. All of the significant main effects and simple main effects involving more than two means were broken down using Bonferroni's adjustment. For all comparisons, an effect was deemed significant if p < 0.05. Partial eta square () is the effect size reported for all significant effects (Cohen, 1988).
Results
Total Movement Time
The ANOVA computed on |CE| (Figure 2, upper panel) revealed significant main effects for the variable group, F(2, 87) = 5.04, p = 0.08, = 0.10, and phase, F(2, 174) = 5.16, p = 0.007, = 0.06, as well as a significant phase × group interaction, F(4, 174) = 4.93, p = 0.001, = 0.10. The breakdown of this interaction did not reveal any significant group differences in the pre-test (F < 1). In the 10-min retention test, F(2, 87) = 10.12, p < 0.001, = 0.19, the post-hoc comparisons revealed that the control group had a significantly larger | CE| than both the FW and the FB groups (p < 0.05 in both cases), which did not differ significantly from one another (p = 0.19). In the 24-h retention test, F(2, 87) = 4.34, p = 0.016, = 0.09, the FW group had a significantly smaller |CE| than the control group (p = 0.012)1.
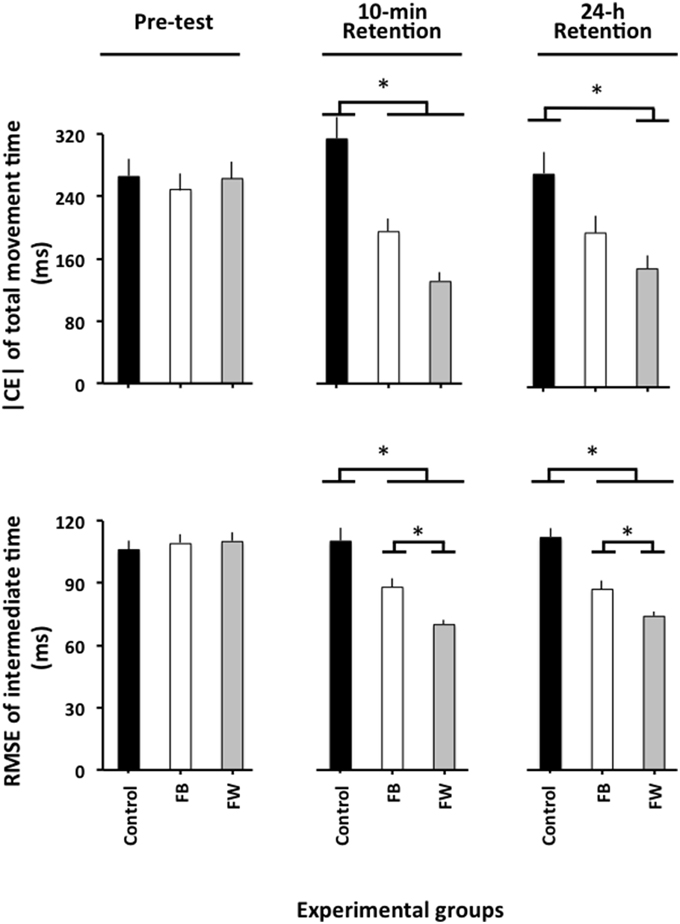
Figure 2. Absolute constant error of TMT and root mean square error of relative timing as a function of the experimental phases and experimental groups (Experiment 1). *p < 0.05. Error bars indicate standard error of the mean.
The ANOVA computed on VE (not shown) revealed significant main effects for the variable phase, F(2, 174) = 13.12, p < 0.001, = 0.13, and block, F(3, 261) = 48.79, p < 0.001, = 0.36. Post-hoc comparisons of the phase effect revealed a larger VE of total time in the pre-test than in both the 10-min and the 24-h retention tests (p < 0.002 in both cases), which did not differ significantly from one another (p = 0.68). The block main effect resulted from a significantly larger VE of total time for the first than for the three remaining blocks of trials (p < 0.001 in all cases), which did not differ significantly from one another (p>0.05 in all cases).
Relative Timing
The ANOVA computed on the RMSE of relative timing revealed significant main effects for the variable group, F(2, 87) = 21.49, p < 0.001, = 0.33, phase, F(2, 174) = 39.98, p < 0.001, = 0.31 and block, F(3, 261) = 14.77, p < 0.001, = 0.14, as well as a significant phase × group interaction, F(4, 174) = 12.81, p < 0.001, = 0.23. The block main effect resulted from a significantly larger RMSE of relative timing for the first than for the three remaining blocks of trials (p < 0.001 in all cases), which did not differ significantly from one another (p>0.3 in all cases). More interestingly, the breakdown of the phase × group interaction (Figure 2, lower panel) did not reveal any significant group differences in the pre-test (F < 1). In the 10-min, F(2, 87) = 14.85, p < 0.001, = 0.34, and the 24-h retention tests, F(2, 87) = 23.23, p < 0.001, = 0.35, although the FB group significantly outperformed the control group (p = 0.001 in both cases), the FB group was, in turn, significantly outperformed by the FW group (p = 0.001 and p = 0.02, respectively)2.
Discussion
The present experiment was designed to extend our knowledge of the observation conditions that optimize learning of a new relative timing pattern. In this learning situation, two observation groups, which observed a variety of demonstrations, were provided KR either before or after each trial during the acquisition phase. Specifically, we wanted to assess whether learning would be enhanced when the learners know the “quality” or characteristics of a demonstration before they observe the demonstration. The results are straightforward.
First, as illustrated in Figure 2, both the FW and the FB groups outperformed the control group on the retention tests. This was true for the learning of both the TMT and the relative timing. This expected result confirms previous findings that indicated that observation enables one to learn a new motor skill (see McCullagh et al., 1989; Hodges et al., 2007; Vogt and Thomaschke, 2007; Ste-Marie et al., 2012; Lago-Rodríguez et al., 2014, for reviews on observational learning) and, notably, a new relative timing pattern (Rohbanfard and Proteau, 2011; Andrieux and Proteau, 2013, 2014).
The most important finding of the present study is that the FB group was outperformed by the FW group in the retention tests. Although the two groups observed the same demonstrations, the results revealed that learning is optimized when one is given advance knowledge of the quality or characteristics of the witnessed demonstration. This finding fits well with previous reports from our laboratory (Rohbanfard and Proteau, 2011; Andrieux and Proteau, 2013) showing that a mixed observation regimen, in which the observers know who is the expert model and who is the novice model, favors learning of a new relative timing pattern better than either expert or novice observation alone.
Having advance knowledge that a less than perfect demonstration will be shown may be critical, considering that it has been reported that novice participants, such as in the present study, are not good at evaluating the quality of a demonstration. For example, Aglioti et al. (2008) had novice and expert basketball players observe video clips showing free-throw shots, and the video clips were stopped at different times before or immediately after the ball release. Expert basketball players and coaches/specialized journalists were better and quicker at predicting the fate of the shot (successful or not) than were novices (for similar results see also Wright et al., 2010; Abreu et al., 2012; Tomeo et al., 2013; Balser et al., 2014; Candidi et al., 2014; Renden et al., 2014).
The advantage of the FW over the FB protocol is important and, as far as we know, a similar finding has not been reported thus far. Therefore, a replication of this finding appeared important. In addition, we wondered whether the advantage noted for the FW protocol occurred only after a limited amount of observation. Finally, we were curious to see whether alternating the FW and the FB protocol would result in additive effects. We conducted Experiment 2 to address these questions.
Experiment 2
Methods
Participants
The 60 participants who volunteered for this experiment were drawn from the same population as that of Experiment 1 (36 males and 24 females; mean age = 22.7 years; SD = 4.9 years). The participants were naive concerning the purpose of this study and had no prior experience with the task. They completed and signed individual consent forms before participation. The Health Sciences Research Ethics Committee of the Université de Montréal approved this experiment.
Apparatus, Task, Experimental Phases, Procedure, and Data Analysis
We used the same task, apparatus, and procedures as in Experiment 1. The major difference between the present experiment and Experiment 1 is that participants performed two acquisition sessions, which led to a total of five experimental phases: pre-test, acquisition 1, immediate retention test, acquisition 2, and 24-h retention test.
The participants were randomly assigned to one of the three groups, each consisting of 20 participants (8 females per group): feedforward KR and observation during both acquisition 1 and 2 (FW1-2); feedforward observation and KR during acquisition 1 but observation and feedback KR during acquisition 2 (FW/FB); and observation and KR feedback during both acquisition 1 and 2 (FB1-2). We used the same video and models as in Experiment 1; however, the order of video presentation was different in acquisition 2 from that in acquisition 1. All participants were also informed that they would perform the same task after each acquisition phase, but with no KR concerning their own performance.
We used the same dependent variables and data transformation as in Experiment 1. For each dependent variable, we conducted a two-way ANOVA contrasting the three groups (FW1-2, FW/FB and FB1-2) × three experimental phases (pre-test, immediate retention, and 24-h retention). All of the significant main effects and simple main effects involving more than two means were broken down using Bonferroni's adjustment. For all comparisons, an effect was deemed significant if p < 0.05. Partial eta square () is the effect size reported for all significant effects (Cohen, 1988).
Results
Total Movement Time
The ANOVA computed for the |CE| of movement time (Figure 3) revealed significant main effects for the variable group, F(2, 57) = 8.13, p = 0.001, = 0.22, and phase, F(2, 114) = 21.13, p < 0.001, = 0.27, as well as a significant group × phase interaction, F(4, 114) = 2.57, p = 0.042, = 0.08. The breakdown of this interaction did not reveal any significant group differences in the pre-test (F < 1). In the immediate retention test, F(2, 57) = 10.27, p < 0.002, = 0.27, the FB1-2 group had a significantly larger | CE| than both the FW1-2 and the FW/FB groups (p < 0.001 in both cases), which did not differ significantly from one another (p>0.20). In the 24-h retention test, F(2, 57) = 3.19, p = 0.049, = 0.10, the FW1-2 group had a slightly smaller |CE| than the FB1-2 group (p = 0.079)3.
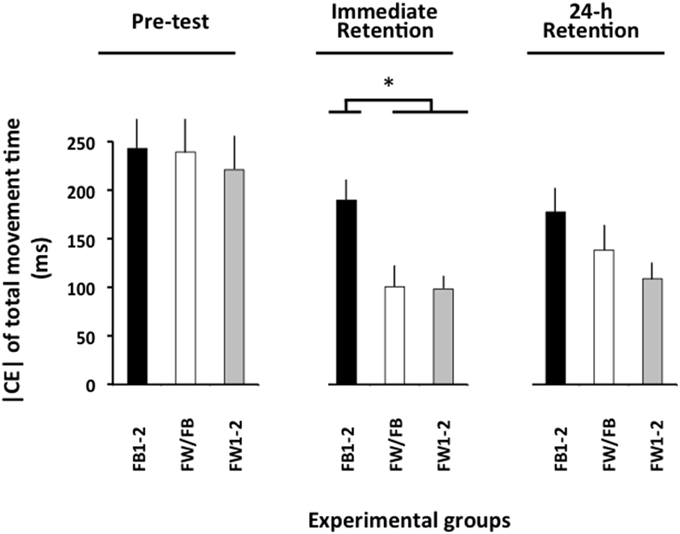
Figure 3. Absolute constant error of TMT as a function of the experimental phases and experimental groups (Experiment 2). *p < 0.05. Error bars indicate standard error of the mean.
The ANOVA computed on VE (not shown) revealed significant main effects for the variable group, F(2, 57) = 7.82, p = 0.001, = 0.21, and phase, F(2, 114) = 21.10, p < 0.001, = 0.27, as well as a significant group × phase interaction, F(4, 114) = 4.38, p = 0.002, = 0.13. The breakdown of this interaction did not reveal any significant group differences in the pre-test (F < 1) and in the 24-h retention test, F(2, 57) = 1.26, p>0.20. In the immediate retention test, F(2, 57) = 10.26, p < 0.002, = 0.27, the FB1-2 group (62.7 ms) had a significantly larger VE than both the FW1-2 (51.1 ms) and the FW/FB (53.4 ms) groups (p < 0.001 in both cases), which did not differ significantly from one another (p>0.20)4.
Relative Timing
The ANOVA computed for the RMSE of relative timing revealed significant main effects for the variable group, F(2, 57) = 4.86, p = 0.01, = 0.15, and phase, F(2, 114) = 78.21, p < 0.001, = 0.58. There was a significantly larger RMSE of relative timing in the pre-test than in both the immediate retention test and the 24-h retention test (p < 0.001 in both cases; see Figure 4, right panel), which did not differ significantly from one another (p>0.20). Finally, the FW1-2 and the FW/FB groups outperformed the FB1-2 group (p = 0.01 and p = 0.07; see Figure 4, left panel) but did not significantly differ from one another (p>0.20).
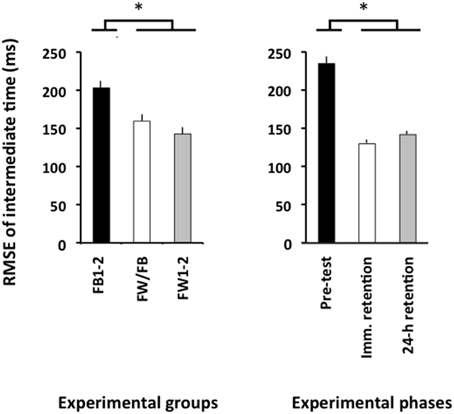
Figure 4. Root mean square error of relative timing (Experiment 2) as a function of the experimental groups (left panel) and experimental phases (right panel). *p < 0.05. Error bars indicate standard error of the mean.
Discussion
As expected, the decrease in error noted when going from pre-test to the retention tests supports previous findings indicating that observation aids learning of a new relative timing pattern (Blandin et al., 1999; Rohbanfard and Proteau, 2011; Andrieux and Proteau, 2013, 2014). More importantly, the results of Experiment 2 replicated those of Experiment 1, in that the FW1-2 group outperformed the FB1-2 group. Therefore, it can be safely concluded that learning to change the relative timing pattern that naturally emerges from the task's constraints to a new, imposed relative timing through observation is favored when one is informed of the model's performance prior to rather than after observation. Finally, the results also showed that what has been learned in a FB protocol does not add up to what can be learned in a FW protocol.
General Discussion
The main goal of the present study was to determine when in an observation protocol should KR concerning the model performance be provided, i.e., before or after each demonstration. The results of the two experiments of the present study clearly indicated that being informed of the model's performance before each demonstration favored learning of a new relative timing pattern better than when the observer was informed of the model's performance after each demonstration. Moreover, the results of Experiment 2 suggest that the advantage of the FW over the FB protocol remained significant even when the number of observation trials was doubled. Concerning this last point, we do not argue that a FW protocol should be favored in all cases and with all levels of expertise of the observers. Rather, we underline that the effect is reliable when novice observers are considered.
Our results may indicate that a feedforward observation protocol prepares the observer to engage specifically in either imitation processes when an expert or advanced performance is shown or in error detection processes when a beginner or novice performance is presented. This idea fits well with previous work from Decety et al. (1997), which stated that the patterns of brain activation during action observation depend on both the nature of the required executive processing and the extrinsic properties of the action presented. Specifically, these authors demonstrated that different areas of the brain become more active when one observes to recognize, which could be the case when observing a novice model or a poor or intermediate performance, and when one observes to imitate, which is likely to be the case when observing an expert model.
An alternative explanation of our findings could be that a FW protocol results in a “deactivation” of the AON when the participants were explicitly informed that a poor demonstration would follow. For instance, in an object-lifting task, it has been shown that the modulation of motor evoked potential (MEP) by transcranial magnetic stimulation (TMS) during observation of the lifting action is scaled to the force required to perform the grasping and lifting action (Alaerts et al., 2010a). It was also shown that when visual cues suggested that the object was heavier than in really was, the MEP modulation depended primarily on the observed kinematic profile rather than on the apparent weight of the object (Alaerts et al., 2010b; Senot et al., 2011). However, in a study by Senot et al. (2011), false explicit information concerning the weight of the object was provided in one experimental condition. This resulted in a conflict between the expected kinematic profile given the announced weight and the actual kinematic profile of the grasping and lifting action, leading to a “general inhibition of the corticospinal system.” Stated differently, at least a portion of the AON had been turned off. Therefore, it could be that the participants in our study turned off the AON when poor performance of the model was expected, leaving the AON active only for good trials.
This proposition is difficult to reconcile, however, with recent reports from our laboratory showing that observing both an expert and a novice model resulted in better learning of a new relative timing pattern than observing either a novice model or an expert model alone. If one could turn off the AON when informed that a poor demonstration will be shown (i.e., a novice model), then learning of the mixed observation group would have matched and not surpassed that of the expert observation group. Rather, going back to our first proposition, we suggest that a FW protocol helps novice performers detect and quantify errors in the model's performance, something they usually do poorly (Aglioti et al., 2008; Wright et al., 2010; Abreu et al., 2012; Tomeo et al., 2013; Balser et al., 2014; Candidi et al., 2014; Renden et al., 2014). In turn, the better detection and quantification of the model's performance may favor the development of inverse (Jordan, 1996) and forward models (Wolpert and Miall, 1996) of motor control.
In conclusion, observation is a powerful learning tool that is available to anyone and requires only minimal equipment to be used. It is now well-demonstrated that the benefits of observation for modifying the relative timing (i.e., tempo) of motor skill are enhanced when one has access to a variety of performances ranging from novices to experts either through variable or mixed observation schedules. The results of the present study suggest that those benefits are optimized if the observer knows beforehand the quality of the performance that she or he is about to observe during the first observation session. This could be very important in a classroom context in which a teacher/trainer would use a video observation protocol. For example, if the intention of the observer is to learn a specific aspect of a golf swing, it is likely that the result of the swing (i.e., the ball flight) will not be shown on the video. Therefore, the observer would not be able to “guess” the expertise of the model from the result of the swing and, as we have shown in the present study, learn better if he or she was informed in advance of the quality of what he or she is about to observe.
Author Contributions
All authors listed, have made substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
This work was supported by a Discovery Grant (LP) provided by the Natural Sciences and Engineering Research Council of Canada (grant no. 111280-2013).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^To ascertain that the differences noted in the two retention tests between the control group and the FW and FB groups resulted from a significant decrease in the |CE| of total movement time, in a supplementary analysis we decomposed the group × phase interaction reported in the main text by computing a separate ANOVA for each group. The results revealed that for the control and the FB groups, the |CE| of total movement time did not significantly differ across the phases, [F(2, 86) = 1.58, p = 0.21, = 0.04, and F(2, 86) < 1, p = 0.37, ], respectively. On the contrary, for the FW groups, there was a significant main effect of the phases, F(2, 86) = 11.60, p < 0.01, , that revealed a significant decrease in the |CE| of total movement time going from the pre-test to the two retention tests (p < 0.01), which did not differ significantly from one another (p>0.10).
2. ^As we did for the |CE| of total movement time, in a supplementary analysis we decomposed the group × phase interaction reported in the main text for the RMSE of relative timing by computing a separate ANOVA for each group. The results revealed that for the control group, the RMSE of relative timing did not significantly differ across the phases, F(2, 86) = 0.32, p = 0.72, . On the contrary, for both the FB and the FW groups, there was a significant main effect of the phases [FB: F(2, 86) = 11.82, p < 0.001, ; FW: F(2, 86) = 35.62, p < 0.001, ] that revealed a significant decrease in the RMSE of relative timing going from the pre-test to the two retention tests (p < 0.01), which did not differ significantly from one another (p > 0.10).
3. ^As we did in Experiment 1, in a supplementary analysis we decomposed the group × phase interaction reported in the main text by computing a separate ANOVA for each group. The results revealed that for the FB1-2 group, the |CE| of total movement time did not significantly differ across the phases, F(2, 56) < 1, p = 0.45, . On the contrary, for both the FW1-2 and FW-FB groups, there was a significant main effect of the phases, [FW1-2: F(2, 56) = 8.20, p = 0.001, ; FW-FB: F(2, 56) = 13.76, p < 0.001, ] that, for both groups, revealed a significant decrease in the |CE| of total movement time going from the pre-test to the two retention tests (p < 0.01), which did not differ significantly from one another (p>0.10).
4. ^For the VE of total movement time, the breakdown of the group × phase interaction revealed a significant main effect of phases for all three groups [FW1-2: F(2, 56) = 10.27, p < 0.001, ; FW-FB: F(2, 56) = 4.71, p = 0.013, ; FB1-2: F(2, 56) = 7.38, p = 0.001, ]. For the FW1-2 and the FB1-2 groups, pos-hoc comparisons revealed a significantly larger VE in pre-test than in both retention tests (p < 0.01), which did not differ significantly from one another (p>0.30). For the FW-FB group, the VE of total movement time was significantly larger in the pre-test than in the 24-h retention test (p < 0.01).
References
Abreu, A. M., Macaluso, E., and Azevedo, R. T. (2012). Action anticipation beyond the action observation network: a functional magnetic resonance imaging study in expert basketball players. Eur. J. Neurosci. 35, 1646–1654. doi: 10.1111/j.1460-9568.2012.08104.x
Aglioti, S. M., Cesari, P., Romani, M., and Urgesi, C. (2008). Action anticipation and motor resonance in elite basketball players. Nat. Neurosci. 11, 1109–1116. doi: 10.1038/nn.2182
Al-Abood, S. A., Davids, K. F., and Bennett, S. J. (2001). Specificity of task constraints and effects of visual demonstrations and verbal instructions in directing learners' search during skill acquisition. J. Mot. Behav. 33, 295–305. doi: 10.1080/00222890109601915
Alaerts, K., Senot, P., Swinnen, S. P., Craighero, L., Wenderoth, N., and Fadiga, L. (2010a). Force requirements of observed object lifting are encoded by the observer's motor system: a TMS study. Eur. J. Neurosci. 31, 1144–1153. doi: 10.1111/j.1460-9568.2010.07124.x
Alaerts, K., Swinnen, S. P., and Wenderoth, N. (2010b). Observing how others lift light or heavy objects: which visual cues mediate the encoding of muscular force in the primary motor cortex? Neuropsychologia 48, 2082–2090. doi: 10.1016/j.neuropsychologia.2010.03.029
Andrieux, M., and Proteau, L. (2013). Observation learning of a motor task: who and when? Exp. Brain Res. 229, 125–137. doi: 10.1007/s00221-013-3598-x
Andrieux, M., and Proteau, L. (2014). Mixed observation favors motor learning through better estimation of the model's performance. Exp. Brain Res. 232, 3121–3132. doi: 10.1007/s00221-014-4000-3
Badets, A., and Blandin, Y. (2004). The role of knowledge of results frequency in learning through observation. J. Mot. Behav. 36, 62–70. doi: 10.3200/JMBR.36.1.62-70
Badets, A., and Blandin, Y. (2005). Observational learning: effects of bandwidth knowledge of results. J. Mot. Behav. 37, 211–216. doi: 10.3200/JMBR.37.3.211-216
Badets, A., Blandin, Y., Wright, D. L., and Shea, C. H. (2006). Error detection processes during observational learning. Res. Q. Exerc. Sport 77, 177–184. doi: 10.1080/02701367.2006.10599352
Balser, N., Lorey, B., Pilgramm, S., Naumann, T., Kindermann, S., Stark, R., et al. (2014). The influence of expertise on brain activation of the action observation network during anticipation of tennis and volleyball serves. Front. Hum. Neurosci. 8:568. doi: 10.3389/fnhum.2014.00568
Bird, G., and Heyes, C. (2005). Effector-dependent learning by observation of a finger movement sequence. J. Exp. Psychol. Hum. Percept. Perform. 31, 262–275. doi: 10.1037/0096-1523.31.2.262
Black, C. B., and Wright, D. L. (2000). Can observational practice facilitate error recognition and movement production? Res. Q. Exerc. Sport 71, 331–339. doi: 10.1080/02701367.2000.10608916
Blandin, Y. (1994). Processus Cognitifs Impliqués Lors de L'apprentissage de Tâches de Synchronisation Spatio-Temporelle Sous Différentes Conditions de Pratique et D'observation D'un Sujet Modèle, Thèse De Doctorat Inédite. [Cognitive Processes pu into Play during the Learning of A Spatiotemporal Timing Task throught Different Regimens of Practice or Observation, Unpublished doctoral dissertation], Université de Montréal.
Blandin, Y., Lhuisset, L., and Proteau, L. (1999). Cognitive processes underlying observational learning of motor skills. Q. J. Exp. Psychol. 52, 957–979. doi: 10.1080/713755856
Blandin, Y., Proteau, L., and Alain, C. (1994). On the cognitive processes underlying contextual interference and observational learning. J. Mot. Behav. 26, 18–26. doi: 10.1080/00222895.1994.9941657
Buccino, G., Binkofski, F., Fink, G. R., Fadiga, L., Fogassi, L., Gallese, V., et al. (2001). Action observation activates premotor and parietal areas in a somatotopic manner: an fMRI study. Eur. J. Neurosci. 13, 400–404. doi: 10.1046/j.1460-9568.2001.01385.x
Buchanan, J. J., and Dean, N. J. (2010). Specificity in practice benefits learning in novice models and variability in demonstration benefits observational practice. Psychol. Res. 74, 313–326. doi: 10.1007/s00426-009-0254-y
Buchanan, J. J., Ryu, Y. U., Zihlman, K., and Wright, D. L. (2008). Observational practice of relative but not absolute motion features in a single-limb multi-joint coordination task. Exp. Brain Res. 191, 157–169. doi: 10.1007/s00221-008-1512-8
Candidi, M., Sacheli, L. M., Mega, I., and Aglioti, S. M. (2014). Somatotopic mapping of piano fingering errors in sensorimotor experts: TMS studies in pianists and visually trained musically naives. Cereb. Cortex 24, 435–443. doi: 10.1093/cercor/bhs325
Carroll, W. R., and Bandura, A. (1990). Representational guidance of action production in observational learning: a causal analysis. J. Mot. Behav. 22, 85–97. doi: 10.1080/00222895.1990.10735503
Cisek, P., and Kalaska, J. F. (2004). Neural correlates of mental rehearsal in dorsal premotor cortex. Nature 431, 993–996. doi: 10.1038/nature03005
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences. Hillsdale, NJ: Lawrence Erlbaum.
Collier, G. L., and Wright, C. E. (1995). Temporal rescaling of sample and complex rations in rhythmic tapping. J. Exp. Psychol. Hum. Percept. Perform. 21, 602–627. doi: 10.1037/0096-1523.21.3.602
Cross, E. S., Kraemer, D. J. M., Hamilton, A. F. D., Kelley, W. M., and Grafton, S. T. (2009). Sensitivity of the action observation network to physical and observational learning. Cereb. Cortex 19, 315–326. doi: 10.1093/cercor/bhn083
Decety, J., Grèzes, J., Costes, N., Perani, D., Jeannerod, M., Procyk, E., et al. (1997). Brain activity during observation of actions - influence of action content and subject's strategy. Brain 120, 1763–1777. doi: 10.1093/brain/120.10.1763
Dushanova, J., and Donoghue, J. (2010). Neurons in primary motor cortex engaged during action observation. Eur. J. Neurosci. 31, 386–398. doi: 10.1111/j.1460-9568.2009.07067.x
Frey, S. H., and Gerry, V. E. (2006). Modulation of neural activity during observational learning of actions and their sequential orders. J. Neurosci. 26, 13194–13201. doi: 10.1523/JNEUROSCI.3914-06.2006
Gallese V., Fadiga L., Fogassi L., Rizzolatti G. (2002). “Action representation and the inferior parietal lobule,” in Common Mechanisms in Perception and Action: Attention and Performance, Vol. XIX, eds W. Prinz, and B. Hommel (Oxford: Oxford University Press), 247–266.
Grafton, S. T., Fadiga, L., Arbib, M. A., and Rizzolatti, G. (1997). Promotor cortex activation during observation and naming of familiar tools. Neuroimage 6, 231–236. doi: 10.1006/nimg.1997.0293
Hayes, S. J., Elliott, D., and Bennett, S. J. (2010). General motor representations are developed during action-observation. Exp. Brain Res. 204, 199–206. doi: 10.1007/s00221-010-2303-6
Heyes, C. M., and Foster, C. L. (2002). Motor learning by observation: evidence from a serial reaction time task. Q. J. Exp. Psychol. 55, 593–607. doi: 10.1080/02724980143000389
Hodges, N. J., Chua, R., and Franks, I. M. (2003). The role of video in facilitating perception and action of a novel coordination movement. J. Mot. Behav. 35, 247–260. doi: 10.1080/00222890309602138
Hodges, N. J., Williams, A. M., Hayes, S. J., and Breslin, G. (2007). What is modelled during observational learning? J. Sports Sci. 25, 531–545. doi: 10.1080/02640410600946860
Jordan, M. I. (1996). “Computational aspects of motor control and motor learning,” in Handbook of Perception and Action: Vol. 2, Motor Skills, eds H. Heuer and S. W. Keele (New York, NY: Academic Press), 71–120.
Kilner, J. M., Neal, A., Weiskopf, N., Friston, K. J., and Frith, C. D. (2009). Evidence of mirror neurons in human inferior frontal gyrus. J. Neurosci. 29, 10153–10159. doi: 10.1523/JNEUROSCI.2668-09.2009
Lago-Rodríguez, A., Cheeran, B., and Koch, G. (2014). The role of mirror neurons in observational motor learning: an integrative review. Eur. J. Human Mov. 32, 82–103.
Lee, T. D., Swinnen, S. P., and Serrien, D. J. (1994). Cognitive effort and motor learning. Quest 46, 328–344. doi: 10.1080/00336297.1994.10484130
Lee, T. D., and White, M. A. (1990). Influence of an unskilled models practice schedule on observational motor learning. Hum. Mov. Sci. 9, 349–367. doi: 10.1016/0167-9457(90)90008-2
Martens, R., Burwitz, L., and Zuckerman, J. (1976). Modeling effects on motor-performance. Res. Q. 47, 277–291.
McCullagh, P., and Caird, J. K. (1990). Correct and learning models and the use of model knowledge of results in the acquisition and retention of a motor skill. J. Human Mov. Stud. 18, 107–116.
McCullagh, P., and Meyer, K. N. (1997). Learning versus correct models: influence of model type on the learning of a free-weight squat lift. Res. Q. Exerc. Sport 68, 56–61. doi: 10.1080/02701367.1997.10608866
McCullagh, P., Weiss, M. R., and Ross, D. (1989). Modeling considerations in motor skill acquisition and performance: an integrated approach. Exerc. Sport Sci. Rev. 17, 475–513.
Oosterhof, N. N., Wiggett, A. J., Diedrichsen, J., Tipper, S. P., and Downing, P. E. (2010). Surface-based information mapping reveals crossmodal vision-action representations in human parietal and occipitotemporal cortex. J. Neurophysiol. 104, 1077–1089. doi: 10.1152/jn.00326.2010
Pollock, B. J., and Lee, T. D. (1992). Effects of the model's skill level on observational motor learning. Res. Q. Exerc. Sport 63, 25–29. doi: 10.1080/02701367.1992.10607553
Renden, P. G., Kerstens, S., Oudejans, R. R. D., and Cañal-Bruland, R. (2014). Foul or dive? Motor contributions to judging ambiguous foul situations in football. Eur. J. Sport Sci. 14(Suppl. 1), S221–S227. doi: 10.1080/17461391.2012.683813
Rizzolatti, G., Cattaneo, L., Fabbri-Destro, M., and Rozzi, S. (2014). Cortical mechanisms underlying the organization of goal-directed actions and mirror neuron-based action understanding. Physiol. Rev. 94, 655–706. doi: 10.1152/physrev.00009.2013
Rizzolatti, G., and Fogassi, L. (2014). The mirror mechanism: recent findings and perspectives. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 369:20130420. doi: 10.1098/rstb.2013.0420
Rohbanfard, H., and Proteau, L. (2011). Learning through observation: a combination of expert and novice models favors learning. Exp. Brain Res. 215, 183–197. doi: 10.1007/s00221-011-2882-x
Senot, P., D'Ausilio, A., Franca, M., Caselli, L., Craighero, L., and Fadiga, L. (2011). Effect of weight-related labels on corticospinal excitability during observation of grasping: a TMS study. Exp. Brain Res. 211, 161–167. doi: 10.1007/s00221-011-2635-x
Ste-Marie, D. M., Law, B., Rymal, A. M., Jenny, O., Hall, C., and McCullagh, P. (2012). Observation interventions for motor skill learning and performance: an applied model for the use of observation. Int. Rev. Sport Exerc. Psychol. 5, 145–176. doi: 10.1080/1750984X.2012.665076
Tomeo, E., Cesari, P., Aglioti, S. M., and Urgesi, C. (2013). Fooling the kickers but not the goalkeepers: behavioral and neurophysiological correlates of fake action detection in soccer. Cereb. Cortex 23, 2765–2778. doi: 10.1093/cercor/bhs279
Vogt, S., and Thomaschke, R. (2007). From visuo-motor interactions to imitation learning: behavioural and brain imaging studies. J. Sports Sci. 25, 497–517. doi: 10.1080/02640410600946779
Wolpert, D. M., and Miall, R. C. (1996). Forward models for physiological motor control. Neural Netw. 9, 1265–1279. doi: 10.1016/S0893-6080(96)00035-4
Wright, D. L., Li, Y., and Coady, W. (1997). Cognitive processes related to contextual interference and observational learning: a replication of Blandin, Proteau and Alain (1994). Res. Q. Exerc. Sport 68, 106–109. doi: 10.1080/02701367.1997.10608872
Keywords: action observation network, motor learning, knowledge of results, feedback, feedforward, relative timing
Citation: Andrieux M and Proteau L (2016) Observational Learning: Tell Beginners What They Are about to Watch and They Will Learn Better. Front. Psychol. 7:51. doi: 10.3389/fpsyg.2016.00051
Received: 06 July 2015; Accepted: 11 January 2016;
Published: 29 January 2016.
Edited by:
Thomas Heinen, University of Hildesheim, GermanyReviewed by:
André Klostermann, University of Bern, SwitzerlandStefan Künzell, University of Augsburg, Germany
Copyright © 2016 Andrieux and Proteau. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Luc Proteau, bHVjLnByb3RlYXVAdW1vbnRyZWFsLmNh