 Anjana Talapatra1
Anjana Talapatra1 Shahin Boluki2
Shahin Boluki2 Pejman Honarmandi1
Pejman Honarmandi1 Alexandros Solomou3Guang Zhao2
Alexandros Solomou3Guang Zhao2 Seyede Fatemeh Ghoreishi4
Seyede Fatemeh Ghoreishi4 Abhilash Molkeri1Douglas Allaire4Ankit Srivastava1
Abhilash Molkeri1Douglas Allaire4Ankit Srivastava1 Xiaoning Qian2Edward R. Dougherty2Dimitris C. Lagoudas1,3
Xiaoning Qian2Edward R. Dougherty2Dimitris C. Lagoudas1,3 Raymundo Arróyave1*
Raymundo Arróyave1*- 1Department of Materials Science & Engineering, Texas A&M University, College Station, TX, United States
- 2Department of Electrical & Computer Engineering, Texas A&M University, College Station, TX, United States
- 3Department of Aerospace Engineering, Texas A&M University, College Station, TX, United States
- 4Department of Mechanical Engineering, Texas A&M University, College Station, TX, United States
Over the last decade, there has been a paradigm shift away from labor-intensive and time-consuming materials discovery methods, and materials exploration through informatics approaches is gaining traction at present. Current approaches are typically centered around the idea of achieving this exploration through high-throughput (HT) experimentation/computation. Such approaches, however, do not account for the practicalities of resource constraints which eventually result in bottlenecks at various stage of the workflow. Regardless of how many bottlenecks are eliminated, the fact that ultimately a human must make decisions about what to do with the acquired information implies that HT frameworks face hard limits that will be extremely difficult to overcome. Recently, this problem has been addressed by framing the materials discovery process as an optimal experiment design problem. In this article, we discuss the need for optimal experiment design, the challenges in it's implementation and finally discuss some successful examples of materials discovery via experiment design.
1. Introduction
Historically, the beginning of materials research centered around learning how to use the elements and minerals discovered in nature. The chief challenge at the time was the separation of the pure metal from the mined ore which lead over time to the science of metallurgy—the foundation of current day materials research. Humans then discovered that these pure metals could be combined to form alloys, followed by the principles of heat treatments—advances that shaped history; since the ability to invent new and exploit known techniques to use metals and alloys to forge weapons for sustenance and defense was instrumental in the success, expansion and migration of early civilizations. Additionally, there is evidence that the oft-quoted sequence of copper-tin bronze-iron which lend their names to the “ages” of human progress, occurred in different parts of the world, sometimes even simultaneously (Tylecote and Tylecote, 1992). Thus, the desire to harvest materials from nature and use them to improve the quality of life is a uniquely human as well as universal trait.
With the acceleration of scientific advances over the last few centuries, mankind has moved on from developing applications based on available materials, to demanding materials to suit desired applications. Science and technology are continuously part of this contentious chicken and egg situation where it is folly to prioritize either–scientific knowledge for its own sake or the use of science as just a tool to fuel new applications. Regardless, the majority of the scientific breakthroughs from the materials perspective have resulted from an Edisonian approach and been guided primarily by experience, intuition and to some extent, serendipity. Further, bringing the possibilities suggested by such discoveries to fruition takes decades and considerable financial resources. Also, such approaches when successful, enable the investigation of a very small fraction of a given materials design space leaving vast possibilities unexplored. No alchemic recipes exist, however desirable, which given a target application and desired properties, enables one to design the optimized material for that application. However, to tread some distance on that alchemic road, recently, extensive work has centered on the accelerated and cost-effective discovery, manufacturing, and deployment of novel and better materials as promoted by the Materials Genome Initiative (Holdren, 2011).
1.1. Challenges in Accelerated Materials Discovery Techniques
The chief hurdle when it comes to searching for new materials with requisite or better properties is the scarcity of physical knowledge about the class of materials that constitute the design space. Data regarding the structure and resultant properties may be available, but what is lacking is usually the fundamental physics that delineate the processing-structure-property-performance (PSPP) relationships in these materials. Additionally, the interplay of structural, chemical and micro-structural degrees of freedom introduces enormous complexity, which exponentially increases the dimensionality of the problem at hand, limiting the application of traditional design strategies.
To bypass this challenge, the current focus of the field is on the use of data to knowledge approaches, the idea being to implicitly extract the material physics embedded in the data itself with the use of modern day tools–machine learning, design optimization, manufacturing scale-up and automation, multi-scale modeling, and uncertainty quantification with verification and validation. Typical techniques include the utilization of High-Throughput (HT) computational (Strasser et al., 2003; Curtarolo et al., 2013; Kirklin et al., 2013) and experimental frameworks (Strasser et al., 2003; Potyrailo et al., 2011; Suram et al., 2015; Green et al., 2017), which are used to generate large databases of materials feature / response sets, which then must be analyzed (Curtarolo et al., 2003) to identify the materials with the desired characteristics (Solomou et al., 2018). HT methods, however, fail to account for constraints in experimental / computational) resources available, nor do they anticipate the existence of bottle necks in the scientific workflow that unfortunately render impossible the parallel execution of specific experimental / computational tasks.
Recently, the concept of optimal experiment design, within the overall framework of Bayesian Optimization (BO), has been put forward as a design strategy to circumvent the limitations of traditional (costly) exploration of the design space. This was pioneered by Balachandran et al. (2016) who put forward a framework that balanced the need to exploit available knowledge of the design space with the need to explore it by using a metric (Expected Improvement, EI) that selects the best next experiment with the end-goal of accelerating the iterative design process. BO-based approaches rely on the construction of a response surface of the design space and are typically limited to the use of a single model to carry out the queries. This is an important limitation, as often times, at the beginning of a materials discovery problem, there is not sufficient information to elucidate the feature set (i.e., model) that is the most related to the specific performance metric to optimize.
Additionally, although these techniques have been successfully demonstrated in a few materials science problems (Seko et al., 2014, 2015; Frazier and Wang, 2016; Ueno et al., 2016; Xue et al., 2016a,b; Dehghannasiri et al., 2017; Ju et al., 2017; Gopakumar et al., 2018), the published work tends to focus on the optimization of a single objective (Balachandran et al., 2016), which is far from the complicated multi-dimensional real-world materials design requirements.
In this manuscript, we discuss the materials discovery challenge from the perspective of experiment design-i.e., goal-oriented materials discovery, wherein we efficiently exploit available computational tools, in combination with experiments, to accelerate the development of new materials and materials systems. In the following sections, we discuss the need for exploring the field of materials discovery via the experiment design paradigm and then specifically discuss two approaches that address the prevalent limitations discussed above: i) a framework that is capable of adaptively selecting competing models connecting materials features to performance metrics through Bayesian Model Averaging (BMA), followed by optimal experiment design, ii) a variant of the well-established kriging technique specifically adapted for problems where models with varying levels of fidelity related to the property of interest are available and iii) a framework for the fusion of information that exploits correlations among sources/models and between the sources and ‘ground truth’ in conjunction with a multi-information source optimization framework that identifies, given current knowledge, the next best information source to query and where in the input space to query it via a novel value-gradient policy and examples of applications of these approaches in the context of single-objective and multi-objective materials design optimization problems and information fusion applied to the design of dual-phase materials and CALPHAD-based thermodynamic modeling.
2. Experiment Design
The divergence of modern science from its roots in natural philosophy was heralded by the emphasis on experimentation in the sixteenth and seventeenth centuries as a means to establish causal relationships (Hacking, 1983) between the degrees of freedom available to the experimenter and the phenomena being investigated. Experiments involve the manipulation of one or more independent variables followed by the systematic observation of the effects of the manipulation on one or more dependent variables. An experiment design then, is the formulation of a detailed experimental plan in advance of doing the experiment that when carried out will describe or explain the variation of information under conditions hypothesized to reflect the variation. An optimal experiment design maximizes either the amount of ‘information’ that can be obtained for a given amount of experimental effort or the accuracy with which the results are obtained, depending on the purpose of the experiment. A schematic of the experiment design process is shown in Figure 1.
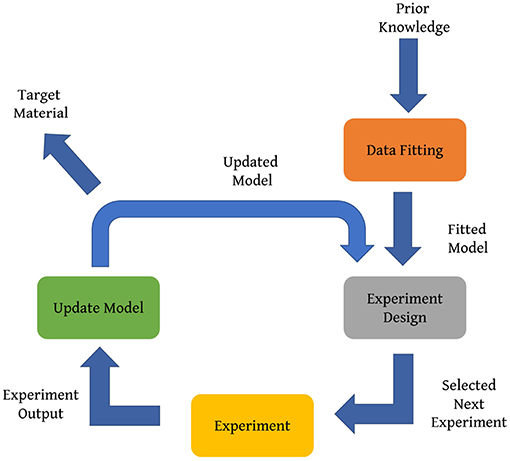
Figure 1. A schematic of the recursive experiment design process.
Taking into consideration the large number of measurements often needed in materials research, design problems are formulated as a multi-dimensional optimization problem, which typically require training data in order to be solved. Prior knowledge regarding parameters and features affecting the desired properties of materials is of great importance. However, often, prior knowledge is inadequate and the presence of large uncertainty is detrimental to the experiment design. Hence, additional measurements or experiments are necessary in order to improve the predictability of the model with respect to the design objective. Naturally, it is then essential to direct experimental efforts such that the targeted material may be found by minimizing the number of experiments. This may be achieved via an experiment design strategy that is able to distinguish between different experiments based upon the information they can provide. Thus, the experiment design strategy results in the choosing of the next best experiment, which is determined by optimizing an acquisition function.
2.1. Experiment Design Under Model Uncertainty
In most materials design tasks, there are always multiple information sources at the disposal of the material scientist. For example, the relationships between the crystal structure and properties/performance can in principle be developed through experiments as well as (computational) models at different levels of fidelity and resolution (-atomistic scale, molecular scale, continuum scale). Traditional holistic design approaches such as Integrated Computational Materials Engineering (ICME), on the other hand, often proceed on the limited and (frankly) unrealistic assumption that there is only one source available to query the design space. For single information sources and sequential querying, there are two traditional techniques for choosing what to query next in this context (Lynch, 2007; Scott et al., 2011). These are (i) efficient global optimization (EGO) (Jones et al., 1998) and its extensions, such as sequential Kriging optimization (SKO) (Huang et al., 2006) and value-based global optimization (VGO) (Moore et al., 2014), and (ii) the knowledge gradient (KG) (Gupta and Miescke, 1994, 1996; Frazier et al., 2008). EGO uses a Gaussian process (Rasmussen, 2004) representation of available data, but does not account for noise (Schonlau et al., 1996, 1998). SKO also uses Gaussian processes, but includes a variable weighting factor to favor decisions with higher uncertainty (Scott et al., 2011). KG differs in that while it can also account for noise, it selects the next solution on the basis of the expected value of the best material after the experiment is carried out. In the case of multiple uncertain sources of information (e.g., different models for the same problem), it is imperative to integrate all the sources to produce more reliable results (Dasey and Braun, 2007). In practice, there are several approaches for fusing information from multiple models. Bayesian Model Averaging (BMA), multi-fidelity co-kriging (Kennedy and O'Hagan, 2000; Pilania et al., 2017, and fusion under known correlation (Geisser, 1965; Morris, 1977; Winkler, 1981; Ghoreishi and Allaire, 2018) are three such model fusion techniques that enable robust design. These approaches shall be discussed in detail in the following sections.
2.1.1. Bayesian Model Averaging (BMA)
The goal of any materials discovery strategy is to identify an action that results in a desired property, which is usually optimizing an objective function of the action over the Materials Design Space (MDS). In materials discovery, each action is equivalent to an input or design parameter setup. If complete knowledge of the objective function exists, then the materials discovery challenge is met. In reality however, this objective function is a black-box, of which little if anything is known and the cost of querying such a function (through expensive experiments/simulations) at arbitrary query points in the MDS is very high. In these cases a parametric or non-parametric surrogate model can be used to approximate the true objective function. Bayesian Optimization (BO) (Shahriari et al., 2016) corresponds to these cases, where the prior model is sequentially updated after each experiment.
Irrespective of whether prior knowledge about the form of the objective function exists and/or many observations of the objective values at different parts of the input space are available, there is an inherent feature selection step, where different potential feature sets might exist. Moreover, there might be a set of possible parametric families as candidates for the surrogate model itself. Even when employing non-parametric surrogate models, several choices for the functional form connecting degrees of freedom in the experimental space and the outcome(s) of the experiment might be available. These translate into different possible surrogate models for the objective function. The common approach is to select a feature set and a single family of models and fix this selection throughout the experiment design loop; however, this is often not a reliable approach due to the small initial sample size that is ubiquitous in materials science.
This problem was addressed by a subset of the present authors by framing experiment design as Bayesian Optimization under Model Uncertainty (BOMU), and incorporating Bayesian Model Averaging (BMA) within Bayesian Optimization (Talapatra et al., 2018). The acquisition function used is the Expected Improvement (EI) which seeks to balance the need to exploit available knowledge of the design space with the need to explore it. Suppose that f′ is the minimal value of the objective function f observed so far. Expected improvement evaluates f at the point that, in expectation, improves upon f′ the most. This corresponds to the following utility function:
If ŷ and s are the predicted value and its standard error at x, respectively, then the expected improvement is given by:
where: ϕ(.) and Φ(.) are the standard normal density and distribution functions (Jones et al., 1998). The Bayesian Optimization under Model Uncertainty approach may then be described as follows:
• There is a collection of potential models (e.g., models based on different features sets)
• The models are averaged, based on the (posterior) model probabilities given initial data set to form a BMA.
• Using the expected acquisition function under the BMA model, an experiment is chosen that maximizes the expected acquisition.
• The experiment is run, each model is updated and the (posterior) model probabilities are updated.
• The expected acquisition under the updated BMA model is computed and an experiment is chosen.
• This iteration is done until some stopping criteria are satisfied (e.g., while objective not satisfied and budget not exhausted), and the best observation so far is selected as the final suggestion.
Incorporating BMA within Bayesian Optimization produces a system capable of autonomously and adaptively learning not only the most promising regions in the materials space but also the models that most efficiently guide such exploration. The framework is also capable of defining optimal experimental sequences in cases where multiple objectives must be met-we note that recent works have begun to address the issue of multi-objective Bayesian Optimization in the context of materials discovery (Mannodi-Kanakkithodi et al., 2016; Gopakumar et al., 2018). Our approach, however, is different in that the multi-objective optimization is carried out simultaneously with feature selection. The overall framework for autonomous materials discovery is shown in Figure 2.
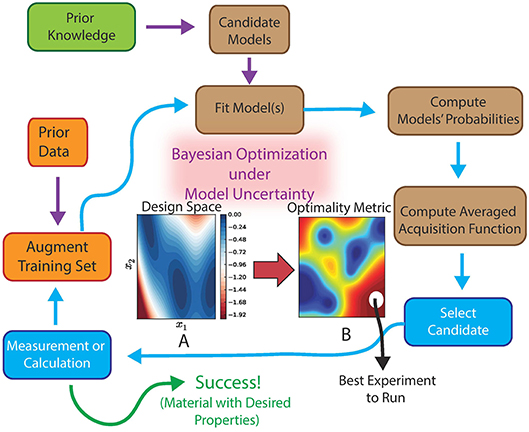
Figure 2. Schematic of the proposed framework for an autonomous, efficient materials discovery system as a realization of Bayesian Optimization under Model Uncertainty (BOMU). Initial data and a set of candidate models are used to construct a stochastic representation of an experiment/simulation. Each model is evaluated in a Bayesian sense and its probability is determined. Using the model probabilities, an effective acquisition function is computed, which is then used to select the next point in the materials design space that needs to be queried. The process is continued iteratively until target is reached or budget is exhausted. Used with permission from Talapatra et al. (2018).
2.1.2. Multi-Fidelity co-kriging
As discussed in Pilania et al. (2017), co-kriging regression is an variant of the well-established kriging technique specifically adapted for problems where models with varying levels of fidelity (i.e., variations both in computational cost and accuracy) related to the property of interest are available. This approach was put forward by Kennedy and O'Hagan (2000) who presented a cogent mathematical framework to fuse heterogeneous variable-fidelity information sources paving the way for multi-fidelity modeling. This framework was then adapted by Forrester et al. (2007) who demonstrated its application in an optimization setting via a two-level co-kriging scheme. The auto-regressive co-kriging scheme may be applied to scenarios where l-levels of variable-fidelity estimates are available, however, practical limitations pertaining to computational efficiency emerge when the number of levels l or number of data points grow large. Recent work by Le Gratiet and Garnier (Le Gratiet, 2013; Le Gratiet and Garnier, 2014) showed that any co-kriging scheme with l-levels of variable-fidelity information sources can be effectively decoupled, and equivalently reformulated in a recursive fashion as an l-independent kriging problem, thereby circumventing this limitation. This facilitates the construction of predictive co-kriging schemes by solving a sequence of simpler kriging problems of lesser complexity. In the context of materials discovery, this approach was successfully implemented by Pilania et al., who presented a multi-fidelity co-kriging statistical learning framework that combines variable-fidelity quantum mechanical calculations of bandgaps to generate a machine-learned model that enables low-cost accurate predictions of the bandgaps at the highest fidelity level (Pilania et al., 2017). Similarly, Razi et al. introduced a novel approach for enhancing the sampling convergence for properties predicted by molecular dynamics based upon the construction of a multi-fidelity surrogate model using computational models with different levels of accuracy (Razi et al., 2018).
2.1.3. Error Correlation-Based Model Fusion (CMF) Approach
As mentioned earlier, model-based ICME-style frameworks tend to focus on integrating tools at multiple scales under the assumption that there is a single model/tool which is significant at a specific scale of the problem. This ignores the use of multiple models that may be more/less effective in different regions of the performance space. Data-centric approaches, on the other hand, tend to focus (with some exceptions) on the brute-force exploration of the MDS, not taking into account the considerable cost associated with such exploration.
In Ghoreishi et al. (2018), the authors presented a framework that addresses the two outstanding issues listed above in the context of the optimal micro-structural design of advanced high strength steels. Specifically, they carried out the fusion of multiple information sources that connect micro-structural descriptors to mechanical performance metrics. This fusion is done in a way that accounts for and exploits the correlations between each individual information source-reduced order model constructed under different simplifying assumptions regarding the partitioning of (total) strain, stress or deformation work among the phases constituting the micro-structure-and between each information source and the ground truth-represented in this case by a full-field micro-structure-based finite element model. This finite element model is computationally expensive, and is considered as a higher fidelity model as part of a multi-fidelity framework, the intention being to create a framework for predicting ground truth. Specifically, the purpose of the work is not to match the highest fidelity model, but to predict material properties when created at ground truth. There is usually no common resource trade-off in this scenario, in contrast to traditional computational multi-fidelity frameworks that trade computational expense and accuracy.
In this framework, the impact of a new query to an information source on the fused model is of value. The search is performed over the input domain and the information source options concurrently to determine which next query will lead to the most improvement in the objective function. In addition, the exploitation of correlations between the discrepancies of the information sources in the fusion process is novel and enables the identification of ground truth optimal points that are not shared by any individual information sources in the analysis.
A fundamental hypothesis of this approach is that any model can provide potentially useful information to a given task. This technique thus takes into account all potential information any given model may provide and fuses unique information from the available models. The fusion goal then is to identify dependencies, via estimated correlations, among the model discrepancies. With these estimated correlations, the models are fused following standard practice for the fusion of normally distributed data. To estimate the correlations between the model deviations when they are unknown, the reification process (Allaire and Willcox, 2012; Thomison and Allaire, 2017) is used, which refers to the process of treating each model, in turn, as ground truth. The underlying assumption here is that the data generated by the reified model represents the true quantity of interest. These data are used to estimate the correlation between the errors of the different models and the process is then repeated for each model. The detailed process of estimating the correlation between the errors of two models can be found in Allaire and Willcox (2012) and Thomison and Allaire (2017).
A flowchart of the approach is shown in Figure 3. The next step then is to determine which information source should be queried and where to query it, concurrently, so as to produce the most value with the tacit resource constraint in mind. For this decision, a utility, which is referred to as the value-gradient utility is used, which accounts for both the immediate improvement in one step and expected improvement in two steps. The goal here is to produce rapid improvement, with the knowledge that every resource expenditure could be the last, but at the same time, to be optimally positioned for the next resource expenditure. In this sense, there is equal weight accorded to next step value with next step (knowledge) gradient information, hence the term value-gradient. As mentioned in the previous section, in the BMA approach, the Expected Improvement (EI) metric is used to choose the next query point, while in this approach, the value gradient is used.
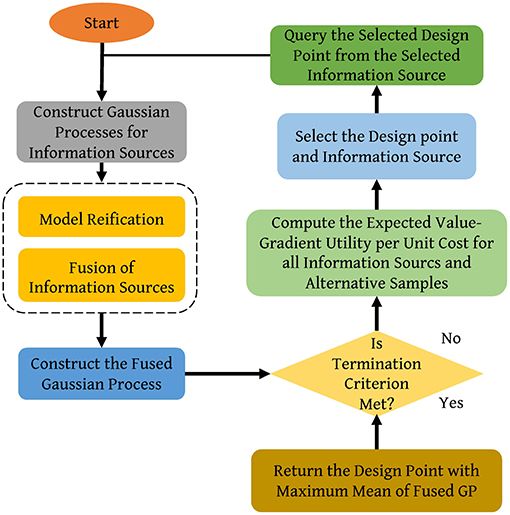
Figure 3. Flowchart of the information fusion approach. Adapted from Ghoreishi et al. (2018).
The knowledge gradient, which is a measure of expected improvement, is defined as:
where HN is the knowledge state, and the value of being at state HN is defined as . The KG policy for sequentially choosing the next query is then given as:
and the value-gradient utility is given by:
where is the maximum value of the mean function of the current fused model and is the maximum expected improvement that can be obtained with another query as measured by the knowledge gradient over the fused model.
2.2. Application of Experiment Design Framework: Examples
2.2.1. Multi-Objective Bayesian Optimization
A Multi-objective Optimal Experiment Design (OED) framework (see Figure 4) based on the Bayesian optimization techniques was reported by the authors in Solomou et al. (2018). The material to be optimized was selected to be precipitation strengthened NiTi Shape memory alloys (SMAs) since complex thermodynamic and kinetic modeling is necessary to describe the characteristics of these alloys. The specific objective of this Bayesian Optimal Experimental Design (BOED) framework in this study was to provide an Optimal Experiment Selection (OES) policy to guide an efficient search of the precipitation strengthened NiTi SMAs with selected target properties by efficiently solving a multi-objective optimization problem. The EHVI (Emmerich et al., 2011) acquisition function was used to perform multi-objective optimization. EHVI balances the trade-off between exploration and exploitation for multi-objective BOED problems, similar to EI for single-objective problems. EHVI is a scalar quantity that allows a rational agent to select, sequentially, the next best experiment to carry out, given current knowledge, regardless of the number of objectives, or dimensionality, of the materials design problem. The optimal solutions in an optimization problem are typically referred as Pareto optimal solutions or Pareto front or Pareto front points. The Pareto optimal solutions in a selected multi-objective space, correspond to the points of the objective space that are not dominated by any other points in the same space.
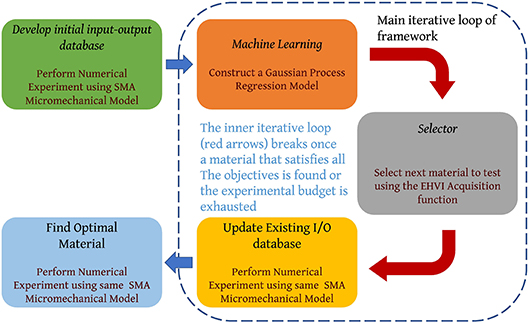
Figure 4. Autonomous closed-loop, multi-objective Bayesian Optimal Experimental Design framework. Adapted from Solomou et al. (2018).
For the NiTi SMA, the considered input variables were the initial homogeneous Ni concentration of the material before precipitation (c) and the volume fraction (vf) of the precipitates while the objective functions were functions of the material properties of the corresponding homogenized SMA. The framework was used to discover precipitated SMAs with (objective 1) an austenitic finish temperature , (objective 2) a specific thermal hysteresis that is defined as the difference of austenitic finish temperature and martensitic start temperature, . The problem was solved for two case studies, where the selected continuous MDS is discretized with a coarse and a dense mesh, respectively. The refined MDS has nT = 21021 combinations of the considered variables c and vf. The utility of the queried materials by the BOED framework within a predefined experimental budget (OES) is compared with the utility of the corresponding queried materials following a Pure Random Experiment Selection (PRES) policy and a Pure Exploitation Experiment Selection (PEES) policy within a predefined experimental budget. An experimental budget is assumed of nB = 20 material queries and for the case of the OES and PEES policies the experimental budget is allocated to nI = 1 randomly queried material and to nE = 19 for sequential experiment design.
The results are shown in Figure 5A. It is seen that the OES policy, even under the limited experimental budget, queries materials that belong to the region of the objective space which approaches the true Pareto front. This is clear by comparing the Pareto front calculated based on the results of the OES (blue dash line) with the true Pareto front found during the case study 1 (red dot line). The results also show that the materials queried by the PRES policy are randomly dispersed in the objective space, as expected, while the materials queried by the PEES policy are clustered in a specific region of the objective space which consists of materials with similar volume fraction values which is anticipated courtesy the true exploitative nature of the policy. Further analysis demonstrates, that the OES on average queries materials with better utility in comparison to the other two policies, while the PRES policy exhibits the worst performance.
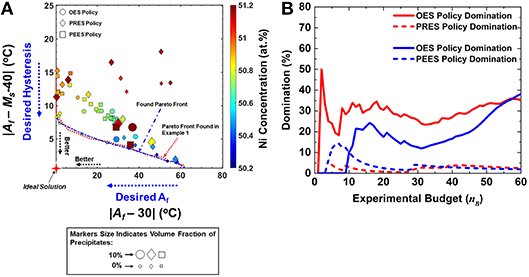
Figure 5. (A) Calculated objective space and Pareto front using the OES, PRES and PEES policies under the nB = 20 experimental budget. Reproduced with permission from Solomou et al. (2018), (B) Comparison of the utility of the queried materials by the OES, PRES and PEES policies as function of the experimental budget for the 2-objectives materials discovery problem. Reproduced with permission from Solomou et al. (2018).
Same trends of performance are maintained through the equivalent comparisons conducted for various experimental budgets as shown in Figure 5 which also indicates similar curves for the coarse mesh. It is apparent that if the OES policy is employed to query a material in a discrete MDS with defined variables bounds, its relative performance in comparison to the PRES policy becomes more definitive as the discretization of the MDS is further refined, as the gap between PRES and OES policies for the case of the dense discretized MDS (red lines) is much bigger than that in the case of the coarse discretized MDS (blue lines) optimally queried materials. The results of the BOED framework thus demonstrate that the method could efficiently approach the true Pareto front of the objective space of the approached materials discovery problems successfully. Such treatment was also carried out for a three-objective problem with the additional objective of maximizing the maximum saturation strain (Hsat) that the material can exhibit and similar conclusions were drawn.
While exact algorithms for the computation of EHVI have been developed recently (Hupkens et al., 2015; Yang et al., 2017), such algorithms are difficult to be extended to problems with more than 3 objectives. Recently, a subset of the present authors (Zhao et al., 2018) developed a fast exact framework for the computation of EHVI with arbitrary number of objectives by integrating a closed-formulation for computing the (hyper)volume of hyperrectangles with existing approaches (While et al., 2012; Couckuyt et al., 2014) to decompose hypervolumes. This framework is capable of computing EHVIs for problems with arbitrary number of objectives with saturating execution times, as shown in Figure 6.
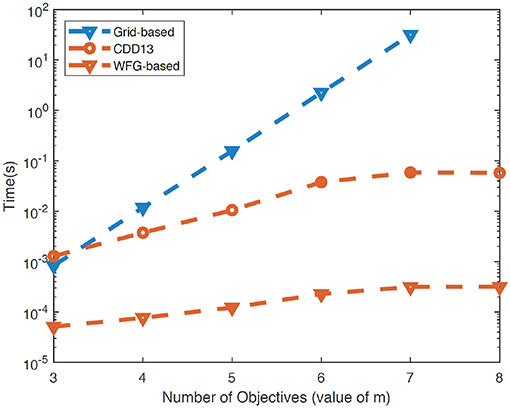
Figure 6. Comparison between traditional (grid-based) and fast approaches (CCD13, WGF) for computing the EHVI with arbitrary number of objectives. WFG corresponds to the updated framework developed in (Zhao et al., 2018).
2.2.2. Bayesian Model Averaging: Search for MAX Phase With Maximum Bulk Modulus
As was mentioned above, the BMA framework has been developed by the present authors to address the problem of attempting a sequential optimal experimenta design over a materials design space in which very little information about the causal relationships between features and response of interest is available. This framework was demonstrated by efficiently exploring the MAX ternary carbide/nitride space (Barsoum, 2013) through Density Functional Theory (DFT) calculations by the authors in Talapatra et al. (2018). Because of their rich chemistry and the wide range of values of their properties (Aryal et al., 2014), MAX phases constitute an adequate material system to test simulation-driven-specifically DFT calculations- materials discovery frameworks.
The problem was formulated with the goals of (i) identifying the material/materials with the maximum bulk modulus K and (ii) the maximum bulk modulus and minimum shear modulus with a resource constraint of permitting experiments totally querying 20% of the MDS. The case of the maximum bulk modulus K is designed as a single-objective optimization problem while the second problem is designed as a multi-objective problem. Features describing the relation between the material and objective functions were obtained from literature and domain knowledge.
In this work, a total of fifteen features were considered: empirical constants which relate the elements comprising the material to it's bulk modulus; valence electron concentration; electron to atom ratio; lattice parameters; atomic number; interatomic distance ; the groups according to the periodic table of the M, A & X elements, respectively; the order of MAX phase (whether of order 1 corresponding to M2AX or order 2 corresponding to M3AX2); the atomic packing factor ; average atomic radius ; and the volume/atom. In relevant cases, these features were composition-weighted averages calculated from the elemental values and were assumed to propagate as per the Hume-Rothery rules. Feature correlations were used to finalize six different feature sets which are denoted as F1, F2, F3, F4, F5, and F6.
Complete details may be found in Talapatra et al. (2018). Some representative results are shown here. Calculations were carried out for a different number of initial data instances N = 2, 5, 10, 15, 20. One thousand five hundred instances of each initial set N were used to ensure a stable average response. The budget for the optimal design was set at ≈ 20% of the MDS i.e., 80 materials or calculations. In each iteration, two calculations were done. The optimal policy used for the selection of the compound(s) to query was based on the EI for the single objective case and the EHVI for the multi-objective case. The performance trends for all problems across different values of N are consistent. The technique is found to not significantly depend on quantity of initial data. Here, representative results for N = 5 are shown.
Figure 7A indicates the maximum bulk modulus found in the experiment design iterations based on each model (feature set) averaged over all initial data set instances for N = 5. The dotted line in the figure indicates the maximum bulk modulus = 300 GPa that can be found in the MDS. F2 is found to be the best performing feature set on average, converging fastest to the maximum bulk modulus. F6 and F5 on the other hand, are uniformly the worst performing feature sets on average, converging the slowest. It is evident that using a regular optimization approach will work so long there is, apriori, a good feature set. Figure 7B shows the swarm plots indicating the number of calculations required to discover the maximum bulk modulus in the MDS using experiment design based on single models for the 1500 initial data instances with N = 5. The width of the swarm plot at every vertical axis value indicates the proportion of instances where the optimal design parameters were found at that number of calculations. Bottom heavy, wide bars, with the width decreasing with the number of steps is desirable, since that would indicate that larger number of instances needed fewer number of steps to converge. The dotted line indicates the budget allotted, which was 80 calculations. Instances that did not converge within the budget were allotted a value of 100. Thus, the width of the plots at vertical value of 100, corresponds to the proportion of instances which did not discover the maximum bulk modulus in the MDS within the budget. From this figure, it is seen that for F1, F2, and F4 in almost 100% of instances the maximum bulk modulus was identified within the budget, while F5 is the poorest feature set and the maximum was identified in very few instances.
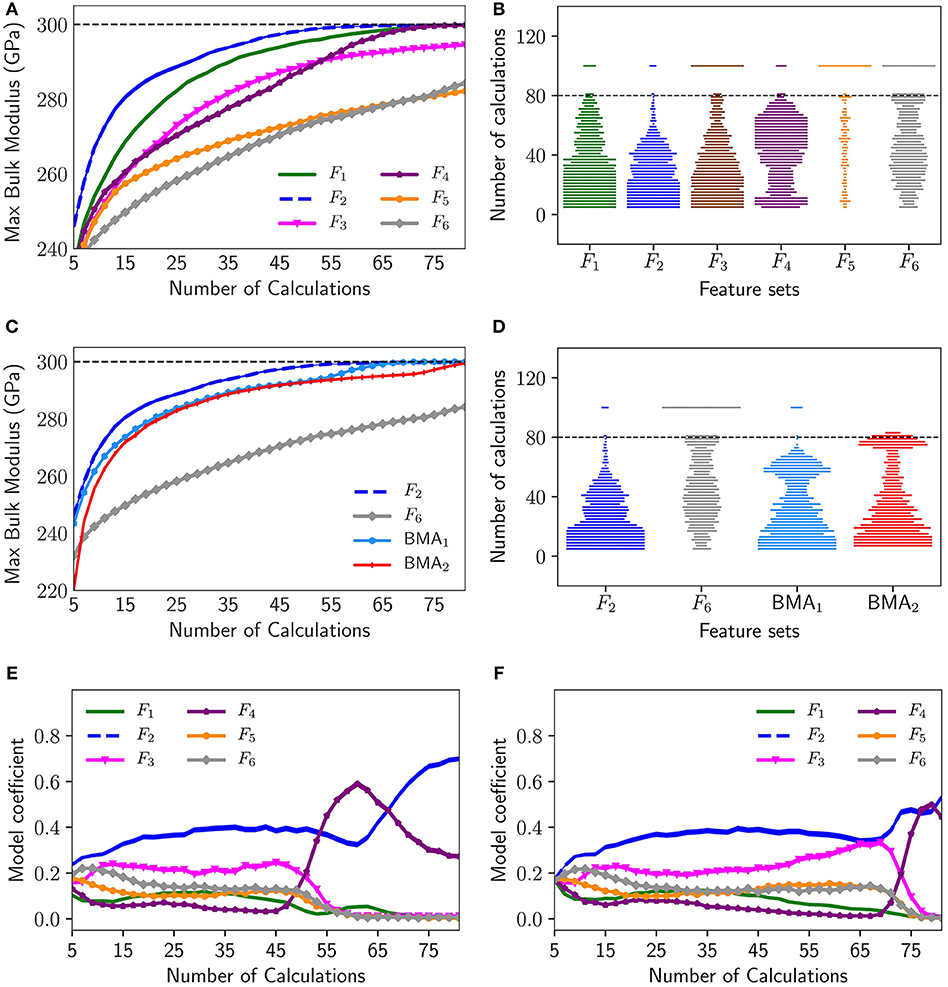
Figure 7. Representative results for single objective optimization–maximization of bulk modulus for N = 5: (A) Average maximum bulk modulus discovered using all described feature sets, (B) swarm plots indicating the distribution of the number of calculations required for convergence using all described feature sets, (C) average maximum bulk modulus discovered using the best feature set F2, worst feature set F6, BMA1, and BMA2, (D) swarm plots indicating the distribution of the number of calculations required for convergence using the best feature set F2, worst feature set F6, BMA1, and BMA2, (E) Average model probabilities for maximizing bulk modulus using BMA1, (F) Average model probabilities for maximizing bulk modulus using BMA2.
Unfortunately, due to small sample size and large number of potential predictive models, the feature selection step may not result in the true best predictive model for efficient Bayesian Optimization. Small sample sizes pose a great challenge in model selection due to inherent risk of imprecision and, and no feature selection method performs well in all scenarios when sample sizes are small. Thus, by selecting a single model as the predictive model based on small observed sample data, one ignores the model uncertainty.
To circumvent this problem the Bayesian Model Averaging (BMA) method was used. Regression models based on aforementioned six feature subsets, were adopted in the BMA experiment design. The BMA coefficients were evaluated in two ways: first-order (BMA1) and second-order (BMA2) Laplace approximation. Figure 7C shows the comparison of the average performance of both the first-order and second-order BMA over all initial data set instances with the best performing model (F2) and worst performing model (F6). It can be seen that both the first-order and second-order BMA performance in identifying the maximum bulk modulus is consistently close to the best model (F2). BMA1 performs as well as if not better than F2. Figure 7D shows the corresponding swarm plots indicating the number of calculations required to discover the maximum bulk modulus in the MDS for N = 5 using BMA1 and BMA2. It can be seen that for a very high percentage of cases the maximum bulk modulus can be found within the designated budget. In Figures 7E,F, the average model coefficients (posterior model probabilities) of the models based on different feature sets over all instances of initial data set are shown with the increasing number of calculations for BMA1 and BMA2 respectively. Thus, we see that, while prior knowledge about the fundamental features linking the material to the desired material property is certainly essential to build the Materials Design Space (MDS), the BMA approach may be used to auto-select the best features/feature sets in the MDS, thereby eliminating the requirement of knowing the best feature set a priori. Also, this framework is not significantly dependent on the size of the initial data, which enables its use in materials discovery problems where initial data is scant.
2.2.3. Multi-Source Information Fusion: Application to Dual-Phase Materials
In Ghoreishi et al. (2018), the authors demonstrated the Multi-Source Information Fusion approach in the context of the optimization of the ground truth strength normalized strain hardening rate for dual-phase steels. They used three reduced-order models (iso-strain, iso-stress, and iso-work) to determine the impact of quantifiable micro-structural attributes on the mechanical response of a composite dual-phase steel. The finite element model of the dual-phase material is considered as the ground truth with the objective being the maximization of the (ground truth) normalized strain hardening rate at ϵpl = 1.5%. The design variable then is the percentage of the hard phase, fhard, in the dual-phase material. A resource constraint of five total queries to (any of) the information sources before a recommendation for a ground truth experiment is made was enforced. If ground truth results were found to be promising, five additional queries were allocated to the information sources. The initial intermediate Gaussian process surrogates were constructed using one query from each information source and one query from the ground truth.
The value-gradient policy discussed earlier was used to select the next information source and the location of the query in the input space for each iteration of the process. The KG policy operating directly on the ground truth was also used to reveal the gains that can be had by considering all available information sources for comparison purposes. To facilitate this, a Gaussian process representation was created and updated after each query to ground truth. The convergence results of the fusion approach using all information sources and the KG policy on the ground truth are indicated in Figure 8. Here, the dashed line represents the optimal value of the ground truth quantity of interest. The proposed approach clearly outperforms the knowledge gradient applied directly to the ground truth, and also converged to the optimal value much faster, thereby reducing the number of needed ground truth experiments. This performance gain may be attributed to the ability of the information fusion approach to efficiently utilize the information available from the three low fidelity information sources to better direct the querying at ground truth. The original sample from ground truth used for initialization was taken at fhard = 95%, which is far away from the true optimal as can be observed in Figure 9 in the left column. The proposed framework, was thus able to quickly direct the ground truth experiment to a higher quality region of the design space by leveraging the three inexpensive available information sources.
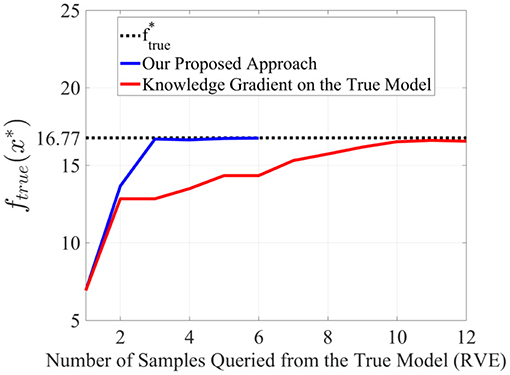
Figure 8. The optimal solution obtained by our proposed approach and by applying the knowledge gradient on a GP of only the true data (RVE) for different number of samples queried from the true model. Image sourced from Ghoreishi et al. (2018); use permitted under the Creative Commons Attribution License CC-BY-NC-SA.
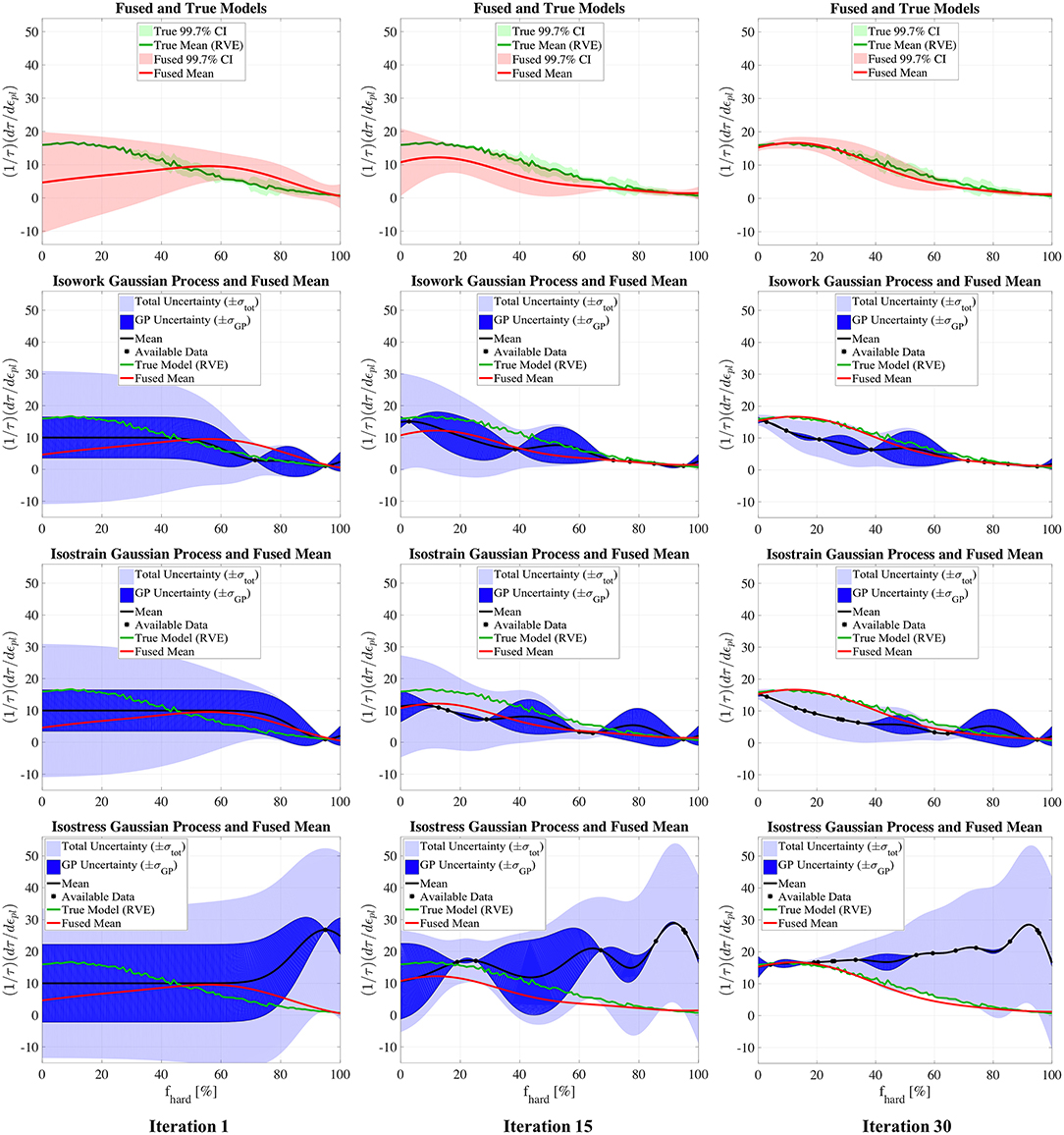
Figure 9. The fused model and Gaussian processes of the isowork, isostrain, and isostress models in comparison with the true (RVE) model in iterations 1, 15, and 30. Image sourced from Ghoreishi et al. (2018); use permitted under the Creative Commons Attribution License CC-BY-NC-SA.
Figure 9 shows the updates to each information source Gaussian process surrogate model and the fused model representing the total knowledge of ground truth for iterations 1, 15, and 30 of the information source querying process. Note that an iteration occurs when an information source is queried. which is distinct from any queries to ground truth. As is evident from the left column, the first experiment from ground truth and the first query from each information source gave scant information about the location of the true objective. However, by iteration 15, the fused model, shown by the smooth red curve, still under-predicts the ground truth at this point but has identified the best region of the design space. At iteration 15, only three expensive ground truth experiments have been conducted. By iteration 30, six ground truth experiments have been conducted and the fused model is very accurate in the region surrounding the optimal design for ground truth. It is clear from Figure 9 that none of the information sources share the ground truth optimum. It is worth highlighting that the ability of the proposed framework to find this optimum rested upon the use of correlation exploiting fusion, and would not have been possible using traditional methods.
Figure 10 presents the history of the queries to each information source and the ground truth. Note that the iteration now counts queries to each information source as well as ground truth experiments. From the figure, it is evident that all three information sources are exploited to find the ground truth optimal design, implying that, however imperfect, the optimal use of all sources available to the designer is essential in order to identify the optimal ground truth.
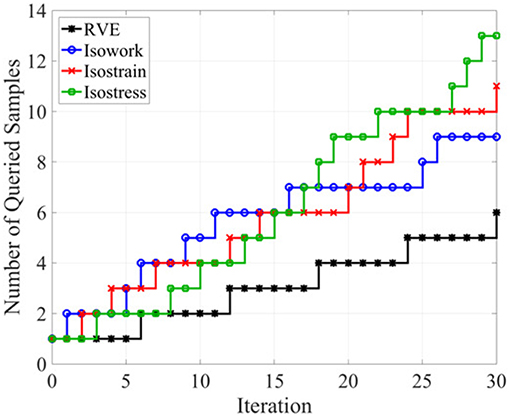
Figure 10. Number of samples queried from the true model (RVE) and the information sources in each iteration. Image sourced from Ghoreishi et al. (2018); use permitted under the Creative Commons Attribution License CC-BY-NC-SA.
2.2.4. Bayesian Model Averaging and Information Fusion: CALPHAD-Based Thermodynamic Modeling
Calculation of phase diagrams (CALPHAD) is one of the fundamental tools in alloy design and an important component of ICME. Uncertainty quantification of phase diagrams is the first step required to provide confidence for decision making in property- or performance-based design. In work that was the first of its kind (Honarmandi et al., 2019), the authors independently generated four CALPHAD models describing Gibbs free energies for the Hf−Si system. The calculation of the Hf−Si binary phase diagram and its uncertainties is of great importance since adding Hafnium to Niobium silicide based alloys (as promising turbine airfoil materials with high operating temperature) increases their strength, fracture toughness, and oxidation resistance significantly (Zhao et al., 2001). The Markov Chain Monte Carlo (MCMC) Metropolis Hastings toolbox in Matlab was then utilized for probabilistic calibration of the parameters in the applied CALPHAD models. These results are shown for each model in Figure 11 where it is seen that there is a very good agreement between the results obtained from model 2 and the data with a very small uncertainty band and consequently a small Model Structure Uncertainty (MSU) (Choi et al., 2008). Models 3 and 4 on the other hand show large uncertainties for the phase diagrams which are mostly attributed to MSU. In the context of BMA, the weight of the applied models was calculated to be 0.1352, 0.5938, 0.1331, and 0.1379, respectively, indicating that Model 2 thus has three times the weight of the other models, which otherwise have similar Bayesian importance, consistent with the phase diagram results in Figure 11. The phase diagram obtained using BMA is shown in Figure 12. The posterior modes of the probability distributions in the BMA model exactly correspond to the posterior modes of the probability distributions in model 2. Thus, the best model results can be considered as the optimum results for the average model, but with broader uncertainties, contributed by the inferior models. In BMA, each model has some probability of being true and the fused estimate is a weighted average of the models. This method is extremely useful in the case of model-building process based on a weighted average over the models' responses, and/or less risk (more confidence) in design based on broader uncertainty bands provided by a weighted average over the uncertainties of the models' responses.
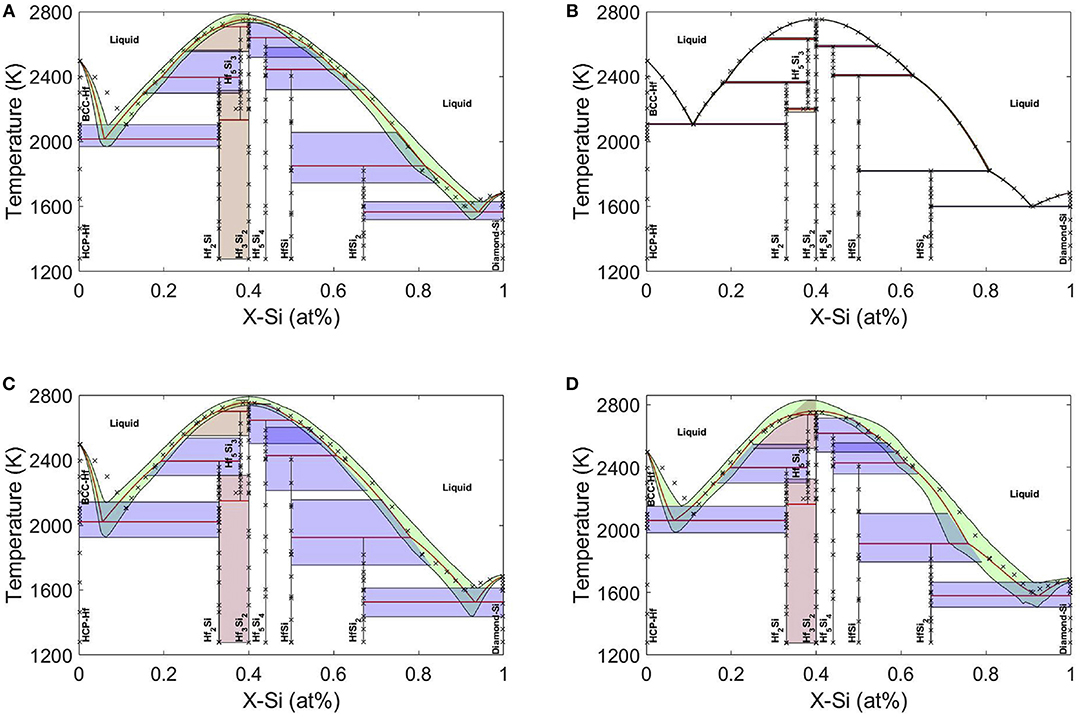
Figure 11. Optimum Hf-Si phase diagrams and their 95% Bayesian credible intervals (BCIs) obtained from models 1–4 (A–D) after uncertainty propagation of the MCMC calibrated parameters in each case. Reproduced with permission from Honarmandi et al. (2019).
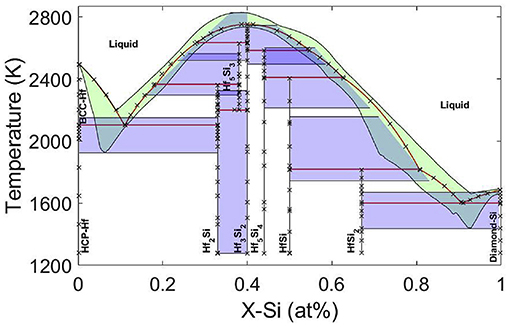
Figure 12. Posterior modes and 95% Bayesian credible intervals (BCIs) at different compositions/regions in Hf-Si phase diagram obtained after BMA. Reproduced with permission from Honarmandi et al. (2019).
Error Correlation-based Model fusion was then used to fuse the models together in two ways: (i) Fuse models 1, 3, 4 to examine whether the resulting fused model maybe closer to the data and reduce the uncertainties and (ii) Fuse models 1, 2, 3, and 4 together. Figure 13A shows that the approach can provide a phase diagram in much better agreement with data and with less uncertainty compared to phase diagrams obtained from each one of the applied models individually. This result implies that random CALPHAD models can be fused together to find a reasonable estimation for phase diagram instead of trial-and-error to find the best predicting model. It is also apparent that better predictions can be achieved as shown in Figure 13B if model 2 (the best model) is also involved in the model fusion. The information fusion technique allowed the acquisition of more precise estimations and lower uncertainties compared to results obtained from each individual model. In summary, the average model obtained from BMA shows larger 95% confidence intervals compared to any one of the individual models, which can provide more confidence for robust design but is likely too conservative. On the other hand, the error correlation-based technique can provide closer results to data with less uncertainties than the individual models used for the fusion. The uncertainty reductions through this fusion approach are also verified through the comparison of the average entropies (as a measure of uncertainty) obtained for the individual and fused models. Therefore, random CALPHAD models can be fused together to find reasonable predictions for phase diagrams with no need to go through the cumbersome task of identifying the best CALPHAD models.
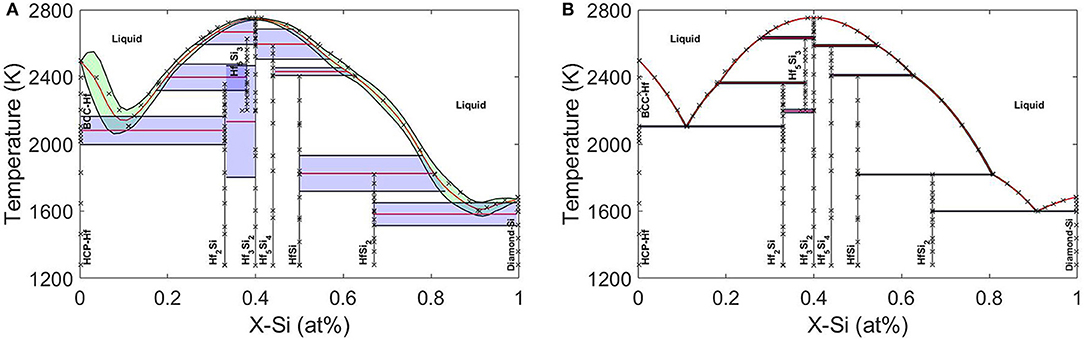
Figure 13. Error correlation-based model fusions of (A) three models (1, 3, and 4) and (B) all four models.Reproduced with permission from Honarmandi et al. (2019).
3. Conclusions and Recommendations
In this work, we have reviewed some of the most important challenges and opportunities related to the concept of optimal experiment design as an integral component for the development of Materials Discovery frameworks, and have presented some recent work by these authors that attempts to address them.
As our understanding of the vagaries implicit in different design problems progresses, tailoring experiment design strategies around the specific material classes under study while further developing the experiment design frameworks will become increasingly feasible and successful. As techniques improve, we will be able to access and explore increasingly complex materials design spaces, opening the door to precision tailoring of materials to desired applications. Challenges in the form of the availability and generation of sufficient and relevant data of high quality need to be continuously addressed. The optimal way to accomplish this would be the implementation of universal standards, centralized databases and the development of an open access data-sharing system in conjunction with academia, industry, government research institutions and journal publishing agencies which is already underway.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
The authors acknowledge the support of NSF through the projects NSF-CMMI-1534534, NSF-CMMI-1663130, and DGE- 1545403. RA and ED also acknowledge the support of NSF through Grant No. NSF-DGE-1545403. XQ acknowledges the support of NSF through the project CAREER: Knowledge-driven Analytics, Model Uncertainty, and Experiment Design, NSF-CCF-1553281 and NSF-CISE-1835690 (with RA). AT and RA also acknowledge support by the Air Force Office of Scientific Research under AFOSR-FA9550-78816-1- 0180 (Program Manager: Dr. Ali Sayir). RA and DA also acknowledge the support of ARL through [grant No. W911NF-132-0018]. The open access publishing fees for this article have been covered by the Texas A&M University Open Access to Knowledge Fund (OAKFund), supported by the University Libraries and the Office of the Vice President for Research.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Calculations were carried out in the Texas A&M Supercomputing Facility.
References
Allaire, D., and Willcox, K. (2012). “Fusing information from multifidelity computer models of physical systems,” in Information Fusion (FUSION), 2012 15th International Conference on (Singapore: IEEE), 2458–2465.
Aryal, S., Sakidja, R., Barsoum, M. W., and Ching, W.-Y. (2014). A genomic approach to the stability, elastic, and electronic properties of the max phases. physica Status Solidi (b) 251, 1480–1497. doi: 10.1002/pssb.201451226
Balachandran, P. V., Xue, D., Theiler, J., Hogden, J., and Lookman, T. (2016). Adaptive strategies for materials design using uncertainties. Sci. Rep. 6, 19660. doi: 10.1038/srep19660
Barsoum, M. W. (2013). MAX Phases: Properties of Machinable Ternary Carbides and Nitrides. Weinheim: John Wiley & Sons.
Choi, H.-J., Mcdowell, D. L., Allen, J. K., and Mistree, F. (2008). An inductive design exploration method for hierarchical systems design under uncertainty. Eng. Optim. 40, 287–307. doi: 10.1080/03052150701742201
Couckuyt, I., Deschrijver, D., and Dhaene, T. (2014). Fast calculation of multiobjective probability of improvement and expected improvement criteria for pareto optimization. J. Glob. Optim. 60, 575–594. doi: 10.1007/s10898-013-0118-2
Curtarolo, S., Hart, G. L., Nardelli, M. B., Mingo, N., Sanvito, S., and Levy, O. (2013). The high-throughput highway to computational materials design. Nat. Mat. 12, 191. doi: 10.1038/nmat3568
Curtarolo, S., Morgan, D., Persson, K., Rodgers, J., and Ceder, G. (2003). Predicting crystal structures with data mining of quantum calculations. Phys. Rev. Lett. 91, 135503. doi: 10.1103/PhysRevLett.91.135503
Dasey, T. J., and Braun, J. J. (2007). Information fusion and response guidance. Lincoln Lab. J. 17, 153–166.
Dehghannasiri, R., Xue, D., Balachandran, P. V., Yousefi, M. R., Dalton, L. A., Lookman, T., et al. (2017). Optimal experimental design for materials discovery. Comput. Mat. Sci. 129, 311–322. doi: 10.1016/j.commatsci.2016.11.041
Emmerich, M. T., Deutz, A. H., and Klinkenberg, J. W. (2011). “Hypervolume-based expected improvement: monotonicity properties and exact computation,” in Evolutionary Computation (CEC), 2011 IEEE Congress on (New Orleans, LA: IEEE), 2147–2154.
Forrester, A. I., Sóbester, A., and Keane, A. J. (2007). Multi-fidelity optimization via surrogate modelling. Proc. R. Soc. 463, 3251–3269. doi: 10.1098/rspa.2007.1900
Frazier, P. I., Powell, W. B., and Dayanik, S. (2008). A knowledge-gradient policy for sequential information collection. SIAM J. Control Optim. 47, 2410–2439. doi: 10.1137/070693424
Frazier, P. I., and Wang, J. (2016). “Bayesian optimization for materials design,” in Information Science for Materials Discovery and Design, eds T. Lookman, F. J. Alexander, and K. Rajan (Cham: Springer), 45–75.
Geisser, S. (1965). A bayes approach for combining correlated estimates. J. Am. Stat. Assoc. 60, 602–607. doi: 10.1080/01621459.1965.10480816
Ghoreishi, S. F., and Allaire, D. L. (2018). “A fusion-based multi-information source optimization approach using knowledge gradient policies,” in 2018 AIAA/ASCE/AHS/ASC Structures, Structural Dynamics, and Materials Conference (Kissimmee, FL), 1159.
Ghoreishi, S. F., Molkeri, A., Srivastava, A., Arroyave, R., and Allaire, D. (2018). Multi-information source fusion and optimization to realize ICME: Application to dual-phase materials. J. Mech. Des. 140, 111409. doi: 10.1115/1.4041034
Gopakumar, A. M., Balachandran, P. V., Xue, D., Gubernatis, J. E., and Lookman, T. (2018). Multi-objective optimization for materials discovery via adaptive design. Sci. Rep. 8, 3738. doi: 10.1038/s41598-018-21936-3
Green, M. L., Choi, C., Hattrick-Simpers, J., Joshi, A., Takeuchi, I., Barron, S., et al. (2017). Fulfilling the promise of the materials genome initiative with high-throughput experimental methodologies. Appl. Phys. Rev. 4, 011105. doi: 10.1063/1.4977487
Gupta, S. S., and Miescke, K. J. (1994). Bayesian look ahead one stage sampling allocations for selecting the largest normal mean. Stat. Pap. 35, 169–177. doi: 10.1007/BF02926410
Gupta, S. S., and Miescke, K. J. (1996). Bayesian look ahead one-stage sampling allocations for selection of the best population. J. Stat. Plan. Inference 54, 229. doi: 10.1016/0378-3758(95)00169-7
Hacking, I. (1983). Representing and Intervening, Vol. 279. Cambridge, UK: Cambridge University Press Cambridge.
Holdren, J. P. (2011). “Materials genome initiative for global competitiveness,” in National Science and Technology Council OSTP (Washington, DC).
Honarmandi, P., Duong, T. C., Ghoreishi, S. F., Allaire, D., and Arroyave, R. (2019). Bayesian uncertainty quantification and information fusion in calphad-based thermodynamic modeling. Acta Mat. 164, 636–647. doi: 10.1016/j.actamat.2018.11.007
Huang, D., Allen, T. T., Notz, W. I., and Miller, R. A. (2006). Sequential kriging optimization using multiple-fidelity evaluations. Struct. Multidiscip. Optim. 32, 369–382. doi: 10.1007/s00158-005-0587-0
Hupkens, I., Deutz, A., Yang, K., and Emmerich, M. (2015). “Faster exact algorithms for computing expected hypervolume improvement,” in International Conference on Evolutionary Multi-Criterion Optimization (Cham: Springer), 65–79.
Jones, D. R., Schonlau, M., and Welch, W. J. (1998). Efficient global optimization of expensive black-box functions. J. Glob. Optim. 13, 455–492. doi: 10.1023/A:1008306431147
Ju, S., Shiga, T., Feng, L., Hou, Z., Tsuda, K., and Shiomi, J. (2017). Designing nanostructures for phonon transport via bayesian optimization. Phys. Rev. X 7, 021024. doi: 10.1103/PhysRevX.7.021024
Kennedy, M. C., and O'Hagan, A. (2000). Predicting the output from a complex computer code when fast approximations are available. Biometrika 87, 1–13. doi: 10.1093/biomet/87.1.1
Kirklin, S., Meredig, B., and Wolverton, C. (2013). High-throughput computational screening of new li-ion battery anode materials. Adv. Energy Mat. 3, 252–262. doi: 10.1002/aenm.201200593
Le Gratiet, L. (2013). Bayesian analysis of hierarchical multifidelity codes. SIAM/ASA J. Uncertain. Quantif. 1, 244–269. doi: 10.1137/120884122
Le Gratiet, L., and Garnier, J. (2014). Recursive co-kriging model for design of computer experiments with multiple levels of fidelity. Int. J. Uncertain. Quantif. 4, 365–386. doi: 10.1615/Int.J.UncertaintyQuantification.2014006914
Lynch, S. M. (2007). Introduction to Applied Bayesian Statistics and Estimation for Social Scientists. New York, NY: Springer Science & Business Media.
Mannodi-Kanakkithodi, A., Pilania, G., Ramprasad, R., Lookman, T., and Gubernatis, J. E. (2016). Multi-objective optimization techniques to design the pareto front of organic dielectric polymers. Comput. Mat. Sci. 125, 92–99. doi: 10.1016/j.commatsci.2016.08.018
Moore, R. A., Romero, D. A., and Paredis, C. J. (2014). Value-based global optimization. J. Mech. Des. 136, 041003. doi: 10.1115/1.4026281
Pilania, G., Gubernatis, J. E., and Lookman, T. (2017). Multi-fidelity machine learning models for accurate bandgap predictions of solids. Comput. Mat. Sci. 129, 156–163. doi: 10.1016/j.commatsci.2016.12.004
Potyrailo, R., Rajan, K., Stoewe, K., Takeuchi, I., Chisholm, B., and Lam, H. (2011). Combinatorial and high-throughput screening of materials libraries: review of state of the art. ACS Combinat. Sci. 13, 579–633. doi: 10.1021/co200007w
Rasmussen, C. E. (2004). “Gaussian processes in machine learning,” in Advanced Lectures on Machine Learning (Tübingen: Springer), 63–71.
Razi, M., Narayan, A., Kirby, R., and Bedrov, D. (2018). Fast predictive models based on multi-fidelity sampling of properties in molecular dynamics simulations. Comput. Mat. Sci. 152, 125–133. doi: 10.1016/j.commatsci.2018.05.029
Schonlau, M., Welch, W. J., and Jones, D. (1996). “Global optimization with nonparametric function fitting,” in Proceedings of the ASA, Section on Physical and Engineering Sciences, 183–186.
Schonlau, M., Welch, W. J., and Jones, D. R. (1998). “Global versus local search in constrained optimization of computer models,” Lecture Notes-Monograph Series (Beachwood, OH), 11–25.
Scott, W., Frazier, P., and Powell, W. (2011). The correlated knowledge gradient for simulation optimization of continuous parameters using gaussian process regression. SIAM J. Optim. 21, 996–1026. doi: 10.1137/100801275
Seko, A., Maekawa, T., Tsuda, K., and Tanaka, I. (2014). Machine learning with systematic density-functional theory calculations: application to melting temperatures of single-and binary-component solids. Phys. Rev. B 89, 054303. doi: 10.1103/PhysRevB.89.054303
Seko, A., Togo, A., Hayashi, H., Tsuda, K., Chaput, L., and Tanaka, I. (2015). Prediction of low-thermal-conductivity compounds with first-principles anharmonic lattice-dynamics calculations and bayesian optimization. Phys. Rev. Lett. 115, 205901. doi: 10.1103/PhysRevLett.115.205901
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and De Freitas, N. (2016). Taking the human out of the loop: a review of bayesian optimization. Proc. IEEE 104, 148–175. doi: 10.1109/JPROC.2015.2494218
Solomou, A., Zhao, G., Boluki, S., Joy, J. K., Qian, X., Karaman, I., et al. (2018). Multi-objective bayesian materials discovery: application on the discovery of precipitation strengthened niti shape memory alloys through micromechanical modeling. Mat. Des. 160, 810–827. doi: 10.1016/j.matdes.2018.10.014
Strasser, P., Fan, Q., Devenney, M., Weinberg, W. H., Liu, P., and Nørskov, J. K. (2003). High throughput experimental and theoretical predictive screening of materials- a comparative study of search strategies for new fuel cell anode catalysts. J. Phys. Chem. B 107, 11013–11021. doi: 10.1021/jp030508z
Suram, S. K., Haber, J. A., Jin, J., and Gregoire, J. M. (2015). Generating information-rich high-throughput experimental materials genomes using functional clustering via multitree genetic programming and information theory. ACS Combinat. Sci. 17, 224–233. doi: 10.1021/co5001579
Talapatra, A., Boluki, S., Duong, T., Qian, X., Dougherty, E., and Arróyave, R. (2018). Autonomous efficient experiment design for materials discovery with bayesian model averaging. Phys. Rev. Mat. 2, 113803. doi: 10.1103/PhysRevMaterials.2.113803
Thomison, W. D., and Allaire, D. L. (2017). “A model reification approach to fusing information from multifidelity information sources,” in 19th AIAA Non-Deterministic Approaches Conference (Grapevine, TX), 1949.
Tylecote, R. F., and Tylecote, R. (1992). A History of Metallurgy. London, UK: Institute of materials London.
Ueno, T., Rhone, T. D., Hou, Z., Mizoguchi, T., and Tsuda, K. (2016). Combo: an efficient bayesian optimization library for materials science. Mat. Discov. 4, 18–21. doi: 10.1016/j.md.2016.04.001
While, L., Bradstreet, L., and Barone, L. (2012). A fast way of calculating exact hypervolumes. IEEE Trans. Evol. Comput. 16, 86–95. doi: 10.1109/TEVC.2010.2077298
Winkler, R. L. (1981). Combining probability distributions from dependent information sources. Manag. Sci. 27, 479–488. doi: 10.1287/mnsc.27.4.479
Xue, D., Balachandran, P. V., Hogden, J., Theiler, J., Xue, D., and Lookman, T. (2016a). Accelerated search for materials with targeted properties by adaptive design. Nat. Commun. 7, 11241. doi: 10.1038/ncomms11241
Xue, D., Balachandran, P. V., Yuan, R., Hu, T., Qian, X., Dougherty, E. R., et al. (2016b). Accelerated search for batio3-based piezoelectrics with vertical morphotropic phase boundary using bayesian learning. Proc. Natl. Acad. Sci. U.S.a. 113, 13301–13306. doi: 10.1073/pnas.1607412113
Yang, K., Emmerich, M., Deutz, A., and Fonseca, C. M. (2017). “Computing 3-d expected hypervolume improvement and related integrals in asymptotically optimal time,” in International Conference on Evolutionary Multi-Criterion Optimization (Cham: Springer), 685–700.
Zhao, G., Arroyave, R., and Qian, X. (2018). Fast exact computation of expected hypervolume improvement. arXiv preprint arXiv:1812.07692.
Keywords: materials discovery, efficient experiment design, Bayesian Optimization, information fusion, materials informatics, machine learning
Citation: Talapatra A, Boluki S, Honarmandi P, Solomou A, Zhao G, Ghoreishi SF, Molkeri A, Allaire D, Srivastava A, Qian X, Dougherty ER, Lagoudas DC and Arróyave R (2019) Experiment Design Frameworks for Accelerated Discovery of Targeted Materials Across Scales. Front. Mater. 6:82. doi: 10.3389/fmats.2019.00082
Received: 07 February 2019; Accepted: 05 April 2019;
Published: 24 April 2019.
Edited by:
Christian Johannes Cyron, Hamburg University of Technology, GermanyReviewed by:
Miguel A. Bessa, Delft University of Technology, NetherlandsZhongfang Chen, University of Puerto Rico, Puerto Rico
Copyright © 2019 Talapatra, Boluki, Honarmandi, Solomou, Zhao, Ghoreishi, Molkeri, Allaire, Srivastava, Qian, Dougherty, Lagoudas and Arróyave. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Raymundo Arróyave, cmFycm95YXZlQHRhbXUuZWR1