 Min Liu
Min Liu Allen G. Harbaugh
Allen G. Harbaugh Jeffrey R. Harring
Jeffrey R. Harring Gregory R. Hancock3
Gregory R. Hancock3- 1Educational Psychology, University of Hawaii, Honolulu, HI, USA
- 2Education Leadership and Policy Studies Cluster, School of Education, Boston University, Boston, MA, USA
- 3Human Development and Quantitative Methodology, University of Maryland, College Park, MD, USA
Extreme and non-extreme response styles (RSs) are prevalent in survey research using Likert-type scales. Their effects on measurement invariance (MI) in the context of confirmatory factor analysis are systematically investigated here via a Monte Carlo simulation study. Using the parameter estimates obtained from analyzing a 2007 Trends in International Mathematics and Science Study data set, a population model was constructed. Original and contaminated data with one of two RSs were generated and analyzed via multi-group confirmatory factor analysis with different constraints of MI. The results indicated that the detrimental effects of response style on MI have been underestimated. More specifically, these two RSs had a substantially negative impact on both model fit and parameter recovery, suggesting that the lack of MI between groups may have been caused by the RSs, not the measured factors of focal interest. Practical implications are provided to help practitioners to detect RSs and determine whether RSs are a serious threat to MI.
Introduction
In the social and behavioral sciences, research instruments using Likert-type scales are often applied to study and compare individuals in different cultures or other well-defined groups. However, if there is significant variation among the groups with regard to how given response scales are interpreted, any findings of similarity or difference among the groups with regard to the intended content of the survey instrument may not be valid. That is to say, comparisons across groups may result in invalid results and possibly incorrect conclusions. This necessitates an examination of the degree to which the scale is measuring the same construct or trait across these groups, that is, whether a given measurement scale could be interpreted in the same way for the respondents from different groups. Exploring or testing a research hypothesis about group differences is only meaningful once measurement invariance (MI) based on a given instrument has been well-established. However, many empirical studies using either confirmatory factor analysis (CFA) or item response theory (IRT) to assess MI have overlooked response styles (Van Vaerenbergh and Thomas, 2013). Response styles (RSs) are a source of measurement error (or bias) that occurs when respondents tend to provide answers not based on the substantive meaning of the questionnaire items but on content-irrelevant factors. Two common and relatively easily identifiable RSs are (1) the extreme response style (ERS) in which a participant is inclined to mark only the extreme ends of the scale, and (2) the non-extreme response style (NERS) in which a participant is inclined to systematically avoid selecting the extreme ends of the scale. Most MI studies that we have reviewed neither mentioned RSs nor examined their potential effects on the statistical models (e.g., Marsh et al., 2012; review study by Vandenberg and Lance, 2000). Although MI and RSs are not new measurement problems to researchers, only a few studies investigated both of them in the same setting (Cheung and Rensvold, 2000; Moors, 2004; Kankaraš and Moors, 2009, 2011). Moreover, none of these empirical studies have ever systematically investigated whether RSs have a detrimental effect on the MI in cross-group studies. The current study examines the hypotheses that ERS and NERS, two RSs that are frequently seen in practice, have a significant effect on MI and that their effects on the levels of MI may vary depending on different percentages of RSs present in the data. This paper is organized as follows. First, the literature review includes a brief introduction to MI as defined in a multi-group CFA model, a bit more detail on RSs, and then a survey of the few studies that have tried to address both measurement problems simultaneously. Second, a simulation study is presented in which we examine whether different percentages of ERS and NERS underlying data have detrimental effects on MI. Finally, the last section presents implications for practitioners and future directions for research based on the findings.
Measurement Invariance
Researchers often use survey data with Likert-type scales to measure and compare subjects' attitudes, perceptions, evaluations, and beliefs across nations, ethnicities, or other segregable groups (e.g., Khine, 2008). All group comparison studies are based on a critical assumption that the instrument operates in exactly the same manner for all of the possible different groups defined by the variable of interest (e.g., gender, ethnicity, or other geographic variables). This assumption suggests that the items of the survey are measuring the same constructs for each group, the items are not showing differential item functioning (DIF) from one group to another (i.e., the possibility of a group × content interaction), and the response scales are being used and interpreted by members of each group in the same manner. More generally, it is assumed that MI of the instrument holds across these groups. Early research examining MI was based on studying factor invariance over several decades (e.g., Thurstone, 1947; Meredith, 1964). More recently, a number of researchers have developed formal procedures for testing MI across groups using multi-group CFA (Jöreskog, 1971; Horn and McArdle, 1992; Meredith, 1993; Millsap and Olivera-Aguilar, 2012). Several widely-available software packages, LISREL (Jöreskog and Sörbom, 2015), EQS (Bentler, 2008), AMOS (Arbuckle, 2012), and Mplus (Muthén and Muthén, 2015), facilitate application of the CFA models in examining MI efficiently and widely in various disciplines. A brief search of the key word “measurement invariance” and “multigroup confirmatory factor analysis” in Google Scholar brought up more than 100 and 400 publications in 2014 and 2015, respectively, and a rough review of these studies indicated that checking MI through multigroup CFA in cross-group studies had been used as a routine preliminary step prior to conducting group mean comparisons.
In the psychometrics literature, Meredith (1993) formulated four levels of hierarchy for cross-group MI ranging from low to high. These levels are (1) configural invariance (CI)—same “shape” for factor model specification across groups; (2) weak invariance (WI)—same factor loadings across groups, also known as metric invariance (Horn and McArdle, 1992); (3) strong invariance (SI)—same factor loadings and intercepts across groups, also known as scalar invariance; and (4) strict invariance (STRI)—same factor loadings, intercepts, and residual variances across groups. With the 2nd level of WI, differences across groups in relationships among measured variables are ascribed to differences across groups in relationships among latent variables. With the 3rd level of SI, group differences in co-variances among measured variables and in means of measured variables are ascribed to group differences in co-variances and means on latent variables. Under strong factorial invariance, group differences in those variances of measured variables could be ascribed to group differences in variances of latent variables as well as to group differences in error variances. With the 4th level of STRI, group differences in variances of measured variables are ascribed only to group differences in variances of latent variables, since error variances are invariant across groups. Although the 2nd and 3rd levels are commonly accepted as sufficient evidence for MI (e.g., Little, 1997; Vandenberg and Lance, 2000), some researchers suggest that the 4th level is a necessary condition for MI (Meredith, 1993; Wu et al., 2007). As our focal concern is not to address this debate, we sequentially investigate MI following this hierarchical structure through all four levels. It is worth noting that levels 3 and 4 may be defined differently for categorical indicators. According to Millsap and Yun-Tein (2004), factor loadings and thresholds are constrained to be equal across groups in level 3 and the additional constraints of equal residual variances are necessary for level 4.
Response Styles
Numerous studies have shown that data collected through survey instruments using Likert-type scales may be subject to different forms of response bias. One source of response bias is the use of different RSs among different subpopulations. According to Baumgartner and Steenkamp (2001), RSs are also referred to as response sets or response biases. Specifically, response bias is defined by Paulhus (1991) as a systematic tendency to respond to questions on some basis that is independent of the content of the question. Messick (1962) suggested that Likert-type scales demonstrated this type of systematic measurement error, stating that response bias was “confounded with legitimate replies to item content” (p. 41) resulting in threats to the validity of scales. Furthermore, the response bias caused by consistent personal styles or traits may be stable and reliable components of responses (Messick, 1962). Thus, RSs may account for another source of variation common to most survey data, a source that could be included in the statistical models.
In cross-cultural research in fields like marketing (Baumgartner and Steenkamp, 2001) and education (Lam and Klockars, 1982; Bond and Hwang, 1986), it is well-noted that respondents from different cultural backgrounds may show systematically different response patterns that are content-irrelevant. For example, American respondents may tend to select the extreme endpoints of non-frequency Likert-type scales more often than Japanese or Chinese peers (Chen et al., 1995). As Baumgartner and Steenkamp (2001) summarized, several types of RSs may occur frequently in cross-cultural or other group comparison studies. A few of these include: (1) ERS, the tendency to select the extreme endpoints of a scale; (2) NERS, the tendency to avoid selecting the extreme endpoints of a scale resulting in only selecting the very middle or the middle-most values of a scale; (3) acquiescence response style (ARS), the tendency to agree with all items regardless of content; and (4) disacquiescence response style (DRS), the tendency to disagree with all items. The pervasiveness of these types of RSs has been evidenced by a growing body of research (e.g., Costa and McCrae, 1992; Rost et al., 1997; Buckley, 2009). In this paper, ERS and NERS are the primary focus because they are the most frequently studied RSs in the social sciences (e.g., Paulhus, 1991; Barnette, 1999; Baumgartner and Steenkamp, 2001; Johnson, 2003) and both appear to be present in a large-scale data set used in this study (see method section for more details).
As Cavusgil and Das (1997) pointed out, the manifestation of RSs in one's data can jeopardize the statistical and external validity of the research as well as affect comparability across samples. While a number of previous studies have examined Likert-type data and the associated response bias, these studies have focused more on practical implications for survey instrument builders such as the optimal number of response categories or the effect of response bias on the reliability and validity of measures (e.g., Barnette, 1999; Preston and Colman, 2000; Liu et al., 2010). Except for Liu and colleagues' (2010) work modeling outliers, none of these previous studies attempted to systematically investigate the effects of the RSs from a statistical modeling perspective. In other words, we still do not know whether (or to what extent) the RSs have a detrimental effect in statistical modeling such as MI in the context of multi-group CFA, nor how serious it could be under different bias conditions. When statistical models derived from sound conceptual theory do not fit the data, researchers commonly explore the modeling space to find an acceptable model. It may be that—despite apparent model-data misfit—the model or latent construct is fine, once accounting for the group-specific differences; the real problem may be an issue of analyzing data “contaminated” by RSs.
Although applied researchers are aware of the possibility that both construct non-equivalence and RSs may distort the comparison of attitudes across groups, only a few studies investigated these two measurement issues simultaneously. Cheung and Rensvold (2000) suggested using multi-group CFA to test for the presence of ERS and ARS and to determine whether group comparison studies on a basis of latent factors are meaningful. As Morren et al. (2011) summarized, this method is useful to determine whether MI is invalidated by a RS. However, it can neither measure the extent of the impact of the RSs, nor correct for the presence of this RS, nor rule out the possibility that non-invariant intercepts and thresholds may still be caused by content-related factors (e.g., DIF). Moors (2003, 2004) proposed a latent class factor analysis (LCFA) approach to detect and correct for ERS, which was modeled as a latent factor in addition to the factors of interest. Although some researchers recommend LCFA because it requires fewer assumptions about the factor capturing the variation brought about by RS (e.g., Morren et al., 2011), it is still unclear whether this method is effective in detecting and correcting ERS. Moreover, none of these researchers investigated the effects of RSs from a statistical modeling perspective.
Little to no reporting on the effects of RSs on MI is found in educational research. This may be attributed to a lack of familiarity with various RSs that have been identified under different names, uncertainty about how to deal with RSs appropriately due to insufficient research in comparing the efficiencies of the proposed methods, or more importantly, the pervasive belief that the RSs do not have substantively deleterious effects on the validity of the statistical analyses used by researchers (Baumgartner and Steenkamp, 2001). Therefore, a series of systematic simulation studies is necessary to address the concern that statistical conclusions from measurement models may be spurious due to RSs and eventually to find out which method is most appropriate to deal with various RSs present in a data set. The current study is an attempt to initiate the former part of this systematic process: this study aims to investigate whether two RSs, ERS and NERS, have substantial effects on construct comparability among different groups. If they do, it would be critical to determine what percentages of contaminated data have detrimental effects on MI. Moreover, Lombardi and Pastore's (2012) examined the performance of structural equation model (SEM) based fit indices in analyzing data with faked observations caused by dishonest responses from participants in answering survey questionnaire. They found that incremental fit indices, such as the Comparative Fit Index (CFI) and the Tucker Lewis Index [TLI, also named as the Non-Normed Fit Index (NNFI)], are more sensitive to the faked observations when participants are not responding honestly. Therefore, another research goal of the current study is to investigate which SEM-based model fit indices are more sensitive to the inclusion of contaminated cases. In sum, the findings of the current study will be informative to practitioners who are interested in applying MI when their data may be suspected to be influenced by RSs.
Methods
Using parameter estimates from an authentic data source, data sets were simulated to represent that which might reasonably be expected from an authentic population. Using a model-based algorithm, contamination via ERS and NERS was introduced into the simulated data sets. The extent to which the congeneric factor analysis model measuring a single latent factor (self-concept in this case) exhibits MI between two groups was investigated with Mplus 7.4 (Muthén and Muthén, 2015). The weighted least squares estimator (WLSMS) and THETA parameterization were used to estimate all the models. DIFFEST was requested to obtain model comparisons between models with different levels of MI.
Generating Raw and Contaminated Data
Our simulation design is based on parameter estimates from a two-group (i.e., U.S. and Hong Kong) factor analysis model for four selected Trends in International Mathematics and Science Study (TIMSS) measures of students' math cognitive self-concept (Mullis et al., 2011). The details of the population model and associated parameters are depicted in Figure 1. As our primary concern is to investigate how ERS and NERS contamination affect four levels of hierarchy for cross-group MI, STRI holds in the true population model; factor loadings, thresholds, and residual variances are equal across two groups, of which the values come from U.S. TIMSS data. To vary the population condition for the two groups, the factor mean and factor variance were respectively fixed to 0 and 1.6 for one group (i.e., U.S. students) and 0.9 and 1 for the other (i.e., Hong Kong students) according to estimates based on the TIMSS data. As WLSMS is known to require large sample size (Boomsma and Hoogland, 2001), n = 3,000 observations for each group is fixed to minimize sampling variability and thus obtain reliable results. One thousand data sets were generated for each manipulated condition.
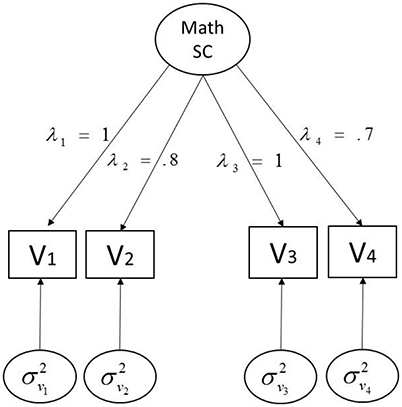
Figure 1. Population model for simulation. λs represent the factor loadings [1, 0.8, 1, 0.7] for V1–V4; σ2s denote the residual variances for V1–V4, and thresholds τs are [0, 2, 3] for V1, [0, 1, 1.5] for V2, and [0, 1, 2] for V3 and V4, respectively.
As indicated above, the current study focuses on ERS and NERS because they are more often seen in reality and clearly prevalent in TIMSS data (see Table 1). We found 20% of the U.S. students chose the end points only while more than 10 percent of Hong Kong (HK) students always selected the middle points for all four of the survey items. The proportion of ERS and NERS are the primary manipulated factor to address our research question. More specifically, if a U.S. respondent has a tendency of ERS, a response pattern of {1,2,4,3} would be expected to convert to {1,1,4,4}, whereas the same response pattern for a HK respondent with a tendency of NERS would convert to {2,2,3,3}. Seven different combined proportions of RS contamination, 5 vs. 5%, 10 vs. 10%, 20 vs. 20%, 10 (HK) vs. 20% (USA), 20 (HK) vs. 30 (USA), 30 vs. 30%, and 40 vs. 40%, were used to transform the raw data into contaminated data with one of the two RSs for one group, i.e., ERS was applied to USA group and NERS was applied to Hong Kong group. This attempts to model the assumption that students in U.S. and HK exhibit ERS and NERS, respectively, in survey items, which has been studied and confirmed by many researchers (e.g., Chen et al., 1995).

Table 1. Percentages of responses to four TIMSS survey items using four-point Likert scales from USA and Hong Kong.
Conducting Measurement Invariance Studies
Following Millsap and Yun-Tein's (2004) guidelines, we proceeded to examine the four levels of MI using the generated data. A few general constraints were imposed for the purpose of scale identification. First, the factor loading of the reference indicator was fixed to 1 whereas other factors loadings were freely estimated. Second, one threshold for each indicator was equally constrained across groups and one additional threshold for the reference indicator was equally constrained across groups. That is to say, two thresholds were constrained for the reference indicator, and one threshold was constrained for all other indicators. Third, the residual variances of the U.S. group were fixed to 1 and those of the HK group were freely estimated. The last general constraint was that the factor mean of the U.S. group was fixed to 0 across all the models. Next, as stated in last section, different sets of parameters were constrained across the models to assess the four levels of MI.
Determining the Effects of ERS and NERS
We applied the CFA model with four levels of MI to analyze eight sets of simulated data (authentic data and data contaminated with seven different percentages of ERS/NERS cases) and obtained a total of 32 sets of estimated results, based on which we could determine the extent of the detrimental effects of different proportions of ERS and NERS to the MI results. As our focus is to address these research concerns from a statistical modeling perspective, we are particularly interested in summarizing aspects of the results to evaluate RS effects from the following two perspectives:
1. Model-data fit. To evaluate the effect on the model-data fit introduced by different RSs, several global model fit indices will be compared: Chi-square test, Chi-square difference test, relative Chi-square (also called normal Chi-square, the ratio of Chi-square test to degree freedom), CFI, TLI, Root Mean Square Error of Approximation (RMSEA), and Weighted Root-Mean-square Residual (WRMR).
2. Parameter recovery. Since additional systematic measurement error is introduced by RSs, we expect that parameter estimates from contaminated data will be more biased as compared with those from less contaminated ones. In our CFA models, the focus will be on the factor loading parameters. The accuracy of each estimated parameter was quantified using bias. Bias is an average difference between true and estimated parameters over all replications:
where θj is the true value of a parameter, and is the estimated value of the parameter for the j-th replication over a total n replications. To gauge the variability of parameter estimates, 90% confidence intervals were also included.
Results
All the models were estimated appropriately except a few replications in the least constrained model imposing only CI. We hypothesized the non-convergent replications may be caused by insufficient sample size or poor starting values because the model with CI requires estimation of more parameters and no starting values were used in our simulation study. As our focal interest is to examine the effects of ERS and NERS on the statistical modeling results, we summarized estimated results in tables in terms of their effects on model fit to data and parameters estimates separately.
RS Effects on Model Fit Indices
Tables 2A,B presents the average model fit results over 1,000 replications for the original and contaminated data (totally eight conditions) in the four levels of MI: CI, WI, SI, and STRI. M0–0 (or M0) represents the model being fitted to the uncontaminated data for both groups and M10–20 represents the models being fitted to one group of data with 10 percentages of NERS and to the other group of data with 20 percentages of ERS. Other models could be interpreted in the same way. Inspecting Tables 2A,B, we found the estimated results based on original (i.e., uncontaminated) data achieved almost perfect model fit to data, as evidenced by the non-significant Chi-square test value, the small ratio of Chi-square test to degree of freedom, perfect CFI, TLI, RMSEA, and WRMR in all M0 results in all four levels of MI models. Moreover, the Chi-square difference testing results also indicates that the restriction of equal factor loadings, equal thresholds, and equal residuals variances do not degrade the model fit to data. Actually the ratio of Chi-square test to degree of freedom decreased, indicating better fit. This result is consistent with the true population model in which STRI holds.
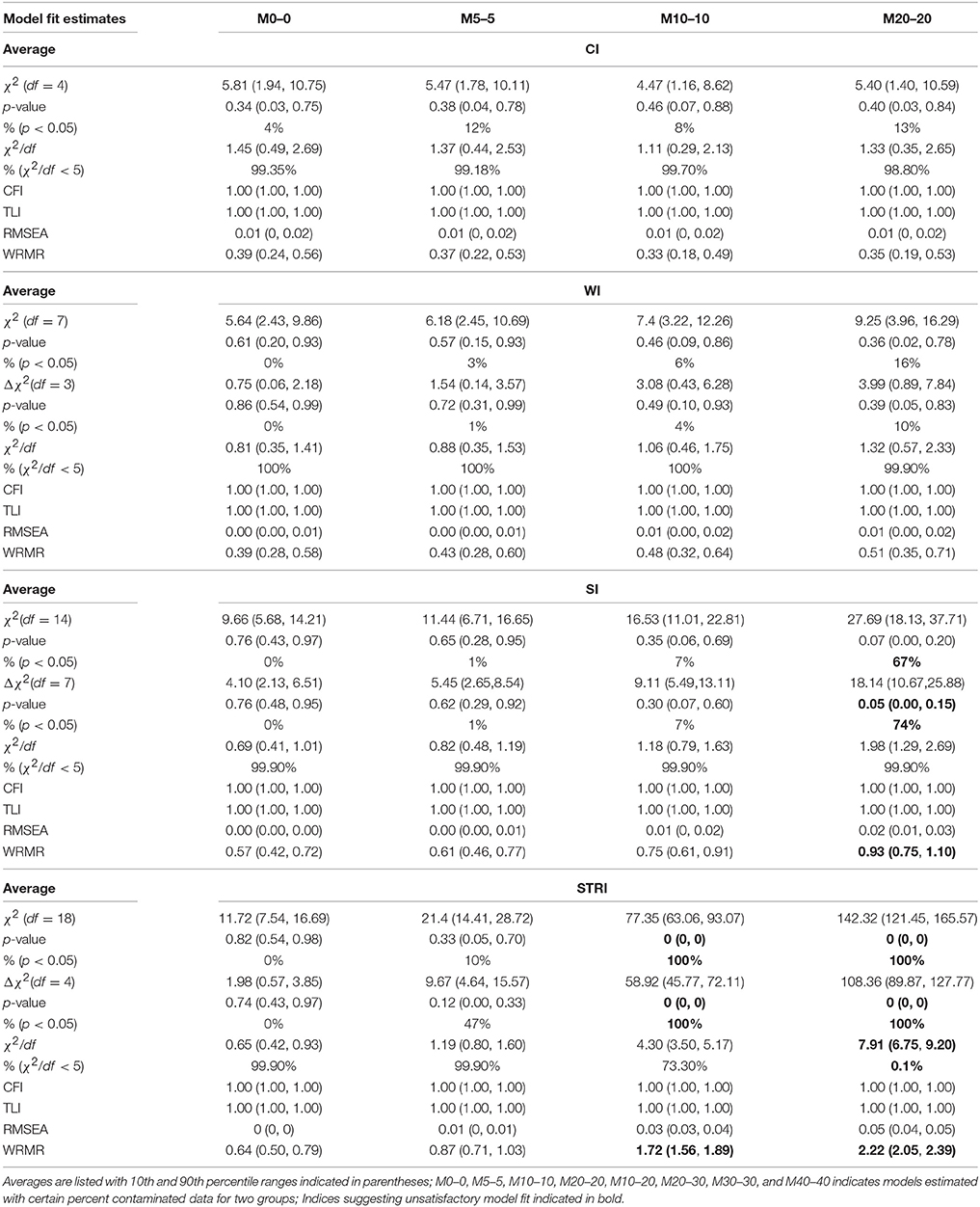
Table 2A. Model fit results from models with four types of measurement invariance across eight different percentages of contaminated data (Conditions 1–4).
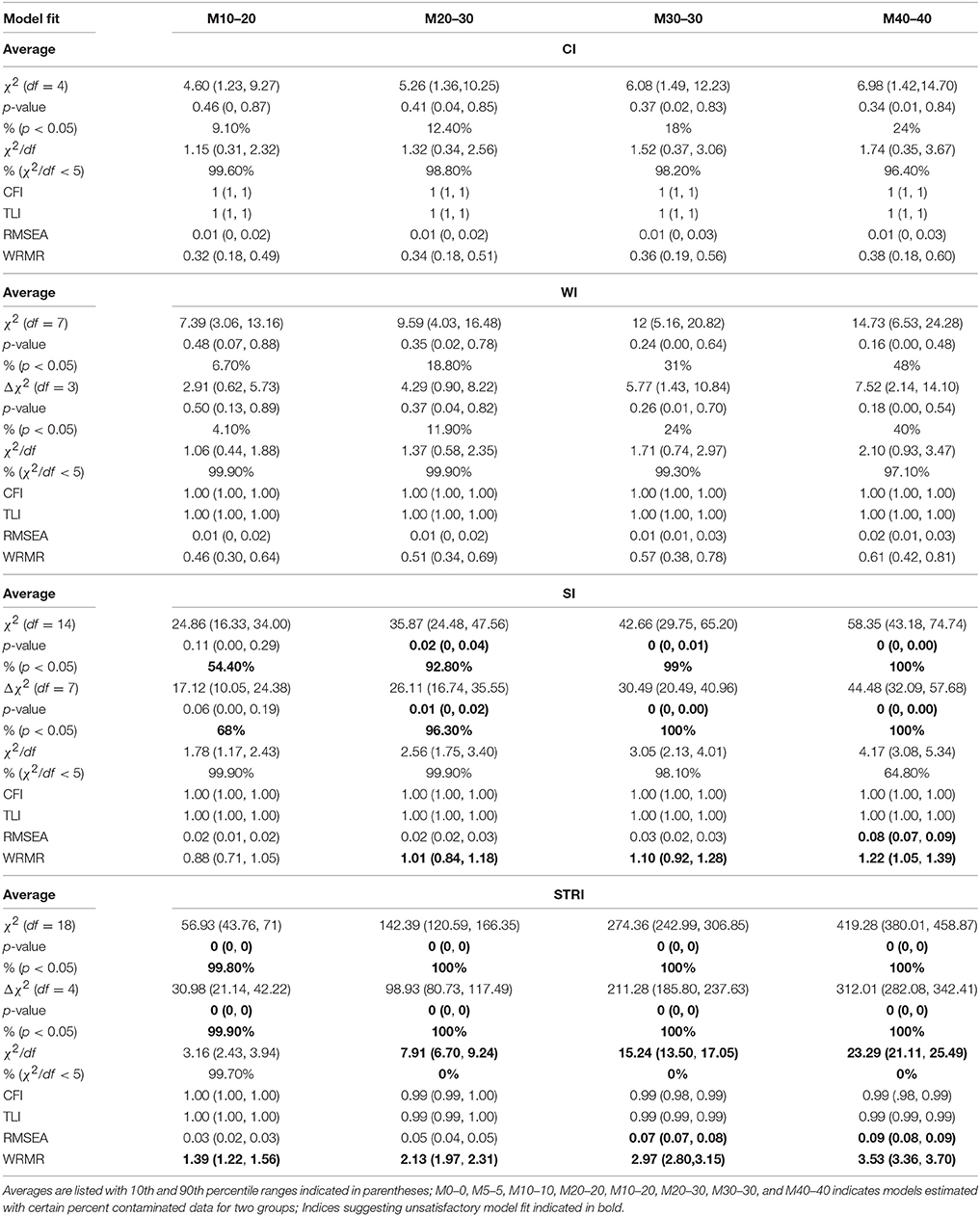
Table 2B. Model fit results from models with four types of measurement invariance across eight different percentages of contaminated data (Conditions 5–8).
In contrast, the model constraints may slightly or substantially decrease model fit using the data contaminated with RSs, as evidenced by the other seven conditions from M5 through M40 across all four levels of MI. In general, CI of this factor analysis model holds for the contaminated data although some model fit indices show increasingly worse fit to data as the percentage of contamination goes up. But the results show the models fit data adequately well.
After equal factor loadings were imposed on the model, as the WI part in Table 2 shows, most model-data fit indices are worse than their corresponding CI models except CFI and TLI. When the proportion of contamination reaches 40%, the probabilities of obtaining significant Chi-square test and Chi-square difference test results increase to 48 and 40% respectively, resulting in higher likelihoods of rejecting the WI model. However, the model fit results are still generally acceptable.
When both equal factor loadings and equal thresholds are imposed on the model (i.e., SI), as shown in the SI part of Table 2, 5 percent of cases with RS does not seem to have a serious effect on model fit as they achieve a satisfactory fit to data; in the M10 models, 10% of contaminated cases increase the chance of achieving a significant Chi-square test and Chi-square difference test above 0.05. Additionally, data sets with 20% contamination result in Chi-square tests and Chi-square difference tests that are significant more than half of what is expected by chance alone, and moreover, the resulting average WRMR of 0.93 exceeds the desired cut score. In the two conditions of unequal percentages of contamination, 10% (NERS) vs. 20% (ERS) and 20% (NERS) vs. 30% (ERS), Chi-square test and Chi-square difference tests tend to be significant more than half of the time. In the latter condition of 20 vs. 30%, WRMR has an average value of 1.01 with 90% confidence interval of 0.84 and 1.18. These results do not support the claim that the models fit the data well. When the percentage of contamination reaches 30%, the Chi-square tests and Chi-square difference tests are always significant, indicating the SI model does not fit the data and the SI model is statistically significantly worse than the WI model; the average value of WRMR increases to 1.10 and almost all of WRMR exceed 0.9. When the percentage reaches 40%, except for the CFI and TLI, all the other model fit indices, including RMSEA, show unacceptable fit to the data. The Chi-square to df ratio suggests that the models do not fit the data about 35% of the time.
The tolerance of STRI models to the contaminated data is even lower. Five percent contamination results in the chance of obtaining statistically significant Chi-square tests and Chi-square difference tests; 10 percent contamination leads to significant Chi-square and Chi-square difference tests and an unsatisfactory average WRMR of 1.72 with 90 percent of confidence interval above 1.56. When the percentage contamination increases to 20 (NERS) and 30 (ERS), most model fit indices indicate unacceptable fit to data except CFI, TLI, and RMSEA. When the percentage of contaminated cases is 30 or above, RMSEA also suggests unsatisfactory model fit results.
Sensitiveness of Model Fit Indices to RSs
According to Tables 2A,B, clearly, the SEM model fit indices that were examined in the current study exhibit different degrees of sensitiveness to the inclusion of contaminated cases. CFI and TLI are the least sensitive measures as they always indicate a perfect fit to data regardless of how many percentage of NERS and ERS cases were included. RMSEA only indicates misfit for SI and STRI models when the percentage of cases goes up to 40 percent. As compared with CFI, TLI, and RMSEA, Chi-square test, Chi-square difference test, and relative Chi-square test are more sensitive to the inclusion of two types of RSs to the data. Using the suggested ratio of 5 (Jackson et al., 1993, p. 755), relative Chi-square test may alert misfit for STRI models when the percentages of contamination are 20% or above. Both Chi-square and Chi-square difference tests are more likely (above 50%) to indicate unfit/less fit for SI models than WI models when the percentage of contamination is 20% or above. Only 10% of contaminated cases would result in STRI models being rejected by the Chi-square and Chi-square difference tests. Among all the fit indices, WRMR may be the most sensitive one to the contaminated cases as it shows misfit for SI models when the percentages of NERS and ERS cases are 20% or above and for STRI models when the percentages reach 10%.
RS Effects on Parameter Estimates
The results of parameter estimates from models with four levels of MI were summarized in Table 3 through Table 6, respectively. All the tables have the same structure. The first two columns list the parameter to be estimated and the true population values for those parameters. As indicated above, M0–0 to M40–40 represent models estimated from data with percentages of contamination varying from 0 to 40% for two groups. Under each model, the bias of parameter estimates and 90% confidence intervals are presented in three columns to evaluate the quality of the parameter estimates. For the non-contaminated data, the estimated parameter results are presented in the M0 section, we found estimation bias in the least residual constrained CI models, in which thresholds are underestimated and residual variances are overestimated for one group, most likely due to CI being the most complicated model, and thus requiring more parameters to be estimated. The bias in other more constrained models, WI, SI, and STRI models, is negligible.
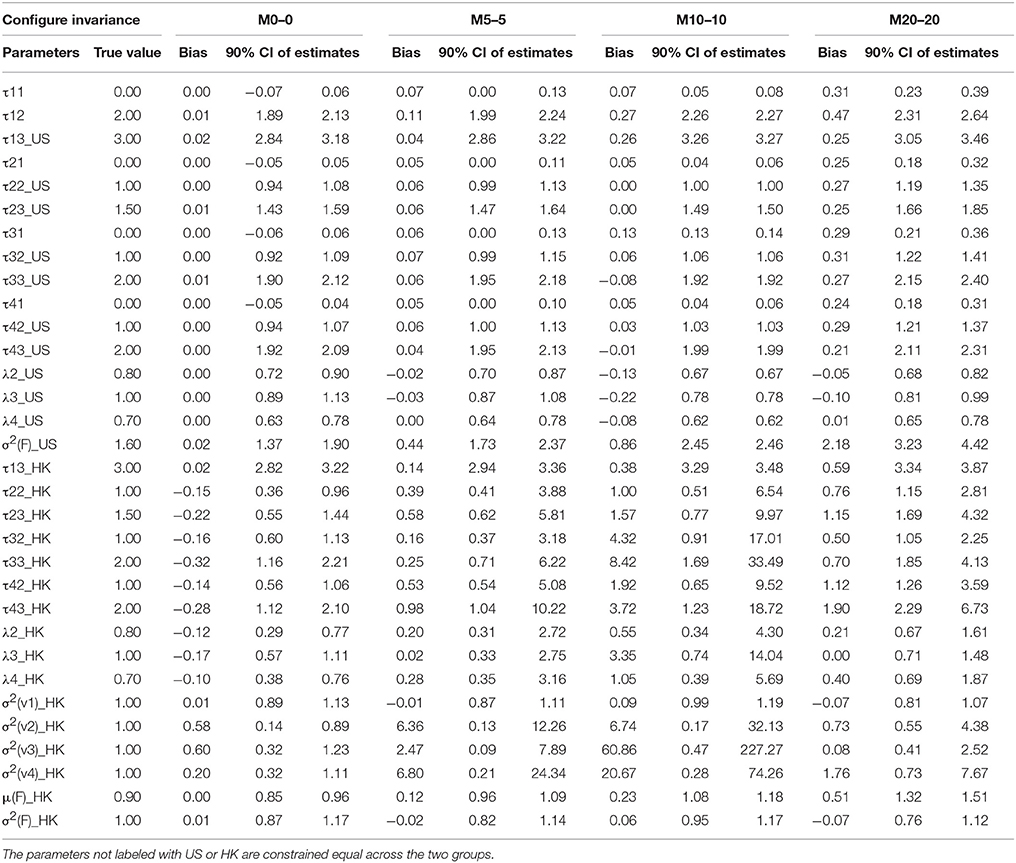
Table 3A. Summary of parameter estimates for models with configural invariance across eight different percentages of contaminated data (Conditions 1–4).
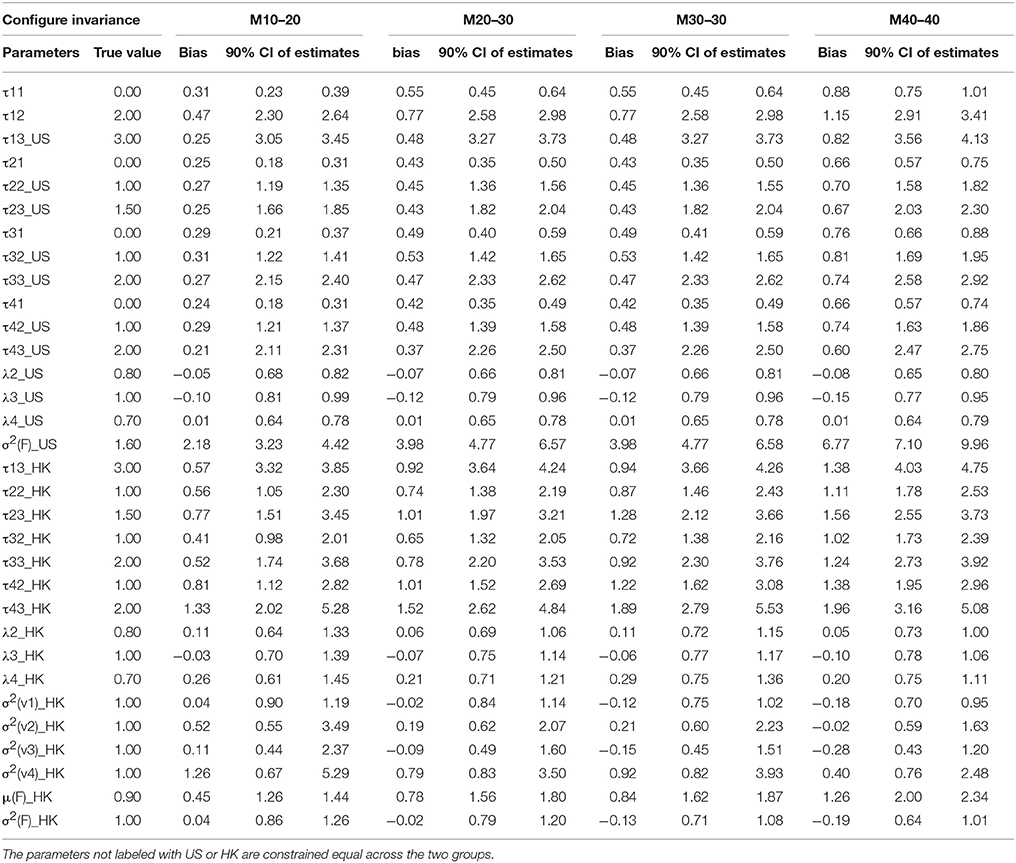
Table 3B. Summary of parameter estimates for models with configural invariance across eight different percentages of contaminated data (Conditions 5–8).
Factor Loadings λs
Factor loadings λs are our primary concern as they represent the relationship between the latent factor and its manifested indicators; they are comparable to slopes in regression analysis, in which factors are predictors and indicators are dependent variables. Therefore, they are the first and most important criteria in evaluating MI using CFA. Inspecting M0 sections across all the four tables, we found that—except for the slightly underestimated factor loadings of the HK group (λi HK) in the CI model—all the other factor loadings in the models with CI or above are appropriately estimated via the original data because all the average estimates over 1,000 replications are nearly identical to the true population values. When the data included contaminated cases, as reflected by M5 to M40 in Tables 3–6, nearly all the estimates of the factor loadings in the models are biased. In general, the absolute bias increases with the percentage of contaminated cases. It is worth noting that the bias is substantial and could not be ignored.
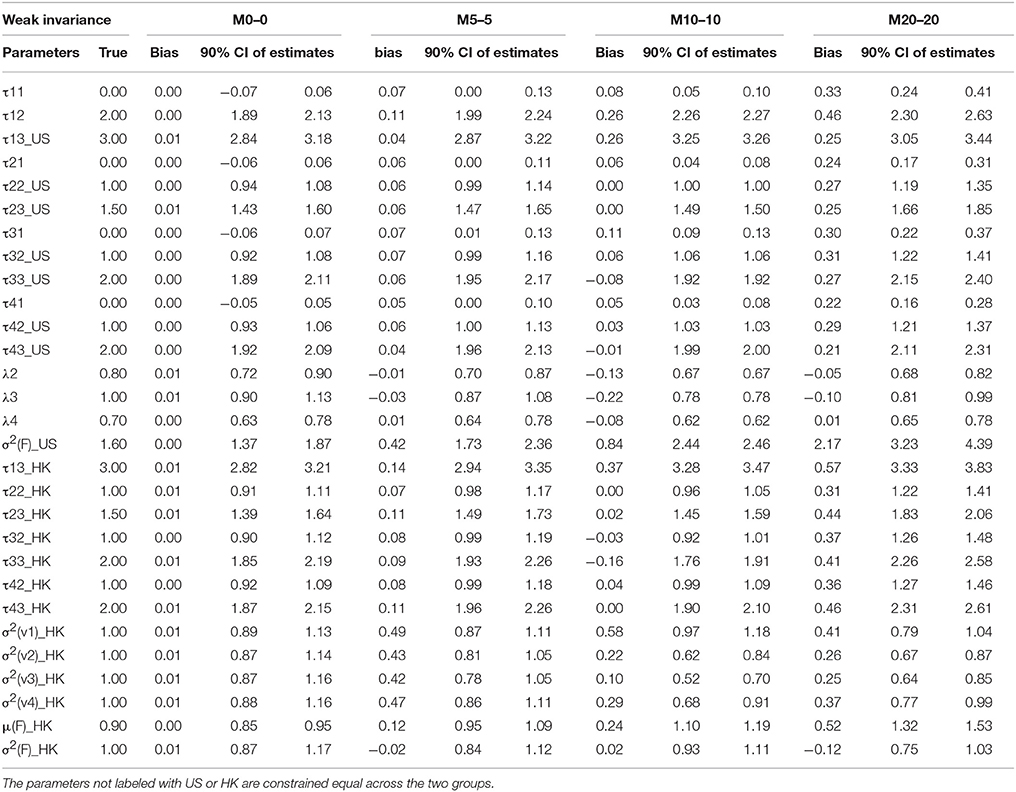
Table 4A. Summary of parameter estimates for models with weak invariance across eight different percentages of contaminated data (Conditions 1–4).
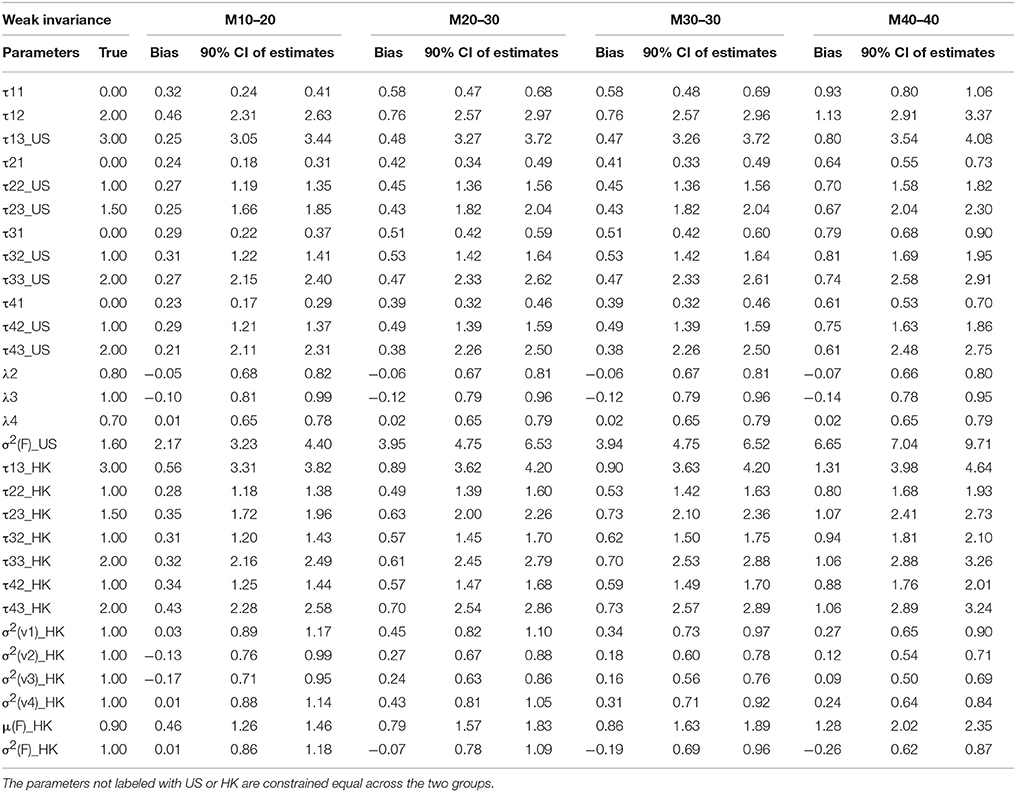
Table 4B. Summary of parameter estimates for models with weak invariance across eight different percentages of contaminated data (Conditions 5–8).
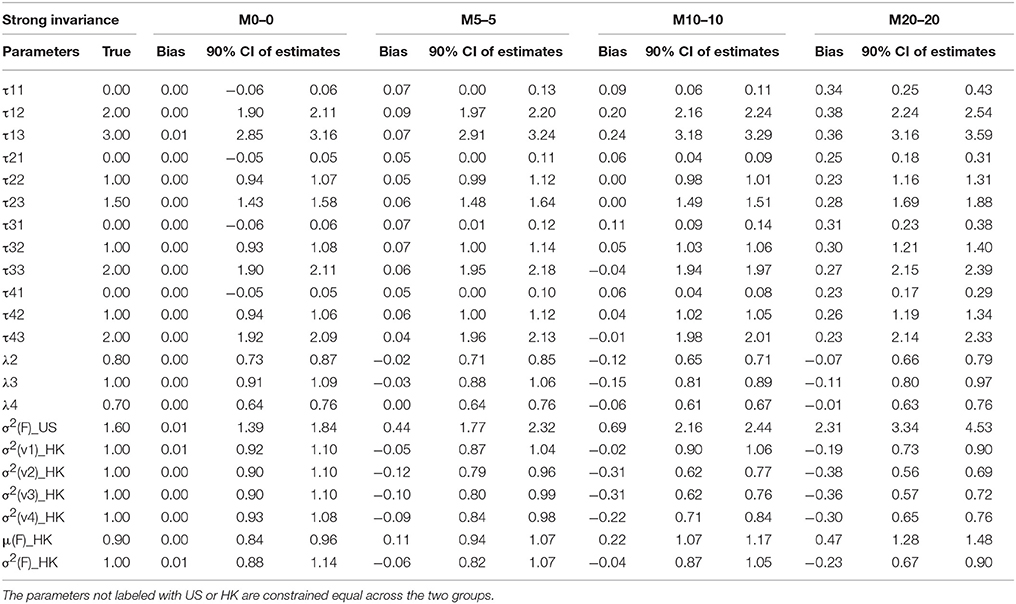
Table 5A. Summary of parameter estimates for models with strict invariance across eight different percentages of contaminated data (Conditions 1–4).
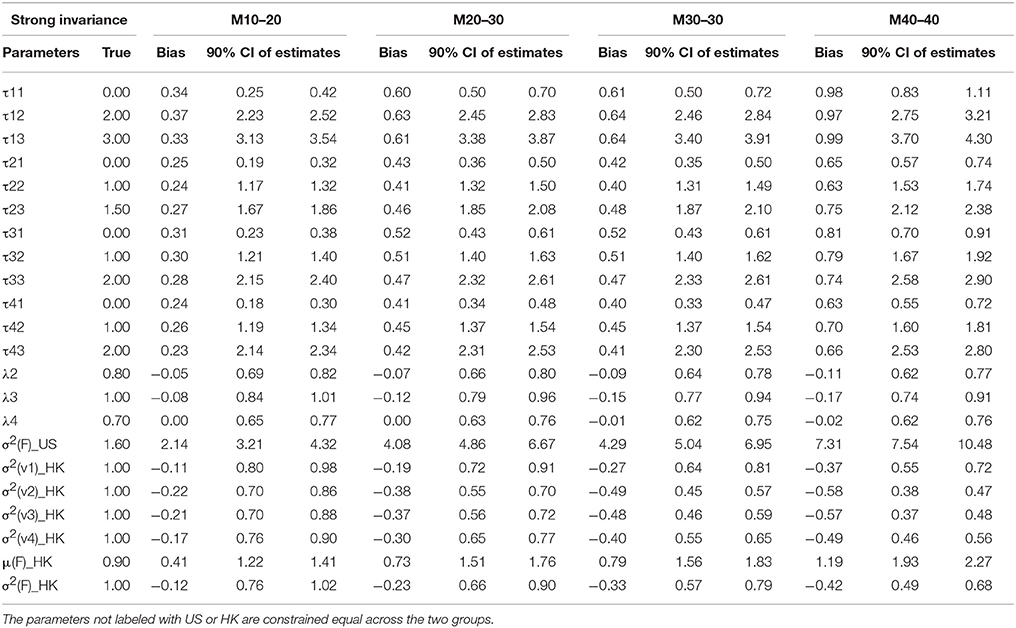
Table 5B. Summary of parameter estimates for models with strong invariance across eight different percentages of contaminated data (Conditions 5–8).
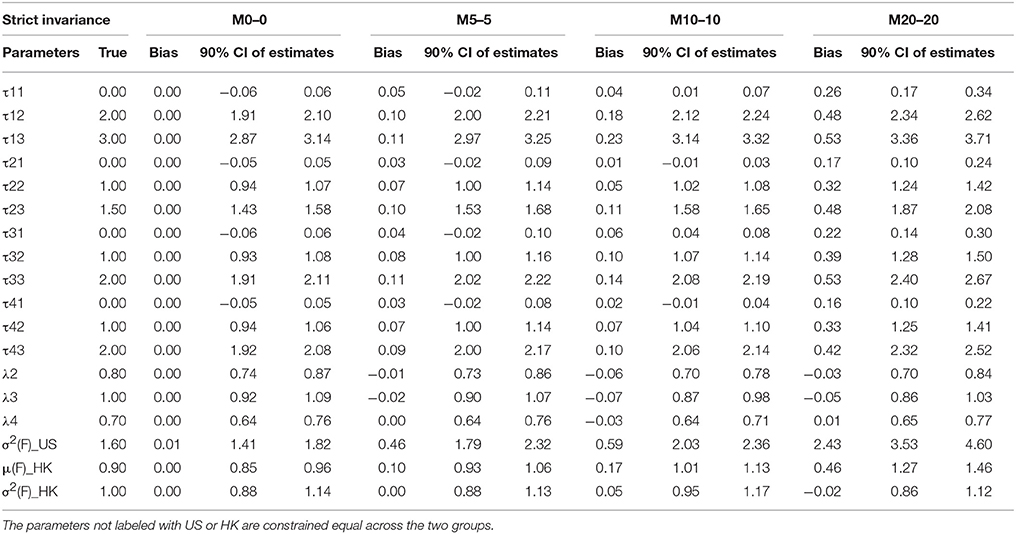
Table 6A. Summary of parameter estimates for models with strong invariance across eight different percentages of contaminated data (Conditions 1–4).
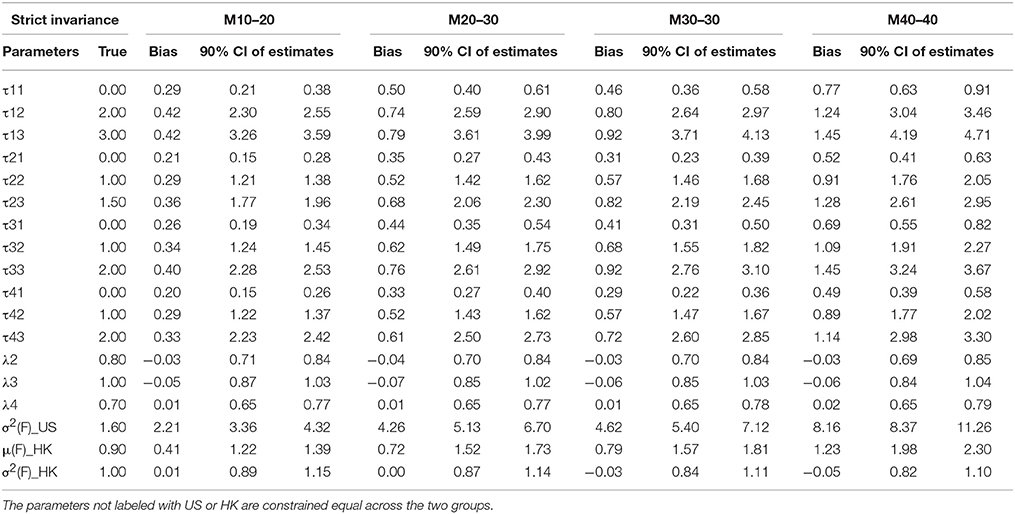
Table 6B. Summary of parameter estimates for models with strict invariance across eight different percentages of contaminated data (Conditions 5–8).
Thresholds τs
Thresholds τs are the next parameter to be constrained to achieve a higher level of MI, namely SI. The invariance of thresholds is the second necessary requirement for comparison of latent means (Muthén and Christoffersson, 1981; Millsap and Yun-Tein, 2004). Taking a closer look at τs from Tables 3–6, we found estimates of thresholds for M0 models using SI and STRI are almost perfect, more accurate than those obtained using CI and WI. This result is reasonable as thresholds are constrained equal across the two groups in SI and STRI models, which is consistent with the true population setting and with fewer parameters being estimated. Comparing threshold estimates for the two groups using CI and WI, estimates for the US group are closer to the true values, while threshold estimates for the HK group tend to be more biased. Inspecting τ estimates in each table, we generally find that, as the percentage of contaminated cases increases, most thresholds are more inclined to be over- or under-estimated. In other words, threshold estimates are more biased as more contaminated cases were included.
Residual Variances
Residual variances were fixed to 1 in the US group for model identification purposes, whereas they were freely estimated for the HK group in models with CI, WI, or SI constraints. Estimates in SI and WI models are reasonable although they are apparently deflated in the WI models as the percentage of RS contamination goes up, and slightly inflated in SI models. Some extremely large estimates of residual variances were found in less than five simulatations under CI. However, the highly distorted estimates for residual variance were in models holding CI. As said earlier, those extreme cases may be caused by insufficient sample size or more likely because no reasonable starting values were used in estimating most parameters among the four types of MI models.
Factor Means and Factor Variance
Factor means and factor variance difference between groups usually are researchers' focal interest when conducting cross-nation comparisons like the example data we used. Small percentages of contamination may not prevent models from achieving MI, and therefore researchers may compare two groups in terms of the two types of factor parameters. As shown in Tables 3–6, they could be estimated accurately if no contaminated cases were included. But as the percentages of NERS and ERS cases increase, they tend to be more biased.
Discussion
The pervasiveness of survey research using Likert-type scales in a multitude of disciplines is generally unquestioned. But the various RSs possibly employed by participants taking these surveys and their potential effects on statistical modeling such as MI have long been ignored, unassessed or simply not reported. As many researchers have noted, the validity of MI from survey data is necessary to ensure that the results of cross-group comparison studies involving latent factors will be appropriate, meaningful, and interpretable.
We have observed that many studies examined MI directly but fail to consider or examine RSs. Only a few studies tried to address RSs together with MI. As they studied RSs using real data, given the fact that the researchers did not know the true nature underlying the data, applied researchers may assume RSs do not have substantial deleterious effects and consequently not apply any effort to detect and correct for these effects.
Our simulation results clearly demonstrated that the magnitude of these effects is not neglible, especially when the proportion of contaminated cases is not too small. Researchers should not ignore RSs such as ERS and NERS because they have significant impact on both model fit and parameter estimates. Five percent of cases contaminated by RSs may not have a significantly detrimental impact to the four levels of MI. This finding indicates model fit indices are not very sensitive to the inclusion of small proportion of RSs, exhibiting certain degree of resilience. Ten percent contamination may further cause STRI to fail, even though the true data held this property. Larger percentages of contamination may result in more severe distortion of model fit results, and in turn, rejection of theoretically correct MI models.
It appears that CFI and TLI are not helpful in detecting model misfit when RSs are introduced to data as they almost always suggest sufficient fit to data. RMSEA can detect the effect of RSs only when the percentages of RSs is very large, such as 40 percent in our case. The Chi-square test family, including Chi-square, Chi-square difference test, and relative Chi-square test, are much more sensitive to the inclusion of contaminated data when the percentages of contamination reach 10 or 20 percent. WRMR may be the most sensitive index because it can alert researchers to model misfit when the percentage reaches 20 for SI models or 10 or less for STRI models.
The effect of varying RSs on parameter estimation is even more substantial. Even five percentages of RS contamination can lead to biased estimates for the factor loadings, the thresholds, residual variance and factor means and variance. Generally, researchers would expect that the larger percentage of contaminated cases, the larger the estimation bias, as evidenced by the simulation results. The empirical 90% confidence intervals of parameter estimates also confirm that the bias of estimates are not ignorable. Moreover, the difference between parameter estimates of two groups was increased by RSs, which directly threaten the validity of MI and render meaningless group comparison by obscuring or exaggerating actual group differences.
This study is expected to have important implications for researchers or practitioners who are interested in studying construct comparability across groups. We would suggest that the examination of the possible presence of RSs should be routine when testing for MI. Although we have not finished examining all possible RSs, the evidence presented here is sufficient to alert researchers to the possible negative effects brought about by the presence of ERS and NERS or potentially other unexamined RSs. The finding of the current study is informative for practitioners to determine what percentages of NERS and ERS may present a serious threat to MI and which model fit indices are more sensitive to detect the RSs in the data. As our original model without RS contamination meets the highest level of MI, STRI, it is reasonable to predict that if the same percentage of contaminated cases were added to the data, to which SI or WI is assumed, the estimated model fit and parameter estimate results would be even worse than what were presented here.
Author Contributions
Estimate of contributions: ML: conceptualization, 60%; writing the article, 80%; analyzing data, 100%. AGH: conceptualization, 30%; writing the article 20%. JRH: conceptualization, 5%. GRH: conceptualization, 5%.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Barnette, J. J. (1999). Nonattending respondent effects on internal consistency of self-administered surveys: a Monte Carlo simulation study. Educ. Psychol. Meas. 59, 38–46. doi: 10.1177/0013164499591003
Baumgartner, H., and Steenkamp, J.-B. E. M. (2001). Response styles in marketing research: a cross-national investigation. J. Market. Res. 38, 143–156. doi: 10.1509/jmkr.38.2.143.18840
Bond, M. H., and Hwang, K. K. (1986). “The social psychology of Chinese people,” in The Psychology of Chinese People, ed M. H. Bond (Oxford: Oxford University Press), 213–266.
Boomsma, A., and Hoogland, J. J. (2001). “The robustness of LISREL modeling revisited,” in Structural Equation Models: Present and Future. A Festschrift in Honor of Karl Jöreskog, eds R. Cudeck, S. du Toit, and D. Sörbom (Chicago: Scientific Software International), 139–168.
Buckley, J. (2009). Cross-National Response Styles in International Educational Assessments: Evidence from PISA 2006. Retrieved from: https://edsurveys.rti.org/PISA/documents/Buckley_PISAresponsestyle.pdf
Cavusgil, S. T., and Das, A. (1997). Methodological issues in empirical cross-cultural research: a survey of the management literature and a framework. MIR. Manage. Int. Rev., 37, 71–96.
Chen, C., Lee, S., and Stevenson, H. W. (1995). Response style and cross-cultural comparisons of rating scales among east Asian and north American students. Psychol. Sci. 6, 170–175.
Cheung, G. W., and Rensvold, R. B. (2000). Assessing extreme and acquiescence response sets in cross-cultural research using structural equation modeling. J. Cross Cult. Psychol. 31, 187–212. doi: 10.1177/0022022100031002003
Costa, P. T., and McCrae, R. R. (1992). Revised NEO Personality Inventory (NEO-PI-R) and NEO Five-Factor Inventory (NEO-FFI). Odessa, FL: Psychological Assessment Resources.
Horn, J. L., and McArdle, J. J. (1992). A practical guide to measurement invariance in aging research. Exp. Aging Res. 18, 117–144.
Jackson, P. R., Wall, T. D., Martin, R., and Davids, K. (1993). New measures of job control, cognitive demand, and production responsibility. J. Appl. Psychol. 78, 753–762.
Johnson, T. R. (2003). On the use of heterogeneous thresholds ordinal regression models to account for individual differences in response style. Psychometrika 68, 563–583. doi: 10.1007/BF02295612
Jöreskog, K. G. (1971). Simultaneous factor analysis in several populations. Psychometrika 36, 409–426.
Jöreskog, K. G., and Sörbom, D. (2015). LISREL 9.2 for Windows [Computer Software]. Skokie, IL: Scientific Software International, Inc.
Kankaraš, M., and Moors, G. (2009). Measurement equivalence in solidarity attitudes in Europe: insights from a multiple group latent class factor approach. Int. Sociol. 24, 557–579. doi: 10.1177/0268580909334502
Kankaraš, M., and Moors, G. (2011). Measurement equivalence and extreme response bias in the comparison of attitude across Europe: a multigroup latent class factor approach. Methodology 7, 68–80. doi: 10.1027/1614-2241/a000024
Khine, M. S. (2008). Knowing, Knowledge and Beliefs: Epistemological Studies across Diverse Cultures. Springer Netherlands.
Lam, T. C. M., and Klockars, A. J. (1982). Anchor point effects in the equivalence of questionnaire items. J. Educ. Meas. 19, 317–322. doi: 10.1111/j.1745-3984.1982.tb00137.x
Little, T. D. (1997). Mean and covariance structures (MACS) analyses of cross-cultural data: practical and theoretical issues. Multivariate Behav. Res. 32, 53–76.
Liu, Y., Wu, A. D., and Zumbo, B. D. (2010). The impact of outliers on Cronbach's coefficient alpha estimate of reliability: ordinal/Rating scale item responses. Educ. Psychol. Meas. 70, 5–21. doi: 10.1177/0013164409344548
Lombardi, L., and Pastore, M. (2012). Sensitivity of fit indices to fake perturbation of ordinal data: a sample by replacement approach. Multivariate Behav. Res. 47, 519–546. doi: 10.1080/00273171.2012.692616
Marsh, H. W., Nagengast, B., and Morin, A. J. S. (2012). Measurement invariance of big-five factors over the life span: ESEM tests of gender, age, plasticity, maturity, and LaDolce Vita effects. Dev. Psychol. 49, 1194–1218. doi: 10.1037/a0026913
Messick, S. (1962). Response style and content measures from personality inventories. Educ. Psychol. Meas. 22, 41–56.
Millsap, R. E., and Olivera-Aguilar, M. (2012). “Investigating measurement invariance using confirmatory factor analysis,” in Handbook of Structural Equation Modeling, ed R. Hoyle (New York, NY: Guilford Press), 380–392.
Millsap, R. E., and Yun-Tein, J. (2004). Assessing factorial invariance in ordered-categorical measures. J. Multivariate Behav. Res. 39, 479–515. doi: 10.1207/S15327906MBR3903_4
Moors, G. (2003). Diagnosing response style behavior by means of a latent-class factor approach. Socio-demographic correlates of gender role attitudes and perceptions of ethnic discrimination reexamined. Qual. Quant. 37, 277–302. doi: 10.1023/A:1024472110002
Moors, G. (2004). Facts and artifacts in the comparison of attitudes among ethnic minorities: a multigroup latent class structure model adjustment for response style behavior. Eur. Sociol. Rev. 20, 303–320. doi: 10.1093/esr/jch026
Morren, M., Gelissen, J. P. T. M., and Vermunt, J. K. (2011). Dealing with extreme response style in cross-cultural research: a restricted latent class factor approach. Sociol. Methodol. 41, 13–47. doi: 10.1111/j.1467-9531.2011.01238.x
Mullis, I. V. S., Martin, M. O., Foy, P., and Arora, A. (2011). TIMSS 2011 International Mathematics Report: International Association for the Evaluation of Educational Achievement (IEA).
Muthén, B., and Christoffersson, A. (1981). Simultaneous factor analysis of dichotomous variables in several groups. Psychometrika 46, 407–419. doi: 10.1007/BF02293798
Muthén, L. K., and Muthén, B. O. (2015). Mplus User's Guide, 7th Edn. Los Angeles, CA: Muthén & Muthén.
Paulhus, D. L. (1991). “Measurement and control of response bias,” in Measures of Personality and Social Psychological Attitudes, eds J. P. Robinson, P. Shaver, and L. S. Wrightsman (San Diego, CA: Academic Press), 17–59.
Preston, C. C., and Colman, A. M. (2000). Optimal number of response categories in rating scales: reliability, validity, discriminating power, and respondent preferences. Acta Psychol. 104, 1–15. doi: 10.1016/S0001-6918(99)00050-5
Rost, J., Carstensen, C. H., and von Davier, M. (1997). “Applying the mixed rasch model to personality questionnaires,” in Applications of Latent Trait and Latent Class Models in the Social Sciences, eds J. Rost and R. Langeheine (Münster: Waxmann), 324–332.
Van Vaerenbergh, Y., and Thomas, T. D. (2013). Response styles in survey research: a literature review of antecedents, consequences, and remedies. Int. J. Public Opin. Res. 25, 195–217. doi: 10.1093/ijpor/eds021
Vandenberg, R. J., and Lance, C. E. (2000). A review and synthesis of the MI literature: Suggestions, practices, and recommendations for organizational research. Organ. Res. Methods 3, 4–69. doi: 10.1177/109442810031002
Keywords: extreme response style, non-extreme response style, measurement invariance, cross-group comparison, survey research
Citation: Liu M, Harbaugh AG, Harring JR and Hancock GR (2017) The Effect of Extreme Response and Non-extreme Response Styles on Testing Measurement Invariance. Front. Psychol. 8:726. doi: 10.3389/fpsyg.2017.00726
Received: 29 September 2016; Accepted: 21 April 2017;
Published: 23 May 2017.
Edited by:
Holmes Finch, Ball State University, USAReviewed by:
Antonio Calcagnì, University of Trento, ItalyDylan Molenaar, University of Amsterdam, Netherlands
Copyright © 2017 Liu, Harbaugh, Harring and Hancock. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Min Liu, bWlubGl1QGhhd2FpaS5lZHU=