 Dana L. Chesney
Dana L. Chesney Percival G. Matthews
Percival G. Matthews- 1Department of Psychology, St. John’s University, Jamaica, NY, United States
- 2Department of Educational Psychology, University of Wisconsin-Madison, Madison, WI, United States
The Approximate Number System (ANS) allows individuals to assess nonsymbolic numerical magnitudes (e.g., the number of apples on a tree) without counting. Several prominent theories posit that human understanding of symbolic numbers is based – at least in part – on mapping number symbols (e.g., 14) to their ANS-processed nonsymbolic analogs. Number-line estimation – where participants place numerical values on a bounded number-line – has become a key task used in research on this mapping. However, some research suggests that such number-line estimation tasks are actually proportion judgment tasks, as number-line estimation requires people to estimate the magnitude of the to-be-placed value, relative to set upper and lower endpoints, and thus do not so directly reflect magnitude representations. Here, we extend this work, assessing performance on nonsymbolic tasks that should more directly interface with the ANS. We compared adults’ (n = 31) performance when placing nonsymbolic numerosities (dot arrays) on number-lines to their performance with the same stimuli on two other tasks: Free estimation tasks where participants simply estimate the cardinality of dot arrays, and ratio estimation tasks where participants estimate the ratio instantiated by a pair of arrays. We found that performance on these tasks was quite different, with number-line and ratio estimation tasks failing to the show classic psychophysical error patterns of scalar variability seen in the free estimation task. We conclude the constraints of tasks using stimuli that access the ANS lead to considerably different mapping performance and that these differences must be accounted for when evaluating theories of numerical cognition. Additionally, participants showed typical underestimation patterns in the free estimation task, but were quite accurate on the ratio task. We discuss potential implications of these findings for theories regarding the mapping between ANS magnitudes and symbolic numbers.
Introduction
Humans and many nonhuman animals are equipped with a phylogenetically ancient approximate number system (ANS) that allows them to rapidly enumerate the items in a set without counting (Kaufman et al., 1949; Mechner, 1958; Meck and Church, 1983; Feigenson et al., 2004; Izard and Dehaene, 2008). These findings have led many to conclude that the meanings of symbolic numbers are grounded in part by mapping number symbols (e.g., 5) to their nonsymbolic analogs (e.g., an array of 5 dots) (Nieder and Dehaene, 2009). This obvious symbol-to-referent match is a large part of the appeal of the analog portion of Dehaene (1992) triple code model and of Piazza (2010) hypothesis about the ANS’ role as a neurocognitive start-up tool for number concepts. Although there is substantial disagreement surrounding ANS-as-foundation arguments (e.g., Lyons et al., 2012; De Smedt et al., 2013; Reynvoet and Sasanguie, 2016; Leibovich et al., 2017; Núñez, 2017), this point of view remains widespread.
Number-line estimation – in which participants place numerical values on a bounded number-line – has become a key task used in research on the link between symbolic numbers and numerical magnitudes (Siegler and Opfer, 2003; Whyte and Bull, 2008; Schley and Peters, 2014). Some consider the spacing and precision of number-line placements to directly reflect the spacing and precision of the magnitudes mapped to symbolic numbers (Siegler and Opfer, 2003; Whyte and Bull, 2008). However, this interpretation of number-line performance remains contested. Some researchers (e.g., Barth and Paladino, 2011) argue that number-line tasks are proportion judgment tasks as they require people to estimate the magnitudes of the stimuli relative to the endpoints. Prior research indicates such anchored tasks are fundamentally different from tasks for which participants are free to give any response (Banks and Coleman, 1981; Hollands and Dyre, 2000). As such, task demands may influence participants’ mapping responses.
Moreover, there is reason to question the underlying assumption that people can exploit a 1-to-1 map from symbols to their analog numerosities. More than 75 years of research suggest that the vast majority of educated humans cannot accurately make such mappings (Taves, 1941; Kaufman et al., 1949; Indow and Ida, 1977; Krueger, 1984; Izard and Dehaene, 2008; Crollen et al., 2011). In study after study, ANS-based estimations yield under-estimations, and performance varies considerably between participants (Indow and Ida, 1977; Krueger, 1984; Izard and Dehaene, 2008). Given that ANS-based estimation is both inaccurate generally and inconsistent among individuals, it is difficult to see how such a system can be used for grounding symbolic numbers.
Here we seek to clarify principles governing the potential links between ANS-perceived magnitudes and symbolic numbers and how responses based on those links are affected by different task constraints. We investigated how three separate tasks that employ the same sorts of ANS stimuli lead to differences in mapping performance: free estimation, number-line estimation, and ratio estimation.
Predictions
Free Estimation
In free estimation tasks, participants are instructed to give numerical estimates for a range of stimuli whose magnitudes vary on a given dimension, with no given upper bound. This sort of estimation with numerosities has often been described as representing subjective numerical magnitudes in a logarithmic fashion, such that the perceived distance between stimuli is proportional to the logarithm of the ratio between them (e.g., Moyer and Landauer, 1967; Dehaene, 1992). Hence, the perceived difference between 10 and 20 dots is the same as that between 22 and 44, or that between 32 and 64 dots. Izard and Dehaene (2008) offered a model whereby idiosyncrasies in mapping between logarithmically encoded perceived magnitude and actual symbolic numerical responses results in performance that is typically fit by power functions (e.g., Stevens, 1957; Crollen et al., 2011; but see Cordes et al., 2001, for a linear interpretation). Indeed, performance patterns on such unbounded estimations in general – whether involving numerosities or other magnitudes like auditory volume or light intensities – are typically fit by accelerating or decelerating power functions [perceived stimulus intensity = C ∗ (Actual stimulus intensity)B, where B is the Stevens’ exponent e.g., Stevens, 1957; Indow and Ida, 1977; Krueger, 1984; Crollen et al., 2011].
In the ANS-based free estimation task we use here, participants were asked to provide estimates of the numerosity of nonsymbolic numerical stimuli (dot arrays). We expected unbounded estimation with dot arrays to be characterized by compressive power functions (i.e., Stevens’ exponent < 1), as is consistent with established theory and prior empirical findings (e.g., Stevens, 1957; Crollen et al., 2011). We also expected estimates to exhibit scalar variability (Cordes et al., 2001; Izard and Dehaene, 2008; Crollen et al., 2011). That is, we expected the variability of estimates to increase in proportion to the size of the stimulus, resulting in a constant coefficient of variation (Whalen et al., 1999; Gallistel and Gelman, 2000; Izard and Dehaene, 2008).
Number-Line Estimation
Our predictions for number line estimation are based on Barth and Paladino (2011) argument that these tasks cannot properly be categorized as free numerical estimation tasks and that they are actually a form of a proportion judgment task. Number line estimation requires that people estimate the magnitude of one stimulus, the to-be-placed value, relative to two other stimuli, the upper and lower endpoints (Spence, 1990; Hollands and Dyre, 2000; Hollands et al., 2002; but see Opfer et al., 2011). For example, when placing 25 on a 0–100 line (whether symbolic or nonsymbolic), it should be 25 units away from 0, and 75 units away from 100. It should therefore be placed at a point corresponding to the proportion between the stimulus and the sum of the stimulus and its complement (25/(25 + 75)), or one fourth of the total length of the line away from 0. No matter what number is estimated, the line must, similarly, be broken into two sections with a constant sum, resulting in a proportion. Spence (1990) offered a cyclical correction to the power model used to describe free estimation that could account for the proportional nature of tasks like number line estimation. This cyclical power model predicts nearly linear performance on number line estimation tasks even given compressive underlying subjective representations of numerical magnitudes (see also Hollands and Dyre, 2000; Hollands et al., 2002; Barth and Paladino, 2011). However, in approaching linearity, cyclical power models show specific patterns of over- and under-estimation for estimates in different segments of the range defined by specific cut points (see Figure 1).
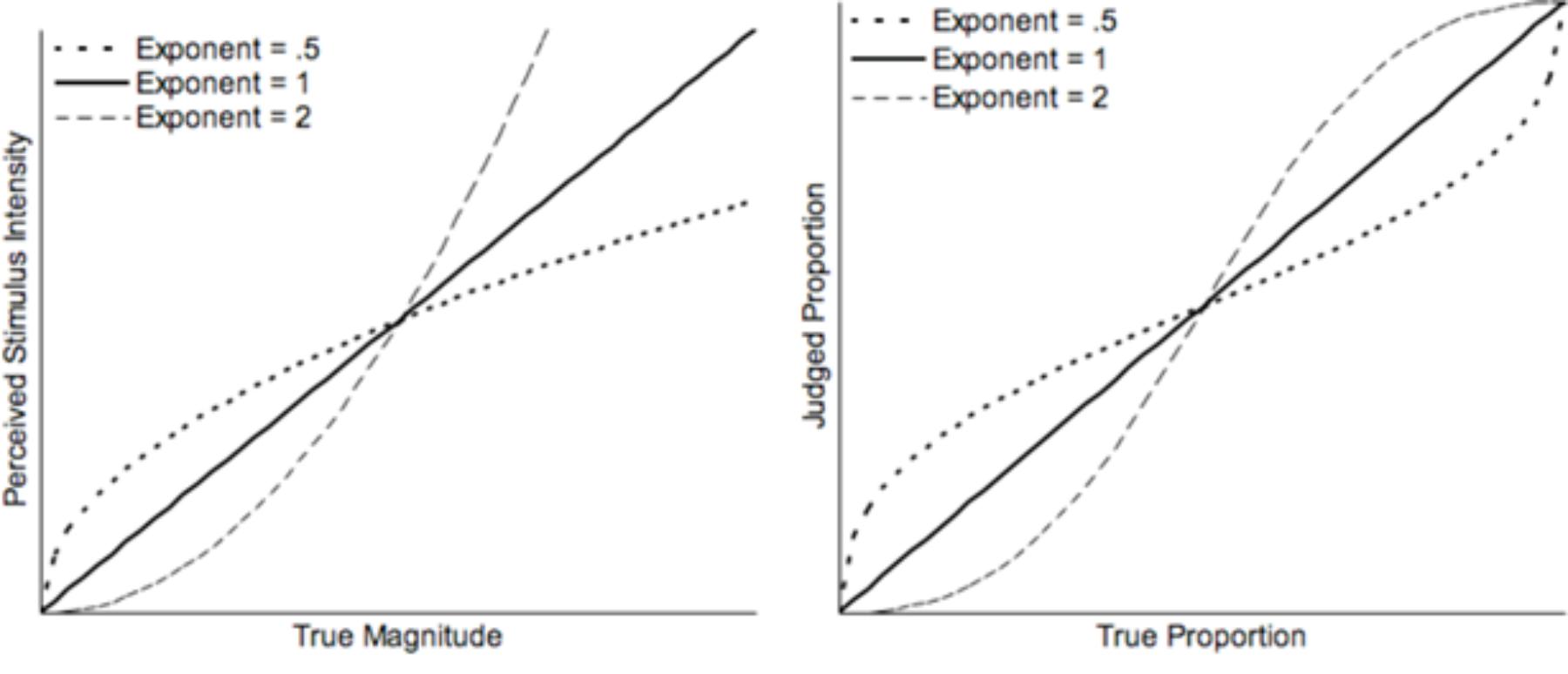
FIGURE 1. Left: Perceived stimulus intensity as a function of true magnitude as predicted by a power model with exponents of 0.5, 1, or 2. Values are scaled such that the perceived intensity of central magnitudes are equal. Right: Judged proportion as a function of true proportion as predicted by a cyclical power model with exponents of 0.5, 1, or 2. The functions illustrated in these graphs are adapted from Hollands and Dyre (2000).
Here, we used an ANS-based number-line estimation task. Participants were instructed to estimate the appropriate placement of a nonsymbolic numerical stimulus (a dot array) on a line segment bounded by nonsymbolic numerical anchors at each end. To date, relatively few studies have attempted to use number-line style tasks using nonsymbolic numerosity (dot arrays) in place of symbolic numbers (Anobile et al., 2012; Sasanguie and Reynvoet, 2013; Kim and Opfer, 2015). None of these investigated whether line estimation with dot array stimuli bears signatures of the cyclical power model as might be predicted following Spence (1990) or Hollands and Dyre (2000). We predicted that these tasks would be fit by a cyclical power model and its characteristics: (a) median estimates should be close to the correct value of the stimulus, (b) the standard deviations of the estimates would not show scalar variability patterns, but rather would decrease at both end-point anchors and at the midpoint of the line, and (c) participant responses should exhibit a cyclical pattern of over and then under estimation.
Ratio Estimation
Here, we used an ANS-based ratio estimation task, asking participants to estimate the ratios instantiated by a pair of nonsymbolic numerical stimuli. Recent research suggests that humans and other animals possess a nonsymbolic ratio processing system (RPS) that is tuned to the magnitudes of nonsymbolically instantiated ratios (Jacob et al., 2012; Matthews and Chesney, 2015; Matthews and Lewis, 2016; Matthews et al., 2016; Bonn and Cantlon, 2017).
Unlike proportion judgment tasks, which are typically conceived of as involving judgment of one portion of the whole relative to the judgment of that portion and its complement (Spence, 1990; Hollands and Dyre, 2000; Hollands et al., 2002; Barth and Paladino, 2011), the part:part ratios used in ratio estimation don’t have the same constraints. Because the physical magnitudes instantiating the high and low anchors vary considerably from trial to trial, the figure-plus-complement logic of the cyclical power model no longer applies. Accordingly, ratio estimation is posited to proceed from a more direct perceptual mechanism (Jacob and Nieder, 2009; Matthews and Chesney, 2015; Lewis et al., 2016) as opposed to the strategy-bound method that results in cyclical performance on line-based proportion judgment tasks (Spence, 1990; Barth and Paladino, 2011; Cohen and Blanc-Goldhammer, 2011). Indeed, single-cell recordings from primates suggest that there are neurons that respond specifically to visuospatially constructed ratios as opposed to the magnitude of either component of a given ratio (Vallentin and Nieder, 2008).
RPS theories posit that humans can extract the magnitudes of ratios made from a variety of different stimuli, and several studies have directly investigated the human ability to process ratios composed of dot arrays (McCrink and Wynn, 2007; Fabbri et al., 2012; Matthews and Chesney, 2015). Past research on direct estimation of nonsymbolic ratios made from dot arrays guide our predictions. For instance, Varey et al. (1990), found approximately linear responses in a task similar to our ratio estimation task. Moreover, when Matthews and Chesney (2015) had participants compare symbolic ratios to nonsymbolic ratios, results indicated that participants mapped nonsymbolic dot ratios to numerical ratios in a linear fashion, albeit with a bias that somewhat inflated the size of the nonsymbolic ratios by a constant factor. Finally, in an unpublished pilot study we conducted, we also found that participants’ average estimates were largely accurate. These behavioral findings have been complemented by single-cell recordings from primates suggesting that there are neurons that respond specifically to visuospatially constructed ratios as opposed to the magnitude of either component of a given ratio (Vallentin and Nieder, 2008).
Thus, we expected a linear relation between participant estimates and actual stimulus values for ratio estimation tasks (as opposed to the curvilinear relations predicted for free estimation and line estimation tasks). Although we also expected the number-line estimation task to yield roughly linear estimates, we expected those results to diverge from ratio estimates. This is because we expected ratio estimation to proceed from a more direct perceptual mechanism (Jacob and Nieder, 2009; Matthews and Chesney, 2015; Lewis et al., 2016) as opposed to the strategy-bound method that results in cyclical performance on line-based proportion judgment tasks (Spence, 1990; Barth and Paladino, 2011; Cohen and Blanc-Goldhammer, 2011). As result, we did not expect to see such strategy-based cyclical bias patterns with the ratio estimation task.
Materials and Methods
Participants
Participants were 31 undergraduates (16 female, 26 white, mean age 19.3 years (SD = 1.1 years) at a highly selective, private university in the Midwestern United States who participated for course credit in the Psychology Department.
Materials and Design
All training and testing stimuli were presented using Superlab 4 software (Cedrus Corporation, 2007) on Apple® iMac 5.1 computers running OS10.6. Each computer had a 17” LCD display with a resolution of 1,440 × 900 pixels and a refresh rate of 60 Hz. These screen dimensions subtended approximately 34° × 22° of visual angle with participants seated ∼60 cm from the screen. Degrees of visual angle are only approximate as no restraints were used to restrict head motion.
Dot Array Stimuli
Arrays were composed of black dots on a white background. For each array, dot sizes ranged from 1.3 mm to 9.9 mm in diameter (0.1–0.9°), and the minimum distance between dots was 1 mm (0.1°). Dots were arranged randomly in a 76 × 76 mm (7° × 7°) area, such that all arrays had the same convex hull. It was essential to our design that participants used the ANS to estimate the cardinality of the dot arrays, rather than relying upon counting. Accordingly, the smallest numerosity displayed in a given array was 20 to ensure that other fast enumeration techniques, such as subitizing, could not be employed (see Kaufman et al., 1949; Revkin et al., 2008). The dot arrays in each task ranged in numerosity from 20 to 300 dots. The 17 magnitudes represented were: 20, 40, 60, 80, 100, 120, 140, 150, 160, 180, 200, 220, 240, 260, 280, 290, and 300. Stimuli were presented only briefly (1,500 ms). Brief presentation times have been used successfully to suppress counting in previous work (e.g., Revkin et al., 2008).
To ensure that nonnumeric features of the arrays would not be consistently related to numerosity, we created three different stimuli for each numerosity, with different controls for individual dot size and summed area (see Figure 2). In the area controlled, dot sizes controlled (ACDC) arrays, the total surface area was controlled such that all arrays had the same total surface area regardless of dot numerosity, and all dots within any given array were of the same size. As a result, the sizes of individual dots in an array varied inversely and density varied directly with the numerosity of the array. In the area controlled, dot size varied arrays (ACDV), total surface area was controlled so that all arrays had the same total surface area regardless of dot numerosity. However, individual dot size varied both within and between arrays, such that the size of a given dot did not precisely correlate with array numerosity. As a result, for these arrays, neither total area nor individual dot size was correlated with numerosity (though the mean dot size of an array was inversely correlated with numerosity). In the area varied, dot size controlled (AVDC) arrays, all dots were the same size, regardless of the numerosity. As a result, surface area and density increased linearly with the total numerosity of dots presented. These controls mirror those that have been used in previous studies of numerosity perception (Xu et al., 2005; Hurewitz et al., 2006).

FIGURE 2. Arrays of 20 and 100 dots in the three continuous extent control conditions: area controlled, dot size controlled (ACDC), area controlled, dot size varied (ACDV), and area varied, dot size controlled (AVDC).
Procedure
Participants first completed the ratio estimation block, followed by the number-line estimation block, and finally the free estimation block (see Figure 3). We placed blocks in this order to minimize the likelihood that any block would affect estimation on the subsequent block. Each block began with a set of instructions, using example stimuli that were different from the experimental stimuli. Participants were told that the dot arrays would be presented too quickly for them to count, and that they should “just try to feel out how many dots there are instead of applying a formula.” In all trials, participants pressed a space bar to initiate the trial, then stimuli were briefly presented (1,500 ms), and finally participants were asked to make their responses. If participants did not answer within 15,000 ms, the trial ended automatically. Trial order was randomized within each block. Participants also completed similar tasks involving circle areas, a symbolic number line task, and several mathematics assessments not discussed in this manuscript. We note that, due to experimenter error, one participant completed nearly double the number of trials for each task.
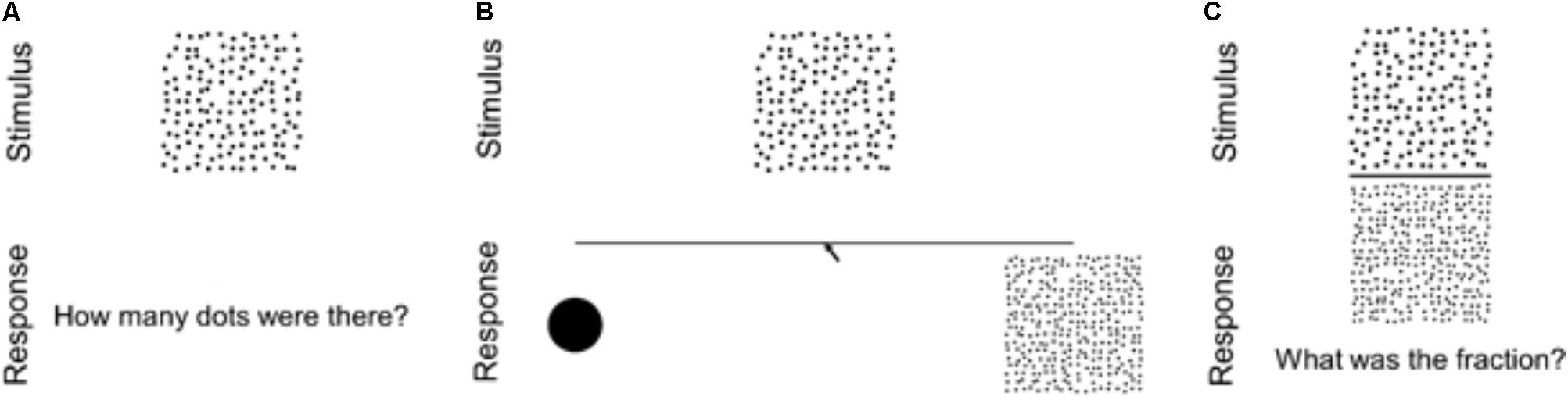
FIGURE 3. Diagrams of trials in the three estimation conditions: (A) free estimation, (B) number-line estimation, (C) ratio estimation.
Free Estimation
For each trial, a stimulus array was presented for 1,500 ms immediately after the participants initiated the trial. Once the stimulus disappeared, a textbox appeared asking, “How many dots were there?” Participants entered their answers into a text box via keyboard. After responding, they were prompted to hit return to move on to the next trial. Participants completed 51 trials, one for each of the 17 dot numerosities presented in each of the 3 dot array types.
Number-Line Estimation
For each trial, participants were shown a “number-line” anchored by one dot on the left and 300 dots on the right. Participants were never told the number of dots on the high anchor. When participants hit the space bar to initiate each trial, the line and anchors appeared. After 1,000 ms elapsed, the stimulus array was presented 25 mm above the center of the line for 1,500 ms. Once the stimulus disappeared, participants used a mouse to indicate the position on the line corresponding to the stimulus numerosity. The line and anchors remained on the screen throughout the duration of each trial. After responding, they were prompted to hit return to move on to the next trial. Participants completed 51 trials, one for each of the 17 dot numerosities presented in each of the 3 dot array types.
Ratio Estimation
In ratio estimation trials, participants were instructed to estimate the ratio between the numbers of dots in the two arrays composing each stimulus. Each stimulus was presented for 1,500 ms immediately after the participants initiated a trial. Once the stimulus disappeared, a textbox appeared asking, “What was the fraction?” Participants then typed their answers into a text box via the keyboard. After responding, they were prompted to hit return to move on to the next trial. Participants completed 51 trials, one for each of the 17 dot numerosities in each of the three formats used in the free estimation and number-line estimation blocks, with the 300 dot stimulus of the matching ACDC, ACDV, or AVDC type in the denominator position (e.g., 20 dots/300 dots, 150 dots/300 dots). Additional trials using denominators of other numerosities were also included, however, only the 300 denominator trials are presented in the results here, so as to increase comparability between blocks.
Results
Coding
On the free estimation trials, analyses used participants’ raw responses. One outlier (“9101”) was dropped from consideration. Participants’ spatial position responses on the number-line estimation trials were converted to numerical form corresponding to each response’s relative location on a 1–300 linear number-line. For example, a click on the midpoint of the line was coded as a response of 150. Responses on the ratio estimation trials were first converted to decimal format (e.g., ½, 50/100, and 150/300 were all coded as 0.5). Decimal answers (e.g., 0.8) were also accepted. Trials where participants failed to provide a complete ratio (19 trials) or provided values greater than 5/2 (5 trials) were dropped from consideration. Coded values were then multiple by 300 to place them on the same scale as the Free estimation and number-line estimation tasks for the purposes of analysis.
Analysis
For each of the 51 stimuli (the 17 magnitudes in the three format) in each of the three blocks, we found the participants’ median responses, and the standard deviation of those responses. Plots of these data are presented in Figure 4. We fit the median responses to four different models:
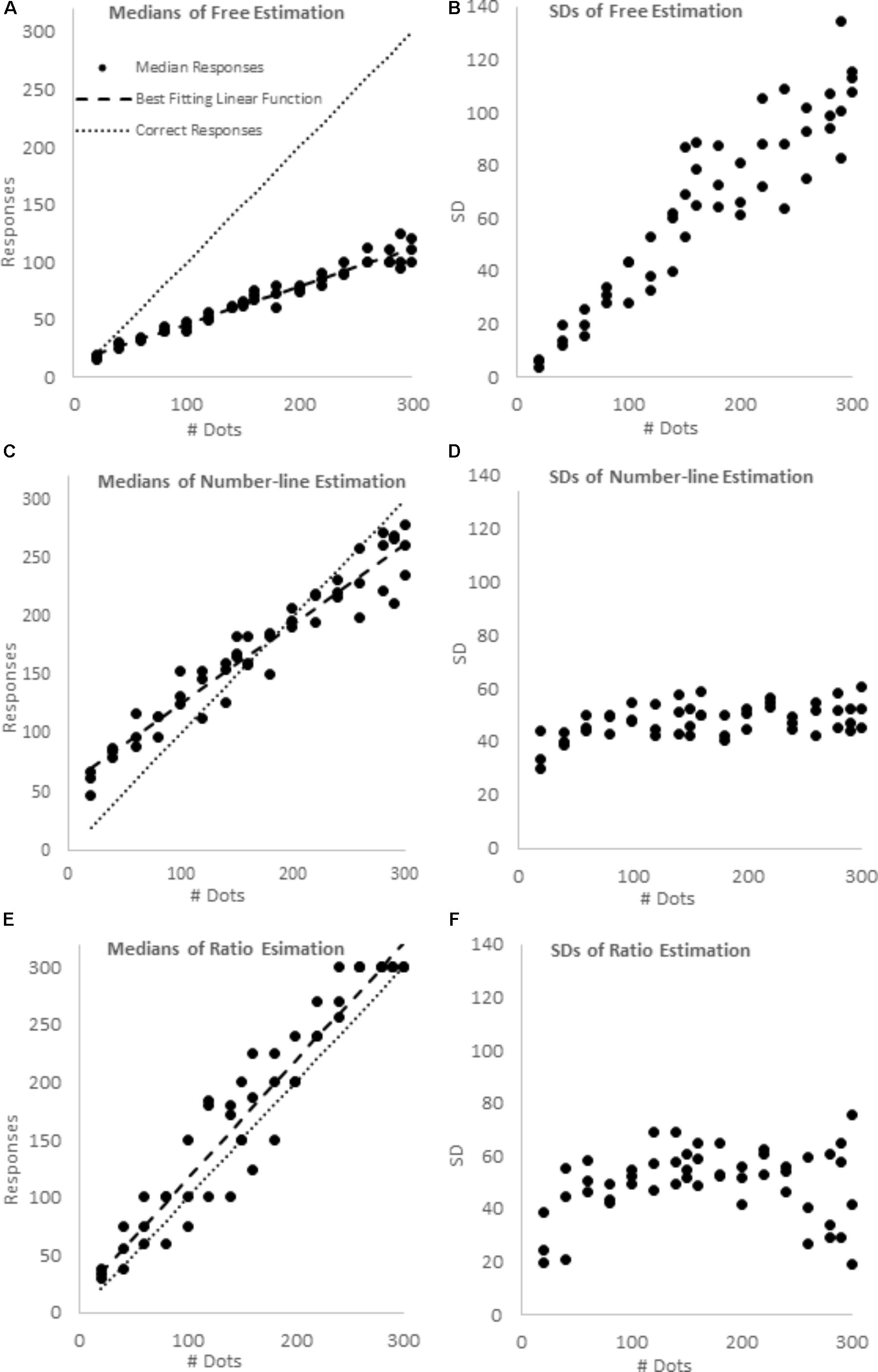
FIGURE 4. Median responses and SDs in the free estimation (A,B), number-line estimation (C,D) and ratio estimation blocks (E,F).
For consistency, all models were fit by minimizing the sum of squares distance to the predicted value, and all R2s were calculated as 1 – (Residual Sum of Squares)/(Corrected Sum of Squares). Parameters B and C were allowed to vary freely in all models. The 1-cycle cyclical power model did not include a C parameter, but rather included a Range parameter, which indicates the range of values over which responses may be given. The 1-cycle model was run both with Range fixed at 300, and with Range allowed to vary, but constrained to be greater than or equal to the maximum median value in the data set. We utilized the nonlinear regression function of SPSS version 21 to conduct these analyses. A linear regression was also run on the standard deviations. Regression results are presented in Table 1.
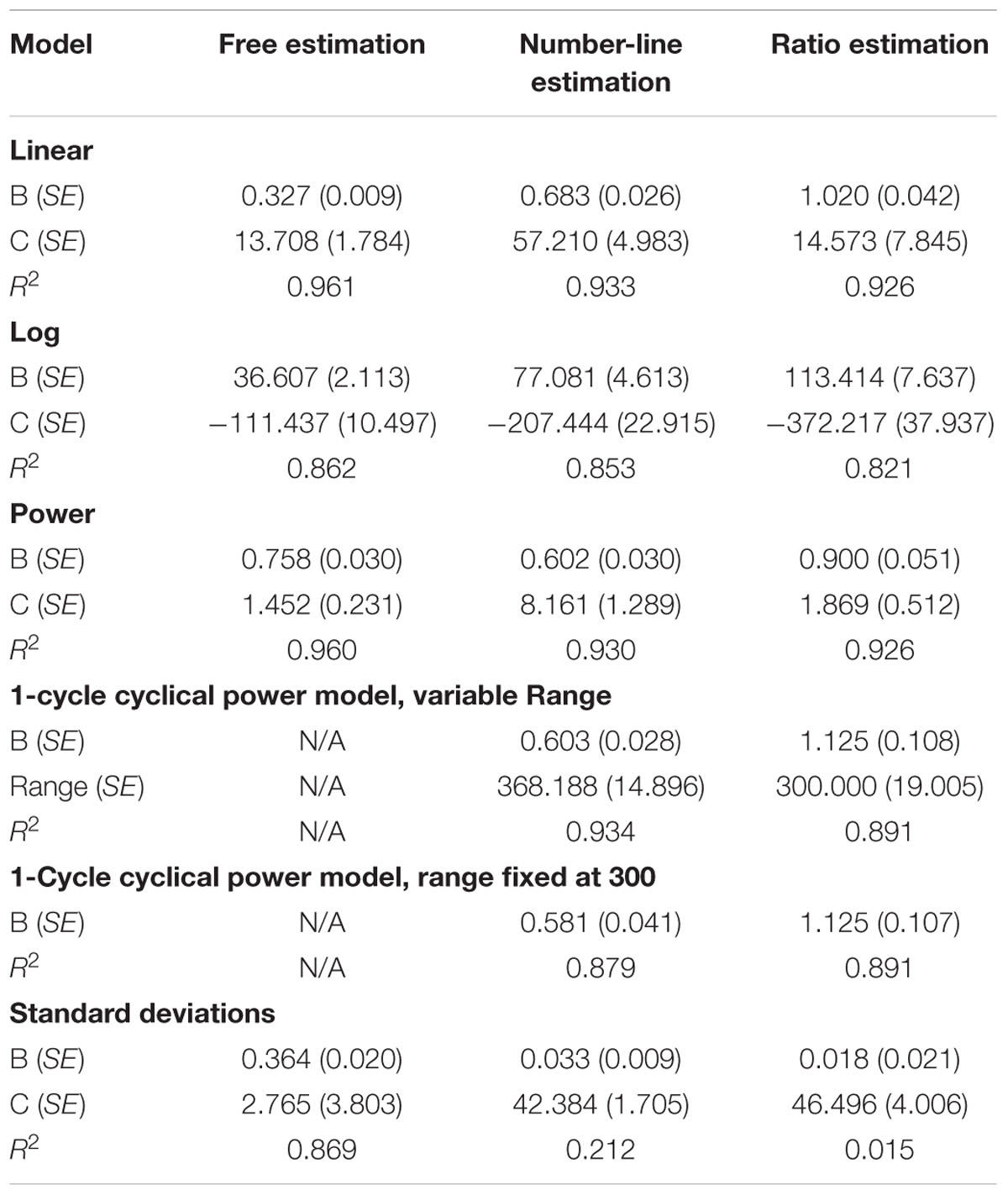
TABLE 1. Various regressions on median estimates and linear regressions on standard deviations for the free estimation, number-line estimation, and ratio estimation tasks.
Regressions
As predicted, only the free-estimation task showed scalar variability (see Table 1 and Figure 4). Indeed, set size accounted for over 86% of the variance in SD for the free estimation task, but less than 22% of the variance in SD for the number-line task, and less than 2% of the variance in SD for the ratio estimation task. In the Number-line estimation trials, SD had little relationship with the stimulus, and in the ratio estimation trials, SDs appear lowest for the extreme proportions of 0 and 1, and to peaknear 0.5.
Participants’ median responses appeared to increase linearly with stimulus magnitudes in all three conditions (see Table 1 and Figure 4). Indeed, for all three blocks, the linear model was a better a fit than the logarithmic model and as good a fit as the standard power model. However, the ratio estimation and number-line estimation tasks were also well fit by cyclical power models, whereas a cyclical power model could not be fit to the free estimation task. Free estimation was the least accurate (Linear regression: slope = 0.327, intercept = 13.708), with responses consistently ∼1/3 of the true value, and ratio estimation was the most accurate (Linear regression: slope = 1.020, intercept = 14.573), with responses quite near the true values. Number-line estimation had intermediate accuracy (Linear regression: slope = 0.683, intercept = 57.210). As would be predicted by a cyclical power model, median number-line estimates were overly high below the midpoint of the range, relatively accurate near the midpoint, and too low above the midpoint. We confirmed that this over- then underestimation pattern was significant using binomial tests. For smaller arrays (i.e., 20, 40, 60, 80, and 100 dot arrays in each of the three formats) 15 out of 15 median estimates were greater than the stimulus values (p < 0.001). For larger arrays (i.e., 200, 220, 240, 260, 280, 290, and 300 dot arrays in each of the 3 formats) 20 out of 21 median estimates were less than the stimulus values (p < 0.001). However, the high and low endpoints failed to converge toward the anchors as we had predicted based on the cyclical power model.
Discussion
Our results showed that task differences did in fact lead to vast differences in participants’ abilities to make accurate estimates from ANS-processed stimuli. We found that free estimation yielded underestimates throughout the tested range. In contrast, number-line estimations first over- and then underestimated the size of the stimuli, though via a shallow linear slope as opposed to the predicted cyclical power model. Finally, performance on ratio estimation tasks was quite accurate. Indeed, ratio estimation yielded an unbiased linear map to symbolic number, whereas both the free and number-line estimation tasks yielded biased maps. Further, only the free estimation task exhibited scalar variability. These differences emerged even though all three tasks featured stimuli that current theory would suggest are processed by the ANS. Such results would not be expected given the assumption that understanding of symbolic numbers is based on a direct mapping between number symbols and ANS-processed numerosities. These findings have implications for theories regarding the degree to which ANS-based estimation might serve as a good foundation for grounding symbolic number magnitudes.
Implications for Mapping
Free Underestimation
Free estimations of dot arrays – a prototypical ANS task – led to considerable underestimates of the numerosities of the arrays, yielding the least accurate mappings of the three task formats. This is consistent with findings in prior literature (e.g., Indow and Ida, 1977; Izard and Dehaene, 2008; Crollen et al., 2011). Indeed, to our knowledge, free estimation of dot arrays has only proven accurate in three specialized situations: The first situation involves numbers in the subitizing range (up to ∼4–5 objects), which recruits the object tracking system (e.g., Chesney and Haladjian, 2011). Second, free estimation for numerosities between 4 and 8 dots are also accurate on average, although estimates are less precise than in the subitizing range (e.g., Taves, 1941; Kaufman et al., 1949). In the third instance, some have found that free estimation, although not precise, is accurate on average, with larger arrays when feedback is given after every single trial to allow calibration (Minturn and Reese, 1951). However, Izard and Dehaene (2008) showed that this calibration can easily be thrown off by a single instance of inaccurate feedback.
This poses considerable difficulties for accounts that argue that the ANS-based magnitude perception serves as a ground for specific numbers. Given the failure of free estimation to facilitate accurate maps between numbers and their nonsymbolic analogs, it makes sense to question whether the ANS can be used to ground number symbols in a direct 1-to-1 fashion. For example, presuming that the ANS response to an array of 20 dots could serve as a stable referent for the symbol “20” seems untenable given the demonstrated inaccuracy of free estimation. This is not to say that we should abandon the ANS-as-ground position entirely. Rather, we believe it necessary to re-examine how ANS magnitudes and symbolic numbers might be linked. The current data may offer some insight into how this might be accomplished.
Performance on the free estimation task was very well fit (R2 = 0.961) by a linear function with a slope of 0.327. Thus, although inaccurate, participants were quite reliable in their underestimation; they underestimated values at a consistent proportion of about 1/3. Of note, this particular underestimation yielded an estimate range with a maximum of approximately 100, even though the maximum array size was 300 dots. The large discrepancy is quite interesting, and we speculate that the value 100 may have a certain cultural status of being a default “large number.” This would explain why participants should happen to scale their responses so that the upper limit would be approximately 100. Given that prior research clearly demonstrates that adults can scale subsequent responses against a standard value (Izard and Dehaene, 2008; Thompson and Siegler, 2010), it is plausible that the 1/3 slope observed here was the result of “auto-scaling,” whereby participants assumed that the largest dot-set had 100 dots and scaled the remaining responses accordingly.
The Relational ANS
Although estimation patterns for all three tasks approximated linearity, ratio tasks clearly yielded the most accurate estimates. Median estimates were extremely well fit by a linear model with a slope of one and an intercept that was statistically equivalent to zero. Even the power model fit for ratio tasks yielded a Stevens’ exponent of 0.9, indicating a curve that is very close linear. Considering this result in light of prior research showing that people can make proportion judgments cross-modally with great accuracy (Matthews and Chesney, 2015), this offers an intriguing possibility for grounding unfamiliar number symbols: Perhaps one way to gain an intuitive understanding for the magnitude of an unfamiliar number symbol is to start with a known number symbol and to use a cross-format proportion to convey how large the unfamiliar number is compared to the familiar number (see also Leibovich et al., 2016).
Chesney and Matthews (2013) found results consistent with this using number lines. They had undergraduates perform a number line estimation task using a line that extended from 0 to 0.999 × 104.5. Participants were unfamiliar with the magnitude of 0.999 × 104.5 (i.e., 31,591) and performed poorly until given the hint that 16,000 was roughly halfway along the number line. This intervention greatly improved performance. Participants used cross format proportion matching (Barth and Paladino, 2011; Sidney et al., 2017) to map the source ratio – the line segments’ lengths – to the target ratio – the symbolic numbers. Thus they began to correctly treat 0.999 × 104.5 as roughly twice as large as 16,000, or about 32,000. The unfamiliar symbol gained meaning. A similar process can be used to map symbolic to nonsymbolic ratios more generally. For example, if a child watches her grandmother mapping 8 grapes to a “handful” in a recipe, and later saw 16 grapes being mapped to a “cup,” she could determine that the ratio of a “handful” to a “cup” was about 1:2, and use this knowledge in deciphering quantities in future recipes.
This process might be used by children learning symbolic numbers. If they observe a set of 25 dots being referred to as “20” and a set of 50 dots being referred to as “40” – such dot arrays are often underestimated (Taves, 1941; Izard and Dehaene, 2008; Crollen et al., 2011) and can even be purposefully mapped to larger or smaller values with inducers (Izard and Dehaene, 2008) – they can learn that the ratio of “20” to “40” is 1:2. The observed symbolic number to nonsymbolic numerosity map might be biased, but the nonsymbolic ratio is maintained. Such enumeration biases would be immaterial if relational mapping is the primary mechanism supporting the link between symbolic and nonsymbolic quantities. Moreover, if a system of ratios between symbols is known (e.g., “5” is half “10,” “10,” is half “20,” “20” is half “40”), and at least one of the symbols is accurately mapped (e.g., five dots is “5”) then a sense of scale for the other mapped symbols can propagate forward. Thus, it may be an approximate sense of proportion that drives the link between ANS estimation and symbolic number, rather than a direct correspondence between a symbolic number and a specific ANS magnitude. This perceptually based ratio sense would have limited utility compared to exact symbolic representations (e.g., one can symbolically represent 300/500 and 301/500, but one is unlikely to distinguish between their nonsymbolic instantiations) but all such perceptually based processes are necessarily limited in this sense.
Although this account is speculative, it is quite consistent with psychophysical accounts of how ANS-based comparison is processed. Indeed, as Sidney et al. (2017) observed, Weber’s law is fundamentally parameterized in terms of ratios, which means that existing conceptions of the ANS are largely compatible with viewing the system as inherently relational (cf., McCrink and Spelke, 2010; McCrink et al., 2013). This viewpoint essentially recapitulates Birnbaum and Veit (1974) observation that differences and ratios are in some sense mathematically equivalent in the logarithmically transformed space of perception, given that a log-transformed ratio yields a subtraction (i.e., log(x/y) = log(x) – log(y). We do note that work remains to be done to square this relational conception with neuroscientific evidence of numerosity specific neurons (e.g., Nieder et al., 2002; Diester and Nieder, 2007). That said, the mathematics of the dominant model is incontrovertible, so a relational conception of the ANS should not be easily dismissed.
The relational view of the ANS may suggest that two numerosities are better than one when it comes to facilitating maps to number symbols. Using two numerosities when mapping ANS magnitude to symbolic numbers solves a perennial problem with free estimations – specifically the vast individual differences in these estimates. Importantly, ratio perception establishes a correspondence among multiple instantiations of the same ratio, e.g., 10/15, 20/30, 50/75, etc. Thus, there is an inherent calibration for ratio judgments that may largely circumvent idiosyncratic scaling seen in single judgments. These observations converge with emerging theories about how ratio might be used to establish maps from perception of continuous magnitudes to specific numbers – as argued, for instance by Sidney et al.’s (2017) commentary on Leibovich et al. (2017) generalized magnitude system theory. They also converge with theories positing that ratio might be the preferred format for equating perceived magnitudes across different modalities (Balci and Gallistel, 2006; Bonn and Cantlon, 2017). All combined, we interpret the data as suggesting that the ANS is perhaps best understood as a system that perceives relations between numerosities, and as such may be more accurate when used to assess ratios as opposed to whole numbers. Future research should investigate this possibility.
Limitations and Future Directions
Memory Issues in Number-Line Estimation
As noted above, our prediction that performance in the number-line estimation task would be characterized by a cyclical power model was not fully supported: although median estimates were overestimated below the midpoint of the range, relatively accurate near the midpoint, and underestimated above the midpoint, the high and low endpoints failed to converge toward the anchors. This may have been due to the speeded presentation protocol we used in order to ensure that participants could not count individual dots. As soon as the stimuli disappeared from view, they had to be maintained in memory and were thus subject to decay. Although this applies to all three tasks, this speed component may have specifically complicated the number-line task. Free estimation and ratio estimation tasks like those used here are typically conceived of as involving relatively direct estimation. However, the proportion judgment model conceived of by Spence (1990) and Hollands and Dyre (2000) involves explicit strategies whereby the observer pegs landmark values that result from segmenting the range (e.g., into halves or fourths) and subsequently estimates the remaining distance between the stimulus and the reference point. Memory decay may thus have more substantially impacted the bounded-estimation process than the other two tasks. In future work, we will compare performance in speeded and unspeeded conditions. We will also investigate potential differences in performance that might be induced by instructions focusing on an explicit ratio match versus instructions that focus on the landmark-based proportion judgment of the Spence (1990) model.
Free Estimation, Linear Compression
One interesting result specific to the free estimation task was that, although participants consistently underestimated the dot array magnitudes, their estimates did not appear compressive in the traditional sense that they were better fit by a logarithmic or power function than a linear function, or that the proportion of underestimation became greater as the set size increased. Rather, the portion of underestimation remained constant. This linear performance is more typical of sequentially presented stimuli than the simultaneous presentation we used here (Taves, 1941; Meck and Church, 1983; Cordes et al., 2001; Izard and Dehaene, 2008; Crollen et al., 2011). While this may have been an idiosyncrasy of our data set, it is possible that this was due to our choice of stimuli. Our smallest value, 20, was well above the subitizing range (∼4, Taves, 1941; Chesney and Haladjian, 2011). Numerosity estimates are known to be quite accurate when people subitize (Taves, 1941; Chesney and Haladjian, 2011). There also appears to be a benefit to accuracy when estimating values immediately above this range (e.g., 6, 7, 8; Taves, 1941; Kaufman et al., 1949), possibly due to subitizing based strategies: at the very least, these values would be known to be greater than ∼4. Our results show that people are linear with a slope less than 1 for larger values. Including both accurately assessed, subitizing-influenced low number values and underestimated higher values in a stimulus set would yield bi-linear performance. Regressions comparing compressive power or log functions to (mono-)linear functions for such bi-linear data would favor the compressive functions. Further work is needed to assess if (mono-) linear rather than compressive estimation patterns are typically seen when values that may be aided by subitizing strategies are excluded from consideration.
Conclusion
There are three main takeaways from these results. First, number-line estimation tasks appear to have limited utility in investigating either the ANS or the mapping between the ANS and symbolic numbers. These tasks do not yield the classic error patterns (i.e., scalar variability) seen in ANS estimation, and the functional form of performance on line-estimation tasks does not necessarily parallel the functional form of individuals’ underlying magnitude representations. The use of nonsymbolic stimuli does not overcome these limitations. Second, the underestimation in the free-estimation task, particularly relative to the accurate performance on the proportion judgments task, is problematic for theories that propose a direct mapping between symbolic numbers and ANS estimation of specific nonsymbolic magnitudes. Third, we suggest that a system that uses a sense of ratio to link symbolic numbers to ANS-perceived magnitudes may overcome these difficulties. Future research is needed to address these possibilities.
Ethics Statement
This study was carried out in accordance with the recommendations regarding human subjects research by the Internal Review Board (IRB) of the University of Notre Dame. The protocol was approved by the IRB of the University of Notre Dame. All subjects gave written informed consent in accordance with the Declaration of Helsinki.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
This research was made possible in part by support from the Moreau Academic Diversity Postdoctoral Fellowship Program of the University of Notre Dame.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Michael Villano for his aid in creating the stimuli, and Nicole McNeil for her help and support.
References
Anobile, G., Cicchini, G. M., and Burr, D. C. (2012). Linear mapping of numbers onto space requires attention. Cognition 122, 454–459. doi: 10.1016/j.cognition.2011.11.006
Balci, F., and Gallistel, C. R. (2006). Cross-domain transfer of quantitative discriminations: is it all a matter of proportion? Psychon. Bull. Rev. 13, 636–642. doi: 10.3758/BF03193974
Banks, W. P., and Coleman, M. J. (1981). Two subjective scales of number. Percept. Psychophys. 29, 95–105. doi: 10.3758/BF03207272
Barth, H. C., and Paladino, A. M. (2011). The development of numerical estimation: evidence against a representational shift. Dev. Sci. 14, 125–135. doi: 10.1111/j.1467-7687.2010.00962.x
Birnbaum, M. H., and Veit, C. T. (1974). Scale convergence as a criterion for rescaling: Information integration with difference, ratio, and averaging tasks. Percept. Psychophys. 15, 7–15. doi: 10.3758/BF03205820
Bonn, C. D., and Cantlon, J. F. (2017). Spontaneous, modality-general abstraction of a ratio scale. Cognition 169, 36–45. doi: 10.1016/j.cognition.2017.07.012
Chesney, D. L., and Haladjian, H. H. (2011). Evidence for a shared mechanism used in multiple-object tracking and subitizing. Atten. Percept. Psychophys. 73, 2457–2480. doi: 10.3758/s13414-011-0204-9
Chesney, D. L., and Matthews, P. G. (2013). Knowledge on the line: Manipulating beliefs about the magnitudes of symbolic numbers affects the linearity of line estimation tasks. Psychon. Bull. Rev. 20, 1146–1153. doi: 10.3758/s13423-013-0446-8
Cohen, D. J., and Blanc-Goldhammer, D. (2011). Numerical bias in bounded and unbounded number line tasks. Psychon. Bull. Rev. 18, 331–338. doi: 10.3758/s13423-011-0059-z
Cordes, S., Gelman, R., Gallistel, C. R., and Whalen, J. (2001). Variability signatures distinguish verbal from nonverbal counting for both large and small numbers. Psychon. Bull. Rev. 8, 698–707. doi: 10.3758/BF03196206
Crollen, V., Castronovo, J., and Seron, X. (2011). Under- and over-estimation. Exp. Psychol. 58, 39–49. doi: 10.1027/1618-3169/a000064
De Smedt, B., Noël, M.-P., Gilmore, C., and Ansari, D. (2013). How do symbolic and non-symbolic numerical magnitude processing skills relate to individual differences in children’s mathematical skills? A review of evidence from brain and behavior. Trends Neurosci. Educ. 2, 48–55. doi: 10.1016/j.tine.2013.06.001
Dehaene, S. (1992). Varieties of numerical abilities. Cognition 44, 1–42. doi: 10.1016/0010-0277(92)90049-N
Diester, I., and Nieder, A. (2007). Semantic associations between signs and numerical categories in the prefrontal cortex. PLoS Biol. 5:e294. doi: 10.1371/journal.pbio.0050294
Fabbri, S., Caviola, S., Tang, J., Zorzi, M., and Butterworth, B. (2012). The role of numerosity in processing nonsymbolic proportions. Q. J. Exp. Psychol. 65, 2435–2446. doi: 10.1080/17470218.2012.694896
Feigenson, L., Dehaene, S., and Spelke, E. (2004). Core systems of number. Trends Cogn. Sci. 8, 307–314. doi: 10.1016/j.tics.2004.05.002
Gallistel, C. R., and Gelman, R. (2000). Non-verbal numerical cognition: from reals to integers. Trends Cogn. Sci. 4, 59–65. doi: 10.1016/S1364-6613(99)01424-2
Hollands, J. G., and Dyre, B. P. (2000). Bias in proportion judgments: the cyclical power model. Psychol. Rev. 107, 500–524. doi: 10.1037/0033-295X.107.3.500
Hollands, J. G., Tanaka, T., and Dyre, B. P. (2002). Understanding bias in proportion production. J. Exp. Psychol. 28, 563–574. doi: 10.1037/0096-1523.28.3.563
Hurewitz, F., Gelman, R., and Schnitzer, B. (2006). Sometimes area counts more than number. Proc. Natl. Acad. Sci. U.S.A. 103, 19599–19604. doi: 10.1073/pnas.0609485103
Indow, T., and Ida, M. (1977). Scaling of dot numerosity. Atten. Percept. Psychophys. 22, 265–276. doi: 10.3758/BF03199689
Izard, V., and Dehaene, S. (2008). Calibrating the mental number line. Cognition 106, 1221–1247. doi: 10.1016/j.cognition.2007.06.004
Jacob, S. N., and Nieder, A. (2009). Tuning to non-symbolic proportions in the human frontoparietal cortex. Eur. J. Neurosci. 30, 1432–1442. doi: 10.1111/j.1460-9568.2009.06932.x
Jacob, S. N., Vallentin, D., and Nieder, A. (2012). Relating magnitudes: the brain’s code for proportions. Trends Cogn. Sci. 16, 157–166. doi: 10.1016/j.tics.2012.02.002
Kaufman, E. L., Lord, M. W., Reese, T. W., and Volkmann, J. (1949). The discrimination of visual number. Am. J. Psychol. 62, 498–525. doi: 10.2307/1418556
Kim, D., and Opfer, J. (2015). “Development of numerosity estimation: a linear to logarithmic shift?,” in Proceedings of the 37th Annual Meeting of the Cognitive Science Society, Pasadena, CA.
Krueger, L. (1984). Perceived numerosity: a comparison of magnitude production, magnitude estimation, and discrimination judgments. Atten. Percept. Psychophys. 35, 536–542. doi: 10.3758/BF03205949
Leibovich, T., Kallai, A. Y., and Itamar, S. (2016). “What do we measure when we measure magnitudes?,” in Continuous Issues in Numerical Cognition, ed. A. Henik (San Diego: Academic Press).
Leibovich, T., Katzin, N., Harel, M., and Henik, A. (2017). From “sense of number” to “sense of magnitude”: the role of continuous magnitudes in numerical cognition. Behav. Brain Sci. 40:e164. doi: 10.1017/S0140525X16000960
Lewis, M. R., Matthews, P. G., and Hubbard, E. M. (2016). “Chapter 6 - neurocognitive architectures and the nonsymbolic foundations of fractions understanding,” in Development of Mathematical Cognition, eds D. B. Berch, D. C. Geary, and K. M. Koepke (San Diego: Academic Press), 141–164. doi: 10.1016/B978-0-12-801871-2.00006-X
Lyons, I. M., Ansari, D., and Beilock, S. L. (2012). Symbolic estrangement: evidence against a strong association between numerical symbols and the quantities they represent. J. Exp. Psychol. 141, 635–641. doi: 10.1037/a0027248
Matthews, P. G., and Chesney, D. L. (2015). Fractions as percepts? Exploring cross-format distance effects for fractional magnitudes. Cogn. Psychol. 78, 28–56. doi: 10.1016/j.cogpsych.2015.01.006
Matthews, P. G., and Lewis, M. R. (2016). Fractions we cannot ignore: the nonsymbolic ratio congruity effect. Cogn. Sci. 41, 1656–1674. doi: 10.1111/cogs.12419
Matthews, P. G., Lewis, M. R., and Hubbard, E. M. (2016). Individual differences in nonsymbolic ratio processing predict symbolic math performance. Psychol. Sci. 27, 191–202. doi: 10.1177/0956797615617799
McCrink, K., and Spelke, E. S. (2010). Core multiplication in childhood. Cognition 116, 204–216. doi: 10.1016/j.cognition.2010.05.003
McCrink, K., Spelke, E. S., Dehaene, S., and Pica, P. (2013). Non-symbolic halving in an Amazonian indigene group. Dev. Sci. 16, 451–462. doi: 10.1111/desc.12037
McCrink, K., and Wynn, K. (2007). Ratio abstraction by 6-Month-Old infants. Psychol. Sci. 18, 740–745. doi: 10.1111/j.1467-9280.2007.01969.x
Mechner, F. (1958). Probability relations within response sequences under ratio reinforcement1. J. Exp. Anal. Behav. 1, 109–121. doi: 10.1901/jeab.1958.1-109
Meck, W. H., and Church, R. M. (1983). A mode control model of counting and timing processes. J. Exp. Psychol. 9, 320–334. doi: 10.1037/0097-7403.9.3.320
Minturn, A. L., and Reese, T. W. (1951). The effect of differential reinforcement on the discrimination of visual number. J. Psychol. 31, 201–231. doi: 10.1080/00223980.1951.9712804
Moyer, R. S., and Landauer, T. K. (1967). Time required for judgements of numerical inequality. Nature 215, 1519–1520. doi: 10.1038/2151519a0
Nieder, A., and Dehaene, S. (2009). Representation of number in the brain. Annu. Rev. Neurosci. 32, 185–208. doi: 10.1146/annurev.neuro.051508.135550
Nieder, A., Freedman, D. J., and Miller, E. K. (2002). Representation of the quantity of visual items in the primate prefrontal cortex. Science 297, 1708–1711. doi: 10.1126/science.1072493
Núñez, R. E. (2017). Is there really an evolved capacity for number? Trends Cogn. Sci. 21, 409–424. doi: 10.1016/j.tics.2017.03.005
Opfer, J. E., Siegler, R. S., and Young, C. J. (2011). The powers of noise-fitting: reply to Barth and Paladino. Dev. Sci. 14, 1194–1204; discussion 1205–1206. doi: 10.1111/j.1467-7687.2011.01070.x
Piazza, M. (2010). Neurocognitive start-up tools for symbolic number representations. Trends Cogn. Sci. 14, 542–551. doi: 10.1016/j.tics.2010.09.008
Revkin, S. K., Piazza, M., Izard, V., Cohen, L., and Dehaene, S. (2008). Does subitizing reflect numerical estimation? Psychol. Sci. 19, 607–614. doi: 10.1111/j.1467-9280.2008.02130.x
Reynvoet, B., and Sasanguie, D. (2016). The symbol grounding problem revisited: a thorough evaluation of the ANS mapping account and the proposal of an alternative account based on symbol–symbol associations. Front. Psychol. 7:1581. doi: 10.3389/fpsyg.2016.01581
Sasanguie, D., and Reynvoet, B. (2013). Number comparison and number line estimation rely on different mechanisms. Psychol. Belg. 53, 17–35. doi: 10.5334/pb-53-4-17
Schley, D. R., and Peters, E. (2014). Assessing “economic value”: symbolic-number mappings predict risky and riskless valuations. Psychol. Sci. 25, 753–761. doi: 10.1177/0956797613515485
Sidney, P. G., Thompson, C. A., Matthews, P. G., and Hubbard, E. M. (2017). From continuous magnitudes to symbolic numbers: the centrality of ratio. Behav. Brain Sci. 40:e190. doi: 10.1017/S0140525X16002284
Siegler, R. S., and Opfer, J. E. (2003). The development of numerical estimation evidence for multiple representations of numerical quantity. Psychol. Sci. 14, 237–250. doi: 10.1111/1467-9280.02438
Spence, I. (1990). Visual psychophysics of simple graphical elements. J. Exp. Psychol. 16, 683–692. doi: 10.1037/0096-1523.16.4.683
Taves, E. H. (1941). Two Mechanisms for the Perception of Visual Numerousness. New York, NY: Archives of Psychology (Columbia University).
Thompson, C. A., and Siegler, R. S. (2010). Linear numerical-magnitude representations aid children’s memory for numbers. Psychol. Sci. 21, 1274–1281. doi: 10.1177/0956797610378309
Vallentin, D., and Nieder, A. (2008). Behavioral and prefrontal representation of spatial proportions in the monkey. Curr. Biol. 18, 1420–1425. doi: 10.1016/j.cub.2008.08.042
Varey, C. A., Mellers, B. A., and Birnbaum, M. H. (1990). Judgments of proportions. J. Exp. Psychol. 16, 613–625. doi: 10.1037/0096-1523.16.3.613
Whalen, J., Gallistel, C. R., and Gelman, R. (1999). Nonverbal counting in humans: the psychophysics of number representation. Psychol. Sci. 10, 130–137. doi: 10.1111/1467-9280.00120
Whyte, J. C., and Bull, R. (2008). Number games, magnitude representation, and basic number skills in preschoolers. Dev. Psychol. 44, 588–596. doi: 10.1037/0012-1649.44.2.588
Keywords: approximate number system, symbolic number mapping, number-lines, ratios, estimation
Citation: Chesney DL and Matthews PG (2018) Task Constraints Affect Mapping From Approximate Number System Estimates to Symbolic Numbers. Front. Psychol. 9:1801. doi: 10.3389/fpsyg.2018.01801
Received: 14 May 2018; Accepted: 05 September 2018;
Published: 16 October 2018.
Edited by:
Marcus Lindskog, Uppsala University, SwedenReviewed by:
Bert Reynvoet, KU Leuven, BelgiumEvelyn Kroesbergen, Radboud University Nijmegen, Netherlands
Copyright © 2018 Chesney and Matthews. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dana L. Chesney, Y2hlc25leWRAc3Rqb2hucy5lZHU=; ZGxjaGVzbmV5QGdtYWlsLmNvbQ==