 M. Teresa Anguera
M. Teresa Anguera Mariona Portell
Mariona Portell Salvador Chacón-Moscoso
Salvador Chacón-Moscoso Susana Sanduvete-Chaves
Susana Sanduvete-Chaves- 1Faculty of Psychology, Institute of Neurosciences, University of Barcelona, Barcelona, Spain
- 2Faculty of Psychology, Department of Psychobiology and Methodology of Health Sciences, Universitat Autònoma de Barcelona, Barcelona, Spain
- 3Facultad de Psicología, Universidad de Sevilla, Seville, Spain
- 4Departamento de Psicología, Universidad Autónoma de Chile, Santiago, Chile
Indirect observation is a recent concept in systematic observation. It largely involves analyzing textual material generated either indirectly from transcriptions of audio recordings of verbal behavior in natural settings (e.g., conversation, group discussions) or directly from narratives (e.g., letters of complaint, tweets, forum posts). It may also feature seemingly unobtrusive objects that can provide relevant insights into daily routines. All these materials constitute an extremely rich source of information for studying everyday life, and they are continuously growing with the burgeoning of new technologies for data recording, dissemination, and storage. Narratives are an excellent vehicle for studying everyday life, and quantitization is proposed as a means of integrating qualitative and quantitative elements. However, this analysis requires a structured system that enables researchers to analyze varying forms and sources of information objectively. In this paper, we present a methodological framework detailing the steps and decisions required to quantitatively analyze a set of data that was originally qualitative. We provide guidelines on study dimensions, text segmentation criteria, ad hoc observation instruments, data quality controls, and coding and preparation of text for quantitative analysis. The quality control stage is essential to ensure that the code matrices generated from the qualitative data are reliable. We provide examples of how an indirect observation study can produce data for quantitative analysis and also describe the different software tools available for the various stages of the process. The proposed method is framed within a specific mixed methods approach that involves collecting qualitative data and subsequently transforming these into matrices of codes (not frequencies) for quantitative analysis to detect underlying structures and behavioral patterns. The data collection and quality control procedures fully meet the requirement of flexibility and provide new perspectives on data integration in the study of biopsychosocial aspects in everyday contexts.
Introduction
Psychological science has shown a growing interest in the study of everyday life. New methodologies have been proposed for the within-person study of real-time biopsychosocial aspects in their natural settings (Bolger et al., 2003; Conner and Lehman, 2013; Reis, 2013; Portell et al., 2015b,c). New technologies have made it possible to record spontaneous behavior—that is, behavior that is not elicited by a researcher but forms part of the subject's behavioral repertoire in his or her natural context (see e.g., Mehl et al., 2001). Compared with elicited behavior, spontaneous behavior has the advantage of occurring in a natural context and natural situation, so it is not influenced by extraneous variables such as a non-natural context or social desirability based on researchers' expectations. However, this area of study remains highly complex, particularly when it comes to obtaining quantitative indicators that make it possible to reconstruct the “who,” “what,” “how,” and “when” of events of interest and position these events in the individuals' ecological niche. The difficult task of obtaining quantitative indicators of spontaneous behavior in everyday contexts has been further complicated by the long-standing clash between the qualitative and quantitative paradigms in psychology. Mixed methods research (Johnson et al., 2007) has provided valuable resources for combining qualitative data derived from non-spontaneous behavior (e.g., questionnaire responses) and narrative data derived from natural settings (e.g., a life story). Nevertheless, the merging of qualitative and quantitative perspectives in cases where only spontaneous behavior is of interest has been little explored. In this article, we describe a mixed methods approach grounded in observational methodology (Anguera, 2003) that we believe fills this gap. The proposed approach combines the strengths and offsets the weaknesses of the qualitative and quantitative perspectives.
We present a methodological framework for studying everyday behavior using a rigorous scientific approach based on indirect observation that involves “liquefying” transcribed verbal material or texts from original settings. The process involves the quantification of qualitative data using techniques that are based on order or sequence of events rather than on traditional frequency measures. The approach proposed is perfectly compatible with any guiding theoretical framework whatsoever; this method is not linked to any concrete theoretical model, it offers numerous methodological opportunities, and it has the potential to lead to significant developments in the field of studying everyday behaviors. This approach differs from previous work in this area (Sandelowski, 2001; Sandelowski et al., 2009; Seltzer-Kelly et al., 2012; Bell et al., 2016) in that it analyzes the order and sequence of events. The parameters of frequency (which only indicates the number of occurrences), order (which also provides information about sequence), and duration (which, in addition to the aforementioned information, also indicates the time in conventional units) provide a higher degree of data consistency (Bakeman, 1978). The use of the order parameter, with the introduction of sequentiality, entails added value of extraordinary importance (Sackett, 1980, 1987; Bakeman and Gottman, 1987; Magnusson, 1996, 2000, 2005, 2016; Sánchez-Algarra and Anguera, 2013; Portell et al., 2015a).
The presented liquefying method enables the systematic analysis of minor details that arise in a multitude of situations involving text (e.g., conversations, speeches, diary, or blog entries) with a level of granularity (Schegloff, 2000) that enables these “natural texts” to be analyzed in combination with other contextual data. The approach is applicable to both conventional and new forms of communication (e.g., WhatsApp messages), regardless of format or source. The source may be verbal behavior (informal conversations, focus group discussions, etc.) or documentary material (diaries, narratives, etc.), including in some cases graphic material, such as photographs and drawings.
Most of the solutions proposed to date for transforming text into quantitative data are either qualitative (e.g., ethnographic methods) or quantitative. Our proposal, however, takes a mixed methods approach in which spontaneously generated qualitative material is transformed into quantifiable code matrices.
In this article, we discuss key aspects of our proposed system. We analyze the concepts and meaning of systematic observation and one of its two branches, indirect observation, alongside key concepts of mixed methods research. We also look at types of qualitative data used in indirect observation and describe a methodological framework for building ad hoc observation instruments, creating matrices of codes for the data collected, and analyzing data and checking their reliability. Finally, we present a protocol specifically designed for indirect observation with examples from each of the stages in the process.
From Systematic to Indirect Observation
Psychologists work in a wide range of fields and subfields that correspond to everyday life situations. To name just a few examples, they are involved in health education programs in nurseries and nursing homes, prosocial programs in primary schools, exercise programs for the elderly, social support programs in neighborhoods, or communities with families of multiple nationalities, AIDS prevention programs for adolescents, support programs for families with a history of child abuse or negligence or families of young car crash victims, relaxation programs for athletes, and social programs in prisons or juvenile correctional institutions. Systematic observation can make important contributions to the study of spontaneous behavior in a vast range of everyday contexts.
Observation is a useful method for collecting, processing, and analyzing information that cannot be studied in the artificial setting of a laboratory. It enables a largely unbiased analysis of everyday behaviors and interactions that occur naturally (Anguera, 2010). Although systematic observation dates back to the 1970s, it has taken on an identity of its own in the last two decades (Anguera, 1979, 2003; Anguera and Izquierdo, 2006; Sánchez-Algarra and Anguera, 2013). It offers both flexibility and rigor as it is built on sound scientific principles, and this combination makes it ideal for use in many fields (Portell et al., 2015b).
Systematic observation differs from ethnography in that its purpose is not to obtain a narrative account of subjective experiences in a process that requires the participation of the researcher or person being studied. Ethnographic studies require a qualitative approach, but unlike systematic observation, they do not require quantitative analysis and rigorous data quality control. Systematic observation, by contrast, is characterized by highly systematic data collection and analysis, stringent data quality controls, and the merging of qualitative and quantitative methods.
Systematic observation follows the four fundamental stages of scientific research: formulation of a research question, collection of data, analysis of data, and interpretation of results. The wealth of data collected in an observational study provides researchers with the opportunity to capture valuable chunks or snippets of everyday realities, without having to specifically ask for the information (there are no interviews, questionnaires, or psychological tests). In addition, it allows the researcher to study spontaneous behavior in a natural, uncontrolled environment.
Everyday activity in context is the cornerstone of observational studies. It is the source of a rich fabric of information that the psychologist/researcher needs to tap into in order to extract relevant information that is subsequently processed systematically to produce a set of “net” data that can be analyzed both qualitatively and quantitatively.
The study of everyday activity provides insights into the diverse behaviors and events that occur throughout a person's life. It provides thus a privileged vantage point from which to observe changes, but everyday life is a highly complex, dynamic process replete with information that is often not even known to exist (Anguera, 2001). Its study requires the examination of diverse phenomena at different levels of a pyramid-like structure. At the top of the pyramid, psychologists analyze how individuals go about their lives and gradually become familiar with what has shaped their life course. As they move down the pyramid, they discover everyday realities at different levels (family, career, social relationships, hobbies, etc.) and come to understand how these are influenced by interacting factors, such as health, satisfaction of needs, and conflicts.
According to Mucchielli (1974) observation equation, O = P+I+Pk−B, observation equals perception plus interpretation plus previous knowledge minus bias. Observation thus is not possible unless what is being observed is perceivable. Perceptibility is a key concept when it comes to differentiating between direct and indirect observation (Anguera, 1979, 2003). In indirect observation, it is always incomplete, and Mucchielli's equation is only partially fulfilled.
In direct observation, perceptibility is considered to be complete when what is being observed (whether in situ or through video or audio recordings) can be captured by visual or auditory senses. In anthropology, for example, the subfield concerned with the study of visual representations is known as visual rather than observational anthropology. Modern-day technology permits maximum levels of precision in visual and auditory perception (Escalera et al., 2009; Bautista et al., 2015) and minimizes the need for interpretation.
Although everyday contexts can take countless shapes and forms, the levels of response (or criteria or dimensions) that can be directly observed are similar. Facial expressions, for example, can be analyzed by software such as Face Reader, which can distinguish between facial and emotional mimicry. Gestures, in turn, which also have an important role in human communication (Holle et al., 2012; Mashal et al., 2012), even in children (Lederer and Battaglia, 2015) can be effectively analyzed using programs such as NEUROGES+ELAN (Lausberg and Sloetjes, 2009, 2016). Finally, vocal behavior (Russ et al., 2008) can be analyzed using sound analysis software. Non-verbal manifestations, or “expressiveness,” are interesting external indicators of a person's emotional state (Rodriguez et al., 2014), although adequate quality control is needed to reduce bias.
While aspects of human communication such as facial expressions, gestures, posture, and voice tone are fully perceivable through visual or auditory channels, they are frequently accompanied by verbal behavior, which has very different characteristics in terms of perceptibility. Indirect observation is an appropriate method for studying both verbal behavior and textual material, whether in the form of transcripts or original material produced by the participants in a study.
Verbal behavior transmits messages and both these and the channels through which they are transmitted can take many shapes and forms. Messages are analyzed differently depending on whether they are spoken or written. Written forms of expression (e.g., self-reports, diaries, biographies) are largely considered to be narratives. Narrative studies have been used in qualitative methodology for many years and have both strengths and shortcomings. One of their main strengths is their adaptability to very different situations and contexts. Narrative studies provide insights into a person's true nature and help to understand their experiences and needs (Riva et al., 2006). They have been used, for example, in a wide range of settings, such as secondary schools (García-Fariña, 2015; García-Fariña et al., 2016), high schools (Tronchoni et al., 2018), family gatherings (Gimeno et al., 2006), support groups for patients (Roustan et al., 2013), therapeutic interaction (Blanchet et al., 2005), and group therapy for adolescents (Arias-Pujol and Anguera, 2017). One of their shortcomings is that perceptibility is limited by the documentary nature of the texts, and it is not uncommon for different researchers to draw different conclusions from the same text.
Human communication does not simply refer to the transmission of information. It involves numerous aspects that vary according to content, the people transmitting or receiving the message, their relationship (hierarchy, previous interactions, etc.), the flow of data or metadata, and the interpretative context. In addition, changing lifestyle habits and new technologies have led to new forms of human communication (Bavelas and Chovil, 2000), such as WhatsApp messages and blog posts, extending the traditional dichotomy between verbal and non-verbal behavior established by the classical sociologist Weick (1968, 1985). In a recent study, for example, Radzikowski et al. (2016) analyzed Twitter messages in a quantitative study on the rubella vaccine, and as stated by Hardley (2014, p. 34), “Over many decades, surveillance methods (often termed “indicator based” methods) have been developed and refined to provide disciplined, standardized approaches to acquiring and recording important information. More recently, ubiquitous and unstandardized data collected from the Internet have been used to gain insight into emerging disease events.”
Indirect observation can be considered a valid scientific method (Webb et al., 1966; Anguera, 1991, 2017, in press; Behar, 1993; Morales-Ortiz, 1999; Morales-Sánchez et al., 2014). It uses similar techniques to systematic observation, and as a procedure, it is structurally identical, although there are important differences dictated by the nature of the source data (verbal behavior and text).
Indirect observation involves the analysis of textual material generated either indirectly from transcriptions of audio recordings of verbal behavior in natural settings (e.g., conversation, group discussions) or directly from narratives (e.g., letters of complaint, tweets, forum posts). The addition of seemingly unobtrusive objects can also provide important insights into daily routines. All these materials constitute an extremely rich source of information for studying everyday life, and they are continuously growing with the burgeoning of new technologies for data recording, dissemination, and storage (Morales-Ortiz, 1999; Morales-Sánchez et al., 2014).
Narratives are an excellent vehicle for studying everyday life through indirect observation, and one option for studying them is to apply a procedure for systematizing and structuring the information through quantitization. This approach makes it possible to integrate qualitative and quantitative elements.
The data used in indirect observation invariably start out as qualitative and the source material varies according to the level of participation of the person being observed and the nature of the source (textual or non-textual).
Common sources of material used in indirect observation studies include:
• Recordings of verbal behavior as it occurs (normally in mp3 files). There may be single or multiple dialogues and it is essential to clearly distinguish between the different “voices” recorded.
• Transcripts of audio recordings of verbal behavior in a natural setting (Krueger and Casey, 2009). These may involve an individual (speaking, for example, in person or on the telephone), or a group (dyad, triad, focus group, etc.), in which each person can be clearly identified.
• Written texts produced by the participants in a research study. These include texts produced by the participants or those close to them (e.g., letters of complaint, letters to a newspaper, tweets, ads, messages on a mural, instant text messages). A variety of communication channels are possible (e.g., paper, e-mail, WhatsApp).
• Texts transmitted through the Internet, such as e-mails (Björk et al., 2014) and forum posts (Vaimberg, 2010). These constitute an extremely rich source of information and are particularly relevant to psychological interventions.
• Everyday objects related to the research question(s). While objects may appear to have a secondary role in communication, they can provide relevant insights into everyday life as they evoke or facilitate the expression of emotions through micro-valences (Lebrecht et al., 2012). Examples are graphs, paintings, models, and clay figures. Technological advances have also opened up new opportunities in this area in recent years.
• Graphic material, particularly photographs. These can constitute an extremely rich source of information (Zaros, 2016). A single photograph captures a moment, something static, but a gallery of photographs separated in time can capture the dynamics of an episode or successive episodes in the life of a person, or even a group or institution. This material can be primary (the only source available) or secondary (complementing other sources).
• Unobtrusive objects, also referred to as aggregates (Webb et al., 1966). These may simply be anecdotal, but in some cases they can reveal the existence of certain behaviors, but only after a process of inference involving variable risk. Examples are fingerprints and objects such as cigarette butts or a napkin with notes or drawings left behind in a café.
The above sources of information give rise to a varied set of data that provides empirical evidence and can position specific events and everyday behaviors along a continuum of time. Finally, the information available becomes progressively richer as one gains access to several sources of documentary material.
As mentioned, the material used to collect data in indirect observation is only partly perceivable (Anguera, 1991) and any conclusions made need to be inferred by a researcher drawing from a theoretical framework or taking a position. This is the main challenge in indirect observation. In the system we propose, rigorous application of a carefully designed observation instrument by duly trained observers offers the necessary guarantees of data reliability. Although direct and indirect observation may vary in terms of source material, level of interpretation, and level of participation, the two methods share a scientific procedure that when properly applied can provide quantitative indicators of the processes underlying everyday behavior.
The Challenges of Mixed Methods Research
Mixed methods research has been increasingly embraced by the scientific community over the past 15 years (Creswell et al., 2003; Johnson et al., 2007; Tashakkori and Teddlie, 2010; Onwuegbuzie and Hitchcock, 2015). The mixed methods approach involves the collection, analysis, and interpretation of qualitative and quantitative data for the same purpose and within the framework of the same study; some authors have even raised the approach to the rank of paradigm. Molina-Azorín and Cameron (2015) acknowledge that mixed methods research is not easy to conduct and requires considerable time and resources. Nonetheless, it is a movement that is gradually gaining supporters. As stated by Leech and Onwuegbuzie (2009) and Onwuegbuzie (2003), mixed methods research lies on a continuum between single-method and fully mixed studies, although the scientific community has yet to agree on which position it holds along this continuum. That said, it is generally agreed that the position will depend on the research objective and the nature of the data, analyses, and level of inference.
Overall, mixed research is largely understood as “a synthesis that includes ideas from qualitative and quantitative research” (Johnson et al., 2007, p. 113). However, this is a very broad framework in which many gaps need to be filled. In the case of indirect observation, the methodological approach must be extremely rigorous as we are dealing with situations in which substantive areas merge with the multiple realities of everyday life.
The exponential growth of mixed methods research in recent decades has generated certain inconsistencies in terms of terminology and definitions. We therefore believe that it is first necessary to clarify the meaning of method/methodology and to discuss the multiple meanings attached to the term “mixed method” before we present our methodological framework for indirect observation.
Greene (2006, p. 93) proposed a broad description of the term “methodology,” understood as an inquiry logic that admits different forms of data collection (questionnaires, interviews, observational datasets, etc.), methods of research (experimental, ethnographic, etc.), and related philosophical issues (ontology, epistemology, axiology, etc.). Greene also refers to specific guidelines for practice, which distinguish between methods that obviously vary in terms of design, sampling, data gathering, analysis, etc. We consider that systematic observation fits with Greene's definition of methodology (Anguera, 2003), although we have not always used the term. We also agree with the following statement by Johnson et al. (2007, p. 118): “It is important to keep in one's mind, however, that the word methods should be viewed broadly.” Accordingly, in the approach we describe in this article, we also consider indirect observation to be a method in the broad sense of the word.
Johnson et al. (2007, p. 123) defined mixed methods research as “the type of research in which a researcher or team of researchers combines elements of qualitative and quantitative research approaches (e.g., use of qualitative and quantitative viewpoints, data collection, analysis, inference techniques) for the broad purposes of breadth and depth of understanding and corroboration” (Johnson et al., 2007, p. 123). They formulated this definition after asking 19 renowned researchers in the field (Pat Bazeley, Valerie Caracelli, Huey Chen, John Creswell, Steve Currall, Marvin Formosa, Jennifer Greene, Al Hunter, Burke Johnsson and Anthony Onwuegbuzie, Udo Kelle, Donna Mertens, Steven Miller, Janice Morse, Isadore Newman, Michael Q. Patton, Hallie Preskill, Margarete Sandelowski, Lyn Shulha, Abbas Tashakkori, and Charles Teddlie) to send in their definition of the term “mixed methods” by e-mail.
We fully agree with the definition proposed by Johnson et al. (2007) and it provided us with the necessary elements to draw up our methodological framework for indirect observation. The success of any mixed methods approach depends on the adequate mixing or integration of qualitative and quantitative elements. Numerous authors have analyzed the term “mixing” in an attempt to provide guidance on the processes required to achieve a seamless result (Bazeley, 2009; O'Cathain et al., 2010; Fetters and Freshwater, 2015). Qualitative and quantitative data can be mixed in three different ways, aptly summed up by Creswell and Plano Clark (2007, p. 7): “There are three ways in which mixing occurs: merging or converging the two datasets by actually bringing them together, connecting the two datasets by having one build on the other, or embedding one data set within the other so that one type of data provides a supportive role for the other data set.” For our proposal, we chose the second form: connecting two databases by having one build on the other. According to Sandelowski et al. (2009), this connection can be achieved through transformation, i.e., by quantitizing qualitative data or qualitizing quantitative data. In our indirect observation framework, we transform non-systematic qualitative data into a format suitable for quantitative analysis.
Mixed methods research is marked by a persistent scientific gap that requires powerful solutions rooted in two key challenges in the field of indirect observation. These two challenges, discussed in this article, are (a) how to rigorously transform qualitative textual material derived largely from everyday human communication into matrices of codes, and (b) how to subsequently analyze these codes using quantitative methods suited to the categorical nature of the data in order to uncover the underlying structure. The proposed transformation system breaks away from the classical theoretical framework of mixed methods, which simply involves integrating qualitative and quantitative elements. The key difference is that it contemplates systematic observation, and hence indirect observation, to be a mixed method in itself (Anguera and Hernández-Mendo, 2016; Anguera et al., 2017a).
Integration of qualitative and quantitative elements is the key to any mixed methods approach (Creswell and Plano Clark, 2007; Bazeley, 2009; O'Cathain et al., 2010; Maxwell et al., 2015). Our approach adds another element: the liquefaction of verbal behavior and texts. This process consists of schematically transforming “solid” textual material into “liquid” matrices of codes apt for quantitative analysis (Anguera et al., 2017b; Anguera, in press). The quantitative processing of originally qualitative data with the aim of detecting hidden behavioral patterns or underlying structures, for example, adds an element of robustness to the integration of qualitative and quantitative data, particularly in the case of everyday life events and behaviors.
Talkativeness and text, for example, can now be analyzed within the framework of mixed methods research using frequency counts (Poitras et al., 2015) thanks to the development of reliable—and extremely useful—measures of verbal productivity and the multiple opportunities offered by modern-day technology (Bazeley, 2003, 2006, 2009). Frequency counts, however, are weak and insufficient measures. Considering that “methodological plenitude” (Love, 2006, p. 455) is not always attainable in applied research, the mixed method framework offers new and interesting possibilities for indirect observation.
The combined use of qualitative and quantitative approaches has been tried and tested in multiple studies and has also been analyzed in several systematic reviews (Elvish et al., 2013). In the following sections, we show that it is necessary to start with qualitative inputs and to then quantify these in a process that ensures reliability throughout the various stages.
Qualitative Datasets in Indirect Observation
The empirical process in indirect observation starts with the collection of qualitative data. While the characteristics and standards that guarantee quality are perfectly outlined in the literature on quantitative methodology, the same cannot be said of qualitative methodology. Qualitative methodology offers enormous flexibility, but interpretations on content and form vary and are not free of controversy. Content provides personal and interpersonal information, which stems from experiences that are temporally unstable and highly influenced by the context and versatility of the moment. As for form, the tools used to support indirect observation (narratives, biographies, self-reports, life stories, in-depth interviews, etc.) cause doubt and distrust in many researchers, who, in the absence of standardized tools, question their stability and consistency.
Much has been written about the forms used to structure narratives (e.g., Hurwitz et al., 2004; De Fina and Georgakopoulo, 2015; Riessman, 2015), and qualitative data can be gathered using many tools, including interviews (e.g., Riera et al., 2015), biographies (e.g., Lindqvist et al., 2014), children's vignettes (e.g., Jackson et al., 2015), focus group vignettes (e.g., Brondani et al., 2008), telephone interviews (e.g., Björk et al., 2014), self-reports (e.g., Coutinho et al., 2014), focus group recordings (e.g., McLean et al., 2011), and participant observation (e.g., Caddick et al., 2015). In our case we are specifically interested in qualitative datasets within the framework of indirect observation. Although systematic observation dates back to the 1970s, it has taken on an identity of its own in the last two decades (Anguera, 2003; Anguera and Izquierdo, 2006; Sánchez-Algarra and Anguera, 2013; Anguera et al., 2017a). Indirect observation shares many of the characteristics previously described for systematic observation, namely, highly systematic data collection and analysis, strict data quality controls, and an approach that requires the merging of qualitative and quantitative techniques.
A Methodological Framework for Liquefying Text
In these next sections, we are going to describe, and illustrate with examples, the stages and sub-stages involved in an indirect observation study. We will focus largely on the extraction and transformation of information from textual material produced using conventional or newer channels of communication in a variety of formats (handwritten letters, reports, transcriptions of group meetings, and interviews, etc.), irrespective of origin (e.g., informal conversations or focus group discussions or documentary material).
Extracting information on human behavior from text and transforming it into suitably systematized and organized categorical data, without loss of key information, is a major challenge in the Behavioral Sciences. In addition, the process must offer sufficient scientific and ethical guarantees and produce results in a format that can be rigorously processed using any of a range of quantitative techniques available for analyzing categorical data.
Our text-liquefying process consists of six stages: (1) specification of study dimensions, (2) establishment of segmentation criteria to divide the text into meaningful units, (3) building of a purpose-designed observation instrument, (4) coding of information, (5) data quality control, and (6) quantitative analysis of data. Table 9 presents detailed steps and guidelines for the “liquefication” of indirect observations. Each of the steps will be explicated within the following sections.
Specification of Study Dimensions
In systematic observation, and by extension, indirect observation, the term “dimension,” also known as level of response (Weick, 1968) or criterion, refers to a distinguishable facet related to the research objective. Dimensions are generally derived from a theoretical framework (e.g., the seminal work of (Weick, 1985) in the field of social interaction), but they can also be created ex novo based on experience or expertise. In the latter case, they must always be justified.
Studies can be one-dimensional or multidimensional. It is not uncommon for researchers to start off with a single dimension and then gradually add others as they delve deeper into the theoretical framework. Below are examples of dimensions and theoretical frameworks used in three indirect observation studies. In the first case, a study of disruptive behavior and communication difficulties in adolescents participating in group communication therapy, Arias-Pujol and Anguera (2004) proposed the dimensions verbal and non-verbal behavior, derived from the corresponding interpersonal theoretical framework (Danzinger, 1982; Gale, 1991; Poyatos, 1993). In the second case, Vaimberg (2010), on studying a psychotherapy group in which participants were able to write what they wanted on an online forum at any time over 3 years, chose the following dimensions: in-person, otherness, emotionality, thoughtfulness, positivity, and realism. The theoretical framework was built from work by various authors (e.g., Winniccott, 1979; Bion, 1985; McDougall, 1991; Lévy, 1995). In the third case, which was a recent study of teacher-led discourse in physical education built on the theoretical framework of the Teaching Games for Understanding model (originally proposed by Bunker and Thorpe, 1982) and work on discourse strategies by Coll and Onrubia (2001), García-Fariña et al. (2016) proposed nine dimensions: exploration and activation of previous knowledge, attribution of positive meaning by students, progressive establishment of increasingly expert and complex representations of subject matter, interactivity segment, message structure, extralinguistic resources, task type, destination of message, and location of session.
Specification of Segmentation Criteria to Create Textual Units
The second step toward liquefying a text is to define the segmentation criteria to divide the text into meaningful units. This process is known as “unitizing.” Although initially proposed by Dickman (1963) and Birdwhistell (1970), Krippendorff (2013, p. 84) defined unitizing as “the systematic distinctions with a continuum of otherwise undifferentiated text—documents, images, voices, websites, and other observables—that are of interest to an analysis, omitting irrelevant matter but keeping together what cannot be divided without loss of meaning.” This definition suggests that it would be logical to first segment the text into primary criteria within the main study dimension and then establish secondary criteria for the other dimensions (e.g., voices, gestural behavior, etc.).
Krippendorff (2013) suggested segmenting text using orthographic, syntactic, contextual, and inter-speaker criteria. In this last case, each intervention by an individual is considered a unit. This is a very useful approach for analyzing interactions between various people. We propose using the inter-speaker criterion as the primary criterion and subsequently establishing secondary criteria (subunits) for verbal or written interventions containing various syntactic elements (phrases).
In cases with several dimensions, such as verbal behavior accompanied by gestures, postures, or exchange of looks, verbal behavior, as the most perceivable behavior, could be established as the primary criterion. The other behaviors could then be segmented into subunits as appropriate. In very specialized cases, however, we consider that the above level of segmentation is insufficient. The initial segmentation stage is crucial as the categories that will be created in the next stage will directly determine the content of the dataset for analysis. Where possible, test runs or pilot studies should be performed first. Table 1 shows how a conversation between two anonymous speakers is segmented into units.

Table 1. Vignette showing the segmentation of a text (transcribed from a conversation) into units.
Building an Indirect Observation Instrument
Indirect observation studies, like systematic observation studies (Anguera, 2003; Anguera and Izquierdo, 2006; Sánchez-Algarra and Anguera, 2013; Portell et al., 2015a) require a purpose-built observation instrument to systematically code the information that will form the subsequent datasets.
Observation instruments can be built using category systems, a field format system, a combination of these systems, or rating scales (Anguera et al., 2007). One-dimensional studies use category systems and rating scales, while multidimensional studies use field formats or field formats combined with category systems. To build a category system, there must be a theoretical framework, and to build a rating scale, it must be possible to grade the corresponding dimensions ordinally. In addition, the category system must fulfill the requirements of exhaustivity and mutual exclusion, and each category must be accurately defined.
The field format is built by creating a catalog of mutually exclusive behaviors for each dimension. As it is not exhaustive, the catalog is left open and is therefore considered to be in a permanent state of construction. While not required, a theoretical framework is recommendable for field format systems.
Observation instruments combining a field format system with category systems are becoming increasingly common. This combination is possible when some or all of the dimensions in the field format have a theoretical framework and the object of research is atemporal (i.e., it is not a process).
To simplify matters, it is highly recommendable to code both categories and dimensions using letters, numbers, or symbols. If A, B, C, and D are categories in a category system, i.e., fulfilling the requirements of exhaustivity and mutual exclusion (e.g., A = XX, B = XX, C = XX, and D = XX), then the notation would be CS (category system) = {A B C D}. If A, B, C, and D are behaviors in an open catalog, i.e., they are mutually exclusive but not exhaustive (e.g., A = XX, B = XX, C = XX, and D = XX), the notation would be Catalogue = A B C D…
Guidelines for Coding Information
Observational datasets created from narratives (Crawford, 1992; Gabriel, 2004; Tuttas, 2015) have wide applications in many everyday life situations. However, before qualitative inputs from human communication can be transformed into quantitative data, it is first necessary to decide how to organize the heterogeneous information available. This process can be extremely complex as it is necessary to bring together data from very different sources, and very possibly, different points in time (Duran et al., 2007). The first step is to correctly record and code the data, and this is where the ad hoc observation instrument becomes invaluable. As started by Bradley et al. (2007, p. 1,761), “coding provides the analyst with a formal system to organize the data, uncovering and documenting additional links within and between concepts and experiences described in the data.”
If the sources have been carefully selected, they will all contribute to creating a stockpile of information on the behaviors or actions of all those involved in the communication process being analyzed (e.g., therapists, participants, supervisors…).
The system for processing narratives or bodies of texts is quite similar to that used in discourse analysis (Calsamiglia and Tusón, 1999), although the information retrieved is richer and more diverse. Once the necessary quality controls are in place, the information can be managed and processed systematically within an empirical research setting that ensures replicability. Examples of texts used for this purpose are interviews, speeches, and conversations (Sidnell and Stivers, 2013). These may be a specific audience, a single speaker or several (with turn-taking), words in isolation, or, when direct and indirect observation are combined, words accompanied by tone/pitch, gestures, facial expressions, posture, objects, etc (Fischer et al., 2012).
Once the study dimensions have been selected (section Specification of Study Dimensions) and the text has been segmented into units (section Specification of Segmentation Criteria to Create Textual Units) and the behaviors coded using the ad hoc observation instrument (section Building an Indirect Observation Instrument), the data can be transformed into a series of complete or incomplete code matrices containing purely qualitative information (Anguera, 2017, in press; Anguera et al., 2017b). This transformation is achieved by organizing the dimensions into columns and adding the behavioral units to the corresponding rows, achieving thus a “liquid” text, ready for quantitative analysis (Table 2 contains an example).

Table 2. Tabular structure for creating a code matrix.
Table 3a shows a hypothetical example of data extracted from a text in a one-dimensional study using an observation instrument with category systems, using a simulated example of the diary of a patient with endogenous depression. Table 3b, in turn, shows the results for a combined field format-category system instrument from a multidimensional study, using a simulated example of an oral mediation situation involving a conflict between the parties A and B, with the assistance of the mediator C. These matrices of codes (Table 3a is atypical as it has just one column due to the single dimension analyzed) show how the qualitative data have been structured.
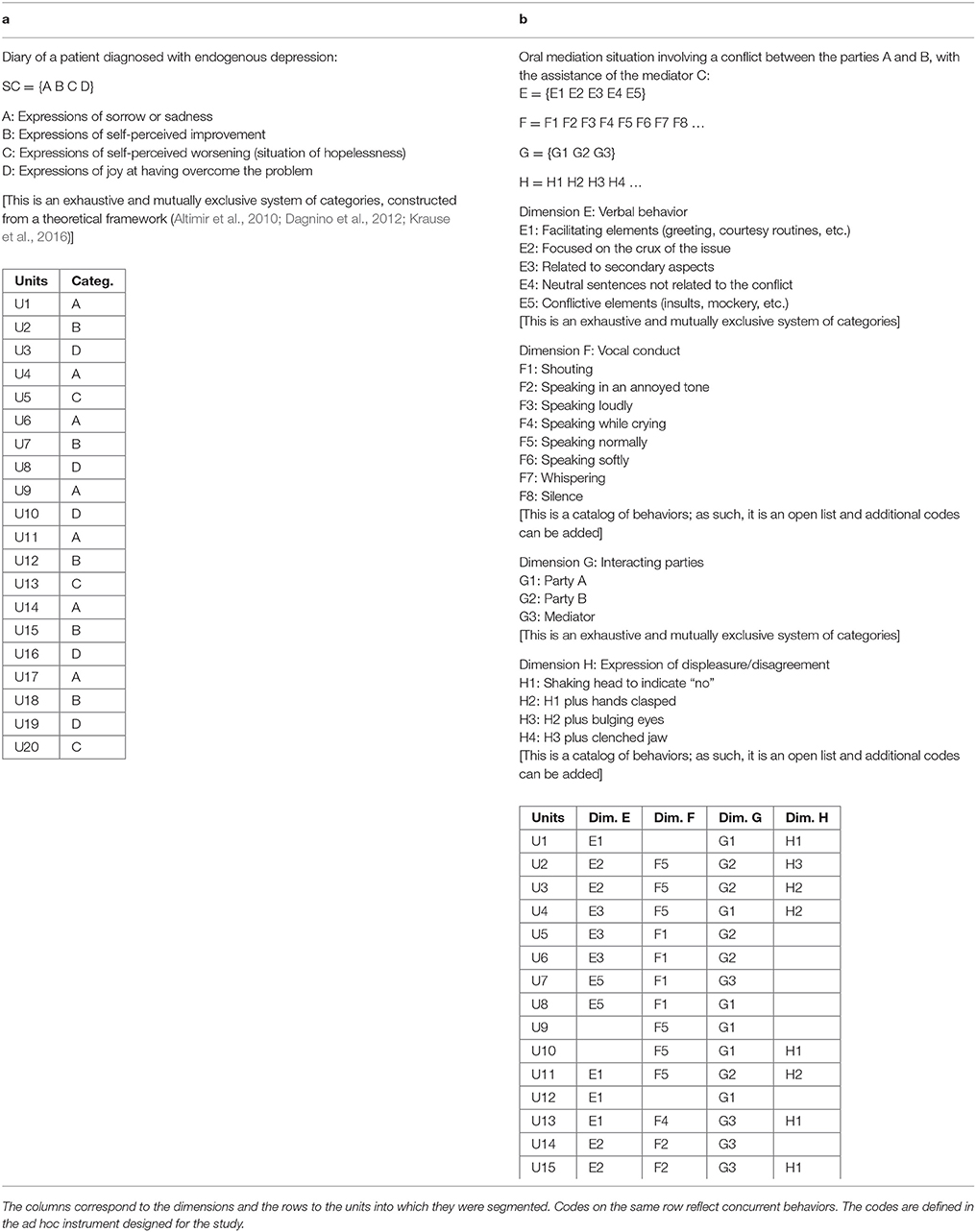
Table 3. (a,b) Hypothetical examples of a code matrix derived from a text.
Additional sources of information, such as drawings, sounds, or photographs can be incorporated simply by adding new dimensions. Although this is still a relatively new concept, it is perfectly feasible with today's advanced coding systems (Saldaña, 2013) and technological possibilities (e.g., Bazeley, 2003, 2006, 2009; Crutcher, 2003, 2007; Holtgraves and Han, 2007; Romero et al., 2007; Dam and Kaufmann, 2008; Taylor et al., 2015). In the ATLAS.ti (v.7) qualitative data analysis program, for example, the text coding feature can be used to supplement the information entered with an object or an audio or video recording.
Researchers now have access to a multitude of software programs that facilitate their work. For those working with indirect observation, the CAQDAS platform (AQUAD6, ATLAS.ti, MAXqda2, NUDIST, NVivo, etc.) offers numerous programs for segmenting and coding text, and there are also open-access programs, such as T-LAB (http://tlab.it/en/presentation.php), IRAMUTEQ (www.iramuteq.org), and those created by the Italian group GIAT (www.giat.org). Numerous considerations are necessary when extracting information from text using content analysis techniques. Content analysis programs have traditionally favored the processing of large, mostly qualitative, bodies of texts, graphs, and audio and video material. The analysis uncovers relational structures (families, networks, etc.) that are relatively stable, or at least appear to be, and are always determined by the choices of the researcher. Nowadays, however, powerful software programs can analyze multiple sources of information to produce code matrices (Vaimberg, 2010) that are of enormous value for analyzing human communication in many fields.
Two programs can be used for both direct and indirect observation. These are HOISAN (Hernández-Mendo et al., 2012) (http://www.menpas.com), which is open-access and is available in several languages (English, Spanish, Portuguese, French) that can be selected from the tab Archivos (Files), and TRANSANA (http://www.transana.com).
Quantitative Processing of Code Matrices
Rigorous Data Quality Control
The issue of data quality in indirect observation has been widely debated in the literature, with a particular focus on reliability and validity, and concerns have led many psychologists and researchers working in this area to modify their approaches. Both intraobserver and interobserver agreement are important measures of reliability, but they are not the only ones. While reliability is necessary, it alone does not guarantee the validity of a dataset (Krippendorff, 2013).
Krippendorff (2013) was the first author to insist on rigorous data quality control as a requirement for the quantification of data resulting from indirect observation. Thanks to his contributions in this area, there are now methodological tools in place to demonstrate the quality of such data. The two main quantitative measures for testing the reliability of data from direct observation (behaviors) and indirect observation (texts) are (a) coefficients of agreement between two observers who separately code behaviors using the same dataset and observation instrument and (b) coefficients of agreement based on correlation. Numerous coefficients exist for quantitatively verifying the quality of data in a wide range of situations. One widely used measure in indirect observation is Krippendorff's canonical agreement coefficient, which is an adaptation of Cohen's kappa coefficient for analyzing three or more datasets. It can be calculated in HOISAN. Another option for use in situations with different sources of variation is generalizability theory (Blanco-Villaseñor, 2001; Escolano-Pérez et al., 2017).
A more qualitative method, the consensus agreement method (Anguera, 1990), is gaining increasing recognition in indirect observation and other studies. In this method, at least three observers work together to discuss and agree on the most suitable code for each unit from the observation unit. This method has obvious advantages, as it produces a single dataset and frequently results in a better observation instrument thanks to the detection of possible gaps and shortcomings. While it offers significant guarantees of quality, however, it also carries risks. An observer may defer to the decisions of a more senior or “expert” colleague, for example, and the need to agree can also give rise to frictions or conflicts. The results of the consensus agreement method can be complemented by quantitative measures of agreement (Arana et al., 2016).
There has been much debate in the field of psychology about the extent to which adherence to a particular theoretical framework may influence agreement between observers. To overcome this potential problem, Pope et al. (2000) proposed using observers from different backgrounds to analyze the data. Such an approach, however, would require even more rigorous quality control measures given the greater difficulty of reaching agreement.
Table 4 shows the canonical agreement coefficient calculated in HOISAN for the data in Table 3b, combined with two other sets of data recorded for the same section of text by the same observer and with the same instrument, but at different moments.
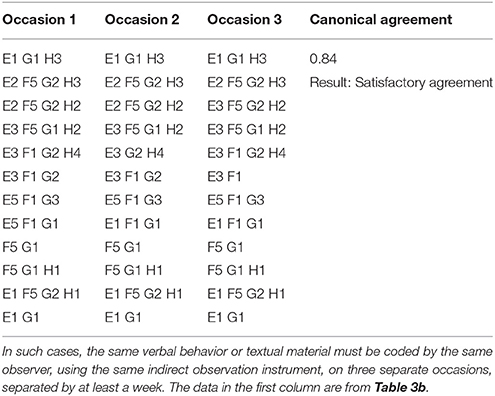
Table 4. Example of datasets used to calculate intraobserver canonical agreement.
Quantitative Processing of Code Matrices
Once the text has been liquefied and the necessary data controls performed, the researcher now has access to a series of code matrices perfectly suited for analysis using different techniques.
The novel nature of our proposal is that we do not study frequency counts, which, despite their serious limitations, were the only measure of quantification used in observation studies for decades.
Over the last 15 years, our group has prioritized three analytical techniques that are particularly well-suited to processing qualitative data in both systematic observation (Blanco-Villaseñor et al., 2003) and indirect observation studies. These are lag sequential analysis, polar coordinate analysis, and T-pattern detection. All three techniques are based on statistical calculations and therefore provide the necessary guarantees of replicability and robustness.
Lag Sequential Analysis
Lag sequential analysis, which works with code matrices (see example in Table 5), is used to detect behavioral patterns that show the structure of interactive episodes (Bakeman, 1978, 1991; Bakeman and Gottman, 1987; Bakeman and Quera, 1996, 2011). The analysis can be performed prospectively (looking forward in time from a given moment) or retrospectively (looking backwards) using positive or negative lag counts. A behavior, for example, with a lag count of +2 would correspond to a behavior that occurs 2 positions after the behavior(s) of interest, while one with a lag count of −2 would correspond to a behavior that occurs 2 positions before the behavior(s) of interest.
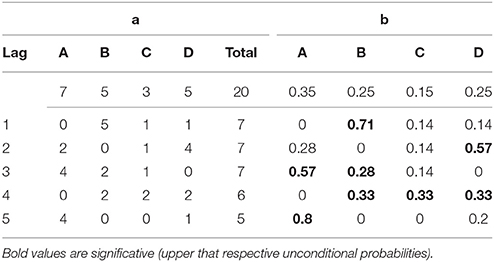
Table 5. (a) The first row shows the simple frequency counts for the data from Table 3a. The matrix below shows the transition frequencies for the given behavior A with the conditional behaviors shown at the head of each column. The different lags are shown by rows. (b) The first row shows the unconditional probabilities while the rows below show the conditional probabilities.
The analysis can be applied to part of a session, to a complete session, to parts of different sessions (e.g., the first few minutes of a series of sessions), or to series of complete sessions. The technique thus offers enormous flexibility in terms of addressing different research questions. Two types of data can be used: data for which only the order of occurrence of concurrent behaviors has been recorded, using any of the free software programs available SDIS-GSEQ v. 4.1.2 (Bakeman and Quera, 2011), GSEQ5 (Bakeman and Quera, 2011), or HOISAN v. 1.6.3.3 (Hernández-Mendo et al., 2012), and data for which both order and duration have been recorded (SDIS-QSEQ and GSEQ5). Lag sequential analysis has been successfully applied in many indirect observation studies conducted over the past 25 years (e.g., Martínez del Pozo, 1993; Arias-Pujol and Anguera, 2004; Cuervo, 2014).
Using the data from Table 3a again, we illustrate how to manually calculate the results for the first, and simple, part of the lag sequential analysis process. The first step is to create tables for the matching frequencies and probabilities (Tables 5a,b) for category A (in our example, expressions of sorrow or sadness), which, according to the hypothesis applied, is the given behavior (the behavior of interest). In row 1, for example, A has a frequency count of 0 because this code does not occur again; B (expressions of self-perceived improvement) has a count of 5 because it occurs after A on five occasions (units 2, 7, 12, 15, and 18); C (expressions of self-perceived worsening) has a count of 1 because it only occurs after A on one occasion (unit 5), similarly to D (expressions of joy at having overcome the problem) (unit 10). In row 2, in turn, A has a count of 2 because it occurs on two occasions (units 6 and 11) in the second position after the given behaviors (units 4 and 9, respectively); B has a count of 0 because it does not occur in the second position after the given behavior; and C has a count of 1 because it occurs just once (unit 13) in the second position after the given behavior (unit 11), and so on.
The data are analyzed to search for behavioral patterns, with consideration of some or all of the other behaviors, known as target behaviors, to see if they form part of the pattern(s) detected.
The information for each of the categories is shown on a graph with the lags on the X-axis and the probability values (ranging between 0 and 1) on the Y-axis. Each of the four Figures 1A–D, shows the value of the unconditional probability (the line parallel to the Y-axis) and the points corresponding to the conditional probability of each lag.
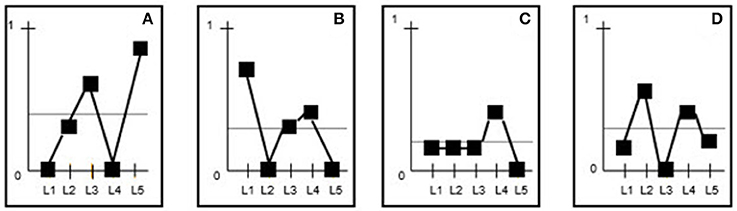
Figure 1. (A–D) The lags are shown on the X-axis and the probabilities on the Y-axis. Based on the results from Table 5b, the values corresponding to the unconditional probabilities (first row) are indicated by the horizontal line parallel to the X-axis (e.g., 0.35 for category A). Also shown are the values for each of the conditional probabilities for each category and lag. These values are linked by a (generally uneven) line for each category. The horizontal line parallel to the X-axis represents the upper limit for the effect of chance. Accordingly, any conditional probabilities in the subsequent lags that are higher than the unconditional probability for the corresponding category are significant and hence form part of the behavioral pattern.
Based on this simple visual output and considering all the statistically significant categories at each lag (i.e., the categories with a conditional probability value greater than that of the unconditional probability), we extracted the behavioral pattern shown in Figure 2. The strength of patterns is assessed using interpretative rules (Bakeman and Gottman, 1987). In the example provided, the first lag that is followed by another lag containing significant categories is considered to be the last lag (max lag) in the pattern (lag 3 in the example).
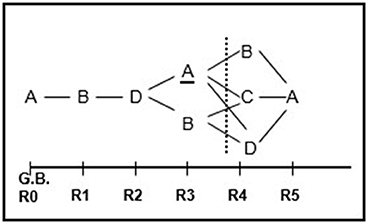
Figure 2. Behavioral pattern extracted after assigning significant conditional behaviors (behaviors with a conditional probability greater than the unconditional probability) to each lag. The behavior pattern extracted from the presented illustration exhibits a regularity consisting of expressions of sorrow or sadness being followed by expressions of self-perceived improvement and these expressions, in turn, being followed by joy at having overcome the problem. From there, the pattern bifurcates, leading either to the initial situation of sorrow and sadness or to expressions of self-perceived worsening.
The robustness of the pattern must then be further strengthened by building a confidence interval around the conditional probabilities, for which only the upper limit is needed. This upper limit is used to determine whether a given category will form part of the pattern at the lag being analyzed, as the conditional probability obtained has to be higher than unconditional probability. The lower limit, by contrast, will always be lower than the unconditional probability and as such, will never be significant. Application of this confidence interval increases the requirements for statistical significance for the categories at each lag, resulting in a more robust corrected pattern.
The results obtained by applying the formula corresponding to the corrected expected or unconditional probability (shown in Table 6a) are presented in Table 6b, which is an extension of Table 5b.
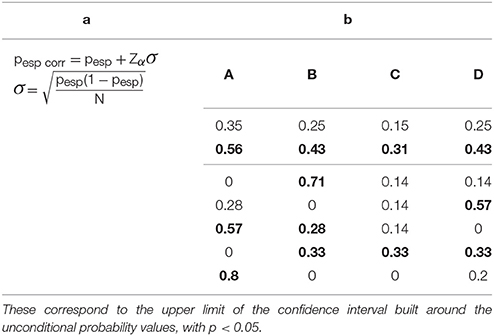
Table 6. (a) Formula for calculating the corrected unconditional (expected) probability. (b) Table showing the probabilities from Table 5b with the addition of the corrected conditional probabilities in the second row (bold values).
A second optimization step involving the calculation of adjusted residuals or hypergeometric Z-values (Allison and Liker, 1982) is also possible but cannot be done manually.
Figure 4 shows the corrected behavioral pattern extracted from the data in Table 6b. As shown, it is different to the uncorrected pattern shown in Figure 3. Note that in both cases, A, the given behavior, is statistically associated with B at the first lag and D at the second lag.
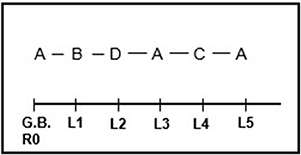
Figure 3. Optimized corrected behavioral pattern following construction of a confidence interval around the unconditional probabilities. The corrected pattern reveals the typical alternation seen in patients with endogenous depression.
Lag sequential analysis is the first of the three key techniques we use in our text-liquefying approach to indirect observation. It has been widely used in systematic observation studies from a range of areas published in journals listed in the Journal Citations Report (JCR) (e.g., Gimeno et al., 2006; Lapresa et al., 2013; Roustan et al., 2013).
Polar Coordinate Analysis
Polar coordinate analysis, which was proposed by Sackett (1980), combines adjusted residuals from lag sequential analysis and the Zsum statistic (Cochran, 1954). This statistic provides a representative value for a series of independent values (adjusted residuals at different prospective or retrospective negative lags) to produce prospective and retrospective Zsum values. Sackett (1980) recommended using the same number of prospective and retrospective lags. Based on experience to date (Sackett, 1987; Anguera and Losada, 1999), we suggest analyzing at least five prospective lags and five retrospective lags (−5 to +5).
The results of the computation determine the quadrant in which the different vectors are located and indicate their respective lengths and angles (Sackett, 1980). Vectors provide information on the nature of the relationship (prospective/retrospective activation/inhibition) between a focal behavior, which is equivalent to a given behavior in lag sequential analysis, and other categories of interest, known as conditional behaviors. The concept of genuine retrospectivity (Anguera, 1997) was introduced at a later stage to improve the classic concept of retrospectivity. The genuine retrospective approach considers negative lags from a backwards rather than a forwards perspective, i.e., it looks at what happened from lag 0 back to lag −5 rather than from lag −5 to lag 0.
Adjusted residuals, Z-values, and vector length and angles can all be computed in the open-access software program HOISAN (v. 1.6.3.3) (Hernández-Mendo et al., 2012), which also includes a feature to produce the results in graph form.
The meaning of the vectors (see below) varies according to the quadrant in which they are located, and the position of a vector in one quadrant or another is determined by the combination of positive or negative signs on the prospective and retrospective Zsum values. In quadrant I (+ +), the focal and conditional behaviors activate each other; in quadrant II (− +), the focal behavior inhibits and is activated by the conditional behavior; in quadrant III (− −), the focal and conditional behaviors inhibit each other; and in quadrant IV (+ −), the focal behavior activates and is inhibited by the conditional behavior. The length of the vectors indicates the strength (statistical significance) of the association between the focal and conditional behaviors.
To illustrate briefly how the technique works, we used the data from Table 3a to produce a vector map showing the relationships between A, the focal behavior (in our example, expressions of sorrow or sadness), and categories B (expressions of self-perceived improvement), C (expressions of self-perceived worsening), and D (expressions of joy at having overcome the problem), the conditional behaviors. Table 7 shows the values for the adjusted residuals and corresponding Zsum values, while Table 8 shows the length and angle of the vectors for each of the conditional behaviors. The corresponding vectors are shown in Figure 4.
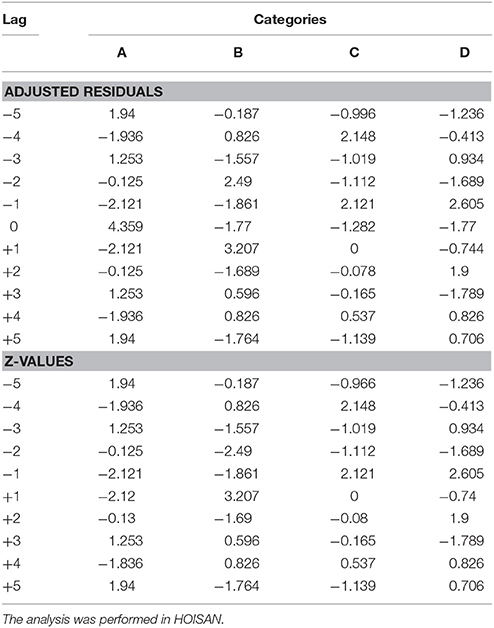
Table 7. Adjusted residuals and corresponding Z-values from the polar coordinate analysis with A as the focal behavior or category and B, C, and D as the conditional behaviors.
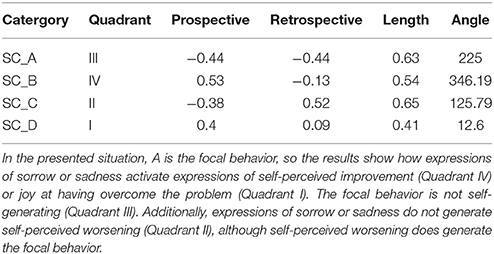
Table 8. Polar coordinate analysis results showing the length and angle of the different vectors, the quadrant in which each vector is located, and the Zsum values (Cochran, 1954) from the prospective and retrospective perspectives.
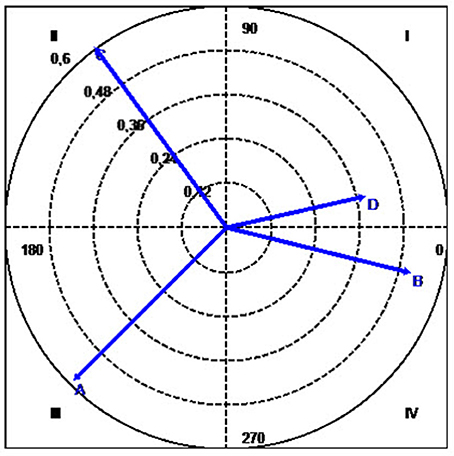
Figure 4. Polar coordinate map showing the vectors for the categories A (focal category), B, C, and D. As indicated in the legend of Table 8, A is the focal behavior and expressions of sorrow or sadness activate expressions of self-perceived improvement (Quadrant IV) and joy at having overcome the problem (Quadrant 1). The focal behavior is not self-generating (Quadrant III). Additionally, expressions of sorrow or sadness do not generate self-perceived worsening (Quadrant II), although self-perceived worsening does generate the focal behavior.
The strongest association detected for the focal behavior A (apart from with itself) was with B (in quadrant IV, with a vector length of 0.54), followed by D (quadrant I, with a vector length of 0.41). Although A and C have the longest vector (0.65), the fact that C is located in quadrant II (because its angle is 125.79°) means that A inhibits rather than activates C. C does not appear because its excitatory activity was insignificant.
Readers can find numerous examples of the application of polar coordinate analysis in a wide range of fields in direct observation (e.g., Gorospe and Anguera, 2000; Herrero Nivela, 2000; Anguera et al., 2003; Castañer et al., 2016, 2017; López et al., 2016; Aragón et al., 2017; Morillo et al., 2017; Santoyo et al., 2017; Suárez et al., 2018), and more recently indirect observation (e.g. Arias-Pujol and Anguera, 2017).
T-Pattern Detection
T-pattern detection was proposed and developed by Magnusson (1996, 2000, 2005, 2016). It involves the use of an algorithm that calculates the temporal distances between behaviors and analyzes the extent to which the critical interval remains invariant relative to the null hypothesis that each behavior is independently and randomly distributed over time. It needs data, in the form of code matrices, for which the duration of each co-occurrence has been recorded. Microanalyses of data are also possible and very useful (Anguera, 2005). The software program, Theme (v. 6 Edu), features different settings that can be modified to obtain complementary results that, analyzed together, can provide a greater understanding of interactive transitions over time. Theme is an open-access software program that provides all the necessary features for analyzing data and presenting the results graphically as dendrograms or tree diagrams.
As with lag sequential and polar coordinate analysis, we have also used the data from Table 3a to illustrate the use of T-pattern detection. It should be noted that the method applied is rather unconventional, as the temporal distance parameter was set at 1 in all cases.
Figure 5 shows the first of the 13 T-patterns obtained (p < 0.05). Note that despite the small size of the dataset, Theme detected a primary relationship between A and B (between expressions of sorrow or sadness and expressions of self-perceived improvement) and A and D (between expressions of sorrow or sadness and expressions of joy at having overcome the problem), as shown graphically in Figure 5.
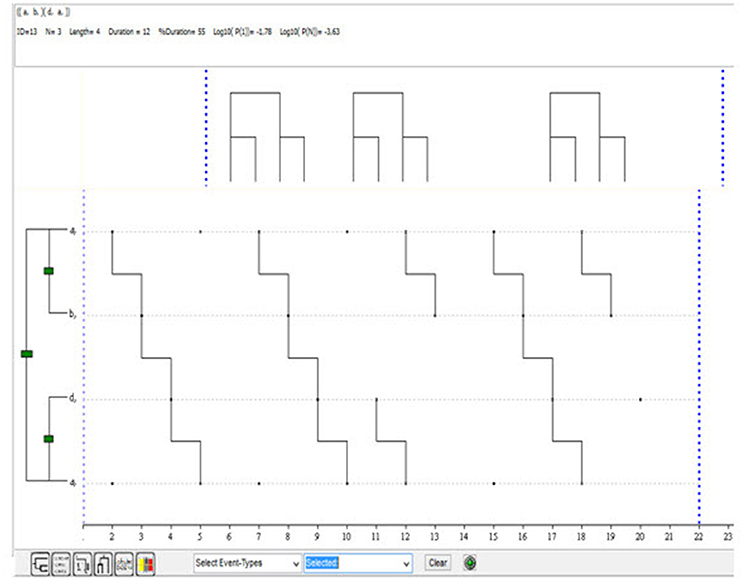
Figure 5. First of the 13 T-patterns detected in the data from Table 3a (p < 0.05).
Examples of the application of T-pattern detection can be found in studies by Castañer et al. (2013), Diana et al. (2017), Lapresa et al. (2013), and Sarmento et al. (2015) in direct observation and by Blanchet et al. (2005) and Baraud et al. (2016) in indirect observation.
Complementary Use of Techniques
Although the specifics of lag sequential analysis, polar coordinate analysis, and T-pattern detection differ, all three techniques serve to analyze and increase understanding of the internal structure of verbal or textual material derived from indirect observation. In addition, they can be applied to the same data to provide complementary insights and unveil invisible structures hidden within data. Their relevance is even greater in indirect observation studies where data have traditionally been analyzed from a purely qualitative perspective.
The convergence of results from three different quantitative approaches is a cause for celebration in a field such as indirect observation, where studies to date have largely relied on frequency counts or on qualitative approaches, which of course have their merits but are prone to considerable subjectivity bias.
There is growing interest in combining these techniques to gain a greater understanding of behavioral patterns that remain hidden to the naked eye. Two recent examples can be found in the studies of Santoyo et al. (2017) and Tarragó et al. (2017).
Adapted Methodological Procedure for Conducting an Indirect Observation Study based on Text Liquefaction
We have presented a structured procedure detailing the successive stages of the method we propose for studying verbal behavior and/or textual material in an indirect observation study (Table 9). Our aim was not to offer a general approach to systematic observation from the perspective of indirect observation, as guidelines already exist for the reporting of systematic studies within observational methodology (Portell et al., 2015a). Our aim rather was to introduce the reader to the key concepts of indirect observation studies and provide step-by-step guidance on how to perform such a study. The procedure we propose is summarized in Table 9 and has already been applied in studies from different fields (Vaimberg, 2010; García-Fariña et al., 2016; Arias-Pujol and Anguera, 2017).
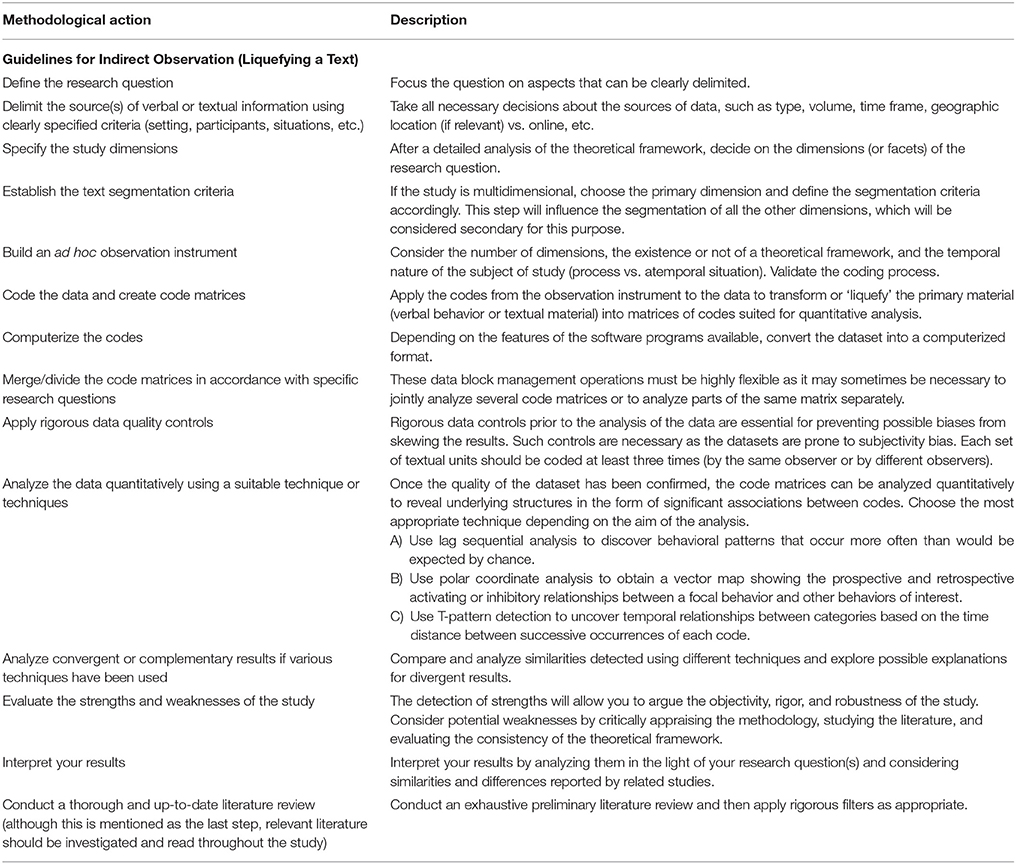
Table 9. Procedure for conducting an indirect observation study based on liquefying a text.
Conclusions and Limitations
Within the broad framework of mixed methods, we have presented indirect observation as a structured method consisting of different steps designed to guarantee scientific rigor. The method consists of the quantitization of qualitative data derived from verbal or textual material to produce code matrices which, following appropriate organization and rigorous quality control procedures, can be analyzed using robust, rigorous, and objective techniques. In a sense, we liquefy the text into a form suitable for quantitative analysis.
Although the materials that support direct and indirect observation are different, the methodological proposal described in this paper shows that both forms of observation share a systematic procedure in which adequately trained observers apply a robust, reliable purpose-designed observation instrument to produce quantitative indicators of the many processes underlying everyday behavior. The main strengths of our approach are that it enables the merging of data from different sources and offers the possibility of taking advantage of the continuous advances in information and communication technologies to study aspects of biopsychosocial behavior in everyday contexts. There are two main limitations. On the one hand, the dimensions in an indirect observation study depend largely on a theoretical framework and a conceptual framework, and these may be lacking. On the other hand, observation instruments comprising category systems, either alone or combined with a field format, also require a theoretical framework. However, the proposed approach has the advantage of allowing all data obtained from narratives to be included in the study, even those which do not fit with the theoretical framework or are contradictory. In fact, the validation of the coding process entails, among other things, checking that no new information has been added, that no information has been eliminated, and that the meaning of the information has not been altered. In this way, there is no omission of information that could lead to bias. This information can be included using bottom-up or top-down processes (Anguera, 1991; Anguera et al., 2007), in other words, the narratives are categorized on the basis of the chosen theoretical framework (top-down) and the theoretical framework is adapted on the basis of the narratives given (bottom-up). An exclusively quantitative study would entail the loss of sensitive and relevant information about the spontaneous behavior, as it would require excluding all variables not envisaged in the chosen theoretical framework. Hence our insistence on the enormous potential of mixed methods research, which suitably integrates both qualitative and quantitative elements.
This work presented a novel approach, based on sequence of occurrence, for transforming qualitative data into quantitative data that can be analyzed using robust quantitative techniques. Additionally, it is important to note that it is possible, at any time during the analysis, to return from the quantitative data to the narrative data. As a result, this approach presents advantages of both qualitative and quantitative methods, at the same time it covers weaknesses of both methods.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
We gratefully acknowledge the support of the Spanish government (Ministerio de Economía y Competitividad) within the Projects Avances metodológicos y tecnológicos en el estudio observacional del comportamiento deportivo [Grant PSI2015-71947-REDT; MINECO/FEDER, UE] (2015-2017), and La actividad física y el deporte como potenciadores del estilo de vida saludable: evaluación del comportamiento deportivo desde metodologías no intrusivas [Grant DEP2015-66069-P; MINECO/FEDER, UE] (2016-2018). We gratefully acknowledge the support of the Generalitat de Catalunya Research Group (GRUP DE RECERCA E INNOVACIÓ EN DISSENYS [GRID]). Tecnología i aplicació multimedia i digital als dissenys observacionals, [Grant 2014 SGR 971]. This research was also funded by the project Methodological quality and effectiveness from evidence (Chilean National Fund of Scientific and Technological Development -FONDECYT-, reference number 1150096). Lastly, first author also acknowledge the support of University of Barcelona (Vice-Chancellorship of Doctorate and Research Promotion), and second author also acknowledge the support of Universitat Autònoma de Barcelona.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank the reviewers whose suggestions and comments greatly helped to improve and clarify this manuscript.
References
Allison, P. D., and Liker, J. K. (1982). Analyzing sequential categorical data on dyadic interaction: a comment on Gottman. Psychol. Bull. 91, 393–403. doi: 10.1037/0033-2909.91.2.393
Altimir, C., Krause, M., de la Parra, G., Dagnino, P., Tomicic, A., Valdés, N., et al. (2010). Clients', therapists', and observers' agreement on the amount, temporal location, and content of psychotherapeutic change and its relation to outcome. Psychother. Res. 20, 472–487. doi: 10.1080/10503301003705871
Anguera, M. T. (1990). “Metodología observacional [Observational methodology],” in Metodología de la Investigación en Ciencias del Comportamiento, eds J. Arnau, M. T. Anguera, and J. Gómez (Murcia: Universidad de Murcia), 125–238.
Anguera, M. T. (1991). La metodología observacional en evaluación de programas [Observational methodology in program evaluation]. Rev. Mex. Anal. Conducta 17, 121–145.
Anguera, M. T. (1997). “From prospective patterns in behavior to joint analysis with a retrospective perspective,” in Colloque sur Invitation Méthodologie d'Analyse des Interactions Sociales. Paris: University of Paris V, Sorbonne.
Anguera, M. T. (2001). “Hacia una evaluación de la actividad cotidiana y su contexto: presente o futuro para la metodología? [Towards an evaluation of everyday activity and its context: present or future for methodology? Lecture of admission to the Royal Europan Academy of Doctors in 1999],” in Estrategias de Evaluación y Medición del Comportamiento en Psicología [Strategies of Evaluation and Measurement of the Behavior in Psychology], eds A. Bazán Ramírez and A. Arce Ferrer (México: Instituto Tecnológico de Sonora y Universidad Autónoma de Yucatán), 11–86.
Anguera, M. T. (2003). “Observational methods (general),” in Encyclopedia of Psychological Assessment, Vol. 2, ed R. Fernández-Ballesteros (London: Sage), 632–637.
Anguera, M. T. (2005). “Microanalysis of T-patterns. Analysis of symmetry/asymmetry in social interaction,” in The Hidden Structure of Social Interaction. From Genomics to Culture Patterns, eds L. Anolli, S. Duncan, M. Magnusson, and G. Riva (Amsterdam: IOS Press), 51–70.
Anguera, M. T. (2010). Posibilidades y relevancia de la observación sistemática por el profesional de la Psicología [Possibilities and relevance of systematic observation for pyschology professionals]. Papeles Psicol. 31, 122–130.
Anguera, M. T. (2017). “Transiciones interactivas a lo largo de un proceso de desarrollo: complementariedad de análisis [Interactive transitions throughout a development process. A complementary analysis approach],” in Mecanismos Básicos de Toma de Decisiones: Perspectivas Desde las Ciencias del Comportamiento y Del Desarrollo, ed C. Santoyo (México: CONACYT 178383/UNAM), 179–213.
Anguera, M. T. (in press). “Is it possible to perform ”Liquefying“ actions in conversational analysis? The detection of structures in indirect observation,” in The Temporal Structure of Multimodal Communication, ed L. Hunyadi (New York, NY: Springer).
Anguera, M. T., Camerino, O., Castañer, M., Sánchez-Algarra, P., and Onwuegbuzie, A. J. (2017a). The specificity of observational studies in physical activity and sports sciences: moving forward in mixed methods research and proposals for achieving quantitative and qualitative symmetry. Front. Psychol. 8:2196. doi: 10.3389/fpsyg.2017.02196
Anguera, M. T., and Hernández-Mendo, A. (2016). Avances en estudios observacionales en Ciencias del Deporte desde los mixed methods [Advances in observational studies in Sport Sciences from a mixed methods approach]. Cuad. Psicol. Deporte 16, 17–30.
Anguera, M. T., and Izquierdo, C. (2006). “Methodological approaches in human communication. From complexity of situation to data analysis,” in From Communication to Presence. Cognition, Emotions and Culture towards the Ultimate Communicative Experience, eds G. Riva, M. T. Anguera, B. K. Wiederhold, and F. Mantovani (Amsterdam: IOS Press), 203–222.
Anguera, M. T., Jonsson, G. K., and Sánchez-Algarra, P. (2017b). Liquefying text from human communication processes: a methodological proposal based on t-pattern detection. J. Multimodal. Comm. Stud. 4, 10–15.
Anguera, M. T., and Losada, J. L. (1999). “Reducción de datos en marcos de conducta mediante la técnica de coordenadas polares [Data reduction in behavioral frameworks through polar coordinate analysis],” in Observación de la Conducta Interactiva en Situaciones Naturales: Aplicaciones, ed M. T. Anguera (Barcelona: E.U.B), 163–188.
Anguera, M. T., Magnusson, M. S., and Jonsson, G. K. (2007). Instrumentos no estándar [Non-standard instruments]. Avances Med. 5, 63–82.
Anguera, M. T., Santoyo, C., and Espinosa, M. C. (2003). “Evaluating links intensity in social networks in a school context through observational designs,” in Culture, Environmental Action and Sustainability, eds R. García Mira, J. M. Sabucedo Cameselle, and J. Romay Martínez (Göttingen: Hogrefe and Huber), 286–298.
Aragón, S., Lapresa, D., Arana, J., Anguera, M. T., and Garzón, B. (2017). An example of the informative potential of polar coordinate analysis: Sprint tactics in elite 1500 m track events. Meas. Phys. Educ. Exerc. Sci. 21, 26–33. doi: 10.1080/1091367X.2016.1245192
Arana, J., Lapresa, D., Anguera, M. T., and Garzón, B. (2016). Ad hoc procedure for optimising agreement between observational records. Anal. Psicol. 32, 589–595. doi: 10.6018/analesps.32.2.213551
Arias-Pujol, E., and Anguera, M. T. (2004). Detección de patrones de conducta comunicativa en un grupo terapéutico de adolescentes [Detection of communicative behavior patterns in an adolescent group therapy group]. Acción Psicol. 3, 199–206. doi: 10.5944/ap.3.3.513
Arias-Pujol, E., and Anguera, M. T. (2017). Observation of interactions in adolescent group therapy: a mixed methods study. Front. Psychol. 8:1188. doi: 10.3389/fpsyg.2017.01188
Bakeman, R. (1978). “Untangling streams of behavior: sequential analysis of observation data,” in Observing Behavior, Vol. 2: Data Collection and Analysis Methods, ed G. P. Sackett (Baltimore, MD: University of Park Press), 63–78.
Bakeman, R. (1991). From lags to logs: advances in sequential analysis. Rev. Mex. Anal. Conducta 17, 65–83.
Bakeman, R., and Gottman, J. M. (1987). “Applying observational methods: a systematic view,” in Handbook of Infant Development, ed J. D. Osofsky (New York, NY: Wiley), 818–853.
Bakeman, R., and Quera, V. (1996). Análisis de la Interacción. Análisis Secuencial con SDIS y GSEQ [Analysis of Interaction. Sequential Analysis with SDIS and GSEQ]. Madrid: Ra-Ma.
Bakeman, R., and Quera, V. (2011). Sequential Analysis and Observational Methods for the Behavioral Sciences. Cambridge: Cambridge University Press.
Baraud, I., Deputte, B. L., Pierre, J.-S., and Blois-Heulin, C. (2016). “Informative value of vocalizations during multimodal interactions in red-capped mangabeys,” in Discovering Hidden Temporal Patterns in Behavior and Interactions: T-Pattern Detection and Analysis with THEME, eds M. S. Magnusson, J. K. Burgoon, M. Casarrubea, and D. McNeill (New York, NY: Springer), 255–278.
Bautista, M. A., Hernández-Vela, A., Escalera, S., Igual, L., Pujol, O., Mora, J., et al. (2015). A gesture recognition system for detecting behavioral patterns of ADHD. IEEE Trans. Cybern. 46, 136–147. doi: 10.1109/TCYB.2015.2396635
Bavelas, J. B., and Chovil, N. (2000). Visible acts of meaning. An integrated message model of language in face-to-face dialogue. J. Lang. Soc. Psychol. 19, 163–194. doi: 10.1177/0261927X00019002001
Bazeley, P. (2003). “Computerized data analysis for mixed methods research,” in Handbook of Mixed Methods in Social and Behavioral Research, eds A. Tashakkori, and C. Teddlie (Thousand Oaks, CA: Sage), 385–422.
Bazeley, P. (2006). The contribution of computer software to integrating qualitative and quantitative data and analyses. Res. Sch. 13, 64–74.
Bazeley, P. (2009). Integrating data analyses in mixed methods research. J. Mix. Methods Res. 3, 203–207. doi: 10.1177/1558689809334443
Behar, J. (1993). “Observación y análisis de la producción verbal de la conducta [Observation and analysis of the verbal production of behavior],” in Metodología Observacional en la Investigación Psicológica. Vol. 1. Fundamentación, ed M. T. Anguera (Barcelona: P.P.U.), 331–389.
Bell, K., Fahmy, E., and Gordon, D. (2016). Quantitative conversations: the importance of developing rapport in standardised interviewing. Qual. Quant. 50, 193–212. doi: 10.1007/s11135-014-0144-2
Birdwhistell, R. L. (1970). Kinesics and Context: Essays and Body Motion Communication. Philadelphia, PA: University of Pennsylvania Press.
Björk, A. B., Sjöström, M., Johansson, E. E., Samuelson, E., and Umefjord, G. (2014). Women's experiences of Internet-based or postal treatment for stress urinary incontinence. Qual. Health Res. 24, 484–493. doi: 10.1177/1049732314524486
Blanchet, A., Batt, M., Trognon, A., and Masse, L. (2005). “Language and behaviour patterns in a therapeutic interaction sequence,” in The Hidden Structure of Social Interaction. From Genomics to Culture Patterns, eds L. Anolli, S. Duncan, M. S. Magnusson, and G. Riva (Amsterdam: IOS Press), 124–140.
Blanco-Villaseñor, A. (2001). Generalizabilidad de observaciones uni y multifaceta: estimadores LS y ML [Generalizability of mono and multifaceted observations: LS and ML estimators]. Metodol. Cienc. Comport. 3, 161–193.
Blanco-Villaseñor, A., Losada, J. L., and Anguera, M. T. (2003). Analytic techniques in observational designs in environment behavior relation. Medio Ambient. Comport. Hum. 4, 111–126.
Bolger, N., Davis, A., and Rafaeli, E. (2003). Diary methods: capturing life as it is lived. Annu. Rev. Psychol. 54, 579–616. doi: 10.1146/annurev.psych.54.101601.145030
Bradley, E. H., Curry, L. A., and Devers, K. J. (2007). Qualitative data analysis for health services research: developing taxonomy, themes, and theory. Health Serv. Res. 42, 1758–1772. doi: 10.1111/j.1475-6773.2006.00684.x
Brondani, M. A., MacEntee, M. I., Bryant, S. R., and O'Neill, B. (2008). Using written vignettes in focus groups among older adults to discuss oral health as a sensitive topic. Qual. Health Res. 18, 1145–1153. doi: 10.1177/1049732308320114
Bunker, D., and Thorpe, R. (1982). A model for the teaching of games in secondary schools. Bull. Phys. Educ. 18, 5–8.
Caddick, N., Smith, B., and Phoenix, C. (2015). Male combat veterans' narratives of PTSD, masculinity, and health. Sociol. Health Illn. 37, 97–111. doi: 10.1111/1467-9566.12183
Calsamiglia, H., and Tusón, A. (1999). Las Cosas del Decir. Manual de Análisis del Discurso [Things About Saying. A Discourse Analysis Manual]. Barcelona: Ariel.
Castañer, M., Barreira, D., Camerino, O., Anguera, M. T., Canton, A., and Hileno, R. (2016). Goal scoring in soccer: a polar coordinate analysis of motor skills used by Lionel Messi. Front. Psychol. 7:806. doi: 10.3389/fpsyg.2016.00806
Castañer, M., Barreira, D., Camerino, O., Anguera, M. T., Fernandes, T., and Hileno, R. (2017). Mastery in goal scoring, T-pattern detection and polar coordinate analysis of motor skills used by Lionel Messi and Cristiano Ronaldo. Front. Psychol. 8:741. doi: 10.3389/fpsyg.2017.00741
Castañer, M., Camerino, O., Anguera, M. T., and Jonsson, G. K. (2013). Kinesics and proxemics communication of expert and novice PE teachers. Qual. Quant. 47, 1813–1829. doi: 10.1007/s11135-011-9628-5
Cochran, W. G. (1954). Some methods for strengthening the common χ2 tests. Biometrics 10, 417–451. doi: 10.2307/3001616
Coll, C., and Onrubia, J. (2001). Estrategias discursivas y recursos semióticos en la construcción de sistemas de significados compartidos entre profesor y alumnos [Discursive strategies and semiotic resources in the construction of shared meaning systems between teachers and students]. Invest. Esc. 45, 21–31.
Conner, T. S., and Lehman, B. J. (2013). “Getting started. Lauching a study in daily life,” in Handbook of Research Methods for Studying Daily Life, eds M. R. Mehl and T. S. Conner (New York, NY: The Guilford Press), 89–105.
Coutinho, J., Ribeiro, E., Sousa, I., and Safran, J. D. (2014). Comparing two methods of identifying alliance rupture events. Psychotherapy 51, 434–442. doi: 10.1037/a0032171
Crawford, T. H. (1992). The politics of narrative form. Lit. Med. 11, 147–162. doi: 10.1353/lm.2011.0234
Creswell, J. W., and Plano Clark, V. L. (2007). Designing and Conducting Mixed Methods Research, 3rd Edn 2017. Thousand Oaks, CA: Sage.
Creswell, J. W., Plano Clark, V. L., Gutmann, M. L., and Hanson, W. E. (2003). “Advanced mixed methods research designs,” in Handbook of Mixed Methods in Social and Behavioral Research, eds A. Tashakkori, and C. Teddlie (Thousand Oaks, CA: Sage), 209–240.
Crutcher, R. J. (2003). A computer-aided digital audio recording and encoding system for improving the encoding of verbal reports. Behav. Res. Methods 35, 263–268. doi: 10.3758/BF03202551
Crutcher, R. J. (2007). CAPAS 2.0: a computer tool for coding transcribed and digitally recorded verbal reports. Behav. Res. Methods 39, 167–174. doi: 10.3758/BF03193145
Cuervo, J. J. (2014). Comunicación y Perdurabilidad en Parejas Viables. Estudio Observacional de Caso Múltiple [Communication and Durability in Viable Couples. A Multiple Observational Case Study]. Ph.D. thesis, Universidad Autónoma de Barcelona: Barcelona.
Dagnino, P., Krause, M., Pérez, J. C., Valdés, N., and Tomicic, A. (2012). The evolution of communicative intentions during change episodes and throughout the therapeutic process. Res. Psychother. 15, 75–86.
Dam, G., and Kaufmann, S. (2008). Computer assessment of interview data using latent semantic analysis. Behav. Res. Methods 40, 8–20. doi: 10.3758/BRM.40.1.8
Danzinger, K. (1982). Comunicación Interpersonal [Interpersonal Communication]. México: Manual Moderno.
De Fina, A., and Georgakopoulo, A. (eds.). (2015). The handbook of narrative analysis. Malden: Wiley-Blackwell.
Diana, B., Zurloni, V., Elia, M., Cavalera, C. M., Jonsson, G. K., and Anguera, M. T. (2017). How game location affects soccer performance: T-pattern analysis of attack actions. Front. Psychol. 8:1415. doi: 10.3389/fpsyg.2017.01415
Dickman, H. R. (1963). “The perception of behavioral units,” in The Stream of Behavior, ed R. Barker (New York, NY: Appleton-Century-Crofts), 23–41.
Duran, N. D., McCarthy, P. M., Graesser, A. C., and McNamara, D. S. (2007). Using temporal cohesion to predict temporal coherence in narrative and expository texts. Behav. Res. Methods 39, 212–223. doi: 10.3758/BF03193150
Elvish, R., Lever, S. J., Johnstone, J., Cawley, R., and Keady, J. (2013). Psychological interventions for careers of people with dementia: a systematic review of quantitative and qualitative evidence. Counsell. Psychother. Res. J. 13, 106–125. doi: 10.1080/14733145.2012.739632
Escalera, S., Martínez, R. M., Vitriá, J., Radeva, P., and Anguera, M. T. (2009). Automatic dominance detection in dyadic conversations. Escr. Psicol. 3, 41–45.
Escolano-Pérez, E., Herrero-Nivela, M. L., Blanco-Villaseñor, A., and Anguera, M. T. (2017). Systematic observation: relevance of this approach in preschool executive function assessment and association with later academic skills. Front. Psychol. 8:2031. doi: 10.3389/fpsyg.2017.02031
Fetters, M. D., and Freshwater, D. (2015). The 1 + 1 = 3 integration challenge. J. Mix. Methods Res. 9, 115–117. doi: 10.1177/1558689815581222
Fischer, A. H., Becker, D., and Veenstra, L. (2012). Emotional mimicry in social context: the case of disgust and pride. Front. Psychol. 3:475. doi: 10.3389/fpsyg.2012.00475
Gabriel, Y. (2004). “The voice of experience and the voice of the expert - Can they speak to each other?,” in Narrative Research in Health and Illness, eds B. Hurwitz, T. Greenhalgh, and V. Skultans (Malden, MA: Blackwell), 168–185.
Gale, J. E. (1991). Conversation Analysis of Therapeutic Discourse. Norwood, OH: Ablex Publishing Corporation.
García-Fariña, A. (2015). Análisis del Discurso Docente Como Recurso Metodológico del Profesorado de Educación Física en la Etapa de Educación Primaria [Analysis of Teacher-Led Discourse as a Methodological Resource for Primary School Physical Education Teachers]. Ph.D. thesis, Universidad de La Laguna, Tenerife.
García-Fariña, A., Jiménez Jiménez, F., and Anguera, M. T. (2016). Análisis observacional del discurso docente del profesorado de educación física en formación a través de patrones comunicativos [Observational analysis of teaching discourse physical education training teachers through communicative patterns]. Cuad. Psicol. Deporte 16, 171–182.
Gimeno, A., Anguera, M. T., Berzosa, A., and Ramírez, L. (2006). Detección de patrones interactivos en la comunicación de familias con hijos adolescentes [Detection of interactive communication patterns in families with adolescent children]. Psicothema 18, 785–790.
Gorospe, G., and Anguera, M. T. (2000). Modificación de la técnica clásica de coordenadas polares mediante un desarrollo distinto de la retrospectividad: aplicación al tenis [Modification to the classic polar coordinate technique using a distinct concept of retrospectivity: an application to tennis]. Psicothema 12(Suppl. 2), 279–282.
Hardley, D. M. (2014). Using social media and Internet data for public health surveillance: the importance of talking. Milbank Q. 92, 34–39. doi: 10.1111/1468-0009.12039
Hernández-Mendo, A., López-López, J. A., Castellano, J., Morales-Sánchez, V., and Pastrana, J. L. (2012). Hoisan 1.2: programa informático para uso en metodología observacional [Hoisan 1.2: software for observational methodology]. Cuad. Psicol. Deporte 12, 55–78. doi: 10.4321/S1578-84232012000100006
Herrero Nivela, M. L. (2000). Utilización de la técnica de coordenadas polares en el estudio de la interacción infantil en el marco escolar [Use of the technic of polar coordinates in the study of the children interaction in the school room]. Psicothema 12, 292–297.
Holle, H., Obermeier, C., Schmidt-Kassow, M., Friederici, A. D., Ward, J., and Gunter, T. C. (2012). Gesture facilitates the syntactic analysis of speech. Front. Psychol. 3:74. doi: 10.3389/fpsyg.2012.00074
Holtgraves, T., and Han, T. L. (2007). A procedure for studying online conversational processing using a chat bot. Behav. Res. Methods 39, 156–163. doi: 10.3758/BF03192855
Hurwitz, B., Greenhalgh, T., and Skultans, V. (eds.). (2004). Narrative Research in Health and Illness. London: British Medical Journal Books and Blackwell.
Jackson, M., Harrison, P., Swinburn, B., and Lawrence, M. (2015). Using a qualitative vignette to explore a complex public health issue. Qual. Health Res. 25, 1395–1409. doi: 10.1177/1049732315570119
Johnson, R. B., Onwuegbuzie, A. J., and Turner, L. A. (2007). Toward a definition of mixed methods research. J. Mix. Methods Res. 1, 112–133. doi: 10.1177/1558689806298224
Krause, M., Altimir, C., Pérez, J. C., Echávarri, O., Valdés, N., and Strasser, K. (2016). Therapeutic verbal communication in change episodes: a comparative microanalysis of linguistic basic forms. Estud. Psicol. 37, 514–547. doi: 10.1080/02109395.2016.1227575
Krippendorff, K. (2013). Content Analysis. An Introduction to Its Methodology, 3rd Edn. Thousand Oaks, CA: Sage.
Krueger, R. A., and Casey, M. A. (2009). Focus Groups. A Practical Guide for Applied Research. Los Angeles, CA: Sage.
Lapresa, D., Arana, J., Anguera, M. T., and Garzón, B. (2013). Comparative analysis of the sequentiality using SDIS-GSEQ and THEME: a concrete example in soccer. J. Sports Sci. 31, 1687–1695. doi: 10.1080/02640414.2013.796061
Lausberg, H., and Sloetjes, H. (2009). Coding gestural behavior with the NEUROGES–ELAN system. Behav. Res. Methods 41, 841–849. doi: 10.3758/BRM.41.3.841
Lausberg, H., and Sloetjes, H. (2016). The revised NEUROGES-ELAN system: an objective and reliable interdisciplinary analysis tool for nonverbal behavior and gesture. Behav. Res. Methods 48, 973–993. doi: 10.3758/s13428-015-0622-z
Lebrecht, S., Bar, M., Barrett, L. F., and Tarr, M. J. (2012). Micro-valences. Perceiving affective valence in everyday objects. Front. Psychol. 3:107. doi: 10.3389/fpsyg.2012.00107
Lederer, S. H., and Battaglia, D. (2015). Using signs to facilitate vocabulary in chldren with language delays. Infants Young Child. 28, 18–31. doi: 10.1097/IYC.0000000000000025
Leech, N. L., and Onwuegbuzie, A. J. (2009). A typology of mixed methods research designs. Qual. Quant. 43, 265–275. doi: 10.1007/s11135-007-9105-3
Lindqvist, O., Threlkeld, G., Street, A. F., and Tishelman, C. (2014). Reflections on using biographical approaches in end-of-life-care: dignity therapy as example. Qual. Health. Res. 25, 40–50. doi: 10.1177/1049732314549476
López, J., Valero, A., Anguera, M. T., and Díaz, A. (2016). Disruptive behavior among elementary students in physical education. Springerplus 5:1154. doi: 10.1186/s40064-016-2764-6
Love, A. C. (2006). History, scientific methodology, and the “squishy” sciences. Perspect. Biol. Med. 49, 452–456. doi: 10.1353/pbm.2006.0042
Magnusson, M. S. (1996). Hidden real-time patterns in intra- and inter-individual behavior. Eur. J. Psychol. Assess. 12, 112–123. doi: 10.1027/1015-5759.12.2.112
Magnusson, M. S. (2000). Discovering hidden time patterns in behavior: T-patterns and their detection. Behav. Res. Methods Instrum. Comput. 32, 93–110. doi: 10.3758/BF03200792
Magnusson, M. S. (2005). “Understanding social interaction: discovering hidden structure with model and algorithms,” in The Hidden Structure of Social Interaction. From Genomics to Culture Patterns, eds L. Anolli, S. Duncan, M. S. Magnusson, and G. Riva (Amsterdam: IOS Press), 4–22.
Magnusson, M. S. (2016). “Time and self-similar structure in behavior and interactions: from sequences to symmetry and fractals,” in Discovering Hidden Temporal Patterns in Behavior and Interactions: T-Pattern Detection and Analysis with THEME, eds M. S. Magnusson, J. K. Burgoon, M. Casarrubea, and D. McNeill (New York, NY: Springer), 3–35.
Martínez del Pozo, M. (1993). Análisis del ”Proceso de Elaboración del Duelo“ en el Hipertenso Esencial: Estudio Empírico de Sus Fases Mediante Observación Sistemática [Analysis of the ”Elaboration of Mourning“ in Individuals with Essential Hypertension: An Empirical Study of Elaboration Phases through Systematic Observation]. Ph.D. thesis, University of Barcelona, Barcelona.
Mashal, N., Solodkin, A., Dick, A. S., Chen, E. E., and Small, S. L. (2012). A network model of observation and imitation if speech. Front. Psychol. 3:84. doi: 10.3389/fpsyg.2012.00084
Maxwell, J. A., Chmiel, M., and Rogers, S. E. (2015). “Designing integration in multimethod and mixed methods research,” in The Oxford Handbook of Multimethod and Mixed Methods Research Inquiry, eds S. N. Hesse-Biber, and R. B. Johnson (New York, NY: Oxford University Press), 223–239.
McLean, M., Cleland, J. A., Worrell, M., and Vögele, C. (2011). “What am I going to say here?” The experiences of doctors and nurses communicating with patients in a cancer unit. Front. Psychol. 2:339. doi: 10.3389/fpsyg.2011.00339
Mehl, M. R., Pennebaker, J. W., Crow, D. M., Dabbs, J., and Price, J. H. (2001). The Electronically Activated Recorder (EAR): a device for sampling naturalistic daily activities and conversations. Behav. Res. Methods Instrum. Comput. 33, 517–523. doi: 10.3758/BF03195410
Molina-Azorín, J. F., and Cameron, R. (2015). “History and emergent practices of mixed and multiple methods in business research,” in The Oxford Handbook of Multimethod and Mixed Methods Research Inquiry, eds S. Hesse-Biber and R. B. Johnson (New York, NY: Oxford University Press), 466–485.
Morales-Ortiz, M. (1999). “La observación indirecta: una aplicación al análisis de textos [Indirect observation applied to text analysis],” in Observación en la Escuela: Aplicaciones, ed M. T. Anguera (Barcelona: Ediciones Universidad de Barcelona), 299–307.
Morales-Sánchez, V., Pérez-López, V., and Anguera, M. T. (2014). Tratamiento metodológico de la observación indirecta en la gestión de organizaciones deportivas [Indirect observational methodology in managing sports services]. Rev. Psicol. Deport. 23, 201–207.
Morillo, J. P., Reigal, R. E., Hernández-Mendo, A., Montaña, A., and Morales-Sánchez, V. (2017). Decision-making by handball referees: design of an ad hoc observation instrument and polar coordinate analysis. Front. Psychol. 8:1842. doi: 10.3389/fpsyg.2017.01842
Mucchielli, R. (1974). L'observation Psychologique et Psychosociologique [Psychological and Psychosociological Observation]. Paris: E.S.F.
O'Cathain, A., Murphy, E., and Nicholl, J. (2010). Three techniques for integrating data in mixed methods studies. BMJ 341:c4587. doi: 10.1136/bmj.c4587
Onwuegbuzie, A. J. (2003). Effect sizes in qualitative research: a prolegomenon. Qual. Quant. 37, 393–409. doi: 10.1023/A:1027379223537
Onwuegbuzie, A. J., and Hitchcock, J. H. (2015). “Advanced mixed analysis approaches,” in The Oxford Handbook of Multimethod and Mixed Methods Research Inquiry, eds S. Hesse-Biber and R. B. Johnson (New York, NY: Oxford University Press), 275–295.
Poitras, J., Hill, K., Hamel, V., and Pelletier, F. B. (2015). Managerial mediation competency: a mixed-method study. Negot. J. 31, 105–115. doi: 10.1111/nejo.12085
Pope, C., Ziebland, S., and Mays, N. (2000). Qualitative research in health care. Analysing qualitative data. BMJ 320, 114–116. doi: 10.1136/bmj.320.7227.114
Portell, M., Anguera, M. T., Chacón-Moscoso, S., and Sanduvete-Chaves, S. (2015a). Guidelines for reporting evaluations based on observational methodology. Psicothema 27, 283–289. doi: 10.7334/psicothema2014.276
Portell, M., Anguera, M. T., Hernández-Mendo, A., and Jonsson, G. K. (2015b). Quantifying biopsychosocial aspects in everyday contexts: an integrative methodological approach from the behavioral sciences. Psychol. Res. Behav. Manag. 8, 153–160. doi: 10.2147/PRBM.S82417
Portell, M., Anguera, M. T., Hernández-Mendo, A., and Jonsson, G. K. (2015c). The legacy of Brunswik's representative design in the 21st century: methodological innovations for studying everyday life. Brunswik Soc. Newslett. 30, 38–40.
Poyatos, F. (1993). Paralanguage. A Linguistic and Interdisciplinary Approach to Interactive Speech and Sound. Amsterdam: John Benjamins Publishing Company.
Radzikowski, J., Stefanidis, A., Jacobsen, K. H., Croitoru, A., Crooks, A., and Delamater, P. L. (2016). The measles vaccination narrative in Twiter: a quantitative analysis. JMIR Public Health Surveill. 2:e1. doi: 10.2196/publichealth.5059
Reis, H. T. (2013). “Why researchers should think “Real-World.” A conceptual rationale,” in Handbook of Research Methods for Studying Daily Life, eds M. R. Mehl and T. S. Conner (New York, NY: The Guilford Press), 3–21.
Riera, A., Ocasio, A., Tiyyagura, G., Krumeich, L., Ragins, K., Thomas, A., et al. (2015). Latino caregiver experiencies with asthma health communication. Qual. Health Res. 25, 16–26. doi: 10.1177/1049732314549474
Riessman, C. K. (2015). Ruptures and sutures: time, audience and identity in an illness narrative. Sociol. Health Illn. 37, 1055–1071. doi: 10.1111/1467-9566.12281
Riva, G., Anguera, M. T., Wiederhold, B. K., and Mantovani, F. (2006). From Communication to Presence. Cognition, Emotions and Culture Towards the Ultimate Communicative Experience. Amsterdam: IOS Press.
Rodriguez, C. S., Spring, H. J., and Rowe, M. (2014). Nurse's experiences of communicating with hospitalized, suddenly speechless patients. Qual. Health. Res. 25, 168–178. doi: 10.1177/1049732314550206
Romero, P., Cox, R., du Boulay, B., Lutz, R., and Bryant, S. (2007). A methodology for the capture and analysis of hybrid data. A case study of program debugging. Behav. Res. Methods 39, 309–317. doi: 10.3758/BF03193162
Roustan, M., Izquierdo Rodríguez, C., and Anguera Argilaga, M. T. (2013). Sequential analysis of an interactive peer support group. Psicothema 25, 396–401. doi: 10.7334/psicothema2012.93
Russ, J. B., Gur, R. C., and Bilker, W. B. (2008). Validation of affective and neutral sentence content for prosodic testing. Behav. Res. Methods 40, 935–939. doi: 10.3758/BRM.40.4.935
Sackett, G. P. (1980). “Lag sequential analysis as a data reduction technique in social interaction research,” in Exceptional Infant. Psychosocial Risks in Infant-Environment Transactions, eds D. B. Sawin, R. C. Hawkins, L. O. Walker, and J. H. Penticuff (New York, NY: Brunner/Mazel), 300–340.
Sackett, G. P. (1987). “Analysis of sequential social interaction data: some issues, recent developments, and a causal inference model,” in Handbook of Infant Development, 2nd Edn, ed J. D. Osofsky (New York, NY: Wiley), 855–878.
Sánchez-Algarra, P., and Anguera, M. T. (2013). Qualitative/quantitative integration in the inductive observational study of interactive behaviour: impact of recording and coding among predominating perspectives. Qual. Quant. 47, 1237–1257. doi: 10.1007/s11135-012-9764-6
Sandelowski, M. (2001). Real qualitative researchers do not count: the use of numbers in qualitative research. Res. Nurs. Health 24, 230–240. doi: 10.1002/nur.1025
Sandelowski, M., Voils, C. I., and Knafl, G. (2009). On quantitizing. J. Mix. Methods Res. 3, 208–222. doi: 10.1177/1558689809334210
Santoyo, C., Jonsson, G. K., Anguera, M. T., and López-López, J. A. (2017). Observational analysis of the organization of on-task behavior in the classroom using complementary data analyses. Anal. Psicol. 33, 497–514. doi: 10.6018/analesps.33.3.271061
Sarmento, H., Bradley, P. S., Anguera, M. T., Polido, T., Resende, R., and Campaniço, J. (2015). Quantifying the offensive sequences that result in goals in elite futsal matches. J. Sports Sci. 34, 621–629. doi: 10.1080/02640414.2015.1066024
Schegloff, E. (2000). On granularity. Annu. Rev. Sociol. 26, 715–720. doi: 10.1146/annurev.soc.26.1.715
Seltzer-Kelly, D., Westwood, S. J., and Pena-Guzmán, D. M. (2012). A methodological self-study of quantitizing: negotiating meaning and revealing multiplicity. J. Mix. Methods Res. 6, 258–274. doi: 10.1177/1558689811425798
Sidnell, J., and Stivers, T. (eds.). (2013). The Handbook of Conversation Analysis. New York, NY: Wiley and Sons.
Suárez, N., Sánchez-López, C. R., Jiménez, J. E., and Anguera, M. T. (2018). Is reading instruction evidence-based? Analyzing teaching practices using T-Patterns. Front. Psychol. 9:7. doi: 10.3389/fpsyg.2018.00007
Tarragó, R., Iglesias, X., Lapresa, D., Anguera, M. T., Ruiz-Sanchís, L., and Arana, J. (2017). Analysis of diachronic relationships in successful and unsuccessful behaviors by world fencing champions using three complementary techniques. Anal. Psicol. 33, 471–485. doi: 10.6018/analesps.33.3.271041
Tashakkori, A., and Teddlie, C. (eds.). (2010). The Sage Handbook of Mixed Methods in Social and Behavioral Research, 2nd Edn. Thousand Oaks, CA: Sage.
Taylor, K., Thorne, S., and Oliffe, J. L. (2015). It's a sentence, not a word. Insights from a keyword analysis in cancer communication. Qual. Health Res. 25, 110–121. doi: 10.1177/1049732314549606
Tronchoni, H., Izquierdo, C., and Anguera, M. T. (2018). Interacción Participativa en las Clases Magistrales: Fundamentacion y Construcción de un Instrumento de Observación [Participatory Interaction in Lectures: Theoretical Framework and Construction of an Observation Instrument]. Publicaciones. Facultad de Educación y Humanidades del Campus de Melilla.
Tuttas, C. A. (2015). Lessons learned using web conference technology for online focus group interviews. Qual. Health Res. 25, 122–133. doi: 10.1177/1049732314549602
Vaimberg, R. (2010). Psicoterapias Tecnológicamente Mediadas [Technology-Mediated Psychotherapy]. Ph.D. thesis, Universidad de Barcelona, Barcelona.
Webb, E. T., Campbell, D. T., Schwartz, R. D., Sechrest, L., and Grove, J. B. (1966). Nonreactive Measures in the Social Sciences. Boston, MA: Houghton Mifflin.
Weick, K. E. (1968). “Systematic observational methods,” in Handbook of Social Psychology, Vol. 2, 2nd Edn., eds G. Lindzey, and E. Aronson (Reading, MA: Addison-Wesley), 357–451.
Weick, K. E. (1985). “Systematic observational methods,” in Handbook of Social Psychology, Vol. 1, 3rd Edn., eds G. Lindzey, and E. Aronson (Reading, MA: Addison-Wesley), 567–634.
Keywords: indirect observation, mixed methods, textual materials, verbal behavior, systematic observation, quantitizing
Citation: Anguera MT, Portell M, Chacón-Moscoso S and Sanduvete-Chaves S (2018) Indirect Observation in Everyday Contexts: Concepts and Methodological Guidelines within a Mixed Methods Framework. Front. Psychol. 9:13. doi: 10.3389/fpsyg.2018.00013
Received: 15 January 2017; Accepted: 04 January 2018;
Published: 30 January 2018.
Edited by:
Pietro Cipresso, Istituto Auxologico Italiano (IRCCS), ItalyReviewed by:
Lietta Marie Scott, Arizona Department of Education, United StatesMelissa Miléna De Smet, Ghent University, Belgium
Copyright © 2018 Anguera, Portell, Chacón-Moscoso and Sanduvete-Chaves. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: M. Teresa Anguera, dGFuZ3VlcmFAdWIuZWR1