 Francesca Lionetti
Francesca Lionetti Loes Keijsers2
Loes Keijsers2 Massimiliano Pastore
Massimiliano Pastore- 1Department of Biological and Experimental Psychology, Queen Mary University of London, London, UK
- 2Department of Developmental Psychology, Tilburg University, Tilburg, Netherlands
- 3Department of Brain and Behavioural Sciences, University of Pavia, Pavia, Italy
- 4Department of Psychology, Salesian University, Rome, Italy
- 5Department of Developmental and Social Psychology, University of Padova, Padova, Italy
For evaluating monitoring and parent-adolescent communication, a set of scales addressing parental knowledge, control and solicitation, and adolescent disclosure was proposed by Kerr and Stattin (2000). Although these scales have been widely disseminated, their psychometric proprieties have often been found to be unsatisfactory, raising questions about their validity. The current study examines whether their poor psychometric properties, which are mainly attributed to the relatively poor conceptual quality of the items, could have been caused by the use of less-than-optimal analytical estimation methods. A cross-validation approach is used on a sample of 1071 adolescents. Maximum likelihood (ML) is compared with the diagonal weighted least squares (DWLS) method, which is suitable for Likert scales. The results of the DWLS approach lead to a more optimal fit than that obtained using ML estimation. The DWLS methodology may represent a useful option for researchers using these scales because it corrects for their unreliability.
1. Introduction
Parental monitoring is a core aspect of family relationships that may help to promote adaptation and prevent youths from going astray. Accordingly, it has received significant attention from developmental psychologists interested in studying adolescent social and emotional development. For instance, differences in the quality of parental monitoring have been linked to adolescent antisocial behavior, delinquency, substance use, deviant relationships, and failure to adhere to medical guidelines (Soenens et al., 2006; Darling et al., 2008; Laird et al., 2008; Smetana, 2008; Keijsers et al., 2009; Kiesner et al., 2009; Racz and McMahon, 2011; Fosco et al., 2012; Tolan et al., 2013). Originally, parental monitoring was perceived as a parent-driven activity (Dishion and McMahon, 1998). However, a significant change in perspective arose with the reinterpretation of Stattin and Kerr, which stresses the adolescents contribution to the degree of parents knowledge and hence the active role of the child in the parent-child relationship (Kerr and Stattin, 2000; Stattin and Kerr, 2000). Within this perspective, children are not considered passive recipients but rather active participants in their interactions with their parents, even when the interactions pertain to sharing or not sharing in the content of the adolescents leisure-time activities, or in other aspects pertaining to contexts in which parents are not present, such as school.
Linked to this theoretical assumption, Kerr and Stattin (2000) propose a set of scales for the assessment of parent-child communication. The assessment is operationalized as follows. Parental knowledge refers to monitoring as prototypical defined; parental control refers to the parents use of rules and restrictions to limit the children abilities to engage in activities without informing the parents; parental solicitation refers to the parents asking their children and/or their children's friends for information; and adolescent disclosure refers to the children spontaneous sharing of information about their activities with their parents. Researchers using these scales have adopted either the whole assessment tool, or have selected a subset of these scales, depending on research aims (Racz and McMahon, 2011; Keijsers, 2015). These easily applicable and widely disseminated self-reports, suitable to be completed by children and/or parents, have garnered the interest of both clinical and developmental psychology research. However, as the number of studies that have employed these tools has increased, concerns regarding the validity of the scales also emerged. Thus, the aim of this paper is to contribute to the study of the psychometric properties of these scales, with a specific focus on the estimation method used in the data analyses.
1.1. Psychometric Properties of Parental Monitoring Scales
After 15 years of research in the field of parental monitoring, there are more than 600 papers indexed in Scopus, PsychInfo, and Web of Science that cite the revised perspective of monitoring in reviews and empirical studies (Kerr and Stattin, 2000; Stattin and Kerr, 2000). This rapid dissemination of the revised construct has been associated with mixed outcomes regarding the internal consistency and factor structure of the scales developed within the parental monitoring framework, thus raising questions about their validity. For example, in a study of 328 Dutch adolescents, Hawk et al. (2008) reported a poor fit of confirmatory factor analysis (CFA) on parental solicitation and parental control scales, a problem that was resolved by removing some of the original items. In a study of 445 Italian adolescents, Miranda et al. (2011) correlated the residuals of two items from the adolescent disclosure scale to obtain an acceptable fit. The same two items had been previously proposed to be part of a different construct, secrecy, by Frijns et al. (2010). This two-factor version of the original scale of disclosure, which was tested longitudinally on a sample of 309 Dutch adolescents, suggested that the common operationalization of adolescent disclosure incorporates two separate constructs. The two factors, secrecy and disclosure, were subsequently tested in an American sample, and marginally acceptable fits were obtained (Keijsers and Laird, 2014).
A common feature of the above-mentioned studies is the use of the maximum likelihood estimation method (ML) for each of the confirmatory factor analyses performed. The ML estimation method treats Likert scales as interval scales. Conversely, statistical recommendations suggest that more reliable results can be derived if Likert-type variables are analyzed while taking into account their categorically ordered nature in an underlying variable approach (Flora and Curran, 2004; Jamieson, 2004; Yang-Wallentin et al., 2010; Pastore and Lombardi, 2014; Casacci and Pareto, 2015). Thus, it cannot be excluded that low fits and CFA estimation problems reported in the literature, and partially solved by removing items or splitting scales, were, in fact, due to statistical rather than theoretical issues. In the current study, to test the factor structure of the well-known and often-applied scales in parental monitoring, we embrace a more analytical approach.
1.2. Underlying Variable Approach
The Stattin and Kerr scales are five-point Likert scales, ranging from 1 = never, to 5 = always. What is assessed, such as the degree to which a child is willing to disclose information about free time and activities to his/her parent(s), is a continuous latent construct that is measured via ordered categorical response items. Nevertheless, the most common statistical analysis technique used assumes that variables have continuous level measurements, an assumption that is based on the belief that statistically treating ordinal data as interval variables will not greatly distort the relationships among variables and results.
An easily applicable approach for analyzing Likert scales that accounts for their ordinal data nature is the Underlying Variable Approach (UVA; Muthén, 1984; Jöreskog, 1990). Consistent with the UVA, it can be assumed that ordinal item response data d, expressed with k ordered categories, approximates a latent variable ξ with a normal distribution and a mean equal to 0. Thus, when d = i (i∈{1, …, k}), the true value ξ is included between two thresholds, i.e.,:
where τ0 = −∞, τ1 < … < τk−1 and τk = +∞ are threshold parameters. It follows that given an ordinal item response data with k values (e.g., a Likert-type scale with five levels of responses), there are four (i.e., k − 1) unknown thresholds. A visual exemplification of how the Likert-type data are related to an underlying continuous distribution is provided in Figure 1. Specifically, Figure 1A represents an item response distribution on a five-point Likert scale, where approximately 4% of the subjects respond 1 to an item, 9% respond 2, 27% respond 3, and 34% respond 4 and 27% respond 5. By using the empirical cumulative distribution function, it is possible to estimate the τ thresholds by applying the formula:
where nj is the number of cases in the jth category, , and Φ−1 is the inverse standard normal distribution function. In panel [B], the underlying normal distribution with thresholds (vertical dotted lines) computed from the discrete distributions depicted in panel [A] is presented.
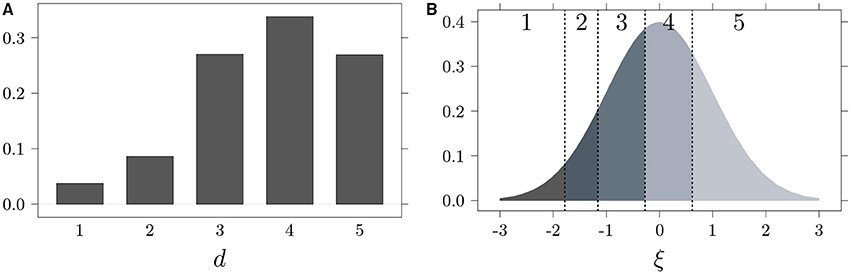
Figure 1. Likert-type data (A) and related underlying continuous distribution (B).
1.3. Aims
In the current study, we aimed to analyze the factorial validity of the parental knowledge, control and solicitation, and adolescent disclosure scales, derived from Kerr and Stattin (2000), testing the scales psychometric properties on a large data set of Italian adolescents. We first evaluated the fit of each separate scale, and we then examined the fit of the theorized structural model—originally tested by Stattin and Kerr within a multiple regression analysis approach—in which parental control, parental solicitation, and adolescent disclosure predict parental knowledge (Kerr and Stattin, 2000; Stattin and Kerr, 2000). Specifically, we explored whether problems originally attributed to the scales, as we have commented in the introduction section, may have been due to the estimation method used in the analysis of the data. In the case of non-satisfactory fit indices, we compared the fit of alternative models derived from the literature.
A core feature characterizing this study is the use of the diagonally weighted least square (DWLS) estimator on a set of scales that are traditionally treated as continuous. The DWLS estimator, which implements UVA and is available in the most widely used software for structural equation modeling, may represent a more reliable option than the popular ML method and avoid estimation biases that can occur with ordered variables (Flora and Curran, 2004; Yang-Wallentin et al., 2010; Pastore and Lombardi, 2014). Also, compared to alternative options for dealing with ordinal variables and non-normal distribution, as the robust ML when continuous observed variables slightly deviate from normality (Rhemtulla et al., 2012), DWLS more explicitly takes into account the ordered nature of categorical variables and may allow avoiding biased results that with the robust ML have been reported with relative small sample size and asymmetric thresholds (Hox et al., 2010; Rhemtulla et al., 2012; Li, 2015). It is the first time, to the best of our knowledge, that the DWLS estimator has been used for testing the factorial structure of the already mentioned scales, i.e., monitoring, knowledge, solicitation, control, and disclosure. Furthermore, it is the first time that the current scales have been analyzed in terms of their psychometric properties on a large data set of Italian adolescents.
2. Materials and Methods
2.1. Participants, Procedure, and Measures
The participants in this study included 1071 Italian adolescents (28% female) between 13 and 18 years of age (M = 16.1, SD = 1.23). Upon consent of the adolescents, their parents, and their teachers, paper-based questionnaires were administered individually in a classroom setting to the participants. The four 5-point Likert-scales, originally proposed by Kerr and Stattin (2000), were used.
The parental knowledge (PK) scale consisted of nine items that captured the degree of parents knowledge of their adolescents activities. These items were as follows: Do your parents know what you do during your free time? (item 1); Do your parents know with whom you associate during your free time? (item 2); Do your parents usually know what type of homework you have? (item 3); Do your parents know what you spend your money on? (item 4); Do your parents usually know when you have an exam or paper due at school? (item 5); Do your parents know how you do in different subjects at school? (item 6); Do your parents know where you go when you are out with friends at night? (item 7); Do your parents normally know where you go and what you do after school? (item 8); and In the last month, have your parents ever had no idea where you were at night? (item 9).
The adolescent disclosure (AD) scale consisted of five items that measured the degree of adolescents disclosure of information to their parents. The questions were as follows: Do you spontaneously tell your parents about your friends (the friends you hang out with and their thoughts and feelings on various topics)? (item 10); How often do you usually want to tell your parents about school (regarding, e.g., details about how you are doing in your classes and your relationships with teachers)? (item 11); Do you keep a lot of secrets from your parents about what you do during your free time? (item 12, reversed); Do you like to tell your parents what you do and where you go during your free time and in the evenings evening? (item 13); and Do you keep information about what you do at night and on the weekends from your parents? (item 14, reversed).
The parental solicitation (PS) scale consisted of five items that captured parents tendency to request information from their children. The items were as follows: How often do your parents talk with your friends when they come over to your house? (item 15); How often do your parents ask you about what happened during your free time? (item 16); During the past month, how often have your parents initiated a conversation with you about your free time? (item 17); When did your parents last have extra time to sit down and listen to you when you talk about what happened during your free time? (item 18); and How often do your parents ask you to tell them what happened at school on a regular school day? (item 19).
The parental control (PC) scale consisted of six items that measured the degree to which adolescents are required to inform parents of their activities. The questions were as follows: Must you have your parents permission before you go out on weeknights? (item 20); If you go out on a Saturday evening, must you inform your parents beforehand about with whom you are going and where you are going? (item 21); If you have been out past curfew, do your parents require that you explain why and tell who you were with? (item 22); Do your parents demand that they know where you are in the evenings, who you are going to be with, and what you are going to do? (item 23); Must you ask your parents before you can make plans with friends about what you will do on a Saturday night? (item 24); and Do your parents require that you tell them how you spend your money? (item 25).
2.2. Analytic Plan
We used a cross-validation approach (Cudeck and Browne, 1983), meaning that we split the original sample into two independent randomly chosen sub-samples, the calibration sample, which included Nc = 643 subjects, and the validation sample, which included Nv = 428 subjects. On the calibration sample, we first explored the item distribution using a visual representation. Second, we performed a series of CFAs for each scale using both the traditional ML estimation method, which is suitable for interval variables, and the DWLS, which implements UVA, as suggested for Likert-type ordinal data (Flora and Curran, 2004). We also tested alternative models, as earlier proposed in the literature, if the fit was not satisfactory. Third, we tested the structural model originally proposed by Stattin and Kerr (2000). Finally, on the validation sample, we re-tested the structural model, and we compared the fit indices and parameter estimates derived from the validation and calibration samples.
For evaluating the similarity between the calibration and validation model estimates, we used the root mean square error (RMSE) based on the following discrepancy measure:
in which and represent the estimated vector parameters into the validation and calibration samples. Additionally, we used the same discrepancy function, modified as follows, for estimating the cross-validation index (CVI; Browne and Cudeck, 1993):
in which is the estimate of the reproduced correlation matrix in calibration sample and Sv the correlation matrix in validation sample.
The data analyses were performed with the R statistical software (R Core Team, 2014) and using lavaan (Rosseel, 2012) and semPlot (Epskamp, 2014) packages.
3. Results
3.1. Items Distribution
A graphical representation of item distribution of the calibration sample is displayed in Figure 2. Items 1 to 9 belong to the PK scale, items 10 to 14 belong to the AD scale, items 15 to 20 belong to the PC scale, and items 21 to 25 belong to the PS scale. Most of the items exhibit a skewed distribution.
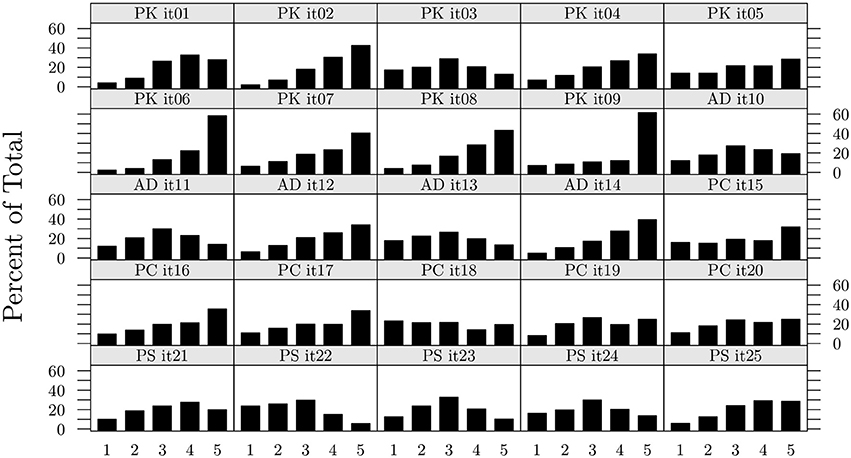
Figure 2. Item distributions of the four parental monitoring scales (calibration sample Nc = 643).
3.2. CFAs of Scales
The following calibration sample CFA fit indices are reported in Table 1: comparative fit index (CFI; Bentler, 1989, 1990), non-normel Fit Index (NNFI; Tucker and Lewis, 1973; Bentler and Bonett, 1980), RMSE of approximation (RMSEA; Steiger and Lind, 1980; Steiger, 1989), ML-based standardized root mean square residual (SRMR), and its DWLS-based equivalent, i.e., the WRMR (Weighted Root Mean Square Residual; Muthén, 2004). Also, the total coefficient of determination (TCD; Bollen, 1989) is considered. The incremental measure of fit CFI and NNFI indicate an optimal fit when their values are greater than 0.95; for the absolute measure of fit named RMSEA and SRMR the cut-off suggested are respectively 0.08 and 0.06 (Hu and Bentler, 1999), and for the DWLS-based WRMR, the closer to 1 is, the better the model (Yu, 2002). TCD estimates the amount of explained model variance and ranges from 0 (i.e., 0% of variance explained) to 1 (i.e., 100%) such that the closer it is to 1, the better the fit (Bollen, 1989). On the left side of Table 1 are the indices computed using the ML estimator, whereas the right side lists the indices computed using the DWLS.
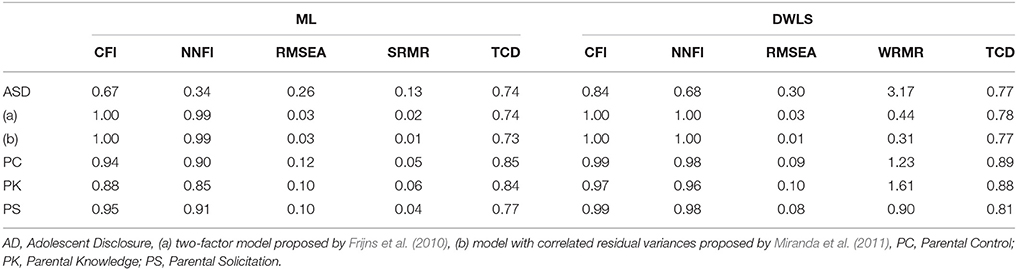
Table 1. CFA fit indices for the four scales (Nc = 643).
Overall, the DWLS fit indices appear to be better than the ML indices along all scales. This is particularly evident for the PK scale, whose items are among the most skewed (see Figure 2, items 10 to 14). Using the ML method would have led to rejecting the scale, whereas conversely, the fit improved substantially with the DWLS for all indices but RMSEA, which remained mediocre. Only one scale, the AD scale, exhibited overall non-acceptable fit indices for both the ML and the DWLS method. Therefore, we tested the two AD alternative options derived from the literature, and reported in the introduction section, one being a two-factor solution that postulates the existence of two separate components named secrecy and disclosure (see Table 1, model AD(a); Frijns et al., 2010), and the other including correlated errors between the two items included by Frijns and colleagues in the secrecy scales (model AD(b); Miranda et al., 2011). Both options exhibited good fit indices, but only the two-factor solution was used for the structural model data analysis as the two-factor option has received theoretical support from the literature (Frijns et al., 2010).
3.3. Structural Model
Subsequently, we tested the structural model depicted in Figure 3 with the latent variables parental control, solicitation, and adolescent disclosure as predictors of the latent variable parental knowledge. The model was tested on the validation and the calibration samples. Again, the DWLS fit indices were more satisfying than were the ML indices in both samples (see Table 2); we thus present and comment factor loadings derived from the DWLS method, as those based on ML were rejected for the less than optimal fit indices obtained1. In Table 3 are reported factor loadings for the effect of the candidate predictors on parental knowledge, and in Table 4 the correlation among all variables; results were comparable in the calibration and in the validation sample, supporting the reliability of the model tested. Specifically, factor loadings estimated using DWLS ranged from 0.43 to 0.86 for the calibration sample, and from 0.35 to 0.98 for the validation sample. It is worth noting that the values for the calibration and validation samples were similar. The RMSE was 0.706 (p = 0.87, estimated by a 3000 bootstrap replicate) and the CVI index was 0.754 (p = 0.993, estimated by a 3000 bootstrap replicate). The parameters of the structural model (see Table 2) suggest that the highest contribution to parental knowledge came from the disclosure scale and, to a lesser extent, from parental control and low levels of secrecy. Conversely, parental solicitation was not significantly linked with parental knowledge.
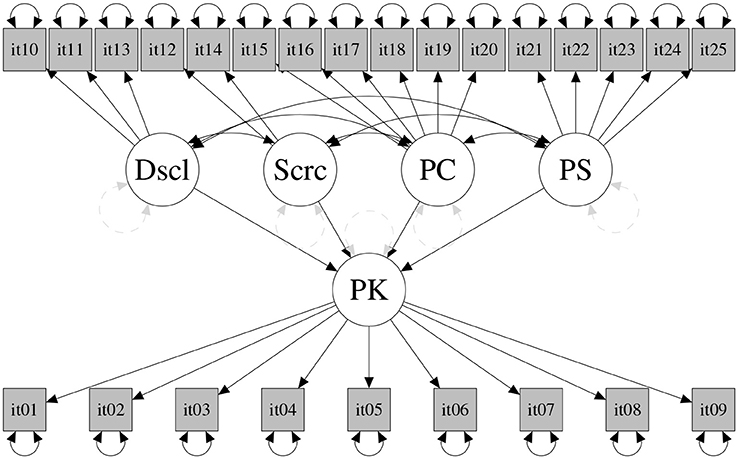
Figure 3. Structural model. Dscl, Disclosure; Scrc, Secrecy; PS, Parental Solicitation; PC, Parental Control (PC); PK, Parental Knowledge.

Table 2. Fit indices for structural model depicted in Figure 3.
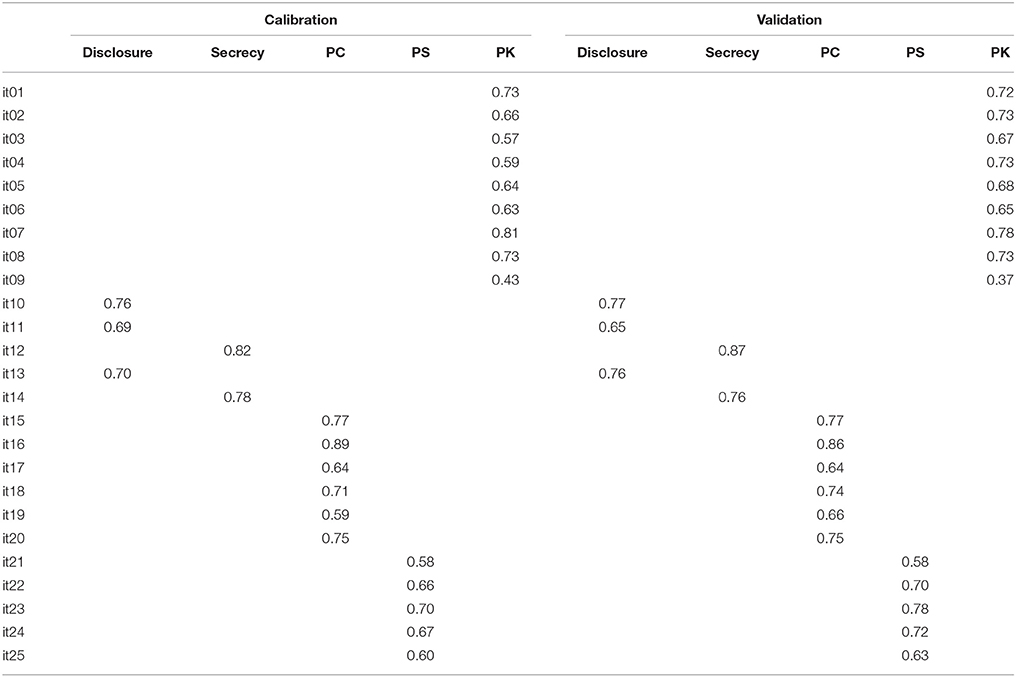
Table 3. Factor loadings of the structural model represented in Figure 3, estimated in the calibration and validation samples.

Table 4. Factor correlations of the structural model represented in Figure 3, estimated in the calibration and validation samples.
4. Discussion
In the last 15 years, many studies have documented the relationships among parental knowledge, adolescents disclosure, and conduct problems (Racz and McMahon, 2011; Keijsers, 2015). Given the wide dissemination of the results from these studies, it is important that the factorial validity of the scales used to tap into these constructs be carefully examined. However, thus far, mixed outcomes about the scales validity have been reported, and these problems have been solved by deleting some items, correlating items, or splitting the scales into two parts.
In the current paper, using an analytical approach, we proposed that previously reported problems may have been due to statistical rather than theoretical issues. We performed a series of CFA analyses for each scale, testing two different estimators, the ML, which is suitable for interval data and most often used in this field, and the DWLS, which is recommended for ordered categorical variables such as Likert scales (Flora and Curran, 2004). Our results suggest that the DWLS estimator, now available in several statistical software, takes into account the ordered nature of the Likert scales, yielding optimal fits. Specifically, this was true for all scales except the adolescent disclosure scale, whose fits were still relatively poor for the original five-item version. Rather, it was the Frijns and colleagues proposed version (2010), with two factors, disclosure and secrecy, to receive the best support.
Although acceptable fits have been achieved using DWLS, it cannot be excluded that the scales might need to be further revised (e.g., see the adapted self-disclosure scale); also it can be posited that low fit indices previously reported in the literature are due to the absence of a truly latent factor. We propose that it is more likely that items included in the scales represent a subset of all possible issues of which parents may have knowledge (or that children disclose), and thus that is parents overall level of actual knowledge—the latent factor—which causes the scores on the items, rather than the reverse. In support of the existence of specific latent constructs are our results derived from the evaluation of the structural model. Further research in this field may contribute to better disentangle this aspect.
To sum up, conclusions that can be drawn from our study are the following: (1) Stattin and Kerrs scales have acceptable factorial validity, (2) adolescent disclosure may be better (theoretically and statistically) assessed if disclosure and secrecy are considered as separate factors Frijns et al. (2010), and (3) taking into account the ordered nature of Likert scales may lead to more reliable results in the parental monitoring field of research. To explore what this implies from a predictive validity perspective in the field of monitoring, and whether these results apply to different assessment measures based on Likert scales, represent new directions of study in the field of psychological assessment and developmental psychology.
Ethics Statement
The study was carried on in accordance with the Declaration of Helsinki and approved by the institutional review board of the Università Pontificia Salesiana, Rome, Italy.
All participants and their parents received an information sheet under the Italian Law and they were asked to give signed consent by both parents and the participant him/herself.
Author Contributions
FL and LK performed literature review and proposed models to be tested, AD performed data collection, data entry and provides support to the literature review, MP and FL performed statistical analyses and supervised methodological aspects of the paper.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank the schools and the personnel for their help and support; the students, who kindly participate, and their parents.
Footnotes
1. ^Parameters estimated using ML are reported in the Appendix. These values, generally lower than DWLS estimates, should be considered with caution given that fit indices identified using ML were not acceptable.
References
Bentler, P. M. (1989). EQS 6 Structural Equations Program Manual. Los Angeles, CA: BMDP Statistic Software.
Bentler, P. M. (1990). Comparative fit indexes in structural models. Psychol. Bull. 107, 238–246. doi: 10.1037/0033-2909.107.2.238
Bentler, P. M., and Bonett, D. G. (1980). Significance tests and goodness of fit in the analysis of covariance structures. Psychol. Bull. 88, 588–606. doi: 10.1037/0033-2909.88.3.588
Browne, M. W., and Cudeck, R. (1993). “Alternative ways of assessing model fit,” in Testing Structural Equation Models, eds K. A. Bollen and J. S. Long (Beverly Hills, CA: SAGE Publications), 136–162.
Casacci, S., and Pareto, A. (2015). Methods for quantifying ordinal variables: a comparative study. Qual. Quant. 49, 1859–1872. doi: 10.1007/s11135-014-0063-2
Cudeck, R., and Browne, M. W. (1983). Cross-validation of covariance structures. Multivariate Behav. Res. 18, 147–167. doi: 10.1207/s15327906mbr1802_2
Darling, N., Cumsille, P., and Martínez, M. L. (2008). Individual differences in adolescents' beliefs about the legitimacy of parental authority and their own obligation to obey: a longitudinal investigation. Child Dev. 79, 1103–1118. doi: 10.1111/j.1467-8624.2008.01178.x
Dishion, T. J., and McMahon, R. J. (1998). Parental monitoring and the prevention of child and adolescent problem behavior: a conceptual and empirical formulation. Clin. Child Family Psychol. Rev. 1, 61–75. doi: 10.1023/A:1021800432380
Epskamp, S. (2014). semPlot: Path Diagrams and Visual Analysis of Various SEM Packages' Output. R Package Version 1.0.1.
Flora, D. B., and Curran, P. J. (2004). An empirical evaluation of alternative methods of estimation for confirmatory factor analysis with ordinal data. Psychol. Methods 9:466. doi: 10.1037/1082-989X.9.4.466
Fosco, G. M., Stormshak, E. A., Dishion, T. J., and Winter, C. E. (2012). Family relationships and parental monitoring during middle school as predictors of early adolescent problem behavior. J. Clin. Child Adolesc. Psychol. 41, 202–213. doi: 10.1080/15374416.2012.651989
Frijns, T., Keijsers, L., Branje, S., and Meeus, W. (2010). What parents don't know and how it may affect their children: qualifying the disclosure–adjustment link. J. Adolesc. 33, 261–270. doi: 10.1016/j.adolescence.2009.05.010
Hawk, S. T., Hale, W. W., Raaijmakers, Q. A., and Meeus, W. (2008). Adolescents' perceptions of privacy invasion in reaction to parental solicitation and control. J. Early Adolesc. 28, 583–608. doi: 10.1177/0272431608317611
Hox, J. J., Maas, C. J., and Brinkhuis, M. J. (2010). The effect of estimation method and sample size in multilevel structural equation modeling. Statistica Neerlandica 64, 157–170. doi: 10.1111/j.1467-9574.2009.00445.x
Hu, L.-T., and Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: conventional criteria versus new alternatives. Struct. Equ. Model. Multidiscipl. J. 6, 1–55. doi: 10.1080/10705519909540118
Jamieson, S. (2004). Likert scales: how to (ab)use them. Med. Educ. 38, 1217–1218. doi: 10.1111/j.1365-2929.2004.02012.x
Jöreskog, K. G. (1990). New developments in LISREL: analysis of ordinal variables using polychoric correlations and weighted least squares. Qual. Quant. 24, 387–404. doi: 10.1007/BF00152012
Keijsers, L. (2015). Parental monitoring and adolescent problem behaviors How much do we really know? Int. J. Behav. Dev. 40, 271–281. doi: 10.1177/0165025415592515
Keijsers, L., Frijns, T., Branje, S. J., and Meeus, W. (2009). Developmental links of adolescent disclosure, parental solicitation, and control with delinquency: moderation by parental support. Dev. Psychol. 45, 1314–1327. doi: 10.1037/a0016693
Keijsers, L., and Laird, R. D. (2014). Mother–adolescent monitoring dynamics and the legitimacy of parental authority. J. Adolesc. 37, 515–524. doi: 10.1016/j.adolescence.2014.04.001
Kerr, M., and Stattin, H. (2000). What parents know, how they know it, and several forms of adolescent adjustment: further support for a reinterpretation of monitoring. Dev. Psychol. 36, 366–380. doi: 10.1037/0012-1649.36.3.366
Kiesner, J., Dishion, T. J., Poulin, F., and Pastore, M. (2009). Temporal dynamics linking aspects of parent monitoring with early adolescent antisocial behavior. Soc. Dev. 18, 765–784. doi: 10.1111/j.1467-9507.2008.00525.x
Laird, R. D., Criss, M. M., Pettit, G. S., Dodge, K. A., and Bates, J. E. (2008). Parents' monitoring knowledge attenuates the link between antisocial friends and adolescent delinquent behavior. J. Abnorm. Child Psychol. 36, 299–310. doi: 10.1007/s10802-007-9178-4
Li, C.-H. (2015). Confirmatory factor analysis with ordinal data: comparing robust maximum likelihood and diagonally weighted least squares. Behav. Res. Methods. doi: 10.3758/s13428-015-0619-7. [Epub ahead of print].
Miranda, M., Bacchini, D., and Affuso, G. (2011). Validazione di uno strumento per la misura del parental monitoring in un campione di adolescenti italiani. Giornale di Psicologia dello Sviluppo 101, 32–47.
Muthén, B. (1984). A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika 49, 115–132. doi: 10.1007/BF02294210
Muthén, B. O. (2004). Mplus Technical Appendices. Technical report, Los Angeles, CA: Muthén & Muthén.
Pastore, M., and Lombardi, L. (2014). The impact of faking on Cronbach's alpha for dichotomous and ordered rating scores. Qual. Quant. 48, 1191–1211. doi: 10.1007/s11135-013-9829-1
R Core Team (2014). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Racz, S. J., and McMahon, R. J. (2011). The relationship between parental knowledge and monitoring and child and adolescent conduct problems: A 10-year update. Clin. Child Family Psychol. Rev. 14, 377–398. doi: 10.1007/s10567-011-0099-y
Rhemtulla, M., Brosseau-Liard, P. É., and Savalei, V. (2012). When can categorical variables be treated as continuous? a comparison of robust continuous and categorical sem estimation methods under suboptimal conditions. Psychol. Methods 17, 354–373. doi: 10.1037/a0029315
Rosseel, Y. (2012). lavaan: an R package for structural equation modeling. J. Stat. Softw. 48, 1–36. doi: 10.18637/jss.v048.i02
Smetana, J. G. (2008). “It's 10 o'clock: Do you know where your children are?” Recent advances in understanding parental monitoring and adolescents' information management. Child Dev. Perspect. 2, 19–25. doi: 10.1111/j.1750-8606.2008.00036.x
Soenens, B., Vansteenkiste, M., Luyckx, K., and Goossens, L. (2006). Parenting and adolescent problem behavior: an integrated model with adolescent self-disclosure and perceived parental knowledge as intervening variables. Dev. Psychol. 42, 305–318. doi: 10.1037/0012-1649.42.2.305
Stattin, H., and Kerr, M. (2000). Parental monitoring: a reinterpretation. Child Dev. 71, 1072–1085. doi: 10.1111/1467-8624.00210
Steiger, J. H. (1989). EzPATH: Causal Modeling: a Supplementary Module for SYSTAT and SYGRAPH. Evanston, IL: SYSTAT.
Steiger, J. H., and Lind, J. C. (1980). “Statistically based tests for the number of common factors,” in Annual meeting of the Psychometric Society, (Iowa City, IA).
Tolan, P. H., Dodge, K., and Rutter, M. (2013). “Tracking the multiple pathways of parent and family influence on disruptive behavior disorders,” in Disruptive Behavior Disorders, eds P. H. Tolan and B. L. Leventhal (New York, NY: Springer), 161–191.
Tucker, L. R., and Lewis, C. (1973). A reliability coefficient for maximum likelihood factor analysis. Psychometrika 38, 1–10. doi: 10.1007/BF02291170
Yang-Wallentin, F., Jöreskog, K. G., and Luo, H. (2010). Confirmatory factor analysis of ordinal variables with misspecified models. Struct. Equat. Model. 17, 392–423. doi: 10.1080/10705511.2010.489003
Yu, C.-Y. (2002). Evaluating Cutoff Criteria of Model Fit Indices for Latent Variable Models with Binary and Continuous Outcomes. Ph.D thesis, University of California, Los Angeles.
Appendix
Parameters Estimated by ML
In the following tables are reported parameters of the structural model depicted in Figure 3 and estimated by Maximum Likelihood (ML). Given that ML fit indices of this model were not acceptable, these parameters should be considered with caution. In Figure A1 we depicted standard errors of ML and DWLS estimates, for each parameter of the model estimated in the validation sample. A specific trend emerged: DWLS estimates present overall lower standard errors compared to ML estimates, in particular for λ (i.e., factor loadings). This suggests that the DWLS estimation for the measurement model performed better in agreement with fit indices we identified (see Table 1).
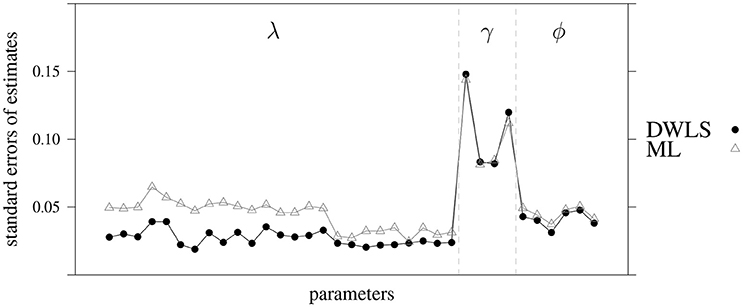
Figure A1. ML and DWLS standard errors of parameters of the model depicted in Figure 3 and estimated in the validation sample. Gray triangles refer to ML, black dots to DWLS. λ are factor loadings (see Tables 3, A2), γ structural parameters (see Tables A1, A4), and ϕ the correlation among factors (see Tables 4, A3).

Table A1. Structural parameters (γ, est), standard errors (se), z-values (z), p, and completely standardized estimates (std) for model in Figure 3.
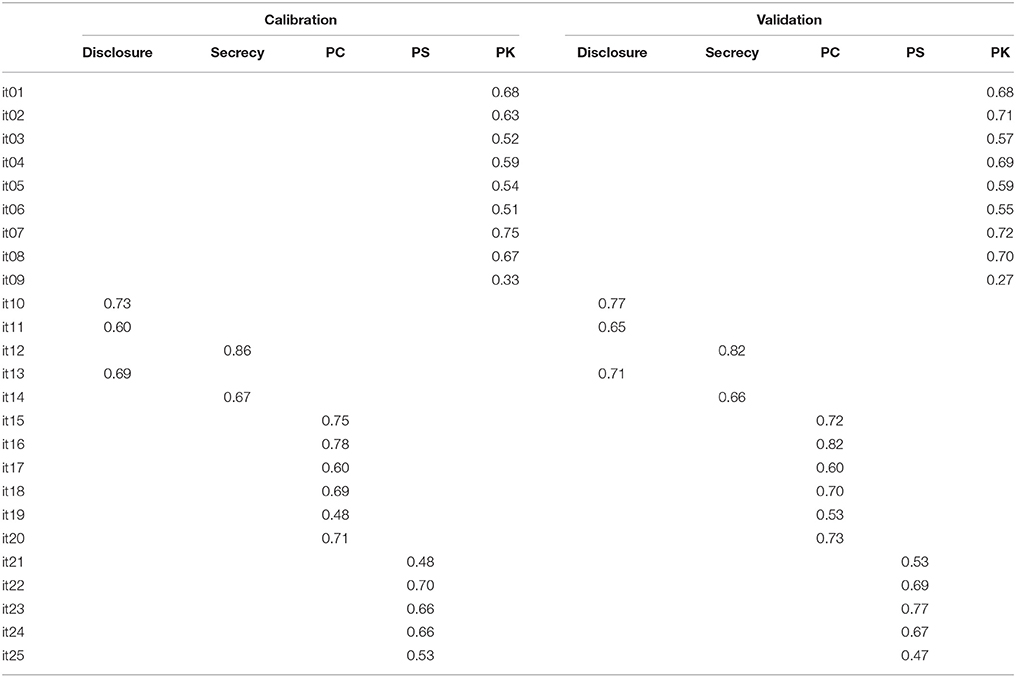
Table A2. Factor loadings of the structural model represented in Figure 3, estimated in the calibration and validation samples (based on ML estimator).

Table A3. Factor correlations of the structural model represented in Figure 3, estimated in the calibration and validation samples (based on ML estimator).

Table A4. Structural parameters (γ, est), standard errors (se), z-values (z), p, and completely standardized estimates (std) for model in Figure 3 (based on ML estimator).
Keywords: parental monitoring, adolescent disclosure, Likert scales, confirmatory factor analysis, diagonal weighted least squares
Citation: Lionetti F, Keijsers L, Dellagiulia A and Pastore M (2016) Evidence of Factorial Validity of Parental Knowledge, Control and Solicitation, and Adolescent Disclosure Scales: When the Ordered Nature of Likert Scales Matters. Front. Psychol. 7:941. doi: 10.3389/fpsyg.2016.00941
Received: 23 April 2016; Accepted: 07 June 2016;
Published: 22 June 2016.
Edited by:
Pietro Cipresso, IRCCS Istituto Auxologico Italiano, ItalyReviewed by:
Caroline Vandeleur, Lausanne University Hospital, SwitzerlandMarcus Mund, Friedrich-Schiller-Universität Jena, Germany
Fabrizio Scrima, Université de Rouen, France
Copyright © 2016 Lionetti, Keijsers, Dellagiulia and Pastore. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Francesca Lionetti, Zi5saW9uZXR0aUBxbXVsLmFjLnVr