 Emanuele Lo Gerfo1,2,3*†
Emanuele Lo Gerfo1,2,3*† Jacopo De Angelis4†
Jacopo De Angelis4† Alessandra Vergallito3,4
Alessandra Vergallito3,4 Francesco Bossi3,5Leonor Josefina Romero Lauro3,4
Francesco Bossi3,5Leonor Josefina Romero Lauro3,4 Paola Ricciardelli3,4
Paola Ricciardelli3,4- 1Department of Economics, Management and Statistics, University of Milano-Bicocca, Milan, Italy
- 2CISEPS, University of Milano-Bicocca, Milan, Italy
- 3NeuroMI – Milan Center for Neuroscience, Milan, Italy
- 4Department of Psychology, University of Milano-Bicocca, Milan, Italy
- 5Social Cognition in Human-Robot Interaction, Istituto Italiano di Tecnologia, Genoa, Italy
Selective visual attention is a primary cognitive function, which allows the selection of the most relevant stimuli in the environment by prioritizing their processing. Several studies showed that this process can be influenced by both social signals, such as gaze direction (i.e., the Gaze Cueing Effect, GCE) and by the motivational valence of gratifying stimuli, such as monetary rewards. The aim of this study was to explore whether GCE could be modulated by a monetary reward. To this end, we created an experiment in which participants performed a gaze cuing task before and after an implicit learning task aiming to induce an association between gaze direction and monetary reward (experimental condition), or after a perceptual task (control condition). Statistical analyses were conducted following both a frequentist and a Bayesian approach. Results supported previous findings showing the presence of the GCE, i.e., faster responses in congruent trials when the target appeared in the gazed-at location. Interestingly, our results did not reveal significant differences among the conditions. Therefore, contrary to what was reported by previous attentional orienting studies with non-social stimuli, monetary reward does not seem to be able to modulate (or interfere with) the orienting of attention mediated by gaze direction as measured by the GCE. Taken together our results suggest that social signals such as gaze direction have a greater impact than monetary reward in orienting selective attention.
Introduction
Selective attention is a primary cognitive process, which allows the selection of the most relevant stimuli in the environment by prioritizing their processing (Desimone and Duncan, 1995; Pashler, 1998; Reynolds and Chelazzi, 2004). This selection has been demonstrated to rely both on bottom-up factors, such as perceptual features of the stimuli (Yantis and Jonides, 1984; Theeuwes, 1992; Ando, 2002), and on top-down factors, such as individual goals (Kristjánsson 2006; Kristjánsson and Campana, 2010), the context in which stimuli are embedded (Wolfe, 1994; Egeth and Yantis, 1997; Chelazzi, 1999) and previous experience (Kristjánsson and Campana, 2010; Chun, 2011; Awh et al., 2012).
Several studies focused on the role played by social signals such as eye gaze direction in orienting selective attention (Ricciardelli et al., 2000; Frishen et al., 2007). Social attention, namely the tendency to attend the same object that another person is looking at (Frishen et al., 2007), has received much consideration by scholars. This attentional orientation, specific to humans and other primates, has been also defined “joint attention” (Bruner, 1983) and emerges in children starting from 2 months (Maurer, 1985; Baron-Cohen, 1994). Following another person’s gaze toward specific regions of the environment provides the observer with considerable information, both in terms of the saliency of the co-attended stimuli and providing cues on the looker’s mental states. Indeed, this ability has a strong adaptive valence since it can communicate the presence of possible danger or threat (Menzel and Halperin, 1975; Byrne, and Whiten, 1991).
Eye Gaze as a Special Cue to Allocate Visual Attention
In experimental settings, modifications of Posner’s cueing paradigm (Posner, 1980) have usually been employed to study the attentional shifts triggered by the observation of eye-gaze direction (Frishen et al., 2007), namely the so-called gaze cueing paradigm (Friesen and Kingstone, 1998; Driver et al., 1999). In this paradigm, participants are required to identify target letters appearing to the left or to the right of a face placed at the center of the screen. Unlike Posner’s paradigm, the gaze direction of a face looking either to the left or right direction substitutes the central arrow cue typically used in traditional attentional paradigms. Previous research has demonstrated that reaction times (RTs) are significantly faster in congruent-cue trials (i.e., with the target appearing in the gazed-at location) than in incongruent-cue ones (Friesen and Kingstone, 1998; Frishen et al., 2007) even when gaze direction is task-irrelevant. This attentional facilitation emerges with relative early stimulus onset asynchrony (SOA) (105–300 ms, Perez-Osorio et al., 2017) and disappears with longer SOA (1005 ms) (Friesen and Kingstone, 1998). This effect is known as the Gaze Cueing Effect (GCE) and has been replicated by many other studies (Hamilton, 2016; Ulloa et al., 2018; for a review see Frishen et al., 2007).
However, a recent study by Takao et al. (2018) showed that GCE might be influenced by cultural differences. In particular, the authors reported that in Western people the GCE emerges both at short and long SOAs (117 ms vs. 700 ms), whereas Japanese participants only show GCE at shorter SOAs. Traditionally in Posner’s paradigm, two types of cues can be used to induce the orientation of visual spatial attention, namely endogenous and exogenous cues. The endogenous cue usually consists of an arrow appearing at the center of the screen above or below a central fixation point. It provides participants with explicit information about the target possible location (i.e., participants expect that the target is more likely to appear at the cued location) and requires a voluntary orientation of visual spatial attention.
By contrast, the exogenous cue consists of a salient event (e.g., a flashing light) appearing in the periphery of the screen. Such a cue, by virtue of its visual saliency, automatically orients attention to the cued location, even if it does not inform about where the target will appear and, therefore, is task-irrelevant (Posner, 1980; Posner and Cohen, 1984).
Concerning GCE, it is still a matter of debate whether it can be considered the result of an endogenous (voluntary) or exogenous (automatic) orientation. Indeed, at least two key criteria need to be present in order to consider a certain process as “automatic” (for a review see Santangelo and Spence, 2008). First, automatic processes are immune to the interference of a concurrent task and of its cognitive load (load-insensitivity criterion). Second, automatic processes are not influenced by the individual’s intentional control (intentionality criterion).
Early studies suggested substantial similarities between spatial cueing induced by gaze direction and the one triggered by exogenous cues, suggesting that both produced significant orienting even when spatially uninformative or counter-informative. Initially, such evidence has been taken to support the automatic nature of GCE (Friesen and Kingstone, 1998; Driver et al., 1999).
Recently, however, scholars suggest that GCE can be influenced by top-down processes such as contextual cues, knowledge and expectation, and reading of other’s mind (Bayliss et al., 2010; Teufel et al., 2010; Wiese et al., 2012, 2013, 2014; Ehrlich et al., 2014; Wykowska et al., 2014; Cole et al., 2015; Perez-Osorio et al., 2017; Hayward and Ristic, 2018).
Regarding the load-insensitivity criterion, it is still debated whether GCE can be modulated by increasing concurrent tasks cognitive loads: some authors posited that increasing working memory demands do not interfere with GCE effects (e.g., Xu et al., 2011; Hayward and Ristic, 2013), whereas others found some interference (Bobak and Langton, 2015).
Authors also highlighted differences between using arrows or gaze as triggers to drive attention (Driver et al., 1999; Friesen and Kingstone, 2003; Friesen et al., 2004), suggesting that orienting attention toward somebody else’s gaze direction could be considered a special type of attentional orienting, due to the strong biological and social significance of gaze.
On the other hand, some evidence questioned these conclusions by showing that gaze and arrows would instead induce similar behavioral effects (Tipples, 2008; Guzzon et al., 2010).
Far from a conclusive definition of the nature of GCE, it seems possible to conclude that it is not a strictly automatic process, since it is not immune to top-down modulation and is somehow similar to the effect elicited by social over-learned cues such as arrows (Brignani et al., 2009; Guzzon et al., 2010).
Reward and Selective Attention
Previous evidence suggests that reward is capable of modulating selective attention (Chelazzi et al., 2013). Similar to the law of effect, which suggests that an action followed by satisfying effects become more likely to reoccur than an action that produces discomfort (Thorndike, 1911), attentional processes are subject to mechanisms that re-modulate attentional focus toward specific items or spatial location based on previous outcomes. The memory system underlying this re-modulation of attentional processes strengthens the trace of items with high reward outcomes more than items with poor consequences (Della Libera and Chelazzi, 2009).
Specifically, behavioral findings revealed that monetary reward significantly improves detection performance in spatial attentional tasks by acting as an incentive to the participants’ performance (Engelmann and Pessoa, 2007; Engelmann et al., 2009; Pessoa and Engelmann, 2010). Interestingly, although this effect has been found to be stronger for congruent trials, RTs significantly decrease also in incongruent conditions with the increase of monetary reward (Engelmann et al., 2009). According to the authors, this evidence suggests that the motivational cue induced by the monetary reward impairs cue processing, or as an alternative explanation, it could facilitate the disengagement from an incongruent cue location (Engelmann et al., 2009). A similar effect was recently found by Bourgeois et al. (2016, 2017), who suggested that high rewarding stimuli may mitigate the typical facilitation induced by both exogenous and endogenous cues in visual search tasks, also when these stimuli are task-irrelevant. Moreover, these findings are consistent with the hypothesis that the motivational valence of visual stimuli may act as a strong exogenous signal, solving competition among different stimuli and guiding visual search behavior (Anderson et al., 2013; Chelazzi et al., 2014).
Chelazzi et al. (2014) also examined the alteration of high and low rewarded spatial priority maps, which authors defined as “real-time representations of the behavioral salience of locations in the visual field,” in a cross stimulus-competition paradigm (for an exhaustive description of the task see Chelazzi et al., 2014). Their behavioral paradigm comprised a baseline session, followed by a learning phase and a final test session. During the learning session, participants performed a visual search task on a target among distractors, in which correct responses in certain spatial locations were associated with high reward and others with low reward.
The results showed that in the test session, compared to the initial baseline, a target presented at a high-reward location increased its priority when paired with a target at a low reward location, and vice-versa. The authors concluded that reward was able to modulate spatial attention inducing plastic changes in the priority maps of space.
Recent evidence reported how reward-based implicit learning processes may affect the motivational valence of a stimulus, by influencing the deployment of attentional resources on features or locations able to optimize the organism adaptation to the environment and to favor positive behavioral outcomes (Chelazzi et al., 2013). For instance, Anderson et al. (2014) found that only target features (i.e., color) carrying information about subsequent reward magnitude, rather than the mere stimulus features per se, predicted attentional capture by those features (Anderson et al., 2014).
Specifically, two separate reward-related learning mechanisms have been identified. The first mechanism concerns conditions in which reward is perceived as a feedback on performance and consequently involves the cognitive monitoring of the individual on his/her performance (O’Doherty, 2004; Schultz, 2006). The second one, instead, takes into account conditions in which reward relates to random events characterizing task performance, where the individual produces associations between objects in the environment and the reward accompanying them (for a review see Chelazzi et al., 2013).
Other studies, based on the classical conditioning paradigm (Pavlov, 1927; Dayan et al., 2000), suggest a third learning mechanism, allowing the passive presentation of the pairing between a certain stimulus and a reward to be learnt. This happens even without awareness of the stimuli or of the contingence between stimulus and reinforcement (Büchel et al., 1998; Pessiglione et al., 2008; Seitz et al., 2009).
It is worth noting that reward influence on attentional orienting and implicit learning seems to last for a long time, by leaving long-term memory traces of the rewarding stimulus (Della Libera and Chelazzi, 2009).
Concerning the neural correlates involved in reward effects on visual attention, neuroimaging studies have highlighted a complex neural network. This includes regions which have been found to be activated during attentional tasks (i.e., frontal eye field, anterior cingulate cortex, intraparietal sulcus and temporo-parietal junction), visual stimuli processing (i.e., occipito-temporal visual cortex sites) and reward (i.e., caudate; orbitofrontal cortex, nucleus accumbens) (Engelmann et al., 2009; Pessoa and Engelmann, 2010). Accordingly, Pessoa and Engelmann (2010) suggested a model in which motivation and attention are “integrated” in affecting attentional behavior and modulated by the activation of a common core of regions involved both in visual attention orienting and in determining the rewarding valence of stimuli.
Aims of the Present Study
As previously mentioned, studies that investigated the motivational role of reward presentation in guiding visual attention orientation for non-social stimuli did not explore a possible interaction between GCE and reward processing. Specifically, no studies tested whether and how monetary reward can modulate the effect of social cues on attention orienting, given that both types of cues (gaze direction and rewarded spatial location) could automatically orient visual attention. To this end, the current study aimed to investigate the role played by monetary reward in modulating social attention.
As in Chelazzi et al. (2014) we created an experimental procedure that was divided in three phases: a baseline phase, consisting of a gaze cueing task; a learning phase, in which we created an implicit association between gaze direction and monetary reward; a test phase, which evaluated the effect of reward on GCE, in which the gaze cueing task was presented again. Crucially, in the baseline and test phases, reward was not used.
Our prediction was that the association between gaze direction and monetary reward, learnt during the implicit learning task, would strengthen the allocation of attention only toward the location rewarded by the direction of gaze. According to this hypothesis, we expected to find a larger GCE for the rewarding than non-rewarding gaze direction.
Materials and Methods
Participants
60 Italian students (female 37, mean age = 23.61) of the University of Milano - Bicocca were randomly assigned to two experimental conditions. Another 30 students (19 female; mean age = 23.12) took part in a control condition. All participants were right-handed with no history of neurological or psychiatric diseases, had normal or corrected-to-normal vision and were naïve as to the experimental purpose. They received 5 Euros for their participation.
The participants gave their written informed consent before starting the experiment. The study was conducted in accordance with the ethical standards laid down in the 2013 Declaration of Helsinki and fulfilled the ethical standard procedure recommended by the American Psychological Association (APA).
The experiment was approved by the Ethics Committee of the University of Milano-Bicocca.
Procedure
The experiment was set up and carried out in the Experimental Psychology Lab of the Department of Psychology at the University of Milano-Bicocca. Stimuli presentation and responses registration were controlled through the software E-Prime 2.0 Professional (Psychology Software Tools1). The participants sat approximately 57 cm away from a 15-inch LCD monitor. A standard Italian keyboard was used to register participants’ responses. The experiment was conducted in a dark room without windows.
The experiment included three sessions: an initial baseline session, with a gaze cuing task; an implicit learning session, in which a certain gaze direction was always associated with a reward; a test session, which was identical to the baseline.
In the control condition, the implicit learning session was replaced by a simple perceptual task, and no reward was delivered.
Gaze Cueing Task
This task was performed by the participants both during the baseline and test sessions. A gray scale photograph (6.2° × 1.7°) of the eye region of a female face was used as the gaze cue. In detail, three photographs versions were used: one with straight gaze, one with the gaze averted leftwards and one with the gaze averted rightwards.
The targets consisted of two capital letters, L or T (0.97°), which could appear on the right or on left sides (6.84°) of the screen. The participants were instructed to press on the keyboard with the right middle finger and the right annular, respectively, the V-key, whenever the letter L appeared on the left side of the screen, and the B-key when the letter L appeared on the right side of the screen (keys was covered by brown and pink paper squares, respectively). No response was required when the letter T appeared. We used a go/no-go task in order to increase task difficulty and investigate whether reward reduced response inhibition toward the reinforcing gaze directions or rewarded space locations.
The experimental session comprised 256 trials that were split into two blocks of 128 trials each, with a break in between. In each trial, the sequence of events was as follows: (1) a fixation cross appeared for 1000 ms at the center of the screen; (2) a gaze-cue looking straight was presented and 1000 ms after its onset, randomly gazed toward the left or the right; (3) an upper-case letter (L or T) then appeared at the right or at the left side of the screen either after 250 or 750 ms (SOAs) with the same probability (6.84°, see Figure 1 for a schematic representation of the procedure). The target letter could appear in the location cued by the gaze (congruent trials) or on the opposite side (incongruent trials). RTs and accuracy were recorded.
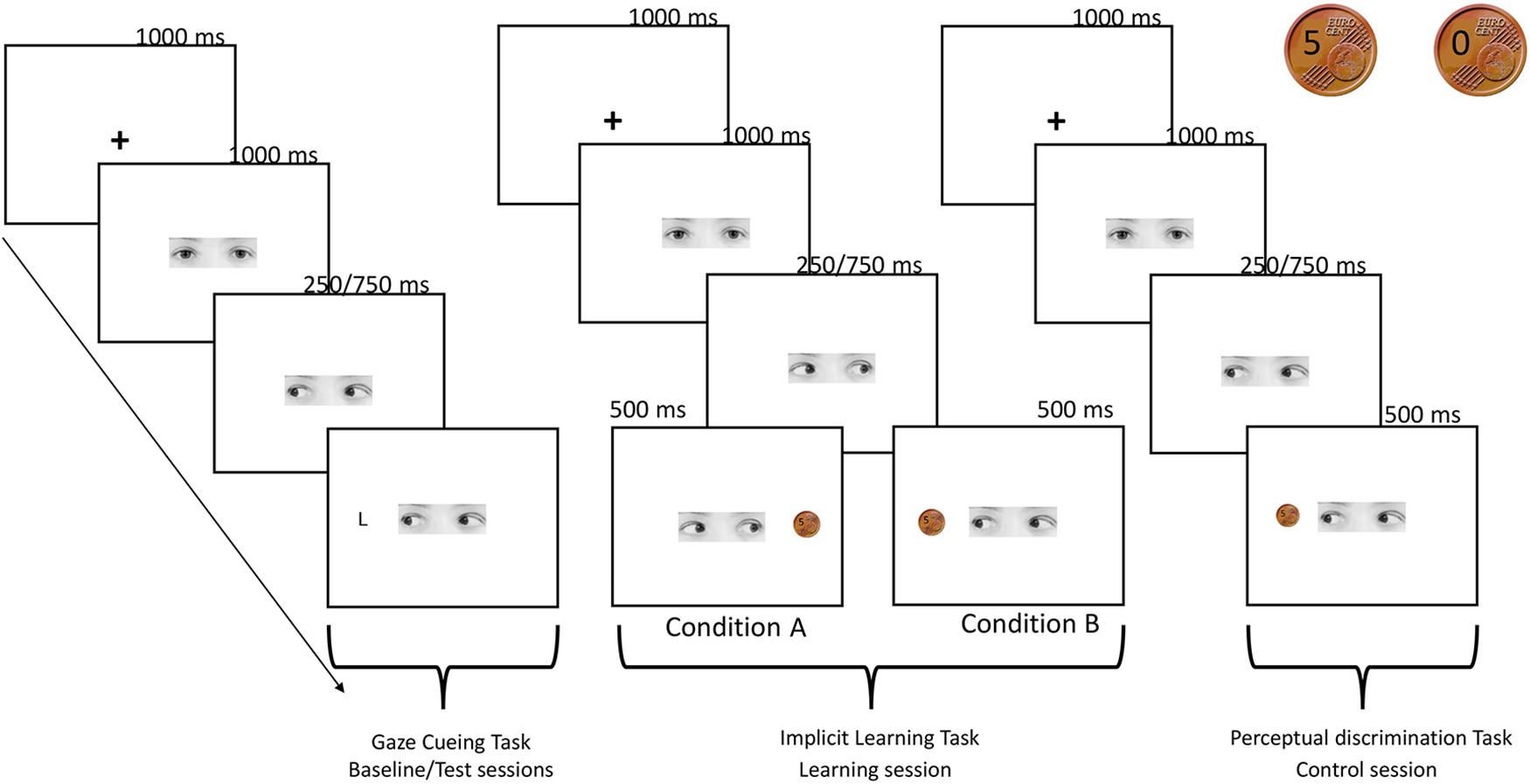
FIGURE 1. Schematic procedure of the experiment. Gaze cueing task: a fixation cross appeared for 1000 ms at the center of the screen then a face-cue looking straight was presented and 1000 ms after the onset, randomly gazed toward left or right. An upper-case letter (L or T) appeared after 250 or 750 ms (SOA) with the same probability at the right or at the left side of the screen. Participants pressed two different keys on the keyboard, depending on whether the target L appeared on the left or right side of the screen. No response was required when the letter T appeared. Implicit learning task: trial sequence of events was the same of the gaze cueing task, except for the target presentation. In this case, 1 s after the gaze shift, a coin indicating the monetary reward (5 cents) or the no-reward (0 cents) appeared in one of the two sides of the screen. In condition A participants were aware that they were receiving a reward of 5 euro cent in the 100% of trials in which gaze direction turned on the right, while when the gaze was directed to the left they were not receiving a reward in the 100% of trials (the two coins used in the reward and control tasks are showed in the right top of the figure). The reverse pattern was true for condition B. Participants were asked to predict the reward presentation. Perceptual discrimination task: trial sequence of events was the same of the implicit learning task, but in this control condition coin’s presentation was not associated to a reward. Participants were asked to predict if the picture of the coin contained either the number 5 or the number 0.
We chose to implement a short (250 ms) and a long (750 ms) SOA because we wanted to be sure of finding a robust GCE effect, considering that there is no clear consensus on the optimal presentation timing (Friesen and Kingstone, 1998; Perez-Osorio et al., 2017; Takao et al., 2018).
Implicit Learning Task
This task comprised 200 trials, i.e., 100 trials of gain and 100 trials of non-gain. At the beginning of the session, participants were informed that they were starting a monetary exchange with another participant, called Participant B, who could decide to split 10 cents between himself and the participant, or to keep for her/himself the entire amount of money. In reality, the procedure was entirely controlled by a pc custom-program. The participants were asked to guess Participant B’s choices so as to keep their attention focused on the entire procedure. The participants were told that Participant B’s choice was independent from their guess. In fact, Participant B’s decision of delivering or not some money (gain or no-gain) was communicated by the direction of the gaze cue, which could shift toward the right or the left side of the screen.
We chose this procedure to create an association between gaze direction and the delivery of monetary reward, thus making it a conditioned stimulus. The key point of our procedure, in fact, was to give to the averted gaze a monetary value through an implicit learning procedure along with (on top of) its intrinsic (or well-established) social meaning and value.
The participants were randomly assigned to two conditions: (condition A – N = 30, female = 19; condition B – N = 30, female = 18) in which the earning was associated with a rightward or leftward gaze shift, respectively. More specifically in condition A, participants were told that they would receive a reward in all the trials in which the gaze was shifted to the right, and no reward in all the trials in which the gaze was shifted to the left. The reverse pattern was true for condition B.
The trial sequence of event was the same to the one described for the gaze cueing task, except for the target presentation. In this case, 1 s after the gaze shift, a coin indicating the monetary reward (5 cents) or the no-reward (0 cents) appeared in one of the two sides of the screen. In order to create two coins which look the same, a real photo of a 5-euro-cents coin was modified with an imaging manipulation program (GIMP 2.8), writing on it the number 5 and number 0 (Figure 1). At the end of each trial, a sentence on the screen summarized the total amount of money that the participants had won up until that trial. Concerning the prediction task, in group A the participants were required to press with the right middle finger the H-key on the keyboard when they expected to win, and with the right annular the N-key when they expected not to win, whereas in group B the participants were instructed to do the opposite.
It is to be noted that in our experiment, the reward was not associated with the participant’s choice or performance. By contrast, the explicit association between gaze direction and the delivery of reward was supposed to be implicitly reinforced by the participants based upon the stimulus contingencies, as in the classical conditioning procedure (Pavlov, 1927; Büchel et al., 1998; Pessiglione et al., 2008; Seitz et al., 2009). At the end of the experiment, the participants received the same amount of money (5 Euros).
Perceptual Discrimination Task
This task was performed only by the participants who took part in the control condition. It comprised 200 trials. The structure of the task was the same of the one used in the implicit learning task (see Figure 1). At the beginning of the task, the participants were informed that they were starting a game, in which they had to predict the moves of a second virtual player, called Participant B. Specifically, Participant B could decide to show a picture of a coin containing either the number 5 or the number 0. The side of the coin presentation was balanced between participants, with half of participants seeing the 5 coin when the gaze turned left and the other half seeing it when the gaze turned right. This procedure was chosen to exactly match the stimuli and the structure of the implicit learning task administered to the participants assigned to conditions A and B. Crucially, in this case, the coin’s presentation was not associated with a reward.
During the task, the participants were required to predict Participant B’s choices (i.e., number 5 vs. number 0 coins), which were indicated by the gaze shifting toward the right or the left side of the screen. The participants made their prediction by pressing the H or N-keys (with the right middle finger and the right annular, respectively), which were covered with blue and yellow paper squares.
Data Analysis
The data of four participants were lost due to an overwrite error. One participant had a high rate of incorrect response ( >35%) and was excluded from the analysis. We report here the number of participants analyzed for each condition: condition A, 28 participants (18 female); condition B, 25 participants (15 female); control condition 30 participants (19 female).
For each participant and each condition, the mean and standard deviation (SD) of correct trials were computed. RTs slower and faster than 2 SD from individual mean were removed and excluded from subsequent analyses. With this procedure the 6,51% of trials was removed. Then for each participant and each condition [congruency (2), SOA (2), condition (2) and side (2)] a mean value of RTs was calculated.
An analysis of errors, i.e., when the participants responded to the no-go trials (with the target “T”), was not carried out because the percentage of these responses was very low (4.83%).
The RTs data for the correct responses were analyzed using JASP software (JASP Team, 2018), an open-source, simple and user-friendly R-based software aimed to run both frequentist (classical) and Bayesian analyses. As explained below, Bayesian analyses bring some important benefits when combined with the results of frequentist analyses.
Unlike frequentist statistical analyses, the output of a Bayesian analysis is typically the Bayes Factor (BF). The BF shows how likely data are to arise from one model, compared to another one (Wagenmakers et al., 2017). Typically, the two models are: a null model, predicting the null hypothesis (H0, i.e., the absence of an effect of the parameter); a second model predicting the alternative hypothesis (H1, i.e., an effect of the parameter). Therefore, the BF reflects the ratio between the likelihood of the data given H0 and the likelihood of the data given H1. In other words, the higher the BF, the more likely are the data given one of the two hypotheses. An important difference between Bayesian and frequentist statistics is the fact that a p-value reflects the likelihood of the data given H0. The likelihood of the data given H1 is not factored into the p-value, whereas it is factored into the BF. Frequentist statistics allows us to reject (or not) the null hypothesis, while Bayesian statistics allows us to evaluate and quantify the evidence in favor of H0 or H1.
The prior distribution of the data was set as a non-informative prior (r scale fixed effect = 0.5, r scale random effects = 1, r scale covariates = 0.354), since we had no specific a priori information. This setting corresponds to JASP default settings for repeated measure ANOVA, as recommended by the software programmers (Wagenmakers et al., 2017).
The BFs related to the effects were computed using a method suggested by Sebastiaan Mathôt (Wagenmakers et al., 2017; JASP Team, 2018), which takes into account the probability of different models given the data [i.e., P(model| data)]: the probability of models containing the effect of interest is compared to the probability of equivalent models stripped of the effect. Higher order interactions are excluded. This method is referred to as “Effects across matched models” output in JASP. Several ANOVAs, reported below, were then performed using this method.
The first two ANOVAs aimed to investigate the presence of GCE in the baseline session (before any manipulations), using both classical (Analysis 1) and Bayesian hypothesis testing (Analysis 2). Both analyses took into account two within-subject independent factors: congruency (2 levels: congruent vs. incongruent) and SOA (2 levels: 250 vs. 750 ms); and one between-subject factor: conditions (3 levels: condition A, condition B, and control condition), in a full factorial model. The dependent variable was RTs averaged across all correct trials in each condition.
The third and fourth ANOVAs aimed to investigate the effect of monetary reward on the GCE, using both classical (Analysis 3) and Bayesian hypothesis testing (Analysis 4). We created a factor named reward with three levels: (1) rewarding gaze direction, namely right (condition A) or left (condition B); (2) no rewarding gaze direction, namely left (condition A) or right (condition B); (3) control condition, in which no reward was delivered.
Both analyses took into account three within-subject independent factors: time (2 levels: baseline vs. test session), SOA (2 levels: 250 vs. 750 ms), congruency (congruent vs. incongruent trials) and one between-subject factor: reward (3 levels: rewarding gaze direction vs. no rewarding gaze direction vs. control condition), in a full factorial model. The dependent variable was the RTs averaged across all correct trials in each condition.
Results
ANOVA 1: with frequentist approach
Results from the first analysis showed a main significant effect of congruency, SOA and conditions: [congruency: F(1,82) = 32.535, p < 0.001, = 0.284; SOA: F(1,82) = 82.491, p < 0.001, = 0.501; conditions: F(2,82) = 5.893, p = 0.004, = 0.126]. All two- and three-way interactions were not statistically significant (all Fs < 2.1, all ps > 0.14).
The main effect of congruency was due to faster RTs for congruent trials (mean = 421.28 ms, std dev = 45.16) than for incongruent trials (mean = 433.49 ms, std dev = 48.79). The main effect of SOA showed faster RTs for the 750 ms SOA (mean = 418.26 ms, std dev = 48.74) than for the 250 ms SOA (mean = 436.50 ms, std dev = 45.22). Post hoc comparisons (Bonferroni-corrected) performed on the main effect of condition highlighted that the participants assigned to the control condition (mean = 406.31 ms, std dev: 35.03) had shorter RTs than the participants assigned to conditions A and B (condition A: mean = 436.26 ms, std dev: 54.54, t = 2.725, p = 0.024; condition B: mean = 441.79, std dev = 45.45, t = 3.137, p = 0.007), while condition A and B did not differ from each other (t = -0.485, p > 0.999).
ANOVA 2: with Bayesian approach
Results of this analysis showed the following effects: congruency: BF10 = 2.051e + 7; SOA: BF10 = 1.304e + 16; conditions: BF10 = 9.029. All the interaction effects showed BF10 < 0.4. Therefore, we can conclude that, with regards to the effects of congruency, SOA and conditions, data were much more likely to be due to the alternative than the null hypothesis (i.e., data were explained in an extremely complete way by these effects). On the other hand, data were more than twice as likely to occur given the null than the alternative hypothesis on all the interaction effects. These results showed anecdotal to moderate evidence for H0 (Lee and Wagenmakers, 2013), indicating that the effect of congruency (i.e., GCE) was most probably not influenced by the effects of SOA, conditions, or the interaction between them.
ANOVA 3: with frequentist approach
Results from the third analysis demonstrated that the time ∗ reward ∗ congruency ∗ SOA interaction effect (i.e., the main effect of interest showing the results of reward on RTs) was not statistically significant: F(2,172.9) = 0.302, p = 0.74 (Figure 2). This result did not show any significant difference in the baseline vs. the test session between the different types of reward assigned to the participants.
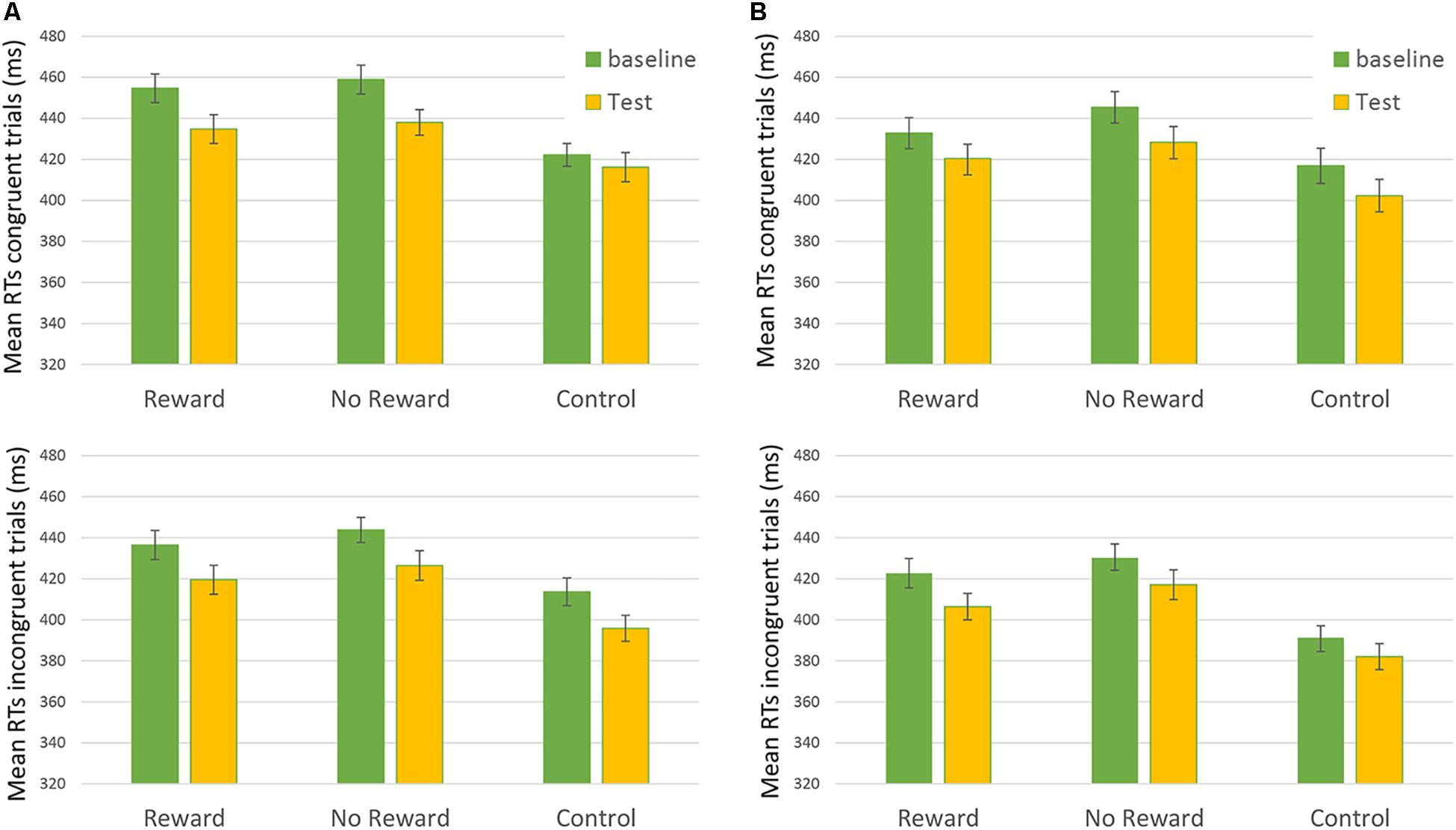
FIGURE 2. Mean RTs of Congruent (upper) and Incongruent (lower) trial in the “Rewarded,” “No-rewarded,” and “Control” conditions in baseline and Test session. On the left of the figure (A) 250-ms SOA are represented, on the Right (B) 750-ms SOA are shown. Bars represent the standard error.
ANOVA 4: with Bayesian approach
The parameters and methods used in this analysis were identical to those used in ANOVA 2, except for the use of BF01 instead of BF10, i.e., the Bayes Factor showing the likelihood of the data given H0 compared to H1, instead of the other way around. To this end, it is important to acknowledge that BF01 = 1/BF10.
This analysis showed that the effect of interest the time ∗ reward ∗ congruency ∗ SOA presented a BF01 = 14.493. This result indicated that data were fourteen times more likely to occur given the null than the alternative hypothesis. Therefore, we can state that this result shows a strong evidence for the H0, when considering different effects of the reward factor on RTs.
Given that our predictions were not confirmed by the analyses performed so far, we tested two other alternative outcomes.
First, we tested whether during the learning phase monetary reward changed the spatial priority map creating an attentional bias toward the rewarded side in the test phase compared to the baseline phase, independent of gaze direction. If this hypothesis was correct, we might expect that RTs for the reinforced spatial side should be faster independent of gaze-direction.
Second, we tested whether spatial side and gaze direction might interact, by reinforcing or decreasing their individual effects. In this case, an interaction between the rewarding gaze direction and the spatial location of the target stimulus should emerge.
Data Analysis on Alternative Outcomes
To test the first alternative outcome we ran two more ANOVAs (the fifth and the sixth), using once again both classical (fifth analysis) and Bayesian (sixth analysis) hypothesis testing. Both analyses took into account two within-subject independent factors: time (2 levels: baseline session vs. test session), and side (2 levels: target appearing on the left vs. right side); and one between-subject factor: conditions (3 levels: condition A, condition B, and control condition), in a full factorial model. The dependent variable was the RTs averaged across all correct trials in each condition. The two SOAs were analyzed separately, since in the previous ANOVAs a statistically significant main effect of SOA was found, but no significant interaction effects involving this factor (see “Results” section). For this reason, RTs obtained for 250-ms SOA condition and for 750-ms SOA were split and analyzed separately.
The seventh and eighth ANOVAs aimed to investigate whether the rewarded spatial side and the rewarding gaze-direction interacted, using both classical analysis (seventh) and Bayesian analysis (eighth). Both analyses took into account three within-subject independent factors: time (2 levels: baseline session vs. test session), side (2 levels: target appearing on the left vs. right side), and congruency (2 levels: congruent vs. incongruent); and one between-subject factor: conditions (3 levels: condition A, condition B, and control condition), in a full factorial model. The dependent variable was the RTs averaged across all correct trials in each condition. These two further analyses were done both for 250-ms SOA and for 750-ms SOA separately for the reason discussed above.
Results
ANOVA 5: effects of reward on target side with frequentist approach
Results from the fifth analysis demonstrated that the time ∗ side ∗ condition interaction effect (indicating the effect of reward on specific target sides) was not statistically significant either for 250-ms SOA [F(2,81) = 0.203, p = 0.817, = 0.005] or for 750-ms SOA [F(2,80) = 0.178, p = 0.838, = 0.004] (Figure 3).
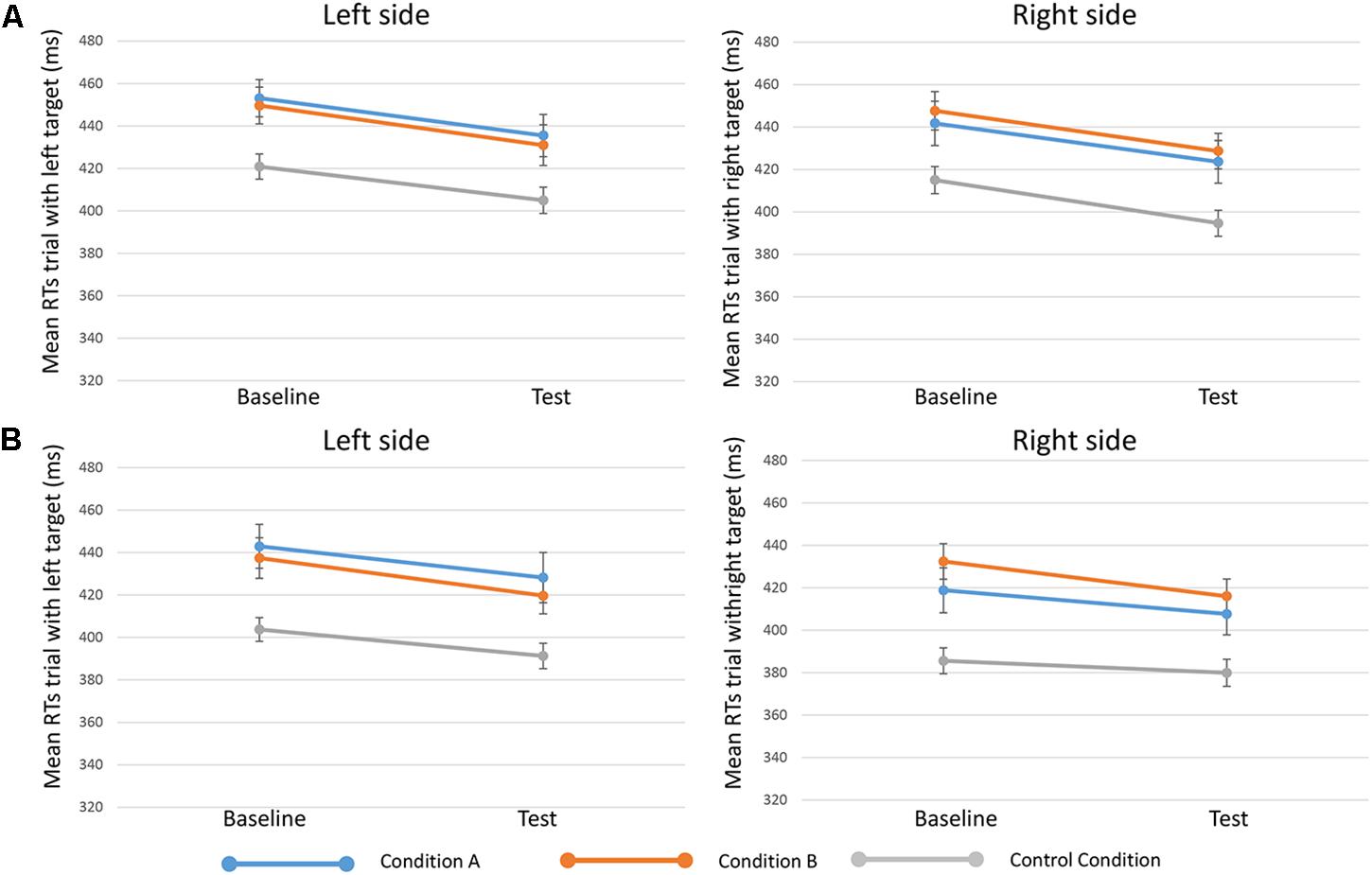
FIGURE 3. Mean RTs of trials when targets appeared on the left (in the left side of the figure, or “Left side”) and targets on the right (in the right side of the figure, or “Right side”) in the three conditions (condition A, condition B, and control condition)”. Upper in the figure (A) results for 250-ms SOA are represented, lower (B) results 750-ms SOA are showed. Bars represent the standard error.
ANOVA 6: effects of reward on target side with Bayesian approach
The sixth analysis showed that the time ∗ side ∗ condition interaction effect presented a BF01 = 14.93 (250-ms SOA) and a BF01 = 15.87 (750-ms SOA). This result indicates that data were about 15 times more likely to occur given the null rather than the alternative hypothesis, thus providing strong evidence (with both SOAs) for H0 (Lee and Wagenmakers, 2013), when considering different effects of reward on different target sides.
ANOVA 7: interaction between spatial side and gaze direction with frequentist approach
Results from the seventh analysis demonstrated that the time ∗ side ∗ condition ∗ congruency interaction effect (indicating the effect of reward on GCE) was not statistically significant either for 250-ms SOA [F(2,81) = 0.135, p = 0.874, = 0.003] or for 750-ms SOA s [F(2,80) = 0.647, p = 0.526, = 0.016] (Figure 4). These results show that H0 (i.e., no effect of reward on the GCE) cannot be rejected by using a frequentist approach. For this reason, we investigated the data also using a Bayesian approach.
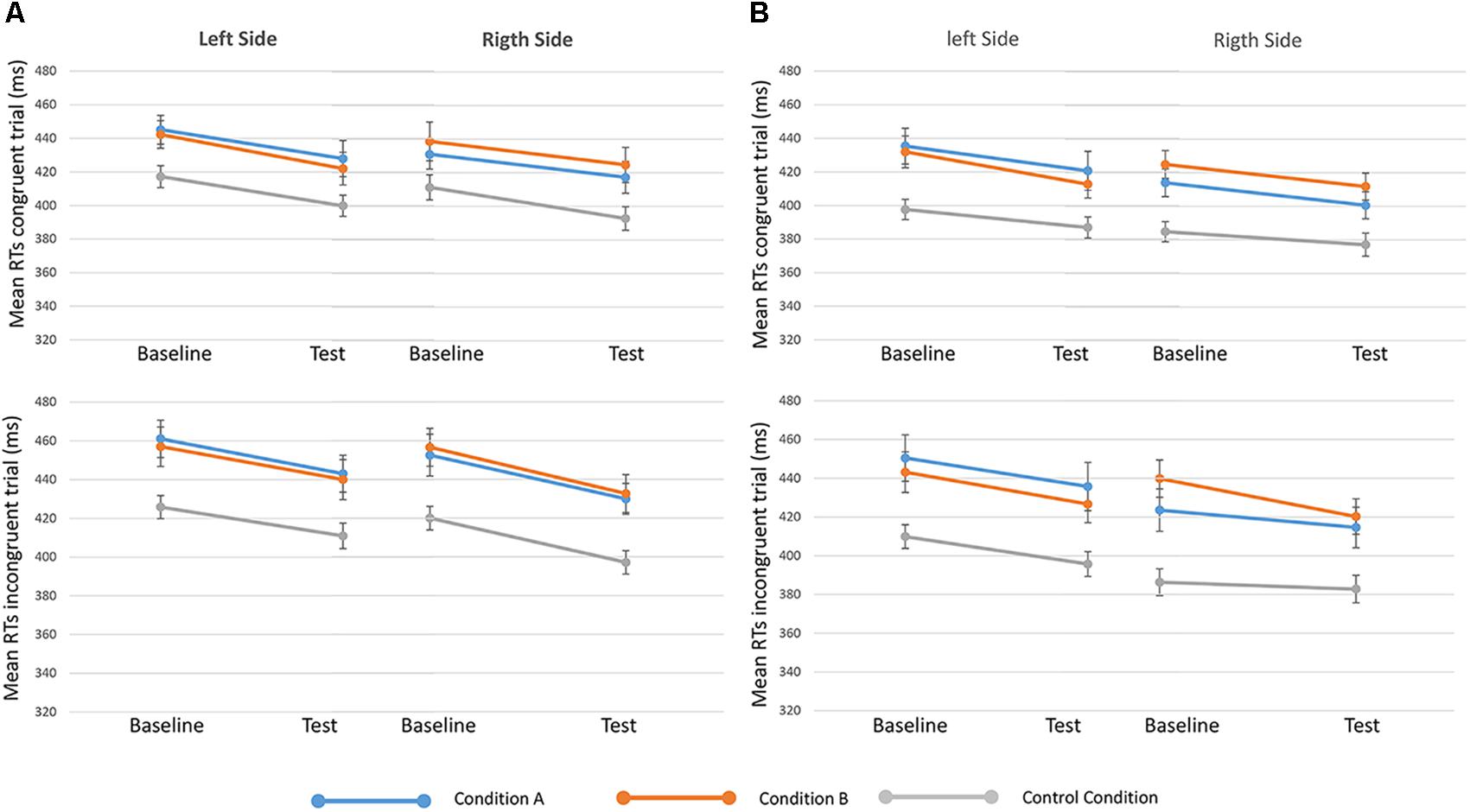
FIGURE 4. Mean RTs of congruent (upper in the figure) and incongruent (lower) trials in baseline and test sessions for the three conditions (condition A, condition B, and control) are showed, separated when targets appeared on the left and right sides. On the left of the figure (A) 250-ms SOA are represented, on the Right (B) 750-ms SOA are showed. Bars represent the standard error.
All the main effects were statistically significant: SOA = 250 ms: time: F(1,81) = 49.638, p < 0.001, = 0.380; side: F(1,81) = 11.439, p = 0.001, = 0.124; congruency: F(1,81) = 65.018, p < 0.001, = 0.445; conditions: F(2,81) = 5.308, p = 0.007, = 0.116. SOA = 750 ms: time: F(1,80) = 21.635, p < 0.001, = 0.213; side: F(1,80) = 50.369, p < 0.001, = 0.386; congruency: F(1,80) = 27.755, p < 0.001, = 0.258; conditions: F(2,80) = 6.818, p = 0.002, = 0.146.
ANOVA 8: interaction between spatial side and gaze direction with Bayesian approach
BF01 was used to test the evidence for the null hypothesis relative to the critical interaction effect of the previous analysis. This analysis showed that the time ∗ side ∗ condition ∗ congruency interaction effect presented a BF01 = 13.33 (SOA = 250 ms) and a BF01 = 3.16 (SOA = 750 ms). This result indicates that data were 13 times (or 3 times) more likely to occur given the null rather than the alternative hypothesis, thus providing strong (with SOA = 250 ms) or moderate (with SOA = 750 ms) evidence for H0 (Lee and Wagenmakers, 2013), when considering different effects of reward on the GCE.
Discussion
The present study aimed at understanding a possible interplay between GCE and reward processing, since, to the best of our knowledge, this has not been previously investigated. Previous studies, in fact, focused only on the motivational, thus implicit, role of reward associated with non-social stimuli in guiding selective visual attention (Della Libera and Chelazzi, 2009).
We investigated whether or not the capability of reward to implicitly orient visual attention, as observed with non-social stimuli, could interact with gaze cueing. Specifically, whether or not reward presentation was able to modulate (i.e., compete or enhance) GCE. To this end, we built a baseline-test experiment in which participants carried out a gaze cueing task before and after a session designed to deliver (implicit learning task) or not (perceptual discrimination task) a monetary reward in one of the two spatial locations in which the gaze cue was looking at. Overall, the aim underlying this baseline-test study was to investigate whether or not the repeated earning of money in relation to a given gaze direction (cueing left or right) could modify the magnitude of the GCE in the test session compared to the baseline session.
We applied both a frequentist and a Bayesian approach in order to analyze our data in the case of null results.
On the one hand, the results of the baseline session showed the presence of GCE – i.e., faster responses in congruent trials when the target appeared in the gazed-at location – and that GCE was not significantly different among the three conditions (condition A, condition B, control condition). Furthermore, we observed faster responses for 750-ms SOA than for 250-ms SOA, whereas no RT differences between congruency and incongruent conditions as a function of SOAs was found. Therefore, our data confirmed the wider literature that considered gaze cue and, more generally, social signals as a source of crucial information for directing the observer’s attention and effectively interacting with other humans to adapt to our social environment (Baron-Cohen and Cross, 1992; Baron-Cohen et al., 1997; Driver et al., 1999; Frishen et al., 2007). Accordingly, the automatic orienting of attention mediated by social cues such as gaze direction have per se a strong rewarding (motivational) valence, given its importance in providing the observer with relevant information about an event or a situation (e.g., about others’ mental states or emotions, possible dangers etc.). For this reason, the term “social motivation” has been coined to define a set of psychological dispositions, which also include gaze perception and gaze following. The perception of gaze direction are thought to be biologically determined and bias human beings to automatically and preferentially orient to the social world as well as to seek and maintain social bonds with other people (Chevallier et al., 2012).
According to our predictions, we expected that monetary reward influenced GCE as measured by incorrect responses or modulation of RTs.
In contrast, but no less interesting, in the present study we did not find evidence of a modulation in GCE following rewarding gaze direction as compared to non-rewarding gaze direction. Moreover, no effect was found for rewarded space location and no significant interaction between gaze direction and space location emerged either.
These findings highlight that, contrary to what was observed in previous attentional studies with non-social stimuli (Pessoa and Engelmann, 2010; Chelazzi et al., 2013; Sali et al., 2014), monetary reward associated with gaze direction (rewarding vs. no-rewarding) does not modulate (by enhancing or interfering) the orienting of attention toward a cued (looked-at) location as measured by GCE.
To date monetary reward and GCE have been separately studied although both are thought to have a significant motivational valence. Rewarding stimuli were reported to play an important role in prioritizing processing by deploying attention (Sali et al., 2014). Particularly, previously rewarded stimuli tend to automatically capture attention. This effect has been interpreted to be due to a learning process through which the presentation of a reward increases the motivational valence of a stimulus that per se had little or no motivational saliency (Chelazzi et al., 2013; Anderson et al., 2014). This learning process, indeed, would act by automatically allocating attentional resources only on target features (i.e., color) carrying information about the possibility to gain a subsequent reward by virtue of experiences (Sali et al., 2014).
Our findings clearly show that the effect of gaze direction in automatically orienting attention is not affected by monetary reward. In other words, it is plausible that the monetary valence of the reward is not relevant enough to either mitigate or enhance the attentional orienting effect of such a powerful social signal. Although researchers in economy and psychology supported that a commodity such as money without a biological valence in itself can nevertheless become a strong motivator (Lea and Webley, 2006), the motivation to obtain money does not have direct adaptive meaning and it does not result from an evolutionary process begun at human birth (Lea and Webley, 2006). It develops throughout the lifespan and through the interaction with the external and modern environment, providing the individual with information about the value of money. For this reason, monetary reward could be less powerful than gaze direction in automatically capturing and orienting attention in humans. On the contrary, orienting attention in the same direction of an averted gaze has the benefit of providing not only crucial information about the world around but also of informing us about the mental states of others (Baron-Cohen and Cross, 1992; Baron-Cohen et al., 1997; Driver et al., 1999). From an evolutionary point of view, social motivation would be at the basis of an adaptive tendency of the individuals to cooperate and create supportive environments (Rilling and Sanfey, 2011). The relevance of social motivation is also highlighted if we consider that the lack of it represents a core feature of some neuropsychiatric conditions, which are characterized by an impairment and strong difficulties in social communication and interaction such as Autism Spectrum Disorders (Chevallier et al., 2012). Nevertheless, evidence coming from studies, which examined gaze processing in Autism Spectrum Disorder (ASD), seems to be controversial as some studies showed that sensitivity to eye gaze is not atypical in this population (Leekam et al., 1998; Nation and Penny, 2008). However, other evidence comes from psychiatric research done on schizophrenic patients who present severe social-cognitive deficits (Mier and Kirsch, 2015). These patients were reported to be impaired in processing information conveyed by eye gaze (Tso et al., 2012; Dalmaso et al., 2013), but showed a normotypical performance in pointing tasks and in orienting of attention in response to arrow cues (Akiyma et al., 2008; Dalmaso et al., 2013).
The absence of a modulatory effect of the monetary reward could be also explained by the different tasks used in studying attentional orienting. For instance, in previous studies, a monetary reward was given as feedback after a correct response (Chelazzi et al., 2013). In our task, instead, the monetary reward was repeatedly associate not to the participant’s performance but to the contingence between a visual stimulus (the eye gaze cue) and the delivery of a reward. Therefore, it is also possible that a much higher number of associations between monetary reward and the gaze cue than that used in the present study is needed to better consolidate the memory trace at the basis of “the law of effect,” thus allowing the modulatory effect of monetary reward on GCE to emerge. This issue could be investigated in future research, for example, by increasing the number of times in which the reward is presented in the learning phase (Della Libera and Chelazzi, 2009).
Another possible interpretation of the null effect found in the present study might be that the automatic nature of GCE and/or the biological valence of gaze direction has determined its imperviousness to higher order motivational effects (i.e., monetary reward). However, as reported in the introduction, the full automaticity of the GCE has been questioned by a consistent number of studies. These studies showed that the orienting of attention induced by gaze direction can be modulated by top-down processes (Bayliss et al., 2010; Teufel et al., 2010; Wiese et al., 2012, 2013, 2014; Ehrlich et al., 2014; Wykowska et al., 2014; Cole et al., 2015; Perez-Osorio et al., 2017; Hayward and Ristic, 2018).
The present study has some limitations. One concerns the subjective valence that participants attributed to monetary reward. We did not systematically check if personality traits might have determined the null effect. Individual differences seem to play a key role in modulating the sensitivity and the relevance that participants attributed to monetary reward, as stated by the Reinforcement Sensitivity Theory of Personality (Corr, 2008). However, most of the aforementioned studies investigating the effect of monetary reward on attentional orienting, with non-social stimuli, did not take this inter-individual variability into account (Chelazzi et al., 2013 for a review).
Another limitation concerns the lack of a manipulation check assessing whether participants were able to learn the association between reward and gaze direction.
Indeed, the lack of interaction among time, side and condition does not allow us to conclude whether the association between gaze and reward was learned or not by participants, but leads to two possible explanation: on the one hand, it is possible that participants did not learn the association (gaze/reward). On the other one, it could be that learning took place, but gaze cues were so powerful in orienting attention that they win the motivational allocation induced during the learning phase through the reward.
Previous studies using the classical conditioning procedure (Pavlov, 1927), suggested that the passive presentation of stimulus-reward pairing is sufficient to induce implicit learning of the contingence between stimulus and reinforcement (Büchel et al., 1998; Pessiglione et al., 2008; Seitz et al., 2009). Together with evidence showing that the reward is a powerful way to allocating attention (e.g., Chelazzi et al., 2013, 2014), we are more likely to lean toward the second explanation. Taken together, the current findings show that the modulatory effect of monetary reward on attentional orienting, typically observed in studies with non-social stimuli, does not emerge when attentional orienting is mediated by gaze direction, a cue with a strong biological and social valence. The present results further highlight the relevance and strength of gaze cueing for humans. However, more studies are needed to corroborate our findings and to drive more exhaustive conclusion on whether and how monetary reward can modulate GCE.
Conclusion
The new and interesting aspects suggested by the present study is that, despite the capital accumulation has become probably the most prominent motivational drive of the Western society, the signals that we receive from others still remain a primary source of information, which cannot be hindered by a monetary incentive.
Author Contributions
PR, LL, and EG conceived and designed the study. EG, AV, and JDA ran the experiments. AV and FB conducted the statistical analysis. JDA, EG, AV, FB, and PR prepared the draft. EG, JDA, LL, and PR jointly produced the final draft.
Funding
This work has been supported by Fondazione Cariplo e Regione Lombardia, Grant No. 2016-0925 awarded to PR.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Jessica Ettaro, Carmen Campana, and Simone Quarto for their help in data collection. We thank Timothy Vaughan for revising the English of the manuscript.
Footnotes
References
Akiyma, T., Kato, M., Muramatsu, T., Maeda, T., Hara, T., and Kashima, H. (2008). Gaze-triggered orienting is reduced in chronic schizophrenia. Psychiatry Res. 158, 287–296. doi: 10.1016/j.psychres.2006.12.004
Anderson, B. A., Laurent, P. A., and Yantis, S. (2013). Reward predictions bias attentional selection. Front. Hum. Neurosci. 7:262. doi: 10.3389/fnhum.2013.00262
Anderson, B. A., Laurent, P. A., and Yantis, S. (2014). Value-driven attentional priority signals in human basal ganglia and visual cortex. Brain Res. 1587, 88–96. doi: 10.1016/j.brainres.2014.08.062
Awh, E., Belopolsky, A. V., and Theeuwes, J. (2012). Top-down versus bottom-up attentional control: a failed theoretical dichotomy. Trends Cogn. Sci. 16, 437–443. doi: 10.1016/j.tics.2012.06.010
Baron-Cohen, S. (1994). How to build a baby that can read minds: cognitive mechanisms in mindreading. Cah. Psychol. Cogn. 13, 513–552.
Baron-Cohen, S., and Cross, P. (1992). Reading the eyes: evidence for the role of perception in the development of a theory of mind. Mind Lang. 7, 172–186. doi: 10.1111/j.1468-0017.1992.tb00203.x
Baron-Cohen, S., Wheelwright, S., and Jolliffe, A. T. (1997). Is there a “language of the eyes”? Evidence from normal adults, and adults with autism or Asperger syndrome. Vis. Cogn. 4, 311–331. doi: 10.1080/713756761
Bayliss, A. P., Schuch, S., and Tipper, S. P. (2010). Gaze cueing elicited by emotional faces is influenced by affective context. Vis. Cogn. 18, 1214–1232.
Bobak, A. K., and Langton, S. R. (2015). Working memory load disrupts gaze-cued orienting of attention. Front. Psychol. 6:1258. doi: 10.3389/fpsyg.2015.01258
Bourgeois, A., Neveu, R., Bayle, D., and Vuilleumier, P. (2017). How does reward compete with goal-directed and stimulus-driven shifts of attention? Cogn. Emot. 31, 109–118.
Bourgeois, A., Neveu, R., and Vuilleumier, P. (2016). How does awareness modulate goal-directed and stimulus-driven shifts of attention triggered by visual learning? PLoS One 11:e0160469. doi: 10.1371/journal.pone.0160469
Brignani, D., Guzzon, D., Marzi, C. A., and Miniussi, C. (2009). Attentional orienting induced by arrows and eye-gaze compared with an endogenous cue. Neuropsychologia 47, 370–381. doi: 10.1016/j.neuropsychologia.2008.09.011
Büchel, C., Morris, J., Dolan, R. J., and Friston, K. J. (1998). Brain systems mediating aversive conditioning: an event-related fMRI study. Neuron 20, 947–957.
Byrne, R., and Whiten, A. (1991). “Computation and mindreading in primate tactical deception,” in Natural Theories of Mind, ed. A. White (Oxford: Blackwell).
Chelazzi, L. (1999). Serial attention mechanisms in visual search: a critical look at the evidence. Psychol. Res. 62, 195–219.
Chelazzi, L., Estocinova, J., Calletti, R., Lo Gerfo, E., Sani, I., Della Libera, C., et al. (2014). Altering spatial priority maps via reward-based learning. J. Neurosci. 34, 8594–8604. doi: 10.1523/JNEUROSCI.0277-14.2014
Chelazzi, L., Perlato, A., Santandrea, E., and Della Libera, C. (2013). Reward teach visual selective attention. Vis. Res. 85, 58–72. doi: 10.1016/j.visres.2012.12.005
Chevallier, C., Kohls, G., Troiani, V., Brodkin, E. S., and Schultz, R. T. (2012). The social motivation theory of autism. Trends Cogn. Sci. 16, 231–239.
Chun, M. M. (2011). Visual working memory as visual attention sustained internally over time. Neuropsychologia 49, 1407–1409. doi: 10.1016/j.neuropsychologia.2011.01.029
Cole, G. G., Smith, D. T., and Atkinson, M. A. (2015). Mental state attribution and the gaze cueing effect. Attent. Percept. Psychophys. 77, 1105–1115.
Corr, P. J. (ed.). (2008). The Reinforcement Sensitivity theory of Personality. Cambridge: University Press.
Dalmaso, M., Galfano, G., Tarqui, L., Forti, B., and Castelli, L. (2013). Is social attention impaired in schizophrenia? Gaze, but not pointing gestures, is associated with spatial attention deficits. Neuropsychology 27, 608–613. doi: 10.1037/a0033518
Dayan, P., Kakade, S., and Montague, P. R. (2000). Learning and selective attention. Nat. Neurosci. 3, 1218–1223.
Della Libera, C., and Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychol. Sci. 20, 778–784. doi: 10.1111/j.1467-9280.2009.02360.x
Desimone, R., and Duncan, J. (1995). Neural mechanisms of selective visual attention. Annu. Rev. Neurosci. 18, 193–222.
Driver, J., Davis, G., Ricciardelli, P., Kidd, P., Maxwell, E., and Baron-Cohen, S. (1999). Gaze perception triggers reflexive visuospatial orienting. Vis. Cogn. 6, 509–540.
Egeth, H. E., and Yantis, S. (1997). Visual attention: control, representation and time course. Annu. Rev. Psychol. 48, 269–297.
Ehrlich, S., Wykowska, A., Ramirez-Amaro, K., and Cheng, G. (2014). “When to engage in interaction—and how? EEG-based enhancement of robot’s ability to sense social signals in HRI,” in Proceedings of the RAS International Conference on Humanoid Robots, Piscataway, NJ.
Engelmann, J. B., and Pessoa, L. (2007). “Motivation sharpens exogenous spatial attention”: Correction to Engelmann and Pessoa (2007). Emotion 7:875. doi: 10.1037/1528-3542.7.4.875
Engelmann, J. B., Damaraju, E., Padmala, S., and Pessoa, L. (2009). Combined effects of attention and motivation on visual task performance: transient and sustained motivational effects. Front. Hum. Neurosci. 3:4. doi: 10.3389/neuro.09.004.2009
Friesen, C. K., and Kingstone, A. (2003). Abrupt onsets and gaze direction cues trigger independent reflexive attentional effects. Cognition 87, B1–B10. doi: 10.1016/S0010-0277(02)00181-6
Friesen, C. K., and Kingstone, A. (1998). The eyes have it! Reflexive orienting is triggered by nonpredictive gaze. Psychon. Bull. Rev. 5, 490–495.
Friesen, C. K., Ristic, J., and Kingstone, A. (2004). Attentional effects of counterpredictive gaze and arrow cues. J. Exp. Psychol. Hum. Percept. Perform. 30, 319–329.
Frishen, A., Bayliss, A. P., and Tipper, S. P. (2007). Gaze cueing of attention: visual attention, social cognition, and individual differences. Psychol. Bull. 133, 694–724.
Guzzon, D., Brignani, D., Miniussi, C., and Marzi, C. A. (2010). Orienting of attention with eye and arrow cues and the effect of overtraining. Acta Psychol. 134, 353–362. doi: 10.1016/j.actpsy.2010.03.008
Hamilton, A. F., and de, C. (2016). Gazing at me: the importance of social meaning in understanding direct-gaze cues. Philos. Trans. R. Soc. B Biol. Sci. 371:20150080. doi: 10.1098/rstb.2015.0080
Hayward, D. A., and Ristic, J. (2013). The uniqueness of social attention revisited: working memory load interferes with endogenous but not social orienting. Exp. Brain Res. 231, 405–414. doi: 10.1007/s00221-013-3705-z
Hayward, D. A., and Ristic, J. (2018). Changes in tonic alertness but not voluntary temporal preparation modulate the attention elicited by task-relevant gaze and arrow cues. Vision 2:18.
Kristjánsson,Á., and Campana, G. (2010). Where perception meets memory: a review of repetition priming in visual search tasks. Attent. Percept. Psychophys. 72, 5–18. doi: 10.3758/APP.72.1.5
Lea, S. E., and Webley, P. (2006). Money as tool, money as drug: the biological psychology of a strong incentive. Behav. Brain Sci. 29, 161–209.
Lee, M. D., and Wagenmakers, E. J. (2013). Bayesian Cognitive Modeling: A Practical Course. Cambridge: Cambridge University Press.
Leekam, S. R., Hunnisett, E., and Moore, C. (1998). Targets and cues: gaze-following in children with autism. J. Child Psychol. Psychiatry 39, 951–962.
Maurer, D. (1985). “Infants perception of facedness,” in Social Perception in Infants, eds T. Field and M. Fox (Norwood, NJ: Ablex).
Menzel, E., and Halperin, S. (1975). Purposive behavior as a basis for objective between chimpanzees. Science 189, 652–654.
Mier, D., and Kirsch, P. (2015). “Social-cognitive deficits in schizophrenia,” in Social Behavior from Rodents to Humans, eds M. Wöhr and S. Krach (Cham: Springer), 397–409.
Nation, K., and Penny, S. (2008). Sensitivity to eye gaze in autism: is it normal? Is it automatic? Is it social? Dev. Psychopathol. 20, 79–97. doi: 10.1017/S0954579408000047
O’Doherty, J. P. (2004). Reward representations and reward-related learning in the human brain: insights from neuroimaging. Curr. Opin. Neurobiol. 14, 769–776.
Pavlov, I. (1927). Conditioning Reflexes: an Investigation of the Physiological Activity of the Cerebral Cortex. Oxford: Oxford University Press.
Perez-Osorio, J., Müller, H. J., Wiese, E., and Wykowska, A. (2017). Gaze following is modulated by expectations regarding others’ action goals. PLoS One 12:e0170852. doi: 10.1371/journal.pone.0170852
Pessiglione, M., Petrovic, P., Daunizeau, J., Palminteri, S., Dolan, R. J., and Frith, C. D. (2008). Subliminal instrumental conditioning demonstrated in the human brain. Neuron 59, 561–567. doi: 10.1016/j.neuron.2008.07.005
Pessoa, L., and Engelmann, J. B. (2010). Embedding reward signals into perception and cognition. Front. Neurosci. 4:17. doi: 10.3389/fnins.2010.00017
Posner, M. I., and Cohen, Y. (1984). “Components of visual orienting,” in Attention and Performance X, eds H. Bouma and D. G. Bowhuis (Hove: Lawrence Erlbaum Associates Ltd.).
Reynolds, J. H., and Chelazzi, L. (2004). Attentional modulation of visual processing. Annu. Rev. Neurosci. 27, 611–647.
Ricciardelli, P., Baylis, G., and Driver, J. (2000). The positive and negative of human expertise in gaze perception. Cognition 77, B1–B14. doi: 10.1016/S0010-0277(00)00092-5
Rilling, J. K., and Sanfey, A. G. (2011). The neuroscience of social decision-making. Annu. Rev. Psychol. 62, 23–48. doi: 10.1146/annurev.psych.121208.131647
Sali, A. W., Anderson, B. A., and Yantis, S. (2014). The role of reward prediction in the control of attention. J. Exp. Psychol. Hum. Percept. Perform. 40,1654–1664.
Santangelo, V., and Spence, C. (2008). Is the exogenous orienting of spatial attention truly automatic? Evidence from unimodal and multisensory studies. Conscious. Cogn. 17, 989–1015. doi: 10.1016/j.concog.2008.02.006
Schultz, W. (2006). Behavioral theories and the neurophysiology of reward. Annu. Rev. Psychol. 57, 87–115.
Seitz, A. R., Kim, D., and Watanabe, T. (2009). Rewards evoke learning of unconsciously processed visual stimuli in adult humans. Neuron 61, 700–707. doi: 10.1016/j.neuron.2009.01.016
Takao, S., Yamani, Y., and Ariga, A. (2018). The gaze-cueing effect in the United States and Japan: influence of cultural differences in cognitive strategies on control of attention. Front. Psychol. 8:2343. doi: 10.3389/fpsyg.2017.02343
Teufel, C., Fletcher, P. C., and Davis, G. (2010). Seeing other minds: attributed mental states influence perception. Trends Cogn. Sci. 14, 376–382. doi: 10.1016/j.tics.2010.05.005
Tipples, J. (2008). Orienting to counterpredictive gaze and arrow cues. Percept. Psychophys. 70, 77–87.
Tso, I. F., Mui, M. L., Taylor, S. F., and Deldin, P. J. (2012). Eye-contact perception in schizophrenia: relationship with symptoms and socioemotional functioning. J. Abnorm. Psychol. 121, 616–627. doi: 10.1037/a0026596
Ulloa, J. L., Dubal, S., Yahia-Cherif, L., and George, N. (2018). Gaze perception induces early attention orienting effects in occipito-parietal regions. Neuropsychologia 109, 173–180. doi: 10.1016/j.neuropsychologia.2017.12.029
Wagenmakers, E. J., Marsman, M., Jamil, T., Ly, A., Verhagen, J., Love, J., et al. (2017). Bayesian inference for psychology. Part I: theoretical advantages and practical ramifications. Psychon. Bull. Rev. 25, 35–57. doi: 10.3758/s13423-017-1343-3
Wiese, E., Wykowska, A., and Müller, H. J. (2014). What we observe is biased by what other people tell us: beliefs about the reliability of gaze behavior modulate attentional orienting to gaze cues. PLoS One 9:e94529. doi: 10.1371/journal.pone.0094529
Wiese, E., Wykowska, A., Zwickel, J., and Müller, H. J. (2012). I see what you mean: how attentional selection is shaped by ascribing intentions to others. PLoS One 7:e45391. doi: 10.1371/journal.pone.0045391
Wiese, E., Zwickel, J., and Müller, H. J. (2013). The importance of context information for the spatial specificity of gaze cueing. Attent. Percept. Psychophys. 75, 967–982. doi: 10.3758/s13414-013-0444-y
Wykowska, A., Wiese, E., Prosser, A., and Müller, H. J. (2014). Beliefs about the minds of others influence how we process sensory information. PLoS One 9:e94339. doi: 10.1371/journal.pone.0094339
Xu, S., Zhang, S., and Geng, H. (2011). Gaze-induced joint attention persists under high perceptual load and does not depend on awareness. Vis. Res. 51, 2048–2056. doi: 10.1016/j.visres.2011.07.023
Keywords: social attention, orienting of attention, gaze cueing effect, monetary reward, social cognition
Citation: Lo Gerfo E, De Angelis J, Vergallito A, Bossi F, Romero Lauro LJ and Ricciardelli P (2018) Can Monetary Reward Modulate Social Attention? Front. Psychol. 9:2213. doi: 10.3389/fpsyg.2018.02213
Received: 28 June 2018; Accepted: 25 October 2018;
Published: 14 November 2018.
Edited by:
Matthias Gamer, Universität Würzburg, GermanyReviewed by:
Nicola Jean Gregory, Bournemouth University, United KingdomDelin Sun, Duke University, United States
Roxane J. Itier, University of Waterloo, Canada
Copyright © 2018 Lo Gerfo, De Angelis, Vergallito, Bossi, Romero Lauro and Ricciardelli. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Emanuele Lo Gerfo, ZW1hbnVlbGUubG9nZXJmb0B1bmltaWIuaXQ=
†These authors have contributed equally to this work