 David M. Sidhu
David M. Sidhu Alison Heard
Alison Heard Penny M. Pexman
Penny M. Pexman- Language Processing Laboratory, Department of Psychology, University of Calgary, Calgary, AB, Canada
We examined how several semantic richness variables contribute to verb meaning, across a number of tasks. Because verbs can vary in tense, and the manner in which tense is coded (i.e., regularity), we also examined how these factors moderated the effects of semantic richness. In Experiment 1 we found that age of acquisition (AoA), valence, arousal and embodiment predicted faster response times in LDT. In Experiment 2 we examined a particular semantic richness variable, verb embodiment, and found that it was moderated by tense and regularity. In Experiment 3a we found that AoA predicted faster response times in verb reading. Finally, in Experiment 3b, semantic diversity predicted response times in a past tense generation task, either facilitating or inhibiting responses for regular or irregular verbs, respectively. These results demonstrate that semantic richness variables contribute to verb meaning even when verbs are presented in isolation, and that these effects depend on several factors unique to verbs.
Introduction
Semantic Richness Effects
In recent years, a great deal has been learned about representation of word meaning through the study of semantic richness effects in word recognition tasks. The term semantic richness effects is used to describe the fact that words that are associated with more semantic information tend to be recognized more efficiently in various lexical and semantic tasks (see Pexman, 2012, for a review). Semantic information can take many forms, as different dimensions of meaning can be derived from different theoretical frameworks for semantic representation. As such, many different semantic richness effects have been observed, and each has been taken as a clue about the nature of semantic representation. For instance, lexical decision responses tend to be faster for words that appear in more diverse linguistic contexts [semantic diversity (SemD) effects, Hoffman and Woollams, 2015], suggesting that information about word usage is important to lexical-semantic representation. Lexical decision responses also tend to be faster for words that easily evoke sensory imagery (imageability effects, Cortese and Fugett, 2004), or for words with referents with which the human body can easily interact (body-object interaction effects, Siakaluk et al., 2008), suggesting that sensorimotor information is important to word meaning. Facilitory semantic richness effects are attributed to stronger semantic activation for semantically richer words, which feeds back to the orthographic and phonological representations, which are presumed to be the focus of lexical decision and pronunciation responses, respectively (Hino and Lupker, 1996; Siakaluk et al., 2008).
Importantly, a number of studies have examined the simultaneous effects of various semantic richness dimensions in lexical-semantic processing and have shown that multiple dimensions can have unique relationships with processing within a single task (Pexman et al., 2008; Yap et al., 2011, 2012). This type of work has lead to the conclusion that semantic representation is multidimensional, incorporating several different types of information, including linguistic or language-based information and experiential or object-based information (e.g., Barsalou et al., 2008; Dove, 2009; Vigliocco et al., 2009; Louwerse, 2010; Binder and Desai, 2011). These inferences have, however, been drawn from research that has focused primarily on concrete nouns, and some of these dimensions are likely not relevant for other word types. A small amount of work has examined semantic richness effects for abstract nouns and has shown that the dimensions of meaning for abstract nouns are somewhat different than those for concrete nouns; for instance, abstract word meaning seems to involve more emotion information than does concrete word meaning (Kousta et al., 2011; Zdrazilova and Pexman, 2013; Siakaluk et al., 2014; Moffat et al., 2015).
Even less attention has been given to verb meaning with the semantic richness approach. Verbs tend to be less concrete than nouns (Allport and Funnell, 1981; Jones, 1985; Bird et al., 2001), and some of the dimensions that are important to noun meaning are not relevant for verbs (e.g., body-object interaction). While concrete nouns refer to objects, verbs refer to actions, states, and relations, and may be inflected for tense, aspect, etc., to agree with the context in which they are used. As such, the dimensions of verb meaning are likely to be somewhat different than those for nouns. It seems possible that much could be learned about those dimensions, and their implications for representation of verb meaning, by extending the semantic richness approach to verbs. This was the purpose of the present study.
Recently, Kemmerer (2015) suggested that the same type of hybrid or multidimensional models that have been used to explain noun meanings (e.g., Binder and Desai, 2011) will also be relevant for verb meanings although, presumably, the particular dimensions involved may differ. Further, these models are flexible and dynamic, so different dimensions of meaning will be more relevant in some contexts than in others. Similar conclusions were reached in a recent study with stroke patients (Desai et al., 2015). Desai et al. (2015) explored representation of verb and noun meanings in a group of stroke patients who had suffered various degrees of motor impairment. Results showed that patients’ degree of impairment was selectively related to their processing of action verbs in lexical decision and also in semantic judgments. For manipulable nouns this relationship was observed only when the task was explicitly semantic (semantic judgments). Desai et al. (2015) concluded that embodied simulations are particularly important to the meanings of action verbs, and that these simulations are modulated by task demands.
In the present study we investigated several candidate dimensions of verb meaning, including semantic richness dimensions derived from emotion information, embodied experience, and linguistic experience, and examined their effects across multiple task contexts. We adopted an approach that has been used in a number of recent megastudies: rather than comparing processing for sets of items that have been matched on specific characteristics, we examined lexical processing for a large number of items, and used regression analyses to examine the effects of candidate semantic richness variables on responses to those items.
If the same kind of flexible, multidimensional models that have been used to describe noun meaning can be applied to verbs, then we expected that some or the entire candidate dimensions examined here would be related to lexical processing. On the other hand, there may be differences in the representation of verb meaning that preclude semantic richness effects for verbs. That is, in lexical decision, naming, and other word recognition tasks, words are presented in isolation. Cordier et al. (2013) posited that when presented in isolation, verbs are impoverished and more ambiguous than nouns, since they are presented without the arguments that come with sentence context. Consequently, Cordier et al. (2013) suggested that verbs generate less semantic activation and less semantic feedback in lexical decision than do nouns. If this is the case, semantic richness effects may be small and difficult to observe for verbs in lexical tasks, and this approach may not reveal dimensions of verb meaning.
Candidate Dimensions of Verb Meaning
Age of Acquisition
Words acquired earlier in life tend to be recognized more efficiently than words acquired later in life, even when related dimensions like frequency and imageability are controlled (e.g., Morrison and Ellis, 1995; Stadthagen-Gonzalez et al., 2004; Cortese and Schock, 2013). This AoA effect has been demonstrated many times, in many different lexical and semantic tasks (for reviews see Ghyselinck et al., 2004; Juhasz, 2005; Johnston and Barry, 2006). One explanation for the effect is that words acquired earlier enjoy richer semantic representations, with more connections to concepts learned later (Steyvers and Tenenbaum, 2005). Indeed, AoA effects do tend to be larger in tasks that involve semantic processing, such as picture naming (Juhasz, 2005). Another explanation is that early-acquired words are represented in a more plastic system, and thus have a stronger influence on network structure (Ellis and Lambon Ralph, 2000). As the system matures, some plasticity is lost, and so later-acquired words have less influence on network structure. One implication of this network plasticity view is that AoA effects are not strictly semantic; instead, AoA affects multiple components of the lexical-semantic system and also the connections between those components (Lambon Ralph and Ehsan, 2006).
Kuperman et al. (2012) collected AoA ratings for over 30,000 words. Using these ratings, Kuperman et al. (2012) reported that AoA had a linear relationship with lexical decision latencies, with faster latencies to words acquired earlier in life. They did not examine this relationship for verbs separately. To our knowledge, AoA effects have been examined separately for verbs in only two studies. In both cases, noun and verb stimuli were presented in mixed lists but responses to the two word types were analyzed separately. All verbs were presented in present tense. Boulenger et al. (2007) compared AoA effects for concrete nouns and action verbs in lexical decision and found that AoA effects were significant only for nouns, once frequency, imageability, and several other factors were controlled. Boulenger et al. (2007) took these results as evidence for differences in the ways that noun and verb meanings are represented. Colombo and Burani (2002) drew a similar conclusion but from the opposite pattern of results, as they found AoA was a stronger predictor of lexical decision latencies for Italian verbs than Italian nouns.
Emotion (Valence, Arousal, and Dominance)
Emotion information also seems a good candidate dimension for verb meaning. In a recent study, Warriner et al. (2013) collected ratings of valence (the pleasantness of a stimulus), arousal (the intensity of emotion provoked by a stimulus) and dominance (the degree of control exerted by a stimulus) for 13,915 English lemmas. These included verbs, but only in their base (non-inflected) form. Warriner et al. (2013) assumed that the emotion ratings of present and inflected forms would be similar. Based on their ratings, they concluded that valence and arousal are separate constructs. They did, however, find a strong linear relationship between valence and dominance, suggesting that dominance may not describe a separable affective state. Indeed, most previous studies on emotion in lexical processing have tended to examine only valence and arousal.
Using the Warriner et al. (2013) norms, Kuperman et al. (2014) conducted a megastudy to examine effects of valence and arousal and found that lexical decision and naming responses were faster for positively valenced words and for arousing words. The offered explanation is that negatively valenced words capture more attention than do positive words, due to an automatic vigilance mechanism (Pratto and John, 1991). As a result, processing latencies are often longer for negative words. While this pattern is common, we should note that it is not universal: other patterns of valence and arousal effects have been observed in some studies (e.g., Kousta et al., 2009; Adelman and Estes, 2013; Vinson et al., 2014; Yap and Seow, 2014). Importantly, none of the previous studies on valence or arousal effects have examined verbs separately from nouns.
Ambiguity (Semantic Diversity)
Ambiguity is another factor that has not been examined separately for verbs but that could be important to verb meaning. That is, some words have multiple meanings while others have only a single meaning, and this variability has been shown to influence lexical processing. In standard word recognition tasks such as lexical decision, the effect of ambiguity is typically facilitory (e.g., Jastrzembski and Stanners, 1975; Borowsky and Masson, 1996; Hino and Lupker, 1996; cf. Rodd et al., 2002). In contrast, in tasks like semantic relatedness or semantic categorization where word meaning plays an even more central role ambiguity typically has null or inhibitory effects (e.g., Piercey and Joordens, 2000; Pexman et al., 2004; Hargreaves et al., 2011; Yap et al., 2011).
Recently, Hoffman et al. (2011) developed an objective strategy for quantifying the ambiguity of words’ meanings. On the assumption that words that appear in more diverse contexts have more varied meanings, Hoffman et al. (2013) devised the construct of SemD and provided values on this dimension for over 30,000 English words (Hoffman et al., 2013). Hoffman and Woollams (2015) showed that lexical decision responses were faster to high SemD words than to low SemD words and the effect was reversed, with faster responses to low SemD words than to high SemD words, in a semantic relatedness decision task. The assumption is that high SemD words generate noisy semantic representations. These noisy representations facilitate lexical decision responses. When the task requires more fine-grained semantic processing, however, as in semantic relatedness tasks, the noisy semantic representation for high SemD words must be resolved, slowing responses for those items.
Sensorimotor (Embodiment and Imageability)
There is now substantial evidence that processing action verbs activates sensory and motor regions of the brain (e.g., Hauk et al., 2004; Pulvermüller et al., 2005), suggesting that sensorimotor information is important to those words’ meanings. Of course, many verbs do not describe specific actions. In a recent study Sidhu et al. (2014) developed a semantic richness dimension called relative embodiment that could be applied to all verbs, not just those describing specific overt actions. Note that the term relative was used to emphasize that verb embodiment was being measured as a continuous variable, in contrast to studies which had characterized it dichotomously. For the present study, however, this dimension will simply be referred to as embodiment. Sidhu et al. (2014) collected embodiment ratings for a large set of verbs, and showed that lexical decision latencies were faster to high embodiment verbs (e.g., breathe) than to low embodiment verbs (e.g., resolve), even after a number of other lexical and semantic variables were controlled. In addition, action naming latencies (for picture stimuli) and syntactic classification latencies (is it a noun or verb?) were faster for high embodiment verbs. As such, Sidhu et al. (2014) concluded that embodiment is an important dimension of verb meaning.
Imageability refers to the ease with which a word evokes a sensory image. It is a dimension closely related to embodiment. Imageability ratings for verbs are available from norms collected by Chiarello et al. (1999) and Bird et al. (2001). Sidhu et al. (2014) found that for verb stimuli, imageability and embodiment were strongly correlated (at about r = 0.70), but that embodiment was a better predictor of lexical processing latencies. Imageability is also highly correlated with concreteness. Colombo and Burani (2002) examined concreteness effects for Italian verbs, but found no significant effect of concreteness on lexical decision latencies.
We examined the effects of these candidate semantic dimensions on lexical processing for verb stimuli under three different task conditions: lexical decision (LDT; Experiment 1), reading (Experiment 3a) and past-tense generation (Experiment 3b). If observed at all, semantic richness effects were expected to be facilitory in these tasks. We also expected differences across LDT and pronunciation tasks, since semantic effects are typically larger in LDT than in naming (Kuperman et al., 2014). Typically, semantic effects are relatively modest in word naming tasks (Balota et al., 2004) since the task does not require participants to identify the meaning of the word.
As mentioned, one of the ways that verb meanings are different from noun meanings is that verb meanings can be inflected for tense. Thus, to fully explore semantic richness effects in verbs, we thought it important to examine these effects beyond the present tense. In Experiments 2 and 3 we explored how verb meaning varies with present vs. past-tense inflection. This also involved an exploration of how semantic richness effects differ with verb regularity. While most verbs can be inflected with the addition of –ed, as in reach (reached), other verbs are exceptions to the rule, as in break (broke), say (said), etc. Most models of past tense generation assume that word knowledge plays a stronger role in past tense generation for irregular verbs than for regular verbs, although there are disagreements about whether this knowledge is lexical (e.g., Pinker and Ullman, 2002) or semantic (e.g., Joanisse and Seidenberg, 1999; Ramscar, 2002; Woollams et al., 2009). That is, the past tense form of irregular verbs is likely to be generated by accessing word-specific knowledge in lexical memory. In contrast, inflection of regular verbs requires less semantic involvement since regular verbs all follow the same rules or procedures for inflection.
Thus, as a strategy to further explore verb meaning, we compared embodiment ratings for regular and irregular verbs in present and past tense in Experiment 2. We selected this particular semantic dimension because previous research has shown that tense can modulate the extent of sensorimotor activation for action verbs. For instance, Candidi et al. (2010) reported stronger activation of hand muscles when reading hand-related action verbs in future tense vs. past tense. Similarly, studies have shown that as temporal distance increases, for instance, from the present into the past, representations become less concrete (for a review see Trope and Liberman, 2010). While the present implies direct experience, the past is necessarily distinct from direct experience. Thus, it seemed possible that embodiment ratings might be lower for verbs in past tense than in present tense.
Further, in Experiment 3 we included both a reading (pronunciation) and a past tense generation task, and examined potential interactions of semantic richness variables with verb regularity in these pronunciation tasks. While past tense generation latencies have not often been examined in healthy adult populations (cf. Butler et al., 2012; Cohen-Shikora et al., 2013), we saw the task as an opportunity to further explore verb meaning, particularly for irregular verbs. Since semantic processing is assumed to be more relevant to past tense generation for irregular verbs than regular verbs, it seemed possible that semantic richness effects might interact with regularity in that task. This would be consistent with a study by Butler et al. (2012), which found that the effects of imageability on past tense generation were moderated by verb regularity.
We considered it important to ensure that participants were processing the verb meanings of our stimuli. Many verbs also have noun meanings (e.g., play) and if the verbs were presented in a mixed list with noun stimuli, or were presented without cueing to interpret the word as a verb, the noun meanings might be prioritized. As such, in all experiments, participants were only presented with verb stimuli and were prompted to process the items as verbs. That is, in Experiment 1 the word “to” appeared in front of each letter string presented for lexical decisions, while in Experiments 2 and 3 participants were told that they would only be presented with verbs, and would be asked to rate (Experiment 2), read (Experiment 3a) or generate the past tense (Experiment 3b) for each verb.
In summary, we expected that if semantic richness effects are observed for verbs, those effects might not be large in tasks that depend primarily on lexical processing (LDT, Experiment 1; verb reading, Experiment 3a). Hence, we included tasks that require more extensive semantic processing, and where verb-specific factors like regularity and tense might be influential (ratings, Experiment 2; past tense generation, Experiment 3b), in order to gain additional insights about verb meaning.
Experiment 1
Method
This and subsequent studies were carried out in accordance with the University of Calgary Ethics Committee, with written informed consent from all subjects. All subjects gave written informed consent in accordance with the Declaration of Helsinki.
The LDT data obtained for Experiment 1 were from Sidhu et al. (2014; Experiment 1). That study, and each of the following experiments, were approved by the University of Calgary Conjoint Faculties Research Ethics Board. In the Sidhu et al. (2014) study, 30 undergraduate participants made LD responses to 400 verbs and 400 non-words. Each trial began with an asterisk, which then was replaced by a letter string after 1500 ms. Verbs were presented in their infinitive form (e.g., to leap), and non-words were also preceded by the word to. Sidhu et al. (2014) analyzed LDT latencies only for correct trials, and excluded trials on which latencies were more than 2.5 SD from a participant’s mean. In addition, eight verbs were excluded from the analyses due to high error rate, leaving a total of 392 verbs. These data were the starting point for the present analysis. For a small number of these items, however, values for valence, arousal, and dominance were not available in the Warriner et al. (2013) norms, and/or SemD values were not available from the Hoffman et al. (2013) norms. As such, the LDT analyses below include 369 verbs. Descriptive characteristics for this subset of the Sidhu et al. (2014) items are presented in Table 1.
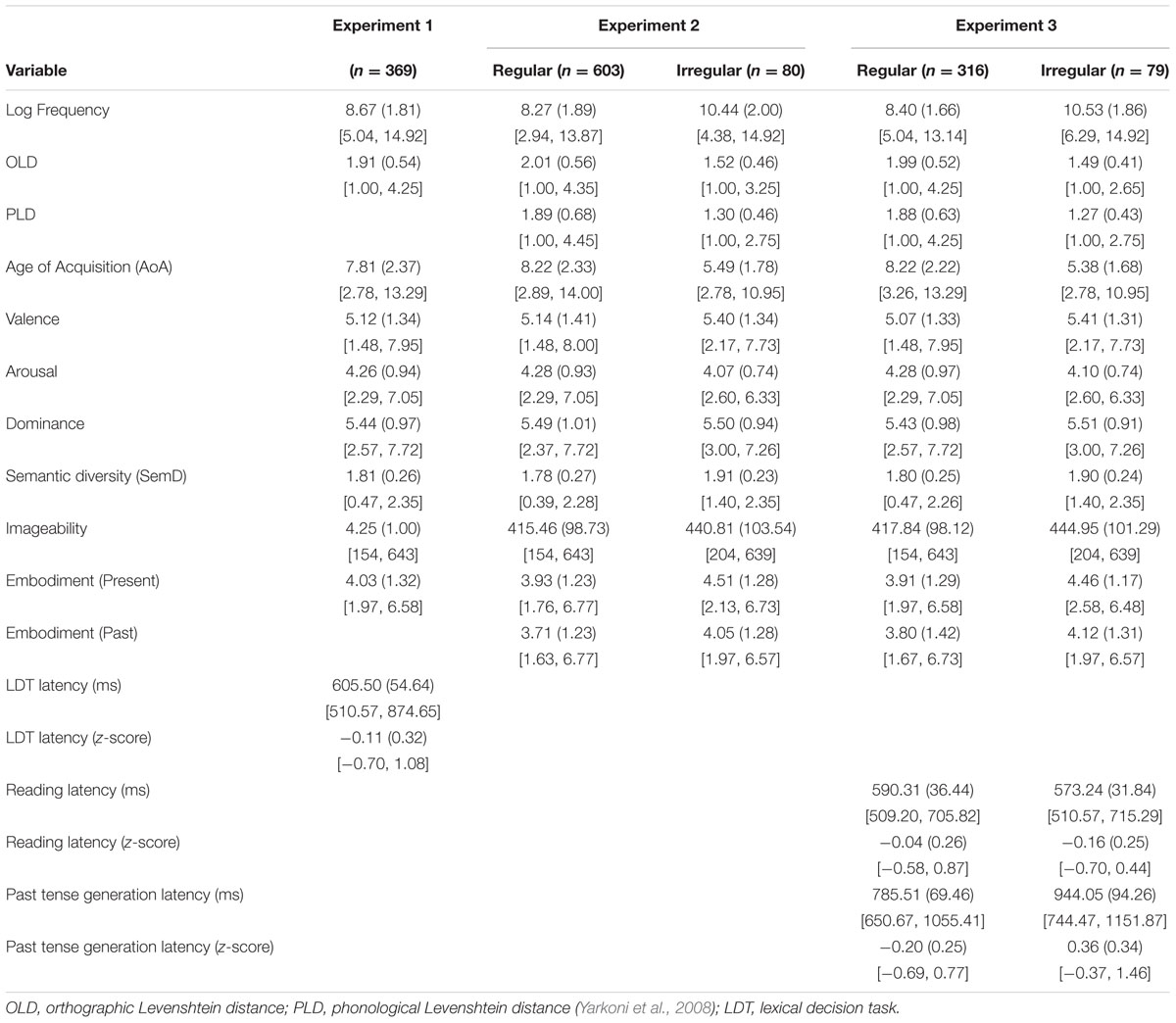
TABLE 1. Mean descriptive statistics (standard deviations in parentheses; minimum and maximum values below) for verb stimuli in Experiments 1 (LDT), 2 (Embodiment Ratings), and 3 (Reading and Past Tense Generation).
Results
The variables in the analysis were divided into two clusters: control variables and semantic variables. Control variables included the lexical variables that have been shown to be the most important predictors of LDT performance (Brysbaert et al., 2011): frequency (log transformed HAL word frequency, Lund and Burgess, 1996) and orthographic similarity (orthographic Levenshtein distance; OLD, Yarkoni et al., 2008). Semantic variables were AoA (Kuperman et al., 2012), valence, arousal, and dominance (Warriner et al., 2013), SemD (Hoffman et al., 2013), imageability (Chiarello et al., 1999; Bird et al., 2001) and embodiment (Sidhu et al., 2014). We also included regularity as a predictor in this latter cluster of variables.
Correlations between variables are presented in Table 2. The relationships between most of the richness variables were modest, suggesting that these dimensions capture somewhat different aspects of meaning. In contrast, the correlations between valence and dominance, and imageability and embodiment, were relatively high. To avoid multicollinearity we included valence (but not dominance) and embodiment (but not imageability) in the regression analyses presented below, as the previous literature suggested these were the more likely predictors of LDT latencies, and these variables had the higher raw correlations with LDT latencies (and also with the criterion variables in Experiment 3).1
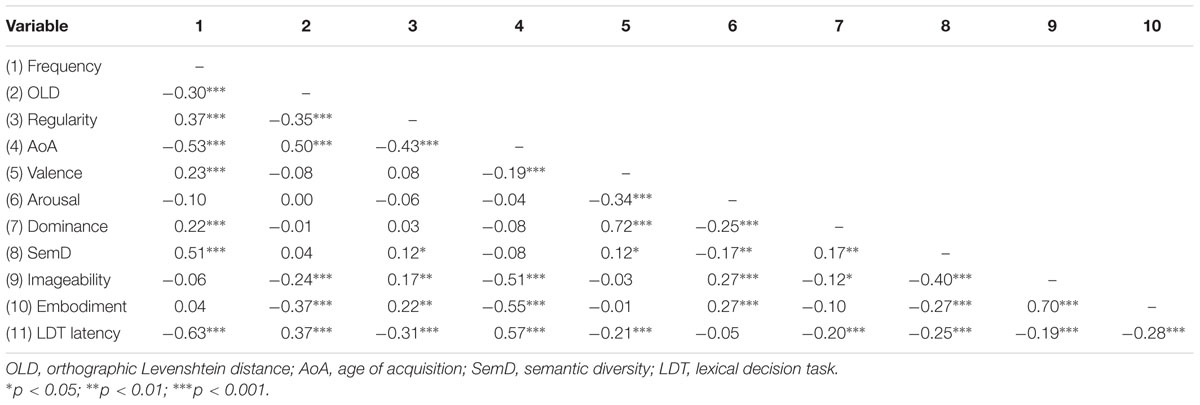
TABLE 2. Correlations between predictor variables and dependent measures in Experiment 1 (LDT).
While we predicted that valence would be linearly related to LDT latencies, we also wanted to evaluate the possibility that valence might have the inverted U-shaped relationship with LDT latencies (faster latencies for both positive and negative words than for neutral words) observed in some previous studies (e.g., Yap and Seow, 2014). As such, we also coded valence in terms of extremity (distance from scale mid-point, see also Adelman and Estes, 2013) but found that while the correlation between valence and LDT latencies was significant (r = -0.21, p < 0.001), the correlation between extremity and LDT latencies was not (r = -0.03, p = 0.61) and so we included valence and not extremity in our analyses.
LDT latencies were standardized as z-scores since these minimize the influence of a participant’s processing speed and variability (Faust et al., 1999). All predictor variables were centered. A hierarchical regression analysis was conducted on the standardized LDT latencies. Control variables were entered in step 1 and semantic variables in step 2, and the regression results are presented in Table 3. Results for the control variables showed the typical effects: word frequency and OLD were both significant predictors of LDT latencies for verbs, with faster latencies for more frequent and less orthographically distinct verbs. Together the semantic variables accounted for a small but significant amount of additional variability, and significant unique relationships with LDT latencies were observed for AoA, valence, arousal and embodiment. That is, LDT latencies were faster for verbs acquired earlier in life, and for verbs with more positive, arousing, and embodied meanings. The unique relationship between verb regularity and LDT latencies was not significant, likely because verbs were presented in present tense and no inflection was required for the response. The relationship between SemD and LDT latencies was also not significant. This finding is consistent with the results of Taikh et al. (2015) for noun stimuli, where SemD did not have a unique relationship to LDT latencies once other lexical and semantic variables were included in the analysis.
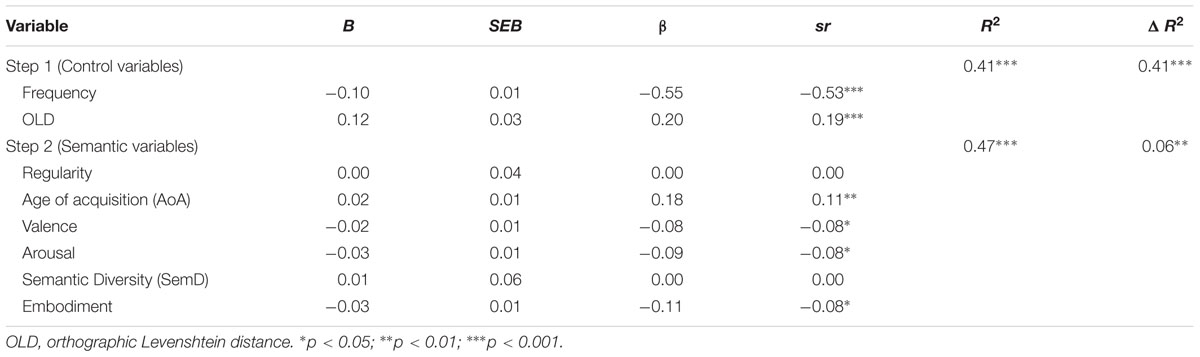
TABLE 3. Regression coefficients from item-level regression analyses for standardized LDT latencies, Experiment 1.
Thus, several semantic richness effects were observed in LDT, consistent with the notion that even when presented in isolation, verbs do generate measurable semantic feedback. These results suggest, further, that semantic representations for verbs are multidimensional (Kemmerer, 2015), and include episodic, emotional, and sensorimotor information. We next investigated two factors that could be important for verb meaning and could modulate richness effects: tense and regularity. We did so in a ratings task that encouraged participants to consider word meanings more specifically.
Experiment 2
The purpose of Experiment 2 was to explore effects of tense and regularity on verb meaning. We examined these effects on a dimension of meaning that might be expected to vary as a function of tense: embodiment. That is, the present tense implies direct experience, which may lead to higher embodiment ratings than for the same verbs presented in past tense.
Method
Participants
Participants in Experiment 2 were 120 undergraduate students at the University of Calgary who participated for bonus credit in a Psychology course. All participants had normal or corrected-to-normal vision, and reported English proficiency.
Stimuli and Procedure
The stimuli for Experiment 2 were the 687 verbs from the Sidhu et al. (2014) embodiment ratings. These were divided into four lists. Each participant was presented with the items from two of the four lists, with one list presented in present tense and the other presented in past tense. Present and past tense verbs were randomly intermixed for each participant and presented for ratings. Ratings instructions were the same as those used in Sidhu et al. (2014), and are presented in the current Appendix A.
Verbs were presented for ratings in an on-line study using the survey tool Survey Monkey2. Participants were asked to rate each verb for relative embodiment using a 1–7 scale, and made their selection via mouse click.
The data for one participant who used only two points on the rating scale were not included in the analysis. In addition, the ratings data for four of the verbs were not usable: ratings for found were not analyzed because this word takes the same form as the past tense of find, which was also included in the survey, and the past tense versions of three other verbs were misspelled in the ratings task so the resulting ratings were not analyzed. The descriptive characteristics of the remaining 683 items are presented in Table 1. The correlation between present and past tense ratings for these 683 items was r = 0.92, which is consistent with Warriner et al.’s (2013) assumption that ratings for base form meaning would be very similar to ratings for inflected form meaning. The correlation between the present tense ratings collected here and the original Sidhu et al. (2014) present tense ratings was also r = 0.92, suggesting reasonable reliability.
We then examined the embodiment ratings with a 2 (tense: present, past) × 2 (regularity: regular, irregular) ANOVA. Results showed a significant interaction between tense and regularity [F(1,681) = 15.13, MSE = 0.12, p < 0.001, η2= 0.02], such that embodiment ratings were higher for present tense irregular verbs (M = 4.52, SD = 1.28) than for past tense irregular verbs (M = 4.06, SD = 1.28), and this tense difference was attenuated for present tense regular verbs (M = 3.93, SD = 1.23) and past tense regular verbs (M = 3.71, SD = 1.23). The main effects of tense [F(1,681) = 131.76, MSE = 0.12, p < 0.001, η2= 0.16], and regularity [F(1,681) = 10.47, MSE = 2.95, p = 0.001, η2= 0.01], were also significant. Thus, consistent with predictions, embodiment ratings tended to be lower for verbs presented in past tense. This difference was more pronounced for irregular verbs.
The descriptive statistics presented in Table 1 show, however, that frequency (log transformed HAL word frequency, Lund and Burgess, 1996) was significantly higher for irregular verbs (M = 10.44, SD = 2.00) than for regular verbs [M = 8.27, SD = 1.89; t(681) = 9.60, p < 0.001]. We conducted a supplementary analysis to investigate whether this might have contributed to the effects of tense and regularity observed in the embodiment ratings. We examined embodiment ratings with a 2 (tense: present, past) × 2 (regularity: regular, irregular) ANCOVA, including verb frequency as a covariate. Results indicated that frequency was not significantly related to embodiment [F(1,680) = 3.21, p = 0.07], and that the interaction of tense and regularity [F(1,680) = 7.65, MSE = 0.12, p = 0.006, η2= 0.01] and main effect of regularity [F(1,680) = 13.40, MSE = 2.94, p < 0.001, η2= 0.02] were still significant. The main effect of tense, however, was not significant [F(1,680) = 0.97, p = 0.32], These results suggest that differences in frequency may explain some of the effects of tense on embodiment.
We next investigated semantic richness effects for verbs under different task demands. In Experiment 3a we used a verb reading (pronunciation) task and in Experiment 3b we used a past-tense generation task. We increased the number of irregular verbs included in the stimulus list that had been presented in Experiment 1 and, in both Experiments 3a and 3b, tested for interactions of regularity with the semantic richness variables. We expected that interactions with regularity would be most likely in Experiment 3b since in the past-tense generation task semantic processing was expected to be relatively more extensive for irregular verbs.
Experiment 3a
Method
Participants
Participants in Experiment 3a were 30 undergraduate students at the University of Calgary who participated for bonus credit in a Psychology course. All participants had normal or corrected-to-normal vision, and reported English proficiency.
Stimuli and Procedure
The stimuli for Experiment 3a were the same as described for Experiment 1, plus an additional 22 irregular verbs that had not been presented in Experiment 1. This exhausted the pool of irregular verbs from the original Sidhu et al. (2014) ratings. In total, 422 verb stimuli were presented in Experiment 3a.
Participants were seated in front of a computer, and on each trial a verb was presented on the screen in present tense. Participants were asked to simply say the verb out loud as quickly and as accurately as they could. Stimuli were presented to each participant in a different random order. Reading latencies were detected via a microphone connected to a voice key. Reading responses were also recorded for later coding of response errors.
Results
Pronunciation latencies were excluded from analyses for trials on which participants failed to trigger the voice key (1.42% of trials), stuttered (0.26% of trials), or mispronounced the target (1.76% of trials). We also excluded reading latencies faster than 200 ms (0.36% of trials), slower than 3000 ms (0.77% of trials), or greater than 2.5 SD from the participant’s mean (2.56% of trials). There were too few genuine mispronunciation errors to warrant analysis, so only the latency data were analyzed.
We had a complete set of predictors for 395 items. The descriptive characteristics for these items are presented in Table 1. As in Experiment 1, we first examined correlations between variables (Table 4) and then used hierarchical linear regression analyses to examine the influence of the semantic richness variables on reading latencies (Table 5). All predictor variables were centered and correct reading latencies were standardized. Since the task involved vocal responses, on step 1 of the regression analysis we included a set of variables that code for item differences in initial phoneme onsets. Dichotomous variables were used to code the initial phoneme of each word (1 = presence of a feature; 0 = absence of a feature) on 13 features: affricative, alveolar, bilabial, dental, fricative, glottal, labiodental, liquid, nasal, palatal, stop, velar, and voiced (Balota et al., 2004). On step 2 we included the key lexical variables: log transformed HAL word frequency (Lund and Burgess, 1996) and phonological Levenshtein distance (PLD, Yarkoni et al., 2008). We used PLD here (instead of OLD, which was included in Experiment 1) because, while OLD and PLD tend to be highly correlated, phonological neighborhoods tend to be more important to pronunciation tasks. We also included phonological consistency (Ziegler et al., 1997) as this also tends to predict responses in pronunciation tasks. On step 3 we included the same semantic variables as in Experiment 1, but here we added terms for regularity (1 = irregular; 0 = regular) and the interactions of the semantic richness variables with regularity.
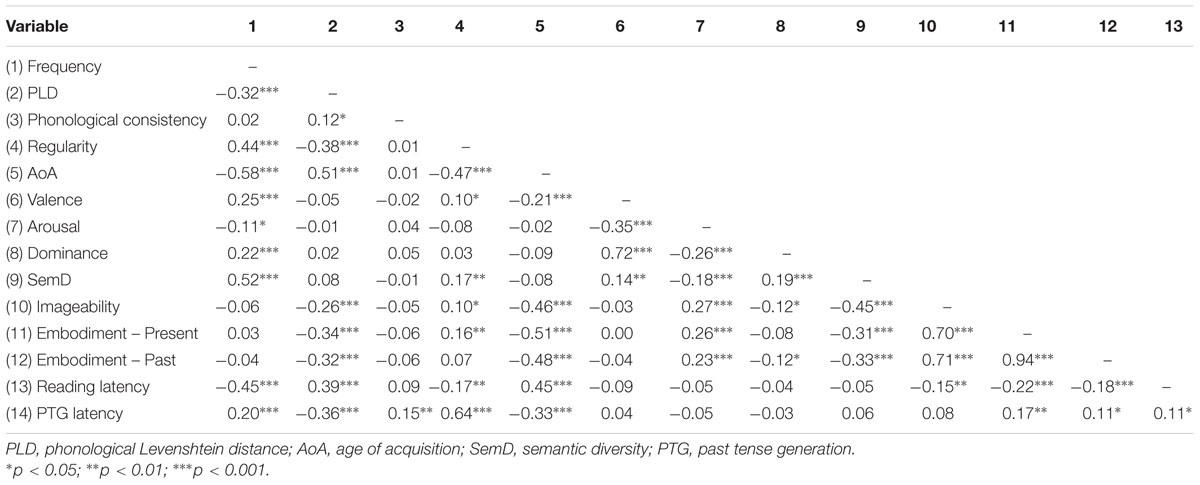
TABLE 4. Correlations between predictor variables and dependent measures in Experiment 3a and 3b (Reading and Past Tense Generation).
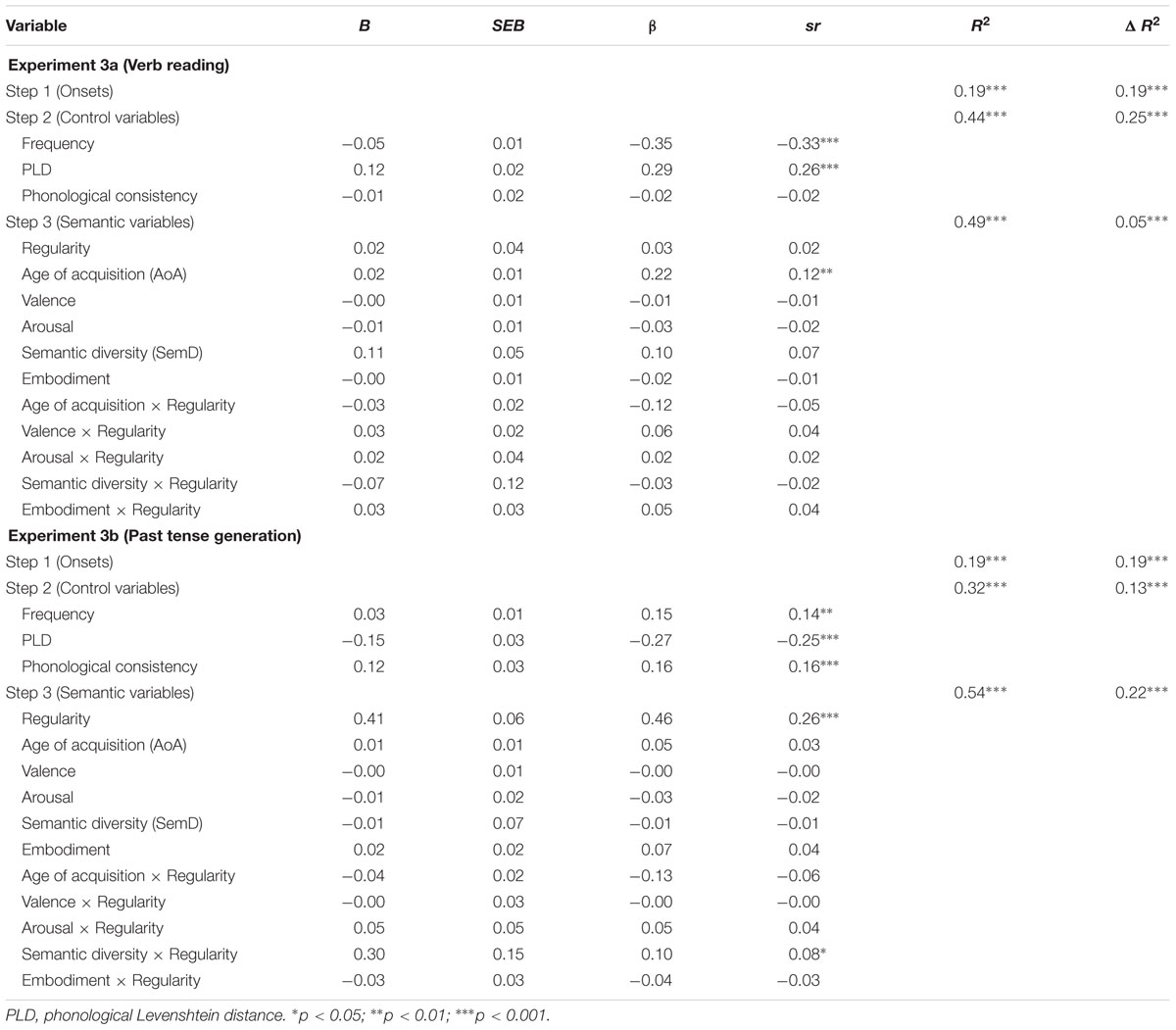
TABLE 5. Regression coefficients from item-level regression analyses for standardized reading and past tense generation latencies, Experiments 3a and 3b.
The regression analysis showed that the onsets and control variables explained a substantial amount of variance in verb reading latencies. Responses were faster for more frequent verbs and less phonologically distinct verbs. A small but significant amount of variance was explained by the semantic variables. Although several of the semantic richness variables had significant relationships with reading latencies in the raw correlations, only AoA was significant once the control variables were entered in the regression analysis. That is, reading latencies were faster for verbs acquired earlier in life. While the AoA effect in pronunciation has been demonstrated in several previous studies (e.g., Morrison and Ellis, 1995), to our knowledge this is the first time it has been demonstrated specifically for verbs.
The regression analyses also showed that regularity was not significantly related to reading latencies, and none of the terms for interactions of semantic richness variables with regularity were significant. Our expectation, however, was that these predictors might be significantly related to past tense generation latencies, in Experiment 3b.
Experiment 3b
Method
Participants
Participants in Experiment 3b were 30 undergraduate students at the University of Calgary who participated for bonus credit in a Psychology course. All participants had normal or corrected-to-normal vision, and reported English proficiency.
Stimuli and Procedure
The stimuli and procedure for Experiment 3b were the same as described for Experiment 3a except that in this task participants were asked to pronounce the past tense form of each verb presented, as quickly and as accurately as possible.
Results
Past tense generation latencies were excluded from analyses for trials on which participants failed to trigger the voice key (1.82% of trials), stuttered (0.23% of trials), or mispronounced the target (3.30% of trials). In addition, participants occasionally produced a regularized past tense version of irregular verbs; these comprised an additional 1.69% of trials (8.58% of irregular trials) and were also excluded from latency analyses. We further excluded latencies faster than 200 ms (0.35% of trials), slower than 3000 ms (2.53% of trials), or greater than 2.5 SD from the participant’s mean (2.87% of trials). As in Experiment 3a, there were too few mispronunciation errors to warrant analysis, so only the latency data were analyzed.
The raw correlation results in Table 4 showed that the various predictors tended to have opposite relationships with latencies in the verb reading (Experiment 3a) and past tense generation (Experiment 3b) tasks. The variables that were facilitory for verb reading tended to be inhibitory for past tense generation, and vice versa: for instance, in raw correlations, frequency, regularity, and embodiment were all facilitory for verb reading but inhibitory for past tense generation. Latencies for the two tasks were only modestly related. These results suggest that very different processes are at work in the two tasks.
We again used hierarchical linear regression analyses (Table 5), here to examine the influence of the semantic richness variables on past tense generation latencies. The predictors were the same as those used in Experiment 3a. As mentioned, the raw correlation between present and past tense embodiment ratings was high. We opted to use present tense embodiment ratings in the regression analysis as this embodiment variable had higher raw correlations with past tense generation performance than did the past tense embodiment ratings. The regression results showed that phonological consistency was a significant predictor of past tense generation latencies, with slower past tense generation latencies for phonologically inconsistent verbs. This is presumably because competition from a verb’s consistent body neighbors delays activation of the phonological code.
In the regression analyses, regularity had a strong positive relationship with past tense generation latencies. The nature of the regularity effect was that past tense generation latencies were much faster for regular verbs (M = 785.51, SD = 69.46) than for irregular verbs (M = 944.05, SD = 94.26). This is consistent with the results of previous past-tense generation studies (Woollams et al., 2009; Cohen-Shikora and Balota, 2013), and suggests that past tense generation for irregular verbs involves additional processing that is not necessary for past tense generation of regular verbs. Other aspects of our results suggest that the additional processing for irregular verbs likely involves semantic processing. That is, the semantic variable that had a significant unique relationship with past-tense generation latencies in the regression analysis was the interaction of SemD and regularity. The nature of the interaction between SemD and regularity was explored with separate correlation analyses for regular and irregular verbs (Table 6). These showed that the relationship between SemD and past-tense generation latencies was negative for regular verbs and positive for irregular verbs. Thus, for regular verbs past tense generation latencies were facilitated by SemD, while for irregular verbs past tense generation latencies were inhibited by SemD. We give this finding fuller consideration in Section “General Discussion.”
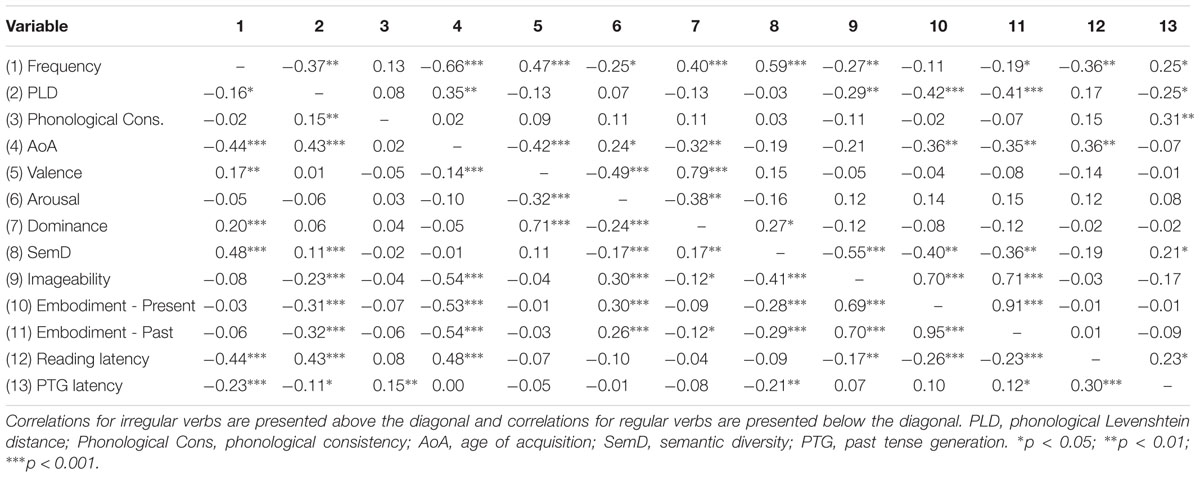
TABLE 6. Correlations between predictor variables and dependent measures in Experiment 3a and 3b (Reading and Past Tense Generation).
The correlation results presented in Table 6 provide more insight about the inhibitory effect of frequency found on the second step of the regression analysis. That is, for regular verbs the relationship between frequency and past-tense generation latencies was in the typical facilitory direction, while for irregular words there was an inhibitory relationship between frequency and past-tense generation latencies. That is, past-tense generation latencies were slower for more frequent irregular verbs, and this seemed to drive the overall results in the main regression analysis. A similar inhibitory effect of frequency for past tense generation latencies for Dutch verbs was reported by Tabak et al. (2005). One explanation is that in the past tense generation task, because the verb is presented in present form (e.g., bring), participants automatically generate the phonology of the present tense form, which produces response conflict with the inflected form (brought; Woollams et al., 2009). The response conflict is greater for irregular verbs, where the phonology of present and past tense forms are more distinct, and is also greater for more frequent verbs, for which the phonology of the present tense form is generated more readily. Thus, past tense generation responses are slower for more frequent verbs. These findings suggest that in the past tense generation task, response conflict between what is presented and what must be produced drives some of the effects observed.
General Discussion
The purpose of the present study was to investigate semantic richness effects for verb stimuli in order to test several candidate dimensions of verb meaning. We presented only verb stimuli and encouraged participants to treat the stimuli as verbs. Although there has been some suggestion that verbs presented in isolation will generate relatively little semantic feedback (Cordier et al., 2013), we found significant semantic richness effects in LDT for dimensions that tap several different aspects of verb meaning: AoA, valence, arousal, and embodiment. Under different task demands, we found that only AoA was related to verb reading and that SemD tended to be facilitory for regular verbs but inhibitory for irregular verbs in a past-tense generation task. As such, our results are consistent with assertions that verb meaning is multidimensional and flexible (Desai et al., 2015; Kemmerer, 2015). Our findings suggest that dimensions of verb meaning include episodic, emotional, and sensorimotor information, and the influence of these and other unexplored factors will depend on the context in which verb meaning is processed.
We observed facilitory frequency effects and inhibitory AoA effects in LDT and in verb reading but not in past tense generation. This confirms that these are the tasks where lexical processes dominate. Additionally, the fact that AoA effects were observed in these tasks provides insight about the locus of AoA effects. That is, AoA effects were observed in lexical tasks that involve several components: orthographic, phonological (particularly in verb reading) and semantic (particularly in LDT) processing. This is consistent with the claim that there is a broad basis for AoA effects. That is, processing is facilitated for early acquired words because these have a stronger influence on system structure than do later-acquired words.
Our results are also consistent with previous studies (e.g., Balota et al., 2004) in showing that semantic variables explained more variance in lexical decision than in pronunciation tasks. The past-tense generation task, however, presented an opportunity to examine somewhat more extensive semantic processing than is involved in most pronunciation tasks, and to explore a central distinction for verb stimuli, by examining latencies for regular and irregular verbs. As mentioned, research with nouns suggests that ambiguity tends to function differently than other semantic richness effects. Most richness dimensions are facilitory in both lexical and semantic tasks (Pexman et al., 2014). In contrast, the effects of variables like SemD that capture ambiguity are typically facilitory in LDT, but null or inhibitory in semantic tasks (e.g., Hargreaves et al., 2011; Yap et al., 2011, 2012; Hoffman and Woollams, 2015). The explanation for these task differences has been that ambiguous words generate a noisy semantic code that facilitates LDT (e.g., Hino and Lupker, 1996). In contrast, in semantic tasks the noisy code must be resolved to some degree in order to respond, and this takes time, often delaying responses to ambiguous words (e.g., Hoffman and Woollams, 2015).
While these dissociations between ambiguity effects (for SemD and other ambiguity metrics) have been observed across tasks for nouns in previous research, here we observed the dissociation for verbs within a single task. Our assumption is that in the past-tense generation task, responses to irregular verbs require more extensive semantic processing than do responses to regular verbs (Butler et al., 2012). The semantic processing involved in generating the past tense of irregular verbs is slowed by high SemD. Thus, while high SemD tends to be an advantage for generating the past-test forms of regular verbs, it is a disadvantage for irregular verbs.
In a recent megastudy, Cohen-Shikora et al. (2013) examined the effect of imageability on past tense generation latencies for a larger set of verb stimuli (2200 items), only some of which overlap with the present, smaller set of items.3 They found that imageability was a significant predictor of past tense generation latencies, after onsets, frequency, and orthographic characteristics had been controlled. In their analysis, Cohen-Shikora et al. (2013) did not examine other semantic variables and, importantly, did not examine interactions with regularity. In contrast, Butler et al. (2012) did test the interaction of imageability and regularity in past tense generation and found that imageability effects were significantly larger for irregular verbs than for regular verbs. Further, Butler et al. (2012) found that semantic priming influenced past tense generation latencies for irregular verbs but not for regular verbs. The results of both of these previous studies are consistent with our inference that semantic richness effects can be observed for verb stimuli. Further, it has been argued that the particular pattern of semantic effects observed in past tense generation tasks will depend on factors such as list context (Cohen-Shikora and Balota, 2013), and other aspects of task demands (Woollams et al., 2009). Our findings, and the differences between our findings and those of previous studies, can be taken as support for this inference.
In Experiment 2, in addition to regularity, we explored another distinction that is only relevant to verb meaning; we manipulated verb tense and examined effects on ratings of embodiment. We found that embodiment ratings were modulated by an interaction of tense and regularity: ratings tended to be lower for irregular verbs presented in past tense than in present tense, suggesting that tense is relevant to verb meanings, even those derived in simple ratings studies. When making embodiment ratings, participants are asked to judge how easily the human body is involved in the action, state, or relation referenced by the verb. Thus, they consider the extent to which the human body is involved in the verb’s meaning. Our results suggest that they consider the body to be more easily involved in sit than in sat. If this is true, one prediction for future research would be that if verbs were presented in the past tense in LDT, lexical decision latencies would not be affected by embodiment to the same extent as they were in the present Experiment 1, where verbs were presented in present tense.
An important caveat is that differences in frequency seem to contribute to the effects of tense on embodiment. These patterns should be explored more fully in future research. To the extent that verbs do differ in embodiment in their present and past tense forms, this would be consistent with studies on temporal construal level, which have found that the farther away an event is temporally, the more likely it is to be represented in terms of its abstract features (Trope and Liberman, 2003). These abstract, high-level construals include general features capturing the essence of the event, but omit concrete and incidental details. Thus, when imagining the extent to which the body is involved in an event taking place in the past, sensorimotor features may be less pronounced, leading to lower ratings. Indeed Trope and Liberman (2010) theorized that as the distance to event increases, that event’s representation will include less multimodal simulation, and more amodal symbolic representation.
An interesting potential to emerge from Experiment 2 was that the difference between embodiment ratings for verbs in the present and past tense tended to be observed for irregular as compared to regular verbs. One explanation might be that the transparent morphology of the regular past tense verbs made the verb stem (the present tense form) more salient, attenuating the effect of temporal distance on embodiment ratings. Another explanation could be based in the frequency difference for regular and irregular verbs: irregular verbs tended to be more common (as measured in their present tense form, though this also holds true when in their past tense form), and this familiarity may have prompted more vivid simulations for irregular verbs. These more vivid simulations could produce the higher relative embodiment ratings we observed for irregular verbs in general, and could also have been more strongly affected by the effects of temporal distance. Clearly this is a question that requires further research to fully explore.
In the present study, there were several differences observed between regular and irregular verbs. Our understanding of some of these can be informed by previous research. For instance, research has demonstrated that the more frequently an irregular verb is used, the more resistant it is to regularization (i.e., adopting a regular -ed ending; Lieberman et al., 2007). This helps clarify why irregular verbs had higher mean frequency than regular verbs in our sample – these are the irregular verbs that have survived regularization by virtue of their frequent use. Other differences are more difficult to explain, such as the higher valence and embodiment of irregular verbs. It might be informative to examine differences in the historical origins of regular and irregular verbs. Many irregular verbs can be traced back to a system of conjugation in Old English in which “strong” verbs were conjugated by way of a stem vowel change (e.g., grinde to grand, the ancestor of grind/ground; Lieberman et al., 2007). This was contrasted with “weak” verbs, which took on variants of the suffixes –t or -d, the origin of Modern English’s regular past tense inflection (Hare and Elman, 1995). Interestingly there were some differences in which kinds of verbs belonged to either system. Verbs created out of nouns or adjectives tended to take on the “weak” verb inflection, as did verbs adopted from other languages; conversely many “strong” verbs can be traced back to Proto-Germanic. Of course in the intervening millennia many verbs have shifted from one type of inflection to another, and it is certainly true that not all irregular verbs followed the “strong” pattern of inflection. Nevertheless future research might examine if these historical factors contributed to some of the differences observed in this study.
Certainly, there are limitations to the present study. Our analyses were focused on dimensions that seemed to be likely candidates for verb meaning and for which we had values for a reasonable number of verbs, in order to facilitate item-wise regressions. We also limited our investigation to semantic dimensions that could theoretically apply to all verbs. We did examine effects of verb regularity and tense, but there are other distinctions one can draw between types of verbs. As such, there are other dimensions and distinctions that should be examined in future studies (see, e.g., Gennari and Poeppel, 2003, for discussion of other distinctions and dimensions that may be important for verbs).
We treated regularity as a binary category in the present study, as a convenient way to explore potential differences in semantic richness effects. This is certainly not the only possible approach to coding the quasi-regularities involved in English past tense inflection (e.g., Woollams et al., 2009), but the results provide insight about differences in semantic richness effects for regular and irregular verbs. As mentioned, there is considerable debate about past tense inflection of regular and irregular verbs (e.g., Pinker and Ullman, 2002; Joanisse and Seidenberg, 2005), and our results do speak to that theoretical issue. That is, while some models of past tense inflection (e.g., Pinker and Ullman, 2002) suggest that lexical knowledge is the main driver of past tense generation, our results suggest, instead, that semantic knowledge is important when generating the past tense for irregular verbs. Thus, our findings are more consistent with models that suggest semantic knowledge is the more influential factor in explaining irregular past tense inflection (e.g., Joanisse and Seidenberg, 1999; Woollams et al., 2009).
Conclusion
The present results provide evidence that the semantic richness approach can be extended beyond nouns, and that much can be learned about verb meaning by examining the effects of semantic richness variables, even when verbs are presented in isolation. While certain factors particular to verbs such as tense and regularity may make this somewhat more complicated, they may also provide fruitful avenues for future research. Our findings suggest that verb meaning is multidimensional, and that the effects of different aspects of verb meaning will depend on task demands.
Author Contributions
DS designed and ran all experiments and collaborated on manuscript writing. AH analyzed some of the data and collaborated on study design and manuscript writing. PP collaborated on study design, data analysis, and manuscript writing.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by the Natural Sciences and Engineering Research Council (NSERC) of Canada, through a Postgraduate Scholarship to DS and a Discovery Grant to PP (217309-2013).
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fpsyg.2016.00798
Footnotes
- ^ We ran the same regression analysis, but included dominance instead of valence; the relationship between dominance and LDT latencies was significant, sr = -0.10, p < 0.01. We also ran the same regression analysis, but included imageability instead of embodiment; the relationship between imageability and LDT latencies was not significant, sr = -0.04, p = 0.35.
- ^ www.surveymonkey.com
- ^ Of the 422 verbs used in the present study, 238 were also included in Cohen-Shikora et al.’s (2013) Past Tense Inflection Project (PTIP). For these items, the correlation between past tense generation latencies across the two data sets was strong, r(238) = 0.80, p < 0.001.
References
Adelman, J. S., and Estes, Z. (2013). Emotion and memory: a recognition advantage for positive and negative words independent of arousal. Cognition 129, 530–535. doi: 10.1016/j.cognition.2013.08.014
Allport, D. A., and Funnell, E. (1981). Components of the mental lexicon. Philos. Trans. R. Soc. Lond. B 295, 397–410. doi: 10.1098/rstb.1981.0148
Balota, D. A., Cortese, M. J., Sergent-Marshall, S., Spieler, D. H., and Yap, M. J. (2004). Visual word recognition of single-syllable words. J. Exp. Psychol. Gen. 133, 336–345.
Barsalou, L. W., Santos, A., Simmons, W. K., and Wilson, C. D. (2008). “Language and simulation in conceptual processing,” in Symbols, Embodiment, and Meaning, eds M. De Vega, A. M. Glenberg, and A. C. Graesser (Oxford: Oxford University Press), 245–283.
Binder, J. R., and Desai, R. H. (2011). The neurobiology of semantic memory. Trends Cogn. Sci. 15, 527–536. doi: 10.1016/j.tics.2011.10.001
Bird, H., Franklin, S., and Howard, D. (2001). Age of acquisition and imageability ratings for a large set of words, including verbs and function words. Behav. Res. Methods Instrum. Comput. 33, 73–79. doi: 10.3758/BF03195349
Borowsky, R., and Masson, M. E. J. (1996). Semantic ambiguity effects in word identification. J. Exp. Psychol. Learn. Mem. Cogn. 22, 63–85.
Boulenger, V., Décoppet, N., Roy, A. C., Paulignan, Y., and Nazir, T. A. (2007). Differential effects of age-of-acquisition for concrete nouns and action verbs: evidence for partly distinct representations? Cognition 103, 131–146. doi: 10.1016/j.cognition.2006.03.001
Brysbaert, M., Buchmeier, M., Conrad, M., Jacobs, A. M., Bölte, J., and Böhl, A. (2011). The word frequency effect: a review of recent developments and implications for the choice of frequency estimates in German. Exp. Psychol. 58, 412–424. doi: 10.1027/1618-3169/a000123
Butler, R., Patterson, K., and Woollams, A. M. (2012). In search of meaning: semantic effects on past-tense inflection. Q. J. Exp. Psychol. 65, 1633–1656. doi: 10.1080/17470218.2012.661441
Candidi, M., Leone-Fernandez, B., Barber, H. A., Carreiras, M., and Aglioti, S. M. (2010). Hands on the future: facilitation of cortico-spinal hand-representation when reading the future tense of hand-related action verbs. Eur. J. Neurosci. 32, 677–683. doi: 10.1111/j.1460-9568.2010.07305.x
Chiarello, C., Shears, C., and Lund, K. (1999). Imageability and distributional typicality measures of nouns and verbs in contemporary English. Behav. Res. Methods Instrum. Comput. 31, 603–637. doi: 10.3758/BF03200739
Cohen-Shikora, E. R., and Balota, D. A. (2013). Past tense route priming. Cognition 126, 397–404. doi: 10.1016/j.cognition.2012.11.009
Cohen-Shikora, E. R., Balota, D. A., Kapuria, A., and Yap, M. J. (2013). The past tense inflection project (PTIP): speeded past tense inflections, imageability ratings, and past tense consistency measures for 2,200 verbs. Behav. Res. Methods 45, 151–159. doi: 10.3758/s13428-012-0240-y
Colombo, L., and Burani, C. (2002). The influence of age of acquisition, root frequency, and context availability in processing nouns and verbs. Brain Lang. 81, 398–411. doi: 10.1006/brln.2001.2533
Cordier, F., Croizet, J.-C., and Rigalleau, F. (2013). Comparing nouns and verbs in a lexical task. J. Psycholinguist. Res. 42, 21–35. doi: 10.1007/s10936-012-9202-x
Cortese, M. J., and Fugett, A. (2004). Imageability ratings for 3,000 monosyllabic words. Behav. Res. Methods Instrum. Comput. 36, 384–387. doi: 10.3758/BF03195585
Cortese, M. J., and Schock, J. (2013). Imageability and age of acquisition effects in dysyllabic word recognition. Q. J. Exp. Psychol. 66, 946–972. doi: 10.1080/17470218.2012.722660
Desai, R. H., Herter, T., Riccardi, N., Rorden, C., and Fridriksson, J. (2015). Concepts within reach: action performance predicts action language processing in stroke. Neuropsychologia 71, 217–224. doi: 10.1016/j.neuropsychologia.2015.04.006
Dove, G. O. (2009). Beyond perceptual symbols: a call for representational pluralism. Cognition 110, 412–431. doi: 10.1016/j.cognition.2008.11.016
Ellis, A. W., and Lambon Ralph, M. A. (2000). Age of acquisition effects in adult lexical processing reflect loss of plasticity in maturing systems: insights from connectionist networks. J. Exp. Psychol. Learn. Mem. Cogn. 26, 1103–1123.
Faust, M. E., Balota, D. A., Spieler, D. H., and Ferraro, F. R. (1999). Individual differences in information-processing rate and amount: implications for group differences in response latency. Psychol. Bull. 125, 777–799. doi: 10.1037/0033-2909.125.6.777
Gennari, S., and Poeppel, D. (2003). Processing correlates of lexical semantic complexity. Cognition 89, B27–B41. doi: 10.1016/S0010-0277(03)00069-6
Ghyselinck, M., Lewis, M. B., and Brysbaert, M. (2004). Age of acquisition and the cumulative-frequency hypothesis: a review of the literature and a new multi-task investigation. Acta Psychol. 115, 43–67. doi: 10.1016/j.actpsy.2003.11.002
Hare, M., and Elman, J. L. (1995). Learning and morphological change. Cognition 56, 61–98. doi: 10.1016/0010-0277(94)00655-5
Hargreaves, I. S., Pexman, P. M., Pittman, D. J., and Goodyear, B. G. (2011). Tolerating ambiguity: ambiguous words recruit the left inferior frontal gyrus in absence of a behavioral effect. Exp. Psychol. 58, 19–30. doi: 10.1027/1618-3169/a000062
Hauk, O., Johnsrude, I., and Pulvermuller, F. (2004). Somatotopic representation of action words in human motor and premotor cortex. Neuron 41, 301–307. doi: 10.1016/S0896-6273(03)00838-9
Hino, Y., and Lupker, S. J. (1996). Effects of polysemy in lexical decision and naming: an alternative to lexical access accounts. J. Exp. Psychol. Hum. Percept. Perform. 22, 1331–1356.
Hoffman, P., Lambon Ralph, M. A., and Rogers, T. T. (2013). Semantic diversity: a measure of semantic ambiguity based on variability in the contextual usage of words. Behav. Res. Methods 45, 718–730. doi: 10.3758/s13428-012-0278-x
Hoffman, P., Rogers, T. T., and Lambon Ralph, M. A. (2011). Semantic diversity accounts for the “missing” word frequency effect in stroke aphasia: insights using a novel method to quantify contextual variability in meaning. J. Cogn. Neurosci. 23, 2432–2446. doi: 10.1162/jocn.2011.21614
Hoffman, P., and Woollams, A. M. (2015). Opposing effects of semantic diversity in lexical and semantic relatedness decisions. J. Exp. Psychol. Hum. Percept. Perform. 41, 385–402. doi: 10.1037/a0038995
Jastrzembski, J., and Stanners, R. (1975). Multiple word meanings and lexical search speed. J. Verbal Learn. Verbal Behav. 12, 534–537. doi: 10.1016/S0022-5371(75)80030-2
Joanisse, M., and Seidenberg, M. S. (1999). Impairments in verb morphology after brain injury: a connectionist model. Proc. Natl. Acad. Sci. U.S.A. 96, 7592–7597. doi: 10.1073/pnas.96.13.7592
Joanisse, M. F., and Seidenberg, M. S. (2005). Imaging the past: neural activation in frontal and temporal regions during regular and irregular past-tense processing. Cogn. Affect. Behav. Neurosci. 5, 282–296. doi: 10.3758/CABN.5.3.282
Johnston, R. A., and Barry, C. (2006). Age of acquisition and lexical processing. Vis. Cogn. 13, 789–845. doi: 10.1080/13506280544000066
Jones, G. V. (1985). Deep dyslexia, imageability, and ease of predication. Brain Lang. 24, 1–19. doi: 10.1016/0093-934X(85)90094-X
Juhasz, B. J. (2005). Age-of-acquisition effects in word and picture identification. Psychol. Bull. 131, 684–712. doi: 10.1037/0033-2909.131.5.684
Kemmerer, D. (2015). Are the motor features of verb meanings represented in the precentral motor cortices? Yes, but within the context of a flexible, multilevel architecture for conceptual knowledge. Psychon. Bull. Rev. 22, 1068–1075. doi: 10.3758/s13423-014-0784-1
Kousta, S.-T., Vigliocco, G., Vinson, D. P., Andrews, M., and Del Campo, E. (2011). The representation of abstract words: why emotion matters. J. Exp. Psychol. Gen. 140, 14–34. doi: 10.1037/a0021446
Kousta, S.-T., Vinson, D. P., and Vigliocco, G. (2009). Emotion words, regardless of polarity, have a processing advantage over neutral words. Cognition 112, 473–481. doi: 10.1016/j.cognition.2009.06.007
Kuperman, V., Estes, Z., Brysbaert, M., and Warriner, A. B. (2014). Emotion and language: valence and arousal affect word recognition. J. Exp. Psychol. Gen. 143, 1065–1081. doi: 10.1037/a0035669
Kuperman, V., Stadthagen-Gonzalez, H., and Brysbaert, M. (2012). Age-of-acquisition ratings for 30,000 English words. Behav. Res. Methods 44, 978–990. doi: 10.3758/s13428-012-0210-4
Lambon Ralph, M. A., and Ehsan, S. (2006). Age of acquisition effects depend on the mapping between representations and the frequency of occurrence: empirical and computational evidence. Vis. Cogn. 13, 928–948. doi: 10.1080/13506280544000110
Lieberman, E., Michel, J. B., Jackson, J., Tang, T., and Nowak, M. A. (2007). Quantifying the evolutionary dynamics of language. Nature 449, 713–716. doi: 10.1038/nature06137
Louwerse, M. (2010). Symbol interdependency in symbolic and embodied cognition. Top. Cogn. Sci. 3, 1–30.
Lund, K., and Burgess, C. (1996). Producing high-dimensional semantic spaces from lexical co- occurrence. Behav. Res. Methods Instrum. Comput. 28, 203–208. doi: 10.3758/BF03204766
Moffat, M., Siakaluk, P. D., Sidhu, D., and Pexman, P. M. (2015). Situated conceptualization and semantic processing: effects of emotional experience and context availability in semantic categorization and naming tasks. Psychon. Bull. Rev. 22, 408–419. doi: 10.3758/s13423-014-0696-0
Morrison, C. M., and Ellis, A. W. (1995). Roles of word frequency and age of acquisition in word naming and lexical decision. J. Exp. Psychol. Learn. Mem. Cogn. 21, 116–133.
Pexman, P. M. (2012). “Meaning-based influences on visual word recognition,” in Visual Word Recognition Volume 2: Meaning and Context, Individuals, and Development, ed. J. S. Adelman (Hove: Psychology Press), 24–43.
Pexman, P. M., Hargreaves, I. S., Siakaluk, P. D., Bodner, G. E., and Pope, J. (2008). There are many ways to be rich: effects of three measures of semantic richness on visual word recognition. Psychon. Bull. Rev. 15, 161–167. doi: 10.3758/PBR.15.1.161
Pexman, P. M., Hino, Y., and Lupker, S. J. (2004). Semantic ambiguity and the process of generating meaning from print. J. Exp. Psychol. Learn. Mem. Cogn. 30, 1252–1270.
Pexman, P. M., Siakaluk, P. D., and Yap, M. J. (eds) (2014). Meaning in Mind: Semantic Richness Effects in Language Processing. Lausanne: Frontiers Media SA.
Piercey, C. D., and Joordens, S. (2000). Turning an advantage into a disadvantage: ambiguity effects in lexical decision versus reading tasks. Mem. Cogn. 28, 657–666. doi: 10.3758/BF03201255
Pinker, S., and Ullman, M. T. (2002). The past and future of the past tense. Trends Cogn. Sci. 6, 456–463. doi: 10.1016/S1364-6613(02)01990-3
Pratto, F., and John, O. (1991). Automatic vigilance: the attention-grabbing power of negative social information. J. Pers. Soc. Psychol. 61, 380–391. doi: 10.1037/0022-3514.61.3.380
Pulvermüller, F., Shtyrov, Y., and Ilmoniemi, R. (2005). Brain signatures of meaning access in action word recognition. J. Cogn. Neurosci. 17, 884–892. doi: 10.1162/0898929054021111
Ramscar, M. (2002). The role of meaning in inflection: why the past tense does not require a rule. Cogn. Psychol. 45, 45–94. doi: 10.1016/S0010-0285(02)00001-4
Rodd, J., Gaskell, M., and Marslen-Wilson, W. (2002). Making sense of semantic ambiguity: semantic competition in lexical access. J. Mem. Lang. 46, 245–266. doi: 10.1006/jmla.2001.2810
Siakaluk, P. D., Knol, N., and Pexman, P. M. (2014). Effects of emotional experience for abstract words in the Stroop task. Cogn. Sci. 38, 1698–1717. doi: 10.1111/cogs.12137
Siakaluk, P. D., Pexman, P. M., Aguilera, L., Owen, W. J., and Sears, C. R. (2008). Evidence for the activation of sensorimotor information during visual word recognition: the body-object interaction effect. Cognition 106, 433–443. doi: 10.1016/j.cognition.2006.12.011
Sidhu, D. M., Kwan, R., Pexman, P. M., and Siakaluk, P. D. (2014). Effects of relative embodiment in lexical and semantic processing of verbs. Acta Psychol. 149, 32–39. doi: 10.1016/j.actpsy.2014.02.009
Stadthagen-Gonzalez, H., Bowers, J. S., and Damian, M. F. (2004). Age of acquisition effects in lexical decision: evidence from expert vocabularies. Cognition 93, 11–26. doi: 10.1016/j.cognition.2003.10.009
Steyvers, M., and Tenenbaum, J. B. (2005). The large-scale structure of semantic networks: statistical analyses and a model of semantic growth. Cogn. Sci. 29, 41–78. doi: 10.1207/s15516709cog2901_3
Tabak, W., Schreuder, R., and Baayen, R. H. (2005). “The processing of regular and irregular verbs,” in Proceedings of the Interdisciplinary Workshop on the Identification and Representation of Verb Features and Verb Classes, Saarbrücken, 121–126.
Taikh, A., Hargreaves, I. S., Yap, M., and Pexman, P. M. (2015). Semantic classification of pictures and words. Q. J. Exp. Psychol. (Hove) 68, 1502–1518. doi: 10.1080/17470218.2014.975728
Trope, Y., and Liberman, N. (2003). Temporal construal. Psychol. Rev. 110, 403–421. doi: 10.1037/0033-295X.110.3.403
Trope, Y., and Liberman, N. (2010). Contrual-level theory of psychological distance. Psychol. Rev. 117, 440–463. doi: 10.1037/a0018963
Vigliocco, G., Meteyard, L., Andrews, M., and Kousta, S. (2009). Toward a theory of semantic representation. Lang. Cogn. 1, 219–248. doi: 10.1515/LANGCOG.2009.011
Vinson, D., Ponari, M., and Vigliocco, G. (2014). How does emotional content affect lexical processing? Cogn. Emot. 28, 737–746. doi: 10.1080/02699931.2013.851068
Warriner, A. B., Kuperman, V., and Brysbaert, M. (2013). Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 45, 1191–1207. doi: 10.3758/s13428-012-0314-x
Woollams, A. M., Joanisse, M., and Patterson, K. (2009). Past-tense generation from form versus meaning: behavioural data and simulation evidence. J. Mem. Lang. 61, 55–76. doi: 10.1016/j.jml.2009.02.002
Yap, M. J., Pexman, P. M., Wellsby, M., Hargreaves, I. S., and Huff, M. J. (2012). An abundance of riches: cross-task comparisons of semantic richness effects in visual word recognition. Front. Hum. Neurosci. 6:72. doi: 10.3389/fnhum.2012.00072
Yap, M. J., and Seow, C. S. (2014). The influence of emotion on lexical processing: insights from RT distributional analysis. Psychon. Bull. Rev. 21, 526–533. doi: 10.3758/s13423-013-2525-x
Yap, M. J., Tan, S. E., Pexman, P. M., and Hargreaves, I. S. (2011). Is more always better? Effects of semantic richness on lexical decision, speeded pronunciation, and semantic classification. Psychon. Bull. Rev. 18, 742–750. doi: 10.3758/s13423-011-0092-y
Yarkoni, T., Balota, D. A., and Yap, M. J. (2008). Moving beyond Coltheart’s N: a new measure of orthographic similarity. Psychon. Bull. Rev. 15, 971–979. doi: 10.3758/PBR.15.5.971
Zdrazilova, L., and Pexman, P. M. (2013). Grasping the invisible: semantic processing of abstract words. Psychon. Bull. Rev. 20, 1312–1318. doi: 10.3758/s13423-013-0452-x
Keywords: semantic richness, verb meaning, past-tense generation, lexical decision, regularity, tense
Citation: Sidhu DM, Heard A and Pexman PM (2016) Is More Always Better for Verbs? Semantic Richness Effects and Verb Meaning. Front. Psychol. 7:798. doi: 10.3389/fpsyg.2016.00798
Received: 11 December 2015; Accepted: 11 May 2016;
Published: 31 May 2016.
Edited by:
Guy Dove, University of Louisville, USAReviewed by:
Anna M. Woollams, University of Manchester, UKLori Buchanan, University of Windsor, Canada
Copyright © 2016 Sidhu, Heard and Pexman. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Penny M. Pexman, cGV4bWFuQHVjYWxnYXJ5LmNh