 Yan Wu
Yan Wu Zili Zhang
Zili Zhang- College of Computer and Information Science, Southwest University, Chongqing, China
To clean and correct abnormal information in domain-oriented knowledge bases (KBs) such as DBpedia automatically is one of the focuses of large KB correction. It is of paramount importance to improve the accuracy of different application systems, such as Q&A systems, which are based on these KBs. In this paper, a triples correction assessment (TCA) framework is proposed to repair erroneous triples in original KBs by finding co-occurring similar triples in other target KBs. TCA uses two new strategies to search for negative candidates to clean KBs. One triple matching algorithm in TCA is proposed to correct erroneous information, and similar metrics are applied to validate the revised triples. The experimental results demonstrate the effectiveness of TCA for knowledge correction with DBpedia and Wikidata datasets.
1 Introduction
Domain-oriented knowledge bases (KBs) such as Wikidata [1] and DBpedia [2] are extracted from Wikipedia articles. Since KBs are constructed automatically, some errors are imported from Wikipedia, including inconsistencies, typing errors, and numerical outliers [3–6]. One of the major errors is a range violation of triples in KBs. The problem arises when triples contain some abnormal information. For example, one triple
Fact validation and a rule-based model are applied to detect erroneous information by searching candidates in KBs [11–15]. These cleaning algorithms are designed to look for existing errors in training datasets, but they cannot search for more errors in KBs. This study analyzes the characteristics of incorrect information and extracts the featurization of triples to improve the effectiveness of mining incorrect triples in KBs. For correcting these errors [6, 16, 17], some semantic embedding methods were designed to build a correction framework. The accuracy of the model depends on the pre-training model. For these methods, some pre-trained parameters are applied to make the correction decision. Every triple is checked for consistency. The framework is not suitable for tons of errors, i.e., for large KBs. Correction rules are acquired by rule models [18] for solving large KBs. However, positive and negative rules are generated before constructing correction rules. Correction rules are applied to solve a batch of errors. For a single error, it takes a lot of time to obtain the correction rule. Similarly, for errors without redundant information, the corresponding correction rules are not obtained.
In this study, an automatic framework, triples correction assessment (TCA), is developed to clean abnormal triples and revise these facts for refining large KBs. First, statements of erroneous triples are analyzed to acquire some new negative candidates and more negative sampling by small erroneous triples with range violations. After the process of data cleaning in TCA, small samples are used to obtain a large amount of abnormal information to clean up a large knowledge base. In our framework, the abnormal information in data cleaning is transmitted to mine interesting features for data correction. So, one triple matching method is proposed to find some repairs in target KBs by matching co-occurring triples between original and target KBs in the part of data correction. Other parts assist the whole framework to screen better correction results by similarity measures. Here, one new correction similarity is designed to acquire final repair to perform the alteration in incorrect triples. Our TCA framework is designed to correct range violations of the triple by discovering evidence triples from an external knowledge base. There are already a large number of Wikipedia-related knowledge bases, and they are quite mature and have a higher quality of triples. Our framework skips the pre-training part and further explores the relationship between KBs with the original source to correct the knowledge base. Also, our framework bridges sample inconsistencies between data cleaning and data rectification, further refining large knowledge bases.
1.1 Contributions
The novel contributions are as follows:
• An automatic framework, TCA, is developed to clean abnormal information and find consensus from other knowledge bases to correct the range errors of RDF triples.
• Some negative candidate search strategies are collected to filter abnormal information, and cross-type negative sample methods are applied to clean erroneous knowledge. Here, correction similarity metrics are designed to evaluate candidates for gathering final repairs.
• One co-occurring triple matching algorithm is designed to match similar triples to find candidates for correcting abnormal information in two different KBs.
The organization of this paper is as follows: In Sections 2 and 3, related work and preliminary materials are presented. Section 4 introduces the proposed framework containing negative candidate searching strategies and a correction model, respectively. Section 5 shows the experiments and analysis of our model. At last, the conclusion is presented in Section 6.
2 Related work
Some mistaken tails of the triples are recognized by wrong links between different KBs, and each link is embedded into a feature vector in the learning model [19]. In addition, the PaTyBRED [20] method incorporated type and path features into local relation classifiers to search triples with incorrect relation assertions in KB. Integrity rules [21] and constraints of functional dependencies [22–24] are considered to solve constraint violations in KBs. Preferred update formulations are designed to repair ABox concepts in KBs through active integrity constraints [25]. Data quality is improved with statistical features [26] or graph structure [27] by type. Liu et al. [11] proposed consensus measures to crawl and clean subject links in data fact validation. Usually, a fact-checking model is trained to detect erroneous information in KBs. Some rules are generated to perform correctness checking by searching candidate triples [13]. So, candidate triples are leveraged to find more erroneous triples for cleaning KBs. Wang et al. [14] used relational messages for passing aggregate neighborhood information to clean data. It seems inevitable that knowledge acquisition [28] is strongly affected by the noise that exists in KBs. Triples accuracy assessment (TAA) [12] is used to filter erroneous information by matching triples between the target KB and the original KBs.
Piyawat et al. [29] correct the range violation errors in the DBpedia for data cleaning. The Correction of Confusions in Knowledge Graphs [16] model was designed to correct errors with approximate string matching. The correction tower [30] was designed to recognize errors and repair knowledge with embedding methods. The incorrect facts are removed by the embedding models with the Word2vec method in KBs [17]. Embedding algorithms, rule-based models, edit history, and other approaches are leveraged to correct errors in KBs. A new family of models to predict corrections has received increasing attention in the domain of embedding methods, such as TransE [31], RESCAL [32], TransH [33], TransG [34], DistMult [35], HolE [36], or ProjE [37]. Our work focuses on associated KBs to search for similar triples and connections for KB repairs. Bader et al. [38] considered previous repair methods to correct abnormal knowledge with source codes. One error correction system [39] contains the majority of fault values in the tables and leverages the correction values as the sample repairs. Baran et al. [39] without these prerequisites was designed for data correction in tabular data. The edit history [40] of KBs was considered in the correction models for repairing Wikidata. They ignored contextual errors in the edit history of KBs.
Mahdavi et al. [41] designed an error detection system (Raha) and updated a system (Baran) for error correction by transfer learning. Other studies correct entity type [5, 16, 42] in the task of cleaning KBs. The work of fixing bugs is carried out by checking whether the KB violates the constraints of the schema [6, 43] automatically. Some erroneous structured knowledge in Wikipedia is repaired by using pre-trained language model (LM) probes [44]. Natural language processing methods are combined with knowledge-correction algorithms [45]. Some models were designed to validate the syntax of knowledge and clean KBs, such as ORE [46], RDF:ALERTS [47], VRP [48], and AMIE [49]. Some clean systems were proposed to solve inconsistencies in tabular data [50–53]. Also, some correction systems [30, 41] are designed to refine KBs. Usually, some correction methods focus on solving specific problems [5, 6, 16, 42, 43]. Extending these studies, natural language processing methods are combined with knowledge correction algorithms [44, 45]. To solve the errors existing in structured knowledge, pre-trained models are trained to set parameters and a framework to correct errors or eliminate them [54, 55]. In these correction models, errors are predefined in the training datasets and not in the KBs. Such models ignore the process of exploring errors and fail to achieve good correction results in large KBs.
These methods are used when there is a lack of association between KBs, and these cannot be scaled to multiple large KBs. While the problem of correcting errors has been neglected in the field of knowledge application, the available repair methods mainly result in the undesired knowledge loss caused by the data removal. Triples with the correct subject are considered in this study. A method to correct these errors is posited by a post factum investigation of the KB.
3 Preliminaries
A KB (such as Wikidata) following Semantic Web standards covering RDF (Resource Description Framework), RDF Schema, and the SPARQL Query Language [56] is considered in our experiment. A KB is composed of a TBOX (terminology) and an ABox (assertions). Through the TBox level, the KB defines classes, a class hierarchy (via rdfsLsubClassOf), properties (relations), and property domains and ranges. The ABox contains a set of facts (assertions) describing concrete entities represented by a Uniform Resource Identifier (URI). Let K1 and K2 represent two KBs. K1 is the original knowledge base for validation, and K2 is the additional KB that is leveraged to provide matching information or correction features. The entities of two KBs are represented as E1 and E2, respectively. The predicates are R1 and R2, and the type sets of entities are T1 and T2 which include the domain and range of relation, respectively.
3.1 Overlapping type of entity
Two entities e1 ∈ E1 and e2 ∈ E2 are selected: ei, (i = 1, 2) is an entity with overlapping type, if e1 and e2 denote the same real-world facts. The connection of e1 and e2, can be represented as e1 = e2, and the connection of types in two entities,
Most of the KB-embedding algorithms [31, 33] follow the open-world assumption (OWA), stating that KBs include only positive samples and that non-observed knowledge is either false or just missing. The negative samples (i.e., (⋅, r, eo) or (es, r, ⋅)) are found by applying the type property of source triple (es, r, eo). For instance, (⋅, r, eo) has wrong domain property of relation and (es, r, ⋅) has wrong range property of predicate name.
3.2 Overlapping type pair of entities
Given two triples and type pair,
If
Example 1. (Monte_Masi, nationality, Australia), (Person, Country) are in K1. (Monte Masi, country of citizenship, Egypt), (Person, country) are in K2. For the relations “nationality” and “country of citizenship,” they share the overlapping entities “Monte_Masi” and “Egypt” and the overlapping type pair (Person, country). Hence, the overlapping entity pair of predicates “nationality” and “country of citizenship” is (Monte_Masi, Australia), i.e., O (nationality, country of citizenship) = (Monte_Masi, Australia). At the same time, the overlapping type pair of relations “nationality” and “country of citizenship” is (Person, Country), i.e., Oτ(nationality, country of citizenship) = (Person, Country).
Example 1. In Figure 1, (Berlin, locatedat, Germany), (Germany, city), (Germany, country) are in the target base, and (Berlin, locatedin, Germany), (Germany, city), (Germany, country) is in the external base. The overlapping entities (“Berlin”, “Germany”) and the overlapping type pair (city, country) are shared in the predicates “locatedat” and “locatedin.” Therefore, the overlapping entities group of predicates “locatedat” and “locatedin” is (Berlin, Germany), i.e., O (locatedat, locatedin) = (Berlin, Germany). At the same time, the overlapping type group of predicates “locatedat” and “locatedin” is (city, country), i.e., Oτ(locatedat, locatedin) = (city, country).
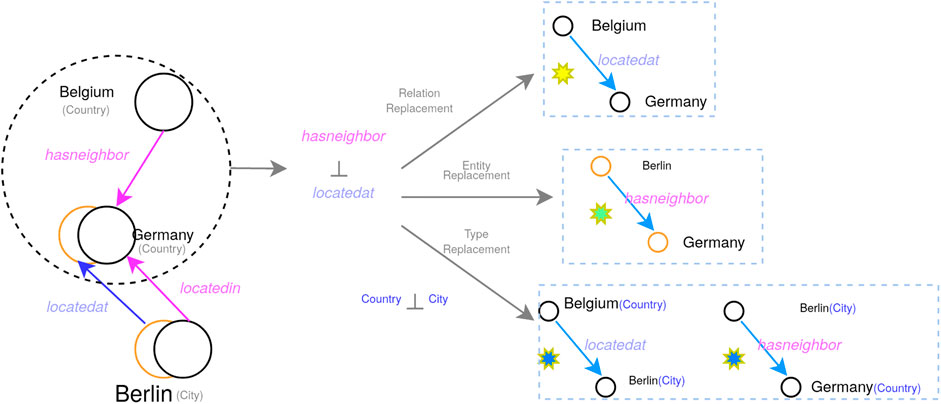
FIGURE 1. Three conditions of cross-KB negative sampling.
3.3 Evaluation measures
To fairly validate the performance of algorithms, three classical evaluation measures are used in our experiment, i.e., Mean_Raw_Rank, Precision@K, and Recall [57]. To mathematically explain the measures, the evaluation set is defined as D, consisting of positive/negative feedback set D+/D−. For the ith triple, the rank i represents its rank in the evaluation set D. Triples with higher scores are filtered out as positive feedback. The rank of incorrect triples has lower values with better performance.
3.3.1 Triple semantic similarity
Word-to-word similarity is leveraged to calculate the consensus confidence of two entities in triples. By the confidence, some co-similar entities have near confidences and they are leveraged in matching methods.
3.3.2 Correction similarity
For calculating the correction similarity for repairs, a harmonic average similarity is proposed to validate the revised triples. The dL denotes the distance in similarity of words for entities. Also, some special features are considered in similarity measures, e.g., the predicate wikiPageWikiLink discovers the same parts of two triples in the original sources, regarded as semantic_measure(e0, ei). The outer semantic measure calculates the quantity of matching parts in (
3.3.3 Soft harmonic similarity
A new soft harmonic means function is generated with character-level measure and semantic-relatedness in Func. 1, in order to balance the features of semantics and characters. The consensus is acquired by searching repair similarity of the optimal correction. Let single word T be a set of n tokens: T = {T1, T 2…T n}. d(T i, T j) is a character-level similarity measure scaled in the interval [0,1]. The soft cardinality of the single word T is calculated as in Function 3.
Cross-similarity measures are leveraged to validate repairs of erroneous triples in KBs. After our model operations, some mistaken assertions are matched with multiple values in the process of repairs. Here, a new cross-similarity measure is proposed to analyze final revised assertions of triples in KBs, aiming to discover common features between original entities and repairs after correction. In Eq. (6), the Jaro–Winkler distance [59] is suitable for calculating the similarity between short strings such as names, where dj is the Jaro–Winkler string similarity between e0 and ei, m is the number of strings matched, and t is the number of transpositions. Then sim_external(,) analyzes the external similarity probability, matching co-occurrence Wikipages in the (wikiPageWikiLink) property. s(e0, ei) is a pair of compared objects. A new cross-function, fcross, in Eq. (7) is the harmonic mean of distance and external similarity, which is designed to cover all correlations of assertions and candidate repairs.
3.3.4 Relation semantic similarity
The framework uses a method to calculate the semantic similarity between two relations based on word-to-word similarity and the abstract-based information content (IC) of words, which is a measure of concept specificity. More specific type concepts (e.g., scientist) have higher values of IC over some type concepts (e.g., person). Generally, types of entities have underlying hierarchy concepts and structures, such as the structure among types with sub-concepts {actor, award_winner, person} in types of Freebase. Given the weights of hierarchy-based concepts [60], entity e and its type set are denoted as Te. A hierarchy structure among concepts is presented as C = /t1/t2/…/ti/…/tn, where ti ∈ Te, n is the counts of hierarchy levels, tn is the most specific semantic concept, and t1 is the most general semantic concept. Usually, the range concept of a relation picks t1 as the value.
4 The proposed framework
The TCA framework comprises five units (Figure 2). The first two elements recognize equivalent head entity links for a group of source triples, while the middle two parts select negative candidates with erroneous ranges from the source triples and perform the correction. The last item calculates a confidence score for each repair, representing the level of accuracy of the corrected entities.

FIGURE 2. TCA framework.
The Head Link Fetching (HLFetching) is used to attain similar links of the candidate instance of a source entity. Since there may be duplicate and non-resolvable tails for different head entities, the second part, Tail Link Filtering (TLFiltering), makes a genuine attempt to find these tail links of tuples co-occurring in two KBs. Then, the Negative Tails Retrieving (NTR) accumulates target values including the identified candidate property links from external KBs. The third component, target triple correction (TTC), integrates a set of functions to identify repaired triples semantically similar to the source triple. The last component, confidence calculation (CC), calculates the confidence score for corrected triples from external KBs.
4.1 Problem statements
In knowledge bases, there is some noisy and useless information. Before the utilization of the knowledge base, some invalid data are removed and some knowledge is corrected for reuse in the application of KBs. So, knowledge base completion (KBC) is a hot research topic in the field of web science. Most research studies of KBC focus on predicating new information. Here, removing some invalid data and correcting some erroneous facts are our tasks. Aiming at the abnormal information in the knowledge base, this topic filters out invalid data and corrects error information for cleaning and completing KBs. In our approach, the first step is to find more error triples in KBs. Then, some valid erroneous triples are corrected to expand KBs.
Even when the selected entities are correct in KBs, incorrect relations between entities can still cause these triples to go wrong. Here, some other problem statements are explained.
4.1.1 Triple with conflict range type.
For instance, one selected triple
4.1.2 Error information in original source
The following two triples (illustrated in Figure 3) are about professor Bobby Noble: (Bobby Noble (academic), nationality, Canadians) in DBpedia as of September, 2022, and (Bobby Noble, nationality, Canadian) in Wikipedia. The triples from the two associated knowledge bases have the same errors since their original source contains incorrect information. Referring to the Wikidata database, the corrected triple (Bobby Noble, country of citizenship, Canada) equals (Bobby Noble (academic), nationality, Canada), since the predicate name nationality has the equivalent property of “country of citizenship.”
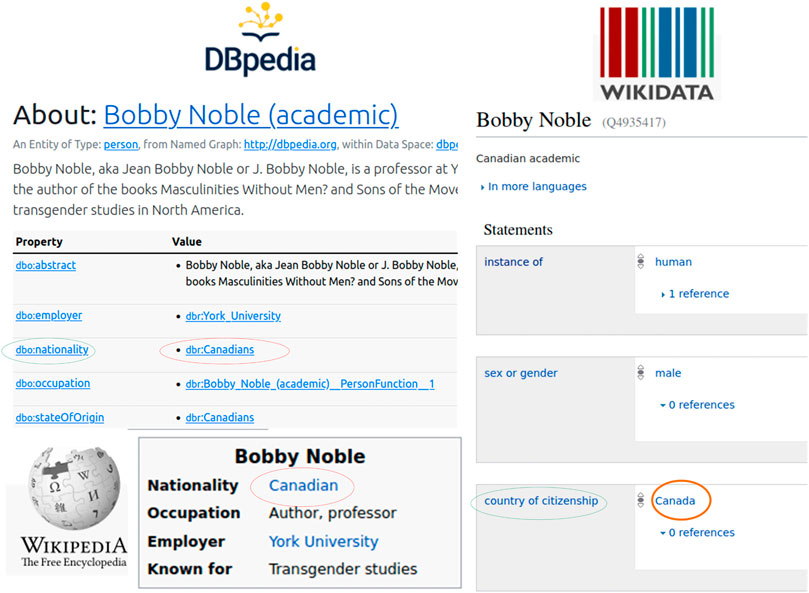
FIGURE 3. Structured information about Bobby Noble (academic).
4.1.3 Type errors
Given a fixed relation “birthplace” in the DBpedia as the sample, the noise type information is detected by the TBox property. Here, the hierarchical property rdfs: subClassOf is considered in the experiment to find the erroneous types. By the manual evaluation, the precision of corrected type is 95% in the relation of birthplace. Similarly, the quantity of the incorrect type (dbo: Organisation, dbo: SportsClub, dbo: Agent, etc.) is small. The corrected type contains some more subcategories, i.e., dbo: City < dbo: Settlement < dbo: PopulatedPlace < dbo: Place. So, searching the errors of types refers to the range of type and their inner property. In the closed-world assumption (CWA), negative triples with erroneous type are found by the type property, i.e., the range of the predicate. Then, in the open world assumption, the tail of the triple is replaced with another type of property.
For example, the positive triple:
4.1.4 Conflict feedback
Conflict feedback is assumed to consist of binary true/false assessments of facts that have the same subjects contained in the KB. Two different triples have the same subject and predicate but different objects. Not all positive examples can find corresponding counterexamples; conflict feedback cannot be obtained with a small number of examples. Two different paths are proposed to find the conflict feedback. First, range violation errors of triples are considered to search abnormal facts. The default settings are that subjects are always correct and objects have range violations. For example, the triple
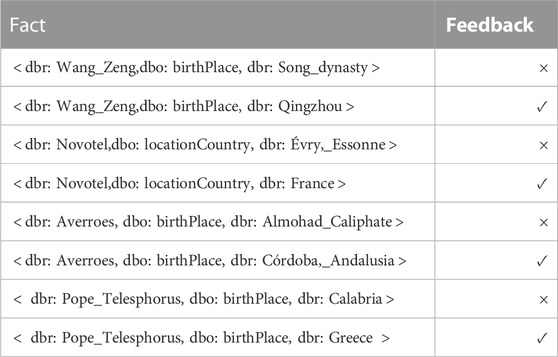
TABLE 1. Some examples of conflict feedbacks.
4.2 Generated erroneous entities
Negative statements are regarded as incorrect triples. One major problem statement is that an object of triple has a type without a matching range of predicate. This error is also called a range violation of relation [61]. For the erroneous triples, cross-type negative sampling is used to generate erroneous entities. Also, the convenient way of error generation is to refer to TBox property, such as a class hierarchy (via rdfs:subClassOf) and owl:equivalentClass In the incorrect examples, the subject is not unique. For some conflict feedback, the same subject and the same property have different objects. Conflict feedback is considered to clean KBs, since some conflict feedback contains negative statements obfuscating facts in the real world.
4.2.1 Cross-type negative sampling
The model presents how to produce cross-KB negative samples over two KBs based on cross-KB negative predicates. The cross-KB negative samples can be caused by three strategies: predicate replacement, entity substitution, and type replacement.
4.2.1.1 Cross-KB negative type of predicate
There are two predicates: r1 ∈ R1 and r2 ∈ R2. ri, i = 1, 2 has an empty overlapping type pair, i.e., Oτ(r1, r2) = ∅; then the predicates r1,r2 are shown as
Example 2. Let us assume that K1 = {Germany, Berlin, Albert_Einstein, Belgium} and R1 = {locatedat, livesin}. Three observed triples are (Berlin, locatedat, Germany), (Berlin, locatedin, Germany), and (Albert_Einstein, livesin, Berlin). The predicate “livesin” in Figure 1 is taken as an instance. The pair of entities on this predicate is (Albert_Einstein, Berlin). This pair of entities does not fulfill any predicate in the additional links. Thus, all predicates in the external links are its cross-KB negative type of predicates, i.e., N (livesin) = {locatedin, hasneighbor}. For the property “hasneighbor” in another knowledge base, its cross-KB negative type of predicate is N (livesin, locatedat).
4.2.1.2 Predicate replacement
Let us assume Q2 represents the set of triples in the other KB K2. For a triple
Example 3. As shown in Figure 1, since hasneighbor ⊥ locatedat, “hasneighbor” is alternated by “locatedat” between the entities “Belgium” and “Germany” to obtain a negative sample (Belgium, locatedat, Germany).
4.2.1.3 Entity substitution
Given a triple
Example 4. Since (Berlin, Germany) contains the predicate “locatedat” shown in Figure 1, and hasneighbor ⊥ locatedat, substituting the negative predicate “locatedat,” the entity pairs have alternates on the predicate “hasneighbor.” So, a new negative candidate is acquired, i.e., (Berlin, hasneighbor, Germany).
The cross-KB negative sampling efficiently acquires validation knowledge from additional KB for the source KB. Although tons of negative samples are produced without semantic similarity, such negative samples are still very instructive for embedding learning. Since the method needs to learn from easy examples (e.g., negative relations “hasneighbor” and “hasPresident”) to difficult instances (e.g., “hasneighbor” and “locatedat”), negative sample sets containing many simple conditions are beneficial for simple model learning. Difficult negative triples are more informative for complex models.
4.2.1.4 Type replacement
There are
r1 ∈ N(r2) and t1 ∈ N(r2),
4.2.2 Search strategy to generate negative candidates
In the CHAI model [13], they regard the candidate triples as true when the original triples are correct. Extending this idea; the negative candidates are also false. Considering the criteria from the CHAI model and the RVE model [29], a new search strategy is defined to explore more negative candidates. In short,
4.2.2.1 Existing subject and object
The criterion collects all candidates whose subject and object appear as such for some triples in K; p′ and p have the same ObjectPropertyRange:
4.2.2.2 Existing subject and predicate:
The criterion collects all candidates whose subject and predicate occur as such for some triples in K. There exists no candidate with the correct property type:
4.2.2.3 Existing predicate and object
The criterion collects all candidates whose object entity replaces the subject one or more times in a triple that has another predicate p′ or the object entity appears at least once as the object in a triple that has another predicate p′:
For instance, one negative triple (Bobby Noble (academic), nationality, Canadians) is chosen as the example. In criterion a, one candidate (Bobby Noble (academic), dbo:stateOfOrigin, Canadians) can be generated. In criterion b, one erroneous triple is (Bonipert, nationality,French_people) and the candidate is (Bonipert, nationality,Italians). In criterion c, there are erroneous objects Canadians, French_people, Italians, etc. The number of candidate samples about (?a, nationality, Canadians) is over 4,900. The number of candidates about French_people is over 1,300 and the quantity about Italians is near 1,000. For positive triples, the results of candidates have a lower number of incorrect or noisy candidates, which also exist in the original KB. So, sparsity negative examples can be crawled by some features, and then our previous work produced a GILP model [15] to acquire more negative examples in iterations.
Combining the search strategy of negative candidates with the method of cross-type negative sampling, erroneous entities, and their triples can be generated for cleaning. Also, some interesting negative statements are selected to be corrected as new facts for knowledge base completion.
4.3 Fetching and filtering erroneous tails links
The HLFetching part acquires the tail of a source triple as input by the http://sameas.orgsameAs service and equivalent links of the candidate instances are fetched in external KB. The sameAs property supplies service to quickly get equivalent links with arbitrary URIs, and 200 million URIs are served, currently. The SameAs4J API is used to fetch equivalent tails links from the sameAs service [62].
In a KB, a target predicate Pr,
4.4 Target triple correction
For target triple correction, the model takes co-occurring similar entities into consideration. One fixed predicate name is chosen as the sample to illustrate the process of correction. In the CWA, some simple queries can be serviced to find erroneous entities without correct ObjectPropertyRange, i.e.,
Algorithm 1 describes the triple matching algorithm to correct negative candidates. First, in the former methods, it is proposed to generate erroneous triples. Then, conflict feedback is removed from sets of erroneous entities. The predicate name is extracted from one erroneous triple. True ObjectPropertyRange τ is leveraged to find candidate property p′in associated KB K′. Also, p′ can be found by overlapping type pairs of entities. At the same time, corresponding candidate instance s′ is acquired by owl: sameAs relation from original subject s of
Our problem is simplified to finding the corresponding property in Wikidata based on a co-occurring similar triple in DBpedia. Especially, the equivalent property of the predicate name of triples is selected to find repairs for the wrong entity. One entity Mariana_Weickert extracted from DBpedia is regarded as an example of a correcting task. An evidence graph is shown in the TCA, in Figure 4. For erroneous triple
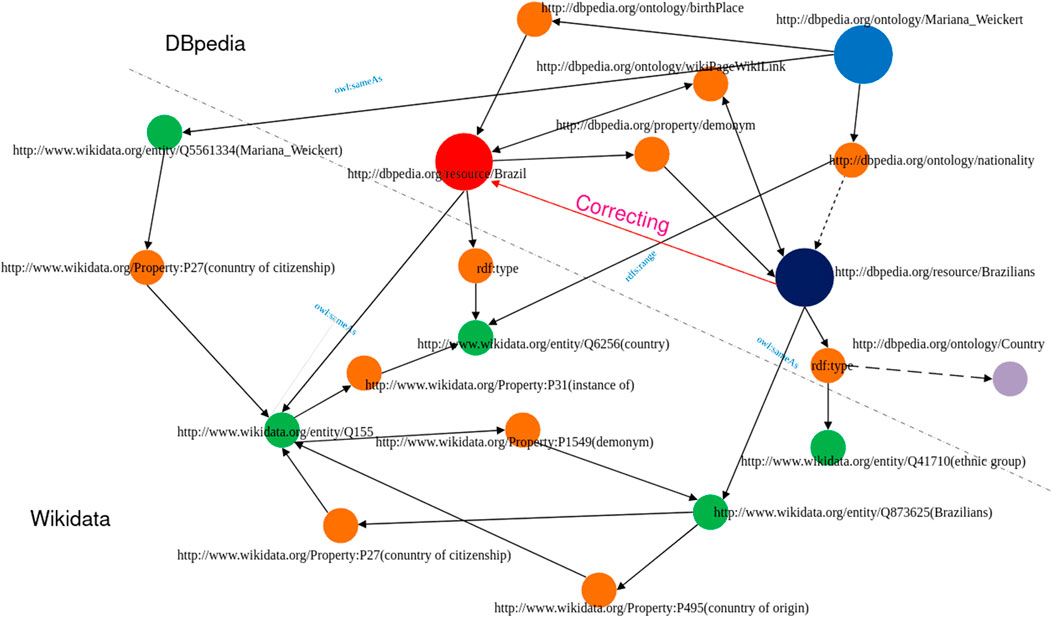
FIGURE 4. Evidence graph as displayed in the TCA (the dark dot denotes erroneous entity and the red one is corrected. Orange dots denote predicate property, and other colors show the entities between DBpedia and Wikidata).
Algorithm 1Co-occurring Triple Matching Algorithm.
Input: pand
Output: Corrn;
Corri = null, i = 0;
Erroneous_entities_sets: (s, p, o) ∈ E;
while K ≠ ∅ or Corri changed do
p → ObjectPropertyRange(τ(true)orτ′(false));
(p, τ, owl: equivalentProperty) → candidate_property: p′;
(s, owl: sameAs) − > candidate_instance: s′;
(o′, owl: sameAs, ?) → repairs: set{obj};
Corri≔ < s, p, obj > ∪ Corri; i = ++;
end
return Corrn;
Two major paths are expressed in the process of repairing the wrong range constraint. First, based on subject Mariana_Weickert, a similar entity in Wikidata is filtered by owl: sameAs and the equivalent property of nationality is replaced by Wikidata:P27 (country of citizenship). So, the repair entity is wikidata: Q155, and the corresponding entity is Brazil in DBpedia. dbr: Brazilians has wrong type dbo: Country. Second, referring to the wrong object and the correct range type, Brazilians and Brazil are related by properties wikidata: P495 (country of origin) and wikidata: P27. Finally,
4.4.1 Hierarchy information for knowledge correction
The taxonomy and hierarchy of knowledge can be applied to many downstream tasks. Hierarchical information originated from concept ontologies, including semantic similarity [63, 64], facilitating classification models [65], knowledge representation learning models [66], and question–answer systems [67]. Well-organized algorithms or attentions of hierarchies are widely applied in the works of relation extraction, such as concept hierarchy, relation hierarchy with semantic connections, a hierarchical attention scheme, and a coarse-to-fine-grained attention [68, 69].
4.4.2 Hierarchical type
In Freebase and DBpedia, selecting one hierarchical type c with k layers as example, c(i) is the ith sub-type of c. The most precise sub-type is considered the first layer, and the most general sub-type is regarded as the last layer, while each sub-type c(i) has only one parent sub-type c(i + 1). Taking a bottom-up path in the hierarchy, the form of hierarchical type is represented as c = c(1), c(2), …, c(k). In YAGO, subclass Of is used to connect the concepts (sub-types). In logic rules, like the inversion, r1(x, y) < => r2(y, x) and the variables x, y can be the entities in general. Here, we expand the logic relations with entity hierarchical types and acquire the fixed domain entities.
As shown in Figure 5, the inversion-type logic are r1(author, written_work)
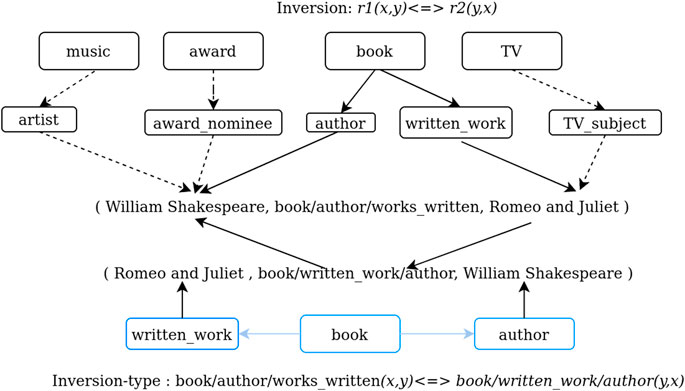
FIGURE 5. Example of logic relations with entity hierarchical types in Freebase.
For example, the object of irthplace in entity Nick_Soolsma follows the type path: Andijk(dbo: Village) < Medemblik(dbo: Town) < North_Holland(dbo: Region) < Netherlands(dbo: Country). One logic path: country containing one birthplace of a person is the person’s nationality. By hierarchical property, dbr:Nick_Soolsma acquires one new nationality, dbr:Netherlands. Repair results can be obtained by predicting erroneous information by hierarchical type. The correction method was proposed in our previous work [18]. For the explanation of hierarchical correction, related paths, and relationships can be used to acquire corrections for negative triples.
5 Experiments
Our approach is tested by using four datasets from four predicate names. Here, mean reciprocal ranking (MRR), HITS@1, and HITS@10 [6] are selected to measure the confidence calculation of corrected triples in the knowledge base. All training datasets are leveraged in the experiments from http://ri-www.nii.ac.jp/FixRVE/Dataset8. Some baseline algorithms were realized in Python, using Ref. 6. Our framework is constructed in the Ubuntu 20.04.5 system and Java 1.8.0, and experimental analysis is run on a notebook with a 12th Gen Intel Core i9-12900KF × 24 and 62.6 GB memory.
5.1 Negative feedback generation
P is given a constraint predicate. A constraint has several lines when it leverages a specified relation. #constr is the total quantity of constraints of the errors type in Dbpedia. #triple is the number for calculating all these constraints of triples with the predicate P. #violations is the quantity of violations for this constraint in Dbpedia in October 2016. #current_cor is the quantity of current corrections collected from Dbpedia in 2020.
In type classification of nationality, objects with the country property are up to 67%, and entities with ethnic group is 31%. Other types are less than 2%, such as language, island, and human settlement. After analysis of negative constraints of nationality, there are duplicate triples between problem statements. In Dbpedia, the type of the entity is a parallel relationship in the SPARQL query results, and the hierarchical relationship between the attributes cannot be obtained from the query results. Therefore, there are overlapping parts among all these errors because the object value of the predicate “nationality” is not unique. Nearly 20% of the triples determined as can be corrected to complete KBs since the objects can have multiple values for nationality, explained in Table 2. For the relation birthplace, the conflict feedback is removed because the predicate objects have a single value. Also, there are over 70% conflict types in error types for nationality. Here, some examples extracted from nationality are applied to validate our correction model.

TABLE 2. Negative constraints of nationality in DBpedia.
For a single incorrect triple, a search strategy is proposed to generate negative candidates. Following strategy a for nationality, some new predicate names isCitizenOf, stateOfOrigin are acquired from KBs. In strategy b, the object types of triples are all exception properties. Negative candidates are obtained by determining the type of a multi-valued object. In search c, the set of all errors for such a predicate name can be found with a single incorrect entity object.
5.2 Discussion
Some examples of repairs with predicate nationality are shown in Table 3. Most subjects have word similarity of repair and tail. The results of some samples about nationality are shown in Figure 6. For predicate nationality, there are a large number of different subjects for one incorrect object. Therefore, for triples with the same erroneous object, such subjects from triples are aggregated into a set, which can ignore the quantity of subjects. Incorrect triples are revised from the perspective of the object. For each pair of error object and repair, the correction similarity is calculated by harmonic correction similarity with different distance methods. In TCA framework, the confidence calculation component holds maximum similarity to filter corrections. The precision of repairs is focused on the interval of [0.3, 0.6], since the great majority of incorrect objects have few connections. In our validation part, the precision of repairs is over 0.5, and these revised triples are regarded as final corrections.
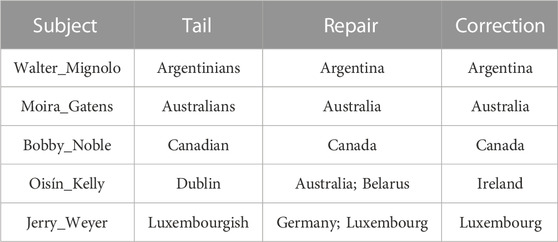
TABLE 3. Repairs examples.
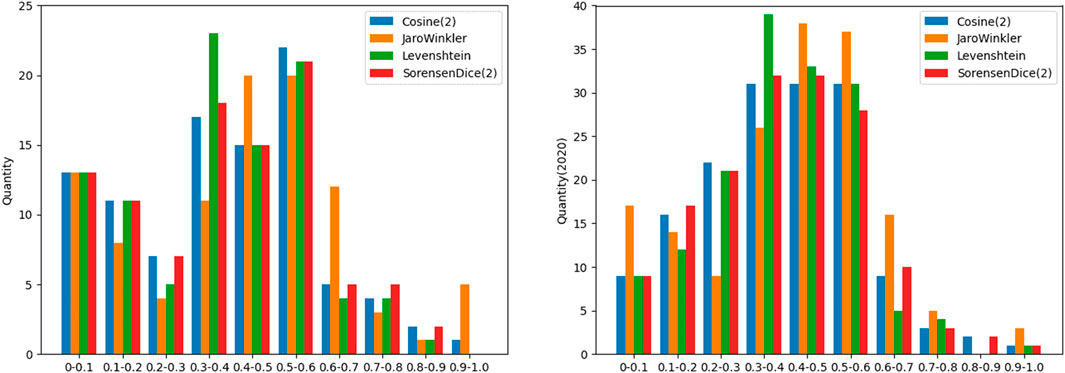
FIGURE 6. Correction similarity with distance methods.
In Figure 7, string similarity methods are leveraged to replace distance methods in harmony correction similarity. String similarity measures are extracted from two aspects, i.e., character-level measures and token-level measures. Nine repair examples are randomly used to validate the correction rates. Fourteen similarity measures are separated by their values. By the nature of repairs, TCA only focuses on the words, not the sentences. So, the results show the Qgram(2) and NGram(i), NormalizedLevenshtein has the better performance. Compared with word and string features, correction similarity is suitable to acquire repairs with word similarity.

FIGURE 7. Comparison of similarity measures.
Some similarity measures are used to compare these repairs in TCA, as shown in Figure 8. The mistaken entities have single values as the final correction. For multiple values as repairs, cross-similarity is proposed to discover final corrections. Distance similarity measures are leveraged to validate repairs, such as the longest common subsequence (LCS), Optimal String Alignment (OSA), and normalized Levenshtein distance (NLD). Compared to DBpedia, the similarity of repairs in Wikidata focuses on word similarity. For a single erroneous triple, Jaro–Winkler similarity is used to validate repairs, and the revised correction has an interval with high precision. In the experiment, 2,000 negative entities were randomly selected to verify the TCA model. The best performance of cross-similarity is shown in Figure 8 and Eq. (7). So, cross-similarity is leveraged to filter final repairs in the EILC model. The final pairs of errors and corrections exhibit unique characteristics that have a high degree of word similarity. Here, multiple repairs indicate that some examples have over 90% similarity probability, i.e., Jaro–Winkler similarity.
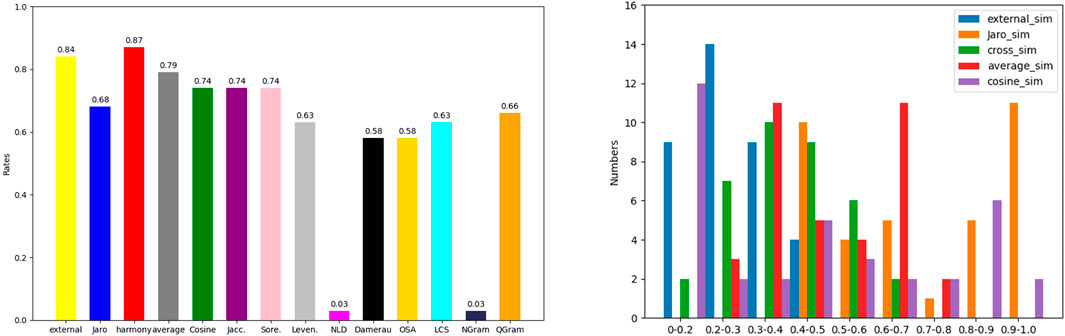
FIGURE 8. Correction rates and intervals based on different similarity measures.
The traditional measures, e.g., Mean_Raw_Rank, Precision, and Recall, are used to evaluate the effect of our correction model and to make comparisons with other classic algorithms. The bold value of M stands for Mean_Raw_Rank, explained in evaluation measures. And the @1 and @10 present the value of precison @K. The comparison results are shown in Table 4 Our approach is compared to six baseline methods. Two are normally leveraged for entity search (DBpedia lookup and dbo:wikiPageDisambiguates) to find entities with the correct range type of predicate name and object. Two baseline methods were originally created for knowledge graph completion (TransE [70] and AMIE+ [49]) for finding the correct object from a given subject and a predicate name. Also, the graph method and keyword method [2] are leveraged to correct triples with range violations.
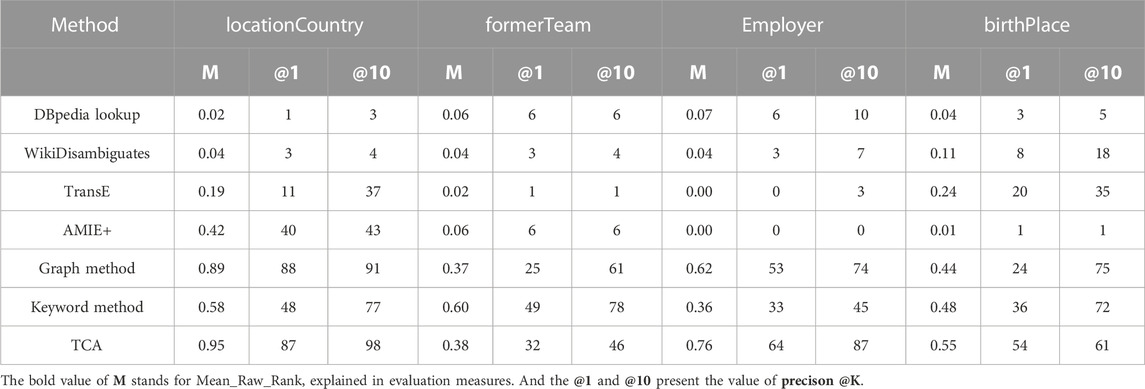
TABLE 4. Comparison of baseline methods.
For positive examples in DBpedia and Wikidata, one example of overlapping type pair is Oτ(dbo: locationCountry, country of citizenship) = (person, country). The negative triple follows the equation: Oτ(r1, r2)=(?a, country). Here, ?a does not equal country. Following an overlapping type pair of entities, corresponding predicates are acquired from positive examples in target KBs. Predicate comparisons from DBpedia and Wikidata are explained in Table 5. By the comparisons, some properties are used to search the repairs from co-occurring similar subjects. For these type pairs, some predicate names in external KBs are acquired for correcting negative candidates.

TABLE 5. Some examples overlapping type pair of entities.
Three evaluation measures are used to calculate the correct object provided for each method. It is evident that our model outperforms common algorithms for all training sets. One condition is that the incorrect object of an erroneous triple has a unique corresponding subject (e.g., locationCountry). TCA and graph methods work closely, since the pair of object and subject has more connections and the paths of triples contain more details. In another condition, one incorrect object has multiple subjects and a graph method. There is a lot of redundant and ambiguous information provided by the graph algorithm with graph structure, which makes it impossible to find the correct object. In this condition (e.g., formerTeam), the keyword method is more effective because it takes advantage of external information from abstracts of triples, including subject and object. In order to be faster and more efficient in the algorithm, TCA explores knowledge correction methods from different perspectives.
TCA is more effective than other basic methods and the keyword method. For these basic methods, they can only correct some single error entity. To make up for such shortcomings and save time complexity, TCA is leveraged to correct range violations by using co-occurring similar entities. By making full utilization of other related knowledge bases for knowledge correction, it is beneficial to think about linked open data. The predefined paths are applied for hierarchy correction. The paths are derived from positive examples. In AMIE+, some paths can be provided by AMIE+. Not all predicates have a logical relationship, and hierarchical learning is very dependent on path information. The final result is close to AMIE+. After analysis of all methods, our proposed TCA model has better performance in base methods. If the source is not Wikipedia, or if the target is not DBpedia or YAGO, the original data sets need to do some changes. While the correction model is applied to other background knowledge bases, the training sets are changed to a triple formulation. All testing facts are transferred to
6 Conclusion
This paper proposed a TCA framework to detect abnormal information and correct negative statements that exist in Wikipedia automatically by co-occurring similar facts in external KBs. Based on ontology-aware substructures of triples, fixing extracted errors is a significant research topic for KB curation. Additionally, our framework is executed post factum, with no changes in the process of KB construction. Two new strategies are applied to search for negative candidates for cleaning KBs. One triple matching algorithm in TCA is proposed to correct erroneous information. Our compared experimental results show that TCA is effective over some baseline methods and widely applied in large knowledge bases. Our framework is straightforwardly adapted to detect erroneous knowledge on other KBs, such as YAGO and Freebase.
In the future, conflicting feedback facts or predictions can be used to refine the KBs. Also, our framework will focus on the search space of triples with other similar contents, such as the abstracts, the labels, and the derived peculiarities. Moreover, more features of similar facts with logic rules are detected in the hub research of knowledge base completion. In our next work plan, a neural network is added to explore more paths for searching for mistakes in KBs. Next, the number of associated knowledge bases can be expanded and the problem of completing large knowledge bases can be solved by associating and matching more effective information toward the goal of completing large KBs.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
YW and ZZ contributed to the design and implementation of the research, to the analysis of the results, and to the writing of the manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Vrandečić D, Krötzsch M. Wikidata: A free collaborative knowledgebase. Commun ACM (2014) 57:78–85. doi:10.1145/2629489
2. Auer S, Bizer C, Kobilarov G, Lehmann J, Cyganiak R, Ives Z. Dbpedia: A nucleus for a web of open data. The semantic web. Springer) (2007). p. 722–35.
3. Raimbault F, Ménier G, Marteau PF, et al. On the detection of inconsistencies in rdf data sets and their correction at ontological level (2011). p. 1–11. Available at: https://hal.archives-ouvertes.fr/hal-00635854 (Oct 26, 2011).
4. Zaveri A, Kontokostas D, Sherif MA, Bühmann L, Morsey M, Auer S, et al. User-driven quality evaluation of dbpedia. Proceedings of the 9th International Conference on Semantic Systems (2013). p. 97–104.
5. Paulheim H, Bizer C. Type inference on noisy rdf data. International semantic web conference. (Springer) (2013). p. 510–25.
6. Lertvittayakumjorn P, Kertkeidkachorn N, Ichise R. Resolving range violations in dbpedia. Joint international semantic technology conference. Springer) (2017). p. 121–37.
7. Dubey M, Banerjee D, Abdelkawi A, Lehmann J. Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia. Springer). Proceedings of the 18th International Semantic Web Conference (ISWC) (2019). p. 1–8.
8. Rajpurkar P, Jia R, Liang P. "Know what you don’t know: Unanswerable questions for squad," in Proceedings of the 56th annual meeting of the association for computational linguistics (short papers), Melbourne, Australia, July 15 - 20, 2018. arXiv preprint arXiv:1806.03822 (2018). p. 784–9.
9. Ferrucci D, Brown E, Chu-Carroll J, Fan J, Gondek D, Kalyanpur AA, et al. Building watson: An overview of the deepqa project. AI Mag (2010) 31:59–79. doi:10.1609/aimag.v31i3.2303
10. Suchanek FM, Kasneci G, Weikum G. Yago: A core of semantic knowledge. Proceedings of the 16th international conference on World Wide Web (2007). p. 697–706.
11. Liu S, d’Aquin M, Motta E. Towards linked data fact validation through measuring consensus. Springer, Cham. Portorož, Slovenia: LDQ@ ESWC (2015). p. 21.
12. Liu S, d’Aquin M, Motta E. Measuring accuracy of triples in knowledge graphs. International conference on language, data and knowledge. Springer) (2017). p. 343–57.
13. Borrego A, Ayala D, Hernández I, Rivero CR, Ruiz D. Generating rules to filter candidate triples for their correctness checking by knowledge graph completion techniques. Proceedings of the 10th International Conference on Knowledge Capture (2019). p. 115–22.
14. Wang H, Ren H, Leskovec J. Entity context and relational paths for knowledge graph completion. arXiv preprint arXiv:2002.06757 (2020).
15. Wu Y, Chen J, Haxhidauti P, Venugopal VE, Theobald M. Guided inductive logic programming: Cleaning knowledge bases with iterative user feedback. EPiC Ser Comput (2020) 72:92–106.
16. Melo A, Paulheim H. An approach to correction of erroneous links in knowledge graphs. CEUR Workshop Proc (Rwth) (2017) 2065:54–7.
17. Chen J, Chen X, Horrocks I, B Myklebust E, Jimenez-Ruiz E. Correcting knowledge base assertions, Proceedings of The Web Conference (2020). p. 1537–47.
18. Wu Y, Zhang Z, Wang G. Correcting large knowledge bases using guided inductive logic learning rules. Pacific rim international conference on artificial intelligence. Springer (2021). p. 556–71.
19. Paulheim H. Identifying wrong links between datasets by multi-dimensional outlier detection. WoDOOM (2014) 27–38.
20. Melo A, Paulheim H. Detection of relation assertion errors in knowledge graphs. Proceedings of the Knowledge Capture Conference (2017). p. 1–8.
21. Zhang L, Wang W, Zhang Y. Privacy preserving association rule mining: Taxonomy, techniques, and metrics. IEEE Access (2019) 7:45032–47. doi:10.1109/access.2019.2908452
22. Fan W, Geerts F. Foundations of data quality management. Springer, Cham: Morgan and Claypool Publishers (2012). doi:10.1007/978-3-031-01892-3
23. Galárraga LA, Teflioudi C, Hose K, Suchanek F. "Amie: Association rule mining under incomplete evidence in ontological knowledge bases," in WWW '13: Proceedings of the 22nd international conference on World Wide Web. Rio de Janeiro, Brazil: WWW (2013). p. 413–22. doi:10.1145/2488388.2488425
24. Zeng Q, Patel JM, Page D. QuickFOIL: Scalable inductive logic programming. PVLDB (2014) 8:197–208. doi:10.14778/2735508.2735510
25. Rantsoudis C, Feuillade G, Herzig A. "Repairing aboxes through active integrity constraints. 30th international workshop on description logics (DL 2017)," In 30th international workshop on description logics (DL workshop 2017), 18 July 2017 - 21 July 2017. Montpellier, France: CEUR-WS: Workshop proceedings (2017). p. 1–13. https://oatao.univ-toulouse.fr/22739/.
26. Paulheim H, Bizer C. Improving the quality of linked data using statistical distributions. Int J Semantic Web Inf Syst (Ijswis) (2014) 10:63–86. doi:10.4018/ijswis.2014040104
27. Liang J, Xiao Y, Zhang Y, Hwang SW, Wang H. "Graph-based wrong isa relation detection in a large-scale lexical taxonomy," In Proceedings of the thirty-first AAAI conference on artificial intelligence. San Francisco California USA (2017). p. 1–6. doi:10.1609/aaai.v31i1.10676
29. Lertvittayakumjorn P, Kertkeidkachorn N, Ichise R. Correcting range violation errors in dbpedia. International semantic web conference. Kobe, Japan. (Springer): Posters, Demos and Industry Tracks (2017). p. 1–4. https://ceur-ws.org/Vol-1963/.
30. Abedini F, Keyvanpour MR, Menhaj MB. Correction tower: A general embedding method of the error recognition for the knowledge graph correction. Int J Pattern Recognition Artif Intelligence (2020) 34:2059034. doi:10.1142/s021800142059034x
31. Bordes A, Usunier N, Garcia-Duran A, Weston J, Yakhnenko O. Translating embeddings for modeling multi-relational data. Adv Neural Inf Process Syst (2013) 26.
32. Nickel M, Tresp V, Kriegel HP. A three-way model for collective learning on multi-relational data. Icml (2011) 1–8.
33. Wang Z, Zhang J, Feng J, Chen Z. Knowledge graph embedding by translating on hyperplanes. Proc AAAI Conf Artif Intelligence (2014) 28:1112–9. doi:10.1609/aaai.v28i1.8870
34. Xiao H, Huang M, Hao Y, Zhu X. "Transg: A generative mixture model for knowledge graph embedding," in Proceedings of the 54th annual meeting of the association for computational linguistics (Germany) (2015). p. 2316–25. doi:10.48550/arXiv.1509.05488
35. Yang B, Yih WT, He X, Gao J, Deng L. "Embedding entities and relations for learning and inference in knowledge bases. Proceedings of the international conference on learning representations. San Diego, CA, USA: ICLR (2014). p. 1–13. doi:10.48550/arXiv.1412.6575
36. Nickel M, Rosasco L, Poggio T. Holographic embeddings of knowledge graphs. Proc AAAI Conf Artif Intelligence (2016) 30:1955–61. doi:10.1609/aaai.v30i1.10314
37. Shi B, Weninger T. Proje: Embedding projection for knowledge graph completion. Proc AAAI Conf Artif Intelligence (2017) 31:1236–42. doi:10.1609/aaai.v31i1.10677
38. Bader J, Scott A, Pradel M, Chandra S. Getafix: Learning to fix bugs automatically. Proc ACM Programming Languages (2019) 3:1–27. doi:10.1145/3360585
39. Mahdavi M, Baran AZ. Effective error correction via a unified context representation and transfer learning. Proc VLDB Endowment (2020) 13:1948–61.
40. Pellissier Tanon T, Suchanek F. Neural knowledge base repairs. European Semantic Web Conference (Springer) (2021). p. 287–303.
41. Mahdavi M, Abedjan Z, Castro Fernandez R, Madden S, Ouzzani M, Stonebraker M, et al. Raha: A configuration-free error detection system. Proceedings of the 2019 International Conference on Management of Data (2019). p. 865–82.
42. Zhao Y, Hou J, Yu Z, Zhang Y, Li Q. Confidence-aware embedding for knowledge graph entity typing. Complexity (2021) 2021:1–8. doi:10.1155/2021/3473849
43. Chen J, Jiménez-Ruiz E, Horrocks I, Chen X, Myklebust EB. An assertion and alignment correction framework for large scale knowledge bases. Semantic Web Pre-press, IOS Press (2021). p. 1–25. doi:10.3233/SW-210448
44. Arnaout H, Tran TK, Stepanova D, Gad-Elrab MH, Razniewski S, Weikum G. Utilizing language model probes for knowledge graph repair. Wiki Workshop (2022) 2022:1–8.
45. Petroni F, Rocktäschel T, Lewis P, Bakhtin A, Wu Y, Miller AH, et al. "Language models as knowledge bases?," In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics (2019). p. 2463–73. doi:10.18653/v1/D19-1250
46. Lehmann J, Bühmann L. Ore-a tool for repairing and enriching knowledge bases. International semantic web conference. Springer) (2010). p. 177–93.
47. Knuth M, Hercher J, Sack H. "Collaboratively patching linked data," In Proceedings of 2nd international workshop on usage analysis and the web of data (USEWOD 2012) p. 1–6. doi:10.48550/arXiv.1204.2715
48. Ma Y, Qi G. An analysis of data quality in dbpedia and zhishi. me. China Semantic Web Symposium and Web Science Conference. Springer (2013). p. 106–17.
49. Lajus J, Galárraga L, Suchanek F. Fast and exact rule mining with amie 3. European Semantic Web Conference. Springer (2020). p. 36–52.
50. Chu X, Morcos J, Ilyas IF, Ouzzani M, Papotti P, Tang N, et al. Katara: Reliable data cleaning with knowledge bases and crowdsourcing. Proc VLDB Endowment (2015) 8:1952–5. doi:10.14778/2824032.2824109
51. Krishnan S, Franklin MJ, Goldberg K, Wang J, Wu E. Activeclean: An interactive data cleaning framework for modern machine learning. Proceedings of the 2016 International Conference on Management of Data (2016). p. 2117–20.
52. Rekatsinas T, Chu X, Ilyas IF, Holoclean RC. Holistic data repairs with probabilistic inference. Proc. VLDB Endow. (2017) 10(11):1190–201. arXiv preprint arXiv:1702.00820.
53. Krishnan S, Franklin MJ, Goldberg K, Wu E. Boostclean: Automated error detection and repair for machine learning. arXiv preprint arXiv:1711.01299 (2017).
54. De Melo G. Not quite the same: Identity constraints for the web of linked data. Twenty-Seventh AAAI Conference on Artificial Intelligence (2013). p. 1092–8.
55. Ngonga Ngomo AC, Sherif MA, Lyko K. Unsupervised link discovery through knowledge base repair. European semantic web conference. Springer) (2014). p. 380–94.
56. Domingue J, Fensel D, Hendler JA. Handbook of semantic web technologies. Springer Science and Business Media (2011).
57. Wang Y, Ma F, Gao J. Efficient knowledge graph validation via cross-graph representation learning. Proceedings of the 29th ACM International Conference on Information and Knowledge Management (2020), 1595–604.
58. Vargas SGJ. A knowledge-based information extraction prototype for data-rich documents in the information technology domain. [Dissertation/master's thesis]. Columbia: National University (2008).
59. Wang Y, Qin J, Wang W. Efficient approximate entity matching using jaro-winkler distance. International conference on web information systems engineering. Springer (2017). p. 231–9.
60. Cui Z, Kapanipathi P, Talamadupula K, Gao T, Ji Q. "Type-augmented relation prediction in knowledge graphs," in The thirty-fifth AAAI conference on artificial intelligence (AAAI-21). Vancouver, Canada (2020). doi:10.1609/aaai.v35i8.16879
61. Dimou A, Kontokostas D, Freudenberg M, Verborgh R, Lehmann J, Mannens E, et al. International semantic web conference. Springer (2015). p. 133–49.Assessing and refining mappings to rdf to improve dataset quality
62. Fiorentino A, Zangari J, Darling MM. DaRLing: A datalog rewriter for owl 2 RL ontological reasoning under SPARQL queries. Theor Pract Logic Programming (2020) 20:958–73. doi:10.1017/s1471068420000204
63. Leacock C, Chodorow M. Combining local context and wordnet similarity for word sense identification. WordNet: Electron lexical database (1998) 49:265–83.
64. Zhang K, Yao Y, Xie R, Han X, Liu Z, Lin F, et al. Open hierarchical relation extraction. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2021). p. 5682–93.
65. Weinberger KQ, Chapelle O. Large margin taxonomy embedding for document categorization. Adv Neural Inf Process Syst (2009) 1737–44.
66. Xie R, Liu Z, Sun M, et al. Representation learning of knowledge graphs with hierarchical types. IJCAI (2016) 2965–71.
67. Toba H, Ming ZY, Adriani M, Chua TS. Discovering high quality answers in community question answering archives using a hierarchy of classifiers. Inf Sci (2014) 261:101–15. doi:10.1016/j.ins.2013.10.030
68. Han X, Yu P, Liu Z, Sun M, Li P. Hierarchical relation extraction with coarse-to-fine grained attention. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (2018). p. 2236–45.
69. Zhang N, Deng S, Sun Z, Wang G, Chen X, Zhang W, et al. "Long-tail relation extraction via knowledge graph embeddings and graph convolution networks," In Proceedings of the 2019 conference of the north american chapter of the association for computational linguistics: Human language technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics (2019). p. 3016–25. doi:10.18653/v1/N19-1306
Keywords: abnormal information, matching algorithm, knowledge correction, Q&A systems, negative candidates
Citation: Wu Y and Zhang Z (2023) Refining large knowledge bases using co-occurring information in associated KBs. Front. Phys. 11:1140733. doi: 10.3389/fphy.2023.1140733
Received: 09 January 2023; Accepted: 23 January 2023;
Published: 23 February 2023.
Edited by:
Leilei Chen, Huanghuai University, ChinaReviewed by:
Xin Zhang, Southwest Jiaotong University, ChinaFang-Yuan Shi, Ningxia University, China
Copyright © 2023 Wu and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zili Zhang, emhhbmd6bEBzd3UuZWR1LmNu