 Alexandra Marquis
Alexandra Marquis Meera Al Kaabi
Meera Al Kaabi Tommi Leung
Tommi Leung Fatima Boush
Fatima Boush- Department of Cognitive Sciences, United Arab Emirates University, Al Ain, United Arab Emirates
Phonological awareness is the ability to perceive and manipulate the sounds of spoken words. It is considered a good predictor of reading and spelling abilities. In the current study, we used an eye-tracking procedure to measure fixation differences while adults completed three conditions of phonological awareness in Emirati Arabic (EA): (1) explicit instructions for onset consonant matching (OCM), (2) implicit instructions for segmentation of initial consonant (SIC), and (3) rhyme matching (RM). We hypothesized that fixation indices would vary according to the experimental conditions. We expected explicit instructions to facilitate task performance. Thus, eye movements should reflect more efficient fixation patterns in the explicit OCM condition in comparison to the implicit SIC condition. Moreover, since Arabic is consonant-based, we hypothesized that participants would perform better in the consonant conditions (i.e., OCM and SIC) than in the rhyme condition (i.e., RM). Finally, we expected that providing feedback during practice trials would facilitate participants’ performance overall. Response accuracy, expressed as a percentage of correct responses, was recorded alongside eye movement data. Results show that performance was significantly compromised in the RM condition, where targets received more fixations of longer average duration, and significantly longer gaze durations in comparison to the OCM and SIC conditions. Response accuracy was also significantly lower in the RM condition. Our results indicate that eye-tracking can be used as a tool to test phonological awareness skills and shows differences in performance between tasks containing a vowel or consonant manipulation.
Introduction
Phonological awareness is the ability to perceive and manipulate the sounds of language (e.g., Goswami and Bryant, 1990; Holm et al., 2008). It emerges from acquired implicit phonological and lexical knowledge (Rvachew et al., 2017). In addition, it is a strong predictor of literacy (i.e., reading and spelling) skills in children (e.g., Bird et al., 1995; Schneider et al., 2000; Rvachew, 2007; Holm et al., 2008; Melby-Lervåg et al., 2012). Phonological skills in kindergartens have been found to be associated with spelling skills a year later (e.g., Speece et al., 1999). Moreover, phonological awareness deficits are characteristic of dyslexia resulting in poor reading skills (Bruck, 1992; Elbeheri and Everatt, 2007).
Rvachew et al. (2017) used a phonological awareness task where covert responses (i.e., not requiring any spoken responses or explicit articulation of speech) were analyzed so that children’s performance would be assessed independently of their speech accuracy. Children’s performance in their task ranged from random guessing to perfect performance and could be used (alone or with their other oral tasks) to predict writing difficulties (Rvachew et al., 2017). Previously, Schneider et al. (2000) found a link between phonological awareness and literacy, but their participants’ literacy better improved when phonological awareness was combined with letter-sound training. In adults, Metsala et al. (2019) found that phonological awareness skills of English-speaking adults did contribute to reading accuracy. A recent study comparing children learning to write in either English, French, German, Dutch, or Greek revealed that phonological awareness influences reading abilities differentially for the different languages studied (Landerl et al., 2019).
Phonological awareness skills and spelling abilities appear to be correlated in Arabic, as demonstrated by Taibah and Haynes (2011) and Rakhlin et al. (2019) with (Saudi) Arabic-speaking children, and Mannai and Everatt (2005) with Bahraini Arabic-speaking children. Recent results from Asadi and Abu-Rabia (2019) show that Arabic-speaking children were better at phonemes in the initial versus final position and significantly improved from the second year of kindergarten to the third, while direct comparisons between consonants and vowels/rhymes were not performed. Moreover, phonological training has been shown to improve reading skills in Arab dyslexic children (Layes et al., 2015, 2019) as well as in neurotypical Arab children (Dallasheh-Khatib et al., 2014) among other metalinguistic skills. Another study by Makhoul (2017) found that phonological awareness skills training to be implicated in improving reading development in Arab first graders and especially in at-linguistic risk groups.
The linguistic situation in the Arab world could be considered slightly complex given the diglossic nature of Arabic, which is exhibited in two distinct forms. On the one hand, there is the literary form, referred to as Modern Standard Arabic (MSA), also known as “fusha,” which is used by educated people in order to read and write as well as in formal communications, interviews, newspapers and other formal settings. On the other hand, there is the second form, the spoken form or dialect, which is known as “ammia” and used by speakers for daily conversations and informal settings. While MSA is more generally understood by all Arabic speakers, dialects can differ greatly from one region to another. Previous studies proposed that these two forms are couched in two cognitive systems of Arabic-speaking children and adults. For example, Saiegh-Haddad (2008) and Asaad and Eviatar (2014) conducted studies on letter learning and suggested that letters that correspond to sounds that do not occur in the Arabic dialects are more difficult to learn and to identify than the ones that do exist in the spoken Arabic variety of the speakers. Moreover, Tibi and Kirby (2018) pointed out that the diglossic situation of Arabic could pose a potential challenge in learning to use the language, since ammia, or dialectal Arabic is considered a child’s first language (Shendy, 2019) and precedes their exposure to literary MSA in most cases. Children learning to read and write for the first time in MSA may face difficulties coping with a linguistic system that is essentially foreign (Taha, 2013; Horn, 2015). One study found that reading to pre-literate children in MSA familiarizes them with the literary language (Feitelson et al., 1993). Moreover, preschoolers who were exposed to MSA were found to have better reading comprehension in subsequent years in comparison to those only exposed to the spoken dialect of Arabic (Abu-Rabia, 2000; Leikin et al., 2014). Furthermore, studies by Saiegh-Haddad (2003, 2004) found that children were better able to isolate phonemes found in their spoken dialect in comparison to those only found in literary MSA. Additionally, phonological structures found only in MSA but not in spoken Arabic dialects were less likely to be recognized (Saiegh-Haddad, 2012).
Arabic words, at least under the root-based approach, are analyzed in terms of a consonantal root, a vocalic template and other affixes (if any), all of which are considered to be independent morphological units (e.g., McCarthy, 1979, 1981; Prunet et al., 2000; Idrissi et al., 2008; among others). The consonantal roots in Arabic convey the core meaning of the word. MSA has six phonemes to represent vowels: three short vowels: /a/, /u/, and /i/ which may optionally appear in written text; and three long vowels: /a:/, /u:/, and /i:/. It is worth noting that words in MSA always begin with a consonant followed by a vowel. Alamri (2017) used eye-tracking to investigate co-activation effects of phonology, semantics, and shared roots in Arabic in the presence of competitors to the target word and concluded that roots are fundamental morphological units in the Arabic mental lexicon separate from phonology and semantics.
Arabic is described as having a consonant-based orthography (Tibi and Kirby, 2018). Arabic writing, when fully expressed (i.e., when all diacritical marks are present), may be considered to be orthographically transparent (Saiegh-Haddad and Henkin-Roitfarb, 2014), where the written form maps directly to spoken language. It is important to note that this orthographics style is not typical of texts intended for skilled adult readers who often read unvowelized Arabic text. Asaad and Eviatar (2014) proposed a further characteristic of Arabic orthography which is the presence of visual and phonological neighbors among its letters. That is, many Arabic letters share the same basic form and only differ by the number and/or the placement of dots. See examples in Table 1 below as it appears in Asaad and Eviatar (2014).
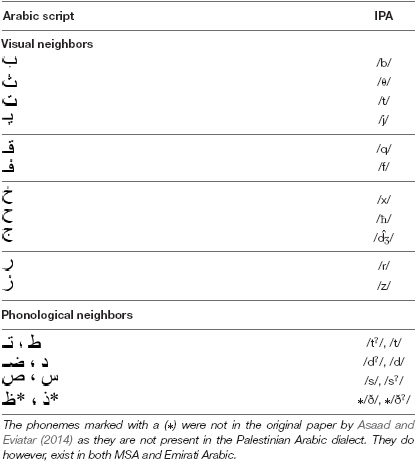
Table 1. Examples of visual and phonological neighbors in Arabic (Source: adapted from Asaad and Eviatar, 2014).
Emirati Arabic is the dialect spoken in the United Arab Emirates. While MSA has 28 consonant phonemes (e.g., Amayreh, 2003), EA includes 30 consonant phonemes (e.g., Al Ameri, 2009). The differences between MSA and EA are that EA includes the voiced velar plosive /g/, the voiced /x/ and voiceless /ɣ/ velar fricatives as well the voiceless postalveolar affricate /tʃ/. In addition, compared to MSA, EA lacks the emphatic voiced dental plosive /dʕ/, the voiced /ʁ/ and voiceless /χ/ uvular fricatives.
Measuring eye movement data has an added advantage over traditional measurements of attention such as reaction time (RT) data, as eye movements are governed by an automatic process that does not impose additional operational requirements alongside the primary task goals. In most cases, eye movements allow us to gain a “naturalistic,” yet indirect, understanding of the cognitive processes associated with task completion moment-by-moment. Therefore, we consider eye-tracking measurements as an additional index to where attention is directed moment by moment and perhaps even a superior one, as it eliminates potential confounds of recording responses mechanically.
Eye-tracking research relies heavily on what is known as the “eye-mind” hypothesis (Just and Carpenter, 1976a, b): the assumption that the direction at which the eyes are fixated at any given time is where attention, and therefore information processing, is actively taking place. Objects falling within the immediate visual field are the subject of direct attention and are therefore under active cognitive processing (e.g., Pickering et al., 2004; Conklin and Pellicer-Sánchez, 2016). Moreover, the duration of a gaze also reflects the associated processing demands on that object, such that as soon as an object is no longer fixated, it no longer requires further processing. However, it is now understood that at least for more cognitively demanding tasks, such as understanding complex sentence structures, some information processing can occur even after the text being comprehended is not being fixated foveally (Rayner et al., 2016). Therefore, it is assumed that different task demands will result in differential fixation patterns depending on the cognitive load associated with the task. In general, average fixations during free viewing of visual scenes tend to last approximately 330 milliseconds (Conklin and Pellicer-Sánchez, 2016). However, this number varies according to the task being completed. Items requiring reduced cognitive processing receive shorter fixations than those that require higher cognitive processing loads (Conklin and Pellicer-Sánchez, 2016).
Apart from reading studies (see Rayner, 2009 for a review), eye-tracking has been increasingly implicated in behavioral experiments including choice tasks (e.g., Orquin and Mueller Loose, 2013; Krajbich, 2018; for reviews), data visualization and perception of various displays (e.g., Bylinskii et al., 2015; Lahrache et al., 2018), as well as speech perception and comprehension (e.g., Tanenhaus and Trueswell, 2006). The latter area of research, and most relevant to the current study, is associated with what is known as the Visual World Paradigm (VWP), where “on each trial the participants hear an utterance while looking at an experimental display. Participants’ eye movements are recorded for later analyses” (Huettig et al., 2011). In such experiments, a visual display is coupled with spoken utterances. Eye movements are recorded, as they are thought to be influenced by participants’ goal for completing a particular task (e.g., Salverda et al., 2011; Pyykkönen-Klauck and Crocker, 2016; Salverda and Tanenhaus, 2017), integrating a spoken utterance with a visual display.
The current study of phonological awareness in Emirati Arabic (EA) was conducted using the VWP as the experimental method for spoken word recognition (e.g., Cooper, 1974; Tanenhaus et al., 1995; Allopenna et al., 1998; Altmann and Kamide, 1999; Richardson and Spivey, 2000; Spivey and Geng, 2001; Altmann, 2004; Knoeferle and Crocker, 2007; Ferreira et al., 2008; Richardson et al., 2009; Huettig et al., 2011). The VWP is now widely considered as a standard protocol to investigate the interplay between linguistic and visual information processing. Since the seminal work by Cooper (1974), it has been established that there exists an interactive relation between the locus of eye fixation and spoken language in the sense that the latter somehow controls the former in a time-logged fashion.
A series of work (e.g., Tanenhaus et al., 1995; Allopenna et al., 1998) further detailed a particular version of the VWP commonly used by many subsequent work. In such a version, line drawings of four objects (usually arranged on a 2 × 2 grid) are shown on a computer screen. Upon receiving audio instructions, participants have to move the displayed object by clicking on the computer mouse and dragging it to the location of a fixed geometric shape (e.g., after hearing the sentence “Pick up the beaker. Now, put it below the diamond.”). The objects displayed usually include the target (which is sometimes called the “referent”) and three distractors. Among the distractors, some are competitive in that they share some linguistic properties with the target (e.g., same onset syllable as in “candle” vs. “candy”). The primary objective of this particular configuration is not only to test how fast subjects move their eye gaze to the correct target, but also how the distractors may shed light on the language processing system vis-à-vis word recognition/identification. The distractors must therefore be carefully chosen depending on the type of language processing task targeted (e.g., phonological, semantic or pragmatic).
In an influential experiment conducted by Allopenna et al. (1998), who focused on the real time phonetic processing within the VWP given a particular target (e.g., “beaker”), the first distractor was an “onset competitor” (e.g., “beetle”), the second one was a “rhyme competitor” (e.g., “speaker”), and the third one was unrelated (e.g., “carriage”). As the spoken linguistic message started to unfold, participants demonstrated comparable fixations on the objects that shared the same onset (e.g., “beaker” and “beetle”). As more phonetic cues were presented to the participants, fixations on the onset competitor started to decline, and interestingly, fixations on the rhyme competitor (e.g., “speaker”) started to increase. This dynamic shift of fixation provides insights to the word recognition model such as the Cohort model (Marslen-Wilson, 1987), the TRACE model (McClelland and Elman, 1986), and the Shortlist model (Norris, 1994).
The purpose of many researchers when studying phonological awareness is to determine the link between phonological awareness and literacy (e.g., Holm et al., 2008; Rvachew et al., 2017; Landerl et al., 2019). The current research aims at exploring the feasibility of using eye-tracking to assess phonological awareness in EA speaking adults using a variant of the VWP in which the entire assessment tool was designed and delivered using the local EA dialect as opposed to MSA. The current phonological awareness assessment is an extension of the phonological awareness task used in the Language Acquisition Test for Arabic (LATFA, Marquis, 2016–2018); an i-Pad delivered assessments of oral literacy skills in EA children. The LATFA phonological awareness assessment comprises three phonological conditions which are expanded on below.
(1) Explicit instructions for onset consonant matching (OCM): participants are introduced to a cartoon character preceding the following example statement “This animal likes things that start with the same sound. The sound that it likes is /s/. Which of these things does it like? a. /0ʔarnab/ b. /səkiin/ c. /ʕəriiʃ/ d. /nemer/.”
(2) Implicit instructions for segmentation of initial phoneme (SIC): participants are introduced to a cartoon character preceding the following example statement “This is Dana. Dana likes things that begin with the same sound as her name. Which of these things does Dana like? a. /ħaywaan/ b. /dallah/ c. /xaðʕ ra/ d. /ʕətʕər/.”
(3) Rhyme matching (RM): participants are introduced to a cartoon character preceding the following example statement “This is Lulu. Lulu likes things that sound like her name, which of these things is the one that Lulu likes? a. /ʔubuu/ b. /mətʕar/ c. /dənya/ d. /mənaz/.”
The current study employs the same task conditions above, adapted for compatibility with an eye-tracker. The use of eye-tracking may allow us to gain further insight on the implicit knowledge associated with phonological awareness. Successful validation of the use of eye-movements on adults will allow us to use this task with children in order to evaluate their phonological awareness skills, which can be translated into a well-developed user-friendly mobile application used to assess phonological awareness skills. We hypothesized that fixation indices would vary across the experimental conditions relative to the easiness of each task as reflected in gaze patterns: targets in the easier tasks should receive shorter, fewer fixations and fewer visits to the interest region of the target. We expected explicit instructions to facilitate participants’ performance on the task. Thus, we predicted that eye movements would reflect more efficient fixation patterns in the OCM condition in comparison to the SIC condition. Moreover, since Arabic is consonant-based, we hypothesized that participants would perform better in the two consonant conditions (i.e., OCM and SIC) in comparison to the rhyme condition (i.e., RM). Additionally, we expected to find the same pattern of results in the accuracy data. Finally, we expected that providing feedback during practice trials would facilitate participants’ performance overall.
Materials and Methods
Participants
Fifty-nine female native speakers of EA took part in the experiment (AgeM = 20.09 SD = 2.12). All participants were students enrolled at United Arab Emirates University. Data from six additional participants were excluded from the analyses because they spoke a dialect of Arabic other than EA. Of the remaining participants, half received automatic, online corrective feedback during the practice trial phase (Feedback group), while the other half received no feedback (No Feedback group). All participants reported at least 18 years of permanent residence within the United Arab Emirates, and spoke the native EA dialect. None of the participants reported to have prior identified speech, hearing or visual impairments.
Stimuli
The task is an adaptation of the French Test de Conscience Phonologique Préscolaire (Brosseau-Lapré and Rvachew, 2008, modeled on the phonological awareness test by Bird et al., 1995), developed for EA. Images used for the current experiment were adapted from the stimuli set used for the LATFA phonological awareness assessment (Marquis, 2016–2018), with minor substitutions for items that became heavily pixelated due to re-scaling on the monitor screen used for eye-tracking. In cases where images were replaced, the new ones were either identical, or as visually similar to the originals as possible. The Emirati Arabic Language Acquisition Corpus (EMALAC, Ntelitheos and Idrissi, 2017) was used as a reference for highly familiar nouns for the construction of the images to ensure participants’ familiarity with the items and to avoid saliency effects. In total, there were 192 images arranged in combinations of four for the VWP task (see Figure 1). No image was repeated more than twice throughout the experiment, and never for the same phoneme or phonological condition. Auditory stimuli consisted of verbal task instructions in EA. All auditory stimuli were recorded by a native female EA adult. There were 4 different target phonemes for each of the three conditions, each were tested on three separate trials embedded within different targets. Each trial began with a script associated with a cartoon character whose name served as a probe for the target phoneme. There was a script for each target phoneme, where each script introduced the nature of the task. An example for each condition is given below.
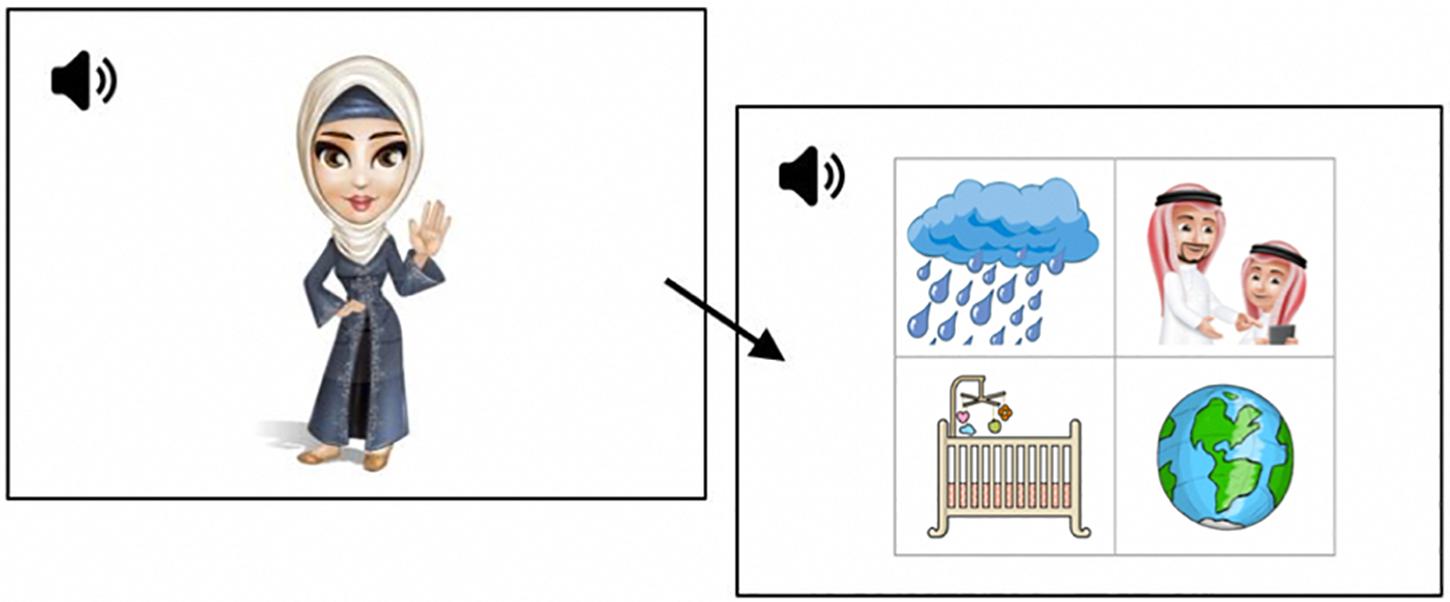
Figure 1. An example of a trial. Screen 1: “This is Lulu. Lulu likes things that sound like her name. Which of these things is the one that Lulu likes?’ Screen 2: /ʔubuu/ ‘father’ (target) and distractors: /metʕar/ ‘rain’, /dənja/ ‘world’, /mənaz/ ‘cradle’.”
(1) OCM condition: 
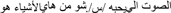
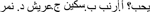
“This animal likes things that start with the same sound. The sound that it likes is /s/. Which of these things does it like? a. /ʔarnab/ ‘rabbit’ b. /səkkiin/ ‘knife’ c. /ʕəriiʃ/ ‘palm house’ d. /nəmər/ ‘tiger’.”
(2) SIC condition: 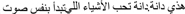
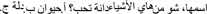
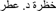
“This is Dana. Dana likes things that begin with the same sound as her name. Which of these things does Dana like? a. /ħaywaan/ ‘animal’ b. /dallah/ ‘flask’ c. /xaðʕ ra/ ‘vegetables’ d. /ʕətʕər/ ‘perfume’.”
(3) RM condition: 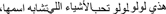
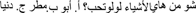
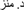
“This is Lulu. Lulu likes things that sound like her name, which of these things is the one that Lulu likes? a. /ʔubuu/ ‘father’ b. /mətʕar/ ‘rain’ c. /dənya/ ‘world’ d. /mənaz/ ‘cradle’.”
Apparatus
The experiment was designed and delivered through EyeLink 1000 Plus tracker systems (SR Research Ltd.) with a high-speed desktop-mounted 35 mm lens. Monocular eye movements were monitored and recorded with a sampling rate of 1000 Hz (1000 recordings per second). Visual stimuli were displayed on a 24″ BENQ ZOWIE XL 2430 monitor with resolution at 1920 × 1080 pixels. Participants sat at a distance of 80 cm from the screen, and their head movements were stabilized using a head-and-chin support. Audio instructions were delivered through Sennheiser HD 26 Pro noise-canceling headphones. Participants used a mouse to record their answer choices.
Design
The behavioral tool was adapted to a computer-delivered, audio-coupled VWP. For each trial, an auditory question was introduced by a character whose name served as a prime for the target phonological condition, followed by a display showing the four possible choices arranged in a 2 × 2 grid containing the target noun and three distractors (see Figure 1). For each phonological condition, 12 test trials were presented, resulting in 36 test trials in total. In addition, at the beginning of each phonological condition block, four practice trials (not included in the analyses) were presented in order to familiarize participants with each task. Trials within each block were pseudorandomized.
Procedure
Prior to the experiment, all participants read and signed a consent form and completed a demographic background questionnaire inquiring, amongst other things, about their linguistic history. The experiment took place in a quiet room in the Linguistics laboratory at United Arab Emirates University. Participants were asked to sit comfortably in front of the screen and adjust the height of their seat if necessary, with their chin and head on the table mounted support. A nine-point grid calibration was performed and validated for each participant before the experiment started. Participants then put on the headphones and were instructed to listen carefully to the instructions and recordings presented and make a selection, using the mouse, between the four different images appearing on the display. Each trial ended when the participant recorded their choice by left clicking on the mouse and the next trial automatically began. Participants sat through 12 trials per condition, for a total of three condition blocks. Participants were allowed breaks in between blocks, and the experiment resumed at the participant’s discretion. A central drift correction was performed before each block. Participants were debriefed by the experimenter at the end of the experiment and were allowed to ask questions. On average, each session lasted about 20 min.
Measures
For all participants, the following measures were collected and later analyzed: Accuracy, Average Fixation Count, Average Fixation Duration, and Average Visits (Runs) to Region of Interest. A brief definition of these terms is outlined below.
Accuracy
The accuracy measure is the percentage of correct responses (i.e., correctly selecting the target) for each trial, automatically calculated for each participant by the Data Viewer software and then averaged across participants.
Average Fixation Count
The average fixation count is the average number of fixations made to the target in each trial, automatically calculated for each participant by the Data Viewer software and then averaged across participants. Individual fixations were defined as periods where the eyes were maintained stable and the saccade amplitude of eye movements did not exceed 0.0 degree per second. Fixations spanning 1 degree or less were automatically merged together by the Data Viewer software.
Average Fixation Duration
The average fixation duration is the average length in milliseconds (ms) of individual fixations made to the target in each trial, automatically calculated for each participant by the Data Viewer software and averaged across participants.
Average Visits (Runs) to Region of Interest
The average visits (runs) to region of interest is the number of individual visits to the target image. That is, the number of times participants looked at the quadrant containing the target, also called Region of Interest (ROI), left that particular ROI and then re-entered the pre-defined region, automatically calculated for each participant by the Data Viewer software and averaged across participants.
Fixations were included in the analysis only if they fell inside one of the four quadrants of the 2 × 2 grid. Any fixations falling outside of this region, or within close proximity to the grid outlines were discarded from the analyses.
Results
A multivariate analysis of variance (MANOVA) was performed to test the effect of the three phonological conditions (OCM, SIC, and RM) as within-subjects variables and feedback group (Feedback vs No Feedback) as the between-subjects variable on three eye movement measures: average fixation duration, average fixation count, average ROI runs, and accuracy. We found significant main effects of Phonological condition, F(8,15) = 14.56, p < 0.001, Wilk’s Λ = 0.114, partial η2 = 0.886. There was no main effect of feedback group, F(4,19) = 0.364, p = 0.823, and the interaction between phonological condition and feedback failed to reach statistical significance, F(2,15) = 2.18, p = 0.092.
Univariate tests show significant differences in means due to phonological condition for average fixation duration F(1,22) = 14.38, p = 0.001, average number of fixations F(1,22) = 14.39, p = 0.001, average runs to the target F(1,22) = 8.07, p = 0.009, and response accuracy F(1,22) = 26.55, p < 0.001; the details of which were further analyzed as summarized below.
The MANOVA was followed up by post hoc pairwise comparisons for each measure with Bonferroni corrected alpha level of 0.0167 (0.05/3). Average Fixation Duration was significantly shorter in the OCM (M = 294 ms) and SIC (M = 284 ms) conditions, both ps = 0.003, in comparison to the RM condition (M = 332 ms).
Average Fixation Count was significantly shorter in the OCM (M = 1.8, p = 0.002) and SIC conditions (M = 1.8, p = 0.003) in comparison to RM condition (M = 2.8).
Average Visits (Runs) to Region of Interest were significantly lower in the OCM (M = 1.0, p = 0.013) and SIC condition (M = 1.1, p = 0.028) compared to the RM condition (M = 1.3).
Finally, Accuracy was significantly higher in the OCM (M = 98.7%) and SIC conditions (M = 96.7%, both ps < 0.001) in comparison to the RM condition (M = 75.5%).
No significant differences were found between the OCM and SIC conditions across all measures (ps > 0.05).
Table 2 below summarizes the means and standard deviations for each of the aforementioned measures across the three phonological conditions.
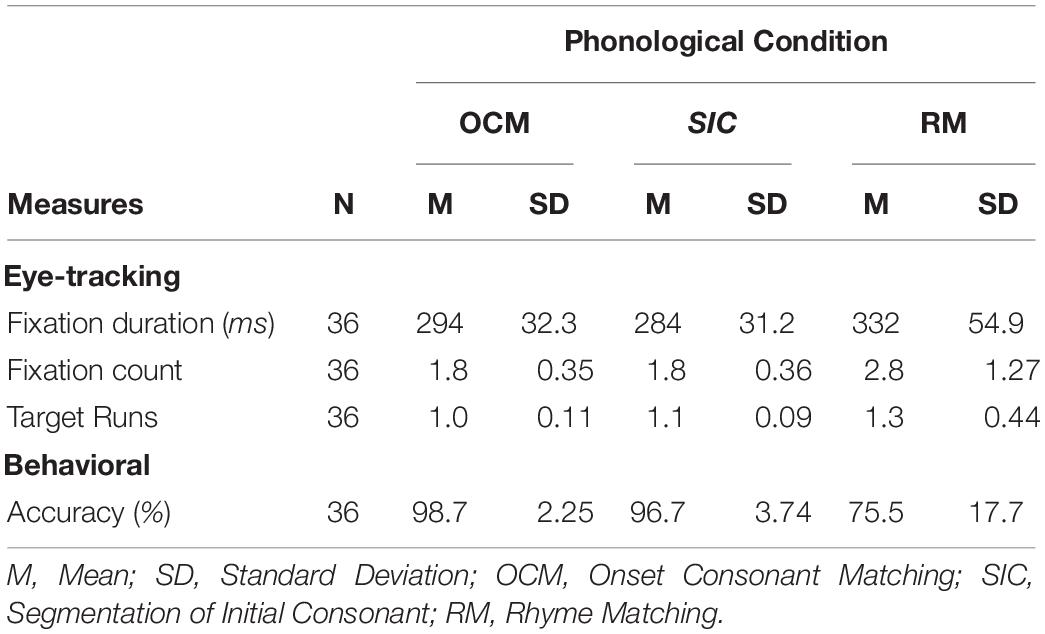
Table 2. Summary of means along with standard deviations of eye-tracking and behavioral data for the three conditions.
Discussion
The goal of this study was twofold. First, we wanted to test the transferability of the behavioral tool which was developed specifically to test the phonological awareness skills of EA speaking children on EA speaking adults. The assessment is performed on the speakers’ native dialect, which is the language they first acquire. Second, the tool was adapted into a computer-delivered VWP using the eye-tracking methodology where participants’ eye positions could be tracked automatically as an indicator of allocated attention. This allows us to test the validity of using eye movements as an implicit indicator of phonological awareness skills. Our final goal, not presented here, but projected for future directions, was to transfer this computer-based experiment with children.
Our hypotheses were as follows:
(1) Fixation indices of eye movements should differ according to the three phonological conditions.
(2) Explicit instructions should facilitate participants’ performance on the task in comparison to implicit instructions, where we predicted that eye movements would reflect more efficient fixation patterns in the explicit OCM condition in comparison to the implicit SIC condition.
(3) As Arabic words consist of consonantal roots as fundamental units, we expected to see the greatest hindrance in terms of eye movements and performance for the RM condition when compared to the consonant-based OCM and SIC conditions.
(4) Administering feedback during practice trials should facilitate performance overall on all measures in comparison with the no feedback group.
The results we obtained confirm two of these hypotheses. First, we did find significant differences between the phonological conditions for all fixation indices (Hypothesis #1). Second, in support to Hypothesis #3, we found that participants had significantly more problems performing in the RM condition compared to the consonant conditions, where they made longer average fixations, more fixations, more re-visits to individual targets (i.e., “runs”), and their accuracy scores were significantly lower than both consonant conditions (OCM and SIC). However, in terms of accuracy or eye movements, we did not find any differences between the explicit OCM and implicit SIC conditions (Hypothesis #2). Finally, there was no difference between the feedback and no feedback groups across all measures (Hypothesis #4).
Our results show that despite full native-language competence, EA adult speakers exhibit an asymmetry of phonological awareness between consonants (onsets) and vowels (rhymes). Participants consistently performed worse on the rhyme-based RM condition in comparison to the consonant-based conditions (OCM and SIC). Targets in the RM condition received more, longer average fixations, more target re-visits and were less accurately identified, indicating greater task difficulty. This is an interesting finding, since there is agreement in the literature that the development of phonological awareness skills in children mirrors the hierarchical structure of the syllable, with awareness to rhymes typically preceding sensitivity to phonemes (e.g., Ziegler and Goswami, 2005; Goswami, 2010). The consensus is that children first acquire sensitivity and awareness to larger linguistic “chunks” (i.e., words) before mastering more detailed, finer-level phonological units such as syllables, onset-rhymes, and phonemes, respectively (Goswami, 2010). Our findings suggest a trend in the opposite direction, as adults performed better in tasks concerning consonants than rhymes.
However, orthographic transparency also affects the way readers acquire the phonological skills necessary when learning to read. In languages where grapheme-to-phoneme mappings are consistent in alphabetic orthographies (such as German and vowelized Arabic), sensitivity to phonemes develops quicker than in languages with inconsistent orthographies, since they are the most salient phonological units in these languages (Goswami, 2010). In the case of Arabic, consonants make up the majority of the phonemes in the language. Short vowels (shown as optional diacritics) are often left out of writing and do not typically appear in printed text. This is reflected in the current methods of literacy instruction, where children are first taught to read and write using full vowelization. However, later in primary education years, children are discouraged from using diacritics in writing except in cases where those are necessary to disambiguate homographic words (Abu-Rabia, 2002). Therefore, it is almost as though from a very young age native Arabic speakers are taught to disregard vowels at least in writing, perhaps for their redundancy in context. Instead, readers often rely on contextual clues to disambiguate words during reading (Abu-Rabia, 1997, 2012, 2019). Both vowels and context play a role in disambiguating homographs and, therefore, facilitate text comprehension (Abu-Rabia, 1997). Therefore, it was predicted and subsequently shown that Arabic speakers would show the highest efficiency in performance, as reflected by fewer, shorter average fixations and re-visits to target ROIs, for consonant-based conditions as opposed to rhyme-based (vowels) conditions.
We found no evidence to support the claim that performance will differ between the two consonant conditions. However, this lack of results may possibly be attributed to the low number of trials (12 total) in each condition group yielding low statistical power. Moreover, we could not find differences across feedback groups. Perhaps this is due to the characteristics of the sample population recruited for this study, since all participants were adults recruited from a university pool; it is highly likely that their phonological skills are well developed, such that they are able to successfully complete the given tasks without needing further instructions and without benefiting further from practice feedback. This would not be expected with a much younger sample population who will likely be at different mastery levels of phonological awareness skills.
We showed that it is possible to use eye-tracking to assess phonological awareness in EA speaking adults and demonstrated that eye movements differed depending on the phonological conditions. Our study could be used to examine EA speaking children’s phonological awareness. It is important to note that this particular study is not exhaustive of all the possible phonemes in EA, and further research is needed to test the feasibility of using this experiment design to capture the same differences between and within conditions of the full list of phoneme in EA. In addition, the current experiment could be adapted to evaluate processing of Arabic script, in order to determine the link between phonological awareness and literacy. While the current aim is to focus on the phonological knowledge of EA words which may not correspond to MSA words, further research can be conducted so that the phonological awareness of EA and MSA can be compared using the eye movement study (cf. Saiegh-Haddad, 2003).
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Ethics Statement
The studies involving human participants were reviewed and approved by Social Sciences Research Ethics Committee Human Medical Research Ethics Committee United Arab Emirates University. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
AM, MA, and TL conceived the project and planned the experiment design. The task, conditions and stimuli were selected and developed by AM and her research assistants. FB programed the study, collected data and performed statistical analyses. All authors discussed the results and contributed to the final manuscript.
Funding
This project was supported by the United Arab Emirates University Research Start-up Grant Award No. 31H128.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We are thankful to Akeela Fatheen Abdul Gafoor, Al Yazia Mohammed Al Mansouri and Wadha Ayed Muaid Asi Al Otaibi for research assistance.
References
Abu-Rabia, S. (1997). Reading in Arabic orthography: the effect of vowels and context on reading accuracy of poor and skilled native Arabic readers. Read. Writ. 9, 65–78.
Abu-Rabia, S. (2000). Effects of exposure to literary Arabic on reading comprehension in a diglossic situation. Read. Writ. 13, 147–157. doi: 10.1023/A:1008133701024
Abu-Rabia, S. (2002). Reading in a root–based–morphology language: the case of Arabic. J. Res. Read. 25, 299–309. doi: 10.1111/1467-9817.00177
Abu-Rabia, S. (2012). The role of morphology and short vowelization in reading morphological complex words in Arabic: evidence for the domination of the morpheme/root-based theory in reading Arabic. Creat. Educ. 3, 486–494. doi: 10.4236/ce.2012.34074
Abu-Rabia, S. (2019). The role of short vowels in reading Arabic: a critical literature review. J. Psycholinguist. Res. 48, 785–795. doi: 10.1007/s10936-019-09631-4
Al Ameri, H. (2009). A Phonological Description of EA. Master dissertation, West Lafayette, Purdue University.
Alamri, A. (2017). Phonological, Semantic and Root Activation in Spoken Word Recognition in Arabic: Evidence from Eye Movements. Doctoral dissertation, Ottawa, University of Ottawa.
Allopenna, P. D., Magnuson, J. S., and Tanenhaus, M. K. (1998). Tracking the time course of spoken word recognition using eye movements: evidence for continuous mapping models. J. Mem. Lang. 38, 419–439. doi: 10.1006/jmla.1997.2558
Altmann, G. T. M. (2004). Language-mediated eye movements in the absence of a visual world: the ‘blank screen paradigm.’. Cognition 93, B79–B87. doi: 10.1016/j.cognition.2004.02.005
Altmann, G. T. M., and Kamide, Y. (1999). Incremental interpretation at verbs: restricting the domain of subsequent reference. Cognition 73, 247–264. doi: 10.1016/S0010-0277(99)00059-1
Amayreh, M. M. (2003). Completion of the consonant inventory of Arabic. J. Speech Lang. Hear. Res. 46, 517–529. doi: 10.1044/1092-4388(2003/042)
Asaad, H., and Eviatar, Z. (2014). Learning to read in Arabic: the long and winding road. Read. Writ. 27, 649–664. doi: 10.1007/s11145-013-9469-9
Asadi, I. A., and Abu-Rabia, S. (2019). The impact of the position of phonemes and lexical status on phonological awareness in the diglossic Arabic language. J. Psycholinguist. Res. 48, 1051–1062. doi: 10.1007/s10936-019-09646-x
Bird, J., Bishop, D. V. M., and Freeman, N. (1995). Phonological awareness and literacy development in children with expressive phonological impairments. J. Speech Hear. Res. 38, 446–462. doi: 10.1044/jshr.3802.446
Brosseau-Lapré, F., and Rvachew, S. (2008). Test de Conscience Phonologique Préscolaire [Computer Software]. Montréal: McGill University.
Bruck, M. (1992). Persistence of dyslexics’ phonological awareness deficits. Dev. Psychol. 28, 874–886. doi: 10.1037/0012-1649.28.5.874
Bylinskii, Z., Borkin, M. A., Kim, N. W., Pfister, H., and Oliva, A. (2015). “Eye fixation metrics for large scale evaluation and comparison of information visualizations,” in Eye Tracking and Visualization, eds M. Burch, L. Chuang, B. Fisher, A. Schmidt, and D. Weiskopf (Cham: Springer), 235–255. doi: 10.1007/978-3-319-47024-5_14
Conklin, K., and Pellicer-Sánchez, A. (2016). Using eye-tracking in applied linguistics and second language research. Second Lang. Res. 32, 453–467. doi: 10.1177/0267658316637401
Cooper, R. M. (1974). The control of eye fixation by the meaning of spoken language: a new methodology for the real-time investigation of speech perception, memory, and language processing. Cognitive Psychol. 6, 84–107. doi: 10.1016/0010-0285(74)90005-X
Dallasheh-Khatib, R., Ibrahim, R., and Karni, A. (2014). Longitudinal data on the relations of morphological and phonological training to reading acquisition in first grade: the case of Arabic language. Psychology 5, 918–940. doi: 10.4236/psych.2014.58103
Elbeheri, G., and Everatt, J. (2007). Literacy ability and phonological processing skills amongst dyslexic and non-dyslexic speakers of Arabic. Read. Writ. 20, 273–294. doi: 10.1007/s11145-006-9031-0
Feitelson, D., Goldstein, Z., Iraqi, J., and Share, D. L. (1993). Effects of listening to story reading on aspects of literacy acquisition in a diglossic situation. Read. Res. Q. 28, 71–79. doi: 10.2307/747817
Ferreira, F., Apel, J., and Henderson, J. M. (2008). Taking a new look at looking at nothing. Trends Cogn. Sci. 12, 405–410. doi: 10.1016/j.tics.2008.07.007
Goswami, U. (2010). “A psycholinguistic grain size view of reading acquisition across languages,” in Reading and Dyslexia in Different Orthographies, eds N. Brunswick, S. McDougall, and P. de Mornay Davies (London: Psychology Press), 41–60.
Goswami, U., and Bryant, P. (1990). Phonological Skills and Learning to Read. Hillsdale: Lawrence Erlbaum Associates.
Holm, A., Farrier, F., and Dodd, B. (2008). Phonological awareness, reading accuracy and spelling ability of children with inconsistent phonological disorder. Int. J. Lang. Commun. Disord. 43, 300–322. doi: 10.1080/13682820701445032
Horn, C. (2015). Diglossia in the Arab world(educational implications and future perspectives. Open J. Mod. Linguist. 5, 100–104. doi: 10.4236/ojml.2015.51009
Huettig, F., Rommers, J., and Meyer, A. S. (2011). Using the visual world paradigm to study language processing: a review and critical evaluation. Acta Psychol. 137, 151–171. doi: 10.1016/j.actpsy.2010.11.003
Idrissi, A., Prunet, J. F., and Béland, R. (2008). On the mental representation of Arabic roots. Linguist. Inq. 39, 221–259. doi: 10.1162/ling.2008.39.2.221
Just, M. A., and Carpenter, P. A. (1976a). Eye fixations and cognitive processes. Cogn. Psychol. 8, 441–480. doi: 10.1016/0010-0285(76)90015-3
Just, M. A., and Carpenter, P. A. (1976b). The role of eye-fixation research in cognitive psychology. Behav. Res. Meth. Instr. 8, 139–143. doi: 10.3758/BF03201761
Knoeferle, P., and Crocker, M. W. (2007). The influence of recent scene events on spoken comprehension: evidence from eye movements. J. Mem. Lang. 57, 519–543. doi: 10.1016/j.jml.2007.01.003
Krajbich, I. (2018). Accounting for attention in sequential sampling models of decision making. Curr. Opin. Psychol. 29, 6–11. doi: 10.1016/j.copsyc.2018.10.008
Lahrache, S., El Ouazzani, R., and El Qadi, A. (2018). Visualizations memorability through visual attention and image features. Proc. Comput. Sci. 127, 328–335. doi: 10.1016/j.procs.2018.01.129
Landerl, K., Freudenthaler, H. H., Heene, M., De Jong, P. F., Desrochers, A., Manolitsis, G., et al. (2019). Phonological awareness and rapid automatized naming as longitudinal predictors of reading in five alphabetic orthographies with varying degrees of consistency. Sci. Stud. Read. 23, 220–234. doi: 10.1080/10888438.2018.1510936
Layes, S., Lalonde, R., and Rebai, M. (2015). Reading speed and phonological awareness deficits among Arabic-speaking children with dyslexia. Dyslexia 21, 80–95. doi: 10.1002/dys.1491
Layes, S., Lalonde, R., and Rebai, M. (2019). Effects of an adaptive phonological training program on reading and phonological processing skills in Arabic-speaking children with dyslexia. Read. Writ. Q. 35, 103–117. doi: 10.1080/10573569.2018.1515049
Leikin, M., Ibrahim, R., and Eghbaria, H. (2014). The influence of diglossia in Arabic on narrative ability: evidence from analysis of the linguistic and narrative structure of discourse among pre-school children. Read. Writ. 27, 733–747. doi: 10.1007/s11145-013-9462-3
Makhoul, B. (2017). Moving beyond phonological awareness: the role of phonological awareness skills in arabic reading development. J. Psycholinguist. Res. 46, 469–480. doi: 10.1007/s10936-016-9447-x
Mannai, H., and Everatt, J. (2005). Phonological processing skills as predictors of literacy amongst Arabic speaking Bahraini children. Dyslexia 11, 269–291. doi: 10.1002/dys.303
Marquis, A. (2016–2018). Development of an Assessment Tool for Oral Skills in Emirati Arabic Speaking Children. Emirates: UAEU.
Marslen-Wilson, W. D. (1987). Functional parallelism in spoken word-recognition. Cognition 25, 71–102. doi: 10.1016/0010-0277(87)90005-9
McCarthy, J. J. (1981). A prosodic theory of nonconcatenative morphology. Linguist. Inq. 12, 373–418.
McClelland, J. L., and Elman, J. L. (1986). The TRACE model of speech perception. Cogn. Psychol. 18, 1–86. doi: 10.1016/0010-0285(86)90015-0
Melby-Lervåg, M., Lyster, S. A., and Hulme, C. (2012). Phonological skills and their role in learning to read: a meta-analytic review. Psychol. Bull. 138, 322–352. doi: 10.1037/a0026744
Metsala, J. L., Parrila, R., Conrad, N. J., and Deacon, S. H. (2019). Morphological awareness and reading achievement in university students. Appl. Psycholinguist. 40, 743–763. doi: 10.1017/S0142716418000826
Norris, D. (1994). Shortlist: a connectionist model of continuous speech recognition. Cognition 52, 189–234. doi: 10.1016/0010-0277(94)90043-4
Ntelitheos, D., and Idrissi, A. (2017). “Language growth in child Emirati Arabic,” in Perspectives on Arabic Linguistics XXIX, ed. H. Ouali (Amsterdam: John Benjamins), 229–224.
Orquin, J. L., and Mueller Loose, S. (2013). Attention and choice: a review on eye movements in decision making. Acta Psychol. 144, 190–206. doi: 10.1016/j.actpsy.2013.06.003
Pickering, M. J., Frisson, S., McElree, B., and Traxler, M. J. (2004). “Eye movements and semantic composition,” in The On-Line Study of Sentence Comprehension: Eyetracking, ERP, and Beyond, eds M. Carreiras and C. Clifton, Jr. (New York, NY: Psychology Press), 33–50. doi: 10.4324/9780203509050
Prunet, J. F., Béland, R., and Idrissi, A. (2000). The mental representation of Semitic words. Linguist. Inq. 31, 609–648. doi: 10.1162/002438900554497
Pyykkönen-Klauck, P., and Crocker, M. W. (2016). “Attention and eye movement metrics in visual world eye tracking,” in Visually Situated Language Comprehension, eds P. Knoeferle, P. Pyykkönen-Klauck, and M. W. Crocker (Amsterdam: John Benjamins Publishing Company), 67–82. doi: 10.18452/19861
Rakhlin, N. V., Aljughaiman, A., and Grigorenko, E. L. (2019). Assessing language development in Arabic: the Arabic language: evaluation of function (ALEF). Appl. Neuropsychol. Child doi: 10.1080/21622965.2019.1596113 [Epub ahead of print].
Rayner, K. (2009). Eye movements and attention in reading, scene perception, and visual search. Q. J. Exp. Psychol. 62, 1457–1506. doi: 10.1080/17470210902816461
Rayner, K., Schotter, E. R., Masson, M. E. J., Potter, M. C., and Treiman, R. (2016). So much to read, so little time: how do we read, and can speed reading help? Psychol. Sci. Publ. Int. 17, 4–34. doi: 10.1177/1529100615623267
Richardson, D. C., Altmann, G. T. M., Spivey, M. J., and Hoover, M. A. (2009). Much ado about eye movements to nothing: a response to Ferreira et al.: taking a new look at looking at nothing. Trends Cogn. Sci. 13, 235–236. doi: 10.1016/j.tics.2009.02.006
Richardson, D. C., and Spivey, M. J. (2000). Representation, space and Hollywood squares: looking at things that aren’t there anymore. Cognition 76, 269–295. doi: 10.1016/S0010-0277(00)00084-6
Rvachew, S. (2007). Phonological processing and reading in children with speech sound disorders. Am. J. Speech Lang. Pathol. 16, 260–270. doi: 10.1044/1058-0360(2007/030)
Rvachew, S., Royle, P., Gonnerman, L. M., Stanké, B., Marquis, A., and Herbay, A. (2017). Development of a tool to screen risk of literacy delays in French-speaking children: PHOPHLO. Can. J. Speech Lang. Pathol. Audiol. 41, 321–340.
Saiegh-Haddad, E. (2003). Linguistic distance and initial reading acquisition: the case of Arabic diglossia. Appl. Psycholinguist. 24, 431–451. doi: 10.1017/S0142716403000225
Saiegh-Haddad, E. (2004). The impact of phonemic and lexical distance on the phonological analysis of words and pseudowords in a diglossic context. Appl. Psycholinguist. 25, 495–512. doi: 10.1017/S0142716404001249
Saiegh-Haddad, E. (2008). On the challenges posed by diglossia to the acquisition of basic reading processes in Arabic. Literacy Lang. 1, 101–126.
Saiegh-Haddad, E. (2012). “Literacy reflexes of Arabic diglossia,” in Current Issues in Bilingualism, Literacy Studies (Perspectives from Cognitive Neurosciences, Linguistics, Psychology and Education), Vol. 5, eds M. Leikin, M. Schwartz, and Y. Tobin (Dordrecht: Springer), 43–55. doi: 10.1007/978-94-007-2327-6_3
Saiegh-Haddad, E., and Henkin-Roitfarb, R. (2014). “The structure of Arabic language and orthography,” in Handbook of Arabic Literacy. Literacy Studies (Perspectives from Cognitive Neurosciences, Linguistics, Psychology and Education), Vol. 9, eds E. Saiegh-Haddad and R. Joshi (Dordrecht: Springer), 3–28. doi: 10.1007/978-94-017-8545-7_1
Salverda, A. P., Brown, M., and Tanenhaus, M. K. (2011). A goal-based perspective on eye movements in visual world studies. Acta Psychol. 137, 172–180. doi: 10.1016/j.actpsy.2010.09.010
Salverda, A. P., and Tanenhaus, M. K. (2017). “The visual world paradigm,” in Research Methods in Psycholinguistics and the Neurobiology of Language: A Practical Guide, eds A. M. B. de Groot and P. Hagoort (New York, NY: Wiley & Sons), 89–110.
Schneider, W., Roth, E., and Ennemoser, M. (2000). Training phonological skills and letter knowledge in children at risk for dyslexia: a comparison of three kindergarten intervention programs. J. Educ. Psychol. 92, 284–295. doi: 10.1037/0022-0663.92.2.284
Shendy, R. (2019). The limitations of reading to young children in literary arabic: the unspoken struggle with Arabic diglossia. Theor. Pract. Lang. Stud. 9, 123–130.
Speece, D. L., Roth, F. P., Cooper, D. H., and De La Paz, S. (1999). The relevance of oral language skills to early literacy: a multivariate analysis. Appl. Psycholinguist. 20, 167–190. doi: 10.1017/S0142716499002015
Spivey, M. J., and Geng, J. J. (2001). Oculomotor mechanisms activated by imagery and memory: eye movements to absent objects. Psychol. Res. 65, 235–241. doi: 10.1007/s004260100059
Taha, H. (2013). Reading and spelling in Arabic: linguistic and orthographic complexity. Theor. Pract. Lang. Stud. 3, 721–727. doi: 10.4304/tpls.3.5.721-727
Taibah, N. J., and Haynes, C. W. (2011). Contributions of phonological processing skills to reading skills in Arabic speaking children. Read. Writ. 24, 1019–1042. doi: 10.1007/s11145-010-9273-8
Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., and Sedivy, J. C. (1995). Integration of visual and linguistic information in spoken language comprehension. Science 268, 1632–1634. doi: 10.1126/science.7777863
Tanenhaus, M. K., and Trueswell, J. C. (2006). “Eye movements and spoken language comprehension,” in Handbook of Psycholinguistics, eds M. J. Traxler and M. A. Gernsbacher (Cambridge, MA: Academic Press), 863–900. doi: 10.1016/B978-012369374-7/50023-7
Tibi, S., and Kirby, J. R. (2018). Investigating phonological awareness and naming speed as predictors of reading in Arabic. Sci. Stud. Read. 22, 70–84. doi: 10.1080/10888438.2017.1340948
Keywords: neurolinguistics, Arabic language, phonological awareness, eye-tracking, word recognition, Emirati Arabic (EA), adults
Citation: Marquis A, Al Kaabi M, Leung T and Boush F (2020) What the Eyes Hear: An Eye-Tracking Study on Phonological Awareness in Emirati Arabic. Front. Psychol. 11:452. doi: 10.3389/fpsyg.2020.00452
Received: 19 July 2019; Accepted: 26 February 2020;
Published: 17 March 2020.
Edited by:
Manuel Perea, University of Valencia, SpainReviewed by:
Rob Davies, Lancaster University, United KingdomLucia Colombo, University of Padua, Italy
Copyright © 2020 Marquis, Al Kaabi, Leung and Boush. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexandra Marquis, YWxleGFuZHJhbWFycXVpc0B1YWV1LmFjLmFl; Meera Al Kaabi, bV9hbGthYWJpQHVhZXUuYWMuYWU=