Abstract
This article serves as a step-by-step guide of a new application of Q-methodology to investigate people’s preferences for multivariate stimuli. Q-methodology has been widely applied in fields such as sociology, education and political sciences but, despite its numerous advantages, it has not yet gained much attention from experimental psychologists. This may be due to the fact that psychologists examining preferences, often adopt stimuli resulting from a combination of characteristics from multiple variables, and in repeated measure designs. At present, Q methodology has not been adapted to accommodate. We therefore developed a novel analysis procedure allowing Q-methodology to handle these conditions. We propose a protocol requiring five analyses of a decision process to estimate: (1) the preference of stimuli, (2) the dominance of variables, (3) the individual differences, (4) the interaction between individual differences and preference, and (5) the interaction between individual differences and dominance. The guide comes with a script developed in R (R Core Team, 2020) to run the five analyses; furthermore, we provide a case study with a detailed description of the procedure and corresponding results. This guide is particularly beneficial to conduct and analyze experiments in any research on people’s preferences, such as experimental aesthetics, prototype testing, visual perception (e.g., judgments of similarity/dissimilarity to a model), etc.
Introduction
Decision-making is a very complex process during which individuals draw on different resources to inform their choices (Weber and Johnson, 2009). Psychologists have developed a number of theoretical models to interpret decisions (Guitoni and Martel, 1998). This article seeks to contribute to the psychological inquiry into decision-making in relation to preferences (i.e., aesthetic preferences) by extending the application of Q-methodology and by further developing its data analysis capabilities.
Developed by William Stephenson in the 1930s (Stephenson, 1935a,b) Q-methodology was originally designed to investigate subjectivity (e.g., attitudes, viewpoints, perspectives, and so on). It provides a robust and systematic method to reveal consensus and disagreement among responders. While Q-methodology has been widely applied in fields such as sociology (e.g., Hedges, 2014), education (e.g., Gao, 2019) and political sciences (e.g., Lehtonen and Aalto, 2016) it has not yet gained much attention from psychologists interested in decision-making, despite of its methodological advantages that are summarized below. This may be partly due to the fact that conventional Q-methodology studies mostly use statements (with some exceptions, e.g., Gauger and Wyckoff, 1973; Gelineau, 1981; Somerstein, 2014), whereas in psychologists studding preferences usually adopt stimuli such as images, sounds, etc. Furthermore, these stimuli often include a combination of characteristics from multiple variables and they are presented, in repeated measures designs.
To our knowledge, there is no comprehensive guidance on how to conduct a Q-methodology study with stimuli combining characteristics from multiple variables and how to comprehensively analyze the data collected with this procedure. While psychologists usually measure the stimulus characteristics most identified by participants, the conventional analysis in Q-methodology does not typically pay much attention to this aspect. For example, in experimental aesthetics - the field of psychology funded by Fechner (1860) pertaining to the empirical investigation of the sensations evoked by stimuli – psychologists are chiefly concerned with the characteristics of a stimulus which are perceived overall as beautiful or appealing. This article provides a detailed account on how to analyze this data in Q-methodology; thereby promoting the application of Q-methodology in experimental psychology.
This article is organized in four sections. Section one outlines the advantages of Q-methodology. Section two explains why it is meaningful to distinguish between preference and dominance of the variables in study. Section three demonstrates the procedure of measuring dominance (i.e., the relative importance of a variable). Section four provides a comprehensive protocol to conduct the analysis and interpret the data with an example study.
Advantages of Q-Methodology
Many methods to measure Multi-Criteria Decision-Making methods (MCDM) have been proposed; a comprehensive review is presented by Guitoni and Martel (1998). As the authors outlined, none of these methods can be considered optimal for all kind of experiments as they have been developed for specific purposes. For example, the SMART and SMARTS and SMARTER (Edwards, 1977; Edwards and Barron, 1994) which base their analysis on a weight attribution to ratings (or raking in the case of SMARTER) have been specifically developed for market research. Although these methods of analysis could be applied to experimental psychology, they present a number of limitations (see Guitoni and Martel, 1998; Table 1) that restrain their use. For example, elegant methods such as the UTA method (Jacquet-Lagreze and Siskos, 1982) that consider utility functions, have been successfully applied in managerial decision-making, but it might not be appropriate to process ordinal data such as those arising from a study on preferences.
TABLE 1
| Variable | df | Chi-square | p |
| Size | 1 | 2.05 | 0.15 |
| Texture | 1 | 6.44 | 0.004 |
| Contour | 1 | 10.38 | 0.001 |
| Behavior | 3 | 206.74 | <0.001 |
Results of Wald chi-square test.
We advanced a new MCDM specifically devoted to experimental aesthetics which benefits of the advantages of Q-methodology. Firstly, it has a unique data collection method, the Q-sorting procedure, which has several appealing characteristics. In the Q-sorting procedure, participants are required to rank-order a set of stimuli (or statements) into one single continuum based on instruction. The shape of the continuum is quasi-normal (in the sense that it resembles a normal gaussian distribution with more stimuli in the middle than in the tails of the continuum) to form a bell-shaped grid (Brown, 1980)1. Figure 1 shows an example of a Q-sorting grid for 32 stimuli. The figure shows a “typical” configuration for an experiment with 32 stimuli; however, this shape could be altered if desired. Brown (1980) showed that the actual shape of the grid does not affect the analysis of the results.
FIGURE 1
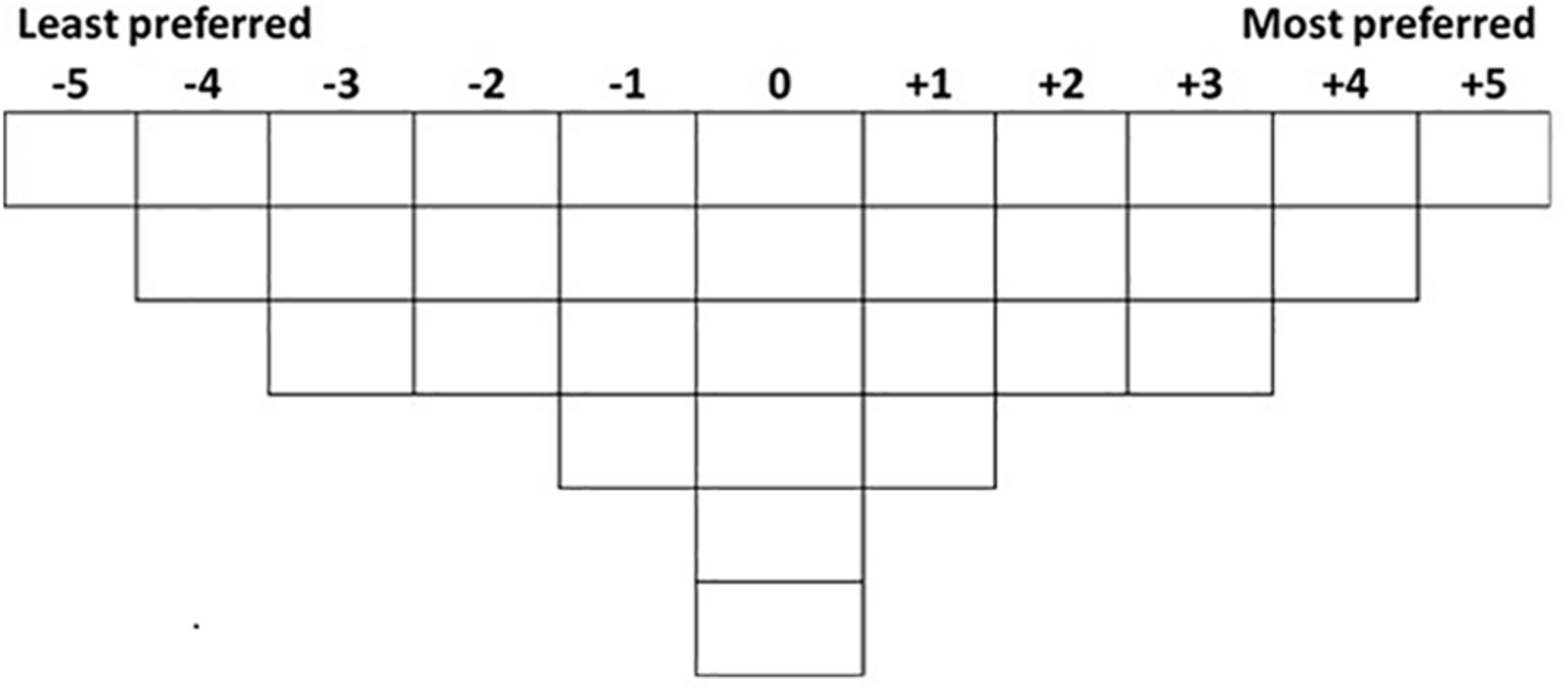
Example of a Q-sorting grid for an experiment with 32 stimuli.
The Q-sorting procedure is less time-consuming, more engaging for participants and more natural than assigning abstract scores using questionnaires with Likert scales (Klooster et al., 2008). Participants are given the opportunity to make a systematic comparison between all the items presented at the same time. Therefore, the Q-sorting outcome is based on a holistic thinking process rather than isolated ratings (Watts and Stenner, 2012). The Q-sorting procedure facilitates the decision process and enables participants to accurately differentiate the subtle differences in their judgments. Moreover, the Q-sorting procedure minimizes the order effect, which psychologists often encounter in experiments (Atmanspacher and Römer, 2012). As all stimuli are presented simultaneously, participants can change the relative rank of each stimulus in the continuum, making therefore possible comparisons among all stimuli. Hence, as order and fatigue effects are minimized and there is the possibility to change the ranking, a more coherent and accurate analysis of the decision process can be obtained.
In Q-methodology studies, Q-factor analysis identifies the clusters of participants who produce similar outcomes. The clustering of participants instead of items differentiates this from a conventional factor analysis. This statistical procedure is similar to Latent Profile Analysis (Vermunt and Magidson, 2002) and clustering analysis (Kaufman and Rousseeuw, 2009), which all serve the purpose of grouping similar participants into clusters. The identification of clusters of participants can be appealing to experimental psychologists who are interested in individual differences. Traditional experimental designs that aim to investigate individual differences often build upon the assumptions that these differences result from demographic or personality traits. Q-methodology instead takes a bottom-up approach to reveal individual differences beyond any prior assumptions. The Q-factor analysis of Q-sorting data generates evidence of individual differences based on the data per se (Zabala and Pascual, 2016). Based on the emerged clusters of participants, psychologists can further explore where the individual differences come from. For example, by examining whether participants’ gender is differently distributed across the Q-factors, a researcher can infer whether gender differences exist.
Furthermore, psychologists may want to explore individual differences even when this is not their primary goal. Appelt et al. (2011) underlined that researchers should not neglect the effects of individual differences. In situations where no clear tendency emerges from the overall sample, it is likely that individual differences have canceled out the expected effect and that the effect was evident but only for a sub-set of participants. For example, in experimental aesthetics, scholars found stable and statistically robust individual preferences which were masked by weak population preference (McManus, 1980; McManus et al., 2010). Q-methodology enables psychologists to detect potential individual differences.
In addition, taking a mixed-methods approach, Q-methodology also includes a post-sorting interview which allows the rankings to be interpreted qualitatively (Watts and Stenner, 2012). Interview data complements the Q-sorting data to provide a more detailed and comprehensive account of the data than other methods.
Preference vs. Dominance
We introduce a new data analysis procedure which will add to these methodological advantages, extending the application of Q-methodology to experimental psychology.
People pay attention to multiple information when making decisions. For example, when judging the aesthetics of a painting, people may consider variables such as the style, the compositions, the colors, etc., at the same time.
People may differ in their preference for a certain variable but agree on the importance of the variable. We refer to the importance of a variable as its dominance. For example, individual A may prefer contemporary art whilst B prefers pop art; but both A and B may regard the style as the dominant variable, the variable on which they put most of the focus for their choice. Similarly, in a study on facial attraction, the researcher might wish to examine preferred eye color or shape of mouth, as well as which of these two variables is the most dominant in determining facial attraction. To recap, we use the term “preference” to indicate the preference for one level over another within the same variable (e.g., preference for blue eyes over green eyes), and the term “dominance” to indicate the importance of a variable across the variables (e.g., dominance of eye color over mouth shape).
By supplementing conventional Q-methodology with the possibility of investigating dominance and distinguishing it from preference, we provide a more comprehensive inquiry to deepen the study of decision making in experimental psychology.
Distinguishing between dominance and preference has an additional advantage. In conventional Q-methodology these two aspects are intertwined with each other and the clusters of people emerging from the Q-factor analysis represent a combination of both aspects. Hence, participants may differ in both preference and dominance, or on just one of them without this explicitly emerging from the analysis. By differentiating between these two aspects of the decision process, it is possible to measure the interactions between Q-factors and both preference and dominance. This is meaningful because it allows clarifying the similarities among people to be identified as well as the differences.
In this way, it is possible to conduct a more comprehensive analysis. In particular, we propose a protocol consisting of five analyses each aimed at answering to a specific research question:
- (1)
Analysis of overall preference: Which are the overall preferred characteristics of each variable?
- (2)
Analysis of overall dominance: Which are the important variables that influence people’s decisions?
- (3)
Analysis of individual differences: Do people differ in their decisions?
- (4)
Analysis of the interaction between individual differences and preferences: Do different clusters of people prefer different characteristics of a variable?
- (5)
Analysis of the interaction between individual differences and dominance: Are different clusters of people driven by different variables?
Importance of a Variable: The Qdominance () Function
The QDominance()function provided in the supplemented QDominance.R file is designed to measure the dominance of each variable. The analysis of dominance has a similar meaning in a regression analysis of finding out whether a variable can predict an outcome. QDominance() utilizes the Q-sorting data directly and provides a more straightforward way to address the issue of the importance of a variable.
The dominance (D) of each variable (v) is given by the maximum difference between the sums of scores of each level (l) in a variable with n levels (equation 1):
This is the maximum value resulting from the combinations of two of the differences between the sums of scores of the stimuli in the same level with those of the stimuli in the other levels. Intuitively, the dominance of a variable is a measure of the spread of the stimuli across the Q-sorting grid based on its levels. If a variable is very important, all the stimuli or items in the same level that share a desirable characteristic will receive a high score whilst the stimuli which do not possess that specific desirable characteristic, will all receive a low score. The difference between the scores will be relatively large in this case. Vice-versa if a variable is not important, the stimuli in the same level will be scattered over the grid rather than receiving extreme scores, making the difference between the sums relatively small.
Equation 1, however, cannot be used directly to compare different variables in experimental designs where variables have different number of levels. This is because of the nature of the Q-grid; the smaller the number of the level of a variable is, the higher the maximum difference will be. That is, the maximum difference between the levels of a variable depends on the number of its levels. For example, for a variable with only two levels the maximum difference that would be obtained would be when all the stimuli in one level (i.e., half of the experimental stimuli) are highly ranked whilst the stimuli in the other level (i.e., the other half of the experimental stimuli) are ranked lowly. If instead a variable has 4 levels, the maximum difference that can be obtained would be when only 1/4 of the experimental stimuli are highly ranked and 1/4 are lowly ranked. Variables with a lower number of levels therefore have a higher potential maximum difference. For this reason, Dv has to be weighted for the maximum difference that each variable can get, which depends on the number of its levels n. Equation 2 shows how to calculate the weighted dominance for variable v (WDv).
The maximum difference for a certain variable (the denominator in equation 2) is twice the maximum the sum of the rating scores of stimuli (or items) at the same level. This is the sum of each score in the Q-sort grid (scoreingrid) from the maximum value in the grid (maxingrid; +5 in the example in Figure 1) backward to the number of items or stimuli (nstimuli) divided by the number of levels in the variable v (nv).
The product between the weighted scores and the average of the maximum differences between the v variables gives the Comparable Score Difference for each variable (CSDv). This difference among the scores is comparable across all variables (equation 3).
It is useful to get the proportion of dominance for each variable (PDv). This is the weighted average of the weighted dominance (WDv), shown in equation 4:
These equations are implemented in the supplemented QDominance() function. This function takes three arguments as input: 1) scores: a vector of scores or a vector/matrix of Q-factor scores; 2) v: A matrix indicating the levels for each variable; and 3) isfs: logical value: if this is set to True, scores are Q-factor scores, generated by the Q-factor analysis (see below Analysis 3); if False, they are scores from the Q grid; that is the ranks provided by all the participants (default is False).
QDominance() returns the Proportion of Dominance (PD) for each variable v if isfs is False; and it returns both the Comparable Score Difference (CSD) as well as the Proportion of Dominance (PD) for each variable v if isfs is True.
By incorporating QDominance() in the original Q-methodology, this procedure can be used to address a wide range of research questions in the decision process; specifically, the five analysis outlined above. The following section presents a detailed guide of how to use the protocol. An example with simulated data is provided to help readers gain a better understanding of the method.
Protocol
To conduct a Q-methodology study, the first step is to design the Q-sorting grid and prepare the stimuli according to the research question. Readers seeking detailed instruction on how to prepare for Q-sorting can refer to Brown (1980). To demonstrate how the protocol works, we present a study example on Interactive Objects (IOs) which are objects which contain electronic components that exhibit autonomous behavior when handled, e.g., vibrating, playing a sound, or lighting-up. This is a repetition of a study conducted by Soranzo et al. (2018) which used a the following method. In a first qualitative phase, the aesthetic dimensions to be measured were identified. In a second, experimental phase, participants rated each object on a scale of 1 to 7 on each of the dimensions emerged in the first phase. The study overall included a large number of participants (more than 600) and one variable was measured between subjects. In this study, instead, only eighteen participants were included, and all the variables were measured within subjects. This small number of participants was decided to examine whether similar results obtained with a large sample size can be replicated with a smaller one by adopting the Q-methodology. A small number of participants is typical in Q methodology (Brown, 1980). Participants were provided with thirty-two IOs with different levels of four variables: 1) Size, 2) Surface texture, 3) Contour and 4) Behavior. The variables differ in the number of levels (this illustrates the procedure properly) as indicate in Table 2. Participants were asked to rank-order these IOs into the quasi-normal Q-grid.
TABLE 2
| Form | Behavior | ||
| Size | Surface texture | Contour | |
| Small (7.5 cm) | Smooth (plastic) | Round (sphere) | Emit a light |
| Large (15 cm) | Rough (fabric) | Angular (cube) | Play a sound |
| Vibrate | |||
| Quiescent | |||
The variables with the corresponding levels of the study example.
In line with Watts and Stenner’s guidance (Watts and Stenner, 2012), with a total of thirty-two stimuli, a grid such as the one in Figure 1, with ranks ranging from −5 (’the least preferred’) to +5 (’the most preferred), is appropriate as it provides adequate variety in the rankings, yet it does not over-complicate the procedure.
Data Preparation
After the experiment has been conducted, the data needs to be available in a tabular/matrix format and saved as data.csv file. The Q-sorting data are organized in a matrix with stimuli in rows and participants in columns. In addition to the data file, users also need to generate a spreadsheet indicating the levels of variables for each of their stimulus (the variables.csv file). The variable file is organized as stimuli in rows and variables in columns. Each row indicates the levels of each variable in the dataset. Levels can be entered as names or numbers.
The dataset (data.csv) and the variable file (variable.csv) of the IOs study are included in the Supplementary Materials for download.
R Scripts
There are two R files: the Qdominance.R which runs the Qdominance() function and the QmultiProtocol.R which conducts the five analysis outlined above. A step-by-step tutorial of applying the QmultiProtocol.R is also included in the Supplementary Materials. The complete project (i.e., R scripts and data examples) is available online2.
The QmultiProtocol.R makes use of the following packages:
’qmethod’ (Zabala, 2014);
’ordinal’ (Christensen, 2018);
’data.table’ (Dowle et al., 2019).
Users need to store both R scripts in the same working directory with the two ∗.csv spreadsheets (i.e., the dataset and the variable file). The protocol can be readily used without further programming (if not wished) apart from setting the working directory’s path in Line 1 by the setwd()function and specifying the number of Q-factors in Line 3. The QmultiProtocol.R generates a text file named Qfact.txt which contains the information needed to decide how many Q-factors to select (see Analysis 3 for suggestions on how to decide the number of Q-factors). The Qfact.txt is automatically saved in the same working directory as specified by the user.
Analysis 1: Overall Preference: Which Are the Overall Preferred Characteristics of Each Variable?
The first analysis aims to answer the question of whether people share similar preferences, for example, whether overall the participants prefer Level 1 to Level 2 of Variable A. Q-sorting data is distributed at an ordinal level and data are entangled and interdependent because there is a fixed number available for each rank (see Figures 1, 2). Therefore, data need to be analyzed with an ordered-probit model (Liddell and Kruschke, 2018). Moreover, Q-sorting data have an additional characteristic: the median and deviance of the ranks are the same for all subjects. Hence, although data come from a within-subject procedure, there is no subject-level variation, i.e., no random effects.
FIGURE 2
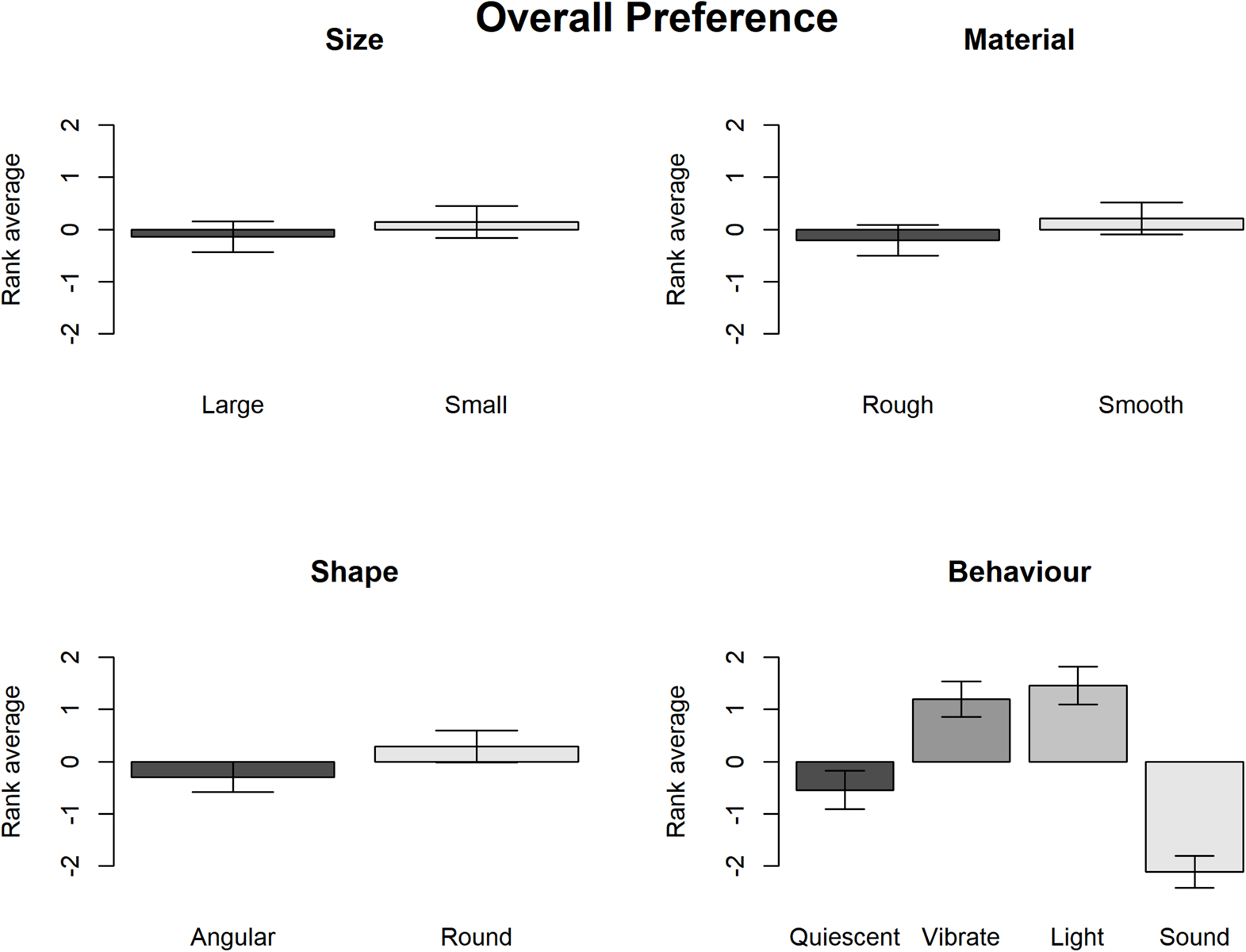
The rank of overall preference for each variable of the study example.
The QmultiProtocol.R adopts the frequentist approach and runs the ordered-probit model by the clm() function included in the “ordinal” package (Christensen, 2018). The effects of the independent variables are tested by analyzing the deviance, which is analogous to analyzing the variance in linear models.
Model assumptions are tested by the nominal_test() and the scale_test() functions; which provide the likelihood ratio test of the proportional odds assumption and of the scale effect assumption, respectively.
Lines 19–109 in QmultiProtocol.R perform Analysis 1. The clm() function is used to examine the cumulative link model for the overall preference. As for the present IOs study example, the estimates and corresponding z scores of each variable are illustrated in Table 3.
TABLE 3
| Estimate | Z | p | |
| SizeSmall | 0.21 | 1.43 | 0.152 |
| TextureSmooth | 0.37 | 2.47 | 0.013 |
| ContourRound | 0.48 | 3.22 | 0.001 |
| BehaviourVibrate | 1.48 | 6.91 | <0.001 |
| BehaviourLight | 1.75 | 7.96 | <0.001 |
| BehaviourSound | −1.40 | −6.42 | <0.001 |
The variable estimates of the study example.
The nominal test reveals that there is no violation of the partial proportional odds (all ps > 0.02) whilst there is a small violation of the scale assumption for the Surface texture variable (LRT(1) = 6.09; p = 0.014). Therefore, the results from this variable should be interpreted with caution.
Subsequently, the Wald chi-square test shows that participants demonstrated relatively strong overall preferences in terms of the Surface texture, Contour and Behavior but not the Size (see Table 1). The graphs in Figure 2 show that overall participants preferred smooth to rough surface texture, round to angular shape and lighting/vibrating to sounding/quiescent objects.
Analysis 2: Overall Dominance: Which Are the Important Variables That Influence People’s Decisions?
In addition to overall preference, psychologists may be interested in overall dominance which reveals the variable(s) which obtained the most attention from participants. Analysis 2 addresses this issue by adopting the QDominance()function. The analysis procedure is carried out by Line 112 to 148 in QmultiProtocol.R. Lines 142–148 generate a matrix of dominance weights with participants in rows and variables in columns. The result of the IOs study example is presented in Table 4.
TABLE 4
| Participant ID | Size | Texture | Contour | Behavior |
| P01 | 0.19 | 0.21 | 0.06 | 0.53 |
| P02 | 0.20 | 0.23 | 0.04 | 0.53 |
| P03 | 0.17 | 0.48 | 0.13 | 0.21 |
| P04 | 0.14 | 0.27 | 0.23 | 0.36 |
| P05 | 0.18 | 0.09 | 0.05 | 0.68 |
| P06 | 0.05 | 0.16 | 0.16 | 0.63 |
| P07 | 0.08 | 0.15 | 0.38 | 0.40 |
| P08 | 0.18 | 0.49 | 0.04 | 0.30 |
| P09 | 0.14 | 0.23 | 0.23 | 0.39 |
| P10 | 0.18 | 0.34 | 0.04 | 0.44 |
| P11 | 0.03 | 0.03 | 0.13 | 0.81 |
| P12 | 0.02 | 0.00 | 0.24 | 0.74 |
| P13 | 0.02 | 0.44 | 0.08 | 0.46 |
| P14 | 0.02 | 0.37 | 0.21 | 0.40 |
| P15 | 0.07 | 0.18 | 0.22 | 0.52 |
| P16 | 0.44 | 0.15 | 0.13 | 0.28 |
| P17 | 0.09 | 0.03 | 0.00 | 0.88 |
| P18 | 0.15 | 0.14 | 0.20 | 0.50 |
| Mean | 0.13 | 0.22 | 0.14 | 0.50 |
The variable weights for each participant of the study example.
The weights are compared by the lm()function as they distribute at an interval level. This is implemented by Lines 135–136 of the QmultiProtocol.R. The results of the IOs study example are shown in Figure 3 and Tables 5, 6. As can be seen, it seems that overall the participants took into consideration the Behavior variable more than the other variables, which suggests that the Behavior variable plays a relatively dominant role in influencing participants’ preference of IOs.
FIGURE 3
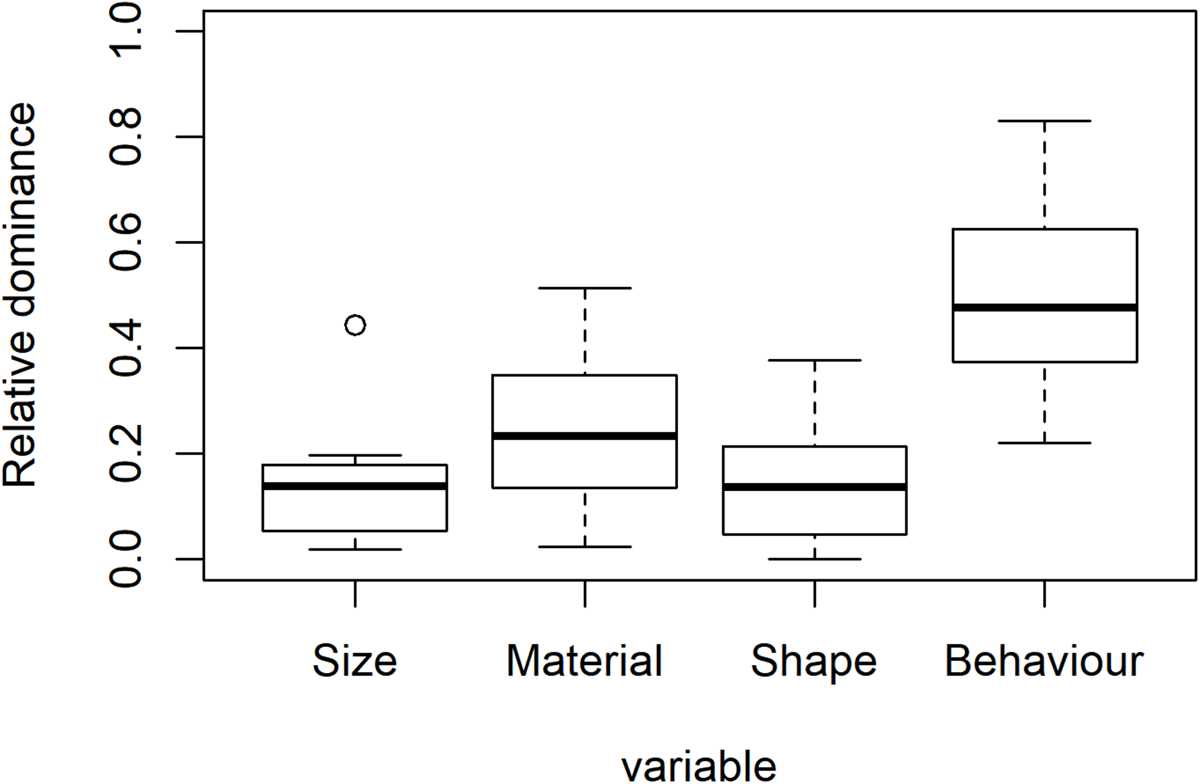
The overall dominance for the four variables of the study example.
TABLE 5
| Estimate | t-value | p | |
| Intercept (Size) | 0.13 | 4.04 | <0.001 |
| Texture | 0.09 | 1.96 | 0.054 |
| Contour | 0.01 | 0.25 | 0.806 |
| Behavior | 0.37 | 8.06 | <0.001 |
The estimates of the linear model of overall dominance.
TABLE 6
| Df | Sum squares | Mean squares | F | p | |
| Variables | 3 | 1.62 | 0.54 | 28.34 | <0.001 |
| Residuals | 68 | 1.30 | 0.02 |
Result of analysis of variance.
To summarize, the analysis 1 and 2 generate different information about the decision process for all participants, namely, preference and dominance. To use the IOs study as an example, the analysis of preference suggests that, overall, participants expressed specific preferences for surface texture, shape and behavior of the IOs but not for the size. Furthermore, the analysis of dominance suggests that the Behavior variable plays the most important role in participants’ preference of IOs overall.
Analysis 3: Individual Differences: Do People Differ in Their Decisions?
Analysis 3 consists of three steps: Q-factor analysis, variance analysis of Q-factor scores and analysis of dominance in clusters. Each analysis sheds light on a different aspect of the individual differences in people’s decision processes.
Q Factor Analysis
Q-factor analysis groups participants together instead of items (Brown, 1980). Q-factor analysis has been used in several experimental psychology studies to examine individual differences. For example, McManus et al. (2010) found that the participants could be categorized into two clusters based on their aesthetic preferences for rectangles: those who preferred rectangles closer to a square shape, and those preferring elongated rectangles. Spehar et al. (2016) identified two clusters of participants based on their appreciation of fractal patterns: one cluster preferred images with extreme values of the spectrum slope and the other preferred intermediate slope values. Soranzo et al. (2018) found that the participants of their experiments could be categorized into two clusters based on their aesthetic preferences for interactive objects (i.e., physical artifacts that exhibit autonomous behavior when handled): one cluster based their judgments on the objects’ behavior only and the other also took into consideration the objects’ texture and shape. Apparently, experimental psychologists have been paying attention to individual differences, especially in situations where the overall preference or dominance may have been masked by individual differences that balance out the effect.
As in conventional factor analysis, principal component analysis(PCA) or centroid factor analysis is often used to analyze the Q-sorting data (Brown, 1980). The QmultiProtocol.R (Lines 153–158) employs the ‘qmethod’ (Zabala, 2014) to conduct PCA with Varimax rotation. Users can adjust the method of rotation based on their own data.
As mentioned earlier, users need to enter the number of Q-factors to extract in Line 3 of QmultiProtocol.R. The number of Q-factors is dependent on the data as well as the research topic. Watts and Stenner (2012) provided a discussion on the criteria to use to decide how many Q-factors to extract, including the Kaiser-Guttman criterion (Guttman, 1954; Kaiser, 1960, 1970), the magic number seven (Brown, 1980), the scree test (Guttman, 1954; Cattell, 1966), parallel analysis (Horn, 1965) and two (or more) significantly loading Q sorts and Humphrey’s Rule (Brown, 1980). To decide how many Q-factors to extract, users can check these criteria in the text file Qfact.txt generated by export.qm() function (Zabala, 2014) in Line 158 of QmultiProtocol.R. Users can test out different factor solutions to identify the one that best fits the data (see Brown, 1980; Watts and Stenner, 2012 for more details).
In the IOs study example, we compared different factor solutions with regard to the factor eigenvalues, the variance explained by factors, the number of participants loaded on each factor and the factor scores. As a result, the three-factor solution was chosen because it fits the data best and demonstrates a sound representation of the participants’ Q-sorting outcomes. The three Q-factors account for 70% of the variance. Table 7 shows the factor loadings of participants. Eight participants were significantly loaded on Q-factor 1, six on Q-factor 2 and three on Q-factor 3, which suggests that there are three clusters of participants expressing different preferences of the IOs. It is important to note that the participants are grouped on the basis of their differences in decision process which preference and dominance are intertwined. In the remaining of the Protocol these aspects are further explored.
TABLE 7
| Participant | Q-factor 1 | Q-factor 2 | Q-factor 3 |
| P01 | 0.28 | 0.70* | 0.29 |
| P02 | 0.24 | 0.74* | 0.05 |
| P03 | −0.36 | 0.65* | −0.38 |
| P04 | 0.58* | 0.18 | 0.47 |
| P05 | 0.47 | 0.61* | −0.04 |
| P06 | 0.54 | 0.43 | 0.41 |
| P07 | 0.16 | 0.80* | 0.22 |
| P08 | 0.82* | −0.16 | 0.13 |
| P09 | 0.71* | 0.16 | 0.16 |
| P10 | 0.89* | 0.27 | −0.15 |
| P11 | 0.02 | −0.04 | 0.86* |
| P12 | 0.09 | 0.28 | 0.86* |
| P13 | 0.91* | 0.16 | 0.02 |
| P14 | 0.83* | 0.26 | 0.05 |
| P15 | 0.20 | 0.81* | 0.37 |
| P16 | 0.52* | 0.28 | 0.10 |
| P17 | 0.06 | 0.17 | 0.85* |
| P18 | 0.70* | 0.62 | 0.12 |
| Eigenvalue | 5.4 | 4.1 | 3.1 |
| Variance | 30% | 23% | 17% |
The Q-factor loadings of participants of the study example.
*Indicates significant loading.
Table 8 illustrates the factor scores of the IOs for each Q-factor. Using the object labeled LRRL (Large-Rough-Round-Lighting) as an example, participants clustered into Q-factor 1, on average (weighted average is used to calculate the factor scores of each stimuli; Watts and Stenner (2012) ranked it as slightly less preferred (−1); participants clustered into Q-factor 2, on average, ranked it as most preferred (+5) and participants clustered into Q-factor 3, on average, ranked it as slightly referred (+1). By reading these factor scores, we can gain an understanding of how different clusters of participants rank-ordered the IOs in the Q-sorting procedure.
TABLE 8
| IO | Q-factor 1 | Q-factor 2 | Q-factor 3 |
| LRAQ | −2 | 0 | −2 |
| LRAV | −2 | 1 | 2 |
| LRAL | −1 | 1 | −1 |
| LRAS | −4 | −2 | 0 |
| LRRQ | −1 | 2 | −3 |
| LRRV | 0 | 4 | 4 |
| LRRL | −1 | 5 | 1 |
| LRRS | −4 | −3 | 1 |
| LSAQ | 1 | −2 | −4 |
| LSAV | 1 | −1 | 2 |
| LSAL | 4 | 0 | 2 |
| LSAS | −1 | −4 | −1 |
| LSRQ | 2 | −1 | −2 |
| LSRV | 3 | 2 | 3 |
| LSRL | 3 | 3 | 1 |
| LSRS | −3 | −3 | −1 |
| SRAQ | 0 | 0 | −4 |
| SRAV | 0 | 2 | 3 |
| SRAL | 0 | 1 | 0 |
| SRAS | −5 | −2 | 0 |
| SRRQ | 0 | 1 | −3 |
| SRRV | 0 | 3 | 5 |
| SRRL | 1 | 4 | 0 |
| SRRS | −3 | −3 | 0 |
| SSAQ | 3 | −1 | −5 |
| SSAV | 2 | 0 | 3 |
| SSAL | 5 | 0 | 1 |
| SSAS | −3 | −4 | −2 |
| SSRQ | 1 | −1 | −3 |
| SSRV | 2 | 0 | 4 |
| SSRL | 4 | 3 | 0 |
| SSRS | −2 | −5 | −1 |
The Q factor scores of each IO.
The first letter of IO represents the size (L = Large, S = Small); the second is the surface texture (R = Rough, S = Smooth); the third is the contour (A = Angular, R = Round); and the forth is the behavior (Q = Quiescent, V = Vibrate, L = Light, S = Sound).
Analysis of Variance of Q-Factor Scores for Preference
Subsequently, analysis of variance on the factor scores can be run to examine whether there is a difference in preference within variable for each cluster of participants (Brown, 1993). This is carried out from Line 160 to 171 in QmultiProtocol.R. Table 9 shows the results of the IOs study example.
TABLE 9
| Size | Texture | Contour | Behavior | ||
| Q-factor 1 | Df1, Df2 | 1, 30 | 1, 30 | 1, 30 | 3, 28 |
| F | 0.48 | 13.01** | 0.08 | 12.06*** | |
| p | 0.495 | 0.001 | 0.786 | <0.001 | |
| Q-factor 2 | Df1, Df2 | 1, 30 | 1, 30 | 1, 30 | 3, 28 |
| F | 0.08 | 3.54 | 2.45 | 19.95*** | |
| p | 0.786 | 0.070 | 0.128 | <0.001 | |
| Q-factor 3 | Df1, Df2 | 1, 30 | 1, 30 | 1, 30 | 3, 28 |
| F | 0.08 | 0.02 | 0.69 | 59.80*** | |
| p | 0.786 | 0.892 | 0.413 | <0.001 | |
The results of analysis of variance of Q-factor scores.
Analysis of Dominance in Clusters
To further explore each cluster of participants, the factor scores can be analyzed using the QDominance() function by setting the isfs parameter to True (Line 175 in QmultiProtocol.R). The result generates the dominance weights for each cluster of participants (i.e., Q-factors). It provides a straightforward overview of how the variables are weighted by each cluster of participants.
As for the present IOs study example, the results of analysis of dominance in clusters are illustrated in Table 10 and Figure 4, participants in Q-factor 2 and 3 mainly paid attention to the Behavior variable; whereas participants in Q-factor 1 considered both Surface texture and Behavior variables. These dominance weights depict a straightforward picture of how each cluster of participants differs or concurs in the dominance of decision process.
TABLE 10
| Q-factor 1 | Q-factor 2 | Q-factor 3 | |
| Size | 0.093 | 0.038 | 0.049 |
| Texture | 0.410 | 0.248 | 0.024 |
| Contour | 0.037 | 0.210 | 0.146 |
| Behavior | 0.459 | 0.504 | 0.780 |
The dominance weights for each Q-factor.
FIGURE 4
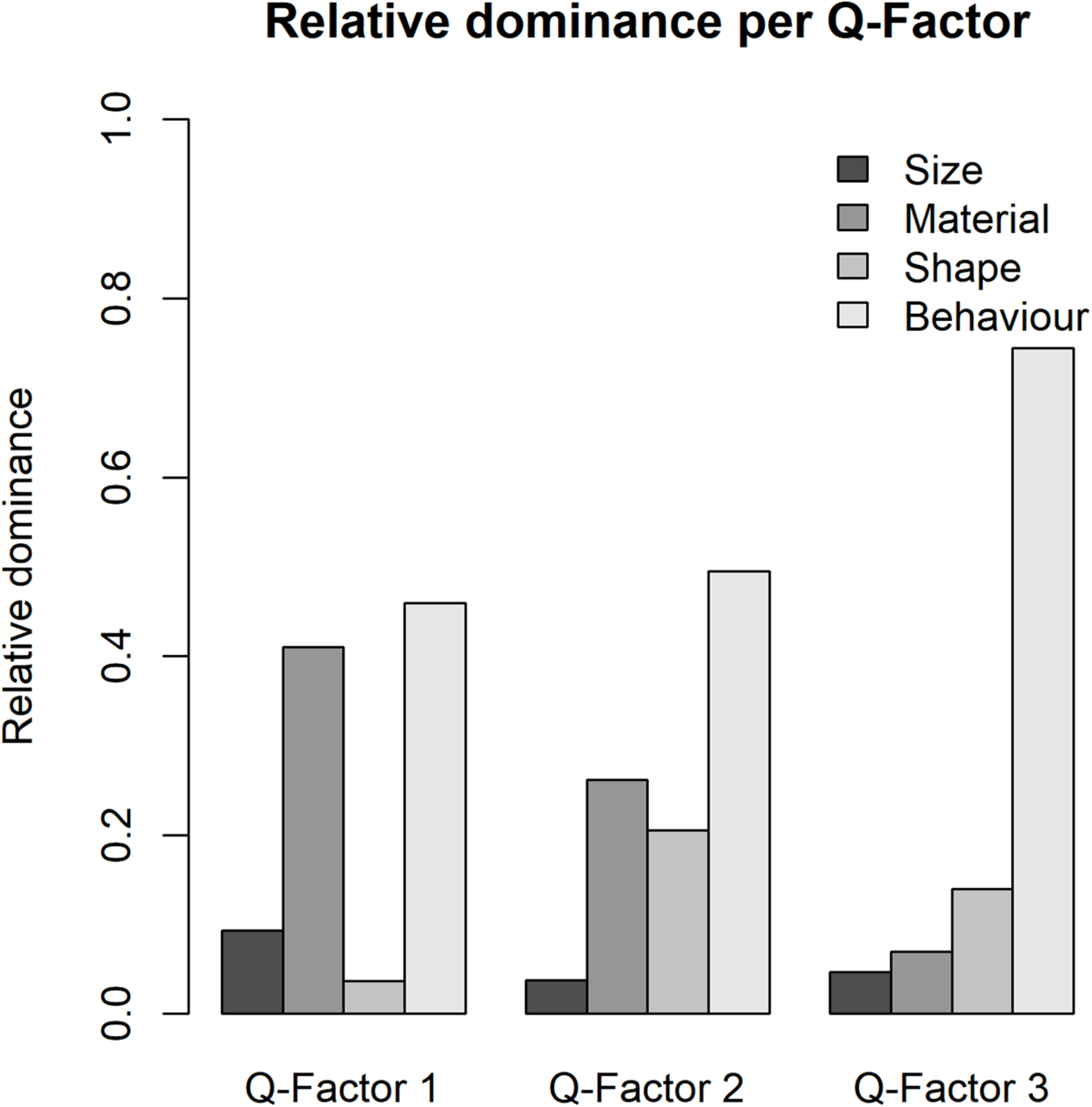
The bar chart of the dominance for each Q-factor of the study example.
Analysis 4: Interaction Between Individual Differences and Preferences: Do Different Clusters of People Prefer Different Characteristics of a Variable?
Analysis 4 focuses on the interaction between individual differences and preferences. Accordingly, QmultiProtocol.R runs a cumulative link model by the clm() function (Christensen, 2018).
Detailed estimates and coefficients of the IOs study example are presented in Tables 11, 12. Figure 5 shows these interactions in graphs. As can be seen, interesting interactions emerge when the preferences are explored as a function of individual differences. For example, participants in the Q- factor 1 expressed a preference for rough to smooth texture in whilst participants in Q-factors 2 preferred smooth to rough texture. Besides, the interaction between preference of behavior and the Q-factors shows that the participants in Q-factor 3 disliked quiescent objects whereas participants in Q-factor 1 and 2 showed a strong dislike of sounding objects.
TABLE 11
| Estimate | Z | p | |
| Q-factor.2 | −0.18 | −0.37 | 0.710 |
| Q-factor.3 | 0.02 | 0.04 | 0.968 |
| SizeSmall | 0.22 | 1.01 | 0.311 |
| TextureSmooth | 0.33 | 1.46 | 0.143 |
| ContourRound | 0.26 | 1.14 | 0.253 |
| BehaviourVibrate | 1.57 | 4.13 | <0.001 |
| BehaviourLight | 1.63 | 3.52 | <0.001 |
| BehaviourSound | −1.28 | −3.32 | <0.001 |
| Q-factor.2:SizeSmall | −0.07 | −0.20 | 0.84 |
| Q-factor.3:SizeSmall | 0.10 | 0.22 | 0.82 |
| Q-factor.2: TextureSmooth | −0.22 | −0.63 | 0.53 |
| Q-factor.3: TextureSmooth | 0.44 | 1.01 | 0.31 |
| Q-factor.2: ContourRound | 0.61 | 1.78 | 0.07 |
| Q-factor.3: ContourRound | 0.03 | 0.06 | 0.95 |
| Q-factor.2: BehaviourVibrate | 0.81 | 1.32 | 0.19 |
| Q-factor.3: BehaviourVibrate | −0.19 | −0.29 | 0.77 |
| Q-factor.2: BehaviourLight | 0.15 | 0.28 | 0.78 |
| Q-factor.3: BehaviourLight | 0.30 | 0.47 | 0.64 |
| Q-factor.2: BehaviourSound | 0.28 | 0.46 | 0.64 |
| Q-factor.3: BehaviourSound | −0.70 | −1.04 | 0.30 |
The variable estimates of the study example.
TABLE 12
| Variable | df | Chi-square | p |
| Factor * Size | 2 | 0.13 | 0.935 |
| Factor * Texture | 2 | 1.98 | 0.372 |
| Factor * Contour | 2 | 3.52 | 0.172 |
| Factor * Behavior | 6 | 5.32 | 0.503 |
Result of Wald chi-square test for the Preference per Q-factor interactions.
FIGURE 5
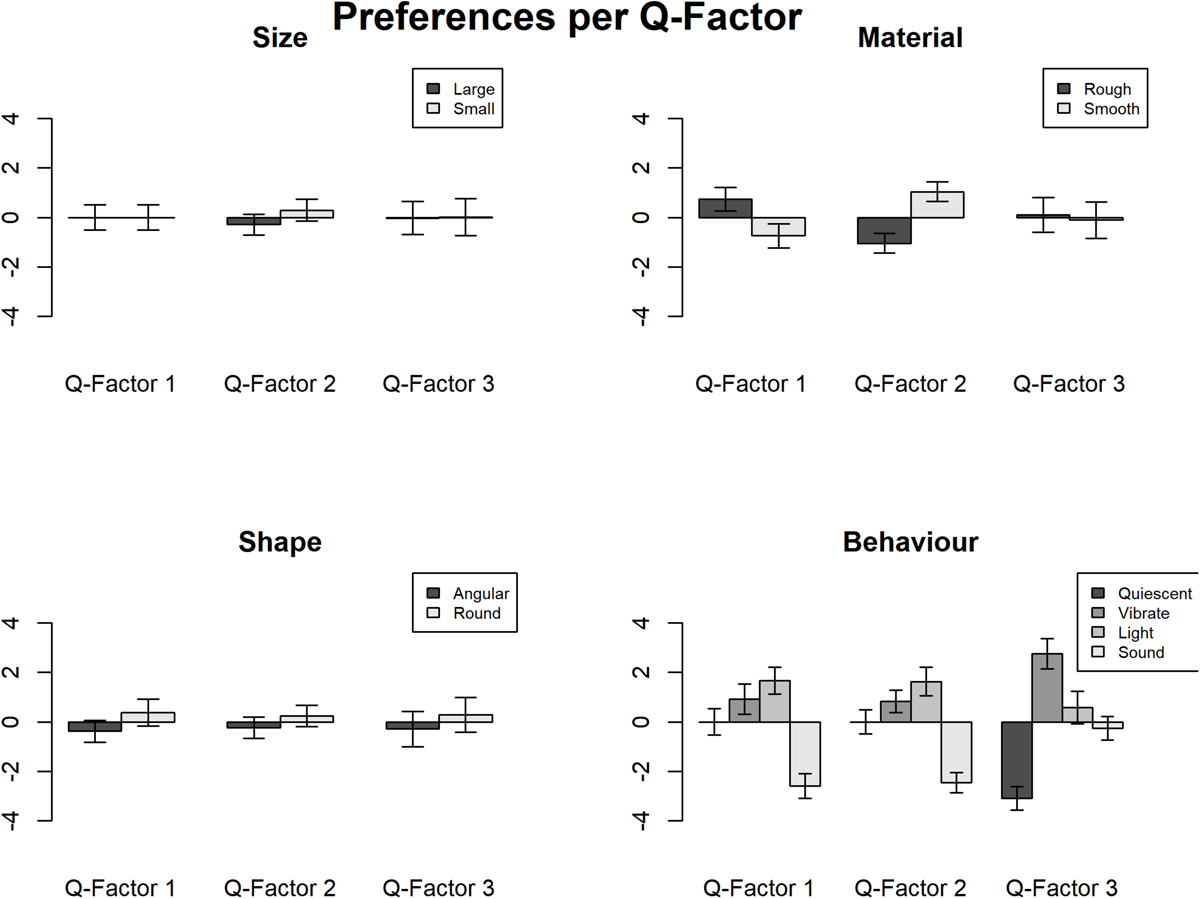
The ranks of preference of each of the three Q-factors of the study example.
Analysis 5: Interaction Between Individual Differences and Dominance: Are Different Clusters of People Driven by Different Variables?
Analysis 5 focuses on the interaction between individual difference and dominance. It is conducted by simply adding a between-subjects variable indicating the Q-factor of each participant to the dominance weights obtained by QDominance(). A Linear model with interaction between individual differences and dominance is conducted subsequently as shown in QmultiProtocol.R (Lines 304–332).
In the present IOs study example, the results are shown in Figure 6 and Tables 13, 14. As can be inferred from the results, participants in Q-factor 3 were considerably different from participants in Q-factor 1 and 2 in terms of the variables they paid attention to when choosing an IO.
FIGURE 6
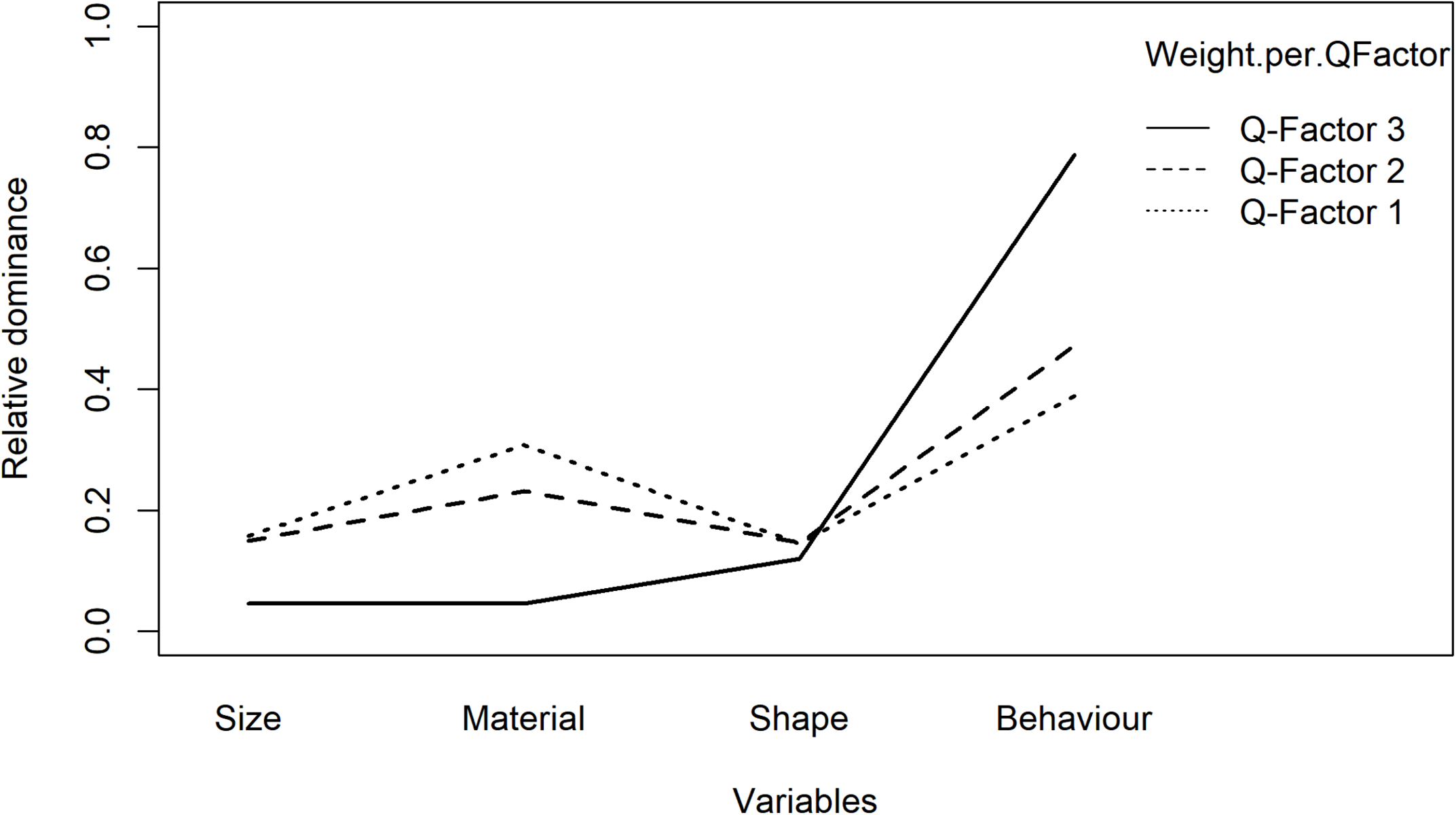
The interaction between the dominance and the Q-factors of the study example.
TABLE 13
| Estimate | t-value | p | |
| Intercept (Size) | 0.16 | 4.06 | <0.001 |
| Texture | 0.14 | 2.61 | 0.011 |
| Contour | −0.01 | −0.24 | 0.815 |
| Behavior | 0.23 | 4.22 | <0.001 |
| Factor2 | −0.01 | −0.14 | 0.892 |
| Factor3 | −0.11 | −1.48 | 0.146 |
| Texture*Factor2 | −0.07 | −0.84 | 0.406 |
| Contour*Factor2 | 0.01 | 0.12 | 0.908 |
| Behavior*Factor2 | 0.09 | 1.12 | 0.273 |
| Texture*Factor3 | −0.17 | −1.63 | 0.109 |
| Contour*Factor3 | 0.09 | 0.82 | 0.418 |
| Behavior*Factor3 | 0.53 | 4.99 | <0.001 |
Estimates of the linear model of the interaction between individual differences and dominance.
TABLE 14
| Df | Sum squares | Mean squares | F | p | |
| Variables*Factor | 6 | 0.59 | 0.10 | 8.02 | <0.001 |
| Residuals | 56 | 0.68 | 0.01 |
Result of analysis of variance.
Validation of the Method
As mentioned, the aesthetics of the IOs has been measured in Soranzo et al. (2018). Two phases were carried out in the study, a qualitative phase to individuate the aesthetics dimensions involved and a quantitative phase where participants were requested to rate each IO on a Likert scale for each of the dimensions emerged in the first study. In the quantitative phase, over 600 participants were needed and one variable was manipulated between subjects to minimise participants’ fatigue. Results obtained with the new method are consistent with those obtained with the traditional method in terms of the preferences: favored aesthetics features are vibration (in line with Carbon and Jakesch, 2013), roughness (in line with Jehoel et al., 2005) and roundness (in line with Bertamini et al., 2016). As seen, with only 18 participants it was possible, in this case, to get comparable results as with over 600. In addition, being the task more enjoyable and quicker for the participants it was possible to run all the variables within-participants allowing for more reliable results.
Moreover, clear advantages of the new procedure are the following:
Dominance emerged more clearly. With traditional Likert scale methods, the dominance of a variable could be inferred only indirectly, whilst this procedure explicitly reveals this feature.
Q-factors are clearer. Both analyses showed similar factorial solutions; however, with the new method it was possible to compare both preference and dominance for the different clusters of participants.
The qualitative data were obtained directly, from the same participants that ranked the IOs, speeding up the procedure. Such qualitative data generate in-depth perspective on how participants make aesthetic decisions during experiments.
Limitations
There are a few limitations in applying this method. Firstly, it requires a relatively large number of stimuli for Q-sorting to ensure the validity and credibility of statistics tests. Secondly, given that all the stimuli need to be presented at the same time for participants to choose from, it may turn out to be tricky to conduct online Q-sorting or use digital stimuli because they may not all fit in the screen. Finally, as Q methodology is not yet widely used in experimental pscyhology, the researcher may require more effort to describe the method to disseminate their finding.
Conclusion
This project extends the application of Q-methodology to experimental psychology by incorporating ‘QDominance()’ to analyze data varying in multiple variables and to interpret the dominance. The combination of Q-methodology with ‘QDominance()’ has numerous methodological advantages and can bring about new insights into the field of experimental psychology.
We provide a protocol of five analyses which are adaptable to a wide range of psychological experiments. While this guide adopts a specific experiment on aesthetics study as the example, the same procedure can be used in various aesthetics contexts such as preferences or judgments of similarity/dissimilarity to a model. By following the protocol or picking and choosing the analysis as needed, experimental psychologists can address a variety of research questions. An R script to run the five analyses is provided which can be readily used with very little further programming.
The advantages of this method are evident when compared with more traditional methods and can be summarized as follow: quicker and more enjoyable for the participants (giving rise to more reliable results); more straightforward demonstration of clearer Q-factors, clearer and direct comparison between preference and dominance among the Q-factors.
In addition, while the protocol mainly focuses on further developing the quantitative analysis procedure of Q-methodology, the qualitative analysis of post-sorting interview data should not be neglected. Experimental psychologists can make the most of the methodological advantages of Q-methodology by applying this protocol together with proper qualitative analysis of the post-sorting interview in Q.
Statements
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, and here: https://osf.io/pzvfb. Further inquiries can be directed to the corresponding author.
Ethics statement
The studies involving human participants were reviewed and approved by Sheffield Hallam University ethics committee. The patients/participants provided their written informed consent to participate in this study.
Author contributions
AS developed the R script and the Dominance function, and wrote the manuscript. JG applied the method to a practical example and wrote the manuscript. All authors contributed to the article and approved the submitted version.
Acknowledgments
The reviewers MB and DL are gratefully acknowledged.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. The reviewer MB declared a past co-authorship with one of the authors, AS, to the handling editor.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.556509/full#supplementary-material
Footnotes
1.^There is a debate about whether the use of free distributions is acceptable in Q methodology. Interested readers can refer to Watts and Stenner, 2012, p.77.
References
1
AppeltK. C.MilchK. F.HandgraafM. J.WeberE. U. (2011). The decision-making individual differences inventory and guidelines for the study of individual differences in judgment and decision-making research.Judgm. Decis. Mak.6252–262.
2
AtmanspacherH.RömerH. (2012). Order effects in sequential measurements of non-commuting psychological observables.J. Math. Psychol.56274–280. 10.1016/j.jmp.2012.06.003
3
BertaminiM.PalumboL.GheorghesT. N.GalatsidasM. (2016). Do observers like curvature or do they dislike angularity?Br. J. Psychol.107154–178. 10.1111/bjop.12132
4
BrownS. (1993). A Primer on Q-methodology.Operant Subjectivity1691–138.
5
BrownS. R. (1980). Political Subjectivity: Applications of Q-methodology in Political Science.New Haven: Yale University Press.
6
CarbonC. C.JakeschM. (2013). A model for haptic aesthetic processing and its implications for design.Proc. IEEE1012123–2133. 10.1109/jproc.2012.2219831
7
CattellR. B. (1966). The scree test for the number of factors.Mult. Behav. Res.1245–276. 10.1207/s15327906mbr0102_10
8
ChristensenR. H. B. (2018). ordinal - Regression Models for Ordinal Data. R package version 8-25. Avaliable at: http://www.cran.r-project.org/package=ordinal/(accessed December 15, 2019).
9
DowleM.SrinivasanA.GoreckiJ.ChiricoM.StetsenkoP.ShortT.et al (2019). Package ‘data. table’.
10
EdwardsW. (1977). How to use multiattribute utility measurement for social decision making.IEEE Trans. Syst.Man Cybernetics SMC7326–340.
11
EdwardsW.BarronF. H. (1994). SMARTS and SMARTER: improved simple methods for multiattribute utility measurement.Organ. Behav. Hum. Dec.60306–325. 10.1006/obhd.1994.1087
12
FechnerG. T. (1860). Elemente der Psychophysik (“Elements of psychophysics”).Leipzig: Breitkopf and Härtel.
13
GaoJ. (2019). Sources of mathematics self-efficacy in Chinese students: a mixed-method study with Q-sorting procedure.Int. J. Sci. Math Educ.18713–732. 10.1007/s10763-019-09984-1
14
GaugerS. E.WyckoffJ. B. (1973). Aesthetic preference for water resource projects: an application of Q-methodology.JAWRA J. Am. Water Resour. Assoc.9522–528. 10.1111/j.1752-1688.1973.tb01766.x
15
GelineauE. P. (1981). A psychometric approach to the measurement of color preference.Percept. Mot. Skills53163–174. 10.2466/pms.1981.53.1.163
16
GuitoniA.MartelJ. M. (1998). Tentative guidelines to help choosing an appropriate MCDA method.Eur. J. Oper Res.109501–521. 10.1016/s0377-2217(98)00073-3
17
GuttmanL. (1954). Some necessary conditions for common factor analysis.Psychometrika.19149–161. 10.1007/bf02289162
18
HedgesC. (2014). The gender factor of survivor: a Q Method approach.Operant Subjectivity372–22.
19
HornJ. L. (1965). A rationale and test for the number of factors in factor analysis.Psychometrika30179–185. 10.1007/bf02289447
20
Jacquet-LagrezeE.SiskosJ. (1982). Assessing a set of additive utility functions for multicriteria decision-making, the UTA method.Eur. J. Operat. Res.10151–164. 10.1016/0377-2217(82)90155-2
21
JehoelS.UngarS.McCallumD.RowellJ. (2005). An evaluation of substrates for tactile maps and diagrams: scanning speed and users’. Preferences.J. Vis. Impair. Blind.9985–95. 10.1177/0145482x0509900203
22
KaiserH. F. (1960). The application of electronic computers to factor analysis.Educ. Psychol. Meas.20141–151. 10.1177/001316446002000116
23
KaiserH. F. (1970). A second generation Little Jiffy.Psychometrika35401–417. 10.1007/bf02291817
24
KaufmanL.RousseeuwP. J. (2009). Finding Groups in Data: An Introduction to Cluster Analysis, Vol. 2. Hoboken, NJ: John Wiley and Sons.
25
KloosterP. M.VisserM.de JongM. D. (2008). Comparing two image research instruments: the Q-sort method versus the Likert attitude questionnaire.Food Qual. Prefer.19511–518. 10.1016/j.foodqual.2008.02.007
26
LehtonenP.AaltoP. (2016). Policy requirements for automated border control systems: a Q methodological study of finland in the context of a large european research project.Operant Subjectivity381–14.
27
LiddellT. M.KruschkeJ. K. (2018). Analyzing ordinal data with metric models: what could possibly go wrong?J. Exp. Soc. Psychol.79328–334. 10.1016/j.jesp.2018.08.009
28
McManusI. C. (1980). The aesthetics of simple figures.Br. J. Psychol.71505–524. 10.1111/j.2044-8295.1980.tb01763.x
29
McManusI. C.CookR.HuntA. (2010). Beyond the golden section and normative aesthetics: why do individuals differ so much in their aesthetic preferences for rectangles?Psychol. Aesthet.Creat.Arts4113–126. 10.1037/a0017316
30
R Core Team (2020). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online at: https://www.R-project.org/
31
SomersteinR. (2014). The taste test: applying q-methodology to aesthetic preference.Operant Subjectivity.3772–96.
32
SoranzoA.PetrelliD.CiolfiL.ReidyJ. (2018). On the perceptual aesthetics of interactive objects.Q. J. Exp. Physiol.712586–2602. 10.1177/1747021817749228
33
SpeharB.WalkN.TaylorR. P. (2016). Taxonomy of individual variations in aesthetic responses to fractal patterns.Front. Hum. Neurosci.10:350. 10.3389/fnhum.2016.00350
34
StephensonW. (1935a). Correlating persons instead of tests.J. Pers.417–24. 10.1111/j.1467-6494.1935.tb02022.x
35
StephensonW. (1935b). Technique of factor analysis.Nature136:297. 10.1038/136297b0
36
VermuntJ. K.MagidsonJ. (2002). Latent class cluster analysis.Appl. Latent Class Anal.1189–106. 10.1017/cbo9780511499531.004
37
WattsS.StennerP. (2012). Doing Q Methodological Research: Theory, Method and Interpretation.London: SAGE Publications Ltd, 10.4135/9781446251911
38
WeberE. U.JohnsonE. J. (2009). Mindful judgment and decision making.Annu. Rev. Psychol.6053–85. 10.1146/annurev.psych.60.110707.163633
39
ZabalaA. (2014). qmethod: a Package to explore human perspectives using q-methodology.R J.6163–173. 10.32614/rj-2014-032
40
ZabalaA.PascualU. (2016). Bootstrapping Q-methodology to improve the understanding of human perspectives.PLoS One11:e0148087. 10.1371/journal.pone.0148087
Summary
Keywords
individual differences, dominance – rank orders, preference, repeated measures analyses, Q-methodology
Citation
Gao J and Soranzo A (2020) Applying Q-Methodology to Investigate People’ Preferences for Multivariate Stimuli. Front. Psychol. 11:556509. doi: 10.3389/fpsyg.2020.556509
Received
28 April 2020
Accepted
16 November 2020
Published
10 December 2020
Volume
11 - 2020
Edited by
Dominique Makowski, Nanyang Technological University, Singapore
Reviewed by
Marco Bertamini, University of Liverpool, United Kingdom; Daniel Lüdecke, University Medical Center Hamburg-Eppendorf, Germany
Updates
Copyright
© 2020 Gao and Soranzo.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alessandro Soranzo, a.soranzo@shu.ac.uk
This article was submitted to Quantitative Psychology and Measurement, a section of the journal Frontiers in Psychology
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.