 Yumeng Lin
Yumeng Lin Duo Xu
Duo Xu Junying Liang
Junying Liang- 1Department of Linguistics, Zhejiang University, Hangzhou, China
- 2School of Foreign Languages and Cultures, Nanjing Normal University, Nanjing, China
Prominent interpreting models have illustrated different processing mechanisms of simultaneous interpreting and consecutive interpreting. Although great efforts have been made, a macroscopic examination into interpreting outputs is sparse. Since complex network is a powerful and feasible tool to capture the holistic features of language, the present study adopts this novel approach to investigate different properties of syntactic dependency networks based on simultaneous interpreting and consecutive interpreting outputs. Our results show that consecutive interpreting networks demonstrate higher degrees, higher clustering coefficients, and a more important role of function words among the central vertices than simultaneous interpreting networks. These findings suggest a better connectivity, better transitivity, and a lower degree of vocabulary richness in consecutive interpreting outputs. Our research provides an integrative framework for the understanding of underlying mechanisms in diverse interpreting types.
Introduction
Interpreting is an extremely intricate language processing task for the cognitive system (Christoffels et al., 2006; Tzou et al., 2012; Pöchhacker, 2016; Defrancq and Plevoets, 2018; Liang et al., 2019), which involves listening and comprehending of the input speech, memory storage, production of target equivalents, and sometimes alternately activating and suppressing production in two languages (Christoffels et al., 2003; Aparicio et al., 2017; Lin et al., 2018). Among different types of interpreting, simultaneous interpreting (SI) and consecutive interpreting (CI) tasks are generally supposed to be highly cognitive demanding and with sheer complexity. Characterized by the simultaneity of input comprehension and output production, SI involves temporary storage and extraction of meaning (Christoffels et al., 2003), reformulation of the earlier segments of the source message into the target language, and articulation of even earlier segments (Gerver, 1976; Padilla et al., 1995). By contrast, CI is performed in such cases where the stages of perception and production are processed serially. Interpreters prefer to finish a complete session before he “pauses for interpretation,” such as in international press conferences. Faced with the need to render speeches lasting up to a few minutes or more, interpreters may resort to note-taking to assist memorization (Gile, 2009; Pöchhacker, 2011).
Regardless of the interpreting modes, it has been substantiated in a volume of research that cognitive resources are crucial to the interpreting performances (Padilla et al., 1995; Tzou et al., 2012; Injoque-Ricle et al., 2015; Plevoets and Defrancq, 2018; Liang and Lv, 2020). Cognitive load is defined as a “multi-dimensional construct representing the load imposed on the working memory during performance of a cognitive task” (Paas and Van Merriënboer, 1994). This construct is based on models of working memory which is limited in capacity and duration (Baddeley, 1992). According to Baddeley’s (1992) model, only a limited number of discrete items can be stored and manipulated in working memory at the same time. Specifically, Miller (1956) suggested that normal individuals can only hold seven (plus or minus two) discrete units in working memory at one time and only for limited duration (Chen et al., 2016). Given that interpreting is a complex task where extremely high demands are placed on working memory, the explanatory potential of the concept of cognitive load for the interpreting process is manifest. Gile (1985) introduced the notion of cognitive load into the field of interpreting studies, aiming to explain information loss observed in professional interpreters (Pöchhacker, 2015). He argued that interpreting failures are ascribed to deficient cognitive capacity instead of insufficient linguistic or extralinguistic knowledge of interpreters (Gile, 1999, 2009). This conforms to the “Tightrope Hypothesis” which postulates that interpreters generally work close to their maximum capacity of cognitive load (saturation) when performing the interpreting tasks (Gile, 1999).
Such severe cognitive constraints can be elaborated by theoretical models of SI and CI, which highlight the critical role of cognitive capacity in each proportion of efforts in the interpreting activities. The composition and allocation of mental operations during the processing of SI are best captured by the Effort Model (Gile, 2009, 2016), in which SI can be conceptualized as a process consisting of listening and analysis effort, the short-term memory effort, the speech production effort, and a coordination effort. These efforts are largely non-automatic and concurrent and thus compete for the limited cognitive resources, suggesting that the increments of one effort are at the expense of another (Koshkin et al., 2018). By contrast, CI is processed in two phases, namely the comprehension phase and the reformulation phase (Gile, 2009, 2016). To ensure the smooth production in SI and CI, the processing capacity available must exceed the capacity required; otherwise, errors or infelicities may occur due to insufficient cognitive resources.
The above-mentioned models, albeit conceptually presented only, explain that there exist different cognitive mechanisms underlying SI and CI, indicating that the processes of SI and CI may consume different amount of cognitive resource. This stimulates discussions on whether the difference of cognitive load between SI and CI may influence interpreting production. The disentanglement of this issue can be of great significance to our understanding of both cognitive processing and language use. On the one hand, the cognitive load of different interpreting types reflected by the quantifications of interpreting outputs helps explore the coping mechanism of interpreters. On the other hand, it also illustrates how language shifts under the extreme cognitive load, and hence complements comparative studies on fully fledged common language uses (Liang et al., 2018; Lv and Liang, 2019; Jia and Liang, 2020).
The recent 10years has witnessed booming interest in the research of cognitive load in interpreting. Some of current attempts concern capturing and understanding the difficult and demanding nature of the task as well as figuring out how interpreters deal with the challenges (Chen, 2017). Seeber (2011) postulated that cognitive load in SI varies according to the micro-strategy (waiting, stalling, text chunking, and anticipation) used by interpreters between syntactically different languages, and further suggested that cognitive load during SI of syntactically asymmetrical structures increased toward the end of the sentence (Seeber and Kerzel, 2012). Quite in the same vein, Shao and Chai (2020) found a significant drop in SI performance occurred when local cognitive load reached four chunks, corroborating the notion that interpreters generally experience cognitive saturation even in relatively easy SI tasks. Bóna and Bakti (2020) examined the effect of cognitive load on temporal and disfluency patterns between CI and sight translation and found that sight translation generated more cognitive load. Additionally, a latest study demonstrated a positive correlation between cognitive load and explicitating shifts in SI (Gumul, 2021).
Indeed, one of the major challenges in applying the construct of cognitive load to research in interpreting has been the difficulty of measuring this notion (Pöchhacker, 2015). Apart from some techniques testing brain activations or pupillary response in the experiments, language complexity can be used as a potential measure to monitor cognitive load (Chen et al., 2016; Chen 2017). For instance, Plevoets and Defrancq (2016) operationalized cognitive load in interpreting in terms of linguistic features such as delivery rate and lexical density, and a high source text delivery rate and a high target text lexical density were determinants triggering significantly higher disfluencies in the interpretations. Similar measurement was also adopted in the research by Lv and Liang (2019). To systematically probe into the connection between cognitive load and interpreting, a line of quantitative research examined the interpreting outputs between SI and CI from various perspectives. As a seminal research quantifying different interpreting modes, Liang et al. (2017) calculated the dependency distance of output texts and suggested that CI bears heavier cognitive demands than SI. Later on, they found consistent evidence in the lexical features (Lv and Liang, 2019) and language sequences (Liang et al., 2019). A more recent study (Jia and Liang, 2020) probed into the lexical category realm with the activity index and found that CI outputs yield greater activity than SI outputs, indicating “a dynamic adaptive mechanism of language representations to accommodate cognitive constraints.”
Clearly, prior studies on the comparison of SI and CI cognitive processes were conducted from syntactic, lexical and language sequential perspectives, but without taking an interconnected and comprehensive feature into consideration. Since language is represented in an integrated way, the complex network (Newman, 2018), as a systematic approach, may be a possible solution to investigate the features of different interpreting types from a macroscopic view. Therefore, we employ a novel approach of complex network to pin down the characteristics of interpreting production motivated by different cognitive constraints during SI and CI.
The rationale of complex networks as an operational approach for linguistic inquiry is from the representative theories which posit language as a system (Saussure, 2001; Hudson, 2007). Such a system is deemed as a network of relations which can be described by a number of vertices and edges. The vertices represent entities, while edges denote relationships among the vertices (Barabási, 2002; Čech et al., 2007). Linguistic networks generally exhibit scale-free structure (Liu, 2008a; Čech and Mačutek, 2009), where only a small number of vertices have extremely great combinatorial capacity, while most vertices have rather low combinatorial capacity. Among all these vertices, the well-connected vertices in the networks serve as hubs, which play an important role in the topology of a linguistic network. Displayed in Figure 1 is a panorama of dependency syntactic network based on the language data obtained from speeches on the international forums. Although there are only about 3,000 vertices in this network, it has already presented a clear picture of the complexity. Also, language sub-systems of various types generally possess the small-world structure, where there is a low degree of separation between vertices and a high level of clustering (Cong and Liu, 2014a). Such a structure can enhance the communication efficiency between the vertices and thus facilitates mental navigation (Ferrer-i-Cancho, 2005; Vitevitch, 2008). Complex networks thus provide a quantitative measure and an interdisciplinary context to explore the properties of linguistic units at the system level (Cong and Liu, 2014b).

Figure 1. Overall view of a language network.
Prior studies demonstrate the feasibility of using the complex network approach to characterize and classify human languages, including the exploration of statistical patterns of different languages, stylistic research (Ferrer-i-Cancho et al., 2004; Liu, 2008a), typological properties of languages (Liu and Xu, 2011), hierarchical structures of a language (Chen et al., 2015), the evolution of languages (Cui et al., 2017; Chen et al., 2018), and linguistic features in language learning (Jin and Liu, 2016; Jiang et al., 2019; Hao et al., 2021). It is probable that network properties can also discriminate linguistic features of different interpreting types. By utilizing this approach to interpreting, it is likely to examine the quantitative properties of interpreting outputs at the system level. In other words, both the linguistic units and their relations can be taken into consideration.
Meanwhile, given that the ultimate goal of our study is to explore whether different cognitive processing in SI and CI has impact on language production during SI and CI, it will be beneficial to adopt an approach which can effectively connect to the cognitive constructs. In this regard, the network approach is a good choice to realize our goal, since this approach has been proved to be advantageous for the representation of the cognitive system by capturing the interaction of structure and processes in the networks (Siew et al., 2019). For instance, research concerning human semantic memory conceptualizes cognitive system as networks in which concepts are connected based on their semantic similarity to account for behavioral phenomena (Collins and Loftus, 1975; Steyvers and Tenenbaum, 2005). Besides, cognitive impairment (Lerner et al., 2009), lexical retrieval (Goldstein and Vitevitch, 2017; Siew, 2018) and human navigation (Sudarshan Iyengar et al., 2012) are frequently investigated via the network science. The network representations serve as a mental map of the cognitive space, according to which, we can make predictions about how structural properties of such network maps influence cognitive search behavior (Siew et al., 2019). Collectively, research in this domain demonstrates the accessibility and feasibility of this measure to exploit cognitive constructs.
To examine the quantitative properties between different interpreting types at the system level and to connect these properties to cognitive constraints, here in the current research, we intend to build syntactic dependency networks. The adoption of the syntactic complex network approach has two primary considerations. On the one hand, syntax is a fundamental feature of language that concerns the organization of words and the structure of sentences. Hence, it serves as an essential foundation for understanding the processes of communication. Prior research demonstrated that dependency distance, the number of words intervening between two syntactically related words in a sentence, can reflect the cognitive constraints during varying interpreting tasks (Liang et al., 2017; Liu et al., 2017). This suggests that the syntactic feature is an applicable dimension to reflect the cognitive load. The employment of syntactic dependency networks thus conforms to the aim of our study. On the other hand, syntactic dependency networks based on syntactic relations are not related to the text content. However, the features of other types of networks such as co-occurrence networks and semantic networks can easily be affected by the content of texts. The choice of syntactic networks can exclude the influence of this factor. Given the two reasons above, the present study employs the syntactic dependency network approach.
To sum up, firstly, prior quantitative investigations into the underlying differences across different interpreting types generally focus on one particular aspect, whereas a global and systematic view into the macroscopic features between SI and CI is rather limited. The network approach is beneficial in that all the words in a text can be linked together and generate a holistic picture, instead of investigating linguistic features based on separated sentences. Secondly, the network approach proved to be very fruitful in examining linguistic features systematically and representing cognitive constructs. Thus, complex networks may facilitate our understanding of the properties of interpreting outputs under the extreme cognitive load, providing insights into the interconnection between language and cognitive sciences.
The present study therefore investigates different properties of syntactic dependency networks between SI and CI outputs, to explore whether different underlying mechanisms between SI and CI can influence interpreting production in SI and CI. The following questions will be addressed:
1. Do the syntactic networks of CI and SI outputs display the scale-free and small-world network structures?
2. What are the differences in the cognitive complexity between SI and CI processes reflected by the main properties of syntactic networks?
3. Can the characteristics of central vertices in the networks discriminate SI and CI?
Materials and Methods
Corpus Descriptions
We adopted the transcribed real-world interpretations and the input texts of SI and CI as the corpus of the current research. The CI sub-corpus consisted of speeches given by Chinese Premiers Wen Jiabao and Li Keqiang at the annual press conference of two sessions (the National People’s Congress and the Chinese Political Consultative Conference), where the Prime Minister met and answered the questions raised by Chinese and overseas journalists. The SI sub-corpus comprised keynote speeches delivered by Chinese government leaders such as Wen Jiabao, Li Keqiang, and Xi Jinping on the international forums including sessions of the UN General Debate, the Davos Forum, the BRICS summit, the Boao Forum for Asia, the G20 Summit, the World Economic Forum, the ASEM Summit, and China-ASEAN Business and Investment Summit during the same time span. All the corresponding interpretations were from the interpreters’ mother tongue (Mandarin Chinese) into their second language (English).
To maximize the consistency of the text content, our corpus was composed of 12 SI input texts and 12 CI input texts, together with their corresponding outputs, without synthesizing all the texts into one. Therefore, all together, we built 24 input networks and the corresponding 24 networks of SI and CI. To ensure comparability and integrality, each text was trimmed to be of similar length without separating a complete paragraph, and the alignment between input and output on the sentence level was also taken into consideration. The summary of the corpus is presented in Table 1.
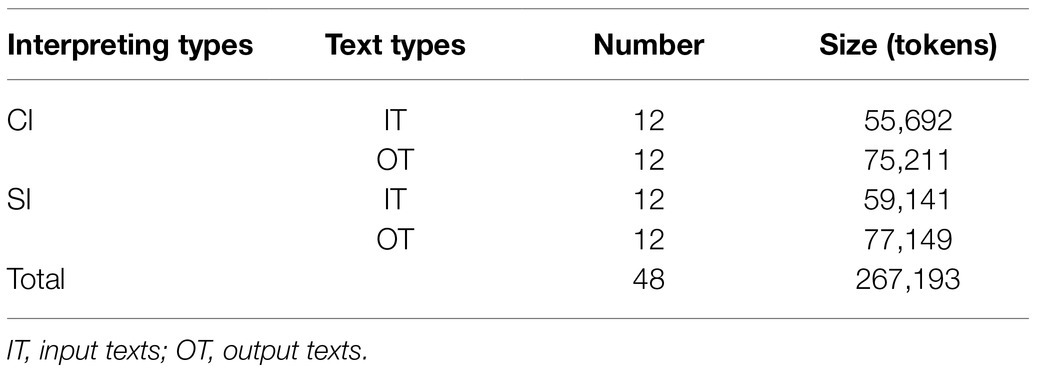
Table 1. Summary of the selected texts in the corpus.
The input speeches in the CI and SI corpus are comparable in the following aspects. First, the input texts of CI and SI were all public speeches delivered on internationally high-level conferences from 2007 to 2018, with equivalent topic areas in political and economic fields. Thus, the source speeches were homogeneous in formality, delivery rate, language register, topic area, and time span. Second, the results of type–token ratio (TTR), an indicator of lexical diversity, showed that no significant difference was observed between CI and SI input speeches (t=−0.775, p=0.447), ensuring the comparability of the input speeches in terms of lexical diversity. Third, as for the syntactic complexity, a previous study of Liang et al. (2017) using an identical corpus computed the mean dependency distance (MDD) of the input speeches and demonstrated that SI and CI input speeches are homogeneous in terms of syntactic complexity. Fourth, regarding the speakers and interpreters, all the speeches were addressed by the Chinese government heads and interpreted by top-level professional interpreters from the Department of Translation and Interpretation of China’s Ministry of Foreign Affairs, and both the CI and SI interpreters were seated at a table or in an interpreting booth during interpreting, ensuring the consistency of the speaking and interpreting style.
The Construction of Networks
The focus of our study is to build the syntactic dependency networks of SI and CI interpreting texts, in which vertices represent the word forms, and edges are syntactic dependencies between them (Liu, 2008a). A syntactic dependency network is usually converted from a dependency-annotated tree bank which is constructed with dependency grammar (Cong and Liu, 2014a). Dependency grammar is a syntactic analysis approach which concerns asymmetric pairwise relations with one of the two-word units as Governor and the other as Dependent (Mel’čuk, 1988). Each pair of relations is indicated by a directed arc pointing from Governor to Dependent with a label of dependency type on the top of the sentence. Given that dependency analysis involves binary relation between two linguistic units (Nivre, 2006; Hudson, 2007), it is more suitable to be employed in the network analysis. From the perspective of the complex network, the dependent and the governor are vertices, and the links of dependency are edges (Liu, 2008a). The analysis of the sentence “The man bought a car” using dependency grammar is illustrated as in Figure 2.
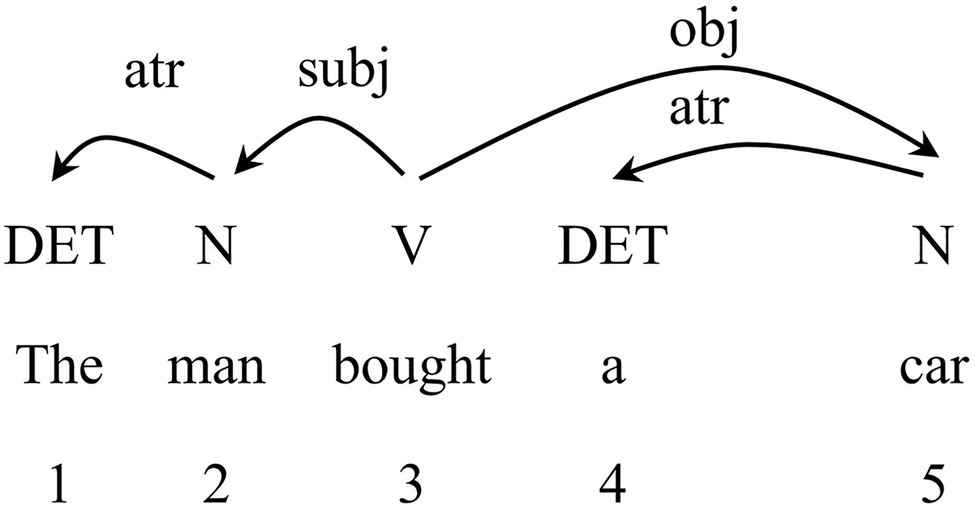
Figure 2. Dependency structure of sample sentence “The man bought a car.”
Treebanks are syntactically annotated corpus based on dependency analysis (Abeillé, 2003), from which the syntactic dependency networks can be constructed. Therefore, to start with, we built a dependency-annotated treebank of authentic speeches based on the input texts and the interpreted texts of SI and CI. The syntactic treebanks were automatically built by Stanford Parser 3.6.0 (Marneffe and Manning, 2008), and the annotation accuracy was manually checked. Then, two columns of words which represent the governors and the dependents were extracted from the treebanks. Hence, the dependency relation of the example sentence extracted from its treebank is displayed in Table 2.

Table 2. Dependency relations of the sample sentence extracted from the treebank.
In this way, a list of binary relations of all the words in each text were generated in the EXCEL which can be easily converted into the net. File format by Createpajek1 (a network converting software). These files were then put into Pajek2 (version 5.06) to construct syntactic dependency networks. The network of the sample sentence built by Pajek is shown in Figure 3. The parameters of each syntactic dependency network were calculated, which would be introduced in the following section.
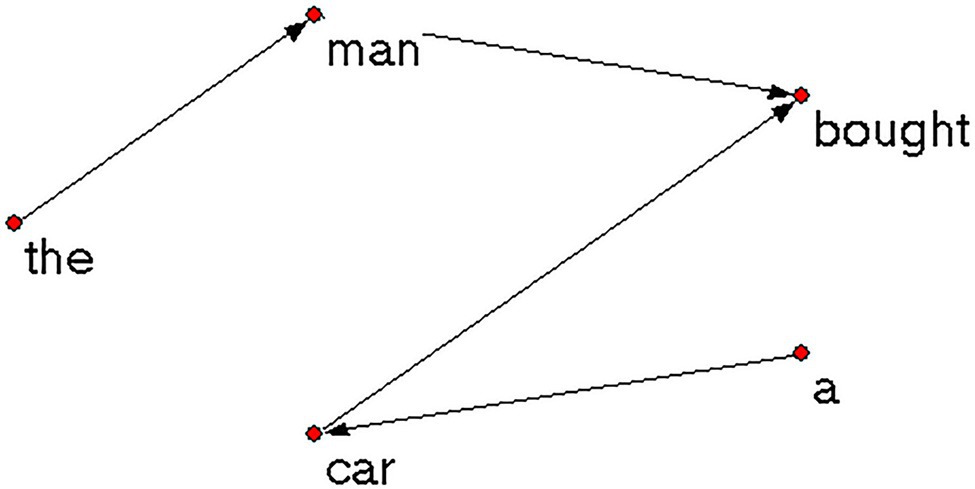
Figure 3. An example of syntactic dependency network.
Network Parameters
A multitude of quantitative measures were adopted to investigate the characterization of complex networks (Newman, 2010; Estrada, 2011). The present study focuses on some commonly used measures of a linguistic network involving degree, average degree, clustering coefficient, average path length, diameter, density, centrality, and small-world and scale-free structures.
In a linguistic network, a vertex’s degree refers to the number of edges which connect to it, representing the connectivity of a linguistic unit in the language sub-system. In a syntactic dependency network, degree denotes the range of a word’s possible dependency connections with other words (Chen et al., 2011). It is a measure for the corresponding word’s combinatorial capacity to form syntactic dependency relations.
The average degree (⟨k⟩) is the mean of degrees of all its vertices, frequently used to estimate any given linguistic unit’s connectivity (number of edges) in the sub-system:
In this formula, N denotes the number of vertices, and ki represents the number of edges of the vertex i in the network.
The clustering coefficient C is defined as a measure of the degree to which the vertices in a network tend to cluster together, or of the patterns of clusters. It reflects the proportion of a node’s neighbors that are themselves neighbors, or the degree to which a cluster’s connectivity is perfect (Cong and Liu, 2014b). The clustering coefficient Ci of a vertex i is formulated as:
The average path length L is the average distance of the shortest path length over all possible pairs of vertices, which represents the degree of separation between a pair of linguistic units:
Diameter D is the maximal shortest path length in a network.
Density (ρ) is defined as “the ratio of the actual number of edges in the network to the maximal possible number of edges (Cong and Liu, 2014a).”
The centrality of a node reflects its importance and authority in the complex network. It is usually defined by different measures, such as degree centrality, betweenness centrality and closeness centrality (Jin and Liu, 2016). Degree centrality quantifies the number of edges which are directly linked to the vertices. Betweenness centrality is calculated by the number of the shortest distance paths passing through a vertex v, which is defined as:
Based on the above-mentioned parameters, the scale-free and small-world properties of a network can be evaluated. The scale-free property is examined by degree distribution which is presented by a distribution function P(k), representing the probability that a randomly chosen node will have degree k.
Generally, the real-world networks have the characteristics of the scale-free feature, that is, the degree distribution of a linguistic complex network follows the power-law formula (Barabási and Albert, 1999; Caldarelli, 2007):
The scale-free feature indicates that only a small number of vertices have extremely high degrees whereas most vertices have rather low degrees (Cong and Liu, 2014a).
The small-world property is evaluated by the relations between the average path length L and the clustering coefficient C of an actual network and those of its corresponding random network which has the same number of vertices and edges as the actual one. If a network satisfies the condition that L~Lrand and C≫Crand , it is a small-world with the feature of a low degree of separation between vertices and high level of clustering (Watts and Strogatz, 1998; Cong and Liu, 2014a). Humphries and Gurney (2008) also define a precise measure of small-worldness which is denoted as:
Small-world networks often have S≫1 (Humphries and Gurney, 2008; Rubinov and Sporns, 2010).
Results
We first checked the equivalence of the text size of inputs by an independent-samples t-test to ensure the comparability of two sets of networks. Then, one-way ANCOVAs were performed to examine the differences of the network parameters between SI and CI by excluding the interference from the input values of the parameters. The values of each input network parameter were used as a covariate, and the interpreting mode was utilized as an independent variable. The values of each output network parameter were adopted as a dependent variable. Furthermore, to investigate the features of the hubs in the two interpreting modes, the proportion of function words in the top-ranking values of centrality was calculated and the differences were evaluated by a Mann–Whitney U test.
The sizes of CI and SI input texts conformed to the normal distribution, and no outlier was detected. The independent-samples t test indicated no significant difference in the sizes of SI and CI input texts, t (22)=−1.954, p>0.05.
Small-World and Scale-Free Properties of SI and CI Networks
To investigate the global characteristics of the output networks, the scale-free and small-world properties, we first observed the cumulative degree distributions of the two types of syntactic dependency networks, respectively, for the evaluation of the scale-free feature. Figures 4, 5 display the cumulative degree distributions (in log–log scales) of SI and CI output networks.
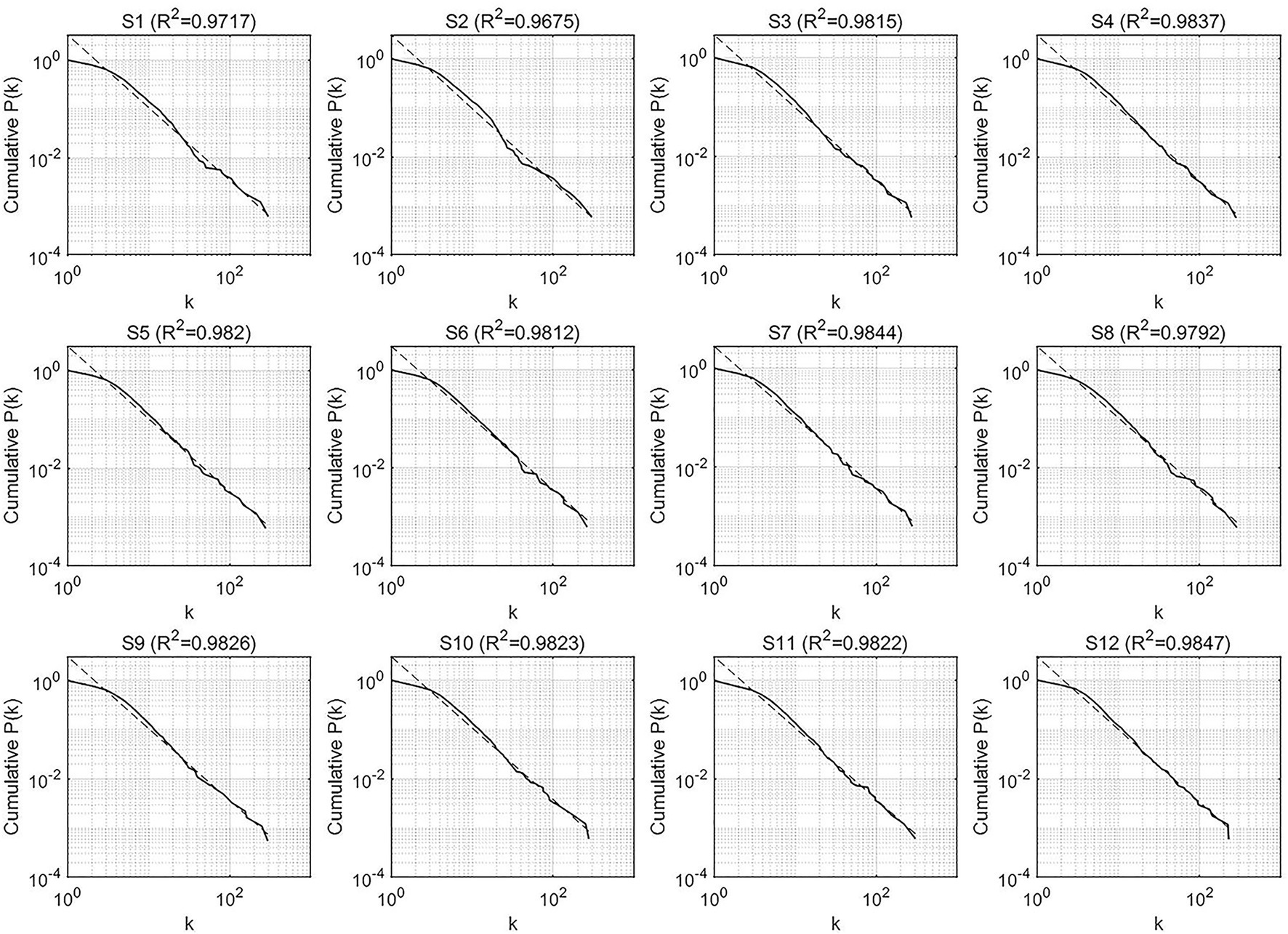
Figure 4. The cumulative degree distributions of the syntactic dependency networks of CI outputs.
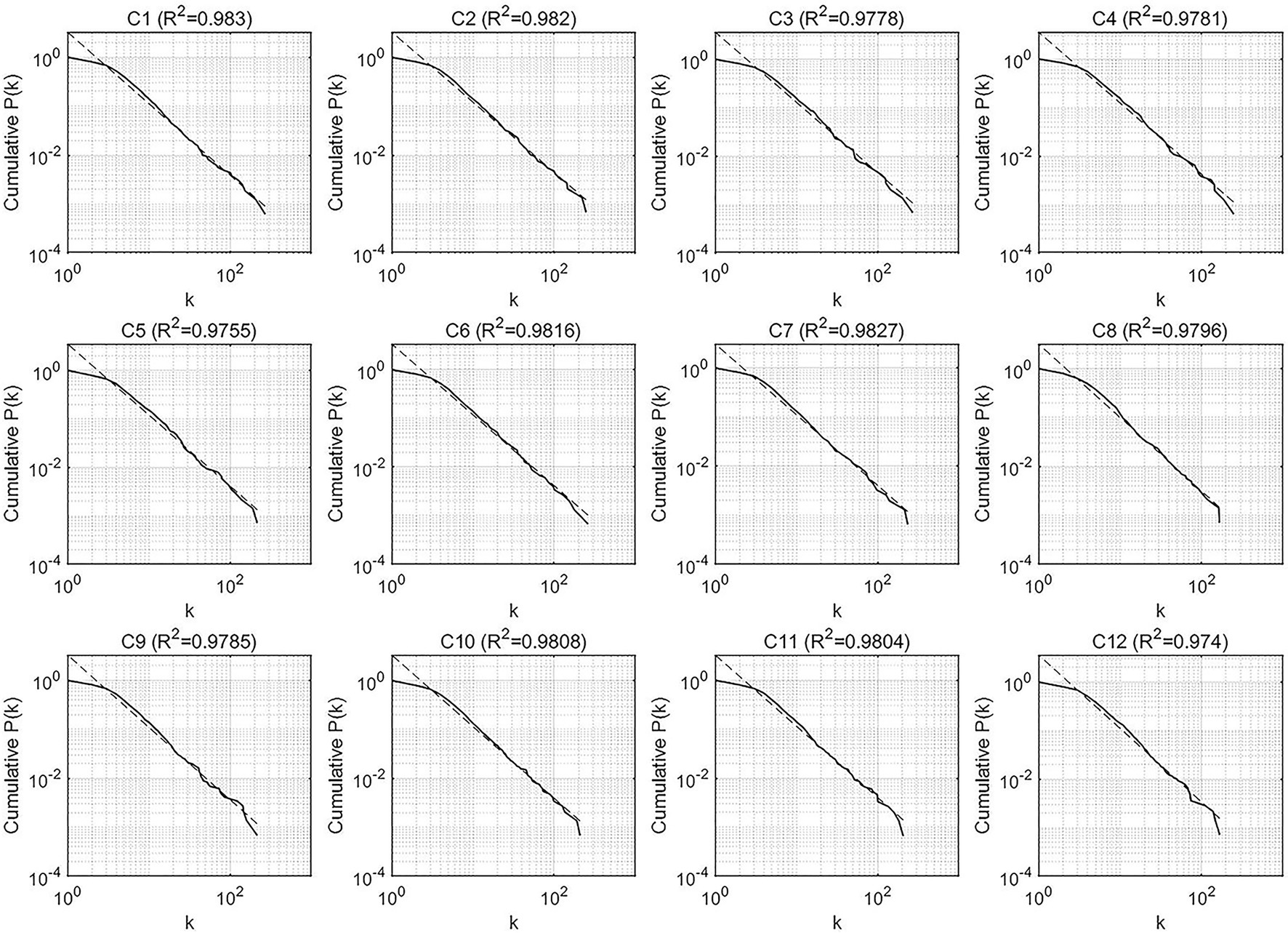
Figure 5. The cumulative degree distributions of the syntactic dependency networks of SI outputs.
Obviously, all the cumulative degree distributions of CI and SI networks followed the power law with all the determination coefficients R2 above 0.9, indicating that the degrees of CI and SI fit the power-law distribution well and all the networks possess the scale-free property.
With regard to the small-world property, the values of average path length and clustering coefficient of the syntactic dependency networks and their corresponding random networks yielded expected results. As is introduced in the previous section, the small-world structure of a complex network is defined by two key parameters: the average path length L and the clustering coefficient C. To determine this property precisely, Crand and Lrand of all networks were calculated first, and then the values of S were obtained. Statistical results of key parameters measuring small-worldness of input and output networks are displayed in Tables 3 and 4, respectively. According to the above-mentioned measure of small-worldness (Humphries and Gurney, 2008), since the values of S of all these networks all satisfied S≫1, all the networks possess the small-world property.
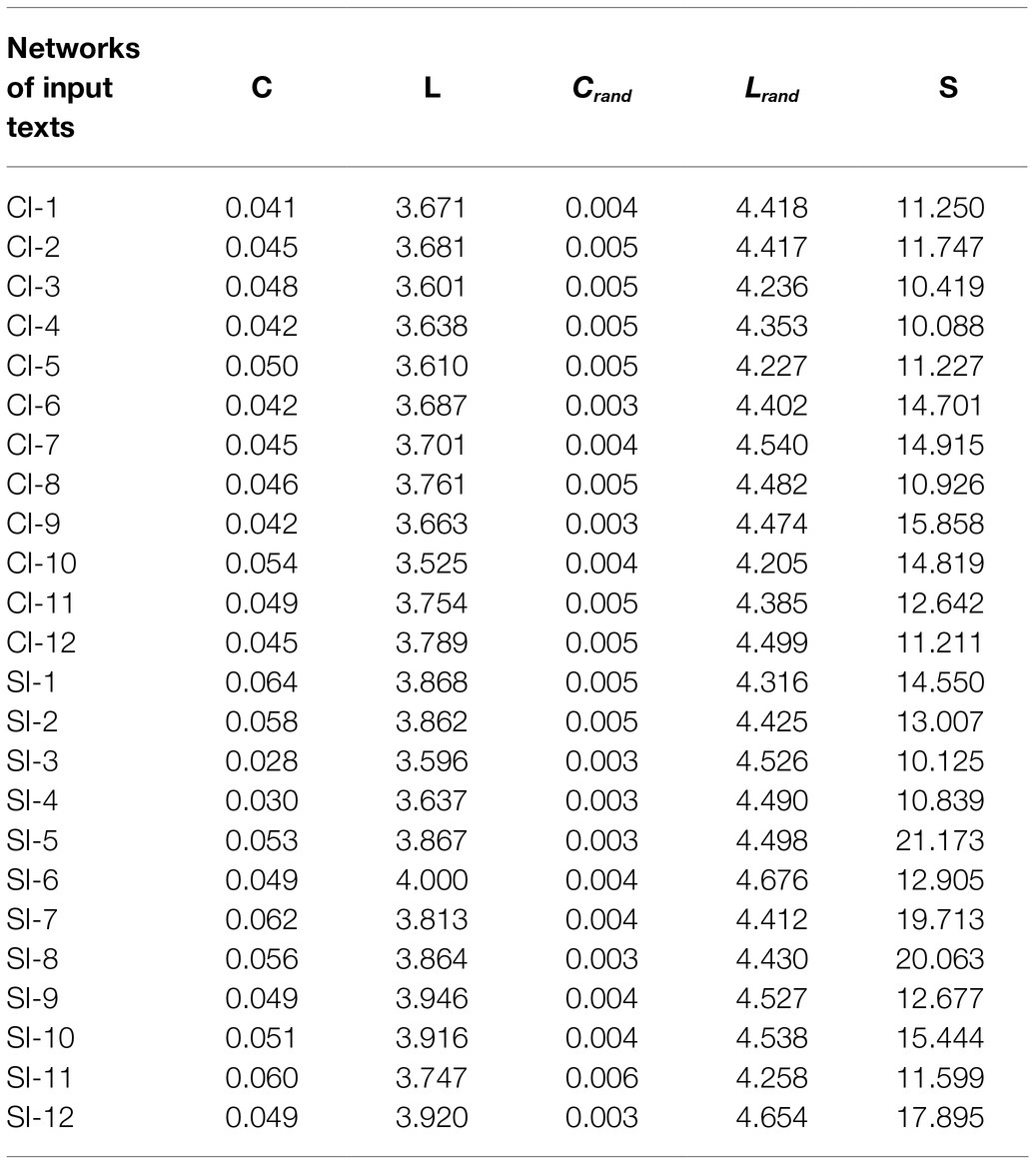
Table 3. Results of key parameters measuring network small-worldness (networks of input texts).
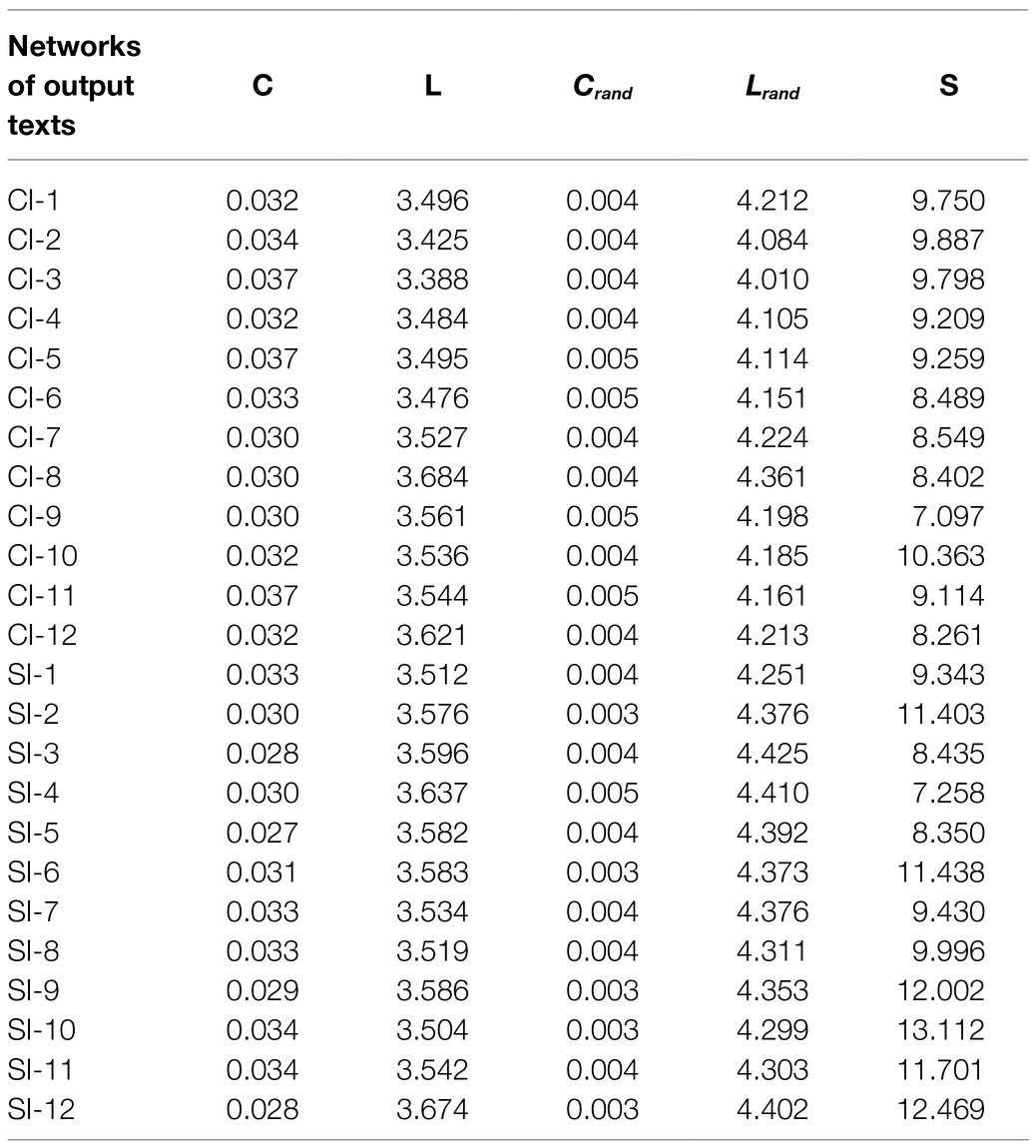
Table 4. Results of key parameters measuring network small-worldness (networks of output texts).
Distinctions in Main Parameters of CI and SI Syntactic Dependency Networks
The values of some common-used parameters of SI and CI dependency networks of inputs and outputs are presented in Appendix I in Supplementary Material. To investigate the discrepancy of CI and SI output network properties by excluding the interference from the input values, a series of one-way ANCOVAs were conducted. As is shown in Table 5, significant differences were observed in the number of vertices (N), F(1,21)=23.675, p<0.001, partial η2=0.53, and the estimated marginal means showed that SI networks had more vertices than CI networks (M=1493.47, SD=19.725 for CI, M=1641.53, SD=19.725 for SI). Significant differences also existed in average degree [<k>; F(1,21)=16.511, p=0.001, partial η2=0.44], clustering coefficient [C; F(1,21)=8.019, p=0.01, partial η2=0.276], density [ρ; F(1,21)=48.166, p<0.001, partial η2=0.696], betweenness centrality [F(1,21)=51.636, p<0.001, partial η2=0.711], and degree centrality [F(1,21)=22.916, p<0.001, partial η2=0.522]. Comparing the estimated marginal means, the results showed that, for parameter <k>, the average degree of CI output networks was significantly larger than that of SI networks (M=6.318, SD=0.06 for CI, M=5.971, SD=0.06 for SI); for parameter C, CI output networks had a larger clustering coefficient than SI (M=0.33, SD=0.01 for CI, M=0.30, SD=0.01 for SI); for parameter ρ, the networks of CI yielded a larger density than SI (M=0.0042, SD=0.00 for CI, M=0.0037, SD=0.00 for SI); and for betweenness centrality and degree centrality, SI was significantly larger than CI (betweenness centrality: M=0.196, SD=0.009 for CI, M=0.297, SD=0.009 for SI; degree centrality: M=0.13, SD=0.006 for SI, M=0.185, SD=0.006 for SI). However, no significant difference of the shortest path length (L; p=0.38) and diameter (D; p=0.479) was observed between SI and CI.
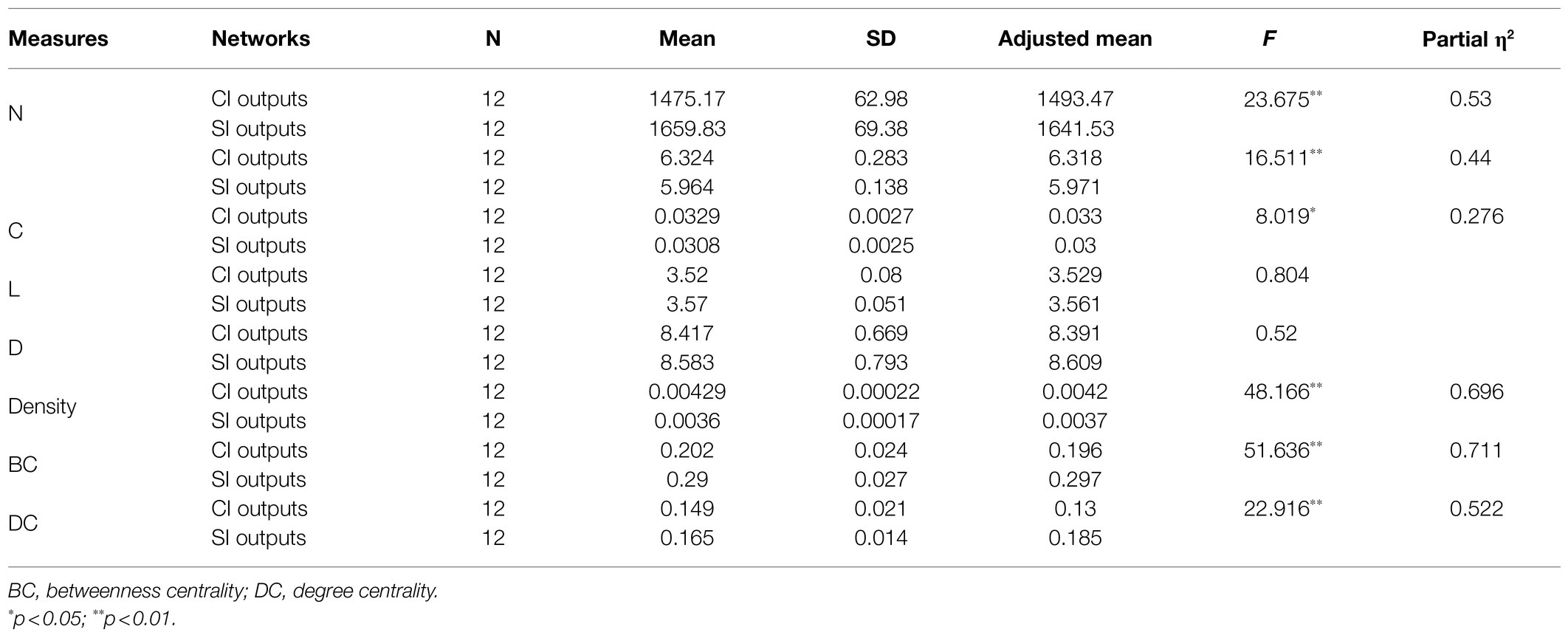
Table 5. Results of ANCOVAs on main parameters of CI and SI output networks.
Characteristics of Central Vertices in SI and CI
The degree centrality and betweenness centrality of SI and CI output networks demonstrated significantly different results, suggesting that distinctions exist in the prominence of vertices in the SI and CI networks from a global perspective. However, the centrality of each vertex, which is a proxy for the combinatorial capacity of a certain linguistic unit behaving as a hub, is also worthy of examination. Vertices with higher centrality behave as the powerful hubs of a network, representing more importance and a stronger combinatorial capacity. It is well documented that, in a syntactic dependency network, the hubs have the tendency to be function words (e.g., articles, conjunctions, and prepositions; Ferrer-i-Cancho and Solé, 2001; Solé et al., 2010), which play an important role in identifying grammatical relationships and the structure of a sentence (Jin and Liu, 2016). In the context of interpreting, the comparison of function words used in the interpreted speech among the highly connective linguistic units between SI and CI may reflect different processing mechanisms and cognitive demand in diverse interpreting modes.
Hence, to probe into the characteristics of central vertices in the networks of SI and CI, we investigated the percentages of function words in the top 20 values of betweenness centrality and degree centrality. The results are shown in Table 6.
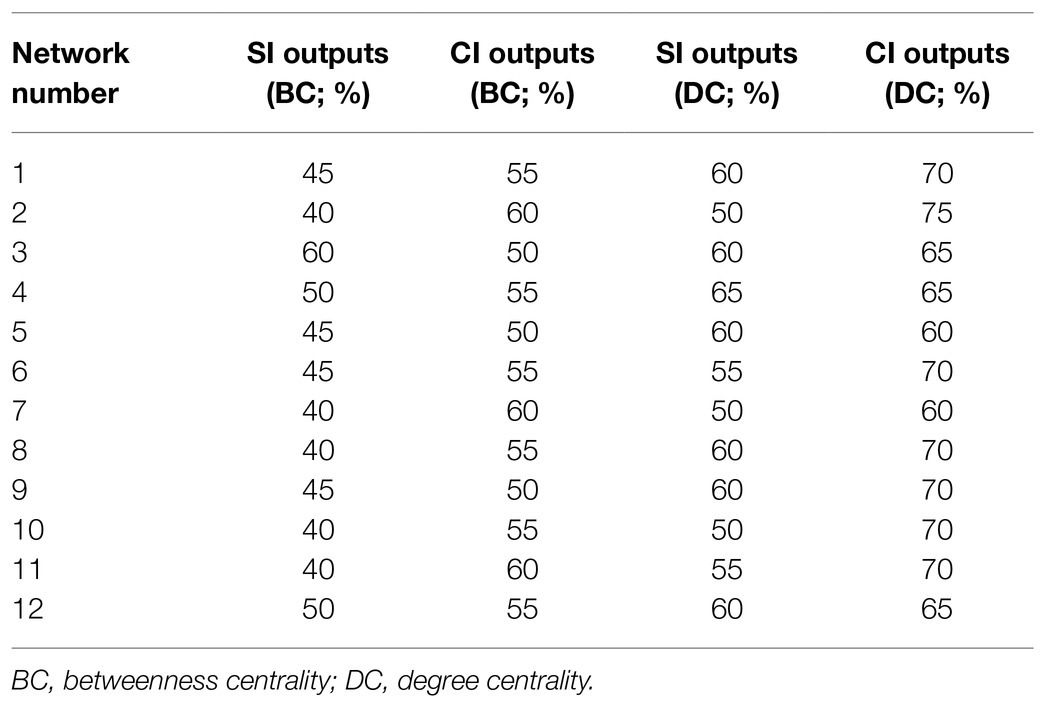
Table 6. The percentages of function words in the top 20 values of betweenness centrality and degree centrality.
The Mann–Whitney U test showed that significant differences existed between SI outputs and CI outputs in both betweenness centrality (p=0.001) and degree centrality (p<0.001). The difference of distribution between CI and SI output texts is illustrated in Figures 6, 7. The percentages of CI outputs were significantly higher than SI outputs for both betweenness centrality and degree centrality.
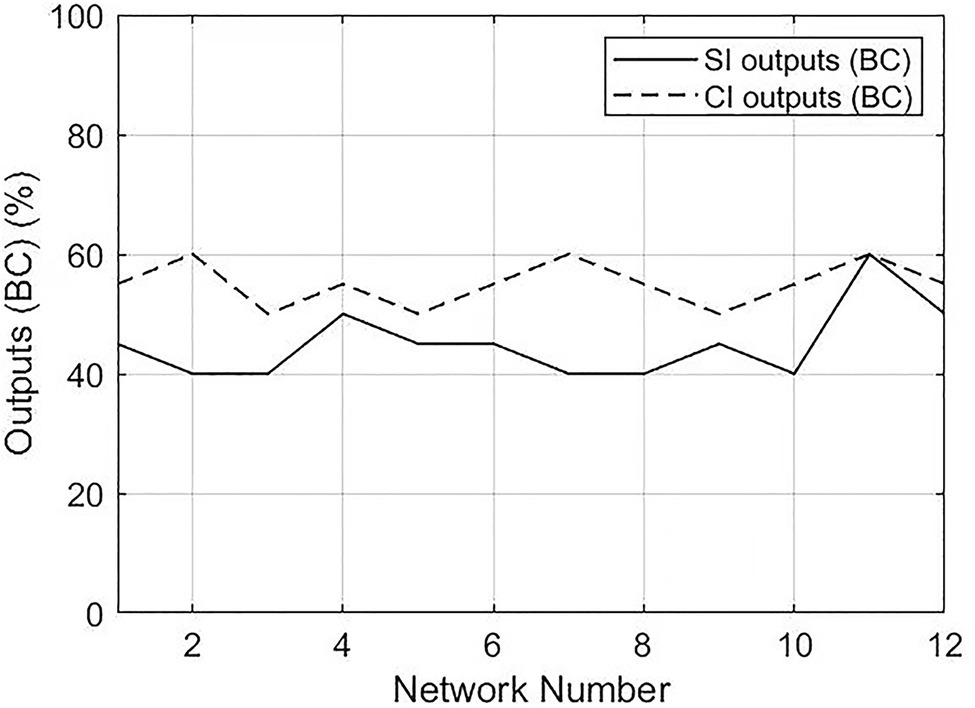
Figure 6. Distributions of percentages of function words in the top 20 values between SI and CI outputs. BC, betweenness centrality.
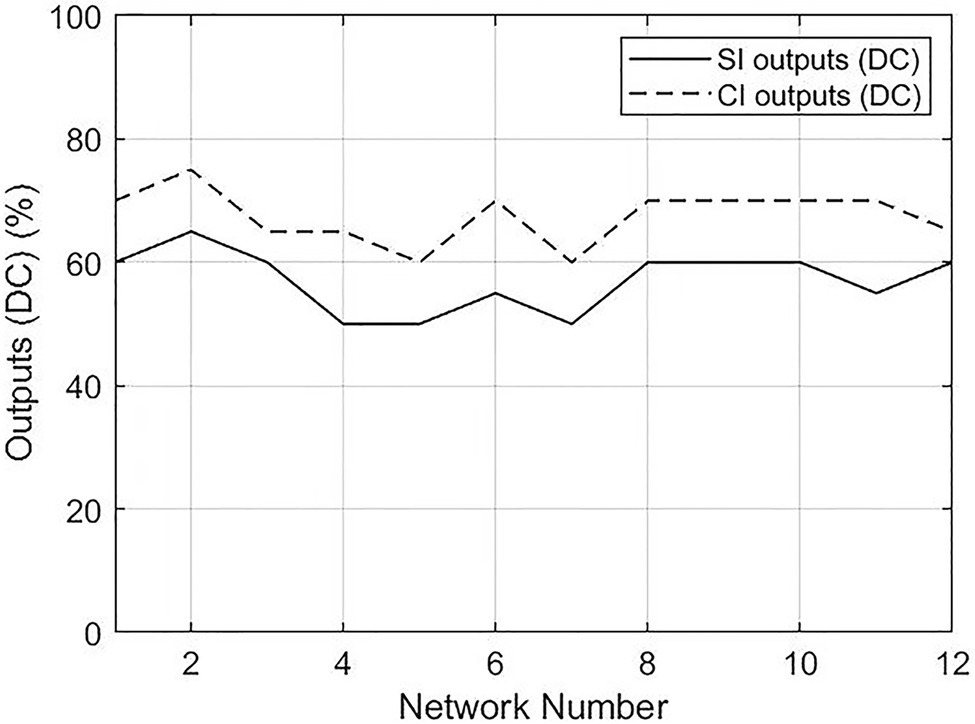
Figure 7. Distributions of percentages of function words in the top 20 values between SI and CI outputs. DC, degree centrality.
Discussion
The current research examined the properties of syntactic dependency networks of SI and CI outputs. To our knowledge, this is the very first effort in quantifying interpreting types by adopting the complex networks approach from a macroscopic perspective, complementing to previous findings pertaining to the features of individual linguistic units.
Our results showed that, firstly, all the networks of SI and CI exhibited the scale-free and small-world properties. The syntactic networks of CI showed higher degrees, clustering coefficients, and density with a larger number of vertices, suggesting that CI has a higher connectivity between vertices and a higher transitivity of information than SI. Second, the parameter of the network centrality can differentiate CI and SI syntactic dependency networks. CI networks demonstrate a more important role of function words among the central vertices than SI networks.
Small-World and Scale-Free Properties of SI and CI Networks
Judging from the observed data, all the networks of SI and CI displayed the small-world properties. According to measurement of small-world structure introduced in the previous section, the small-world structure is determined by clustering coefficient and the shortest path length. The clustering coefficient indicates that two neighbors of a given vertices are also connected to each other. As contrast to the corresponding random networks, real networks with the small-world structures have much greater clustering coefficients (Watts and Strogatz, 1998). Our results indicate that the neighbors of a given vertex are highly interconnected in both SI and CI networks, which promotes the efficiency of transmitting the message from the input language and eases the cognitive burden imposed in the interpreting processes.
Similarly, a network with the small-world structure has a shorter average path length which denotes higher global efficiency of information transmission. In the process of the interpreting production, interpreters have to retrieve the expressions and information stored in the long-term memory as soon as possible as well as comprehending the source message simultaneously. As proposed by Collins and Loftus (1975), the fundamental mechanism of information retrieval in the human mind is spreading activation, and the resources allocated to the activation can be inevitably consumed during the course of spreading. The small-world topology observed in the SI and CI syntactic networks reveals that each pair of vertices can be linked by a small path length, thus minimizing the loss of activation energy and maximizing the success of the information retrieval during the process of interpreting. Moreover, given the associations between the shortest path length and dependency distance (Liu, 2008b), Our findings are also in line with the tendency of minimization of dependency distance in natural language (Liu, 2008b; Futrell et al., 2015; Liu et al., 2017) and adhere to the principle of Least Effort (Zipf, 1949).
The scale-free structure of SI and CI syntactic networks denotes the heterogeneity of connectivity of vertices. Our results showed the power-law-like distribution of degree, suggesting that only a small number of linguistic units have extremely great combinatorial capacity while most vertices have rather low degrees. Hence, the scale-free networks of SI and CI possess the properties of “extreme resilience to random deletion of vertices coupled with extreme sensitivity to the targeted deletion of the most connected vertices” (Albert et al., 2000; Baronchelli et al., 2013).
Furthermore, the non-trivial properties of networks of CI and SI are in line with the findings by Liu (2008a), in which Chinese syntactic dependency networks are observed to exhibit similar patterns. These results converge to reinforce the universality of such network patterns in human languages (Ferrer-i-Cancho et al., 2004; Ferrer-i-Cancho, 2005).
Distinctions in Main Parameters of CI and SI Syntactic Dependency Networks
The disparity of the properties in SI and CI networks can be explicated by cognitive mechanisms during SI and CI and thus have cognitive implications.
The most important findings point to the distinctions between average degree and clustering coefficient of CI and SI. The average degree, on the one hand, denotes the efficiency of a word type being used in the texts. Our results showed that, with a similar size of word tokens, the average degrees of CI networks were significantly larger than SI, suggesting that the same word types are more repeatedly and frequently used in CI networks. This is in line with our result of a lower degree of lexical diversity in CI networks, which provides support for the heavier cognitive load demanded in CI. As postulated by Cowan (1999), working memory is a complex construct which contains activated elements of long-term memory, and the focus of attention is basically capacity limited. In SI, the input information is comprehended in segments, and only the most local content is stored in working memory. The cognitive load for accommodating and processing the chunks of information can instantly be relieved once it is interpreted (Liang et al., 2017). However, CI interpreters need to hold more chunks of information in the focus of attention, and the cognitive load may keep accelerating and accumulating. Additionally, due to limited time of note-taking, CI interpreters can take down only part of information. Thus, the cognitive burden from memorizing long chunks of information and insufficient note-taking information may result in heavier cognitive load in the reformulation phase in CI than in SI. To reduce the processing burden, CI interpreters have an inherent tendency toward using less-varied words.
On the other hand, in the context of a syntactic dependency network, the degree of a given vertex implies the combinatorial capacity of a word to form syntactic dependency relations. The average degree of a whole network reflects the connectivity between linguistic units in the syntactic sub-system (Cong and Liu, 2014a). The higher average degree of CI networks demonstrates the better connectivity and communicating efficiency in CI than SI. Such an efficient organizational sub-system of CI may be due to the accumulation of long chunks of information from the source language before articulating the interpreted speech. A higher average degree of CI networks thus greatly facilitates the understanding of the original message as a whole and enables CI interpreters to reformulate the intended meaning in a comprehensive way. By contrast, the process of SI requires the simultaneity of listening and production. The lag between the hearing of the source speech segment and its corresponding reformulation (the Ear-Voice Span) is much shorter (Gile, 2009). To avoid the potential overloading of memory, interpreters sometimes even shorten the lag to reduce the requirements of short-term memory, which may deprive SI interpreters of adequate understanding and increase the risks of misunderstanding and infelicities such as the incompleteness of the sentence structure and incoherence of the target information (Gile, 2009). In such cases, a smaller volume of information stored in the short-term memory for comprehension may result in lower degree of connectivity in SI output networks, while the overall grasp of intended meaning and the integration of more information segments in CI contributes to the enhancement of connectivity in CI output networks.
As a quantitative measure of transitivity, the clustering coefficient offers another perspective for the understanding of cognitive complexity (Watts and Strogatz, 1998; Baronchelli et al., 2013). The higher clustering coefficient values in CI networks indicate a better transitivity of information in CI than SI, which is consistent with the result of density that the probability of any pair of CI linguistic unit to be involved in a relation is larger than SI. Given the high memory load during CI reformulation phase which has been explicated above, these findings suggest a natural requirement for CI interpreters to lessen cognitive burden by generating less cognitively costly output. The evidence of the association between cognitive costs and clustering coefficient has been presented in several studies (Vitevitch, 2006, 2008; Goldstein and Vitevitch, 2014), among which it has been demonstrated that words with a high clustering coefficient were responded more quickly than words with a low clustering coefficient (Vitevitch, 2006). Hence, in this case, to save more time and energy for the reformulation of the unfolding sentences, CI interpreters are inclined to retrieve words that have more syntactic relations with each other.
The average clustering coefficient of a network is a parameter of local communitization, whereas the average path length is a proxy for macro-scale communitization in a network (Borodkin et al., 2016). The higher clustering in CI networks helps ease the cognitive burden and facilitates the local processing of information segments in CI. It is noted that the average path lengths and diameter of CI and SI networks were similar, suggesting that the two types of networks have no significant difference in terms of the macro-scale communitization. Although the disparity of local processing exists between SI and CI due to various cognitive demands in the processes of interpreting, the global integration of information in the process of SI and CI remains the same in a broader sense.
Besides the average degree and clustering coefficient, several other parameters that distinguish SI and CI are worthy to be discussed. Since the vertices in a syntactic dependency network represent word types, our finding that the number of SI vertices was significantly higher than CI indicates higher degree of vocabulary richness and lexical complexity in SI. This result, on the one hand, might stem from the fact that CI interpreters tend to build a mental map which focuses on interconnections and general architecture of the intended meaning, without much attention to lexical reformulation. This is consistent with previous findings that CI output texts yields more simplified outputs than SI (Lv and Liang, 2019). On the other hand, the differences in lexical complexity might arise from cognitive load. According to the Effort Model (Gile, 2009), interpreting is conceived as comprising functional “efforts” which compete with each other in terms of processing capacity, and thus the increments of one effort will result in the decrements in another. Given that CI interpreters have to maintain a large volume of information segments from the source language, the burden on the memory is constantly accumulating to saturation in the reformulation phase. Moreover, due to the long time lag between listening and production, reformulation during CI is more self-paced and independent from the source structure (Gile, 2005). In this case, CI interpreters may tend to use less sophisticated and more repetitive vocabulary to reduce cognitive efforts (Liang et al., 2017; Lv and Liang, 2019). On the contrary, SI interpreters generally maintain the syntactic structure of source speech due to the simultaneity of perception and production in SI (Bacigalupe, 2010), and the cognitive load for the storage of previous information segments can soon be alleviated (Liang et al., 2017). Thus, lexical access, even of complex words, might be less challenging for the mind than syntactic reformulation in SI.
With regard to the network property of centralization, degree centralization and betweenness centralization can differentiate SI and CI syntactic dependency networks. Degree centralization reflects the degree of variation among the vertices, and betweenness centralization indicates the tendency of a network to exhibit a star-like topology. Here in the present study, a larger degree of variation was observed in SI compared with CI. Among all the vertices in a network, linguistic units with relatively greater connectivity are more important, and these powerful vertices are regarded as hubs (Cong and Liu, 2014a). Convergent evidence suggests that hubs tend to be function (grammatical) words (e.g., Ferrer-i-Cancho and Solé, 2001; Solé et al., 2010; Cong and Liu, 2014a; Jin and Liu, 2016). Given the significance of function words in identifying grammatical relationships as well as its potential to reflect different processing mechanisms and cognitive complexity in diverse interpreting modes, the following section will discuss the proportion of function words in the hubs of SI and CI networks.
Characteristics of Central Vertices in SI and CI
In exploring the characteristics of central vertices, our result showed that the percentages of function words in the hubs of CI networks were higher than SI networks. This indicates a better use and higher importance of function words in the processes of CI, conforming to previous findings that function words are conceived to be more densely distributed in CI than SI output (Liang et al., 2019). The distinction of the proportion of function words among the central vertices in CI and SI networks may be explicated by different processing mechanisms and cognitive complexity in CI and SI.
For SI interpreters, the interpretation begins immediately after the articulation of the original speech, with several units of information stored in the working memory. According to Cowan (1995), the number of units that can be held in the “focus of attention” in working memory is said to be 3 to 4 chunks. Constrained by the limited cognitive resources, the outputs of SI generally follow the structure of the original chunks without much altering the order of the input text segments (Bacigalupe, 2010; Liang et al., 2017, 2019). To minimize the chunks held in the working memory, the SI production needs to be generated in an efficient way, which renders interpreters to give priority to the content words with specific meanings other than the function words which has limited meaning but occupy the cognitive resources in the process of word selections. In this way, not only can the meaning of the source speech achieve the maximum retention, but also the efficient processing of the current information segments reduces the number of items to be held in the working memory and avoids any delay of the processing of subsequent chunks (Mizuno, 2017). Moreover, as suggested by Hatim and Mason (2002), because the reception and production of the text occur almost simultaneously, SI interpreters receive the input in piecemeal, and thus they generally make tentative anticipations of the context and structure. Since these various hypotheses have to be confirmed or disapproved by the incoming detailed information, SI interpreters “rely more heavily on the emerging texture in order to make and maintain sense. In other words, the rich variety of detailed information must be “relied upon the most tangible point of reference” (Hatim and Mason, 2002). The content words, which are variable and rich in meaning, thus outweigh the function words for SI interpreters when handling the production.
By contrast, given the distinctive feature of CI that the utterance of the production has a long time lag after the source speech, interpreters start interpreting when a large proportion of the input information is fully processed, and hence, they can have a holistic comprehension of the original meaning. With longer segments stored in the working memory, CI interpreters tend to discard the linguistic form of the source language and restructure the sentence instead of interpreting in the word-for-word consistency to relieve the pressure (Ouyang, 2018). That means, the extra load on memory makes it hard to retain the detailed information of the texture and context from the input text. To achieve smooth and successful production, CI interpreters generally utilize the manifestation of the detailed information as the means to arrange the structure in a comprehensive manner (Hatim and Mason, 2002). Such a way of relying on the structure in CI outputs indicates that the use of function words is of vital necessity, since function words define and signal sentence structure. As claimed by Gervain et al. (2013), function words act as entry points “with respect to which the structural roles and sequential positions of other constituents can be encoded and remembered.” Consequently, the role of function words in CI is demonstrated to be more significant than in SI. CI interpreters may resort to the function words more frequently than in the SI tasks to produce smooth and coherent outputs with the added pressure on the memory.
Connections Between Complex Network and Cognition
The networks we constructed provide important insights into a deeper understanding of cognition by capturing the interplay between the structure of the underlying networks and cognitive processes operating in interpreting. The small-world structure of SI and CI outputs networks has close associations with the domain of cognition. As claimed by Siew et al. (2019), the small-world structure “may emerge from systematic growth processes that may adapt to environmental constraints to give rise to a beneficial structure.” Considering the context of interpreting which represents a special case of language use under the extreme cognitive load, such a structure may mirror the trade-off effect between the path length among the words and the cost of creating connections between the words. A similar process has been found in the brain networks, and these findings support the view that the small-world structure may offer a quantitative means to optimize the organizational structure (Bullmore and Sporns, 2012). It also provides a vital clue into the representation of the structure of cognitive systems which can maximize the efficiency of interpreting processes under the cognitive constraints and minimize cognitive load of interpreting in the language system. In short, the construction of interpreting networks demonstrates how different types of interpreting tasks mediate the global structural organization of the interpreting outputs to achieve cognitive load minimization. This echoes previous research quantifying interpreting types by language sequence (Liang et al., 2019).
Our results also indicate that the networks of interpreting outputs are inherently dynamic due to different cognitive constraints in various modes of interpreting processes. The properties and representations of interpreting networks vary among different manipulations in the interpreting processes. We posit that the disparate properties between CI and SI networks reflect different cognitive processes operating in interpreting. As is shown in our findings, CI output networks display a better connectivity, more efficient transitivity and higher importance of function words than SI. These results show the convergent evidence of a more efficient organizational sub-system of CI, which may be partly associated with a cognitive load accumulation in CI and a cognitive load relief process in SI. Therefore, our study demonstrates the role of complex network in re-conceptualizing the cognitive processes of complex interpreting tasks as dynamic processes. This novel approach offers an avenue to explore the processing mechanisms of interpreting that lead to cognitive insights.
Furthermore, the measure of complex networks in the current research, together with such a quantitative approach as the calculation of dependency distance (Liang et al., 2017) and the quantification of lexical features in the output interpreting texts (Lv and Liang, 2019) which are adopted in the prior studies, serves as a means to calculate the cognitive processing underlying different types of interpreting tasks. Hence, information processing is an important concept in understanding how interpreting processes operate, and it points toward computing as a fundamental instrumental approach for modeling and exploring cognitive complexity (Cioffi-Revilla, 2014).
In synthesizing the above analyses, our study provides valuable evidence from the domain of interpreting to support the view that the network of interconnected vertices is closely connected with the study of cognition. The complex network offers a unifying framework to investigate different system under the same conceptual lens and facilitates our understanding of cognitive processes (Barabási, 2011; Baronchelli et al., 2013).
Conclusion
In the present study, we examine the properties of syntactic dependency networks of SI and CI outputs. We find that both SI and CI networks exhibit the scale-free and small-world structures, corroborating the universality of such network patterns in human language. Most of the network parameters can discriminate SI and CI networks, and CI networks demonstrate higher degrees, clustering coefficients and density with a larger number of vertices, suggesting a better connectivity, transitivity and a lower degree of vocabulary richness in CI outputs. These may be ascribed to the constant accumulation of memory burden as well as the long chunks of information in the process of CI. In terms of the characteristics of central vertices, our results also reveal the higher importance of function words in the processes of CI, which can be explicated by different underlying mechanisms and cognitive complexity in CI and SI.
Our study offers a valuable integrative framework for the understanding of processing mechanisms during SI and CI, shedding light on interpreting training. Specific strategies can be given to interpreters in reference to distinctive cognitive features and coping mechanisms of a particular interpreting type. The findings also offer insights into the artificial intelligence that cognitive factors can be integrated into the development of the machine translation to approach human cognition.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Author Contributions
YL, DX, and JL conceived and designed the experiments, performed the experiments and data analyses, and collected the data. All authors contributed to the interpretation of results, the writing of the manuscript, and approved the final version of the manuscript for submission.
Funding
This work was partly supported by the National Social Science Foundation of China (Grant No. 17BYY068), the Fundamental Research Funds for the Central Universities of China (Programme of Big Data PLUS Language Universals and Cognition, Zhejiang University), and the Zhejiang Provincial Teaching Reform Project (Grant No. JG20180014).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We would like to thank Matthew Reeve for his help in polishing the language.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2021.590399/full#supplementary-material
Footnotes
1. ^Createpajek can be downloaded from http://vlado.fmf.uni-lj.si/pub/networks/pajek/howto/excel2pajek.htm
2. ^Pajek is used for analysis and visualization of large networks. It can be downloaded from http://mrvar.fdv.uni-lj.si/pajek/default.htm
References
Albert, R., Jeong, H., and Barabási, A. L. (2000). Error and attack tolerance of complex networks. Nature 406, 378–382. doi: 10.1038/35019019
Aparicio, X., Heidlmayr, K., and Isel, F. (2017). Inhibition efficiency in highly proficient bilinguals and simultaneous interpreters: evidence from language switching and stroop tasks. J. Psycholinguist. Res. 46, 1427–1451. doi: 10.1007/s10936-017-9501-3
Bacigalupe, L. (2010). Information processing during simultaneous interpretation: a three-tier approach. Perspectives 18, 39–58. doi: 10.1080/09076760903464278
Barabási, A. L., and Albert, R. (1999). Emergence of scaling in random networks. Science 286, 509–512. doi: 10.1126/science.286.5439.509
Baronchelli, A., Ferrer-I-Cancho, R., Pastor-Satorras, R., Chater, N., and Christiansen, M. H. (2013). Networks in cognitive science. Trends Cogn. Sci. 17, 348–360. doi: 10.1016/j.tics.2013.04.010
Bóna, J., and Bakti, M. (2020). The effect of cognitive load on temporal and disfluency patterns of speech: evidence from consecutive interpreting and sight translation. Targets 32, 482–506. doi: 10.1075/target.19041.bon
Borodkin, K., Kenett, Y., Faust, M., and Mashal, N. (2016). When pumpkin is closer to onion than to squash: the structure of the second language lexicon. Cognition 156, 60–70. doi: 10.1016/j.cognition.2016.07.014
Bullmore, E., and Sporns, O. (2012). The economy of brain network organization. Nat. Rev. Neurosci. 13, 336–349. doi: 10.1038/nrn3214
Caldarelli, G. (2007). Scale-Free Networks: Complex Webs in Nature and Technology. New York, NY: Oxford University Press.
Čech, R., and Mačutek, J. (2009). Word form and lemma syntactic dependency networks in Czech: a comparative study. Glottometrics 19, 85–98.
Čech, R., Mačutek, J., and Liu, H. (2007). Syntactic complex networks and their applications. Under. Complex Syst. 99, 167–186. doi: 10.1007/978-3-662-47238-5_8
Chen, F., Zhou, J., Wang, Y., Yu, K., Arshad, S. Z., Khawaji, A., et al. (2016). Robust Multimodal Cognitive Load Measurement. Switzerland: Springer.
Chen, H., Chen, X., and Liu, H. (2018). How does language change as a lexical network? An investigation based on written Chinese word co-occurrence networks. PLoS One 13:e0192545. doi: 10.1371/journal.pone.0192545
Chen, S. (2017). The construct of cognitive load in interpreting and its measurement. Perspectives 25, 640–657. doi: 10.1080/0907676X.2016.1278026
Chen, X., Liu, H., and Gerdes, K. (2015). “Classifying syntactic categories in the Chinese dependency network.” in Proceedings of the Third International Conference on Dependency Linguistics; August 24–26, 2015; Depling.
Chen, X., Xu, C., and Li, W. (2011). “Extracting valency patterns of word classes from syntactic complex networks.” in Proceedings of the International Conference on Dependency Linguistics. eds. K. Gerdes, E. Hajičová and L. Wanner (Barcelona); September 5–7, 2011, 165–172.
Christoffels, I. K., de Groot, A. M. B., and Kroll, J. F. (2006). Memory and language skills in simultaneous interpreters: the role of expertise and language proficiency. J. Mem. Lang. 54, 324–345. doi: 10.1016/j.jml.2005.12.004
Christoffels, I. K., de Groot, A. M. B., and Waldorp, L. J. (2003). Basic skills in a complex task: a graphical model relating memory and lexical retrieval to simultaneous interpreting. Biling. Lang. Congn. 6, 201–211. doi: 10.1017/S1366728903001135
Cioffi-Revilla, C. (2014). Introduction to Computational Social Science. London and Heidelberg: Springer.
Collins, A. M., and Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychol. Rev. 82, 407–428. doi: 10.1037/0033-295X.82.6.407
Cong, J., and Liu, H. (2014a). Approaching human language with complex networks. Phys. Life Rev. 11, 598–618. doi: 10.1016/j.plrev.2014.04.004
Cong, J., and Liu, H. (2014b). Linguistic complex networks: rationale, application, interpretation, and directions: reply to comments on “approaching human language with complex networks”. Phys. Life Rev. 11, 644–649. doi: 10.1016/j.plrev.2014.09.001
Cowan, N. (1999). “An embedded-processes model of working memory,” in Models of Working Memory: Mechanisms of Active Maintenance and Executive Control. eds. A. Miyake and P. Shah (New York: Cambridge University Press), 62–101.
Cui, X., Qi, J., Tan, H., and Chen, F. (2017). Comparison of ancient and modern Chinese based on complex weighted networks. PLoS One 12:e0187854. doi: 10.1371/journal.pone.0187854
Defrancq, B., and Plevoets, K. (2018). “Over-uh-load, filled pauses in compounds as a signal of cognitive load,” in Making Way in Corpus-Based Interpreting Studies. eds. C. Bendazzoli, M. Russo, and B. Defrancq (Singapore: Springer), 43–64.
Estrada, E. (2011). The Structure of Complex Networks: Theory and Applications. New York: Oxford University Press.
Ferrer-i-Cancho, R. (2005). “The structure of syntactic dependency networks: insights from recent advances in network theory,” in The Problems of Quantitative Linguistics. eds. G. Altmann, V. Levickij, and V. Perebyinis (Chernivtsi: Ruta), 60–75.
Ferrer-i-Cancho, R., and Solé, R. V. (2001). The small world of human language. Proc. Biol. Sci. 268, 2261–2265. doi: 10.1098/rspb.2001.1800
Ferrer-i-Cancho, R., Solé, R. V., and Köhler, R. (2004). Patterns in syntactic dependency networks. Phys. Rev. E 69:051915. doi: 10.1103/PhysRevE.69.51915
Futrell, R., Mahowald, K., and Gibson, E. (2015). Large-scale evidence of dependency length minimization in 37 languages. Proc. Natl. Acad. Sci. U. S. A. 112, 10336–10341. doi: 10.1073/pnas.1502134112
Gervain, J., Sebastian-Galles, N., Diaz, B., Laka, I., Mazuka, R., Yamane, N., et al. (2013). Word frequency cues word order in adults: cross-linguistic evidence. Front. Psychol. 4:689. doi: 10.3389/fpsyg.2013.00689
Gerver, D. (1976). “Empirical studies of simultaneous interpretation: a review and a model,” in Translation, Application and Research. ed. R. W. Brislin (New York, NY: Garden Press), 165–207.
Gile, D. (1985). Le modèle d’efforts et l’équilibre d’interprétation en interprétation simultanée. Meta 30, 44–48. doi: 10.7202/002893ar
Gile, D. (1999). Testing the effort models' tightrope hypothesis in simultaneous interpreting - a contribution. Hermes 23, 153–172.
Gile, D. (2005). “Directionality in conference interpreting: a cognitive view,” in Directionality in Interpreting. The ‘Retour’ or the Native? eds. R. Godijns and M. Hindedael (Ghent: Communication and Cognition), 9–26.
Gile, D. (2009). Basic Concepts and Models for Interpreter and Translator Training. Amsterdam: John Benjamins.
Gile, D. (2016). The Effort Models - Clarifications and update. 2016.01.20 Version. Available at: http://www.researchgate.net/publication/303249990_The_Effort_Models_-_Clarifications_and_update (Accessed August 26, 2021).
Goldstein, R., and Vitevitch, M. S. (2014). The influence of clustering coefficient on word-learning: how groups of similar sounding words facilitate acquisition. Front. Psychol. 5:1307. doi: 10.3389/fpsyg.2014.01307
Goldstein, R., and Vitevitch, M. S. (2017). The influence of closeness centrality on lexical processing. Front. Psychol. 8:1683. doi: 10.3389/fpsyg.2017.01683
Gumul, E. (2021). Explicitation and cognitive load in simultaneous interpreting: product- and process-oriented analysis of trainee interpreters’ outputs. Interpreting 23, 45–75. doi: 10.1075/intp.00051.gum
Hao, Y., Wu, M., and Liu, H. (2021). Syntactic networks of interlanguage across L2 modalities and proficiency levels. Front. Psychol. 12:643120. doi: 10.3389/fpsyg.2021.643120
Hatim, B., and Mason, I. (2002). “Interpreting: a text linguistic approach,” in The Interpreting Studies Reader. eds. F. Pochhacker and M. Shlesinger (London: Routledge), 255–265.
Humphries, M. D., and Gurney, K. (2008). Network `smallworld-ness': a quantitative method for determining canonical network equivalence. PLoS One 3:0002051. doi: 10.1371/journal.pone.0002051
Injoque-Ricle, I., Barreyro, J. P., Formoso, J., and Jaichenco, V. I. (2015). Expertise, working memory and articulatory suppression effect: their relation with simultaneous interpreting performance. Adv. Cogn. Psychol. 11, 56–63. doi: 10.5709/acp-0171-1
Jia, H., and Liang, J. (2020). Lexical category bias across interpreting types: implications for synergy between cognitive constraints and language representations. Lingua 239:102809. doi: 10.1016/j.lingua.2020.102809
Jiang, J., Yu, W., and Liu, H. (2019). Does scale-free syntactic network emerge in second language learning? Front. Psychol. 10:925. doi: 10.3389/fpsyg.2019.00925
Jin, H., and Liu, H. (2016). Chinese writing of deaf or hard-of-hearing students and normal-hearing peers from complex network approach. Front. Psychol. 7:1777. doi: 10.3389/fpsyg.2016.01777
Koshkin, R., Shtyrov, Y., Myachykov, A., and Ossadtchi, A. (2018). Testing the efforts model of simultaneous interpreting: an ERP study. PLoS One 13:e0206129. doi: 10.1371/journal.pone.0206129
Lerner, A., Ogrocki, P. K., and Thomas, P. (2009). Network graph analysis of category fluency testing. Cogn. Behav. Neurol. 22, 45–52. doi: 10.1097/WNN.0b013e318192ccaf
Liang, J., Fang, Y., LV, Q., and Liu, H. (2017). Dependency distance differences across interpreting types: implications for cognitive demand. Front. Psychol. 8:2132. doi: 10.3389/fpsyg.2017.02132
Liang, J., and Lv, Q. (2020). “Converging evidence in empirical interpreting studies: peculiarities, paradigms and prospects,” in New Empirical Perspectives on Translation and Interpreting. eds. L. Vandevoorde, J. Daems, and B. Defrancq (New York, NY: Routledge), 303–332.
Liang, J., Lv, Q., and Liu, Y. (2018). Interpreting as a mirror for language foundations: comment on “rethinking foundations of language from a multidisciplinary perspective” by T. Gong et al. Phys. Life Rev. 26-27, 139–141. doi: 10.1016/j.plrev.2018.06.002
Liang, J., Lv, Q., and Liu, Y. (2019). Quantifying interpreting types: language sequence mirrors cognitive load minimization in interpreting tasks. Front. Psychol. 10:285. doi: 10.3389/fpsyg.2019.00285
Lin, Y., Lv, Q., and Liang, J. (2018). Predicting fluency with language proficiency, working memory, and directionality in simultaneous interpreting. Front. Psychol. 9:1543. doi: 10.3389/fpsyg.2018.01543
Liu, H. (2008a). The complexity of Chinese syntactic dependency networks. Phys. A: Stat. Mech. Appl. 387, 3048–3058. doi: 10.1016/j.physa.2008.01.069
Liu, H. (2008b). Dependency distance as a metric of language comprehension difficulty. J. Cogn. Sci. 9, 159–191. doi: 10.17791/jcs.2008.9.2.159
Liu, H., and Xu, C. (2011). Can syntactic networks indicate morphological complexity of a language? EPL 93:28005. doi: 10.1209/0295-5075/93/28005
Liu, H., Xu, C., and Liang, J. (2017). Dependency distance: a new perspective on syntactic patterns in natural languages. Phys. Life Rev. 21, 171–193. doi: 10.1016/j.plrev.2017.03.002
Lv, Q., and Liang, J. (2019). Is consecutive interpreting easier than simultaneous interpreting? – a corpus-based study of lexical simplification in interpretation. Perspectives 27, 1–16. doi: 10.1080/0907676X.2018.1498531
Marneffe, M., and Manning, C. (2008). Stanford Typed Dependencies Manual. Available at: http://nlp.stanford.edu/software/dependencies_manual.pdf (Accessed September 5, 2016).
Mel′čuk, I. A. (1988). Dependency Syntax: Theory and Practice. Albany: State University of New York Press.
Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychol. Rev. 63, 81–97. doi: 10.1037/h0043158
Ouyang, Q. (2018). Assessing meaning-dimension quality in consecutive interpreting training. Perspectives 26, 196–213. doi: 10.1080/0907676X.2017.1369552
Paas, F. G. W. C., and Van Merriënboer, J. J. G. (1994). Instructional control of cognitive load in the training of complex cognitive tasks. Educ. Psychol. Rev. 6, 351–371. doi: 10.1007/BF02213420
Padilla, P., Bajo, M. T., Cañas, J. J., and Padilla, F. (1995). “Cognitive processes of memory in simultaneous interpretation,” in Topics in Interpreting Research. ed. J. Tommola (Turku, Finland: University of Turku), 61–72.
Plevoets, K., and Defrancq, B. (2016). The effect of informational load on disfluencies in interpreting A corpus-based regression analysis. Transl. Interpret. Stud. 11, 202–224. doi: 10.1075/tis.11.2.04ple
Plevoets, K., and Defrancq, B. (2018). The cognitive load of interpreters in the European Parliament: a corpus-based study of predictors for the disfluency uh(m). Interpreting 20, 1–28. doi: 10.1075/intp.00001.ple
Pöchhacker, F. (2011). “Consecutive interpreting,” in The Oxford Handbook of Translation Studies. eds. K. Malmkjær and K. Windle (New York, NY: Oxford University Press), 201–209.
Rubinov, M., and Sporns, O. (2010). Complex network measures of brain connectivity: uses and interpretations. NeuroImage 52, 1059–1069. doi: 10.1016/j.neuroimage.2009.10.003
Saussure, F. D. (2001). A Course in General Linguistics. trans.
Seeber, K. G. (2011). Cognitive load in simultaneous interpreting: existing theories — new models. Interpreting 13, 176–204. doi: 10.1075/intp.13.2.02see
Seeber, K. G., and Kerzel, D. (2012). Cognitive load in simultaneous interpreting: model meets data. Int. J. Biling. 16, 228–242. doi: 10.1177/1367006911402982
Shao, Z. M. Z., and Chai, M. J. (2020). The effect of cognitive load on simultaneous interpreting performance: an empirical study at the local level. Perspectives 28, 1–17. doi: 10.1080/0907676X.2020.1770816
Siew, C. (2018). The orthographic similarity structure of English words: insights from network science. Appl. Netw. Sci. 3:13. doi: 10.1007/s41109-018-0068-1
Siew, C. S., Wulff, D. U., Beckage, N. M., and Kenett, Y. N. (2019). Cognitive network science: a review of research on cognition through the lens of network representations, processes, and dynamics. Complexity [Preprint].
Solé, R. V., Corominas-Murtra, B., Valverde, S., and Steels, L. (2010). Language networks: their structure, function, and evolution. Complexity 15, 20–26. doi: 10.1002/cplx.20305
Steyvers, M., and Tenenbaum, J. B. (2005). The large-scale structure of semantic networks: statistical analyses and a model of semantic growth. Cogn. Sci. 29, 41–78. doi: 10.1207/s15516709cog2901_3
Sudarshan Iyengar, S. R., Veni Madhavan, C. E., Zweig, K. A., and Natarajan, A. (2012). Understanding human navigation using network analysis. Top. Cogn. Sci. 4, 121–134. doi: 10.1111/j.1756-8765.2011.01178.x
Tzou, Y. Z., Eslami, Z. R., Chen, H. C., and Vaid, J. (2012). Effect of language proficiency and degree of formal training in simultaneous interpreting on working memory and interpreting performance: evidence from mandarin–English speakers. Int. J. Biling. 16, 213–227. doi: 10.1177/1367006911403197
Vitevitch, M. S. (2006). The clustering coefficient of phonological neighborhoods influences spoken word recognition. J. Acoust. Soc. Am. 120:3252. doi: 10.1121/1.4788314
Vitevitch, M. S. (2008). What can graph theory tell us about word learning and lexical retrieval? J. Speech Lang. Hear. Res. 51, 408–422. doi: 10.1044/1092-4388(2008/030)
Watts, D. J., and Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature 393, 440–442. doi: 10.1038/30918
Keywords: interpreting types, holistic features, complex networks, cognitive load, interpreting mechanisms
Citation: Lin Y, Xu D and Liang J (2021) Differentiating Interpreting Types: Connecting Complex Networks to Cognitive Complexity. Front. Psychol. 12:590399. doi: 10.3389/fpsyg.2021.590399
Edited by:
Sidarta Ribeiro, Federal University of Rio Grande do Norte, BrazilReviewed by:
Jianlong Zhou, University of Technology Sydney, AustraliaWeiwei Wang, Guangdong University of Foreign Studies, China
Shuxian Song, China University of Petroleum, China
Copyright © 2021 Lin, Xu and Liang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Junying Liang, anlsZXVuZ0B6anUuZWR1LmNu; Duo Xu, aGVucnl4dTU5QDE2My5jb20=