 Ana Franco*
Ana Franco* Axel Cleeremans and Arnaud Destrebecqz
Axel Cleeremans and Arnaud Destrebecqz
- Consciousness, Cognition, and Computation Group, Université Libre de Bruxelles, Bruxelles, Belgium
Statistical learning is assumed to occur automatically and implicitly, but little is known about the extent to which the representations acquired over training are available to conscious awareness. In this study, we focus on whether the knowledge acquired in a statistical learning situation is available to conscious control. Participants were first exposed to an artificial language presented auditorily. Immediately thereafter, they were exposed to a second artificial language. Both languages were composed of the same corpus of syllables and differed only in the transitional probabilities. We first determined that both languages were equally learnable (Experiment 1) and that participants could learn the two languages and differentiate between them (Experiment 2). Then, in Experiment 3, we used an adaptation of the Process-Dissociation Procedure (Jacoby, 1991) to explore whether participants could consciously manipulate the acquired knowledge. Results suggest that statistical information can be used to parse and differentiate between two different artificial languages, and that the resulting representations are available to conscious control.
Introduction
Statistical learning broadly refers to people’s ability to become sensitive to the regularities that occur in their environment by means of associative learning mechanisms. Such sensitivity often extends to the temporal domain, inasmuch as temporal structure is a central feature of many skills, ranging from language processing to action planning. The first studies dedicated to statistical learning per se essentially focused on language acquisition, and in particular on speech segmentation. Thus, Saffran et al. (1996b) investigated whether distributional cues could be used to identify words in continuous speech. In their study, participants were exposed to a stream of continuous speech composed of six trisyllabic words that were repeated in seemingly random order. The continuous speech was produced by a speech synthesizer and contained no other segmentation cues than statistical information, that is, the transitional probabilities between the syllables. These probabilities were higher for within-word syllable transitions than for between-word transitions. After a brief exposure phase, participants had to discriminate between words of the artificial language and non-words. Results indicated that they were able to do so, thus proving that transitional probabilities convey sufficient information to effectively parse continuous speech into units.
Subsequent studies have extended this seminal finding in many different directions, documenting the central role that statistical learning mechanisms play in different aspects of language acquisition, such as speech segmentation (Saffran et al., 1996b; Jusczyk, 1999; Johnson and Jusczyk, 2001), lexicon development (Yu and Ballard, 2007), or learning about the orthographic regularities that characterize written words (Pacton et al., 2001). Further, the importance of statistical learning has also been explored in other domains, such as non-linguistic auditory processing (Saffran et al., 1999), visual processing (Fiser and Aslin, 2002; Kim et al., 2009), human action processing (Baldwin et al., 2008) or visuomotor learning (Cleeremans, 1993). While most of these studies involved adult participants, many have also demonstrated that children (Saffran et al., 1997) and infants (Aslin et al., 1998; Saffran et al., 2001) are capable of statistical learning. Taken together, these studies suggest that such learning can occur without awareness (Saffran et al., 1997), automatically (Saffran et al., 1996a; Fiser and Aslin, 2001, 2002; Turk-Browne et al., 2005) and through simple observation (Fiser and Aslin, 2005).
Though statistical learning can be viewed as a form of implicit learning (Reber, 1967), this is not necessarily the case, and the relevant literatures have so far remained rather disconnected from each other. According to some authors, statistical and implicit learning represent different ways of characterizing essentially the same phenomenon (Conway and Christiansen, 2005; Perruchet and Pacton, 2006). Indeed, just like statistical learning, implicit learning is assumed to occur without awareness (Cleeremans et al., 1998) and automatically (Jimenez and Mendez, 1999; Shanks and Johnstone, 1999), or at least, incidentally. Although statistical learning research has been essentially dedicated to exploring language acquisition – with particular emphasis on development – most implicit learning studies have instead been focused on adult performance, with particular emphasis on understanding the role of awareness in learning and the nature of the acquired knowledge. Recently however, the two fields have begun to converge as it became increasingly recognized that the processes involved in artificial grammar or sequence learning are of a similar nature as those involved in statistical learning studies (e.g., Cleeremans et al., 1998; Hunt and Aslin, 2001; Saffran and Wilson, 2003; Perruchet and Pacton, 2006).
Despite this emerging convergence, statistical learning studies have seldom addressed what has long been the central focus of implicit learning research, namely, the extent to which the representations acquired by participants over training or exposure are available to conscious awareness. As discussed above, most statistical learning studies claim that such learning occurs without conscious awareness. However, most of the relevant studies have consisted in an incidental exposure phase followed by a two-alternative forced-choice test (2AFC; Saffran et al., 2001; Saffran, 2002; Perruchet and Desaulty, 2008) in which participants are instructed to choose the stimuli that feel most “familiar.” Familiarity, however, can involve either implicit or explicit knowledge: One can judge whether an item has been seen before based on intuition or on recollection (for review Richardson-Klavehn et al., 1996). The assumption that knowledge is implicit because people learn incidentally and perform well on a familiarity task is therefore unwarranted. In this respect, the implicit learning literature is suggestive that considerable care should be taken when drawing conclusions about the extent to which acquired knowledge is available to conscious awareness or not. This literature has also suggested that which type of measure is used to assess awareness is instrumental to our conclusions about whether learning was truly implicit. A distinction is generally made between two types of measures that can be used to assess awareness: Objective and subjective measures.
Objective measures are quantitative (e.g., accuracy, reaction times) and typically require participants to perform a discrimination task, such as deciding whether a stimulus was present or not (identification) or deciding whether a stimulus has been seen before or not (recognition). Subjective measures, by contrast, require participants to report on their mental states and typically take the form of free verbal reports or confidence ratings (Dienes and Berry, 1997). Both types of measures have been criticized and have generated substantial debate. Subjective measures, for instance, can be questioned based on the fact that they are biased and depend on the manner in which participants interpret the instructions (Eriksen, 1960; Reingold and Merikle, 1993; Dulany, 1997). Thus, conservative participants may claim to be guessing while actually knowing more about the stimulus than they report. As a consequence, subjective measures may overestimate unconscious knowledge. On the other hand, objective measures may be contaminated by unconscious influences. Thus, a participant who correctly recognizes a stimulus as “old” may do so not on the basis of conscious recollection, but rather on the basis of a feeling of familiarity. Objective measures may thus underestimate the influence of unconscious knowledge.
Another issue comes from the fact that tasks in general involve both conscious and unconscious knowledge. In this context, Jacoby (1991 proposed his process-dissociation procedure (PDP) as a way of overcoming the limitations of both objective and subjective measures. The method rests on the assumption that conscious knowledge is amenable to voluntary control whereas information held without awareness is not. The PDP involves contrasting performance in two versions of the same task. As an illustration, imagine an experiment in which participants are exposed to two different lists of words that they have to remember. Their memory of the words is tested through two tasks: an inclusion and exclusion task. In Inclusion, participants are asked to perform a simple old/new recognition judgment. Here, it is assumed that both familiarity and recollection contribute to task performance as participants may correctly classify a training item either based on a feeling of familiarity or conscious recollection. In Exclusion, by contrast, participants are instructed to recognize only the words from the first (or second) list. Under such instructions, successful performance has to be based on conscious recollection, as a mere feeling of familiarity may impair participants’ ability to effectively differentiate between the test items belonging either to the first or the second language. Familiarity may influence participants so that they incorrectly recognize words of the second (or first) list. Familiarity and recollection thus act in opposition during exclusion. By comparing performance in the two tasks, it is therefore possible to estimate the extent to which processing is conscious or not.
The PDP has been widely used to explore awareness in situations that involve tracking probabilities, such as in sequence learning (Buchner et al., 1997, 1998; Destrebecqz and Cleeremans, 2001, 2003; Fu et al., 2008) or in artificial grammar learning (Dienes et al., 1995). However, to the best of our knowledge, the PDP has never been used in a paradigm more typical of statistical learning situations, such as speech segmentation. In fact, little is known about participants’ ability to consciously access the knowledge they acquire during typical statistical learning situations. Only one recent study (Kim et al., 2009) has directly attempted to address this issue. Using a rapid serial visual presentation (RSVP) paradigm and a matching task (i.e., an 11-alternative forced-choice task), the authors assessed sensitivity to the regularities contained in the stream by means of reaction times to certain predictable or unpredictable events and through correct responses on the matching task. Participants exhibited faster RTs in response to predictable events while remaining unable to perform above chance on the matching task. Based on these results, Kim et al. concluded that visual statistical learning results in representations that remain implicit. However, we believe that an 11-alternative forced-choice task may fail to be sufficiently sensitive to all the relevant conscious knowledge acquired by participants. Thus, this task may fail to fulfill the sensitivity criterion (Shanks and St John, 1994). Therefore, participants’ failure could be due to task difficulty rather than to the absence of explicit knowledge of the statistical regularities.
Here, we specifically focus on using a more sensitive test of explicit knowledge so as to assess whether or not statistical learning results in conscious representations. More specifically, we assess the extent to which learners are aware of the relevant contingencies present in two artificial languages and on how conscious they are of the representations of the languages acquired in a statistical learning situation.
To do so, we conducted three experiments. In Experiment 1, we first explore whether learners can correctly find the word boundaries in each of two artificial speech streams. In Experiment 2, participants were successively exposed to the two speech streams and immediately presented with two tasks: a 2AFC task and a language decision task, in which they were asked to differentiate words from the two artificial languages. If participants successfully performed the two tasks, this would suggest that they can process two different sets of statistical information and that they formed two separate sets of representations, one for each language. Finally, Experiment 3 aimed at assessing the relative contributions of implicit and explicit memory by using the PDP. The exposure phase was identical to Experiment 2 and was immediately followed by an inclusion and an exclusion task. In Inclusion, participants were asked to perform a simple old/new recognition judgment. In Exclusion, participants are instructed to recognize not only the test items but also the context (e.g., the language it comes from) in which it has been presented. By comparing performance on the two tasks, it is possible to estimate the extent to which processing is conscious or not. Thus in Experiment 3, if participants learned the two artificial languages consciously and independently (i.e., they consider the material to consist of two distinct languages and they are able to differentiate them), we expect high performance in the inclusion and the exclusion task. Participants should be able to differentiate items belonging to the two languages from novel items. They should also be able to differentiate items from the first and the second language. However, if learning was implicit or if participants formed a single lexicon gathering words from both languages, inclusion performance should be above chance (as it may be based on familiarity) but exclusion should be at chance as participants should not explicitly differentiate test items belonging to the first or the second language.
Experiment 1
Method
The goal of Experiment 1 was to establish that both languages can be learned when presented in isolation.
Participants
Twenty monolingual French-speaking undergraduate psychology students (mean age: 20.8) were included in this study and received class credits for participation. None of the participants had previous experience with the artificial languages presented in this experiment. All reported no hearing problems.
Stimuli
We tested two different speech streams created from the same sound inventory (the same syllable set), with a similar underlying statistical structure. For clarity of discussion, we label each stream as an “artificial language”: L1 and L2. Each language consisted of 4 artificial trisyllabic (CV.CV.CV) words composed of the same 12 syllables (see Figure 1). The two artificial languages were generated using the MBROLA speech synthesizer (Dutoit et al., 1996) using two different male voices (fr1 and fr4).
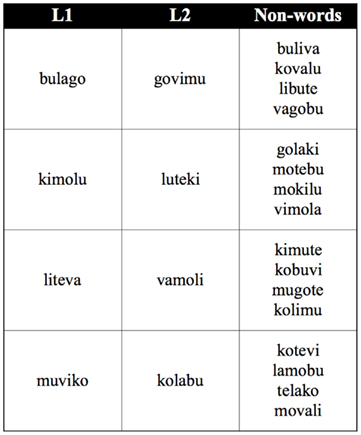
Figure 1. This figure shows the design of languages L1, L2.
We chose 12 French syllables that were considered as easily distinguishable. We assembled the syllables to obtain a set of trisyllabic words. Four were assigned to L1 (bulago, kimolu, liteva, and muviko) and four were assigned to L2 (govimu, luteki, vamoli, and kolabu). The others were used as non-words and were never presented during the exposure phase. All the words were pretested in order to ensure that none of them sounded similar to a French word. Finally, using Matlab, we created a script in order to generate the artificial speech streams. There were two conditions, which differed by the time of exposure to the artificial languages: 10 or 20 min. Each word was presented 300 times (in the 10-min condition) or 600 times (in the 20-min condition) in pseudo-random order: the same word could not occur twice in succession. There were no pause between syllables and no other acoustic cues to signal word boundaries. As the succession of words was pseudo-randomized, the transitional probabilities between each syllable were 100% within words and 33% between words in both artificial languages. Non-words had syllable transitional probabilities of 0%. L1 and L2 words did not share any syllable transition between languages or with the non-words, that is all the transitional probabilities of 100 or 33% in one language were null in the other or in the non-words.
Procedure
Participants were instructed to watch a series of cartoons during which they would hear continuous speech spoken in an unknown language. They were not informed about the length or structure of the words or about how many words each language contained. They were randomly assigned to the short or the long exposure condition. Stimuli were presented during either 10 or 20 min. After the exposure, participants performed a recognition task. In each trial a trisyllabic string (spoken by a female voice, V3) was presented and participants had to decide if the string was a word from the language they had heard or not. The material consisted of the four words of the language and randomly chosen non-words, which consisted in trisyllabic words composed by the same syllables as the language but with null transitional probabilities between syllables (see Figure 1).
Results and Discussion
The results are presented in Figure 2. As typically used in statistical learning studies (Saffran et al., 1996a; Gebhart et al., 2009), we analyzed recognition data by assessing mean percentages of correct responses. Performance exceeded chance for both languages. L1 Participants averaged 68.93% of correct responses, t(10) = 4.464, p < 0.005, Cohen’s d = 1.470. L2 participants averaged 69.38% of correct responses, t(9) = 4.378, p < 0.005, Cohen’s d = 1.850. An independent-sample t-test revealed no difference between L1 and L2, t(19) = −0.503, p > 0.5. We thus pooled L1 and L2 participants together for further analysis. We asked whether exposure duration had an effect on performance. Another independent-sample t-test revealed no difference between the two exposure durations, t(19) = 0.882, p > 0.5. Participants exposed to the artificial language for 10 min averaged 68.76% of correct responses, whereas those who had been exposed for 20 min averaged 69.63% of correct responses. Results demonstrate that the two different artificial languages were learnable when presented in isolation. Moreover, learning across both languages did not differ significantly and 10 min appear to be sufficient to learn the language. The next experiment investigates whether the two languages remain learnable when they are presented successively for 10 min each.
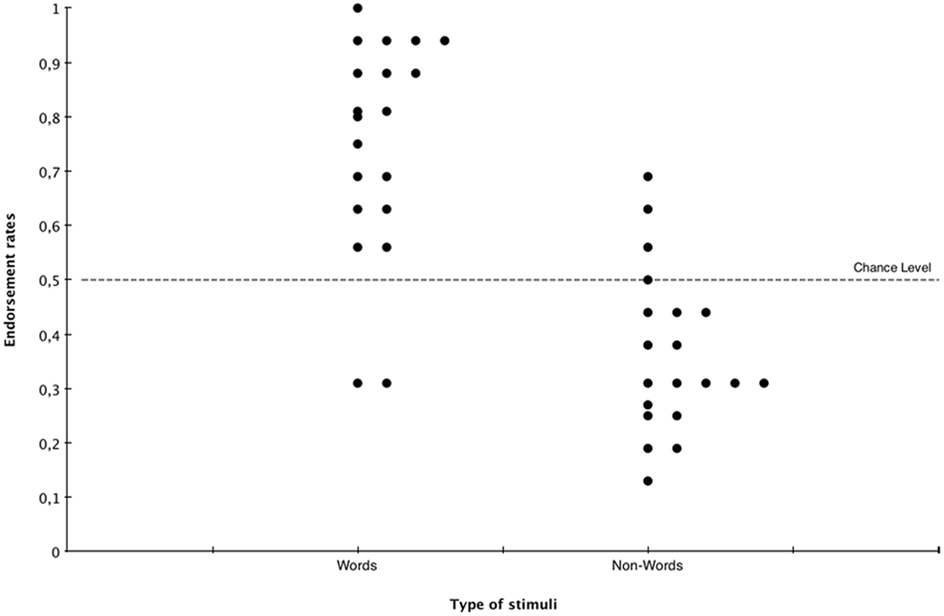
Figure 2. Endorsement rates for words and for non-words in the recognition task.
Experiment 2
Method
Participants
Twenty-eight monolingual French-speaking undergraduate psychology students (mean age: 20.8) were included in this study and received class credits for participation, with the same conditions as in Experiment 1.
Stimuli
The stimuli were identical to Experiment 1.
Procedure
As in Experiment 1, participants watched a set of cartoons and were exposed to two continuous speech streams. First, they were exposed to L1 (spoken by V1) for 10 min. Then, participants were told that they were going to see another set of cartoons accompanied by another stream of continuous speech in an unknown language, different from the first one. They were exposed to L2 (spoken by V2) during 10 min. A short break was given between the two exposures. Language order, voices, and the set of cartoons were fully counterbalanced. After exposure, participants were told that the continuous speech they had heard was composed by words presented successively and repeated several times. As in Experiment 1, they were neither informed about the length of the words nor about how many words each language contained. To test learning of the languages, participants were asked to perform a 2AFC task. On each trial, participants heard a word from one of the two languages and a non-word (separated by 400 ms of silence). They were instructed to indicate which one sounded more like one of the languages that they had heard. There were 32 trials: each word of each language was presented four times (either in the first or in the second position) and was paired with one of the non-words (chosen randomly). The trials were presented in pseudo-random order: the same word was never presented twice in succession. To test whether participants were able to differentiate the two languages, we finally asked them to perform a discrimination task in which, on each trial, a word from either L1 or from L2 was presented, and participants were asked to indicate whether the word belonged to the first or the second language. Each word was presented three times in pseudo-random order.
Results and Discussion
The results are presented in Figure 3. In the AFC task, L1 and L2 words were presented four times each, as the non-words were only presented twice. In order to ensure that responses were not influenced by the frequency of each stimulus, we checked consistency between participants’ responses to the first occurrence of each word and the responses to the subsequent occurrences. A paired-sample t-test showed that average performance on the first and the subsequent presentations of the words did not differ from each other, t(27) = −1.003, p > 0.1. Thus, while we cannot exclude that participants’ responses were influenced by item frequency, these results nevertheless indicate that no such difference exists in our sample. However, in the following analysis we will first present results based only on the first presentations of each word and then results based on the four presentations. All the statistical analyses were carried out with two-tailed tests. A single-sample t-test showed that mean performance was above chance, t(27) = 5.062, p < 0.001, Cohen’s d = 0.957. A paired-samples t-test revealed no differences in performance across languages, t(27) = 1.451, p > 0.1. Also, there was no significant difference due to the order of presentation of the languages, t(26) = 0.142, p > 0.5. The mean score on the first presentation of each word was 18.71 out of a possible 32 (58.48%), with chance performance at 16. A single-sample t-test showed that mean performance was above chance, t(27) = 2.139, p < 0.05, Cohen’s d = 0.574. The mean score on the 2AFC task based on all four presentations of each word was 19.64 (61.43%). We also compared the mean performance for the first and the second language presented. Participants’ mean performance for the first language was 65.88%, t(27) = 5.578, p < 0.001, Cohen’s d = 1.054 and 56.95%, t(27) = 2.136, p < 0.05, Cohen’s d = 0.404, for the second language presented. The mean performance was significantly higher for the first than for the second language presented, t(27) = 2.168, p < 0.05, Cohen’s d = 0.593.
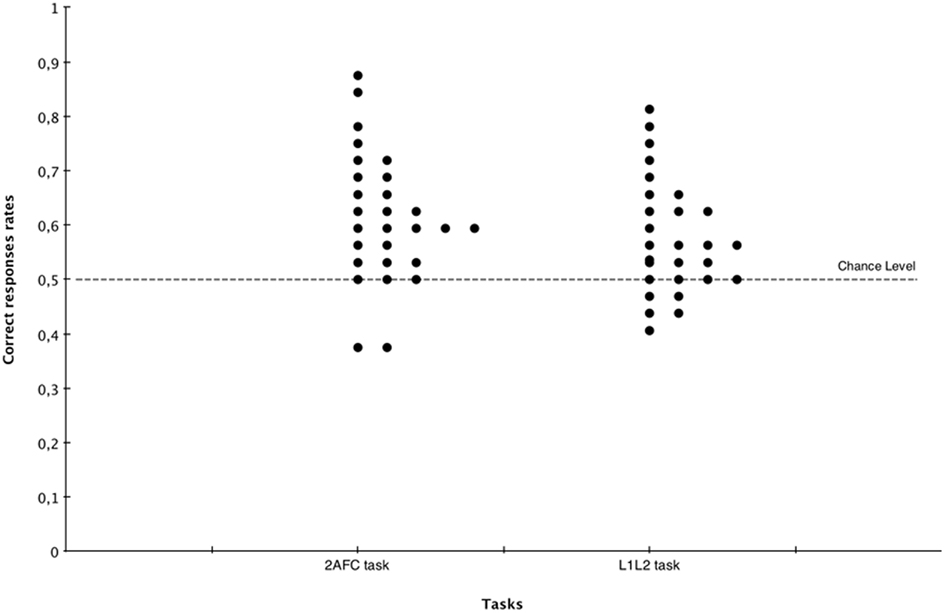
Figure 3. Mean percentage of correct responses for words and non-words (plotted together) in the 2AFC task and the L1L2 decision task.
Finally, a independent-sample t-test revealed a significant difference with Experiment 1 when languages were presented in isolation, t(36) = 2.095, p < 0.05, Cohen’s d = 0.698. This difference was due to weak performance in the second language presented. Indeed, while the mean performance in Experiment 1 did not differ from the first language presented (p > 0.1), it was significantly higher than for the second language presented t(36) = 3.120, p < 0.05.
The mean score on the decision task was 13.82 of a possible 24 (57.61%). A single-sample t-test showed that performance was above chance, t(27) = 3.840, p < 0.001, Cohen’s d = 0.755. A paired-samples t-test revealed no difference across languages, t(27) = 0.125, p > 0.5. Another paired-samples t-test revealed that the mean performance in this task did not significantly differ from the performance in the forced-choice task, t(27) = 1.296, p > 0.1.
Experiment 2 demonstrates that learners are able to learn two artificial languages based only on statistical information such as the transitional probabilities between syllables. Both languages are learned, but the first language is better learned that the second. Indeed, while participants perform for the first language presented as when the language is presented in isolation, the mean performance for the second language presented is weaker (although above chance level). It seems that the learning of the statistical regularities of the first language has a decreasing effect on the capacity to learn a new set of transitional probabilities based on the same corpus of syllables. This is consistent with recent studies (Gebhart et al., 2009). Results on the discrimination task are consistent with Weiss et al. (2009) findings: participants form distinct representations for the words of each language, since they are able to categorize the words as belonging to the first or to the second language. A proper interpretation of the PDP requires ensuring that participants learned both languages separately. The success of the 2AFC task and the discrimination task guarantees that results we will find with the PDP are not biased by the fact that participants could not learn the languages, or that they learned both languages as one. In Experiment 3, we used an adaptation of the PDP in order to determine the amount of conscious and automatic processing that contribute to the acquisition and differentiation of the two artificial languages.
Experiment 3
Method
Participants
Forty monolingual French-speaking undergraduate psychology students (mean age: 20.6) were included in this study and received class credits for participation. None of the participants had previous experience with the artificial languages presented in this experiment. All reported no hearing problems.
Stimuli
The stimuli were identical to Experiment 1.
Procedure
The material and the exposure phase of Experiment 3 were identical to that of Experiment 2. Participants were subsequently asked to perform the inclusion and exclusion tasks (all the participants performed first the inclusion and then the exclusion task). In both tasks, the stimuli presented were identical, only the instructions changed. There were 32 trials in which a trisyllabic string was presented (all the words of each language were presented twice and non-words chosen randomly were presented once). In Inclusion, they were asked to answer “yes” when the presented trisyllabic string (spoken by a female voice, V3) was a word from L1 or from L2, and “no” when it was a new word. In Exclusion, participants were asked to answer “yes” when the string was a word from L1 (re: L2) and “no” when it was a word from L2 (re: L1) or a new word.
Results and Discussion
In both Inclusion and Exclusion tasks the L1 and L2 words were presented two times each, Non-Words were only presented once. In order to ensure that participants responses had not been influenced by the frequency of occurrence of each stimulus we first checked whether there was a difference in performance for the occurrence and the second occurrence of each word. Two paired-sample t-tests showed that the mean performance for the first and the second presentation of the words differed neither in Inclusion, t(39) = −0.142, p > 0.5, nor in Exclusion, t(39) = 0.773, p > 0.1. Second, we analyzed inclusion results by calculating the mean percentages of correct responses. Participants discriminated L1 and L2 words from non-words better than chance, achieving 61.88% correct responses, t(39) = 7.806, p < 0.001, Cohen’s d = 1.234. We then compared endorsement rates – that is the amount of responses “yes” – for words (from L1 and L2) and for non-words. A paired-samples t-test indicated that the tendency to answer “yes” was significantly higher when the stimuli were L1 or L2 words (62.34%) than when they were non-words (38.60%), t(39) = −7.799, p < 0.001, Cohen’s d = 1.905. Further, we compared the mean percentages of correct responses of the first and the second language that they had been exposed to (i.e., regardless of whether this had been L1 or L2). Participants averaged 68.44%, t(39) = 5.713, p < 0.001, Cohen’s d = 0.907 of correct responses on words from the first language to which they were exposed and 56.25%, t(39) = 2.105, p < 0.05, Cohen’s d = 0.333 of correct responses on words from the second language. A paired-sample t-test showed that participant’s performance on the first language was significantly higher than on the second language t(39) = −2.404, p < 0.05, Cohen’s d = 0.597 (Figure 4).
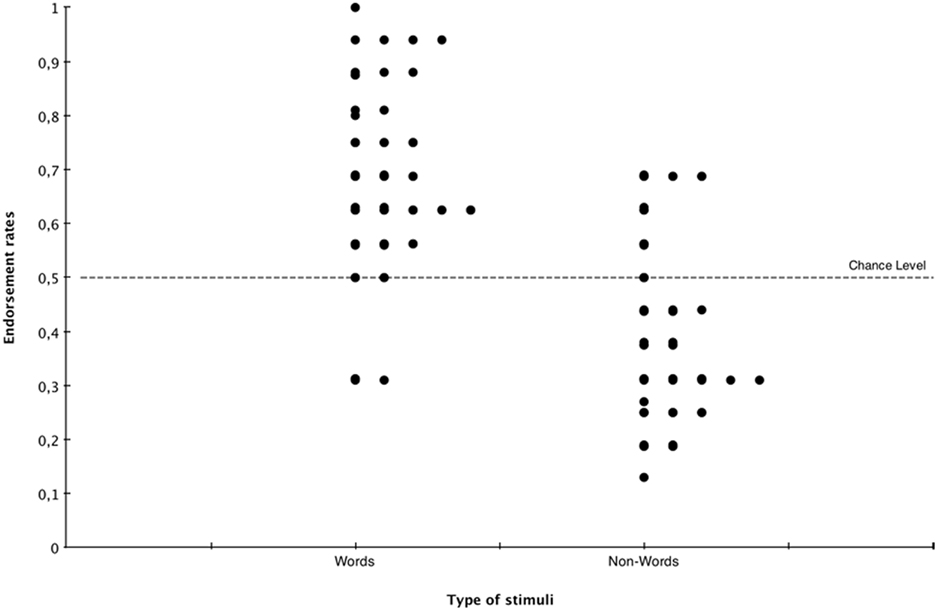
Figure 4. Endorsement rates for words and for non-words in the inclusion task.
Second, we analyzed exclusion performance. The average percentage of correct responses was 58.60%, which exceeded chance level, t(39) = 4.433, p < 0.001, Cohen’s d = 0.701. As it appeared in the inclusion task that participants performed better for the words of the first language presented than those of the second language, we wanted to check if exclusion performance depended on the language that they were instructed to exclude, namely the first or the second language they were exposed to. An independent-sample t-test indicated that performance did not differ significantly whether they had to exclude the first language or the second language (p > 0.1). We then compared the endorsement rates for words to include (i.e., words from the language that they had to answer “yes”), words to exclude (the words from the language they had had to exclude), and non-words (Figure 5).
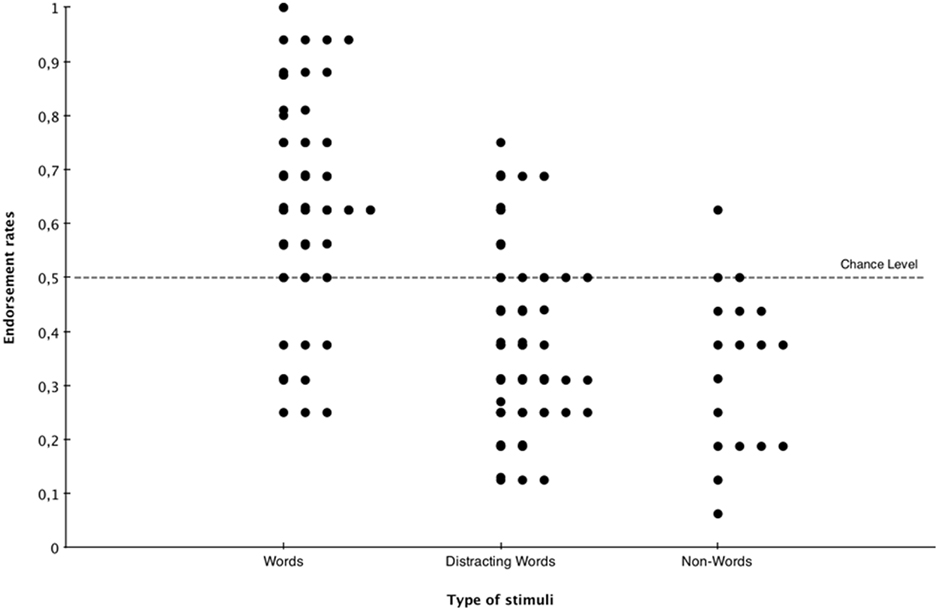
Figure 5. Endorsement rates for target words, distracting words, and for non-words in the exclusion task.
A paired-samples t-test revealed a significant difference between the tendency to answer “yes” to target words (49.06% of “yes” responses) and to non-words (37.04%), t(39) = 2.757, p < 0.005, Cohen’s d = 0.506. The same analysis showed a marginal difference words to exclude (40.63%) and words to include, t(39) = −1.770, p = 0.084. The tendency to answer “yes” did not differ between words to exclude and non-words (p > 0.1).
These results suggest that even if participants seem to be able to perform the exclusion task, it is not clear that they differentiate the two languages. However, the results of Experiment 2 show that, when exposed to two artificial languages presented successively, participants form two distinct representations for the words of each language. Previous research shows that in this kind of learning situation individual differences can be observed: for a given exposure, some participants will be able to extract the words from the continuous speech while some other won’t. In order to see if when participants learn both languages the knowledge acquired is amenable to conscious control, we applied the method as used by Sanders et al. (2002) in order to analyze separately high and low learners. Participants were divided into two groups based on a median split (M = 64.10%) of mean performance on inclusion task (which was highly correlated to the mean performance on exclusion task, r = 0.460, p < 0.005).
High learners had a mean performance of 69.85%, t(19) = 19.379, p < 0.001, Cohen’s d = 4.333, in the inclusion task. The mean performance for the first language was 74.38%, t(19) = 6.253, p < 0.001, Cohen’s d = 2.334, and 65.00% for the second language, t(19) = 3.040, p < 0.01, Cohen’s d = 1.270. A paired-sample t-test showed that performance for the first and second language did not differ significantly (p > 0.05). In the exclusion task, high learners showed a mean performance of 63.90%, t(19) = 5.160, p < 0.001, Cohen’s d = 1.540. The endorsement rates for words to include (M = 50.63) significantly differed from words to exclude (M = 35.63), t(19) = −2.239, p < 0.05, Cohen’s d = 0.706, and from non-words (M = 29.70), t(19) = 3.436, p < 0.005, Cohen’s d = 0.985. Words to exclude and non-word’s endorsement rates did not differ significantly (p > 0.1).
Low learners had a mean performance of 53.29%, t(19) = 2.930, p < 0.01, Cohen’s d = 0.655 in the inclusion task. Endorsement rates for the first language did not reach significance (M = 56.25, p > 0.1) and was marginal for the second language (M = 58.13, p = 0.067). Congruently, results on the exclusion task show that low learners’ mean performance failed to reach significance (M = 53.29, p > 0.1). These results show that even if the mean performance on inclusion task is above the chance level, low learners correctly rejected non-words but also rejected words and failed to learn the two languages.
Taken together, the results on the inclusion and exclusion task show high learners were able to extract words from the first and the second languages presented. Moreover, they were able to follow exclusion instructions and to intentionally exclude items from one of the two learned languages. On the other hand, low learners seem to learn both languages and to succeed on the inclusion task, which is suggestive that they were somehow sensitive to statistical information. However we also found that above chance performance was only due to the large number of correct rejections for these participants. Thus, it appears that low learners did not truly extract words from continuous speech but merely acquired a certain familiarity with the material, which was sufficient to enable them to correctly reject the non-words but not strong enough to correctly accept the words. One possibility could be that participants parsed the continuous speech into smaller units, but that these units failed to respect the actual boundaries between the artificial words (e.g., bisyllabic words).
Finally, we wanted to estimate the extent to which knowledge about the two languages was available to conscious awareness. To do so, we computed an awareness score for each participant, as follows: We first computed the frequency with which a word had been correctly accepted in inclusion. Next, we computed the frequency with which a word had been incorrectly accepted in exclusion. Finally, we subtracted, for each participant, the latter from the former. A positive difference between the inclusion and exclusion scores reflects a capacity to recognize the words of each language and to control this knowledge so as to follow the exclusion instructions. We should thus conclude, in the case of a positive score, that knowledge is at least partly conscious. On the other hand, a negative or null difference would indicate an inability to control one’s knowledge about the languages and to follow the exclusion instructions. In this case, we should thus conclude that knowledge about the two languages is at least partly unconscious, as participants cannot intentionally differentiate between L1 and L2. The analysis showed that the mean scores were 5.22 in Inclusion and 3.25 in Exclusion (Figure 6), resulting in a mean difference of 1.97. A single-sample t-test showed that this difference was significantly above zero, t(40) = 5.897, p < 0.001, Cohen’s d = 0.932.
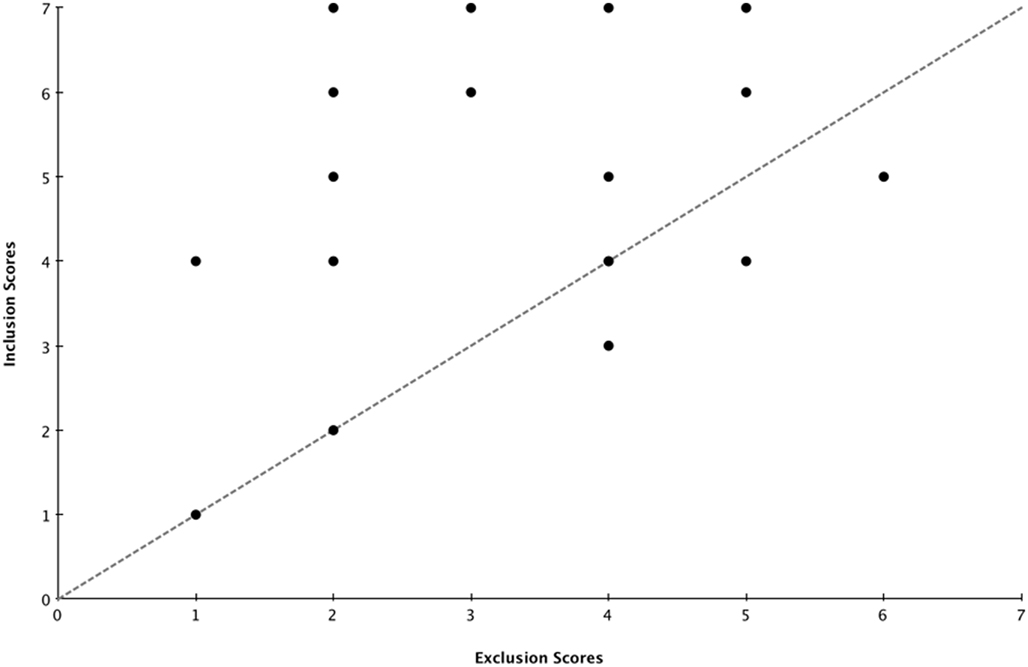
Figure 6. Awareness scores for each participant. Individual scores are represented as points with coordinates corresponding to the frequency with which a word has been correctly accepted under inclusion instructions (Y-axis) and the frequency with which a word has been incorrectly accepted in the exclusion task (X-axis). When the inclusion score is higher than the exclusion score (that is, when the corresponding point falls above the diagonal), participant’s knowledge can be considered to be at least partly conscious. When the inclusion score is smaller or equal to the exclusion score (the point falls below or on the diagonal), participant’s knowledge can be considered to be at least partly unconscious.
As can be seen on Figure 6, eight participants obtained a difference score that was either negative or null. Two of them were high learners and the other six were low learners. To find out whether these participants had applied unconscious knowledge or had simply failed to learn about the two languages, we examined their inclusion scores separately. The mean inclusion score was 56.26%, which, t(7) = 2.080, p = 0.076. However, as the endorsement rates for the first language (M = 56.25%, p > 0.5) or the second (M = 48.44%, p > 0.5) failed to reach significance, this marginal score was only due to a high correct rejection of the non-words.
These findings are consistent with the previous experiment. Experiment 3 thus confirms that learners can parse the two speech streams presented successively. Congruently with the results of Experiment 2, the learning of a first language seems to decrease – but not inhibit – the capacity to learn a second language based on the exact same corpus of syllables. The strength of the effect of the first language on the second language learning seems to be prone to important individual differences. Moreover, our analysis of the awareness scores shows that – when participants learn both languages – the knowledge acquired during exposure is amenable to conscious control, and should thus be taken to be conscious knowledge as per the PDP assumptions. Altogether, our results are suggestive that participants who have been able to learn about the two languages are also able to subsequently exert intentional, conscious control on the application of this knowledge, that is, more specifically, to refrain from accepting to-be-excluded words under exclusion instructions.
General Discussion
The aim of our study was to rethink the idea that statistical learning occurs without conscious awareness. To do so, we used the PDP as a sensitive measure of the relative contributions of conscious and unconscious knowledge to the control of knowledge acquired during statistical learning. Our results suggest that the statistical information contained in a speech stream can be used to correctly track word boundaries in a situation of double language input: Adult participants can track the transitional probabilities present in two artificial languages presented successively. When the two languages share all the same characteristics but for the transitional probabilities between syllables, the learning of the first language reduces the capacity to learn the second language. However, participants still learn the second language and, congruently with previous studies, form distinct representations for the words of each language. Our study further suggests, through our application of the PDP, that participants who learned both languages have conscious knowledge of the two languages, to the extent that they can use the knowledge intentionally (in particular, they can refrain from using it when instructed to do so). In the following, we first discuss our results concerning segmentation of artificial languages, and then turn to the issue of awareness.
Experiment 1 was aimed at demonstrating that our two artificial languages were learnable and to the same extent over the course of a 10-min exposure. In Experiment 2, two speech streams were presented successively for 10 min each in order to explore how the statistical information allow extracting word units from two distinct artificial languages. Participants parsed the two speech streams and, more importantly, they were capable of differentiating between the two languages, suggesting that two separate representations were formed. In Experiment 3, we extended the results of Experiment 2 by exploring, using the PDP, the extent to which participants who learn both languages were able to intentionally manipulate their knowledge of the two languages.
Results of Experiment 2 partially converge with the results obtained by Weiss et al. (2009) and Gebhart et al. (2009). In both studies, participants were exposed to two streams of continuous speech that shared part of the syllables. The two different streams were produced by two different voices, providing a strong contextual cue for the change of language. Their results showed that learners can track and maintain separate two sets of statistics when a strong contextual cue (talker’s voice) was present. In these studies, participants learned both languages equally, while in our study the first language was better learned than the second. This difference could be due to the fact that in Weiss et al.’s and Gebhart et al. (Experiment 3) the two languages shared only a few syllables, while in our study all the syllables were common to both languages. Therefore, if participants learned the first language, learning the second would imply a reorganization of the whole corpus of transitional probabilities between and within syllables resulting in a weaker mean performance for the second language. It is possible that with a longer exposition to the second language (as in Gebhart et al., 2009, Experiment 5) combined with contextual cues would result in similar performance on the first and second language.
The aim of Experiment 3 was to explore the issue of the conscious awareness in a statistical learning situation. We found that participants who have been able to correctly parse the speech streams learned the two artificial languages, could differentiate them and are able to exert conscious control on this knowledge. However, there was an important variation between participant’s performance: while some participants seemed to have no difficulties to follow the inclusion and the exclusion instructions, some other were unable to succeed the inclusion task. As the aim of our study was to explore the access to the knowledge acquired during the exposition phase, we had to make sure that participants actually acquired the knowledge. To do so, we applied a method used by Sanders et al. (2002), which consists in splitting (at the median at the inclusion task) the sample in two groups: the low and the high learners. First, the analysis of high learners showed that only this group learned both languages. Moreover, they were able to follow the exclusion instructions and exclude the words from on of the languages – either if it was the first or the second language presented. These results suggest that when participants can parse the continuous speech of two distinct artificial languages properly differentiated (with context cues), the two languages are encoded separately and amenable to conscious control: participants are capable of a deep processing that is required to succeed in the exclusion task: identify the source of the word (first or second language) and then correctly reject the word if it belongs to the language to exclude. Second, the analysis of low learners showed that these participants are not just unable to follow the exclusion instructions: they actually did not learn the artificial languages (both or just one of them).
This difference between low and high learners raises one recent issue about individual differences in statistical learning. Indeed, little is known about statistical learning variation in normal adults. Most recent evidence comes from the implicit learning literature (Robinson, 2005; Brooks et al., 2006; Kempe et al., 2010) and reports a positive correlation between IQ Test scores and implicit learning tasks. Recently, Misyak and Christiansen(in press) reported an existing relation between adjacent dependencies in artificial grammar learning – which can be linked to transitional probabilities in speech segmentation – and subjects’ performance on verbal working memory and forward digit span tasks. Thus it seems that these individual differences could be related to short-term memory spam and verbal working memory. Unfortunately, in our study none of these measures were taken. However, in future studies short-term and working memory tasks could provide a reliable indication of the low and high learners.
The second issue of this paper concerned the conscious access to the representations acquired during learning. Statistical learning is often considered to be an automatic, incidental (see Perruchet and Pacton, 2006 for review), and implicit (Kim et al., 2009) process similar to those involved in implicit learning (Reber, 1967; see also Cleeremans et al., 1998). Little is known, however, about the extent to which the acquired representations are themselves implicit or explicit. One possible reason is that the central issues in statistical learning research traditionally focus on language acquisition and not on the role of awareness in learning. However, Saffran et al. (1997) found that adult and children learners were able to process transitional probabilities in passive situations and concluded that statistical learning can proceed incidentally without awareness. More recently, Kim et al. (2009) suggested that visual statistical learning occurs without conscious awareness of the regularities. They took an implicit (reaction times in a RSVP detection task) and an explicit measure (correct responses in a matching task) of learning. While participants’ reaction times performance indicated that they did learn the exposed sequences, their performance at the matching task was at chance. The authors thus concluded that they acquired implicit but not explicit knowledge of the visual sequences. However, the matching task used to measure explicit knowledge of the sequences consisted in an 11 forced-choice task, and one could argue that this test of awareness may not be sufficiently sensitive to all relevant conscious knowledge acquired during the learning phase. It is possible that this matching task do not meet the requirements of the “sensitivity criterion” (Shanks and St John, 1994) and therefore the low performance observed may be due to the difficulty of the task rather than the absence of explicit knowledge. Indeed, Bertels et al. (under revision) replicated Kim et al.’s study using a four forced-choice task as an explicit measure of knowledge. They found that participants were able to perform above chance the explicit task, suggesting that visual statistical learning lies on both implicit and explicit knowledge.
Taken together, these two studies highlight the importance to use implicit (indirect) tasks combined with the usual explicit (direct) tasks used in statistical learning studies. Indeed, direct tasks can be performed based on either recollection or familiarity, or based on a combination of both (Merikle and Reingold, 1991). For this reason, Jacoby (1991) has claimed that tasks in general, be they direct or indirect, are never process-pure. Instead, all of them can be influenced by both controlled (explicit knowledge) and automatic (familiarity) processes. Thus, the PDP provides an elegant way to separate the relative contribution of controlled and automatic processes to performance (Yonelinas and Jacoby, 1994). This procedure was often used in implicit learning studies, namely sequence learning (Buchner et al., 1997, 1998; Destrebecqz and Cleeremans, 2001, 2003) and artificial grammar learning experiments (Dienes et al., 1995). In their study, Dienes et al. 1995) presented participants with letter strings generated by two different artificial grammars. Their results showed that they could control their knowledge in a subsequent test phase performed under inclusion and exclusion instructions. Consistent with these results, our study constitutes the first attempt to adapt the PDP to a statistical learning situation. The results of Experiment 3 are suggestive that although participants are not explicitly instructed to find the words in our experimental situation, the resulting representations are nevertheless explicit. These results are consistent with previous studies in implicit learning (Perruchet and Vinter, 1998; Cleeremans and Jiménez, 2002), indicating that automatic and incidental learning processes can nevertheless result in conscious representations, at least under these specific training and testing conditions. Further research should investigate whether this kind of knowledge remains conscious when the languages and/or the links between the languages become more complex. For instance, when the two languages share some of the syllabic transitions. In conclusion, our results provide a first evidence that distributional information can allow segmentation and the creation of two different representations of two distinct artificial speeches presented successively and, more importantly, that these representations are available to conscious access and to cognitive control by adult learners.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Ana Franco is supported by a FNR governmental grant (Luxembourg). Axel Cleeremans is a Research Director with the National Fund for Scientific Research (FRS – FNRS, Belgium). Arnaud Destrebecqz is supported by a FNRS grant number 1.5.057.07F.
References
Aslin, R. N., Saffran, J. R., and Newport, E. L. (1998). Computation of conditional probability statistics by 8-month-old infants. Psychol. Sci. 9, 321–324.
Baldwin, D., Andersson, A., Saffran, J., and Meyer, M. (2008). Segmenting dynamic human action via statistical structure. Cognition 106, 1382–1407.
Brooks, P. J., Kempe, V., and Sionov, A. (2006). The role of learner and input variables in learning inflectional morphology. Appl. Psycholinguist. 27, 185–209.
Buchner, A., Steffens, M. C., Erdfelder, E., and Rothkegel, R. (1997). A multinomial model to assess fluency and recollection in a sequence learning task. Q. J. Exp. Psychol. 50A, 631–663.
Buchner, A., Steffens, M. C., and Rothkegel, R. (1998). On the role of fragment knowledge in a sequence learning task. Q. J. Exp. Psychol. 51A, 251–281.
Cleeremans, A. (1993). Mechanisms of Implicit Learning: Connectionist Models of Sequence Processing Cambridge: MIT Press.
Cleeremans, A., Destrebecqz, A., and Boyer, M. (1998). Implicit learning: news from the front. Trends Cogn. Sci. (Regul. Ed.) 2, 406–416.
Cleeremans, A., and Jiménez, L. (2002). “Implicit learning and consciousness: a graded, dynamic perspective,” in Implicit Learning and Consciousness, eds R. M. French and A. Cleeremans (Hove: Psychology Press), 1–40.
Conway, C., and Christiansen, M. H. (2005). Modality constrained statistical learning of tactile, visual, and auditory sequences. J. Exp. Psychol. Learn. Mem. Cogn. 31, 24–39.
Destrebecqz, A., and Cleeremans, A. (2001). Can sequence learning be implicit? New evidence with the process dissociation procedure. Psychon. Bull. Rev. 8, 343–350.
Destrebecqz, A., and Cleeremans, A. (2003). “Temporal effects in sequence learning,” in Attention and Implicit Learning, ed. L. Jiménez (Amsterdam: John Benjamins), 181–213.
Dienes, Z., Altmann, G. T. M., Kwan, L., and Goode, A. (1995). Unconscious knowledge of artificial grammars is applied strategically. J. Exp. Psychol. Learn. Mem. Cogn. 21, 1322–1338.
Dienes, Z., and Berry, D. (1997). Implicit learning: below the subjective threshold. Psychon. Bull. Rev. 4, 3–23.
Dulany, D. E. (1997). “Consciousness in the explicit (deliberative) and implicit (evocative),” in Scientific Approaches to the Study of Consciousness, eds J. D. Cohen and J. W. Schooler (Hillsdale, NJ: Erlbaum), 179–212.
Dutoit, T., Pagel, V., Pierret, N., Bataille, F., and Van der Vreken, O. (1996). “The MBROLA project: towards a set of high-quality speech synthesizers free of use for non-commercial purposes,” in Proceedings of ICSLP’96, Philadelphia, Vol. 3, 1393–1396.
Eriksen, C. W. (1960). Discrimination and learning without awareness: a methodological survey and evaluation. Psychol. Rev. 67, 279–300.
Fiser, J., and Aslin, R. N. (2001). Unsupervised statistical learning of higher-order spatial structures from visual scenes. Psychol. Sci. 12, 499–504.
Fiser, J., and Aslin, R. N. (2002). Statistical learning of new visual feature combinations by infants. Proc. Natl. Acad. Sci. U.S.A. 99, 15822–15826.
Fiser, J., and Aslin, R. N. (2005). Encoding multielement scenes: statistical learning of visual feature hierarchies. J. Exp. Psychol. Gen. 134, 521–537.
Fu, Q., Fu, X., and Dienes, Z. (2008). Implicit sequence learning and conscious awareness. Conscious. Cogn. 17, 185–202.
Gebhart, A. L., Aslin, R. N., and Newport, E. L. (2009). Changing structures in mid-stream: learning along the statistical garden path. Cogn. Sci. 33, 1087–1116.
Hunt, R. H., and Aslin, R. N. (2001). Statistical learning in a serial reaction time task: simultaneous extraction of multiple statistics. J. Exp. Psychol. Gen. 130, 658–680.
Jacoby, L. L. (1991). A process dissociation framework: separating automatic from intentional use of memory. J. Mem. Lang. 30, 513–541.
Jimenez, L., and Mendez, C. (1999). Which attention is needed for implicit sequence learning? J. Exp. Psychol. Learn. Mem. Cogn. 25, 236–259.
Johnson, E. K., and Jusczyk, P. W. (2001). Word segmentation by 8-month-olds: when speech cues count more than statistics. J. Mem. Lang. 44, 548–567.606–621.
Jusczyk, P. W. (1999). How infants being to extract words from speech. Trends Cogn. Sci. (Regul. Ed.) 3, 9, 323–328.
Kempe, V., Brooks, P. J., and Kharkhurin, A. V. (2010). Cognitive predictors of generalization of Russian grammatical gender categories. Lang. Learn. 60, 127–153.
Kim, R., Seitz, A., Feenstra, H., and Shams, L. (2009). Testing assumptions of statistical learning: is it implicit and long-term? Neurosci. Lett. 461, 145–149.
Merikle, P. M., and Reingold, E. M. (1991). Comparing direct (explicit) and indirect (implicit) measures to study unconscious memory. J. Exp. Psychol. Learn. Mem. Cogn. 17, 224–233.
Misyak, J. B., and Christiansen, M. H. (in press). Statistical learning and language: an individual differences study. Lang. Learn. doi: 10.1111/j.1467-9922.2010.00626.x
Pacton, S., Perruchet, P., Fayol, M., and Cleeremans, A. (2001). Implicit learning out of the lab: the case of orthographic regularities. J. Exp. Psychol. Gen. 130, 401–426.
Perruchet, P., and Desaulty, S. (2008). A role for backward transitional probabilities in word segmentation? Mem. Cogn. 36, 1299–1305.
Perruchet, P., and Pacton, S. (2006). Implicit learning and statistical learning: two approaches, one phenomenon. Trends Cogn. Sci. (Regul. Ed.) 10, 233–238.
Perruchet, P., and Vinter, A. (1998). PARSER: a model for word segmentation. J. Mem. Lang. 39, 246–263.
Reingold, E. M., and Merikle, P. M. (1993). “Theory and measurement in the study of unconscious processes,” in Consciousness, eds M. Davies and G. W. Humphreys (Oxford: Blackwell), 40–57.
Richardson-Klavehn, A., Gardiner, J. M., and Java, R. I. (1996). “Memory: task dissociations, process dissociations, and dissociations of awareness,” in Implicit Cognition, ed. G. Underwood (Oxford: Oxford University Press), 85–158.
Robinson, P. (2005). Cognitive abilities, chunk-strength, and frequency effects in implicit artificial grammar and incidental L2 learning: replications of Reber, Walkenfeld, and Hernstadt (1991) and Knowlton and Squire (1996) and their relevance for SLA. Stud. Second Lang. Acquisition 27, 235–268.
Saffran, J., Senghas, A., and Trueswell, J. C. (2001). The acquisition of language by children. Proc. Natl. Acad. Sci. U.S.A. 98, 12874–12875.
Saffran, J. R., Aslin, R. N., and Newport, E. L. (1996a). Statistical learning by 8-month-old infants. Science 274, 1926–1928.
Saffran, J. R., Newport, E. L., and Aslin, R. N. (1996b). Word segmentation: the role of distributional cues. J. Mem. Lang. 35, 606–621.
Saffran, J. R., Johnson, E. K., Aslin, R. N., and Newport, E. L. (1999). Statistical learning of tone sequences by adults and infants. Cognition 70, 27–52.
Saffran, J. R., Newport, E. L., Aslin, R. N., Tunick, R. A., and Barrueco, S. (1997). Incidental language learning. Psychol. Sci. 8, 101–105.
Saffran, J. R., and Wilson, D. P. (2003). From syllables to syntax: multi-level statistical learning by 12-month-old infants. Infancy 4, 273–284.
Sanders, L. D., Newport, E. L., and Neville, H. J. (2002). Segmenting nonsense: an event-related potential index of perceived onsets in continuous speech. Nat. Neurosci. 5, 700–703.
Shanks, D. R., and Johnstone, T. (1999). Evaluating the relationship between explicit and implicit knowledge in a serial reaction time task. J. Exp. Psychol. Learn. Mem. Cogn. 25, 1435–1451.
Shanks, D. R., and St. John, M. F. (1994). Characteristics of dissociable human learning systems. Behav. Brain Sci. 17, 367–447.
Turk-Browne, N. B., Jungé, J. A., and Scholl, B. J. (2005). Attention and automaticity in visual statistical learning. Talk presented at Vision Sciences Society Conference, Sarasota, FL.
Weiss, D. J., Gerfen, C., and Mitchel, A. (2009). Speech segmentation in a simulated bilingual environment: a challenge for statistical learning? Lang. Learn. Dev. 5, 30–49.
Yonelinas, A. P., and Jacoby, L. L. (1994). Dissociations of processes in recognition memory: effects of interference and of response speed. Can. J. Exp. Psychol. 4, 516–535.
Keywords: statistical learning, process-dissociation procedure, implicit learning, consciousness
Citation: Franco A, Cleeremans A and Destrebecqz A (2011) Statistical learning of two artificial languages presented successively: how conscious? Front. Psychology 2:229. doi: 10.3389/fpsyg.2011.00229
Received: 03 March 2011; Accepted: 25 August 2011;
Published online: 21 September 2011.
Edited by:
Ping Li, Penn State University, USAReviewed by:
Gert Westermann, Oxford Brookes University, UKDaniel J. Weiss, Penn State University, USA
Copyright: © 2011 Franco, Cleeremans and Destrebecqz. This is an open-access article subject to a non-exclusive license between the authors and Frontiers Media SA, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and other Frontiers conditions are complied with.
*Correspondence: Ana Franco, Consciousness, Cognition, and Computation Group, Université Libre de Bruxelles, CP 191, 50 Avenue F.-D. Roosevelt, 1050 Bruxelles, Belgium. e-mail:YWZyYW5jb0B1bGIuYWMuYmU=