 Sebastian Kahl
Sebastian Kahl Stefan Kopp
Stefan Kopp- Social Cognitive Systems Group, CITEC, Bielefeld University, Bielefeld, Germany
During interaction with others, we perceive and produce social actions in close temporal distance or even simultaneously. It has been argued that the motor system is involved in perception and action, playing a fundamental role in the handling of actions produced by oneself and by others. But how does it distinguish in this processing between self and other, thus contributing to self-other distinction? In this paper we propose a hierarchical model of sensorimotor coordination based on principles of perception-action coupling and predictive processing in which self-other distinction arises during action and perception. For this we draw on mechanisms assumed for the integration of cues for a sense of agency, i.e., the sense that an action is self-generated. We report results from simulations of different scenarios, showing that the model is not only able to minimize free energy during perception and action, but also showing that the model can correctly attribute sense of agency to own actions.
1. Introduction
In everyday social interaction we constantly try to deduce and predict the underlying intentions behind others' social actions, like facial expressions, speech, gestures, or body posture. This is no easy problem and the underlying cognitive mechanisms and neural processes even have been dubbed the “dark matter” of social neuroscience (Przyrembel et al., 2012). Generally, action recognition is assumed to rest upon principles of prediction-based processing (Clark, 2013), where predictions about expected sensory stimuli are continuously formed and evaluated against incoming sensory input to inform further processing. Such a predictive processing does not only inform our perception of actions of others, but also our action production in which we constantly predict the sensory consequences of our own actions and correct them in case of deviations. Both of these processes are assumed to be supported by the structure of the human sensorimotor system that is characterized by perception-action coupling (Prinz, 1997) and common coding of the underlying representations.
It seems natural to assume that these general mechanisms of prediction-based action processing underly also the perception and generation of social behavior when we interact with others. However, in dynamic social interaction, perception, and action often need to be at work simultaneously and for both, actions of self and other. If the motor system is to be involved in both processes, this simultaneous processing and attribution of actions to oneself and the interaction partner must be maintained during social interaction without confusion.
As of yet, it is not clear how self-other distinction is reflected in, or possibly even constituted by the sensorimotor system. What role does it play in distinguishing social actions of the self and the other? What are the underlying prediction-based processes? And how do they interact with higher-level cognitive processes like mentalizing to solve the social differentiation problem? Evidence from cognitive neuroscience suggests that the motor systems may be involved differentiately in processing self-action and other-action, indicating a role in social cognition (Schütz-Bosbach et al., 2006) and the selective attribution of beliefs, desires, and intentions during the dynamic process of intersubjective sense-making. We contribute a computational modeling perspective. In previous work we devised a model of the interplay of mentalizing and prediction-based mirroring during social interaction (Kahl and Kopp, 2015). In that work two virtual agents interacted in a communication game, each of which equipped with models of a mirroring system and a mentalizing system, respectively. This demonstrated how mentalizing—even with minimal abilities to account for beliefs, desires, and intentions—affords interactive grounding and makes communication more robust and efficient. However, both agents took separate and successive turns such that their mirroring systems worked either for perception or production of social actions (albeit with activations being carried on).
In this paper, we present an extended Bayesian model of a sensorimotor system based on a prediction-based processing hierarchy, called Hierarchical Predictive Belief Update (HPBU). Our aim is to explore how such a prediction-based sensorimotor system can be able to differentiate by itself actions of its own (predicted for production) from potential actions of the interaction partner (predicted for perception), thus contributing to self-other distinction in social interaction.
For our computational model of sensorimotor processes and the model of sense of agency we rely on assumptions from the predictive processing framework. Specifically, the model will rely on principles of active inference and free energy minimization (Friston et al., 2010) based on assumptions in accord with the predictive brain hypotheses (Clark, 2013) and hierarchical predictive coding (Rao and Ballard, 1999). From that follows a hierarchical organization of ever more abstract predictive representations. These representations are also generative processes, which together form a hierarchical generative model which maps from (hidden) causes in the world to their perceived (sensory) consequences. The tight coupling between action and perception in active inference means, that following prediction errors, either the model hypotheses have to be updated or action in the world is necessary to make future sensory evidence meet the model predictions. Free energy is merely the term for the negative log model evidence of a perceived event given the model prediction, i.e., the prediction error which is to be minimized. Technically, variational free energy is an upper bound on Bayesian model evidence, such that minimizing free energy corresponds to minimizing (precision-weighted) prediction error—or, equivalently, maximizing model evidence or marginal likelihood.
Also, we will identify, integrate and then test mechanisms and processes in the SoA (sense of agency) literature that are compatible with a predictive processing view and that have reliably been identified to contribute to sense of agency. Our goal here is to present a conceptual computational model of the sense of agency which is functionally embedded in a hierarchical predictive processing model for action production and perception. The model of sense of agency itself integrates different aspects important for sensorimotor processing and motor control. At the core of our argument for the presented modeling approach is the assumption that we strongly rely on the predictability of our own body to be able to not only identify our own hands or arms, but also to differentiate between our own and other's actions through the information gathered especially on the unpredictability of others. It is that unpredictability of their actions and its timing that can help to differentiate. The functional simulation at the end of our paper helps to evaluate whether the identified mechanisms implemented in the model are sufficient to correctly infer own actions, given altered feedback to its action production.
We start with introducing HPBU and how it forms, tests, and corrects so-called motor beliefs. Then we discuss how this model can be extended with a mechanism for differentiating between actions produced by oneself from actions produced by a potential interlocutor in social situations. The mechanism includes the ability to flexibly integrate predictive and postdictive cues to form a sense of agency (SoA). Finally, we present results from simulations that test the model's ability to infer SoA for its own actions in different test scenarios. We then discuss our results with the literature concerning the mechanisms underlying SoA and discuss the mechanism's implications for the process of attributing beliefs during communication.
2. Hierarchical Predictive Belief Update
We adopt a Bayesian approach to computationally model the human sensorimotor system at a functional level. The model, called Hierarchical Predictive Belief Update (HPBU) realizes an active inference and free energy minimization. Doing so it is able to form, test, and correct so-called motor beliefs in perception and production of actions. Based on our previous work (Sadeghipour and Kopp, 2010) and other attempts to model the sensorimotor system (Wolpert et al., 2003), we chose to make use of a hierarchical representation of increasing abstractions over representations of movement. Each level contains a generative model that infers probabilities to perceive (and produce) these variants of abstractions over actions in the form of discrete probability distributions about discrete representations that can be influenced both bottom-up, in the form of evidence for its last prediction from the next lower level, and top-down in the form of a prediction by the next higher level. Following the assumption that the main flow of information is top-down and that motor control is also just top-down sensory prediction or “active inference," all levels receive their next higher level's prediction and evaluate it for their own bottom-up prediction in the next time step. The distinction to previous models of the sensorimotor system is that in active inference we solely rely on each level's generative process to map from (hidden) causes to their (sensory) consequences. Without separate inverse models the generative process itself is inverted to predict the next steps in the next lower level and thus, explain away or suppress prediction errors. In the lowest level of the hierarchy this suppression can take the form of triggering the production of actions and change the environment as to minimize prediction errors.
The representations in our hierarchy code for both, the perception and production of an action and in that follow the common-coding theory of perception-action coupling (Prinz, 1997), a defining characteristic for representations in the mirror neuron system (Gallese et al., 1996). The human mirror neuron system has indeed also been attributed to have a hierarchical organization, which is distributed across interconnected brain areas (Grafton and Hamilton, 2007) and similarly, predictive coding and active inference have repeatedly been linked to the mechanisms underlying the function of the mirror neuron system (Kilner et al., 2007; Friston et al., 2010).
Also, in the predictive coding and active inference literature the attribution of agency was attributed to rely on mechanisms central also to the model presented in this paper, i.e., the correct prediction of the consequences of producing actions of handwriting (Friston et al., 2011). But other than the mechanisms we will later go into, they rely heavily on the proprioceptive information which is missing when perceiving other's actions in contrast to actions performed by oneself. We will argue that there is sufficient information already available in the visual information only.
HPBU can be described as a three-level hierarchy of motor beliefs as abstractions over primitive motor acts (see Figure 1). At the top, in the Schema level (C) we represent abstract clusters of action sequences grouped by similarity. Below that, the Sequence level (S) represents sequences of motor acts. Levels in our hierarchy are loosely associated with the following (sub-)cortical structures: The Vision level corresponds to early level V5 in the visual cortex for its direction selectivity in the perception of motion, while the Motor Control level corresponds to the reflex arcs embedded in the tight coordination of basal ganglia, spinal cord, and cerebellum. The Sequence and Schema levels are loosely associated with primary motor and premotor areas that code for representing action sequences. We assume these representations to be the basis for active inference for both action perception and production. Further, we assume the representations to be multimodal, i.e., combining visual, motor, and proprioceptive aspects of action, if available. Consequently, they are used as more or less high-level or visuomotor representations of action and their outcomes. This is based on converging evidence for the multimodal nature of representations that can be found in somatosensory, primary motor, and premotor areas of the human brain, which can code for both visual and proprioceptive information (Wise et al., 1997; Graziano et al., 2000; Fogassi and Luppino, 2005; Pipereit et al., 2006; Gentile et al., 2015). The lowest levels in the model hierarchy allow for action production and visual and proprioceptive input and feedback in the form of two separate models; the Vision level (V) and Motor Control level (M) that will be further described below.
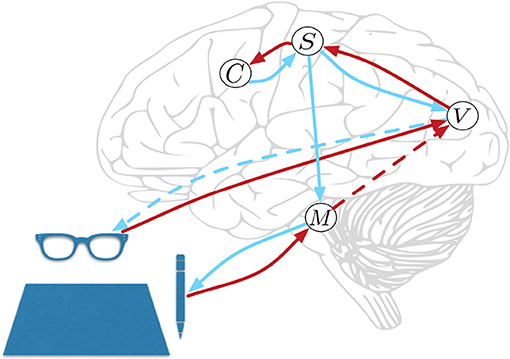
Figure 1. Hierarchical Predictive Belief Update, based on predictive processing and perception-action coupling. Predictions are sent top-down and compared with sensory (bottom-up) evidence to drive belief updates within the hierarchy. We have loose associations with the displayed cortical and subcortial structures. The connections shown will be explained in great detail below. At the top, in the Schema level (C) we represent abstract clusters of action sequences grouped by similarity. Below that, the Sequence level (S) represents sequences of motor acts. The lowest levels in the model hierarchy allow for action production, and proprioceptive feedback in Motor Control level (M) and visual input and action feedback in the Vision level (V). Red and blue lines represent bottom-up and top-down information propagation, respectively. The blue dotted line from V represents a visual prediction without any effect on the world, while the blue line from M has a causal effect. The red dotted line from M represents a long range connection, further explained below.
2.1. Motor Coordination
In motor control two problems have to be solved. First, how to learn action sequences in order to reach a goal, i.e., a mapping from an extrinsic coordinate frame (describing the action perception) into an intrinsic frame (describing the muscle movement) and second, how to activate the appropriate muscles to reach a goal, i.e., from an intrinsic frame to an extrinsic frame to produce the desired movement. What makes this problem hard is that there are many possibilities how the intrinsic frame could produce the extrinsic frame.
To solve the problem of action production toward a goal often the planning of an optimal trajectory was assumed using forward models trying to find an optimal sequence of muscle activations leading to the reached goal before the action even starts (Kawato, 1999). Todorov and Jordan (2002) brought up a different solution trying to explain the high variability in the detailed movements that occured even in repeated actions. They proposed a control strategy that allowed for variability in redundant task dimensions during the action production. That is, during action production feedback is used to only correct variability that interferes with reaching the goal. The use of feedback was often discussed in this context, famously the MOSAIC model by Wolpert et al. (2003) proposed how using a comparison of produced action and its sensory feedback could stabilize and guide action. What counts as feedback in this context are the visually perceived positions of the joints controlled by the muscles and the proprioceptive feedback by the muscle spindles surrounding the muscles.
An important distinction on such models of optimal control is highlighted by Friston (2011) in that the forward models in motor control are not the generative models used in perceptual inference and hence should not be conflated. He argues that one could get rid of the forward models for action by replacing the control problem with an inference problem over motor reflex arcs and in that simplifying optimal control to be active inference. In active inference the extrinsic frame can be utilized as action-production tools, to circumvent the need for detailed programming of motor commands.
We follow this argumentation. First, we transform the perceived action into a gaze- or vision-centered oculomotor frame of reference that has been shown to also code the visual targets for reaching and other actions (Russo and Bruce, 1996; Engel et al., 2002; Ambrosini et al., 2012). Using those we are also able to circumvent the need for detailed programming of motor commands. Instead, the oculocentric frame of reference can guide the actions or parts of an action.
The lowest levels of the hierarchy represent two aspects in active inference that are necessary for motor coordination. The Vision level receives continuous coordinates of a writing trajectory at discrete points in time, which is perceived in the form of a discrete probability distribution over a discrete set of writing angles at each point in time. Following the narrative by Zacks et al. (2007) and Gumbsch et al. (2017) on event segmentation using surprise as a separator, we identify surprising deviations of the current writing angle given the writing angles of the past. In the context of free energy minimization, a sudden increase in the amplitude of prediction errors—induced by a surprising event—is reflected by free energy increases in the Vision level. The surprising stroke consists of the writing angle and its length, which are both transformed into the oculocentric reference frame, i.e., into relative polar coordinates with the last surprising stroke coordinates at its center. This information is send to the Sequence level, together with the time passed since the last surprising stroke. The Sequence level stores these sequences of surprising events in the oculocentric reference frame, which can also be used for generation. Following the argument by Friston (2011) we circumvent the need for detailed programming of motor commands by utilizing the surprising events consisting of relative polar coordinates as action targets, which are send to the Motor control level. There, a reflex arc in the form of a damped spring system (inspired by Ijspeert et al., 2013) will realize the motion toward the action target following simple equations of motion with the spring's point of equilibrium at the relative polar coordinate of the action target. This implementation of active inference is formally related to the equilibrium point hypothesis (Feldman and Levin, 1995). In other words, the top-down or descending predictions of the proprioceptive consequences of movement are regarded as setting and equilibrium or set point to which the motor plant converges, via the engagement of motor reflexes. This will later be explained in more detail.
An important aspect in motor coordination model can be seen in Figure 1, where the Motor Control level has no direct feedback connection to the Sequence level. This is for three reasons. First, we would like to see if sequential motor coordination as well as the inference of a sense of agency are possible with visual feedback only. Second, other than Friston et al. (2011) who rely heavily on proprioceptive information we want to allow for visual input to drive motor coordination and a sense of agency. Instead, we close the motor coordination loop using a direct long range connection that is used by the Motor Control level to inform the Vision level when it is done coordinating actions to reach a subgoal (see red dotted line in Figure 1). Vision level will then check if visual information can confirm the movement, then sending the information to the Sequence level, closing the motor coordination loop. Third, making the model's sequence coordination independent from direct proprioceptive feedback allows for future developments that can associate actions in the world with intended effects that not directly influence the motor system, e.g., switching on a light or influencing another agent's beliefs.
During action perception, we further assume that the correspondence problem is solved in the sense that an observed action by another agent is mapped into one's own body-centered frame of reference. That is, we feed the perceived action trajectory directly and bottom-up into HPBU. The next section will describe the active inference and free energy minimization in the model hierarchy.
3. Model Update Details
The HPBU model is defined as a hierarchical generative model which learns to predict and explain away prediction errors and in this sense minimize the free energy. This section will briefly introduce our free energy minimization strategy and the generative model updates, which we have implemented and extended to encompass and allow the distinction of self and other in the context of action production.
In the hierarchical generative model, each level maps the internal discrete state space from one level in the hierarchy to the domain of its next lower level. Each level contains a discrete probability distribution about that level's discrete states. The difference between continuous and discrete states in the context of active inference is well discussed in Friston et al. (2017a). All levels of the hierarchy are updated sequentially starting at the top in Schema level C, i.e., they are updated in sequence from its next higher and next lower levels, learning to represent and produce the states in the next lower level and the environment. At the top, the Schema level C represents clusters of similar representations of its next lower level, which is the Sequence level S. S represents sequences of representations of Vision level V that occured over time. Also, representations that can map to V are compatible with representations in Motor Control level M. In each level posteriors are updated bottom-up and top-down and free energy is calculated with respect to prior and posterior distributions as described in the following. These mappings can be understood as generative processes, where one level predicts the states of the level below. In the Motor Control level M this mapping results in action production.
3.1. Free Energy Minimization
Free energy describes the negative log model evidence of a generative model that tries to explain hidden states, i.e., the environment. Evidence corresponds to probabilities of data from the environment, given the model at hand.
The free energy in system X is expressed as the sum of surprise and a cross entropy of two states (a posterior P, and a prior Q before evidence has arrived). When free energy is minimized the cross entropy becomes zero, thus leaving free energy to be just surprise (entropy with regard to the posterior) (Equation 1).
In our interpretation the difference between perception and production lies in the question which signal drives the updates in calculating free energy, the bottom-up signal or the top-down signal? When it comes to calculating free energy in perception the posterior distribution (for calculating surprise and the cross-entropy) is the top-down signal Ptd and the prior, i.e., the driving signal is the bottom-up signal Pbu, so that F = H(Ptd) + DKL(Ptd||Pbu). In production the top-down signal Ptd becomes the driving signal for the free energy update F = H(Pbu) + DKL(Pbu||Ptd). The deviation is then calculated with respect to Pbu (see the yellow box in Figure 2). To update level beliefs, both posteriors will be combined to form the current level posterior Pt, in which the bottom-up signal will be combined similarly as in the identified microcircuitry for predictive coding (Bastos et al., 2012). There, connections between cortical columns are mostly inhibitory. In this setting, the bottom-up and top-down posteriors in Equation (1) play the role of predictions. This means that we can treat the differences in the bottom-up and top-down predictions as a prediction error and enter them into a Kalman filter. In this formulation, the Kalman gain is used to differentially weight bottom-up and top-down predictions and plays the role of a precision. Crucially, this precision is a function of the free energy computed at each level in the hierarchical model—such that a very high free energy (i.e., prediction error) emphasizes top-down predictions. We model this effect during perception as a top-down inhibitory influence on the bottom-up signal using a Kalman filter Pt = Pbu + Kt(Ptd − Pbu) with a Kalman gain calculated from the level free energy F and precision π to integrate this filter into the model context (see below in Equation 5 for a more detailed description). Again, the current driving signal can invert the belief update so that during production Pt = Ptd + Kt(Pbu − Ptd). The level posterior Pt will be send to the next higher level in the hierarchy and to the next lower level. In the following time step the level posterior will be used as an empirical prior for calculating Pbu and Ptd respectively. Figure 2 examplifies our belief update scheme in Sequence level S. There posteriors and relevant likelihoods are combined to calculate updated top-down and bottom-up posteriors necessary to calculate the free energy within level S and the final belief update step which combines top-down and bottom-up posteriors. For more details on our generative model hierarchy please refer to the Supplementary Materials.
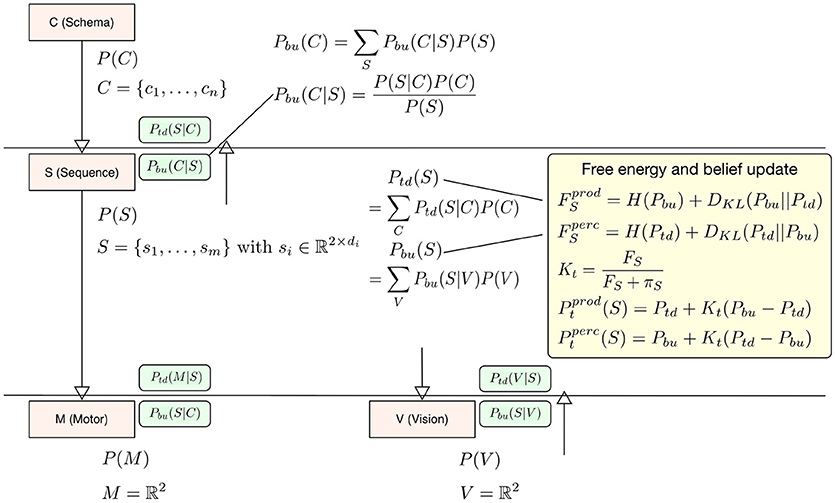
Figure 2. To exemplify the belief update scheme in HPBU, here the updating of posteriors and free energy within Sequence level S are shown. Within S the top-down and bottom-up posteriors are calculated from posteriors of C and V. That information is used to update free energy either for production (prod) or for perception (perc). The updated free energy and precision (π) are used to calculate the Kalman gain necessary for calculating the level posterior P(S) using a Kalman filter, again either for production or perception. The green boxes show the calculated likelihoods necessary for updating within S or in the levels above and below (Pbu(C|S) is one example). For more details please refer to the Supplementary Materials.
Following the assumption in active inference that overt action is basically action-oriented predictive processing (Friston et al., 2010), we allow strongly predicted next actions of representations in the Sequence level to be acted out. Without any constraints this leads to overt automatic enactment, similar to the automatic imitation seen in patients suffering from echopraxia (Ganos et al., 2012). To control this motor execution, we introduced a gating signal into the top-level of the hierarchy, which acts as a motor intention for a specific schema, including a strong boost of this schema's probability (acting as a trigger to act-out an abstract motor belief). This intention percolates down the hierarchy to boost associated representations and inform the intention to act. Once it reaches the lowest level of the hierarchy, the act to produce the motor representation will be allowed.
3.2. Motor Coordination Loop
In active inference and the actual production of an action, predictions guide the minimization of free energy, the Motor level receives position (xi) and timing (Δt) goals from Sequence level S. The realization of the movement goal within the Motor Control level is left to an action-proprioception loop modeled as a dampened spring system. This models the angular movements of a single joint, which in our simulations will represent a writing pencil. A similar approach was used by Friston et al. (2011) but instead of a system with two joints following one attractor-state at a time in attractor space we model just one joint which moves toward the spring system's point of equilibrium at the relative polar coordinate of the action goal. To allow for smooth and curving trajectories that are similar to handwriting in spatial and temporal properties, we were inspired by work on dynamic movement primitives (DMP) that are used for modeling attractor behaviors of autonomous non-linear dynamical systems with the help of statistical learning techniques (Ijspeert et al., 2013). We will not make use of the DMPs ability to learn and reproduce trajectories, but will configure a dampened spring system similarly to a DMP and instead of applying a forcing term that activates the system's non-linear dynamics over time we make use of an obstacle avoidance technique mentioned in Hoffmann et al. (2009) which we adpoted and inverted its force to actually move toward the goal in a forcing function g (see Equation 2). The reason for this is that when we simply applied the spring system to each goal sequentially, we would accelerate toward and slow down at the goal. To keep up the momentum we need to look ahead several goals xi+3 (here 3 steps ahead) in the core spring system, but with a goal forcing function that sequentially tries to visit each goal xi. α = 25, β = 6.25, γ = 10, and are constants that specify the behavior of the system. φ is the angle to the goal (or its velocity, see Equation 3) and y is the current position.
With this hierarchical model in place, we set out to investigate how a sensorimotor system can distinguish activations that stem from own actions from those arising due to the observation of an interaction partner's actions. In particular we are interested in how self-other distinction is realized within the system itself based on its prediction-based processing. This ability would be a prerequisite for the assumed dual use of the sensorimotor system (in perception and action) in dynamic social interaction. Note that, at a higher cognitive level, self-other distinction will have additional components based on sensory modalities like vision (e.g., seeing who the agent of an action is) or proprioception, as well as awareness of control of own actions (e.g., feeling or knowing that one is executing an action). Here we are interested in how a more fundamental sensorimotor basis for self-other distinction can contribute in correctly attributing a perceived sensory event to self-action or other-action—a process that would be likely to underlie many of the these additional higher-level components. To that end, we extended HPBU to include a sensorimotor account of sense of agency (SoA), i.e., the sense that an action is self-generated.
4. Self-Other Distinction and Sense of Agency
How does the human brain distinguish between information about ourselves and others? Or to be more specific, how can we distinguish ourselves from others so that we do not falsely attribute an action outcome to ourselves? These questions are related to the general mechanisms that give rise to a sense of “feeling of control,” agency, and “self.”
Reviews on the neural mechanisms of the SoA and the social brain (David et al., 2008; Van Overwalle, 2009) show a strong overlap of differential activity during SoA judgement tasks with functional brain areas of the human mirror-neuron system and the mentalizing network. Especially noteworthy is TPJ (temporo-parietal junction) as a candidate to infer the agency of a social action, spanning areas STS (superior temporal sulcus) which mainly responds to biological motion, to IPL (inferior parietal lobule) which may respond to the intentions behind someone's actions, connecting to mPFC (medial prefrontal cortex) which probably hold trait inferences or maintains different representations of self- or other-related intentions or beliefs (please see the mentioned reviews for a more thorough analysis). Generally, a person's SoA is believed to be influenced through predictive and postdictive (inferential) processes, which when disturbed can lead to misattributions of actions as in disorders such as schizophrenia (van der Weiden et al., 2015). In Schizophrenia as a deficit of sensory attenuation, but also hallucinations, we can point to disfunctional precision encodings as a core pathology, i.e., the confidence of beliefs about the world (Adams et al., 2013). Precision as such is believed to be encoded in dopaminergic neuromodulation and can as such be linked to the sensory attenuation effects during the attribution of agency in healthy subjects (Brown et al., 2013). We aim to identify mechanisms in order to model these processes and their integration into a combined SoA.
4.1. Predictive Process in Sense of Agency
The predictive process makes use of people's ability to anticipate the sensory consequences of their own actions. It allows to attenuate, i.e., decrease the intensity of incoming signals which enables people to distinguish between self-caused actions and their outcomes and those actions and outcomes caused by others. One account to model these processes is based on inverse and forward models to account for disorders of awareness in the motor system and delusion of control (Frith et al., 2000). This view suggests that patients suffering from such disorders of awareness can no longer link their intentions to their actions, that is they can become aware of the sensory consequences of an action, but may have problems to integrate them to the intention underlying the action, making it hard to ascribe actions to oneself or another agent. Research on schizophrenia has shown that reliable and early self-other integration and distinction is important not only for the correct attribution of SoA, but also for the correct attribution of intentions and emotions to others in social interaction (van der Weiden et al., 2015). Weiss et al. (2011) also showed that there is a social aspect to predictive processes that influence SoA by comparing perceived loudness of auditory action effects in an interactive action context. They found that attenuation occured also in the interactive context, comparable to the attentuation of self-generated sound in an individual context.
Another aspect of the processing of differences between predictions and feedback from reality is the intrinsic robustness and invariance to unimportant aspects in the sensory input. The kinds of predictive processing hierarchies we talk about, that concern themselves with allowing ourselves to act in (and perceive) the ever-varying nature of our environments, are able to ignore or explain away the prediction-errors that aren't surprising enough to lead to any form of adaptation. That this is also likely true for temporal prediction-errors was found in Sherwell et al. (2016), who using EEG saw significant N1 component suppression in predicted stimulus onset timings. In a predictive processing perspective this is possible through higher levels in the hierarchy correctly predicting the next lower level's state, and by taking into account its generative model's precision, minimize its prediction-error. Or as Clark states: “[…] variable precision-weighting of sensory prediction error enables the system to attend to current sensory input to a greater or lesser degree, flexibly balancing reliance upon (or confidence in) the input with reliance upon (or confidence in) its own higher level predictions” (Clark, 2016, p. 216). Consistent with this perspective is work by Rohde and Ernst (2016), who investigated if and in which cases we can compensate for sensorimotor delay, i.e., the time between an action and its sensory consequence. They find that if an error signal (a discrepancy between an expected and an actual sensory delay) occurs we recalibrate our expectations only if the error occurs systematically. This kind of temporal adaptation is a well studied finding (e.g., Haering and Kiesel, 2015 for sense of agency or Cunningham et al., 2001 in motor control). What interests us for the here presented model of self-other distinction are the unexpected, unsystematic and sudden deviations that cannot be explained away easily. These are the temporal aspects of sensorimotor processing that we will focus on next.
4.2. Postdictive Process in Sense of Agency
The postdictive process relies more on inferences drawn after the movement in order to check whether the observed events are contingent and consistent with specific intentions (Wegner and Wheatley, 1999), influenced by higher-level causal beliefs. One important aspect of this inferential process relies on the temporal aspects of action-outcome integration. It was shown that increasing action outcome delay decreases feeling of control (Sidarus et al., 2013). Colonius and Diederich (2004) describe a model that can explain the improved response time in saccadic movements toward a target that is visually and auditorily aligned. Their time-window-of-integration model serves as a framework for the rules of multisensory integration (visual, auditory, and somatosensory), which occurs only if all multimodal neural excitations terminate within a given time interval. In van der Weiden et al. (2015) this time interval of integration is taken as a solution to a problem posed in the classic comparator model of motor prediction. The brain needs to integrate action production signals with their predicted effects which can be perceived via multiple sensory channels (e.g., visual, auditory, proprioceptive, …). This integration needs to account for the different time scales in which effects (or outcomes) of actions may occur. This is where the time-window-of-integration model can help us explain the effect such integration can have.
A point not taken into account by Colonius and Diederich was, how such an integrating mechanism knows how long it has to wait for all action outcomes to occur. Hillock-Dunn and Wallace (2012) investigated how these temporal windows for integration, which have been learned in childhood develop through life. They analyzed responses to a judgement task of a visual and an auditory stimulus to occur simultaneously in participants with ages ranging from 6 to 23 years. Their analysis showed an age dependent decrease in temporal integration window sizes. We hypothesize that a wider window of integration can be associated with unpredictability and greater variance in action outcome timings and that this integration window size decrease may be due to an adult person's experience advantage about effects their actions may have on their environment, or the mere better predictability of their full grown bodies.
Such an integration of an intended action with its predicted consequences learned through associations between action events can lead to an interesting phenomenon, often reported in the SoA literature. In this phenomenon an integration can lead to the effect that predicted action consequences can be perceived to occur at the same time. This phenomenon is called temporal binding, or also intentional binding when the effects of an intended action are predicted and are perceived as occurring closer together as unintended actions that were merely observed in an unrelated party (Haggard et al., 2002; Haggard and Clark, 2003). We have trained our sensorimotor hierarchy to allow the model of sense of agency to be able to predict also the timing of its intended action outcomes. This way it is able to integrate action and consequence, while simultaneously evaluating the success of its outcome prediction and allowing the detection of unpredicted delays, which may be a cue for another agent's action and their action outcome or an outcome delayed by an unknown reason. Being able to make such a distinction allows people to monitor, infer, and distinguish between causal relations for own and other's behavior.
In sum, by and large there are two processes that can inform SoA and hence can help to distinguish actions of self and other in social interaction. A predictive process is based on (assumed or given) causes of the action, e.g., the motor command and utilizes forward models to predict the to-be-observed sensory events. A postdictive process works with features of an observed action outcome and applies higher-level causal beliefs and inferential mechanisms, e.g., a given intention to act or temporal binding, to test the consistency of the action outcome and infer a likely explanation.
How are these two processes integrated to inform SoA and what if their cues are unreliable? When disorders of SoA were first studied, the comparator model was the first proposal concerning its underlying mechanism. This was soon questioned as the comparator model failed to account for external agency attributions. It was argued that its evidence has to be weighted and integrated with more high-level sources of evidence for sense of agency (Synofzik et al., 2008). Such a weighting and integration of evidence cues was first studied by Moore et al. (2009), who found that external cues like prior beliefs become more influential if predictive cues are absent. Neurological evidence for a differential processing of cues that inform SoA comes from Nahab et al. (2010), who found in an imaging study that there is a leading and a lagging network that both influence SoA prior to and after an action. The leading network would check whether a predicted action outcome is perceived, while the lagging network would process these cues further to form a SoA that is consciously experienced. Further, an EEG study found evidence for separate processing areas in the brain (Dumas et al., 2012). There, predictive and postdictive cues were triggered in two tasks. One induced an external attribution of agency, while the other used a spontaneuous attribution condition. It seems that in order to generate SoA, both systems do not necessarily have to work perfectly together. Instead, there is evidence that the SoA is based on a weighted integration of predictive and postdictive cues based on their precision (Moore and Fletcher, 2012; Synofzik et al., 2013; Wolpe et al., 2014). Furthermore, the fluency of action-selection processes may also influence self-other distinction because the success of repeatedly predicting the next actions seem to accumulate over time to inform SoA (Chambon and Haggard, 2012; Chambon et al., 2014). This action selection fluency aspect seems to contribute prospectively to a sense of agency, similar to a priming effect.
4.3. Estimating Sense of Agency During Action and Perception
During online social interaction, the sensorimotor system potentially gets involved in simultaneous action perception and production processes. Our goal is to investigate how our prediction-based HPBU model can cope with the social differentiation problem during such dual-use situations. To that end we integrate three cues that arise in predictive and postdictive processes, into a SoA for produced actions which will depend on the likelihood calculated in the Sequence level: In the predictive process, we calculate the likelihood of the perceived action sequence s′, given the predicted action sequence si∈S in the sequence comparison function . In the postdictive process, we have the intention to act and the delay in the action-outcome for temporal binding. This temporal binding depends on the predicted and perceived temporal delay of the predicted action, and the sequence level's precision. Precision in this context will stretch or sharpen the likelihood of temporal binding (see Equation 4 and refer to Supplementary Materials for more details on S and the sequence comparison function).
Following the evidence for a fluency effect that accumulates the repeated success in correctly predicting and selecting actions (Chambon et al., 2014), we model this accumulation of evidence. That is, we feed the likelihood of the current action of the intended sequence sI into a Kalman filter to estimate the agency (see Equation 5). The Kalman filter estimates the agency ât from the likelihood and the previous agency estimate ât−1, the Kalman gain Kt is calculated from the sequence level's free energy FS and precision πS. This form of Bayesian belief updating is implemented as follows (noting that the conventional update of Kalman gain is replaced by a function of variational free energy):
By allowing the agency estimate only to accumulate through this filter, strong fluctuations are dampened. Further, with the gain governed by precision and free energy the influence of the estimate will strongly depend on the success of previous predictions. The essential elements for the sense of agency of the perception-action loop are an intent for a specific action production, the correct prediction of the action, and its timing, which was learned. In our generative model in the Sequence level, the prediction and evaluation of an action and its timing are embedded in each sequence. The comparison function returns a value between 0 and 1. The intent for a specific action production essentially can be described as a high precision prediction that is very strong and stable over time. If it is then the case that such a high precision prediction is the driving signal and the probability for the predicted sequence stays low, the model free energy will be high. Our interpretation of this process and its outcome is that either something unpredicted is influencing the action production or it is not the system's production at all that is perceived.
5. Simulations and Results
To test the extended model's ability to solve the problem of the dual use of the sensorimotor system and of differentiating between self and other, we have simulated a number of scenarios and trained HPBU on a corpus of handwritten digits from 0 to 9. The handwriting corpus was previously recorded using a self-implemented app on an 6th generation iPad using the Apple Pencil as an input device. Each digit was recorded ten times by the same person. The learned temporal and spatial dynamics were learned by the system to allow for both the spatial and temporal information to influence the correct production and perception of a writing sequence. We leave the details of how HPBU learns new representations to a future publication.
We simulated the production and perception of hand written digits in four scenarios and over time recorded the respective changes in free energy, probability distribution and the sense of agency estimate. First, we simulated the pure perception of (a) a known sequence of actions to write a digit and (b) an unknown way to write a digit. Then, we simulated the writing of a digit with (c) correct visual and proprioceptive feedback. To simulate scenarios in which the distinction of self and other is relevant (d) we had the model write a digit, gave the correct temporal and spatial proprioceptive feedback, but gave temporal and spatial visual feedback of a different (but known) way to write another digit. Figure 3 shows the probability dynamics in the model as heatmaps of the probability distributions over time in the different levels of the HPBU hierarchy for the different scenarios. The heatmap color codes the probability distributions from dark green to white for best differentiability. Each heatmap shows the level's posterior probabilities after beliefs are updated bottom-up and top-down. Simultaneously, the free energy dynamics are plotted for each level, showing the level of adaptation and model evidence given the current state of the system. The bottom row represents activity in the Motor Control level, which is non-existent in the purely perceptual scenarios (a) and (b).
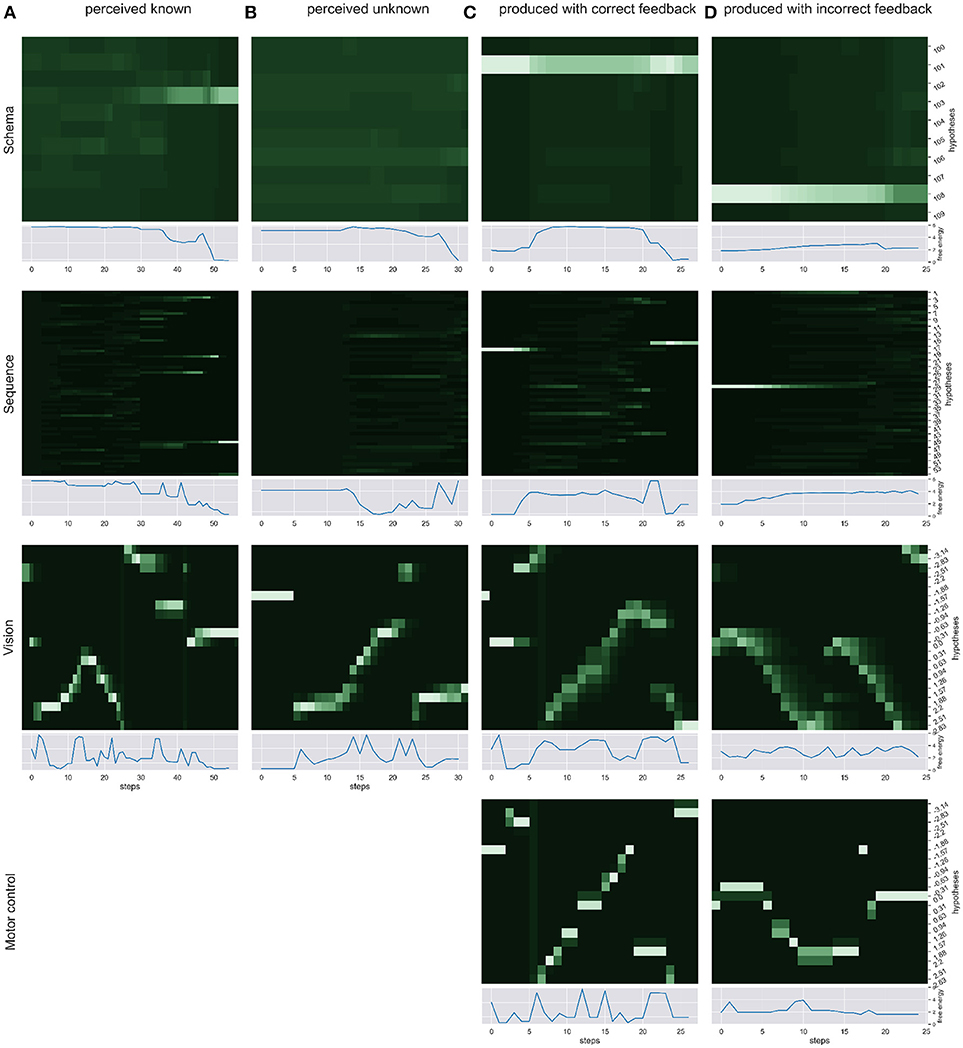
Figure 3. We show the probability dynamics in the model as heatmaps over the probability distributions over time in the different levels of the HPBU (color coded from dark green to white from P = 0 to P = 0.6 for best differentiability). The different scenarios are (A) perceived known: the perception of a known digit (here a 5), (B) perceived unknown: the perception of an unknown digit (here a 4), (C) produced correct feedback: the production of a digit by means of active inference (here the digit 9), and (D) produced incorrect feedback: the production of a digit (here a 1), using the correct proprioceptive feedback while the simulated production of another digit (here a 3) is received as visual feedback. In addition the free energy dynamics for each level is shown. As one can see, the visual input clearly influences the perception of sequences and schemas of sequences in higher levels, thereby minimizing free energy over time. Also, during production the belief created in the schema representing the digit 9 percolates down the hierarchy, activating and acting out a selected sequence. In scenario (d) the sequential activation is shown for producing one digit in the motor control level, while seeing the activation dynamics for visually perceiving another digit in the vision level. The resulting confusion is immediately visible in sequence level, and reduces in schema level by settling on a lower probability for the preferred hypothesis.
In scenario (a) the heatmaps show nicely how the Vision level perceives the different movement angles over time. Simultaneously, evidence for the sequence hypotheses accumulates slowly with each new salient visual feature, finally leading to at first only a limited number of probable sequence representations and finally to a single one. Also, the schema hypotheses accumulate evidence even more slowly, predicting the underlying sequences. Schema level predictions have a strong influence on the Sequence level which is most evident in the final Sequence level distributions in which only a number of sequences are still probable and most of them belong the the most probable schema hypothesis. In scenario (b) no such evidence accumulation is present, as the shown digit was not known.
Between scenarios (c) and (d) the most important difference can be seen between Motor Control and Vision levels of each. There, the posterior probabilities shown in the Motor Control level heatmap should be similar to the Vision level heatmap, but is only so in scenario (c), where production and perception align. To that effect, the heatmaps of Sequence and Schema levels show how evidence for predictions cannot be met in scenario (d), but are mostly met in scenario (c). Interestinly, in scenario (c) evidence for the first predicted sequence is not met at some point, so that another viable sequence hypothesis from the same schema hypothesis becomes active after some time. This pertubation may be due to spring dynamics in the Motor Control.
Having a look at the free energy throughout the hierarchy can give us an idea how well the model is able to find explanations for the perceived input. Strong fluctuations can be a clue to highly irregular input, e.g., in the vision level where bottom-up sensory evidence and top-down predictions can change rapidly. To get a better idea for the model's explanatory power in our case, i.e., the perception and production of sequences of writing digits, the sequence level's free energy dynamics can quickly respond to unpredicted input but still receives predictions from the schema level to inhibit the most unlikely explanations.
In Figure 4 we plot the free energy dynamics of the sequence level during each test scenario. As the different writing sequences are of different length, so are the model responses shown in this figure. The free energy plots show a successful minimization in scenario (a) where the model perceives a known stimulus. It appears to quickly choose the correct hypotheses right from the beginning. In contrast, the model cannot successfully minimize its free energy in response to perceiving the unknown stimulus in scenario (b). Interestingly, in response to the production in scenario (c) the model first minimizes free energy, acting out a chosen sequence, but free energy spikes during production as some dynamics during motor control have not been predicted. In the end the sequence hypothesis switches to a similar sequence from the same schema and free energy minimization continues. In scenario (d) the production and proprioceptive feedback of one written out digit is met be the visual temporal and spatial feedback of another digit. The free energy can thus not be minimized as predictions from schema and sequence levels are not met by correct visual feedback.
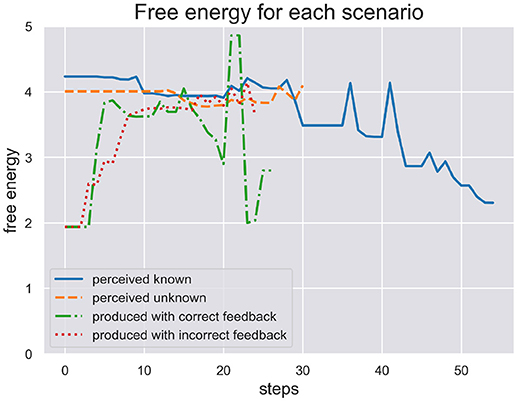
Figure 4. Here we plot the free energy of the sequence level during each test scenario. The different sequences perceived or produced in each scenario have different lenghts. First, the perception of a known and unknown writing sequence clearly shows a difference in that free energy is minimized during perception of the former sequence, but not the later. Second, the production of a writing sequence also minimizes free energy as it would in active inference as long as the sequential production is successfull, i.e., the temporal and spatial prediction of sequential acts are met. In production scenario (d) with incorrect feedback these predictions are met only proprioceptively but not visually. This shows in the plot where free energy cannot be minimized through active inference when its action driving predictions are met with contradicting visual feedback.
We are interested in the SoA estimate calculated during active inference in order to see how well the model can be sure if it actually has acted on the world as expected. We ran two test scenarios, (c) and (d), where the model produced a writing sequence so only those are interesting to inspect its inferred SoA estimate. In Figure 5 we plot the SoA estimate dynamics produced in the scenarios (c) (production with correct feedback) and (d) (production with incorrect feedback). As one can see, the later scenario didn't take as long as the other to complete and in both scenarios the SoA can accumulate up to a certain point, but remains at a rather low level of 0.2 in the end of scenario (d), because temporal and spatial predictions about produced actions are met with contradicting visual feedback. In contrast, the SoA estimate can quickly accumulate quite high in scenario (c), despite the spring dynamics during motor control, that lead to a spike in free energy and a switch to a different sequence hypothesis.
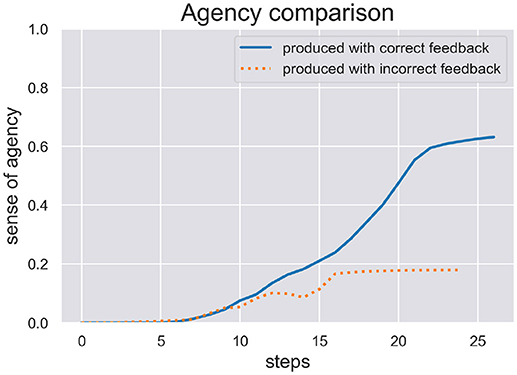
Figure 5. Here we see the SoA estimate dynamics produced by the HPBU in the production scenarios (c) and (d) with correct and incorrect feedback, respectively. Production and perception in the later scenario didn't take as long as in the scenario (c). In both scenarios the SoA estimate rises up to a certain point but it remains at a low level of 0.2 in scenario (d) where predictions of produced actions are met with contradicting visual feedback.
6. Discussion
In dynamic social scenarios of concurrent perception and production of actions, where sensory events can originate either from own or from other's actions, a "dual-use" sensorimotor system that is presumed to be involved in both processes has a challenging task. Specifically, it needs to distinguish in its processing between self-action and other-action, subserving its functions for action execution and recognition. We have presented a model called empirical belief correcting hierarchy based on active inference and extended it with mechanisms of a SoA that enables the judgement—already at these levels of sensorimotor processing—that an action is self-generated. In line with current views on SoA, this extension consists in a dynamic integration of predictive and postdictive cues which is embedded in the likelihood function that matches temporal and spatial aspects of perceived action sequences with those of known sequences.
The resulting dynamics of our simulation scenarios show the successful minimization of free energy during perception and production (see scenarios a and c in Figure 3). There, over time the different possible schemas and their sequences are either considered as possible explanations for the perceived stimuli, or the sequences and actions are chosen for the intended schema to be acted out. In both cases free energy is minimized. In the perception case the minimization is due to the selection of possible explanations, which then can correctly predict further aspects of the action. In the production case the correct selection and prediction of action effects that allow for the intended schema to be a possible explanation leads to the free energy minimization. In both cases free energy is not merely an epiphenomenon of the system, i.e., an acausal property that results from the system dynamics. Free energy is part of the belief update scheme that integrates top-down and bottom-up posteriors, by influencing the Kalman gain that allows for the signal to influence the prior. Dependend on the current mode, whether free energy is minimized through action or perception, the top-down and bottom-up posteriors take different roles (prior or signal) in this update scheme. In addition, free energy also similarly to the belief update scheme, controls the precision or Kalman gain controlling the accumulation of the continuous SoA estimate. Together, this qualifies as active inference. Furthermore, the implementation we present here can be described as an example of a “deep temporal model” (Friston et al., 2017b). For example, during bottom-up inference the model accumulates evidence over time to consider different possible explanations, and top-down a state at any level of the model hierarchy can entail a sequence of state transitions in its next lower level.
A possible line of criticism is that we control for our simulation scenarios which mode the model finds itself in, through our intention signal. The intention signal is received by the Schema level and tags one of its hypotheses for production in active inference. Then, using additional connections to other levels in the hierarchy the intention is spread, giving, and maintaining a boost of probability to associated hypotheses in those levels. In our implementation we found this maintained probability boost to be necessary for the inference to inhibit sudden switches to other explanations (and action sequences). This maintained probability or activation is similar to activity that is maintained during attentional tasks in area MT (Treue and Mart́ınez Trujillo, 1999), i.e., where monkeys were tasked to follow a single moving visual stimulus while other movements were also on display. Naturally, the probability of intended sequences should be maintained through the correct prediction of actions. In reality small differences in the feedback to early actions of an action sequence can lead to increased probabilities of more similar sequences that not always belong to the intended schema. Even with the intention signal in our production scenario c), small unpredicted pertubations in the spring dynamics of Motor Control led to a switch to a similar sequence from the intended schema. We argue that while such an intention signal seems artificial in our implementation, it is necessary in a limited hierarchy, such as ours. It may well be the case that in an extended hierarchy the maintained boost in probability may be provided by higher levels through appropriate priors.
During scenario (b) an unknown writing sequence was perceived and free energy could not be minimized, although the Schema level seems to settle for one possible hypothesis. In the Sequence level no viable hypothesis can be found and free energy stays high. In our implementation this maintained inability to minimize free energy is a reliable signal for the need to extend upon possible hypotheses to choose from. As such, Bayesian models lack the ability to extended upon their hypothesis space for the reason that renormalization becomes necessary. In a hierarchical model such an additional sequence would have to be associated with a corresponding schema in the Schema level in order to embed and associate it with similar sequences, if there are any. For a sequence such as which was used in scenario (b) no similar sequence could be found simply because the model was not trained on these. Specifically, from all digits seens during learning, all writing sequences of fours have been excluded. This way, no similar sequence could be found which could have explained the perceived stimuli. For HPBU learning this not only means that another sequence should be learned, but also the addition of a new schema becomes necessary. The learning strategy is still in its early stages, thus we do not go into much detail here and leave this for future work.
The results of our simulations show (see Figure 5) that the cue integration mechanism, which is integrated into the likelihood function of the Sequence level, supports results reported in the literature. First, it is sound with regard to results where the reliability (here: precision) of the predictive process was reduced and the system put more weight on postdictive processes, conforming evidence for a weighted integration based on the cues' precision (Moore and Fletcher, 2012; Synofzik et al., 2013; Wolpe et al., 2014). This aspect can be observed in scenario (d), where the SoA estimate increases slowly even though a completely different digit is being perceived visually. This may be due to the fact that when drawn simultaneously, a perceived 3 and a drawn 1 start similarly, despite the roundness in the trajectory of a three. When either timing or spatial predictions are met to a degree they can accumulate. In our simulation it is then only the lower, second curved trajectory of the 3 that is in total contrast to the trajectory of the 1, which finally prohibits further accumulation of agency. Second, our results are in line with a fluent correct prediction of actions (Chambon et al., 2014). The accumulation of the SoA estimate over time is done using a Kalman Filter, which depending on the current free energy and precision of the sequence level, filters out strong fluctuations. The more accurate the hierarchy's predictions the faster the uptake of SoA evidence (positive and negative). Looking at scenario (c), this may be the reason why the later spike in free energy can stop the further increase of SoA, which plateaus in the end. Finally, even though the cue integration model is flexible with regard to the precision of predictive and postdictive cues, scenario (d) showed that a false attribution of SoA is not likely when both cues show no signs of agency.
Other than Friston et al. (2011), who rely heavily on proprioceptive information we allowed for visual information to solely drive motor coordination. We closed the motor coordination loop using a direct connection that is used by the Motor Control level to inform the Vision level when it is done coordinating actions to reach a subgoal. Vision level will then check if visual information can confirm the movement and close the motor coordination loop by sending the information to Sequence level. Using a motor coordination loop that heavily depends on visual information allowed us to easily trick the model into doubting its own action production, by feeding it visual information of a different writing sequence, as in scenario (d), the production with incorrect feedback.
Overall, the results reported here show that the model's attribution of SoA to its own action outcomes is affected in relatively realistic and, more importantly, differentiated ways when receiving different simultaneous perceptual information. This suggests, at least to some extent, that the motor system can play an important role in realtime social cognition as proposed by Schütz-Bosbach et al. (2006). Still, the literature on the social brain suggests that motor cognition as well as the distinction of self and other are influenced by higher-level processes, causal beliefs, and the mentalizing network. We agree that the interplay between mentalizing and mirroring needs to be incorporated to meet the demands of truly social systems in interaction scenarios with multiple agents. Also, we need to mention that since this is a deterministic model with a representation size that can be handled without any need for sampling we report purely qualitative descriptions of our simulation results. Also, we have disabled learning during our simulation runs, so that every simulation will return the same results, without any variance. A line of criticism might be that from the mere attribution of SoA to an action in our HPBU model we can hardly deduce more than a kind of tagging of an action within the hierarchy. But we think that when the current conceptual model is embedded within an extended HPBU model that will also cover the functionality of mentalizing areas, an agency attribution will help to confirm motor beliefs attributed to a prospective model of the self or distinguish its own actions from those of an interaction partner.
7. Conclusion
We have presented Hierarchical Predictive Belief Update (HPBU) which models a predictive sensorimotor hierarchy. We integrated HPBU with a model of the sense of agency, which allows to dynamically integrate cues for sense of agency (SoA). This SoA attribution to an action enables the judgement that an action is self-generated. At the core of this modeling approach is the assumption that we strongly rely on the predictability of our own body to be able to differentiate between our own and other's actions through the information gathered especially from the unpredictability of others. The functional simulation helped to evaluate that the identified mechanisms in the model are sufficient to correctly infer own actions from feedback to its action production.
Furthermore, we presented simulation results of different scenarios of perception and production. We discussed how the model's dynamics and how it is able to minimize its free energy in each situation. In two scenarios we simulated action productions in which the SoA could be inferred and compared them to the literature on SoA and the influence of the motor system on social cognition. This comparison suggests that HPBU can correctly attribute SoA for its own actions, using a flexible integration of predictive and postdictive cues while integrating the evidence over time.
We made the model's sequence coordination independent of direct proprioceptive feedback by closing the motor coordination loop via the Vision level, without direct Motor Control level to Sequence level connection. This may have broad implications for the coordination and association of actions in the world with distal effects that do not directly or necessarily feed back into motor coordination. One example is the association of a switch on the wall with the distal effect of switching on the light on the ceiling. A more social example is the association of an action on another agent like smiling, with the effect of influencing that agent's emotional state. We want to explore this exciting possibility in future work.
The presented work is part of a research project investigating computational mechanisms underlying the intra-personal interplay between mentalizing and mirroring and the inter-personal coordination between interaction partners. We believe that computational cognitive modeling such as ours can be informative to the investigation of social cognitive processes which neuroscience is currently not yet able to elucidate, but where an analysis of the behavior of cognitive models based on findings from the neuroscientific literature can help to shed some light.
In future work, we want to improve our setup by making use of the information provided by the present model of self-other distinction to inform computational models of higher-level cognition through an interplay with the mentalizing system, in the process helping it to grasp another agent's intentions and beliefs. In a first step toward this belief attribution we explored a rule based mentalizing model in previous work (Kahl and Kopp, 2015). Here, we lay the foundation to integrate a mentalizing model (higher-level social cognition) with the HPBU model on the common basis of active inference. This way, the mentalizing model will naturally be informed by a model of the sensorimotor system, while influencing it through its predictions. We conjecture that this interplay between the mentalizing and sensorimotor systems can yield the distinction between one's own and an interaction partner's beliefs needed in social interaction, where informed reciprocity is the key to efficient and successful communication.
Author Contributions
SKa and SKo developed the model together. SKa designed the computational frame work and performed the computational simulations. SKa and SKo contributed to the final version of the manuscript. SKo supervised the project.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank the reviewers for their valuable and very helpful comments. We would also like to thank Jan Pöppel for our discussions and his valuable feedback. This research/work was supported by the Cluster of Excellence Cognitive Interaction Technology CITEC (EXC 277) at Bielefeld University, which is funded by the German Research Foundation (DFG).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2018.02421/full#supplementary-material
References
Adams, R. A., Stephan, K. E., Brown, H. R., Frith, C. D., and Friston, K. J. (2013). The computational anatomy of psychosis. Front. Psychiatry 4:47. doi: 10.3389/fpsyt.2013.00047
Ambrosini, E., Ciavarro, M., Pelle, G., Perrucci, M. G., Galati, G., Fattori, P., et al. (2012). Behavioral investigation on the frames of reference involved in visuomotor transformations during peripheral arm reaching. PLoS ONE 7:e51856. doi: 10.1371/journal.pone.0051856
Bastos, A. M., Usrey, W. M., Adams, R. A., Mangun, G. R., Fries, P., and Friston, K. J. (2012). Canonical microcircuits for predictive coding. Neuron 76, 695–711. doi: 10.1016/j.neuron.2012.10.038
Brown, H., Adams, R. A., Parees, I., Edwards, M., and Friston, K. (2013). Active inference, sensory attenuation and illusions. Cogn. Process. 14, 411–427. doi: 10.1007/s10339-013-0571-3
Chambon, V., and Haggard, P. (2012). Sense of control depends on fluency of action selection, not motor performance. Cognition 125, 441–451. doi: 10.1016/j.cognition.2012.07.011
Chambon, V., Sidarus, N., and Haggard, P. (2014). From action intentions to action effects: how does the sense of agency come about? Front. Hum. Neurosci. 8:320. doi: 10.3389/fnhum.2014.00320
Clark, A. (2013). Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 36, 181–204. doi: 10.1017/S0140525X12000477
Clark, A. (2016). Surfing Uncertainty. Prediction, Action, and the Embodied Mind. New York, NY: Oxford University Press.
Colonius, H., and Diederich, A. (2004). Multisensory interaction in saccadic reaction time: a time-window-of-integration model. J. Cogn. Neurosci. 16, 1000–1009. doi: 10.1162/0898929041502733
Cunningham, D. W., Billock, V. A., and Tsou, B. H. (2001). Sensorimotor adaptation to violations of temporal contiguity. Psychol. Sci. 12, 532–535. doi: 10.1111/1467-9280.d01-17
David, N., Newen, A., and Vogeley, K. (2008). The “sense of agency” and its underlying cognitive and neural mechanisms. Conscious. Cogn. 17, 523–534. doi: 10.1016/j.concog.2008.03.004
Dumas, G., Martinerie, J., Soussignan, R., and Nadel, J. (2012). Does the brain know who is at the origin of what in an imitative interaction? Front. Hum. Neurosci. 6:128. doi: 10.3389/fnhum.2012.00128
Engel, K. C., Flanders, M., and Soechting, J. F. (2002). Oculocentric frames of reference for limb movement. Arch. Ital. Biol. 140, 211–219. doi: 10.4449/aib.v140i3.469
Feldman, A. G., and Levin, M. F. (1995). The origin and use of positional frames of reference in motor control. Behav. Brain Sci. 18, 723–744. doi: 10.1017/S0140525X0004070X
Fogassi, L., and Luppino, G. (2005). Motor functions of the parietal lobe. Curr. Opin. Neurobiol. 15, 626–631. doi: 10.1016/j.conb.2005.10.015
Friston, K. (2011). What is optimal about motor control? Neuron 72, 488–498. doi: 10.1016/j.neuron.2011.10.018
Friston, K., Mattout, J., and Kilner, J. (2011). Action understanding and active inference. Biol. Cybern. 104, 137–160. doi: 10.1007/s00422-011-0424-z
Friston, K. J., Daunizeau, J., Kilner, J., and Kiebel, S. J. (2010). Action and behavior: a free-energy formulation. Biol. Cybern. 102, 227–260. doi: 10.1007/s00422-010-0364-z
Friston, K. J., Parr, T., and de Vries, B. (2017a). The graphical brain: belief propagation and active inference. Netw. Neurosci. 1, 381–414. doi: 10.1162/NETN_a_00018
Friston, K. J., Rosch, R., Parr, T., Price, C., and Bowman, H. (2017b). Deep temporal models and active inference. Neurosci. Biobehav. Rev. 77, 388–402. doi: 10.1016/j.neubiorev.2017.04.009
Frith, C. D., Blakemore, S. J., and Wolpert, D. M. (2000). Abnormalities in the awareness and control of action. Philos. Trans. R. Soc. B Biol. Sci. 355, 1771–1788. doi: 10.1098/rstb.2000.0734
Gallese, V., Fadiga, L., Fogassi, L., and Rizzolatti, G. (1996). Action recognition in the premotor cortex. Brain 119 ( Pt 2), 593–609. doi: 10.1093/brain/119.2.593
Ganos, C., Ogrzal, T., Schnitzler, A., and Münchau, A. (2012). The pathophysiology of echopraxia/echolalia: relevance to gilles de la Tourette syndrome. Mov. Disord. 27, 1222–1229. doi: 10.1002/mds.25103
Gentile, G., Björnsdotter, M., Petkova, V. I., Abdulkarim, Z., and Ehrsson, H. H. (2015). Patterns of neural activity in the human ventral premotor cortex reflect a whole-body multisensory percept. Neuroimage 109, 328–340. doi: 10.1016/j.neuroimage.2015.01.008
Grafton, S. T. and de Hamilton, A. F. C. (2007). Evidence for a distributed hierarchy of action representation in the brain. Hum. Mov. Sci. 26, 590–616. doi: 10.1016/j.humov.2007.05.009
Graziano, M. S., Cooke, D. F., and Taylor, C. S. (2000). Coding the location of the arm by sight. Science 290, 1782–1786. doi: 10.1126/science.290.5497.1782
Gumbsch, C., Otte, S., and Butz, M. V. (2017). “A computational model for the dynamical learning of event taxonomies,” in Proceedings of the th Annual Meeting of the Cognitive Science Society (London), 452–457.
Haering, C., and Kiesel, A. (2015). Was it me when it happened too early? Experience of delayed effects shapes sense of agency. Cognition 136, 38–42. doi: 10.1016/j.cognition.2014.11.012
Haggard, P., and Clark, S. (2003). Intentional action: conscious experience and neural prediction. Conscious. Cogn. 12, 695–707. doi: 10.1016/S1053-8100(03)00052-7
Haggard, P., Clark, S., and Kalogeras, J. (2002). Voluntary action and conscious awareness. Nat. Neurosci. 5, 382–385. doi: 10.1038/nn827
Hillock-Dunn, A., and Wallace, M. T. (2012). Developmental changes in the multisensory temporal binding window persist into adolescence. Dev. Sci. 15, 688–696. doi: 10.1111/j.1467-7687.2012.01171.x
Hoffmann, H., Pastor, P., Park, D.-H., and Schaal, S. (2009). “Biologically-inspired dynamical systems for movement generation: Automatic real-time goal adaptation and obstacle avoidance,” in 2009 IEEE International Conference on Robotics and Automation (ICRA) (IEEE) (Kobe), 2587–2592.
Ijspeert, A. J., Nakanishi, J., Hoffmann, H., Pastor, P., and Schaal, S. (2013). Dynamical Movement Primitives: Learning Attractor Models for Motor Behaviors, Vol. 25. MIT Press, 328–373.
Kahl, S., and Kopp, S. (2015). “Towards a Model of the Interplay of Mentalizing and Mirroring in Embodied Communication,” in EuroAsianPacific Joint Conference on Cognitive Science, eds G. Airenti, B. G. Bara, and G. Sandini (Torino), 300–305.
Kawato, M. (1999). Internal models for motor control and trajectory planning. Curr. Opin. Neurobiol. 9, 718–727. doi: 10.1016/S0959-4388(99)00028-8
Kilner, J. M., Friston, K. J., and Frith, C. D. (2007). Predictive coding: an account of the mirror neuron system. Cogn. Process. 8, 159–166. doi: 10.1007/s10339-007-0170-2
Moore, J. W., and Fletcher, P. C. (2012). Sense of agency in health and disease: a review of cue integration approaches. Conscious. Cogn. 21, 59–68. doi: 10.1016/j.concog.2011.08.010
Moore, J. W., Wegner, D. M., and Haggard, P. (2009). Modulating the sense of agency with external cues. Conscious. Cogn. 18, 1056–1064. doi: 10.1016/j.concog.2009.05.004
Nahab, F. B., Kundu, P., Gallea, C., Kakareka, J., Pursley, R., Pohida, T., et al. (2010). The neural processes underlying self-agency. Cereb. Cortex 21, 48–55. doi: 10.1093/cercor/bhq059
Pipereit, K., Bock, O., and Vercher, J.-L. (2006). The contribution of proprioceptive feedback to sensorimotor adaptation. Exp. Brain Res. 174, 45–52. doi: 10.1007/s00221-006-0417-7
Prinz, W. (1997). Perception and action planning. Eur. J. Cogn. Psychol. 9, 129–154. doi: 10.1080/713752551
Przyrembel, M., Smallwood, J., Pauen, M., and Singer, T. (2012). Illuminating the dark matter of social neuroscience: Considering the problem of social interaction from philosophical, psychological, and neuroscientific perspectives. Front. Hum. Neurosci. 6:190. doi: 10.3389/fnhum.2012.00190
Rao, R. P., and Ballard, D. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 2, 79–87. doi: 10.1038/4580
Rohde, M., and Ernst, M. O. (2016). Time, agency, and sensory feedback delays during action. Curr. Opin. Behav. Sci. 8, 193–199. doi: 10.1016/j.cobeha.2016.02.029
Russo, G. S., and Bruce, C. J. (1996). Neurons in the supplementary eye field of rhesus monkeys code visual targets and saccadic eye movements in an oculocentric coordinate system. J. Neurophysiol. 76, 825–848. doi: 10.1152/jn.1996.76.2.825
Sadeghipour, A., and Kopp, S. (2010). Embodied gesture processing: motor-based integration of perception and action in social artificial agents. Cogn. Comput. 3, 419–435. doi: 10.1007/s12559-010-9082-z
Schütz-Bosbach, S., Mancini, B., Aglioti, S. M., and Haggard, P. (2006). Self and other in the human motor system. Curr. Biol. 16, 1830–1834. doi: 10.1016/j.cub.2006.07.048
Sherwell, C., Garrido, M., and Cunnington, R. (2016). Timing in predictive coding: the roles of task relevance and global probability. J. Cogn. Neurosci. 29, 780–792. doi: 10.1162/jocn_a_01085
Sidarus, N., Chambon, V., and Haggard, P. (2013). Priming of actions increases sense of control over unexpected outcomes. Conscious. Cogn. 22, 1403–1411. doi: 10.1016/j.concog.2013.09.008
Synofzik, M., Vosgerau, G., and Newen, A. (2008). Beyond the comparator model: a multifactorial two-step account of agency. Conscious. Cogn. 17, 219–239. doi: 10.1016/j.concog.2007.03.010
Synofzik, M., Vosgerau, G., and Voss, M. (2013). The experience of agency: an interplay between prediction and postdiction. Front. Psychol. 4:127. doi: 10.3389/fpsyg.2013.00127
Todorov, E., and Jordan, M. I. (2002). Optimal feedback control as a theory of motor coordination. Nat. Neurosci. 5, 1226–1235. doi: 10.1038/nn963
Treue, S., and Martínez Trujillo, J. C. (1999). Feature-based attention influences motion processing gain in macaque visual cortex. Nature 399, 575–579. doi: 10.1038/21176
van der Weiden, A., Prikken, M., and van Haren, N. E. M. (2015). Self-other integration and distinction in schizophrenia: a theoretical analysis and a review of the evidence. Neurosci. Biobehav. Rev. 57, 220–237. doi: 10.1016/j.neubiorev.2015.09.004
Van Overwalle, F. (2009). Social cognition and the brain: a meta-analysis. Hum. Brain Mapp. 30, 829–858. doi: 10.1002/hbm.20547
Wegner, D. M., and Wheatley, T. (1999). Apparent mental causation. Sources of the experience of will. Am. Psychol. 54, 480–492. doi: 10.1037/0003-066X.54.7.480
Weiss, C., Herwig, A., and Schütz-Bosbach, S. (2011). The self in social interactions: sensory attenuation of auditory action effects is stronger in interactions with others. PLoS ONE 6:e22723. doi: 10.1371/journal.pone.0022723
Wise, S. P., Boussaoud, D., Johnson, P. B., and Caminiti, R. (1997). Premotor and parietal cortex: corticocortical connectivity and combinatorial computations. Annu. Rev. Neurosci. 20, 25–42. doi: 10.1146/annurev.neuro.20.1.25
Wolpe, N., Moore, J. W., Rae, C. L., Rittman, T., Altena, E., Haggard, P., et al. (2014). The medial frontal-prefrontal network for altered awareness and control of action in corticobasal syndrome. Brain 137, 208–220. doi: 10.1093/brain/awt302
Wolpert, D. M., Doya, K., and Kawato, M. (2003). A unifying computational framework for motor control and social interaction. Philos. Trans. R. Soc. B Biol. Sci. 358, 593–602. doi: 10.1098/rstb.2002.1238
Keywords: active inference, predictive processing, perception-action coupling, intentionality, social brain, mirroring, sense of agency, cognitive model
Citation: Kahl S and Kopp S (2018) A Predictive Processing Model of Perception and Action for Self-Other Distinction. Front. Psychol. 9:2421. doi: 10.3389/fpsyg.2018.02421
Received: 05 February 2018; Accepted: 19 November 2018;
Published: 03 December 2018.
Edited by:
Francesca Marina Bosco, Università degli Studi di Torino, ItalyReviewed by:
Valeria Manera, University of Nice Sophia Antipolis, FranceKarl Friston, University College London, United Kingdom
Copyright © 2018 Kahl and Kopp. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sebastian Kahl, c2thaGxAdW5pLWJpZWxlZmVsZC5kZQ==