 Marie-Pier Plouffe-Demers
Marie-Pier Plouffe-Demers Daniel Fiset
Daniel Fiset Camille Saumure1
Camille Saumure1 Justin Duncan
Justin Duncan Caroline Blais
Caroline Blais- 1Département de Psychologie, Universtité du Québec en Outaouais, Gatineau, QC, Canada
- 2Département de Psychologie, Université du Québec à Montréal, Montreal, QC, Canada
Facial expressions of emotion play a key role in social interactions. While in everyday life, their dynamic and transient nature calls for a fast processing of the visual information they contain, a majority of studies investigating the visual processes underlying their recognition have focused on their static display. The present study aimed to gain a better understanding of these processes while using more ecological dynamic facial expressions. In two experiments, we directly compared the spatial frequency (SF) tuning during the recognition of static and dynamic facial expressions. Experiment 1 revealed a shift toward lower SFs for dynamic expressions in comparison to static ones. Experiment 2 was designed to verify if changes in SF tuning curves were specific to the presence of emotional information in motion by comparing the SF tuning profiles for static, dynamic, and shuffled dynamic expressions. Results showed a similar shift toward lower SFs for shuffled expressions, suggesting that the difference found between dynamic and static expressions might not be linked to informative motion per se but to the presence of motion regardless its nature.
Introduction
In social settings, the human face represents one of the richest nonverbal sources of information. It is thus an essential skill for humans to continually monitor the facial expressions of others in order to appropriately tailor their behavior throughout social interactions. The ability to accurately extract emotional information plays a major role in prosociality (Marsh et al., 2007), and this capacity is often found to be altered in numerous psychiatric conditions characterized by impaired social functioning, such as schizophrenia (Mandal et al., 1998; Edwards et al., 2002; Lee et al., 2010; Clark et al., 2013; Kring and Elis, 2013) and autism spectrum disorder (Baron-Cohen and Wheelwright, 2004; Harms et al., 2010).
Until recently, a majority of studies investigating the visual processes underlying facial emotion recognition have relied on static pictures displaying facial emotions at their apex (i.e., highest intensity). However, facial emotions are dynamic and transient by nature; thus, the visual information necessary to recognize a facial expression in everyday life must be extracted quickly. The present study was aimed at gaining a better understanding of this process by investigating the mechanisms subtending this important endeavor, using more ecological dynamic facial expressions. More specifically, we were interested in utilization of spatial frequencies (SF), considered the “atom” upon which primary visual cortex neurons base their world representation (DeValois and DeValois, 1990), during recognition of static and dynamic facial expressions. Simply put, lower SFs code coarser visual information, such as global face shape or facial feature location, while higher SFs code finer visual information, such as facial feature shape or details like wrinkles.
Behavioral, neuroimaging, and lesion data suggest that static and dynamic facial expressions rely on partially nonoverlapping perceptual mechanisms. For instance, dynamic expressions are associated with enhanced onlooker facial muscular reactions (Weyers et al., 2006; Rymarczyk et al., 2011), and they are also better recognized than static expressions (Wehrle et al., 2000; Kamachi et al., 2001; Ambadar et al., 2005; Bould and Morris, 2008; Hammal et al., 2009; Cunningham and Wallraven, 2009a; Chiller-Glaus et al., 2011; Recio et al., 2011; see however Kätsyri and Sams, 2008; Fiorentini and Viviani, 2011; Gold et al., 2013; Widen and Russell, 2015). In addition, neuroimaging studies have shown that dynamic expressions, compared to static ones, lead to a greater activation of many structures involved in facial emotion processing (Kilts et al., 2003; LaBar et al., 2003; Sato and Yoshikawa, 2004; Schultz and Pilz, 2009; Trautmann et al., 2009; Recio et al., 2011). Crucially, dynamic expressions engage areas of the magnocellular-dorsal pathway to a greater extent than static ones (e.g., area MT; Schultz and Pilz, 2009). This parallels the findings from studies performed on patients with ventral visual stream lesions, whom exhibit dramatically impaired recognition of static emotions (Adolphs et al., 1994; Humphreys et al., 2007; Fiset et al., 2017), but a relatively preserved ability to recognize dynamic emotions (Humphreys et al., 1993; Adolphs et al., 2003; Richoz et al., 2015).
Interestingly, the magnocellular-dorsal pathway is associated with processing of motion and shows a higher sensitivity to lower SFs (Livingstone and Hubel, 1988), which might explain these various findings pertaining to dynamic emotion recognition. In contrast, the parvocellular-ventral pathway, which encompasses most of the areas involved in static face processing, is associated with processing of typically higher SF information (Livingstone and Hubel, 1988). Seeing as static and dynamic emotion recognition may rely on partially nonoverlapping cortical structures, one might expect this to be reflected in different visual information extraction strategies, namely a reliance on lower SFs during the processing of dynamic expressions compared to static ones.
Previous work by our team and others also feeds this hypothesis according to which dynamic facial emotion recognition might rely on comparatively lower SFs – though this prediction has not been explicitly tested. Indeed, although diagnostic (i.e., relevant) facial features are mostly the same for static and dynamic expressions (namely, the eyes and mouth), eye fixation patterns underlying the extraction of these features differ. Specifically, participants spend more time directly fixating diagnostic features for static expressions, whereas they spend more time fixating the center of the face (i.e., nose) for dynamic expressions (Buchan et al., 2007; Blais et al., 2012, 2017; see however, for videos of longer duration, Calvo et al., 2018). Seeing as diagnostic features will be processed in parafoveal vision for dynamic expressions viewed at a conversational distance (i.e., face span of approx. 6–14°; Yang et al., 2014) and that sensitivity to high SFs monotonically decreases with foveal eccentricity (Hilz and Cavonius, 1974), viewing dynamic (vs. static) expressions is likely to induce a shift away from higher SFs and toward lower SFs.
The finding of different patterns of eye fixations for static and dynamic expressions also begs the question of what the underlying cause might be for such an outcome. One possibility is that dynamic expressions convey additional information through motion, thereby reducing the need to extract precise feature representations coded in higher SFs – which requires foveal processing, and thus, direct fixation. A role for motion has been supported by computational studies showing that information it conveys drastically increases performance of artificial vision systems (e.g., Jiang et al., 2011, 2014). The fact that human performance during dynamic facial emotion recognition is resistant to spatial information degradation (e.g., texture and shape) as long as motion contained within expressions is preserved (e.g., exhibited by point-light displays; Cunningham and Wallraven, 2009b), and that performance is reduced when the emotion unfolding sequence (i.e., video frame order) is shuffled or reversed (Cunningham and Wallraven, 2009a), is also a strong argument in favor of motion conveying crucial information for emotion recognition.
Although many studies have supported the importance of motion for expression processing, it is possible that the different patterns of eye fixations observed for static and dynamic expressions are not necessarily for the purpose of using emotion information that is conveyed by motion. Another possibility is instead that the mere presence of motion could activate mechanisms aimed at processing it, regardless of the emotion information it may or may not convey. Such mechanisms may involve changes in eye fixation patterns, since retinal periphery is more efficient at processing temporal variations and motion (Takeuchi et al., 2004; Thompson et al., 2007; Gurnsey et al., 2008).
In other words, fixating dynamic emotional faces in their center may serve the purpose of optimizing the processing of emotion information conveyed through motion by projecting this content in parafoveal regions of the retina. Or, the change in eye fixation pattern may instead be reflexive and caused by the mere presence of motion – irrespective of the information it might convey. In turn, the SF shift hypothesized above could very well be a consequence of fixation optimization for motion processing.
The objective of the present study was twofold. First, we wished to verify the hypothesis according to which the recognition of dynamic and static facial expressions relies on partially nonoverlapping SFs by comparing tuning profiles for both types of expressions (Experiments 1, 2). Second, we wanted to verify if changes in SF tuning curves are specific to the presence of informative motion by comparing the SF tuning profiles for static, dynamic, and shuffled dynamic expressions (Experiment 2).
Experiment 1
The SF Bubbles method (Willenbockel et al., 2010a, 2012, 2013; Thurman and Grossman, 2011; Tadros et al., 2013; Royer et al., 2017) was used in order to compare SF utilization in two different facial emotion recognition conditions: static and dynamic expressions. Although filtering faces may create stimuli that differ from what observers consciously perceive in everyday life, it directly manipulates the visual information considered as the atom of visual perception according to the dominant theory in the field of vision (DeValois and DeValois, 1990).
The SF Bubbles method consists in creating, trial-by-trial, random SF filters that are applied to an image – here, one depicting a facial expression. Participant accuracy with each filtered image is then used to infer which SF increases the likelihood of a correct answer (see Stimuli section for more details). This method presents important advantages in comparison with the fixed low-pass and high-pass filters that are frequently used to tackle the SF processing during facial emotion recognition (e.g., Vuilleumier et al., 2003). First, instead of simply comparing performance with low vs. high SFs, it allows to measure the complete SF tuning curve of participants. This is particularly important for tasks involving face processing, since it has been shown that sensitivity peaks at SFs between 8 and 16 cycles per face (Näsänen, 1999; Gaspar et al., 2008). Removing those frequencies from the stimuli, as is often done with low-pass and high-pass filter, may thus tap into visual mechanisms that are not specialized for face processing. Relatedly to this last point, a second important advantage of the SF Bubbles method is that, contrary to fixed filters, it does not require an (often arbitrary) decision on where the cutoffs should be applied for the low-pass and high-pass filters; in other words, what SFs should be included in the low-pass (or high-pass filters). Such decision may have a huge impact on the results. SF Bubbles make no a priori decision regarding such cutoffs; it simply randomly samples all of the SFs contained in a stimulus and measure performance with all of these random filters.
Materials and Methods
Participants
Twenty participants (4 males; 22.8 years old on average; SD = 3.24) took part in Experiment 1. The number of participants was chosen based on previous experiments using similar methods (Willenbockel et al., 2010a; Royer et al., 2017; Tardif et al., 2017). Because the method relies on random sampling of visual information, a high number of trials are required to obtain a reasonable signal-to-noise ratio. Studies using SF Bubbles have typically relied on a high total number of trials (i.e., across participants) ranging between 10,800 (Tadros et al., 2013) and 34,500 trials (Estéphan et al., 2018) per condition (see also Tardif et al., 2017, 33,000 trials and Royer et al., 2017, 19,200 trials). The present experiment contained a total of 39,200 trials per condition thus having enough trials to obtain very stable SF tuning for each condition. All participants had normal or corrected-to-normal visual acuity and were naïve to the purpose of the experiment.
Stimuli
The stimuli consisted of videos and photos of 10 actors (5 males) expressing the six basic emotions (i.e., anger, disgust, fear, joy, sadness, surprise; Ekman and Friesen, 1975) as well as neutrality. Stimuli were taken from the STOÏC database (Roy et al., 2007). Videos had a duration of 450 ms and were composed of 15 frames with a duration of 30 ms each. They started with a neutral facial expression and ended at the apex of the expression. Photo stimuli were generated by extracting the last frame from the videos (i.e., the apex). Static and dynamic stimuli were spatially aligned on the main internal features (eyes, nose, mouth) across facial expressions and across actors using linear manipulations such as translation, rotation, and scaling. Additionally, dynamic stimuli were temporally aligned. Faces were cropped to exclude non-facial cues, and they were equated on mean luminance using the SHINE toolbox (Willenbockel et al., 2010b).
On each trial, a stimulus was generated by randomly sampling the SFs of the photo or the frames of the video using the SF Bubbles technique (Willenbockel et al., 2010a). This technique involves the following steps, also depicted in Figure 1. First and foremost, in order to reduce edge artifacts, the stimulus is padded with a uniform gray background (Figure 1A). A fast Fourier transform is then applied to the padded stimulus (Figure 1B), resulting in the base image amplitude spectrum to which a random SF filter is later applied. This filter is created by first generating a random binary vector of X ones among 10,240 zeros, where X is the number of bubbles (Figure 1C). This vector is then convolved with a Gaussian kernel with a standard deviation of1.5 cycles per image (Figure 1D). The smoothed sampling vector (Figure 1E) is then log-transformed in order to fit the human contrast sensitivity function (Figure 1F; see DeValois and DeValois, 1990). The resulting vector is used to generate a two-dimensional isotropic SF filter (Figure 1G) by rotating it 360° on its origin. A pointwise multiplication is performed between the base image amplitude spectrum and the SF filter (Figure 1H). The result is then back-transformed into the image domain by submitting it to an inverse fast Fourier transform (Figure 1I) and cropped to its original size (Figure 1J). The resulting “SF bubblized” image contains a random subset of the base image’s SF content. Note that with videos, the same filter was applied to all the frames within a trial. Examples of stimuli are presented in Figure 2.
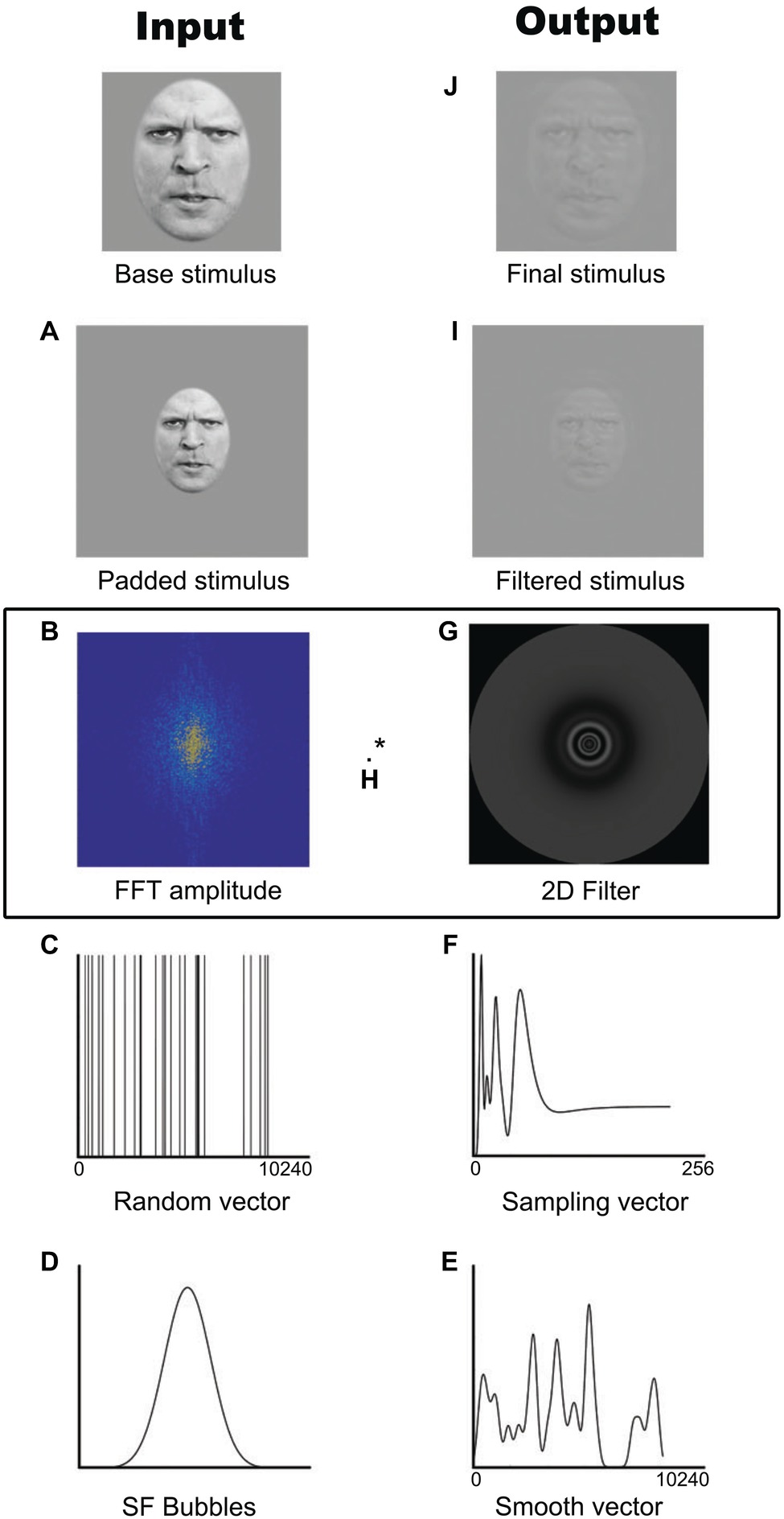
Figure 1. Example of the creation of one stimulus with the SF Bubbles method. (A) Padded stimulus. (B) Fast Fourrier transformed base image amplitude spectrum. (C) Random binary vector. (D) Spatial frequency Bubble. (E) Smoothed sampling vector. (F) Log-transformed sampling vector. (G) Two-dimensional isotropic spatial frequency filter. (H) Pointwise multiplication of the Fast Fourrier transformed base image amplitude spectrum and the spatial frequency filter. (I) Filtered stimulus. (J) Final cropped stimulus. Written informed consent was obtained from the individual for the publication of this image.
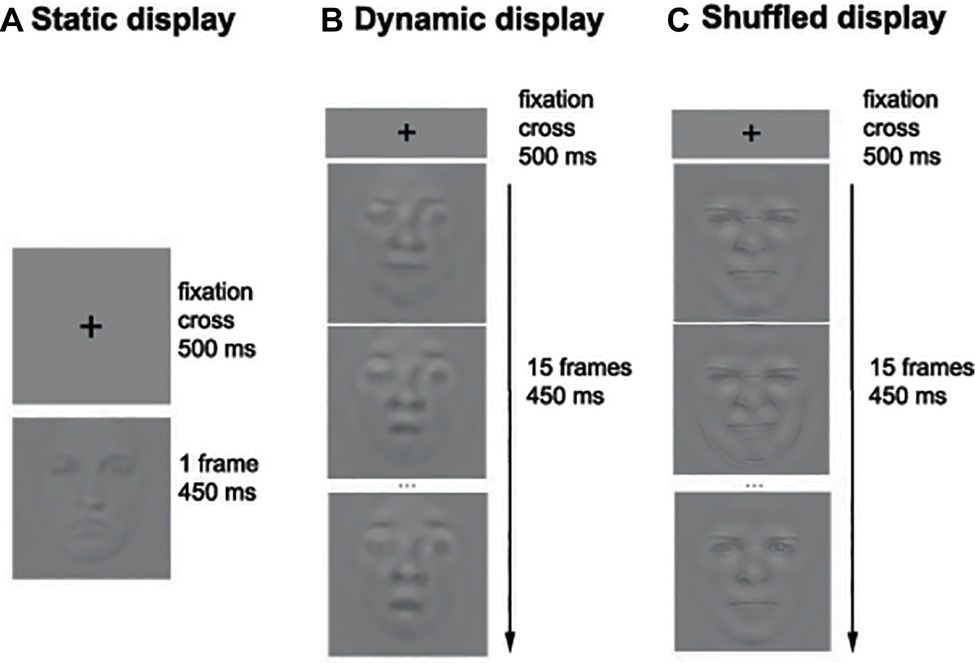
Figure 2. Example of the sequence of events in the Static (A), Dynamic (B), and Shuffled (C) conditions. Note that only three frames out of 15 are represented in the Dynamic and Shuffled conditions.
Apparatus
The faces in all pictures and videos were presented within a square subtending 256 × 256 pixels and were displayed on a calibrated LCD monitor (51 × 28.5cm; resolution of 1,920 × 1,080) with a refresh rate of 100Hz. All participants were asked to place their head on a chin rest at a viewing distance of 38 cm; face width (about 176 pixels) subtended ≈7° of visual angle. The experimental program was written in Matlab (MathWorks, 2012), using functions from the Psychophysics Toolbox (Brainard and Vision, 1997; Pelli, 1997; Kleiner et al., 2007).
Procedure
Each participant completed 14 blocks of 140 trials per condition (i.e., Static and Dynamic), for a total of 3,920 trials. The experiment took on average 4 h per participant that was divided into two sessions taking place on separate days. During each session, the participants were encouraged to take breaks whenever they felt some fatigue. On each trial, a fixation cross was first displayed in the middle of the screen for 500 ms, followed by the stimulus (picture or video) for a duration of 450 ms. A uniform gray background was then displayed until the participant’s response. Participants were asked to categorize the emotion displayed by static or dynamic facial expressions by pressing the button associated with each of the six basic emotions as well as neutrality (e.g., “A” for anger, “D” for disgust, “F” for fear, etc.). Figure 2 shows the sequence of events within one trial.
All participants started with a block containing dynamic expressions and alternated between conditions thereafter. This order was kept for all participants for a specific reason. When using SF Bubbles method, the number of bubbles is manipulated with the objective of maintaining the performance between ceiling and floor. In fact, the analysis procedure allows to infer the SF utilization by comparing the SFs that were available in the stimuli on correct and incorrect trials – hence, it is imperative that a significant number of mistakes is made. In the present experiment, we decided to use the same number of bubbles with dynamic and static expressions in order to ensure that any difference found in SF tuning could not be attributable to a between-condition difference in the number of sampled SFs on each trial. We also decided to adjust the number of bubbles based on the average accuracy with dynamic expressions to minimize the likelihood of a ceiling effect, as previous studies have revealed better performance with these vs. static ones. Thus, for each participant, the number of bubbles was adjusted on a trial basis with QUEST (Watson and Pelli, 1983), but only during the blocks that contained dynamic expressions. The target average accuracy was set to 70%. The number of bubbles used on a given Static block was set to the last output of QUEST in the immediately preceding Dynamic block.
The protocol of this experiment was approved by the Research Ethics Committee of Université du Québec en Outaouais and was conducted in accordance with the Code of Ethics of the World Medical Association (Declaration of Helsinki). All participants provided informed written consent.
Results
Accuracy
An average of 14.4 (SD = 13.5) bubbles was necessary to maintain an approximate accuracy of 70% during the recognition of dynamic expressions. The number of bubbles reflects the quantity of SF information (and, as a result, the total amount of energy contained in the stimulus) needed by the participants.
An average accuracy of 62.6% (SD = 4.8%) and 68.1% (SD = 5.5%) was found in the Static and Dynamic conditions, respectively. The average accuracy with each emotion in each condition is displayed in Figure 3. A 7 (Emotions) × 2 (Conditions) repeated-measure ANOVA was conducted on accuracy. The results indicated significant main effects of the factors of Emotion [F(1, 19) = 72.6, p < 0.001; η2 = 0.79] and Condition [F(6, 114) = 30.8, p < 0.001; η2 = 0.62]. There was also an interaction effect between both factors [F(6, 114) = 5.63, p < 0.001; η2 = 0.23]. A dynamic advantage was found for most facial expressions: anger [t(19) −8.7049; p < 0.001; 95% CI (−10.30 to −6.31%)], fear [t(19) −3.3401; p = 0.0034; 95% CI (−6.77 to −1.55%)], sadness [t(19) −5.2577; p < 0.001; 95% CI (−11.94 to −5.14%)], and surprise [t(19) −7.4219; p < 0.001; 95% CI (−10.94 to −6.13%)]. The effect for disgust did not resist the Bonferroni adjustment (p must be <0.007) [t(19) −2.6413; p = 0.0161; 95% CI (−9.09 to −1.05%)]. No significant effect was found for happiness [t(19) −2.0472; p = 0.0547; 95% CI (−3.84 to 0.04%)]. There was also no significant difference with neutrality [t(19) −1.8383; p = 0.0817; 95% CI (−4.69 to 0.30%)], which is normal considering the absence of motion even in the dynamic stimuli.
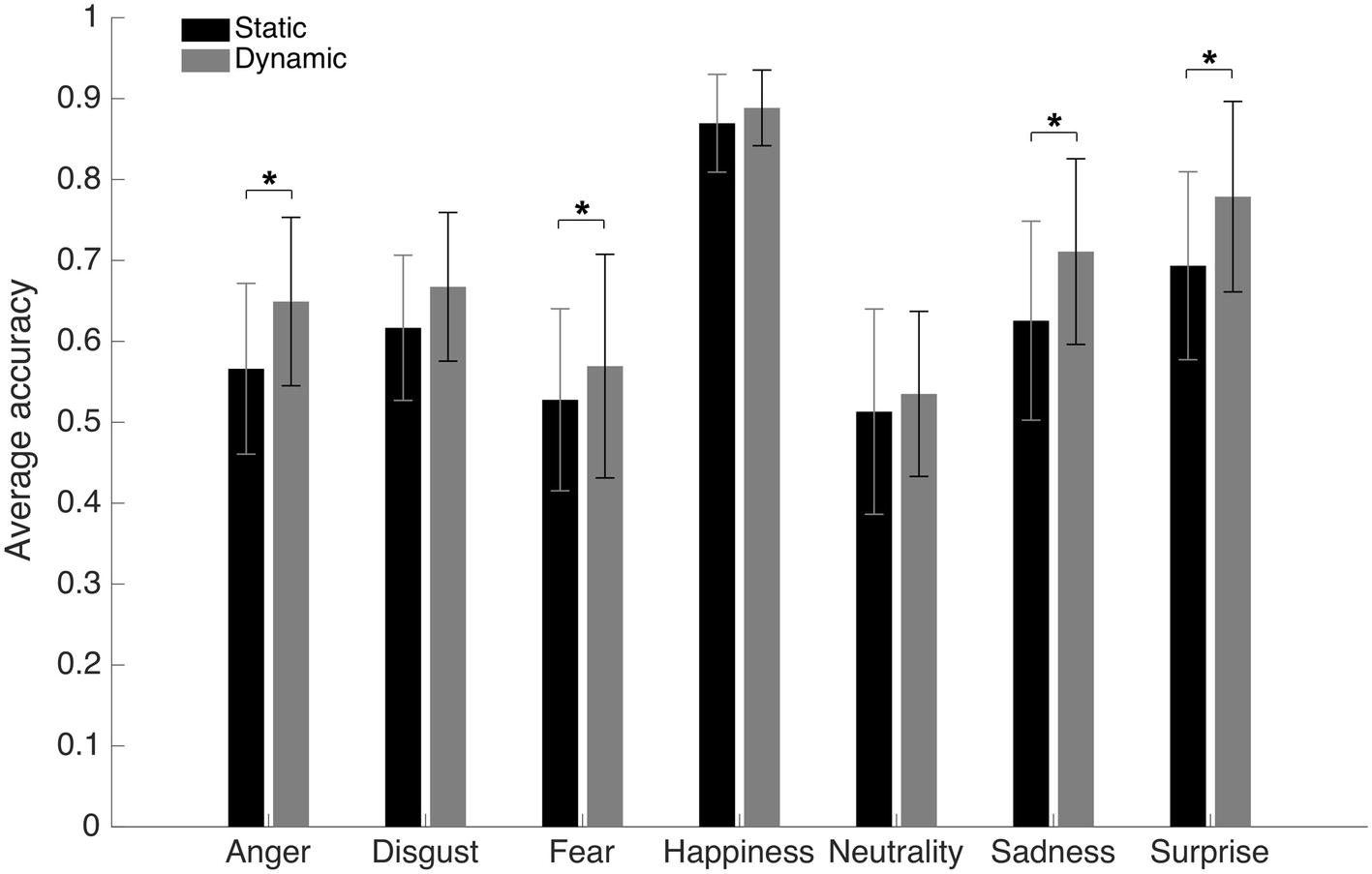
Figure 3. Average accuracy for the static and dynamic facial expressions in Experiment 1. Error bars represent the standard deviations. *Significant at a p <0.007.
Spatial Frequency Tuning
SF tunings for static and dynamic expressions were obtained separately for each participant by calculating a weighted sum of all the unsmoothed SF vectors that were used during testing (see Figure 1C), using accuracies transformed into z-scores as weights (see Willenbockel et al., 2010a; Royer et al., 2017; Tardif et al., 2017; for a similar procedure). Thus, positive weights were granted to SF vectors that led to correct responses and negative weights were given to SF vectors that led to incorrect responses. The resulting classification vectors were smoothed using a Gaussian kernel with a standard deviation of 2.5 cycles per image and then log-transformed. Finally, they were transformed into z scores using a permutation procedure whereby weights were randomly redistributed across trials and random classification vectors were created using these weights. This procedure was repeated 20 times, and the average and standard deviation for each SF across these random classification vectors were used to standardize the coefficients obtained for each SF in the participant’s classification vector.
Group classification vectors were then produced for each condition by summing individual vectors across participants and dividing the outcome by the square root of the number of observers. The statistical threshold was determined with the Pixel test from the Stat4Ci toolbox (Zcrit = 3.1, p < 0.025; Chauvin et al., 2005). This threshold corrects for the multiple comparisons across SFs, while also taking into account the non-independence between contiguous SFs.
Group classification vectors are displayed in Figure 4. A SF tuning peaking at 18.0 cycles per face (cpf) with a full width at half maximum (FWHM) of 30.3 cpf was found in the Static condition, and a SF tuning peaking at 17.3 cpf with a FWHM of 29.3 cpf was found in Dynamic condition. Most importantly, a significant difference in tuning was found between 3 and 7 cpf, indicating that this information was used more efficiently in the Dynamic vs. Static condition.
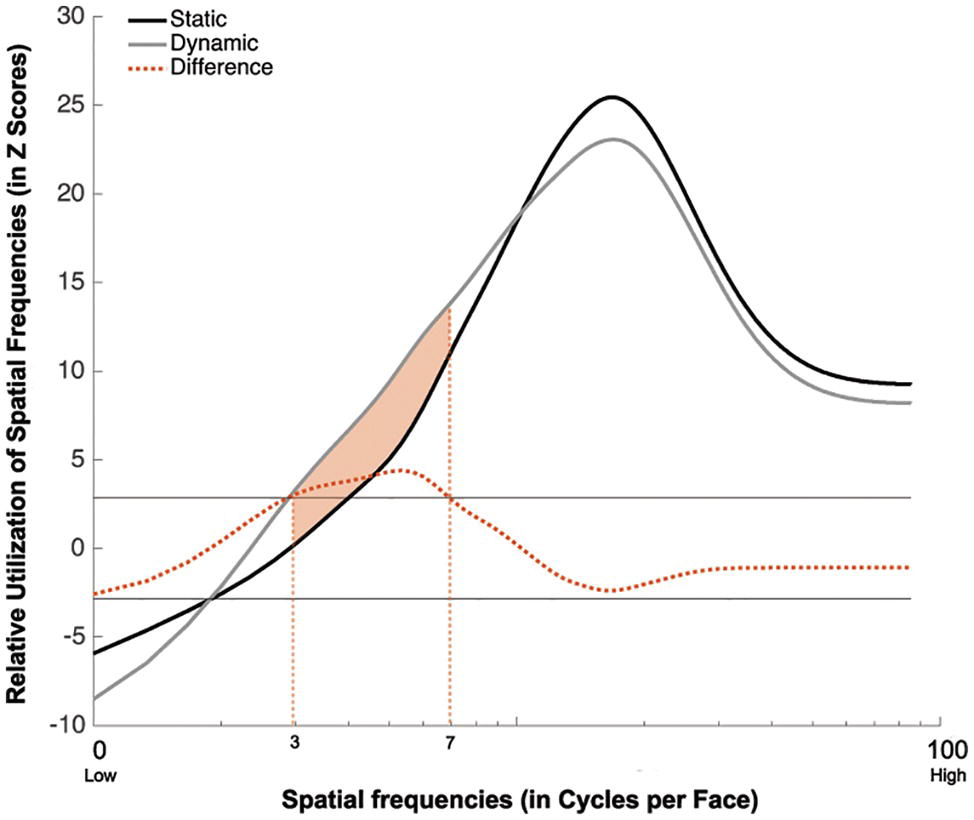
Figure 4. Association between the availability of a given SF and participants accuracy for recognizing static (in black) and dynamic (in gray) expressions. This association is averaged across all participants and emotions. The dotted red line represents the difference between the Dynamic and Static conditions. The SFs that are significantly more used in the Dynamic than Static condition are indicated by the shaded orange area between the curves.
Discussion
The results of Experiment 1 show a shift toward lower SFs for dynamic compared to static expressions. This shift was expected based on the differences previously observed in the eye fixation pattern used with dynamic and static expressions. Experiment 2 aimed at verifying if the difference observed in the SF tuning is related to the presence of informative motion in dynamic expressions.
Experiment 2
Materials and Methods
Participants
Twenty-eight participants (9 males; 23 years old on average; SD = 5.77), none of whom participated in Experiment 1, were tested in Gatineau (Quebec, Canada). The number of participants was selected in order to match the total number of trials per condition in Experiment 1. However, to avoid an excessive increase in the duration of the experiment due to the addition of a third condition, we decreased the number of trials that a participant needed to complete in each condition and increased the number of participants. All participants had normal or corrected-to-normal visual acuity.
Stimuli
The same stimuli as in Experiment 1 were used in the Static and Dynamic conditions. In the Shuffled condition, the stimuli were created by randomizing the order of the 15 frames contained in the original dynamic stimuli.
Apparatus
Same as in Experiment 1.
Procedure
Each participant completed 10 blocks of 140 trials in each condition, for a total of 4,200 trials. The unfolding of events in a trial was the same as in Experiment 1 (see Figure 2). The participant’s task was also the same as in Experiment 1.
All participants started with a block from the Dynamic condition, followed by a block from the Static condition and by a block from the Shuffled condition. The three conditions were then interleaved, and the same order was kept for the rest of the experiment. As was done in Experiment 1, the number of bubbles was adjusted on a trial basis, using QUEST during the Dynamic condition; the same number of bubbles was then applied for the following Static and Shuffled blocks.
The protocol of this experiment was approved by the Research Ethics Committee of Université du Québec en Outaouais and was conducted in accordance with the Code of Ethics of the World Medical Association (Declaration of Helsinki). All participants provided informed written consent.
Results
Accuracy
An average of 13.6 (SD = 4.15) bubbles was necessary to maintain an approximate accuracy rate of 70% in the Dynamic condition. An average accuracy of 66.5% (SD = 2.4%), 71.7% (SD = 2.2%), and 64.3% (SD = 2.7%) was found in the Static, Dynamic, and Shuffled conditions, respectively. The average accuracy with each emotion in each condition is presented in Figure 5. A 7 (Emotions) × 3 (Conditions) repeated-measure ANOVA was conducted on accuracy. The results indicated significant main effects of the factors of Emotion [F(6, 162) = 37.4, p < 0.001; η2 = 0.58] and Condition [F(2, 64) = 201.2, p < 0.001; η2 = 0.88]. These were characterized by the presence of an interaction effect between both factors [F(12, 324) = 37.1, p < 0.001; η2 = 0.58]. One-way ANOVAs were then performed for each emotion. A significant effect of condition was found for disgust [F(2) = 53.8, p < 0.001; η2 = 0.57], happiness [F(2) = 13.3, p < 0.001; η2 = 0.25], sadness [F(2) = 5.3, p = 0.007; η2 = 0.12], and surprise [F(2) = 14.6, p < 0.001; η2 = 0.27]. With anger, the effect of Condition did not resist the Bonferroni adjustment (p must be <0.007) [F(2) = 4.2, p = 0.019; η2 = 0.09]. No significant effect of condition was found for fear [F(2) = 0.20, p = 0.82] or neutrality [F(2) = 1.2, p = 0.31]. For the four emotions showing a significant effect of Condition, as well as for anger (for which there was an effect prior to the Bonferroni adjustment), paired sample t-tests were carried to contrast accuracy for Dynamic vs. Static, Dynamic vs. Shuffled, and Static vs. Shuffled. The detailed results are provided in Table 1. Overall, participants were significantly more accurate in the Dynamic (vs. Static) condition for the emotions of anger, disgust, happiness, surprise, and sadness. They were also significantly more accurate in the Dynamic (vs. Shuffled) condition for the emotions of anger, disgust, happiness, and surprise, but not sadness. Finally, participants were significantly more accurate in the Static (vs. Shuffled) condition for the emotions of disgust, happiness, and surprise and less accurate for the emotions of anger and sadness.
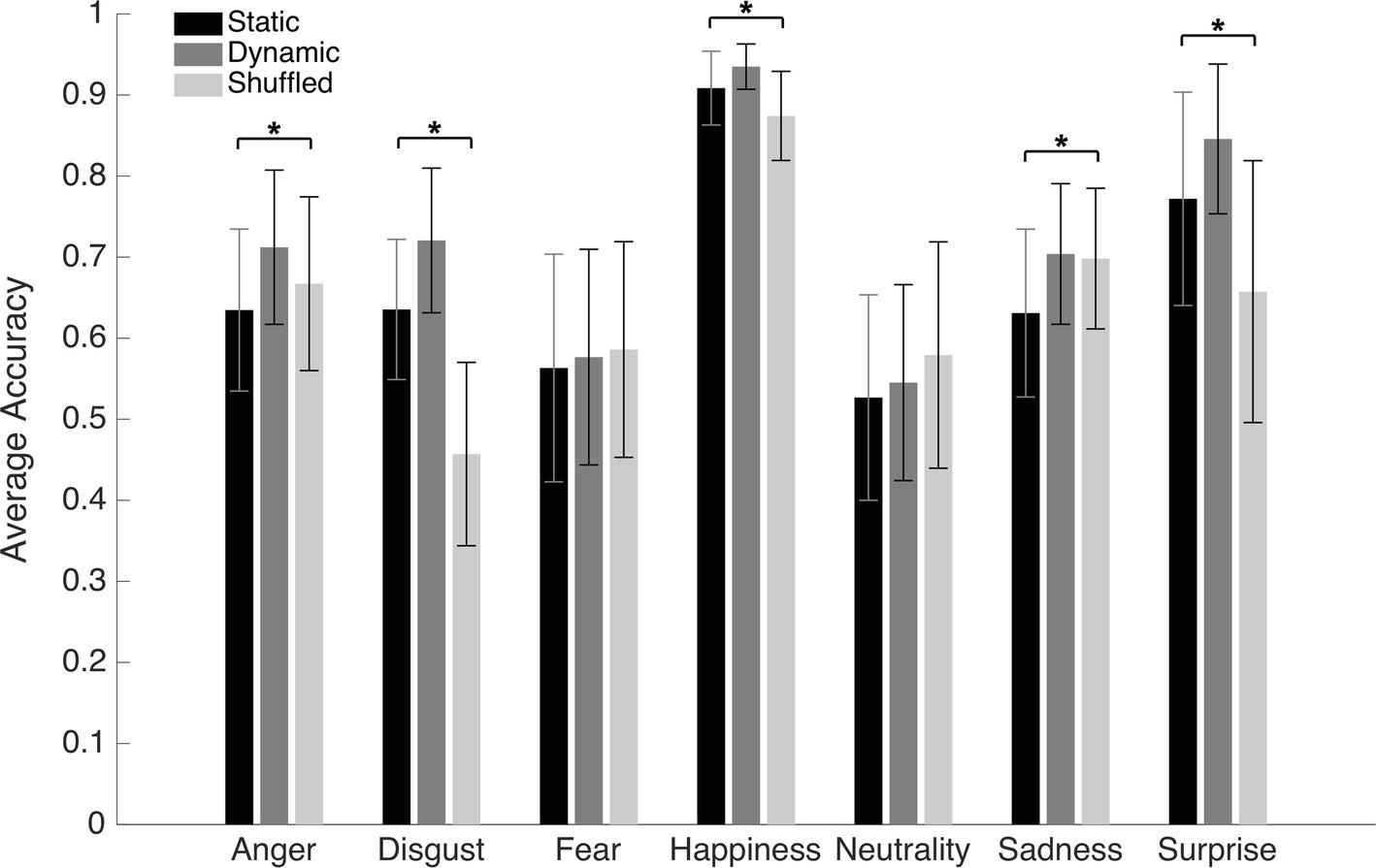
Figure 5. Average accuracy for the static, dynamic, and shuffled facial expressions in Experiment 2. The error bars represent the standard deviations. *Significant at a p <0.007.
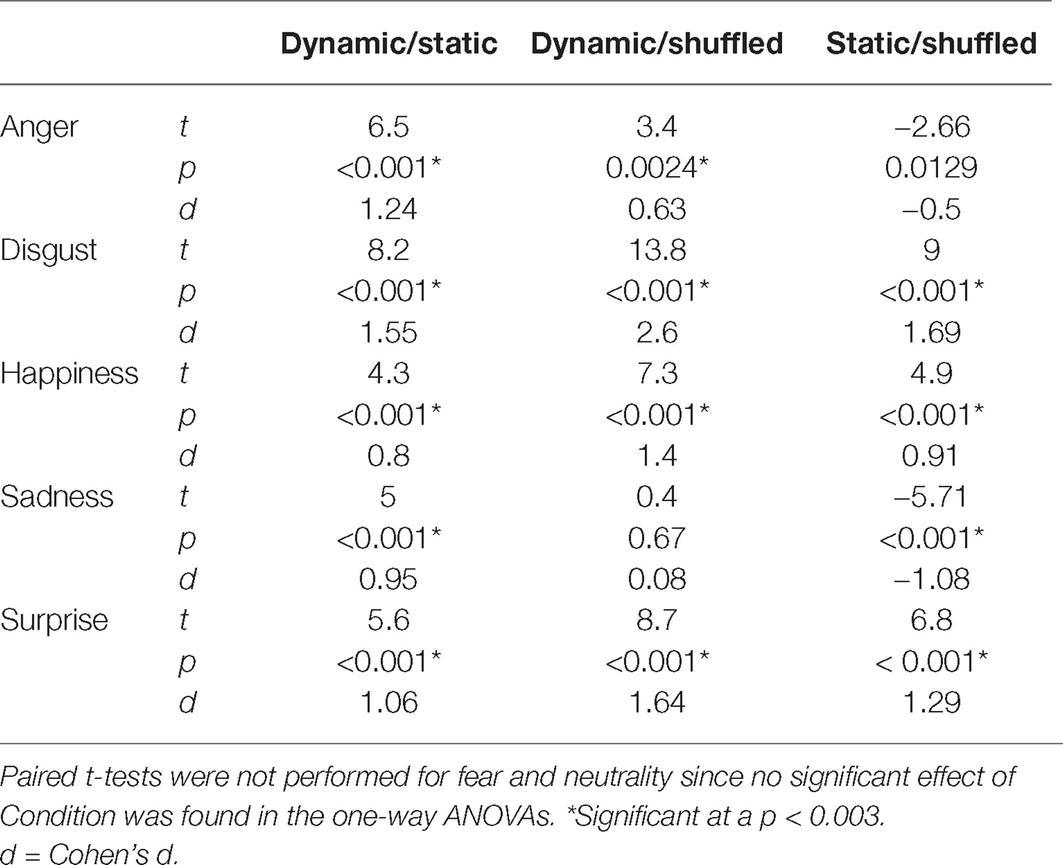
Table 1. Paired t-test results comparing the accuracy in the Dynamic and the Static conditions, the Dynamic and the Shuffled conditions, and the Static and Shuffled conditions.
Spatial Frequency Tuning
The group classification vectors obtained in the Static, Dynamic, and Shuffled conditions were produced using the same procedure as described in Experiment 1. The results are displayed in Figure 6. SF tunings peaking at 17.0, 14.3, and 16.0 cpf with FWHMs of 32.0, 26.7, and 21.0 cpf were found in the Static, Dynamic, and Shuffled conditions, respectively (ZCrit = 3.1, p < 0.025).
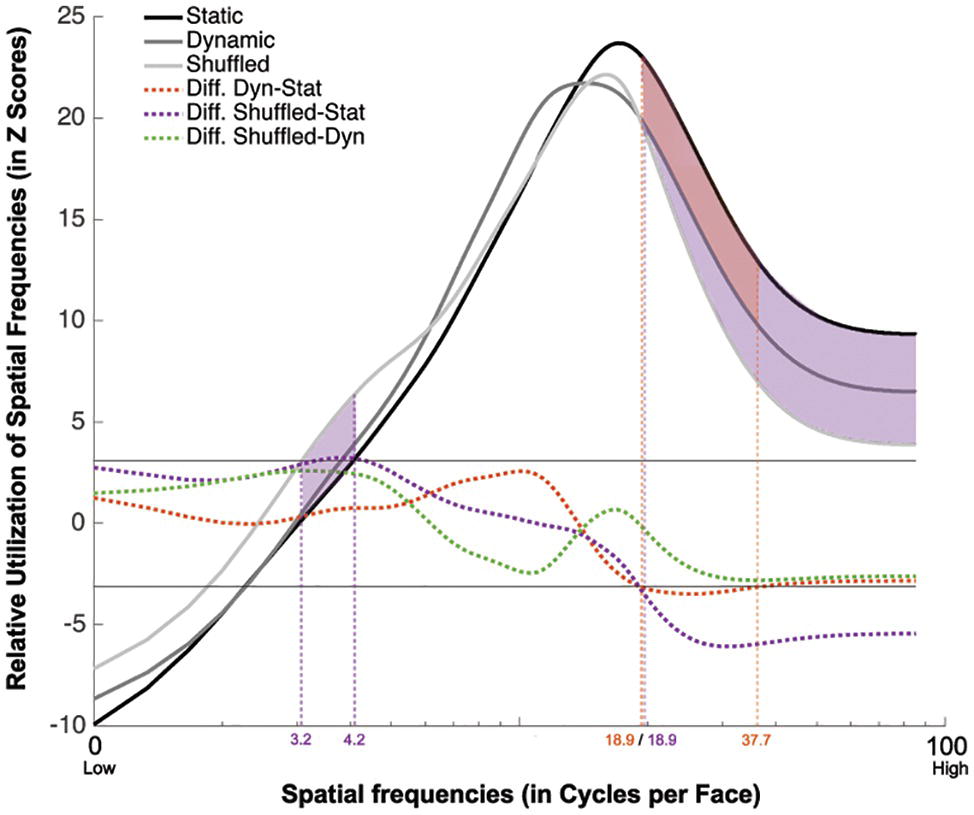
Figure 6. Association between the availability of a given SF and participants accuracy for recognizing static (in black), dynamic (in dark gray), and shuffled (in pale gray) expressions. This association is averaged across all participants and emotions. The dotted red line represents the difference between the Dynamic and Static conditions. The dotted purple line represents the difference between the Shuffled and Static conditions. The dotted green line represents the difference between the Shuffled and Dynamic conditions. The red shaded area indicates the SFs that were significantly less useful in the Dynamic than the Static condition. The purple shaded area indicated the SFs that are significantly more used in the Shuffled than in the Static condition.
A significant tuning difference was found between the tunings of the Static and Dynamic conditions: mid-to-high SFs ranging between 18.9 and 37.7 cpf were significantly more useful for static expressions. Significant differences were also found between the Static and Shuffled conditions, whereby low SFs ranging between 3.2 and 4.2 cpf were significantly more useful in the Shuffled condition and SFs higher than 18.9 cpf were significantly more useful in the Static condition. Moreover, no significative differences were found between the SF tuning of Dynamic and Shuffled conditions.
Discussion
Although the higher reliance on lower SFs with dynamic than with static expressions observed in Experiment 1 was not replicated, we did find a decreased reliance on higher SFs. This is consistent with the idea of a shift in SF tuning between static and dynamic expressions which will be further discussed in the next section.
A shift toward lower SFs was also observed for shuffled expressions. This suggests that the differences observed in the SF tunings for static and dynamic expressions are not caused by the presence of informative motion. In fact, contrary to what was expected, eliminating or reducing the amount of information contained in the motion by altering the natural sequence of facial changes led to a SF tuning significantly lower than the one observed in the Static condition and similar to the one observed in the Dynamic condition.
Analysis of Experiments 1 and 2 Combined
Since participants in Experiments 1 and 2 all completed trials with static and dynamic expressions, additional analyses combining all 48 participants were conducted in order to verify the robustness of the SF tuning shift between these conditions. Group classification vectors based on the 48 participants tested in Experiments 1 and 2 were produced for the Static and Dynamic conditions using the same procedure as described in Experiment 1. The results are presented in Figure 7. A SF tuning peak at 17.3 cpf with a FWHM of 31.3 cpf and a SF tuning peak at 16.0 cpf with a FWHM of 28.3 cpf were found in the Static and Dynamic conditions, respectively. Low SFs ranging between 5.6 and 8.3 cpf were significantly more useful in the Dynamic condition and mid-to-high SFs ranging between 17.6 and 85.3 cpf were significantly more useful in the Static condition. Note that the presence of extremely high SFs (i.e., >25 cpf) in the significant clusters is most likely due to the logarithmic SF sampling mentioned in the Materials and Methods; this impacts the resolution of the high SFs, as we have previously demonstrated in a previous study (see supplementary material in Estéphan et al., 2018).
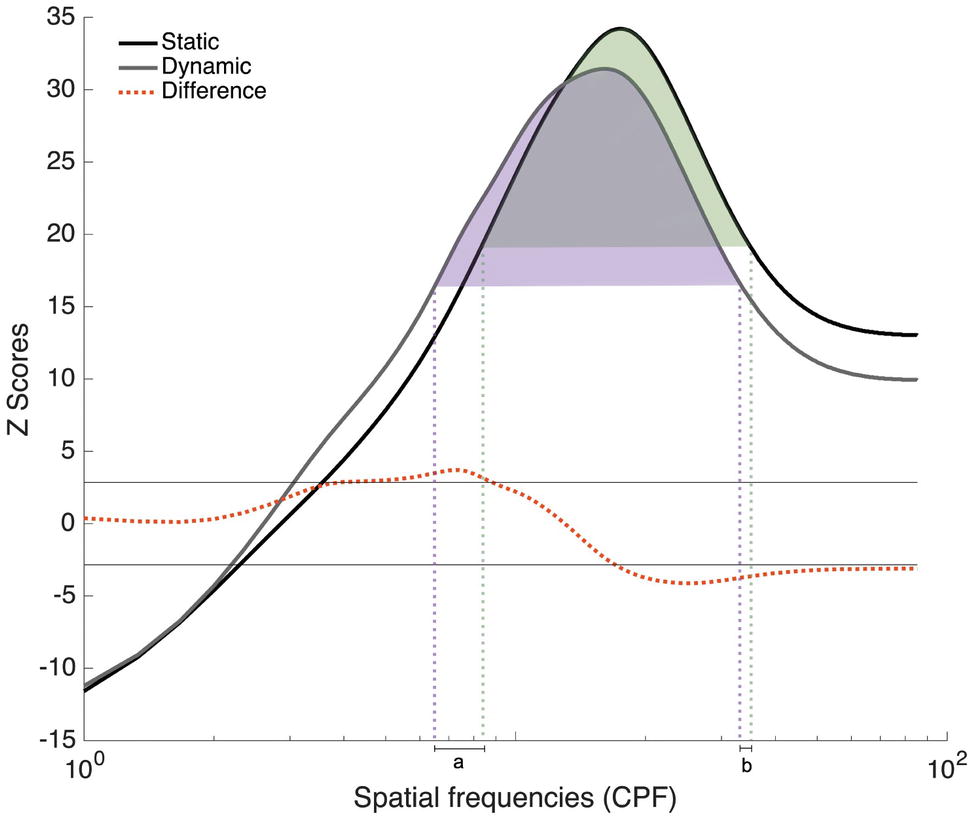
Figure 7. Classification vectors representing the SFs used by the 48 participants tested in Experiments 1 and 2 for static and dynamic facial expressions, averaged across all emotions. The horizontal gray lines represent the statistical thresholds. The dotted red line represents the difference between the Dynamic and Static conditions. The vertical dotted lines corresponded to the beginning and end of each tuning curve at its half maximum (Dynamic in purple and static in green).
In order to better quantify the tuning shift, we conducted a permutation analysis in which we randomly reassigned the Static and Dynamic conditions during the creation of the group classification vectors. More specifically, on each iteration of the permutation analysis, the Static and Dynamic classification vectors of each participant were randomly assigned to either group classification vector. This procedure was repeated 10,000 times, which allowed us to estimate differences that may have occurred by chance. Two measures were taken: the distance between the tuning peaks for static and dynamic expressions and the translation between the two curves. This last measure was calculated in three steps. First, we indexed the SFs that corresponded to the beginning and end of each tuning curve at its half maximum [Figure 7; purple (Dynamic) and green (Static) dotted lines]. Second, SF values delineating the beginning of the static tuning curve were subtracted from those delineating the beginning of the dynamic curve (see value a in Figure 7); and SF values delineating the end of the static tuning curve were subtracted from those delineating the end of the dynamic curve (see value b in Figure 7). Finally, these two values, a and b, were added together. This measure therefore captures differences in the global shape of the tuning curves, as well as their relative position on the SF spectrum, whereas peak displacement reveals differences in SF values to which participants are most sensitive between static and dynamic expressions. For both of these measures, the value corresponding to the 5th percentile across these 10,000 pairs of random classification vectors was used as threshold. In terms of peak displacement, the difference observed between static and dynamic expressions (1.33 cpf) was marginally significant [95% CI (−1.66, 1.66), p = 0.0759]. In terms of tuning curve displacement on the SF spectrum, SF tuning for dynamic expressions was significantly translated toward lower SFs (6.33 cpf), relative to static expressions [95% CI (−5.33, 5.66), p = 0.02]. Note that this permutation analysis only revealed a significant effect on peaks in Exp. 2 [average of 3 cpf; 95% CI (−3, 3), p = 0.05]. There was no significant difference in tuning peaks in Exp. 1 [average of 0.67 cpf; 95% CI (−2, 2), p = 0.33]. The tuning translation was neither significant in Exp. 1 [average translation of 4.33 cpf; 95% CI (−6.33, 6.33), p = 0.11] nor in Exp. 2 [average translation of 8.33 cpf; 95% CI (−48, 48), p = 0.38].
We also conducted an analysis to verify if the shift in SF tuning between dynamic and static expressions is related to the increased accuracy observed with dynamic expressions. We calculated the dynamic advantage in terms of accuracy (i.e., accuracyDynamic − accuracyStatic) for each participant separately. We then measured the correlation between the individual dynamic advantage and the shifts in SF tunings (PeakDynamic − PeakStatic) and the correlation between the individual dynamic advantage and the magnitude of translation between their tunings. The results indicate that the dynamic advantage was not correlated with any of these two measures: r(46) = −0.026, p = 0.86 and r(46) = −0.015, p = 0.92 were obtained for the shift in peaks and the translation of tunings, respectively. Finally, we conducted a preliminary analysis to verify if the SF tuning curves differed between men and women. The results indicated no significant effect of sex on the distance between the tuning peaks for static and dynamic expressions and the translation between the two curves. However, the sample was unbalanced with regards to sex and more research will be necessary to confirm this result.
General Discussion
The present study investigated the SFs used during static and dynamic facial emotion recognition. In Experiment 1, we found higher reliance on lower SFs for dynamic expressions, whereas we found a decrease in higher SF utilization in Experiment 2. Taken together, these results are consistent with the hypothesized SF tuning shift, i.e., away from higher SFs and toward lower SFs for dynamic emotions.
The SF tuning shift was further assessed in a subsequent analysis that combined data from Experiments 1 and 2, using a permutation procedure. This revealed a marginally significant shift in the peak of the tuning curve for dynamic expressions, as well as a significant translation of the tuning curve itself. However, the fact that this result was nonsignificant when datasets of Experiments 1 and 2 were considered separately suggests that the difference is in fact quite small; hence, this last result should be interpreted with caution until replicated again. In the context of the replication crisis that is often discussed nowadays, new practices have been proposed with regard to how statistical results should be reported and interpreted (Amrhein et al., 2017). When interpreting the result of a replication study, as was done here with Exp. 2, it is recommended to base the comparison on the qualitative profile of the results rather than on the p-values or the traditional significance status. That said, the present study described two distinct experiments that generated a similar pattern of results, and this pattern was expected based on the higher sensitivity of the magnocellular pathway to both low SF and motion (Livingstone and Hubel, 1988) and also based on previous eye-tracking results (Buchan et al., 2007; Blais et al., 2017). This, we argue, increases the likelihood that dynamic emotions induce a real shift in SF tuning, however small this shift may be.
Experiment 2 explored if the presence of informative motion in dynamic expressions may be the source of the shift toward lower SFs. In contrast with this hypothesis, the results revealed that altering the information provided by the naturally unfolding motion (i.e., shuffled dynamic emotions) did not eliminate this shift toward lower SFs. In fact, while there was no significant difference in SF tuning for dynamic and shuffled dynamic emotions, there was a significant difference in SF tuning for static and shuffled dynamic stimuli. Specifically, lower SFs were significantly more useful for shuffled dynamic expressions than they were for static expressions, and higher SFs were significantly more useful for static expressions than they were for shuffled dynamic expressions. This suggests that motion increases reliance on low SFs, irrespective of whether the natural unfolding of the expression is preserved or not. This is not however to say that motion was not used to gain an advantage during the recognition of dynamic expressions; in fact, higher accuracy for dynamic expressions may be related to utilization of such information.
As for why a shift toward lower SFs might be induced by motion, one possible – though speculative – explanation pertains to the undoubtedly high importance of motion perception from an evolutionary perspective. As such, the brain has likely developed mechanisms that protect and prioritize processing of motion signals, irrespective of whether this motion conveys information pertinent to a given context or not. Several findings from the literature support this idea. For example, studies have revealed the existence of subcortical pathways, in addition to cortical routes of motion processing, that allow motion perception. Such pathways would explain how visual motion perception can sometimes occur in the cortically blind (Tamietto and Morrone, 2016). Among these subcortical structures is the superior colliculus, a structure known for its role in guiding eye movements (Spering and Carrasco, 2015).
There are also studies indicating that motion processing is suppressed during ocular saccades (Ross et al., 1996), that saccades are suppressed prior to motion processing (Burr et al., 1999), and that rapid motion is better processed in peripheral vision (Tynan and Sekuler, 1982). These mechanisms can inform us as to how prioritizing motion processing should affect eye movements. Indeed, they predict that prioritization of motion processing should lead to saccade suppression (i.e., longer fixations), and a fixation location that allows for parafoveal processing of this information, when motion is detected. As such, fixating a face in its center when viewing dynamic expressions is consistent with prioritizing motion processing. This would also predict central face fixations when viewing shuffled dynamic expressions. In turn, parafoveal processing of diagnostic features may lower the spatial resolution of the visual information extracted.
Finally, it was also shown that processing of low SFs is suppressed during saccades (Burr et al., 1994). Thus, in addition to the fact that features are directly fixated (i.e., processed with highest spatial resolution in the fovea) during the processing of static expressions, the larger number of saccades that is also observed in such conditions may also play a role in lowering visual processing of low SFs and increasing reliance on higher SFs.
A second possible and straightforward explanation for the shift toward lower SFs might be the visual percept itself. Indeed, rapid local changes in time might blur higher SFs as a result of temporal averaging in visual short-term memory (Dubé and Sekuler, 2015). Thus, it may be that high SF information is simply not available to later processing stages in the visual system, leading to a decrease in their use and a commensurate increase in lower SF utilization – i.e., the observed SF tuning shift.
As previously stated, our analysis of accuracies supports the idea that informative motion is beneficial to the recognition of facial expressions. Consistent with this is our observation of a dynamic advantage over a majority of static expressions in both Experiments 1 and 2. Taken together the behavioral results of both experiments add to a growing body of evidence showing that dynamic expressions are often better recognized (Wehrle et al., 2000; Kamachi et al., 2001; Ambadar et al., 2005; Bould and Morris, 2008; Hammal et al., 2009; Cunningham and Wallraven, 2009a; Chiller-Glaus et al., 2011; Recio et al., 2011).
Several studies have found that the dynamic advantage was particularly evident when the physical information contained in the stimuli was either limited in terms of intensity (i.e., expressions not at apex) (Ambadar et al., 2005; Bould and Morris, 2008) or deteriorated in terms of shape, texture, or realism (e.g., photo vs. sketch) (Ehrlich et al., 2000; Wallraven et al., 2008; Cunningham and Wallraven, 2009b). In the present experiment, in addition to physical deterioration associated with the filtering procedure, the presentation time was also constrained (450 ms) in order to respect the natural unfolding of dynamic expressions. This may have favored the emergence of a dynamic advantage. One could even argue that the time restriction is involved in the observation of a dynamic advantage, as most studies that failed to find such an advantage presented their stimuli for more than a 1,000 ms (Gold et al., 2013, 1,059 ms; Fiorentini and Viviani, 2011, ~3,000 ms; Bould and Morris, 2008 ~1,500 ms; Widen and Russell, 2015, ~5,000 ms; Kätsyri and Sams, 2008, until answer). Indeed, such an extended presentation duration might allow a deeper exploration of static stimuli and therefore reducing the relative advantage found for dynamic stimuli.
The results of the second experiment also suggest better recognition of dynamic expressions over shuffled dynamic ones for almost all expressions, with the exception of fear and sadness, for which no significant difference was found. This absence of effect for shuffled expressions of fear and sadness corroborates previous results (Cunningham and Wallraven, 2009a; Richoz et al., 2018). One explanation to this increased accuracy found in shuffled fear and sadness might be attributable to the properties of the stimuli themselves. As reported by various participants, the shuffling of frames might have given the impression that actors performing were either having tremors (in the case of fear) or had their lower lip quivering (in the case of sadness). Again, this general advantage of dynamic expressions over shuffled ones supports the idea that motion containing information facilitates the recognition of dynamic facial expressions. However, our results suggest that the mere presence of motion is nonetheless associated with a shift toward lower SFs and that such shift is not associated with the size of the dynamic advantage.
Despite the obvious limits on ecological validity imposed by an artificial laboratory setting, dynamic expressions such as those used in the present study nonetheless represent a more ecological form of facial expressions compared to the static expressions used in previous research. However, the facial expressions depicted in our stimuli were posed by actors, and posed expressions have been shown to differ from spontaneous expressions with respect to clarity (Matsumoto et al., 2009), achieved intensity (Kayyal and Russell, 2013), and, most importantly, temporal unfolding (Ross et al., 2007; Ross and Pulusu, 2013). As it turns out, these differences between posed and spontaneous static expressions translate as differences in visual strategies in facial feature utilization (Saumure et al., 2018). Future studies should therefore examine the impact of motion on visual strategy variations across posed and spontaneous dynamic expressions.
It should also be mentioned that the samples for both studies were unbalanced with regard to gender. Although there is no clear evidence to suggest that sensitivity to motion differs between females and males (Vanston and Strother, 2017), some anatomical and functional differences have been found in regions of the visual cortex known for motion processing (Amunts et al., 2007; Anderson et al., 2013). Moreover, visual acuity has systematically been shown to be better in males (Burg, 1966; McGuinness, 1976; Ishigaki and Miyao, 1994; Abramov et al., 2012), and males also exhibit higher contrast sensitivity across the entire spatiotemporal domain, especially at higher SFs (Abramov et al., 2012). On the other hand, impact of sex on emotional recognition ability has also been studied, and the evidence favors females over males (e.g., Jenness, 1932; Hall, 1978; Collignon et al., 2010; Derntl et al., 2010; Kret and De Gelder, 2012). It would thus be important for future research to test the impact of sex on SF tuning and on the shift found for dynamic vs. static facial expressions – though our preliminary analysis did not corroborate the presence of sex differences in the SF tuning.
Finally, future studies should be conducted with larger stimuli in order to evaluate the impact of changing the visual eccentricity at which diagnostic information falls on the SF tuning. More specifically, it would be interesting to see if such a change in size would magnify the rather small SF peak shift that was obtained in the present study. It is however important to note that stimulus size alone cannot explain this outcome. In fact, one of our prior work on cross-cultural differences in face identification did reveal a considerably larger SF peak shift (as much as 6.68 cpf) as a function of culture, using face stimuli of similar size (i.e., 256 × 256 pixels) (Tardif et al., 2017).
Conclusion
Although much neuroanatomical and behavioral evidence suggest that dynamic and static facial expressions of emotion could rely on different perceptual mechanisms, little research has directly compared the visual strategies underlying the recognition of both kinds of expressions. The present research sought to address this shortfall by investigating SF tuning underlying the recognition of both types of expressions. Consistent with our hypothesis, our results suggested a shift toward lower SFs for dynamic expressions in comparison to static ones. This shift is not linked to the presence of natural and informative motion per se, but instead appears to be caused by the very presence of motion, notwithstanding the information it conveys. Nevertheless, natural motion does seem to be beneficial to the recognition of facial expressions, since both experiments revealed a dynamic recognition advantage over static or shuffled dynamic expressions. More research will be necessary to better understand the observed shift in SF tuning. One promising avenue is the idea that the mere presence of motion activates mechanisms aimed at prioritizing motion processing and that this in turn affects eye movements and SF processing.
Ethics Statement
The protocol of this experiment was approved by the Research Ethics Committee of Université du Québec en Outaouais and was conducted in accordance with the Code of Ethics of the World Medical Association (Declaration of Helsinki).
Author Contributions
CB, DF, MPPD, and CS conceived and designed the experiments. MPPD and CS performed the experiments. MPPD, CB, DF, and JD analyzed the data. MPPD, CB, and DF drafted the manuscript. CS and JD reviewed the manuscript.
Funding
This work was supported by a grant from the Natural Sciences and Engineering Research Council of Canada (NSERC; # 2108640) to CB, by an undergraduate scholarship from NSERC to MPPD, and by a graduate scholarship from Fonds Québécois de la Recherche sur la Nature et les Technologies to CS.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Abramov, I., Gordon, J., Feldman, O., and Chavarga, A. (2012). Sex & vision I: spatio-temporal resolution. Biol. Sex Differ. 3:20. doi: 10.1186/2042-6410-3-20
Adolphs, R., Tranel, D., and Damasio, A. R. (2003). Dissociable neural systems for recognizing emotions. Brain Cogn. 52, 61–69. doi: 10.1016/s0278-2626(03)00009-5
Adolphs, R., Tranel, D., Damasio, H., and Damasio, A. (1994). Impaired recognition of emotion in facial expressions following bilateral damage to the human amygdala. Nature 372, 669.
Ambadar, Z., Schooler, J. W., and Cohn, J. F. (2005). Deciphering the enigmatic face: the importance of facial dynamics in interpreting subtle facial expressions. Psychol. Sci. 16, 403–410. doi: 10.1111/j.0956-7976.2005.01548.x
Amrhein, V., Korner-Nievergelt, F., and Roth, T. (2017). The earth is flat (p > 0.05): significance thresholds and the crisis of unreplicable research. PeerJ 5:e3544. doi: 10.7717/peerj.3544
Amunts, K., Armstrong, E., Malikovic, A., Hömke, L., Mohlberg, H., Schleicher, A., et al. (2007). Gender-specific left–right asymmetries in human visual cortex. J. Neurosci. 27, 1356–1364. doi: 10.1523/JNEUROSCI.4753-06.2007
Anderson, L., Bolling, D. Z., Schelinski, S., Coffman, M., Pelphrey, K. A., and Kaiser, M. D. (2013). Sex differences in the development of brain mechanisms for processing biological motion. NeuroImage 83, 751–760. doi: 10.1016/j.neuroimage.2013.07.040
Baron-Cohen, S., and Wheelwright, S. (2004). The empathy quotient: an investigation of adults with Asperger syndrome or high functioning autism, and normal sex differences. J. Autism Dev. Disord. 34, 163–175. doi: 10.1023/B:JADD.0000022607.19833.00
Blais, C., Fiset, D., Roy, C., Saumure Régimbald, C., and Gosselin, F. (2017). Eye fixation patterns for categorizing static and dynamic facial expressions. Emotion 17:1107. doi: 10.1037/emo0000283
Blais, C., Roy, C., Fiset, D., Arguin, M., and Gosselin, F. (2012). The eyes are not the window to basic emotions. Neuropsychologia 50, 2830–2838. doi: 10.1016/j.neuropsychologia.2012.08.010
Bould, E., and Morris, N. (2008). Role of motion signals in recognizing subtle facial expressions of emotion. Br. J. Psychol. 99, 167–189. doi: 10.1348/000712607X206702
Brainard, D. H., and Vision, S. (1997). The psychophysics toolbox. Spat. Vis. 10, 433–436. doi: 10.1163/156856897X00357
Buchan, J. N., Paré, M., and Munhall, K. G. (2007). Spatial statistics of gaze fixations during dynamic face processing. Soc. Neurosci. 2, 1–13. doi: 10.1080/17470910601043644
Burg, A. (1966). Visual acuity as measured by dynamic and static tests: a comparative evaluation. J. Appl. Psychol. 50, 460–466. doi: 10.1037/h0023982
Burr, D. C., Morgan, M. J., and Morrone, M. C. (1999). Saccadic suppression precedes visual motion analysis. Curr. Biol. 9, 1207–1209. doi: 10.1016/S0960-9822(00)80028-7
Burr, D. C., Morrone, M. C., and Ross, J. (1994). Selective suppression of the magnocellular visual pathway during saccadic eye movements. Nature 371, 511–513. doi: 10.1038/371511a0
Calvo, M. G., Fernández-Martín, A., Gutiérrez-García, A., and Lundqvist, D. (2018). Selective eye fixations on diagnostic face regions of dynamic emotional expressions: KDEF-dyn database. Sci. Rep. 8:17039. doi: 10.1038/s41598-018-35259-w
Chauvin, A., Worsley, K. J., Schyns, P. G., Arguin, M., and Gosselin, F. (2005). Accurate statistical tests for smooth classification images. J. Vis. 5, 659–667. doi: 10.1167/5.9.1
Chiller-Glaus, S. D., Schwaninger, A., Hofer, F., Kleiner, M., and Knappmeyer, B. (2011). Recognition of emotion in moving and static composite faces. Swiss J. Psychol. Schweizerische Zeitschrift für Psychologie / Revue Suisse de Psychologie 70, 233–240. doi: 10.1024/1421-0185/a000061
Clark, C. M., Gosselin, F., and Goghari, V. M. (2013). Aberrant patterns of visual facial information usage in schizophrenia. J. Abnorm. Psychol. 122, 513–519. doi: 10.1037/a0031944
Collignon, O., Girard, S., Gosselin, F., Saint-Amour, D., Lepore, F., and Lassonde, M. (2010). Women process multisensory emotion expressions more efficiently than men. Neuropsychologia 48, 220–225. doi: 10.1016/j.neuropsychologia.2009.09.007
Cunningham, D. W., and Wallraven, C. (2009a). Dynamic information for the recognition of conversational expressions. J. Vis. 9, 1–17. doi: 10.1167/9.13.7
Cunningham, D. W., and Wallraven, C. (2009b). The interaction between motion and form in expression recognition. Paper presented at the Proceedings of the 6th symposium on applied perception in graphics and visualization.
Derntl, B., Finkelmeyer, A., Eickhoff, S., Kellermann, T., Falkenberg, D. I., Schneider, F., et al. (2010). Multidimensional assessment of empathic abilities: neural correlates and gender differences. Psychoneuroendocrinology 35, 67–82. doi: 10.1016/j.psyneuen.2009.10.006
Dubé, C., and Sekuler, R. (2015). Obligatory and adaptive averaging in visual short-term memory. J. Vis. 15:13. doi: 10.1167/15.4.13
Edwards, J., Jackson, H. J., and Pattison, P. E. (2002). Emotion recognition via facial expression and affective prosody in schizophrenia: a methodological review. Clin. Psychol. Rev. 22, 789–832. doi: 10.1016/S0272-7358(02)00130-7
Ehrlich, S. M., Schiano, D. J., and Sheridan, K. (2000). Communicating facial affect: it’s not the realism, it’s the motion. Paper presented at the CHI’00 Extended Abstracts on Human Factors in Computing Systems.
Ekman, P., and Friesen, W. V. (1975). Unmasking the face: a guide to recognizing emotions from facial cues. Englewood Cliffs, NJ: Prentice Hall.
Estéphan, A., Fiset, D., Saumure, C., Plouffe-Demers, M.-P., Zhang, Y., Sun, D., et al. (2018). Time course of cultural differences in spatial frequency use for face identification. Sci. Rep. 8, 1–14. doi: 10.1038/s41598-018-19971-1
Fiorentini, C., and Viviani, P. (2011). Is there a dynamic advantage for facial expressions? J. Vis. 11:17. doi: 10.1167/11.3.17
Fiset, D., Blais, C., Royer, J., Richoz, A. R., Dugas, G., and Caldara, R. (2017). Mapping the impairment in decoding static facial expressions of emotion in prosopagnosia. Soc. Cogn. Affect. Neurosci. 12, 1334–1341.
Gaspar, C., Sekuler, A. B., and Bennett, P. J. (2008). Spatial frequency tuning of upright and inverted face identification. Vis. Res. 48, 2817–2826. doi: 10.1016/j.visres.2008.09.015
Gold, J. M., Barker, J. D., Barr, S., Bittner, J. L., Bromfield, W. D., Chu, N., et al. (2013). The efficiency of dynamic and static facial expression recognition. J. Vis. 13:23. doi: 10.1167/13.5.23
Gurnsey, R., Roddy, G., Ouhnana, M., and Troje, N. F. (2008). Stimulus magnification equates identification and discrimination of biological motion across the visual field. Vis. Res. 48, 2827–2834. doi: 10.1016/j.visres.2008.09.016
Hall, J. A. (1978). Gender effects in decoding nonverbal cues. Psychol. Bull. 85, 845–857. doi: 10.1037/0033-2909.85.4.845
Hammal, Z., Gosselin, F., and Fortin, I. (2009). How efficient are the recognition of dynamic and static facial expressions? J. Vis. 9:499. doi: 10.1167/9.8.499
Harms, M. B., Martin, A., and Wallace, G. L. (2010). Facial emotion recognition in autism spectrum disorders: a review of behavioral and neuroimaging studies. Neuropsychol. Rev. 20, 290–322. doi: 10.1007/s11065-010-9138-6
Hilz, R., and Cavonius, C. (1974). Functional organization of the peripheral retina: sensitivity to periodic stimuli. Vis. Res. 14, 1333–1337. doi: 10.1016/0042-6989(74)90006-6
Humphreys, G. W., Donnelly, N., and Riddoch, M. J. (1993). Expression is computed separately from facial identity, and it is computed separately for moving and static faces: neuropsychological evidence. Neuropsychologia 31, 173–181. doi: 10.1016/0028-3932(93)90045-2
Humphreys, K., Avidan, G., and Behrmann, M. (2007). A detailed investigation of facial expression processing in congenital prosopagnosia as compared to acquired prosopagnosia. Exp. Brain Res. 176, 356–373.
Ishigaki, H., and Miyao, M. (1994). Implications for dynamic visual acuity with changes in age and sex. Percept. Mot. Skills 78, 363–369.
Jenness, A. (1932). The recognition of facial expressions of emotion. Psychol. Bull. 29, 324–350. doi: 10.1037/h0074342
Jiang, B., Valstar, M. F., Martinez, B., and Pantic, M. (2014). A dynamic appearance descriptor approach to facial actions temporal modeling. IEEE Trans. Cybern. 44, 161–174. doi: 10.1109/TCYB.2013.2249063
Jiang, B., Valstar, M. F., and Pantic, M. (2011). Action unit detection using sparse appearance descriptors in space-time video volumes. Paper presented at the 2011 IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011).
Kamachi, M., Bruce, V., Mukaida, S., Gyoba, J., Yoshikawa, S., and Akamatsu, S. (2001). Dynamic properties influence the perception of facial expressions. Perception 42, 1266–1278. doi: 10.1068/p3131n
Kätsyri, J., and Sams, M. (2008). The effect of dynamics on identifying basic emotions from synthetic and natural faces. Int. J. Human-Comput. Stud. 66, 233–242. doi: 10.1016/j.ijhcs.2007.10.001
Kayyal, M. H., and Russell, J. A. (2013). Americans and Palestinians judge spontaneous facial expressions of emotion. Emotion 13, 891–904. doi: 10.1037/a0033244
Kilts, C. D., Egan, G., Gideon, D. A., Ely, T. D., and Hoffman, J. M. (2003). Dissociable neural pathways are involved in the recognition of emotion in static and dynamic facial expressions. NeuroImage 18, 156–168. doi: 10.1006/nimg.2002.1323
Kleiner, M., Brainard, D., Pelli, D., Ingling, A., Murray, R., and Broussard, C. (2007). What’s new in psychtoolbox-3. Perception 36, 1–16.
Kret, M. E., and De Gelder, B. (2012). A review on sex differences in processing emotional signals. Neuropsychologia 50, 1211–1221. doi: 10.1016/j.neuropsychologia.2011.12.022
Kring, A. M., and Elis, O. (2013). Emotion deficits in people with schizophrenia. Annu. Rev. Clin. Psychol. 9, 409–433. doi: 10.1146/annurev-clinpsy-050212-185538
LaBar, K. S., Crupain, M. J., Voyvodic, J. T., and McCarthy, G. (2003). Dynamic perception of facial affect and identity in the human brain. Cereb. Cortex 13, 1023–1033. doi: 10.1093/cercor/13.10.1023
Lee, J., Gosselin, F., Wynn, J. K., and Green, M. F. (2010). How do schizophrenia patients use visual information to decode facial emotion? Schizophr. Bull. 37, 1001–1008. doi: 10.1093/schbul/sbq006
Livingstone, M., and Hubel, D. (1988). Segregation of form, color, movement, and depth: anatomy, physiology, and perception. Science 240, 740–749. doi: 10.1126/science.3283936
Mandal, M. K., Pandey, R., and Prasad, A. B. (1998). Facial expressions of emotions and schizophrenia: a review. Schizophr. Bull. 24, 399–412. doi: 10.1093/oxfordjournals.schbul.a033335
Marsh, A. A., Kozak, M. N., and Ambady, N. (2007). Accurate identification of fear facial expressions predicts prosocial behavior. Emotion 7, 239–251. doi: 10.1037/1528-3542.7.2.239
MathWorks, I. (2012). MATLAB and statistics toolbox release 2012b. Natick, Massachusetts, United States: The MathWorks, Inc.
Matsumoto, D., Olide, A., Schug, J., Willingham, B., and Callan, M. (2009). Cross-cultural judgments of spontaneous facial expressions of emotion. J. Nonverbal Behav. 33, 213–238. doi: 10.1007/s10919-009-0071-4
McGuinness, D. (1976). Away from a unisex psychology: individual differences in visual sensory and perceptual processes. Perception 5, 279–294.
Näsänen, R. (1999). Spatial frequency bandwidth used in the recognition of facial images. Vis. Res. 39, 3824–3833. doi: 10.1016/S0042-6989(99)00096-6
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: transforming numbers into movies. Spat. Vis. 10, 437–442. doi: 10.1163/156856897X00366
Recio, G., Sommer, W., and Schacht, A. (2011). Electrophysiological correlates of perceiving and evaluating static and dynamic facial emotional expressions. Brain Res. 1376, 66–75. doi: 10.1016/j.brainres.2010.12.041
Richoz, A. R., Jack, R. E., Garrod, O. G., Schyns, P. G., and Caldara, R. (2015). Reconstructing dynamic mental models of facial expressions in prosopagnosia reveals distinct representations for identity and expression. Cortex 65, 50–64. doi: 10.1016/j.cortex.2014.11.015
Richoz, A.-R., Lao, J., Pascalis, O., and Caldara, R. (2018). Tracking the recognition of static and dynamic facial expressions of emotion across the life span. J. Vis. 18:5. doi: 10.1167/18.9.5
Ross, J., Burr, D., and Morrone, C. (1996). Suppression of the magnocellular pathway during saccades. Behav. Brain Res. 80, 1–8. doi: 10.1016/0166-4328(96)00012-5
Ross, E. D., Prodan, C. I., and Monnot, M. (2007). Human facial expressions are organized functionally across the upper-lower facial axis. Neuroscientist 13, 433–446. doi: 10.1177/1073858407305618
Ross, E. D., and Pulusu, V. K. (2013). Posed versus spontaneous facial expressions are modulated by opposite cerebral hemispheres. Cortex 49, 1280–1291. doi: 10.1016/j.cortex.2012.05.002
Roy, S., Roy, C., Fortin, I., Ethier-Majcher, C., Belin, P., and Gosselin, F. (2007). A dynamic facial expression database. J. Vis. 7:944. doi: 10.1167/7.9.944
Royer, J., Willenbockel, V., Blais, C., Gosselin, F., Lafortune, S., Leclerc, J., et al. (2017). The influence of natural contour and face size on the spatial frequency tuning for identifying upright and inverted faces. Psychol. Res. 81, 13–23. doi: 10.1007/s00426-015-0740-3
Rymarczyk, K., Biele, C., Grabowska, A., and Majczynski, H. (2011). EMG activity in response to static and dynamic facial expressions. Int. J. Psychophysiol. 79, 330–333. doi: 10.1016/j.ijpsycho.2010.11.001
Sato, W., and Yoshikawa, S. (2004). Brief report the dynamic aspects of emotional facial expressions. Cognit. Emot. 18, 701–710. doi: 10.1080/02699930341000176
Saumure, C., Plouffe-Demers, M.-P., Estéphan, A., Fiset, D., and Blais, C. (2018). The use of visual information in the recognition of posed and spontaneous facial expressions. J. Vis. 18:21. doi: 10.1167/18.9.21
Schultz, J., and Pilz, K. S. (2009). Natural facial motion enhances cortical responses to faces. Exp. Brain Res. 194, 465–475. doi: 10.1007/s00221-009-1721-9
Spering, M., and Carrasco, M. (2015). Acting without seeing: eye movements reveal visual processing without awareness. Trends Neurosci. 38, 247–258. doi: 10.1016/j.tins.2015.02.002
Tadros, K., Dupuis-Roy, N., Fiset, D., Arguin, M., and Gosselin, F. (2013). Reading laterally: the cerebral hemispheric use of spatial frequencies in visual word recognition. J. Vis. 13:4. doi: 10.1167/13.1.4
Takeuchi, T., Yokosawa, K., and De Valois, K. K. (2004). Texture segregation by motion under low luminance levels. Vis. Res. 44, 157–166. doi: 10.1016/j.visres.2003.09.005
Tamietto, M., and Morrone, M. C. (2016). Visual plasticity: blindsight bridges anatomy and function in the visual system. Curr. Biol. 26, R70–R73. doi: 10.1016/j.cub.2015.11.026
Tardif, J., Fiset, D., Zhang, Y., Estéphan, A., Cai, Q., Luo, C., et al. (2017). Culture shapes spatial frequency tuning for face identification. J. Exp. Psychol. Hum. Percept. Perform. 43, 294–306. doi: 10.1037/xhp0000288
Thompson, B., Hansen, B. C., Hess, R. F., and Troje, N. F. (2007). Peripheral vision: good for biological motion, bad for signal noise segregation? J. Vis. 7:12. doi: 10.1167/7.10.12
Thurman, S. M., and Grossman, E. D. (2011). Diagnostic spatial frequencies and human efficiency for discriminating actions. Atten. Percept. Psychophys. 73, 572–580. doi: 10.3758/s13414-010-0028-z
Trautmann, S. A., Fehr, T., and Herrmann, M. (2009). Emotions in motion: dynamic compared to static facial expressions of disgust and happiness reveal more widespread emotion-specific activations. Brain Res. 1284, 100–115. doi: 10.1016/j.brainres.2009.05.075
Tynan, P. D., and Sekuler, R. (1982). Motion processing in peripheral vision: reaction time and perceived velocity. Vis. Res. 22, 61–68. doi: 10.1016/0042-6989(82)90167-5
Vanston, J. E., and Strother, L. (2017). Sex differences in the human visual system. J. Neurosci. Res. 95, 617–625. doi: 10.1002/jnr.23895
Vuilleumier, P., Armony, J. L., Driver, J., and Dolan, R. J. (2003). Distinct spatial frequency sensitivities for processing faces and emotional expressions. Nat. Neurosci. 6, 624–631. doi: 10.1038/nn1057
Wallraven, C., Breidt, M., Cunningham, D. W., and Bülthoff, H. H. (2008). Evaluating the perceptual realism of animated facial expressions. ACM Trans. Appl. Percept. 4, 1–22. doi: 10.1145/1278760.1278764
Watson, A. B., and Pelli, D. G. (1983). QUEST: a Bayesian adaptive psychometric method. Percept. Psychophys. 33, 113–120. doi: 10.3758/BF03202828
Wehrle, T., Kaiser, S., Schmidt, S., and Scherer, K. R. (2000). Studying the dynamics of emotional expression using synthesized facial muscle movements. J. Pers. Soc. Psychol. 78, 105–119. doi: 10.1037/0022-3514.78.1.105
Weyers, P., Mühlberger, A., Hefele, C., and Pauli, P. (2006). Electromyographic responses to static and dynamic avatar emotional facial expressions. Psychophysiology 43, 450–453. doi: 10.1111/j.1469-8986.2006.00451.x
Widen, S. C., and Russell, J. A. (2015). Do dynamic facial expressions convey emotions to children better than do static ones? J. Cogn. Dev. 16, 802–811. doi: 10.1080/15248372.2014.916295
Willenbockel, V., Fiset, D., Chauvin, A., Blais, C., Arguin, M., Tanaka, J. W., et al. (2010a). Does face inversion change spatial frequency tuning? J. Exp. Psychol. Hum. Percept. Perform. 36, 122–135. doi: 10.1037/a0016465
Willenbockel, V., Lepore, F., Bacon, B. A., and Gosselin, F. (2013). The informational correlates of conscious and nonconscious face-gender perception. J. Vis. 13:10. doi: 10.1167/13.2.10
Willenbockel, V., Lepore, F., Nguyen, D. K., Bouthillier, A., and Gosselin, F. (2012). Spatial frequency tuning during the conscious and non-conscious perception of emotional facial expressions–an intracranial ERP study. Front. Psychol. 3:237. doi: 10.3389/fpsyg.2012.00237
Willenbockel, V., Sadr, J., Fiset, D., Horne, G. O., Gosselin, F., and Tanaka, J. W. (2010b). Controlling low-level image properties: the SHINE toolbox. Behav. Res. Methods 42, 671–684. doi: 10.3758/brm.42.3.671
Keywords: facial expressions, basic emotion, perceptual strategy, spatial frequency tuning, dynamic advantage
Citation: Plouffe-Demers M-P, Fiset D, Saumure C, Duncan J and Blais C (2019) Strategy Shift Toward Lower Spatial Frequencies in the Recognition of Dynamic Facial Expressions of Basic Emotions: When It Moves It Is Different. Front. Psychol. 10:1563. doi: 10.3389/fpsyg.2019.01563
Edited by:
Tjeerd Jellema, University of Hull, United KingdomReviewed by:
Xunbing Shen, Jiangxi University of Traditional Chinese Medicine, ChinaAlessia Celeghin, University of Turin, Italy
Copyright © 2019 Plouffe-Demers, Fiset, Saumure, Duncan and Blais. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Caroline Blais, Y2Fyb2xpbmUuYmxhaXNAdXFvLmNh