 Wycliffe Kabaywe Yumba
Wycliffe Kabaywe Yumba- 1Department of Behavioral Sciences and Learning, Linköping University, Linköping, Sweden
- 2Linnaeus Centre HEAD, Swedish Institute for Disability Research, Linköping University, Linköping, Sweden
Previous studies have demonstrated that successful listening with advanced signal processing in digital hearing aids is associated with individual cognitive capacity, particularly working memory capacity (WMC). This study aimed to examine the relationship between cognitive abilities (cognitive processing speed and WMC) and individual listeners’ responses to digital signal processing settings in adverse listening conditions. A total of 194 native Swedish speakers (83 women and 111 men), aged 33–80 years (mean = 60.75 years, SD = 8.89), with bilateral, symmetrical mild to moderate sensorineural hearing loss who had completed a lexical decision speed test (measuring cognitive processing speed) and semantic word-pair span test (SWPST, capturing WMC) participated in this study. The Hagerman test (capturing speech recognition in noise) was conducted using an experimental hearing aid with three digital signal processing settings: (1) linear amplification without noise reduction (NoP), (2) linear amplification with noise reduction (NR), and (3) non-linear amplification without NR (“fast-acting compression”). The results showed that cognitive processing speed was a better predictor of speech intelligibility in noise, regardless of the types of signal processing algorithms used. That is, there was a stronger association between cognitive processing speed and NR outcomes and fast-acting compression outcomes (in steady state noise). We observed a weaker relationship between working memory and NR, but WMC did not relate to fast-acting compression. WMC was a relatively weaker predictor of speech intelligibility in noise. These findings might have been different if the participants had been provided with training and or allowed to acclimatize to binary masking noise reduction or fast-acting compression.
Introduction
Hearing-impaired individuals often show increased difficulties recognizing speech under adverse listening conditions, including noise and reverberant or distorted speech, even when wearing hearing aids (Committee on Hearing, Bioacoustics, and Biomechanics [CHABA], 1988; Akeroyd, 2008; Larsby et al., 2008; Souza and Arehart, 2015). Previous studies have indicated that older adult hearing aid users may have difficulties handling the consequences of hearing aid signal processing, whether in regard to the distortions caused by the effects of background noise or the unwanted artifacts from certain digital signal processing algorithms (e.g., fast-acting compression; Lunner, 2003; Souza and Arehart, 2015). These consequences may lead to benefits of signal processing in the hearing aid that are less than expected. It may be possible that the signal processing implemented in the hearing aid itself may be cognitively demanding for hearing-impaired hearing aid wearers (Lunner, 2003). Others studies have attributed speech recognition difficulties among hearing-impaired hearing aid users to the slow-down of cognitive speed. This decline in cognitive processing speed may arise from a generalized slowing in brain functioning due to advancement in age, which could be responsible for most, if not all, age-related declines in problem-solving, memory, and language comprehension (Salthouse, 1996; Pichora-Fuller, 2003; Schneider et al., 2005).
Working memory refers to a cognitive system responsible for processing and temporary storage of information during complex cognitive tasks, such as comprehension, learning and reasoning (Baddeley and Hitch, 1974; Daneman and Carpenter, 1980; Baddeley, 1986). This memory system is assumed to have a limited capacity that need be shared between the work and the memory, between the processing and storage demands of the task to which the working memory is applied (Daneman and Carpenter, 1980; Baddeley, 2012). Working memory capacity (WMC) is generally assessed with span tests, such as reading span test (Daneman and Carpenter, 1980), semantic word-pair span test (Rönnberg et al., 2016). Cognitive processing speed (CPS) is the rate at which relatively simple perceptual and automatic cognitive operations can be carried out; usually this is measured under time pressure in such that a degree of focused attention is involved (Salthouse, 1996, 2000). Several types of tasks are used to measure cognitive processing speed ability, including lexical decision speed test (LDT), rapid automatized naming test (RAN), physical matching test (PMT), Rhyme judgment test, the digital symbol substitution test (DSST), the flanker task, etc. (Wingfield et al., 1985; Rönnberg, 1990; Salthouse, 1996; Wiig et al., 2002). For example, LDT is considered as one of the most often used tasks in the field of visual word recognition. In this task, participants have to judge as quickly and accurately as possible whether a displayed letter string is a real word or a non-word (Rönnberg, 1990). The overall assumption that underlies the use of LDT is that the rate and the accuracy of reacting to word stimuli shows the effectiveness with which word representations are activated or retrieved from long-term lexical memory (Rönnberg, 1990). Previous studies suggested that cognitive processing speed may be affected by individuals’ knowledge base and experience. That is, the more an individual knows about something and/ or the experience she/he has with it, the greater the probability that her/his cognitive processing speed on tasks related to this information will be increased (Lunner, 2003; Pichora-Fuller, 2003; Desjardins and Doherty, 2014).
A comprehensive way of viewing the relationship between working memory and speech recognition is via the Ease of Language Understanding (ELU) model (Rönnberg et al., 2008, 2013). The ELU model considers language input as consisting of phonological, syntactic prosodic, and semantic information. That is, when speech signal input is degraded or altered from its ordinary form, it can be more difficult to match those acoustic patterns to phonological representations stored in the long term memory, and working memory may be explicitly engaged to a greater extent to reconcile a match (mismatch, Rönnberg et al., 2008). However, under favorable conditions, the incoming speech signal input are not degraded (audible or undistorted), it can be easily matched to a phonological representation stored in long -term memory); and WMC may be engaged to a lesser extent (Rönnberg et al., 2013). In the context of this model, signal degradation refers to whatever may substantially modify the available acoustic signal cues of the target signal (Rönnberg et al., 2008). The sources of signal degradation may be single (e.g., noise) or multiple (e.g., combined hearing aid signal processing and noise for older persons with hearing loss). Other studies suggest that for listeners with hearing loss, various signal processing algorithms implemented in hearing aids may be a potential source of speech signal degradations (Gatehouse et al., 2003, 2006; Foo et al., 2007; Souza and Arehart, 2015).
Modern digital hearing aids are typically equipped with a wide range of signal processing algorithms, including wide dynamic range compression speed, noise reduction, and directional microphones (Dillon, 1996, 2001, 2012; Kates, 2008). Although many hearing-impaired persons may benefit from such signal processing algorithms, they may introduce distortions that may counteract or reduce the intended benefits for some listeners (Lunner, 2003). Fast-acting wide dynamic range compression (fast-acting WDRC) is intended to simultaneously improve the audibility of weak sounds and maintain loudness and comfort for higher-intensity sounds (Dillon, 2001, 2012). Moreover, improved audibility requires signal modification, and a greater modification of the expected acoustic signal may place greater demand on WMC (Rönnberg et al., 2008, 2013). Fast-acting compression may modify the speech amplitude envelope, which may cause a challenging listening situation for hearing-impaired persons who rely on envelope cues (Kates, 2008; Dillon, 2012). In addition, other studies suggest that fast-acting compression may introduce unwanted artifacts, which may create greater signal modification (Dillon, 2001; Lunner, 2003). A number of studies found a relationship between cognitive abilities and the ability to recognize speech in noise using different types of hearing aid signal processing algorithms. In particular, these studies showed that WMC was associated with speech recognition in noise performance when spoken sentences were amplified by fast-acting wide dynamic range compression (Gatehouse et al., 2003, 2006; Foo et al., 2007; Lunner and Sundewall-Thorén, 2007; Akeroyd, 2008; Ohlenforst et al., 2015; Souza and Arehart, 2015). Other studies indicated that WMC, executive function and cognitive speed were related to wide dynamic range compression (Schwartz et al., 2008; Souza and Arehart, 2015) and to frequency compression (Arhart et al., 2013; Souza and Arehart, 2015). Rudner et al. (2011) found that hearing impaired listeners with lower WMC demonstrated poor benefit with fast-acting compression than slow-acting compression, compared with listeners with higher working memory who benefited more with fast-acting compression (see also Foo et al., 2007). A study by Gatehouse et al. (2003) indicated that cognitive capacity was associated with speech recognition in noise with fast-acting compression. That is, there was a greater benefit from fast-acting compression for listeners with greater cognitive capacity than those with poorer cognitive ability in modulated noise background. In further study, the same authors (Gatehouse et al., 2006) reported that cognitive capacity related to speech recognition in noise performance differently (both with fast and slow acting compression), suggesting that fast-acting compression provided greater benefit for listeners with larger cognitive capacity, while slow-acting provided better benefit for listeners with smaller cognitive capacity.
The rationale for noise reduction algorithms is to identify and suppress the adverse effects of background noise on speech recognition and sound quality by improving the signal-to-noise ratios (SNRs) for listeners with hearing loss (Kates, 2008; Dillon, 2012). Although, noise reduction systems are intended to improve speech intelligibility, they may also affect speech quality and ease of listening by introducing signal distortions (Kates, 2008; Wang et al., 2009; Souza and Arehart, 2015). A few studies found a relationship between WMC and spoken sentences amplified by digital noise reduction (Ng et al., 2013, 2015; Arhart et al., 2015). Recently, Ng et al. (2013) conducted a study where they examined the effects of WMC, noise and binary mask-based noise reduction on speech recognition and recall. They found that listeners with larger WMC were better at recalling more words than listeners with smaller WMC, as a result of noise reduction processing. The results showed that noise reduction effectively suppressed the adverse effects of background noise on speech recall performance of listeners with larger WMC. In another recent study, Ng et al. (2015) carried out a research where they tested the Non-ideal version of noise reduction in a follow-up experimental based on essentially the same set-up with elderly hearing aid users. Arhart et al. (2015) investigated the effects of ideal binary mask-based noise reduction processing and several non-ideal versions resulting from the systematic manipulations of two algorithmic parameters. The results showed that WMC was a potential predictor of the overall speech intelligibility performance; however, there was no interaction between WMC and the level of signal distortions in explaining the performance. Related to WMC, recent study by Neher (2014) examined the effects of WMC and hearing loss on response to noise reduction for the three levels of a binaural coherence algorithms (i.e., none, moderate, and strong). They found that speech recognition performance was poor when speech was amplified with noise reduction, and there was no significant difference between listeners with larger WMC and those with smaller WMC. Nevertheless, working memory appeared to be important for the fact that participants with smaller WMC preferred more aggressive (strong) noise reduction than moderate noise reduction (in terms of speech quality).
A number of studies suggested that the association between working memory and noise reduction is likely to be stronger for speech recognition performance under low-context speech material in modulated background noise and relatively weaker under unmodulated background noise (Rudner et al., 2011; Ng et al., 2013). A few studies supporting this view suggested that sentence material may play an important role. For example, shorter speech segments in relatively favorable signal -to- noise ratios may reduce the activation for engagement for WMC compared with longer speech segments which activate the deployment of working memory to a greater extent (Rudner et al., 2009; Souza and Arehart, 2015). Previous studies have suggested that processing speed, WMC and selective attention are essential for linguistic analysis for speech in challenging listening situations (Lunner, 2003; Rönnberg et al., 2013).
The present study investigated the relationship between cognitive abilities (cognitive processing speed, WMC) and individual listeners’ responses to digital signal processing settings in noise. Here, we manipulated hearing aid signal processing and background noise, resulting in six conditions (see Table 1) in which Hagerman sentences were presented. We hypothesized that cognitive abilities would be correlated with Hagerman sentence intelligibility in noise. We would expect stronger associations between WMC and speech recognition when speech is acoustically degraded and weaker associations when speech is audible. Numerous studies have supported this view, showing stronger relationship between WMC and speech comprehension in adverse listening conditions in hearing-impaired participants (Foo et al., 2007; Akeroyd, 2008; Rudner et al., 2011; Rönnberg et al., 2013; Ohlenforst et al., 2015; Souza and Arehart, 2015).

TABLE 1. Means (M) and Standard Deviations (SD) for speech recognition in noise, age, and cognitive measures.
Materials and Methods
Participants
A total of 194 native Swedish speakers (83 women and 111 men), aged 33–80 years (mean = 60.75 years, SD = 8.89), with bilateral, symmetrical mild to moderate sensorineural hearing loss who had completed a LDT and semantic word-pair span test, and the Hagerman matrix sentence test (Hagerman and Kinnefors, 1995) were included in this study. The pure-tone average hearing threshold for both ears at frequencies 0.5, 1, 2, and 4 kHz (PTA4) was 39.23 dB HL (SD = 19.64). The participants were randomly selected from the hearing clinic patient registry at the University Hospital of Linköping, where the testing took place, and were invited to participate by letter. Regarding the inclusion criteria, all participants were bilaterally fitted with digital hearing aids with common features such as WDRC, noise reduction, and directional microphones. All participants had used the hearing aids for a minimum of 1 year at the time of testing. The participants were healthy native Swedish speakers, with normal vision or corrected-to-normal vision (wearers of glasses). The participants had no history of otological problems or psychological disorders. The study was approved by the Linköping regional ethics committee (Dnr: 55-09 T122-09). All participants gave written informed consent to participate.
Cognitive Tests
Semantic Word Pair Span Test
A semantic word-pair span task (Rönnberg et al., 2016) is a visual working memory test that does not compared to reading span test include any syntactic elements in the processing and storage components. The test material consists of a series of word-pairs (such as “Bun, Hippo”). The list length varied from 2 to 5, with three trials per length. The task was to comprehend word and to recall either the first or the final words in the displayed series of pair words (Baddeley et al., 1985). The word-pairs were displayed on a computer screen at a speed of 800 ms per word. Half of the word-pairs were living thing (e.g., “cat”), and half of the word-pairs were no living thing (e.g., “paper”). The participants were instructed to read and identify the words representing the living thing on the screen, then press the button stating in which position the word representing the living thing was presented (e.g., Left–Right). To press the left button (green) if the living thing is at the left side, and press the right button (red) if the living thing is at the right side. After each sequence of word-pair, the participants were asked to repeat orally and loudly all the words that were recently presented either at left or right, and should be in the correct order of presentation. The participants’ responses were scored by the experimenter in terms of total number of words correctly recalled. The maximum total score is 42 points.
Lexical Decision Speed Test
The LDT (Rönnberg, 1990; Rönnberg et al., 2016) was used to measure the participants’ cognitive processing speed. In the LDT, eighty words presented visually one item at a time on the computer screen were used as test material, 40 of which were real Swedish words and 40 were not. In this task, participants have to decide as quickly and accurately as possible whether visually displayed combinations of letters are real words or not, by pressing the button “yes” for real word or “no” for no word/ pseudo word. For example, when the word (e.g., “SNÖ, snow”) was displayed, the participant pressed “yes,” this is a real Swedish word, but when the letters (e.g., “NÄKK”) was displayed, the participant pressed “NO” this is not a real Swedish word. The response time was set at 5 s, and the word disappeared when the participants pressed the button. Accuracy and speed of performance were measured based on the reaction times for the correct trials.
The Hagerman Test
Speech recognition was measured using the Hagerman matrix sentence test (Hagerman and Kinnefors, 1995). Three lists of 10 sentences, highly constrained in their nature, with low semantic redundancy, were used as test material. The sentences all consisted of five Swedish words, and had the following structure: proper noun, verb, number, adjective, and object, in that order. The sentences were presented in two types of background noise, steady state noise (SSN) or four-talker babble (4TB). An experimental hearing aid with three different signal processing features, including three signal processing features (1) linear amplification without noise reduction (NoP, baseline), (2) linear amplification with noise reduction (NR) and (3) non-linear amplification with fast-acting compression (Fast, without noise reduction), fitted based on each participant’s audiogram was employed. 4TB consisted of recordings of two male and two female native Swedish speakers reading different paragraphs of a newspaper text and SSN (i.e., stationary speech-shaped noise with the same long-term average spectrum as the speech material) were used. These two types of background noise were presented at equal root mean square (RMS) levels (Larsby et al., 2005).
Background Noise
Two types of background noises were used in this study: SSN and 4TB. SSN is the stationary noise speech-shaped noise (i.e., similar long-term average spectrum as HINT sentences, Hällgren et al., 2006). The 4TB is a type of competing speech, consisting of recordings of two males and two females’ native Swedish speakers reading different paragraphs of a newspaper text (Hagerman and Kinnefors, 1995). The speech babble was introduced 3 s before the onset of sentence stimuli and ended 1 s after sentence offset.
Signal Processing Algorithms Setting
Noise Reduction
The primary goal of binary masking noise reduction systems is to counteract the effects of noise on speech recognition and sound quality by improving the SNR for hearing aid users (Wang et al., 2009; Dillon, 2012; Souza and Arehart, 2015). The time-frequency units were recorded using a 64-channel gammatone filter bank and time-windowing. The idea here is that for each time-frequency unit (in binary matrix), there is a decrease of 10 dB; the local SNR of each given time-frequency unit is less than 0 dB, which means that the signal energy is greater than the noise energy. In this way, there is an optimization of the SNR benefits provided by binary masking (Li and Wang, 2009). The present study used a binary masking noise reduction algorithm as a processing condition (Boldt et al., 2008), rather than a non-ideal estimation of noise reduction.
Linear Amplification and Compression
Audibility was provided by setting up the hearing aid in such a way that linear amplification was based on the hearing thresholds of each subject, as a function of voice aligned compression. The settings were then modified using software programmed for a linear 1:1 compression ratio corresponding to pure-tone input levels ranging from 30 to 90 dB SPL. Subsequently, all signals and noises were distributed in such a way that the noise level corresponded to the region of the linear compression ratio, ensuring that there was no effect of any compression knee point or output limiting. The primary goal of voice aligned compression, known as curvilinear WDRC, is to reduce compression at a high input level, and to increase compression at low input levels, by using lower compression knee points (ranging from 30 to 40 dB SPL, depending on the frequency region affected and the degree of hearing loss). The loudness data of Buus and Florentine (2001) has contributed in part to this compression model, which focuses on providing better sound quality, while maintaining speech intelligibility, rather than focusing solely on loudness. The attack time of 10 ms and release time of 40 ms (with a compression ratio of 2:1 in all channels) were employed in fast-acting multichannel WDRC conditions.
Procedure
The data in this study were collected as part of a larger investigation (Rönnberg et al., 2016), which involved three sessions of approximately 3 h each. Data for this study were collected during the first session (background data and pure-tone average hearing threshold data) and the third session (Hagerman test). All testing was administered individually during a 6-week period. Vision correction was used when necessary.
The Hagerman sentences test took place in a sound-treated test booth, and the participants sat on a chair at a distance of 1 m from a single loudspeaker. The master hearing aid was implemented in an anechoic box (Brüël and Kjaer, type 4232), containing an experimental well checked hearing aid. This experimental hearing aid was fitted based on each participant’s audiogram. This enabled audibility, and control of target signal processing settings such as: linear amplification (without noise reduction, and with noise reduction (Wang et al., 2009; Ng et al., 2013) and fast-acting compression (Dillon, 2001, 2012). Two types of background noise were presented at equal RMS levels; these were the modulated speech-shaped noise based on the modulated pattern of 4TB (consisting of recordings of two male and two female native speakers of Swedish reading different paragraphs of a newspaper text) and the steady state speech-shaped noise.
These hearing aid features and the background noise were manipulated to examine the predictions of aided speech recognition in noise in which cognition abilities are challenged. Linear amplification without binary noise reductions (NoP) served as a baseline to clarify the difference between linear amplification with binary NR and non-linear fast-acting compression (with NR) in terms of benefits.
After calibrating the setup, for each participant, a baseline measure was performed using linear amplification without binary masking noise reduction prior to applying linear amplification with binary masking noise reduction and the non-linear amplification fast-acting compression (without noise reduction) setting. The testing began with two lists of 10 sentences used as practice before the test session. Each practice sentence was presented one at a time in a randomized order at a constant 65 dB SPL in two background noise conditions. The order in which the conditions were tested was fully randomized across participants and between tests. Each participant was tested individually, and for each test and participant, an initial SNR of 0 dB was selected to facilitate the familiarization period with a somewhat easy recognition task. In the experimental session, Hagerman sentences were presented as described in the practice session. Three lists of 10 sentences each were presented to each participant in a randomized order for each condition. For each sentence, the participant was asked to repeat as many of the words as possible. The number of words correctly repeated was recorded on a computer terminal. On the basis of word scores, the SNR was automatically adapted using a standard algorithm that applies an interleaved technique to determine individual SNRs for 50 and 80% correct levels of performance, respectively (Brand, 2000). The 50% threshold represents 2.5 words correct out of five, and 4 words correct out of five corresponds to 80% threshold. The randomization process was beneficial because it reduces the possibility of memorizing or guessing the sentence and reduces the overall learning effect and thus increases the degree of reliability of the Hagerman test. Although the speech signal was fixed, the noise level was adaptively adjusted to match the appropriate SNR.
Data Analysis
Data analysis was conducted using a 3 × 2 within-group analysis of variance design, with digital signal processing algorithm setting (no processing, noise reduction, and fast-acting compression) and noise type (SSN and 4TB) as independent variables, and speech recognition in noise performance as the dependent variable. The relationship between the measures of cognitive speed, WMC and speech recognition in noise performance was analyzed using Pearson correlations. Given that a large number of correlations were computed, the Bonferroni correction was applied in order to control the chance of committing a Type I errors which could increase. To obtain the Bonferroni corrected/adjusted p-value, the original α-value [critical value of p(0.05) was divided by the number of comparisons on the dependent variable (i.e., 36]. This yields a new p-value (0.0014) that controls for family-wise Type I error rate.
A series of hierarchical multiple linear regression analyses were conducted in aided six conditions, respectively, performance on Hagerman sentences test, under the following test conditions: (1) Linear amplification without noise reduction (NoP) in an unmodulated noise background; (2) Linear amplification combined with noise reduction (NR) in an unmodulated noise background; (3) Linear amplification without noise reduction (NoP) in a multi-talker background; (4) Linear amplification combined with noise reduction (NR) in a multi-talker background; (5) Fast-acting compression (Fast) signal processing in an unmodulated noise background (no noise reduction); (6) Fast-acting compression (Fast) signal processing in a multi-talker background (no noise reduction, Rönnberg et al., 2016), to examine the extent to which cognitive speed and WMC may relate to aided speech recognition performance in noise. All the significance levels were set at p < 0.05, and P < 0.01(two-tailed). All analyses were performed using SPSS statistical package 23.0 for windows.
Results
Means and standard deviations for the predictor (cognitive speed and working memory) and the mean SNR (dB) for speech recognition in noise in the various conditions are shown in Table 1. Lower SNR scores means better speech recognition performance because low SNR shows that the participants correctly identified the speech signal despite a high level of background noise, while high SNR scores indicate that the sentences could only be correctly repeated at low noise levels (Hagerman and Kinnefors, 1995). The scoring method for the Hagerman sentences boosted a level of performance where 80% (i.e., four out of five) of the words in any particular sentence were recognized correctly. That is, optimal performance can be found even if one word in each sentence is meaningless due to under-amplification or masking. Nevertheless, the SNR at which 50% of words correctly recognized (or 2.5 words out of 5 words) was applied for the calculation of the thresholds in accordance with Plomp and Mimpen (1979).
Speech Recognition in Noise Performance
A two-way, within-participant analysis of variance, which included the digital signal processing algorithm (no processing, noise reduction, and fast-acting compression) and noise type (SSN and 4TB), was conducted. The results revealed a main effect of the digital signal processing algorithm, F(2,386) = 2137.82, p < 0.001, = 0.91, in which the mean SNR for the noise reduction condition (-6.81 dB, SE = 0.13) was lower than that for the no processing condition (-1.33 dB, SE = 0.13) and the fast-acting compression condition (-0.47 dB SNR, SE = 0.14). Post hoc t-tests (Bonferroni adjusted for multiple comparisons) showed that the test performance in the linear amplification with noise reduction condition was better (i.e., with a lower average SNR) than that in the linear amplification without noise reduction condition (p < 0.001) (Wang et al., 2009; Ng et al., 2013). In addition, performance in the linear amplification with noise reduction condition was better than that in the non-linear amplification with fast-acting compression condition (p < 0.001). This suggests that linear amplification resulted in a better speech recognition performance than non-linear amplification with fast-acting compression. There was also a significant main effect of the noise type, F(1,193) = 3637.09, p < 0.001, = 0.95, in which the mean SNR in the SSN condition (-5.25 dB SNR, SE = 0.13) was lower than that in the 4TB condition (-0.48 dB SNR, SE = 0.12). This indicates that competing speech noise has a stronger masking effect than stationary noise.
Interestingly, a significant two-way interaction effect between the digital signal processing algorithm and the noise type was found, F(2,386) = 122.00, p < 0.001, = 0.38 (Figure 1). Further investigation of the interaction using post hoc t-testing with Bonferroni adjustment for multiple comparisons showed that the difference between speech recognition performance in SSN and in 4TB was relatively not significant (p > 0.05) when binary masking noise reduction was applied. That is, when NR was applied, the presence of noise effect was no longer significant, possibly due to the effectiveness of NR at reducing the masking effect of noise (Ng et al., 2013), compared to when fast-acting compression was applied, where the difference between SSN and 4TB was significant (p < 0.05, relative to NoP baseline). As observed in Figures 1, 2, this interaction has been driven by the fact that the background noise has a larger effect in the no processing condition (difference of -5.5) and the fast-acting compression (difference -5.48) compared to the in the noise reduction condition (difference of -3.32). This may suggest that background noise rather than cognitive ability is the key factor influencing the interaction (Larsby et al., 2005). We may suggest that there was a relatively smaller dependence on cognitive abilities in the noise reduction condition and a relatively larger dependence on cognitive abilities in fast-acting compression due to the detrimental masking effects of the 4TB condition (e.g., Ng et al., 2013).
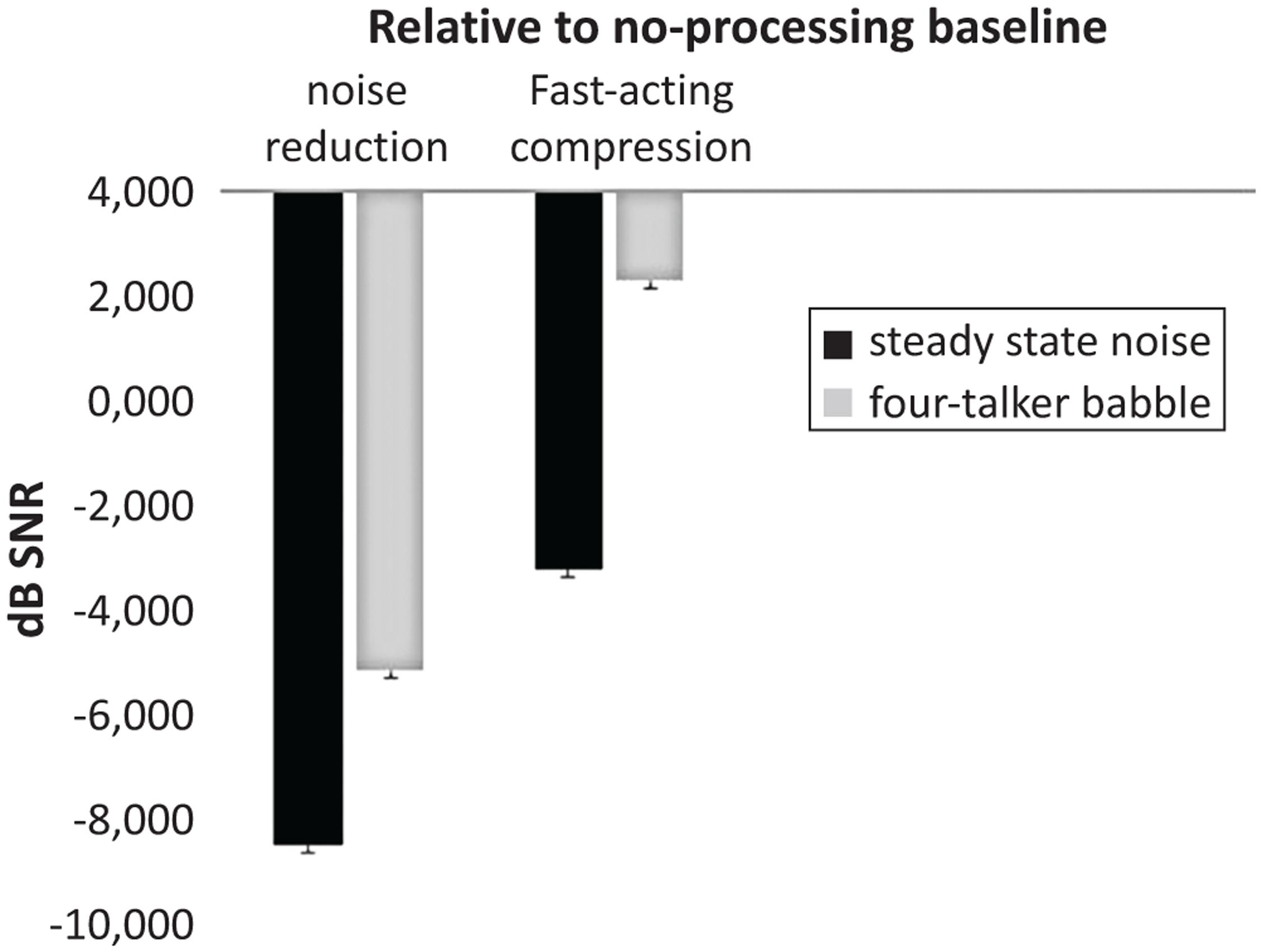
FIGURE 1. Significant two-way interaction between hearing aid signal processing setting (noise reduction and fast-acting compression) and noise type [steady state noise (SSN), four-talker babble (4TB)] in aided conditions with Hagerman test (relative to NoP baseline, error bars represent standard errors).
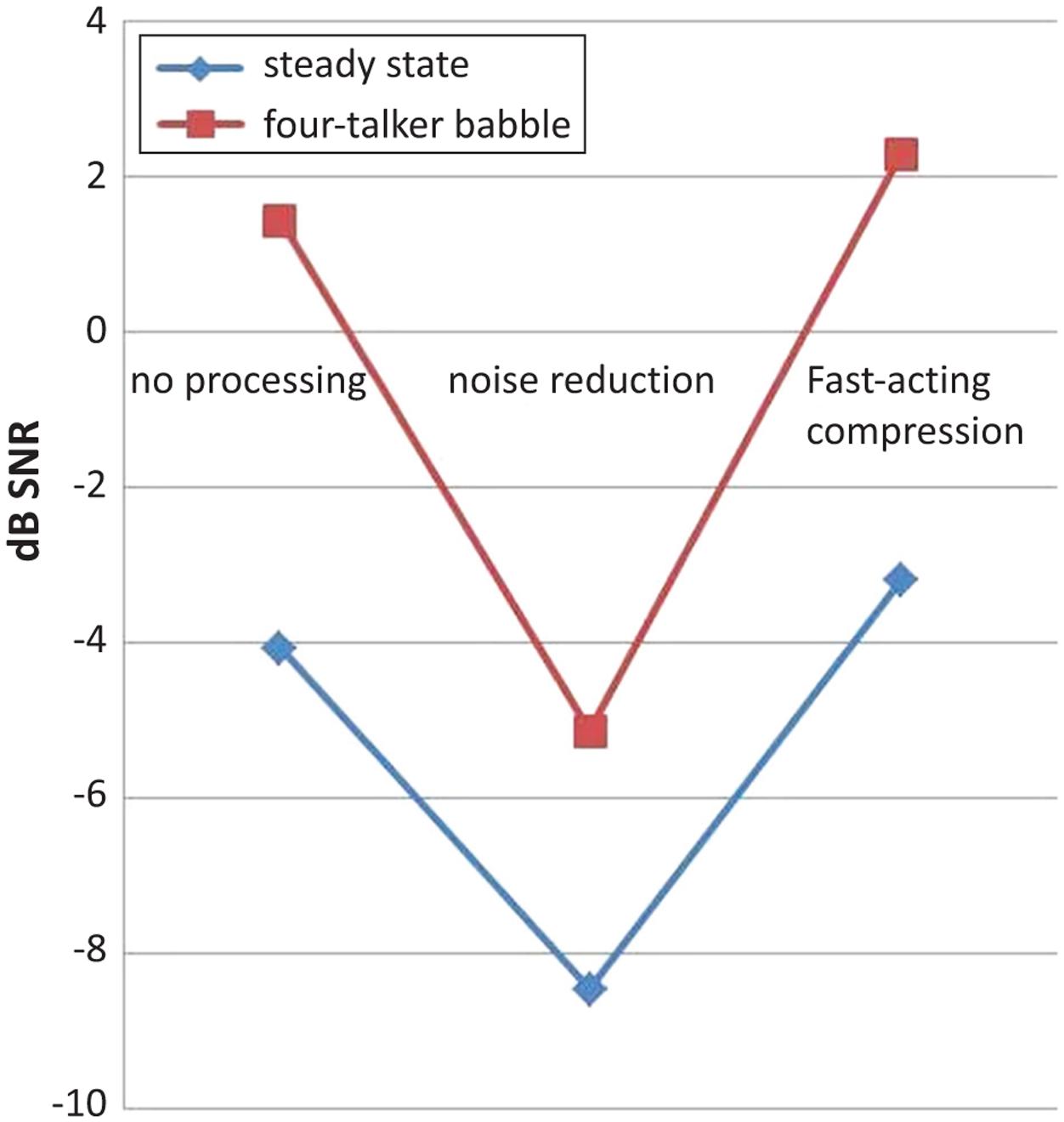
FIGURE 2. A two-way interaction effect between hearing aid signal processing setting (linear amplification without noise reduction, linear amplification with noise reduction and fast-acting compression) and noise type (SSN, 4TB) in aided conditions with Hagerman test are shown. There was a significant difference between SSN and 4TB (i.e., in dB, in terms of speech recognition performance) in linear amplification without noise reduction, and in non-linear amplification fast-acting compression condition. However, there was no significant difference between SSN and 4TB in linear amplification with noise reduction condition.
The negative masking effects of 4TB might have disrupted and delayed the amplification effectiveness of fast-acting compression (e.g., the compressor speed: attack time or release time) compared to noise reduction. This study indicates that performance was better when spoken sentences were presented in SSN with a noise reduction algorithm. Noise reduction appears to be effective in reducing stable background noise. This is in line with recent studies that suggest that noise reduction provides greater benefits in SSN conditions (Ng et al., 2013; Arhart et al., 2015).
Correlations
Pearson’s correlations coefficient was calculated to examine the relationship between age, scores on the LDT and the SWPST, and performance on the Hagerman sentences test for the six conditions. Age significantly correlated with the LDT scores (r = 0.19, p < 0.05) and the SWPST scores (r = -0.30, p < 0.01). The correlations between age and the cognitive tests suggest that as people become older, cognitive performance becomes worse (e.g., Salthouse, 1996). That is, advanced age corresponds to longer reaction times and lower WMC (Rönnberg et al., 1989; Rönnberg, 1990; Larsby et al., 2005). Age also significantly correlated with the Hagerman sentences test performance under all six aided conditions. This is in line previous studies (e.g., Larsby et al., 2005). The LDT scores also significantly correlated with the Hagerman sentences test performance under all conditions when NoP, NR, and fast-acting compression were used. This finding indicates that cognitive processing speed may be relatively associated with both noise reduction and fast-acting acting compression in terms of speech recognition in noise performance. This pattern of correlations demonstrates the importance of cognitive speed in the ability of hearing aid users to recognize speech in noise.
The performance on the semantic word-pair span scores negatively and significantly correlated with the Hagerman sentences test performance under only 5 out of 6 aided conditions, that is, when NoP, NR, and fast-acting compression were used. This is in line with previous studies that suggested that WMC was related to speech recognition in noise performance with NR (Ng et al., 2013; Arhart et al., 2015) and fast-acting compression (Lunner and Sundewall-Thorén, 2007; Rudner et al., 2011). However, the fact that the semantic word-pair span did not significantly correlate with the Hagerman sentences test performance when there was no processing and in SSN with fast-acting compression contrasts with the findings of Gatehouse et al. (2006) and Lunner and Sundewall-Thorén (2007; see also Ng et al., 2013). The lexical decision speed and semantic word-pair span significantly correlated, showing that a longer reaction time on speech recognition performance is associated with lower WMC.
Results after Bonferroni Correction Was Applied
When Bonferroni correction was applied, a new p-value was obtained (0.0014), and to determine whether any of the corrections was significant, the p-value must be p ≤ 0.001. The correlations between age, the LDT scores, the SWPST scores and the Hagerman sentences test scores when Bonferroni correction was used are shown in Table 2. Surprisingly, age did not significantly correlate with the LDT scores (r = 0.19, p > 0.05) but correlated with the SWPST scores (r = -0.30, p < 0.05) at the verge of significance. However, age significantly correlated with the Hagerman sentences test performance under all six aided conditions (p < 0.05, see Table 2). This is consistent with previous studies that indicate that there was an age-related decline in speech recognition in adverse listening in older adults compared to younger listeners (Larsby et al., 2008; Gordon-Salant and Cole, 2016). Interestingly, the LDT scores significantly correlated with the Hagerman sentences test performance under 5 out of 6 aided conditions (p < 0.05) when NoP, NR, and fast-acting compression (in SSN) were used. The SWPST scores significantly correlated with the Hagerman sentences test performance in 3 out of 6 aided conditions. In addition, the correlation between the LDT scores and the SWPST scores did not significantly correlate (p > 0.05), which contrasts with previous studies (Larsby et al., 2005). In summary, verbal information processing speed (LDT scores) was associated with a large benefit from binary masking NR and from fast-acting WDRC (in SSN). WMC (SWPST scores) was related to a larger benefit from binary masking NR but not related to fast-acting WDRC outcomes.
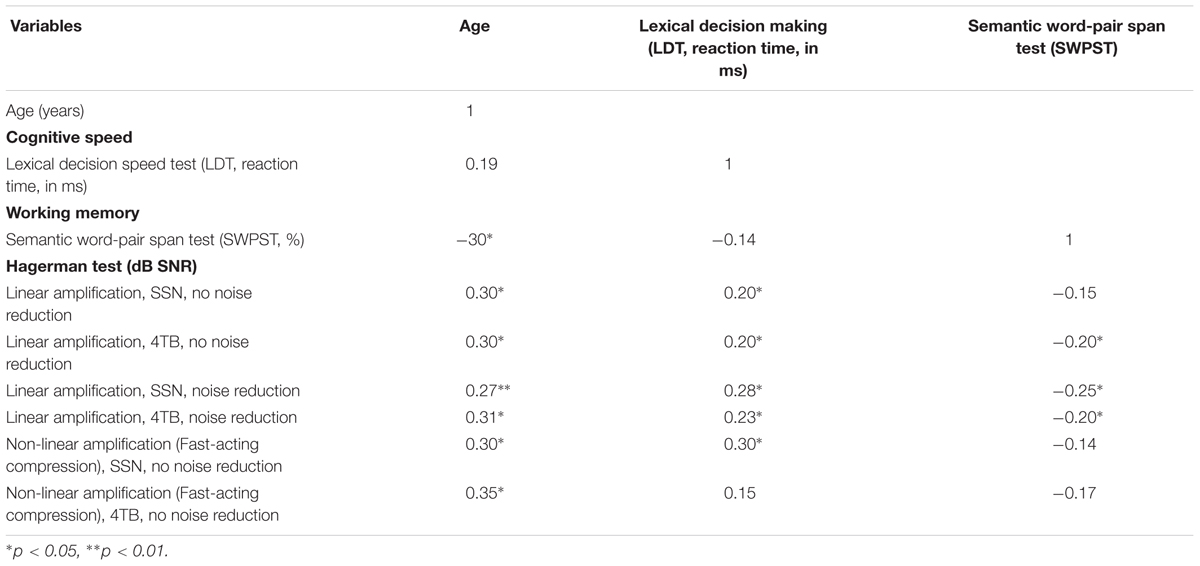
TABLE 2. Correlation matrix of selected predictor variables and speech recognition performance measures (Hagerman test) after applying Bonferroni corrections.
In the present study, the focus was on the investigation of how cognitive abilities (i.e., cognitive speed, WMC) may relate to aided speech recognition performance in adverse listening conditions. To perform a more robust test of the prediction concerning the relative involvement of cognitive speed and WMC as predictors of aided speech recognition in noise under six aided conditions, we performed a series of hierarchical multiple regression analyses.
Hierarchical Multiple Regression Analysis
To investigate the relative role of cognitive speed and WMC in explaining the variance in aided speech recognition in noise performance under six aided conditions, age was controlled to eliminate its confounding effects. After controlling for age, a series of hierarchical regressions was applied under six aided conditions, and in each regression, age was entered in step 1, and the LDT and SWPST were entered in step 2. The results of these hierarchical regressions are shown in Tables 3, 4. As shown in Tables 3, 4, the LDT scores predicted speech recognition in 5 out of 6 aided conditions after controlling for age, that is, in (1) SSN with NoP, (2) 4TB with NoP, (3) SSN with NR, (4) 4TB with NR, and (5) SSN with fast-acting compression. However, the LDT scores did not predict speech recognition in 4TB with fast-acting compression (p > 0.05). The SWPST scores predicted speech recognition performance in only 1 aided condition (p < 0.05), beyond age and the LDT. This contrasts with previous studies that found that working memory predicted a large portion of variance when sentences were presented in modulated noise (Gatehouse et al., 2003; Akeroyd, 2008; Rudner et al., 2011; Souza and Arehart, 2015). However, age significantly predicted the decline in speech recognition in all six conditions and explained a large part of the variance when the Hagerman sentences were presented in steady state and 4TB noise background regardless of the hearing aid signal processing algorithms applied.
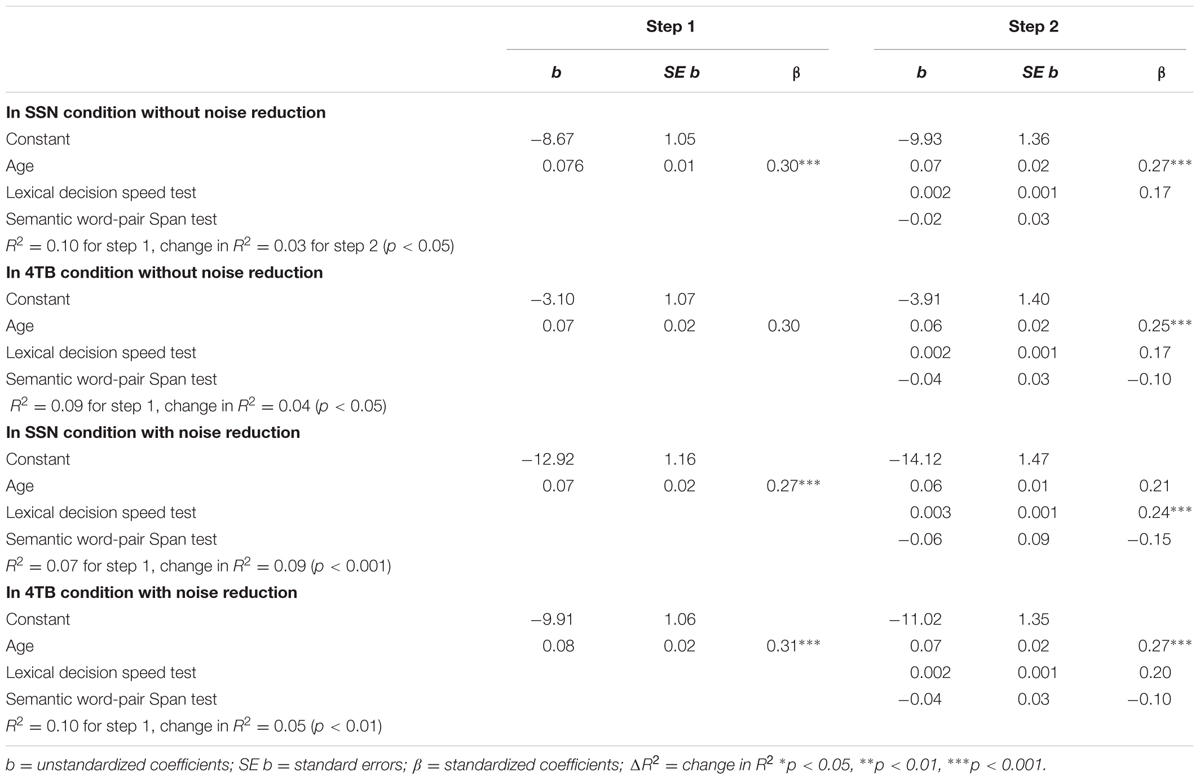
TABLE 3. Hierarchical regressions predicting speech recognition performance in SSN, 4TB conditions with and without noise reduction processing.
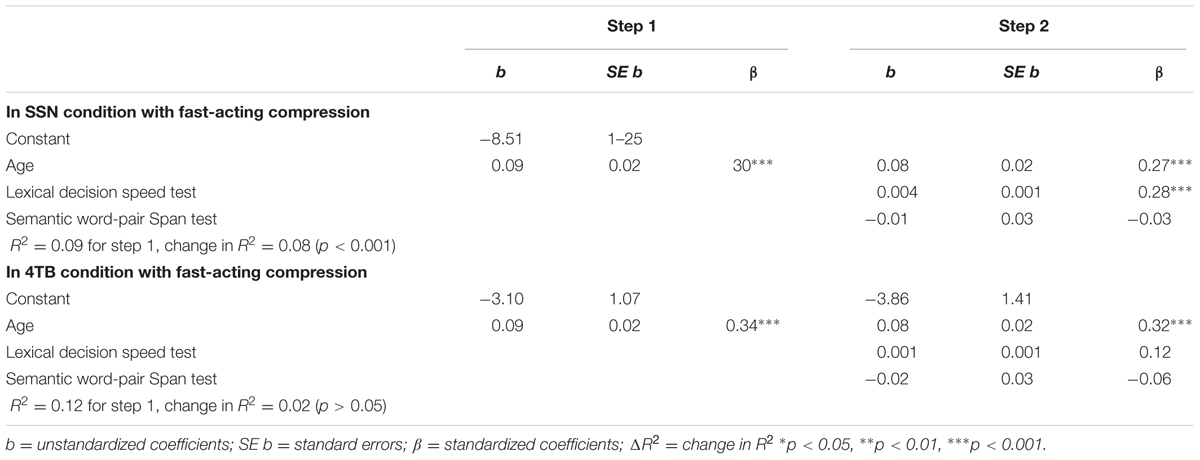
TABLE 4. Hierarchical regressions predicting speech recognition performance in SSN, 4TB conditions, with fast-acting compression.
Discussion
The purpose of the present study was to examine the extent to which cognitive abilities (cognitive speed, and WMC) may relate to individual listeners’ responses to digital signal processing settings in adverse listening conditions. We consider adverse listening conditions very generally to mean any background noise (e.g., 4TB) and/or modifications of the acoustic signal (in this study, by noise reduction and fast-acting compression) that may offset the listener’s performance (Larsby et al., 2005; Souza et al., 2015a,b). Overall, our findings are in line with previous studies in showing that cognitive abilities such as WMC and cognitive processing speed play an important role in effective speech recognition in difficult listening environments (Akeroyd, 2008; Rönnberg et al., 2008, 2013, 2016; Rudner et al., 2011; Souza and Arehart, 2015) and decline with age (Salthouse, 1996, 2000). A recent information processing model (ELU; Rönnberg et al., 2013) provides a theoretical background for a better understanding of the relationship observed between cognitive abilities and speech recognition in noise. This model suggests that when the speech signal is presented clearly without distortion, the listener will rapidly and effectively perform a lexical match with the engagement of cognitive resources to a lesser extent (i.e., WMC, processing speed). In contrast, if the speech signal is distorted (caused by either background noise or unwanted signal processing artifacts), then lexical matching may be more difficult, and the listener may have to engage his or her cognitive ability to a greater extent to unlock the meaning of the message or to fill in the missing acoustic information. Our results are consistent with the assumptions of the ELU model.
The Effects of Hearing Aid Signal Processing and Background Noise
Recent studies have suggested that advances in the hearing aid industry are of great potential benefit to hearing-impaired persons who communicate using the auditory channel (Dillon, 2012; Ng et al., 2013; Souza et al., 2015a,b). In support of this suggestion, several studies have shown relative benefits from fast-acting compression (Gatehouse et al., 2006; Foo et al., 2007; Akeroyd, 2008; Rudner et al., 2011; Souza et al., 2015a,b) and from binary masked noise reduction (Wang et al., 2009; Ng et al., 2013; Rönnberg et al., 2016; Souza et al., 2015b) for persons with hearing impairment. The results of the present study showed that binary masking noise reduction provides a greater benefit than fast-acting compression in adverse listening conditions (Rönnberg et al., 2016). Noise reduction signal processing reduced the adverse effect of modulated noise on speech recognition performance for listeners with good cognitive ability (Souza and Arehart, 2015). This may suggest that the lexical matching of target speech information in long-term memory becomes less explicit and less cognitively taxing (Rönnberg et al., 2008). However, listeners with poor cognitive abilities may not benefit from noise reduction to a greater extent because any significant benefits provided by the signal processing might have been canceled out by the additional cognitive demand exercised by the distortions created by signal processing artifacts (Lunner, 2003; Rudner et al., 2011). On the other hand, fast-acting compression presented limited benefits (relative to the NoP baseline), in support of previous studies that suggested that the fast-acting compression setting may introduce signal distortions or alter the speech envelope, resulting in a phonological mismatch and hence dependence on the listeners’ cognitive capacities (Lunner, 2003; Akeroyd, 2008; Souza and Arehart, 2015). Given that binary masking noise reduction is more aggressive at reducing the effect of background noise, it may have lesser speech signal modification effects than fast-acting compression in terms of speech intelligibility (Wang et al., 2009).
As observed in the two-way interaction, it should be noted that this interaction was driven by the fact that the background noise has a stronger effect in the no processing condition and the fast-acting compression condition compared to noise reduction condition (see the SNR differences; Figure 2). This may suggest that background noise rather than cognitive ability is the key factor influencing the interaction effect of signal processing and the noise type on speech recognition performance (relative to the NoP baseline; Larsby et al., 2005). The present findings showed that when noise reduction was applied, speech recognition performance was not significantly different from either that in SSN or in 4TB. That is, when noise reduction was used, the main effect of noise was no longer significant. It may suggest that there was relatively lesser dependence on cognitive resources and more dependence on hearing aid signal processing. On the other hand, speech recognition performance was significantly different in SSN and in 4TB when fast-acting compression was applied (relative to NoP baseline, Figures 1, 2). That is, when fast-acting compression was applied, the 4TB disruptive masking effect remained relatively significant, resulting in more dependence on cognitive resources to a greater extent (ELU model, Rönnberg et al., 2008, 2013). The findings also showed that 4TB background noise was more disruptive than SSN, affecting the ease with which a lexical match can be made and taxing cognitive resources (Larsby et al., 2005). Moreover, multiple-talker babble delayed and substantially reduced the benefit obtained from fast-acting compression compared to noise reduction (relative to the NoP baseline; Ng et al., 2013). Our results may also suggest that 4TB may be one of the major contributors to a source of signal degradation in speech recognition performance (see Larsby et al., 2005; Rudner et al., 2011). Moreover, given that the 4TB background noise also consisted of words spoken by two male and two female native Swedish speakers in the present study, the use of native speakers might have stronger masking effects on speech with fast-acting compression than with noise reduction. Our results may suggest that the combination of fast-acting compression and 4TB noise may constitute a major source of degradation that contributes to an impoverishment of the performance on the speech recognition task or to the poor benefit from the hearing instrument. That is, the combination of fast-acting compression-4TB may influence the engagement of explicit cognitive resources to a greater extent than that of noise reduction-SSN does. This finding is in agreement with previous studies (Larsby et al., 2005, 2008; Akeroyd, 2008; Ng et al., 2013). Nevertheless, the combination of binary masking noise reduction and SSN may constitute a minor source of speech signal degradation for hearing-impaired persons (Ng et al., 2013; Rönnberg et al., 2016). We may suggest that older adult hearing aid users may be more vulnerable to the signal degradation created by a combination of the unwanted effects of fast-acting compression and 4TB noise.
The Effects of Cognitive Speed and Working Memory
The current findings are consistent with the assumption that signal distortion from the combination of fast-acting WDRC and 4TB constitutes a major source of signal degradation that results in an impoverished representation at the auditory periphery. In the context of the information processing models for speech perception, listeners undergoing these multiple sources of signal degradation must assign more processing resources to prior processing phases (Rönnberg et al., 2008; Lunner et al., 2009). This distribution of resources may impoverish the subsequent processes required for the identification of the linguistic content of the sentence materials. Then, a listener may be required to depend on his/her WMC for effective processing of the degraded speech signal and comprehension of the meaning of the message. Nevertheless, when the WMC is limited, this processing may be more difficult or may fail. Our findings show that the WMC scores (SWPST) and cognitive processing speed scores (LDT) did not significantly correlate with speech intelligibility only in 4TB with fast-acting WDRC after using Bonferroni correction and that they did not significantly predict the performance of speech recognition in 4TB with fast-acting compression. In the case of working memory, this finding contrasts with the previously confirmed relationship between working memory and fast-acting compression in a modulated noise background (Gatehouse et al., 2003, 2006; Foo et al., 2007; Rudner et al., 2011). This could be because the amount of resources to be allocated to processing and storage might have been limited or might have exceeded the available capacity, which may result in tax errors, loss of information or slower processing. If we may postulate that stronger fast-acting WDRC processing results in a greater modification of the input signal, then we will expect a relationship between WMC (SWPST scores) and better speech intelligibility (greater benefit) with fast-acting WDRC (Rudner et al., 2011); however, this was not the case in both the correlations and the regression results (see Tables 2–4). A possible reason for this could be that stronger fast-acting WDRC processing may be having concurrent effects: improving the audibility of the speech signal while maintaining loudness comfort (by applying gain as a function of intensity, with a lower gain applied to higher input levels) and introducing unwanted processing artifacts that may create more distortions rather than less aggressive processing (Dillon, 2001; Lunner, 2003). Possibly the net effect of these opposing factors contributes to the weak association between the SWPST and fast-acting WDRC (Dillon, 2012).
On the other hand, our results indicate that the effects of a combination of noise reduction and SSN may constitute a minor source of degradation, contributing to a greater benefit or better speech intelligibility. That is, there were significant associations between WMC (SWPST scores) and the binary masking NR outcomes and between the cognitive processing speed (LDT scores) and the binary masking NR outcomes (see Table 2). This may be viewed via the ELU model, which assumes a larger influence of cognitive ability (e.g., WMC) when the phonological form of the perceived language signal does not match the phonological representations stored in long-term memory. We may postulate that stronger binary masking NR processing results in a significant modification of the input signal; we would expect a relationship between working memory and better speech intelligibility (or greater benefits from NR processing), and this was the case in the present study. A possible explanation for this could be that stronger binary masking NR processing may have two balanced effects: improving the audibility of the speech signal (as a result of an effective noise suppression), introducing relatively lesser distortion but more aggressive processing (relatively less explicit cognitive resources; Neher, 2014). The results of the present study show that cognitive ability is an important factor in aided speech recognition in adverse listening conditions for persons with hearing impairment.
Effects of Age
The relationship between age and the measure of cognitive processing speed was observed before applying Bonferroni correction but not after. The pattern of this relationship was contrary to our expectations, in support of previous studies that indicate that processing speed declines with age (Salthouse, 1996; Lunner, 2003; Larsby et al., 2005). However, a relationship between age and the measures of working memory was observed before and after applying Bonferroni correction, suggesting a decline in WMC with age (Salthouse, 1996). As expected, the effects of age on speech recognition in noise performance were observed before and after the use of Bonferroni correction. This pattern of the relationship is in support of previous studies showing poorer performance for older adult listeners compared to younger listeners (Gordon-Salant and Fitzgibbons, 2001; Gordon-Salant and Cole, 2016). The effect of age on speech recognition in noise performance is also underlined by the results of the hierarchical regression analysis, which showed that age, above and beyond the effects of the cognitive processing speed and working memory, contributed to variance in the intelligibility scores, suggesting that hearing aid users may have age-related degradations in higher-level processing that extend beyond what is captured in the SWPST and the SDT. This may suggest that there are other factors associated with aging other than cognitive functioning that may be involved in the age-related decline in speech recognition among older hearing aid users (Baltes and Lindenberger, 1997; Wingfield and Tun, 2001; Larsby et al., 2008).
Conclusion
The present study adds to previous studies a new way of viewing the relationship between cognitive abilities and binary masking noise reduction and fast-acting WDC for speech recognition in noise for hearing aid users (Lunner, 2003; Akeroyd, 2008; Ng et al., 2013; Souza and Arehart, 2015). The results showed that after controlling for age, cognitive processing speed was a better predictor of speech intelligibility in noise (in both SSN and 4TB), suggesting a significant association between cognitive processing speed (measured by LDT) and binary masking NR and fast-acting compression (in SSN). However, there were weaker associations between WMC (measured by the SWPST) and speech intelligibility in noise with NR, and no association when fast-acting WDRC was used. That is, WMC was a weaker predictor of speech intelligibility in noise. The findings might have been different if the participants had been provided with training and/or allowed to acclimatize to binary masking noise reduction or fast-acting compression (Rudner et al., 2011). Taken together, the results suggest that assessing the effects of cognitive processing speed, WMC, and hearing aid signal processing settings in noise may provide important insights into the source of hearing aid users’ complaints of difficulty recognizing speech in noise.
Ethics Statement
The subjects were informed about the voluntariness, confidentiality and they were free to decline participation at any time. They also filled up a written informed consent form in which they give the researchers the right to collect and restore personal information relevant to the study. Personal information was collected and stored in a way that participant’s integrity was maximized (Breakwell et al., 2006).
Author Contributions
WY has substantially contributed to the following phases of the present study: the conception, the design, the acquisition, analysis, and the interpretation of data; the draft and critical revision; the final approval of the version to be published. The author is accountable for all aspects of this work.
Funding
This work was supported by a Linnaeus Centre Hearing and Deafness (grant number 349-2007-8654) from the Swedish Research Council.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The author thanks Jerker Rönnberg and Henrik Danielsson for their insightful comments on this manuscript. Mathias Hällgren (from the Department of Technical Audiology, Linköping University) for his technical support; Tomas Bjuvmar and Helena Torlofson (from the Hearing Clinic, University Hospital, Linköping); Elaine Ng (from the Swedish Institute for Disability Research, Linköping University) for her assistance in data collection; and Thomas Karlsson, Björn Lidestam, Shahram Moradi, Rachel Jane Ellis, Örjan Dahlström, and Emil Holmer for their support. The author would like to thank three reviewers for their helpful and insightful comments on this manuscript.
References
Akeroyd, M. A. (2008). Are individual differences in speech reception related to individual differences in cognitive ability? A survey of twenty experimental studies with normal and hearing-impaired adults. Int. J. Audiol. 47(Suppl.2), S53–S71. doi: 10.1080/14992020802301142
Arhart, K. H., Souza, P., Baca, R., and Kates, J. M. (2013). Working memory, age, and hearing loss: susceptibility to hearing aid distortion. Ear Hear. 34, 251–260. doi: 10.1097/AUD.0b013e318271aa5e
Arhart, K. H., Souza, P., Kates, J., Lunner, T., and Pedersen, M. S. (2015). Relationship among signal fidelity, hearing loss, and working memory for digital noise suppression. Ear Hear 36, 505–516. doi: 10.1097/AUD.0000000000000173
Baddeley, A. (2012). Working memory: theories, models, and controversies. Annu. Rev. Psychol. 63, 1–29. doi: 10.1146/annurev-psych-120710-100422
Baddeley, A., Logie, R., Nimmosmith, I., and Brereton, N. (1985). Components of fluent reading. J. Mem. Lang. 24, 119–131. doi: 10.1016/0749-596X(85)90019-1
Baddeley, A. D., and Hitch, G. J. L. (1974). “Working memory,” in The Psychology of Learning and Motivation: Advances in Research and Theory, Vol. 8, ed. G. A. Bower (New York: Academic Press), 47–89.
Baltes, P. B., and Lindenberger, U. (1997). Emergence of powerful connection between sensory and cognitive functions across the adults’ life span: a new window to the study of cognitive aging? Psychol. Aging 12, 12–21. doi: 10.1037/0882-7974.12.1.12
Boldt, J. B., Kjems, U., Pedersen, M. S., Lunner, T., and Wang, D. L. (2008). “Estimation of the ideal binary mask using directional systems,” in Proceedings of the 11th International Workshop on Acoustic Echo and Noise Control,Seattle, WA.
Brand, T. (2000). Analysis and Optimization of Psychophysical Procedures in Audiology. Ph.D. dissertation, Bibliotheks- und Informations system der Universität Oldenburg, Oldenburg.
Breakwell, G. M., Hammond, S., and Fife-Shaw, C. (eds). (2006). Research Methods in Psychology, 3rd Edn. London: Sage.
Buus, S., and Florentine, M. (2001). Growth of loudness in listeners with cochlear hearing losses: Recruitment reconsidered. J. Assoc. Res. Otolaryngol. 3, 120–139. doi: 10.1007/s101620010084
Committee on Hearing, Bioacoustics, and Biomechanics [CHABA] (1988). Speech understanding and aging. J. Acoust. Soc. Am. 83, 859–895.
Daneman, M., and Carpenter, P. A. (1980). Individual differences in working memory and reading. J. Verbal Learn. Verbal Behav. 19, 450–466. doi: 10.1016/S0022-5371(80)90312-6
Desjardins, J. L., and Doherty, K. A. (2014). The effect of hearing aid noise reduction on listening effort in hearing-impaired adults. Ear Hear. 35, 600–610. doi: 10.1097/AUD.0000000000000028
Dillon, H. (1996). Compression? Yes, but for low or high frequencies, for low or high intensities, and with what response times? Ear Hear. 17, 287–307.
Foo, C., Rudner, M., Rönnberg, J., and Lunner, T. (2007). Recognition of speech in noise with new hearing instrument compression release settings requires explicit cognitive storage and processing capacity. J. Am. Acad. Audiol. 18, 618–631. doi: 10.3766/jaaa.18.7.8
Gatehouse, S., Naylor, G., and Elberling, C. (2003). Benefits from hearing aids in relation to the interaction between the users and the environment. Int. J. Audiol. 42(Suppl. 1), S77–S85. doi: 10.3109/14992020309074627
Gatehouse, S., Naylor, G., and Elberling, C. (2006). Linear and nonlinear hearing aid fittings–1. Patterns of benefit. Int. J. Audiol. 45, 130–152. doi: 10.1080/14992020500429518
Gordon-Salant, S., and Cole, S. S. (2016). Effects of age and working memory capacity on speech recognition performance in noise among listeners with normal hearing. Ear Hear. 37, 593–602. doi: 10.1097/AUD.0000000000000316
Gordon-Salant, S., and Fitzgibbons, P. J. (2001). Sources of age -related recognition difficulty for time compressed speech. J. Speech Lang. Hear. Res. 44, 709. doi: 10.1044/1092-4388(2001/056)
Hagerman, B., and Kinnefors, V. (1995). Efficient adaptive methods for measurements of speech perception thresholds in quiet and noise. Scand. Audiol. 24, 71–77. doi: 10.3109/01050399509042213
Hällgren, M., Larsby, B., and Arlinger, S. (2006). A Swedish version of hearing in noise test (HINT) for measurement of speech recognition. Int. J. Audiol. 45, 227–237. doi: 10.1080/14992020500429583
Larsby, B., Hällgren, M., and Lyxell, B. (2008). The interference of different background noises on speech processing in elderly hearing impaired subjects. Int. J. Audiol. 47, S83–S90. doi: 10.1080/14992020802301159
Larsby, B., Hällgren, M., Lyxell, B., and Arlinger, S. (2005). Cognitive performance and perceived effort in speech processing tasks: effects of different noise backgrounds in normal-hearing and hearing-impaired subjects. Int. J. Audiol. 44, 131–143. doi: 10.1080/14992020500057244
Li, Y., and Wang, D. (2009). On the optimality of ideal binary time-frequency masks. Speech Commun. 51, 230–239. doi: 10.1016/j.specom.2008.09.001
Lunner, T. (2003). Cognitive function in relation to hearing aid use. Int. J. Audiol. 42(Suppl.1), S49–S58. doi: 10.3109/14992020309074624
Lunner, T., Rudner, M., and Rönnberg, J. (2009). Cognition and hearing aids. Scand. J. Psychol. 50, 395–403. doi: 10.1111/j.1467-9450.2009.00742.x
Lunner, T., and Sundewall-Thorén, E. (2007). Interactions between cognition, compression, and listening conditions: effects on speech-in-noise performance in a two-channel hearing aid. J. Am. Acad. Audiol. 18, 604–617. doi: 10.3766/jaaa.18.7.7
Neher, T. (2014). Relating hearing loss and executive functions to hearing aid users’ preference for, and speech recognition with, different combinations of binaural noise reduction and microphone directionality. Front. Neurosci. 8:391. doi: 10.3389/fnins.2014.00391
Ng, E. H. N., Rudner, M., Lunner, T., Pedersen, M. S., and Rönnberg, J. (2013). Effects of noise and working memory capacity on memory processing of speech for hearing-aid users. Int. J. Audiol. 52, 433–441. doi: 10.3109/14992027.2013.776181
Ng, E. H. N., Rudner, M., Lunner, T., and Rönnberg, J. (2015). Noise reduction improves memory for target language speech in competing native but not foreign language speech. Ear Hear. 36, 82–91. doi: 10.1097/AUD.0000000000000080
Ohlenforst, B., MacDonald, E., and Souza, P. (2015). Exploring the relationship between working memory, compressor speed and background noise characteristics. Ear Hear. 37, 137–143. doi: 10.1097/AUD.0000000000000240
Pichora-Fuller, M. K. (2003). Processing speed and timing in aging adults: psychoacoustics, speech perception, and comprehension. Int. J. Audiol. 42(Suppl.1), S59–S67. doi: 10.3109/14992020309074625
Plomp, R., and Mimpen, A. M. (1979). Improving the reliability of testing the speech recognition threshold for sentences. Audiology 18, 43–52. doi: 10.3109/00206097909072618
Rönnberg, J. (1990). Cognitive and communicative function: the effects of chronological age and handicap age. Eur. J. Cogn. Psychol. 2, 253–273. doi: 10.1080/09541449008406207
Rönnberg, J., Arlinger, S., Lyxell, B., and Kinnefors, C. (1989). Visual evoked potentials: relation to adult speechreading and cognitive function. J. Speech Hear. Res. 32, 725–735. doi: 10.1044/jshr.3204.725
Rönnberg, J., Lunner, T., Ng, E. H., Lidestam, B., Zekveld, A. A., Sörqvist, P., et al. (2016). Hearing impairment, cognition and speech understanding: exploratory factor analyses of a comprehensive test battery for a group of hearing aid users, the n200 study. Int. J. Audiol. 55, 623–642. doi: 10.1080/14992027.2016.1219775
Rönnberg, J., Lunner, T., Zekveld, A. A., Sörqvist, P., Danielsson, H., Lyxell, B., et al. (2013). The ease of language understanding (ELU) model: theoretical, empirical, and clinical advances. Front. Syst. Neurosci. 7:31. doi: 10.3389/fnsys.2013.00031
Rönnberg, J., Rudner, M., Foo, C., and Lunner, T. (2008). Cognition counts: a working memory system for ease of language understanding (ELU). Int. J. Audiol. 47(Suppl.2), S99–S105. doi: 10.1080/14992020802301167
Rudner, M., Foo, C., Rönnberg, J., and Lunner, T. (2009). Cognition and aided speech recognition in noise: specific role for cognitive factors following nine-week experience with adjusted compression settings in hearing aids. Scand. J. Psychol. 50, 405–418. doi: 10.1111/j.1467-9450.2009.00745.x
Rudner, M., Rönnberg, J., and Lunner, T. (2011). Working memory supports listening in noise for persons with hearing impairment. J. Am. Acad. Audiol. 22, 156–167. doi: 10.3766/jaaa.22.3.4
Salthouse, T. A. (1996). The processing speed theory of adults’ age differences in cognition. Psychol. Rev. 103, 403–428. doi: 10.1037/0033-295X.103.3.403
Salthouse, T. A. (2000). Aging and measures of processing speed. Biol. Psychol. 54, 35–54. doi: 10.1016/S0301-0511(00)00052-1
Schneider, B. A., Daneman, M., and Murphy, D. R. (2005). Speech comprehension difficulties in older adults: cognitive slowing or age-related changes in hearing? Psychol. Aging 20, 261–271. doi: 10.1037/0882-7974.20.2.261
Schwartz, K. C., Chatterjee, M., and Gordon-Salant, S. (2008). Recognition of spectrally-degraded phonemes by younger and older normal-hearing listeners. J. Acoust. Soc. Am. 124, 3972–3988. doi: 10.1121/1.2997434
Souza, P., and Arehart, K. H. (2015). Robust relationship between reading span and speech recognition in noise. Int. J. Audiol. 54, 705–713. doi: 10.3109/14992027.2015.1043062
Souza, P. E., Arehart, K. H., Souza, P., Arehart, K. H., Shen, J., Anderson, M., et al. (2015a). Working memory and intelligibility of hearing-aid processed speech. Front. Psychol. 6:526. doi: 10.3389/fpsyg.2015.00526
Souza, P. E., Arehart, K., and Neher, T. (2015b). Working memory and hearing aid processing: literature findings, future directions, and clinical applications. Front. Psychol. 6:1894. doi: 10.3389/fpsyg.2015.01894
Wang, D., Kjems, U., Pedersen, M. S., Boldt, J. B., and Lunner, T. (2009). Speech intelligibility in background noise with ideal binary time-frequency masking. J. Acoust. Soc. Am. 125, 2336–2347. doi: 10.1121/1.3083233
Wiig, E. H., Nielsen, N. P., Minthon, L., and Warkentin, S. (2002). AQT: A Quick Test of Cognitive Speed. San Antonio, TX: Pearson/PsychCorp.
Wingfield, A., Poon, L. W., Lombardi, L., and Lowe, D. (1985). Speed of processing in normal aging: effects of speech rate, linguistic structure, and processing time. J. Gerontol. 40, 579–585. doi: 10.1093/geronj/40.5.579
Keywords: aging, cognition, speech recognition in noise, hearing aid, signal processing algorithms, hearing impairment
Citation: Yumba WK (2017) Cognitive Processing Speed, Working Memory, and the Intelligibility of Hearing Aid-Processed Speech in Persons with Hearing Impairment. Front. Psychol. 8:1308. doi: 10.3389/fpsyg.2017.01308
Received: 14 December 2016; Accepted: 17 July 2017;
Published: 15 August 2017.
Edited by:
Claudia Repetto, Università Cattolica del Sacro Cuore, ItalyReviewed by:
Pietro Spataro, Sapienza Università di Roma, ItalyChristian Desloovere, Universitaire Ziekenhuizen Leuven, Belgium
Copyright © 2017 Yumba. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wycliffe Kabaywe Yumba, d3ljbGlmZmUueXVtYmFAbGl1LnNl; d3ljbGlmZmUueXVtYmFAZ21haWwuY29t