 Rodrigo Montero
Rodrigo Montero Miguel Vargas
Miguel Vargas Diego Vásquez2
Diego Vásquez2- 1Facultad de Economía y Negocios, Universidad Andrés Bello, Santiago, Chile
- 2Observatorio Social, Ministerio de Desarrollo Social, Santiago, Chile
Our aim is to cast light on socioeconomic residential segregation effects on life satisfaction (LS). In order to test our hypothesis, we use survey data from Chile (Casen) for the years 2011 and 2013. We use the Duncan Index to measure segregation based on income at the municipality level for 324 municipalities. LS is obtained from the CASEN survey, which considers a question about self-reported well-being. Segregation’s impact upon LS is not clear at first glance. On one hand, there is evidence telling that segregation’s consequences are negative due to the spatial concentration of poverty and all the woes related to it. On the other hand, segregation would have positive effects because people may feel stress, unhappiness, and alienation when comparing themselves to better-off households. Additionally, there is previous evidence regarding the fact that people prefer to neighbor people of a similar socioeconomic background. Hence, an empirical test is needed. In order to implement it, we should deal with two problems, first, the survey limited statistical significance at the municipal level, hence we use the small area estimation (SAE) methodology to improve the estimations’ statistic properties, and second, the double causality between segregation and LS; to deal with the latter, we include lagged LS as a regressor. Our findings indicate that socioeconomic segregation has a positive effect on LS. This result is robust to different econometric specifications.
Introduction
What is the effect of socioeconomic residential segregation on subjective life satisfaction (LS)? This is the research question of the present investigation. The relevance of this question lies, mainly, in the following reasons. First, LS is an important component of individuals’ well-being, and therefore, it should be analyzed for exploring appropriate policies to protect and improve well-being (Ruggeri et al., 2020). The latter demands to have an understanding of what the drivers are behind LS, and according to the literature, there is a nexus between LS and residential satisfaction (Ibem and Amole, 2013). As a matter of fact, LS is an aggregate satisfaction in the different life domains (Van Praag et al., 2003). These include social relationships, education, and housing (Argyle, 2001). Previous investigations have identified a link between housing environment and overall well-being (LS is part of the overall well-being) (Bovaird and Elke, 2003; Park, 2006). The type of housing and quality of surrounding environment have a significant influence on people’s overall well-being (Bashir, 2002; Cazacova et al., 2010; Theriault et al., 2010). Hence, previous investigations suggest that households’ LS is influenced by their satisfaction with housing environment, which is composed, among others, of the location and socioeconomic characteristic of their neighborhoods (Ibem and Amole, 2013).
Second, the answer to this question is not clear at first sight. Previous investigations have pointed out the pernicious effects of segregation on a wide range of individuals’ economic, health, and educational outcomes (Jencks and Mayer, 1990; Brooks-Gunn et al., 1993; Cutler and Glaeser, 1997; Leventhal and Brooks-Gunn, 2000; Fabio et al., 2009; Jargowsky, 2014; Chetty et al., 2016 and Sampson et al., 2002). Regarding mental health, Ludwig et al. (2012) find that neighborhoods have effects on subjective well-being (SWB) (once again, LS is one of the components of well-being) and mental health; hence, people living in high-poverty neighborhoods will improve their LS if they move to lower-poverty neighborhoods. In the same line, Bittencourt et al. (2020) explore how differences in scale, geography, and race interact with segregation and the impact that these interactions have on the access to cities’ amenities by public transport, finding that accessibility varies across the socio-spatial structure. Gibbons et al. (2020) found that segregation is associated with clusters of poor health households albeit the final effect depends on races and ethnicities being poor—afro descent households the most affected group. Jimmy et al. (2019) describe the association between residential segregation and quality of life in the city of Nairobi. They found a positive correlation between symbolic integration, safety, and quality of life related to housing in poor neighborhoods but a negative correlation of these variables in gated communities. However, evidence about segregation’s positive effects on individuals’ LS has been found as well. For instance, racial homogeneity is related to lower rates of psychosis, suicide, common mental disorders, and mortality (Okulicz-Kozaryn, 2019). Besides, segregated neighborhoods may induce people to a greater sense of belongingness, which induces social cohesion, trust, participation, mutual support, collective action, and social capital (Alesina and La Ferrara, 2000; Luttmer, 2001; Luttmer and Singhal, 2008; Stafford et al., 2010). Additionally, the poor may feel stress, unhappiness, and alienation when comparing themselves to better-off people (Davis, 1988), and there is previous evidence regarding the fact that, on average, adult people prefer to neighbor people of a similar socioeconomic background (Luttmer, 2005). Segregation, particularly when the segregated group corresponds to better-off members of society, produces a greater level of labor productivity (Díaz et al., 2020). Social interactions within neighborhoods are a significant device to find a job among peers; hence, they boost labor market matchings. Segregated neighborhoods may provide consumption benefits due to the fact that individuals of similar income and preferences tend to consume similar goods and similar local amenities (Cheshire, 2007). Moving grown-ups and adolescents from poor to richer neighborhoods has a negative impact maybe due to disruption effects (Chetty et al., 2016). In the same line, it has been found that Whites, Afro Americans, and Hispanics are happier among their own race (Okulicz-Kozaryn, 2019). From the mental health point of view, there are several investigations pointing out the possible positive effects of segregation (Wilkinson and Pickett, 2008; Stafford et al., 2010; Shaw et al., 2012). Particularly, the focus is on what has been called “the ethnic density hypothesis,” which suggests that living in neighborhoods of higher own-group density may be protective for mental health. This effect may operate through a buffering effect for individuals living in high own-group density areas through improved social networks or due to the reduction of the frequency of negative experiences like racism (Das-Munshi et al., 2010). Possible mechanisms behind protective effects of own-group density on mental health have to do with enhanced social support, mitigated negative attitudes from other groups, positive identity, and higher self-evaluation. In this sense, own-group density may promote resilience by providing appropriate social support with which to resist the psychological stresses due to negative attitudes coming from different socioeconomic groups. Living in areas with people more like oneself may reinforce one’s own identity and allow an individual to view himself or herself with higher self-esteem, as it is widely acknowledged that identity and self-evaluation are both self-determined and shaped by the definitions of others, which may incorporate the perceived views of one’s local community (Jenkins, 2004; Shaw et al., 2012). Similar results are found in Chile as discrimination has a negative impact on psychological well-being, and collective identity has a positive one. Consequently, promoting the sense of belongingness and the own-group self-esteem would encourage mental health (García et al., 2017).
To answer this question, we conduct an econometric analysis using the Chilean National Socio-Economic Characterization Survey (Casen) for the years 2011 and 2013. In 2011 and 2013, CASEN includes a question about LS. As a dependent variable, we use the municipality average level of LS, and as regressors, those controls that theory and previous research have identified as determinants of LS plus municipalities segregation, which have been measured using the Duncan Index. Our main result is that socioeconomic segregation has a positive and significant effect on LS. We run different specifications: ordinary least square (OLS), OLS including lagged LS, and first difference to control for non-observed fixed effects. In all these specifications, the socioeconomic segregation estimated parameter is positive and significant. To the best of our knowledge, this is the first investigation that searches to cast light on income base segregation effects on LS in a Latin American country.
It is important to stress here the difference between a municipality socioeconomic composition and its segregation. A municipality may be poor, for instance, if 80% of the population is poor, but not necessarily segregated if every block has the same 80% of poor households, but it will be segregated if it has the same 80% of poor people but some blocks concentrate the total amount of poor inhabitants. In the present investigation, the focus is on segregation. Residential segregation is a multidimensional phenomenon, as it has been defined in the literature (Massey and Denton, 1988). Specifically, this article defines five dimensions: evenness, exposure, concentration, centralization, and clustering. The vast majority of investigation on this subject has been focused on evenness, and it is not very common to find an article dealing with more than one dimension, a phenomenon called hypersegregation (see, for instance, Massey and Tannen, 2015). In the present investigation, we consider as residential segregation evenness because it fixes better to the Chilean cities geographical structure and because it has been widely used and hence it is easier to make comparisons with other findings in the literature. Additionally, some dimensions, like centralization, have lost relevance. The best index to measure evenness is the Dissimilarity Index (Massey and Denton, 1988), which is the one used here. It is important to point out the fact that Chilean cities exhibit high levels of segregation, something that has been corroborated by different investigations and using different segregation measures (Lambiri and Vargas, 2011; Vargas, 2016; Garrido and Vargas, 2020).
Our result may seem controversial; however, it is important to point out the fact that well-being is a multidimensional construct that goes beyond hedonism and the pursuit of happiness or pleasurable experiences and that an informative measure of well-being must encompass both hedonic and eudaimonic aspects (Ruggeri et al., 2020), and, albeit this is an important component of well-being, because of that, it is relevant to pay attention to those factors that are behind it; in order to implement a public policy, it is crucial to know how segregation would affect the full set of dimensions that compose well-being.
Summarizing, the effort of understanding determinants of LS is important to individuals and society as a whole because it is strongly connected to people quality of life, hence it will help design public policies that contribute to improve society’s quality of life (Skevington and Böhnke, 2018; Ruggeri et al., 2020). LS offers a good measure of human progress as well because it takes into account more factors than gross domestic product (GDP) alone (Diener et al., 2013). Besides, there are several investigations that have shown that LS has objective benefits on major life domains such as health and longevity; income, productivity, and organizational behavior; and individual and social behavior (De Neve et al., 2013).
Materials and Methods
We use the Casen survey for the years 2011 and 2013. This survey is one of the main sources of socioeconomic characterization used in Chile for public policy design and impact evaluation. This survey is taken every 2 years, and the sample design is probabilistic and stratified according to geography and population size. The sample selection is made in two stages in urban areas and in three stages in rural areas. In 2011, this survey was applied to 59,084 households; meanwhile, that in 2013, to 66,725—both in 324 municipalities. However, the statistical significance is not at municipality level but at national and regional levels and at urban and rural areas. The latter presents a challenge as we use segregation at the municipality level; therefore, we need to characterize LS at the same level. In order to deal with this problem and to improve the statistical properties of our estimations, we implement the small area estimation (SAE) methodology, which is explained in section Small Areas Estimations. Each municipality is divided into segments (census tracts), which are the primary sampling units.
The decision of using these two particular years is based on the fact that the Casen survey included a question about LS in 2011 and 2013. The exact question was: “Taking into account all aspects in your life: How satisfied are you with your life?” According to international standards, the answer to this question is in a scale that goes from 1, fully unsatisfied, to 10, fully satisfied.
Small Area Estimations
As mentioned, to face the statistical limitations of Casen when the unit of analysis is more disaggregated, we implement the SAE methodology. Following this procedure, we improve the precision of our dependent variable (Molina and Rao, 2010; Ministerio de Desarrollo Social y Familia, 2013; Casas-Cordero et al., 2016; Molina, 2019).
SAEs comprise a range of alternative procedures, but given the nature of the Casen data, we will use the Fay–Herriot model, which provides estimates at the area level. This model links an indicator δd for all areas d = 1…D using information from the survey () and the prediction of a synthetic regression model.
The advantages of this procedure are multiple. This estimator usually improves the efficiency of the direct estimations, and regression incorporates heterogeneity not explained by the areas. Additionally, the estimator of the mean square error is stable.
The direct estimator has the form , where ed∼iid(0,ψd), and the synthetic estimator can be written as , where . In general, the model is formulated as follows:
where is the feasible least squares:
and is the shrinkage factor .
Finally, the Fay–Herriot model can be expressed as a linear combination of both estimations:
The variance of the estimations will determine the weight assigned to each source of information. The smaller the variance of the direct estimate, the greater is the weight. Another thing to consider is that variances of the direct estimate are heteroscedastic. Each municipality (local area) has a different variance, which is estimated based on its standard error. In our case, this corresponds to the standard error of the average of LS by municipality. The variance of the synthetic model is homoscedastic, and the efficiency will depend on the goodness of fit achieved. We estimate using the Restricted Maximun Likelihood (Molina and Marhuenda, 2015).
The main objective of the SAE estimation is to fortify the direct estimates and absorb the impact of working at a small area level, especially due to the probability of being in the presence of inaccurate indicators (Polettini and Arima, 2015). To solve this problem in the LS variable, we have resorted to the use of external information, where the mission is to provide support to the data that we are faced with. Having auxiliary data with no out-of-range observations and no measurement error is vital to safeguard the good properties of this implementation (Xie et al., 2007; Ybarra and Lohr, 2008).
The variables previously described were used to make the SAE poverty estimations published by the Ministry of Social Development and Family. The selection of these variables was carried out following Casas-Cordero et al. (2016) using the stepwise procedure (Table 1). On the other hand, these data were collected from reliable administrative records that are reported periodically. The percentage of people in both private and public health systems is calculated as the number of people who attend these systems (granted by each of the relevant institutions) divided by the total number of people in each municipality (information based on population projections). The number of people in the formal employment system is provided by the Unemployment Fund Administrator (AFC), and the percentage of people living in rural conditions is provided by the National Institute of Statistics.

Table 1. Descriptive statistics of auxiliary information.
Socioeconomic segregation is measured using the Dissimilarity Index. This index indicates departure from an even distribution across the space by taking the weighted mean absolute deviation of every unit’s minority proportion from the city’s minority proportion and expressing this quantity as a proportion of its theoretical maximum (James and Taeuber, 1985; Massey and Denton, 1988). This index varies between 0 and 1, and, conceptually, it represents the proportion of minority members that would have to change their area of residence to achieve an even distribution, with the number of minority members moving being expressed as a proportion of the number that would have to move under conditions of maximum segregation (Jakubs, 1977; Massey and Denton, 1988). This index has been widely used in the literature because it is very easy to calculate; it demands very few data, and it is easy to make comparisons with other studies. Additionally, this is the index with the best statistics properties to measure the segregation dimension of evenness (Massey and Denton, 1988). However, it possesses some weaknesses as well. The most important is that this index does not take into account spatial aspects of segregation such the well-known modifiable areal unit problem where the arbitrary selection spatial partition, such as census tracts, county districts, or post code areas, would generate statistical bias. Several corrections to this issue have been proposed (see, for example, O’Sullivan and Wong, 2007); however, all of them demand spatial data. The nature of our data does not allow us to undertake a spatial analysis; consequently, we will use the traditional Dissimilarity Index without spatial adjustments. Notwithstanding, it has been shown that the traditional Dissimilarity Index is highly correlated with other more sophisticated measures of evenness.
The formula of this index is as follows:
where ti and pi are the total population and minority proportion of areal unit i, in our case, municipalities’ segments, and T and P are the population size and minority proportion of the municipality, which is subdivided into n segments.
Table 2 shows descriptive statistics after implementing SAE methodology. Regarding LS, it is possible to see that it is around 7 on a scale of 1 to 10 (7.09 for 2011 and 7.47 for 2013). The segregation index, calculated with Duncan’s methodology, is around 0.7 in said period. As expected, for that period, the unemployment rate was around its natural level (between 3 and 4% in the case of Chile). As can be seen, for both years, information is available for 324 municipalities.
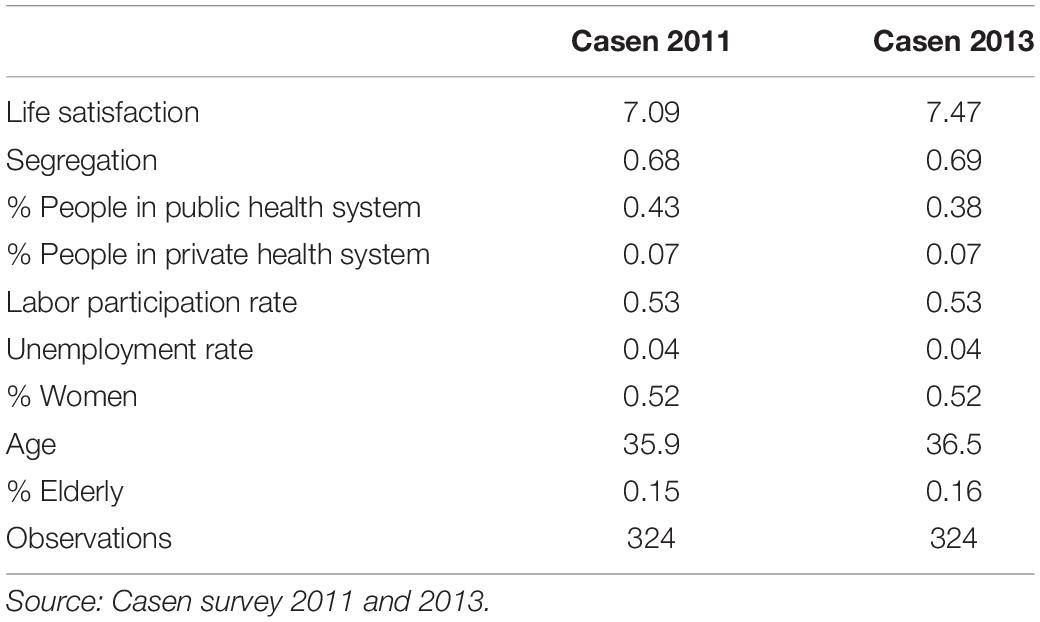
Table 2. Descriptive statistics.
As a way to appreciate the effect of estimating LS through the SAE methodology, Figures 1, 2 present the relationship between the original variable (X axis) and its estimation via SAE (Y axis) for the years 2011 and 2013. The municipalities that are on the red line (45 degrees) are those where the SAE estimate does not make a difference from the original variable. In this way, it is possible to appreciate that the majority of the municipalities experience a significant change in the variable “life satisfaction” for both years. It is also possible to notice that there are some communes that experience a substantive variation in this variable. Hence, what is learned from this exercise is that the estimation by SAE offers an improvement when working with data at the municipality level—at least for the case of Chile.
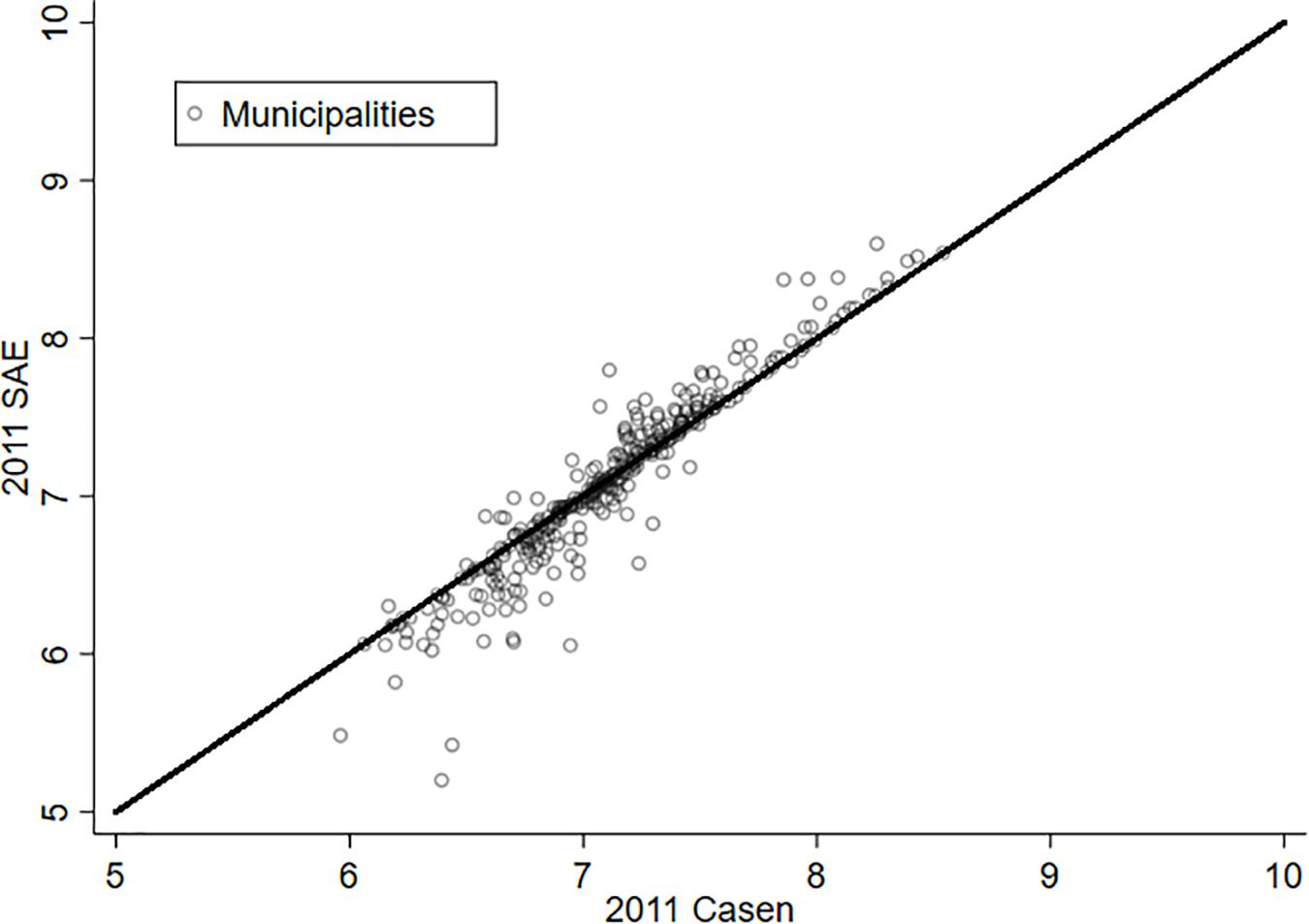
Figure 1. Life satisfaction and SAE, 2011.
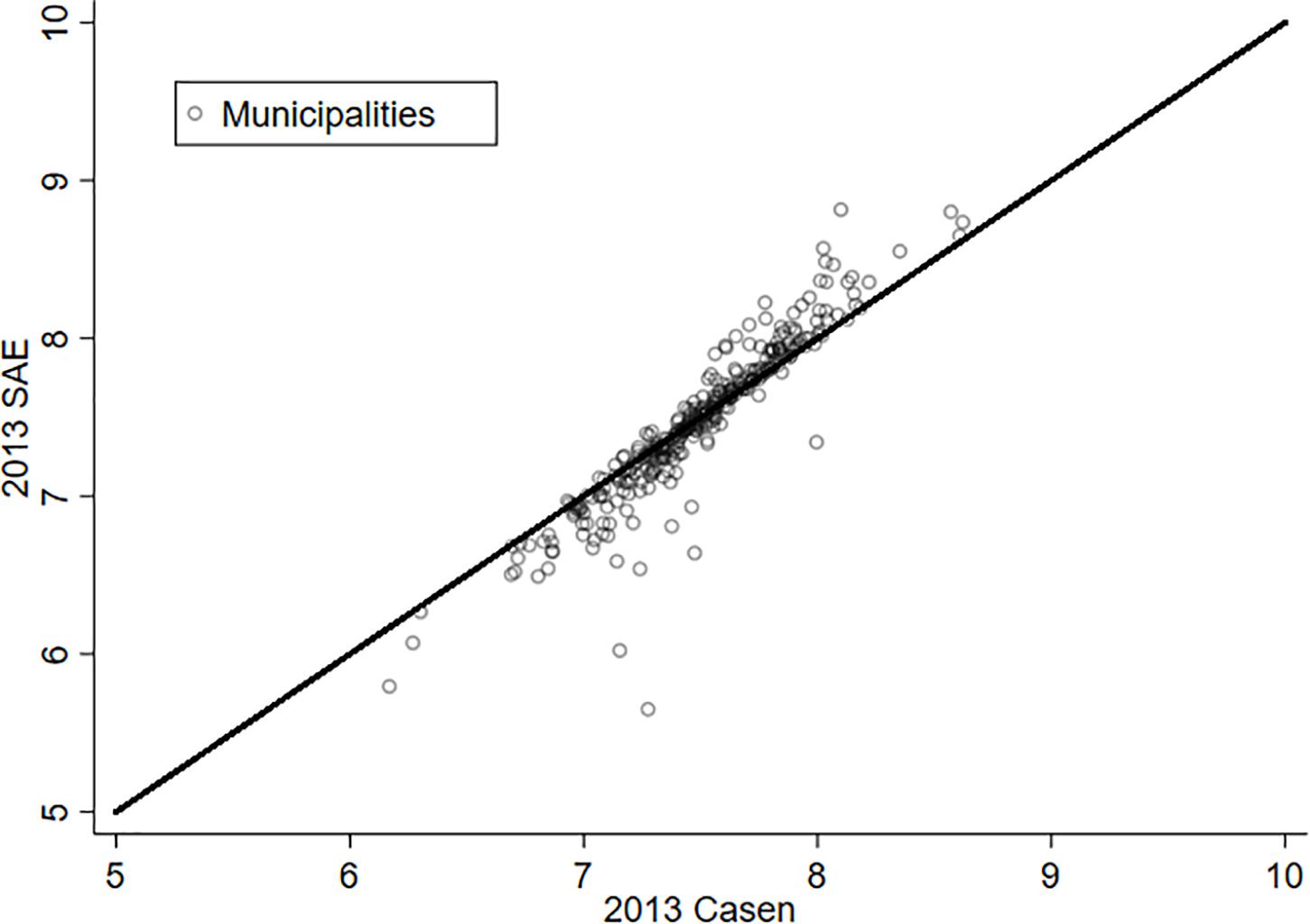
Figure 2. Life satisfaction and SAE, 2013.
Robustness Analysis: Regression to the Proportion
The database we have is at an aggregate level. Given this, the variables are at the average level. According to O’Connell (2000), we could have problems in the measure of average LS, since its original nature is ordinal. To solve and reaffirm the robustness of the results, a regression was performed on the transformed dependent variable of satisfaction with life. This variable represents “the percentage of people who are satisfied with their life at the communal level,” and it is a variable that is in the interval [0,1].
In addition, SAE estimates are subject to additional variance treatments, since an endogeneity problem arises: The definition of variance of a proportion depends on the estimated proportion.
Jiang et al. (2001) proposed a transformation to the dependent variable when it is a proportion and in this way avoids the endogeneity of variance problems. The transformation is arcosenic and is defined as , while the variance estimate associated with this transformation takes the form , where deff is the design effect associated with each area, in our case, municipalities, and 4n is four times the size of the sample associated with each area.
Considering these estimations represents a challenge that allows verifying the robustness of the available data. The following is the regression of the synthetic estimate associated with the proportion of people satisfied with their life, which takes the value 1 when the person answers 6 or more to the question described previously and 0 otherwise (Table 3).
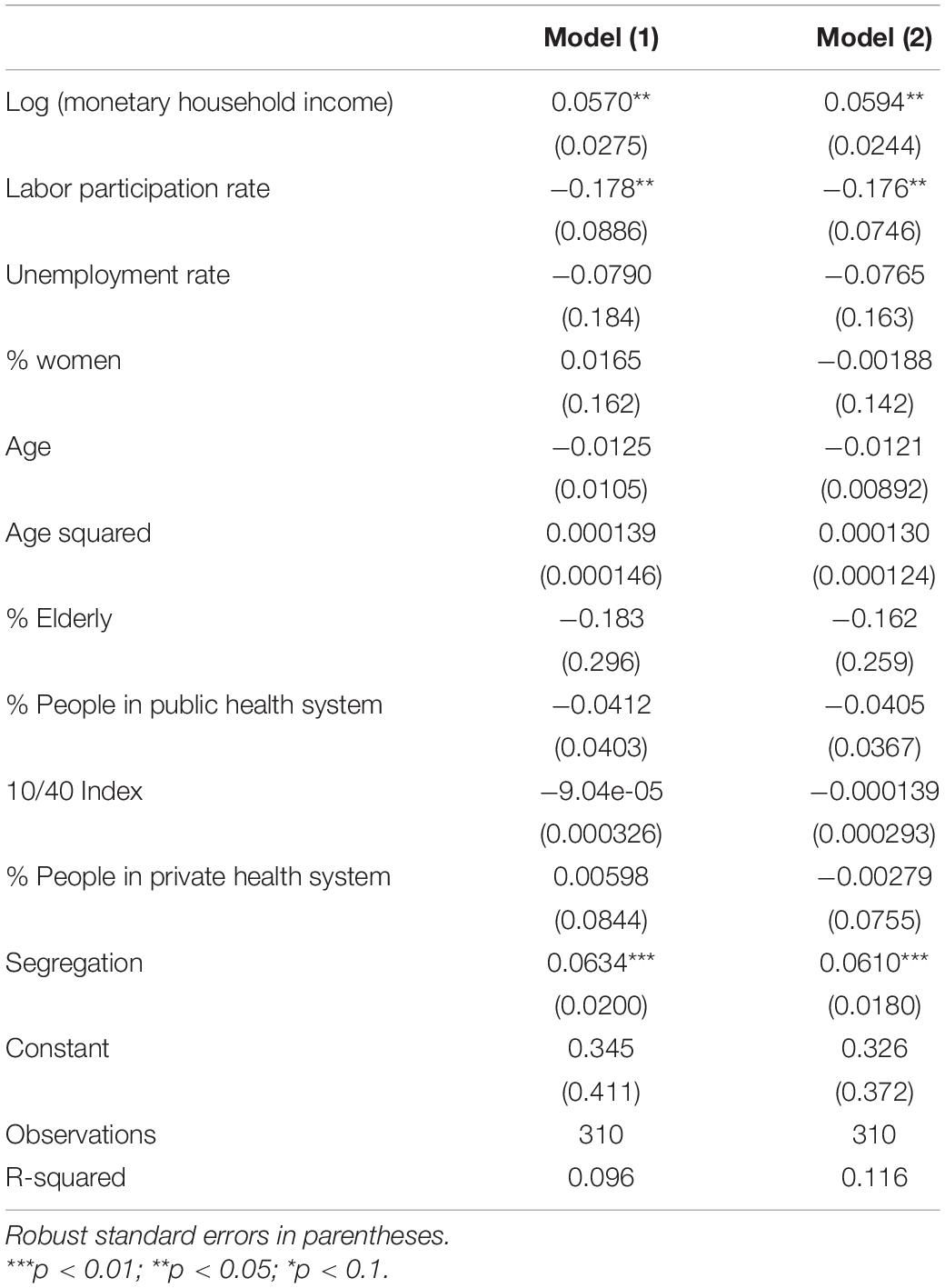
Table 3. Proportion analysis.
We have chosen to follow model 2. This model incorporates the SAE poverty rate as a predictor. The inclusion of regions as control variables does not allow the percentage of rurality to remain significant, but the recommendations aim to maintain the variable even when it loses significance.
Finally, it should be noted that when we consider SAE technology to improve the characteristics of the LS variable, in addition to the considerations applied to the direct variance estimates, they allow us to conclude that the LS variable is robust. The constriction factor rises from 0.678 to 0.936, which implies that the direct estimation has the greatest participation within the model (Figure 3).
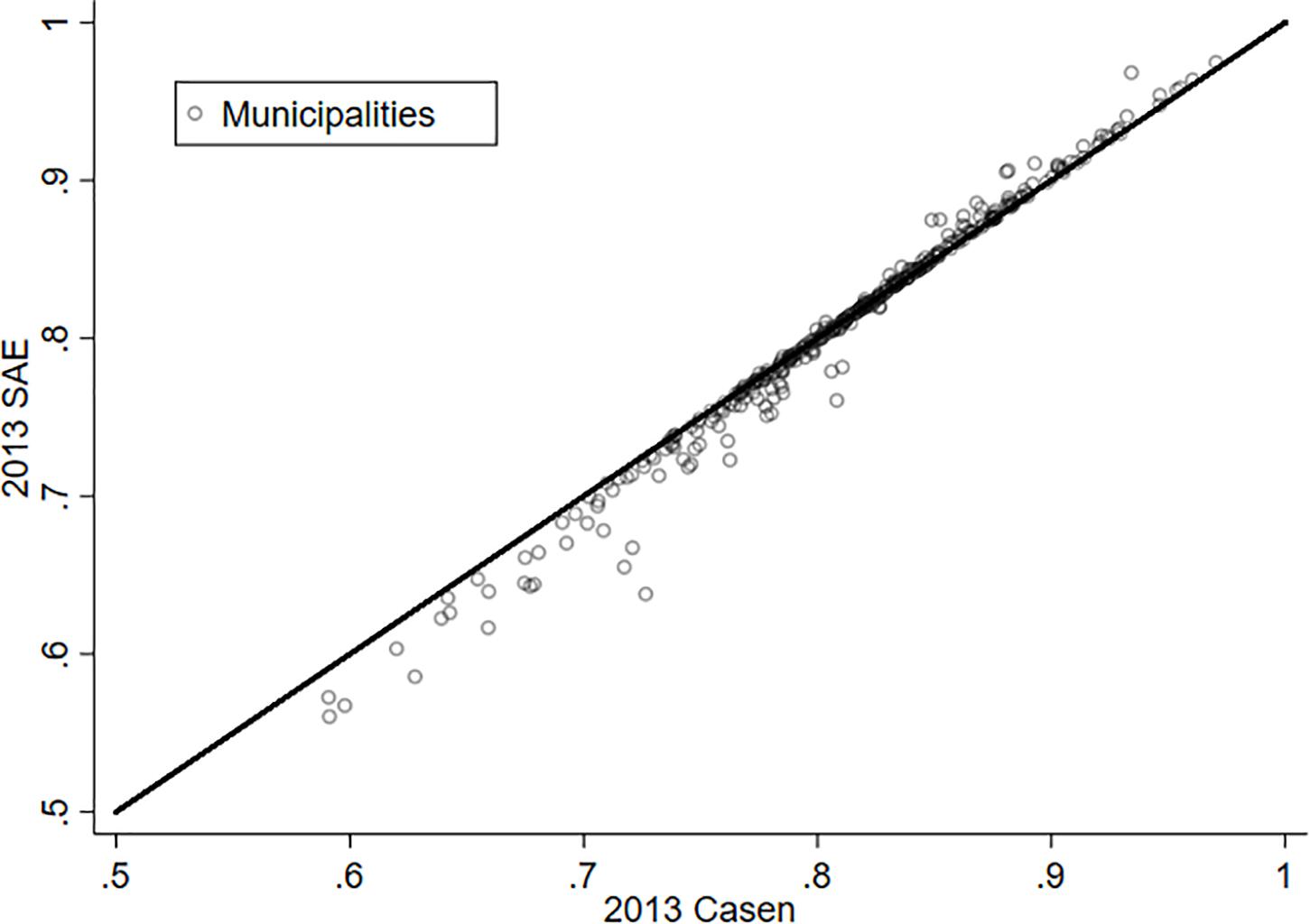
Figure 3. Life satisfaction and SAE for the proportion of people who are satisfied with their lives, 2013.
Results
Table 4 presents the model’s estimates for LS. Columns 1 and 2 show the estimates when the variable LS is used as the dependent variable. On the other hand, columns 3 and 4 show the estimates when the variable LS estimated by SAE is used as the dependent variable.
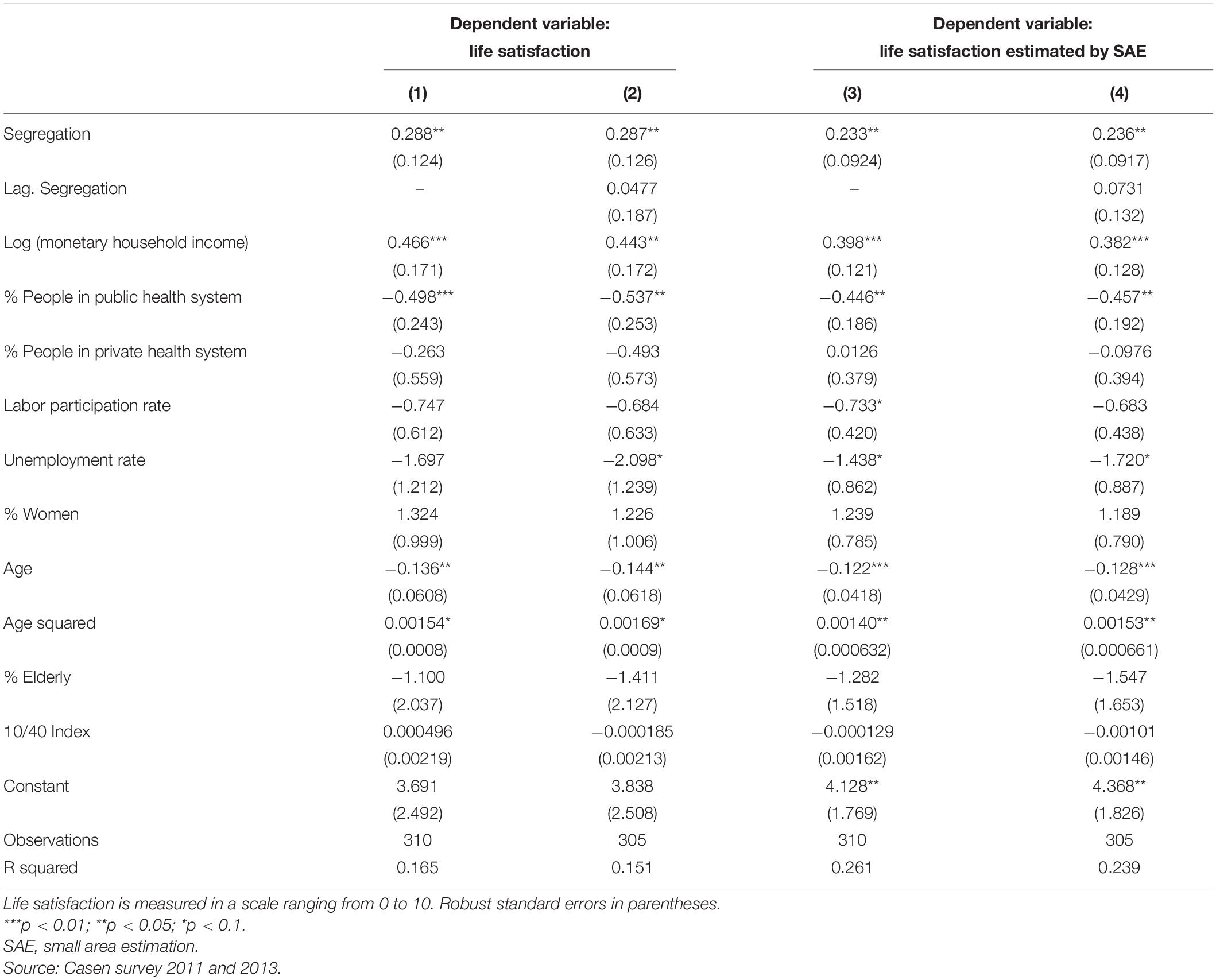
Table 4. Determinants of life satisfaction.
Firstly, it stands out as the main result that the segregation variable has a positive and statistically significant impact (at 5%) on LS. This result is maintained regardless of whether it is estimated with the LS variable (columns 1 and 2) or with the LS variable estimated by SAE (columns 3 and 4). Since socioeconomic segregation can have a dynamic effect on the LS variable, its lag is incorporated into the right side of the equation. When this is done, it is appreciated that the lagged variable does not have a statistically significant effect.
With respect to the other variables incorporated in the model, the results are in line with the previous empirical evidence.1 The coefficient associated with the logarithm variable of household monetary income is positive and statistically significant (in three of the four models, it is significant at 1%). This means that the monetary income of the home has a diminishing marginal return on LS. This result is maintained regardless of whether it is estimated with the LS variable or with the LS variable estimated by SAE. With respect to age, a U-shaped relationship is seen. This means that satisfaction with life is greater at the ends of life and reaches a minimum value around the average age of the person. In fact, it is possible to calculate the age at which satisfaction with life is minimized, which in the case of Chile, and according to these estimates, is obtained at 42 years of age. Finally, it should be noted that the four models have a high R squared (between 15 and 26%).
One aspect that may affect the previous estimates has to do with the role of the unobservable factors, which would bias the estimated coefficients.2 If these unobservable factors are assumed to be invariant over time, a difference estimate eliminates the problem. Therefore, Table 5 presents the results of estimating the model in differences, with data from the Casen survey 2011 and 2013.
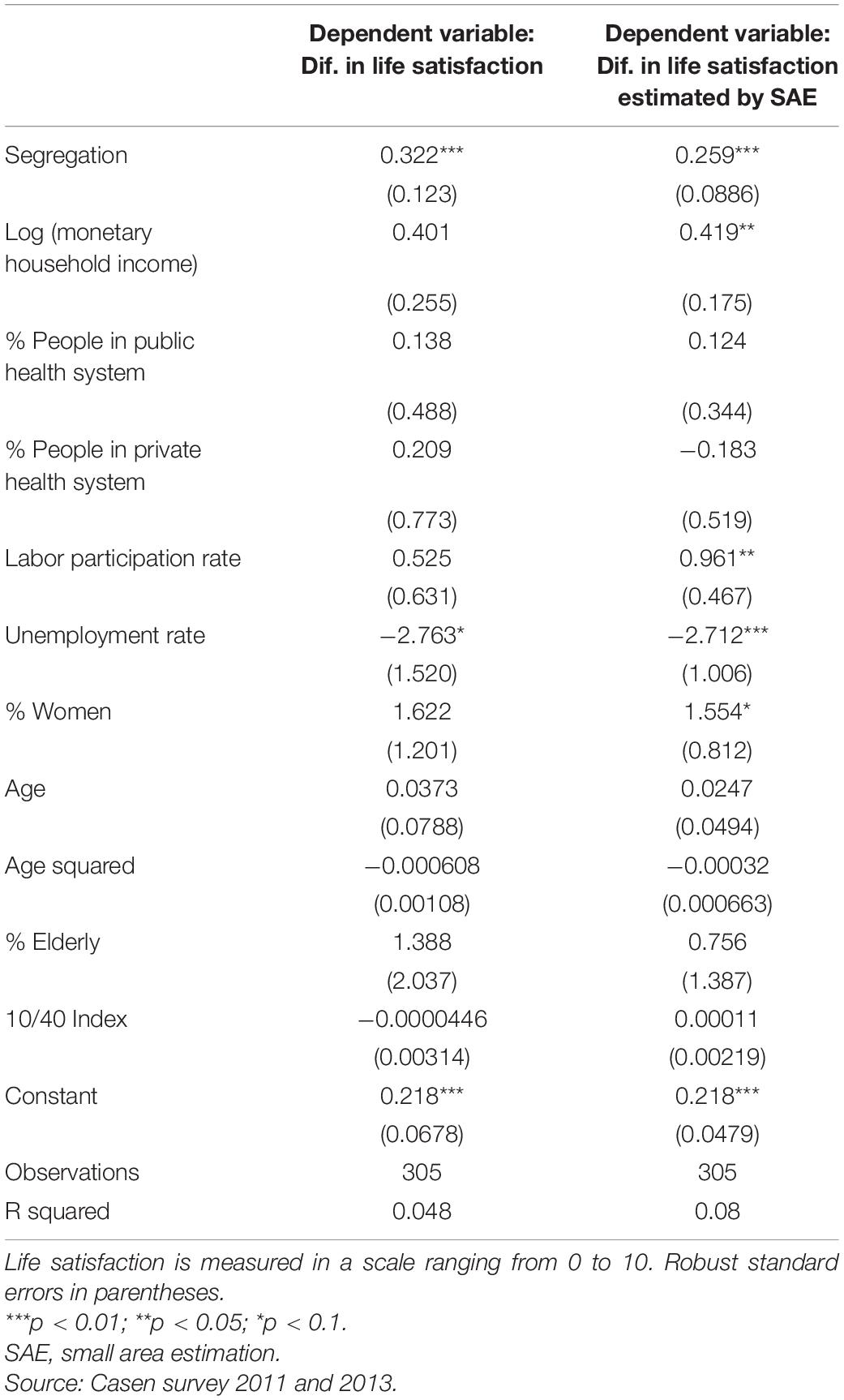
Table 5. Determinants of life satisfaction (model in differences 2013–2011).
The results show that the variable socioeconomic “segregation” is, practically, the only variable that remains significant. The coefficient associated with it is positive and statistically significant at 1%. The logarithm of household monetary income has a positive effect on LS but only when the LS variable estimated by SAE is used. And the unemployment rate has a negative effect on the LS of the population.
A final aspect that is evaluated has to do with a supposed persistence that the variable LS may have. That is why an estimation of a first-order autoregressive model is carried out for the variable LS. The results of the estimation for a model with these characteristics are presented in Table 6. Columns 1 and 2 present the estimates when the variable LS is considered as the dependent variable, while columns 3 and 4 show the estimates when the LS variable estimated by the SAE methodology is used. It should be noted that columns 2 and 4 show the estimates when the lagged segregation variable is added as a control.
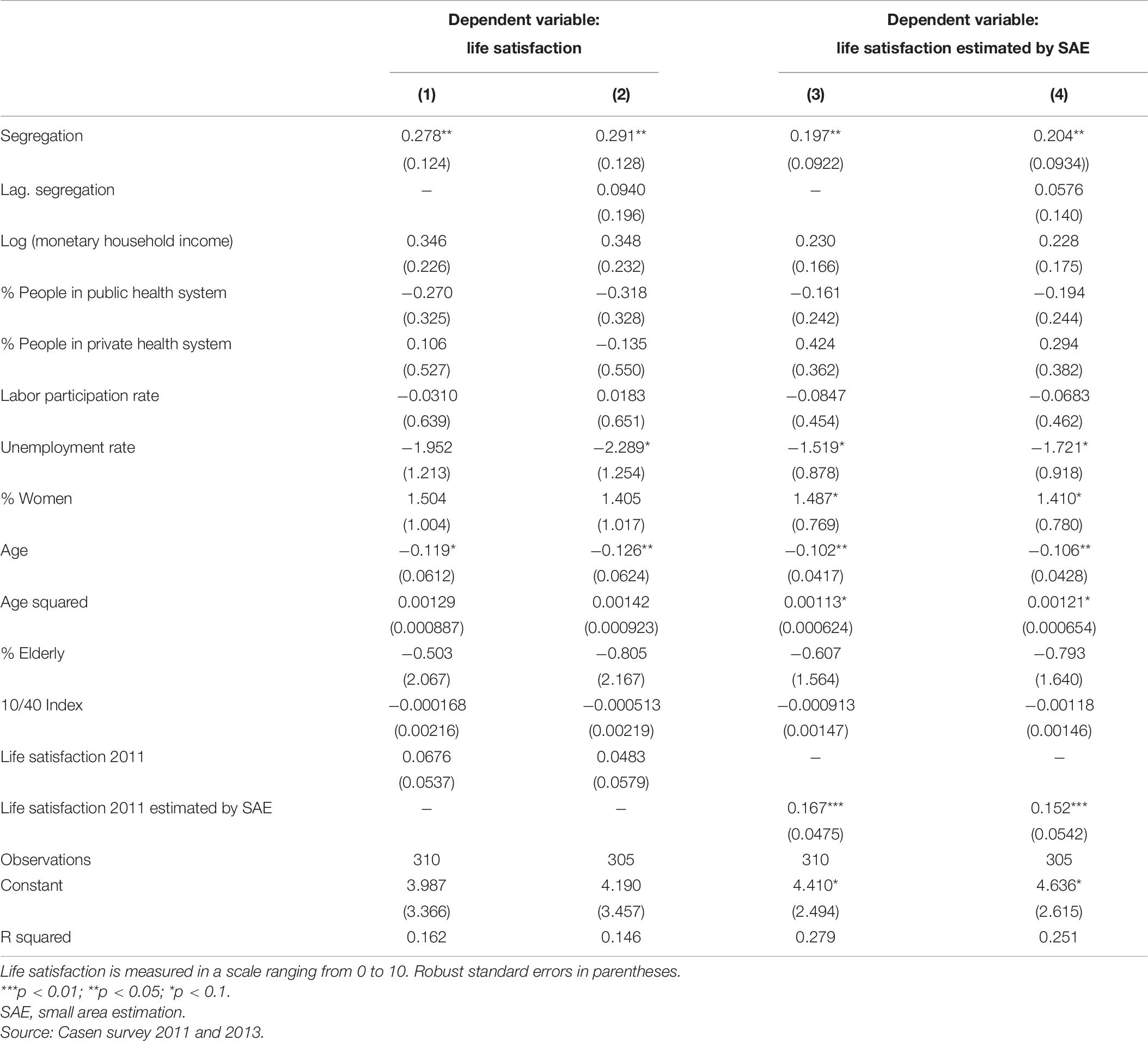
Table 6. Determinants of life satisfaction (evaluating persistence).
The main result that has been shown is maintained, that is, segregation has a positive and statistically significant effect (at 5%) on the satisfaction with life of the population. The difference that can be seen basically has to do with the effect of the lagged dependent variable. While in models 1 and 2, it is seen that the lagged variable does not have a significant effect on the LS variable, in models 3 and 4, a positive and statistically significant effect is found.
The results indicate that segregation continues to have a positive and significant effect at 1%. Also note that the expected signs and significance for the household income variables, measured in logarithm, and the labor force are maintained (Table 7).
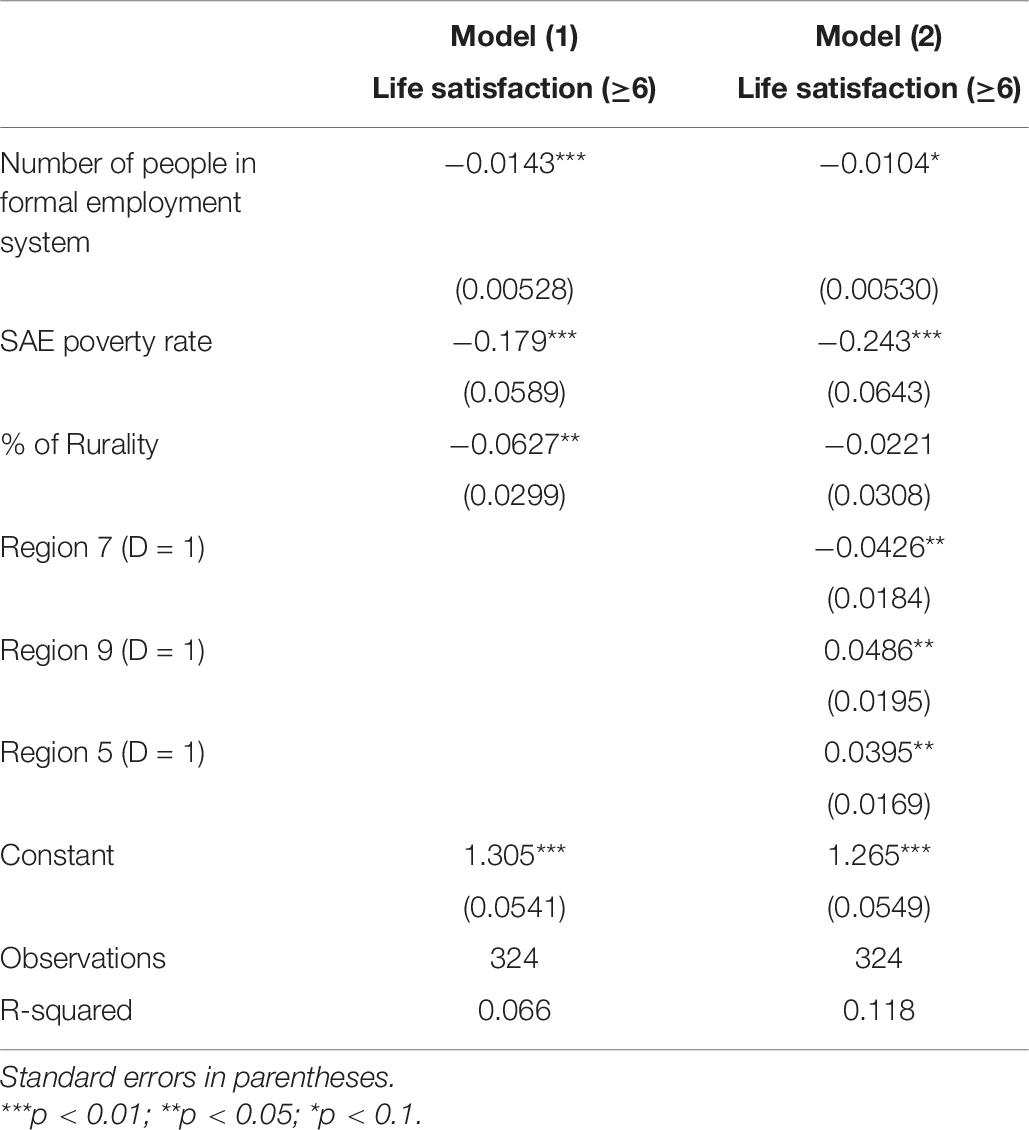
Table 7. SAE for life satisfaction measured as proportion.
Finally, it is worth mentioning that the segregation variable is robust to these considerations. Significance is maintained by changing its nature and by incorporating the SAE methodology to evaluate its robustness, even when we have a variance estimation that is more exact than the previous ones.
A requirement for the arcosenic transformation is that the prediction of the synthetic model must be kept within the real numbers that the transformation supports. By definition, the arcsine of a variable X is real if its values are in the range [0,]. The prediction values for the LS variable range between 1.03 and 1.22, which guarantees valid results.
In this way, what has been shown, through the different models that have been estimated, is that the socioeconomic segregation variable has a robust, positive, and statistically significant impact on the LS.
Discussion
We have tested the hypothesis that socioeconomic segregation has a negative effect on individuals’ LS. Several investigations produced by social scientists coming from different backgrounds such as sociology, psychology, and economics have shown the pernicious consequences of segregation on well-being. Consequently, at first sight, we would expect to observe a similar result regarding segregation impact on LS. Notwithstanding, our finding goes in an opposite direction: socioeconomic segregation has a positive effect on LS. Despite the latter may seem as a striking result, there is empirical and theoretical background supporting it. First, similar results have been found about the effects of racial segregation on SWB in the USA regarding the fact that households are happier living among households of the same race. Social capital may be increased as well if people of similar income, needs, and tastes share the same neighborhoods. Segregated households may have a greater sense of belongingness, social cohesion, trust, participation, and mutual support and collective action. Another possible explanation to this result has to do with the acculturation process. For instance, in an integrated neighborhood, people of different socioeconomic backgrounds may face the stress of acculturation, which would have a negative effect on LS. Albeit it is not the same situation that has been studied here, it has been found in literature that immigrants must deal with the stress due to acculturation and rooting with the host country (Urzúa et al., 2019). Hence, our finding has support in literature. However, we are aware about the severe negative effects that segregation imposes to minorities. Additionally, we have to consider the fact that even if segregation has a positive effect on LS, it does not mean that the final effect on well-being will be positive, as both concepts are not the same, as the former is just a constituent part of the latter (Diener, 1984; Samman, 2007; Busseri and Sadava, 2010; Diener et al., 2018; Ruggeri et al., 2020). But the problem seems to be that grown-ups and adolescents will face just disruptive effects because of the dismantling of their social networks, among others, if they are moved to richer neighborhoods. Therefore, any public policy design to reduce segregation should take into account these effects and maybe it should be focused on children; otherwise, it will cause just distress, a reduction of LS, and its positive impact will be almost negligible.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://observatorio.ministeriodesarrollosocial.gob.cl/encuesta-casen.
Author Contributions
RM: econometric analysis, results’ analysis, and interpretation. MV: research question, methodological design, results’ interpretation, and write down the document. DV: econometric analysis and data analysis. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
MV acknowledges the support of the Centre for Social Conflict and Cohesion Studies, project ANID/FONDAP/15130009.
Footnotes
- ^ These results should be viewed with caution, as there are potentially other elements that also affect life satisfaction. For example, the role played by unobservables (in terms of individual personality traits) is well documented in the literature. Unfortunately, with the information available, it is not possible to take these types of factors into account. However, the signs for the rest of the explanatory variables incorporated in the model have the expected sign.
- ^ These unobservables have to do with those existing at the municipality level.
References
Alesina, A., and La Ferrara, E. (2000). Participation in heterogeneous communities. Q. J. Econ. 115, 847–904. doi: 10.1162/003355300554935
Bashir, S. A. (2002). Home is where the harm is: inadequate housing as a public health crisis. Am. J. Public Health 92, 733–738. doi: 10.2105/AJPH.92.5.733
Bittencourt, T. A., Giannotti, M., and Marques, E. (2020). Cumulative (and self-reinforcing) spatial inequalities: interactions between accessibility and segregation in four Brazilian metropolises. Environ. Plan. B Urban Anal. City Sci. doi: 10.1177/2399808320958426
Bovaird, T., and Elke, L. (2003). Evaluating the quality of public governance: indicators, models and methodologies. Int. Rev. Admin. Sci. 69, 313–328. doi: 10.1177/0020852303693002
Brooks-Gunn, J., Duncan, G. J., Klebanov, P. K., and Sealand, N. (1993). Do neighborhoods influence child and adolescent development? Am. J. Sociol. 99, 353–395. doi: 10.1086/230268
Busseri, M. A., and Sadava, S. W. (2010). A review of the tripartite structure of subjective well-being: implications for conceptualization, operationalization, analysis, and synthesis. Pers. Soc. Psychol. Rev. 15, 290–314. doi: 10.1177/1088868310391271
Casas-Cordero, C., Encina, J., and Pratesi, M. (2016). “Analysis of poverty data by small area estimation,” in Poverty Mapping for the Chilean Comunas 379, ed. M. Pratesi, (Hoboken, NJ: John Wiley & Sons). doi: 10.1002/9781118814963.ch20
Cazacova, L., Erdelhun, A., Saymanlier, A. M., Cazacova, N., and Ulbar, U. (2010). Social and spatial aspects of housing development affecting urban quality of life-the case of Famagusta. World Acad. Sci. Eng. Technol. 66, 931–944.28.
Cheshire, P. C. (2007). Segregated Neighbourhoods and Mixed Communities: A Critical Analysis. York: Joseph Rowntree Foundation.
Chetty, R., Hendren, N., and Katz, L. F. (2016). The effects of exposure to better neighborhoods on children: new evidence from the Moving to Opportunity experiment. Am. Econ. Rev. 106, 855–902. doi: 10.1257/aer.20150572
Cutler, D. M., and Glaeser, E. L. (1997). Are ghettos good or bad? Q. J. Econ. 112, 827–872. doi: 10.1162/003355397555361
Das-Munshi, J., Becares, L., Dewey, M. E., Stansfeld, S. A., and Prince, M. J. (2010). Understanding the effect of ethnic density on mental health: multi-level investigation of survey data from England. BMJ 341:c5367. doi: 10.1136/bmj.c5367
De Neve, J.-E., Diener, E., Tay, L., and Xuereb, C. (2013). “The objective benefits of subjective well-being,” in World Happiness Report 2013, eds J. Helliwell, R. Layard, and J. Sachs, (New York, NY: UN Sustainable Development Solutions Network).
Díaz, R., Garrido, N., and Vargas, M. (2020). Segregation of high-skilled workers and the productivity of cities. Regional Sci. Policy Pract. doi: 10.1111/rsp3.12355
Diener, E. (1984). Subjective well-being. Psychol. Bull. 95, 542–575. doi: 10.1037/0033-2909.95.3.542
Diener, E., Lucas, R. E., and Oishi, S. (2018). Advances and open questions in the science of subjective well-being. Collabra Psychol. 4:15. doi: 10.1525/collabra.115
Diener, E., Tay, L., and Oishi, S. (2013). Rising income and the subjective well-being of nations. J. Pers. Soc. Psychol. 104:267. doi: 10.1037/a0030487
Fabio, A., Sauber-Schatz, E. K., Barbour, K. E., and Li, W. (2009). The association between county-level injury rates and racial segregation revisited: a multilevel analysis. Am. J. Public Health 99, 748–753. doi: 10.2105/AJPH.2008.139576
García, F. E., Castillo, B., García, A., and Smith-Castro, V. (2017). Bienestar psicológico, identidad colectiva y discriminación en habitantes de barrios estigmatizados. Pensando Psicología 13, 41–50. doi: 10.16925/pe.v13i22.1987
Garrido, N., and Vargas, M. (2020). High-skilled workers’ segregation and productivity in Latin American cities. Cepal Rev.
Gibbons, J., Yang, T. C., Brault, E., and Barton, M. (2020). Evaluating residential segregation’s relation to the clustering of poor health across American cities. Int. J. Environ. Res. Public Health 17:3910. doi: 10.3390/ijerph17113910
Ibem, E., and Amole, D. (2013). Subjective life satisfaction in public housing in urban areas of Ogun State, Nigeria. Cities 35, 51–61. doi: 10.1016/j.cities.2013.06.004
Jakubs, J. F. (1977). Residential segregation: the Taeuber index reconsidered. J. Regional Sci. 17, 281–283. doi: 10.1111/j.1467-9787.1977.tb00497.x
James, D. R., and Taeuber, K. E. (1985). Measures of segregation. Sociol. Methodol. 15, 1–32. doi: 10.2307/270845
Jargowsky, P. A. (2014). “Segregation, neighborhoods, and schools,” in Choosing Homes, Choosing Schools, eds A. Lareau, and K. Goyette, (New York, NY: Russell Sage Foundation), 97–136.
Jencks, C., and Mayer, S. E. (1990). “The social consequences of growing up in a poor neighborhood,” Inner-City Poverty in the United States, eds L. E. Lynn, & M. F. H. McGeary, (Washington, DC: National Academy Press), 111–186.
Jiang, J., Lahiri, P., Wan, S. M., and Wu, C. H. (2001). Jackknifing in the Fay-Herriot model with an example. 75–79.
Jimmy, E. N., Martinez, J., and Verplanke, J. (2019). Spatial patterns of residential fragmentation and quality of life in Nairobi City, Kenya. Appl. Res. Quality Life 15, 1493–1517. doi: 10.1007/s11482-019-09739-8
Lambiri, D., and Vargas, M. (2011). Residential segregation and public housing policy, the case of Chile. Paper Presented at Serie de Documentos de Trabajo, Departamento de Economía, Universidad Diego Portales, No 29, Santiago.
Leventhal, T., and Brooks-Gunn, J. (2000). The neighborhoods they live in: the effects of neighborhood residence on child and adolescent outcomes. Psychol. Bull. 126:309. doi: 10.1037/0033-2909.126.2.309
Ludwig, Duncan, J. G., Gennetian, L., Katz, L., Kessler, R., Kling, J., et al. (2012) “Neighborhood Effects on the Long-Term Well-Being of Low-Income Adults.” Science 337, 1505–1510.
Luttmer, E. F. (2001). Group loyalty and the taste for redistribution. J. Political Econ. 109, 500–528. doi: 10.1086/321019
Luttmer, E. F. (2005). Neighbors as negatives: relative earnings and well-being. Q. J. Econ. 120, 963–1002. doi: 10.1093/qje/120.3.963
Luttmer, E. F. P., and Singhal, M. (2008). Culture, context, and the taste for redistribution. Paper Presented at NBER Working Paper Series, 14268, Santiago. doi: 10.3386/w14268
Massey, D. S., and Denton, N. A. (1988). The dimensions of residential segregation. Social Forces 67, 281–315. doi: 10.2307/2579183
Massey, D. S., and Tannen, J. (2015). A research note on trends in black hypersegregation. Demography 52, 1025–1034. doi: 10.1007/s13524-015-0381-6
Ministerio de Desarrollo Social y Familia, (2013). “Procedimiento de cálculo de la tasa de pobreza a nivel comunal mediante la aplicación de metodología de estimación para áreas pequeas (SAE). División Observatorio Social,” in Paper Presented at Serie Documentos Metodológicos, Santiago.
Molina, I. (2019). Desagregación de Datos en Encuestas de Hogares: Metodologías de Estimación en Áreas Pequeas. Santiago: Comisión Económica para América Latina y el Caribe.
Molina, I., and Rao, J. (2010). Small area estimation of poverty indicators. Can. J. Stat. 38, 369–385. doi: 10.1002/cjs.10051
O’Connell, Ann Aileen (2000). Methods for modeling ordinal outcome variables. Measurement and Evaluation in Counseling and Development, 33, 170–193.
Okulicz-Kozaryn, A. (2019). Are we happier among our own race? Econ. Sociol. 12, 11–35. doi: 10.14254/2071-789X.2019/12-2/1
O’Sullivan, D., and Wong, D. W. (2007). A surface-based approach to measuring spatial segregation. Geographical Anal. 39, 147–168. doi: 10.1111/j.1538-4632.2007.00699.x
Park, H. (2006). Housing welfare indicators for the quality of life in Korea. Housing Stud. Rev. 14, 5–26.
Polettini, S., and Arima, S. (2015). Small area estimation with covariates perturbed for disclosure limitation. Statistica 75, 57–72.
Ruggeri, K., Garcia-Garzon, E., Maguire, Á, Matz, S., and Huppert, F. A. (2020). Well-being is more than happiness and life satisfaction: a multidimensional analysis of 21 countries. Health Quality Life Outcomes 18, 1–16. doi: 10.1186/s12955-020-01423-y
Samman, E. (2007). Psychological and subjective well-being: a proposal for internationally comparable indicators’. Paper Presented at OPHI Working Paper 5, University of Oxford, Oxford. doi: 10.1080/13600810701701939
Sampson, R. J., Morenoff, J. D., and Gannon-Rowley, T. (2002). Assessing “neighborhood effects”: social processes and new directions in research. Annu. Rev. Sociol. 28, 443–478. doi: 10.1146/annurev.soc.28.110601.141114
Shaw, R. J., Atkin, K., Bécares, L., Albor, C. B., Stafford, M., Kiernan, K. E., et al. (2012). Impact of ethnic density on adult mental disorders: narrative review. Br. J. Psychiatry 201, 11–19. doi: 10.1192/bjp.bp.110.083675
Skevington, S. M., and Böhnke, J. R. (2018). How is subjective well-being related to quality of life? Do we need two concepts and both measures? Soc. Sci. Med. 206, 22–30. doi: 10.1016/j.socscimed.2018.04.005
Stafford, M., Bécares, L., and Nazroo, J. (2010). “Ethnicity, and integration,” in Racial Discrimination and Health: Exploring the Possible Protective Effects of Ethnic Density, eds J. Stillwell, and M. van Ham, (Berlin: Springer), 225–250. doi: 10.1007/978-90-481-9103-1_11
Theriault, L., Lecclerc, A., Wisniewski, A. E., Chouinard, O., and Martin, G. (2010). Not just an apartment building: residents quality of life in a social housing cooperative. Can. J. Nonprofit Soc. Econ. Res. 1, 82–100. doi: 10.22230/cjnser.2010v1n1a11
Urzúa, A., Leiva-Gutiérrez, J., Caqueo-Urízar, A., and Vera-Villarroel, P. (2019). Rooting mediates the effect of stress by acculturation on the psychological well-being of immigrants living in Chile. PLoS One 14:e0219485. doi: 10.1371/journal.pone.0219485
Van Praag, B., Frijters, P., and Ferrer-i-Carbonell, A. (2003). The anatomy of subjective well-being. J. Econ. Behav. Organ. 51, 29–49. doi: 10.1016/S0167-2681(02)00140-3
Vargas, M. (2016). Tacit collusion in housing markets, the case of Santiago, Chile. Appl. Econ. 48, 5257–5275. doi: 10.1080/00036846.2016.1176111
Wilkinson, R., and Pickett, K. (2008) Income Inequality and Social Gradients in Mortality, Am. J. Public Health, 98, 699–704.
Xie, D., Raghunathan, T. E., and Lepkowski, J. M. (2007). Estimation of the proportion of overweight individuals in small areas—a robust extension of the Fay–Herriot model. Stat. Med. 26, 2699–2715. doi: 10.1002/sim.2709
Keywords: subjective wellbeing, quality of life, segregation, inequality, social capital, small area estimations
Citation: Montero R, Vargas M and Vásquez D (2021) Segregation and Life Satisfaction. Front. Psychol. 11:604194. doi: 10.3389/fpsyg.2020.604194
Received: 08 September 2020; Accepted: 11 December 2020;
Published: 05 February 2021.
Edited by:
Dario Paez, University of the Basque Country, SpainReviewed by:
Alfonso Urzua, Catholic University of the North, ChileMarcelo Lufin, Catholic University of the North, Chile
Copyright © 2021 Montero, Vargas and Vásquez. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Miguel Vargas, bWlndWVsLnZhcmdhc0B1bmFiLmNs; bXZhcmdhc3JvbWFuQGdtYWlsLmNvbQ==