 Diederik Aerts
Diederik Aerts Jan Broekaert
Jan Broekaert Liane Gabora
Liane Gabora Sandro Sozzo
Sandro Sozzo- 1Center Leo Apostel for Interdisciplinary Studies, Free University of Brussels, Brussels, Belgium
- 2Department of Psychology, University of British Columbia, Kelowna, BC, Canada
- 3School of Management, Institute for Quantum Social and Cognitive Science, University of Leicester, Leicester, UK
Theories of natural language and concepts have been unable to model the flexibility, creativity, context-dependence, and emergence, exhibited by words, concepts and their combinations. The mathematical formalism of quantum theory has instead been successful in capturing these phenomena such as graded membership, situational meaning, composition of categories, and also more complex decision making situations, which cannot be modeled in traditional probabilistic approaches. We show how a formal quantum approach to concepts and their combinations can provide a powerful extension of prototype theory. We explain how prototypes can interfere in conceptual combinations as a consequence of their contextual interactions, and provide an illustration of this using an intuitive wave-like diagram. This quantum-conceptual approach gives new life to original prototype theory, without however making it a privileged concept theory, as we explain at the end of our paper.
1. Introduction
Theories of concepts struggle to capture the creative flexibility with which concepts are used in natural language, and combined into larger complexes with emergent meaning, as well as the context-dependent manner in which concepts are understood (Geeraerts, 1989). In this paper, we present some recent advances in our quantum approach to concepts. More specifically, we follow the general lines illustrated in Gabora and Aerts (2002), Aerts and Gabora (2005a,b), and Gabora et al. (2008), and generalize the quantum-theoretic model elaborated in Aerts (2009b) and Aerts et al. (2013a).
According to the “classical,” or “rule-based” view of concepts, which can be traced back to Aristotle, all instances of a concept share a common set of necessary and sufficient defining properties. Wittgenstein pointed out that: (i) in some cases it is not possible to give a set of characteristics or rules defining a concept; (ii) it is often unclear whether an object is a member of a particular category; (iii) conceptual membership of an instance strongly depends on the context.
A major blow to the classical view came from Rosch's work on color. This work showed that colors do not have any particular criterial attributes or definite boundaries, and instances differ with respect to how typical they are of a concept (Rosch, 1973, 1978, 1983). This led to formulation of “prototype theory,” according to which concepts are organized around family resemblances, and consist of characteristic, rather than defining, features. These features are weighted in the definition of the “prototype.” Rosch showed that subjects rate conceptual membership as “graded,” with degree of membership of an instance corresponding to conceptual distance from the prototype. Moreover, the prototype appears to be particularly resistant to forgetting. Prototype theory also has the strength that it can be mathematically formulated and empirically tested. By calculating the similarity between the prototype of a concept and a possible instance of it, across all salient features, one arrives at a measure of the “conceptual distance” between the instance and the prototype. Another means of calculating conceptual distance comes out of “exemplar theory” (Nosofsky, 1988, 1992), according to which a concept is represented by, not a set of defining or characteristic features, but a set of salient “instances” of it stored in memory. Exemplar theory has met with considerable success at predicting empirical results. Moreover, there is evidence of preservation of specific training exemplars in memory. Classical, prototype, and exemplar theories are sometimes referred to as “similarity based” approaches, because they assume that categorization relies on data-driven statistical evidence. They have been contrasted with “explanation based” approaches, according to which categorization relies on a rich body of knowledge about the world. For example, according to “theory theory” concepts take the form of “mini-theories” (Murphy and Medin, 1985) or schemata (Rumelhart and Norman, 1988), in which the causal relationships among properties are identified.
Although these theories do well at modeling empirical data when only one concept is concerned, they perform poorly at modeling combinations of two concepts. As a consequence, cognitive psychologists are still looking for a satisfactory and generally accepted model of how concepts combine.
The inadequacy of fuzzy set models of conceptual conjunctions (Zadeh, 1982) to resolve the “Pet-Fish problem” identified by Osherson and Smith (1981) highlighted the severity of the combination problem. People rate the item Guppy as a very typical example of the conjunction Pet-Fish, without rating Guppy as a typical example neither of Pet nor of Fish (“Guppy effect”) (Osherson and Smith, 1981, 1982). Studies by Hampton on concept conjunctions (Hampton, 1988a), disjunctions (Hampton, 1988b) and negations (Hampton, 1997) confirmed that traditional fuzzy set and Boolean logical rules are violated whenever people combine concepts, as one usually finds “overextension” and “underextension” in the membership weights of items with respect to concepts and their combinations. It has been shown that people estimate a sentence like “x is tall and x is not tall” as true, in particular when x is a “borderline case” (“borderline contradictions”) (Bonini et al., 1999; Alxatib and Pelletier, 2011), again violating the rules of set-theoretic Boolean logic. The seriousness of the combination problem was pointed out by various scholars (Komatsu, 1992; Fodor, 1994; Kamp and Partee, 1995; Rips, 1995; Osherson and Smith, 1997). More recently, other theories of concepts have been developed, such as “Costello and Keane's constraint theory” (Costello and Keane, 2000), “Dantzig, Raffone, and Hommel's connectionist CONCAT model of concepts” (Van Dantzig et al., 2011), “Thagard and Stewart's emergent binding model” (Thagard and Stewart, 2011), and “Gagne and Spalding's morphological approach” (Gagne and Spalding, 2009). However, none of these theories has a strong track record of modeling the emergence and non-compositionality of concept combinations.
The approach to concepts presented in this paper grew out earlier work on the application to concept theory on the axiomatic and operational foundations of quantum theory and quantum probability (Aerts, 1986; Pitowsky, 1989; Aerts, 1999). A major theoretical insight was to shift the perspective from viewing a concept as a “container” to viewing it as “an entity in a specific state that is changing under the influence of a context” (Gabora and Aerts, 2002). This allowed us to provide a solution to the Guppy effect and to successfully represent the data collected on Pet, Fish and Pet-Fish by using the mathematical formalism of quantum theory (Aerts and Gabora, 2005a,b). Then, we proved that none of the above experiments in concept theory can be represented in a single probability space satisfying the axioms of Kolmogorov (1933). We developed a general quantum framework to represent conjunctions, disjunctions and negations of two concepts, which has been successfully tested several times (Aerts, 2009a,b; Sozzo, 2014, 2015; Aerts et al., 2015a), and we put forward an explanatory hypothesis for the observed deviations from traditional logical and probabilistic structures and for the occurrence of quantum effects in cognition (Aerts et al., 2015b). We recently identified a strong and systematic non-classical phenomenon effect, which is deeper than the ones typically detected in concept combinations and directly connected with the mechanisms of concept formation (Aerts et al., 2015c). This work is part of a growing domain of cognitive psychology that uses the mathematical formalism of quantum theory and quantum structures to model empirical situations where the application of traditional probabilistic approaches is problematical (probability judgments errors, decision-making errors, violations of expected utility theory, etc.; Aerts and Aerts, 1995; Aerts et al., 2000, 2013a,b, 2014, 2015; Aerts and Sozzo, 2011, 2014; Busemeyer and Bruza, 2012; Haven and Khrennikov, 2013; Pothos and Busemeyer, 2013; Khrennikov et al., 2014; Wang et al., 2014).
This paper outlines recent progress in the development of a quantum-theoretic framework for concepts and their dynamics. Section 2 explains how the “SCoP formalism” can be interpreted as a “contextual and interfering prototype theory that is a generalization of standard prototype theory” in which prototypes are not fixed, but change under the influence of a context, and interfere as a consequence of their contextual interactions (see also Gabora et al., 2008; Aerts et al., 2013a). Section 3 presents an amended explanatory version of the quantum-mechanical model in complex Hilbert space worked out in Aerts (2009b) and Aerts et al. (2013a) for the typicality of items with respect to the concepts Fruits and Vegetables, and their disjunction Fruits or Vegetables. This improved quantum model illustrates how the prototype of Fruits (Vegetables) changes under the influence of the context Vegetables (Fruits) in the combination Fruits or Vegetables. The latter combination is represented using the quantum-mathematical notion of linear superposition in a complex Hilbert space, which entails the genuine quantum effect of “interference.” Hence, our model shows that the prototypes of Fruits and Vegetables interfere in the disjunction Fruits or Vegetables. Sections 2, 3 also justify the fact that our quantum-theoretic framework for concepts can be considered as a “contextual and interfering generalization of original prototype theory.” The presence of linear superposition and interference could suggest that concepts combine and interact like waves do. In Section 4 we develop this intuition in detail and propose an intuitive wave-like illustration of the disjunction Fruits or Vegetables. Finally, Section 5 discusses connections between the quantum-theoretic approach to concepts presented here, and other theories of concepts. Although this approach can be interpreted as a specific generalization of prototype theory, it is compatible with insights from other theories of concepts.
We stress that our investigation does not deal with the elaboration of a “specific typicality model” that represents a given set of data on the concepts Fruits, Vegetables, and their disjunction Fruits or Vegetables. We inquire into the mathematical formalism of quantum theory as a general, unitary and coherent formalism to model natural concepts. Our quantum-theoretic model in Section 3 has been derived from this general quantum theory, hence it satisfies specific technical and general epistemological constraints of quantum theory. As such, it does not apply to any arbitrary set of experimental data. Our formalism exactly applies to those data that exhibit a peculiar deviation from classical set-theoretic modeling; such deviations are taken in our framework as indicative of interference and emergence. Data collected on combinations of two concepts systematically exhibit deviations from classical set-theoretical modeling, and traditional probabilistic approaches have difficulty coping with this. In this sense, the success of the quantum-theoretic modeling can be interpreted as a confirmation of the effectiveness of quantum theory to model conceptual combinations. We should also mention that our quantum-theoretic approach has recently produced new predictions, allowing us to identify entanglement in concept combinations (Aerts and Sozzo, 2011, 2014), and systematic deviations from the marginal law, deeply connected to the mechanisms of concept formation (Aerts et al., 2015a,c). These effects would not have been identified in a more traditional investigation of overextension and underextension.
It follows from the above analysis that our quantum-theoretic modeling rests on a “theory based approach,” as it straightforwardly derives from quantum theory as “a theory to represent natural concepts.” Hence, it should be distinguished from an “ad-hoc modeling based approach,” only devised to fit data. One should be suspicious of models in which free parameters are added after the fact on an ad-hoc basis to fit the data more closely. In our opinion, the fact that our “theory derived model” reproduces different sets of experimental data is a convincing argument to support its advantage over traditional modeling approaches and to extend its use to more complex combinations of concepts.
2. The SCoP Formalism as a Contextual Interfering Prototype Theory
This section summarizes the SCoP approach to concepts by providing new insights to the research in Aerts and Gabora (2005a,b) and Gabora et al. (2008).
We mentioned in Section 1 that, according to prototype theory, concepts are associated with a set of characteristic, rather than defining, features (or properties), that are weighted in the definition of the prototype. A new item is categorized as an instance of the concept if it is sufficiently similar to this prototype (Rosch, 1973, 1978, 1983). The original prototype theory was subsequently put into mathematical form as follows. The prototype consists of a set of features {a1, a2, …, aM}, with associated “weights” (or “application values”) {xp1, xp2, …, xpM}, where M is the number of features that are considered. A new item k is also associated with a set {xk1, xk2, …, xkM}, where the number xkm refers to the applicability of the m-th feature to the item k (for a given stimulus). Then, the conceptual distance between the item k and the prototype, defined as
is a measure of the similarity between item and prototype. The smaller the distance dk for the item k, the more representative k is of the given concept.
Prototype theory was developed in response to findings that people rate conceptual membership as graded (or fuzzy), with the degree of membership of an instance corresponding to the conceptual distance from the prototype. A second fundamental element of prototype theory is that it can in principle be confronted with empirical data, e.g., membership or typicality measurements.
A fundamental challenge to prototype theory (but also to any other theory of concepts) has become known as the “Pet-Fish problem.” The problem can be summarized as follows. We denote by Pet-Fish the conjunction of the concepts Pet and Fish. It has been shown that people rate Guppy neither as a typical Pet nor as a typical Fish, they do rate it as a highly typical Pet-Fish (Osherson and Smith, 1981). This phenomenon of the typicality of a conjunctive concept being greater than—or overextends—that of either of its constituent concepts has also been called the “Guppy effect.” Using classical logic, or even fuzzy logic, there is no specification of a prototype for Pet-Fish starting from the prototypes of Pet and Fish that is consistent with empirical data (Osherson and Smith, 1981, 1982; Zadeh, 1982). Fuzzy set theory falls short because standard connectives for conceptual conjunction involve typicality values that are less than or equal to each of the typicality values of the conceptual components, i.e., the typicality of an item such as Guppy is not higher for Pet-Fish than for either Pet or Fish.
Similar effects occur for membership weights of items with respect to concepts and their combinations. Hampton's experiments indicated that people estimate membership in such a way that the membership weight of an item for the conjunction (disjunction) of two concepts, calculated as the large number limit of relative frequency of membership estimates, is higher (lower) than the membership weight of this item for at least one constituent concept (Hampton, 1988a,b). This phenomenon is referred to as “overextension” (“underextension”). “Double overextension” (“double underextension”) is also an experimentally established phenomenon, when the membership weight with respect to the conjunction (disjunction) of two concepts is higher (lower) than the membership weights with respect to both constituent concepts (Hampton, 1988a,b). Furthermore, conceptual negation does not satisfy the rules of classical Boolean logic (Hampton, 1997). More, Bonini et al. (1999), and Alxatib and Pelletier (2011), identified the presence of “borderline contradictions,” directly connected with overextension, namely, a sentence like “John is tall and John is not tall” is estimated as true by a significant number of participants, again violating basic rules of classical Boolean logic. More generally, for each of these experimental data, a single classical probability framework satisfying the axioms of Kolmogorov does not exist (Aerts, 2009a,b; Aerts et al., 2013a,b, 2015a; Sozzo, 2014, 2015). To clarify the latter sentence no single probability space can be constructed for an item whose membership weight with respect to the conjunction of two concepts is overextended with respect to both constituent concepts.
These problems—compositionality, the graded nature of typicality, and the probabilistic nature of membership weights—present a serious challenge to any theory of concepts.
We have developed a novel theoretical model of concepts and their combinations (Gabora and Aerts, 2002; Aerts and Gabora, 2005a,b), conjunction (Aerts, 2009a; Aerts et al., 2013a, 2015a; Sozzo, 2014, 2015), disjunction (Aerts, 2009a; Aerts et al., 2013a), conjunction and negation (Aerts et al., 2015a; Sozzo, 2015). It uses the mathematical formalism of quantum theory in Hilbert space to represent data on conceptual combinations, which has been successfully tested several times. This quantum-conceptual approach enables us to model the above-mentioned deviations from classicality in terms of genuine quantum phenomena (contextuality, emergence, entanglement, interference, and superposition), thus capturing fundamental aspects of how concepts combine. More importantly, we have recently identified stronger deviations from classicality than overextension and underextension, which unveil, in our opinion, deep non-classical aspects of concept formation (Aerts et al., 2015c).
The approach was inspired by similarity based theories, such as prototype theory, in several respects:
(i) a fundamentally probabilistic formalism is needed to represent concepts and their dynamics;
(ii) the typicality of different items with respect to a concept is context-dependent;
(iii) features (or properties) of a concept vary in their applicability.
A key insight underlying our approach is considering a concept as, not a “container of instantiations” but, rather, an “entity in a specific state,” which changes under the influence of a context. In our quantum-conceptual approach, a context is mathematically modeled as quantum physics models of a measurement on a quantum particle. The (cognitive) context changes the state of a concept in the way a measurement in quantum theory changes the state of a quantum particle (Aerts and Gabora, 2005a,b). For example, in our modeling of the concept Pet, we considered the context e expressed by Did you see the type of pet he has? This explains that he is a weird person, and found that when participants in an experiment were asked to rate different items of Pet, the scores for Snake and Spider were very high in this context. In this approach, this is explained by introducing different states for the concept Pet. We call “the state of Pet when no specific context is present” its ground state . The context e changes the ground state into a new state pweird person pet. Typicality here is an observable semantic quantity, which means that it takes different values in different states of the concept. As a consequence, a substantial part of the typicality variations that are encountered in the Guppy effect are due to, e.g., changes of state of the concept Pet under the influence of a context. More specifically, the typicality variations for the conjunction Pet-Fish are in great part similar to the typicality variations for Pet under the context Fish (and also for Fish under the context Pet). Not only does context play a role in shaping the typicality variations for Pet-Fish, but also interference between Pet and Fish contributes, as we will analyze in detail in Section 3.
In general, whenever someone is asked to estimate the typicality of Guppy with respect to the concept Pet in the absence of any context, it is the typicality in the ground state that is obtained, and whenever the typicality of Guppy is estimated with respect to the concept Fish in the absence of any context, it is the typicality in the ground state that is obtained. But, whenever someone is asked to estimate the typicality of Guppy with respect to the conjunction Pet-Fish, it is the typicality in a new ground state that is obtained. This new ground state is different from as well as from . It is close but not equal to the changed state of the ground state under the context eFish, and close but not equal to the changed state of the ground state under the context ePet, the difference being due to interference taking place between Pet and Fish when they combine into Pet-Fish (see Section 3). The “changes of state under the influence of a context” and corresponding typicalities behave like the changes of state and corresponding probabilities behave in quantum theory, giving rise to a violation of corresponding fuzzy set and/or classical probability rules. This partly explains the high typicality of Guppy in the conjunction Pet-Fish, and its normal typicality in Pet and Fish, and the reason why we identify the Guppy effect as an effect at least partly due to context. There is also an interference effect, as we will see later.
We developed this approach in a formal way, and called the underlying mathematical structure a “State Context Property (SCoP) formalism” (Aerts and Gabora, 2005a). Let A denote a concept. In SCoP, A is associated with a triple of sets, namely the set Σ of states—we denote states by p, q, …, the set of contexts, we denote contexts by e, f, …, and the set of properties—we denote properties by a, b, …. The “ground state” of the concept A is the state where A is not under the influence of any particular context. Whenever A is under the influence of a specific context e, a change of the state of A occurs. In case A was in its ground state , the ground state changes to a state p. The difference between states and p is manifested, for example, by the typicality values of different items of the concept, as we have seen in the case of the Guppy effect, and the applicability values of different properties being different in the two states and p. Hence, to complete the mathematical construction of SCoP, also two functions μ and ν are needed. The function μ:Σ × ×Σ → [0, 1] is defined such that μ(q, e, p) is the probability that state p of concept A under the influence of context e changes to state q of concept A. The function ν:Σ × → [0, 1] is defined such that ν(p, a) is the weight, or normalization of applicability, of property a in state p of concept S. The function μ mainly accounts for typicality measurements, the function ν mainly accounts for applicability measurements. Through these mathematical structures the SCoP formalism captures both “contextual typicality” and “contextual applicability” (Aerts and Gabora, 2005a).
A quantum representation in a complex Hilbert space of data on Pet and Fish and different states of Pet and Fish in different contexts was developed (Aerts and Gabora, 2005a), as well as of the concept Pet-Fish (Aerts and Gabora, 2005b). Let us deepen the connections between the quantum-theoretic approach to concepts and prototype theory (see also Gabora et al., 2008). This approach can be interpreted in a rather straightforward way as a generalization of prototype theory which mathematically integrates context and formalizes its effects, unlike standard prototype theory. What we call the ground state of a concept can be seen as the prototype of this concept. The conceptual distance of an item from the prototype can be reconstructed from the functions μ and ν in the SCoP formalism. Thus, as long as individual concepts are considered and in the absence of any context, prototype theory can be embodied into the SCoP formalism, and the prototype of a concept A can be represented as its ground state . However, any context will change this ground state into a new state. An important consequence of this is that when the concept is in this new state, the prototype changes. An intuitive way of understanding this is to consider this new state a new “contextualized prototype.” More concretely, the concept Pet, when combined with Fish in the conjunction Pet-Fish, has a new contextualized prototype, which could be called “Pet contextualized by Fish.” The new state can be thought of as a “contextualized prototype.” Hence, this is a prototype-like theory that is capable of mathematically describing the presence and influence of context. From the point of view of conceptual distance, this contextualized prototype will be close to, e.g., Guppy.
The interpretation of the SCoP formalism as a contextual prototype theory can be applied not just to conjunctions and disjunctions of two concepts, but also to abstract categories such as Fruits. It is very likely that the prototype of Fruits is close to, e.g., Apple, or Orange. But let us now consider the combination Tropical Fruits, that is, Fruits under the context Tropical. It is then reasonable to maintain that the new contextualized prototype of Tropical Fruits is closer to, e.g., Pineapple, or Mango, than to Apple, or Orange. The introduction of contextualized prototypes within the SCoP formalism enables us to incorporate abstract categories as well as deviations of typicality from fuzzy set behavior.
Another interesting aspect of this approach to prototype theory comes to light if we consider again the conceptual combination Pet-Fish. It is reasonable that the prototypes of Pet and Fish—ground states and —interfere in Pet-Fish whenever the typicality of an item, e.g., Guppy, is measured with respect to Pet-Fish. This sentence cannot, however, be made more explicit in the absence of a concrete quantum-theoretic representation of typicality measurements of items with respect to concepts and their combinations. Indeed, interference and superposition effects can be precisely formalized in such quantum representation. This will be the content of Sections 3 and 4.
3. A Hilbert Space Modeling of Membership Measurements
One can gain insight into how people combine concepts by gathering data on “membership weights” and “typicalities.” To obtain data on “typicalities,” participants are given a concept, and a list of instances or items, and asked to estimate their typicality on a Likert scale. In other experiments participants are asked to choose which instance they consider most typical of the concept. Averages of these estimates or relative frequencies of the picked items give rise to values representing the typicalities of the respective items. A membership weight is obtained by asking participants to estimate the membership of specific items with respect to a concept. This estimation can be quantified using the 7-point Likert scale and then converted into a relative frequency, and then into a probability called the “membership weight.”
Hampton used membership weights instead of typicalities (Hampton, 1988b), because all you can do with typicalities is fuzzy set type calculations: the minimum rule of fuzzy sets for conjunction or the maximum rule for disjunction. This approach has many serious shortcomings; indeed the Pet-Fish problem could not be addressed by it. More serious failures are revealed by membership weight data. Hampton measured “membership weights” and “degrees of non-membership or membership,” making these two measurements in one experiment. More specifically, Hampton's experiment generates magnitude data, measuring the “degree of membership or non-membership” using a 7-point Likert scale providing −1, −2, −3 for degrees of non-membership, 1, 2, 3 for degrees of membership and, 0 for borderline cases. From the same experiment membership weight data are obtained, with 8 possible triplets [±, ±, ±] per item. Each triplet indicating with a + whether the participant considered item k to be a member of the first category (A), the second category (B) and the third disjunction category (AorB), and with a − respectively otherwise. In the present Hilbert space model we use the “degree of membership or non-membership” values obtained by Hampton, add +3 to them to make them all non-negative, sum them, and divide each one by this sum. Since there are 24 items in total, in this way we get a set of 24 values in the interval [0,1], that sum up to 1. We will use these values as a substitute for membership collapse probabilities.
Let us first explain how we arrive at the membership collapse probabilities as a consequence of a measurement, and why we can use the above-mentioned calculated values of “degree of membership or non-membership” as substitutes. Suppose that instead of using the data obtained by Hampton, we performed the following experiment. For each pair of concepts and their combination we ask the participant to select one and only one item that they consider the best choice for membership. Then we calculate for each of the 24 items the relative frequency of its appearance. These relative frequencies are 24 values in the interval [0,1] summing up to 1, and their limits for increasing numbers of participants represent the probabilities for each item to be chosen as the best member. These probabilities are what in a quantum model are called the “membership collapse probabilities.” Of course, the above described experiment to determine the membership collapse probabilities has not been performed. However, the values calculated from Hampton's measurement of “degree of membership or non-membership,” after renormalization as explained above, are expected to correlate with what these membership collapse probabilities would be if they were measured. This is why we use them as substitutes for the membership collapse probabilities in our quantum model. As we will see when we construct the quantum model, the exact values of the substitutes for the membership collapse probabilities are not critical. Thus, if we can model the substitutes for the membership collapse probabilities calculated from Hampton's data, we can also model the actual membership collapse probabilities (the data we would have if the experiment had been done).
So, we repeat, in Table 1, Hampton's experimental data (Hampton, 1988b) have been converted into relative frequencies. The “degrees of non-membership and degrees of membership” give rise to μk(X) and now stand for the probability of concepts Fruits (X = A), Vegetables (X = B) and Fruits or Vegetables (X = “A or B”) to collapse to the item k, and thus add up to 1, that is,
for the 24 items. The quantum model for concepts and their disjunction in complex Hilbert space is developed by building appropriate state vectors and projection operators for a given ontology of 24 items of two more abstract “container” concepts.
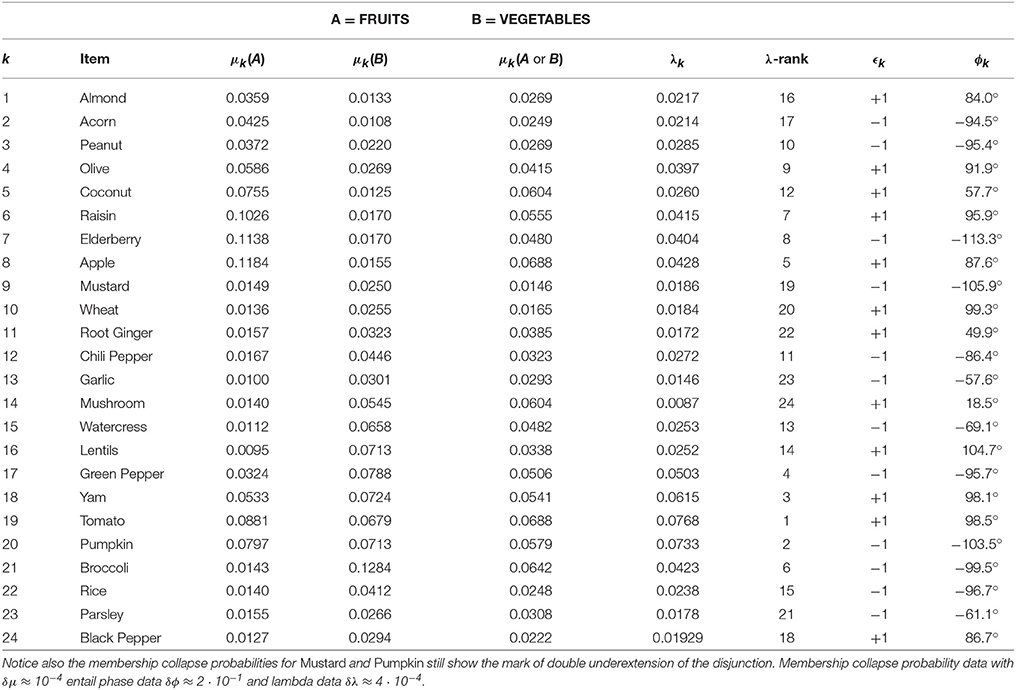
Table 1. Membership collapse probability values μk(X) of 24 items for the categories Fruits, Vegetables, and Fruits or Vegetables (Hampton, 1988b).
In our model, the Hilbert space is a complex n-dimensional ℂn, in which state vectors are n-dimensional complex numbered vectors. We use the “bra-ket” notation – respectively 〈·| and |·〉—for vector states (see the Appendix for further explanation). The complex conjugate transpose of the |·〉 ket-vector (nx1 dim.) is the 〈·| bra-vector (1xn dim.). Projectors and operators are then combined as matrices |·〉〈·|, while scalars are obtained by inner product 〈·|·〉. We represent the measurement, consisting in the question “Is item k a good example of concept X?,” by means of an orthogonal projection operator Mk. Each self-adjoint operator in the Hilbert space has a spectral decomposition on {Mk|k = 1, …, 24}, where each Mk is the projector corresponding to item k from the list of 24 items in Table 1. A priori we set no restrictions to the dimension of the complex Hilbert space, and thus neither to the projection space of the operators Mk. Each separate concept Fruits and Vegetables is now represented by its proper state vector |A〉 and |B〉 respectively, while their disjunction Fruits or Vegetables is realized by their equiponderous superposition . It is precisely this feature of the model—its ability to represent combined concepts as superposed states—that provides the interferential composition of what could not be classically composed using sets.
Following the standard rule of average outcome values of quantum theory, the probabilities, μk(A), μk(B) and μk(A or B) are given by:
After a straightforward calculation, the membership probability expression μk(A or B) becomes:
where ℜ takes the real part of 〈A|Mk|B〉. This expression shows the contribution of the interference term ℜ〈A|Mk|B〉 in μk(A or B) with respect to the “classical average” term . It consists of the real part of the complex probability amplitude of the k-th item in Vegetables (concept |B〉) to be the one in Fruits (concept |A〉).
The quantum concept model imposes the orthogonality of the state vectors corresponding to different concepts. Therefore, we have for the states of Fruits and Vegetables,
Each different item of the projector Mk also provides an orthogonal projection space. Since the conceptual disjunction Fruits or Vegetables spans a subspace of 2 dimensions in the complex Hilbert space (along the rays of |A〉 and |B〉), we set forth the possibility for a complex 2-dimensional subspace for each item. This brings the dimension of the complex Hilbert space to 48. However, we will choose the unit vectors of these subspaces in such a way as to eliminate redundant dimensions whenever possible. Each category vector is built on orthogonal unit vectors, defined by the projection operators Mk. i.e., we define |ek〉 the unit vector on Mk|A〉, and define |fk〉 the unit vector on Mk|B〉. Thus, each item is now represented by a vector spanned by |ek〉 and |fk〉. Due the orthogonality of the projectors Mk, we have
where the Kronecker δkl = 1 for same indices and zero otherwise, i.e., different item states are orthogonal as well. And ck expresses the angle between the two unit vectors |ek〉 and |fk〉 of each 2-dimensional subspace of item k. Notice that should some ck be 1, then the required dimension of the complex Hilbert space diminishes by 1, since the vectors |ek〉 and |fk〉 then coincide—a property that we will use to minimize the size of the required Hilbert space. Should ck be different from 1, then |ek〉 and |fk〉 span a subspace of 2 dimensions. The state vectors |A〉 and |B〉 of the concepts can then be expressed as a superposition of the vectors |ek〉 and |fk〉 for the items:
where ak, bk, αk, βk ∈ ℝ.
We can express their inner product as follows:
where we have defined phase ϕk as ϕk: = βk − αk + γk in the last step. The membership probabilities given in Equations (3 and 4) and the interference terms in Equation (6) can be expanded on the projection spaces of the items:
Notice that the phase of the k-th component of the conceptual disjunction is not at play in the interference term 〈A|Mk|B〉 (Equation 6). Taking the real part of the interference term in Equation (12), we can rewrite the membership probability of the disjunction in Equation (6) as follows:
Rearranging this equation we now choose ϕk must satisfy
Since all the membership probabilities on the right side are fixed, the only remaining free parameters are the coefficients ck. These parameters must now be tuned in order to satisfy the orthogonality of |A〉 and |B〉. Using the expansion on the unit vector sets {|ek〉}, {|fk〉} we obtain for their orthogonality (Equation 7):
The “cosine sum” (Equation 15) is automatically satisfied due to the definition of cosϕk and the normalization of membership probabilities (Equation 2). This can be seen by substituting the expression of cosϕk in Equation (14) and then applying the normalization condition of the membership probabilities (Equation 2). The “sine sum” equation still needs to be satisfied. With the defining relation (Equation 14) of ϕk, and , where ϵk = ± provides the sign, this becomes1
In order to satisfy this equation a simple algorithm was devised (Aerts, 2009a). For convenience of notation we denote the square root expression, with ck = 1, by a separate symbol:
First, we order the values λk from large to small and then assign a sign ϵk to each of them in such a way that each next partial sum (increasing index) remains smallest. The λ-ranking with corresponding values have been tabulated in Table 1. We assign index m to the item with the largest λ-value. In the present case, the item Tomato has the largest value, 0.07679.
We now adopt an optimized complex Hilbert space for our model in which ck = 1 (k ≠ m), which reduces the space to 25 complex dimensions. We again note that all items except Tomato receive a 1-dimensional complex subspace, while Tomato is represented by a 2-dimensional subspace. The “sine sum” equation in Equation (17) can be written as
Next, we define the partial sum of the λk according a scheme of signs ϵk such that from large to small the next ϵkλk is added to make the sum smaller but not negative.
The first summand is thus λm, with ϵm = +1. Finally this procedure leads to
In the Fruits and Vegetables example with membership probability data in Table 1, this procedure gives:
In general the “sine sum” equation then becomes
From which we can fix cm, the remaining ck not equal to 1:
In the present example we obtain the value cm = 0.8032. We thus have fixed the inner product—or “angle”—of the vectors |em〉 and |fm〉, and can now write an explicit representation in the canonical 25 dimensional complex Hilbert space ℂ25. We can take Mk() to be rays of dimension 1 for k ≠ m, and Mm() to be a 2-dimensional plane spanned by the vectors |em〉 and |fm〉.
We let the space ℂ25 be spanned on the canonical base {1i}, i ∈ [1…25]. All items k ≠ m are represented by the respective 1i. While for k = m we express the projections of |A〉 and |B〉 by Mm() accordingly on 1m and 125
with ãm, , ã25, to be specified. The parameters in these expressions should satisfy the inner product (Equation 8) for k, l = m
and the probability weights for k = m
Finally, the representation of all vectors of the items can now be rendered explicit by simply choosing αk = γk = 0, and thus βk = ϕk, ∀k. A further simplification for Tomato is done by setting ã25 = 0, which also allows free choice of βm2 = 0. Then ãm = am and , and . We have rendered explicit these membership probabilities and phases in Table 1. Thus we can write the vectors |A〉 and |B〉 in ℂ25 Hilbert space corresponding to the categories Fruits and Vegetables respectively.
This completes the quantum model for the membership probability of items with respect to Fruits, Vegetables and Fruits or Vegetables. It captures the enigmatic aspects of conceptual overextension and underextension identified in Hampton (1988b), explaining them in terms of genuine quantum phenomena.
Recalling the terminology adopted in Section 2, the unit vectors |A〉 and |B〉 in Equations (32) and (33) represent the ground states of the concepts Fruits and Vegetables, respectively. Equivalently, these unit vectors represent the prototypes of the concepts Fruits and Vegetables in prototype theory. The unit vector instead represents the “contextualized prototype” obtained by combining the prototypes of Fruits and Vegetables in the disjunction Fruits or Vegetables. If one now looks at Equation (6), one sees that the prototypes Fruits and Vegetables interfere in the disjunction Fruits or Vegetables, and the term ℜ〈A|Mk|B〉 in Equation (6) specifies how much interference is present when the membership probability of k is measured.
4. An Illustration of Interfering Prototypes
In this section we provide an illustration of contextual interfering prototypes. It is not a complete mathematical representation as presented in Section 3 but, rather, an illustration that can help the reader with a non-technical background to have an intuitive picture of what a contextual prototype is and how contextual prototypes interfere. Consider the concepts Fruits, Vegetables and their disjunction Fruits or Vegetables. The contextual prototype of Fruits can be represented by the x-axis of a plane surrounded by a cloud containing items, features, etc.—all the contextual elements connected with the prototype of Fruits. Similarly, the contextual prototype of Vegetables can be represented by the y-axis of the same plane surrounded by a cloud containing items, features, etc.—all the contextual elements connected with the prototype of Vegetables. How can we represent the contextual prototype of the disjunction Fruits or Vegetables? Although as we have seen it cannot be represented in traditional fuzzy set theory, it can be represented in terms of waves, with peaks and troughs. Indeed, waves can be summed up in such a way that peaks and troughs of the combined wave reproduce overextension and underextension of the data. In other words, waves provide an intuitive geometric illustration of the interference taking place when contextual prototypes are combined in concept combination as discussed in Section 3. For example, let us demonstrate the interference of the item Almond when its membership probability with respect to the disjunction Fruits or Vegetables is calculated based on its membership probabilities for Fruits and for Vegetables. The membership probabilities for the categories Fruits, Vegetables and Fruits or Vegetables have been calculated from the Hampton's data and are reported in Table 1.
The idea of an illustration would be to show that in addition to “fuzziness” (as modeled using a fuzzy set-theoretic approach) there is a “wave structure.” How can we graphically represent this “wave structure” of a concept? We start from the standard interference formula of quantum theory, which is the following. For an arbitrary item k we have
Now, we have
where αk is the phase angle connected with μk(A), βk the phase angle connected to μk(B), and γk the phase angle connected to 〈A|Mk|B〉. This has not yet been emphasized but if one analyses the rest of the construction in Hilbert space, it is possible to see that one can always choose γk = 0, which means that, with this choice, ϕk becomes the difference in phases βk and αk.
This is all we need to represent the “wave” nature of a concept in a manner analogous to that of quantum theory. Indeed, it is the “phase difference” between the waves—their phases being αk and βk respectively – that we attach to μ(A)k and μ(B)k. They determine, together with the membership probabilities μ(A)k and μ(B)k the interference that gives rise to the measured data for μ(A or B)k.
The choice of the ck is such that only for the biggest value of λk, which in this case of Tomato, the ck is chosen different from 1. The only choice different from 1, for Tomato, still does not influence the fact that ϕk is the difference between βk and αk, when we decide to choose γk = 0. Let us consider for example the first item Almond of the list of 24 in Table 1. We have
These are the data measured by Hampton, and also what exists for the concepts Fruits, Vegetables and their combination Fruits or Vegetables with respect to membership probability of the item Almond in the realm where fuzzy set probability appears. These are the values that do not fit into a model in this realm, and for which a wave-like realm underneath is necessary. Calculating the angle ϕ1 we get
(see Table 1). This angle is the result of a wave being present underneath the fuzzy, probability realm for μ(A)1 and μ(B)1, such that both waves give rise to a difference in phase—where the crests of one wave meet the troughs of the other—which is equal to β1−α1, and is the value of ϕ1. This can be represented graphically by attaching a wave pattern to μ(A)1 and another one to μ(B)1, such that both have a phase difference of 84.0°—see also Figure 1.
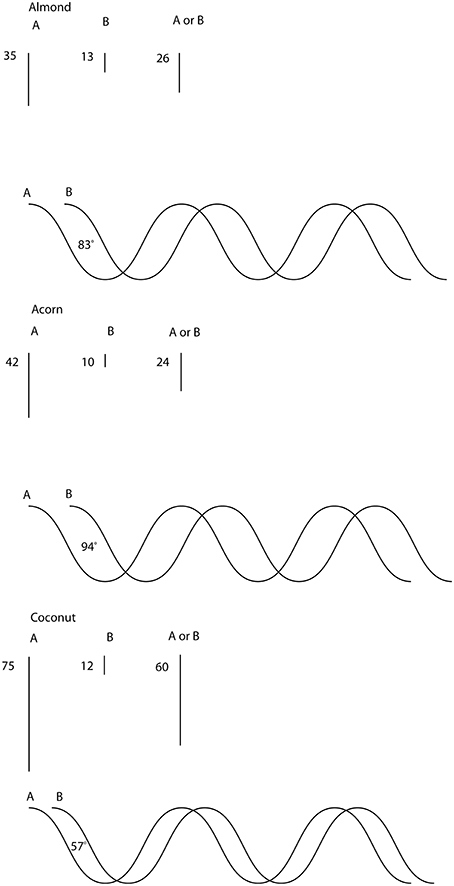
Figure 1. Interference of items Almond, Acorn and Coconut in the concept Fruits or Vegetables. Elementary oscillatory waves and are associated to the components of each given item in Fruits and Vegetables respectively. The weight amplitude of the item in the disjunction Fruits or Vegetables emerges at the origin of .
Let us apply quantum theory to each of the items apart. Each item k has a Schrödinger wave function vibrating in the neighborhood of A, another one vibrating in the neighborhood of B and a third vibrating in the neighborhood of “A or B,” and they are related by superposition. We have:
In each case, this gives us the membership probabilities. Squaring (multiplying by its complex conjugate), we have
If we write the quantum superposition equation for each item we get
where is a normalization factor. It is the squaring (i.e., multiplying each with its complex conjugate) that gives rise to the interference equation. Let us do this explicitly to see it. First we multiply the left hand side with its complex conjugate. We do the multiplication explicitly writing each step of it, to see well how the interference formula appears. Hence, we have
we use now that , , and , to get to the following
see that the term in isin(βk − αk) cancels, to get
Let is multiply now the right hand sight of Equation (46) with its complex conjugate. This gives
Hence, we get, as a consequence of squaring (Equation 46), exactly our interference formula
Note that the difference in phase βk − αk between the waves connected with the item k and A and the item k and B is what generates the interference. The new wave connected to the item k and A or B, of which the phase is δ is not influenced by it, is the amplitude of this new wave which is affected. This is the reason that interference is visible in the realm where the fuzzy nature appears, while it is provoked by the realm where the waves occur.
We put forward this “wave nature” aspect of concepts not just as an illustration, but to help the reader understand the manner in which such an underlying wave structure increases substantially the possible ways in which concepts can interact, as compared to the interaction possibilities in a modeling with fuzzy set structures. Of course the notion of a “wave” only adds clarification if we can imagine it to exist in some space-like realm. This is the case for the type of waves we all know from our daily physical environment, such as water waves, sound waves or light waves. The quantum waves of physical quantum particles can also be made visible in general by looking at probabilistic detection patterns of these quantum particles on a physical screen, and noting the typical interference patterns when the waves interact and the particles are detected on the screen. One might believe that an analogous situation is not possible for concepts, because intuitively concepts, unlike quantum particles, do not exist “inside” space. If we look at things is an operational way, however, an analysis can be put forward for the quantum model of the combination of the two concepts, and the graded structure of collapse probability weights of the 24 items, which does illustrate the presence of an interference pattern, and as a consequence reveals the underlying wave structure of concepts and their interactions. Let us explain how we can proceed to accomplish such an analysis.
We start by considering Figure 2. We see there the 24 different items of Table 1 represented by numbered spots in a plane where a graded pattern, starting with the lightest region around the spot number 8, which is Apple, systematically becomes darker. Different numbers of items are situated in spots in regions of different darkness, for example, number 16, Lentils, is situated in a spot in the darkest region. Let us explain how the figure is constructed. The “intensity of light” of a specific region corresponds to the “weights of the items” with respect to the concept Fruits in Table 1. Looking at Table 1, it is indeed Apple, which has the highest weight, equal to 0.1184, and hence is represented by spot number 8 on Figure 2, in the lightest region. Next comes Elderberry with weight equal to 0.1134, represented by spot number 7 on Figure 2, on the border of the lightest and second lightest region. Next comes Raisin, with weight equal to 0.1026, represented by spot number 6 on Figure 2, on the border of the third and the fourth lightest region. Next comes Tomato, with weight equal to 0.0881, represented by spot number 19 on Figure 2, in the seventh lightest region, etc. last is Lentils, with weight equal to 0.0095, represented by spot number 16 on Figure 2, in the one to darkest region. Hence Figure 2 contains a representation of the values of the collapse probability weights of the 24 items with respect to the concept Fruits. There is however more; we can, for example, wonder what the reason is to choose a representation in a plane? To explain this, turn to Figure 3. Let us first note with respect to the two figures, although it might not seem the case at first sight, all the numbered regions are located at exactly the same spots in both Figures 2, 3, with respect to the two orthogonal axes that coordinate the plane. What is different in both figures are the graded structures of lighter to darker regions, while they are centered around the spot number 8, representing the item Apple, in Figure 2 they are centered around the spot number 21, representing the item Broccoli, in Figure 3. And, effectively, Figure 3 represents analogous to Figure 2 of the same 24 items, their collapse probability weights, but this time with respect to the concept Vegetables. This explains why in Figure 3 the lightest region is the one centered around spot number 21, representing Broccoli, while the lightest region in Figure 2 is the one centered around spot number 8, representing Apple. Indeed, Broccoli is the most characteristic vegetable of the considered items, while Apple is the most characteristic fruit, if “characteristic” is measured by the size of the respective collapse probability, i.e., the probability to choose this item in the course of the study. What might not seem obvious is that in a plane it is always possible to find 24 locations for the 24 items such that a graded structure with center Apple and a second graded structure with center Broccoli can be defined, fitting exactly also the other items in their correct value of “graded light to dark,” corresponding to the collapse probability weights in Table 1. Such a situation is what we show in Figures 2, 3. It can be proven mathematically that a solution always exists, although not a unique one, which means that Figures 2, 3 show one of these solutions.
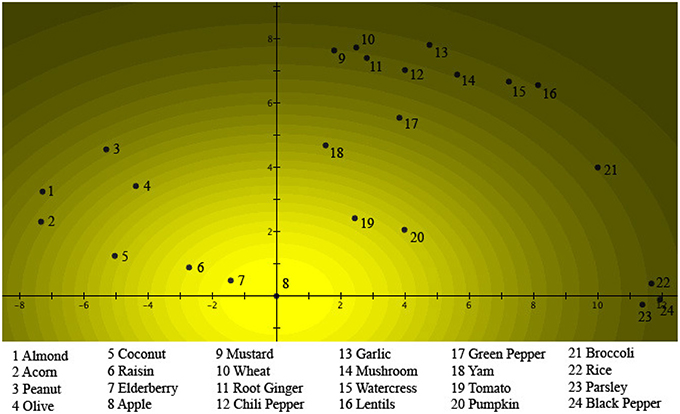
Figure 2. The probabilities μ(A)k of a person choosing the item k as a “good example” of Fruits are fitted into a two-dimensional quantum wave function ψA(x, y). The numbers are placed at the locations of the different items with respect to the Gaussian probability distribution . This can be seen as a light source shining through a hole centered on the origin, and regions where the different items are located. The brightness of the light source in a specific region corresponds to the probability that this item will be chosen as a “good example” of Fruits.
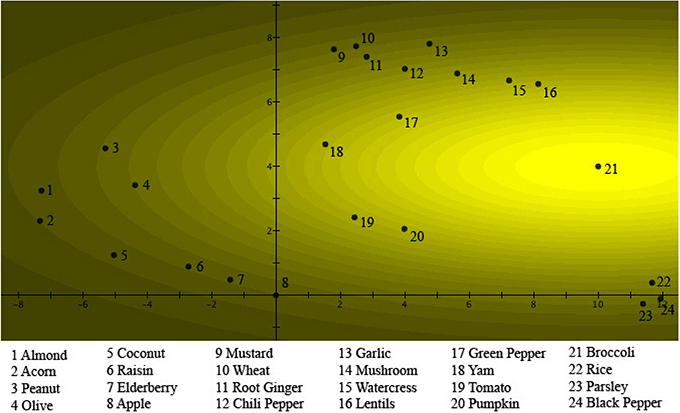
Figure 3. The probabilities μ(B)k of a person choosing the item k as a “good example” of Vegetables are fitted into a two-dimensional quantum wave function ψB(x, y). The numbers are placed at the locations of the different items with respect to the probability distribution . As in Figure 2, it can be seen as a light source shining through a hole centered on point 21, where Broccoli is located. The brightness of the light source in a specific region corresponds to the probability that this item will be chosen as a “good example” of Vegetables.
We have chosen on purpose the graded structure form light to dark to be colored yellow, because we can interpret Figures 2, 3 such that an interesting analogy arises between our study of the 24 items and two concepts Fruits and Vegetables, and the well-known double slit experiment with light in quantum mechanics. It is this analogy that will also directly illustrate the “wave nature” of concepts. Suppose we consider a plane figuring in the experiment as a detection screen, and put counters for quantum light particles, i.e., photons, at the numbered spots on the plane. Then we send light through a first slit, which we call the Fruits slit, which is placed in front of the screen. The slit is placed such that the counters in the spots detect numbers of photons with fractions to the total number of photons send equal the collapse probability weights of the items represented by the respective spots with respect to the concept Fruits. The light received on the screen would then look like what is shown in Figure 2. Similarly, with counters placed in the same spots, we send light through a second slit, which we call the Vegetable slit. Now the counters detect numbers of photons with fractions to the total number of photons equal to the collapse probability weights of the same items with respect to the concept Vegetables. The light received on the screen would then look like what is shown in Figure 3. We can obtain the same figures directly for our psychological study, consisting of each participant choosing amongst the 24 items the one that he or she finds most characteristic of Fruits and Vegetables respectively. The relative frequencies of the first choice gives rise to the image in Figure 2, while the relative frequencies of the second choice gives rise to the image in Figure 3, if, for example, we would mark each chosen item by a fixed number of yellow light pixels on a computer screen.
Before we combine the two slits to give rise to interference, let us specify the mathematics of the quantum mechanical formalism that underlies the two Figures. The situation can be represented quantum mechanically by complex valued Schrödinger wave functions of two real variables ψA(x, y), ψB(x, y). For the light and the two slits, this situation is the “interaction of a photon with the two slits.” For the human participants in the concepts study, this situation is the “interaction with the two concepts of the mind of a participant.” We choose for ψA(x, y) and ψB(x, y) quantum wave packets, such that the radial part for both wave packets is a Gaussian in two dimensions. Considering Figures 2, 3, we choose the top of the first Gaussian in the origin where spot number 8 is located, and the top of the second Gaussian in the point (a, b), where spot number 21 is located. Hence
The phase parts of the wave packets and are determined by two phase fields SA(x, y) and SB(x, y) which will account for the interference and hence carry the wave nature. Of course, these phase parts vanish when we multiply each wave packet with its complex conjugate to find the connection with the collapse probabilities. Hence,
are the Gaussians to be seen in Figures 2, 3, respectively. Let us denote by Δk a small surface specifying the spot corresponding to the item number k in the plane of the two figures. We then calculate the collapse probabilities of this item k with respect to the concepts Fruits and Vegetables in a standard quantum mechanical way as follows
We can prove that the parameters of the Gaussians, DA, σAx, σAy, DB, σBx, σBy can be determined in such a way that the above equations come true, and for the images of Figures 2, 3, exactly as we have done—using an approximation for the integrals, which we explain later.
If we open both slits it will be the normalized superposition of the two wave packets that quantum mechanically describes the new situation
We have
Let us calculate . We have
We can hence rewrite (Equation 56) in the following way
where
is a known Gaussian-like function, remember that we have determined DA, DB, σAx, σAy, σBx, σBy and a and b in choosing a solution to be seen in Figures 3, 4, and
are constants for each k determined by the data, and we have introduced
the field of phase differences of the two quantum wave packets. This field of phases differences will determine the interference pattern and it is the solution of the 24 nonlinear Equations in (58). This set of 24 equations cannot be solved exactly, but even a general numerical solution is not straightforwardly at reach within actual optimization programs. We have introduces two steps of idealization to find a solution. First, we have looked for a solution where θ(x, y) is a large enough, polynomial in x and y, more specifically consisting of 24 independent sub-polynomials that are independent
Secondly, we suppose that Δk = Δ is a sufficiently small square surface such that a good approximation of the integral in Equation (58)—and it is also the approximation we have used for the integrals (Equations 53 and 54)—is given by Δ times the value of the function under the integral in the center of Δ. This transforms the set of 24 nonlinear (Equation 58) into a set of 24 linear equations
We have solved them for the points (xk, yk) where the 24 items are located in Figures 2, 3, for Δ = 0.01, which gives us θ(x, y), and hence also the expression for containing the expected interference term, and we have
In Figure 4 we have graphically represented this probability density . The interference pattern shown in Figure 4 is very similar to well-known interference patterns of light passing through an elastic material under stress. In our case, it is the interference pattern corresponding to “Fruits or Vegetables” as a contextual, interfering prototype. The numerical values of the solutions represented in Figures 2–4 are in Table 2.

Figure 4. The probabilities μ(A or B)k of a person choosing the item k as a “good example” of Fruits or Vegetables are fitted into the two-dimensional quantum wave function , which is the normalized superposition of the wave functions in Figures 2, 3. The numbers are placed at the locations of the different exemplars with respect to the probability distribution , where θ(x, y) is the quantum phase difference at (x, y). The values of θ(x, y) are given in Table 1 for the locations of the different items. The interference pattern is clearly visible.
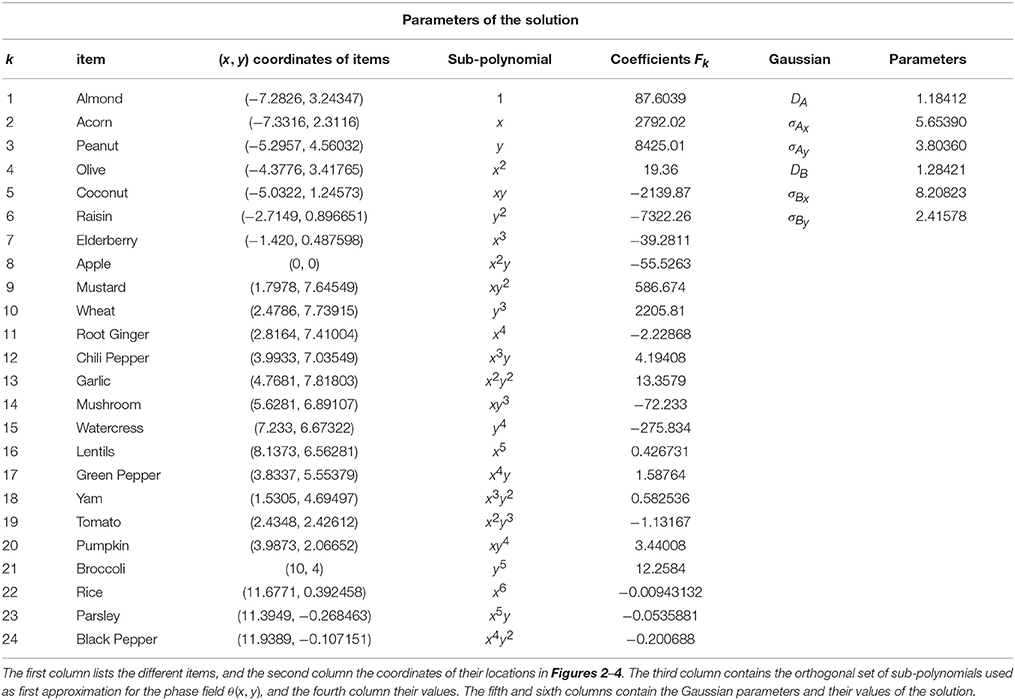
Table 2. The parameters of the interference pattern solution illustrated in Figure 4.
We have thus completed our illustration of contextual interfering prototypes. It is, however, important to remember that this representation is at the subtle level of an illustration, while the real working representation of contextual interfering prototypes needs the complete quantum-mechanical formalism. It can be considered as a pre-representation, exactly as the wave-like representations by de Broglie and Schrödinger in the early days of quantum physics can be considered as useful pre-quantum representations that capture something of the wave aspects of microscopic particles.
5. Discussion
In this paper we showed that a generalization of prototype theory can address the “Pet-Fish problem” and related combination issues. This was done by formalizing the effect of the cognitive context on the state of a concept using a SCoP formalism (Gabora and Aerts, 2002; Aerts and Gabora, 2005a,b; Gabora et al., 2008). We also developed a quantum-theoretic model in complex Hilbert space to show that, in this contextualized prototype theory, prototypes can interfere when concepts combine, as evidenced by data where typicality measurements are performed. This could then lead one to think that the general quantum approach to concepts only presupposes a (contextual) prototype theory. We now explain why this inference is not true.
Let us make more explicit the relationship between our quantum-conceptual approach and other concept theories, such as prototype theory, exemplar theory and theory theory. A deeper analysis shows that our approach is more than a contextual generalization of prototype theory. Roughly speaking, other theories make assumptions about the principles guiding the formation and intuitive representation of a concept in the human mind. Thus, prototype theory assumes that a concept is determined by a set of characteristic rather than defining features, the human mind has a privileged prototype for each concept, and typicality of a concrete item is determined by its similarity with the prototype (Rosch, 1973, 1978, 1983). Exemplar theory assumes instead that a concept is not determined by a set of defining or characteristic features but, rather, by a set of salient instances of it stored in memory (Nosofsky, 1988, 1992). Theory theory assumes that concepts are determined by “mini-theories” or schemata, identifying the causal relationships among properties (Murphy and Medin, 1985; Rumelhart and Norman, 1988). These theories have all mainly been preoccupied with the question of “what predominantly determines a concept.” We agree on the relevance of this question, though it is not the main issue focused on there. Transposed to our approach, these theories mainly investigate “what predominantly determines the state of a concept.” Conversely, the main preoccupation of our approach has been to propose a theory with the following features:
(i) a well-defined ontology, i.e., a concept is in our approach an entity capable of different modes of being with respect to how it influences measurable semantic quantities such as typicality, membership weight and membership probability, and these modes are called “states”;
(ii) the capacity to produce theoretical models fitting data on these measurable semantic quantities.
We seek to achieve (i) and (ii) independent of the question that is the focus of other theories of concepts. More concretely, and in accordance with the results of investigations into the question of “what predominantly determines a concept,” as far as prototype theory, exemplar theory and theory theory are concerned, we believe that all approaches are partially valid. The state of a concept, i.e., its capability of influencing the values of measurable semantic quantities, such as typicality and membership weight, is influenced by the set of its characteristic features, but also by salient exemplars in memory, and in a considerable number of cases—where more causal aspects are at play—mini-theories might be appropriate to express this state. It is important that “a conceptual state is defined and gives rise, together with the context, to the values of the measurable semantic quantities.” The fact that the specification of these values can be only probabilistic is a confirmation that potentiality and uncertainty occur even if the state is completely known, hence quantum structures are intrinsically needed.
It follows from the above that resorting and giving new life to prototype theory does not necessarily entail that contextual prototype theory is the only possible theory of concepts for what concerns the question of “what predominantly determines a concept.” However, we choose to identify our general approach as a “generalized contextual interfering prototype theory,” because the “ground state” of a concept is a fundamental notion of the theory, and this ground state is what corresponds to the prototype. There is not a similar affinity with exemplar theory and theory theory. However, the conceptual state and its interaction with the cognitive context can potentially capture the other conceptual aspects, exemplars and schemata, which are instead predominant in alternative concept theories. In this respect, an interesting analogy must be emphasized. The quantum-theoretic approach only aims at modeling concepts and their combinations in a unitary and coherent mathematical formalism. We do not pretend to give a universal definition of what a concept is and how it forms. Using a known analogy in mathematics, we can say that the quantum-theoretic model is to a concept as a traditional Kolmogorov model is to a probability. A Kolmogorovian model specifies how a probability can be mathematically formalized independent of the definition of probability that is chosen (favorable over possible cases, large number limit of frequencies, subjective, etc.). Analogously, the quantum-theoretic framework for concepts enables mathematical modeling of conceptual entities independent of the definition that is adopted in a specific concept theory (prototype, exemplar, theory, etc.).
We conclude with an epistemological consideration. The quantum-theoretic framework presented here constitutes a step toward the elaboration of a general theory for the representation of any conceptual entity. Hence, it is not just a “cognitive model for typicality, membership weight or membership probability.” Rather, we are investigating whether “quantum theory, in its Hilbert space formulation, is an appropriate theory to model human cognition.” To understand what we mean by this let us consider an example taken from everyday life. As an example of a theory, we could introduce the theory of “how to make good clothes.” A tailor needs to learn how to make good clothes for different types of people, men, women, children, old people, etc. Each cloth is a model in itself. Then, one can also consider intermediate situations where one has models of series of clothes. A specific body will not fit in any clothes: you need to adjust the parameters (length, size, etc.) to reach the desired fit. We think that a theory should be able to reproduce different experimental results by suitably adjusting the involved parameters, exactly as a theory of clothing. This is different from a set of models, even if the set can cope with a wide range of data.
There is a tendency, mainly in empirically-based disciplines, to be critical with respect to a theory that can cope with all possible situations it applies to. This is because the theory contains too many parameters, which may lead one to think that “any type of data can be modeled by allowing all these parameters to have different values.” We agree that, in case we have to do with an “ad-hoc model,” i.e., a model specially made for the circumstance of the situation it models, this suspicion is grounded. Adding parameters to such an ad-hoc model, or stretching the already contained parameters to other values, does not give rise to what we call a theory. On the other hand, a theory needs to be well defined, its rules, the allowed procedures, its theoretical, mathematical, and internal logical structure, “independent” of the structure of the models describing specific situations that can be coped with by the theory. Hence also the theory needs to contain a well defined description of “how to produce models for specific situations.” Coming back to the theory of clothing, if a tailor knows the theory of clothing, obviously he or she can make a cloth for every human body, because the theory of clothing, although its structure is defined independently of a specific cloth, contains a prescription of how to apply it to any possible specific cloth. In this respect, we think that one should carefully distinguish between a model that is derived by a general theory, as the one presented in this paper, and a model specifically designed to test a number of experimental situations.
This brings us to the important question of the “predictive power” of existing quantum-theoretic models. Models derived from a theory will generally need more data from a bigger set of experiments to become predictive for the outcomes of other not yet performed experiments than this is the case for models that are more ad-hoc. The reason is that in principle such models—think of the analogy we present with the theory of clothing above—must be able to faithfully represent the data of all possible experiments that can be performed on the conceptual entity in the same state. A tailor knowing the theory of clothing can in principle make clothes for all human bodies but hence also predicts outcomes of not performed experiments, e.g., the measure of a specific part of the cloth, if enough data of a set of experiments are available to the tailor, e.g., data that determine the possible types of clothes still fitting these data and as a consequence also determine the measure of this part of the clothe. In general in quantum cognition, the scarcity of data is preventing models from having systematic and substantial predictive power. One can wonder, if predictive power is not yet predominantly available in the majority of existing quantum-theoretic models, why so much attention and value is actually attributed to them? Answering this question allows us to clarify an aspect of quantum cognition that is not obvious and even makes it special in a specific way, at least provisionally until more data is available. The success of quantum cognition is due to it “being able to convincingly model data that theoretically can be proven to be impossible to model with any model that relies on classical fuzzy set theory and/or classical Kolmogorovian probability theory.” Hence, a different criterion than predictive power is provisionally used to identify the success of quantum cognition. Of course, as soon as more data are collected, the models will also be able to be tested for their predictive power. Recent work in quantum cognition is starting to reach the level of being predictive, for example study of order effects (Wang et al., 2014), and an elaboration and refinement of the model presented in this article (Aerts et al., 2015a,c). The latter model simultaneously investigates the “conjuntion” and the “negation” of concepts, starting from data collected on such conceptual combinations. To explain the exact nature and also accurateness of the predictive power we gained in the model in Aerts et al. (2015a,c), consider the following mathematical expression
where A and B are the concepts Fruits and Vegetables, respectively, while A′ and B′ are their negations. Thus, “A and B′” means Fruits and not Vegetables, while “A′ and B” means not Fruits and Vegetables and “A′ and B′” means not Fruits and not Vegetables. In Aerts et al. (2015a,c) we published the data for the outcomes of experiments that test the membership of the same 24 items which we considered in the present article, but this time not only for the conjunction of A and B, but also for the conjunctions “A and B′,” “A′ and B,” and “A′ and B′.” Suppose that the data follow a classical probabilistic structure, then has to be theoretically equal to zero for each considered item, and this purely follows from a general “law of probability calculus” related to the so called “de Morgan laws” of classical probability. This means that, under the hypothesis of a classical probabilistic structure, if we measure the relative frequencies of “A and B,” “A and B′” and “A′ and B,” and hence determine experimentally the values of μ(A and B), μ(A and B′) and μ(A′ and B), a “prediction” for μ(A′ and B′) can be made theoretically, namely,
for each considered item. Let is explain what are our findings in Aerts et al. (2015a,c) that make it possible for us to speak of some specific type of predictability for the more elaborated and refined model we developed for the combination of concepts and their negations. In Aerts et al. (2015a,c) we have collected data not only for the pair of concepts Fruits and Vegetables and the 24 items treated also in the present article, but for three more pairs of concepts, and for each of them again 24 items. Due to the already identified non classical nature of overextension of the conjunction we expected that would not be equal to zero, and that indeed showed to be the case. However, we detected a high level of systematics of the value of fluctuating around an average of −0.81. A statistical analysis showed the different values for individual items to be possible to be explained as fluctuations around this average (see Tables 1–4 in Aerts et al., 2015a). Next to the detailed statistical analysis to be found in Aerts et al. (2015a) we also put forward a theoretical explanation of this value. The elaborated and refined model for concept combinations developed in Aerts et al. (2015a) introduces within the model the combination of a pure quantum model and a classical model. It can be shown that for a pure quantum model the value of would be −1. We also find that the quantum effects are dominant as compared to the classical effects in case concepts are combined, which explains why our refined model gives rise to a value of in between the classical one, which is 0, and the pure quantum one, which is −1, but closer to the quantum one, hence −0.81. This finding can be turned into a predictive one in the following way. Suppose we measure μ(A and B), μ(A and B′) and μ(A′ and B) for two arbitrary concepts and an item. Our model allows us to put forward the following prediction for μ(A′ and B′)
By comparing Equations (66) and (67), we get that the quantum-theoretic model in Aerts et al. (2015a) provides a “different prediction” from a classical probabilistic model satisfying the axioms of Kolmogorov, and experiments confirm the validity of the former over the latter. We add that the quantum model has different predictions from a classical model also for the values of other functions than , and these predictions are “parameter independent,” in the sense that they do not depend on the values of free parameters that may accommodate the data.
The results above can be considered as a strong confirmation that quantum-theoretic models of concept combinations provide predictions that deviate, in some situations, from the predictions of classical Kolmogorovian models, which is confirmed by experimental data.
Author Contributions
All authors listed, have made substantial, direct and intellectual contribution to the work, and approved it for publication.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^The cosine value only defines the phase up to its absolute value |ϕk|. Thus, the sign of the sine value is undefined. If ϵk = −1, then ϕk = −|ϕk|.
References
Aerts, D. (1986). A possible explanation for the probabilities of quantum mechanics. J. Math. Phys. 27, 202–210. doi: 10.1063/1.527362
Aerts, D. (1999). Foundations of quantum physics: a general realistic and operational approach. Int. J. Theor. Phys. 38, 289–358. doi: 10.1023/A:1026605829007
Aerts, D. (2009a). Quantum structure in cognition. J. Math. Psychol. 53, 314–348. doi: 10.1016/j.jmp.2009.04.005
Aerts, D. (2009b). Quantum particles as conceptual entities: a possible explanatory framework for quantum theory. Found. Sci. 14, 361–411. doi: 10.1007/s10699-009-9166-y
Aerts, D., and Aerts, S. (1995). Applications of quantum statistics in psychological studies of decision processes. Found. Sci. 1, 85–97. doi: 10.1007/BF00208726
Aerts, D., Aerts, S., Broekaert, J., and Gabora, L. (2000). The violation of Bell inequalities in the macroworld. Found. Phys. 30, 1387–1414. doi: 10.1023/A:1026449716544
Aerts, D., Broekaert, J., Gabora, L., and Sozzo, S. (2013b). Quantum structure and human thought. Behav. Brain Sci. 36, 274–276. doi: 10.1017/S0140525X12002841
Aerts, D., and Gabora, L. (2005a). A theory of concepts and their combinations I: the structure of the sets of contexts and properties. Kybernetes 34, 167–191. doi: 10.1108/03684920510575799
Aerts, D., and Gabora, L. (2005b). A theory of concepts and their combinations II: a Hilbert space representation. Kybernetes 34, 192–221. doi: 10.1108/03684920510575807
Aerts, D., Gabora, L., and S. Sozzo, S. (2013a). Concepts and their dynamics: a quantum–theoretic modeling of human thought. Top. Cogn. Sci. 5, 737–772. doi: 10.1111/tops.12042
Aerts, D., and Sozzo, S. (2011). Quantum Structure in Cognition. Why and How Concepts are Entangled. Quantum Interaction. Lecture Notes in Computer Science 7052. Berlin: Springer.
Aerts, D., and Sozzo, S. (2014). Quantum entanglement in conceptual combinations. Int. J. Theor. Phys. 53, 3587–3603. doi: 10.1007/s10773-013-1946-z
Aerts, D., Sozzo, S., and Tapia, J. (2014). Identifying quantum structures in the Ellsberg paradox. Int. J. Theor. Phys. 53, 3666–3682. doi: 10.1007/s10773-014-2086-9
Aerts, D., Sozzo, S., and Veloz, T. (2015). Quantum nature of identity in human concepts: Bose-Einstein statistics for conceptual indistinguishability. Int. J. Theor. Phys. 54, 4430–4443. doi: 10.1007/s10773-015-2620-4
Aerts, D., Sozzo, S., and Veloz, T. (2015a). Quantum structure of negation and conjunction in human thought. Front. Psychol. 6:1447. doi: 10.3389/fpsyg.2015.01447
Aerts, D., Sozzo, S., and Veloz, T. (2015b). Quantum structure in cognition and the foundations of human reasoning. Int. J. Theor. Phys. 54, 4557–4569. doi: 10.1007/s10773-015-2717-9
Aerts, D., Sozzo, S., and Veloz, T. (2015c). New fundamental evidence of non-classical structure in the combination of natural concepts. Philos. Trans. R. Soc. A 374:20150095. doi: 10.1098/rsta.2015.0095
Alxatib, S., and Pelletier, J. (2011). “On the psychology of truth gaps,” in Vagueness in Communication, eds R. Nouwen, R. van Rooij, U. Sauerland, and H.-C. Schmitz (Berlin; Heidelberg: Springer-Verlag), 13–36. doi: 10.1007/978-3-642-18446-8_2
Bonini, N., Osherson, D., Viale, R., and Williamson, T. (1999). On the psychology of vague predicates. Mind Lang. 14, 377–393. doi: 10.1111/1468-0017.00117
Busemeyer, J. R., and Bruza, P. D. (2012). Quantum Models of Cognition and Decision. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511997716
Costello, J., and Keane, M. T. (2000). Efficient creativity: constraint-guided conceptual combination. Cogn. Sci. 24, 299–349. doi: 10.1207/s15516709cog2402_4
Gabora, L., and Aerts, D. (2002). Contextualizing concepts using a mathematical generalization of the quantum formalism. J. Exp. Theor. Artif. Intell. 14, 327–358. doi: 10.1080/09528130210162253
Gabora, L., Rosch, E., and Aerts, D. (2008). Toward an ecological theory of concepts. Ecol. Psychol. 20, 84–116. doi: 10.1080/10407410701766676
Gagne, C. L., and Spalding, T. L. (2009). Constituent integration during the processing of compound words: does it involve the use of relational structures? J. Mem. Lang. 60, 20–35. doi: 10.1016/j.jml.2008.07.003
Geeraerts, D. (1989). Prospects and problems of prototype theory. Linguistics 27, 587–612. doi: 10.1515/ling.1989.27.4.587
Hampton, J. A. (1988a). Overextension of conjunctive concepts: evidence for a unitary model for concept typicality and class inclusion. J. Exp. Psychol. Learn. Mem. Cogn. 14, 12–32. doi: 10.1037/0278-7393.14.1.12
Hampton, J. A. (1988b). Disjunction of natural concepts. Mem. Cogn. 16, 579–591. doi: 10.3758/BF03197059
Hampton, J. A. (1997). Conceptual combination: conjunction and negation of natural concepts. Mem. Cogn. 25, 888–909. doi: 10.3758/BF03211333
Haven, E., and Khrennikov, A. Y. (2013). Quantum Social Science. Cambridge: Cambridge University Press. doi: 10.1017/CBO9781139003261
Kamp, H., and Partee, B. (1995). Prototype theory and compositionality. Cognition 57, 129–191. doi: 10.1016/0010-0277(94)00659-9
Khrennikov, A. Y., Basieva, I., Dzhafarov, E. N., and Busemeyer, J. R. (2014). Quantum models for psychological measurements: an unsolved problem. PLoS ONE 9:e110909. doi: 10.1371/journal.pone.0110909
Kolmogorov, A. N. (1933). Grundbegriffe der Wahrscheinlichkeitrechnung, Ergebnisse Der Mathematik; translated as Foundations of Probability. New York, NY: Chelsea Publishing Company.
Komatsu, L. K. (1992). Recent views on conceptual structure. Psychol. Bull. 112, 500–526. doi: 10.1037/0033-2909.112.3.500
Murphy, G. L., and Medin, D. L. (1985). The role of theories in conceptual coherence. Psychol. Rev. 92, 289–316. doi: 10.1037/0033-295X.92.3.289
Nosofsky, R. (1988). Exemplar-based accounts of relations between classification, recognition, and typicality. J. Exp. Psychol. Learn. Mem. Cogn. 14, 700–708. doi: 10.1037/0278-7393.14.4.700
Nosofsky, R. (1992). “Exemplars, prototypes, and similarity rules,” in From Learning Theory to Connectionist Theory: Essays in Honor of William K. Estes, eds A. Healy, S. Kosslyn, and R. Shiffrin (Hillsdale, NJ: Erlbaum), 149–167.
Osherson, D., and Smith, E. (1981). On the adequacy of prototype theory as a theory of concepts. Cognition 9, 35–58. doi: 10.1016/0010-0277(81)90013-5
Osherson, D. N., and Smith, E. (1982). Gradedness and conceptual combination. Cognition 12, 299–318. doi: 10.1016/0010-0277(82)90037-3
Osherson, D. N., and Smith, E. (1997). On typicality and vagueness. Cognition 64, 189–206. doi: 10.1016/S0010-0277(97)00025-5
Pitowsky, I. (1989). Quantum Probability, Quantum Logic. Lecture Notes in Physics. Vol. 321. Berlin: Springer.
Pothos, E. M., and Busemeyer, J. R. (2013). Can quantum probability provide a new direction for cognitive modeling? Behav. Brain Sci. 36, 255–274. doi: 10.1017/S0140525X12001525
Rips, L. J. (1995). The current status of research on concept combination. Mind Lang. 10, 72–104. doi: 10.1111/j.1468-0017.1995.tb00006.x
Rosch, E. (1978). “Principles of categorization,” in Cognition and Categorization, eds E. Rosch and B. Lloyd (Hillsdale, NJ: Lawrence Erlbaum), 133–179.
Rosch, E. (1983). “Prototype classification and logical classification: the two systems,” in New Trends in Conceptual Representation: Challenges to Piaget Theory?, ed E. Scholnick (Hillsdale, NJ: Lawrence Erlbaum), 133–159.
Rumelhart, D. E., and Norman, D. A. (1988). “Representation in memory,” in Stevens Handbook of Experimental Psychology, eds R. C. Atkinson, R. J. Hernsein, G. Lindzey, and R. L. Duncan (New York, NY: John Wiley & Sons), 511–587.
Sozzo, S. (2014). A quantum probability explanation in Fock space for borderline contradictions. J. Math. Psychol. 58, 1–12. doi: 10.1016/j.jmp.2013.11.001
Sozzo, S. (2015). Conjunction and negation of natural concepts: a quantum-theoretic modeling. J. Math. Psychol. 66, 83–102. doi: 10.1016/j.jmp.2015.01.005
Thagard, P., and Stewart, T. C. (2011). The AHA! experience: creativity through emergent binding in neural networks. Cogn. Sci. 35, 1–33. doi: 10.1111/j.1551-6709.2010.01142.x
Van Dantzig, S., Raffone, A., and Hommel, B. (2011). Acquiring contextualized concepts: a connectionist approach. Cogn. Sci. 35, 1162–1189. doi: 10.1111/j.1551-6709.2011.01178.x
Wang, Z., Solloway, T., Shiffrin, R. M., and Busemeyer, J. R. (2014). Context effects produced by question orders reveal quantum nature of human judgments. Proc. Natl. Acad. Sci. U.S.A. 111, 9431–9436. doi: 10.1073/pnas.1407756111
Zadeh, L. (1982). A note on prototype theory and fuzzy sets. Cognition 12, 291–297. doi: 10.1016/0010-0277(82)90036-1
Appendix
A. Quantum Mathematics for Conceptual Modeling
We illustrate in this section how the mathematical formalism of quantum theory can be applied to model situations outside the microscopic quantum world, more specifically, in the representation of concepts and their combinations. We will limit technicalities to the essential.
When the quantum mechanical formalism is applied for modeling purposes, each considered entity—in our case a concept—is associated with a complex Hilbert space , that is, a vector space over the field ℂ of complex numbers, equipped with an inner product 〈·|·〉 that maps two vectors 〈A| and |B〉 onto a complex number 〈A|B〉. We denote vectors by using the bra-ket notation introduced by Paul Adrien Dirac, one of the pioneers of quantum theory. Vectors can be “kets,” denoted by |A〉, |B〉, or “bras,” denoted by 〈A|, 〈B|. The inner product between the ket vectors |A〉 and |B〉, or the bra-vectors 〈A| and 〈B|, is realized by juxtaposing the bra vector 〈A| and the ket vector |B〉, and 〈A|B〉 is also called a “bra-ket,” and it satisfies the following properties:
(i) 〈A|A〉 ≥ 0;
(ii) 〈A|B〉 = 〈B|A〉*, where 〈B|A〉* is the complex conjugate of 〈A|B〉;
(iii) 〈A|(z|B〉 + t|C〉) = z〈A|B〉 + t〈A|C〉, for z, t ∈ ℂ, where the sum vector z|B〉 + t|C〉 is called a “superposition” of vectors |B〉 and |C〉 in the quantum jargon.
From (ii) and (iii) follows that inner product 〈·|·〉 is linear in the ket and anti-linear in the bra, i.e., (z〈A| + t〈B|)|C〉 = z*〈A|C〉 + t*〈B|C〉.
The “absolute value” of a complex number is defined as the square root of the product of this complex number times its complex conjugate, that is, . Moreover, a complex number z can either be decomposed into its cartesian form z = x + iy, or into its polar form z = |z|eiθ = |z|(cosθ + isinθ). As a consequence, we have . We define the “length” of a ket (bra) vector |A〉 (〈A|) as . A vector of unitary length is called a “unit vector.” We say that the ket vectors |A〉 and |B〉 are “orthogonal” and write |A〉⊥|B〉 if 〈A|B〉 = 0.
We have now introduced the necessary mathematics to state the first modeling rule of quantum theory, as follows.
A.1. First Quantum Modeling Rule
A state A of an entity—in our case a concept—modeled by quantum theory is represented by a ket vector |A〉 with length 1, that is 〈A|A〉 = 1.
An orthogonal projection M is a linear operator on the Hilbert space, that is, a mapping M: → , |A〉 ↦ M|A〉 which is Hermitian and idempotent. The latter means that, for every |A〉, |B〉 ∈ and z, t ∈ ℂ, we have:
(i) M(z|A〉 + t|B〉) = zM|A〉 + tM|B〉 (linearity);
(ii) 〈A|M|B〉 = 〈B|M|A〉* (hermiticity);
(iii) M·M = M (idempotency).
The identity operator 𝟙 maps each vector onto itself and is a trivial orthogonal projection. We say that two orthogonal projections Mk and Ml are orthogonal operators if each vector contained in Mk() is orthogonal to each vector contained in Ml(), and we write Mk⊥Ml, in this case. The orthogonality of the projection operators Mk and Ml can also be expressed by MkMl = 0, where 0 is the null operator. A set of orthogonal projection operators {Mk |k = 1, …, n} is called a “spectral family” if all projectors are mutually orthogonal, that is, Mk⊥Ml for k ≠ l, and their sum is the identity, that is, .
The above definitions give us the necessary mathematics to state the second modeling rule of quantum theory, as follows.
A.2. Second Quantum Modeling Rule
A measurable quantity Q of an entity—in our case a concept—modeled by quantum theory, and having a set of possible real values {q1, …, qn} is represented by a spectral family {Mk |k = 1, …, n} in the following way. If the entity—in our case a concept—is in a state represented by the vector |A〉, then the probability of obtaining the value qk in a measurement of the measurable quantity Q is . This formula is called the “Born rule” in the quantum jargon. Moreover, if the value qk is actually obtained in the measurement, then the initial state is changed into a state represented by the vector
This change of state is called “collapse” in the quantum jargon.
The tensor product A ⊗ B of two Hilbert spaces A and B is the Hilbert space generated by the set {|Ai〉 ⊗ |Bj〉}, where |Ai〉 and |Bj〉 are vectors of A and B, respectively, which means that a general vector of this tensor product is of the form . This gives us the necessary mathematics to introduce the third modeling rule.
A.3. Third Quantum Modeling Rule
A state C of a compound entity—in our case a combined concept—is represented by a unit vector |C〉 of the tensor product A ⊗ B of the two Hilbert spaces A and B containing the vectors that represent the states of the component entities—concepts.
The above means that we have , where |Ai〉 and |Bj〉 are unit vectors of A and B, respectively, and . We say that the state C represented by |C〉 is a product state if it is of the form |A〉 ⊗ |B〉 for some |A〉 ∈ A and |B〉 ∈ B. Otherwise, C is called an “entangled state.”
The Fock space is a specific type of Hilbert space, originally introduced in quantum field theory. For most states of a quantum field the number of identical quantum entities is not conserved but is a variable quantity. The Fock space copes with this situation in allowing its vectors to be superpositions of vectors pertaining to different sectors for fixed numbers of identical quantum entities. MoreA explicitly, the k-th sector of a Aock space describes a fixed number of k identical quantum entities, and it is of the form ⊗ … ⊗ of the tensor product of k identical Hilbert spaces . The Aock space A itself is the direct sum of all these sectors, hence
Aor our modeling we have only used Aock space for the “two” and “one quantum entity” case, hence = ⊕( ⊗ ). This is due to considering only combinations of two concepts. The sector is called the “first sector,” while the sector ⊗ is called the “second sector.” A unit vector |F〉 ∈ is then written as |F〉 = neiγ|C〉 + meiδ(|A〉 ⊗ |B〉), where |A〉, |B〉 and |C〉 are unit vectors of , and such that n2 + m2 = 1. For combinations of j concepts, the general form of Fock space in Equation (A2) should be used.
The quantum modeling above can be generalized by allowing states to be represented by the so called “density operators” and measurements to be represented by the so called “positive operator valued measures.” However, for the sake of brevity we will not dwell on this extension here.
Keywords: cognition, concept theory, prototype theory, contextuality, interference, quantum modeling
Citation: Aerts D, Broekaert J, Gabora L and Sozzo S (2016) Generalizing Prototype Theory: A Formal Quantum Framework. Front. Psychol. 7:418. doi: 10.3389/fpsyg.2016.00418
Received: 13 August 2015; Accepted: 09 March 2016;
Published: 30 March 2016.
Edited by:
Kevin Bradley Clark, University of California, Los Angeles, USAReviewed by:
Terrence C. Stewart, Carleton University, CanadaBruce MacLennan, University of Tennessee, USA
Copyright © 2016 Aerts, Broekaert, Gabora and Sozzo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sandro Sozzo, c3M4MzFAbGUuYWMudWs=