 Tim Zee
Tim Zee Louis ten Bosch
Louis ten Bosch Ingo Plag
Ingo Plag Mirjam Ernestus1
Mirjam Ernestus1- 1Centre for Language Studies, Radboud University, Nijmegen, Netherlands
- 2Department of English Language and Linguistics, Heinrich Heine University, Düsseldorf, Germany
A growing body of work in psycholinguistics suggests that morphological relations between word forms affect the processing of complex words. Previous studies have usually focused on a particular type of paradigmatic relation, for example the relation between paradigm members, or the relation between alternative forms filling a particular paradigm cell. However, potential interactions between different types of paradigmatic relations have remained relatively unexplored. This paper presents two corpus studies of variable plurals in Dutch to test hypotheses about potentially interacting paradigmatic effects. The first study shows that generalization across noun paradigms predicts the distribution of plural variants, and that this effect is diminished for paradigms in which the plural variants are more likely to have a strong representation in the mental lexicon. The second study demonstrates that the pronunciation of a target plural variant is affected by coactivation of the alternative variant, resulting in shorter segmental durations. This effect is dependent on the representational strength of the alternative plural variant. In sum, by exploring interactions between different types of paradigmatic relations, this paper provides evidence that storage of morphologically complex words may affect the role of generalization and coactivation during production.
1. Introduction
Most psycholinguistic accounts of lexical processing agree that the comprehension and production of a word form can be affected by its morphological relations with other word forms (see, for example, the recent overview in Arndt-Lappe and Ernestus, 2020). In very general terms, two words can be seen as morphologically related if they share phonological features that also reflect a similarity in meaning. Broadly, two types of morphological relations can be distinguished: relations between words that share a base (e.g., burn and burned) and relations between words with shared inflectional or derivational exponence (e.g., burned and cared). In this paper, we will refer to the former as relations within paradigms and to the latter as relations between paradigms. We will make a further distinction between two types of within-paradigm relations: those between the base and a complex form (e.g., burn and burned), and those between two alternative forms (e.g., burned and burnt). Previous psycholinguistic studies on morphological relations have mostly focused on how the different relation types individually affect word processing (e.g., Ernestus and Baayen, 2003 for between-paradigm relations; Hay, 2001 for base-complex relations; Cohen, 2015 for relations between alternatives). Potential interactions between these different types of paradigmatic relations have remained relatively unexplored (but see Milin et al., 2009). In the current research, we will use Dutch plurals to investigate the potentially interacting effects of between- and within-paradigm relations. In doing so, we aim to contribute to a more complete understanding of the mechanisms of generalization, storage and coactivation that are involved in the processing of complex words.
Most Dutch plural nouns are inflected for number by suffixing the singular base form with either of the two regular suffixes -en and -s. In addition, a few plurals are formed with irregular suffixes such as -eren or -a. As noted by dictionaries (e.g., Van Dale, 2020) and textbooks on Dutch morphology (e.g., de Haas and Trommelen, 1993), for certain nouns more than one suffix is acceptable: artikel “article” can be inflected as both artikels and artikelen, and both keuzes and keuzen are acceptable plurals of keuze “choice.” Although some of this variability can be attributed to differences in modality (Kürschner, 2009), register (Baayen et al., 2002) and dialect (Goeman et al., 2005), different plural forms of the same noun can be found in a single utterance, see (1) which was taken from Wilde Haren De Podcast (2019).
(1) de piramides van Gizeh, hè, de drie bekende ‘the pyramids of Giza, right, the three famous piramiden
pyramids’
Baayen et al. (2002) argue that this type of variation occurs when the factors that govern the allomorphy within the Dutch plural system are inconclusive. For instance, most accounts of the Dutch plural agree that the distribution of -en, pronounced /ə(n)/, vs. -s, pronounced /s/, seems to reflect a prosodic preference for a word-final disyllabic trochee. As a result, most nouns with an unstressed final syllable, e.g., bakker /ˈbɑkər/, are pluralized with -s, whereas most nouns ending in a stressed syllable are pluralized with -en, e.g., dier /ˈdir/. However, if a singular noun already ends in schwa, e.g., piramide /ˌpiraˈmidə/, the -en suffix is simplified to -n, such that adding either suffix would result in a word-final trochee and, as a result, an acceptable plural (Kürschner, 2009). Variation may also occur when two factors are in conflict. For instance, the phonological generalization that nouns ending in stressed vowels have the plural suffix -s sometimes conflicts with the preference for a trochee. This may explain the variation in the plural of the noun individu /ˌɪndiviˈdy/: individu's and individuen. In sum, previous discussions of Dutch variable plurals suggest that two alternative forms may exist as a consequence of the application of non-deterministic phonological generalizations. However, we will argue that storage and coactivation mechanisms might also be expected to affect the production of variable plurals, given the different paradigmatic relations that apply to variable plurals. As such, Dutch variable plurals provide an excellent opportunity to investigate how different types of paradigmatic relations interact.
1.1. Paradigmatic Relations
Dutch variable plurals are a suitable phenomenon to illustrate how between-paradigm relations may affect morphological processing. The morpho-phonological patterns that, according to Baayen et al. (2002), govern both the distribution of invariable and variable Dutch plurals can be seen as generalizations among noun paradigms. In fact, these between-paradigm generalizations can be explicitly modeled using the mechanism of analogy. For instance, in order to produce the plural form of vampier “vampire,” generalization by analogy relies on morpho-phonological similarities to singular base forms from other paradigms such as pionier “pioneer” and generalizes their plural forms, i.e., pioniers, to the original base form, resulting in vampiers. An advantage of such an analogical approach is that the production of variation is built-in: the plural of vampier can also be generalized from the papier-papieren “paper(s)” paradigm, resulting in vampieren, which is also an acceptable form. Previous work has shown that computational analogical models accurately predict the variation observed for various phonological and morphological phenomena, and affix choice in particular (e.g., Krott et al., 2001; Wulf, 2002; Ernestus and Baayen, 2003; Keuleers et al., 2007; Arndt-Lappe, 2014). Although analogical models elegantly predict the occurrence of many affixed forms that would be classified as exceptions in categorical rule-based models, analogical mechanisms are not completely successful in their predictions either. The model implemented by Keuleers et al. (2007) shows that inaccurate predictions also exist for Dutch plurals. Although this model improved on the performance of a deterministic rule-based model, it still attributed the wrong allomorph to around 9% of the plural forms they considered. This suggests that not every Dutch plural form can be predicted from between-paradigm relations.
It has been argued that the influence of between-paradigm relations on lexical processing is limited for word forms with high token frequencies (e.g., Bybee, 1995). The reasoning behind this claim is that repeated exposure to a word form results in a strong representation which is easier to access directly, compared to weaker representations of infrequent word forms, which may be easier to process by generalization from related word forms (e.g., Divjak and Caldwell-Harris, 2019). Such storage effects might affect the distribution of morphological structure in a language. For example, Bybee (1995) argues that the irregular past tense in English tends to occur in frequent verbs because their strong representations have resisted the generalization from phonologically similar regular past tense forms (see also Cuskley et al., 2014). This suggests that absolute token frequency is a measure of representational strength. However, some studies (Hay, 2001, 2007; Blumenthal-Dramé, 2012) have claimed that representational strength of complex forms is best measured as the token frequency of the complex word relative to its base word. Hay (2001) observes that models of lexical processing which incorporate both computation and whole-word access involve some type of competition between whole-word representations and representations of the base (e.g., Baayen et al., 1997b). It follows, according to Hay (2001), that relative frequency between these forms, rather than absolute frequency of the complex form, is a better predictor of the degree to which complex representations are accessed directly in lexical processing. Psycholinguistic evidence for this base-complex frequency relation has come from studies on derived words (e.g., Hay, 2001, 2007; Blumenthal-Dramé, 2012) in addition to findings from plural inflection (e.g., Baayen et al., 1997a,b, 2003; New et al., 2004; Biedermann et al., 2013; Beyersmann et al., 2015). For instance, Baayen et al. (1997b) showed that Dutch singular nouns are processed faster than their plural inflections but only if they are singular-dominant, i.e., if the singular forms are more frequent than the corresponding plurals. These findings have led researchers to posit that processing of singular-dominant plurals often requires computation based on the singular, resulting in slower and less accurate processing (Beyersmann et al., 2015). Conversely, in a picture naming study, Baayen et al. (2008) concluded that shorter production latencies for Dutch plural-dominant plurals may reflect that their production is less dependent on analogical generalization. In sum, the base-complex frequency relation has been argued to mediate between distinct processing mechanisms: direct activation of a representation vs. some form of generalization, be it through rules or analogy.
Within-paradigm frequency relations have also been found to affect the phonetic realization of morphologically complex words. For instance, Cohen (2014) found that when speakers read aloud sentences like The choir for the church services seems nervous, the verb agreement suffix -s was longer if the 3rd person singular form (e.g., seems) was frequent compared to the uninflected form (e.g., seem). Various studies have found similar phonetic enhancement of complex words with a higher frequency relative to one or more members of their paradigm (Kuperman et al., 2007; Schuppler et al., 2012; Bell et al., 2020; Tomaschek et al., 2021b, but see Hanique and Ernestus, 2012). This so-called paradigmatic enhancement effect has been argued to occur when the choice between multiple paradigm members is probabilistic (Kuperman et al., 2007). However, studies vary considerably with regard to the paradigm members they deem to contribute to this effect. In the current research, we will follow Cohen (2014) and Cohen (2015) by only considering the paradigmatic enhancement effect associated with the frequency relation between paradigm members that are allowed by the syntactic context and that result in a very similar meaning. We can illustrate such paradigmatic alternatives using Dutch variable plurals: in De drie bekende piramides/piramiden “the three famous pyramids,” both plurals are allowed by the syntactic context and the resulting semantics are very similar (if they differ at all). If paradigmatic enhancement applies to Dutch variable plurals we would expect the frequency ratio between plural variants to affect their pronunciation.
Paradigmatic enhancement can be formulated in terms of probability: words with a higher paradigmatic probability have more enhanced pronunciations. In that light, paradigmatic enhancement is a surprising effect, given many previous studies which show that increased probability of a linguistic structure generally results in reduced pronunciations. For instance, it has been shown that contextually probable segments (e.g., van Son and Pols, 2003), syllables (e.g., Aylett and Turk, 2006), and words (e.g., Bell et al., 2009) are reduced in terms of duration and/or spectral qualities. Moreover, there is even some evidence that increased probability of a complex word relative to its base results in reduced pronunciation (Hay, 2001). This tendency to reduce predictable units can be explained from a communicative perspective if we assume that speakers reduce elements that contribute less to listener comprehension (e.g., Aylett and Turk, 2004). In addition to this listener-oriented account, an alternative, potentially better supported (Bell et al., 2009; Ernestus, 2014), speaker-driven account of reduction has been proposed. In such an account, the reduction of predictable words can be explained using two mechanisms that are relevant to the current study. Firstly, it has been proposed that representations of more predictable words are easier to access, which allows for faster articulation (e.g., Bell et al., 2009). Secondly, the reduction of high probability words can been explained as a direct result of practicing the same articulations over and over (e.g., Bybee and Hopper, 2001). Neither of these mechanisms, however, predicts paradigmatic enhancement, which seems to require a different explanation.
The first detailed theoretical account of paradigmatic enhancement is given by Cohen (2015), who adopts an exemplar theoretic approach (e.g., Goldinger, 1998) in which the pronunciation of a word is codetermined by all exemplars that are activated during production (e.g., Walsh et al., 2010). According to Cohen (2015), during lexical access, multiple representations of paradigmatically related words may be activated. This coactivation is mediated by the linguistic context, which means that paradigm members that are contextually plausible are activated more strongly. For example, in the Dutch sentence de antilopen/antilopes rennen “the antelopes are running,” both the -en and the -s form are allowed, and, as a result, activation of the -s form may lead to coactivation of the -en form. Importantly, the degree to which the exemplars of the coactivated form contribute to the pronunciation of the word depends on the number of exemplars of each activated form, i.e., how often the speaker has encountered the respective forms. For instance, the pronunciation of the -s suffix in Dutch antilopes might be strongly influenced by antilopen exemplars because the -en form is much more frequent for this noun. Cohen (2015) argues that the nature of this influence can be predicted by comparing the target pronunciation and the coactivated pronunciation. In our example, final [s] in the target pronunciation [ɑntilopəs] would be reduced because the coactivated pronunciation [ɑntilopə] does not have a final [s] (the /n/ in the -en suffix is usually omitted). However, if the target form, e.g., piramides, is more frequent than the coactivated form, piramiden, we would expect the [s] in the target pronunciation to be less reduced. According to this account, then, paradigmatic enhancement reflects a relative lack of reduction due to the relative infrequency of coactivated word forms. While direct phonetic influence of the coactivated variants on pronunciation works for this example and the phenomena described by Cohen (2014) and Cohen (2015), it does not explain other manifestations of paradigmatic enhancement (e.g., Tomaschek et al., 2021b). It may also be that coactivation of paradigmatic alternatives indirectly disrupts articulation of the target form. Bell et al. (2020) propose that enhancement of a particular segment depends on the amount of activation available for its articulation, which in turn is decreased by paradigmatic alternatives with a different (or no) segment in the same position. In such an account, a strong representation of an alternative plural variant would take away activation from the articulation of final [s], resulting in reduced pronunciation. Regardless of the precise implementation of reduction, an account in which articulation is affected by coactivated representations of paradigmatic alternatives may explain why produced forms with higher frequencies relative to paradigmatic alternatives have less reduced pronunciations.
1.2. Interactions Between Paradigmatic Relations
While it has been shown that base-complex relations and relations between paradigmatic alternatives affect production, it is unknown whether these different within-paradigm relations interact with each other. Such an interaction might be expected given previous theoretical assumptions about the respective relations. The first assumption is that the base-complex frequency relation (e.g., piramide-piramides) reflects the representational strength of complex words (e.g., Hay, 2001). Whether this assumption applies to Dutch variable plurals is tested separately in our Study 1. The second assumption (as proposed by Cohen, 2015) is that the degree of paradigmatic enhancement depends on the representational strengths of the produced form (e.g., piramides) and the co-activated alternative form (e.g., piramiden). If we apply the definition of representational strength in the first assumption to the second assumption, a hypothesis can be constructed about how paradigmatic enhancement should be affected by an interaction between base-complex relations and relations among paradigmatic alternatives. The first assumption implies that the greatest disparity in representational strength between paradigmatic alternatives can be found if one alternative (A1) is much more frequent than the base form (B) whereas the other alternative (A2) is much less frequent compared to the base (i.e., A2 < B < A1). According to the second assumption, we would expect to see a strong paradigmatic enhancement effect in this case. Conversely, if both alternatives are much less frequent than the base (i.e., A1, A2 < B), we would not expect to see a strong paradigmatic enhancement effect. In terms of processing mechanisms, this means that a paradigmatic enhancement effect would not be expected to surface if production of paradigmatic alternatives might be mostly computational, i.e., if production does not involve strong representations of complex words. Applied to Dutch variable plurals, this interaction hypothesis would predict that the relative frequency of plural variants has a greater effect on pronunciation if the noun paradigm is plural-dominant. After all, in plural-dominant paradigms the differences in representational strength between plural variants are potentially greatest (i.e., A2 < B < A1; or A1 < B < A2). This interaction hypothesis is tested in our Study 2.
Dutch plural variation has a number of features that makes it a suitable phenomenon to test the interaction between base-complex relations and relations among paradigmatic alternatives. Firstly, as the plural variants have the same morphological function (see also morphological overabundance; Thornton, 2019), they form paradigmatic alternatives in every context. Consequently, the context of the plural variants does not need to be controlled in an experiment to collect enough data points, which means that the relations among plural variants can be studied in natural communicative settings. Secondly, for Dutch variable plurals the base-complex relation and the relation between paradigmatic alternatives are not conflated. Such a conflation of relations can be found in English verb agreement to collective nouns: in the the family seem/seems example, seem is both the base form and the alternative of seems (see also Cohen, 2014). Finally, the range of relative frequencies between the members of the noun paradigms that contain variable plurals is large enough to measure their effect on pronunciation. Importantly, given the assumption that the frequency of a complex word relative to its base reflects how it is processed, paradigms should be included in which the singular base is more frequent than the complex plurals as well as paradigms with relative frequencies in favor of the plural forms. Conveniently, a fair number of Dutch nouns are plural-dominant, providing the necessary spread in the relative frequency between complex and base forms. In sum, Dutch variable plurals provide an excellent opportunity to investigate how the different relations within paradigms interact during production.
1.3. The Present Studies
The current research approaches the interaction between singular-plural relations and relations among plural variants in two studies. The first study tests whether previous assumptions about the singular-plural relation for invariable plurals and base-complex relations in general also apply to variable plurals. The second study of this research tests whether the singular-plural relation interacts with the relation between plural variants in affecting the processing of variable plurals. In both studies, we will focus on how production of a single variant is affected by paradigmatic effects. Specifically, we will focus on the -s variant because affixes realized as [s] have reliably shown morphological effects on duration in previous research (e.g., Walsh and Parker, 1983; Cohen, 2014; Plag et al., 2017, 2020; Tomaschek et al., 2021a for -s suffix in English; Kuperman et al., 2007 for -s- interfix in Dutch).
Our first study tests the association between the base-complex frequency relation and the representational strength of complex words. As strong representations have been argued to limit the influence of generalization (e.g., Divjak and Caldwell-Harris, 2019), this association can be evidenced by showing that relatively frequent complex words are less affected by generalization. Specifically, our first study investigates whether PLURAL DOMINANCE, measured as the combined frequency of the plural variants divided by the frequency of the singular form, moderates the influence of phonological generalizations on the choice between plural variants. It has been shown that phonological generalizations can be used to accurately predict the plural suffix of many Dutch nouns (Baayen et al., 2002; Keuleers et al., 2007). Given psycho-linguistic studies on PLURAL DOMINANCE (Baayen et al., 2008; Beyersmann et al., 2015), we would expect that the plural variant of plural-dominant plurals is harder to predict using phonological patterns. In order to test the predictability of a plural variant, we needed a measure of the distribution of plural variants that would be predicted by phonological generalizations and a measure of the actual distribution. The actual distribution can be extracted from a corpus of written Dutch. By counting the number of -s (e.g., piramides) tokens and the number of competing (e.g., piramiden) tokens, the ratio of -s tokens, henceforth -S BIAS, can be computed for each noun. The predicted distribution can be obtained using a computational model that predicts the plural variant based on phonological features of the noun. We adopted the analogical model of Dutch plural formation described by Keuleers et al. (2007) to predict the plural allomorph of variable plurals. In this model, which is implemented using the TiMBL software (Tilburg Memory Based Learner; Daelemans et al., 2018), conflicts between analogies with different nouns are possible, resulting in uncertainty about the plural allomorph that should be chosen. By expressing this uncertainty as the probability of obtaining the -s allomorph and entering it as the -S PREDICTION variable into a regression model of the -S BIAS, we can assess the extent to which phonological generalization predicts the variation. We expect that the positive effect of -S PREDICTION on the observed -S BIAS will be smaller for more frequently pluralized nouns, that is, for nouns with higher PLURAL DOMINANCE. This outcome would support the hypothesis that the frequency relation between variable plurals and their singular forms reflects the influence of different processing mechanisms (generalization vs. whole-word access) on the production of variable plurals. More generally, such an outcome supports the assumption that the base-complex frequency relation reflects the representational strength of complex words.
In our second study, we test the hypothesis that base-complex relations interact with relations among paradigmatic alternatives. Specifically, we used the paradigmatic enhancement phenomenon to investigate the interaction between the singular-plural dominance relation and the coactivation among plural variants. On the basis of Cohen's (2015) theoretical account of paradigmatic enhancement, we can predict that a plural variant that is infrequent relative to its alternative should be pronounced with a more reduced plural suffix. As such, we expect that final -s is shorter for plurals with a more frequent -en or irregular variant. Crucially, we expect that this effect of -S BIAS is mediated by the PLURAL DOMINANCE measure. For noun paradigms with high PLURAL DOMINANCE, a low -S BIAS means that the competing plural variant is frequent relative to both the -s variant and the singular. As such, the final [s] of these nouns is expected to be shorter due to interference of the much stronger representation of the alternative variant. Conversely, a high -S BIAS for plural-dominant nouns suggests that the -s variant has a much stronger representation than the alternative variant, which is therefore not expected to reduce the duration of final [s]. For infrequently pluralized nouns, i.e., nouns with low PLURAL DOMINANCE, we do not expect a strong paradigmatic enhancement effect as neither plural variant is assumed to have a strong representation. These outcomes would provide evidence for an account of plural production in which the representational strength of the plural variants negotiates between the influence of generalizations across different noun paradigms and the influence of alternatives within its own paradigm. In such an account, plural variants that have strong representations are mostly produced by accessing whole word representations, whereas plural variants with weak representations are mostly produced by a generalization mechanism. The influence of the competing plural variant on production is dependent on its representational strength relative to that of the produced variant. More generally, such an outcome would be in line with the hypothesis that base-complex relations interact with relations among paradigmatic alternatives.
2. Distributional Study
2.1. Materials and Methods
2.1.1. Frequency Data
Most of the variables used in this study (see Table 1) were based on word frequency data. The corpus used to compute these word frequencies had to meet a number of criteria. Most importantly, it needed to be sufficiently large. Numerous examples of variable plurals are discussed in the literature (e.g., de Haas and Trommelen, 1993), but many of these are low frequency words and are therefore not likely to occur frequently in small text corpora, which would hamper the computation of reliable ratios of the occurrence of -s vs. other plural affix variants. The second criterion related to the level of annotation. Word tokens needed to be morphologically annotated for the data processing step, which consisted of automatically selecting nouns, identifying which word forms were part of the same inflectional paradigm, and distinguishing between invariable and variable plurals. Finally, we preferred a corpus that was not solely based on formal written language. This was important as formal texts are more sensitive to prescriptive rules and conscious linguistic processing, which might have limited the amount of variation in plural suffixes.
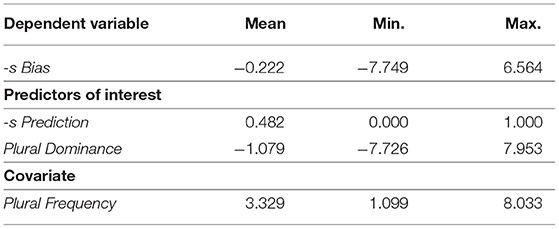
Table 1. Mean, minimum and maximum values of the variables in the distributional study.
The SUBTLEX-NL corpus was found to best match these criteria. With more than 400,000 unique, morphologically annotated word forms, it met two of our requirements. Furthermore, it is based on subtitles, which have word frequency distributions that have been shown to predict word processing measures more accurately than frequencies from alternative sources (Keuleers et al., 2010), presumeably because subtitle frequencies approximate those in natural speech. Using the morphological annotations of the SUBTLEX-NL corpus, we automatically separated the nouns that had a single plural form from those that had multiple. As we focused on -s plural variants, we only considered nouns with multiple plurals if one of those was an -s variant. From this set of variable plurals, we manually excluded nouns that were incorrectly identified as having a variable plural. For instance, certain orthographically identical but phonologically and semantically separate words with different plurals, e.g., sportster+s “female athletes” and sportster+en “sports stars”, were incorrectly conflated under a single lexical entry. Similarly, we excluded nouns if their different plural forms had separate (though sometimes related) meanings, such as wortelen “carots” and wortels “roots” (see Haeseryn et al., 1997). Other cases we excluded involved incomplete interfixed compounds, such as functionerings(gesprek) “appraisal [meeting]”, which were sometimes analyzed as -s plurals by the morphological tagger used for SUBTLEX. Apart from removing obvious mistakes, we also excluded plural forms that occur in very few paradigms such as brandweerman-brandweerlieden “firefighter(s)”, and -en plurals that could also be analyzed as infinitive verb forms such as testen in De onderzoeker houdt van testen “The researcher loves tests/to test”. Finally, we removed forms that occurred more frequently in foreign utterances than in Dutch utterances, e.g., rings.
After excluding mistakes and potentially unreliable data, the selection of variable plurals consisted of 384 noun types. For each of these nouns the dependent variable -S BIAS was computed by dividing the number of -s tokens by the number of tokens with the alternative plural variant and taking the natural logarithm of the resulting ratio. Additionally, the predictor PLURAL DOMINANCE was calculated for each noun type by dividing the total number of plural tokens by the total number of singular tokens and taking the natural logarithm of the resulting ratio. Following Cohen (2015), we expressed these within-paradigm frequency relations using log-transformed ratios to compensate for the enormous range in token frequencies. A positive log-ratio indicates that the numerator (e.g., plural frequency for PLURAL DOMINANCE) is greater than the denominater (e.g., singular frequency for PLURAL DOMINANCE). The reverse frequency relation is true for a negative log-ratio, and a log-ratio of zero indicates that numerator and denominator are equally frequent. In other words, -S BIAS and PLURAL DOMINANCE are centered around the point of equal proportion. In addition to the paradigmatic predictors, the PLURAL FREQUENCY variable was computed by taking the natural logarithm of the total number of plural tokens for each noun. For lower values of PLURAL FREQUENCY, the -S BIAS measure is biased toward 0. In fact, -S BIAS is exactly 0 for all variable plurals that occur only twice in the corpus. These plurals were excluded, as they would lead to less reliable estimates of the regression model. The final set consists of 361 noun types. Section 2.1.3 describes how we used PLURAL FREQUENCY to account for the tendency of -s Bias toward 0 in the remaining data when estimating the effects of the predictors of interest.
2.1.2. Generating -s Predictions With TiMBL
In order to model the influence of between-paradigm relations on the choice of plural variant, we needed detailed phonological transcriptions for the nouns that were identified in the SUBTLEX corpus. As such, we used the CELEX corpus (Baayen et al., 1996) to collect phoneme and word stress features for the singulars forms of both the variable and invariable plurals that were selected from SUBTLEX. In addition to these features, we also needed a computational model that could use them to predict the plural variant. We adopted the approach by Keuleers et al. (2007), who used the TiMBL classifier (Daelemans et al., 2018) to implement a probabilistic model based on phonological and orthographic analogy that predicts the suffix of Dutch plurals. In this approach, each plural was represented as a vector of phonological and orthographical features and a class label indicating the correct plural type; see Table 2 for the example vaders.

Table 2. An example of a TiMBL feature vector and class label for the plural vaders “fathers”.
In the present study, we recognized 3 plural suffix types: -s, -en, and other. TiMBL uses the k-nearest neighbors algorithm (kNN) to predict the plural suffix of noun types that are unseen by TiMBL. This algorithm compares the feature vector of an unseen noun to the feature vectors of nouns for which the plurals are known. The noun with the feature vector most similar to that of the unseen noun is the closest neighbor at k = 1. Similarly, the second-most similar noun is at distance k = 2, et cetera. Consequently, if the parameter k is set to larger numbers, more dissimilar nouns are considered in the comparison. In the standard configuration of the kNN algorithm, the unseen noun is assigned the plural type that was associated with the majority of the neighbors. If distance weighting is enabled, closer neighbors count for more than distant neighbors.
Although this standard implementation of TiMBL has been shown to model phonological factors on invariable Dutch plurals quite well (Keuleers et al., 2007), its categorical output is not a very useful predictor for variable plurals. Therefore, we had our TiMBL model produce two types of output: categorical classifications for training and validation based on the invariable plurals, and continuous probabilities for prediction of the variable plurals. Accordingly, we separated our plural data into a training set, which consisted of 9908 invariable plural types, a validation set, which contained another 1532 invariable plurals, and a test set, which contained 361 variable plurals. The model was subsequently trained and optimized on the training and validation sets using categorical labels. This process involved comparing the validation accuracies for every combination of the hyperparameters listed in Supplementary Table 1.
The best validation accuracy of 0.949 was achieved by a model that used inverse distance decay with k=5, trained on type merged data with feature vectors of 2 syllables (see Supplementary Table 1 for descriptions of features). Subsequently, this model was used to provide probabilities of the respective plural classes for the variable nouns in the test set. The predictor of interest -S PREDICTION (see Table 1) was extracted from the resulting probability distributions.
2.1.3. Modeling -s Bias
To assess the potential for collinearity in our data, we calculated correlations between all the variables in this study. None of the pairwise Pearson correlations between predictor variables exceeded r = 0.20 (see Supplementary Figure 1 for full documentation of all correlations).
In choosing an appropriate statistical model of the interaction effect between PLURAL DOMINANCE and -S PREDICTION on -S BIAS, we considered the nature of the dependent variable. As -S BIAS can be described as a log odds ratio, a binomial model seemed the obvious choice. Binomial models are suitable for our data as they can take into account differences in sample size, i.e., plural frequencies, when calculating the standard errors of the estimated log odds. However, when we considered that the dependent variable is based on characteristics of specific words (see language-as-fixed-effect fallacy, Clark, 1973), it became clear that regular logistic regression would lead to a poorly estimated model. We know from research on invariable Dutch plurals (Keuleers et al., 2007) that the choice of allomorph does not always follow a predictable pattern. A calculation based on the data from Keuleers et al. (2007) shows that around 9% of invariable plurals does not have the allomorph predicted by TiMBL. In other words, for some nouns the choice of plural allomorph is noun-specific. Likewise, we might expect that the distribution of plural variants for certain variable plurals is at least partly specific to the noun. It is therefore likely that modeling -S BIAS using logistic regression would lead to overdispersion, i.e., a case in which the data show more variability than expected on the basis of a regular binomial model. After all, simple logistic regression assumes that the -S BIAS of each noun can be predicted exclusively from fixed effects (e.g., phonological patterns). Instead, an approach was needed which treated the underlying probability of an -s variant as a random variable. Although random structure in binomial data can be modeled using generalized mixed effects models, previous research has shown that beta-binomial regression more reliably results in robust parameter estimates (Harrison, 2015). Beta-binomial regression assumes that the probability parameter of the binomial model is randomly chosen from a beta-distribution for each noun. The additional free parameter of this beta-distribution is estimated when the beta-binomial model is fitted. This allowed us to model both fixed and noun-specific effects on -S BIAS. As such, we used beta-binomial regression, as implemented in the R package aods3 (Lesnoff and Lancelot, 2018), to model -S BIAS. Model diagnostics did indeed reveal that a beta-binomial model fitted the data significantly better than a binomial model, see Supplementary Figure 2.
The -S PREDICTION × PLURAL DOMINANCE interaction was included to test our hypothesis that the representational strength of a plural limits the degree to which the choice between plural variants is governed by analogical generalization. We expected that higher values of PLURAL DOMINANCE, which are assumed to reflect stronger plural representations, would be associated with a weaker relation between -S PREDICTION and -S BIAS. Additionally, the -S PREDICTION × PLURAL FREQUENCY interaction was included to account for the tendency of -S BIAS toward 0 for infrequent plurals. Biased values of -S BIAS for low frequency plurals limit the amount of variance that can be explained by -S PREDICTION. As such, we expected that the positive relation between -S PREDICTION and -S BIAS would diminish for lower values of PLURAL FREQUENCY. By accounting for this effect, the estimation of the -S PREDICTION × PLURAL DOMINANCE interaction should be less influenced by the limited effect of -S PREDICTION at lower PLURAL FREQUENCY.
2.2. Results
Table 3 summarizes the outcome of the fitted beta-binomial model of -S BIAS. The μ coefficients describe the average relations between the predictors and -S BIAS. The ϕ coefficient, a dispersion parameter, describes the estimated shape of the underlying probability distribution of -S BIAS.
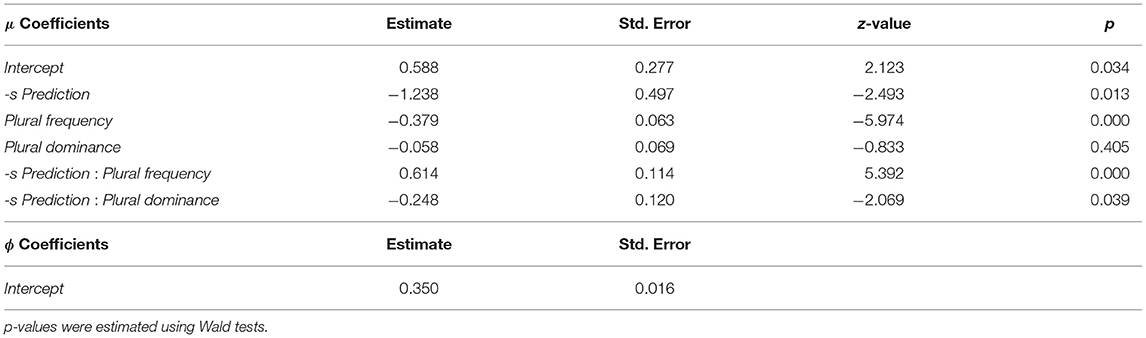
Table 3. Beta-binomial model of -s Bias.
Table 3 reveals a significant interaction between the predictors of interest, -S PREDICTION and PLURAL DOMINANCE. The fitted lines in Figure 1 illustrate the estimated effect of -S PREDICTION on -S BIAS at different values of PLURAL DOMINANCE. A PLURAL DOMINANCE of 4 amounts to a plural/singular ratio of more than 50/1 and it is indicated by the dashed line with an orange confidence band; a value of 0 corresponds to a plural/singular ratio of exactly 1/1 which is represented by the dotted line with a blue confidence band; and a value of –4 reflects a plural/singular ratio of less than 1/50 and it is visualized by the solid line with a teal confidence band. As PLURAL DOMINANCE decreases, the slopes of these lines increase. This result is in line with our expectations, which suggested that generalization, represented by -S PREDICTION, mainly affects the plural variation of plurals with less representational strength (PLURAL DOMINANCE).
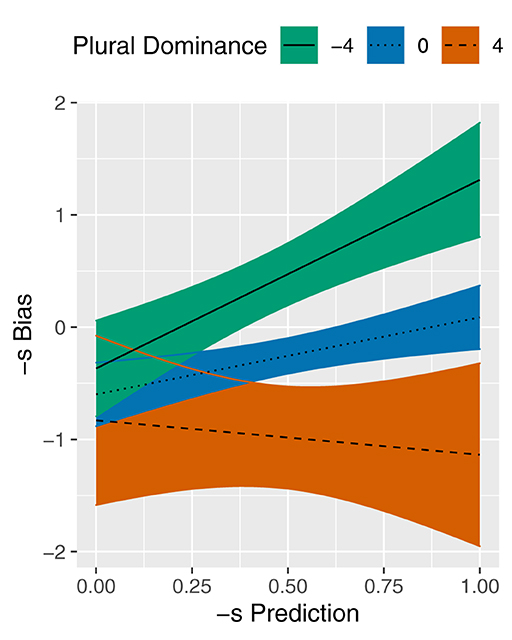
Figure 1. Partial effect plot for the -S PREDICTION × PLURAL DOMINANCE interaction in the model of -S BIAS. PLURAL FREQUENCY is held constant at the median value. Coloured bands reflect 95% confidence intervals.
Additionally, Table 3 indicates a significant interaction between -S PREDICTION and PLURAL FREQUENCY. The fitted lines in Figure 2 visualize the effect of -S PREDICTION on -S BIAS at different values of PLURAL FREQUENCY. The log-transformed values of 2, 4, and 6 correspond to approximate untransformed frequencies of 7, 55, and 403, respectively. As illustrated by the nearly horizontal line, -S PREDICTION does not have a clear effect on -S BIAS for nouns with low PLURAL FREQUENCY. Conversely, for nouns with high PLURAL FREQUENCY, the rising line indicates a positive effect of -S PREDICTION on -S BIAS. This interaction was expected because -S BIAS has a tendency toward 0 for low frequency nouns.
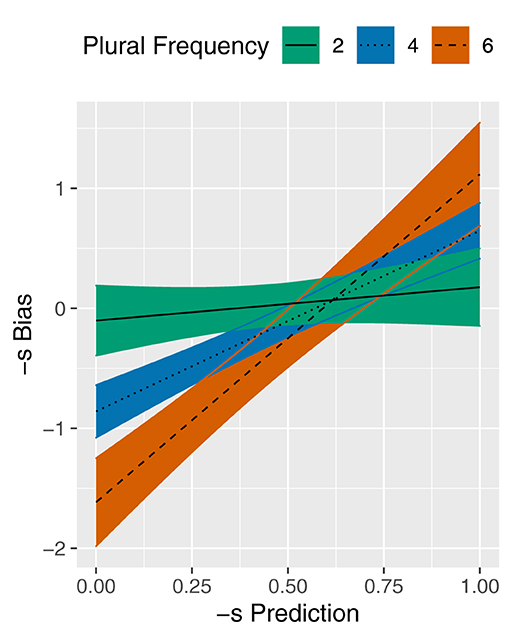
Figure 2. Partial effect plot for the -S PREDICTION × PLURAL FREQUENCY interaction in the model of -S BIAS. PLURAL DOMINANCE is held constant at the median value. Coloured bands reflect 95% confidence intervals.
3. Durational Study
3.1. Materials and Methods
3.1.1. Acoustic Data
The speech material analyzed in this study was extracted from the Dutch speech corpora listed in Table 4. We limited our dataset to Netherlandic Dutch, as the Dutch-Belgian border coincides with a different distribution of plural allomorphs for a number of nouns Goeman et al. (2005). Variable plural tokens were automatically identified using the orthographic transcriptions of the speech corpora and the selection of 361 noun types that occurred with multiple plural forms in SUBTLEX. We arived at a final dataset after discarding observations that would have resulted in unreliable duration measurements. This included tokens in which the final /s/ was preceded or followed by /s/, /z/, /ʃ/, /ʒ/, /t/, /d/ or /j/, as it is very difficult to segment the speech signal into two distinctive sounds in such cases. Furthermore, in certain recordings that involved multiple speakers, the respective speakers' voices were not recorded on separate audio channels. As a result, overlapping speech in those recordings is more difficult to segment, and durational measurements of such data may not be reliable. Therefore, final /s/ tokens from these recordings were excluded if they occurred in overlapped speech. The final data set consisted of 594 -s plural tokens.
Table 4. Overview of the corpora used in the durational study, including the number of -s plural tokens that were selected.
The final /s/ duration of the variable plural tokens was measured by the Kaldi-based (Povey et al., 2011) CLST forced-aligner (Kuijpers et al., 2018) to limit the influence of human biases and inconsistencies. The pronunciation dictionary of the forced-aligner was enriched to allow for reduced pronunciation variants according to the rules laid out by Schuppler et al. (2011). The parameters of the forced-aligner were validated on a separate set of manually annotated utterances in the Spoken Dutch Corpus (Oostdijk, 2000). Using this procedure we selected the settings that resulted in the smallest number of phonetic feature changes, insertions or deletions (as measured by weighted feature edit distance; Mortensen et al., 2016) between the automatic and manual transcriptions. The extracted segment durations from the automatically aligned speech were log-transformed to arrive at our dependent variable -S DURATION.
3.1.2. Predictors
Our paradigmatic predictors of interest -S BIAS and PLURAL DOMINANCE were extracted from the data set used in the distributional study. Additionally, we used SUBTLEX to calculate two alternative measures of lexical representation, -S FREQUENCY and RELATIVE -S FREQUENCY, which have been used in previous research. -S FREQUENCY was computed to represent an account of the lexical representation of the -s plural based on its log-transformed absolute frequency instead of paradigmatic relations (e.g., Schuppler et al., 2012). We also included the RELATIVE -S FREQUENCY to account for the proposal that paradigmatic effects should be measured by dividing the frequency of the -s plural by the lexeme frequency and log-transforming the resulting proportion (e.g., Cohen, 2015).
In order to account for the variance in -S DURATION that is unrelated to our paradigmatic predictors, we included a number of covariates. Specifically, we used covariates that have been used in previous studies that looked at segmental durations in corpus data (e.g., Plag et al., 2017).
One of the more obvious influences on segmental duration comes from the relative speed with which the surrounding speech is uttered. We measured this influence using two different variables. Firstly, SPEECH RATE was calculated in syllables per second by counting the number of syllables in the current utterance and dividing it by the duration of the utterance. Utterances were defined as uninterrupted chunks of speech. The number of syllables was determined by counting the number of vowels that were recognized by the forced aligner. Secondly, BASE DURATION was defined as the natural logarithm of the duration of the word excluding the final /s/. This measure was included to account for the variation in local speaking rate that was not captured by the speech rate variable.
The duration of final /s/ might also be influenced by the phonological characteristics of the word containing and the word following it. As such, NUMBER OF SYLLABLES was included as a variable to account for the segmental reduction that increases with the number of syllables in a word (e.g., Nooteboom, 1972). Additionally, the phonetic class of the PREVIOUS SEGMENT was taken into account, as it might influence the duration of the final /s/. For instance, final /s/ might be shorter if it forms a consonant cluster with the preceding segment (e.g., Klatt, 1976). The phonetic context following final consonants has also been shown to influence segmental duration (e.g., Luce and Charles-Luce, 1985). Therefore, the broad phonetic class of the NEXT SEGMENT was also included as a variable. We considered the following classes for PREVIOUS SEGMENT and NEXT SEGMENT: vowels, liquids, approximants, nasals, fricatives, plosives and silence.
A number of prosodic variables have been shown to affect the pronunciation of consonants (e.g., Cho and McQueen, 2005). On a word level, stressed syllables result in longer segments. Therefore, we used CELEX to implement WORD STRESS as a categorical variable which indicated whether the stressed syllable contained the final /s/. The larger prosodic context also influences segmental duration (Cho and McQueen, 2005). Particularly relevant for the current study is the phenomenon known as final lengthening, in which segments that occur before a prosodic boundary are lengthened (e.g., Hofhuis et al., 1995). Unfortunately, the corpora used in this study were not prosodically annotated. To get around this problem some corpus studies (e.g., Plag et al., 2017) use syntactic boundaries instead, as these sometimes co-occur with prosodic boundaries. We took a similar approach by generating syntactic annotations using the dependency parser (Canisius et al., 2006) included in the FROG natural language processing tool (Hendrickx et al., 2016). We then derived features from these annotations that have been shown to predict prosodic boundaries, such as intermediate or intonational phrase breaks (see features F2–F8 in Ingulfsen, 2004, pp. 36–38). In order to limit the number of prosodic boundary variables, we used a principle component analysis to identify 5 principle components, PROSODYPC1−5, that accounted for more than 94% of the variance described by the 7 original features.
We also considered the distributional characteristics of the words containing and surrounding the /s/. It has been shown, for instance, that words which are predictable given the surrounding words have more reduced realizations (e.g., Pluymaekers et al., 2005; Bell et al., 2009). As such, we used the NLCOW14 corpus (Schäfer, 2015) to measure the bigram frequency of the plural and the word preceding it in addition to the bigram frequency of the plural and the word following it. By dividing these respective bigram frequencies by the frequency of the plural form in the NLCOW14 corpus, we calculated conditional probabilities of the plural form given the preceding and subsequent word. These were log-transformed, resulting in PROBABILITY FROM PREVIOUS WORD and PROBABILITY FROM NEXT WORD, respectively. Similarly, whether or not a word has been recently mentioned may also affect its pronunciation (e.g., Pluymaekers et al., 2005). This was encoded as the binary RECENTLY MENTIONED variable by checking whether the same plural had been uttered in the 30 seconds prior.
Another feature that may influence phonetic reduction concerns a word's phonological similarity to other words. This similarity has been implemented by counting the number of PHONOLOGICAL NEIGHBORS, which are the words that differ from the target word by one sound. Higher neighborhood density has been associated with both more and less reduced segments (see discussion in Gahl et al., 2012). For each plural, we used the pronunciation lexicon that came with the CLST forced aligner (Kuijpers et al., 2018) to find the number of lexical neighbors.
Finally, previous research has shown that more careful speech is associated with longer durations (e.g., van Son and Pols, 1999). We expected that some of the speech used in this study, such as the read-aloud stories, would be more careful compared to speech from spontaneous conversations. Consequently, speech REGISTER was the final influence on the duration of final /s/ that we considered. This variable had three levels: Conversation, Stories and News.
3.1.3. Modeling -s Duration
We used linear mixed effects regression, as implemented in the R package lme4 (Bates et al., 2015), to model -S DURATION. By analyzing the effect of the interaction between -S BIAS and PLURAL DOMINANCE on -S DURATION we hoped to test our hypothesis that the effect of competition between plural variants on pronunciation is more noticeable if the plural variants are representationally strong relative to the singular. Additionally, we wanted to know how well our paradigmatic predictors explained differences in -S DURATION compared to alternative measures like the absolute -S FREQUENCY. As such, we created multiple models.
First, we fitted a Paradigmatic model containing -S BIAS, PLURAL DOMINANCE and their interaction term, all covariates, and random intercepts for SPEAKER and NOUN, which was the maximal random structure that was supported by the data. Additionally, we fitted two alternative models in which the -S BIAS and PLURAL DOMINANCE variables were replaced by alternative measures of representational strength. In the Absolute frequency model we replaced the paradigmatic measures with a single -S FREQUENCY predictor. We also fitted a Relative frequency model, in which we used the RELATIVE -S FREQUENCY measure. Using the AIC scores of the resulting three models, we calculated their relative likelihood to determine whether our paradigmatic predictors provided the best fit to the data.
Subsequently, we wanted to interpret the predictors of interest in our paradigmatic model. As such, we needed to avoid collinearity between our predictors of interest and any covariates. To assess the potential for collinearity in our data, we calculated correlations between all covariates and our predictors of interest; see Supplementary Figure 3. This showed us that -S BIAS was correlated (Pearson's r ≥ 0.4) with the covariates WORD STRESS and NUMBER OF SYLLABLES. This was not very surprising, as both of these covariates can be related to the stress pattern of a noun, which has been shown to affect the choice of plural suffix (Baayen et al., 2002). Removing these covariates would make sure that they could not lead to collinearity issues. However, we wanted to make sure that any potential effect of -S BIAS and its interaction with PLURAL DOMINANCE would not actually be better modeled by the correlated covariates. Therefore, we fitted three linear regression models of -S DURATION: for -S BIAS, WORD STRESS and NUMBER OF SYLLABLES, respectively. Each model contained one of the three correlated variables, the PLURAL DOMINANCE variable and their interaction. An AIC comparison showed that the model containing -S BIAS performed best. As such we excluded the correlated covariates from further analysis. Starting from the resulting Paradigmatic model, we used backward elimination (as implemented in Kuznetsova et al., 2017) on to arrive at a model in which only the significant predictors remained. After fitting the model with the remaining variables, we trimmed the data with residuals that exceeded 2.5 standard deviations and refitted the model on the trimmed data set, following Baayen (2008). The residuals of this final model were approximately normally distributed, see Supplementary Figure 4.
3.2. Results
The full paradigmatic model of -S DURATION containing the -S BIAS × PLURAL DOMINANCE interaction had an AIC of 690.90. By comparison, the best performing alternative model, which contained the -S FREQUENCY predictor, had an AIC of 697.86; see Supplementary Table 2 for full models. This means that the Absolute frequency model was times as likely to minimize the information loss compared to the Paradigmatic model (Burnham and Anderson, 2004). In other words, the Paradigmatic model performed much better than the models with alternative measures of representational strength.
Table 5 summarizes the parameters of the final model, that is, the Paradigmatic model after removal of correlated covariates and insignificant predictors. In addition to the -S BIAS × PLURAL DOMINANCE interaction, this model contains the covariates SPEECH RATE, PROSODYPC2, NEXT SEGMENT, and REGISTER and the random variable SPEAKER. As indicated by the estimates in Table 5, the covariates show the expected effects, e.g., a higher SPEECH RATE reduces -S DURATION and a subsequent Silence is associated with a longer -S DURATION. Importantly, Table 5 also reveals a significant interaction between the predictors of interest, -S BIAS and PLURAL DOMINANCE. The fitted lines in Figure 3 illustrate the estimated effect of -S BIAS on -S DURATION at three different values of PLURAL DOMINANCE (see section 2.2 for interpretation of these values). At high PLURAL DOMINANCE, the slope of the line is positive, which means that final -s becomes longer if -S BIAS becomes larger. This result supports the expected paradigmatic enhancement effect. Unexpectedly, we find the opposite effect at low PLURAL DOMINANCE: for these nouns, final -s becomes shorter as -S BIAS becomes larger. We expected that -S BIAS would have very little effect on -S DURATION at negative PLURAL DOMINANCE, resulting in a horizontal line. However, the model predicts that the paradigmatic enhancement effect is already nullified at a PLURAL DOMINANCE of zero. In noun paradigms with negative PLURAL DOMINANCE, a reduction effect is predicted.
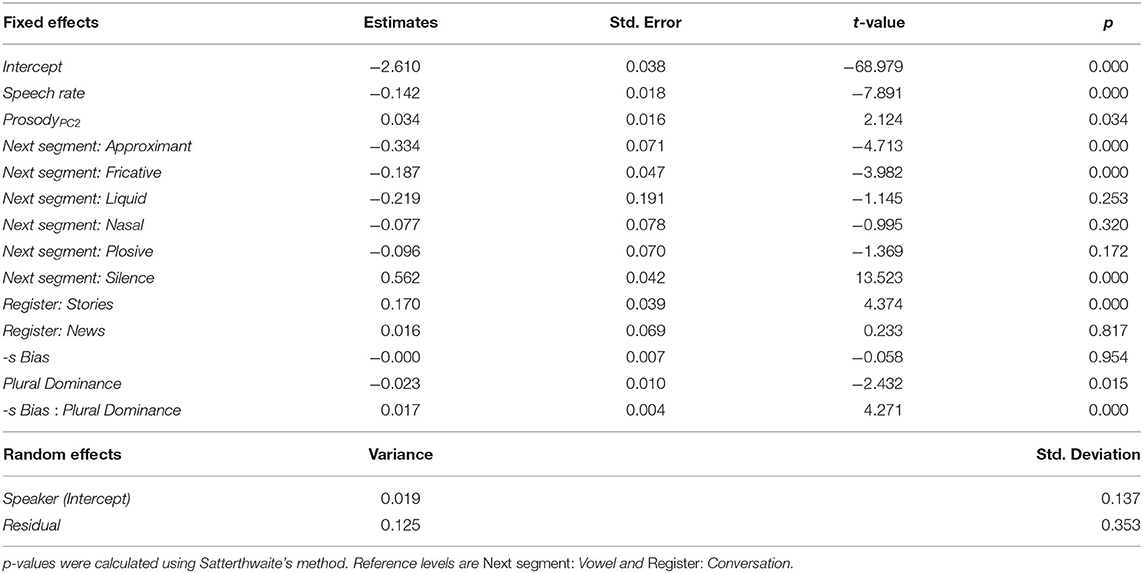
Table 5. Mixed effects model of -s Duration.
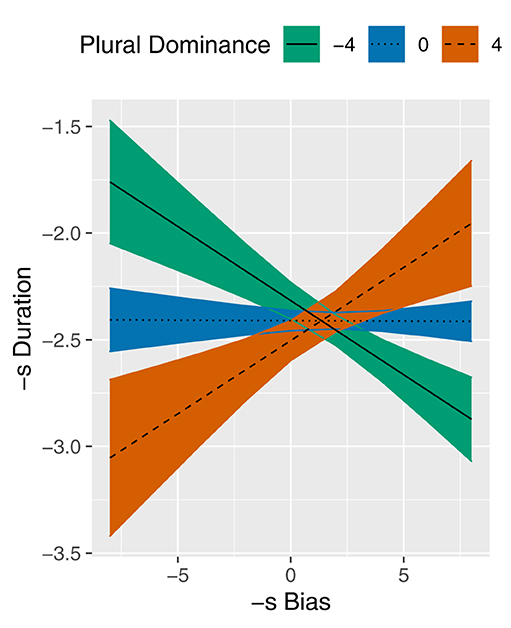
Figure 3. Partial effect plot for the -S BIAS × PLURAL DOMINANCE interaction in the model of -S DURATION. Coloured bands reflect 95% confidence intervals.
4. Discussion
The current research explored how paradigmatic structure relates to the mechanisms that are involved in the processing of complex words. Dutch variable plurals were chosen as the subject of inquiry, as they are involved in paradigmatic relations that have been associated with generalization, storage and coactivation mechanisms.
In our first study we investigated whether the singular-plural frequency relation of a noun influences the distribution of its plural variants in a Dutch subtitles corpus. We hypothesized that the distribution of variants for nouns with higher PLURAL DOMINANCE would be less predictable by a measure of phonological generalization. The results supported this account by showing that the positive effect of the generalization measure -S PREDICTION on the distributional measure -S BIAS decreases with higher values of PLURAL DOMINANCE. These findings are in line with previous accounts of invariable plurals (Baayen et al., 2008; Beyersmann et al., 2015) which suggest that higher plural dominance limits the influence of generalization on plural processing. Presumably, plural-dominant variable plurals are less affected by generalization because they have representations that are more stable or are easier to retrieve during the speech production process. The distributional results also contribute to the wider discussion about the role of token frequency in the generalization of morphological exponents. Whereas, previous distributional research has generally focused on absolute token frequency as an inhibitor of generalization (e.g., Cuskley et al., 2014), this study showed that frequency relative to the base form may also affect the scope of general phonological patterns1 (see also Tiersma, 1982; Collie, 2008).
The goal of the second study was two-fold. Firstly, we wanted to investigate whether the paradigmatic enhancement hypothesis applies to Dutch variable plurals. That is, an -s plural variant that is more frequent than its alternative should be phonetically enhanced compared to an -s variant that is less frequent than its alternative. This hypothesis was based on the assumption that the more frequent -s variant has a stronger representation and therefore its pronunciation is less affected by the coactivated representation of the alternative variant. Additionally, we hypothesized that such a paradigmatic enhancement effect should primarily occur in noun paradigms with relatively high PLURAL DOMINANCE. This qualification was based on the assumption that the representational strengths of plural variants primarily depend on their frequencies relative to the singular. As such, we expected that the differences in representational strengths measured by -S BIAS would be greatest at high PLURAL DOMINANCE. The results revealed an interaction effect of -S BIAS and PLURAL DOMINANCE on -S DURATION. For plural-dominant plurals, a higher -S BIAS was associated with a longer -S DURATION, which suggests that paradigmatic enhancement is reflected in our data. This finding supports previous accounts of paradigmatic enhancement that interpret the frequency relation between paradigmatic alternatives as a measure of their relative representational strengths Cohen (2014, 2015). Furthermore, the results showed that an increased -S BIAS was associated with a shorter -S DURATION for singular-dominant plurals, which was surprising as we expected that the pronunciation of infrequently pluralized plurals would not be affected by the frequency relation between variants. Nonetheless, this interaction effect was in line with our hypothesis that paradigmatic enhancement would primarily affect plural-dominant plurals. As such, this study is the first to provide evidence that, in certain paradigms, paradigmatic enhancement is mediated by the base-complex relation.
By combining the findings from both studies, we might better understand the unexpected reduction effect of -S BIAS on -S DURATION for singular-dominant plurals that was observed in our second study. The interpretation of the -S BIAS predictor is crucial to this understanding. The combined results suggest that what -S BIAS represents depends on the value of PLURAL DOMINANCE. At high PLURAL DOMINANCE, the paradigmatic enhancement effect in the durational study suggests that -S BIAS is a measure of the representational strength of the -s variant relative to its competitor. However, at low PLURAL DOMINANCE, the distributional study suggests that -S BIAS represents the amount of phonological support from similar paradigms, i.e., the -S PREDICTION. In formulating the hypotheses for the duration study, we did not consider that increased analogical support could result in the reduction of final -s, given the lack of precedents for such an effect (but see gang size effect in Tucker et al., 2019). However, the association of reduced final -s with increased -S PREDICTION would fit the more general theory that predictable linguistic elements are reduced (e.g., Bell et al., 2009). Importantly, as this explanation assumes that -S BIAS primarily reflects -S PREDICTION for singular-dominant nouns, it does not conflict with our account of paradigmatic enhancement, which mostly affects frequently pluralized nouns.
The combined results have implications for psycholinguistic models of morphological processing. These models can be categorized according to the relative importance they attribute to abstract rules and lexical storage (see the overviews in Arndt-Lappe and Ernestus, 2020; Fábregas and Penke, 2020). At one end of the spectrum are models that emphasize the role of rules in explaining the paradigmatic structure that arises from commonalities in form and function among the words of a language. In these models, complex words are only stored if they do not submit to morphological rules (e.g., Wunderlich, 1996). Such models often assume that stored exceptions to the rule do not influence regular application of the rule. Our results suggest that the base-complex frequency relation indicates the extent to which variable plurals follow the morpho-phonological rules. As this frequency relation must be stored somehow, either in representations of individual nouns or in weighted connections between morphological exponents and specific semantic representations, the current research questions the complete separation of generalization and storage in rule-based models.
In a second category of models, both abstract rules and lexical storage may affect the production of complex words (see Arndt-Lappe and Ernestus, 2020). In one such a model, the Parallel Dual Route Model (e.g., Baayen et al., 1997b), production of a complex word involves simultaneous retrieval of the complex representation and composition involving the base representation. The relative speed of the composition and retrieval routes determines which route affects production the most. In some dual route models, complex words that are less frequent than their bases are assumed to be more easily (de)composable Hay (2001), which would speed up the (de)composition route. This conceptualization of the base-complex relation can be applied to the PLURAL DOMINANCE variable in our studies. It would predict that singular-dominant plurals are produced using the composition route, whereas plural-dominant plurals are primarily produced using the retrieval route. Such an account would explain why the distribution of plural variants in singular-dominant noun paradigms follows phonological patterns. It would also explain why plural variants in plural-dominant noun paradigms are subject to paradigmatic enhancement. At high PLURAL DOMINANCE, an -s variant with high -S BIAS would be more frequent than the singular. As such it would be produced using the retrieval route, and its pronunciation would not be affected by the alternative variant. However, an -s variant with low -S BIAS would likely be less frequent than the singular while its alternative would be more frequent compared to the singular. The -s variant would then be produced using the composition route, and its pronunciation would be affected by the alternative variant, which was simultaneously activated through the retrieval route.
In a third category of models, processing of complex words involves no abstract computation. In those word-based models (e.g., Bybee, 1995), paradigmatic enhancement findings are easily accounted for, as all word forms including their frequencies of occurrence can be stored. Analogy between stored word forms can be used to explain morpho-phonological patterns across paradigms. Our first study showed that such an analogical mechanism can also account for variation observed for Dutch variable plurals. The reduced influence of analogy on the production of plural-dominant nouns can be explained through a weaker activation level of the singular representation relative to the plural representation: a relatively infrequent singular form results in decreased activation of a noun's singular representation, which, in turn, leads to decreased analogical influence of other noun paradigms with phonologically similar singular forms. As such, models without a separate rule-based processing route can account for the Dutch variable plural data as well.
The current findings shed light on how paradigmatic relations may be related to the mechanisms that are involved in the processing of complex words. While the results cannot be explained by the mechanisms of a primarily rule-based model, both a dual-route model and a word-based model are compatible with the results. Regardless of theoretical framework, the novel implication of this research is that the role of the base-complex relation, whether it is conceptualized using activation levels or (de)composability, should be considered when the effect of additional within-paradigm relations, such as those between plural variants, are investigated. It follows that measures which conflate base-complex relations and relations among paradigmatic alternatives, such as form frequency relative to lexeme frequency, might not adequately capture how processing mechanisms interact. This was evidenced in our durational study by the fact that the model which distinguished between -S BIAS and PLURAL DOMINANCE predictors performed much better than the model that combined them into a single RELATIVE -S FREQUENCY predictor. More generally, these findings show that the nature of the individual morphological relations within a paradigm should be considered when their effect on processing is investigated.
In addition to providing answers about paradigmatic relations, our findings also raise questions. This research was concerned with paradigmatic relations and their psycholinguistic relevance during speech production. It would therefore be interesting to know whether our interpretations of the -S BIAS, PLURAL DOMINANCE and -S PREDICTION relations are representative for the processing mechanisms of individual speakers. However, these relations were measured using type and token frequencies from corpus data. As Blumenthal-Dramé (2012) points out, corpus frequencies do not necessarily reflect the input frequencies of individual language users, but rather a simplified and likely biased approximation of the input of multiple language users. With regard to Dutch plurals in particular, it seems unlikely that all speakers encounter and/or produce the different variants of a plural with the same -S BIAS. Presumably, this also leads to differences among speakers in the processing of variable plurals. It is therefore likely that the paradigmatic effects found in this research do not affect the speech of all language users equally. This is particularly true for the distributional study, as it does not relate the paradigmatic measures to the production of individual speakers. Unfortunately, the small size of our data set meant that we could not investigate inter-speaker differences in the paradigmatic enhancement effect. Additionally, due to the nature of the data, we could not take other potentially relevant factors, such as register, into account in our distributional study. These issues may be addressed by studies with better control over the relevant variables.
Furthermore, the findings from the durational study are primarily relevant for a narrow definition of paradigmatic enhancement. In this account, the coactivation resulting in paradigmatic enhancement only involves paradigm members that occur in the same linguistic context. In other words, the context works as a filter that determines which representations are coactivated: in utterances like the boy runs/run/running only one paradigm member (runs) is likely and therefore no paradigmatic enhancement effect would be expected. As such, this account does not provide clear explanations of paradigmatic enhancement effects on forms that can be predicted from the communicative context (e.g., Kuperman et al., 2007; Schuppler et al., 2012). Our research does provide naturalistic support for previous experimental findings of paradigmatic enhancement in which the linguistic context was controlled to allow for multiple paradigm members (e.g., Cohen, 2014, 2015; Bell et al., 2020; Tomaschek et al., 2021b).
Regardless of the limitations of the current research, its relevance is not limited to obscure morphological alternations. As documented by work on morphological overabundance (e.g., Thornton, 2019), the existence of paradigmatic alternatives is far from exceptional. As such, this research paves the way for similar investigations of paradigmatic relations using other overabundance phenomena. Apart from highlighting the underexplored variation in the realization of complex words, such research would contribute to morphological theory by identifying paradigmatic effects on processing that must be accounted for by psycho-linguistic models. As this research has emphasized, those paradigmatic effects can only be understood if paradigmatic relations are considered both individually and taken together.
Data Availability Statement
The original contributions presented in the study are publicly available. This data can be found here: https://doi.org/10.17026/dans-xvr-qscf.
Ethics Statement
The studies involving human participants were reviewed and approved by Ethics Assessment Committee Humanities Radboud University. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
TZ conducted the research and wrote the initial draft of the manuscript. LB, ME, and IP provided feedback and suggestions for the research, and contributed to the writing of the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This research was funded by the Deutsche Forschungsgemeinschaft (Research Unit FOR2373 ‘Spoken Morphology,’ Project ER 547/1-1 ‘Dutch morphologically complex words: The role of morphology in speech production and comprehension’), which we gratefully acknowledge.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We acknowledge the authors of the speech corpora for providing access to their data, the Centre for Language and Speech Technology at the Radboud University for providing technical support, the reviewers for providing helpful feedback, and Taki Bremmers for the example in (1).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2021.720017/full#supplementary-material
Footnotes
1. ^A reviewer pointed out that the interaction effect of our absolute token frequency measure, PLURAL FREQUENCY, and our generalization measure, -S PREDICTION, seems to suggest that higher token frequency facilitates generalization, which would be completely contrary to previous findings. However, this interaction is confounded by sampling bias: a frequent plural is more likely to show variation compared to an infrequent plural, especially when the general patterns strongly favour a particular variant. As we only included plurals that showed variation in our data set, this resulted in a better match between -S PREDICTION and observed -S BIAS for high frequency plurals. The interaction between the absolute token frequency and the generalization measure was included to account for the effect of this bias in the estimation of the other predictors, see section 2.1.3.
References
Arndt-Lappe, S. (2014). Analogy in suffix rivalry: the case of English -ity and -ness. Engl. Lang. Linguist. 18, 497–548. doi: 10.1017/S136067431400015X
Arndt-Lappe, S., and Ernestus, M. (2020). “Morpho-phonological alternations: the role of lexical storage,” in Word Knowledge and Word Usage, eds V. Pirrelli, I. Plag and W. U. Dressler (Berlin: De Gruyter Mouton), 191–227.
Aylett, M., and Turk, A. (2004). The smooth signal redundancy hypothesis: A functional explanation for relationships between redundancy, prosodic prominence, and duration in spontaneous speech. Lang Speech. 47, 31–56. doi: 10.1177/00238309040470010201
Aylett, M., and Turk, A. (2006). Language redundancy predicts syllabic duration and the spectral characteristics of vocalic syllable nuclei. J. Acoust. Soc Am. 119, 3048–3058. doi: 10.1121/1.2188331
Baayen, H., Burani, C., and Schreuder, R. (1997a). “Effects of semantic markedness in the processing of regular nominal singulars and plurals in Italian,” in Yearbook of Morphology 1996 (Dordrecht: Kluwer), 13–34.
Baayen, R. H. (2008). Analyzing Linguistic Data: A Practical Introduction to Statistics Using R. Cambridge: Cambridge University Press.
Baayen, R. H., Dijkstra, T., and Schreuder, R. (1997b). Singulars and plurals in Dutch: evidence for a parallel dual-route model. J. Mem. Lang. 37, 94–117. doi: 10.1006/jmla.1997.2509
Baayen, R. H., Levelt, W., Schreuder, R., and Ernestus, M. (2008). “Paradigmatic structure in speech production,” in Proceedings From the Annual Meeting of the Chicago Linguistic Society, Vol. 43, eds M. Elliott, J. Kirby, O. Sawada, E. Staraki and S. Yoon (Chicago: Chicago Linguistic Society), 1–29.
Baayen, R. H., McQueen, J. M., Dijkstra, T., and Schreuder, R. (2003). “Frequency effects in regular inflectional morphology: revisiting Dutch plurals,” in Morphological Structure in Language Processing, eds R. H. Baayen and R. Schreuder (Berlin: De Gruyter Mouton), 355–390.
Baayen, R. H., Piepenbrock, R., and Gulikers, L. (1996). The CELEX Lexical Database (CD-ROM). Philadelphia, PA: Linguistic Data Consortium. doi: 10.35111/gs6s-gm48
Baayen, R. H., Schreuder, R., De Jong, N., and Krott, A. (2002). “Dutch inflection: the rules that prove the exception,” in Storage and Computation in the Language Faculty, eds S. G. Nooteboom, F. Weerman and F. N. K. Wijnen (Dordrecht: Kluwer), 61–92.
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Bell, A., Brenier, J. M., Gregory, M., Girand, C., and Jurafsky, D. (2009). Predictability effects on durations of content and function words in conversational English. J. Mem. Lang. 60, 92–111. doi: 10.1016/j.jml.2008.06.003
Bell, M. J., Ben Hedia, S., and Plag, I. (2020). How morphological structure affects phonetic realisation in English compound nouns. Morphology 31, 87–120. doi: 10.1007/s11525-020-09346-6
Beyersmann, E., Dutton, E. M., Amer, S., Schiller, N. O., and Biedermann, B. (2015). The production of singular- and plural-dominant nouns in Dutch. Lang. Cogn. Neurosci. 30, 867–876. doi: 10.1080/23273798.2015.1027236
Biedermann, B., Beyersmann, E., Mason, C., and Nickels, L. (2013). Does plural dominance play a role in spoken picture naming? a comparison of unimpaired and impaired speakers. J. Neurolinguist. 26, 712–736. doi: 10.1016/j.jneuroling.2013.05.001
Blumenthal-Dramé, A. (2012). Entrenchment in Usage-Based Theories: What Corpus Data do and do Not Reveal About the Mind. Berlin: Walter De Gruyter.
Burnham, K. P., and Anderson, D. R. (2004). Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33, 261–304. doi: 10.1177/0049124104268644
Bybee, J. (1995). Regular morphology and the lexicon. Lang. Cogn. Process 10, 425–455. doi: 10.1080/01690969508407111
Bybee, J., and Hopper, P. (2001). “Introduction to frequency and emergence of linguistic structure,” in Frequency and the Emergence of Linguistic Structure, eds J. Bybee and P. Hopper (Amsterdam: John Benjamins Publishing), 1–24.
Canisius, S., Bogers, T., Van Den Bosch, A., Geertzen, J., and Sang, E. T. K. (2006). “Dependency parsing by inference over high-recall dependency predictions,” in Proceedings of the Tenth Conference on Computational Natural Language Learning (CoNLL-X) (New York, NY), 176–180.
Cho, T., and McQueen, J. M. (2005). Prosodic influences on consonant production in Dutch: effects of prosodic boundaries, phrasal accent and lexical stress. J. Phon. 33, 121–157. doi: 10.1016/j.wocn.2005.01.001
Clark, H. H. (1973). The language-as-fixed-effect fallacy: a critique of language statistics in psychological research. J. Verbal Learn. Verbal Behav. 12, 335–359. doi: 10.1016/S0022-5371(73)80014-3
Cohen, C. (2014). Probabilistic reduction and probabilistic enhancement. Morphology 24, 291–323. doi: 10.1007/s11525-014-9243-y
Cohen, C. (2015). Context and paradigms: Two patterns of probabilistic pronunciation variation in Russian agreement suffixes. Ment Lex. 10, 313–338. doi: 10.1075/ml.10.3.01coh
Collie, S. (2008). English stress preservation: the case for 'fake cyclicity'. Engl. Lang. Linguist. 12, 505–532. doi: 10.1017/S1360674308002736
Cuskley, C. F., Pugliese, M., Castellano, C., Colaiori, F., Loreto, V., and Tria, F. (2014). Internal and external dynamics in language: evidence from verb regularity in a historical corpus of English. PLoS ONE 9:e102882. doi: 10.1371/journal.pone.0102882
Daelemans, W., Zavrel, J., van der Sloot, K., and van den Bosch, A. (2018). TiMBL: Tilburg Memory-Based Learner, Version 6.4. Technical Report 11-01, Induction of Linguistic Knowledge Research Group, Tilburg University. Reference Guide.
de Haas, W., and Trommelen, M. (1993). Morfologisch Handboek van het Nederlands: Een Overzicht van de Woordvorming. The Hague: SDU Uitgeverij.
Divjak, D., and Caldwell-Harris, C. L. (2019). “Frequency and entrenchment,” in Cognitive Linguistics, eds E. Dąbrowska and D. Divjak (Berlin: De Gruyter), 61–86.
Ernestus, M. (2000). Voice Assimilation and Segment Reduction in Casual Dutch. Utrecht: Holland Institute of Generative Linguistics.
Ernestus, M. (2014). Acoustic reduction and the roles of abstractions and exemplars in speech processing. Lingua 142, 27–41. doi: 10.1016/j.lingua.2012.12.006
Ernestus, M., and Baayen, R. H. (2003). Predicting the unpredictable: Interpreting neutralized segments in Dutch. Language 79, 5–38. doi: 10.1353/lan.2003.0076
Fábregas, A., and Penke, M. (2020). “Word storage and computation,” in Word Knowledge and Word Usage, eds V. Pirrelli, I. Plag, and W. U. Dressler (Berlin: De Gruyter Mouton), 455–505.
Gahl, S., Yao, Y., and Johnson, K. (2012). Why reduce? Phonological neighborhood density and phonetic reduction in spontaneous speech. J. Mem. Lang. 66, 789–806. doi: 10.1016/j.jml.2011.11.006
Goeman, T., de Schutter, G., van den Berg, B., and de Jong, T. (2005). Morfologische Atlas van de Nederlandse Dialecten, Vol. 1. Amsterdam: Meertens Instituut; KANTL; Amsterdam UP.
Goldinger, S. D. (1998). Echoes of echoes? an episodic theory of lexical access. Psychol. Rev. 105, 251. doi: 10.1037/0033-295X.105.2.251
Haeseryn, W., Romijn, K., Geerts, G., de Rooij, J., and Van den Toorn, M. C. (1997). Algemene Nederlandse Spraakkunst, 2nd Edn. Groningen; Deurne: Martinus Nijhoff uitgevers; Wolters Plantyn.
Hanique, I., and Ernestus, M. (2012). The role of morphology in acoustic reduction. Lingue e Linguaggio 11, 147–164. doi: 10.1418/38783
Harrison, X. A. (2015). A comparison of observation-level random effect and beta-binomial models for modelling overdispersion in binomial data in ecology &evolution. PeerJ. 3:e1114. doi: 10.7717/peerj.1114
Hay, J. (2001). Lexical frequency in morphology: Is everything relative? Linguistics 39, 1041–1070. doi: 10.1515/ling.2001.041
Hay, J. (2007). “The phonetics of ‘un’,” in Lexical Creativity, Texts and Contexts, ed J. Munat (Amsterdam: John Benjamins), 39–57.
Hendrickx, I., van den Bosch, A., van Gompel, M., and van der Sloot, K. (2016). Frog, a Natural Language Processing Suite for Dutch. Nijmegen: Reference guide, Radboud University Nijmegen.
Hofhuis, E., Gussenhoven, C., and Rietveld, T. (1995). “Final lengthening at prosodic boundaries in Dutch,” in Proceedings of the XIIIth International Congres of Phonetic Sciences, Vol. 1, eds E. Elenius and P. Branderud (Stockholm: Stockholm University), 154–157.
Ingulfsen, T. (2004). Influence of syntax on prosodic boundary prediction. Technical Report 610, University of Cambridge Computer Laboratory.
Keuleers, E., Brysbaert, M., and New, B. (2010). SUBTLEX-NL: a new measure for Dutch word frequency based on film subtitles. Behav. Res. Methods 42, 643–650. doi: 10.3758/BRM.42.3.643
Keuleers, E., Sandra, D., Daelemans, W., Gillis, S., Durieux, G., and Martens, E. (2007). Dutch plural inflection: the exception that proves the analogy. Cogn. Psychol. 54, 283–318. doi: 10.1016/j.cogpsych.2006.07.002
Klatt, D. H. (1976). Linguistic uses of segmental duration in English: acoustic and perceptual evidence. J. Acous.t Soc. Am. 59, 1208–1221. doi: 10.1121/1.380986
Krott, A., Baayen, R. H., and Schreuder, R. (2001). Analogy in morphology: modeling the choice of linking morphemes in Dutch. Linguistics 39, 51–93. doi: 10.1515/ling.2001.008
Kuijpers, L., Ganzeboom, M., and Wei, X. (2018). CLST ASR Forced Aligner. Available online at: https://www.cls.ru.nl/clst-asr/doku.php?id=forced-aligner (accessed April 22, 2021).
Kuperman, V., Pluymaekers, M., Ernestus, M., and Baayen, H. (2007). Morphological predictability and acoustic duration of interfixes in Dutch compounds. J. Acoust. Soc. Am. 121, 2261–2271. doi: 10.1121/1.2537393
Kürschner, S. (2009). Morphological non-blocking in Dutch plural allomorphy: a contrastive approach. Lang. Typol. Univer. 62, 285–306. doi: 10.1524/stuf.2009.0022
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. H. B. (2017). lmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26. doi: 10.18637/jss.v082.i13
Lesnoff, M., and Lancelot, R. (2018). aods3: Analysis of Overdispersed Data Using S3 Methods. aods3 package version 0.4-1.1.
Luce, P. A., and Charles-Luce, J. (1985). Contextual effects on vowel duration, closure duration, and the consonant/vowel ratio in speech production. J. Acous. Soc. Am. 78, 1949–1957. doi: 10.1121/1.392651
Milin, P., Ðurđević, D. F., and del Prado Martín, F. M. (2009). The simultaneous effects of inflectional paradigms and classes on lexical recognition: evidence from Serbian. J. Mem. Lang. 60, 50–64. doi: 10.1016/j.jml.2008.08.007
Mortensen, D. R., Littell, P., Bharadwaj, A., Goyal, K., Dyer, C., and Levin, L. (2016). “PanPhon: a resource for mapping IPA segments to articulatory feature vectors,” in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (Osaka: The COLING 2016 Organizing Committee), 3475–3484.
New, B., Brysbaert, M., Segui, J., Ferrand, L., and Rastle, K. (2004). The processing of singular and plural nouns in French and English. J. Mem. Lang. 51, 568–585. doi: 10.1016/j.jml.2004.06.010
Oostdijk, N. (2000). “The Spoken Dutch Corpus: Overview and first evaluation,” in LREC-2000 Proceedings (Athens), 887–894.
Plag, I., Homann, J., and Kunter, G. (2017). Homophony and morphology: the acoustics of word-final S in English. J. Linguist. 53, 181–216. doi: 10.1017/S0022226715000183
Plag, I., Lohmann, A., Ben Hedia, S., and Julia, Z. (2020). “An S is an 'S, or is it? plural and genitive plural are not homophonous,” in Complex Words: Advances in Morphology, eds L. Körtvélyessy and P. Štekauer (Cambridge: Cambridge University Press), 260–292.
Pluymaekers, M., Ernestus, M., and Baayen, R. (2005). Articulatory planning is continuous and sensitive to informational redundancy. Phonetica 62, 146–159. doi: 10.1159/000090095
Povey, D., Ghoshal, A., Boulianne, G., Burget, L., Glembek, O., Goel, N., et al. (2011). “The Kaldi speech recognition toolkit,” in IEEE 2011 Workshop on Automatic Speech Recognition and Understanding (Hawaii: IEEE Signal Processing Society; IEEE Catalog No.: CFP11SRW-USB).
Schäfer, R. (2015). “Processing and querying large web corpora with the COW14 architecture,” in Challenges in the Management of Large Corpora (CMLC-3) (Lancaster), 28.
Schuppler, B., Ernestus, M., Scharenborg, O., and Boves, L. (2011). Acoustic reduction in conversational Dutch: a quantitative analysis based on automatically generated segmental transcriptions. J. Phon. 39, 96–109. doi: 10.1016/j.wocn.2010.11.006
Schuppler, B., van Dommelen, W. A., Koreman, J., and Ernestus, M. (2012). How linguistic and probabilistic properties of a word affect the realization of its final /t/: studies at the phonemic and sub-phonemic level. J. Phon. 40, 595–607. doi: 10.1016/j.wocn.2012.05.004
Thornton, A. M. (2019). “Overabundance in morphology,” in Oxford Research Encyclopedia of Linguistics. Oxford: Oxford University Press.
Tomaschek, F., Plag, I., Ernestus, M., and Baayen, R. H. (2021a). Phonetic effects of morphology and context: modeling the duration of word-final s in English with naïve discriminative learning. J. Linguist. 57, 123–161. doi: 10.1017/S0022226719000203
Tomaschek, F., Tucker, B. V., Ramscar, M., and Baayen, R. H. (2021b). Paradigmatic enhancement of stem vowels in regular English inflected verb forms. Morphology 31, 171–199. doi: 10.1007/s11525-021-09374-w
Tucker, B. V., Sims, M., and Baayen, R. H. (2019). Opposing forces on acoustic duration. PsyArXiv [Preprint]. doi: 10.31234/osf.io/jc97w
Van Dale (2020). Gratis woordenboek. Available online at: https://www.vandale.nl/opzoeken (accessed April 22, 2021).
van Son, R., and Pols, L. C. (1999). An acoustic description of consonant reduction. Speech Commun. 28, 125–140. doi: 10.1016/S0167-6393(99)00009-6
van Son, R., Wesseling, W., Sanders, E., and van den Heuvel, H. (2008). “The IFADV corpus: a free dialog video corpus,” in LREC-2008 Proceedings, (Marrakech) 501–508.
Walsh, M., Möbius, B., Wade, T., and Schütze, H. (2010). Multilevel exemplar theory. Cogn. Sci. 34, 537–582. doi: 10.1111/j.1551-6709.2010.01099.x
Walsh, T., and Parker, F. (1983). The duration of morphemic and non-morphemic /s/ in English. J. Phon. 11, 201–206. doi: 10.1016/S0095-4470(19)30816-2
Wilde Haren De Podcast (2019). Huub Pragt: WHDP S06E05. Available online at: https://www.youtube.com/watch?v=fBoIBI_hlUk (accessed April 22, 2021).
Wulf, D. J. (2002). “Applying analogical modeling to the German plural,” in Analogical Modeling, eds R. Skousen, D. Lonsdale and D. B. Parkinson (Amsterdam: John Benjamins), 109–122.
Keywords: morphology, phonetics, paradigms, reduction, inflection, Dutch, plural, variation
Citation: Zee T, ten Bosch L, Plag I and Ernestus M (2021) Paradigmatic Relations Interact During the Production of Complex Words: Evidence From Variable Plurals in Dutch. Front. Psychol. 12:720017. doi: 10.3389/fpsyg.2021.720017
Received: 03 June 2021; Accepted: 29 July 2021;
Published: 01 September 2021.
Edited by:
Walter Daelemans, University of Antwerp, BelgiumReviewed by:
Marc Brysbaert, Ghent University, BelgiumClara Cohen, University of Glasgow, United Kingdom
Marcel Pikhart, University of Hradec Králové, Czechia
Claudia Marzi, Istituto di linguistica computazionale “Antonio Zampolli” (ILC), Italy
Copyright © 2021 Zee, ten Bosch, Plag and Ernestus. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tim Zee, dGltLnplZUBydS5ubA==