 Liron Primor
Liron Primor Tami Katzir
Tami Katzir- Department of Learning Disabilities, University of Haifa, Haifa, Israel
Multiple text integration is an important skill in modern society, required in heterogeneous situations, across many disciplines and in daily life. It is a complex skill that builds on bottom-up and top-down processes (Britt and Rouet, 2012). As a complex skill it has been measured in the literature using different techniques. To date, the different ways in which researchers have defined and operationalized the term have not been reviewed. Therefore, the aim of this paper is to review how multiple text integration has been theoretically and empirically assessed. The current paper reviews which texts were typically used, which aspects of integration were assessed, and with which scoring rubrics. Finally, we propose that despite the diverse use of tasks, important features of multiple text integration are missing from current research.
Introduction
The internet era has changed the very nature of reading. Today, in the click of a mouse, readers are exposed to multiple sources of information on the same topic in personal, academic, occupational, and social contexts (List and Alexander, 2017). This might include reading articles and blogs in order to reach decisions concerning recreational activities, investments, and health, or reading articles for academic purposes. Reading online material almost always involves multiple texts in the form of hyperlinks and comments (Eshet-Alkalai, 2004; Liu et al., 2008; Goldman and Scardamalia, 2013). For this reason, Goldman et al. (2012) argued that multiple text reading is the norm rather than the exception.
Generating a coherent representation based on multiple texts is a demanding task that builds on numerous top-down and bottom-up processes (Rouet, 2006; Britt and Rouet, 2012); in order to construct a coherent and complete representation of multiple texts, readers first need to efficiently process each text separately and build a situation model in the context of a certain reading goal (Kintsch, 1988). Readers also need to evaluate the reliability and relevance of each text (Richter, 2011). Furthermore, they must construct a model of the relationships among the texts. They do so based on several processes: they link details and ideas between the texts (Rouet and Britt, 2011); they compare and contrast information across texts, notice inconsistencies, and decide how to deal with them; finally, they organize the various details and ideas into a coherent representation (Goldman et al., 2012).
Integration of multiple texts is a complex procedure that can result in different types of integration. Texts can be integrated based on their contents, linguistic features, rhetorical aspects, or information external to the text, such as the source or context of the writing. Different logical relationships can be formed, such as cause and effect, chronology, hierarchy, etc. Finally, readers can integrate segments of information that are explicitly stated, or implicit ideas that are deduced from the texts. Integration will also be influenced by text and task features (Snow, 2002).
Whereas research on single text comprehension deals with types and levels of reading comprehension and their correspondence to different assessment methods, a similar discussion is currently missing from multiple text research. For example, single text reading comprehension studies compared reading comprehension assessment methods, and conclusions were reached regarding what skills are tapped by the various measures (e.g., Cutting and Scarborough, 2006; Keenan et al., 2008; Keenan, 2012). Theoretical models have also addressed the notion that there are different levels of comprehension, tapped by various assessment methods (Kintsch, 1988; McNamara et al., 2015).
Multiple text integration (MTI) has been assessed with different types of tasks based on expressive, receptive, and think aloud procedures. Even while using similar tasks, the scoring rubric utilized in the literature varies (e.g., Barzilai et al., 2018). Nevertheless, discussions of types, levels of integration, and comparisons of assessment methods are scarce. Therefore, the aim of this paper is to examine which aspects of MTI have been studied, by carefully mapping MTI tasks and theoretical models. We will begin by discerning the nature of MTI, and how this concept was defined and assessed in the literature. We will review MTI assessment methods and compare them on the basis of the texts, tasks, and assessment rubrics. Finally, we will point to important gaps in the current literature and suggest future directions of research.
Theoretical Models of MTI
The first studies that focused on the integration of multiple texts were conducted during the 1990s by Wineburg (1991, 1998), and investigated differences between expert and novice reading of multiple texts in the history discipline. Wineburg (1991, 1998) work focused on the field of history, where scholars must integrate and reconcile conflicts between different sources. Results of these studies pointed to major differences in reading strategies between experts and novices. The findings suggested that only experts use strategies such as sourcing, corroboration, and contextualization. Expert readers paid attention to the source and context and looked for inconsistencies across documents, whereas novices did not apply these strategies and were not able to deal with conflicts. Following these works, more and more studies suggested that MTI is a challenging task even for college students (e.g., Segev-Miller, 2007). Following Wineburg (1991, 1998) work in history, the research expanded to study MTI in more disciplines and new contexts, and examined a variety of aspects of engagement with multiple texts, such as use of sources (e.g., Strømsø et al., 2010), individual differences (e.g., Barzilai and Strømsø, 2018), task characteristics (e.g., Gil et al., 2010a,b), and how to promote integration (e.g., Barzilai et al., 2018).
In addition, theoretical models were developed to describe the mental structures that readers generate when deeply engaging with multiple texts (DMF, Britt et al., 1999; Perfetti et al., 1999; Rouet, 2006) and the cognitive procedures that readers undergo (MD-TRACE; Rouet and Britt, 2011; Goldman et al., 2012). Contextual factors (RESOLV, Rouet et al., 2017; MD-TRACE; Rouet and Britt, 2011) and individual differences in MTI were also discussed (CAEM; List and Alexander, 2015, 2017, MD-TRACE; Rouet and Britt, 2011; Britt and Rouet, 2012). In addition, the role of contradictions between texts (Braasch et al., 2012; Braasch and Bråten, 2017) and the interaction between readers’ prior knowledge and texts’ contents were addressed (Richter and Maier, 2017). Different frameworks investigated how readers derive meaning from multiple texts and use different terminology to describe it (Barzilai et al., 2018).
In order to clarify the various terms, MTC (multiple text comprehension) is used to describe readers’ engagement with multiple texts, and includes a variety of processes and abilities such as understanding the literal meaning of the texts, noticing sources and differences between them, etc. MTI (multiple text integration) describes the specific act of linking pieces of information from various texts, which is a subprocess or component of MTC. The current review includes models stemming from reading research, dealing with MTC and MTI.
Bråten et al. (2013a, pp. 322–323) defined multiple text comprehension (MTC) as the “building of a coherent mental representation of an issue from the contents of multiple text that deal with the same issue from different perspectives.” List and Alexander (2017, p. 143) used a similar definition, but one that emphasized the processes involved rather than the product of comprehension: “MTC refers to the processes and behaviors whereby students make sense of complex topics or issues based on information presented not within a single source but rather across multiple texts.” MTC has also been referred to as “multiple documents literacy” and “multiple sources comprehension.”
Goldman et al. (2012, 2013) proposed a model that breaks down MTC into several subcomponents and offers a specific definition of MTI. The subcomponents include: gathering resources; sourcing and selecting resources; analyzing, synthesizing, and integrating information within and across sources; applying information to accomplish the task; and evaluating processes and products. According to Goldman et al. (2013), analysis, synthesis, and integration operate across sources as well as within sources (see also Perfetti et al., 1999). Analysis is the process of sorting out the information relevant to the inquiry task, since not all the material is relevant for the specific task. Synthesis across multiple texts is defined as an inferential reasoning process that compares and contrasts contents in order to determine the relationship between the various pieces of information (e.g., complementary, overlapping, or redundant). Finally, integration “involves organizing the outcomes of analysis and synthesis processes to form the integrated model” (p. 185).
The documents model framework (DMF; Britt et al., 1999; Perfetti et al., 1999; Rouet, 2006), the first theoretical model to account for MTC, did not explicitly define integration, but rather described the types of links that are formed during MTC. The model outlined the mental structures that readers generate in order to represent source information and to assemble heterogeneous and sometimes conflicting document information to create an integrated mental model (Britt et al., 2013). The integrated mental model (originally called the intertext model) is a product of two types of links: links between the information represented in each text (referred to as Document node), and links between contents and sources (called intertext Links). Connections between contents are made across the different levels of presentation, so that a reader might notice similarities or differences in surface structure, text base, or situation model (Britt and Sommer, 2004).
Britt et al. (2013) explained that the documents model assumes that a document is an “entity,” which means that readers do not encounter an isolated text but rather a text that was written by an author, with certain values and motives, within a specific context. The various features of the source, such as the identity of the author and his or her aim in writing, are important for the selection, evaluation, and synthesis of the various texts. In addition, Perfetti et al. (1999) point out that factors such as type of task and reading goal may influence the quality of the integrated situation model and of the intertext model.
The MD-TRACE model (Rouet and Britt, 2011; Britt and Rouet, 2012) expands the DMF to include not only the mental structures the reader generates, but also a description of specific processes, products, and resources needed to complete tasks that involve multiple texts. One of the steps involved is text processing that leads to the next step, formation or update of the documents model. Yet, the exact procedures that take place in this step are not elaborated.
Two recently proposed models discuss the role of inconsistencies and contradictions between texts, or between texts and prior knowledge and beliefs in MTC. These models thus imply that MTI is based on processes of comparison between types of information. The DIS-C model (Braasch et al., 2012; Braasch and Bråten, 2017) “provides a detailed description of processes that occur when reading-to-understand controversial messages presented by multiple information sources” (Braasch and Bråten, 2017; p. 2). The model builds on both single text discourse comprehension theories as well as on MTC models and focuses on contradictions between texts or between previous knowledge and the current text, as conditions that stimulate a deeper processing and consideration of information sources. These conflicts are assumed to promote attention to source information (who the author is, context of writing, where it was published, etc.) as means of resolving the conflict.
Similarly, Richter and Maier (2017) discuss the role of prior knowledge and beliefs in comprehending multiple texts that are consistent or inconsistent with readers’ prior beliefs. According to their two-step model, readers detect text-belief inconsistencies through a routine process of validation, or epistemic monitoring of incoming text information for internal consistency and plausibility (Richter, 2011). In the next step, factors such as motivation and reading goal affect the extent of strategic effortful processing of the inconsistent information.
In a paper dealing specifically with MTI, Cerdán Otero (2005, p. 25) suggested the following definition of MTI: “A mental process that connects different units of information into the reader’s mind.” She further proposed that this process is the product of two strategies: The first is corroboration, which means comparing and contrasting information from several documents in order to identify unique pieces of information, contradictions, and overlaps. The second is the reinstatement-and-integration strategy proposed by Mannes (1994); Mannes and Hoyes (1996). According to this strategy, when reading multiple texts, sets of prepositions that were read before are reinstated when relevant prepositions are read in another text, on the basis of similarity. This allows integration of the two sets of prepositions by means of inference making and elaborations. Cerdán Otero (2005) also points out that this is an active, effortful, and time-consuming process rather than an automatic process, and that it also depends on the characteristics of the task and on the relationship between the texts, which may favor or limit such active processing.
In conclusion, MTC has been conceptualized by a variety of models, while only some of them have specifically and directly discussed MTI. Two definitions of integration were presented, sharing the core idea that integration is the act of linking and synthesizing pieces of information. Yet, the nature of these links was not specified. Links between texts are formed on the basis of similarities and differences between pieces of information, a process that is referred to as synthesis (Goldman et al., 2012, 2013), epistemic validation (Richter, 2011), or corroboration (Wineburg, 1991; Cerdán Otero, 2005). This synthesis occurs within the contents of the texts, and between the contents and source information (Perfetti et al., 1999; Britt et al., 2013). Next, we sought to examine how theoretical models of MTI were translated to empirical tasks.
Goals of the Current Review
The MTC models described above provide a general definition of MTI, suggestions as to the processes and strategies readers employ while engaging with multiple texts, and speculated factors that also take part in this process (such as context, reader, and task characteristics). However, the various theoretical models rarely discuss the type of links formed between texts and how they are represented in the empirical assessment methods used in various studies. We were therefore interested in a thorough review of types of integration tasks and two questions were asked: What types of integration tasks were studied in the empirical research? What types or levels of integration were addressed, based on the nature of the tasks given to readers? To address these questions, we reviewed how integration was assessed across studies, and compared text types, tasks, and assessment rubrics.
Methods
Literature Base and Inclusion Criteria
Multiple text integration studies were retrieved by searching peer-reviewed journals published in English in the PsycINFO and ERIC databases. Articles published until 2017 were included.
Following the literature review we chose several keywords and formed the following search string for searching in article titles: (multiple AND text∗) OR (multiple AND document∗) OR (text∗ AND integ∗) OR (text∗ AND source∗). The search was not limited to any time range or population. The search yielded 257 articles from ERIC and 340 from PsychINFO. In addition, we included a classical article that did not come up during the database search (Wineburg, 1991).
Fifty studies met the following inclusion criteria:
(1) Studies that focused on integration between texts. We did not include studies that focused on integration of texts and visual information, integration of words in texts, or integration within single texts. Nevertheless, when integration of texts and pictures was examined along with integration of texts, the study was included (e.g., Wineburg, 1991).
(2) Studies that specifically assessed integration of multiple texts. We did not include studies that used an MTI task in order to measure other constructs (such as attention to sources or memory for conflicts) and did not directly measure MTI.
(3) For reviewing MTI assessment methods we included only empirical studies that specified how MTI was assessed. Studies in which MTI assessment was not sufficiently elaborated were not included. In addition, we found no theoretical studies that reviewed MTI tasks.
(4) We chose to focus on studies conducted in L1.
(5) Studies were written in English, but the research itself was not limited to any language.
Coding Scheme
In reviewing the literature, we used the following categorizations and coding schemes:
Participants
Number of participants and demographic information.
Texts
We shortly described the number of texts, their topic, and marked the relationships between them in the following manner: A≠B was used to describe any set of texts that included a contradiction, a conflict, or a disagreement. In this category we included only texts where the conflict was central to the integration. A+B was used to describe texts that were convergent and required adding pieces of information together.
Tasks and Assessment Rubrics
We divided the tasks into receptive and expressive tasks, presented in separate tables, and specified the various task types (e.g., essay writing, open ended questions, etc.), since each type of task requires the reader to employ different skills. MTI tasks that required writing or providing oral accounts of comprehension were classified as expressive measures, whereas tasks that demanded marking a correct response were referred to as receptive tasks. In the case of expressive tasks we also included the instructions given to readers (when these were available). As for expressive tasks, a variety of categories were employed in order to assess integration. We examined the scoring technique (e.g., holistic scoring or analyzing smaller units) and the categories used to evaluate the products (e.g., paraphrasing, elaborations, supporting arguments, etc.).
Levels of Integration
Next, we endeavored to map the list of evaluation categories used for integration assessment. Following a consultation between the two authors, we divided these into three levels: selecting information, intertextual relationships, and inference making. The first two categories are similar to the terms analysis and synthesis proposed by Goldman et al. (2013). The first level, selecting information, refers to selecting the relevant pieces of information from the various texts and including them in the answers. Goldman et al. (2013) referred to this level as analysis. Selection of information means extracting a main idea from a single text in the context of multiple texts, and therefore differs from extracting main ideas from a single text in isolation. We considered categories such as “covering main ideas or arguments” and “referring to sources” (e.g., Blaum et al., 2017) as subsumed under the title of selecting information.
The second category was generating relationships between the texts. It referred specifically to linking pieces of information extracted from different texts or about sources, and noticing the relationship between them (e.g., complementary, conflicting). Goldman et al. (2013) named this level synthesis. We considered categories such as “corroboration” (comparing documents to one another, Wineburg, 1991) and “reconciling conflicts” (e.g., Bråten et al., 2014a), which require the readers to actively form connections between the texts. The third category we used was inference making, including what we interpreted as transforming information or adding something new. We considered categories such as “statement including novelty” (e.g., Linderholm et al., 2014) and “using prior knowledge” (e.g., Goldman et al., 2013) to fall under this category.
Each level was divided again to three types: conceptual, linguistic, and rhetoric (Segev-Miller, 2007). These terms are borrowed from Segev-Miller (2007), who listed strategies writers employ when synthesizing texts. We found this structure to be useful for pointing to differences between what is measured in expressive versus receptive tasks and for illuminating aspects of text integration. The conceptual level deals with ideas and contents (e.g., covering main ideas or arguments; Blaum et al., 2017). The rhetorical level involves integration as exhibited in the structure of the written text (e.g., relating to sources; Stadtler et al., 2013). Finally, the linguistic level refers to linguistic means that express integrated representation (e.g., using connectives to note relationships between the texts; List and Alexander, 2015).
Mapping assessment categories across the various tasks was a complicated endeavor for several reasons. First, different terms were used and we had to judge whether different terms point to the same concept or, on the contrary, whether identical terms found in several places had different meanings. For example, we judged rebuttals and reconciling conflicts as referring to the same construct. Second, descriptions of tasks and assessment methods were sometimes not sufficient for us to determine the exact level of integration required. For example, main ideas and arguments can be stated explicitly or, on the contrary, implicitly extracted from the text. Therefore it is possible that in one set of texts extracting main ideas involved higher levels of inference making, while in another text it required only understanding the literal meaning. Third, MTI is a complex task with many underlying processes, such that clear-cut distinctions between these processes are challenging (McNamara et al., 2015). Any disagreements between the two authors in mapping assessments by the categories described above were resolved through discussion and required at least 90% agreement.
Tables 1, 2 present details of text integration studies divided into expressive (Table 1) and receptive tasks (Table 2). In each table, similar tasks are grouped together and are then arranged alphabetically by authors’ names (essay writing, open ended questions, etc.). When several studies used the same MTI assessment method, only one study was fully presented. Other similar studies were mentioned under the task assessment description (“Assessment” rubric), so that the same methodology was presented only once. Table 3 includes results of these studies as well. In total there were 50 studies that examined 61 tasks and used 33 categories to assess them.
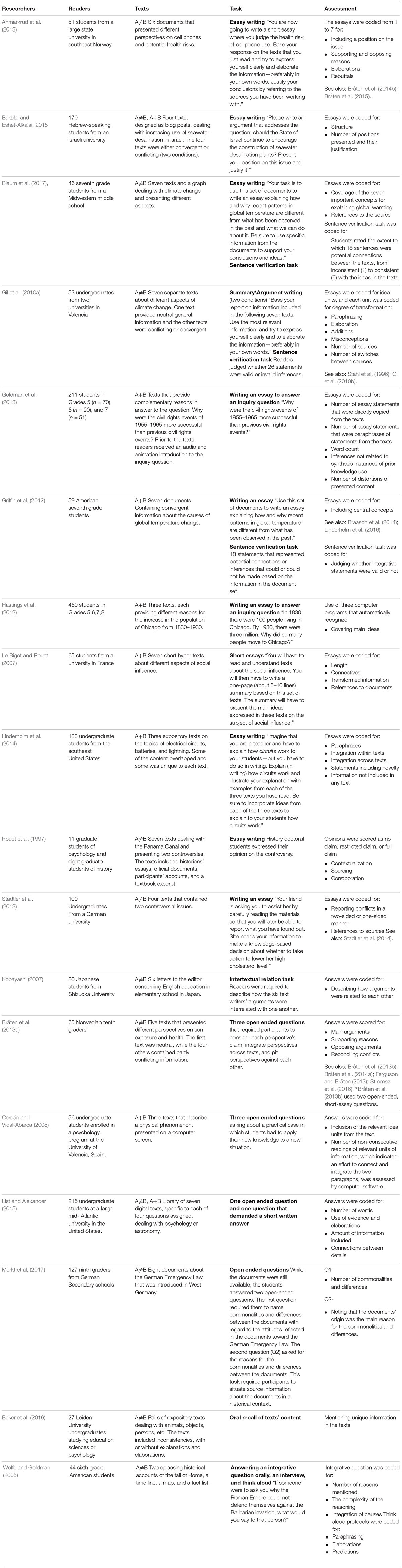
TABLE 1. Literature review of expressive integration tasks.
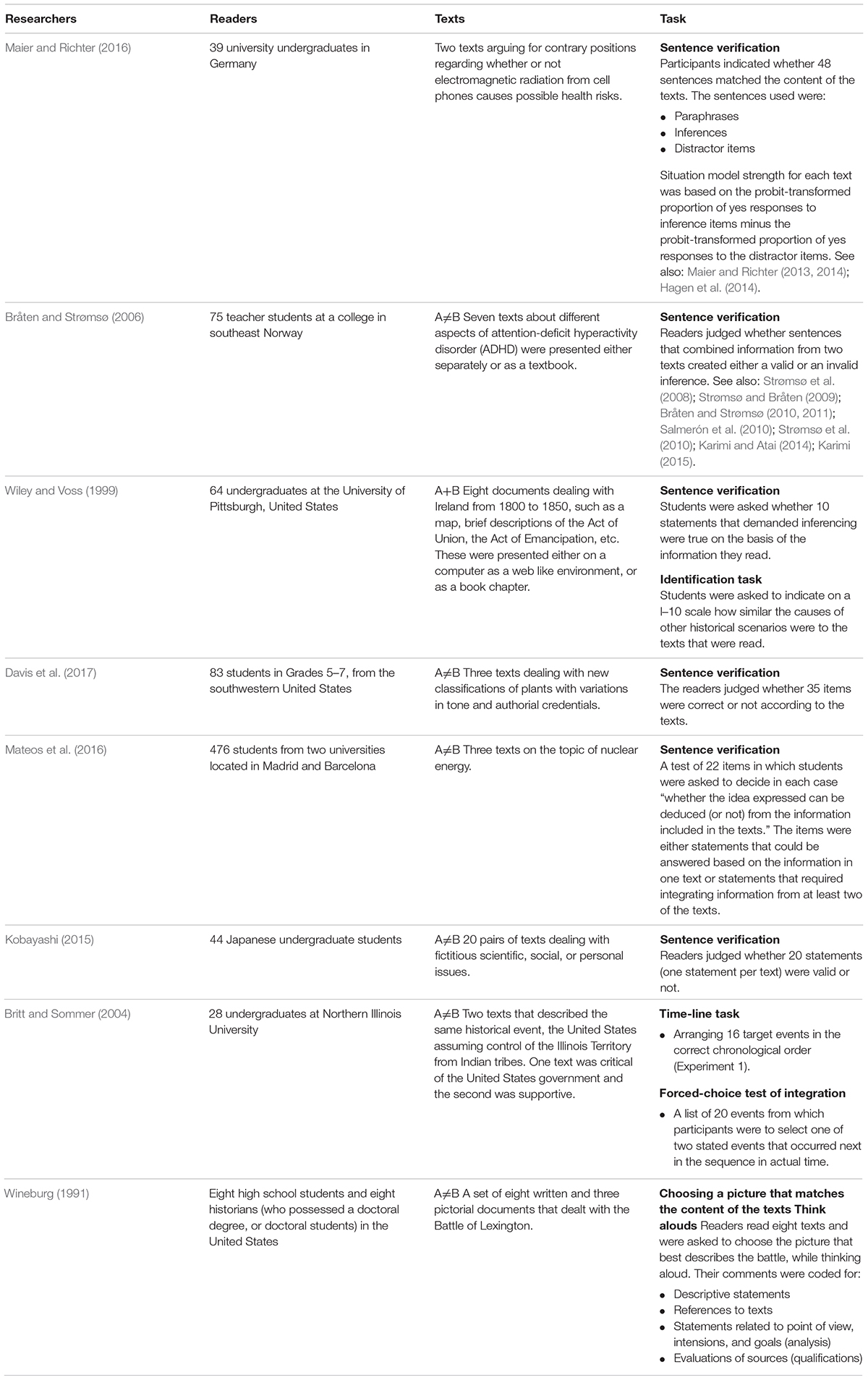
TABLE 2. Literature review of receptive integration tasks.
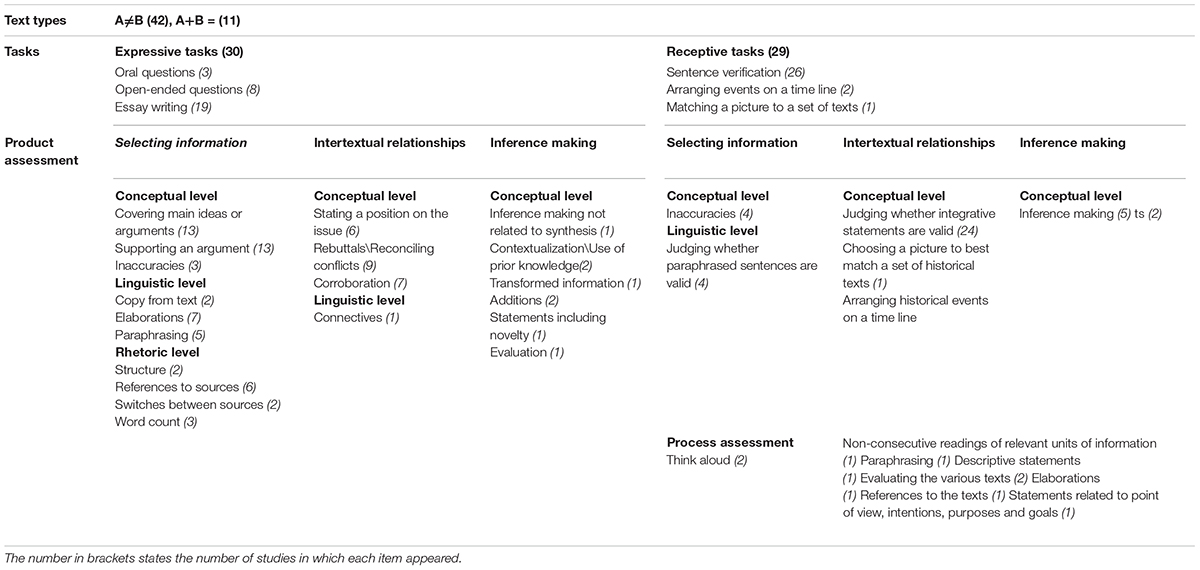
TABLE 3. Results of MTI tasks review presented by text types, tasks, assessments of products and processes.
Literature Review Results
The review resulted in 50 MTI studies. Table 3 summarizes the results of the review in a table, divided by text, type of task, and assessment method. Different coding schemes were used to measure text integration, where some of the parameters were repeated across studies and others were unique. We categorized them by different levels and types (see “Method” section), listed them, and noted in brackets the number of studies in which each was used. We based our coding scheme on the aim of the review, and mainly discuss text types, tasks, and assessment rubrics.
Participants
Multiple text integration has been examined with readers of varying age, from as young as fifth grade to undergraduate students.
Texts
The studies cited here used two to eight expository texts, such as journal articles, arguments, textbook excerpts, etc. Some also included visual information such as graphs and pictures (e.g., Wineburg, 1991). Earlier studies used historical texts, and later studies also encompassed texts from other fields, such as biology, health, and science. Comparisons of text integration across different disciplines suggest that integration is related to conventions of the disciplines chosen. For example, inconsistencies between historical accounts can be explained by different perspectives or agendas. In contrast, inconsistencies in scientific findings would be explained by differences in methodology, artifacts, etc.
Our review did not examine sourcing, or how readers examine the credibility of sources and decide on which text to rely. The participants did not search for the documents themselves, rather the texts used in the studies were presented as credible sources and the readers did not have to decide which to trust. Usually, the texts were equally relevant to the target questions. In one exceptional study, Anmarkrud et al. (2013) used texts that varied in their relevance to the inquiry question and each text had a different weight in the integration process.
The various sets of texts had two types of relationships between them: 42 studies used texts that represented a major conflict. For example, two texts that describe a historical event: one that supports United States government actions, and another that criticizes them and supports the Indian tribes’ position (e.g., Britt and Sommer, 2004). Eleven studies used texts that presented different aspects of an issue or texts that complemented each other. For example, Goldman et al. (2013) designed three texts that each offered a possible reason for a historical event. The different reasons did not contradict each other but rather supported each other. Three studies used two research conditions, one with conflicting texts and another with contradictory texts. These were coded as both A+B, A≠B.
Expressive Tasks
Nineteen studies used essay writing as a measure of MTI, eight studies used open ended questions, and three used oral questions. Regarding essay writing, readers typically received a specific question to answer and elaborate instructions regarding what the essay should contain. For example: “Use this set of documents to write an essay explaining how and why recent patterns in global temperature are different from what has been observed in the past” (Griffin et al., 2012).
Usually, the researchers developed a set of specific categories for coding the essays. For example, Goldman et al. (2013) coded essays for: number of essay statements that were copied directly from the texts, number of paraphrases of statements from the texts, word count, inferences not related to synthesis, and instances of prior knowledge. In other cases, essays were separated into idea units and divided into categories such as paraphrasing, elaborations, etc. (e.g., Gil et al., 2010a). Two other scoring systems used were examining whether the relevant information was included in the answer, and scoring the essay holistically (not by dividing it into units) according to the quality and quantity of arguments. This was also the common coding system for open ended questions (e.g., Bråten et al., 2013a). Other coding systems for open ended questions were coding the content according to specific categories or idea units, as explained above. The same types of coding systems were used when integration was measured with oral questions. The written products were typically assessed by two judges, disagreements were solved through discussions, and the percentage of interrater agreement was reported.
Receptive Tasks
The common measure was the sentence verification task (e.g., Bråten and Strømsø, 2010) that was used in 26 studies. This task is comprised of phrases that combine information from different sentences in the various texts, or a combination of information from the text with information that was not written explicitly, in a way that forms either a valid or invalid inference. Bråten and Strømsø (2010) reported that the reliability for the scores on this task of sentence verification as measured by Cronbach’s alpha was 0.58. They note that although this seems to be lower than desired, data from the same study conducted in English indicated that participants who included more relevant information from most of the texts in their essays and linked information from the different texts performed much better on the intertextual inference verification task compared to participants who included less information and had difficulty integrating the texts. Another receptive measure used is multiple choice comprehension questions (Britt and Sommer, 2004; Le Bigot and Rouet, 2007). In addition, Wineburg (1991) asked participants to choose a picture that best matches the integration of the texts.
Comparisons of Expressive and Receptive Tasks
Comparisons between assessments were scarcely reported and more empirical research is needed in order to compare the various measures. Griffin et al. (2012) examined MTI with a written essay and also with a sentence verification task. They reported that the two measures of MTI correlated only modestly with each other, but correlated similarly with other variables. They further concluded that the two measures “reflect somewhat different aspects of multiple-documents comprehension” (Griffin et al., 2012, p. 74). In contrast, Gil et al. (2010b) applied two MTI measures, essay writing and sentence verification. They found positive intercorrelations within and across the MTI measures and presented this as support for the validity of the dependent measures.
Expressive tasks appear to have higher reliability compared to receptive tasks and they are considered to measure deeper levels of integration. In a more recent work, Bråten et al. (2014a) preferred short-essay questions over intertextual inference verification tasks that they had previously used. They explained that receptive tasks have lower reliability scores and that expressive tasks make it possible “to evaluate students’ abilities to corroborate information from different sources and reason about an issue in terms of claims and evidence concerning different perspectives” (Bråten et al., 2014a, p. 18).
Expressive and Receptive Task Assessment
Coding schemes used to evaluate integration products were heterogeneous. Regarding the assessment of expressive tasks, we found that assessment categories that belonged to the first level of selecting information were most prevalent (56). There were 23 instances of generating intertextual relationships, and only eight examples of inference making. A different pattern was found for receptive tasks. The most prevalent level was generating intertext relationships (27) compared to selecting information (8) and inference making (5). In both expressive and receptive assessments, most coding schemes focused on the conceptual level of integration, and to a lesser extent on the rhetorical and linguistic level.
Interestingly, we found at times that a task had the potential of encouraging readers to generate new inferences. However, the assessment method did not relate to instances of inference making, but only to information selecting (e.g., Griffin et al., 2012). Therefore, it seems that the level and type of integration the reader exhibits is related to the choice of texts, tasks, and assessment categories.
Integration Process Assessment
Two experiments used think aloud protocols, usually in order to learn about strategies that support integration (Bråten and Strømsø, 2003; Cerdán and Vidal-Abarca, 2008). Think aloud protocols provide some insight on the cognitive processes that take place when readers integrate texts and on the strategies used. In addition, Cerdán and Vidal-Abarca (2008) used a computer software to measure non-consecutive reading of relevant units of information, which according to the authors indicate an effort to connect and integrate two paragraphs.
Discussion
The aim of the current review was to map which types of text integration were examined in empirical research. We reviewed 50 studies and noticed meaningful differences as well as similarities between them. Regarding the texts utilized in MTI tasks, we found that they were frequently contradictory (e.g., presented different opinions). Fewer studies used complementary texts, and other types of relationships were not reported. Goldman (2015) noted that the research should develop taxonomies of intertextual relations that explain how readers process multiple texts, in order to detect these relationships and how they are related to features of texts. Goldman (2015) gave examples not only of texts that agree or disagree, but also of texts that overlap in terms of content, or texts that explain one another. Recently, Strømsø (2017) also noted that “Less is known about how models of multiple source use apply to information sources containing only overlapping, complementary, or unique information” (Strømsø, 2017, p. 22).
Regarding the tasks, one salient finding was that in all the studies we reviewed the participants were given scaffolds in the form of a specific inquiry question. The inquiry question often served as a criterion that assisted the readers in selecting the relevant information from each text and in detecting associations between the texts. Readers either had to locate conflicts between the texts or join together pieces of information. We encountered no cases where participants were given a set of texts and were required to generate a title, an inquiry question, or conclusions by themselves.
For example, students were asked about the relationship between sun exposure and health, and were given texts stating that sun exposure is dangerous and other texts reporting the benefits of sun exposure (Bråten et al., 2013a). Another possible integration task would be to present students with the same texts attached to questions asking about the relationship between the texts or about conclusions that can be derived from them. In this manner, students would be encouraged to employ higher level thinking, to generate generalizations, and to form their own categorizations.
As for assessment methods, we found variations in assessments of integration tasks that reflected different conceptualizations. First, we found differences between receptive and expressive tasks in the types of integration measures as well as in the reported reliability. Second, the various scoring systems of expressive measures gave different weight to the conceptual, rhetorical, and linguistic level. While some essay scoring systems considered the structure and coherence of the argument (e.g., Anmarkrud et al. (2013); Barzilai and Eshet-Alkalai, 2015, other scoring systems reflected the conceptual level and coded essays for including key ideas (e.g., Linderholm et al., 2016). Third, among the three integration categories that we chose to use, the salient ones were selecting information and generating relationships. The category of inference making that related to transforming the information and producing new information was used less often.
We argue that the type of text, task, and assessment method employed focused on the literal level of the texts. Providing readers with a specific inquiry question serves as a scaffold for generating intertext links. In addition, using conflicting texts and the assessment methods described above focus only on selecting information and creating intertext relationships. We propose that more attention should be assigned to MTI that does not include scaffolds. Assessment methods described here rarely asked students to integrate texts in a way that transforms knowledge or creates new categories. We therefore wish to suggest which types of integration are currently missing from empirical research and theoretical models.
What is Missing from Current Research?
As stated earlier, we propose that MTI tasks should also include tasks where readers generate their own categories for integration. This involves generalization and abstraction, which we consider to be higher level processes because they build on selecting information and synthesis and require the person to create his own category relevant to the texts rather than using an existing one.
According to classical definitions of Greek philosophy (Bäck, 2014), generalizing is the process of reaching general conclusions or formulating principles from an array of details. For example, a person may read three texts by the same author and conclude that all the texts deal with family relationships. Generalizing is therefore a form of creating new knowledge. This knowledge is not absolute, and is subject to change if new information appears, such as a new text by the same author that deals with different issues.
Abstraction refers to the process of disregarding contingent details for the sake of reaching the essence of a certain object. An example might be recognizing a common underlying assumption across several texts, or designing a rule or a theoretical model based on several concrete situations. In these cases several features of objects are ignored in order to reveal core similarities between them.
Generalization and abstraction are common in academic settings. Scholars read articles describing specific findings and generate synthesis, organization of information, generalizations, and abstractions on a daily basis. One type of integration involves recognizing main ideas and similar themes and understanding whether the findings support or contradict each other and how they relate to previous findings. A higher level of integration would be performing generalizations and abstractions, reaching general conclusions, and identifying a common essence of the various texts. Imagine, for example, a student reading several journal articles about various variables that predict reading comprehension. The student may identify the main ideas in each text, recognize relationships between the texts, and organize the information as follows: “Accuracy and speed of word reading, as well as vocabulary knowledge, contribute to reading comprehension in primary school.” However, the student may also try to reach a higher level of integration (generalization and abstraction) and add that the type of reading comprehension assessment affects study results, or realize that reading comprehension research focuses more on simple rather than on deep reading comprehension. Other examples might be reading different works of the same writer to describe common elements in his or her work, or reading different studies and exposing similarities and differences in the underlying theoretical models.
Integration based on generalization and abstraction is common in academic contexts, and in these situations the relationships between the texts, the reading goal or task, can be different than those presented in experimental studies. Similarities between texts are more implicit, non-concrete, and are sometimes not found on the text base level but only on the situation model level. The texts might share core features that the readers need to extract, generalize, and abstract. The relationships between the texts are less structured and clear, and the reading goal may also be less specific. Instead of one correct answer, there might be different options of information integration.
We wish to incorporate the main themes from the definitions presented earlier and to suggest that MTI is a process of linking pieces of information from various texts and their sources. Links are formed on the basis of identifying similarities and differences, as well as on inference making on different levels of the text, such as the textbase and the situation model (Kintsch, 1988, 1998). MTI results in several possible types of links between texts: extracting relevant ideas, synthesis, generalization, and abstraction.
The type of integration that takes place depends on the reader, the task, the reading activity, and the context (Snow, 2002). Readers can be more or less likely to reach different types of integration. Hartman (1995) suggested that different readers integrate sets of texts differently, and identified three approaches: The logocentric approach refers to limiting oneself to the author’s intent. The intertextual approach means trying to link as much information as possible, and the resistant approach refers to criticizing the texts and arguing with them. Thus, certain readers will pursue higher order integration even when dealing with simple texts and tasks, and when the assignments are freer in nature, the various readers will exhibit different types of integration. In addition, research has suggested that MTI is a difficult task that often does not occur spontaneously (Rouet, 2006; Rouet and Britt, 2011). Furthermore, differences between experts and novices reading multiple texts in their field of expertise have been demonstrated (e.g., Wineburg, 1991, 1998) and substantial research supports the contribution of various aspects of epistemic thinking (Bråten and Strømsø, 2011) and other personal traits (Barzilai and Strømsø, 2018) to multiple text integration.
Regarding the texts, it is possible that texts that are closer in their contents and that have more structured and easily recognized interrelations, direct the reader to more simple synthesis such as “Text A contradicts Text B.” When the texts share similarities that are more abstract, similarities on the situation level, integration requires more effort, and has the potential of pushing the reader to higher levels of generalization and abstraction. Thus, examination of MTI with texts that hold a variety of interrelations might yield other types of synthesis and integration.
Regarding the role of the task in integration assignments, it is possible that designing different types of tasks would result in higher levels of integration. First, different types of inquiry questions might direct the reader to different levels of integration. Specific and direct inquiry questions indeed direct the reader to analysis, synthesis, and coherent organization of information (Goldman et al., 2013). However, tasks with less scaffolding have the potential of directing the reader to reach higher levels of integration. A question that is general rather than specific can also lead to a larger variety of questions.
Second, it is possible that within the context of a research design that includes a time constraint and an encounter with new texts, reaching the highest levels of integration is extremely challenging. Perhaps in more natural settings, when dealing with familiar topics with more time in hand, readers have the potential of reaching higher levels of integration.
Conclusion
Multiple text integration is a complex concept that builds on different processes and skills and is influenced by variables related to the reader, the texts, and the reading activity (Snow, 2002; List and Alexander, 2017). In this paper we sought to map how MTI is assessed in current research. We argue that more research is needed in order to compare between text integration tasks and that current MTI research does not represent the wide variety of MTI situations. More specifically, we suggest that empirical studies have focused on integration that is scaffolded. Finally, we describe two levels of integration, which we call generalization and abstraction, that have not received research attention so far, partly due to the choice of texts, tasks, and assessment rubrics in the various studies (Goldman, 2014; Strømsø, 2017).
We believe that this review has both theoretical and practical importance. First, this work extends our understanding of the essence of integration and serves as an initial taxonomy of types and levels of integration that will eventually lead to a deeper and broader understanding of integration processes. This work is therefore important not only for multiple text research but also for single text reading research, as the concept of integration is relevant to any form of reading comprehension. On the practical level, we pointed to a lack of studies that examine the highest levels of integration common in academia, in the work of scholars and students, as they read specific findings and are required to reach general conclusions. Thus, research of integration in the form of generalization and abstraction will extend our knowledge of these processes, which could later be used to promote integration among students.
Author Contributions
LP conceptual development, data review, and write up. TK conceptual.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Anmarkrud,Ø., McCrudden, M. T., Bråten, I., and Strømsø, H. I. (2013). Task-oriented reading of multiple documents: online comprehension processes and offline products. Instr. Sci. 41, 873–894. doi: 10.1007/s11251-013-9263-8
Bäck, A. (2014). Aristotle’s Theory of Abstraction. The New Synthese Historical Library 73. Switzerland: Springer International Publishing doi: 10.1007/978-3-319-04759-1
Barzilai, S., Zohar, A. R., and Mor-Hagani, S. (2018). Promoting integration of multiple texts: a review of instructional approaches and practices. Educ. Psychol. Rev. 30, 1–27. doi: 10.1007/s10648-018-9436-8
Barzilai, S., and Eshet-Alkalai, Y. (2015). The role of epistemic perspectives in comprehension of multiple author viewpoints. Learn. Instruct. 36, 86–103.
Barzilai, S., and Strømsø, H. I. (2018). “Individual differences in multiple document comprehension,” in Handbook of Multiple Source use, eds J. L. G. Braasch, I. Bråten, and M. T. McCrudden (New York, NY: Routledge).
Beker, K., Jolles, D., Lorch, R. F., and Broek, P. (2016). Learning from texts: activation of information from previous texts during reading. Read. Writ. 29, 1161–1178. doi: 10.1007/s11145-016-9630-3
Blaum, D., Griffin, T. D., Wiley, J., and Britt, M. A. (2017). Thinking about global warming: effect of policy-related documents and prompts on learning about causes of climate change. Discourse Process. 54, 303–316. doi: 10.1080/0163853X.2015.1136169
Braasch, J. L., and Bråten, I. (2017). The discrepancy-induced source comprehension (D-ISC) model: basic assumptions and preliminary evidence. Educ. Psychol. 52, 1–15. doi: 10.1080/00461520.2017.1323219
Braasch, J. L., Bråten, I., Strømsø, H. I., and Anmarkrud, Ø. (2014). Incremental theories of intelligence predict multiple document comprehension. Learn. Individ. Differ. 31, 11–20. doi: 10.1016/j.lindif.2013.12.012
Braasch, J. L., Rouet, J. F., Vibert, N., and Britt, M. A. (2012). Readers’ use of source information in text comprehension. Mem. Cogn. 40, 450–465. doi: 10.3758/s13421-011-0160-6
Bråten, I., Anmarkrud,Ø., Brandmo, C., and Strømsø, H. I. (2014a). Developing and testing a model of direct and indirect relationships between individual differences, processing, and multiple-text comprehension. Learn. Instr. 30, 9–24. doi: 10.1016/j.learninstruc.2013.11.002
Bråten, I., Ferguson, L. E., Strømsø, H. I., and Anmarkrud, Ø. (2014b). Students working with multiple conflicting documents on a scientific issue: relations between epistemic cognition while reading and sourcing and argumentation in essays. Br. J. Educ. Psychol. 84, 58–85. doi: 10.1111/bjep.12005
Bråten, I., Braasch, J. L., Strømsø, H. I., and Ferguson, L. E. (2015). Establishing trustworthiness when students read multiple documents containing conflicting scientific evidence. Read. Psychol. 36, 315–349. doi: 10.1080/02702711.2013.864362
Bråten, I., Ferguson, L. E., Anmarkrud,Ø., and Strømsø, H. I. (2013a). Prediction of learning and comprehension when adolescents read multiple texts: the roles of word-level processing, strategic approach, and reading motivation. Read. Writ. 26, 321–348. doi: 10.1007/s11145-012-9371-x
Bråten, I., Ferguson, L. E., Strømsø, H. I., and Anmarkrud, Ø. (2013b). Justification beliefs and multiple-documents comprehension. Eur. J. Psychol. Educ. 28, 879–902. doi: 10.1007/s10212-012-0145-2
Bråten, I., and Strømsø, H. I. (2003). A longitudinal think-aloud study of spontaneous strategic processing during the reading of multiple expository texts. Read. Writ. 16, 195–218. doi: 10.1023/A:1022895207490
Bråten, I., and Strømsø, H. I. (2006). Effects of personal epistemology on the understanding of multiple texts. Read. Psychol. 27, 457–484. doi: 10.1080/02702710600848031
Bråten, I., and Strømsø, H. I. (2010). When law students read multiple documents about global warming: examining the role of topic-specific beliefs about the nature of knowledge and knowing. Instr. Sci. 38, 635–657. doi: 10.1007/s11251-008-9091-4
Bråten, I., and Strømsø, H. I. (2011). Measuring strategic processing when students read multiple texts. Metacogn. Learn. 6, 111–130.
Britt, M. A., and Rouet, J. F. (2012). “Learning with multiple documents: component skills and their acquisition,” in Enhancing the Quality of Learning: Dispositions, Instruction, and Learning Processes, eds J. R. Kirby and M. J. Lawson (New York, NY: Cambridge University Press), 276–314.
Britt, M. A., Perfetti, C. A., Sandak, R., and Rouet, J. F. (1999). “Content integration and source separation in learning from multiple texts,” in Narrative, Comprehension, Causality, and Coherence: Essays in Honor of Tom Trabasso, eds S. R. Goldman, A. C. Graesser, and P. van den Broek (Mahwah, NJ: Erlbaum) 209–233.
Britt, M. A., Rouet, J.-F., and Braasch, J. L. G. (2013). “Documents as entities: extending the situation model theory of comprehension,” in Reading: from Words to Multiple Texts, eds M. A. Britt, S. R. Goldman, and J.-F. Rouet (New York, NY: Routledge) 160–179.
Britt, M. A., and Sommer, J. (2004). Facilitating textual integration with macro-structure focusing tasks. Read. Psychol. 25, 313–339. doi: 10.1080/02702710490522658
Cerdán, R., and Vidal-Abarca, E. (2008). The effects of tasks on integrating information from multiple documents. J. Educ. Psychol. 100, 209–222. doi: 10.1037/0022-0663.100.1.209
Cerdán Otero, R. (2005). Integration: Information Processes Form Multiple Documents. Available at: http://roderic.uv.es/handle/10550/15435
Cutting, L. E., & Scarborough, H. S. (2006). Prediction of reading comprehension: relative contributions of word recognition, language proficiency, and other cognitive skills can depend on how comprehension is measured. Sci. Stud. Read. 10, 277–299.
Davis, D. S., Huang, B., and Yi, T. (2017). Making sense of science texts: a mixed-methods examination of predictors and processes of multiple-text comprehension. Read. Res. Q. 52, 227–252. doi: 10.1002/rrq.162
Eshet-Alkalai, Y. (2004). Digital literacy: a conceptual framework for survival skills in the digital era. J. Educ. Multimed. Hypermedia 13, 93–106.
Ferguson, L. E., and Bråten, I. (2013). Student profiles of knowledge and epistemic beliefs: changes and relations to multiple-text comprehension. Learn. Instr. 25, 49–61. doi: 10.1016/j.learninstruc.2012.11.003
Gil, L., Bråten, I., Vidal-Abarca, E., and Strømsø, H. I. (2010a). Summary versus argument tasks when working with multiple documents: which is better for whom? Contemp. Educ. Psychol. 35, 157–173. doi: 10.1016/j.cedpsych.2009.11.002
Gil, L., Bråten, I., Vidal-Abarca, E., and Strømsø, H. I. (2010b). Understanding and integrating multiple science texts: summary tasks are sometimes better than argument tasks. Read. Psychol. 31, 30–68. doi: 10.1080/02702710902733600
Goldman, S. R. (2015). “Reading and the web: broadening the need for complex comprehension,” in Reading at a Crossroads? Disjunctures and Continuities in Current Conceptions and Practices, eds R. J. Spiro, M. DeSchryver, M. S. Hagerman, P. Morsink, and P. Thompson (New York, NY: Routledge).
Goldman, S. R., Braasch, J. L. G., Wiley, J., Graesser, A. C., and Brodowinska, K. (2012). Comprehending and learning from internet sources: processing patterns of better and poorer learners. Read. Res. Q. 47, 356–381.
Goldman, S. R., Lawless, K., and Manning, F. (2013). “Research and development of multiple source comprehension assessmentm,” in Reading from Words to Multiple Texts, eds M. A. Britt, S. R. Goldman, and J.-F. Rouet (New York, NY: Routledge) (160-179).
Goldman, S. R., and Scardamalia, M. (2013). Managing, understanding, applying, and creating knowledge in the information age: next-generation challenges and opportunities. Cogn. Instr. 31, 255–269. doi: 10.1080/10824669.2013.773217
Goldman, S. R. (2014). “Reading and the web: broadening the need for complex comprehension,” in Reading at a Crossroads? Disjunctures and Continuities in Current Conceptions and Practices, eds R. J. Spiro, M. DeSchryver, P. Morsink, M. S. Hagerman, and P. Thompson (New York, NY: Routledge).
Griffin, T. D., Wiley, J., Britt, M. A., and Salas, C. R. (2012). The role of CLEAR thinking in learning science from multiple-document inquiry tasks. Int. Electron. J. Elem. Educ. 5:63.
Hagen,Å. M., Braasch, J. L., and Bråten, I. (2014). Relationships between spontaneous note-taking, self-reported strategies and comprehension when reading multiple texts in different task conditions. J. Res. Read. 37, 141–157. doi: 10.1111/j.1467-9817.2012.01536.x
Hartman, D. K. (1995). Eight readers reading: the intertextual links of proficient readers reading multiple passages. Read. Res. Q. 30, 520–561. doi: 10.2307/747631
Hastings, P., Hughes, S., Magliano, J. P., Goldman, S. R., and Lawless, K. (2012). Assessing the use of multiple sources in student essays. Behav. Res. Methods 44, 622–633. doi: 10.3758/s13428-012-0214-0
Karimi, M. N. (2015). L2 multiple-documents comprehension: exploring the contributions of L1 reading ability and strategic processing. System 52, 14–25. doi: 10.1016/j.system.2015.04.019
Karimi, M. N., and Atai, M. R. (2014). ESAP students’ comprehension of multiple technical reading texts: insights from personal epistemological beliefs. Read. Psychol. 35, 736–761. doi: 10.1080/02702711.2013.802753
Keenan, J. (2012). Measure for measure: challenges in assessing reading comprehension in Measuring up: Advances in How to Assess Reading Ability, eds J. P. Sabatini, F. Albro, and T. O’Reilly (Lanham, MD: Rowman and Littlefield Education) 77–87.
Keenan, J. M., Betjemann, R. S., and Olson, R. K. (2008). Reading comprehension tests vary in the skills they assess: differential dependence on decoding and oral comprehension. Sci. Stud. Read. 12, 281–300. doi: 10.1080/10888430802132279
Kintsch, W. (1988). The role of knowledge in discourse comprehension: a construction-integration model. Psychol. Rev. 95, 163–182. doi: 10.1037/0033-295X.95.2.163
Kintsch, W. (1998). Comprehension: A Paradigm for Cognition. New York, NY: Cambridge University Press.
Kobayashi, K. (2007). The influence of critical reading orientation on external strategy use during expository text reading. Educ. Psychol. 27, 363–375. doi: 10.1080/01443410601104171
Kobayashi, K. (2015). Learning from conflicting texts: the role of intertextual conflict resolution in between-text integration. Read. Psychol. 36, 519–544. doi: 10.1080/02702711.2014.926304
Le Bigot, L., and Rouet, J. F. (2007). The impact of presentation format, task assignment, and prior knowledge on students’ comprehension of multiple online documents. J. Lit. Res. 39, 445–470. doi: 10.1080/10862960701675317
Linderholm, T., Dobson, J., and Yarbrough, M. B. (2016). The benefit of self-testing and interleaving for synthesizing concepts across multiple physiology texts. Adv. Physiol. Educ. 40, 329–334. doi: 10.1152/advan.00157.2015
Linderholm, T., Therriault, D. J., and Kwon, H. (2014). Multiple science text processing: building comprehension skills for college student readers. Read. Psychol. 35, 332–356. doi: 10.1080/02702711.2012.726696
List, A., and Alexander, P. A. (2015). Examining response confidence in multiple text tasks. Metacogn. Learn. 10, 407–436. doi: 10.1007/s11409-015-9138-2
List, A., and Alexander, P. A. (2017). Analyzing and integrating models of multiple text comprehension. Educ. Psychol. 52, 143–147. doi: 10.1080/00461520.2017.1328309
Liu, O. L., Lee, H. S., Hofstetter, C., and Linn, M. C. (2008). Assessing knowledge integration in science: construct, measures, and evidence. Educ. Assess. 13, 33–55. doi: 10.1080/10627190801968224
Maier, J., and Richter, T. (2013). Text belief consistency effects in the comprehension of multiple texts with conflicting information. Cogn. Instr. 31, 151–175. doi: 10.1080/07370008.2013.769997
Maier, J., and Richter, T. (2014). Fostering multiple text comprehension: how metacognitive strategies and motivation moderate the text-belief consistency effect. Metacogn. Learn. 9, 51–74. doi: 10.1007/s11409-013-9111-x
Maier, J., and Richter, T. (2016). Effects of text-belief consistency and reading task on the strategic validation of multiple texts. Eur. J. Psychol. Educ. 31, 479–497. doi: 10.1007/s10212-015-0270-9
Mannes, S. (1994). Strategic processing of text. J. Educ. Psychol. 86, 577–588. doi: 10.1037/0022-0663.86.4.577
Mannes, S., and Hoyes, S. M. (1996). Reinstating knowledge during reading: a strategic process. Discourse Process. 21, 105–130. doi: 10.1080/01638539609544951
Mateos, M., Solé, I., Martín, E., Castells, N., Cuevas, I., and González-Lamas, J. (2016). Epistemological and reading beliefs profiles and their role in multiple text comprehension. Electron. J. Res. Educ. Psychol. 14, 226–252. doi: 10.14204/ejrep.39.1505
McNamara, D. S., Jacovina, M. E., and Allen, L. K. (2015). “Higher order thinking in comprehension,” in Handbook of Individual Differences in Reading: Text and Context, ed. P. Afflerbach (Abingdon: Routledge), 164–176
Merkt, M., Werner, M., and Wagner, W. (2017). Historical thinking skills and mastery of multiple document tasks. Learn. Individ. Differ. 54, 135–148. doi: 10.1016/j.lindif.2017.01.021
Perfetti, C. A., Rouet, J. F., and Britt, M. A. (1999). “Toward a theory of documents representation,” in The Construction of Mental Representation During Reading, eds H. Van Oostendorp and S. R. Goldman (Mahwah, NJ: Erlbaum), 99–122.
Richter, T. (2011). “Cognitive flexibility and epistemic validation in learning from multiple texts,” in Links Between Beliefs and Cognitive Flexibility, eds J. Elen, E. Stahl, R. Bromme, and G. Clarebout (NewYork, NY: Springer), 125–140. doi: 10.1007/978-94-007-1793-0_7
Richter, T., and Maier, J. (2017). Comprehension of multiple documents with conflicting information: a two-step model of validation. Educ. Psychol. 52, 1–19. doi: 10.1080/00461520.2017.1322968
Rouet, J. F. (2006). The Skills of Document Use. From Text Comprehension to Web-Based Learning. Mahwah, NJ: Erlbaum.
Rouet,J-F., and Britt, M. A. (2011). “Relevance processes in multiple document comprehension,” in Text Relevance and Learning from Text, eds M. T. McCrudden, J. P. Magliano, and G. Schraw (Greenwich, CT: Information Age Publishing), 19–52.
Rouet,J-F., Britt, M. A., and Durik, A. M. (2017). RESOLV: readers’ representation of reading contexts and tasks. Educ. Psychol. 52, 200–215. doi: 10.1080/00461520.2017.1329015
Rouet,J-F., Favart, M., Britt, M. A., and Perfetti, C. A. (1997). Studying and using multiple documents in history: effects of discipline expertise. Cogn. Instr. 15, 85–106. doi: 10.1207/s1532690xci1501_3
Salmerón, L., Gil, L., Bråten, I., and Strømsø, H. I. (2010). Comprehension effects of signaling relationships between documents in search engines. Comput. Hum. Behav. 26, 419–426. doi: 10.1016/j.chb.2009.11.013
Segev-Miller, R. (2007). “Cognitive processes in discourse synthesis: the case of intertextual processing strategies,” in Writing and Cognition, eds M. Torrance, L. VanWaes, and D. Galbraith (Bingley: Emerald Group), 231–250 doi: 10.1108/S1572-6304(2007)0000020016
Snow, C. (2002). Reading for Understanding: Toward an R&D Program in Reading Comprehension. Santa Monica, CA: Rand Corporation.
Stadtler, M., Scharrer, L., Brummernhenrich, B., and Bromme, R. (2013). Dealing with uncertainty: readers’ memory for and use of conflicting information from science texts as function of presentation format and source expertise. Cogn. Instr. 31, 130–150. doi: 10.1080/07370008.2013.769996
Stadtler, M., Scharrer, L., Skodzik, T., and Bromme, R. (2014). Comprehending multiple documents on scientific controversies: effects of reading goals and signaling rhetorical relationships. Discourse Process. 51, 93–116. doi: 10.1080/0163853X.2013.855535
Stahl, S. A., Hynd, C. R., Britton, B. K., McNish, M. M., and Bosquet, D. (1996). What happens when students read multiple source documents in history?. Read. Res. Q. 31, 430–456. doi: 10.1598/RRQ.31.4.5
Strømsø, H. I. (2017). Multiple models of multiple-text comprehension: a commentary. Educ. Psychol. 52, 216–224. doi: 10.1080/00461520.2017.1320557
Strømsø, H. I., and Bråten, I. (2009). Beliefs about knowledge and knowing and multiple-text comprehension among upper secondary students. Educ. Psychol. 29, 425–445. doi: 10.1080/01443410903046864
Strømsø, H. I., Bråten, I., Anmarkrud,Ø., and Ferguson, L. E. (2016). Beliefs about justification for knowing when ethnic majority and ethnic minority students read multiple conflicting documents. Educ. Psychol. 36, 638–657. doi: 10.1080/01443410.2014.920080
Strømsø, H. I., Bråten, I., and Britt, M. A. (2010). Reading multiple texts about climate change: the relationship between memory for sources and text comprehension. Learn. Instr. 20, 192–204. doi: 10.1016/j.learninstruc.2009.02.001
Strømsø, H. I., Bråten, I., and Samuelstuen, M. S. (2008). Dimensions of topic-specific epistemological beliefs as predictors of multiple text understanding. Learn. Instr. 18, 513–527. doi: 10.1016/j.learninstruc.2007.11.001
Wiley, J., and Voss, J. F. (1999). Constructing arguments from multiple sources: tasks that promote understanding and not just memory for text. J. Educ. Psychol. 91, 301–311. doi: 10.1037/0022-0663.91.2.301
Wineburg, S. S. (1991). Historical problem solving: a study of the cognitive processes used in the evaluation of documentary and pictorial evidence. J. Educ. Psychol. 83, 73–87. doi: 10.1037/0022-0663.83.1.73
Wineburg, S. S. (1998). Reading abraham lincoln: an expert/expert study in the interpretation of historical texts. Cogn. Sci. 22, 319–346. doi: 10.1207/s15516709cog2203_3
Keywords: text integration, reading comprehension, assessment methods, adults population, synthesis
Citation: Primor L and Katzir T (2018) Measuring Multiple Text Integration: A Review. Front. Psychol. 9:2294. doi: 10.3389/fpsyg.2018.02294
Received: 14 March 2018; Accepted: 02 November 2018;
Published: 29 November 2018.
Edited by:
Michael S. Dempsey, Boston University, United StatesReviewed by:
Maria De Luca, Fondazione Santa Lucia (IRCCS), ItalyManuel Soriano-Ferrer, University of Valencia, Spain
Copyright © 2018 Primor and Katzir. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Liron Primor, bGlyb25wcmltb3JAZ21haWwuY29t Tami Katzir, a2F0emlydGFAZ21haWwuY29t