 Shoucheng Shen1
Shoucheng Shen1 Jinling Fan2*
Jinling Fan2*- 1School of Marxism, Dalian Maritime University, Dalian, China
- 2Office of Academic Affairs, Hebei University of Science and Technology, Shijiazhuang, China
Theoretical research into the emotional attributes of ideological and political education can improve our ability to understand human emotion and solve socio-emotional problems. To that end, this study undertook an analysis of emotion in ideological and political education by integrating a gate recurrent unit (GRU) with an attention mechanism. Based on the good results achieved by BERT in the downstream network, we use the long focusing attention mechanism assisted by two-way GRU to extract relevant information and global information of ideological and political education and emotion analysis, respectively. The two kinds of information complement each other, and the accuracy of emotion information can be further improved by combining neural network model. Finally, the validity and domain adaptability of the model were verified using several publicly available, fine-grained emotion datasets.
Introduction
The emotional attributes of ideological and political education go hand-in-hand with those of ideology, society, practice, and culture. The unique features and causes of emotional attributes can be determined through the process of linking and distinguishing between them. Ideological and political education is based on the reality of people’s existences, including their emotions, which gives this form of education its distinctive emotional character. As a practical activity, ideological and political education deals with thinking human subjects, whose ideological and moral character it aims to improve. Emotion is not only fundamental to such aspects of character but also motivates the dialectical development of additional elements such as knowledge, intention, faith, and action. Ideological and political education aims to promote people’s all-round development, including their emotional development.
Recently, deep neural networks have increasingly been used in emotion analysis. GRU network is a simplified deformation model of long short-term memory (LSTM) first proposed by Ortigosa in 2014 (Ortigosa et al., 2012). The model simplified the three gate structures of the LSTM unit into two. The GRU network can retain long-distance sequence information, which means that these characteristic signals will not be weakened over time, nor will they be deleted due to irrelevant predictions. Peng proposed a gated convolutional network model based on convolutional neural networks (CNNs) and a gated mechanism (Peng et al., 2017). An attention mechanism in deep learning was first used in machine translation by Quadrana (Quadrana et al., 2018), and variations in this model were subsequently applied to emotion classification tasks. Gao proposed two attention mechanisms to improve model performance by considering the relationship between dimensional words and contextual semantic information (Gao et al., 2017).
With the continuous development and improvement of deep learning models, some scholars have combined multiple network structures to carry out emotion analysis research tasks. These have used the TF-IDF method to calculate feature weights and the support vector method to analyze the emotion, an approach that has delivered promising experimental results (Su and Li, 2013). The NBSVM hybrid model integrates the unique advantages of a support vector machine and naive Bayes algorithms, considerably improving the accuracy of emotion analysis compared with a single model (Kyunghyun et al., 2015). CNN and LSTM network structures have been used to classify emotions in comments on TikTok, also achieving good experimental results (Lopamudra et al., 2016). A bottom-up and end-to-end emotion analysis model combining CNN and RNN has also been proposed. Overall, this work demonstrates that approaches to emotion analysis based on deep learning offer higher levels of performance and accuracy (Liu et al., 2020) and point to their use in ideological and political education, ultimately supporting the emotional development of those who benefit from such learning opportunities.
This study investigated the application of end-to-end aspect-based emotion analysis (E2E-ABSA) to recommendation systems in ideological and political education. The study aimed to identify the most efficient and accurate model of emotion analysis, uncover further educational applications for emotion analysis, expand current approaches to text-based emotion analysis, and provide a durable theory to support its implementation.
Improved Recurrent Neural Network Variant Theory and Technology
When training recurrent neural networks (RNNs), the gradient descent method may be used to counter gradient disappearance or explosion. Given this problem, many scholars have proposed variants in RNN neural networks, such as two-way LSTM and GRU networks. One method classified malware based on an RNN using API calling functions at an average of 71% accuracy. Comparisons of the effectiveness of GRU, backward GRU (BGRU), LSTM and backward LSTM networks, and regular RNN models for malware detection and classification showed that the backward LSTM model achieved the highest accuracy rate (97.85%). When malware samples were detected and classified using a combined model of a CNN and LSTM, the classification accuracy of the model reached 98.8%.
Long Short-Term Memory
At present, the LSTM neural network architecture most widely used in practical applications is the model proposed by Hochreiter et al., which not only solves the problem of gradient disappearance in RNN but also performs much better than RNN in long sequence data-dependent tasks (Harper and Konstan, 2015) and avoids the problem of gradient disappearance during backpropagation. The network can accurately model any long-span-dependent data based on time series. While the basic principles behind LSTM and RNN are highly similar, LSTM networks can carry out more detailed internal processing and thus manage dependent information more effectively. Since the unique characteristics of LSTM neural networks are superior to those based on RNN, it is more widely used in time series-based learning-related tasks. LSTM aims to solve the long-term dependency problem mentioned above. Traditional RNN node outputs are determined only by weights, biases, and activation functions: RNN is a chain structure and each time slice uses the same parameters.
However, the LSTM model introduced a memory unit and gated memory unit, solving complex artificial long-delayed tasks, which had never been solved by previous recursive network algorithms.
In this study, the term LSTM element describes the hidden element in the LSTM recurrent neural network (LSTM). The LSTM architecture introduced in this study was originally proposed by Graves (Song et al., 2017).
The LSTM unit has three types of gating, as shown in Figure 1. The LSTM unit consists of input gate i, forget gate f, and output gate o. Gated units act as a full connection layer that enables the LSTM to store and update information. In more vivid and specific terms, the implementation of gating is the weight and sequence in the dot product when bias is added and is achieved through the sigmoid function. When internal information is sequenced, gating means that additional information is not provided. The mathematical expression of gating is shown below:
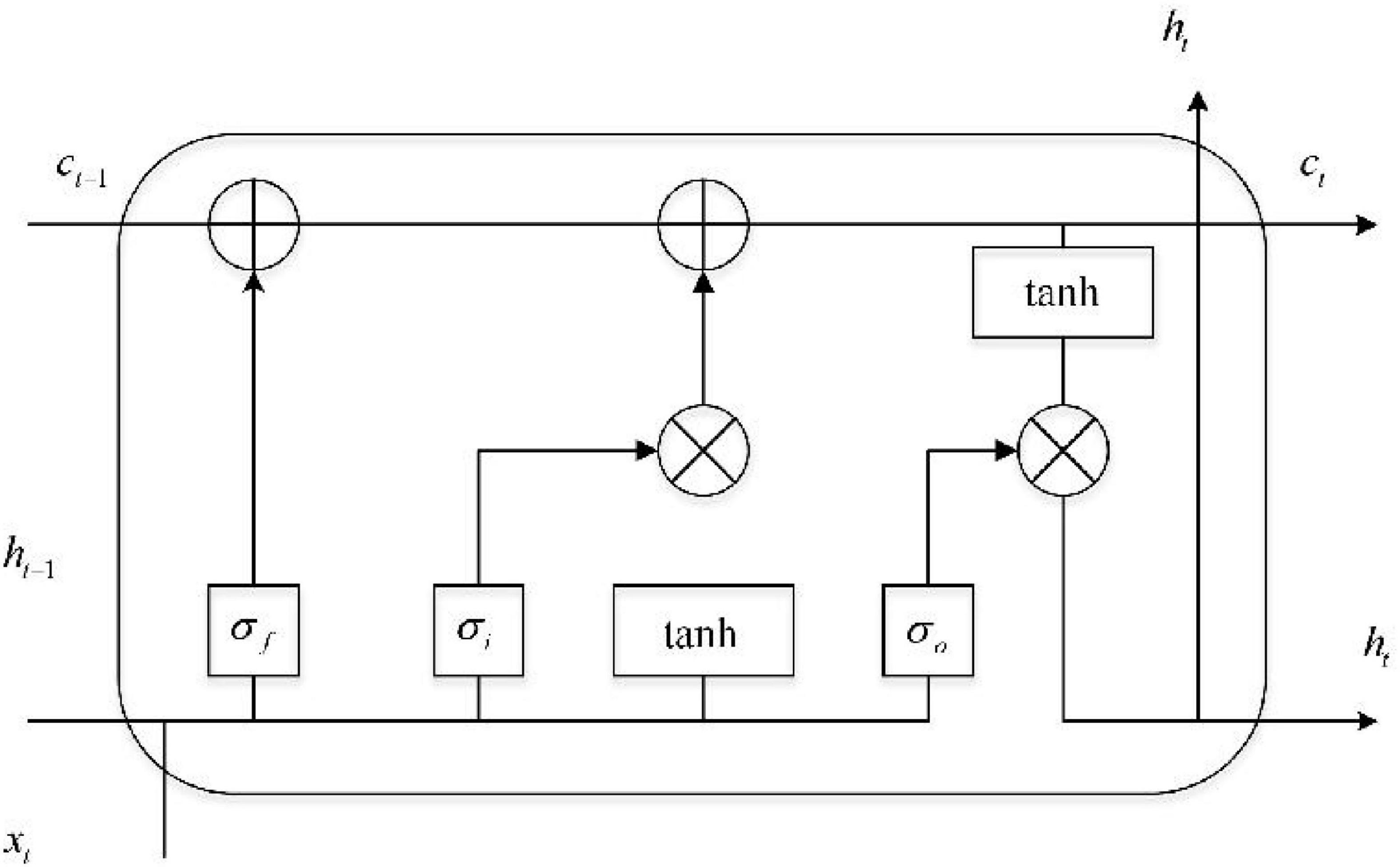
Figure 1. LSTM neural network structure.
where σ(x) = 1/(1 + e−x) denotes the sigmoid function, the most frequently used non-linear activation function in machine learning, which is used to normalize data and map it to the interval [0,1]. The function of gate control is to describe how much information is passed. When g(x) = 0, all information is blocked and cannot be transmitted; when g(x) = 1, all information can be sent to the next unit. W and b represent the weight matrix and bias vector of the network, respectively.
The forward calculation process of the bidirectional long short-term memory network is expressed in Equations 2–6 below. At time T, the input of the hidden layer of LSTM is xt, the output vector of the hidden layer is ht, and its memory unit is ct. The function of the input gate is to control the amount of input data xt and transfer them into memory units, i.e., amounts that can be saved into ct. Its mathematical expression is shown in the formula below:
The forget gate is an important part of the LSTM neural network because it controls the degree to which information is forgotten; its mathematical expression is shown in Equation 3, below. It also avoids problems such as gradient disappearance and explosion caused by backpropagation. Forget gates determine which information is discarded based on the characteristics of historical information, that is, the influence of memory unit ct–1 at the previous moment on memory unit ct at the present moment, and are expressed mathematically by the formula below (4):
The output value ht of the output gate is related to the control memory unit ct. The output expression is shown in Equation 5 below and state at time t in Equation 6:
Gated Loop Unit
A gated recurrent unit (GRU) is a network structure that uses multiple gated units to realize the flow, regulation, storage, memory, and other functions of information flow in the network (Li et al., 2019). In GRU, the activation of the gating unit depends only on the current input and the previous output. With fewer parameters and fast convergence, it can adaptively capture the dependence of different time scales. In some time-series data-processing tasks, GRU-based models are often superior to other network models (Mühlbacher et al., 2018). The specific internal structure of the gated recurrent unit GRU is shown in Figure 2.
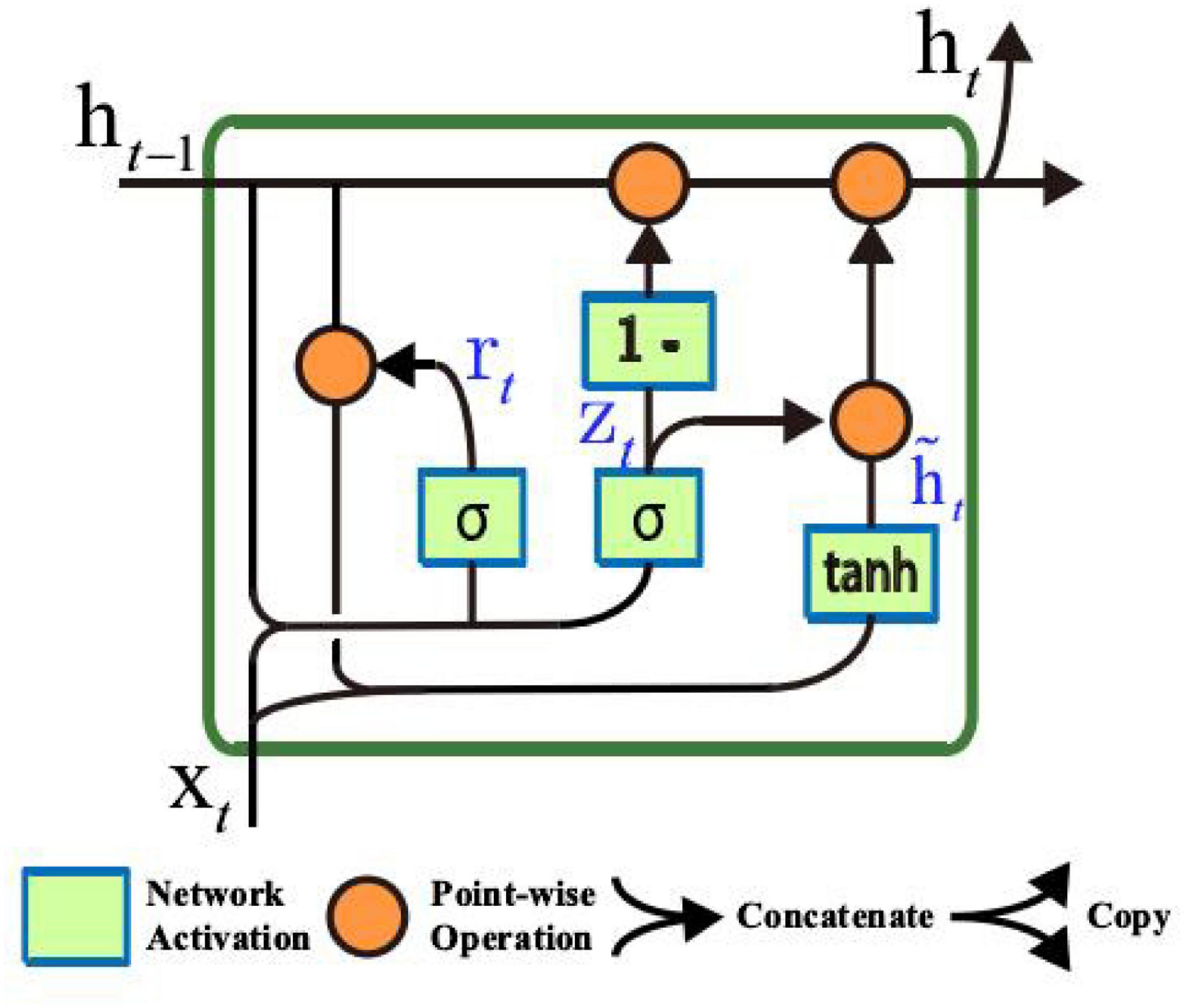
Figure 2. Gated recurrent unit (GRU).
The output of the gated loop unit GRU at time point t is , where j represents the j neuron, and is the linear interpolation between the output of the previous time point t-1 and the candidate activation value of the current time point:
where is the j unit of gate zt, and determines the update ratio of output unit of the GRU. The updated gating unit is calculated using the following formula:
where xt represents the input value at time t, and represent the j output unit at the last time point t-1. The method for calculating the candidate activation value is similar to the traditional regression unit:
where represents the reset gate, ⊗ represents the interelement (Hadamard) product, and tanh (⋅) represents the hyperbolic tangent function. The hyperbolic tangent function tanh (⋅) is defined as follows:
The reset gate rt is represented by the following formula:
When the reset gate is closed (when has a value of 0), the reset gate effectively causes the GRU unit to behave as if it were reading the first symbol of the input sequence, causing the GRU to forget the previously calculated state. Using the update and reset gates, the gated loop unit GRU can realize the memory and update functions and adaptively capture the dependencies of different time scales.
Recursive Neural Network Based on the Gated Loop Unit
A recursive neural network based on the gated loop unit GRU can be built and applied to a MEG signal decoding task (Huo et al., 2016). The GRU-based recurrent neural network (GRNN) can adaptively capture the dependence of the MEG signal in different time scales, and its deep network structure enables complex MEG signal characteristics to be extracted (Han et al., 2018), thus decoding the signals effectively. Figure 3 shows a recursive neural network based on gated cyclic units, which consists of two GRU unit groups, two lower sampling layers, and an output layer.
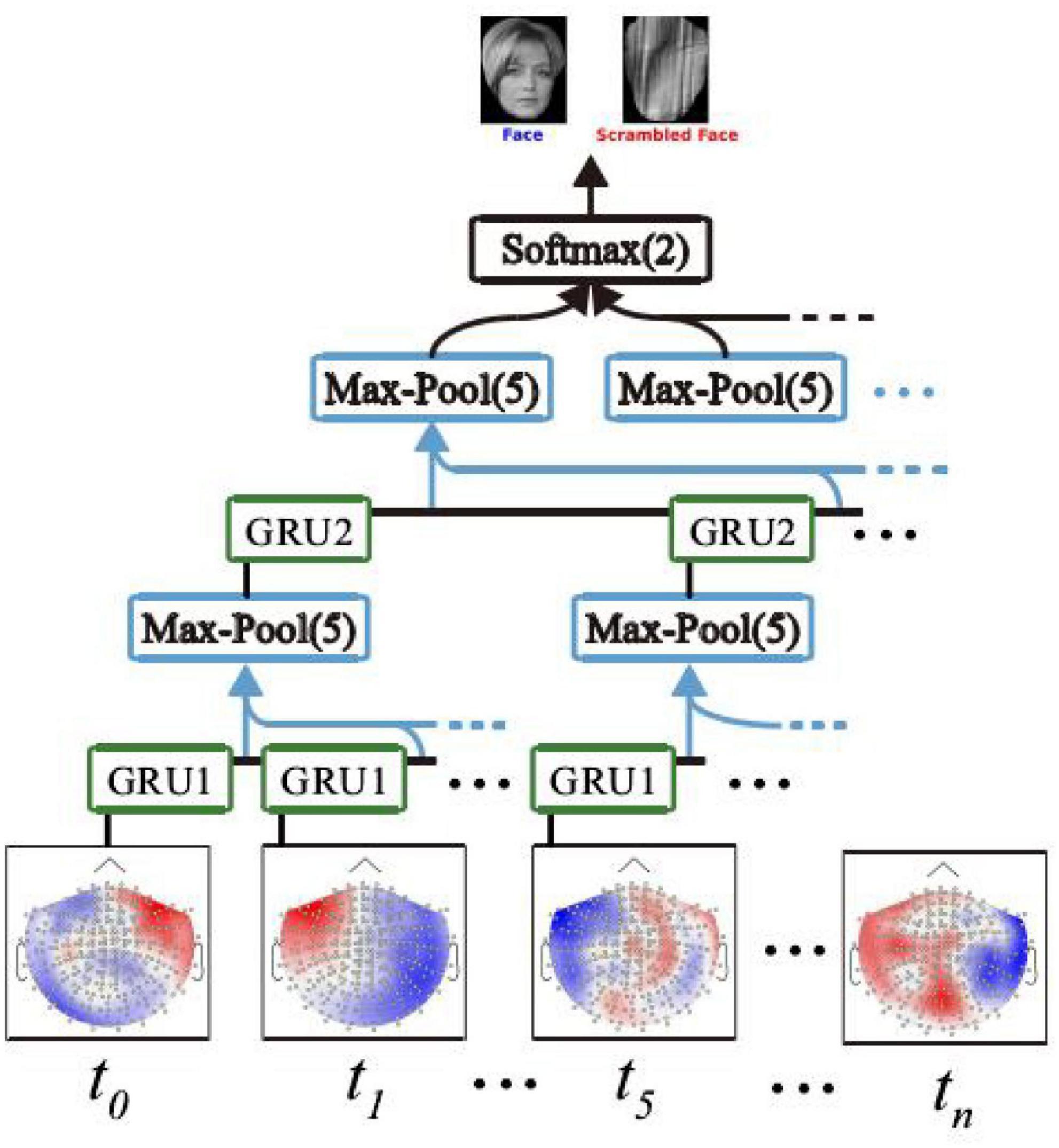
Figure 3. Recursive neural network based on gated loop unit GRU. Human image reproduced with permission from the TikTok dataset.
In Figure 3, the two-layer GRU unit group includes GRU1 and GRU2, which are distributed on two different network layers. At each time point of the same network layer t0, ti., the GRU unit on tn is shared. The sampling method of the lower sampling layer is max-pool (Hansen and Hasan, 2015). Max-pool (5) means that the maximum activation value at five time points is taken as the sampling value (Khan and Amjad, 2016). In addition, the output layer of the GRNN model is a fully connected layer with two output units, and the activation function of the output unit is the softmax function. The softmax function output can be used to generate prediction labels to determine whether the stimulus image corresponding to the current MEG signal is face or non-face.
The network can be trained and optimized by minimizing the cross-drops between the predicted and actual tags of the GRNN model, with the corresponding loss function as follows:
where c = 1 represents the MEG signal induced by a face image, and c = 2, the MEG signal stimulated by a non-face image. p1 represents the probability of the GRNN model detecting a face-prompted MEG signal, and p2, the probability that a MEG signal induced by non-face images is detected. [y1,y2]T represents the actual label of the input signal, if the input signal is induced by face image stimulation, then [y1, y2]T = [1, 0]T, otherwise .
Emotion Analysis of Ideological and Political Education Integrating Gru and the Attention Mechanism
Overall Framework of Emotion Analysis Model Based on Deep Learning
The emotion analysis model of ideological and political education based on deep learning includes BERT text processing, semantic feature extraction, and feature fusion calculation. The main model architecture is shown in Figure 4
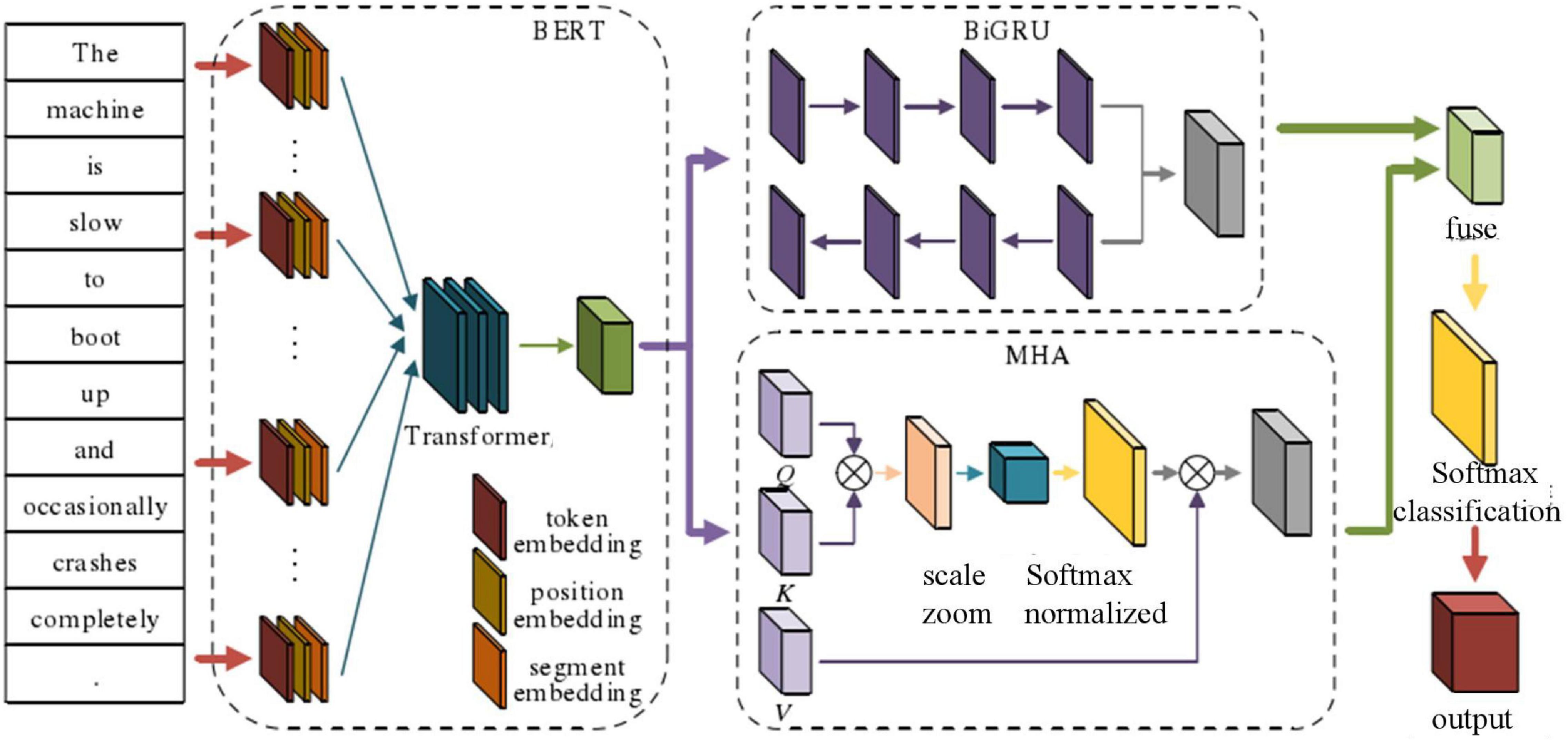
Figure 4. Overall architecture of E2E-ABSA model integrating GRU and MHA.
A parallel approach was taken to the process of deep feature extraction. On the one hand, a bidirectional GRU network was adopted to solve the context-dependent problem and extract the associated semantics of similar texts. On the other hand, multi-head attention (MHA) based on the self-attention mechanism was taken as the main network (Herath et al., 2017). The aim was to capture the relationships and importance of each word in the text to achieve the overall capture of associated attributes and emotions; the feature fusion calculation link was inspired by the long attention mechanism concat operation and aimed to capture the characteristics of parallel deep features through integration in the form of weight, combining their advantages on the parallel network to comprehensively determine their characteristics. Finally, the softmax classification function was adopted to improve performance on the task of classifying and labeling text emotions.
Text Feature Extraction Combining Gated Recurrent Unit and the Attention Mechanism
Following BERT processing to obtain the corresponding text feature vector representation x = (x1, x2, xn), the next step was to develop the deep network architecture for semantic parsing and understanding. The processes of text feature extraction, text relevance capture, and semantic representation have always been the primary tasks of deep learning neural networks; the richness of feature extraction determines the accuracy of subsequent classification tasks. Among numerous feature representation networks, GRU is renowned for its ability to capture context-related information and efficient training methods, enabling it to solve the problem of text-long dependence (Zhao et al., 2017). The multi-attentional mechanism has attracted much interest since being proposed. The multi-attentional parallel training method not only allows models to learn relevant information in different representation subspaces but also improves their learning performance and greatly reduces learning time, thereby improving the model’s overall efficiency. This study integrated GRU and the attention mechanism for the parallel extraction of text features.
Semantic Association Feature Representation in the Bidirectional Gated Recurrent Unit Network
The feature representation network needs to fully extract the expression of emotion words near feature attributes and identify their interactive relationship. The gating unit of the GRU network can capture long-distance relationships between elements of the text and can also represent the interaction between characters.
After the text vector x = (x1, x2, xn) passes through a GRU unit, the corresponding hidden layer output is . Unidirectional GRU networks can capture the semantic information of the first half of the word, but not the second half. To deal with this constraint, GRU semantic capture networks imitating the bidirectional cascade of LSTM networks including two opposite directions (forward and backward) are widely adopted. After the forward and backward GRU units that traverse the sentence from the beginning and end of the text, respectively, the forward neuron hidden output and the backward neuron hidden output can be obtained, and the two can be cascaded to obtain the coding output yt of the bidirectional GRU network:
In the process of forward and backward propagation, all W parameters need to be learned. In this study, the backpropagation through time (BPTT) algorithm was adopted to continuously adjust and optimize the weight vector of the GRU network. Assuming the loss of a single sample at a certain time is Pt = (yd−yt)2/2, where yd represents the true value and yt represents the predicted value, the loss of the sample at all times is , and T represents the time sequence length. The partial derivative of the loss function to each weight parameter is obtained, and the loss convergence is achieved by successive generations that update the parameters:
The eight parameters are as follows:
The sequence vector x = (x1, x2, xn) is sent into the BiGRU network to extract corresponding features through BPTT algorithm training, and the corresponding state matrix is obtained. The specific calculation method is as follows:
and
where d represents the dimension of the output state matrix of the hidden layer, d∈R.
Multi-Attentional Network Based on the Self-Attentional Mechanism
Because different words in the same text vary in importance, weights must be allocated based on specific attributes. To accurately predict tags in the E2E-ABSA task, the model must be able to capture key information. Initially, the attention mechanism allocates more resources to model the key local information, and a more incisive and vivid long attention mechanism is developed. The parallel learning mechanism enables different dimensions of multi-angle text calculations to be made.
In this study, a self-attention-based multi-attentional mechanism was added after BERT text representation to calculate correlations and assign importance to the words used in each sentence of the text. The process of extracting volume semantic features is shown in Figure 5, below.
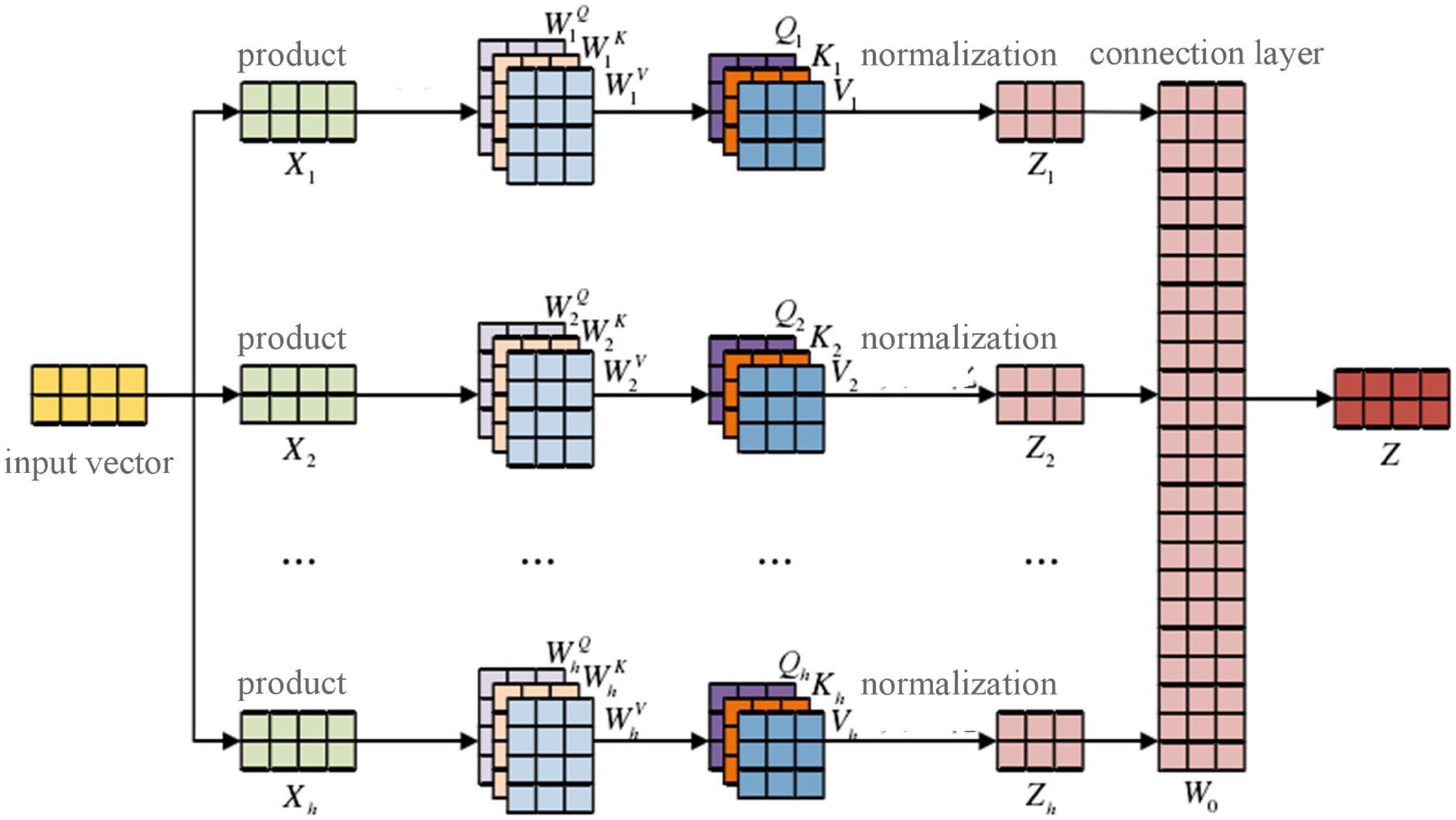
Figure 5. Semantic feature extraction based on the multi-attentional mechanism.
The input vector x = (x1, x2, xn) is mapped to h subspace, that is, the multi-headed attention mechanism has h heads, and the corresponding dimension representation X1,X2,…,Xn is obtained by
where a × b is the dimension of the corresponding subspace g, g ∈ [1,h].
The corresponding initialization Qg, Kg, Vg and the vector are calculated as follows:
where , , and are the appropriate parameters learned by the model in the training process. After the corresponding attention calculation, the attention output Zg of each subspace is follows:
The attention vectors of each subspace are concat-spliced to form a combined multi-head attention matrix, and the final semantic parsing output is obtained by calculating the weight matrix for the fully connected layer (Bai et al., 2016):
and
where W0 is the weight vector of the full connection layer.
Feature Fusion and Calculation
After obtaining the semantic representation of the BiGRU and multi-attention feature extraction networks, the matrix representation of the two is merged and calculated in the next step to achieve multi-angle semantic capture of the text combining their representational advantages (Adeniyi et al., 2016). To fully retain the original acquisition characteristics of BiGRU and MHA, this study adopted a simple matrix weight splicing method to merge them. The specific calculation is as follows:
where O is the final feature output vector representation of the text statement, μ is the feature reserved weight of the BiGRU network, and its initial value is set artificially and continuously adjusted automatically in the model learning process.
The output O = (o1, o2, …, on), with the softmax function used for classification calculations is
where P(yt|ot) represents the probability of yt output when the feature vector is input ot, and ot is the t vector of O.
Test Process and Analysis of Results
The TikTok and network service evaluation datasets were added on the basis of the Laptop14 and Rest14 sets. A horizontal comparison of the classical depth feature extraction network was carried out on the TikTok dataset, and the service dataset was compared vertically, layer-by-layer (Jiang et al., 2017). The results of Laptop14 and Rest14 were compared to some advanced benchmark models. All datasets were annotated with supplementary sequences and applied to the emotion analysis model after label transformation, which further verified the stability and superiority of the E2E-ABSA model combined with GRU and the attention mechanism in multi-domain text learning.
Test Setting and Parameter Selection
The BiGRU network was set as a single-layer bidirectional cascade. The platform configuration and parameter settings of the BERT model processing link in the depth model integrating BiGRU and MHA are shown in Table 1.

Table 1. Parameter settings related to the model.
Construction of Multi-Attention Network Based on the Self-Attention Mechanism
The TikTok dataset contains ten cross-datasets, each of which is divided into training and test sets. Since the original text of the ten sets is basically identical, we randomly selected one to serve as the experimental dataset for the model. In total, 10% of the total data in the training and test sets were randomly extracted from the training set to form the verification set. The specific distributions of semantic aspects in these datasets are shown in Table 2.
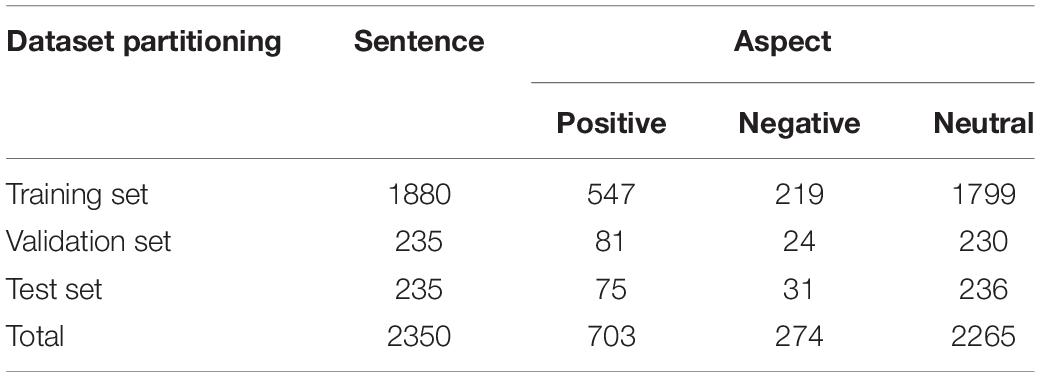
Table 2. Specific distributions of semantic aspects in the TikTok datasets.
A total of four evaluation indexes (Micro-P, Micro-R, Micro-F1, and Macro-F1) were used to evaluate the model. A batch size of 32 was set for training on the TikTok dataset. Figure 6 shows that the model adding GRU and the attention mechanism feature extraction network based on BERT maintained fast convergence speeds and high accuracy across 30 epochs of the training process.
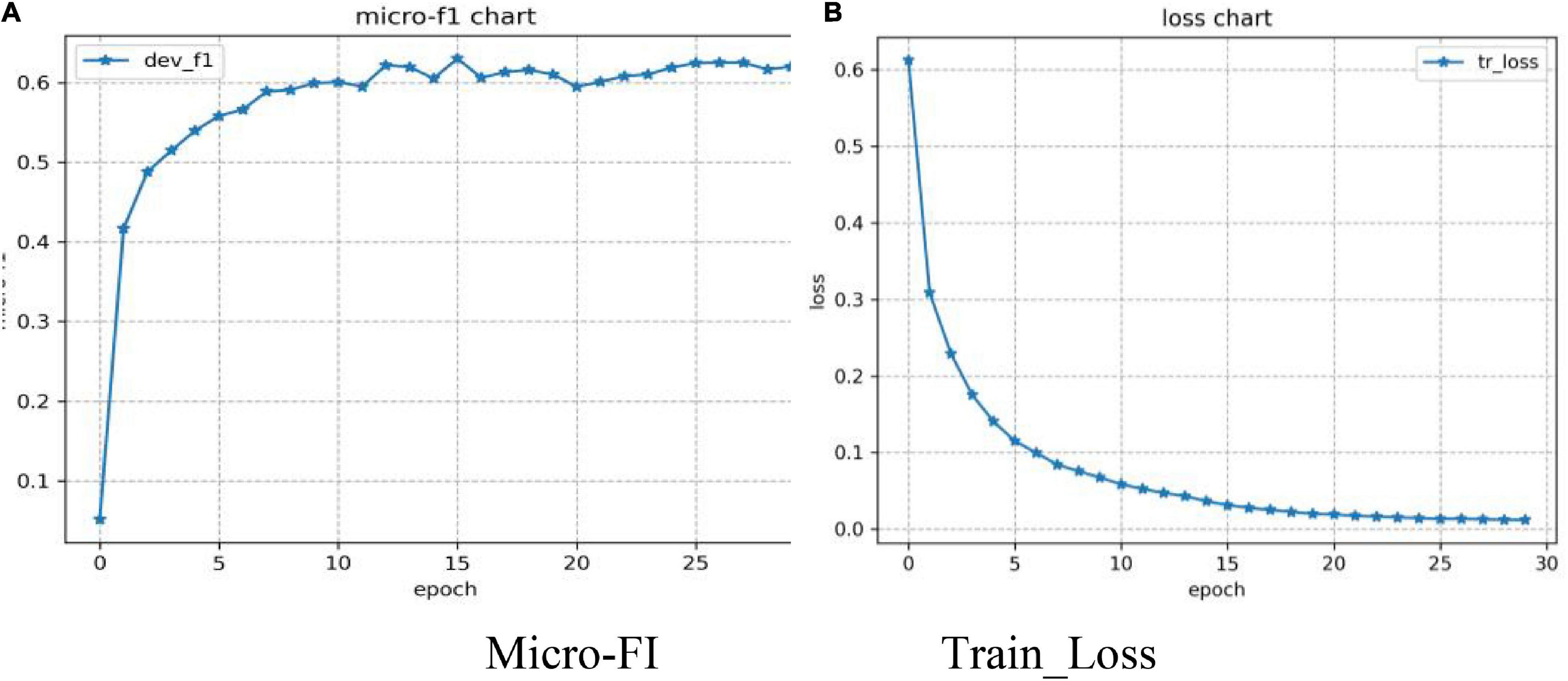
Figure 6. Changes in the BERT-BiGRU-MHA model on the TikTok dataset. (A) Micro-FI; (B) Train_Loss.
To verify the validity of the BERT-BiGRU-MHA model, feature extraction was performed in combination with the classic bidirectional long short-term memory network (BiLSTM) and CRF model using the BERT-based model. A horizontal comparison was made using the depth model that integrates BiGRU and MHA. The experimental results are shown in Table 3.
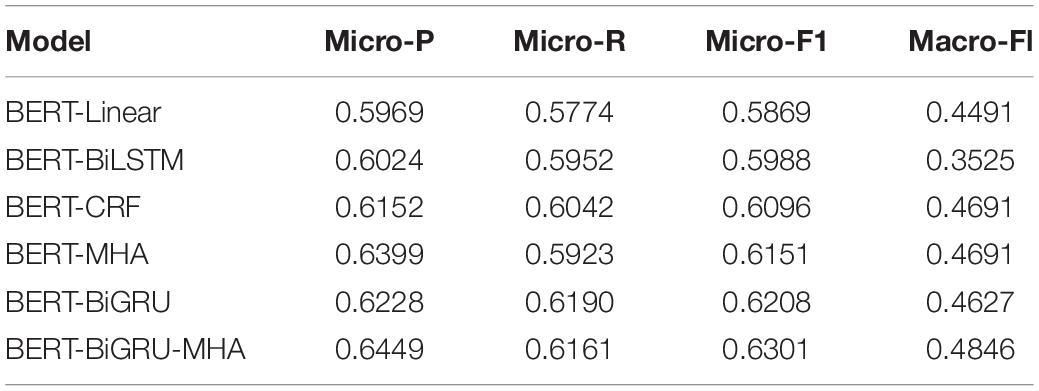
Table 3. Comparison between the experimental results of models based on the TikTok dataset.
Table 3 shows that the emotion analysis models using BiLSTM and CRF scored more highly on the Micro-F1 index compared with BERT-Linear (the benchmark model lacking other feature extraction networks), indicating they were capable of representing the sequence of features. However, the Macro-F1 index of the BERT-BiLSTM model was 9.66% lower than the benchmark. It thus struggled to extract the features of less distributed categories, producing disappointing results in the search and classification accuracy of small sample category labels. At the same time, the Micro-F1 result for the BiGRU model was 2.20% higher than that of the BiLSTM. Thus, although BiGRU and BiLSTM would be expected to perform in similar ways, the performance of BiGRU on the actual E2E-ABSA task was much stronger.
It can be seen from the analysis of data distribution in Table 3 that the TikTok dataset suffers from a serious sparsity of data, whose distribution varies greatly between different emotional polarities. There was a large quantity of neutral emotional data, whereas obviously, positive and negative emotions were much less common. The BERT-BiGRU-MHA model data show that its results against the four indicators of Micro-P, Micro-R, Micro-F1, and Macro-F1 were 4.8, 3.87, 4.32, and 3.55% higher, respectively, than those of the BERT-Linear model. Moreover, its results for the Micro-F1 indicator were 3.13 and 2.05% higher than the traditional BERT-BiLSTM and BERT-CRF models, respectively. These results confirm that the feature extraction fusion model proposed in this study is superior to the traditional single feature extraction model and can fully adapt to uneven data distribution while simultaneously performing the dual representation of text attributes and emotions. As a result, the correlations between two words can be identified, enabling their interrelationships to be understood from a deeper perspective.
Experimental Results and Analysis of the Service Dataset
The service dataset is used less frequently than other sets for the E2E-ABSA task, mainly because its data are initially used for sentence-level and subject-related tasks. However, it was used to expand the scope of the application of the model presented in this study. The effects of the GRU network and multiple attention on feature extraction were verified longitudinally. The specific distributions of semantic aspects in the service datasets are shown in Table 4.
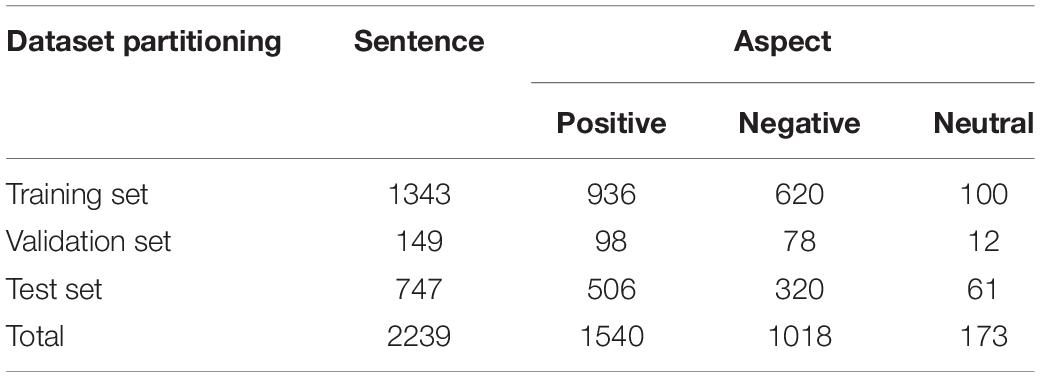
Table 4. Specific distributions of semantic aspects in the service datasets.
The depth feature extraction network was added layer-by-layer based on the BERT model to verify the depth model’s adaptability to datasets from different fields (refer to results in Table 5).
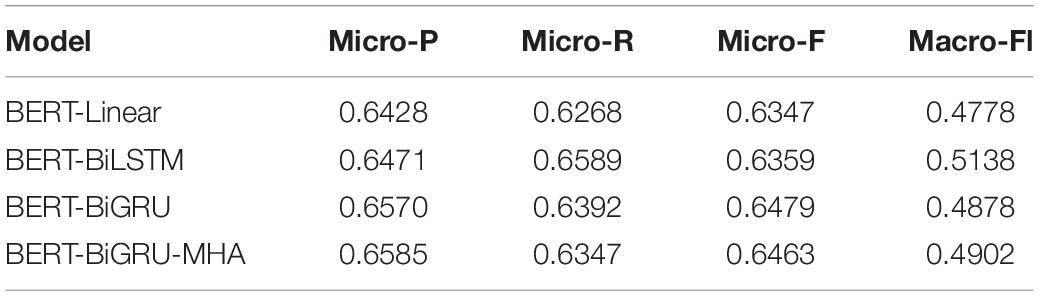
Table 5. Comparison between the experimental results of models based on the service dataset.
In terms of overall performance indicators, the BERT-MHA and BERT-BiGRU models performed similarly when locating and classifying most tags, but there was a 2.6% difference in performance on the Macro-F1 indicator, demonstrating that the capture of key information essential for attribute extraction and emotion classification is more important than capturing long-distance information in sparsely-distributed tag categories. Overall, however, the BERT-BiGRU-MHA model outperformed the benchmark, indicating that fusing the two improved the analysis of emotion in the service dataset.
Taking the most important index (Micro-F1) as the starting point, the BERT-MHA model with a multi-attentional mechanism and the BERT model combined with the BiGRU model in the downstream network improved on the BERT-Linear benchmark model by 1.24 and 1.32%, respectively. These results indicate that both the multi-attentional mechanism and GRU network can capture deep features and compute their semantic relevance very effectively. However, the Micro-F1 index for BERT-BİGRU-MHA shows that it did not outperform the separate feature extraction models BERT-MHA and BERT-BiGRU. This result is primarily because the service dataset contains an insufficient quantity of overall text and attributable emotions. As the model’s complexity increases, a greater quantity of data are required and only sufficient training can make the model fit completely. Thus, while the attention mechanism and feature extraction of datasets provided by GRU are sufficient, the increased complexity of the fusion model requires more modeling and data to comprehensively learn the characteristics of the domain. This explains why the index values for the basic and fusion models were similar. Future research may consider how to improve the adaptability of complex models with relatively small datasets.
Experimental Results and Analysis of the Laptop14 and Rest14 Datasets
The experimental results for the two datasets were compared with those of other advanced baseline models to conduct quantitative and qualitative analyses of the models. The experimental results of this process are shown in Table 6.
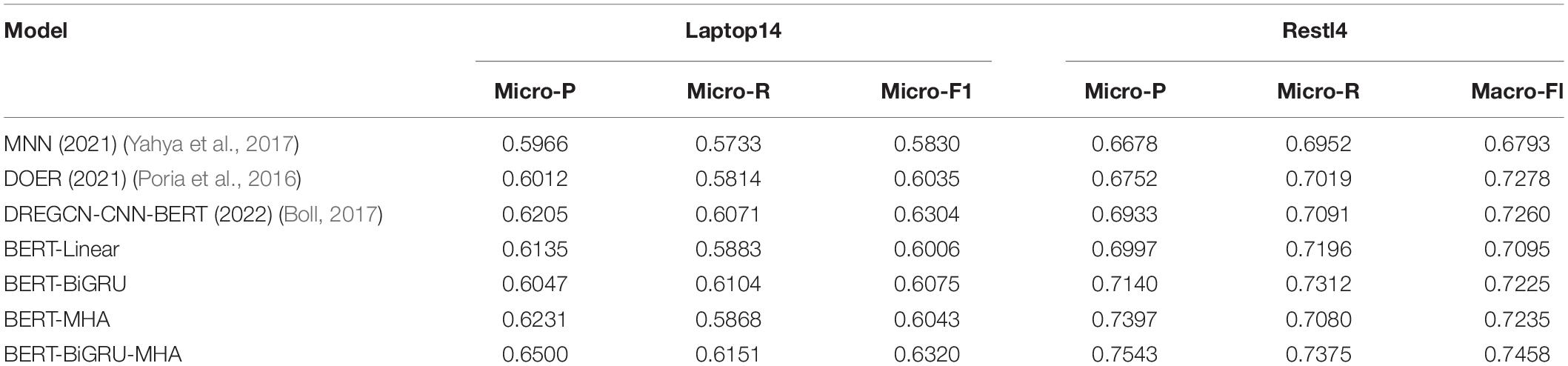
Table 6. Primary experimental results of each model on the Laptop14 and Rest14 datasets.
(1) MNN. This model uses a multi-task neural network (MNN) to solve the end-to-end unified text emotion analysis task. A combined CNN-BiLSTM network equipped with the self-attention mechanism was used to capture the relationship between attributes and emotions. The interactive attention mechanism was integrated with the feature output of the combined network to analyze emotions without external language resources on a unified sequence annotation dataset.
(2) Dual cross-shared RNN (DOER). Similar to the RNN network stack utilization in reference, the DOER model is based on dual cross-shared RNN for emotion analysis. The residual network connected the GRU network, and a cross-sharing unit was set to carry out interactive calculations of attributes and emotions.
(3) DREGCN-CNN-BERT. Based on the DREGCN model in reference, the CNN network and BERT were added to extract additional local and global features.
Compared with the MNN model, the BERT-based model achieved Micro-F1 improvements of 1.76 and 3.02% on the Laptop14 and Rest14 datasets, respectively. Thus, compared to the multi-task network model, the unified task model structure is not centralized and the end-to-end performance is relatively poor. The DOER and BERT-Linear models performed at similar levels, further confirming the former’s powerful text-processing capability. However, when GRU and the attention mechanism were added to BERT, the effect was significantly improved, fully verifying the analysis they had performed. The MNN model based on the attention mechanism and the DOER model using GRU performed better than the BERT-MHA and BERT-BiGRU models in this study. This indicates that the combination of BERT, GRU, and the multi-attention mechanism may maximize their respective advantages in the feature network. The DREGCN-CNN-BERT and BERT-BiGRU-MHA models recorded similar values against the indicators on the Laptop14 dataset. On Rest14, the Micro-F1 values for the BERT-BiGRU-MHA model reached 74.58%, confirming its superiority over CNN for extracting local information. The context-related features of GRU and the multi-attention mechanism complemented the global features of this dataset more effectively.
For the Laptop14 and Rest14 datasets, the BERT-MHA and (particularly) BERT-BiGRU models improved on the Micro-F1 values recorded for the benchmark BERT-Linear model by 3.14 and 3.63%, respectively. Compared with the single feature extraction model, the fusion model of the Laptop14 and Rest14 sets reached 63.20 and 74.58% on Micro-F1, with average improvements of 2.61 and 2.28% further confirming the superiority of the fusion model. The Micro-P values were higher than those of Micro-R in both datasets for the BERT-BiGRU-MHA model, with the Micro-P 2.585% higher than the Micro-R on average, indicating that the model’s ability to make accurate predictions is higher than its tag-searching ability (refer to Figure 7).
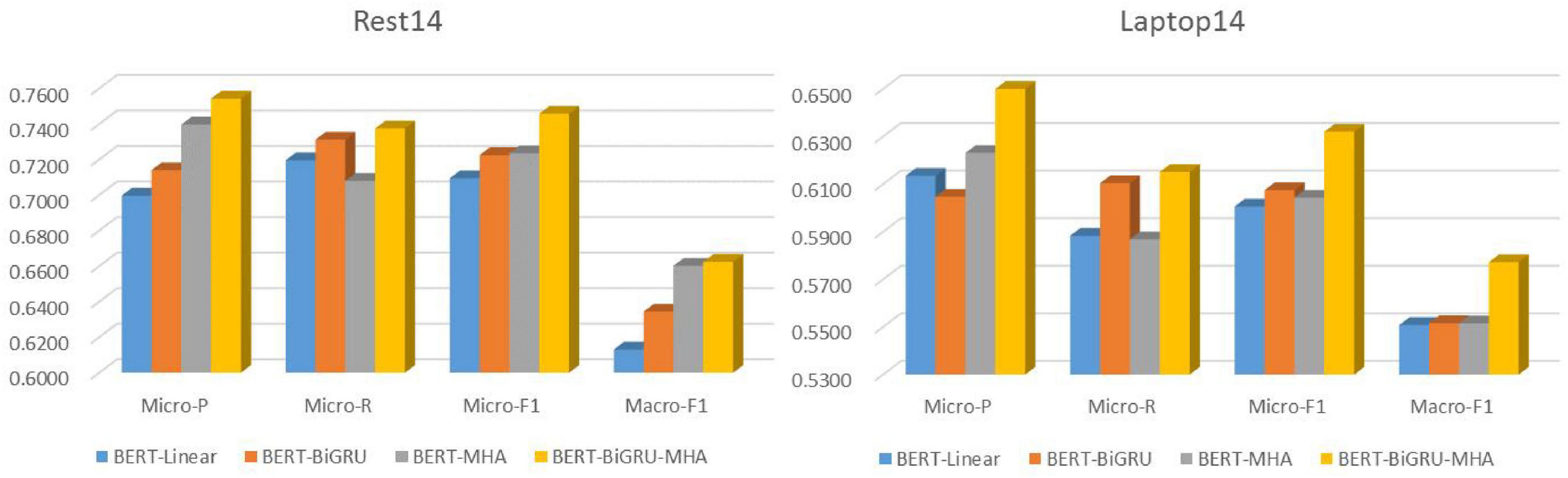
Figure 7. Comparison of corresponding performance indexes of each model.
There was a clear difference in the effect of MHA and BiGRU on the two datasets. The BERT-MHA model with attentional mechanism produced significant improvements in Micro-P, indicating that the mechanism can screen and capture key information. Meanwhile, the BERT-BiGRU model combined with GRU had a clear effect on Micro-R, indicating the effectiveness of GRU for extracting associated text semantics. The integrated network fully combines the advantages of both and performed better on all indicators, including Macro-F1.
Overall, GRU helped with the attention mechanism and while the fusion feature extraction of the network on small datasets requires a certain amount of fitting, the labels were found and the classification was accurate. This performance on the E2E-ABSA task demonstrated its potential use as a backbone network for extracting text semantics and contextual relevance.
Conclusion
Text emotion analysis offers an intelligent and efficient means of locating hidden information in large-scale data and is an effective way for machines to “read” people. It has great potential in application fields such as recommendation systems. this study aimed to optimize a model for analyzing the emotional depth of ideological and political education. The analysis can be adapted to a variety of subtasks, including the exploration of dispersed emotion and the theory and practical application of cohesion in texts. It can also be used to analyze the emotional content of personalized recommendation systems and the convergence properties test. It is capable of deeper, end-to-end, and fine-grained exploration of the emotional content of texts. Using BERT text processing, a feature extraction depth model combining a bidirectional GRU network with a multi-attentional mechanism is proposed, constructing a complete E2E-ABSA model framework. Focusing on a deep learning model of text emotion analysis, this study has introduced the feature extraction principle of BiGRU and the method of its realization using the multi-attention mechanism and has expounded the calculations for fusing them. Second, a comparative test of the model was conducted on multiple datasets to analyze the role of each network and the effectiveness of the whole model.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/IsakZhang/Generative-ABSA.
Author Contributions
SS: manuscript writing and the experiments. JF: supervision. Both authors contributed to the article and approved the submitted version.
Funding
This work was partly supported by 2019 Youth Fund for Humanities and Social Sciences Research of the Ministry of Education of China (No. 19YJC710043).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We would like to thank all the reviewers.
References
Adeniyi, D. A., Wei, Z., and Yongquan, Y. (2016). Automated web usage data mining and recommendation system using K-Nearest Neighbor (KNN) classification method. Appl. Comput. Inform. 12, 90–108.
Bai, X., Yao, C., and Liu, W. (2016). Strokelets: a learned multi-scale mid-level representation for scene text recognition. IEEE Trans. Image Process. 25, 2789–2802. doi: 10.1109/TIP.2016.2555080
Boll, S. (2017). Multimedia at CHI: telepresence at Work for Remote Conference Participation. IEEE Multimedia 24, 5–9.
Gao, L. L., Guo, Z., Zhang, H. W., Heng, X. X., and Shen, T. (2017). Video captioning with attention-based LSTM and semantic consistency. IEEE Trans. Multimedia 19, 2045–2055.
Han, J., Zhang, D., Cheng, G., Liu, N., and Xu, D. (2018). Advanced deep-learning techniques for salient and category-specific object detection: a survey. IEEE Signal Process. Mag. 35, 84–100.
Hansen, J. H., and Hasan, T. (2015). Speaker recognition by machines and humans: a tutorial review. IEEE Signal Process. Mag. 32, 74–99.
Harper, F. M., and Konstan, J. A. (2015). The movielens datasets: history and context. ACM Trans. Interact. Intell. Syst. 5, 1–19.
Herath, S., Harandi, M., and Porikli, F. (2017). Going deeper into action recognition: a survey. Image Vis. Comput. 60, 4–21.
Huo, J. H., Hou, S. X., and Wang, X. Z. (2016). Rough fuzzy Decision Tree Induction Algorithm. J. Nanjing Univ. Nat. Sci. 2, 306–312.
Jiang, Y. G., Wu, Z. X., Wang, J., Xue, X. Y., and Chang, S. F. (2017). Exploiting feature and class relationships in video categorization with regularized deep neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 40, 352–364.
Khan, R., and Amjad, M. (2016). Automatic generation of test cases for data flow test paths using K-means clustering and generic algorithm. Int. J. Appl. Eng. Res. 11, 473–478.
Kyunghyun, C., Aaron, C., and Yoshua, B. (2015). Describing multimedia content using attention-based encoder-decoder networks. IEEE Trans. Multimedia 17, 1875–1886.
Li, G. M., Li, P., and Wang, C. (2019). Distributed Data Acquisition and Analysis based on Scrapy: a Case study of Zhihu Topic. J. Hubei Normal Univ. 39, 1–7.
Liu, Y., Lu, J. H., Yang, J., and Mao, F. (2020). Emotion analysis for e-commerce product reviews by deep learning model of Bert-BiGRU-Softmax. Math. Biosci. Eng. 17, 7819–7837. doi: 10.3934/mbe.2020398
Lopamudra, D., Sanjay, C., Anuraag, B., Beepa, B., and Sweta, T. (2016). Emotion analysis of review datasets using Naive Bayes’ and K-NN classifier. Inf. Eng. Electron. Bus. 8, 54–62.
Mühlbacher, T., Linhardt, L., Möller, T., and Piringer, H. (2018). TreePOD: sensitivity-Aware Selection of Pareto-Optimal Decision Trees. IEEE Trans. Vis. Comput. Graph. 24, 174–183. doi: 10.1109/TVCG.2017.2745158
Ortigosa, H. J., Rodriguez, J. D., Alzate, L., Lucania, M., Inza, I., and Lozano, A. J. (2012). Approaching Emotion Analysis by using semi-supervised leaning of multi-dimensional classifiers. Neurocomputing 92, 98–115.
Peng, H., Cambria, E., and Hussain, A. A. (2017). Review of Emotion Analysis Research in Chinese Language. Cognit. Comput. 9, 423–435.
Poria, S., Cambria, E., Howard, N., Huang, G. B., and Hussain, A. (2016). Fusing audio, visual and textual clues for emotion analysis from multimodal content. Neurocomputing 174, 50–59.
Quadrana, M., Cremonesi, P., and Jannach, D. (2018). Sequence-aware recommender systems. ACM Comput. Surv. 51, 1–36.
Song, Y., Yao, S., Yu, D. H., and Hu, Y. Z. A. (2017). New K-Ary Crisp Decision Tree Induction with Continuous Valued Attributes. Chin. J. Electron. 26, 999–1007.
Su, Y., and Li, S. S. (2013). Constructing chinese emotion lexicon using bilingual information[J]. Chin. Lexical Semant. 7717, 322–331.
Yahya, A. A., Osman, A., and El-Bashir, M. S. (2017). Rocchio algorithm-based particle initialization mechanism for effective PSO classification of high dimensional data. Swarm Evol. Comput. 34, 18–32.
Keywords: GRU, deep learning, political and ideological education, emotion analysis, feature fusion
Citation: Shen S and Fan J (2022) Emotion Analysis of Ideological and Political Education Using a GRU Deep Neural Network. Front. Psychol. 13:908154. doi: 10.3389/fpsyg.2022.908154
Received: 30 March 2022; Accepted: 06 June 2022;
Published: 26 July 2022.
Edited by:
Maozhen Li, Brunel University London, United KingdomReviewed by:
Xiao Mansheng, Hunan University of Technology, ChinaShihua Cao, Hangzhou Normal University, China
Juan Yang, Suzhou University, China
Wenhao Ying, Changshu Institute of Technology, China
Copyright © 2022 Shen and Fan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jinling Fan, ZmFuamlubGluZ0BoZWJ1c3QuZWR1LmNu