 Michael Kuhlmann
Michael Kuhlmann Markus J. Hofmann
Markus J. Hofmann Arthur M. Jacobs
Arthur M. Jacobs- 1Department of Education and Psychology, Free University Berlin, Berlin, Germany
- 2Department of Psychology, University Wuppertal, Wuppertal, Germany
- 3Department of Education and Psychology, Dahlem Institute for Neuroimaging of Emotion, Free University Berlin, Berlin, Germany
- 4Department of Education and Psychology, Center for Cognitive Neuroscience, Free University Berlin, Berlin, Germany
How do humans perform difficult forced-choice evaluations, e.g., of words that have been previously rated as being neutral? Here we tested the hypothesis that in this case, the valence of semantic associates is of significant influence. From corpus based co-occurrence statistics as a measure of association strength we computed individual neighborhoods for single neutral words comprised of the 10 words with the largest association strength. We then selected neutral words according to the valence of the associated words included in the neighborhoods, which were either mostly positive, mostly negative, mostly neutral or mixed positive and negative, and tested them using a valence decision task (VDT). The data showed that the valence of semantic neighbors can predict valence judgments to neutral words. However, all but the positive neighborhood items revealed a high tendency to elicit negative responses. For the positive and negative neighborhood categories responses congruent with the neighborhood's valence were faster than incongruent responses. We interpret this effect as a semantic network process that supports the evaluation of neutral words by assessing the valence of the associative semantic neighborhood. In this perspective, valence is considered a semantic super-feature, at least partially represented in associative activation patterns of semantic networks.
Introduction
“I have some good news and some bad news.” This common introduction invites to an affective round-trip. The words “good” and “bad,” verbal stimuli with positive and negative valence, inform about the valence of the entire announcement. In everyday life, the quasi incessant and often unconscious evaluation of stimulus valence provides us with critical information for making decisions and choosing actions that are situation-adequate (Lebrecht et al., 2012). The concept of valence is an integral part of many theories of emotion claiming that the multitude of emotional experiences like states of anger, fear, disgust, or happiness are derived from a core affect that is composed of valence and a second major dimension, representing the general grade of emotional activation, called arousal (e.g., Wundt, 1896; Osgood et al., 1957; Russell, 1980). However, despite its ubiquitous use, valence is not a notion beyond dispute and it remains unclear how, when, and where the brain computes valence signals in even the simplest task, i.e., the valence decision task (VDT) where participants decide whether a stimulus is positive or negative (Maddock et al., 2003; Võ et al., 2006; Jacobs et al., 2015). Recent research therefore focuses on valence as an integral component of mental object representations and on the mechanisms underlying the brain's computation of affective valence from perceptual or semantic representations (e.g., Lebrecht et al., 2012). Assuming that lexico-semantic representations are the result of learning the statistical structure underlying a single joint distribution of both experiential and distributional data (Andrews et al., 2009), valence can be construed as a semantic super-feature (Jacobs et al., 2015).
The experiential aspect of the semantic super-feature of valence is gained by extralinguistic, sensory-motor experience with the word's referents. This can be a physical object or an event, thus the experience includes physical features like color and shape, but also pleasantness. Niedenthal (2007) and Niedenthal et al. (2009) elaborate on the relation of the sensory motor system and emotional processing in their theory of embodied emotions.
The distributional aspect, on the other hand, is grounded in the intralingual dependent distribution of words. Texts are usually used to convey meaningful information, and that does not only influence which words to use, but also creates contextual word patterns within a language. Analyzing the distributive word patterns in texts has become a distinct field in computational linguistics. Some of the models produced in this field are well-known in psychology, for instance latent semantic analysis (Landauer and Dumais, 1997), or Bayesian topics models (Griffiths et al., 2007). The dependent distribution of words can be assessed from a large text corpus that is representative for a language by extracting how often words are occurring close to other words, e.g., within the same sentence. Words that are often co-occurring can be considered to be semantically associated (cf. Evert, 2005). In turn, it can be expected that the co-occurrence of words contributes to define their meaning by shaping the neural connection patterns in semantic networks through Hebbian learning style mechanisms (Hebb, 1949; Rapp, 2002). Therefore, co-occurrence enables to model the spread of activation within semantic networks and hence to predict, which words will receive co-activation from the activation of other words (cf. Hofmann and Jacobs, 2014). Empirical evidence that co-occurrence can partially predict the valence of words comes from Westbury et al. (2015). In a recent study they showed that valence ratings of words can be predicted by their co-occurrence based associations to a selected set of emotion labels, derived from theories of basic emotions (cf. also Hofmann and Jacobs, 2014).
A further step should be to disentangle the contribution of experiential and distributional data in the course of the evaluation process. However, the typical very positive and very negative emotion words used in studies on the processing of valence (e.g., Kissler and Herbert, 2013) will preclude to contrast the two types of data. Instead, we propose that this is possible with “neutral” words. To our knowledge, so far, there is yet no theory of emotion really elaborating on the structures and/or processes underlying stimulus neutrality. Since valence typically is conceived as a bipolar continuum, neutrality initially seems to be regarded as a state of no or insignificant valence. Alternatively, the evaluative space model incorporates the possibility of a combination of positive and negative valence for the same stimulus, i.e., mixed emotions (e.g., Norris et al., 2010; Briesemeister et al., 2012). In this prequantitative model stimulus neutrality can theoretically result from a balanced state of positive and negative affect, but the model does not allow to predict for which stimuli this would be the case. According to recent descriptive models of performance in the VDT (Jacobs et al., 2015), stimulus neutrality could result from a balance between distributional and experiential data with, e.g., positive distributional features counterbalanced by negative experiential ones or vice versa. Another possibility is that experiential and distributional features are both truly neutral, i.e., lack any substantial valence information. Again, however, these prequantitative models allow no specific predictions with regard to individual stimuli. On the other hand, computational models of lexical semantics, such as the Associative Read-Out model (Hofmann et al., 2011; Hofmann and Jacobs, 2014), allow to calculate an estimate of the distributional parts of the valence of single words, and thus specify their neutrality in more detail. Since these models implement an associative spreading of activation within semantic networks, the neutrality of a given word could also stem from a balance between its positive and negative semantic associates together with a neutral experiential feature.
In the present study, we tested the influence of semantic associates on affective word evaluation in a VDT. The semantic associates were computed beforehand from corpus based co-occurrence statistics. We assumed that the valence of the semantic associates provides a useful quantitative estimate of the distributional properties co-determining the overall valence of the neutral words that were presented as items in our experiment. The associated words conversely were not presented to the participants, but we predicted that spread of activation from reading the target words alone will co-activate their a priori determined associates within the semantic networks of the participants. We hypothesized that response type and times in the VDT using neutral words would be a function of their associates' valence values. In particular, we assumed that items with either a majority of positive or negative associates would receive more responses corresponding to their associates' valence, compared to the “baseline” response type distribution for items whose associates do not tend to positivity or negativity. If the evaluation of the valence of these items is consistent with the valence of their associates, we further expected responses to be sped up and also to be faster compared to the same types of response for items with no tendency to positivity or either negativity in the valence of their associates. Our controls, the items whose associates neither generally tended to positivity nor negativity, were subdivided into items with an even distribution of positive and negative associates and those whose associates had negligibly low valence values. In other words the associates were either an ambivalent mix or in the other case considered as neutral themselves. We selected these two types of control conditions, because we assumed them to be a challenge to evaluate for distinct reasons. The ambivalent condition causes competition of associates, while the neutral condition affords a more thorough search for valence.
Materials and Methods
Participants
The 19 participants (11 male; aged 19–28; mean 23.5) who took part in our study were right handed, had normal or corrected-to-normal vision and were native speakers of German. They were recruited at the Free University Berlin and gave written informed consent. They either received course credit or were paid for their participation. The study was approved by the ethics committee of the Free University Berlin.
Materials
We selected our items and associates from words of the BAWL-R (Võ et al., 2006, 2009). Association strength was computed from the German corpus of the “Wortschatz” project (Quasthoff et al., 2006; Hofmann et al., 2011). In general, it is based on the log-likelihood ratio of the actual co-occurrence of two words in a sentence divided by the likelihood expected from the single-word frequencies (Dunning, 1993). For each word of the BAWL-R, we computed the association strength to each other word in the BAWL-R by log-10 transforming the resulting chi-square value. This procedure results in a vector for each word comprised of the association strength values to each other BAWL-R word and ranks the words according to the strength of the association depicted by the chi-square value. The magnitude of association strength values and there distribution is heterogeneous for different words. For example the highest ranking word to one word might have a much larger chi-square value than the highest ranking of another word. Since the role of the magnitude of association strength in cognitive processing is still poorly understood, we resorted only to rank. The highest ranking associates of a given word should predominantly be co-activated by spread of activation. Therefore, and also to minimize computational load, we focused on the 10 highest ranking words by association strength to each word individually, which we will further refer to as semantic neighborhood. We defined words as neutral when their BAWL-R valence values (7 point rating scale from –3 to 3) were between –1 and 1. For these words we calculated mean and sd of valence and arousal of their semantic neighborhood derived from BAWL-R valence and arousal values of the respective neighborhood words. The mean and standard deviation of the valence values of neighborhood words defined the experimental category of the neutral target words. Words with a neighborhood valence sd below 1 were assigned to the positive category when the mean neighborhood valence was larger than 0.8, to the negative category when the mean neighborhood valence was below –0.8, and to the neutral neighborhood category when the mean was between –0.2 and 0.2. When neighborhood valence sd was larger than 1 and the mean was between –0.2 and 0.2 the word was assigned to the ambivalent category. An example of each category together with its neighborhood can be found in Table 1. We selected 50 words from each of the four categories to build an item set with no significant differences in valence, arousal, and imageability mean and sd, and also letter count, syllable count, and word frequency (t's < 1; Baayen et al., 1993, see Table 2). The complete item set is included in Table 3.
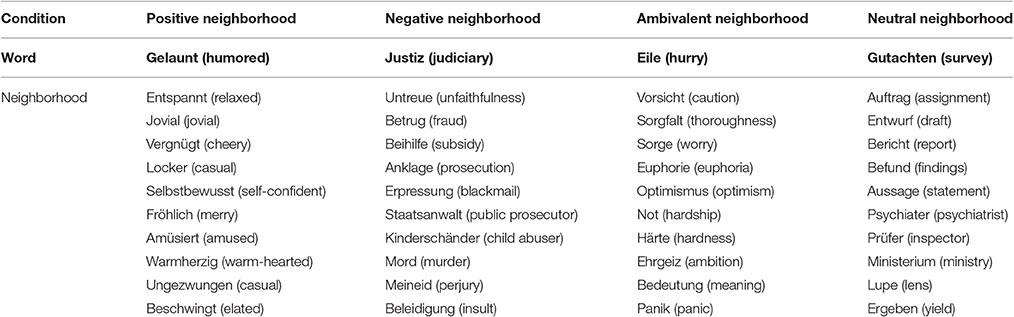
Table 1. Example words for each condition with corresponding neighborhood.

Table 2. Means of neighborhood and word properties for the experimental conditions with sd in parentheses.
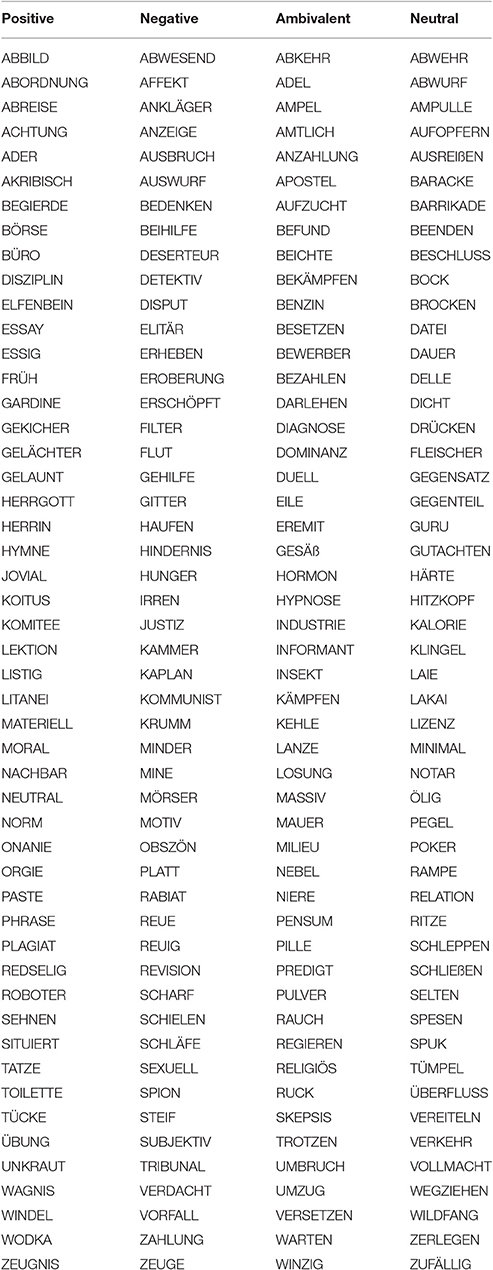
Table 3. List of items.
Procedure
The participants were informed that they could resign their participation at any time without the need of justification or any negative consequences. They then received the instructions on the screen. Their task was to decide whether a word presented for a brief time was either positive or negative and to press one of two buttons accordingly. The assignment of the response buttons was counterbalanced across participants. Participants were told that they would have the possibility to practice the task and to respond within the time window of presentation. They then worked through 10 practice trials and after a short break through the 200 main trials with a short break after half of the trials. Each trial started with a fixation cross in the screen center with a jittered duration between 2,500 and 5,000 ms. The trial continued with the stimulus item being presented for 2,000 ms. The order of item presentation was fully randomized. We collected response of the first button press within item presentation and reaction time (RT). The duration of breaks was left to the decision of the participants. On average they lasted 1 min.
Analyses
Trials without response were excluded from the analyses (6.5%, n = 247). We tested whether the response patterns for each condition were different from chance (0.5 response probability) with χ2 tests. Using a nominal-logistic regression we tested experimental condition (positive, negative, neutral, ambivalent) as a predictor for response type (positive, negative). Planed pairwise comparisons tested the conditions with unambiguous, i.e., positive and negative, neighborhoods separately against the ambiguous neighborhood conditions: ambivalent and neutral.
RT data were analyzed with a mixed fixed and random effects model using the Statistical software JMP 11Pro (SAS Institute Inc.). The conditions (positive, negative, neutral, ambivalent) and response type (positive, negative) nested into participants were modeled as a fixed effect. Although we had controlled variables that are known to affect latencies in the processing of words, we also inserted word valence, word arousal, word imageability, word frequency, number of letters, and number of syllables as covariates to achieve a more detailed model of data variance. For the same reason we also inserted mean neighborhood arousal as a covariate. Participants and items nested within conditions were modeled as random effects.
Results
Responses
There was a shift of the response ratio. Positive neighborhood items had more positive than negative responses. The neutral and ambivalent neighborhood items had more negative than positive responses at a similar level. The negative neighborhood items had more negative than positive responses to even a larger extent. The responses to each single condition were significantly different from a chance-distribution. There was a significant effect of experimental condition on the response type [ = 94.32, p < 0.001, Nagelkerkes R2 = 0.04]. Planned comparisons revealed that positive neighborhood items were significantly different from ambivalent neighborhood items [ = 44.56, p < 0.001, odds ratio = 0.54] and from neutral neighborhood items [ = 29.73, p < 0.001, odds ratio = 0.59]. Likewise, negative neighborhood items were significantly different from ambivalent [χ2 (1, N = 1784) = 7.78, p = 0.005, odds ratio = 1.31] and neutral [χ2 (1, N = 1776) = 16, p < 0.001, odds ratio = 1.48] neighborhood items. These effects are based on a shift of the response ratio from (i) more positive than negative responses for positive neighborhood items, to increasingly more negative than positive responses in the order of (ii) neutral, (iii) ambivalent, and maximally for (iv) negative neighborhood items (see Table 4).

Table 4. χ2 tests vs. 0.5 probability with 95% CI.
Reaction Times
For RTs, the main effects of condition (positive, negative, ambivalent, neutral) [F(3, 181) = 1.93, p = 0.13] and response [positive, negative; F(1, 3217.8) = 2.69, p = 0.1] were not significant. However, we found a significant effect for the interaction between condition and response type [F(3, 3088.3) = 3.87, p = 0.01]. Pairwise comparisons revealed no significant effects. Descriptively they showed the following differences: Considering condition alone, negative neighborhood items produced the fastest responses shortly followed by positive neighborhood items. Neutral and ambivalent neighborhood items were considerably slower. When taking the given response into account, responses to negative and positive neighborhood items that were congruent with the respective neighborhood valence were faster than incongruent responses. Neutral and ambivalent neighborhood items had similar latencies with generally faster negative responses than positive ones (see Figure 1). The covariates valence, arousal, word frequency, number of letters, and number of syllables revealed no significant effects, while imageability revealed a significant effect [F(1, 174) = 3.99, p = 0.05].
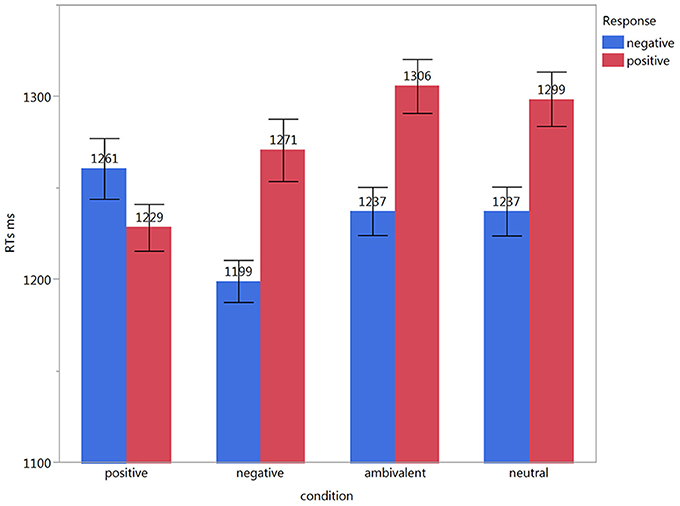
Figure 1. Mean RTs for responses given in each condition. Error-bars represent standard error.
Discussion
The influence of neighborhood valence was apparent in the pattern of responses in the present VDT. Although all items were neutral as established by previous valence ratings, positive neighborhood items elicited more positive responses and negative neighborhood items produced more negative responses than items with a neutral neighborhood. This suggests that a more or less tacitly retrieved positive or negative language context co-determines the valence of a given word (Harris, 1951).
While there is extensive co-occurrence data, the more limited amount of available valence data prevents from applying our computational procedure to any word. Moreover, it limits the pool of associates for the semantic neighborhoods. Still our results show that they were sufficient for estimating the distributive aspect of valence. This gives rise to the assumption that the distribution of valence in associates without available valence ratings does not crucially deviate.
We also found that ambivalent and neutral neighborhood items showed a negativity bias with more negative responses than expected by chance. This is consistent with recent data obtained in the VDT. When noun-noun compounds are composed of both, a negative and a positive word, participants judge them to be relatively negative (Jacobs et al., 2015). A dominance of negativity over positivity in emotion is often found (see Baumeister et al., 2001). Rozin and Royzman (2001) stated that evaluations tend to be more negative than the algebraic sum of integrated positive and negative information would predict and Ito et al. (1998) presented evidence that the negativity bias originates at the stage of evaluative categorization. Moreover, such a negativity bias is also well known in many other tasks, when a great amount of affective information is available (Norris et al., 2010). Norris et al. (2010, p. 431) suggested “that under conditions in which little to no affective information is available…, positivity outweighs negativity.” Thus, the present negativity bias suggests that associations in semantic networks can bring a significant amount of valence information into the evaluative space of actually neutral words, although the affective information is generated by an internal process and not triggered by additional external stimuli. This dominance of affective contextual word features was also present in the RT data. Thus, items with an unequivocal positive or negative semantic neighborhood were evaluated faster than those with an ambivalent or neutral neighborhood. Moreover, for items with ambivalent and neutral semantic neighborhoods, we found that negative responses were faster than positive responses. Thus, much as our recently observed faster RTs in ambivalent, directly available valences of noun–noun compounds consisting of a positive and negative word (cf. Jacobs et al., 2015; Kuhlmann et al., 2016), a negativity bias can also be elicited by absent, but associated words. This finding corroborates the notion that a large amount of affective information can spread from affective words to its directly associated neutral neighbors, which can also be used to predict the valence of a word (Recchia and Louwerse, 2014).
In sum, our results can be explained in terms of spreading (associative) activation models. For example Bower (1981) proposed that positive or negative valence can be considered a node in a semantic network (cf. Schröder and Thagard, 2013). Such a positive and negative “super-feature unit” could be added to computational models accounting for orthographic, phonological, or semantic neighborhood effects (Grainger and Jacobs, 1996; Jacobs et al., 1998; Hofmann et al., 2011; Hofmann and Jacobs, 2014) to allow judgments of the valence of a word. Thus, if no valence information is available for a stimulus, associated items become co-activated (Collins and Loftus, 1975; Hofmann and Jacobs, 2014), and thus the meaning of these items co-resonates (Hofmann et al., 2011; Baayen et al., 2016), the resonance spreading toward super-feature units finally determining word valence (Hofmann et al., 2011).
If a great amount of associated word units activate the negative unit, a “negative” response is given, and vice versa for positive words. If the valence of most of the neighbors spreads toward either the positive or the negative super-feature units, more evidence is fed forward within the same amount of time (cf. Grainger and Jacobs, 1996), and thus responses are faster than in neutral or ambivalent neighborhoods. If there is an associative spread toward positive and negative super-feature units, this leads to competition (Botvinick et al., 2001), and thus RTs are delayed. Similarly, responses are delayed, when activation must spread across several intermediate neutral units, to reach the criterion level sufficient to execute a (binary) valence response. Thus, it takes you more time to know the valence of a word by the positive or negative company it kept during its learning history (cf. Firth, 1957).
Ethics Statement
Ethikkommission der Freien Universität Berlin Free University Berlin Habelschwerdter Allee 14195 Berlin Before the experiment all participants were verbally informed that they could resign from participation at any time without explanation and without negative consequences. No vulnerable populations were involved
Author Contributions
MK conducted the analyses and prepared figures and tables. MK, MH, and AJ wrote the manuscript.
Funding
This research was partly supported by grants from the Deutsche Forschungsgemeinschaft to AJ (JA823/4-2) and to MH (HO5139/2-1).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Judit Pekár and Chiara Eden for their help during data acquisition.
References
Andrews, M., Vigliocco, G., and Vinson, D. (2009). Integrating experiential and distributional data to learn semantic representations. Psychol. Rev. 116, 463–498. doi: 10.1037/a0016261
Baayen, R. H., Piepenbrock, R., and van Rijn, H. (1993). The {CELEX} Lexical Data Base on {CD-ROM}. Philadelphia, PA: Linguistic Data Consortium.
Baayen, R. H., Shaoul, C., Willits, J., and Ramscar, M. (2016). Comprehension without segmentation: a proof of concept with naive discriminative learning. Lang. Cogn. Neurosci. 31, 106–128. doi: 10.1080/23273798.2015.1065336
Baumeister, R. F., Bratslavsky, E., Finkenauer, C., and Vohs, K. D. (2001). Bad is stronger than good. Rev. Gen. Psychol. 5, 323–370. doi: 10.1037/1089-2680.5.4.323
Botvinick, M. M., Braver, T. S., Barch, D. M., Carter, C. S., and Cohen, J. D. (2001). Conflict monitoring and cognitive control. Psychol. Rev. 108, 624–652. doi: 10.1037/0033-295X.108.3.624
Briesemeister, B. B., Kuchinke, L., and Jacobs, A. M. (2012). Emotional valence a bipolar continuum or two independent dimensions? SAGE Open 2, 1–12. doi: 10.1177/2158244012466558
Collins, A. M., and Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychol. Rev. 82, 407–428. doi: 10.1037/0033-295X.82.6.407
Dunning, T. (1993). Accurate methods for the statistics of surprise and coincidence. Comput. Linguist. 19, 61–74.
Evert, S. (2005). The Statistics of Word Cooccurrences : Word Pairs and Collocations. Available online at: http://elib.uni-stuttgart.de/opus/volltexte/2005/2371/
Grainger, J., and Jacobs, A. M. (1996). Orthographic processing in visual word recognition: a multiple read-out model. Psychol. Rev. 103, 518–565. doi: 10.1037/0033-295X.103.3.518
Griffiths, T. L., Steyvers, M., and Tenenbaum, J. B. (2007). Topics in semantic representation. Psychol. Rev. 114:211. doi: 10.1037/0033-295X.114.2.211
Harris, Z. S. (1951). Methods in Structural Linguistics, Vol. xv, Chicago, IL: University of Chicago Press.
Hebb, D. O. (1949). The Organization of Behavior: A Neuropsychological Approach. New York, NY: John Wiley & Sons.
Hofmann, M. J., and Jacobs, A. M. (2014). Interactive activation and competition models and semantic context: from behavioral to brain data. Neurosci. Biobehav. Rev. 461, 85–104. doi: 10.1016/j.neubiorev.2014.06.011
Hofmann, M. J., Kuchinke, L., Biemann, C., Tamm, S., and Jacobs, A. M. (2011). Remembering words in context as predicted by an associative read-out model. Front. Psychol. 2:252. doi: 10.3389/fpsyg.2011.00252
Ito, T. A., Larsen, J. T., Smith, N. K., and Cacioppo, J. T. (1998). Negative information weighs more heavily on the brain: the negativity bias in evaluative categorizations. J. Pers. Soc. Psychol. 75, 887–900. doi: 10.1037/0022-3514.75.4.887
Jacobs, A. M., Rey, A., Ziegler, J. C., and Grainger, J. (1998). “MROM-P: An interactive activation, multiple read-out model of orthographic and phonological processes in visual word recognition,” in Localist Connectionist Approaches to Human Cognition, eds J. Grainger and A. M. Jacobs (Mahwah, NJ: Lawrence Erlbaum Associates, Inc.), 147–188.
Jacobs, A. M., Võ, M. L.-H., Briesemeister, B. B., Conrad, M., Hofmann, M. J., Kuchinke, L., et al. (2015). 10 years of BAWLing into affective and aesthetic processes in reading: what are the echoes? Lang. Sci. 6:714. doi: 10.3389/fpsyg.2015.00714
Kissler, J., and Herbert, C. (2013). Emotion, Etmnooi, or Emitoon? – Faster lexical access to emotional than to neutral words during reading. Biol. Psychol. 92, 464–479. doi: 10.1016/j.biopsycho.2012.09.004
Kuhlmann, M., Hofmann, M. J., Briesemeister, B. B., and Jacobs, A. M. (2016). Mixing positive and negative valence: affective-semantic integration of bivalent words. Sci. Rep. 6:30718. doi: 10.1038/srep30718
Landauer, T. K., and Dumais, S. T. (1997). A solution to Plato's problem: the latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev. 104:211. doi: 10.1037/0033-295X.104.2.211
Lebrecht, S., Bar, M., Barrett, L. F., and Tarr, M. J. (2012). Micro-valences: Perceiving affective valence in everyday objects. Front. Psychol. 3:107. doi: 10.3389/fpsyg.2012.00107
Maddock, R. J., Garrett, A. S., and Buonocore, M. H. (2003). Posterior cingulate cortex activation by emotional words: fMRI evidence from a valence decision task. Hum. Brain Mapp. 18, 30–41. doi: 10.1002/hbm.10075
Niedenthal, P. M., Winkielman, P., Mondillon, L., and Vermeulen, N. (2009). Embodiment of emotion concepts. J. Pers. Soc. Psychol. 96, 1120–1136. doi: 10.1037/a0015574
Norris, C. J., Gollan, J., Berntson, G. G., and Cacioppo, J. T. (2010). The current status of research on the structure of evaluative space. Biol. Psychol. 84, 422–436. doi: 10.1016/j.biopsycho.2010.03.011
Osgood, C. E., Suci, G. J., and Tannenbaum, P. H. (1957). The Measurement of Meaning. Oxford: University Illinois Press.
Quasthoff, U., Richter, M., and Biemann, C. (2006). “Corpus portal for search in monolingual corpora,” in Proceedings Fifth International Conference on Language Resources and Evaluation. (Vol. 17991802) (Genoa).
Rapp, R. (2002). “The computation of word associations: comparing syntagmatic and paradigmatic approaches,” in Proceedings of the 19th International Conference on Computational Linguistics-Vol. 1. (Taipei: Association for Computational Linguistics), 1–7. doi: 10.3115/1072228.1072235
Recchia, G., and Louwerse, M. M. (2014). “Grounding the ungrounded: estimating locations of unknown place names from linguistic associations and grounded representations,” in Proceedings of the 36th Annual Conference of the Cognitive Science Society (Austin, TX: Cognitive Science Society), 1270–1275.
Rozin, P., and Royzman, E. B. (2001). Negativity bias, negativity dominance, and contagion. Pers. Soc. Psychol. Rev. 5, 296–320. doi: 10.1207/S15327957PSPR0504_2
Russell, J. A. (1980). A circumplex model of affect. J. Pers. Soc. Psychol. 39, 1161–1178. doi: 10.1037/h0077714
Schröder, T., and Thagard, P. (2013). The affective meanings of automatic social behaviors: three mechanisms that explain priming. Psychol. Rev. 120, 255–280. doi: 10.1037/a0030972
Võ, M. L. H., Conrad, M., Kuchinke, L., Urton, K., Hofmann, M. J., and Jacobs, A. M. (2009). The Berlin Affective Word List Reloaded (BAWL-R). Behav. Res. Methods 41, 534–538. doi: 10.3758/BRM.41.2.534
Võ, M. L. H., Jacobs, A. M., and Conrad, M. (2006). Cross-validating the Berlin affective word list. Behav. Res. Methods 38, 606–609. doi: 10.3758/BF03193892
Westbury, C., Keith, J., Briesemeister, B. B., Hofmann, M. J., and Jacobs, A. M. (2015). Avoid violence, rioting, and outrage; approach celebration, delight, and strength: using large text corpora to compute valence, arousal, and the basic emotions. Q. J. Exp. Psychol. 68, 1599–1622. doi: 10.1080/17470218.2014.970204
Keywords: neutral words, valence, ambivalence, semantic processing, co-occurrence networks
Citation: Kuhlmann M, Hofmann MJ and Jacobs AM (2017) If You Don't Have Valence, Ask Your Neighbor: Evaluation of Neutral Words as a Function of Affective Semantic Associates. Front. Psychol. 8:343. doi: 10.3389/fpsyg.2017.00343
Received: 29 May 2016; Accepted: 22 February 2017;
Published: 13 March 2017.
Edited by:
Guillaume Thierry, Bangor University, UKReviewed by:
Francesco Vespignani, University of Trento, ItalyErich David Jarvis, Duke University, USA
Copyright © 2017 Kuhlmann, Hofmann and Jacobs. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Michael Kuhlmann, bWljaGFlbC5rdWhsbWFubkBmdS1iZXJsaW4uZGU=