 Jiahui Li*
Jiahui Li* Meifang Yao*
Meifang Yao*- School of Management, Jilin University, Changchun, China
To solve the limitations of the current entrepreneurial ecosystem, the research on the digital entrepreneurial ecosystem is more meaningful. This article aims to study the dynamic evolution mechanism of the digital entrepreneurship ecosystem based on text sentiment computing analysis. It proposes an improved Bi-directional long short-term memory (Bi-LSTM) model, which uses a multilayer neural network to deal with classification problems. It has a higher accuracy rate, recall rate, and F1 value than the traditional LSTM model and can better perform sentiment analysis on text. The algorithm uses the optimized Naive Bayes algorithm, which is based on Euclidean distance weighting and can assign different weights to the final classification results according to different attributes. Compared with the general Bayes algorithm, it improves the calculation efficiency and can better match the digital entrepreneurial ecosystem, which is evolving dynamically, predicting and analyzing its future development. The experimental results in this article show that the improved Bi-LSTM is better than the traditional Bi-LSTM model in terms of accuracy and F1 value. The accuracy rate is increased by 1.1%, the F1 value is increased by 0.6%, and the recall rate is only <0.2%. Running on the Spark platform, although 3% accuracy is sacrificed, the running time is increased by 320%. Compared with the traditional cellular neural network (CNN) algorithm, the accuracy rate is increased by 4%, the recall rate is increased by 14%, and the F1 value is increased by 9%, which proves that it has a strong non-linear fitting ability. The performance improvement brought by the huge data set is very huge, which fully proves the feasibility of the digital entrepreneurship ecosystem.
Introduction
Since 2015, supply-side reforms have come into being, emphasizing that innovation should be the first engine driving economic development, stimulating innovation potential and optimizing industrial structure. Entrepreneurship activities are very important for improving regional economic development, talent gathering, and promoting the sustainable development of industries. However, the technological content of entrepreneurship of Chinais still low, and the strong scientific and technological strengths have not been absorbed by entrepreneurial enterprises. Under different technological systems and market environments, issues such as the allocation of scientific and technological resources and the efficiency of resource utilization have a significant impact on the sustainable development of enterprises. The entrepreneurial practice of Chinese enterprises shows that the “national system” type of entrepreneurial support has not made the national entrepreneurial system out of the “island phenomenon” in technological innovation. The gestation and growth processes of entrepreneurship are nested in a series of complex systems that influence each other. In these systems, each subsystem interacts with other systems and individuals, affecting all aspects of entrepreneurial activities. In recent years, the construction of an entrepreneurial ecosystem has become an inevitable way to cultivate unique regional competitive advantages. The self-organization and self-regulation capabilities of the entrepreneurial ecosystem play an important role in the sustainable development of their internal enterprises. Due to the lack of a scientific evaluation mechanism, the construction of entrepreneurial ecosystem of China is still in the exploratory stage, and the promotion of typical cases established by following the trend can easily lead to the waste of resources, such as repeated construction. “No Measurement, No Improvement,” how to use a reasonable evaluation system to provide targeted and operable suggestions for the optimization of the entrepreneurial ecosystem is worthy of further research. As a diversified, mutually beneficial, and win-win innovation and entrepreneurship system, the business ecosystem is of great significance to the formulation of innovation and entrepreneurship policies by analyzing the impact of different factors on its operation.
The entrepreneurial ecosystem is composed of three aspects: entrepreneurial enterprises, stakeholders, and the entrepreneurial environment. The entrepreneurial entities are connected by formal or informal relationships. Different communities influence and depend on each other, and evolve together over time, and they have obvious regional characteristics. On the one hand, the existence of the entrepreneurial ecosystem can save excessive transaction costs and organization costs. On the other hand, it can provide a more advantageous development environment for new start-ups in an unstable market environment, and improve the competitiveness of start-ups, which is a guarantee keyway to the quality and vitality of new ventures. However, the effective operation of the entrepreneurial ecosystem is inseparable from the coevolution and mutual synergy between the constituent communities and elements. Therefore, through efficiency evaluation and analysis of influencing factors, the various elements within the entrepreneurial ecosystem, the linkages between the elements, and the driving force of the linkages are discussed. It has an important guiding role in the formation of a real-time, creative, and orderly entrepreneurial ecosystem.
At present, the Internet is developing rapidly, and many people are paying attention to the digital entrepreneurial ecosystem. The following people have unique insights on this. Singh SK proposed a new framework for a spell-check system that extracts user reactions, emotions, and opinions from social media text (SMT). User opinions are extracted from their written texts on social media and based on SMT sentiment scores, using dictionary-based methods and binary classifiers, which are classified as positive or negative opinions. The dictionary-based method uses the opinion verb dictionary (OVD) to extract the sentiment of opinion verbs that appear in SMT. This OVD contains only opinion verbs and their sentiment scores. The various steps of the framework have been discussed, such as lowercase conversion, tokenization, spell-checking, part-of-speech tagging, stop word elimination, stemming, sentiment score calculation, and SMT classification. Although Singh introduced the new concept of threshold negative parameters to facilitate the extraction of text information data, the efficiency of this extraction method is slightly low. If the optimized Bayes algorithm is used, the efficiency can be greatly improved (Singh and Sachan, 2019). Le X proposed that the rapid popularization of digital technology with new functions has profoundly changed the competitive environment and reshaped traditional business strategies and processes. Such technologies have also spawned new ways of collaboration, using resources, service design, development, and deployment based on open standards and shared technologies. At the micro-level, digital technology has also reshaped the mindset of entrepreneurs, thereby affecting their decision-making process. Digital entrepreneurship includes venture capital and the transformation of existing enterprises through the creation of new digital technologies and new uses of these technologies. At present, many countries regard digital entrepreneurship as an important pillar for the development of the digital economy, and it is necessary to have a detailed understanding of digital entrepreneurship. Although Le has formulated the relevant content of digital entrepreneurship, he has not made an in-depth dynamic evolution of the digital entrepreneurship system, which makes it impossible for him to estimate the future development of digital entrepreneurship (Le et al., 2019). Allenby CE discovered that digital health entrepreneurship is a topic widely discussed in non-professional and professional media. Innovators in this field continue to raise large amounts of funds to develop applications and devices that will change the way health care is managed in the United States. As many as one-third of American consumers use wearable devices and mobile health applications, which provide important opportunities for putting health care in the hands of consumers. However, it remains to be seen who will play the greatest role in this field. Technology giants, biopharmaceutical companies, and start-ups all have the opportunity to take advantage of new areas and change the way health care interacts with patients. Although entrepreneurs are in a leading position in the technology industry, they lack the regulatory and healthcare expertise of large pharmaceutical companies. However, as start-ups and large technology companies continue to promote innovation in this field, the pharmaceutical industry will not be able to continue to pack lightly. Companies that decide to take stock in this market will have to decide on how to interact with the health care sector. He discovered that digital entrepreneurship has great potential for development. He focused his attention on the development of medical and health care, but this development relied on large local technology companies and biopharmaceutical companies. He did not take advantage of the convenience of text sentiment calculation and analysis. If based on text sentiment calculation analysis to dynamically evolve digital entrepreneurship, then he can develop on his own (Allenby et al., 2018).
The innovations of this article are the following: (1) Using text sentiment calculation and analysis methods, combined with deep learning algorithms, the traditional Bayesian algorithm is improved and optimized, and the efficiency is improved. (2) Putting forward the theory of the digital entrepreneurship ecosystem, discovering the huge potential for future development, and analyzing the important components of the system and its influencing factors. (3) Comparing the algorithm with other models, a better Bi-LSTM model is obtained. It is found that the running time under the Spark platform is much shorter than the running time on the native model.
The first section of this article introduces the background and significance of the current domestic and foreign entrepreneurial ecosystems, and cites several references that have important results in emotional computing, and also describes the innovations of this article. The second section briefly introduces the creation of ecological theory, core competitiveness theory, text sentiment calculation analysis, naive Bayes algorithm, and entrepreneurial process theory. In the introduction of naive Bayes algorithm, it proposes its improvement and optimization. In the later Bayesian algorithm theory. The third section introduces the experimental purpose, experimental procedures, and experimental methods of this article. The fourth section focuses on the analysis of the influencing factors of sentiment computing in the dynamic evolution of the digital entrepreneurship ecosystem, compares the performance of various traditional algorithms, and then analyzes and introduces the optimized and improved text sentiment computing algorithms in this article. The fifth section is a summary of this article and puts forward the shortcomings in the article and the outlook for the future.
Dynamic Evolution Mechanism of Digital Entrepreneurship Ecosystem Based on Text Sentiment Calculation Analysis
Entrepreneurship Ecosystem
The concept of an entrepreneurial ecosystem originates from the combination of entrepreneurial theory and ecological theory. To be precise, it is a reexamination of entrepreneurial theory from an ecological perspective. With the advancement of science and technology and the shortening of product life cycles, the knowledge required for product innovation is distributed in fragments, and the process of technological innovation shows more non-linear characteristics. The effect of research and development (R&D) investment on R&D performance also depends on the collaboration of various entrepreneurial entities. From the beginning of the establishment to the final demise, start-ups have always been in dynamic communication with the environment in which they are located (the inflow of key elements and product output). The competition and cooperation between different entrepreneurs are complicated, but they have always maintained the entire entrepreneurial system. These characteristics make the entrepreneurial process naturally have an analysis function of ecological significance (Shen et al., 2018). Moore (1996) first proposed the concept of the business ecosystem and analyzed the relationship between entrepreneurial enterprises and their related multiple entrepreneurial entities from an ecological perspective, setting a precedent for entrepreneurial ecological research. After that, many scholars have conducted more in-depth research on entrepreneurial ecology (Gabison, 2019).
The ecosystem needs the inflow and outflow of material and energy to maintain the normal operation of the system. For business ecology, this means the need to study the creation and development of new businesses in various fields related to the business environment and business resources. Gnyawali and Fogel (1994) divided the entrepreneurial environment into five dimensions: financial support, non-financial environment, policy regulations, socioeconomic support, and entrepreneurship and management skills, and the impact of these factors on entrepreneurial performance in the entrepreneurial ecosystem perform analysis (Chen, 2021). Li et al. (2011) has very in-depth research in the field of entrepreneurship. He has conducted multidimensional analysis on the relationship between entrepreneurial networks and entrepreneurial performance. In the entrepreneurial environment, entrepreneurial resources have a positive impact on the growth and performance of new ventures. Verify shows (Hutson, 2018). Only when organisms exchange material and energy with the environment can they ensure their development, and entrepreneurial companies can only ensure their sustainable development if they fully utilize and integrate resources and the environment. The entrepreneurial ecosystem has the characteristics of regionality, diversity, symbiosis, external spillover, self-organization, and self-regulation. Many literature studies have conducted relevant research on its regionality and diversity, but the research on its self-organization and self-regulation is still relatively scarce. At present, with the further development of the entrepreneurial ecological theory, the research on the entrepreneurial ecosystem has gradually shifted from its conceptual framework to the analysis of its dynamic evolution. The method of metaphor alone cannot fully play the role of ecology in the entrepreneurial field. Think about the integration of the two from a deeper level (Nuseir, 2018).
Core Competitiveness Theory
The core competitiveness theory focuses on the ability to integrate related technologies and knowledge, and at the same time points out that the core competence is transferable between organizations and can be transferred to all members of the enterprise in accordance with the organizational structure (Ishmukhametov et al., 2020). Domestic experts and scholars have carried out rich and in-depth research on this theory. The earliest domestic research on core competitiveness was done by Professor Jin Bei of the Chinese Academy of Social Sciences, which can make enterprises stand out from the competition (Miao and Chonghui, 2018). The core competitiveness has the following characteristics: user value, user evaluation, and feedback are the most objective and direct standards to measure the competitiveness of an enterprise. The core competitiveness can be improved only by continuously improving the quality of products and services and by increasing user satisfaction. Occupancy, the company has a long-term occupation of certain necessary development resources, which makes itself have a unique advantage different from other competitors. This resource is difficult to obtain by other companies and will be occupied by the company for a long time; malleability, the core competitiveness of the company can be extended from ideas or technologies to products and services and maintained market advantages. Uniqueness, core competence can give enterprises an advantage in a series of products or services. There are differences in the core competitiveness of different enterprises. This kind of competitiveness is gradually formed in the long-term development of enterprises and has a high degree of imitation (Liu et al., 2018).
Text Sentiment Calculation Analysis
As shown in Figure 1, the text sentiment calculation analysis model is built on the LSTM artificial neural network. The word vector is extracted from the top text source, and the input layer is the input word vector for sentiment calculation analysis, like the hidden layer input data, training, and filtering. After that, select the data that suit the requirements for output (Frank, 2018). In recent years, sentiment analysis has flourished in computer science, and a large number of articles on sentiment analysis of text have also appeared in major well-known natural language processing-related conferences. According to the granularity of the text, sentiment analysis can be divided into word-level, sentence-level, and text-level. The first two are fine-grained, and the latter are coarse-grained (Zeng et al., 2021). Because an article often has multiple sentences expressing different emotions, and words are the smallest unit of expressing sentence emotions, which are likely to be affected by other vocabulary or sentence patterns, most research are more inclined to use sentences as the granularity. Taking into account complicated situations such as the omission of evaluation objects in emotional expression, experiments have proved that this work can provide a certain basis for emotional analysis based on supervised learning. In terms of sentiment classification, methods based on rules and machine learning are more common. Among unsupervised classification methods, sentiment dictionaries and their construction work also play an important role. A sentiment dictionary is constructed by integrating three parts of psychology domain vocabulary, WordNet ontology dictionary, and commonly used slang words on the Internet. Then, based on this dictionary, it analyzes the incentives and laws of emotions of people in three different cities over time (Chang and Huo, 2018). It can also combine information increment, support vector machine, decision tree, and naive Bayes algorithm for feature selection and sentiment classification, and use positive and negative feature mean to evaluate sentiment similarity; construct a method based on graph learning and semi-supervision, a classifier of Weibo sentiment polarity is constructed. This classifier takes into account the community relationship of Weibo users and the similarity of Weibo text. Experiments have shown that this classifier can replace part of the manual annotation work (Hamdi et al., 2018). After finishing the work of removing stop words and feature extraction on Twitter text, the improved positive feedback neural network method is used to classify the sentiment tendency of the text. Although satisfactory results are finally achieved, the algorithm is trained when the text is too large. The usefulness of the memory needs to be optimized; it can be found that long text and short text have a high degree of overlap in terms. Therefore, based on the characteristics of short text and traditional feature filtering methods, the long text features and short text common features are left, and the superior information is added to the short text classification process (Nam and Lee, 2019). An improved conditional random field model is also proposed, which treats the tendency analysis of phrase sentiment as sequence labeling (Hahn et al., 2020). A method for calculating the similarity of comments posted by users based on cosine similarity is proposed, and each text is assigned a value of emotional orientation strength from −2 (negative) to +2 (positive). The result is similar to the traditional shell, where maximum entropy and support vector machines are all improved (Li et al., 2020); linguistic knowledge is integrated into the traditional sentiment classification, a large number of rules are expanded, and the improved N-grams model is used to solve the language morphology where there are more complicated sentence patterns in characteristics (Kotelnikov, 2018). However, the purely rule-based method requires domain experts to define a large number of rules, which is costly and has limitations. In recent research results, concept-level sentiment analysis is often be mentioned; a concept-level sentiment analysis system is constructed, which integrates semantic analysis, subjectivity detection, irony syntax detection, topic positioning, and other multidimensional, experimental. It is proved that this method can solve the performance defects of some supervised sentiment analysis algorithms in different situations (Singh and Sachan, 2021); through the use of the conceptual hierarchical model to extract text emotional features, extract the semantics of the text, and finally explore some microblog text and natural semantic relevance of language text; it proves that the performance of sentiment analysis at the concept level is better than the performance of sentiment analysis at the lexical level. In addition, in the sentiment analysis corpus, the corpus that does not contain sentimental tendencies is also of practical value. There is a map-reduce-based e-commerce user opinion recognition framework, and new dictionary-based technology is used to mine the products. Neutral evaluation to correct the results of these opinions being classified as positive or negative, to reduce the error of sentiment analysis (Bhagat and Mane, 2019; Schmidt et al., 2020).
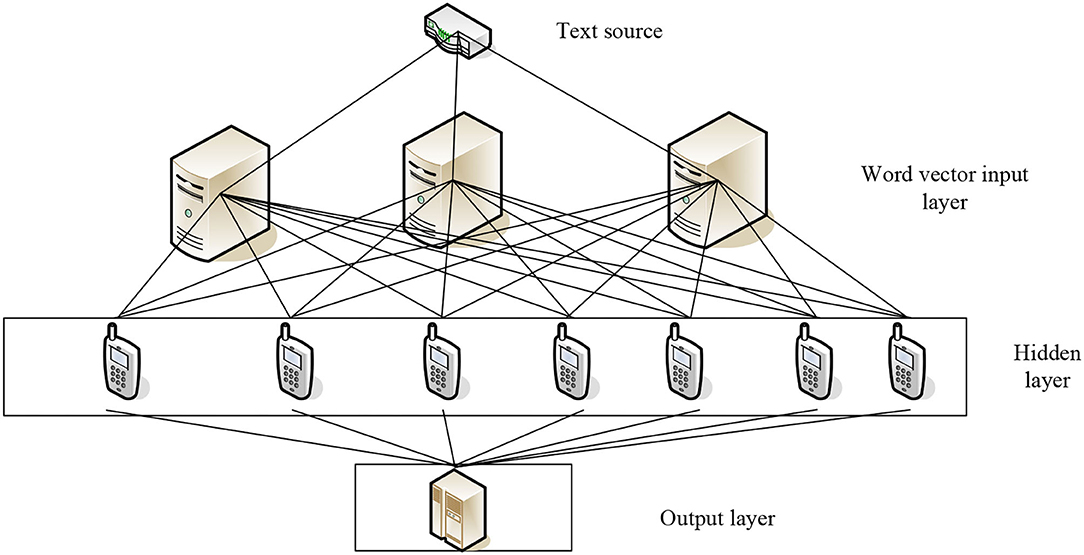
Figure 1. LSTM model.
Naive Bayes Algorithm
Conditional probability refers to the occurrence of event B as the premise. In this case, the probability of occurrence of event A is recorded as P(A|B).
Let A and B be two events in the sample space Ω, if P(B) > 0, then it is called as shown in Equation 1:
Event B occurs first. On this basis, the probability that event A will occur. Among them, the probability P(B) of event B is called the prior probability, P(A|B) is the probability that event A will occur based on the occurrence of event B, this probability is called the posterior probability of event A, P (AB) represents the probability that both events A and B will occur. Let A and B be events in the sample space Ω, if P(B) > 0, then equation 2 is described as follows:
If P(A1A2A3…An−1) > 0, then
Assuming that B1, B2, …Bn is a self of the sample space Ω, then B1, B2, …Bn will be mutually exclusive, and , if P(B) > 0, then any event A has
From the above, we can integrate the two formulas into one formula, which is the formula of Bayes' theorem:
The most likely hypothesis Fj ∈ F for a given sample C is selected from a set of candidate hypotheses f. This hypothesis or category is called the maximal posterior hypothesis, namely
Under certain circumstances, assuming that the prior probability of each hypothesis in F is the same, just consider P(C|f) to find the most probable hypothesis, so P(C|f) is called when f The likelihood of data C, where the hypothesis that maximizes P(C|f) is called the maximum likelihood hypothesis (Lutfullaeva et al., 2018):
It can be seen from the Bayesian formula that the posterior probability P(f|C) depends on the product of P(C|f) P(f), which is also the most important idea of the Bayesian classification algorithm. According to Bayes' theorem:
Among them, Pi is the probability that the text belongs to the category di in the training text. In the partially selected categories, Bayesian classification assumes that the attributes in the classification are independent of each other, then Equation 11 is given as follows:
Substituting the prior probability P(y1, di), P(y2, di), …P(yn, di), calculated from the training set into the above formula, we can get the following Equation 12:
The denominator in the formula is a constant, and the Naive Bayes model formula is a maximum value of the calculation formula:
In the above formula, because it is necessary to calculate a large number of product operations, which brings difficulties to the calculation, the formula is modified as follows:
The naive Bayes classification algorithm simplifies the estimation of the prior probability when the assumption of independence of distribution is established, without considering the correlation between different attributes. The process of predicting the sample to be predicted is simple, the classification complexity is low, the speed is fast, and the cost in the calculation process is relatively low.
Among them, the weight of the attribute A is wk, that is, the weight of the P(Y|Dj). The larger wk, the greater the importance of the attribute to the classification result, which affects the classification result.
Entrepreneurship Process Theory
Many scholars have conducted in-depth research on entrepreneurial-related theories, such as entrepreneurial characteristics theory, entrepreneurial process theory, entrepreneurial cycle theory, entrepreneurial network theory, etc., discussing the factors of entrepreneurial success and failure from multiple aspects. The first to emerge is the entrepreneurial characteristics theory, which believes that the personal characteristics of an entrepreneur (enterprise willingness, risk tolerance, ability to formulate strategies, etc.) play a decisive role in the success of entrepreneurship. With the deepening of entrepreneurial research, scholars have begun to pay attention to the influence of more traits of non-entrepreneurs on entrepreneurial activities, and the research on the entrepreneurial process has gradually attracted the attention of relevant scholars.
Gartner (1985) first proposed that the success of entrepreneurship is not only related to the characteristics of entrepreneurs. The entrepreneurial process is a dynamic, complex, and diverse process. It is a synthesis of many factors in the entrepreneurial process. He compared these related to entrepreneurship. The elements are summarized into four aspects, namely entrepreneurs, stakeholders, entrepreneurial environment, and entrepreneurial practices. Morris et al. (1994) combined previous entrepreneurial research results, regarded the entrepreneurial process as a dynamic process of resource input-product output, and constructed an input-output integration model based on the entrepreneurial process. Xuebing and Gang (2009) believe that entrepreneurship is a process by which entrepreneurs transform new products and new patents into economic benefits by integrating entrepreneurial resources and identifying market opportunities in technological innovation. Entrepreneurship process theory is a very important theory in the field of entrepreneurship. It makes entrepreneurial activity no longer a “black box.” People can analyze the different stages of the entrepreneurial process and explore the impact of different stages on entrepreneurial performance, making the part and the whole static Take into account the dynamics (Lian et al., 2020; Sodhar et al., 2020).
Experiment on the Dynamic Evolution Mechanism of Digital Entrepreneurship Ecosystem Based on Text Sentiment Calculation Analysis
The key to understanding the digital entrepreneurship ecosystem is to clearly define the core role of the system, which is also the prerequisite for the construction of the system structure model. By combining and analyzing the existing literature, it is found that there is good consistency in the division of the roles of the digital entrepreneurship ecosystem in the existing research, which has laid a good foundation for the following experimental parts.
Subjects
The digital entrepreneurship ecosystem is a big data ecosystem based on text sentiment calculation analysis. The digital entrepreneurship ecosystem can be divided from a micro and macro perspective. From a micro perspective, the core roles in the big data ecosystem are divided into users and providers and data. From a macro perspective, the system can be divided into a core layer, an extension layer, and an environment layer. The microscopic digital entrepreneurship system is the main research object of this experiment.
As shown in Figure 2, the digital entrepreneurship ecosystem is divided into three levels, namely the core entrepreneurial layer, the extended entrepreneurial layer, and the peripheral environment layer. The core entrepreneurial layer is composed of big data companies, data platforms, and users. Big data companies can be divided into big data core companies and big data niche companies based on the entrepreneurial ecological perspective.
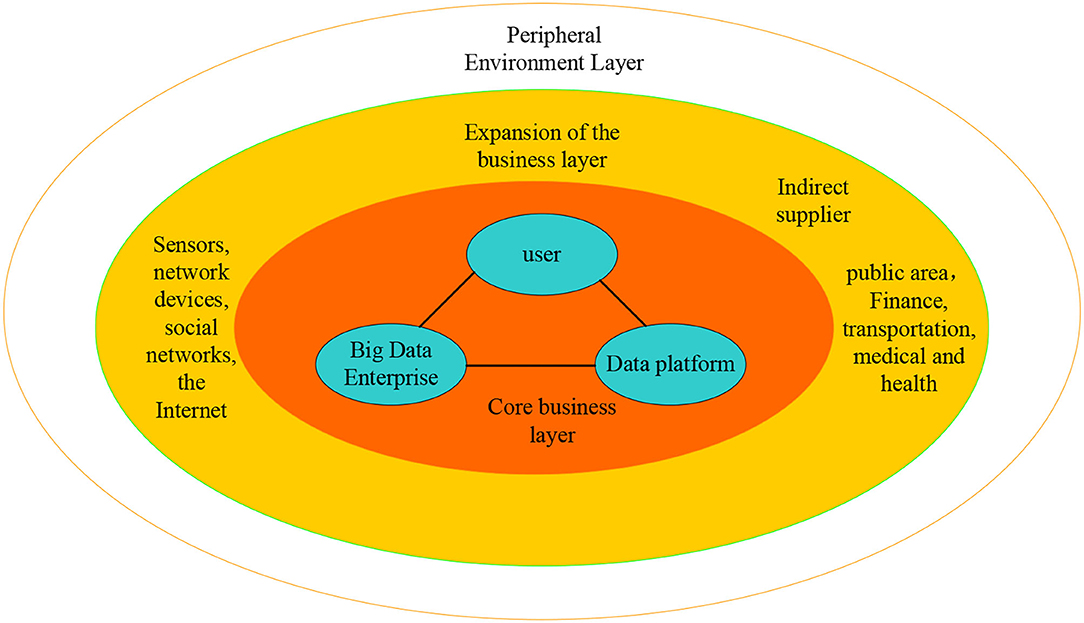
Figure 2. Digital entrepreneurship ecosystem structure model.
Purpose of the Experiment
The purpose of the experiment in this article is to analyze the elements of the digital entrepreneurship ecosystem model and then analyze the pros and cons of the algorithm by comparing text-based sentiment computing with other algorithms.
Experimental Procedure
As shown in Figure 3, the first step of this experiment is to build a digital entrepreneurship ecosystem model, then analyze the construction elements of the digital entrepreneurship model, analyze the key points of its elements and the difference between the manufacturing ecological models, and then compare the algorithms. The cross-experiment method will perform performance screening based on text sentiment computing and other artificial intelligence algorithms, and finally, the experiment ends.
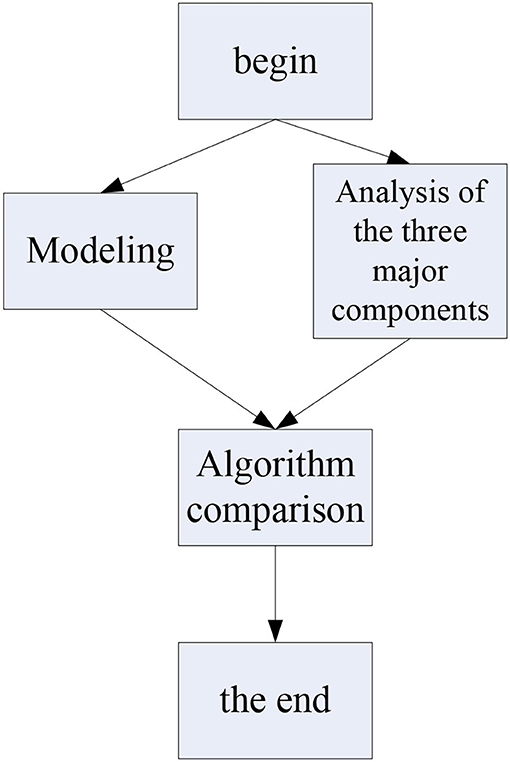
Figure 3. Experimental flowchart.
Dynamic Evolution Mechanism of Digital Entrepreneurship Ecosystem Based on Text Sentiment Computing Analysis
Influencing Factors
The relationship between the three core elements of the digital entrepreneurship ecosystem is shown in Figure 4. The relationship between the elements can be understood from two levels. One is from the macro-level of system composition. The second is from the internal components of each level. Among them, big data companies are the main force driving the formation of the digital entrepreneurial ecosystem, which provides users with a wealth of data products and services; the data platform, as an exchange and circulation platform for data resources and a related technical service platform, continues to provide the development of the big data industry. “Raw materials” and technology and service support; users are consumers of data products and services, and the ultimate channel for product value to be realized. Their huge demand for data products and services is the driving force behind the development of the big data industry.
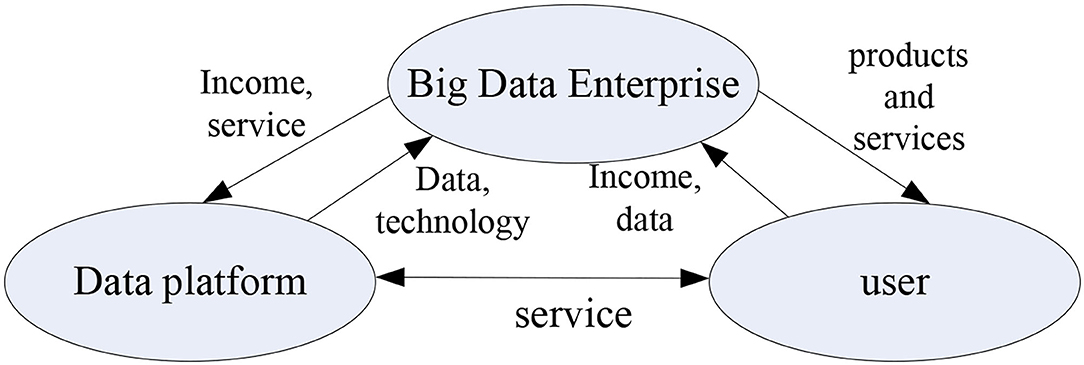
Figure 4. The relationship between the three major elements of the ecosystem.
As shown in Table 1, one is the efficient operation of the entrepreneurial ecosystem (M1, M2) brought about by good regional economic conditions, and the other is the operation of the entrepreneurial ecosystem due to the interaction between the maturity of the technology market and the entrepreneurial support institutions. The high efficiency obtained (M3) is the high efficiency brought about by the combined effect of the degree of cooperation between industry, university, and research institute and the characteristics of entrepreneurs (M4). It can be seen that the progress of entrepreneurial activities is closely related to the entrepreneurial environment in which they are located. A relaxed entrepreneurial atmosphere and an active market environment are the keys to the smooth progress of entrepreneurial activities.
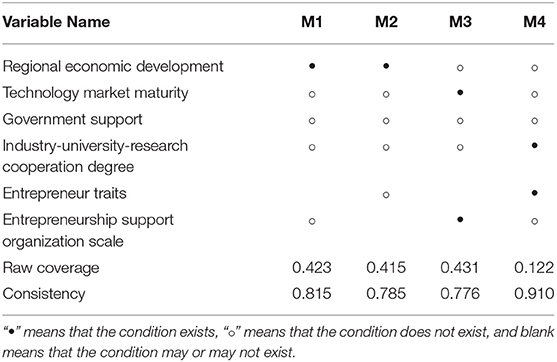
Table 1. Combination analysis of sufficient conditions for efficient operation of an entrepreneurial ecosystem.
Performance Comparison of Algorithm Classification Results
As shown in Figure 5, the overall effect of the Bi-LSTM algorithm is better than other comparative experimental methods, indicating that more effective semantic information can be obtained after considering the contextual information of the input data to improve the accuracy of the results. Bi-LSTM uses a randomly initialized vector to represent the input text data, and then uses a two-way long and short-term memory network structure for text classification. The network selected for the feature expression process is Bi-LSTM, and the number of hidden layer nodes is set to 256. The learning rate is set to 0.01, and the stochastic gradient descent algorithm is used to update and iterate the weight to obtain a stable model. Bi-LSTM is one level higher than the traditional artificial intelligence algorithm in terms of accuracy, recall, or F1 measurement.
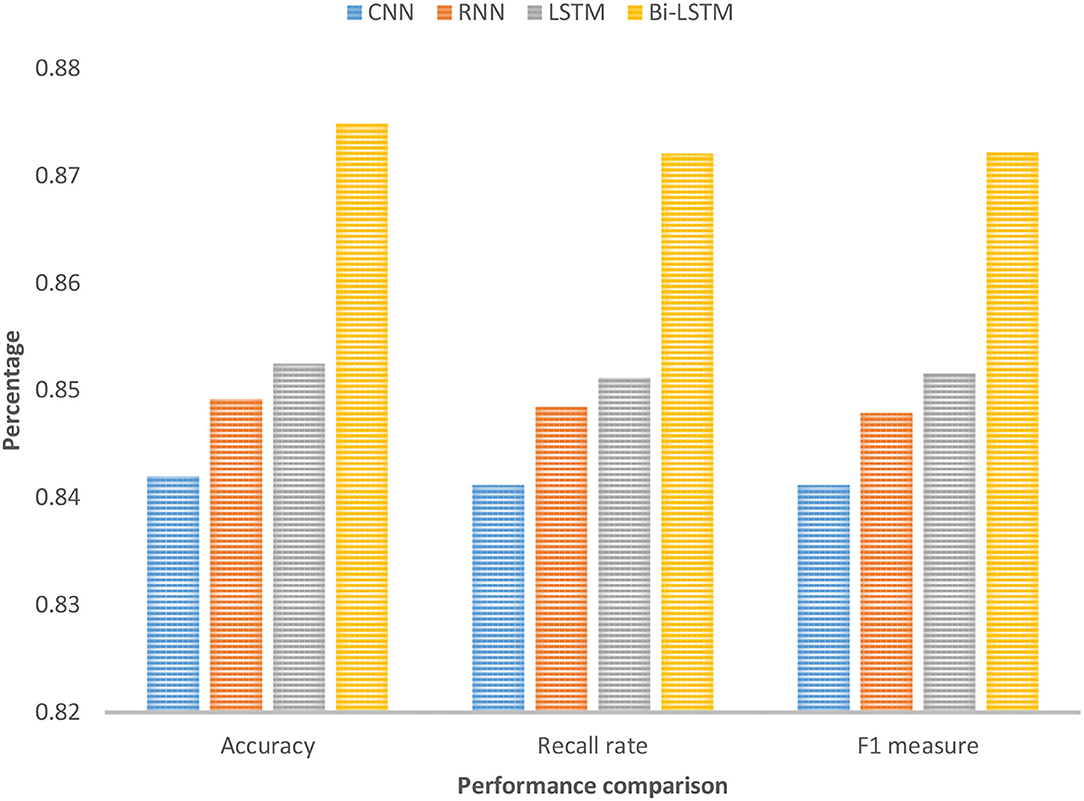
Figure 5. Performance comparison of classification results.
As shown in Table 2, the improved Bi-LSTM is superior to other models in terms of accuracy and F1 value, and the recall rate is only lower than the highest 0.2%, which fully proves that this model is reasonable. In addition, it can be seen that the accuracy of the traditional artificial intelligence CNN algorithm is significantly higher than that of LSTM, but the recall rate is lower, which proves that strong non-linear fitting ability of LSTM guarantees its high recall rate.
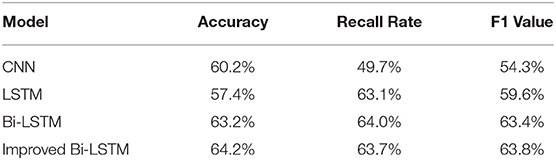
Table 2. Comparative data of different models.
As shown in Figure 6, it is found that the result of using word vector training is better than the training result of a random word vector. The reason is that in the training process, the context information between the words can be considered to get a better representation, thereby improving the text sentiment analysis, the accuracy, and other effects of the comparison; the training result of the comparison word vector is better than the training result of the word vector. The reason is that in the Chinese language, compared to the word, the word is a more effective collection of semantic information. This training method can be more effective. It effectively represents the semantic information of the data, thereby obtaining more meaningful relevant features in the text sentence, and improving the effectiveness of text sentiment analysis; the result of word vector training is better than the result of word vector, because for Chinese, in the training process of the word vector, the words in the context are also introduced, so that in the training process, the context space of the word vector can contain the semantic information of the words in the data, which can make the semantic information of the context richer and obtain better word representation, thereby improving the effect of text sentiment analysis.
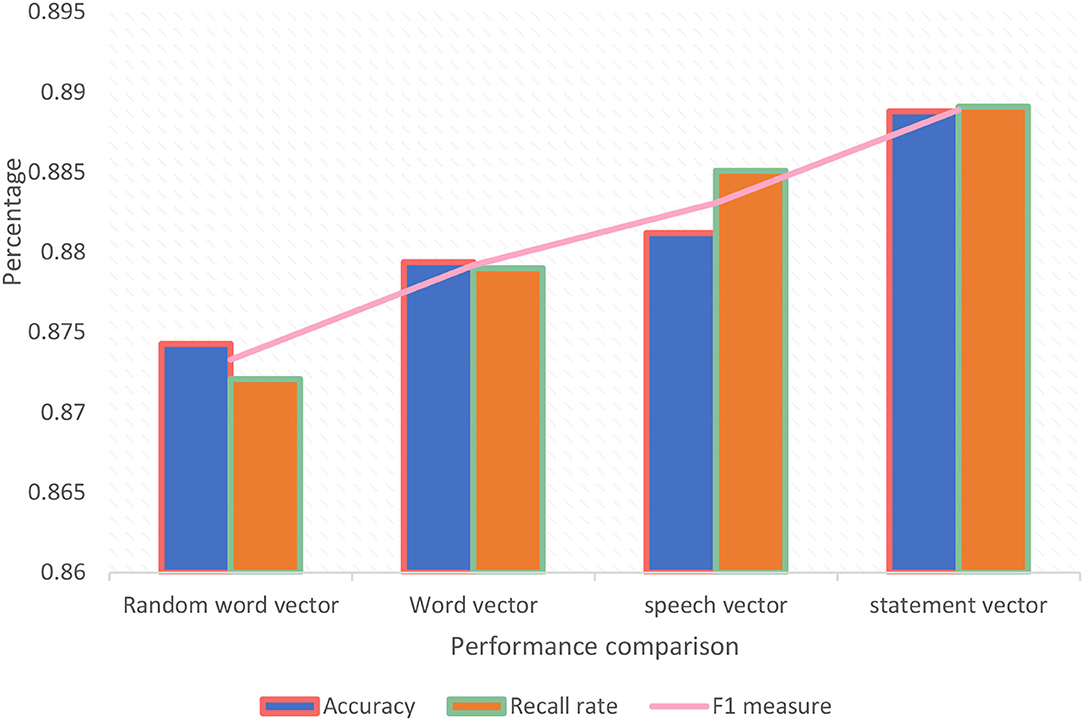
Figure 6. Performance comparison between models.
Algorithm Analysis Based on Improved Text Sentiment Calculation
In the text-based sentiment calculation analysis, the improved naive Bayes algorithm is used. In this article, the 10-fold crossover method is selected to evaluate the performance of the classifier, and the classification accuracy results are averaged to the final classification results. The higher the average, the better the accuracy.
As shown in Figure 7, the improved naive Bayes algorithm has a higher accuracy rate than the traditional Bayes algorithm. The improved Naive Bayes algorithm, based on Euclidean distance weighting, can give different weights to the final classification results according to different attributes to improve the classification performance of the algorithm, thereby improving the classification accuracy of the algorithm. Finally, it can be concluded that the improved naive Bayes algorithm is more effective. The optimized Bayesian algorithm uses the existing data information, and the prior probability obtained by weighting the attributes replaces the traditional naive Bayes prior probability, which improves the classification accuracy. Then, transplant the improved weighted naive Bayes classifier to the Spark platform, and use caching mechanism of Spark and the operation of the resilient distributed datasets (RDD) conversion operator to greatly speed up the execution time, reflecting the advantages of parallelization of the program running in the Spark cluster.
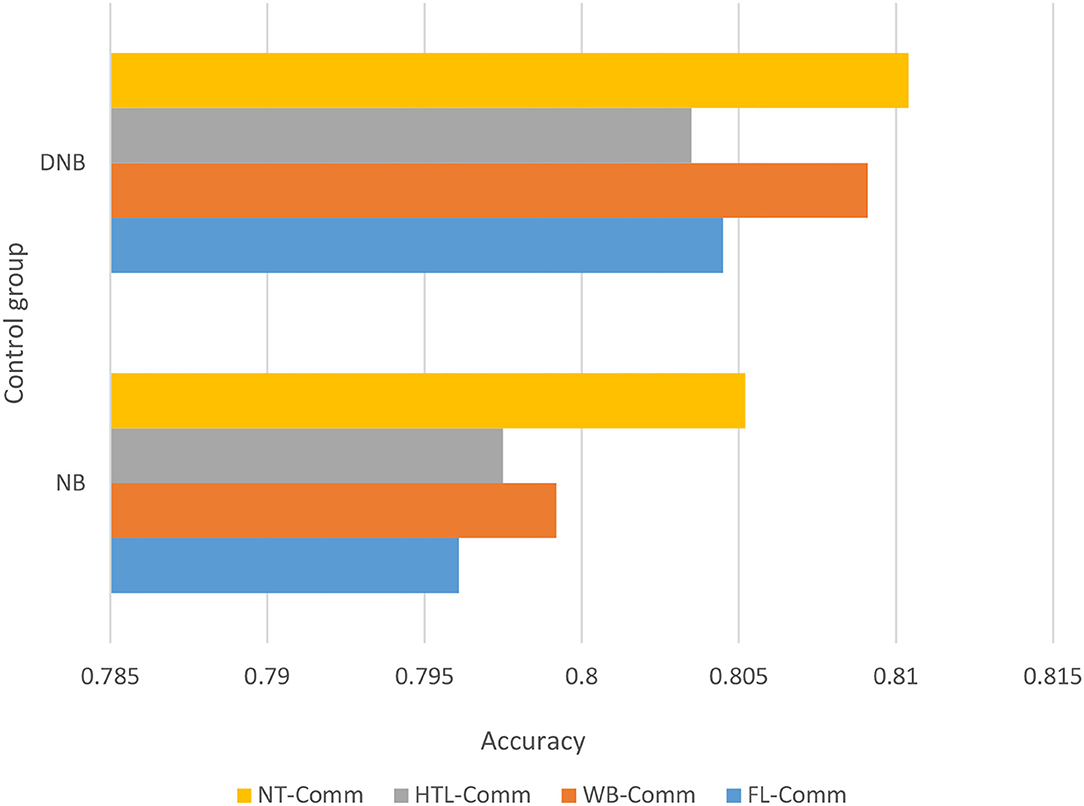
Figure 7. Comparison of accuracy of different classifiers on different data sets.
As shown in Figure 8, under different data scales, the running speed of a single machine and the running speed under the Spark platform have their own merits. On a scale of <100,000, the running speed of a single machine is faster, because, between nodes under the Spark platform, communication will consume time and will consume more time in communication and scheduling. On the scale of more than 100,000, the running speed of the Spark platform will be faster than that of a single machine, because the Spark platform will divide the data set into many small pieces, then divide it into different tasks according to different types, and then distribute according to the principle of data locality. Therefore, the traditional algorithm will affect the classification ability of Naive Bayes on the assumption of independence, and the optimized Naive Bayes improves the classification accuracy.
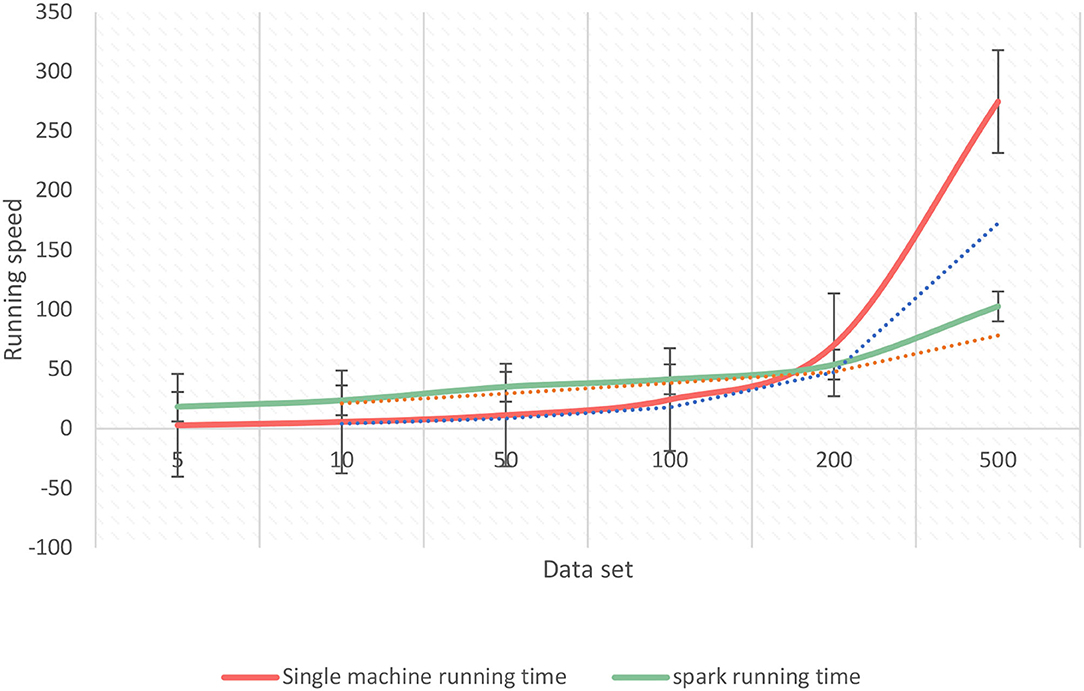
Figure 8. Comparison of running time of different scale data sets.
As shown in Table 3, Spark has achieved better results in the selected theme emotional trend sequence. The Spark model + native model proposed in this article is slightly lower than the Spark model but much higher than the native model, which illustrates this article proposes the validity of the model.

Table 3. Comparison of root mean square error and model training time result comparison.
As shown in Figure 9, when comparing three sets of experiments, the training time of the Spark model is much lower than the other two models, and the training time of the native model is the longest. In summary, although the Spark model loses part of its accuracy, it greatly shortens the model training time and is more in line with the scenario of public opinion trend prediction. When the data set is increased to a certain extent, memory overflow and other problems will occur in a stand-alone environment, and Spark will greatly accelerate the execution speed because of the caching mechanism and the operation of the RDD conversion operator, which reflects the advantages of parallelization of the program running in the Spark cluster. Therefore, the experiment shows that the classifier based on the Spark platform has an advantage in the running speed of the algorithm over the classifier on a stand-alone machine.
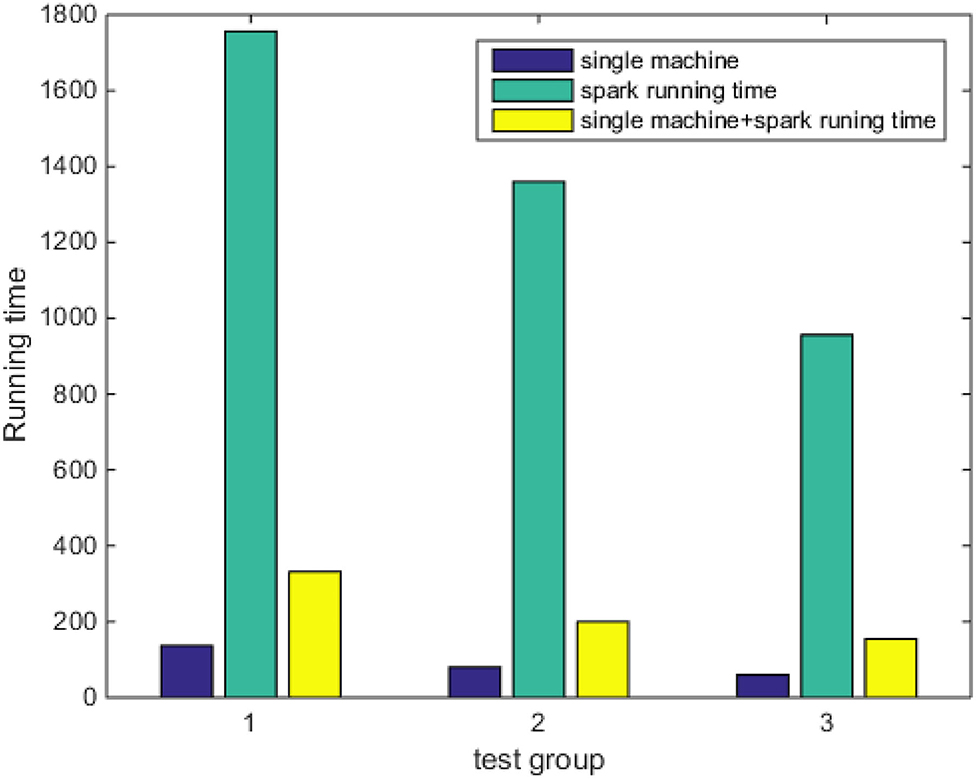
Figure 9. Comparison of model training time.
Conclusions
With the abundance of Internet resources and the vigorous development of mobile Internet. People's participation in the Internet is increasing. Due to the active participation of people, the digital entrepreneurial ecosystem has great development potential, but because these data exist in an unstructured way. Guidance lacks the ability of text sentiment analysis. Therefore, if emotional information can be extracted from these unstructured data, it will greatly promote the ability of text sentiment analysis, which has great value in scientific research and practical applications. With the rapid development of artificial intelligence technology and the maturity of large-scale data computing frameworks, digital entrepreneurship ecosystems have also become possible. This article mainly studies the ability of text emotional word extraction and trend prediction technology based on the digital entrepreneurial ecosystem and models and analyzes and predicts text data. The optimized Bayesian algorithm is used, which has a higher accuracy rate than the traditional Bayesian algorithm. Using the optimized Bi-LSTM model, the accuracy, recall, and F1 values have been slightly improved. On the Spark platform running down, the training time is greatly reduced. In the digital entrepreneurial ecosystem designed in this article, many functions are not perfect due to the short time. In the next step, it is anticipated to improve the functions of the system.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author Contributions
JL: writing–editing. MY: data analysis. Both authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Allenby, C. E., Babiash, E. S., Blank, P. N., Marco, D. C., Isabelle, G. L., Robin, B. L., et al. (2018). Analysis of the market, regulatory landscape, and current state of clinical trials pertaining to digital health. Technol. Transf. Entrepreneurship 5, 21–34. doi: 10.2174/2213809905666180816115016
Bhagat, C., and Mane, D. (2019). Survey on text categorization using sentiment analysis. J. Sci. Technol. Res. 8, 1189–1195.
Chang, G., and Huo, H. (2018). A method of fine-grained short text sentiment analysis based on machine learning. Neural Netw. World 28, 325–344. doi: 10.14311/NNW.2018.28.019
Chen, Y. S. (2021). Sustainability innovation enabled by digital entrepreneurship in Franchise organizations. Int. J. E-Entrepreneurship Innov. 11, 71–85. doi: 10.4018/IJEEI.2021010105
Gabison, G. A. (2019). Government-sponsored patent monetizing entities. J. Bus. Entrepreneurship Law 12, 9–9. doi: 10.2139/ssrn.3279544
Gartner, W. B. (1985). A conceptual framework for describing the phenomenon of new venture creation[J]. Acad. Manage. Rev. 10, 696–706.
Gnyawali, D. R., and Fogel, D. S. (1994). Environments for entrepreneurship development: key dimensions and research implications. Entrep. Theory Pract. 18, 43–62.
Hahn, A., Klug, K., and Riedmüller, F. (2020). Digital empathy: kombinierte erfassung über affective computing und eye tracking. Digitale Welt 4, 24–27. doi: 10.1007/s42354-020-0278-4
Hamdi, A., Shaban, K., and Zainal, A. (2018). CLASENTI: a class-specific sentiment analysis framework. ACM Trans. Asian Lang. Inf. Process. 17, 32.1–32.28. doi: 10.1145/3209885
Hutson, M. (2018). Artificial intelligence faces reproducibility crisis. Science 359, 725–726. doi: 10.1126/science.359.6377.725
Ishmukhametov, E. M., Khisaeva, A. I., and Gaysina, R. (2020). Institutional trends of entrepreneurship development in the republic of Bashkortostan. Bull. USPTU Sci. Educ. Econ. Ser. Econ. 2, 92–100. doi: 10.17122/2541-8904-2020-2-32-92-100
Kotelnikov, E. V. (2018). TextJSM: text sentiment analysis method. Autom. Doc. Math. Linguist. 52, 24–34. doi: 10.3103/S0005105518010089
Le, X., Chu, J., Deng, S., Jiao, Q., Pei, J., Zhu, L., et al. (2019). CiteOpinion: evidence-based evaluation tool for academic contributions of research papers based on citing sentences. J. Data Inf. Sci. 4, 26–41. doi: 10.2478/jdis-2019-0019
Li, C., Biao'an, S., Zhao, L., and Hongqing, G. (2011). Research on the impact of entrepreneurial network on new enterprise performance – the intermediary role of organizational learning. Sci. Res. 28, 1592–1600.
Li, N., Jin, X., and Li, Y. (2020). Identification of key customer requirements based on online reviews. J. Intel. Fuzzy Syst. 39, 1–14. doi: 10.3233/JIFS-200057
Lian, Z., Li, Y., Tao, J. H., Huang, J., and Niu, M. (2020). Expression analysis based on face regions in read-world conditions. Int. J. Autom. Comput. 17, 96–107. doi: 10.1007/s11633-019-1176-9
Liu, J., Nandhakumar, J., and Zachariadis, M. (2018). When guanxi meets structural holes: Exploring the guanxi networks of Chinese entrepreneurs on digital platforms. J. Strat. Inf. Syst. 27, 311–334 doi: 10.1016/j.jsis.2018.10.003
Lutfullaeva, M., Medvedeva, M., Komotskiy, E., and Spasov, K. (2018). Optimization of sentiment analysis methods for classifying text comments of bank customers - ScienceDirect. IFAC-PapersOnLine 51, 55–60. doi: 10.1016/j.ifacol.2018.11.353
Miao, Y., and Chonghui, G. (2018). Using news to predict Chinese medicinal material price index movements. Ind. Manage. Data Syst. 118, 998–1017. doi: 10.1108/IMDS-06-2017-0287
Morris, M. H., Davis, D. L., and Allen, J. W. (1994). Fostering corporate entrepreneurship: cross-cultural comparisons of the importance of individualism versus collectivism. J. Int. Bus. Stud. 25, 65–89.
Nam, S., and Lee, H. C. (2019). A text analytics-based importance performance analysis and its application to airline service. Sustainability 11, 61–78. doi: 10.3390/su11216153
Nuseir, M. T. Al. (2018). Digital media impact on smes performance in the UAE. Acad. Entrepreneurship J., 24, 1–13.
Schmidt, T., Schlindwein, M., Lichtner, K., and Wolff, C. (2020). Investigating the relationship between emotion recognition software and usability metrics. i-com 19, 139–151. doi: 10.1515/icom-2020-0009
Shen, K. N., Lindsay, V., and Xu, Y. C. (2018). Digital entrepreneurship. Inf. Syst. J. 28, 1125–1128. doi: 10.1111/isj.12219
Singh, S. K., and Sachan, M. (2019). SentiVerb system: classification of social media text using sentiment analysis. Multimed. Tools Appl. 78, 32109–32136. doi: 10.1007/s11042-019-07995-2
Singh, S. K., and Sachan, M. K. (2021). Classification of code-mixed bilingual phonetic text using sentiment analysis. Int. J. Semantic Web Inf. Syst. 17, 59–78. doi: 10.4018/IJSWIS.2021040104
Sodhar, I. N., Jalbani, A. H., Buller, A. H., Channa, M., and Hakro, D. (2020). Sentiment analysis of romanized sindhi text. J. Intel. Fuzzy Syst. 38, 1–7. doi: 10.3233/JIFS-179675
Xuebing, P., and Gang, Z. (2009). Research on technological entrepreneurship and technological innovation. Sci. Technol. Prog. Countermeas. 27, 15–19.
Keywords: text sentiment analysis, deep learning, digital entrepreneurship ecosystem, dynamic evolution, computing analysis
Citation: Li J and Yao M (2021) Dynamic Evolution Mechanism of Digital Entrepreneurship Ecosystem Based on Text Sentiment Computing Analysis. Front. Psychol. 12:725168. doi: 10.3389/fpsyg.2021.725168
Received: 15 June 2021; Accepted: 28 July 2021;
Published: 20 September 2021.
Edited by:
Yizhang Jiang, Jiangnan University, ChinaReviewed by:
Li Ming, Jiangxi University of Finance and Economics, ChinaSang-Bing Tsai, University of Electronic Science and Technology of China, China
Copyright © 2021 Li and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiahui Li, amlhaHVpbDE4QG1haWxzLmpsdS5lZHUuY24=; Meifang Yao, eWFvbWZAamx1LmVkdS5jbg==