 Fabian Greb
Fabian Greb Jochen Steffens
Jochen Steffens Wolff Schlotz
Wolff Schlotz- 1Max Planck Institute for Empirical Aesthetics, Frankfurt am Main, Germany
- 2Audio Communication Group, Technische Universität Berlin, Berlin, Germany
- 3Institute of Psychology, Goethe University, Frankfurt am Main, Germany
Music listening has become a highly individualized activity with smartphones and music streaming services providing listeners with absolute freedom to listen to any kind of music in any situation. Until now, little has been written about the processes underlying the selection of music in daily life. The present study aimed to disentangle some of the complex processes among the listener, situation, and functions of music listening involved in music selection. Utilizing the experience sampling method, data were collected from 119 participants using a smartphone application. For 10 consecutive days, participants received 14 prompts using stratified-random sampling throughout the day and reported on their music-listening behavior. Statistical learning procedures on multilevel regression models and multilevel structural equation modeling were used to determine the most important predictors and analyze mediation processes between person, situation, functions of listening, and music selection. Results revealed that the features of music selected in daily life were predominantly determined by situational characteristics, whereas consistent individual differences were of minor importance. Functions of music listening were found to act as a mediator between characteristics of the situation and music-selection behavior. We further observed several significant random effects, which indicated that individuals differed in how situational variables affected their music selection behavior. Our findings suggest a need to shift the focus of music-listening research from individual differences to situational influences, including potential person-situation interactions.
Introduction
Music listening in recent years has become a highly individualized activity. The rapid growth of music digitalization and mobile music listening devices, such as smartphones and music streaming services, provide individuals with the freedom to listen to almost any kind of music during their daily life (Berthelmann, 2017; Gesellschaft für Konsumforschung, 2017). Given this freedom of choice, people indeed tend to actively select and use music to accomplish specific goals in certain situations (DeNora, 2000; Krause et al., 2015). In contrast to the widespread use of new technological developments by music listeners, little is known about the processes underlying the selection of music in daily life, and scientific research about music listening in everyday life still is underdeveloped. To some extent, the high degree of complexity due to the large amount of contributing factors and their interactions has led to this lack of current knowledge. Thus, the goal of the current study was to explain this complexity when people actively select music in their daily life. In particular, we aimed to identify personal and situational variables of high relevance for music-selection behavior, and to integrate these factors into a comprehensive model predicting music selection while strictly avoiding overfitting. This also includes an investigation of the role that functions of music listening play in the selection of music. By using the experience sampling method, we captured almost unbiased behavioral data representative of participants' daily lives. We used statistical learning procedures for variable selection to make predictions of unseen data and avoid overfitting (Yarkoni and Westfall, 2017). Clarifying the role of listener, situation, and functions of music listening in music selection aids in the understanding of why people listen to music in certain situations and how situational and person-related factors govern the selection of music and its characteristics. This knowledge helps to answer the question of who listens to what kind of music in which situation and why, and might contribute to an improvement of music recommendation systems.
Contributions of Person and Situation to Music-Listening Behavior
Past research on music listening mostly focused on one of two major determinants of music-listening behavior, namely influences of individual or situational factors. Research on individual differences mainly seeks to answer questions such as why some people predominantly listen to aggressive rock music, whereas others prefer listening to smooth jazz (Delsing et al., 2008; Gardikiotis and Baltzis, 2012) or why some individuals mainly listen to music for intellectual stimulation and others use it for mood regulation (e.g., Chamorro-Premuzic and Furnham, 2007). This research revealed a large number of significant associations between music listening and person-related variables, particularly age, gender, personality traits, musical taste, and musical training (e.g., LeBlanc et al., 1999; Chamorro-Premuzic et al., 2009; Boer et al., 2012; Ferwerda et al., 2015; Greenberg et al., 2015; Cohrdes et al., 2017).
Complementary research investigating situational influences on music listening addresses questions such as where people listen to music (e.g., Sloboda et al., 2001; North et al., 2004), why people listen to music in everyday life (e.g., North et al., 2004; Randall and Rickard, 2017b), with whom they listen to music (e.g., North et al., 2004; Liljestrom et al., 2013), when they listen to music (North et al., 2004; Krause et al., 2016), during which activity people listen to music (North et al., 2004; Juslin et al., 2008), and how these situational factors influence the selection, judgement, or experience of the music (North et al., 2004; Juslin et al., 2008; Greasley and Lamont, 2011; Krause et al., 2016; Krause and North, 2017a,b; Randall and Rickard, 2017b).
Since both person and situation usually influence behavior at the same time, investigating variables of both domains simultaneously is of high importance. Combining this synthesis approach proposed by Fleeson and Noftle (2008) with daily-life research methods (Mehl and Conner, 2012) can potentially provide more reliable results as well as more valid conclusions and behavioral predictions. Integrating both levels of variance better reflects the complexity of the multitude of factors interacting in daily life. The simultaneous investigation of individual and situational influences also allows an estimate of the amount of variance explained by both domains. In music psychology, research integrating person-related and situational factors is scarce. The few existing studies indicated that both domains are important for explaining the presence of music (Krause and North, 2017b), emotional responses to music (Randall and Rickard, 2017a), or functions of music listening in different situations (Greb et al., 2018a). Up to now, only one study specifically addressed music-selection behavior (Greb et al., 2018b). This study showed that the characteristics of selected music are largely attributable to situational influences and it revealed a detailed pattern of variables being associated with the selection of music (Greb et al., 2018b). Functions of music listening referring to the intentional use of music to accomplish specific goals were the most important variables for predicting music selection (Greb et al., 2018b). However, the study relied on retrospective self-reports of three listening situations obtained via an online survey, potentially introducing bias to the data.
Functions of music listening also vary by situation (North et al., 2004) and are largely influenced by the activity performed while listening to music (Greb et al., 2018a). In addition, functions were shown to reliably predict music selection in specific situations (Randall and Rickard, 2017a; Greb et al., 2018b). Hence, functions of music listening might mediate music selection in daily life, such that activity or mood determines why a person wants to listen to music in a given situation, whereas the subsequent process of selecting a specific musical piece is largely driven by these functions of music listening. Thus, the specific role of musical functions in the process of music selection needs further clarification.
Methodological Challenges
Investigating music-selection behavior in daily life is associated with considerable methodological challenges. First, measuring real-life behavior requires a suitable data collection method. Many of the studies mentioned above used retrospective data collection based on online surveys or laboratory studies, which are relatively easy to conduct but are limited in their ecological validity and are likely to be biased in several ways (e.g., memory biases, limited representativeness of situations). The gold standard of investigating real-life behavior in ecologically valid settings leading to almost unbiased data is the collection of data in people's daily life. To measure subjective perceptions and experiences involved during music listening and selection, the experience sampling method (ESM) was identified as a suitable method (Sloboda et al., 2001; Hektner et al., 2007; Greasley and Lamont, 2011; Randall and Rickard, 2013). ESM provides a multitude of data points per participant that allows the investigation of between- (i.e., person-related) and within-subject (i.e., situational) variance (Hektner et al., 2007). The widespread distribution of smartphones makes it easier to conduct ESM studies compared with the past when people had to carry around large extra devices (e.g., palmtop computers).
Second, a data collection method investigating person-related and situational factors simultaneously requires appropriate statistical models. Multilevel modeling (MLM) is the most appropriate method for analyzing nested or longitudinal data, as it allows modeling of several levels of variance simultaneously and estimation of the relative impact of person-related and situational factors on the outcome variable (Nezlek, 2008). ESM data with its nested structure in combination with MLM can be used for building reliable models to predict real-life behavior (Fleeson, 2007). In music psychology, this possibility has often been neglected and ESM data were averaged at the listener level while ignoring situational variance (e.g., Juslin et al., 2008; Greasley and Lamont, 2011).
Third, the proposed approach of investigating person-related and situational factors in an integrative model inevitably leads to a large number of variables to be included in the analysis (e.g., Randall and Rickard, 2017a; Greb et al., 2018b). Consequently, the question of which variables should be selected as the most significant predictors of behavior becomes an important issue. Commonly used selection procedures, such as all sorts of step-wise regression, are highly problematic as they often lead to overestimation of regression coefficients and tend to select irrelevant predictors (Derksen and Keselman, 1992; Steyerberg et al., 1999; Whittingham et al., 2006; Flom and Cassell, 2007). These problems—also known as overfitting—are addressed by the field of statistical learning, which has developed a broad set of methods and procedures to overcome such limitations (Babyak, 2004; Chapman et al., 2016). Many of these methods provide new opportunities to enrich psychological research (Chapman et al., 2016; Yarkoni and Westfall, 2017). For instance, the least absolute shrinkage and selection operator (Lasso), originally proposed by Tibshirani (1996), offers a promising alternative to common variable selection procedures. As the Lasso is applicable on linear regression and multilevel linear regression models, it is especially useful if researchers aim to interpret model coefficients, as is often the case in psychological research. Especially, the percentile-Lasso—an empirical extension of the original Lasso—was shown to select very few false positives (i.e., irrelevant predictors) by using repeated cross-validation and thereby focusing on prediction (Roberts and Nowak, 2014). In addition, it features a penalization term that shrinks the coefficients toward smaller values and thereby avoids overestimation of coefficients. Notably, the issue of overfitting and the application of statistical learning to overcome such limitations have rarely found its way into music psychology. In the context of music listening in daily life, only one study has successfully applied cross-validation and a Lasso algorithm for variable selection to find the most significant predictors of music-selection behavior (i.e., Greb et al., 2018b). However, that study employed retrospective assessments and a very limited variety of situations, which might facilitate biased results despite appropriate statistical analysis based on statistical learning.
Present Research
We sought to explore music-selection behavior in daily life by investigating situational and person-related factors simultaneously. Given the research findings and theoretical considerations above, our research was guided by the model shown in Figure 1. To take the multitude of potentially influential factors in all domains (person, situation, functions) into account simultaneously, we built comprehensive models by including a broad set of variables. With the greater objectives of avoiding overfitting and maximizing predictive accuracy, our study had the following research aims:
1. Investigate the relative contribution of person-related and situational variables to variance in daily-life music-selection behavior (i.e., estimating between- and within-subject variance components).
2. Identify the most important variables involved in the process of music selection as outlined in Figure 1 (i.e., detect all relevant direct effects).
3. Identify the potential mediating role of functions of music listening in the association of situational and person-related variables with music selection.
4. Explore whether effects of situational variables on music selection vary across individuals by testing for individual differences in the associations identified earlier (i.e., effects resulting from research aim 2).
5. As we consider replication to be an important aspect of our research, we aimed at comparing the results of the current study using daily-life research methodology to those of another study that used the same statistical approach but was based on retrospective reports of very few music listening situations (i.e., Greb et al., 2018b).
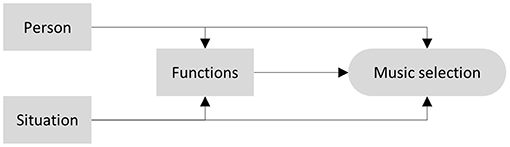
Figure 1. Model of music selection guiding the current investigation.
To address these aims, we conducted an experience sampling study in which participants reported on their music listening using smartphones. Participants reported on situational cues, the music they heard, and on functions of music listening. In addition, we collected a broad set of person-related variables in an initial laboratory session. Our study design is an improvement of a previous study in which we investigated all direct effects on music selection in daily life (Greb et al., 2018b). To address the methodological problems discussed in the introduction and to be able to compare results, we applied the same statistical learning procedure (i.e., percentile-Lasso) as that study.
Method
All experimental procedures were ethically approved by the Ethics Council of the Max Planck Society, and were undertaken with written informed consent of each participant.
Sample
In total, 119 participants (54 men, 65 women; mean = 24.4 years; SD = 4.4) were recruited via the participant database of the Max Planck Institute for Empirical Aesthetics. To ensure sufficient within-subject variance, we only included participants who indicated listening to music for at least 2 h a day for a minimum of 5 days per week. People received 25 € for voluntarily participating in the study. Depending on the amount of valid responses to prompts, each participant could receive a graded bonus of up to 25 € (for details see the procedure section).
Measures
Prescreening
Frequency of music listening in daily life was measured by two items: (1) “How often do you listen to music during the week?” (response scale with nine scale points: less than once a week, once, twice, thrice, four times, five times, six times, seven times, more than seven times a week); and (2) “On average, how long do you listen to music per day?” (response scale with nine scale points: <0.5, 0.5, 1, 1.5, 2, 2.5, 3, 4 h, more than 4 h). Additionally, we asked participants to report if they owned a smartphone and, if yes, which operating system is running on their device (Android, iOS, Windows Mobile, Blackberry, other).
Person-Related Variables
In addition to age and gender, we assessed musical sophistication using the German version of the Gold-MSI (Schaal et al., 2014), the intensity of music preference using six items from Schäfer and Sedlmeier (2009), musical taste using liking ratings for 19 musical styles (see Greb et al., 2018a for details), and the Big Five personality traits using a German version of the IPIP-NEO-120 (Johnson, 2014) translated by Treiber et al. (2013). For the musical taste ratings, we computed sum scores based on the factor structure reported by Greb et al. (2018a). As the questions about musical taste included the possibility to select “I don't know” for a musical style, we used imputation to replace missing data with the mean value of the ratings of the respective musical style.
ESM Measures
Each assessment started with the initial question “Are you listening to music right now?” If the answer was “no,” the assessment was finished; if the answer was “yes,” it continued. The remainder of the assessment consisted of three sections about the situation, the music, and the functions of music listening in the current situation. The first section asked participants to indicate how long they have been listening to music already, what their main activity was using a list of categories developed by Greb et al. (2018a), if other people were present, if they chose the music, and how much control they had in what music they were listening to (see Supplementary Material online for exact wording and response scales). Additionally, we asked for their mood at the time they decided to listen to music [valence and arousal (Russell, 1980)]. We also asked how important participants considered their mood state for the decision to listen to music and how much attention they were paying to the music. The second section included questions about musical characteristics as well as the composer/interpreter, name of the piece, and musical style. First, participants reported on the volume (quiet–loud) and their liking of the music (I like it less–I like it a lot) on seven-step bipolar rating scales. Musical characteristics were measured by seven items from Greb et al. (2018b)—specifically designed to easily describe music in daily life—on bipolar rating scales with seven scale points, but here we added one item (intensity) for completeness, resulting in the following list of items: calming–exciting, slow–fast, sad–happy, less melodic–very melodic, less rhythmic–very rhythmic, simple–complex, peaceful–aggressive, less intense–very intense. Additionally, we asked for familiarity of the music (unfamiliar–familiar) and asked the participants to differentiate whether they listened to vocal or instrumental music. Furthermore, we requested participants to name the specific piece, the artists, or the musical style they were listening to at the time of measurement. Given the wide range of different styles people might listen to, we used an open-ended response format, as this was shown to suit this kind of questions best (Greasley et al., 2013). The third section about functions of music listening used a subset of functions developed by Greb et al. (2018a). To keep the ESM measures within each assessment as short as possible but as comprehensive as necessary we took 15 items out of the 22 items comprising the questionnaire by Greb et al. (2018a). In detail, we took three items per dimension that showed the highest factor loadings in Greb et al. (2018a). These 15 items should therefore represent the same dimensions as found by Greb et al. (2018a), namely intellectual stimulation, mind wandering & emotional involvement, motor synchronization & enhanced well-being, updating one's musical knowledge, and killing time & overcoming loneliness (all items are listed in the Supplementary Material). As people might use different functions of music listening with different intensities in everyday life, we assessed functions using a seven-step bipolar rating scale (Not at all–Fully agree). For example, a person might attentively listen to music for intellectual stimulation (high intensity) while, at the same time, aims at updating his/her musical knowledge, but to a lesser degree. We computed sum scores based on the factor structure reported by Greb et al. (2018a).
The following variables—being part of another research project—were not part of the current analyses: duration of music listening at time of measurement, familiarity of the music, liking of the music, instrumental/vocal music, and free responses on musical pieces, artists, and styles.
Sampling Design and Hardware
The prescreening was completed online through Unipark/EFS Survey software (Questback GmbH, 2015). Person-related variables were reported on a tablet computer (Samsung Galaxy Tab A 1.7) in the laboratory. The ESM measures (daily-life assessments) were presented using movisensXS, Version 1.0.1 (movisens GmbH, 2015), a smartphone application for Android specifically programmed for ESM studies. Participants used either their own smartphone or a loan device (Motorola Moto G3) to run the application.
The study ran for 10 consecutive days (Friday–Sunday). Participants each received 14 alarms within an individual 14-h time window per day. The number of alarms was pretested in a pilot study and was considered acceptable by our pretesting candidates. The alarms occurred randomly within the pre-selected period with a minimum time of 20 min between each alarms. Participants were instructed to answer as many alarms as possible, but they could postpone (by 5, 10, or 15 min) or reject alarms. In addition to this strictly time-based sampling plan, we implemented an event-based plan to capture as many music listening situations as possible. Participants were encouraged to start the assessment manually when they were listening to music by pressing a button in the movisensXS application.
Procedure
Participants received an e-mail containing an individual participation link. After clicking on the link, they were redirected to an online survey and answered the first questionnaire (prescreening). Participants who fulfilled the inclusion criteria for attending in our main study (i.e., reported listening to music on average for a minimum of 2 h a day for at least 5 days a week) could choose a date for their first session in the lab. People who did not meet the inclusion criteria were informed that they could not participate in the study and were thanked for their time. At their first appointment in the lab, participants completed the questionnaire containing the person-related variables. Afterwards they were informed about the general procedure of the ESM study. Participants who owned an Android smartphone were asked if they were willing to use their own smartphone for the study. All others received a loan device with movisensXS as the only usable application installed. Participants who decided to use their own device received free wireless internet access and guidance for downloading and installing movisensXS from the Google Play store. Thereafter, a demo version of the study was transferred and started. Participants were shown how to accept, delay, or reject an alarm and then simulated a situation in which they were listening to music and answered the items. When participants were familiar with the questionnaire and the handling of the application, they were asked to indicate three 14-h periods between 00:01 and 23:59 they were willing to receive alarms. We chose three blocks—Monday–Thursday, Friday & Saturday, and Sunday—as we expected people to get up earlier during workdays and eventually stay up longer on Friday and Saturday. People were free to choose different periods or use the same period for all assessment days. The event-based (button-pressed) assessments could also be activated outside of the individually selected periods. Participants then received details about the reimbursement. To encourage the participants to answer as many alarms as possible, we decided to employ a graded system. People received 25 € for their participation when answering <50% of random alarms. For each additional 1%−10% of answered alarms they received 5 € extra. This led to a maximum compensation of 50 € if 90%−100% of all alarms were answered. Participants were explicitly instructed that any answer—including “no” I do not listen to music—was counted as an answered alarm to avoid false reporting of music-listening situations to receive higher compensation. Event-based (button-pressed) assessments were not considered for the calculation of the reimbursement. Finally, participants received a small booklet that contained information about the study and contact addresses should they encounter problems.
In the final lab session—after the 10 days of experience sampling—the researcher controlled and transferred the data of the movisensXS application. At this time, participants completed a short evaluation questionnaire and received their reimbursement. Finally, participants received assistance with de-installing movisensXS from their smartphone.
Data Analysis
As the major aim of the study was to predict music-selection behavior (i.e., active selection of music), we excluded all situations in which participants indicated that they did not have any control about the music in a given situation (“How much control do you have in what you hear?” 1 = No control). In addition, we excluded situations in which participants did not choose the music (“Did you choose the music?” “No”) or listened to music at a club or in a concert. The final data included 2,674 situations reported by 119 participants.
Time data was centered at each participant's earliest response to a random trigger depending on weekdays and weekends. As participants were free to report music listening at any time (button-pressed), very few listening events (3%) were reported shortly before an individual's earliest random trigger. We decided to treat button-pressed events in close proximity to a participant's centering time as “getting up earlier,” whereas time stamps earlier than 2 h before an individual's centering time were considered as “still being awake”. For example, when a participant's earliest answer to a random trigger was 7 a.m., an answer at 8:30 was counted as 1.5, an answer at 6:30 as −0.5, and an answer at 4:30 am was counted as 21.5.
The resulting ESM data reflects a three-level structure (i.e., situations nested within days nested within persons). We checked the different levels of variance and decided not to include days as a separate level, as days explained only minor variability in the outcome variables. The resulting two-level model also is less complex and more readily comparable with that reported by Greb et al. (2018b). In addition, the Lasso implemented in the glmmLasso package (Groll, 2017) used here and by Greb et al. (2018b) cannot estimate three-level models.
We used multilevel linear regressions to model our data, as it allows the analysis of unbalanced designs and the inclusion of time-varying (i.e., situation-related) predictors, while accounting for non-independence of observations within participants. All variables that varied at the within-subject level were centered at the person-mean to clearly differentiate levels of variation (Enders and Tofighi, 2007).
As we considered the sampling of situations within participants to result in a good representation of a person's episodes of music listening in daily life, we also took aggregated measures of all situational variables into account. In the case of continuous situational variables such as arousal, the aggregated measure represents a person's average arousal level while listening to music across situations. For categorical situational variables such as presence of others, this aggregated measure was calculated for each category. It reflects the individual average frequency of that category (e.g., “others present & no interaction”) while listening to music across situations. These aggregated measures describe individual differences in the context (mood, presence of others, etc.) of listening to music, and can be used to predict individual differences in music-selection behavior.
We used intercept-only models to estimate the intraclass correlation coefficient (ICC), which indicates variance components of person and situation levels for functions of music listening and music selection.
To identify the most important variables and to explore all direct effects involved in the music selection process as outlined in our model (Figure 1), our analysis consisted of four steps. These steps followed the logic of a classical mediation analysis as proposed by Baron and Kenney (1986), but considered multiple predictors simultaneously. Step A tested all direct effects of person- and situation-related variables on music selection (i.e., y on x), step B tested all relevant direct effects of person- and situation-related variables on functions of music listening (i.e., m on x), and step C tested all direct effects of musical functions on music selection (i.e., y on m). Finally, step D tested all direct effects of person, situation, and musical functions on music selection (i.e., y on x and m). Step D represents a replication of the statistical analysis by Greb et al. (2018b). Throughout these analyses, we implemented the percentile-Lasso method proposed by Roberts and Nowak (2014), using the 95th percentile for variable selection. We repeated 100 5-fold cross validations with a random sample split for each repetition. For each outcome variable, we determined λmax by successively increasing λ by one until all coefficients were set to zero. We then used a linear λ grid of length 100 running from λmax to zero. Data was split into training and test set at the level of the individual (Level 2), such that models were optimized to make predictions on unseen participants (Roberts et al., 2017). The following lines illustrate model equations entered into the percentile-Lasso procedure for Step D, which includes all covariates analyzed here (see Supplementary Material for model equations of steps A, B, and C):
Level 1:
Level 2:
where Yij denotes the expected musical characteristic selected by person j at situation i and β0j represents a participant-specific intercept. This intercept is modeled following the second equation including all person-related variables. Within-subject effects are represented by the beta coefficients (β1-β25) and γ01-γ041 represent between-subject effects. Capital letter C denotes within-subject centered variables and M denotes aggregated variables at the person level. The terms Rij and Uj denote residuals at Levels 1 and 2.
For the categorical variables “activity” and “presence.of.others,” we used the group Lasso estimator as implemented in the glmmLasso package (Groll, 2017). This group Lasso estimator treats all categories (i.e., dummy variables) of a categorical variable as belonging together and therefore either includes all categories or excludes all categories pertaining to a categorical variable (Yuan and Lin, 2006; Meier et al., 2008; for details see Groll and Tutz, 2014). P-values of non-zero coefficients were estimated by Fisher scoring re-estimation as implemented in glmmLasso (Groll, 2017).
To obtain an overview of the holistic mediation analysis, we calculated a consistency indicator IF including the number of direct associations for each step of analysis. IF was calculated as
Where si is the amount of direct effects of variable s across the m models of the respective step (i.e., eight for musical characteristics during step A, B, D and five for functions of music listening during step C) and i denotes the number of variables showing direct effects on at least one of the eight outcome variables of step A. For steps B and C, only those variables were considered which already revealed a direct effect in step A (following the logic of a mediation analysis that a direct effect of y on x is mandatory). Given that the percentile-Lasso selects the most important variables, this indicator should decrease if variables selected during step A were not selected during step D. This decrease would indicate the presence of full mediations.
While these steps provided a holistic overview of all variables and effects involved in music selection, they do not directly provide estimates of direct and indirect effects of person- and situation-related variables on music-selection behavior via functions of music listening. Based on the results of the analysis described above, we constructed and tested mediation models for each outcome using multilevel structural equation modeling (MSEM; Preacher et al., 2010). We selected all person- and situation-related variables of steps A and C that showed significant and robust direct effects on music selection as indicated by the percentile-Lasso method. From this set, we then selected those variables that also showed a significant and robust direct effect on the proposed mediating variable (i.e., functions of music listening as indicated by step B). As mentioned earlier, we used a group Lasso estimator that either includes the complete set of dummy variables pertaining to one categorical variable or excludes them all. However, our aim was to keep models as parsimonious as possible. Therefore, we selected single significant dummy variables, but not the full set. Based on these selection criteria, we built one multilevel structural equation model for each of the eight musical characteristics.
To explore individual differences in associations between predictor variables and music-selection behavior, we re-estimated models based on step D using the lme4 package (Bates et al., 2015) and included random slopes for all situational variables that had shown significant associations during the re-estimation step of the glmmLasso package. Significance of these random parameters was tested by likelihood ratio tests using the lmerTest package (Kuznetsova et al., 2015).
MSEM mediation analyses were performed using the software Mplus v.7.3 (Muthén and Muthén, 1998-2017). All other analyses were performed within the development environment R-Studio (R Studio Team, 2015) of the software R.3.0.2 (R Core Team, 2015).
All major steps of the analyses can be found in Figure 2.
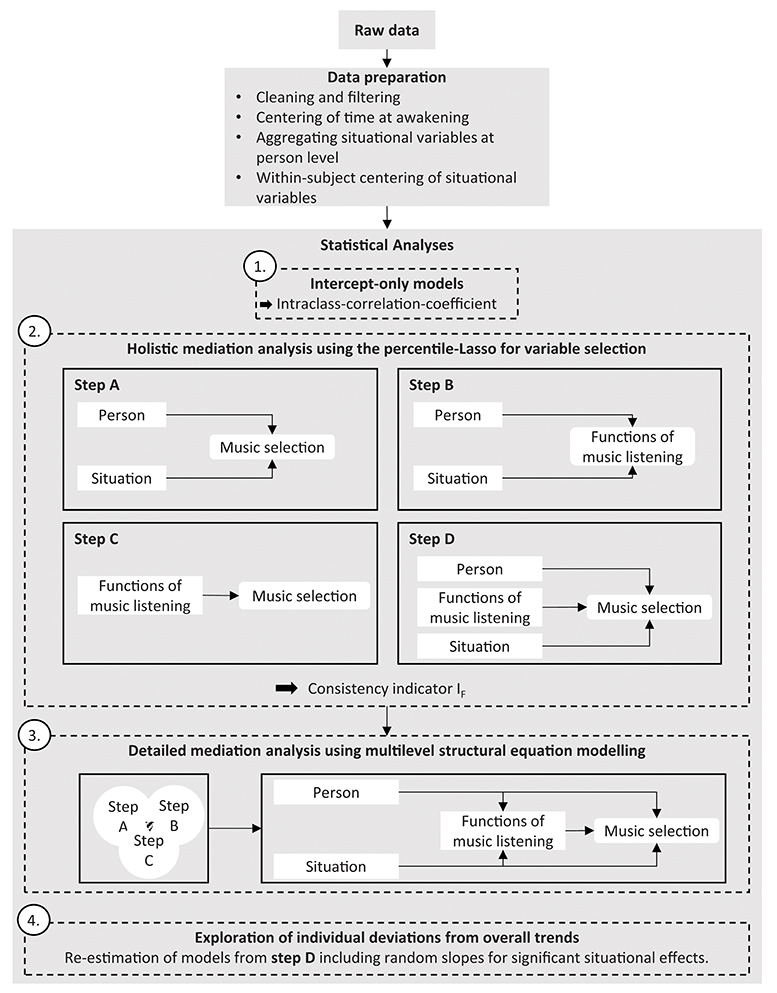
Figure 2. Pipeline detailing major steps from raw data to statistical analysis. For further details about the single steps see the data analysis section.
Results
Compliance Rate
Of the 15,708 random triggers sent during the study, 117 (0.7%) were dismissed, 2,446 (15.6%) were ignored, and 62 (0.4%) were answered but not finished. This resulted in an overall compliance rate of 83% (13,083 out of 15,708 cases). Participants additionally reported 542 music listening situations by pressing the event button; 23 of those (2.7%) were incomplete.
Descriptive Statistics
Participants reported 3,564 music-listening situations. In 523 situations, participants did not choose to listen to music; in 25 situations, participants reported listening to music in a concert; in 28 situations, participants were listening to music in a club; and in 676 situations, they reported not having any control over the music. Of the 2,674 music-listening situations considered for the present analysis, 2,202 were based on random triggers and 472 were reported voluntarily by pressing the event button. Participants reported a mean of 3 (SD = 2.3, Mdn = 2) listening situations per day, with an average of 7.5 music listening days (SD = 2.3), resulting in 22.5 (SD = 17.6) listening situations per participant throughout the study. None of the distributions of functions of music listening indicated bimodality, supporting our assumption that functions of music listening in daily life vary in their intensity, and thus are continuous rather than categorical in nature. The following frequencies of main activities while listening to music were reported: being on the move (518; 19%), working & studying (476; 18%), pure music listening (476; 18%), household activity (328; 12%), other activity (230; 9%), social activity (170; 6%), relaxing & falling asleep (147; 5%), personal hygiene (132; 5%), exercise (68; 3%), coping with emotions (50; 2%), making music (50; 2%), and party (17;1%).
Variance Components
The ICC indicates the relative amount of variance in the outcome variable attributable to person-related and situational differences. The ICC for the five dimensions of functions of music listening were: 0.48 for intellectual stimulation, 0.42 for mind wandering & emotional involvement, 0.40 for motor synchronization & enhanced well-being, 0.42 for updating one's musical knowledge, and 0.51 for killing time & overcoming loneliness. Across the five dimensions, on average 44% of the variance of functions of music listening was attributable to between-person differences, whereas 56% were attributable to within-person differences between situations. The ICC for the eight musical characteristics were 0.10 for calming–exciting, 0.10 for slow–fast, 0.17 for sad–happy, 0.22 for less melodic–very melodic, 0.24 for less rhythmic–very rhythmic, 0.16 for simple–complex, 0.08 for peaceful–aggressive, and 0.22 for less intense–very intense. Across all characteristics, between-person differences on average accounted for 16% of variance, whereas within-person differences between situations accounted for 84% of variance. This means that music selection was influenced largely by situational factors. In contrast, reported functions of music showed higher between-person variance, but were still outweighed by within-subject variability.
Most Important Predictors of Music Selection
Models resulting from the analysis of the initial three steps A to C are presented in the Supplementary Material, and the models of the final analysis step D—representing the most comprehensive models—are shown in Table 1. Modeling results revealed that time (time of day, weekday vs. weekend) strongly contributed to the prediction of functions of music listening (step B), but played a minor role in the prediction of music selection (steps A and D). A closer inspection of the comprehensive models including all potential predictors in Table 1 shows that situation-specific arousal, degree of attention, and functions of music listening proved to be most important in the prediction of music selected in a specific situation. The theory-based assumption (cf. Figure 1) that functions of music listening play a significant role in music selection was supported by the observation that almost all direct effects that were detected during step C were also selected when all potential covariates were included in the model during step D, while regression coefficients remained virtually identical. Furthermore, the percentile-Lasso almost exclusively selected situational (Level 1) predictors of music-selection behavior, whereas only very few person-related (Level 2) variables were selected, namely a few aggregated mood and function scores. None of the personality traits or musical sophistication scores contributed to the prediction of music selection. Although momentary activity contributed substantially to the prediction of functions of music listening during step B (activity was included in four out of five models) and was also selected in four out of eight models during step A, it was only of marginal importance during step D as it was only included in two out of eight models. This clearly indicates the potential mediating role of functions of music listening in the association of person- and situation-related variables with music selection.
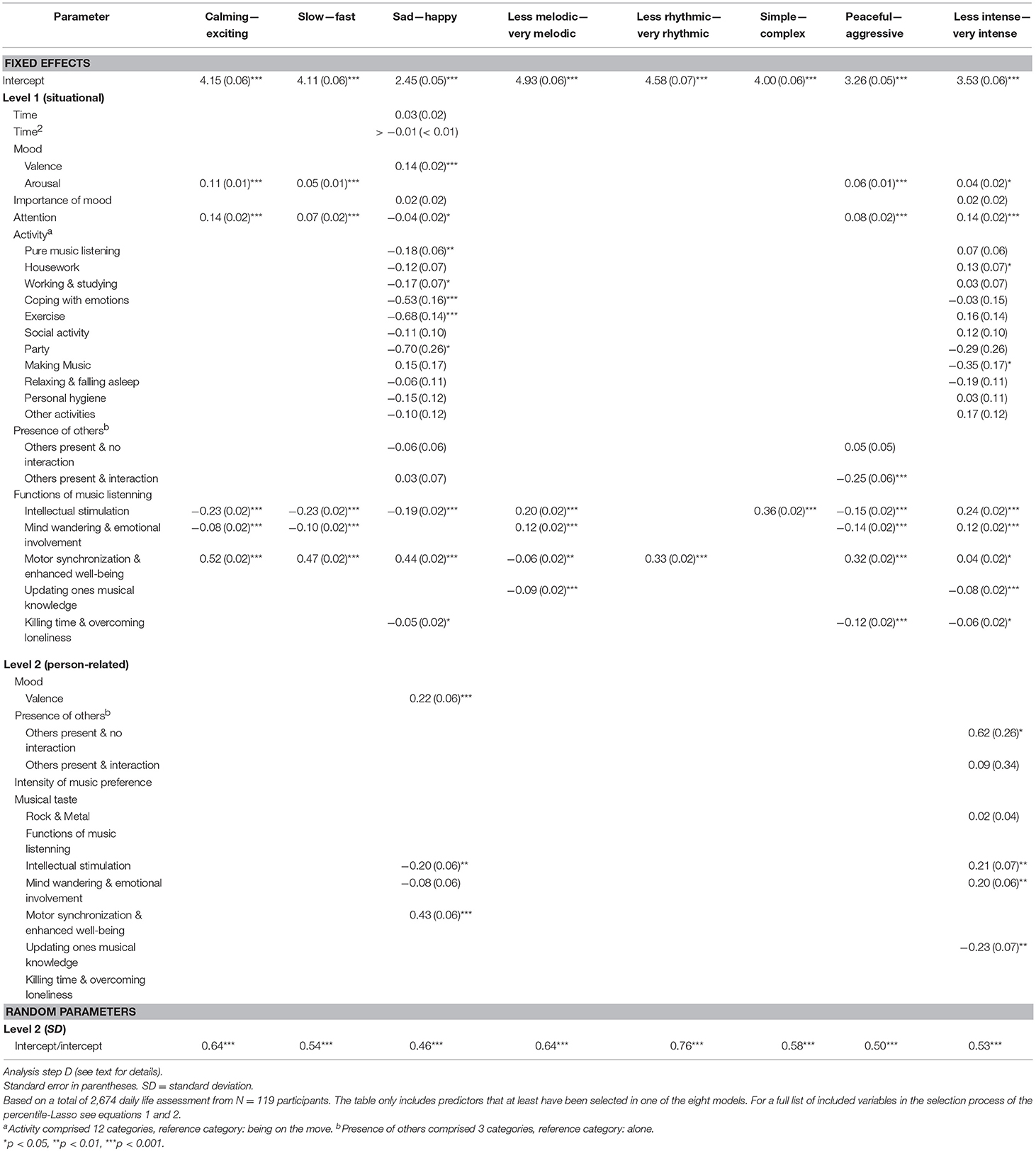
Table 1. Fixed effects estimates (top) and standard deviations of random parameters (bottom) for models of the predictors of music selection.
Mediation Analysis
The mediation hypothesis was further supported by the consistency indicator IF shown in Figure 3. The decrease of IF from steps A to D clearly indicated that some of the variables selected in step A were no longer selected in step D in which functions of music listening were included as covariates. Exclusion of direct effects in the presence of potential mediators can be interpreted as full mediation.
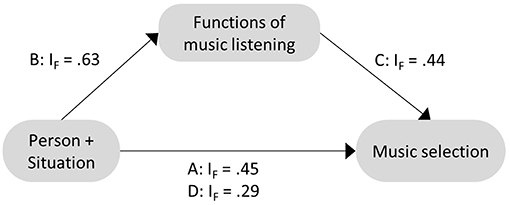
Figure 3. Summary of holistic mediation analysis using the percentile-Lasso. IF is a consistency indicator summarizing all included person and situation predictors across all respective models for each step of analysis A–D (see text for details).
Figure 4 depicts all mediation models including indirect effects (see Supplementary Material for detailed model summaries including coefficients of all effects). The results of these analyses revealed a similar pattern as seen above, but provided further insights, particularly with regard to direct effect tests and residual paths. For example, when people reported to be in a positive mood (valence), felt higher arousal, and payed higher attention to the music compared with their individual average, they tended to listen to music because they could move to it and feel fitter. This mediating functional state was in turn associated with a higher tendency to listen to rhythmic music (Figure 4, Model E). None of the three variables in this model showed a significant residual direct effect on the selection of rhythmic music, but all indirect effects were statistically significant. In another mediation model, the model for predicting selection of sad–happy music (Figure 4, Model C) revealed detailed findings on the broad effects of valence at the moment of the decision to listen to music. The model included an indirect positive effect of valence on happy music via motor synchronization and enhanced well-being, which was also found for choosing rhythmic (Model E), exciting (Model A), and fast music (Model B). In addition, there was a residual direct positive effect of valence on the selection of happy music, which reflects mood congruent selection of happy music. Moreover, the significant indirect path via intellectual stimulation demonstrates that people were more likely to listen to music for intellectual stimulation when they were in a positive mood, but tended to select sad music in that case. Such differentiated insights in specific associations including opposing directions within a mediation path were found for several models (Models A, B, C, D, and H). The mediation paths found in this study highlight both the general importance and the role of functions of music listening as a mediator in music-selection behavior. Overall, 52 (69%) of the 72 indirect effects tested throughout the eight models were significant (see Table 2).
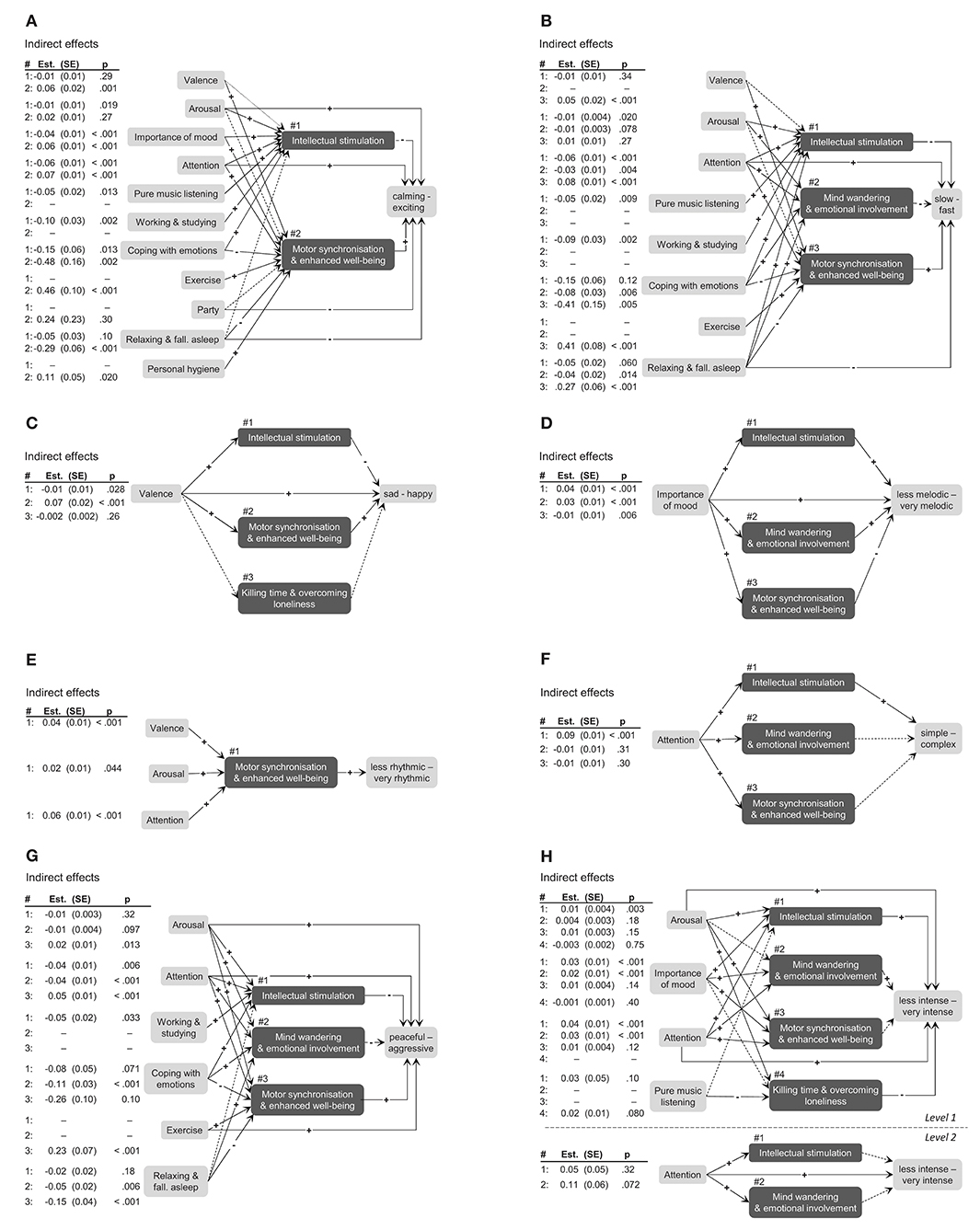
Figure 4. Multilevel mediation models for musical characteristics selected. (A–G) represent 1-1-1 mediations, (H) shows 1-1-1 and 2-2-2 mediations. Variables included in the analyses where selected by the percentile-Lasso (see text for details). Plus and minus signs indicate direction of effects. Solid lines represent significant effects and dashed lines represent non-significant effects (α = 0.05). Indirect effect parameters and tests from mediation models are shown in the tables left to each subfigure. Direct effects parameters are included in the detailed figures of the Supplementary Material.
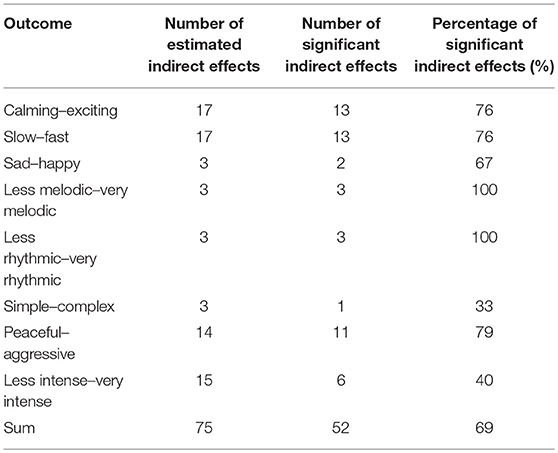
Table 2. Number of significant indirect effects of MSEM mediation analyses.
Individual Differences of Situational Effects on Music Selection
Table 3 shows the re-estimation of the models derived from step D including random slopes for those predictors that yielded significant fixed effects in the percentile-Lasso model output. Many of the random parameters revealed significant individual variability around the overall mean effect. This variability was found consistently across all of the eight models of music-selection behavior. Overall, 24 (60%) of the 40 random parameters of this analysis step were statistically significant. Particularly, the three functions of music listening intellectual stimulation, mind wandering & emotional involvement, and motor synchronization & enhanced well-being consistently showed individual variability in their association with music-selection behavior. Estimations of fixed effects were only affected marginally by the inclusion of random effects, and almost all fixed effects remained significant. This indicates that general trends can be detected reliably, but some individuals deviate from this overall trend. Such individual deviations from overall trends offer the opportunity to investigate person-related moderators in future studies.
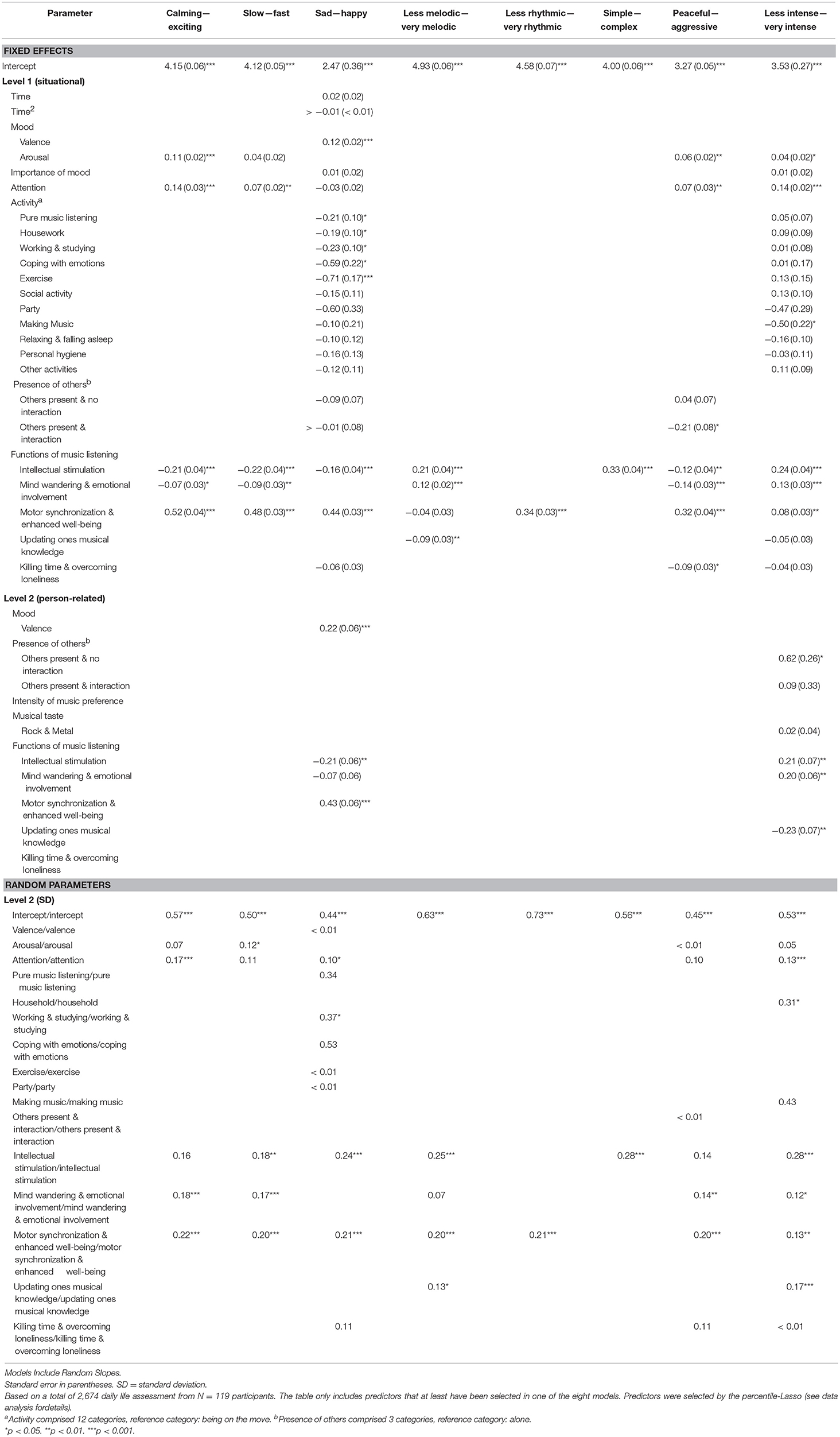
Table 3. Fixed effects estimates (top) and standard deviations of random parameters (bottom) for models of the predictors of music selection.
Comparison of Results With Greb et al. (2018b)
As we largely measured the same variables and used the same statistical-learning method for data analysis and variable selection (percentile-Lasso) as in an earlier study (Greb et al., 2018b), we had the opportunity to compare results between two studies that differ in their participant samples and assessment methods (retrospective online survey vs. momentary assessments in daily life). Table 4 shows comparisons of variance components and fixed effects consistently selected in both studies. ICC values were virtually identical for four of the outcome variables but deviated for simple–complex and peaceful–aggressive. Exclusively situational (i.e., within-subject centered) predictors were congruently selected across both studies. For the functions of music listening, intellectual stimulation and motor synchronization & enhanced well-being, results were most consistent. For example, when people reported listening to music for intellectual stimulation, they tended to select slower, more melodic, less happy, more peaceful, and more complex music in both studies. However, even though all effects shared the same directions, effect sizes of the current study were smaller when compared with the effects of the retrospective online study. As all effects shown in Table 4 consistently contributed to the prediction of music selection of unseen persons, these effects can be regarded as highly robust and reliable.
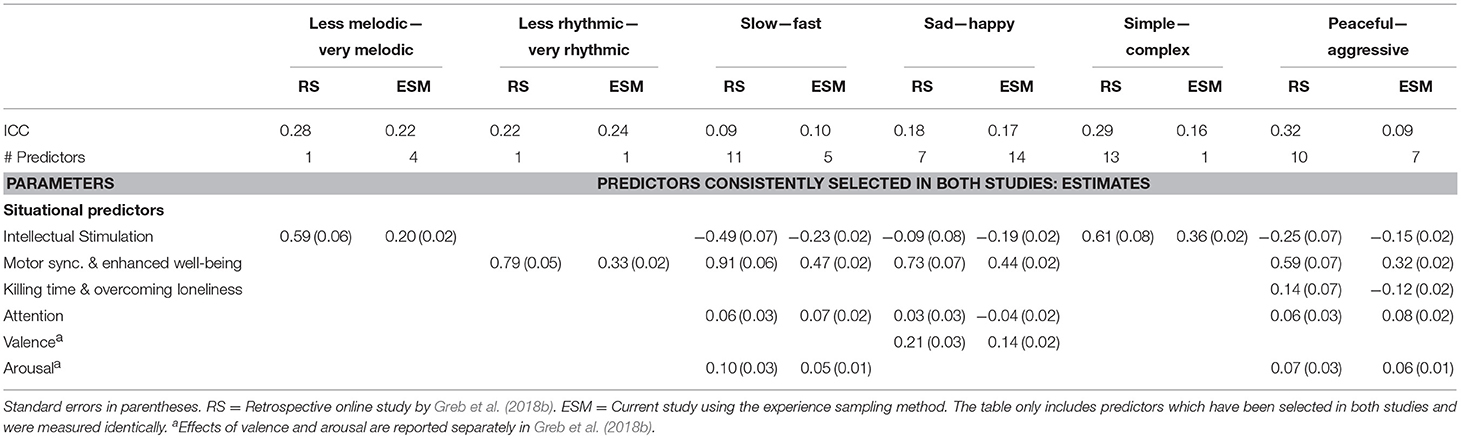
Table 4. Comparison of key indicators (top) and predictor variables (bottom) of retrospective online study by Greb et al. (2018b) and the current ESM study.
Discussion
The current study investigated music selection in daily life by using daily life research and statistical learning methods. Our first aim was to investigate to what extent person-related and situational variables influence music selection. Findings demonstrated that characteristics of music chosen in daily life were influenced largely by the situation a person resides in, with 84% of variance being attributable to situational factors. The predominance of situational influence is consistent with Greb et al. (2018b) whose results revealed virtually identical ICC values for four outcome variables. For the two variables simple–complex and peaceful–aggressive, the ICC values were considerably smaller in the present study. This difference might be explained by the fact that the results of Greb et al. (2018b) were based on retrospective self-reports of three listening situations collected in an online study. The two variables for which the differences occurred are probably most susceptible to response bias due to self-perception processes. For example, people perceiving themselves as highly intellectual music connoisseurs are more likely to report situations in which they listen to complex music when being asked retrospectively. As momentary assessments are less susceptible to such biasing factors (Schwarz, 2012), they very likely represent situational influences more accurately. In addition, the daily life research design employed here reflects a much more comprehensive representation of participants' daily lives as compared with reports of just three situations. Our results concerning the ICC values of sad–happy and calming–exciting are very similar to those of Randall and Rickard (2017a) who also used daily-life assessments and measured music selection via valence and arousal. In summary, the high situational variability of music-listening behavior revealed in the current study should initiate a shift from research on individual differences to situational influences and potential interactions on music-selection behavior. However, investigating the significance of situational variability means that studies need to be designed in a way that ensures ecological validity of observations, limits recall bias due to retrospective assessment, provides sufficiently large and heterogeneous samples of situations, and measures a wide variety of potentially relevant variables. In addition, suitable statistical methods need to be applied that can be used to separate within-subject from between-subject associations, and properly deal with a large number of predictors in the model. We believe that the sampling design and analysis procedure used in this study (cf. Figure 2) could serve as a template for a shift of research focus toward situational factors in music-listening behavior.
Our second aim was to identify the key variables involved in music selection. Our multi-step analytic plan revealed a detailed pattern of findings for a broad set of relevant variables. The finding that activity was important in predicting functions of music listening is consistent with previous research also revealing activity as very important in predicting listening functions or music perception in daily life (Krause and North, 2017b; Randall and Rickard, 2017a; Greb et al., 2018a). Regarding the aggregated situational variables, results showed that presence of others was the only situational variable that yielded an effect on level 2. This effect indicates that individuals with a propensity to listen to music in the presence of others while not communicating with them, tend to select more intense music. This is largely in line with (Tarrant et al., 2000), who also found individual differences in why people listen to music with regard to the presence of others (i.e., people with a propensity to listen to music alone tended to use music for emotional needs). The insight that, when controlling for the largest possible set of covariates, situation-specific attention, arousal, and functions of music listening were most important in predicting music selection is largely in line with findings by Greb et al. (2018b). Many of the direct effects that were revealed in the first steps of our analysis dropped out when controlling for functions of music listening. This supports our theoretical model proposing a mediating role of functions of music listening for the association between person- and situation-related predictor variables and music-selection behavior.
Clarifying the mediating role of functions of music listening in music selection was our third aim. Several analyses supported the mediation hypothesis. First, our consistency indicator clearly suggested several full mediations. Second, our findings demonstrated that in many cases (69% of tested indirect effects) functions of music listening acted as mediators on the selection of music with specific characteristics. It is important to mention that the mediation processes found in our study were exclusively located on the situational level (Level 1). Momentary mood, attention, and activity largely determined why participants listened to music, and the specific functions ultimately predicted which music participants selected. We did not find any significant mediation effects on the between-subject level (Level 2). The large within-subject variance of musical characteristics selected might explain this absence of between-subject mediations. The novel findings on within-subject mediations help to understand the important role of functions of music listening in music selection that would have been neglected by an analysis strategy strictly focusing on direct effects. For example, our results related to the direct effect of valence on the selection of happy–sad music confirm mood-congruent selection of music (Thoma et al., 2012; Randall and Rickard, 2017a), whereas the indirect effect via intellectual stimulation demonstrates mood-incongruent selection of music. These findings for the first time clearly differentiate the complex processes involved when people select music in daily life.
Our fourth aim was to investigate individual variations of situational effects identified in the previous analyses. Here, findings demonstrated that many associations significantly varied around the estimated mean effect. The three functions of intellectual stimulation, mind wandering & emotional involvement, and motor synchronization & enhanced well-being most consistently showed individual deviations. For example, this indicates that people generally tend to select faster, happier, less melodic, more rhythmic, more aggressive, more intense, and more exciting music to move to and enhance their well-being, but individuals do deviate from these overall trends. Hence, future research should investigate which person-related factors might explain the individual variability found here. One analysis strategy might be to add cross-level interaction parameters. Such an analysis could focus on two associations outlined by our theoretical model (Figure 1): individual variability in the association between situational variables and functions of music listening and music-selection behavior. In addition, moderated mediation models could be used to check whether person-related variables are capable of explaining individual variation in the mediation of the association between predictors and music-selection behavior by functions of music listening. This approach would also provide an opportunity to integrate person-related variables more precisely into theoretical models of music-selection behavior. It might well be the case that very few direct effects of person-related variables on music selection exist, and that person-related variables primarily act as moderators. Once more, this would suggest a shift from exclusively investigating individual differences to interaction effects between situational and person-related variables on music-listening behavior.
Finally, we aimed to compare the results of this daily-life study to those of a recent study on music selection that was very similar in terms of theoretical background and statistical analysis but analyzed data from a retrospective online survey (Greb et al., 2018b). Besides the virtual identical ICC values discussed above, we found numerous effects going in the same direction. Exclusively situational predictors were selected congruently across both studies. Consensus was greatest for intellectual stimulation and motor synchronization & enhanced well-being. For example, findings consistently indicated that people tend to select more melodic, less fast, less happy, less aggressive, and more complex music when they listen to music for intellectual stimulation. Although some effect sizes were largely identical, others differed in size with effects of this study being smaller than those obtained through the online study. This difference might be due to memory biases and a tendency to respond stereotypically in retrospective reports (Holmberg and Homes, 2012). The effects found across both studies can be regarded as highly robust and reliable. As in both studies, models were optimized to make predictions on unseen participants, these effects can be used to guide stimulus selection for experimental research investigating specific functions or effects of music listening. In addition, the similarity of results highlights the power of using statistical learning methods, the percentile-Lasso in this case, for reliable variable selection. Despite broad congruency between the two studies, some differences were evident that mainly concern the selection of person-related predictors. In the online study, musical taste factors were found to be important predictors—being selected in three out of six models—but in the current study, only one musical taste factor was selected in one out of eight models. As already discussed above, simple–complex and peaceful–aggressive showed different ICC values across both studies with values of the online study being considerably larger. This further supports the point made above that participants in the online study might have reported stereotypical situations that match their attitudes and beliefs, such as musical taste, whereas in the daily life study, the behavioral report was much less biased. Hence, the current findings clearly reject the notion that musical taste is significantly associated with the selection of certain musical characteristics.
None of the Big Five personality traits was selected as a predictor of music-selection behavior in the current study. This is consistent with Schäfer and Mehlhorn (2017) who showed that personality traits cannot substantially account for differences between individuals in musical taste and preferences. However, Big Five personality traits might be too broad to predict fine-grained behavior such as music selection. Future research might investigate if facets of Big Five personality traits, which represent specific and unique aspects underlying the broad personality traits, are better predictors of music selection.
Our study includes several notable limitations. First, music selection was measured based on subjectively perceived musical characteristics based on a particular conceptualization of music-selection behavior. Convergence with objective measures, such as musical features, obtained by music information retrieval methods would provide interesting comparative data for some of the current findings. In particular, this comparison might reveal whether the perception of musical characteristics is congruent with objective characteristics or if subjective perception is influenced by the situation as well. Music-selection behavior could also be conceptualized via musical styles selected, which might yield a different pattern of results than that found here. A style-based conceptualization would help to clarify if people predominantly select and listen to their favorite styles of music but at the same time adjust their specific musical choices (i.e., characteristics of the music) within their favorite styles to the situation they reside in. Hence, future research should try to model these different conceptualizations simultaneously to best reflect interdependencies and isolate effects of individual variables in the context of the complex entirety of potentially relevant variables.
Second, not accounting for covariations of outcome variables constitutes another limitation. This restriction is due to a lack of software solutions that could be used to perform a Lasso regression in a multivariate multilevel model framework. It should be noted that a single multivariate model might yield slightly different results.
Third, participants had the possibility to skip the questionnaire by reporting that they did not listen to music in a specific situation. This might be related to their current mood or some other unknown variable but cannot be investigated further with the given data.
Lastly, our findings are based on a specific sample of young people who frequently listen to music and are familiar with digital technologies. These “digital natives” grew up with technologies that enable situation-specific music selection. Future studies should also including infrequent music listeners with greater age variability. Nevertheless, the fact that we found a large overlap of effects between the present and an earlier study that did not focus on frequent music listeners suggests that our results are reliable.
The current study investigated music-selection behavior in daily life from a comprehensive perspective, using representative and unbiased momentary samples from participants' everyday life and innovative statistical learning procedures suitable for this endeavor. We demonstrated that situational factors mainly drive music selection and identified detailed patterns of variables contributing to music-selection behavior. We also showed for the first time that functions of music listening act as mediators between the situation and music-selection behavior. Our study therefore contributes to the understanding of music-selection behavior, in particular how situational characteristics influence people's motives to listen to a particular kind of music and actual musical choices. These findings emphasize the importance of accounting for situational influences in music psychological research, and might contribute to improved music recommendation systems.
Author Contributions
FG, JS, and WS designed the study. FG collected data. FG and WS developed and performed the statistical analysis. FG wrote the first draft of the manuscript. All authors interpreted data, reviewed, and edited the manuscript, and approved the final version of the manuscript.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This article partly overlaps with a chapter of the first author's dissertation (Greb, 2018). We thank Melanie Wald-Fuhrmann for her critical reading of earlier versions of the manuscript. Finally, we are thankful to Claudia Lehr, Cordula Hunt, and Henry Balme whose support has been of great value for the realization of the study.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2019.00390/full#supplementary-material
References
Babyak, M. (2004). What you see may not be what you get: a brief, nontechnical introduction to overfitting in regression-type models. Psycho. Med. 66, 411–421. doi: 10.97/01.psy.0000127692.23278.a9
Baron, R. M., and Kenney, D. A. (1986). The moderator-mediator variable distinction in social psychological research: conceptual, strategic, and statistical considerations. J. Person. Soc. Psychol. 51, 1173–1182. doi: 10.1037/0022-3514.51.6.1173
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Berthelmann, T. (2017). Digit. Media Rep. 2017 - Digital Music. Available online at:https://de.statista.com/statistik/studie/id/39313/dokument/digital-media-report/
Boer, D., Fischer, R., Tekman, H. G., Abubakar, A., Njenga, J., and Zenger, M. (2012). Young people's topography of musical functions: personal, social and cultural experiences with music across genders and six societies. Int. J. Psychol. 47, 355–369. doi: 10.1080/00207594.2012.656128
Chamorro-Premuzic, T., and Furnham, A. (2007). Personality and music: can traits explain how people use music in everyday life? Br. J. Psychol. 98(Pt 2), 175–185. doi: 10.1348/000712606X111177
Chamorro-Premuzic, T., Swami, V., Furnham, A., and Maakip, I. (2009). The big five personality traits and uses of music: a replication in malaysia using structural equation modeling. J. Individ. Diff. 30, 20–27. doi: 10.1027/1614-0001.30.1.20
Chapman, B. P., Weiss, A., and Duberstein, P. R. (2016). Statistical learning theory for high dimensional prediction: application to criterion-keyed scale development. Psychol. Methods.21, 603–620. doi: 10.1037/met0000088
Cohrdes, C., Wrzus, C., Frisch, S., and Riediger, M. (2017). Tune yourself in: valence and arousal preferences in music-listening choices from adolescence to old age. Develop. Psychol. 53, 1777–1794. doi: 10.1037/dev0000362
Delsing, M. J. M. H., ter Bogt, T. F. M., Engels, R. C. M. E., and Meeus, W. H. J. (2008). Adolescents' music preferences and personality characteristics. Euro. J. Person. 22, 109–130. doi: 10.1002/per.665
Derksen, S., and Keselman, H. J. (1992). Backward, forward and stepwise automated subset selection algorithms: frequency of obtaining authentic and noise variables. Br. J. Math. Stat. Psychol. 45, 265–282. doi: 10.1111/j.2044-8317.1992.tb00992.x
Enders, C. K., and Tofighi, D. (2007). Centering predictor variables in cross-sectional multilevel models: a new look at an old issue. Psychol. Methods 12, 121–138. doi: 10.1037/1082-989X.12.2.121
Ferwerda, B., Yang, E., Schedl, M., and Tkalcic, M. (2015). “Personality traits predict music taxonomy preferences,” in Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (Seoul), 2241–2246.
Fleeson, W. (2007). “Using experience sampling and multilevel modeling to study person-situation interactionist approaches to positive psychology,” in Series in Positive Psychology. Oxford Handbook of Methods in Positive Psychology, eds A. D. Ong, V. Dulmen, H. M. Manfred (Oxford, NY: Oxford University Press), 501–514.
Fleeson, W., and Noftle, E. (2008). The end of the person–situation debate: an emerging synthesis in the answer to the consistency question. Soc. Person. Psychol. Compass 2, 1667–1684. doi: 10.1111/j.1751-9004.2008.00122.x
Flom, P. L., and Cassell, D. L. (2007). “Stopping Stepwise: Why stepwise and similar selection methods are bad, and what you should use,” in NESUG Proceedings. (Baltimore, MD).
Gardikiotis, A., and Baltzis, A. (2012). ‘Rock music for myself and justice to the world!’: musical identity, values, and music preferences. Psychol. Music 40, 143–163. doi: 10.1177/0305735610386836
Gesellschaft für Konsumforschung (2017). Umsatz mit Smartphones Weltweit in den Jahren 2013 bis 2016 und eine Prognose für 2017 (in Milliarden US-Dollar). Wolrdwide revenue of smartphones from 2013−2016 and a prognosis for 2017 (in billion USD).
Greasley, A., Lamont, A., and Sloboda, J. (2013). Exploring musical preferences: An in-depth qualitative study of adults' liking for music in their personal collections. Qual. Res. Psychol. 10, 402–427. doi: 10.1080/14780887.2011.647259
Greasley, A. E., and Lamont, A. (2011). Exploring engagement with music in everyday life using experience sampling methodology. Musicae Sci. 15, 45–71. doi: 10.1177/1029864910393417
Greb, F. (2018). Determinants of Music-Selection Behavior: Development of a Model. Dissertation, Technische Universität Berlin, Berlin.
Greb, F., Schlotz, W., and Steffens, J. (2018a). Personal and situational influences on the functions of music listening. Psychol. Music 46, 763–794. doi: 10.1177/0305735617724883
Greb, F., Steffens, J., and Schlotz, W. (2018b). Understanding music-selection behavior via statistical learning: using the percentile-Lasso to identify the most important factors. Music Sci. 1, 1–17. doi: 10.1177/2059204318755950
Greenberg, D. M., Baron-Cohen, S., Stillwell, D. J., Kosinski, M., and Rentfrow, P. J. (2015). Musical preferences are linked to cognitive styles. PLoS ONE 10:e0131151. doi: 10.1371/journal.pone.0131151
Groll, A. (2017). Glmmlasso: Variable Selection for Generalized Linear Mixed Models by l1-Penalized Estimation. R package version 1.5.1. Available online at:https://CRAN.R-project.org/package=glmmLasso
Groll, A., and Tutz, G. (2014). Variable selection for generalized linear mixed models by L 1-penalized estimation. Stat. Comput. 24, 137–154. doi: 10.1007/s11222-012-9359-z
Hektner, J. M., Schmidt, J. A., and Csikszentmihalyi, M. (2007). Experience Sampling Method: Measuring the Quality of Everyday Life. Thousand Oaks, CA: Sage Publications.
Holmberg, D., and Homes, J. G. (2012). “Reconstruction of relationship memories: a mental models approach,” in Autobiographical Memory and the Validity of Retrospective Reports, eds N. Schwarz and S. Sudman (New York, NY:Springer), 267–288.
Johnson, J. A. (2014). Measuring thirty facets of the five factor model with a 120-item public domain inventory: development of the IPIP-NEO-120. J. Res. Person. 51, 78–89. doi: 10.1016/j.jrp.2014.05.003
Juslin, P. N., Liljeström, S., Västfjäll, D., Barradas, G., and Silva, A. (2008). An experience sampling study of emotional reactions to music: listener, music, and situation. Emotion 8, 668–683. doi: 10.1037/a0013505
Krause, A. E., and North, A. C. (2017a). How do location and control over the music influence listeners' responses? Scand. J. Psychol. 58, 114–122. doi: 10.1111/sjop.12352
Krause, A. E., and North, A. C. (2017b). Pleasure, arousal, dominance, and judgments about music in everyday life. Psychol. Music 45, 355–374. doi: 10.1177/0305735616664214
Krause, A. E., North, A. C., and Hewitt, L. Y. (2015). Music-listening in everyday life: devices and choice. Psychol. Music 43, 155–170. doi: 10.1177/0305735613496860
Krause, A. E., North, A. C., Hewitt, L. Y., and Hewitt, L. Y. (2016). The role of location in everyday experiences of music. Psychol. Pop. Media Cult. 5, 232–257. doi: 10.1037/ppm0000059
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. B. (2015). Lmertest: Tests in Linear Mixed Effects Models. R package version 2.0-29. Available online at:http://CRAN.R-project.org/package=lmerTest
LeBlanc, A., Jin, Y. C., Stamou, L., and McCrary, J. (1999). Effect of age, country, and gender on music listening preferences. Bull. Council Res. Music Edu. 141, 72–76.
Liljestrom, S., Juslin, P. N., and Västfjäll, D. (2013). Experimental evidence of the roles of music choice, social context, and listener personality in emotional reactions to music. Psychol. Music 41, 579–599. doi: 10.1177/0305735612440615
Mehl, M. R., and Conner, T. S. (Eds.). (2012). Handbook of Research Methods for Studying Daily Life. New York, NY: Guilford Press.
Meier, L., Van De Geer, S., and Bühlmann, P. (2008). The group lasso for logistic regression. J. R. Stat. Soc. Series B 70, 53–71. doi: 10.1111/j.1467-9868.2007.00627.x
Muthén, L. K., and Muthén, B. O. (1998-2017). Mplus User's Guide, 8th Edn. Los Angeles, CA: Muthén & Muthén.
Nezlek, J. B. (2008). An introduction to multilevel modeling for social and personality psychology. Soc. Person. Psychol. Compass 2, 842–860. doi: 10.1111/j.1751-9004.2007.00059.x
North, A. C., Hargreaves, D. J., and Hargreaves, J. J. (2004). Uses of music in everyday life. Music Percept. 22, 41–77. doi: 10.1525/mp.2004.22.1.41
Preacher, K. J., Zyphur, M. J., and Zhang, Z. (2010). A general multilevel SEM framework for assessing multilevel mediation. Psychol. Methods 15, 209–233. doi: 10.1037/a,0020141
R Core Team (2015). R: a Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna. Available online at:https://www.R-project.org/
R Studio Team (2015). RStudio: Integrated Development for R. RStudio, Inc. Boston, MA. Available online at:http://www.rstudio.com/
Randall, W. M., and Rickard, N. S. (2013). Development and trial of a mobile experience sampling method (m-ESM) for personal music listening. Music Percept. 31, 157–170. doi: 10.1525/mp.2013.31.2.157
Randall, W. M., and Rickard, N. S. (2017a). Personal music listening: a model of emotional outcomes developed through mobile experience sampling. Music Percept. 34, 501–514. doi: 10.1525/mp.2017.34.5.501
Randall, W. M., and Rickard, N. S. (2017b). Reasons for personal music listening: a mobile experience sampling study of emotional outcomes. Psychol. Music 45, 479–495. doi: 10.1177/0305735616666939
Roberts, D. R., Bahn, V., Ciuti, S., Boyce, M. S., Elith, J., Guillera-Arroita, G., et al. (2017). Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 40, 913–929. doi: 10.1111/ecog.02881
Roberts, S., and Nowak, G. (2014). Stabilizing the lasso against cross-validation variability. Comput. Stat. Data Anal. 70, 198–211. doi: 10.1016/j.csda.2013.09.008
Russell, J. A. (1980). A circumplex model of affect. J. Person. Soc. Psychol. 39, 1161–1178. doi: 10.1037/h0077714
Schaal, N. K., Bauer, A.-K. R., and Müllensiefen, D. (2014). Der Gold-MSI: replikation und validierung eines fragebogeninstrumentes zur messung musikalischer erfahrenheit anhand einer deutschen stichprobe [the Gold-MSI: replication and validation of a questionnaire measuring musical sophistication using a german sample]. Musicae Scient. 18, 423–447. doi: 10.1177/1029864914541851
Schäfer, T., and Mehlhorn, C. (2017). Can personality traits predict musical style preferences? a meta-analysis. Pers. Individ. Diff. 116, 265–273. doi: 10.1016/j.paid.2017.04.061
Schäfer, T., and Sedlmeier, P. (2009). From the functions of music to music preference. Psychol. Music 37, 279–300. doi: 10.1177/0305735608097247
Schwarz, N. (2012). “Why researchers should think “real-time”: a cognitive rationale,” in Handbook of Research Methods for Studying Daily Life, eds M. R. Mehl and T. S. Conner (New York, NY: Guilford Press), 22–42.
Sloboda, J. A., O'Neill, S. A., and Ivaldi, A. (2001). Functions of music in everyday life: an exploratory study using the experience sampling method. Musicae Sci. 5, 9–32. doi: 10.1177/102986490100500102
Steyerberg, E. W., Eijkemans, M. J. C., and Habbema, D. F. (1999). Stepwise selection in small data sets: a simulation study of bias in logistic regression analysis. J. Clin. Epidemiol. 52, 935–942. doi: 10.1016/S0895-4356(99)00103-1
Tarrant, M., North, A. C., and Hargreaves, D. J. (2000). English and American adolescents' reasons for listening to music. Psychol. Music 28, 166–173. doi: 10.1177/0305735600282005
Thoma, M. V., Ryf, S., Mohiyeddini, C., Ehlert, U., and Nater, U. M. (2012). Emotion regulation through listening to music in everyday situations. Cogn. Emotion 26, 550–560. doi: 10.1080/02699931.2011.595390
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Series B 58,267–288.
Treiber, L., Thunsdorff, C., Schmitt, M., and Schreiber, W. H. (2013). “The translation and convergent validation of the 300-Item-IPIP-scale with its wellknown counterpart, the NEO-PI-R,” in Poster Presented at the First World Conference on Personality (Stellenbosch).
Whittingham, M. J., Stephens, P. A., Bradbury, R. B., and Freckleton, R. P. (2006). Why do we still use stepwise modelling in ecology and behaviour? J. Anim. Ecol. 75, 1182–1189. doi: 10.1111/j.1365-2656.2006.01141.x
Yarkoni, T., and Westfall, J. (2017). Choosing prediction over explanation in psychology: lessons from machine learning. Perspec. Psychol. Sci. 12, 1100–1122. doi: 10.1177/1745691617693393
Keywords: music-listening behavior, music-selection behavior, functions of music listening, machine learning, experience sampling method, user behavior analysis
Citation: Greb F, Steffens J and Schlotz W (2019) Modeling Music-Selection Behavior in Everyday Life: A Multilevel Statistical Learning Approach and Mediation Analysis of Experience Sampling Data. Front. Psychol. 10:390. doi: 10.3389/fpsyg.2019.00390
Received: 25 October 2018; Accepted: 07 February 2019;
Published: 19 March 2019.
Edited by:
Egon L. Van Den Broek, Utrecht University, NetherlandsReviewed by:
William M. Randall, University of Jyväskylä, FinlandIballa Burunat, University of Jyväskylä, Finland
Copyright © 2019 Greb, Steffens and Schlotz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fabian Greb, ZmFiaWFuLmdyZWJAYWVzdGhldGljcy5tcGcuZGU=