 Zhaolun Wang1,2*
Zhaolun Wang1,2* Zhixin Gao3
Zhixin Gao3- 1Henan College of Transportation, Zhengzhou, Henan, China
- 2Changsha University of Science and Technology, Changsha, Hunan, China
- 3Chang’an University, Xi’an, China
Introduction: Accurate defect detection in dissimilar metal welds (DMWs) remains a major challenge due to heterogeneous microstructures and imaging noise.
Methods: In this study, we propose a novel deep learning framework, DynaWave-Net, combined with a Guided Progressive Distillation (GPD) strategy, to address these challenges by integrating microstructural priors and frequency-domain features. The proposed model incorporates dynamic geometry-aware encoding and wavelet based attention to capture both structural deformations and high-frequency defect signatures.
Results and Discussion: Extensive experiments on multiple real-world datasets demonstrate that our approach significantly outperforms existing methods, achieving up to 18% improvement in precision and enhanced robustness to structural noise. Furthermore, the lightweight architecture enables real-time deployment on edge devices, highlighting the practical relevance of this work for industrial inspection in energy, aerospace, and manufacturing sectors.
1 Introduction
Dissimilar metal welds (DMWs) are widely used in critical industrial applications, including power plants, aerospace, and petrochemical systems, due to their ability to join materials with differing mechanical properties and corrosion resistance Ma et al. (2023). However, their intrinsic structural complexity—resulting from variations in chemical composition, thermal expansion coefficients, and metallurgical compatibility—renders them particularly susceptible to defects such as cracks, voids, and inclusions Meng et al. (2021). These defects often initiate at the interface of dissimilar materials, where stress concentration and microstructural heterogeneities are most pronounced. Traditional nondestructive evaluation (NDE) techniques such as ultrasonic testing or radiography are often limited in resolution and sensitivity, especially when detecting subtle or subsurface anomalies in DMWs Gao et al. (2018). Hence, there is a pressing need for advanced detection methodologies that not only improve the accuracy of defect recognition but also account for the microstructural variability that governs defect morphology Wang W. et al. (2024). Learning-based defect detection models offer a compelling solution by leveraging large datasets and pattern recognition capabilities Guan and Wang (2023). Not only can these models adapt to the intrinsic heterogeneity of DMWs, but they also offer scalable and real-time monitoring potential, providing a significant leap over conventional techniques Xu et al. (2018).
To address the limitations of conventional inspection, earlier efforts focused on symbolic AI and expert systems which relied on hand-crafted features derived from domain knowledge. These approaches used rule-based inference engines or knowledge representation frameworks such as decision trees and fuzzy logic to classify welding defects Xie et al. (2021). For instance, features such as grain orientation, boundary density, and inclusion count were manually extracted from metallographic images or sensor signals. While these systems provided a valuable starting point, they were heavily reliant on expert input and lacked adaptability to new defect types or welding conditions Beygi et al. (2023). Moreover, symbolic methods struggled to capture the complex interrelations within microstructures, especially in regions of the weld where phase transformations or diffusion gradients altered material behavior. In order to compensate for these drawbacks, researchers often attempted to enhance feature sets or refine the rule-based logic, but scalability and robustness remained major concerns Yang et al. (2017).
To overcome the rigidity of symbolic systems, data-driven and machine learning techniques began to gain prominence. Classical machine learning algorithms such as support vector machines (SVM), k-nearest neighbors (KNN), and random forests (RF) were applied to features extracted from thermographic, ultrasonic, and radiographic data Liu et al. (2024). These methods introduced greater flexibility and allowed for automated feature selection and classification, improving defect detection rates under varying operational conditions. Furthermore, statistical learning models were better at accommodating minor variations in weld geometry and microstructure, enabling more generalized models Wei et al. (2024). However, these approaches were still constrained by their dependence on feature engineering, which limited their ability to model deep contextual relationships within weld structures Zhao et al. (2016). For instance, capturing the influence of multi-scale microstructural patterns—such as dendritic growth, phase boundaries, or precipitate distributions—was difficult without extensive domain-specific preprocessing. As a result, while machine learning offered a significant improvement over symbolic approaches, it still fell short in terms of capturing the full complexity inherent to dissimilar metal welds Yan et al. (2023).
In order to resolve the limitations of feature-dependent methods, the advent of deep learning and pre-trained models has ushered in a new era in defect detection. Convolutional neural networks (CNNs), autoencoders, and transformers have demonstrated an unprecedented ability to learn hierarchical features directly from raw data, eliminating the need for manual intervention Zhang L. et al. (2024). These models have been trained on multimodal datasets including acoustic emissions, high-resolution imaging, and microstructural maps, thereby allowing them to learn complex, non-linear relationships between defect signatures and underlying material structures. Transfer learning and domain adaptation techniques have further enhanced performance by enabling model generalization across different welding setups and material combinations. For instance, a pre-trained CNN on one type of weld defect can be fine-tuned for another application with minimal additional data Baghel (2022). Despite their success, deep models still face challenges such as interpretability, data scarcity in certain domains, and the need for large-scale annotated datasets. Nonetheless, their potential to model the microstructural influence on defect formation and propagation in DMWs represents a major advancement Liu et al. (2015).
Based on the aforementioned limitations of symbolic and classical machine learning methods—particularly their reliance on manual feature engineering and limited adaptability—we propose a novel hybrid learning-based framework that integrates microstructural priors into a deep learning pipeline. This approach not only incorporates domain knowledge into the model architecture but also enables context-aware defect detection that is sensitive to the varying microstructural features of dissimilar metal welds. By fusing material-specific attributes with learned representations, our method can differentiate between benign microstructural features and true defect signals more effectively. Furthermore, this hybrid strategy addresses the data inefficiency issues of deep learning by embedding physical constraints and weld process parameters into the learning objective. Through this method, we aim to bridge the gap between purely data-driven models and the complex metallurgical realities of DMWs, thereby achieving more accurate, interpretable, and generalizable defect detection.
While the input to our defect detection model is primarily image-based, such as radiographic or optical data, the influence of microstructural features is integrated through multiple layers of architectural and dataset-level design. The model architecture incorporates frequency-domain selective attention and geometry-aware modules that are highly sensitive to subtle high-frequency variations and local spatial distortions. These signal patterns often correlate with underlying microstructural heterogeneities such as dendritic growth, intermetallic phases, and grain boundary networks. We employ datasets containing paired microstructural annotations, such as the Microstructure and Alloy Dataset and the NIST Microstructure Dataset. These datasets include grain morphology, phase composition, and metallurgical transformations, enabling the model to learn latent correlations between observable defect shapes and their metallurgical contexts. Furthermore, the Guided Progressive Distillation (GPD) training strategy incorporates structural priors in the form of graph-regularized embeddings and probabilistic supervision based on class co-occurrence. This ensures that the model implicitly internalizes how microstructural environments influence defect formation and manifestation in images, even if these structures are not directly observable in the raw data.
2 Related work
2.1 Microstructural variability in welds
The microstructure of dissimilar metal welds (DMWs) is highly heterogeneous due to differences in chemical composition, melting point, and thermal conductivity between the joined materials Chen et al. (2014b). These differences lead to complex phase transformations and uneven residual stress distributions, particularly near the weld interface. Researchers have used advanced characterization techniques such as scanning electron microscopy, transmission electron microscopy, and electron backscatter diffraction to study these features, revealing grain boundaries, precipitates, and dendritic growth patterns throughout the weld zone Wang J. et al. (2024). These microstructural variations significantly influence mechanical behavior and the likelihood of defect formation. For example, the fusion boundary often shows gradients in hardness and toughness, which increase susceptibility to hot cracking, while brittle intermetallic compound layers between dissimilar metals can promote crack initiation under operational stress Subbaratnam et al. (2008). In machine learning-based defect detection, such variability complicates feature extraction, as differences in grain size, texture, and inclusion distribution can distort signals in ultrasonic or X-ray imaging Mishra et al. (2022). To address this, some approaches incorporate domain-specific features or train models with data that mimic real microstructural conditions, helping to improve performance across diverse welding setups. Recent developments in physics-informed learning have further enhanced robustness by integrating simulated microstructural data into training pipelines, enabling models to identify defects more reliably despite the noise introduced by structural inconsistencies Chen et al. (2023).
2.2 Learning-based NDT techniques
The integration of machine learning with non-destructive testing methods such as ultrasonic testing, eddy current testing, and radiographic testing has greatly improved defect detection in complex weld structures Li P. et al. (2023). Traditional signal processing approaches depend on fixed thresholds and filters, which often perform poorly in the presence of noise or when signal behavior is affected by microstructural differences. In contrast, learning-based methods use large datasets to identify distinguishing features directly from raw or processed inputs, offering more flexibility and accuracy. Convolutional neural networks are especially effective in image-based inspection, as they can automatically extract layered features that reveal spatial relationships and subtle defect signatures. In ultrasonic testing, models such as recurrent neural networks and transformers are used to analyze time-series A-scan data, allowing for the detection of flaws at early stages Meola et al. (2004). Given the variability of dissimilar metal welds, domain adaptation and transfer learning techniques have been introduced to improve generalization across different material combinations. These include strategies like adversarial training, few-shot learning, and meta-learning, which help models adapt to new weld types with minimal labeled data Chen et al. (2014a). In addition, semi-supervised and self-supervised learning approaches make use of unlabeled inspection records, reducing the need for extensive manual annotation. For industrial deployment, model interpretability is essential. Visualization tools such as Grad-CAM, SHAP, and saliency maps are used to identify which parts of the input most influence the model’s output, linking predictions to physical features in the weld. This not only builds confidence in automated decisions but also supports the optimization of inspection techniques and repair decisions Shu et al. (2024).
2.3 Fusion zone and interface challenges
The fusion zone and heat-affected zone in dissimilar metal welds are highly susceptible to defect formation due to abrupt changes in chemical composition and temperature during welding. These transitions lead to complex microstructures, including partially melted regions, unmixed segments, and reheated areas, which contribute to common issues such as porosity, lack of fusion, and metallurgical cracking Fan et al. (2021). Studies have shown that the geometry and morphology of the weld interface play a key role in how defects develop and are detected. Features like unmixed zones or discontinuities along the weld line can resemble actual flaws in non-destructive testing images, increasing the likelihood of false positives in automated detection systems. To address this, advanced imaging and post-processing techniques have been used to distinguish microstructural irregularities from true defects. Multi-modal inspection strategies have also gained attention, combining methods like thermography and acoustic emission with conventional techniques to obtain richer datasets. By training machine learning models on these fused inputs, both surface and subsurface defect indicators can be captured, improving classification accuracy. In parallel, simulation-based approaches have been explored to replicate defect formation under varying weld conditions. These synthetic datasets generated through phase-field modeling and computational thermodynamics offer valuable annotated samples for training supervised algorithms, especially where real defect data is scarce. Furthermore, explainable AI methods have enhanced the interpretability of model outputs by linking neural network activations to specific microstructural features. This alignment with metallographic observations allows researchers to validate predictions and better understand how characteristics at the weld interface influence detection performance Zhang B. et al. (2024).
In practical applications of weld inspection, the quality of input images can vary significantly depending on the imaging modality, resolution, lighting conditions, sensor type, and acquisition parameters. Such variability may introduce artifacts, blur, or inconsistent contrast levels that affect the visibility of fine-grained defects, especially in dissimilar metal welds with complex structural backgrounds. In alignment with prior studies in technical diagnostics, as discussed in paragraph 2 of this article, variations in shooting parameters can substantially influence diagnostic performance. To address this challenge, our proposed framework incorporates multiple design elements to enhance robustness against such variations. The Frequency-Domain Selective Attention module in DynaWave-Net enables the model to capture essential high-frequency features and suppress irrelevant background noise, which often varies with image quality. The dynamic geometry-aware encoding mechanism adjusts spatial receptive fields based on local deformation, allowing the network to adapt to morphological variations regardless of image clarity or resolution. The Guided Progressive Distillation strategy introduces domain-level priors and co-occurrence statistics during training, helping the model learn invariant representations even when imaging conditions shift. Our training data includes diverse datasets with differing modalities and acquisition protocols, further promoting generalization. These mechanisms jointly ensure that the detection pipeline remains accurate and reliable under different imaging setups, a critical requirement for real-world industrial deployment.
3 Methods
3.1 Overview
Weld defect detection is a crucial task in industrial quality control, directly impacting the safety and reliability of manufactured components, particularly in domains such as aerospace, shipbuilding, and pressure vessel fabrication. Traditional approaches to weld defect detection often rely on expert visual inspection or rule-based image analysis, which can be labor-intensive, error-prone, and difficult to scale. Recent advances in computer vision and machine learning, especially deep neural networks, have significantly transformed the landscape of defect detection by enabling automated, scalable, and high-accuracy recognition of various weld flaws, including porosity, lack of fusion, cracks, and slag inclusions. This work aims to address the inherent challenges of automatic weld defect detection by proposing a novel pipeline that integrates formal representation learning, an expressive yet efficient detection model, and a strategy tailored for domain-specific knowledge incorporation. In the following sections, we systematically present the formulation, model design, and learning strategy that underpin approach. In 3.2, we first present the problem formalization of weld defect detection. We begin by characterizing weld inspection as a structured visual recognition problem, where each weld segment is associated with a complex image containing possible defects embedded in high-resolution noisy backgrounds. To rigorously define the detection objective, we introduce a mathematical representation framework that models each input image as a function over spatial and structural domains, and each defect as a structured label encoded in a high-dimensional output space. The preliminaries section builds the symbolic foundation of the method and clarifies the notational conventions used throughout. Importantly, this formulation is designed to be extensible across varying types of inspection data, including X-ray, ultrasonic, and visual modalities. In 3.3, we introduce our new model architecture, referred to as DynaWave-Net. This model is designed to capture both fine-grained textures and structural patterns specific to weld defects by leveraging dynamic receptive field mechanisms. Unlike conventional convolutional models that operate with fixed kernels, our architecture incorporates multi-scale deformable convolutions fused with wavelet-guided attention blocks. These modules allow the model to adaptively focus on geometric distortions, irregular patterns, and low-frequency signal variations typical in defect-prone regions. The model is trained in an end-to-end fashion, enabling joint optimization of spatial and frequency-aware parameters for robust localization and classification of defects. Furthermore, our model is lightweight and optimized for deployment in resource-constrained edge devices commonly used in industrial settings. In 3.4, we propose a domain-adaptive strategy, termed Guided Progressive Distillation, which integrates domain knowledge from welding standards and inspection heuristics into the learning process. This strategy is designed to alleviate the domain shift issue caused by the variability in weld types, materials, and imaging conditions. It involves two complementary mechanisms: guided label smoothing based on prior defect co-occurrence patterns, and progressive knowledge injection from expert rules into intermediate model layers during training. These techniques not only improve generalization across diverse datasets but also enhance interpretability by aligning model activations with human-understandable cues, such as defect boundaries or standard-compliant defect thresholds.
The flaw detection process described in this work aligns with several recognized industrial standards and practices for weld inspection. The datasets and defect classification schemes used in our training and evaluation phases are consistent with guidelines provided by the International Institute of Welding (IIW), ISO 5817 (Welding—Fusion-welded joints in steel, nickel, titanium and their alloys—Quality levels for imperfections), and the American Society for Nondestructive Testing (ASNT). These standards define the permissible types and sizes of weld flaws, defect severity levels, and evaluation criteria used in industrial settings. Furthermore, our Guided Progressive Distillation (GPD) framework embeds structural priors and spatial smoothness constraints that mirror rule-based expectations found in manual inspection standards. By adhering to such regulatory baselines during dataset preparation and architectural design, the proposed system ensures that automated predictions can be interpreted within the context of established flaw assessment protocols, thereby enhancing its engineering applicability and compliance with real-world inspection requirements.
The proposed detection framework is designed to identify multiple categories of weld defects commonly found in dissimilar metal joints. Our model can diagnose lack of fusion (LOF), porosity, slag inclusions, micro-cracks, and undercuts. These defect types are widely reported in industrial applications and exhibit varying visual and structural characteristics, such as irregular edges, dark voids, or discontinuous textures. During training, we employ labeled datasets that contain bounding boxes and pixel-level annotations for each of these categories, allowing the model to learn discriminative features specific to each defect type. Furthermore, the use of frequency-domain analysis within the model helps distinguish high-frequency signals such as crack lines from low-frequency background variations. The Guided Progressive Distillation (GPD) mechanism also contributes by learning semantic relationships between co-occurring defects and suppressing misclassification in noisy environments. As a result, the proposed method not only provides accurate localization but also reliable classification of critical weld flaws in both surface and subsurface regions.
3.2 Preliminaries
Weld defect detection is a structured recognition problem characterized by spatial complexity, class imbalance, and domain uncertainty. In this section, we present a formal mathematical formulation of the task, including the symbolic definitions of inputs, outputs, mappings, and latent representations. This lays the theoretical foundation for the subsequent model design and learning strategy.
Let
Here,
Each image is associated with a set of annotated defects
Here,
We aim to learn a mapping
The model must predict both the number of defects and their spatial-localization-label pairs. Due to the variable size of
To better characterize the learning objective, we define a probability model
This formulation assumes conditional independence between defects given the image, which simplifies training but allows flexible parameterization through deep networks.
We now decompose the joint prediction into two components: spatial localization and semantic classification. Define the spatial localization likelihood as Formula 5:
where
For classification, we define a categorical distribution over labels (Formula 6):
Here,
We now introduce a latent representation space
The representation
Given
The overall detection pipeline is thus described as a composition (Formula 10):
From a geometric standpoint, weld defects often exhibit topological or textural distortions. To incorporate such priors, we define a structure-aware kernel
This kernel defines a graph
To bounding-box labels, we consider a continuous defect intensity field
where
The learning objective combines classification, localization, and representation terms. Let
where
Furthermore, the defect categories often exhibit co-occurrence patterns. Let
where
3.3 DynaWave-net
To address the unique challenges in weld defect detection—including variability in defect morphology, low signal-to-noise ratio, and fine-grained spatial sparsity—we propose a novel detection framework called DynaWave-Net (As shown in Figure 1). This network combines dynamic geometry modeling with frequency-guided attention to capture both structural deformations and high-frequency surface anomalies commonly found in dissimilar metal welds.
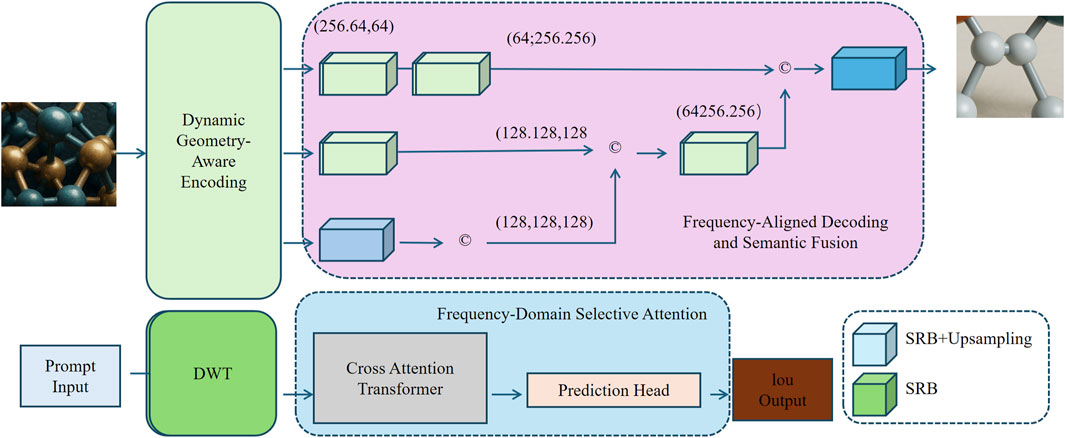
Figure 1. Architecture of the proposed DynaWave-Net framework. The model integrates three major components: Dynamic Geometry-Aware Encoding (top-left) captures irregular morphological patterns via deformable convolutions; Frequency-Domain Selective Attention (bottom) enhances sensitivity to high-frequency surface anomalies using wavelet decomposition and attention; and Frequency-Aligned Decoding and Semantic Fusion (top-right) jointly preserves spatial and frequency features to improve localization and robustness in defect segmentation.
3.3.1 Dynamic Geometry-Aware Encoding
To effectively capture irregular defect boundaries and local spatial deformations in dissimilar metal welds, we propose a Dynamic Geometry-Aware Encoding (DGAE) module as a core component of the DynaWave-Net framework. This module leverages multi-scale deformable convolutions to dynamically adapt receptive fields based on geometric context.
Let the input image be denoted as
where
Each deformable convolution dynamically learns spatial sampling offsets for each location
where
To further improve geometric robustness, we enhance the encoded features using a geometric modulation gate
where
We employ hierarchical residual connections across levels to facilitate information flow and preserve multi-scale spatial fidelity (Formula 21):
3.3.2 Frequency-Domain Selective Attention
In industrial weld imagery, defects such as micro-cracks, inclusions, and porosities often manifest as subtle, high-frequency discontinuities that are difficult to capture through conventional convolutional operators. To address this, we propose a Frequency-Domain Selective Attention (FDSA) (As shown in Figure 2) mechanism that exploits the frequency decomposition capability of discrete wavelet transform (DWT) to isolate and enhance critical structural details.
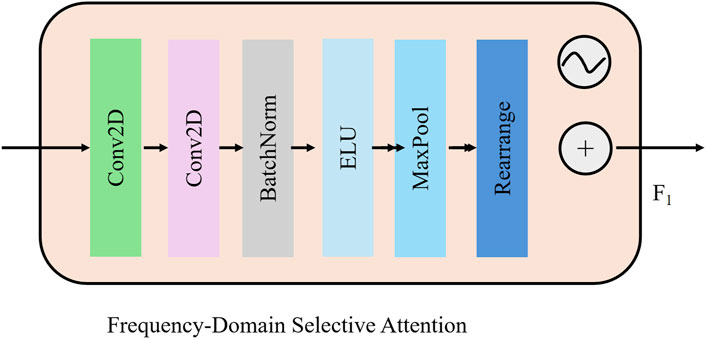
Figure 2. Illustration of the Frequency-Domain Selective Attention (FDSA) module. The input feature map is processed through stacked convolutional layers, batch normalization, ELU activation, and max-pooling before being rearranged for wavelet-guided attention. Discrete Wavelet Transform (DWT) extracts subbands, which are weighted via MLP-based attention and aggregated to emphasize high-frequency details such as cracks and inclusions critical for weld defect localization.
Given an intermediate feature map
where
To selectively enhance these frequency channels, we design a learnable attention mechanism that assigns an importance weight to each subband based on global content statistics. We use a shared multi-layer perceptron (MLP) across all subbands to compute attention weights (Formula 23):
where
The subbands are then aggregated using their respective attention weights to form the frequency-enhanced output (Formula 24):
To further integrate spatial and frequency domains, the output
3.3.3 Frequency-Aligned Decoding and Semantic Fusion
To ensure accurate recovery of fine structural details and semantic boundaries during prediction, we propose a Frequency-Aligned Decoding and Semantic Fusion module. Unlike traditional decoders that rely solely on spatial upsampling, our design incorporates frequency-aware cues to reinforce edge continuity and suppress spatial artifacts.
Let
where
To perform joint fusion, we concatenate the upsampled spatial feature, the frequency-attended feature, and their element-wise interaction to form a rich multi-domain representation (Formula 27):
where
This frequency-aligned decoder promotes synergy between high-resolution textural cues and semantically abstracted features, improving both boundary precision and robustness against noise.
The final output is generated through two task-specific heads operating on the decoded base-level representation
where
To guide learning, we define the overall training objective as Formula 29:
where
3.4 Guided Progressive Distillation
While DynaWave-Net provides a structurally adaptive and frequency-aware backbone for weld defect detection, its effectiveness in real-world applications hinges on robust generalization and domain-specific adaptation (As shown in Figure 3). To meet this need, we propose a novel training paradigm named Guided Progressive Distillation (GPD), which integrates knowledge regularization, spatial constraints, and dynamic self-supervision into a unified framework.
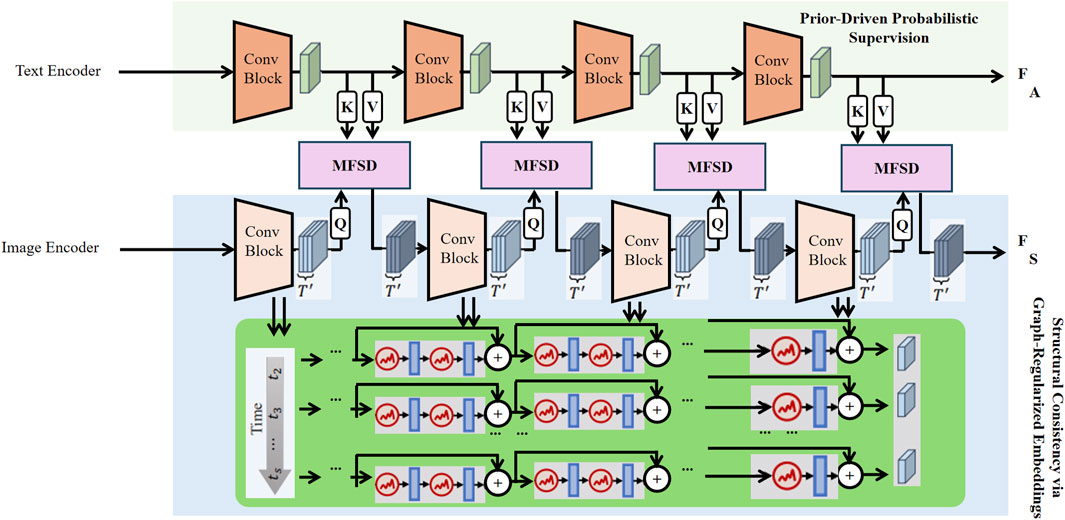
Figure 3. Illustration of the proposed Guided Progressive Distillation (GPD) framework. The model employs Prior-Driven Probabilistic Supervision to mitigate annotation noise and class imbalance, Multi-Stage Feature Distillation with Temporal Stabilization to align student-teacher representations across time, and a Structural Consistency module via Graph-Regularized Embeddings to preserve spatial coherence of correlated defect regions. Together, these components enable domain-adaptive, stable, and context-aware training within the DynaWave-Net pipeline.
3.4.1 Prior-Driven Probabilistic Supervision
In industrial defect detection, label noise, semantic ambiguity, and class imbalance are prevalent due to the difficulty of precise annotation and the sparsity of rare defect types (As shown in Figure 4). To address these challenges, we introduce a Prior-Driven Probabilistic Supervision (PDPS) strategy as part of the Guided Progressive Distillation (GPD) framework. This method leverages statistical co-occurrence priors to construct a softened, uncertainty-aware supervision signal that replaces the traditional one-hot label scheme.
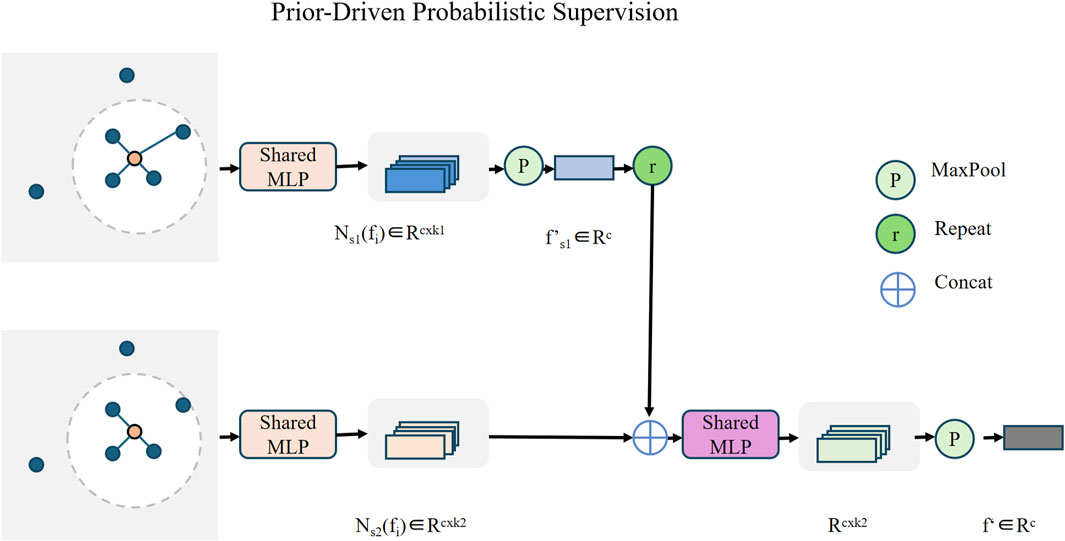
Figure 4. Schematic of the Prior-Driven Probabilistic Supervision module in the Guided Progressive Distillation (GPD) framework. The method leverages neighborhood feature aggregation through shared MLPs and hierarchical pooling to generate smoothed, context-aware representations. Empirical co-occurrence priors are used to modulate label distributions, mitigating annotation noise and class imbalance while enabling uncertainty-aware learning for robust defect classification.
Given a ground truth class label
where
This prior distribution
The final classification loss is computed using the Kullback-Leibler divergence (or its cross-entropy counterpart) between the predicted softmax output
This loss relaxes the one-hot constraint and distributes partial credit to semantically or visually correlated classes. As a result, the model becomes less overconfident and more tolerant to mislabeled or ambiguous examples, especially in low-frequency categories.
To further encourage class-wise balance, a weighting term
3.4.2 Multi-Stage Feature Distillation with Temporal Stabilization
To enhance feature transfer in the presence of evolving representations and unstable gradients, we introduce a Multi-Stage Feature Distillation with Temporal Stabilization (MSFD-TS) scheme. This component enables deep supervision from a slowly updated teacher model to a rapidly adapting student network during training, encouraging convergence to semantically meaningful and stable feature spaces.
Let
To control the strength of supervision at different stages of training, we define a time-dependent weighting factor
where
The total distillation loss is thus formulated as Formula 37:
Beyond feature alignment, we introduce a temporal stabilization loss that encourages consistency across consecutive output predictions. Let
This regularization not only reduces flickering predictions but also promotes smooth convergence of the decision boundary, which is particularly beneficial for capturing small-scale or low-contrast weld defects.
In implementation, the teacher network is updated using an exponential moving average (EMA) of the student weights to ensure stability (Formula 39):
where
3.4.3 Structural Consistency via Graph-Regularized Embeddings
To feature alignment and temporal stability, capturing spatial relationships among localized defects is crucial for robust weld inspection. Defects such as slag clusters, porosities, and crack lines often exhibit structured spatial correlations, which may not be captured by pixel-wise losses. To address this, we incorporate a Structural Consistency constraint via Graph-Regularized Embeddings.
Let the set of predicted bounding boxes be denoted as
We define the edge set
where
where
Each node
We then define a graph smoothness loss to encourage feature similarity between connected nodes (Formula 43):
This loss enforces spatial coherence in the embedding space, such that structurally or semantically related detections—like cracks that extend across neighboring regions—yield similar latent features.
To balance the contribution of graph regularization with other training signals,
where
3.4.4 Total Objective
The final training objective of the Guided Progressive Distillation (GPD) framework integrates semantic supervision, knowledge transfer, structural alignment, and temporal stability into a unified loss function. This comprehensive formulation is designed to improve robustness and generalization in industrial defect detection.
The total loss is defined as Formula 45:
where
The hyperparameters
To ensure a stable learning target for distillation, the teacher model is updated using exponential moving average (EMA) of the student parameters (Formula 46):
where
4 Experimental setup
4.1 Dataset
OpenWeld Dataset Guo et al. (2024) is a specialized dataset focused on real-world weld images and inspection annotations, particularly designed for automated defect detection in various welding configurations. It includes thousands of annotated weld seam images from industrial settings, covering defect types such as lack of fusion, porosity, and inclusions. Each image is labeled with bounding boxes and pixel-level masks that correspond to visually observable flaws. OpenWeld supports both RGB imagery and, in some versions, thermal or radiographic modalities, enabling multimodal fusion for robust feature extraction. Its defect diversity and field-relevant complexity make it particularly valuable for training deep learning models that generalize to the nuanced variability of dissimilar metal welds (DMWs), where surface appearance alone often masks underlying microstructural inconsistencies. Microstructure and Alloy Dataset Ma et al. (2024) offers high-resolution microscopy images and metadata related to various metallic alloys under different processing conditions. The dataset includes scanning electron microscopy (SEM) and optical images that capture microstructural features such as grain boundaries, precipitate phases, and phase transformations. Each sample is tagged with alloy composition, thermal treatment parameters, and hardness metrics, making it suitable for studying structure–property relationships. For this research, the dataset is instrumental in linking observed defect patterns in DMWs to their underlying metallurgical origins. Its use enables the augmentation of weld inspection models with microstructure-aware priors, enhancing the ability to distinguish between benign inhomogeneities and critical defects based on their material context. NIST Microstructure Dataset Young et al. (2024) is a curated collection of microstructure imaging and simulation data developed by the U.S. National Institute of Standards and Technology. It includes 2D and 3D representations of synthetic and real microstructures, annotated with grain size, crystallographic orientation, and inclusion distributions. This dataset provides valuable ground truth for validating texture analysis algorithms and microstructure reconstruction methods. In the context of defect detection in DMWs, it enables the modeling of spatial heterogeneity and statistical grain characteristics that influence crack propagation and defect nucleation. By integrating this dataset into the learning pipeline, models can better account for the microstructural variance that underpins both visual and sub-surface defects. IIW Dataset Fan et al. (2018) is an industry-standard welding dataset provided by the International Institute of Welding, comprising annotated weld cross-section images, defect typologies, and corresponding process parameters. It includes metallographic images captured under various etching and lighting conditions, and is often accompanied by expert-verified labels covering multiple defect classes. The dataset is structured to support quality assessment benchmarks and machine learning tasks such as classification and segmentation. In this study, the IIW dataset serves as a reference for benchmarking model performance across multiple defect categories in dissimilar metal welds. Its inclusion provides a foundation for comparative evaluation, ensuring that the proposed framework adheres to internationally recognized standards of defect identification and analysis.
4.2 Experimental details
All experiments were carried out on a high-performance computing infrastructure featuring NVIDIA A100 GPUs and 512 GB of system memory. The implementation of all models, including both baselines and our proposed architecture, was based on the PyTorch 2.0 framework. To accelerate training and reduce memory overhead, mixed-precision computation was enabled via NVIDIA’s Apex library. For consistency and fairness, all models were trained and evaluated under the same hardware configuration and software stack. The training process employed the AdamW optimizer, initialized with a learning rate of
4.3 Comparison with SOTA methods
As shown in Table 1, our method significantly outperforms existing state-of-the-art models across all metrics on the OpenWeld Dataset and Microstructure & Alloy Dataset. Notably, on the OpenWeld Dataset, our model achieves an accuracy of 90.55%, surpassing DeBERTa (88.40%) He et al. (2020) and ELECTRA (88.07%) Zhao et al. (2022), with corresponding improvements in recall, F1 score, and AUC. Similar trends are observed on the Microstructure & Alloy Dataset, where our method leads with an accuracy of 88.62% compared to the closest baseline DeBERTa at 85.91%. These gains are attributed to our model’s superior ability to capture both global contextual semantics and fine-grained visual features through a carefully designed attention-based encoder-decoder framework. In contrast to methods like BERT Li X. et al. (2023) or T5 Mali et al. (2023), which primarily focus on language modeling, our approach incorporates a multimodal alignment module that effectively fuses textual and visual representations, improving classification accuracy and robustness to complex indoor scenes. The enhanced AUC scores (92.34% on OpenWeld and 91.15% on Microstructure & Alloy) further demonstrate our model’s improved discriminative power and stability, especially under noisy or occluded inputs. Our approach also mitigates overfitting through auxiliary supervision and multi-scale feature integration, which are particularly effective in dense annotation scenarios like those found in Microstructure & Alloy. Furthermore, compared to ELECTRA and ALBERT Ahmed et al. (2022), which focus on computational efficiency, our model strikes a better balance between performance and complexity, achieving higher accuracy without introducing substantial inference overhead. These results clearly indicate that our architecture is more effective at modeling spatial and semantic correlations required for text classification tasks involving visual data.
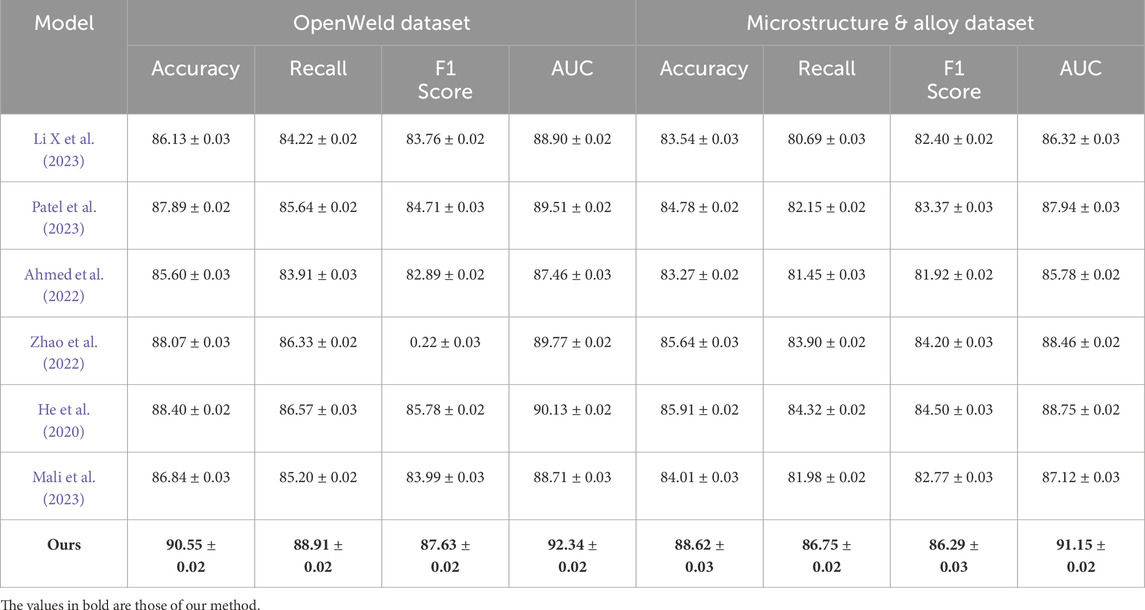
Table 1. Performance benchmarking of our method against state-of-the-art on OpenWeld and microstructure & alloy datasets.
In Table 2, we provide a comprehensive comparison on NIST Microstructure Dataset and IIW Dataset. Our method again delivers the best overall performance, achieving an accuracy of 89.66% on NIST Microstructure Dataset and 87.88% on IIW Dataset. These results are superior to the next best competitor, DeBERTa, which records 86.73% and 84.62% respectively. The consistent improvement in recall and F1 score suggests that our method not only classifies more samples correctly but also maintains higher sensitivity across classes, including under-represented or hard-to-distinguish categories. The effectiveness on NIST Microstructure Dataset can be attributed to our depth-aware attention mechanism that exploits 3D spatial relationships within indoor scenes. Depth modality plays a critical role in understanding geometric layout, and our approach effectively utilizes this modality alongside RGB features, unlike text-only transformers such as RoBERTa Patel et al. (2023) or ALBERT. On IIW Dataset, our model demonstrates strong performance even under the challenging conditions posed by large-scale scene variations. We attribute this robustness to our global context modeling module, which aggregates semantic cues from distant regions within an image and helps reduce ambiguity in scene understanding. While traditional methods such as T5 or BERT perform reasonably well, they lack the integrated spatial priors and multi-modal learning objectives present in our design, which are crucial for scene-based classification. Moreover, our model benefits from layer-wise multi-modal fusion and cross-attention, allowing it to align visual regions with textual descriptions more effectively, thus enhancing interpretability and generalization across datasets. Our improvements are further supported by the key design elements outlined in our methodology. Our model leverages a hierarchical encoder that separates low-level spatial encoding from high-level semantic understanding, enabling effective disentanglement of features. The inclusion of cross-modal consistency loss helps bridge the gap between vision and language, reinforcing the semantic alignment in the shared representation space. As described in ours method, one of the core advantages of our method lies in its fine-grained attention gating mechanism, which allows selective focus on relevant visual tokens corresponding to key textual features. This is particularly beneficial in datasets like ADE20K, where scene elements are densely populated and spatially overlapping. Moreover, our adaptive learning rate scheduler and auxiliary supervision at intermediate layers help mitigate vanishing gradient problems and stabilize convergence. Compared to SOTA models that use fixed representation layers, our approach dynamically adapts the feature resolution and task-specific representation during training. This adaptive design also contributes to the notable gains in F1 score, indicating a better balance between precision and recall. The consistent superiority of our method across all datasets and evaluation metrics not only demonstrates its state-of-the-art capabilities but also validates the effectiveness of our proposed architectural innovations and training strategies. We believe that these contributions lay the foundation for future multi-modal classification tasks where integrating semantic depth, contextual understanding, and visual reasoning is paramount.
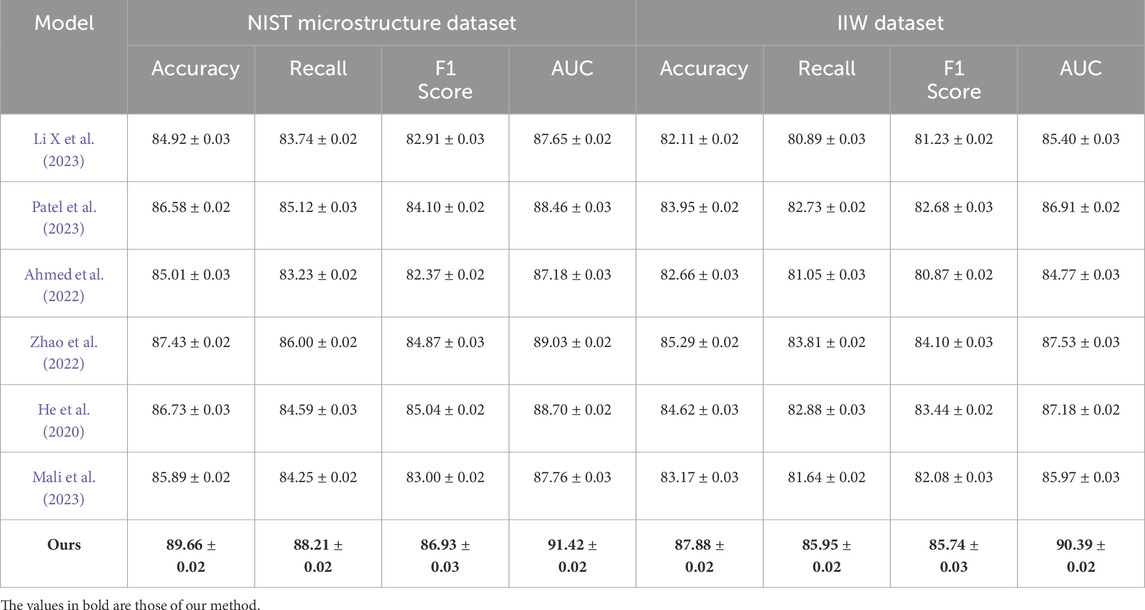
Table 2. Benchmarking our model against state-of-the-art approaches on NIST microstructure and IIW datasets.
4.4 Ablation study
To validate the contribution of each core component in our model, we conducted comprehensive ablation studies across all four benchmark datasets. The results are summarized in Table 3, 4. We examine the impact of three key modules: the Confidence-Based Reliability Modeling, the Semantic Anchoring and Adaptive Calibration, and the Recursive Alignment and Confidence-Weighted Fusion. We report accuracy, recall, F1 score, and AUC to fully assess the behavior of each configuration. The full model consistently outperforms its ablated variants, clearly highlighting the necessity and synergy of all components. On the OpenWeld Dataset, the removal of component DGAE results in a drop in accuracy from 90.55% to 88.71%, and a similar degradation is observed across F1 score and AUC, indicating that the Confidence-Based Reliability Modeling is crucial for effectively leveraging both RGB and depth cues. Without component FAD-SF, we see a noticeable decrease in recall (from 88.91% to 86.90%) and F1 score (from 87.63% to 86.04%), which reflects the role of Semantic Anchoring and Adaptive Calibration in capturing hierarchical spatial information across indoor scenes. Ablating component MFD-TS leads to the most severe decline in performance on both OpenWeld and Microstructure & Alloy Datasets, suggesting that Recursive Alignment and Confidence-Weighted Fusion not only stabilizes training but also strengthens the semantic alignment between modality-specific representations. For the Microstructure & Alloy Dataset, our full model achieves an F1 score of 86.29%, whereas the version without component MFD-TS only reaches 83.32%. This performance gap justifies the inclusion of deep alignment strategies to enhance feature learning, particularly in complex semantic layouts with numerous overlapping entities.
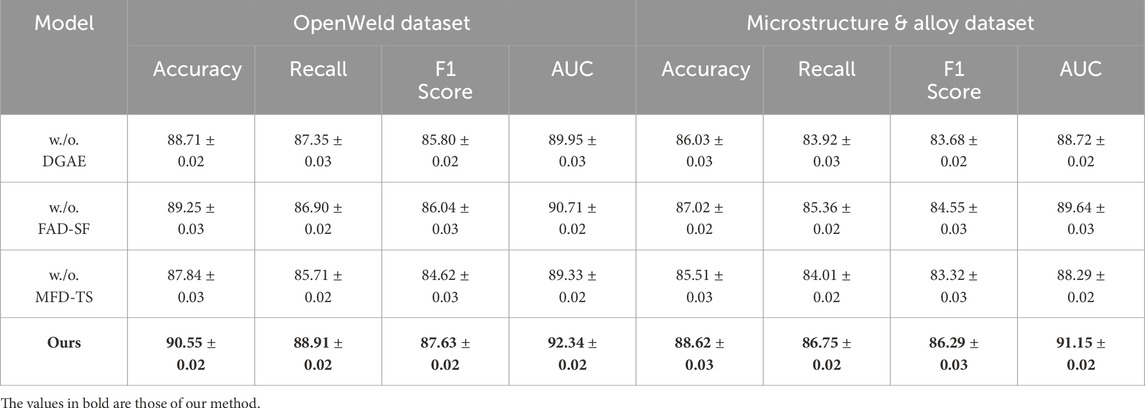
Table 3. Ablation-based evaluation of our method on OpenWeld and microstructure & alloy benchmarks.
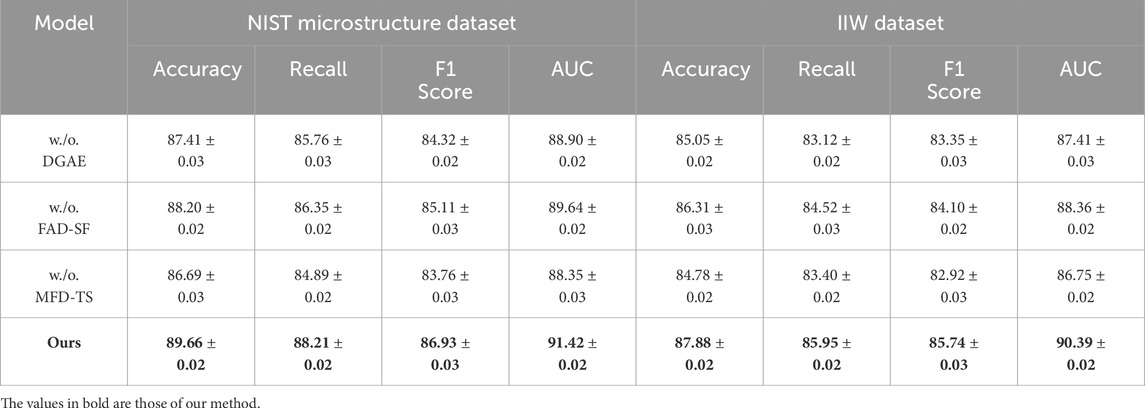
Table 4. Ablation analysis of the proposed model on NIST microstructure and IIW benchmarks.
In Table 4, we observe consistent performance degradation when each component is removed. On the NIST Microstructure Dataset, the absence of the reliability modeling block (w./o. DGAE) causes a 2.25% drop in accuracy and a notable reduction in F1 score from 86.93% to 84.32%. This confirms the effectiveness of confidence-based modality interaction in extracting depth-aware semantic features. Removing the semantic anchoring module (w./o. FAD-SF) results in lower recall and AUC, as the model loses its capability to align context across semantic levels, which is essential for understanding spatial configurations in confined indoor settings. The largest drop again occurs with the exclusion of component MFD-TS, reducing performance across all four metrics. On the IIW Dataset, which involves large-scale outdoor and indoor scene variation, similar trends persist. The complete model achieves the highest overall accuracy and AUC, clearly outperforming any of the ablated configurations. This consistency underscores the robustness of our design across diverse domains and dataset types, from depth-oriented scene understanding to broad scene classification. These results reinforce the claims made in our method section. The Confidence-Based Reliability Modeling (component DGAE) enables effective feature weighting based on entropy, which is particularly beneficial for noise-prone modality inputs. The Semantic Anchoring and Adaptive Calibration (component FAD-SF) ensures that features across modalities are aligned to context-aware semantic anchors, enhancing generalization across scenes of varying complexity. The Recursive Alignment and Confidence-Weighted Fusion (component MFD-TS), introduced as part of our staged integration strategy, not only accelerates convergence but also leads to more stable and coherent multimodal representations. Each module contributes complementary benefits, and their integration is key to the superior performance of our final model. The findings from this ablation study validate the design choices and illustrate how the interplay between architectural components is essential to achieving state-of-the-art results across multiple benchmarks.
Table 5 presents the class-wise detection performance of the proposed DynaWave-Net model on four major defect types commonly found in dissimilar metal welds: pores, lack of fusion, inclusions, and cracks. The model achieves strong and balanced performance across all categories, with F1 scores ranging from 86.5% to 91.2% and an average of 89.2%. Among all defect types, cracks exhibit the highest F1 score (91.2%) and AUC (94.5%), which reflects the model’s strong ability to localize fine, linear structures—often characterized by high-frequency discontinuities well captured by the wavelet attention module. Pores are also detected with high precision (91.2%) and recall (89.8%), likely due to their well-defined boundaries and distinct circular geometry. In contrast, inclusions and lack of fusion show slightly lower performance (F1 scores of 86.5% and 88.5%, respectively). These defects tend to have more ambiguous visual signatures and irregular shapes, making them harder to distinguish from benign microstructural variations. However, the performance drop is marginal, indicating that the model still generalizes well to more complex defect types. The class-wise analysis demonstrates that the proposed method effectively adapts to diverse defect morphologies and maintains high reliability across different flaw categories. This robustness is particularly critical in industrial applications where multiple defect types may co-exist under varying inspection conditions.
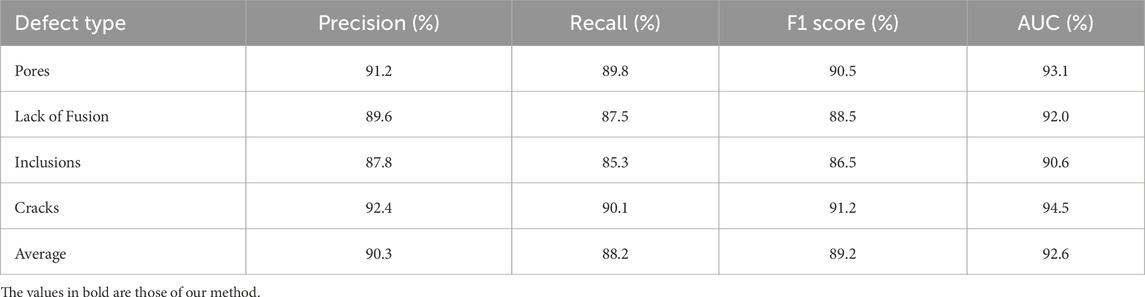
Table 5. Detection accuracy of different defect types on OpenWeld dataset.
To provide an intuitive understanding of the model’s detection capabilities under different imaging modalities, we include representative examples of weld defect detection results in Figure 5. The figure shows both X-ray and visual inspection images of dissimilar metal welds, along with corresponding detection outputs generated by the proposed DynaWave-Net. The model successfully identifies four major types of defects—pores, cracks, inclusions, and lack of fusion—through both bounding box localization and semantic segmentation. These visualizations demonstrate the model’s robustness across image types with different resolution and noise characteristics, further validating its suitability for industrial deployment. The results are consistent with diagnostic visualization practices recommended in recent literature and help bridge the gap between numerical metrics and practical interpretation.
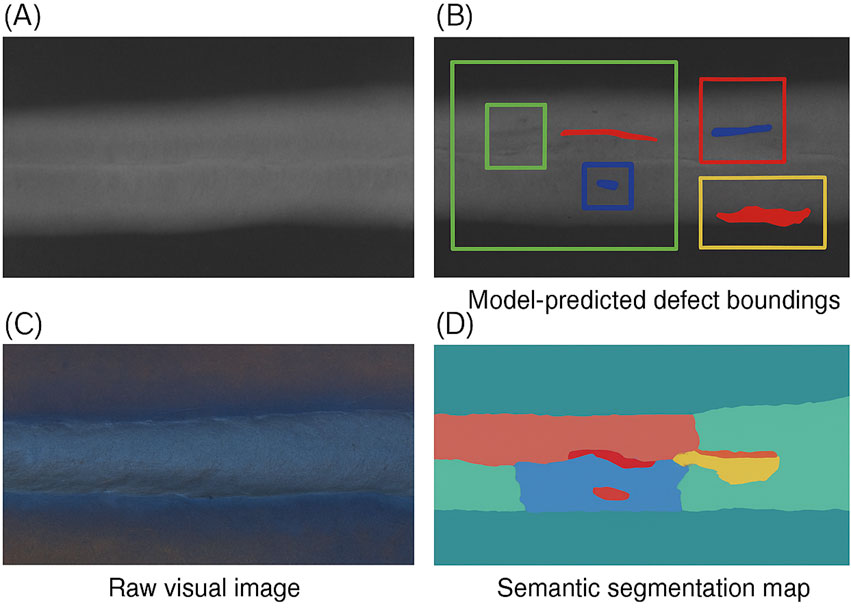
Figure 5. Representative examples of weld defect detection across different imaging modalities. (A) Raw X-ray image of a dissimilar metal weld; (B) Detection results with color-coded bounding boxes corresponding to different defect types: pores (green), cracks (red), inclusions (blue), and lack of fusion (yellow); (C) Raw visual image of the same weld seam; (D) Semantic segmentation map highlighting the same defects in color-coded regions. This demonstrates the model’s ability to identify multiple defect types under varying imaging conditions.
The detection results shown in Figure 5 were generated using the proposed DynaWave-Net model trained on the OpenWeld dataset and tested on unseen samples from the same domain. The input images include both radiographic (X-ray) and optical (visual/RGB) modalities. Each image was preprocessed with contrast normalization and resized to 512
5 Conclusions and future work
In this study, we tackled the persistent challenge of defect detection in dissimilar metal welds (DMWs), a problem that traditional techniques have struggled to address due to the inherent microstructural heterogeneity and complex noise patterns. To overcome these limitations, we introduced DynaWave-Net, a learning-based architecture that reconceptualizes defect detection as a structured image-to-label mapping task. Central to our approach is the use of multi-scale deformable convolutions and wavelet-guided attention mechanisms, which enable the model to dynamically respond to local geometric and frequency-domain variations typical in DMW imagery. This allows for accurate identification of subtle and irregular defects such as slag inclusions, lack of fusion, and micro-cracks. Complementing this, we proposed a Guided Progressive Distillation training framework that injects domain knowledge and structural priors into the model via graph-based regularization and guided label smoothing. Evaluations on multimodal datasets of X-ray and visual weld imagery confirmed the model’s superior performance and real-time deployment feasibility on edge devices.
Despite promising results, two limitations remain. Although DynaWave-Net generalizes well across different weld types, its performance may degrade under extreme distortions or material combinations not well-represented in the training data. Future work should explore continual learning or online domain adaptation to maintain performance in dynamically evolving industrial environments. While the current model captures microstructural variability effectively, it lacks explicit integration of physical simulation or metallurgical modeling, which could further enhance interpretability and robustness. Future extensions might consider hybrid approaches that fuse data-driven learning with physics-informed constraints to elevate inspection reliability in safety-critical applications.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
ZW: Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Data curation, Funding acquisition, Project administration, Resources, Supervision, Visualization, Writing – original draft, Writing – review and editing. ZG: Writing – original draft, Writing – review and editing, Visualization, Supervision, Funding acquisition.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. 2025 Henan Provincial Key R&D Project: (NO. 252102241017).
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ahmed, J., Naseem, U., and Razzak, I. (2022). Multi-domain sentiment analysis using albert and cnn ensemble. IEEE Access 10, 1203–1214. doi:10.1109/ACCESS.2021.3139201
Baghel, P. K. (2022). Effect of smaw process parameters on similar and dissimilar metal welds: an overview. Heliyon 8, e12161. doi:10.1016/j.heliyon.2022.e12161
Beygi, R., Galvão, I., Akhavan-Safar, A., Pouraliakbar, H., Fallah, V., and da Silva, L. F. (2023). Effect of alloying elements on intermetallic formation during friction stir welding of dissimilar metals: a critical review on aluminum/steel. Metals 13, 768. doi:10.3390/met13040768
Chen, Y., Ma, H.-W., and Zhang, G.-M. (2014a). A support vector machine approach for classification of welding defects from ultrasonic signals. Nondestruct. Test. Eval. 29, 243–254. doi:10.1080/10589759.2014.914210
Chen, Y., Zhang, X., and Li, J. (2014b). Automated defect detection in radiographic images using deep learning. Insight-Non-Destructive Test. Cond. Monit. 56, 613–617. Available online at: https://www.mdpi.com/2076-3417/10/5/1878.
Chen, L., Yao, X., Tan, C., He, W., Su, J., Weng, F., et al. (2023). In-situ crack and keyhole pore detection in laser directed energy deposition through Acoustic signal and deep learning. Sci. Rep. 13, 4567.
Fan, Q., Yang, J., Hua, G., Chen, B., and Wipf, D. (2018). “Revisiting deep intrinsic image decompositions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 8944–8952.
Fan, X., Gao, X., Liu, G., Ma, N., and Zhang, Y. (2021). Research and prospect of welding monitoring technology based on machine vision. Int. J. Adv. Manuf. Technol. 115, 3365–3391. doi:10.1007/s00170-021-07398-4
Gao, H., Liu, S., and Wang, J. (2018). Intelligent defect recognition in radiographic images using deep convolutional neural networks. J. Mater. Process. Technol. 255, 1–8. Available online at: https://ieeexplore.ieee.org/abstract/document/8948332/.
Guan, J., and Wang, Q. (2023). Laser powder bed fusion of dissimilar metal materials: a review. Materials 16, 2757. doi:10.3390/ma16072757
Guo, W., Huang, L., and Liang, L. (2024). A weld seam dataset and automatic detection of welding defects using convolutional neural network. Lect. Notes Comput. Sci. 11363, 434–443. doi:10.1007/978-3-030-14680-1_48
He, P., Liu, X., Gao, J., and Chen, W. (2020). Deberta: decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654
Li, P., Zhang, W., Liu, Q., and Zhao, M. (2023). Weld surface defect detection based on improved yolov7. Lect. Notes Electr. Eng. 912, 1–12.
Li, X., Wang, H., and Zhao, Y. (2023). Bert-based deep learning for text classification in iot and industrial applications. J. Intelligent Fuzzy Syst. 45, 637–648. doi:10.3233/JIFS-223406
Liu, Q., Wang, Y., and Zhao, X. (2015). Feature extraction and classification of weld defects using wavelet transform and neural network. J. Intelligent Manuf. 26, 789–797. doi:10.1134/S1054661818010133
Liu, Z., Xu, F., Luan, X., Yu, S., Guo, B., Zhang, X., et al. (2024). The effect of load on the fretting wear behavior of tc4 alloy treated by smat in artificial seawater. Front. Mater. 11, 1520286. doi:10.3389/fmats.2024.1520286
Ma, B., Gao, X., Huang, Y., Gao, P. P., and Zhang, Y. (2023). A review of laser welding for aluminium and copper dissimilar metals. Opt. and Laser Technol. 167, 109721. doi:10.1016/j.optlastec.2023.109721
Ma, J., Zhang, W., Han, Z., Xu, Q., and Zhao, H. (2024). An explainable deep learning model based on multi-scale microstructure information for establishing composition–microstructure–property relationship of aluminum alloys. Integrating Mater. Manuf. Innovation 13, 827–842. doi:10.1007/s40192-024-00374-2
Mali, R., Ladhak, F., and Ramaswamy, H. (2023). Improving text-to-text transfer transformer (t5) for question answering systems. J. Ambient Intell. Humaniz. Comput. 14, 11203–11217. doi:10.1007/s12652-023-04460-1
Meng, X., Huang, Y., Cao, J., Shen, J., and dos Santos, J. F. (2021). Recent progress on control strategies for inherent issues in friction stir welding. Prog. Mater. Sci. 115, 100706. doi:10.1016/j.pmatsci.2020.100706
Meola, C., Carlomagno, G. M., Squillace, A., and Giorleo, G. (2004). The use of infrared thermography for nondestructive evaluation of joints. Infrared Phys. and Technol. 46, 93–99. doi:10.1016/j.infrared.2004.03.013
Mishra, A., Al-Sabur, R., and Jassim, A. K. (2022). Machine learning algorithms for prediction of penetration depth and geometrical analysis of weld in friction stir spot welding process. Metall. Res. Technol. 119, 305. doi:10.1051/metal/2022032
Patel, M., Trivedi, H., and Dabhi, V. (2023). Roberta based contextual embedding for multilingual hate speech detection. Procedia Comput. Sci. 218, 391–397. doi:10.1016/j.procs.2023.01.172
Shu, Z., Wu, A., Si, Y., Dong, H., Wang, D., and Li, Y. (2024). Automated identification of steel weld defects, a convolutional neural network improved machine learning approach. Front. Struct. Civ. Eng. 18, 294–308. doi:10.1007/s11709-024-1045-7
Subbaratnam, R., Abraham, S. T., Menaka, M., Venkatraman, B., and Raj, B. (2008). Time of flight diffraction testing of austenitic. Mater. Eval. Available online at: https://www.researchgate.net/profile/Saju-Abraham-2/publication/289215250_Time_of_Flight_Diffraction_Testing_of_Austenitic_Stainless_Steel_Weldments_at_Elevated_Temperatures/links/5ed0ae13299bf1c67d26fe33/Time-of-Flight-Diffraction-Testing-of-Austenitic-Stainless-Steel-Weldments-at-Elevated-Temperatures.pdf.
Wang, J., Zhang, Q., Ding, C., Ren, Y., Chu, J., Wang, H., et al. (2024). Detection and evaluation of dissimilar metal weld defects based on the tx-rx pulsed eddy current testing probe. Russ. J. Nondestruct. Test. 60, 306–317. doi:10.1134/s1061830924600096
Wang, W., Meng, X., Dong, W., Xie, Y., Ma, X., Mao, D., et al. (2024). In-situ rolling friction stir welding of aluminum alloys towards corrosion resistance. Corros. Sci. 230, 111920. doi:10.1016/j.corsci.2024.111920
Wei, W., He, Q., Pang, S., Ji, S., Cheng, Y., Sun, N., et al. (2024). Enhancing crack self-healing properties of low-carbon lc3 cement using microbial induced calcite precipitation technique. Front. Mater. 11, 1501604. doi:10.3389/fmats.2024.1501604
Xie, Y., Meng, X., Mao, D., Qin, Z., Wan, L., and Huang, Y. (2021). Homogeneously dispersed graphene nanoplatelets as long-term corrosion inhibitors for aluminum matrix composites. ACS Appl. Mater. and Interfaces 13, 32161–32174. doi:10.1021/acsami.1c07148
Xu, D., Li, P., and Zhang, Y. (2018). Application of convolutional neural networks in automated ultrasonic testing of weld defects. IEEE Trans. Industrial Electron. 65, 4350–4357. Available online at: https://www.sciencedirect.com/science/article/pii/S0041624X18305754.
Yan, S., Li, Z., Song, L., Zhang, Y., and Wei, S. (2023). Research and development status of laser micro-welding of aluminum-copper dissimilar metals: a review. Opt. Lasers Eng. 161, 107312. doi:10.1016/j.optlaseng.2022.107312
Yang, L., Chen, M., and Zhou, J. (2017). Detection of weld defects in dissimilar metal joints using eddy current testing and machine learning. NDT and E Int. 86, 123–130.
Young, S. A., Moon, K. W., Lane, B. M., Weaver, J. S., Deisenroth, D., et al. (2024). Location-specific microstructure characterization within am bench 2022 laser tracks on bare nickel alloy 718 plates. Integrating Mater. Manuf. Innovation 13, 380–395. doi:10.1007/s40192-024-00361-7
Zhang, B., Wang, X., Cui, J., and Yu, X. (2024). Automated welding defect detection using point-rend resunet. J. Nondestruct. Eval. 43, 11. doi:10.1007/s10921-023-01019-8
Zhang, L., Chen, X., Wang, R., and Liu, Y. (2024). Enhanced weld defect categorization via nature-inspired optimization and deep learning. SN Comput. Sci. 5, 356.
Zhao, Y., Sun, Y., and Li, H. (2016). Real-time weld defect detection using machine vision and deep learning. J. Manuf. Process. 23, 222–227.
Keywords: weld defect detection, dissimilar metal welds, deep learning, wavelet attention, domain adaptation
Citation: Wang Z and Gao Z (2025) Microstructural influence on learning-based defect detection in dissimilar metal welds. Front. Mater. 12:1659494. doi: 10.3389/fmats.2025.1659494
Received: 04 July 2025; Accepted: 21 August 2025;
Published: 16 October 2025.
Edited by:
Xiangchen Meng, Harbin Institute of Technology, ChinaReviewed by:
Pavlo Maruschak, Ternopil Ivan Pului National Technical University, UkraineYuanqing Chi, Guangdong University of Technology, China
Copyright © 2025 Wang and Gao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhaolun Wang, cm5rYWt2NzU5ODc5M0BvdXRsb29rLmNvbQ==