 Baitao Liu
Baitao Liu- School of Education Science, Nanyang Normal University, Nanyang, China
This study mainly focuses on the emotion analysis method in the application of psychoanalysis based on sentiment recognition. The method is applied to the sentiment recognition module in the server, and the sentiment recognition function is effectively realized through the improved convolutional neural network and bidirectional long short-term memory (C-BiL) model. First, the implementation difficulties of the C-BiL model and specific sentiment classification design are described. Then, the specific design process of the C-BiL model is introduced, and the innovation of the C-BiL model is indicated. Finally, the experimental results of the models are compared and analyzed. Among the deep learning models, the accuracy of the C-BiL model designed in this study is relatively high irrespective of the binary classification, the three classification, or the five classification, with an average improvement of 2.47% in Diary data set, 2.16% in Weibo data set, and 2.08% in Fudan data set. Therefore, the C-BiL model designed in this study can not only successfully classify texts but also effectively improve the accuracy of text sentiment recognition.
Introduction
In today’s society, because people’s current social environment is unique and unprecedented, in the face of the rapid development of society and increasing personal pursuit, young people’s outlook on life and values has also undergone great changes. The Institute of Psychology of the Chinese Academy of Sciences found that in today’s society, young people aged 20–30 years bear the highest psychological and mental pressure in all age groups. Under such pressure, more and more young people are out of balance, and their psychological problems are becoming increasingly serious.
College students, as an important group in society and the pillar of the country’s future development, are prone to psychological abnormalities when they gradually change from students to contact society due to various reasons such as enrollment, employment, environment, education, feelings, and value orientation. Most of them are in a state of mental sub-health or even have mental disorders or mental diseases, and some even mistakenly choose suicide, which have an irreparable negative impact on their families, schools, and society. Therefore, it is of great social significance to develop an application that can accurately identify the psychological state of young people, provide psychological help, and provide correct value orientation.
With the continuous development of artificial intelligence, machine learning, deep learning, and other technologies, natural language processing technology has also made great progress, including sentiment recognition of text, especially in dichotomies. The accuracy rate has been over 90%, and the accuracy rate of multi-classification has been improved with the continuous optimization of the neural network model. Therefore, the pertinence and efficiency of sentiment recognition in diary text can be further studied.
Sentiment recognition is also called sentiment analysis, and sentiment analysis for text is the focus of current research, involving the applications of natural language processing, machine learning (Yi et al., 2022), artificial intelligence, information retrieval, deep learning (Bao and Wang, 2022), and other fields. The main function of sentiment recognition is to enable computers to recognize complex human emotions. In the field of neural networks in deep learning, Kalchbrenner et al. (2014) proposed the DCNN model to improve semantic synthesis by studying the sentence structure. Santo Sand Gatti et al. used the convolutional neural network based on the sentence set and character set to carry out sentiment recognition of short texts, achieving high accuracy (dos Santos and Gattit, 2014). Severyn et al. expressed the feature of sentence meaning of text by training word vector and used the convolutional neural network to extract the deep-seated feature classifier (Severyn and Moschitti, 2015). Shi et al. (2016) proposed a discontinuous non-linear feature mapping classification model based on long and short memory neural networks. Yang et al. (2018) input the vector into the bidirectional LSTM layer and then input the result into the CNN for result fusion, which effectively improved the recognition accuracy. Different from the aforementioned research, this study uses the deep learning model combining the CNN and bidirectional LSTM and fully considers the original semantics and the sequential connection between the CNN and bidirectional LSTM, so as to improve the classification effect.
Materials and Methods
This section describes the sentiment recognition method in the application of psychoanalysis based on sentiment recognition. In this study, an improved C-BiL model is proposed to effectively realize sentiment recognition. This section first describes the implementation difficulties of using the C-BiL model and specific sentiment classification design, then introduces the specific design process of the C-BiL model, and shows the innovation of the C-BiL model. Finally, the experimental results of the model are compared and analyzed.
Design of the C-BiL Model
This study is a psychological analysis application based on sentiment recognition. The main innovation of the function is that users write diaries on the Android client. Through certain methods, we can identify the emotional tendency of diaries so as to know the psychological state of users and give different psychological counseling suggestions according to the different psychological states of users. The difficulty lies in how to accurately identify the emotional tendency of the diary. The realization process of the whole sentiment recognition method is as follows: the user enters the diary text first. Diary text is a long text. Since there is no blank in Chinese sentences, pre-processing is required first. This method uses JieBa open-source tool to divide each sentence into words called word segments. By JieBa segmentation, each statement can be converted to a space-separated sequence of Chinese words. The preprocessed word sequence is input into the word2vec tool, and the word vector is trained in the data set specified in this article. Since the word vector cannot express emotional orientation, it is necessary to use a certain model for training so as to obtain text classification results that can express emotional orientation. According to the identified user emotions, different suggestions for mood adjustment should be given. The realization process of emotion recognition method is shown in Figure 1.
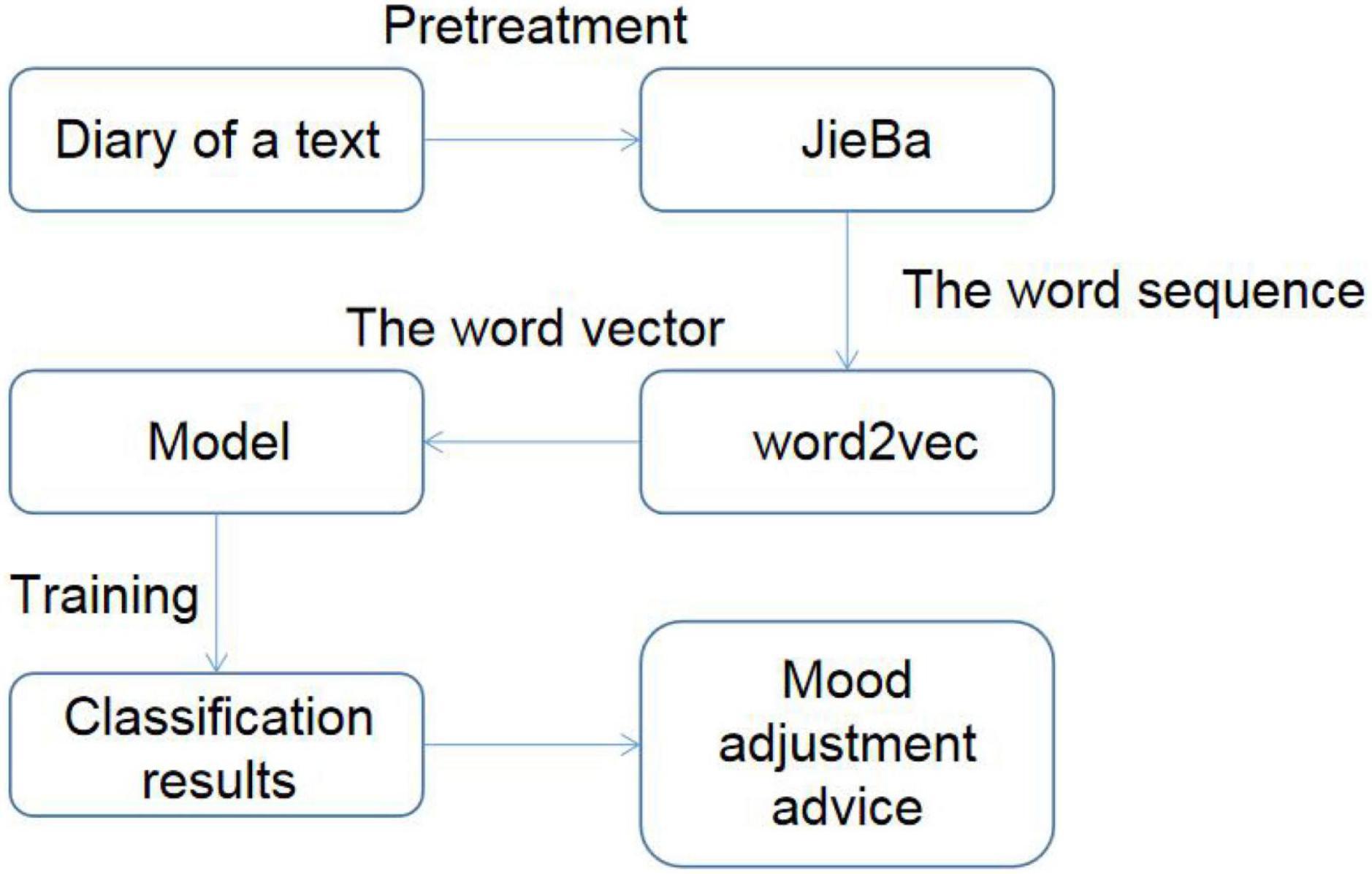
Figure 1. Realization process of the emotion recognition method.
At the same time, due to the particularity of Chinese diary text, diary text will be full of users’ rich emotions, and it cannot express all users’ delicate emotions through simple “positive emotions,” “negative emotions,” and “neutral emotions.” Therefore, according to the professional knowledge of psychological science and combined with the mental health status of contemporary college students, this study designed five emotional results: “pleasure and relaxation,” “cool and calm,” “anxiety and confusion,” “sadness and self-blame,” and “pain and despair.”
“Pleasure and relaxation” mainly refers to the user is in a relatively relaxed emotional psychology. Diary content mainly expresses a happy mood or positive energy content, such as “I believe that as long as it is hard and happy, life is full and beautiful” and “let life be beautiful, and be positive and optimistic to meet every tomorrow.”
“Cool and calm” mainly indicates that the user is in a relatively objective and calm emotional psychology. The diary content mainly expresses a kind of calm, relatively flat emotion or normal narrative content, such as “for me, what I insist on will not be happy,” “let it be natural to deal with life and adapt to this change,” and “I met Wang Xiaoming on the road today.”
“Anxiety and confusion” mainly denotes that the user is in a more anxious and worried mood. The diary content mainly expresses the uneasiness of the unknown future or worries about some things, such as “Ideal, where are you?,” “I don’t know where I am going,” and “The course is so difficult, what should I do when the exam is coming.”
“Sadness and self-blame” mainly shows that the user is in a relatively sad emotional psychology. The diary mainly expresses the existence of a crying phenomenon or the content of chagrin about something, such as “I have always been strong and cried in public,” “I cried my heart and lungs in the middle of the night,” and “why do I hate myself so much.”
“Pain and despair” mainly conveys the user is very sad or close to crazy emotional psychology. The diary mainly expresses their own irrepressible sad mood or despair attitude toward a certain thing, such as “the world is a hell!,” “Are the living happier than the dead?,” and “I have no courage to continue living.”
In terms of suggestions on emotional adjustment, this article provides a variety of emotional adjustment methods and suggestions for the five different psychological emotions mentioned earlier. For example, for the “pleasure and relaxation” emotions, users are recommended to share happy things in life with friends or social networking sites to record every good thing in life. For “cool and calm” mood, it is recommended that users can use relatively calm mood for appropriate study or work, reasonable arrangement of time, and improve themselves. For “anxiety and confusion,” it is recommended that users find their family members or classmates and teachers to communicate with each other. Do not beat yourself up about it and get more hands-on experience, such as getting an internship or attending a school event. For the “sadness and self-blame” mood, users were recommended to take appropriate exercise, go to the playground to run or play ball to relieve the sadness and remorse mood, and calm the heart in the exercise. Finally, it is recommended that users call their closest family members or friends to have a chat with them, or go out for fun. They can also focus on their work and study and forget about other things, so as to divert their attention and relieve their severe emotions. The function of providing mood adjustment suggestions is realized in the emotion recognition module of the server in the following article.
Difficulties in Sentiment Recognition for Diary Text
1. The diary text has its particularity. Due to the variable length of the text, sometimes, it even varies greatly, leading to two difficulties: First, when the diary text is very short, for example, “I watched 007 today, it is not good.” In such a short context, how to decide whether 007 is a movie name or a number will have a certain impact on the final emotional judgment. Second, when the diary text is very long, it is likely to appear the whole diary before and after different emotional tendencies; for example, the beginning is still describing the sunny weather, but the end revealed the sad mood. Such long texts also interfere with sentiment recognition.
2. Different texts and different text classification methods have different feature extraction methods. A single model cannot extract the features uniformly. For example, the CNN only pays attention to the relevance of continuous words without fully considering the relevance of non-continuous words. Although the LSTM model has the correlation of long-distance words, it has no distinct feature extraction. As diary text describes human emotions, it is necessary to fully consider both feature extraction of the diary and emotional coherence or turning point of the full text in emotion recognition, so a single model cannot have a good recognition effect.
3. A separate CNN model or LSTM model is usually only used for binary and tertiary classification recognition. In this study, five categories of emotions are designed according to the different emotions that may be generated by users’ diary texts. Using a single model may have a higher accuracy in binary and tertiary classification, but it cannot improve the performance in quintic classification. Therefore, it is very important to design a targeted sentiment recognition model for diary text.
In view of the aforementioned difficulties, the CNN achieves text sentiment recognition by extracting significant features of the measured data, while Bi-LSTM enhances long-distance text sentiment recognition by improving the generalization ability of the model and can take the semantics of the context into account. Therefore, the CNN and Bi-LSTM have their own advantages and emphases in emotional recognition of different types of texts. A new improved emotion recognition model, C-BiL model, was proposed. The model combines the advantages of the CNN and LSTM algorithm to achieve more accurate emotion recognition. The structure of the C-BiL model is shown in Figure 2.
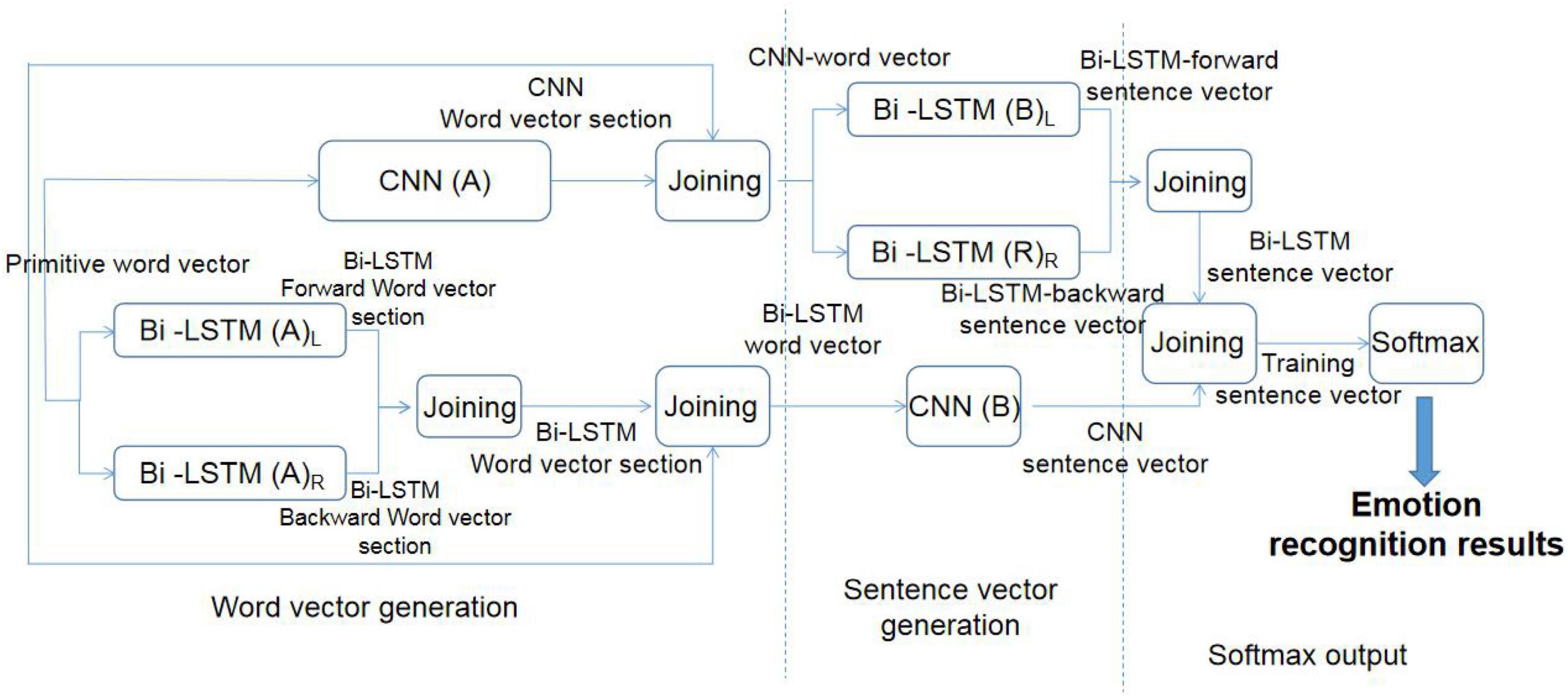
Figure 2. Structure of the C-BiL model.
The whole C-BiL model is divided into three layers. Among them, CNN(A) and CNN(B); Bi-LSTM(A) and Bi-LSTM(B), respectively, represent two sets of parameter rules of the CNN and Bi-LSTM algorithm. The design idea of the C-BiL model is given as follows:
The First Layer: Generation of the CNN and Bi-LSTM Word Vector
The original word vector is trained through the CNN(A) to get the corresponding CNN word vector segment.
The positive order of the original word vector is input into Bi-LSTM(A)L, and the corresponding Bi-LSTM forward word vector segment is trained. The original word vector is input into Bi-LSTM(B)R in a reverse order, and the corresponding Bi-LSTM backward word vector segment is trained. The Bi-LSTM forward word vector segment and Bi-LSTM backward word vector segment are spliced to obtain the Bi-LSTM word vector segment.
The generated CNN word vector segment and Bi-LSTM word vector segment are spliced with the original word vector to generate the CNN word vector and Bi-LSTM word vector, respectively.
The Second Layer: CNN and Bi-LSTM Sentence Vector Generation
The CNN word vector is input into Bi-LSTM(B)L, and Bi-LSTM forward sentence vector is obtained by training. The CNN word vector is input in a reverse order into Bi-LSTM(B)R, and the Bi-LSTM backward sentence vector is obtained by training. The Bi-LSTM forward sentence vector is spliced with the Bi-LSTM backward sentence vector to obtain the Bi-LSTM sentence vector.
Bi-LSTM word vector is input into the CNN(B), and The CNN sentence vector is obtained by training.
The Third Layer: Softmax Output
First, the Bi-LSTM sentence vector and CNN sentence vector are spliced to get the training sentence vector. The training sentence vector is input into Softmax layer to get the final emotion recognition result.
Based on the aforementioned functional requirements of emotion recognition, the C-BiL model proposed in this article can not only accurately identify the five emotions in diary text but also effectively improve the accuracy of recognition and ensure the realization of application functions.
Innovations of the C-BiL Model
1. In the field of text sentiment recognition, many models are based on the CNN only, some models are based on the LSTM only, and some improved models are based on the Bi-LSTM. Due to the particularity of diary text, it is required to fully extract text features and fully combine contextual semantics. Therefore, by combining the advantages of the CNN in capturing local features and LSTM in capturing timing features and considering context semantics, this study improved LSTM to Bi-LSTM, so as to obtain a C-BiL model with better performance.
2. At present, there are many models that combine the CNN and LSTM algorithm. In some models, vectors are input into the CNN and Bi-LSTM, respectively, for encoding, and relevant features are extracted. Finally, the two are fused at the full connection layer for classification network. In some models, vectors are input into the CNN to extract relevant features, and the results are input into the Bi-LSTM layer after passing through the convolutional layer to finally classify. In some models, vectors are input into the Bi-LSTM layer and then the results are input into the CNN (Shi et al., 2016). Some models simultaneously verified three combinations of the CNN and Bi-LSTM: the CNN followed by LSTM, LSTM followed by the CNN, and the CNN in parallel with LSTM. In this study, the C-BiL model generates CNN word vector segments and Bi-LSTM word vector segments, first splicing with the original word vector to ensure that the original word meaning is not lost in the training process. Then, Bi-LSTM and CNN are fused, respectively, to generate Bi-LSTM sentence vectors and CNN sentence vectors. Finally, the two sentence vectors are joined together and input into Softmax to obtain the final classification result. This model not only retains the original semantics to the maximum extent but also fully integrates the CNN and Bi-LSTM. The CNN is followed by Bi-LSTM, and Bi-LSTM is followed by the CNN. The final result also fully integrates the extracted features of the two (Graves et al., 2005; Collobert et al., 2011; Cho et al., 2014; Tai and Socher, 2015; Er et al., 2016; Brachmann et al., 2017; Huang et al., 2017; Jebbara and Cimiano, 2017; Wigington et al., 2017; Yenter and Verma, 2017; Huebner and Willits, 2018).
3. The general models are binary or tripartite experiments on specified data sets. Due to the particularity of diary text, the emotions contained in the text are relatively complex, and binary or tertiary classification cannot fully and accurately express users’ emotions. Therefore, this model designs five classification results.
In summary, the C-BiL model has better performance.
CNN Algorithm Design
The CNN is generally used in computer vision, especially in image processing. On the one hand, since people do not pay too much attention to global pixels when they focus on an image, more local features can be extracted through convolution. This approach is more consistent with the daily image processing. Since each individual neuron only needs to perceive local features, global information can be obtained by integrating several local features at a higher level, which eliminates the perception of global images by each neuron, thus greatly improving efficiency. On the other hand, the CNN has the feature of weight sharing, and only extracting the maximum features of sub-intervals while ignoring other features can greatly reduce the parameter scale of the model. Finally, because the parameters of a convolutional kernel are fixed, the extracted features will be relatively simple, but the CNN can have multiple convolutional kernels, so that things can be analyzed from more perspectives, making the final results more objective and avoiding bias.
Different from images with pixels, in terms of natural language processing, the object is usually a document or sentence, while the input of the CNN needs to be a matrix. Therefore, the word2vec method is used in this model to train every word in every sentence in the diary text into the word vector. Each behavior has a word vector, and there are as many lines of word vectors as there are words. Therefore, the diary text can be converted into a word vector matrix as the input of the CNN algorithm.
The input layer, convolution layer, pooling layer, and full connection layer constitute the network model involved in this study. In the input layer, the text input word vector features are connected in series, and the vector features are extracted from the convolution layer and the pooling layer. The final text classification result is obtained by the Softmax function at the full connection layer. The specific implementation process of the model is described as follows:
Input layer: The input text is converted from words to word vectors to construct feature matrix: x1:L = x1⊕x2⊕⋯⊕xL,
Where any word vector is represented by xi, representing the word vector corresponding to the i-th word in a sentence, and the number of words in a sentence is represented by L. In this model, the dimension of the trained word vector is 300, and the distance is calculated by cosine, where the symbol “⊕” represents the series operation, which means that L 1*300 word vectors can be connected in series into an L*300 eigenmatrix. To ensure that the number of words in each sentence is L, 0 is added when the text length is less than L words, and the text is truncated with length L when the text length is greater than L words.
Convolution layer: It performs convolution operations on input features.
The formula is simplified to obtain:
where the element of the i-th row and j-th column of the input feature is represented by xi,j, the weight of the m-th row and n-th column in the convolution kernel is represented by wm,n, the bias term of the convolution kernel is represented by wb, and the element of the i-th row and j-th column in the feature graph of the convolution result is represented by ci,j, f represents the activation function, and the ReLU function is used in this model. The value of each element in the output matrix is changed to 0 for positions less than 0.
After the convolution operation in the convolution layer, the scale of the eigenmatrix decreases as follows:
where W0 is the width of the feature graph after convolution; W1 is the width of the feature matrix before convolution; F and S, respectively, represent the width and the step of the convolution kernel, where S = 1; H0 is the height of the feature graph after convolution; and H1 is the height of the feature graph before convolution.
Pooling layer: The maximum pooling method of Max Pooling is adopted in this model, where:
In this formula, hi represents the output of the pooling layer, and the sample value after sampling is the maximum value of the m*n sample selected in the maximum pooling layer. In this sampling method, unimportant samples in the feature graph can be ignored to reduce the number of parameters.
Full connection layer: The full connection layer is the full connection calculation of hi:
oj is the output value of the full connection layer, and the output result is classified into the Softmax function to get the final result.
So far, the CNN algorithm in the C-BiL model has been designed.
Bi-LSTM Neural Network Algorithm Design
LSTM is a variant of the RNN model, which can solve the long-term dependence problem of the RNN. The key of LSTM is the state of the cell, and the addition or deletion of information is realized through the gate structure. The gate structure implements selective passage of information through a sigmoid neural layer and point-by-point multiplication operation. LSTM has three gates, namely, the input gate, the forgetting gate, and the output gate.
Input gate: This gate shows how much new information is allowed through the current cell state. The sigmoid layer decides what information needs to be updated, and the tanh layer generates a content vector for alternate updates. See formulas 8, 9:
Combining the previous two steps, the cell state can be updated, in this case to G. The cT-I state is multiplied by f to get the information to be discarded and forgotten. The new candidate value is I, Ct, which can be changed by the degree of updating each state, as shown in Formula 10:
Combining the previous two steps, the cell state can be updated, where Ct–1 is updated to Ct. The Ct–1 state is multiplied by ft to get the information to be discarded and forgotten. The new candidate value is , which can be changed by the degree of updating each state, as shown in formula 10:
Output gate: It determines the output value of the current cell state. The sigmoid layer first determines which part of the output cell state, and after tanh processing, the result is between [−1,1], which is then multiplied by the output of the sigmoid layer to obtain the final output result, as shown in formulas 11, 12:
It can be seen from the derivation of the formula of LSTM that the current cell state Ctis jointly determined by the previous cell state and the current cell information. However, when faced with a long diary text consisting of multiple sentences, context information has to be considered. The standard LSTM model only considers the time sequence information and ignores the subsequent information, so Bi-LSTM model is adopted in this model to improve the performance better.
Bi-LSTM consists of forward LSTM and reverse LSTM, which are independent of each other and have the same structure. The forward LSTM uses forward contextual semantic information as input, and the reverse LSTM uses reverse contextual semantic information as input, that is, the preceding information can be obtained through the forward LSTM, and the following information can be obtained through the reverse LSTM. Bi-LSTM ensures that the information before and after the diary text can be factored in to achieve higher performance. In this model, Bi-LSTML processes the forward input sequence and Bi-LSTMR processes the reverse input sequence, and the two share a set of parameters during model training.
The final output ht of Bi-LSTM can be obtained by splicing forward output and backward output :
So far, the Bi-LSTM algorithm in the C-BiL model has been designed. Next, the whole C-BiL model is designed.
CNN and Bi-LSTM Word Vector Generation
In this model, xi ∈ Rd represents the word vector features of each input word and d represents the dimension of word vector. Thus, x ∈ RL×d represents the input feature matrix of N words. When the input is a sentence, it can be expressed as follows:
where ⊕ indicates the splicing operation. The maximum length is set as N. When the length is insufficient, the eigenmatrix is supplemented with 0, and when the length exceeds N, the eigenmatrix is truncated. Therefore, the length combination of any paragraph of word vector can be expressed as follows:
Word vector X1:N is used as the input vector of CNN(A) and Bi-LSTM (A) algorithms.
Generation of CNN Word Vector
The CNN(A) algorithm adopts K eigenmatrices of the convolution check input for convolution operation, where c is the j-th feature generated by the k-th convolution:
The CNN(A) algorithm adopts K convolution kernels to carry out the convolution operation on the input eigenmatrix. is the j-th feature generated by the k-th convolution:
⊗ stands for the convolution operation, fA is the activation function of CNN(A), and the ReLU function is selected as the activation function in this system. The size of the sliding window is denoted as hA, and the offset value is denoted as bA. Xj:j+h–1 represents the local eigenmatrix consisting of rows j-th through j+h–1-th. Therefore, the feature vector obtained after the convolution operation is as follows:
where j represents the serial number of the convolution kernel. An eigenvector can be obtained through the convolution operation of multiple convolution kernels. Splicing N vectors to obtain the output CNN word vector segment CA1:N:
Let the original word vector X1:N and CNN word vector segment CA1:N merge into A^c1:N :
Splicing N AC into final output CNN word vector :
Bi-LSTM Word Vector Generation
First, the forward word vector of Bi-LSTM(A)L is calculated. Taking vector X as the input vector of the Bi-LSTM(A)L algorithm, the corresponding hidden status update of the j-th word vector is as follows:
where represents the input gate, represents the forget gate, represents the output gate, represents the candidate value of the cell state, represents the cell state of the updated j-th word vector, and represents the value of the hidden state of the j-th word vector.
The output vector of each word is , and the output of N words is spliced to obtain the forward word vector segment of Bi-LSTM(A)L:
Let the original word vector and the forward word vector segment of Bi-LSTM(A)L merge into :
Splicing N into the forward word vector of the final output Bi-LSTM(A)L:
Similarly, taking the reverse vector as the input vector of Bi-LSTM(A)R algorithm, the backward word vector of Bi-LSTM(A)R algorithm can be obtained:
Splicing forward word vector and backward word vector to obtain the final Bi-LSTM word vector :
So far, CNN word vector and Bi-LSTM word vector are obtained through CNN(A) and Bi-LSTM(A).
CNN and Bi-LSTM Sentence Vector Generation
Bi-LSTM Sentence Vector Generation
First, the forward sentence vector of Bi-LSTM(B)L is calculated. The forward word vector of the CNN is taken as the input vector of the Bi-LSTM(B)L algorithm, and the corresponding hidden status update of the j-th word is as follows:
where the input gate, forget gate, and output gate are denoted as , , and , respectively, and the candidate value of cell state is denoted as , the cell state of the updated j-th word vector is denoted as , and the hidden state value of the i-th word vector is denoted as .
The output vector of each word is , and the output of N words is spliced to obtain Bi-LSTM forward sentence vector :
Similarly, the backward word vector of the CNN is taken as the input vector of the Bi-LSTM(B)R algorithm, and the backward sentence vector of Bi-LSTM(B)L:
By splicing forward sentence vector and backward sentence vector , the final Bi-LSTM sentence vector is obtained:
CNN Sentence Vector Generation
Bi-LSTM word vector is taken as input word vector of the CNN(B) algorithm. The CNN(B) algorithm adopts K convolution kernels to carry out convolution operation on the input eigenmatrix. Where is the j-th feature generated by the k-th convolution:
⊗ stands for convolution operation, fB is the activation function of CNN(B), and the ReLU function is selected as the activation function in this system. The size of the sliding window is denoted as hB, and the offset value is denoted as bB. A^Lj:j+h–1 represents the local eigenmatrix consisting of rows j-th through j+h-1-th. Therefore, the feature vector obtained after the convolution operation is as follows:
where j is the j-th convolution kernel. An eigenvector can be obtained through the convolution operation of multiple convolution kernels. Splicing N vectors to get output CB1:N:
CB1:N is input into the pooling layer to carry out the maximum pooling operation and obtain the CNN sentence vector :
So far, the CNN sentence vector and BI-LSTM sentence vector are obtained through CNN(B) and Bi-LSTM(B).
Output From the Softmax Layer
Softmax is widely used in machine learning and deep learning, especially in multi-classification scenarios. The final output unit of the classifier requires the Softmax function for numerical processing (Li et al., 2020). The Softmax functions are defined as follows:
where Vi is the output of the classifier’s pre-output unit, i represents the category index, the total number of categories is C, and Si represents the ratio of the index of the current element to the index sum of all elements. Softmax maps some inputs to real numbers between [0,1], and the normalization guarantees that the sum is 1, and the sum of the probabilities of the multiple categories is exactly 1. Therefore, Softmax can convert the output values of multiple categories into relative probabilities.
In the C-BiL algorithm model, since CNN sentence vectors and Bi-LSTM sentence vectors have been obtained, the sentence vectors of the two parts are spliced to obtain the training sentence vector O′:
O′ is input into the Softmax layer for classification:
Here, Ws ∈ Rd and bs are parameters of the Softmax layer, and bs is the number of classifier classifications.
So far, the final classification result y is obtained, and the whole C-BiL model can complete the function of sentiment recognition.
Experiment and Analysis
This section conducts experiments on the C-BiL model to obtain the accuracy of the model.
Data Set
This model uses three data sets to conduct experiments, namely, Weibo, Fudan, and Diary.
(1) Weibo (Data_1): The data of Sina Weibo is manually collected and labeled. The sample totals 3 million. The experiment randomly selects 40,000 positive emotion data, 50,000 negative emotion data, and 10,000 neutral emotion data as the data set.
(2) Fudan (Data_2): The Fudan University Article Classification Collection is a collection of Chinese articles with nearly 11,000 entries in 20 categories, including art, education, and energy.
(3) Diary (Data_3): In order to train the model, diary texts from the online side about mental health are captured by hand.
Table 1 provides details for each data set, including the number of data set classes (C), the number of training sets (Train)/validation sets (Dev)/test sets (Test), and the average text length (Len).

Table 1. Data set information.
Model Training and Result Analysis
The word vector generator is designed to generate a distributed representation of each word. A common approach to improving performance in the absence of large supervised training sets is to obtain word vector initializations from unsupervised neural language models. In this algorithm model, word vectors are trained in three datasets of Weibo, Fudan, and Diary using the public word2vec tool. The vector has a dimension of 300 and is trained using a continuous skip-gram architecture. It is worth noting that since there is no white space in Chinese sentences, and pre-processing work is required to divide each sentence into word segments with Chinese white space. Here, JieBa open-source tools are used to achieve this goal. By JieBa segmentation, each statement can be converted to a space-separated sequence of Chinese words.
In order to test the accuracy of the C-BiL model, this study conducted comparative experiments with the following four models:
(1) SFCNN (Kim et al., 2019): The convolutional neural network is used for text feature learning after multi-channel semantic synthesis of the word vector.
(2) Bi-LSTM (Zou et al., 2021): Only the Bi-LSTM neural network is used for text feature learning.
(3) CNN-BiLSTM (Zhang et al., 2020): The CNN and Bi-LSTM are input, respectively, for encoding; relevant features are extracted, and finally classified them by fusion in the full connection layer.
(4) BiLSTM-CNN (Zhu et al., 2019): The vector is input into Bi-LSTM and then the result is input into the CNN for final classification.
As the model proposed in this article, the C-BiL model is shown in Table 2 for parameter configuration:
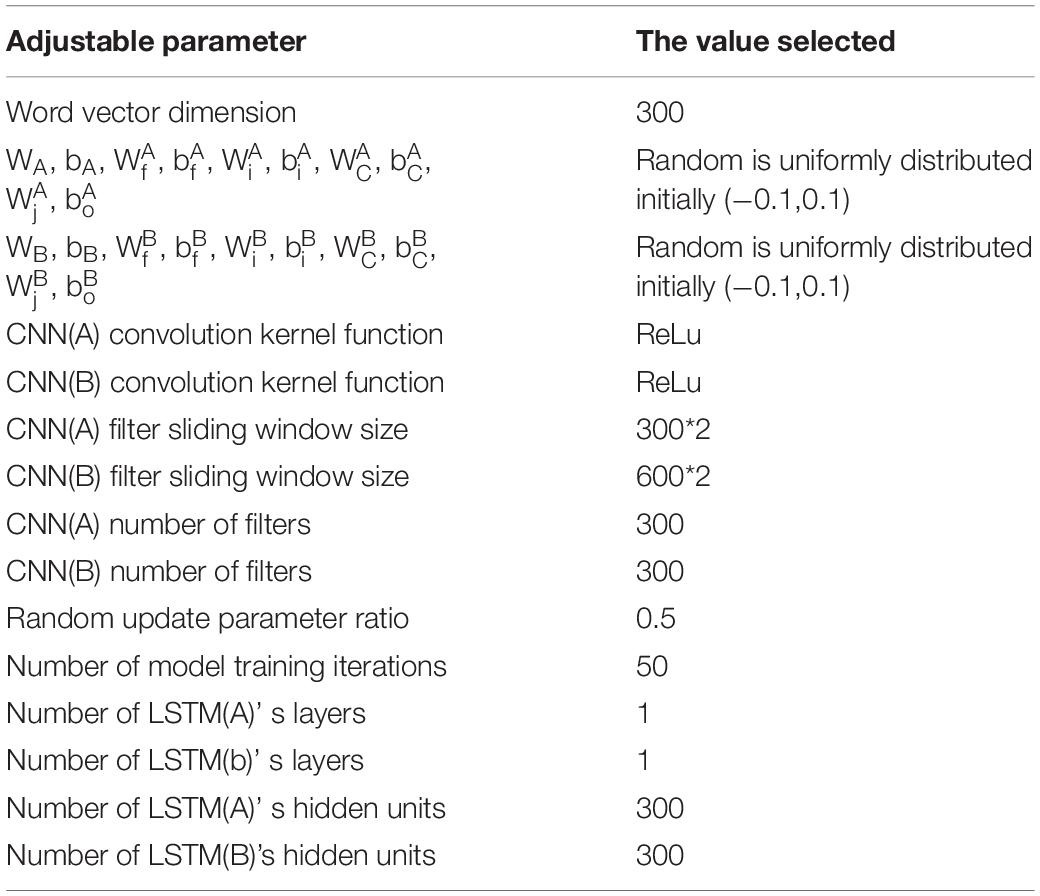
Table 2. Parameters settings for the C-BiL model.
Tables 3, 4, 5 represent the experiment classification result with two, three, and five types, respectively.
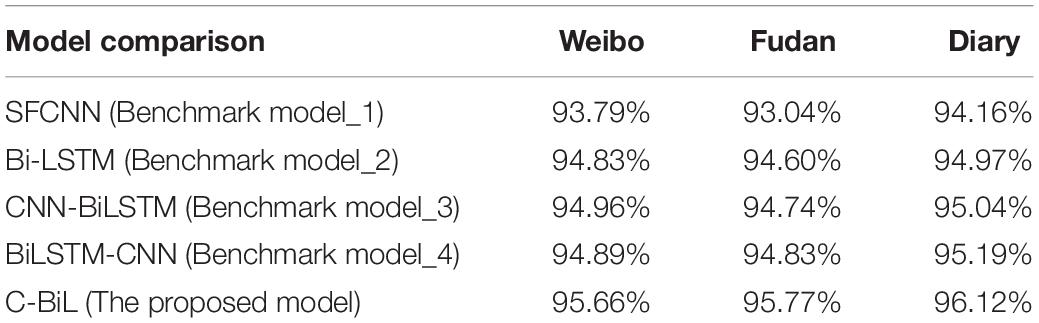
Table 3. Accuracy of dichotomies.
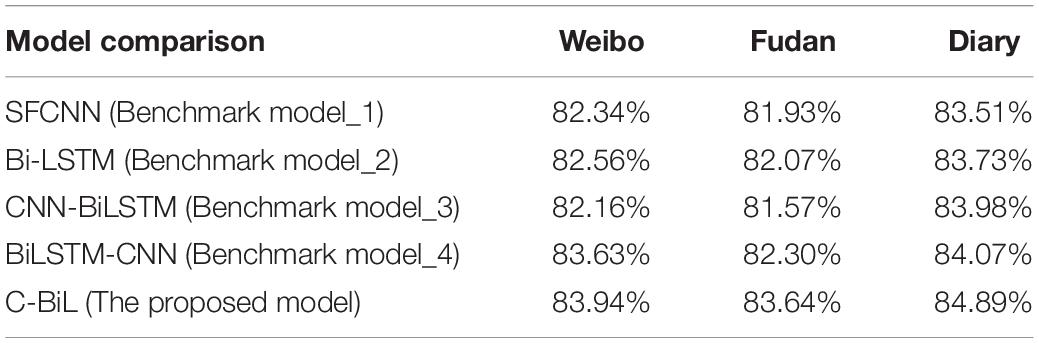
Table 4. Accuracy rate under three categories.
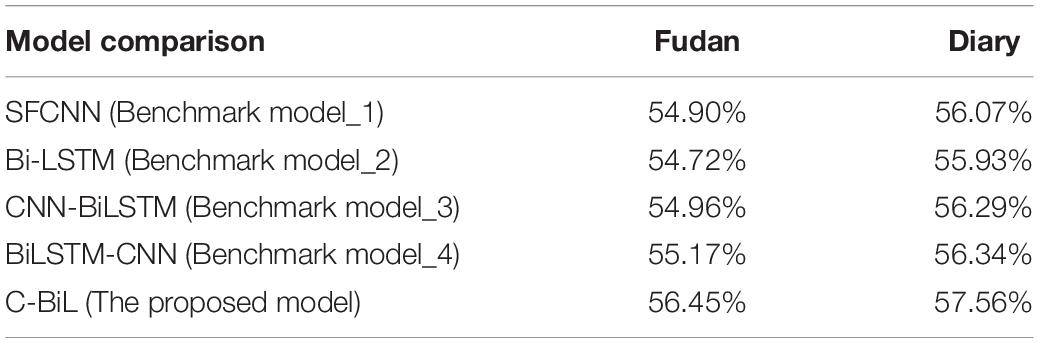
Table 5. Accuracy rate under five categories.
As shown in Tables 3, 4, 5, this study introduces three data sets and uses four models to classify data, among which Weibo is a three-category data set, Fudan is a multi-category data set, and Diary is a five-category data set. On the whole, since the application is for sentiment recognition of diary text, the manual-labeled Diary data set has a higher accuracy rate than Weibo and Fudan data sets (0.69% higher on average) because the training content is closer to the actual demand.
In the dichotomous experiment, the accuracy of the proposed method in Diary data set is 0.93% better than Benchmark model_4, 1.08% better than Benchmark model_3, 1.05% better than Benchmark model_2, and 1.86% better than Benchmark model_1. In the data set of Weibo, the accuracy is 0.77% better than Benchmark model_4, 0.7% better than Benchmark model_3, 0.63% better than Benchmark model_2 and 1.67% better than Benchmark model_1. In The Fudan data set, the accuracy is 0.94% better than Benchmark model_4, 1.03% better than Benchmark model_3, 0.77% better than Benchmark model_2 and 2.33% better than Benchmark model_1.
In the three classification experiments, the accuracy of the proposed method in Diary data set is 0.82% better than Benchmark model_4, 0.91% better than Benchmark model_3, 0.86% better than Benchmark model_2, and 1.08% better than Benchmark model_1; In the data set of Weibo, the accuracy is 0.31% better than Benchmark model_4, 1.78% better than Benchmark model_3, 1.38% better than Benchmark model_2 model, and 1.60% better than Benchmark model_1 model. In The Fudan data set, the accuracy is 1.34% better than Benchmark model_4, 2.07% better than Benchmark model_3, 1.37% better than Benchmark model_2, and 1.51% better than Benchmark model_1.
In the five-category experiment, the accuracy of the proposed method in Diary data set is 1.22% better than Benchmark model_4, 1.27% better than Benchmark model_3, 1.23% better than Benchmark model_2, and 1.09% better than Benchmark model_1. In The Fudan dataset, the accuracy is 1.28% better than Benchmark model_4, 1.49% better than Benchmark model_3, 1.53% better than Benchmark model_2, and 1.35% better than Benchmark model_1.
In conclusion, among the deep learning models, the accuracy of the C-BiL model designed in this study is relatively high irrespective of the binary classification, the three classification, or the five classification, with an average improvement of 2.47% in the Diary data set, 2.16% in the Weibo data set, and 2.08% in the Fudan data set.
Therefore, the C-BiL model designed in this study can not only successfully classify texts but also effectively improve the accuracy of text sentiment recognition.
Conclusion
This article mainly introduces the design and implementation of a psychological analysis application based on emotion recognition algorithm, which is mainly aimed at college students. With the occurrence and reports of adverse events on campus one after another, college students’ mental health problems have gradually become the focus of society. These problems may be general psychological problems of growth or may be psychological disorders caused by various social or environmental reasons. Facing up to and solving these problems have become the task that society, colleges, and families must face. The psychological analysis application based on sentiment recognition designed in this study can meet the established requirements of initial application, and the C-BiL model is proposed by improving the convolutional neural network model and the Bi-LSTM neural network model, which effectively improve the accuracy of emotion recognition. However, there are still areas for further improvement in the algorithm design of this study, for example, in the Bi-LSTM algorithm, attention mechanism can be introduced to assign different weights to different parts of speech of diary text, such as adjectives, nouns, and adverbs so that accuracy can be improved more effectively in emotion recognition. The first and last sentences of the diary can also be weighted to improve the recognition efficiency.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Funding
This work was sponsored in part by the Teacher Education Research Project of Henan Education Department (2020-JSJYZD-031) and National Natural Science Foundation of China (No. 2345678).
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
This study acknowledges the efforts of the reviewers.
References
Bao, Z., and Wang, C. (2022). A multi-agent knowledge integration process for enterprise management innovation from the perspective of neural network. Inf. Process. Manage. 59, 102873. doi: 10.1016/j.ipm.2022.102873
Brachmann, A., Barth, E., and Redies, C. (2017). Using CNN features to better understand what makes visual artworks special. Front. Psychol. 8:830. doi: 10.3389/fpsyg.2017.00830
Cho, K., Merrienboer, B. V., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., et al. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv [Preprint]. arXiv:1406.1078 doi: 10.3115/v1/D14-1179
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., and Kuksa, P. (2011). Natural language processing (almost) from scratch. J. Mach. Learn. Res. 12, 2493–2537.
dos Santos, C., and Gattit, M. (2014). “Deep convolutional neural networks for sentiment analysis of short texts,” in Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, 69–78.
Er, M. J., Zhang, Y., Wang, N., and Pratama, M. (2016). Attention pooling-based convolutional neural network for sentence modelling. Inf. Sci. 373, 388–403. doi: 10.1016/j.ins.2016.08.084
Graves, A., Fernández, S., and Schmidhuber, J. (2005). Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition. DBLP. **city,pubQ. doi: 10.1007/11550907_126
Huang, Q., Chen, R., Zheng, X., and Dong, Z. (2017). “[IEEE 2017 international conference on green informatics (ICGI) – Fuzhou, China (2017.8.15-2017.8.17)],” in Proceedings of the 2017 International Conference on Green Informatics (ICGI) - Deep Sentiment Representation Based on CNN and LSTM, 30–33. **cityQ. doi: 10.1109/ICGI.2017.45
Huebner, P. A., and Willits, J. A. (2018). Structured semantic knowledge can emerge automatically from predicting word sequences in child-directed speech. Front. Psychol. 9:133. doi: 10.3389/fpsyg.2018.00133
Jebbara, S., and Cimiano, P. (2017). Aspect-based sentiment analysis using a two-step neural network architecture. arXiv [Preprint]. arXiv:1709.06311 doi: 10.1007/978-3-319-46565-4_12
Kalchbrenner, N., Grefenstette, E., and Blunsom, P. (2014). A convolutional neural network for modelling sentences. arxiv [Preprint]. arXiv:1404.2188 doi: 10.3115/v1/P14-1062
Kim, T., Lee, H., Son, H., and Lee, S. (2019). “SF-CNN: a fast compression artifacts removal via spatial-to-frequency convolutional neural networks,” in Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP) (Taipei: IEEE). doi: 10.1109/ICIP.2019.8803503
Li, X., Chang, D., Ma, Z., Tan, Z.-H., Xue, J.-H., Cao, J., et al. (2020). OSLNet: deep small-sample classification with an orthogonal softmax layer. IEEE Trans. Image Process. 1.**volQ doi: 10.1109/TIP.2020.2990277
Severyn, A., and Moschitti, A. (2015). “Twitter sentiment analysis with deep convolutional neural networks,” in Proceedings of the International ACM Sigir Conference, Santiago (New York, NY: ACM), 959–962. doi: 10.1145/2766462.2767830
Shi, Y., Yao, K., Tian, L., and Jiang, D. (2016). “Deep LSTM based feature mapping for query classification,” in Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (San Diego, CA). doi: 10.18653/v1/N16-1176
Tai, K. S., and Socher, R. (2015). CD manning. Improved semantic representations from tree-structured long short-term memory networks. Comput. Sci. 5:36. doi: 10.3115/v1/P15-1150
Wigington, C., Stewart, S., Davis, B., Barrett, B., Price, B., and Cohen, S. (2017). “Data augmentation for recognition of handwritten words and lines using a CNN-LSTM network,” in Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, 639–645. doi: 10.1109/ICDAR.2017.110
Yang, S., Sun, Q., Zhou, H., and Gong, Z. (2018). “A multi-layer neural network model integrating BiLSTM and CNN for Chinese sentiment recognition,” in Proceedings of the 2018 International Conference on Computing and Artificial Intelligence, Chengdu (New York, NY: ACM), 23–29. doi: 10.1145/3194452.3194473
Yenter, A., and Verma, A. (2017). “Deep CNN-LSTM with combined kernels from multiple branches for IMDb review sentiment analysis,” in Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, 540–546. doi: 10.1109/UEMCON.2017.8249013
Yi, Y., Zhang, H., Karamti, H., Li, S., Chen, R., Yan, H., et al. (2022). The use of genetic algorithm, multikernel learning, and least-squares support vector machine for evaluating quality of teaching. Sci. Program. 2022:4588643. doi: 10.1155/2022/4588643
Zhang, Q., Li, Y., Hu, Y., and Zhao, X. (2020). An encrypted speech retrieval method based on deep perceptual hashing and CNN-BiLSTM. IEEE Access 8, 148556–148569. doi: 10.1109/ACCESS.2020.3015876
Zhu, F., Ye, F., Fu, Y., Liu, Q., and Shen, B. (2019). Electrocardiogram generation with a bidirectional LSTM-CNN generative adversarial network. Sci. Rep. 9:6734. doi: 10.1038/s41598-019-42516-z
Keywords: emotion analysis, convolutional neural networks, bidirectional long short-term memory, sentiment classification, text sentiment recognition
Citation: Liu B (2022) Research on Emotion Analysis and Psychoanalysis Application With Convolutional Neural Network and Bidirectional Long Short-Term Memory. Front. Psychol. 13:852242. doi: 10.3389/fpsyg.2022.852242
Received: 11 January 2022; Accepted: 21 March 2022;
Published: 30 June 2022.
Edited by:
Fu-Sheng Tsai, Cheng Shiu University, TaiwanReviewed by:
Chenguang Wang, Lingnan University, ChinaZongke Bao, Zhejiang University of Finance and Economics, China
Copyright © 2022 Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Baitao Liu, bGJ0cHN5QG55bnUuZWR1LmNu