 Seungmin Jahng
Seungmin Jahng Phillip K. Wood
Phillip K. Wood- 1Department of Psychology, Sungkyunkwan University, Seoul, South Korea
- 2Department of Psychological Sciences, University of Missouri, Columbia, MO, USA
Intensive longitudinal studies, such as ecological momentary assessment studies using electronic diaries, are gaining popularity across many areas of psychology. Multilevel models (MLMs) are most widely used analytical tools for intensive longitudinal data (ILD). Although ILD often have individually distinct patterns of serial correlation of measures over time, inferences of the fixed effects, and random components in MLMs are made under the assumption that all variance and autocovariance components are homogenous across individuals. In the present study, we introduced a multilevel model with Cholesky transformation to model ILD with individually heterogeneous covariance structure. In addition, the performance of the transformation method and the effects of misspecification of heterogeneous covariance structure were investigated through a Monte Carlo simulation. We found that, if individually heterogeneous covariances are incorrectly assumed as homogenous independent or homogenous autoregressive, MLMs produce highly biased estimates of the variance of random intercepts and the standard errors of the fixed intercept and the fixed effect of a level 2 covariate when the average autocorrelation is high. For intensive longitudinal data with individual specific residual covariance, the suggested transformation method showed lower bias in those estimates than the misspecified models when the number of repeated observations within individuals is 50 or more.
Introduction
Recent developments in data collection methods in the behavioral and social sciences, such as Ecological Momentary Assessment (EMA) (Stone and Shiffman, 1994; Hufford et al., 2001), enabled researchers in this area to gather data with many repeated measurements and to examine more detailed features of intra-individual variations over time. Such data that consist of repeated observations on a large number of occasions for many individuals with relatively short time intervals are called intensive longitudinal data (ILD: Walls and Schafer, 2006; Bolger and Laurenceau, 2013).1
Multilevel models (MLMs) have been widely used statistical tools for the analysis of both ILD and traditional longitudinal data that involves a small to moderate number of repeated observations (Walls et al., 2006; Schwartz and Stone, 2007; Nezlek, 2012). In a typical analysis of traditional longitudinal data using MLMs, within-person residual distributions are assumed to be identical across individuals, which means that all participants in the data have the same residual variance and autocorrelations. There may be several reasons for assuming homogenous within-person error structure in most applications of MLM with traditional longitudinal data. First, heterogeneous residual covariances may be less likely to exist after modeling random effects. Second, violation of the homogenous residual covariance assumption may not produce significant bias in estimation of the model parameters. Third, even if the heterogeneous residual covariances are likely to exist and need to be correctly specified, accurate estimation of individual covariance structure is not plausible with a small to moderate number of observations within individuals.
Due to the longitudinally intensive nature of assessments, however, the common practice of assuming homogenous residual covariance structure in MLM is questionable in case of ILD. First, heterogeneous residual covariances across individuals are very likely to exist in ILD. For example, many recent EMA studies have shown that there are substantial heterogeneity across individuals in the variance and autocorrelation of emotional states over time (e.g., Röcke et al., 2009; Kuppens et al., 2010; Hill and Updegraff, 2012; Koval and Kuppens, 2012; Tompson et al., 2012; Bresin, 2014; Ebner-Priemer et al., 2015). Second, little is known about the influence of violation of homogenous covariance structure on parameter estimation in MLMs with ILD. Misspecified error covariance structure in MLMs is known to produce inaccurate estimation in both fixed effects and variance components (Lange and Laird, 1989; Ferron et al., 2002, 2009; Kwok et al., 2007; Moeyaert et al., 2016) but the previous findings did not investigate the validity of common practice of assuming homogenous error structure in MLM with ILD when the within-person error structure is in fact different across individuals. Third, for such data, it is possible to reliably estimate individual-level covariance structure because a typical ILD has a sufficient number of observations within individuals.
In practice, researchers may fit a regression model with unstructured error covariance matrix to optimally estimate the fixed effects in ILD without modeling heterogeneous error covariance. Unstructured covariance structures in which every element is freely estimated from the data may represent a complicated correlational pattern among occasions. This approach, however, has several limitations when applied to ILD. First, multilevel analysis cannot be employed with unstructured residual covariance. Because unstructured covariance matrix is just identified, no additional random component can be modeled with it, that is random effects and their sources cannot be investigated. In addition, unstructured covariance matrix of ILD has too many parameters to be estimated, because the total number of parameters in the covariance matrix depends on the number of occasions, i.e., n(n+1)/2, where n is the number of occasions. For example, if the number of observations within each individual is 100, the number of parameters in the unstructured covariance is 5050. Models with a large number of parameters may suffer from non-convergence, under-identification, and/or non-positive definite solutions. This is especially true when the number of individuals is less than the number of occasions, which is often found in some ILD studies.
In short, heterogeneous variances and autocorrelations across individuals are likely to exist in ILD and, if ignored, may raise serious problems in estimating effects of covariates in MLM. However, relatively little is known about the influence of violation of homogenous covariance structure on parameter estimation in multilevel models with ILD. Use of unstructured error covariance structure does not successfully address the issue when researchers are interested in random effects or the number of measurement occasions is large.
Alternatively, a transformation method for regression with autocorrelated errors can be applied to the multilevel analysis of ILD in this context. A regression model for a single time-series with autocorrelated residuals can be correctly estimated by fitting OLS regression using data transformed by the inverse of Cholesky factor of the residual covariance matrix (Cochrane and Orcutt, 1949; Watson, 1955). The Cholesky transformation for a single time-series regression can be extended to a multiple time-series regression or MLM for ILD with heterogeneous autocorrelated errors. Specifically, MLM with Cholesky transformation method for ILD estimates a transformation matrix for each individual in the first step and then fit a multilevel model on the transformed data. By this transformation method, researchers can analyze multilevel models for ILD without assuming unrealistic homogenous autocorrelated residuals. In addition, this method does not require a greater number of individuals than the number of measurement occasions.
The present study has two aims. First, we introduce the Cholesky transformation method to model ILD with heterogeneous autoregressive error covariance structure. The transformation is designed to provide a legitimate application of MLM to a serially, and differently, correlated intensive longitudinal data. Second, the effects of misspecifying heterogeneous covariance structure as commonly used homogenous ones are investigated and compared to the result from the transformation method. Because the effect of the misspecification cannot be easily driven analytically and the suggested transformation method is expected to be valid asymptotically, we performed a Monte Carlo simulation by varying sample size, number of occasions, and average residual autocorrelation and then compared relative biases in estimation of fixed effects, random components, and the standard errors of fixed effects between misspecified models and the suggested method. In the next sections, a brief introduction to multilevel models is provided and issues in modeling residual covariance structure in MLMs are discussed. A multilevel modeling approach that uses transformation of an autocorrelated error structure into an independent structure will then be introduced, followed by the simulation study.
Multilevel Models with Heterogeneous Covariance Structure
Covariance Structure in Multilevel Models for Longitudinal Data
In a longitudinal design, observations can be thought of as actualizations of a two-level data structure in which repeated observations (level-1) are nested within individuals (level-2). In a matrix form, the regression equation for individual i is expressed as
where Xi = ZiCi, Zi is the matrix of time-varying, within individual covariates including a column vector of ones, Ci is the matrix of individual-level covariates, γ is the vector of the fixed effects, and ui is the vector of random effects.
A typical two-level linear model has two error terms, ui and ei. The two error terms are assumed to be normally distributed with and . The mixture of the two normal distributions results in a multivariate normal distribution of yi, yi ~ N(Xiγ, Σi), where . For the entire observations , the MLM is written as
where , Z is the block diagonal matrix of Zi, i.e., , and The random vectors u and e are normally distributed with and , where G and R are the block diagonal matrices of Gi and Ri, and y ~ N(Xγ, Σ), where Σ = ZGZ′ + R is the block diagonal matrices of Σi. In practice, Gi and Ri are assumed homogenous across all level-2 individuals (i.e., G1 = G1 = … = GN and R1 = R1 = … = RN) in most applications.
Common use of MLMs for longitudinal data, including linear growth models, assumes an unstructured Gi matrix that allows estimation of variances and covariances of all random effects (e.g., ), and an independent and identical Ri matrix (Ri = I: ID). However, it is likely that residuals of an MLM for ILD have serial correlations across time even after modeling the fixed and random effects. If this is the case, independence assumption in Ri is not appropriate and a suitable covariance structure that models autocorrelations between successive residuals should be specified in Ri. For example, a covariance matrix generated by a first order autoregressive process can be used to model such a structure. If observations are measured at equally spaced time, the first order autoregressive covariance structure, AR(1), with four occasions, is modeled as
where ρ is the first order autoregressive parameter, i.e., autocorrelation between observations measured at time t and t-1.
Because Σ is determined by two covariance matrices G and R as well as a design matrix of random effect Z, misspecification of R may affect the estimation of G, or vice versa. The main diagonal elements of the square root of the covariance matrix of , are the true standard errors of . Thus, misspecification of R may also affect the estimation of the standard errors of fixed effects. These effects of misspecification of R on the estimation of γ and G has been studied by several researchers, in the context of linear growth models (Lange and Laird, 1989; Ferron et al., 2002; Jacqmin-Gadda et al., 2007; Kwok et al., 2007).
Ferron et al. (2002) found that misspecification of AR(1) residual covariance structure as ID structure in linear growth models results in overestimation of both and in G when ρ = 0.3 or 0.6, although bias in estimation of is much smaller than that of . They also found that the coverage rate of 95% confidence interval for the slope was smaller than the true nominal value of 0.95 when the number of individuals is small (N = 30). Following the previous findings, Kwok et al. (2007) investigated the effect of misspecification in Ri for various covariance structures, such as ID, AR(1), first order autoregressive and first order moving average, and second banded Toeplitz structure, and found that underspecification produced minor overestimation in the standard errors of the intercept and the slope as well as noticeable overestimation variance estimates in G. Jacqmin-Gadda et al. (2007) showed that the estimation of γ under the normal ID assumption of Ri is robust to heteroscedastic residuals, unless the residual variance is a function of individual-level covariates, and non-normal residuals. When residuals are serially correlated, however, estimation of γ was biased: The coverage rates of 95% confidence intervals for intercept, slope, individual-level covariate, and the interaction of the last two were significantly smaller than the nominal value of 0.95.
Regression with Autocorrelated Errors in a Single Time Series
For data consisting of a single time series, the effect of autocorrelated errors on estimation of regression parameters is well known and estimation of regressions with autocorrelated residuals has long been of interest to statisticians (Cochrane and Orcutt, 1949; Watson, 1955; Chipman, 1979; Maeshiro, 1980; Park and Mitchell, 1980; Harvey, 1981; Koreisha and Fang, 2001). Although traditional OLS estimation for linear regression model assumes independence of observations, time series data usually violate this assumption. Consider the standard regression model:
where y = (y1, y2, …, yn)′, n is the number of repeated measurements, X is a matrix of covariates, β is the corresponding regression parameter vector, and e = (e1, e2, …, en)′ is a random residual vector with a covariance matrix . If et is independent and has constant variance across t, i.e., or Ve = I, we can apply ordinary least squares to estimate β such that
and its covariance matrix is , where the square root of each diagonal element is the standard error of estimation for the corresponding parameter in β. The OLS estimator in this case is known as an unbiased and efficient estimator, or the best linear unbiased estimator (BLUE), in the sense that it has the smallest variance among all possible linear unbiased estimators.
If et is serially correlated, i.e., however, is no longer efficient. In such cases, generalized least squares (GLS) is used to estimate β such that
Alternatively, a suitable transformation of y can also be used. In that case, multiplying Equation 3 by a transformation matrix A, such that , gives
where w is a white noise vector with covariance matrix Equation 6 then can be expressed as
where y* = Ay and X* = AX. Equations (6, 7) provides a valid OLS estimator of β,
because . The transformation matrix A is obtained as A = L−1, where L denotes the Cholesky root of Vw, where (i.e., ), that is with L lower triangular. If we know the covariance matrix Σ or V, Equations (5, 8) can directly be applied and the two methods will produce identical estimates of β (i.e., ). If not, the GLS estimation involves complicated estimation of Σ but the transformation method may use an alternative algorithm.
One possible approach for estimation of Σ (and thus a transformation matrix A) is to construct Σ from a known autocorrelation structure. Pioneering work in this approach was done by Cochrane and Orcutt (1949) for the simple Markov process. For a Markov process, et = ϕet−1 + wt, wt ~ N(0, ) or AR(1) process, autocovariance γ(h) is well known to be expressed as
where ρ = ϕ is the first order autocorrelation (see Shumway and Stoffer, 2011, pp. 85–86). Autocovariance matrix Σ is then
and its inverse matrix is
Assuming a simple Markov process, the GLS estimator can be obtained by Equation 5, where Σ−1 is specified as in Equation 11.
To form a transformation matrix A, the inverse of Cholesky factor of Vw (i.e., the transpose of Cholesky factor of , where ) then can be obtained from Σ−1, given by
Using Equation 12, a valid OLS estimator is obtained through Equation 8 (Judge et al., 1985). Cochrane and Orcutt (1949) did not provide the exact form of Equation 12 but a similar idea of transformation was offered. If Σ−1 is successfully estimated, either GLS estimation or OLS estimation with transformation can be used. For the general AR(p) model, et = ϕ1et−1 + ϕ2et−2 + … + ϕpet−p + wt, however, estimation of Σ is challenging because the GLS approach requires a complicated nonlinear parameterization of γ(h) and Σ, and the calculations become more complicated as p increases. Because the lower triangular matrix L−1 is much simpler than Σ for the general AR(p) model, the transformation approach is exclusively used to correct higher order autoregressive error process for a single time series (SAS Institute Inc, 2013, p. 364).
Correction for Heterogeneous Autocorrelations for ILD
Application of the transformation method to ILD is straightforward. With a number of repeated observations within individuals, transformation of each single series may correct autocorrelated errors estimated separately by each individual. A time series model for individual i can be written as
where Zi is time-varying covariates. Equation 13 can be extended to a multilevel format as
where Xi = ZiCi, Zi is the matrix of time-varying covariates, Ci is the matrix of individual-level covariates, γ is the fixed effect, and ui is the random effect, respectively, as specified in Equation 1. The random effect ui and the residual ei are assumed to be normally distributed with and
If each individual has one's own covariance for ei, (i.e., R1 ≠ R1 ≠ … ≠ RN, for i = 1, 2, …, N), the transformed equation for each individual will be given by
where random effect ui and residual wi are then normally distributed with and and Ai is the inverse of Cholesky factor of (i.e., ). For the entire system, the transformed equation is written as
where A is the block diagonal matrix of Ai and X, Z, and u are specified as in Equation 2. Assuming homogenous variance of the transformed residuals, the transformed variables Ay, AZ, and AX can be used in a multilevel model with the ID residual structure. Correction through Equation 16 is expected to reduce bias, if any, in estimation of the parameters when there are heterogeneous autocorrelations in the data.
The correction procedure of multilevel models with heterogeneous autocorrelations is summarized as
1. Fit Equation 13 by OLS estimation for each individual. Obtain .
2. Calculate residuals as and investigate autocorrelations for
3. Define order p of AR(p) model for each individual by investigating autocorrelation patterns in residuals.
4. Apply transformation procedure for each individual and obtain the transformed data y* = Ay, Z* = AZ, and X* = AX.
5. Fit the intended MLM using y*, Z*, and X* assuming the ID or other independent residual structure.
Simply speaking, the above procedure consists of two steps. In the first step, transformed variables are obtained from a regression-with-autoregressive-error model for each individual.2 In the second step, the intended MLM is applied to the transformed variables obtained in the first step. We call this correction method as the multilevel model with Cholesky transformation (MLM-CT). The MLM-CT has several strengths in correction of autocorrelation in error structure for intensive longitudinal data. First, correction is applied for by each individual, without unrealistic identical distribution assumption in ILD. Second, time intervals between successive observations are not restricted to be equal across different individuals, although time intervals within individuals are restricted to be similarly spaced.3 Third, the correction is applicable to even higher order autoregressive error structure of general AR(p) models and, if required, allows different orders of autoregressive processes across individuals.
The suggested procedure may seem to be complicated to employ for applied researchers but can be easily done by using a commercial statistical software available. A SAS example code for the MLM-CT along with two commonly used multilevel models and the results of the analyses with a simulated data are presented in Appendix, which can be found in the Supplementary Material for this article.
Performance in Estimation of MLMs with Heterogeneous Autoregressive Errors: A Simulation Study
The previous studies reported that misspecification of error covariance structure is associated with overestimation of variance components of the random effects and the standard errors of the fixed effects (Ferron et al., 2002; Kwok et al., 2007). We also focused on the effect of misspecification of R on the estimation of fixed effects and the variance components in G, in the sense that if MLMs assume homogenous Ri, when it is in fact heterogeneous, the misspecified Ri may cause bias in estimation of the parameters in MLMs. To this end, a simulation study was conducted in which data generated from a longitudinal multilevel structure with heterogeneous autoregressive error process were analyzed by MLMs with homogenous assumption. The two most commonly used covariance structures for the analysis of longitudinal data, that is, ID and AR(1) were used to build misspecified models. In addition, the estimated parameters of the MLM with Cholesky transformation was evaluated against those of the misspecified models.
Method
For simplicity, the following two-level linear mixed model was used to generate data:
where γ00 is the fixed intercept, γ10 is the fixed effect of a time-varying covariate zti, γ01 is the fixed effect of a time-invariant covariate ci, γ11 is the fixed effect of the cross-level interaction of zti and ci, u0i is the random intercept, and u1i is the random effect of zti.4 The time-varying covariate zti and the time-invariant covariate ci were generated from the standard normal distribution. Parameters of all fixed effects were set to 1. The random effect u0i and u1i were distributed multivariate normal as , where , , and σu0u1 = 0.15 (i.e., ru0u1 = .3). The errors were generated with a first order autoregressive model, eti = ρie(t−1)i + wti, wti ~ N(0, 1).
The autoregressive parameter ρi was allowed to vary across individuals, generated from a uniform distribution as ρi ~ U(ρ – 0.3, ρ + 0.3), where ρ = 0.0, 0.3, or 0.6, implying that E(ρi) = 0.0, 0.3, or 0.6, respectively. Each data set was completely balanced with L (series length, or the number of observations within individuals) = 20, 50, 100, or 200 and N (the number of individuals) = 20, 50, 100, or 200. Accordingly, 4(N) × 4(L) × 3(ρ) = 48 conditions were obtained. In each condition, 500 data sets were simulated, resulting in a total of 24,000 data sets. Each data set was analyzed three times separately by three different MLMs: MLM with ID covariance structure (MLM-ID), MLM with a homogenous first order autoregressive covariance structure (MLM-AR), and MLM with Cholesky transformation (MLM-CT), resulting in a total of 72,000 analyses. For the transformation procedure in the first step of MLM-CT, a regression model with autoregressive errors was fitted for each individual and variables were transformed by using the AUTOREG procedure in SAS with ML estimation. After transformation, the transformed variables were fitted by the MLM with ID structure in the second step. All three MLMs were properly modeled and fitted using the MIXED procedure in SAS with restricted maximum likelihood estimation.
Bias in parameter estimation was investigated in terms of relative bias for the fixed effects γ00, γ10, γ01, and γ11 and the variance components, , , and . Relative bias was calculated in percentage as , where θ is the true parameter value, is the corresponding sample estimate of the rth sample, and R is the number of replications converged in each condition.5 Biases in the estimated standard error were also investigated. Relative bias of standard error for the fixed effects was also calculated in percentage as , where θ is the true standard error and is the estimated standard error for the rth sample.
The estimates of the fixed effects obtained by the two misspecified MLMs (i.e., MLM-ID and MLM-AR) were expected to be unbiased because misspecified error covariance structure is unlikely to influence bias in point estimation of the fixed effects. Estimates of the variance components of random effects, however, are likely to be biased for the two MLMs with misspecified covariance structures, especially for the variance of random intercept with high serial correlations (see Ferron et al., 2002; Kwok et al., 2007). This bias was expected to be greater for MLM-ID than MLM-AR because the first is more restricted by the independence assumption. In addition, MLM-CT is expected to reduce biases of estimates of the variance components in some conditions, but not in other conditions. Specifically, because a successful correction of the MLM-CT depends on valid transformation in the first step, which requires enough number of observations for each individual, a less biased estimation in the second step was expected not for the data with a relatively small to moderate number of repeated observations (e.g., L = 20 or 50) but for the data with a large number of observations (e.g., L = 100 or 200) for each individual. Bias in estimation of the standard error of estimation for the fixed effects is also more likely in the MLM-ID and the MLM-AR, for the data with a large number of repeated observations, than in the MLM-CT, because the estimated standard error is a function of the estimated variance components.
Results
Bias in Fixed Effects
A total of 72,000 analyses were all converged. Relative biases for the estimates of the fixed effects (i.e., γ00, γ10, γ01, and γ11) are presented in Table 1. No significant bias was found in the estimation of the fixed effects across all the three methods.6 The result suggests that the estimates of the fixed effects obtained by MLMs with homogenous covariance assumption are not biased when the error covariance structure is in fact heterogeneous. This is true whether the sample size is small or large, series length is short or long, and the average error autocorrelation is null or high. The result also showed that the transformation procedure does not produce biased estimates for the fixed effects in MLMs.
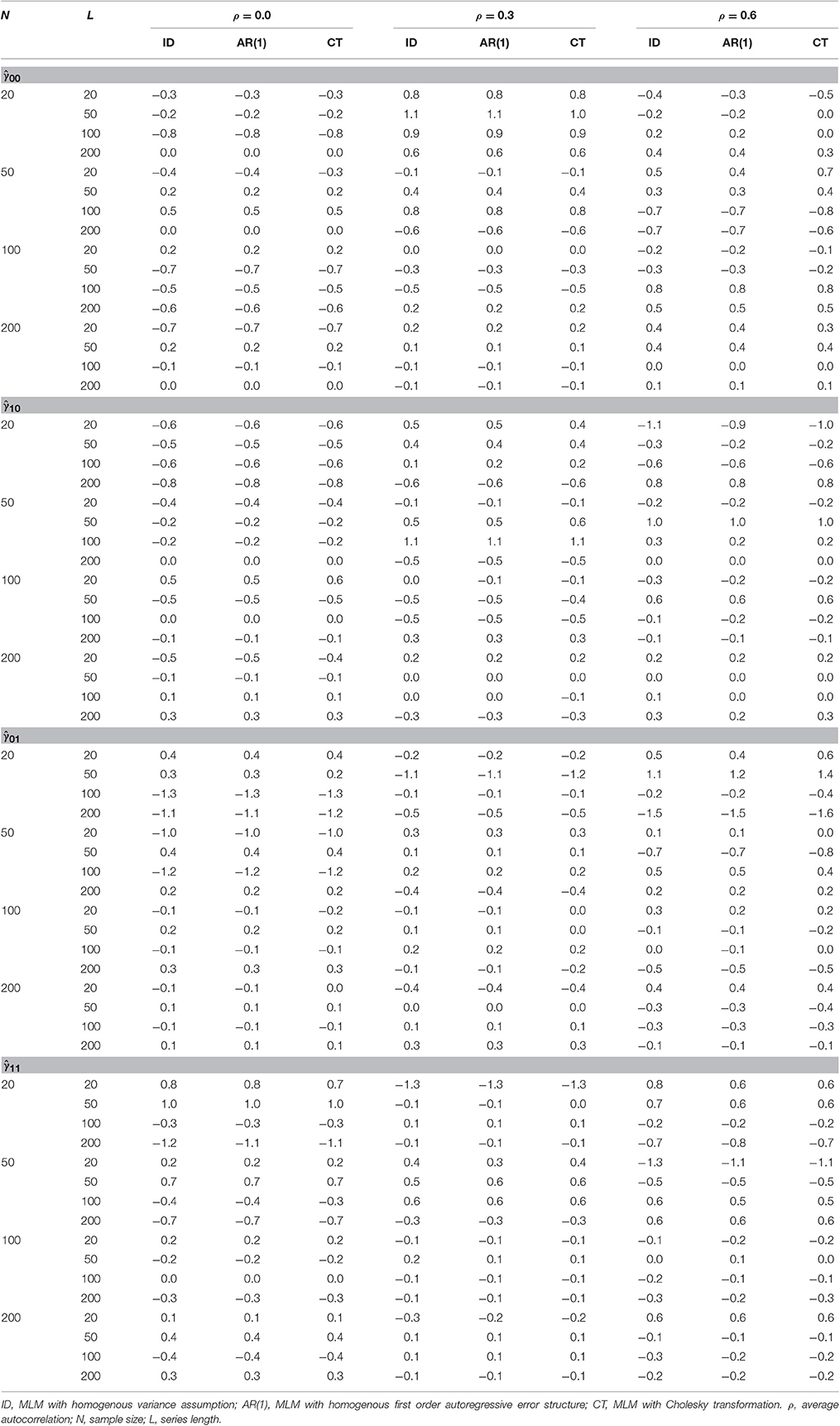
Table 1. Relative Bias (%) of , , and under heterogeneous autocorrelations in error for the three different MLMs.
Bias in Variance and Covariance of Random Effects
Relative biases for the variance of the random effects ( and ) and their covariance () are presented in Table 2. There was a positive bias in the estimation of for the two misspecified models, overall relative biases were 16.3% for the MLM-ID and 5.4% for the MLM-AR. For the MLM-ID, bias appeared particularly large when high autocorrelation was present (η2 = 0.24) or series length was short (η2 = 0.09) and even larger when both conditions occurred (η2 = 0.12) (see Table 2 and Figure 1). A similar pattern of significance of the effects was also found for the MLM-AR although the magnitude of the effects was smaller than that for the ID model: η2 = 0.02 for series length, η2 = 0.05 for autocorrelation, and η2 = 0.03 for their interaction. Bias was much higher in the MLM-ID than the MLM-AR (η2 = 0.26) when analyzed by 2(method) × 3(N) × 4(L) × 3(ρ) repeated ANOVA. This difference was greater especially when series length was short (η2 = 0.14), or autocorrelation was high (η2 = 0.33), and even greater when both conditions occurred (η2 = 0.17) (see Figure 1).
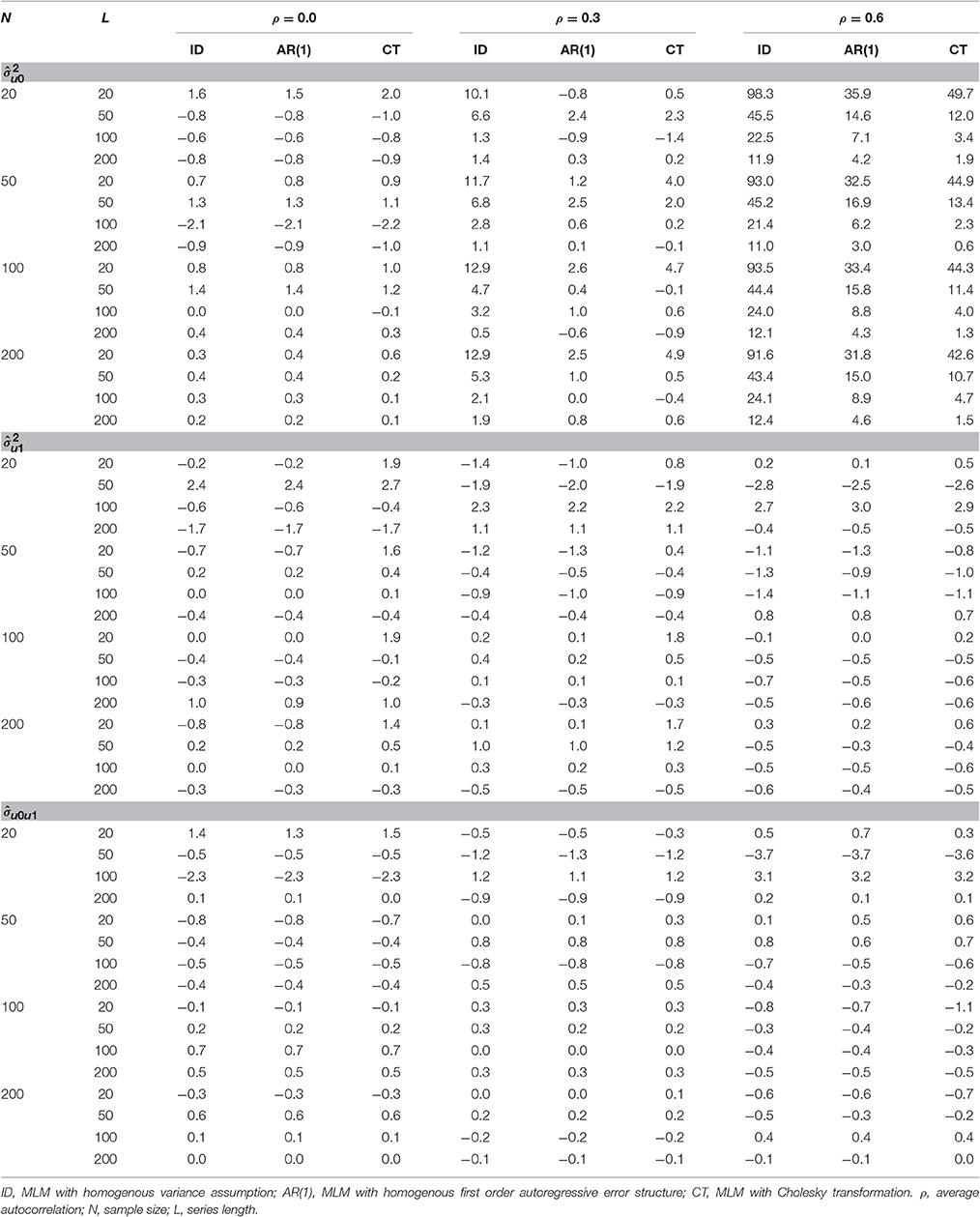
Table 2. Relative bias (%) of , , and under heterogeneous autocorrelations in error for the three different MLMs.
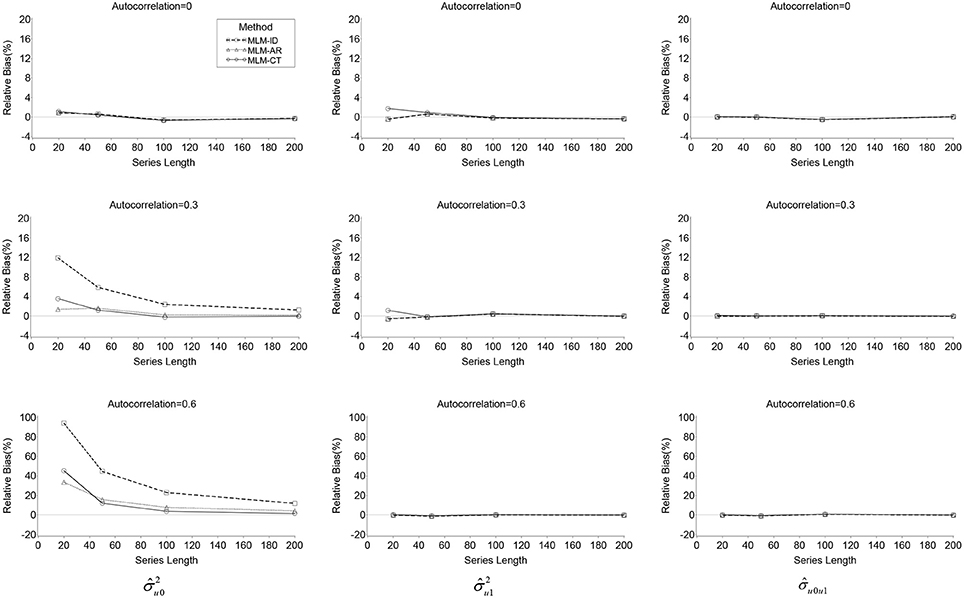
Figure 1. Line plots of relative bias of , , and produced by the three MLMs across autocorrelations and series lengths.
On the other hand, the transformation method did not completely eliminate bias in the estimates of . The MLM-CT method also showed a significant relative bias (overall RB = 5.6%), especially when series length was short (η2 = 0.05), autocorrelation was high (η2 = 0.06), or both conditions occurred (η2 = 0.07). In fact, when series length was 20, regardless of the size of autocorrelation, the MLM-CT showed larger bias than the MLM-AR. However, when series length was 50 or more, the differences were indiscernible and, for ρ = 0.6, the MLM-CT showed smaller bias than the MLM-AR (see Figure 1).
By contrast, no significant bias was found in estimation of the variance of the random regression effect () and the covariance of the two random effects () for the three models. There was no considerable difference of the relative bias among the three models.
Bias in the Standard Error of Estimation for Fixed Effects
Because of the bias in the estimated variance of the random intercept, the standard errors of estimation associated with the fixed effects are also expected to be biased. Table 3 presents relative bias of the estimated standard error for , , , and . Notice the great similarities of the results for the standard errors of and as well as for those of and in Table 3.
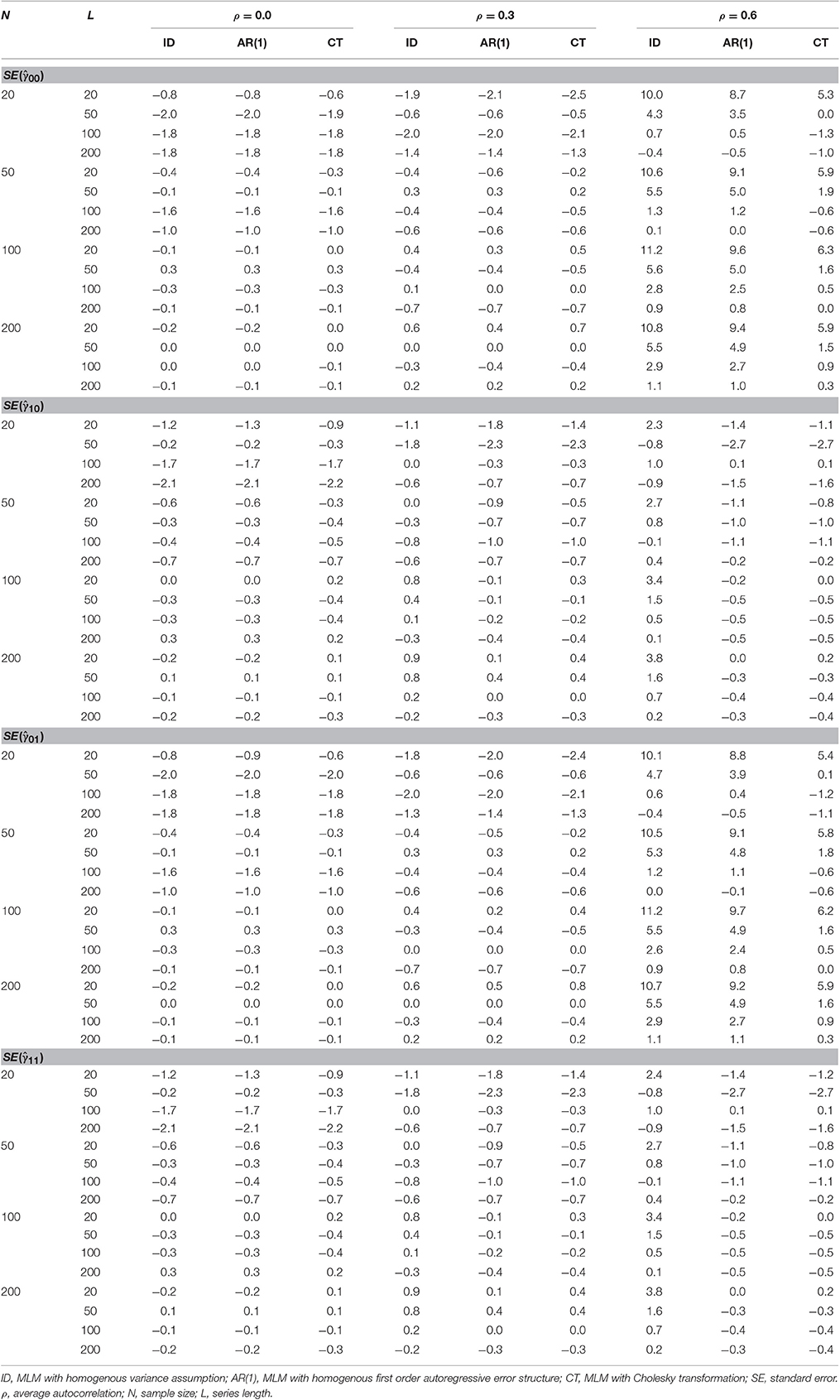
Table 3. Relative bias (%) of the Standard Error of , , and under heterogeneous autocorrelations in error for the three different MLMs.
Overall relative bias of the estimated standard error of the estimates for the fixed intercept () was found in the ID model (RB = 1.2%) and the AR model (RB = 0.9%) but not for the MLM-CT model (RB = 0.2%). Bias of the ID model was mainly affected by series length (η2 = 0.01), autocorrelation (η2 = 0.04), and the interaction of the two (η2 = 0.02). Bias of the AR model was also affected by series length (η2 = 0.01), autocorrelation (η2 = 0.03), and the interaction of the two (η2 = 0.02). Bias of the MLM-CT model was affected by the interaction of series length by autocorrelation (η2 = 0.01).
As in the bias of , relative bias for the standard error of the fixed intercept appeared greater in the ID model than the AR model (η2 = 0.04). Bias difference between the two methods was affected by series length (η2 = 0.04), autocorrelation (η2 = 0.07), and the interaction of the two (η2 = 0.05). On the other hand, the MLM-CT showed smaller bias than the AR model (η2 = 0.05), where the difference was affected by series length (η2 = 0.01), autocorrelation (η2 = 0.11), and their interaction (η2 = 0.03). The results support that the transformation method is less biased in the estimation of the standard error of than the misspecified models, especially when average autocorrelation is high and the series length is long (see Figure 2).
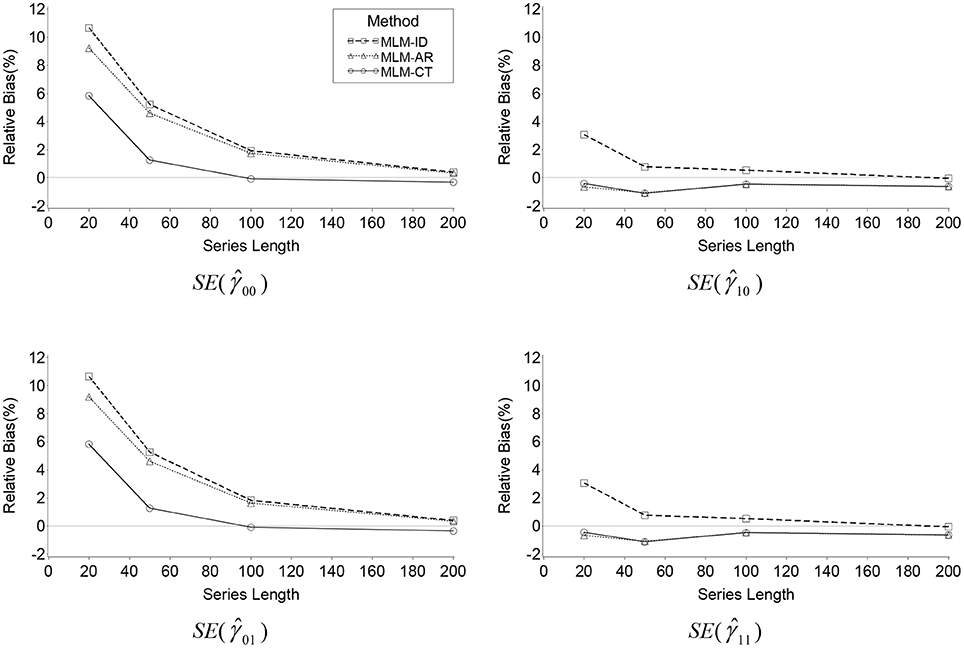
Figure 2. Line plots of relative bias of the standard error of , , and produced by the three MLMs across series lengths when ρ = 0.6.
As seen in Table 3 and Figure 2, the results of the analyses for the standard errors of , the fixed effect of the time-invariant covariate ci, were almost identical to those of . Overall relative bias of the estimated standard error of was found in the ID model (RB = 1.2%) and the AR model (RB = 0.9%) but not for the MLM-CT model (RB = 0.2%). Bias of the ID model was mainly affected by series length (η2 = 0.01), autocorrelation (η2 = 0.04), and the interaction of the two (η2 = 0.02). Bias of the AR model was affected by series length (η2 = 0.01), autocorrelation (η2 = 0.03), and the interaction (η2 = 0.02). Bias of the MLM-CT model was affected by the interaction of series length by autocorrelation (η2 = 0.01).
Relative bias of the standard error of , the fixed effect of the time-varying covariate zti, was statistically significant but their sizes were not practically meaningful. The biases of the three methods were not meaningfully affected by any of the factors considered. The results of the analyses for the standard errors of , the fixed effect of the cross-level interaction of zti and ci, were near identical to those of .
In summary, all three models did not produce biased estimates of the fixed intercept and regression effects. This was also true for estimation of the variance of the random regression effect. Estimation of the variance of the random intercept, however, was severely biased when the average autocorrelation was 0.3 or 0.6, especially for MLM-ID. The MLM-AR was less biased than the MLM-ID in these conditions but the amount of bias was still unsatisfactory. The MLM with Cholesky transformation also produced bias in the estimation of the variance of the random intercept. In fact, the bias of the MLM-CT was higher than MLM-AR when the number of observations within individuals was 20. When the number of observation was large (50 or more), however, the MLM-CT was less biased than the MLM-AR. This was expected before analyzing the data. Because the transformation procedure that actually estimates autoregressive parameters for each individual requires a large number of observations within individuals, the performance of the MLM-CT depends critically on the number of observations. If this is not the case, the first step of the MLM-CT may fail to identify a valid transformation matrix, resulting in poor estimates in the second step. Once enough number of observations are available and analyzed for each individual, however, the MLM-CT produces better estimates than the other misspecified models when residual covariance structure is hetetogeneous. Bias in the estimation of the variance of the random intercept resulted in bias in estimation of the standard error of the fixed intercept and the fixed regression effect of time-invariant covariate. As seen in the results, the MLM-CT may reduce this bias if a large number of observations for each individual (say 50 or more) are available.
Discussion
In this paper, we discussed issues related to the heterogeneity of residual covariance in multilevel analysis of intensive longitudinal data. We investigated bias in estimation of fixed effects, random components, and standard errors of fixed effects by analyzing large sets of simulated data with heterogeneous autoregressive errors using MLMs with misspecified homogenous ID or AR(1) error structure and the suggested MLM with Cholesky transformation. We found that if homogenous covariance is incorrectly assumed, MLMs produce a highly biased estimate of the variance of random intercepts when the average autocorrelation is high. It is also found that biased estimates of random intercept variance also create biased estimates of the standard error of the fixed intercept and fixed effect of level 2 covariate. For intensive longitudinal data, we saw that application of MLMs to variables transformed by the inverse of Cholesky factor of individual specific residual covariance can be used to reduce the bias.
One obvious result of the present study is that bias of the variance component was found only in the variance of random intercepts but not in the variance of random time-varying effects and the covariance of the two. This effect of misspecification is especially true for MLM with homogenous ID error structure when the average residual autocorrelation is high. This result is in line with findings of the previous studies that investigated the effect of underspecification of homogenous within-person covariance, such as misspecifying homogenous autoregressive error structure as homogenous independent error structure (Ferron et al., 2002; Kwok et al., 2007). As pointed out by Kwok et al., the total covariance matrix of the two-level model is constructed from covariance of between-person random components and covariance of within-person random errors, i.e., Σ = ZGZ′ + R. Because the total covariance Σ is primarily determined by a given data set, misspecification of R alters the values of elements in G, i.e., their relations are compensatory to each other. The results of the present study and other related studies suggest that unmodeled autocorrelation in R tends to cause an increased estimate of the variance of random intercepts that helps to explain overall (not first-order) autocorrelation between observations at different time points. Note that Σ of the random intercept only model with independent R is the same as that of the fixed effects only model (i.e., null G) with compound symmetry R. Thus, the notable bias of the variance of random intercepts found in MLM with homogenous ID error structure is mainly caused by misspecification of autoregression rather than by misspecification of heterogeneity. This line of reasoning is supported by the fact that the difference of the biases between MLM with homogenous autoregressive error and MLM with Cholesky transformation, an analytical model that takes heterogeneity of residual autoregression into account, is not as big as the differences of the biases between those models and MLM with homogenous independent error.
On the contrary, MLM with homogenous ID errors and MLM with homogenous AR errors showed similar amounts of bias in the standard errors of fixed intercept and fixed effect of time-invariant level-2 covariate when average autocorrelation is high. Because estimates of the standard errors of fixed effects are determined by the estimated covariance matrix of , , the bias of the standard errors of fixed effects depends on the estimated total covariance. Overall it appears that overestimated , especially the variance estimate of random intercepts, tend to increase certain elements in that construct the variances of the estimates of fixed intercept and fixed effect of level-2 covariate. However, difference in does not necessarily create a similar amount of difference in because and are compensatory to each other. Thus, the greater differences in bias of the standard errors between the two misspecified models and the suggested model with transformation are likely caused by misspecification of heterogeneity, which is not ignorable when average autocorrelation is as high as 0.6.
Another point of the result is that the number of individuals is not an important factor of bias in MLM with ILD. Instead, the number of observations within each individual is a much more important factor of the biases. Thus, if you have intensive longitudinal data with 50 or more repeated observations within individuals and the variable of your interest is highly autocorrelated, the suggested MLM with Cholesky transformation is recommended. If not, there is no practical advantage of using the transformation method and use of MLM with homogenous autoregressive errors has no disadvantage. The transformation method can be applied to EMA data that show different and highly autocorrelated processes with enough number of repeated observations within individuals (e.g., Koval and Kuppens, 2012; Ebner-Priemer et al., 2015).
The idea of transformation to analyze multilevel data has been applied to researchers in other contexts. Moeyaert et al. (2013) standardized a set of single-subject experimental data before employing a three-level regression analysis to synthesize different studies. Lee and Yoo (2014) introduced a Bayesian modeling with Cholesky factor to model random effects covariance matrix for generalized linear mixed models. However, these approaches are not explicitly interested in heterogeneous and autocorrelated error structure.
Several limitations of the present studies are acknowledged. First, because the suggested procedure consists of two steps, it suffers from problems common to any two-step approach. The transformation method requires estimation of autocorrelation or autoregressive parameters of individual time series in the first step and application of the intended MLM on the transformed variables in the second step. As such, a major limitation of the suggested model is a high dependency of the performance in the first step analysis. If poor transformation matrices are obtained in the first step, the final intended MLMs will produce biased estimation of the parameters of interest. For intensive longitudinal data, however, this concern is not critical because performance of the first step analysis gets better as the number of observations within individuals increases. However, for longitudinal data with small to moderate number of observations within individuals, the suggested two-step approaches may produce biased estimation and should not be used. An iterative method alternating the two steps may converge to a better solution.
Another limitation is related to the assessed time intervals between successive measurements. The error covariance structures used in the transformation method in this study assume constant and equally spaced time of measurements. Because ILD are often measured at randomly prompted times, e.g., within-day random assessments of electronic diary, transformation methods introduced in the present study cannot be applied directly to ILD with random time intervals. However, the suggested transformation method should be extended to ILD with random time intervals. In such cases, heterogeneous covariance with autocorrelation that exponentially decreases over random time intervals may be modeled and estimated by individual and then transformation of original variables by multiplying the inverse of the Cholesky factor of the estimated covariance matrix can be applied to get valid estimation of fixed effects and the variance of random effects. Another simulation study can be conducted to evaluate the performance of the transformation method on ILD with random time intervals and heterogeneous autocorrelation.
Intensive longitudinal data are useful to investigate various patterns of intra-individual processes. Although we restricted our discussion on the analysis of ILD to the multilevel models for fixed effects and random components, there are still other possibilities of modeling intra-individual processes using ILD. For example, heterogeneity of autocorrelation can be modeled in MLMs. In this regard, an interesting extension of MLM has been suggested by Rovine and Walls (2006). They showed that the autoregressive parameters can be modeled as random effects in MLM, which allow estimation of individual specific autoregressive parameters. This model has been applied to many EMA studies (e.g., Kuppens et al., 2010; Koval and Kuppens, 2012; Tompson et al., 2012; Bresin, 2014). Hedeker et al. (2008) proposed a multilevel model for EMA data that allows person-specific and time-varying heterogeneous variance. Kapur et al. (2014) extended the model to data with multivariate outcomes by a Bayesian modeling. More recently, multilevel models that simultaneously estimate both heterogeneous autocorrelation and heterogeneous error variance have been applied to ILD with emphasis on Bayesian modeling (Wang et al., 2012; Gasimova et al., 2014; Ebner-Priemer et al., 2015). Jahng et al. (2008) suggested a multilevel random instability model for EMA data where instability is equated as frequent and extreme fluctuations over time and expressed as a function of variance and autocorrelation. Other possibilities for modeling heterogeneous intra-individual process include time-varying regression effects (Fan and Gijbels, 1996; Li et al., 2006), nonlinear multilevel models (Davidian and Giltinan, 1995; Fok and Ramsay, 2006), state space models (Durbin and Koopman, 2001; Ho et al., 2006), and differential equation models (Boker, 2001; Boker and Laurenceau, 2006; Ramsay, 2006).
Author Contributions
SJ was responsible for all aspects of writing, study design, data analysis, and reporting. PW contributed to the literature review and the writing of the manuscript.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Part of this work was derived from the first author's dissertation research (Jahng, 2008).
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fpsyg.2017.00262/full#supplementary-material
Footnotes
1. ^There is no clear consensus on the number of occasions to define the “intensive” longitudinal data. Walls and Schafer (2006) stated that the traditional longitudinal analysis tends to focus on data with “no more than about ten occasions” in comparison to the analysis of ILD. But, as Bolger and Laurenceau (2013, p. 2) pointed out, specification of a minimum number of measurements for ILD is somewhat arbitrary.
2. ^Commercial statistical software such as AUTOREG procedure in SAS can be used for this step. See Appendix for more details.
3. ^For unequally spaced observations often encountered in ecological momentary assessment, a continuous time Markov process, , where ϕ = e−θ, θ > 0, wt ~ N(0, ), h ≥ 0, can be used to model R and thus the transformation matrix A.
4. ^The matrix form of the model can be expressed as in Equation 14.
5. ^Because all true fixed effects were set to 1, relative biases of the fixed effects are in fact the same as unstandardized biases.
6. ^All biases were analyzed using appropriate statistical tests, e.g., t-test or ANOVA. In the result section we only reported effect sizes with practical meaning (|RB| ≥ 1.0 % and η2 ≥.01) but did not report test statistics and p-values because they may distract the major findings of this simulation study with a large number of replications.
References
Boker, S. M. (2001). “Differential structural modeling of intraindividual variability,” in New Methods for the Analysis of Change, eds L. Collins and A. Sayer (Washington, DC: American Psychological Association), 3–28.
Boker, S. M., and Laurenceau, J. (2006). “Dynamical systems modeling: An application to the regulation of intimacy and disclosure in marriage,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 195–216.
Bolger, N., and Laurenceau, J. (2013). Intensive Longitudinal Methods: An Introduction to Diary and Experience Sampling Research. New York, NY: The Guilford Press.
Bresin, K. (2014). Five indices of emotion regulation in participants with a history of nonsuicidal self-injury: a daily diary study. Behav. Ther. 45, 56–66. doi: 10.1016/j.beth.2013.09.005
Chipman, J. S. (1979). Efficiency of least squares estimation of linear trend when residuals are autocorrelated. Econometrica 47, 115–128. doi: 10.2307/1912350
Cochrane, D., and Orcutt, G. H. (1949). Application of least squares regression to relationships containing autocorrelated error terms. J. Am. Stat. Assoc. 44, 32–61.
Davidian, M., and Giltinan, D. M. (1995). Nonlinear Models for Repeated Measurement Data. New York, NY: Chapman and Hall.
Durbin, J., and Koopman, S. J. (2001). Time Series Analysis by State-Space Models. New York, NY: Oxford University Press.
Ebner-Priemer, U. W., Houben, M., Santangelo, P., Kleindienst, N., Tuerlincks, F., Oravecz, Z., et al. (2015). Unraveling affective dysregulation in borderline personality disorder: a theoretical model and empirical evidence. J. Abnorm. Psychol. 124, 186–198. doi: 10.1037/abn0000021
Fan, J., and Gijbels, I. (1996). Local Polynomial Modeling and Its Applications. London: Chapman and Hall.
Ferron, J. M., Bell, B. A., Hess, M. R., Rendina-Gobioff, G., and Hibbard, S. T. (2009). Making treatment effect inferences from multiple-baseline data: the utility of multilevel modeling approaches. Behav. Res. Methods 41, 372–384. doi: 10.3758/BRM.41.2.372
Ferron, J., Dailey, R., and Yi, Q. (2002). Effects of misspecifying the first-level error structure in two-level models of change. Multivariate Behav. Res., 37, 379–403. doi: 10.1207/S15327906MBR3703_4
Fok, C. C. T., and Ramsay, J. O. (2006). “Fitting curves with periodic and nonperiodic trends and their interactions with intensive longitudinal data,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 109–123.
Gasimova, F., Robitzsch, A., Wilhelm, O., and Hülür, G. (2014). A hierarchical Bayesian model with correlated residuals for investigating stability and change in intensive longitudinal data settings. Methodology 10, 126–137. doi: 10.1027/1614-2241/a000083
Hedeker, D., Mermelstein, R. J., and Demirtas, H. (2008). An application of a mixed-effect location scale model for analysis of ecological momentary assessment (EMA) data. Biometrics 64, 627–634. doi: 10.1111/j.1541-0420.2007.00924.x
Hill, C. L., and Updegraff, J. A. (2012). Mindfulness and its relationship to emotional regulation. Emotion 12, 81–90. doi: 10.1037/a0026355
Ho, M. R., Shumway, R., and Ombao, H. (2006). “The state-space approach to modeling dynamic processes,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 148–175.
Hufford, M. R., Shiffman, S., Paty, J., and Stone, A. A. (2001). “Ecological momentary assessment: real-world, real-time measurement of patient experience,” in Progress in Ambulatory Assessment: Computer-Assisted Psychological and Psych Physiological Methods in Monitoring and Field Studies, eds J. Fahrenberg and M. Myrtek (Kirkland, WA: Hogrefe and Huber), 69–92.
Jacqmin-Gadda, H., Sibillot, S., Proust, C., Molina, J., and Thiébaut, R. (2007). Robustness of the linear mixed model to misspecified error distribution. Comput. Stat. Data Analysis 51, 5142–5154. doi: 10.1016/j.csda.2006.05.021
Jahng, S. (2008). Multilevel Models for Intensive Longitudinal Data with Heterogeneous Error Structure: Covariance Transformation and Random Variance Models. Dissertation, Columbia, MO, University of Missouri.
Jahng, S., Wood, P. K., and Trull, T. J. (2008). Analysis of affective instability in ecological momentary assessment: Indices using successive difference and group comparison via multilevel modeling. Psychol. Methods 13, 354–375. doi: 10.1037/a0014173
Judge, G. G., Griffiths, W. E., Hill, R. C., Lütkepohl, H., and Lee, T. C. (1985). The Theory and Practice of Econometrics, 2nd Edn. New York, NY: John Wiley and Sons.
Kapur, K., Li, X., Blood, E. A., and Hedeker, D. (2014). Bayesian mixed-effects location and scale models for multivariate longitudinal outcomes: an application to ecological momentary assessment data. Stat. Med. 34, 630–651. doi: 10.1002/sim.6345
Koreisha, S. G., and Fang, Y. (2001). Generalized least squares with misspecified serial correlation structures. J. R. Stat. Soc. Ser. B 63, 515–531. doi: 10.1111/1467-9868.00296
Koval, P., and Kuppens, P. (2012). Changing emotion dynamics: individual differences in the effect of anticipatory social stress on emotional inertia. Emotion 12, 256–267. doi: 10.1037/a0024756
Kuppens, P., Allen, N. B., and Sheeber, L. (2010). Emotional inertia and psychological maladjustment. Psychol. Sci. 21, 984–991. doi: 10.1177/0956797610372634
Kwok, O., West, S. G., and Green, S. B. (2007). The impact of misspecifying the within-subject covariance structure in multiwave longitudinal multilevel models: a monte carlo study. Multivariate Behav. Res. 42, 557–592. doi: 10.1080/00273170701540537
Lange, N., and Laird, N. (1989). The effect of covariance structure on variance estimation in balanced growth-curve models with random parameters. J. Am. Stat. Assoc. 84, 241–247 doi: 10.1080/01621459.1989.10478761
Lee, K., and Yoo, J. K. (2014). Bayesian Cholesky factor models in random effects covariance matrix for generalized linear mixed models. Comput. Stat. Data Analysis 80, 111–116. doi: 10.1016/j.csda.2014.06.016
Li, R., Root, T. L., and Shiffman, S. (2006). “A local linear estimation procedure for functional multilevel modeling,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 63–83.
Maeshiro, A. (1980). Small sample properties of estimators of distributed lag models. Int. Econ. Rev. 21, 721–733. doi: 10.2307/2526364
Moeyaert, M., Ugille, M., Ferron, J., Beretvas, S. N., and Van den Noortgate, W. (2013). Three-level analysis of standardized single-case experimental data: empirical validation. Multivariate Behav. Res. 48, 719–748. doi: 10.1080/00273171.2013.816621
Moeyaert, M., Ugille, M., Ferron, J., Beretvas, S. N., and Van den Noortgate, W. (2016). The misspecification of the covariance structures in multilevel models for single-case data: a monte carlo simulation study. J. Exp. Educ. 84, 473–509. doi: 10.1080/00220973.2015.1065216
Nezlek, J. B. (2012). “Multilevel modeling analyses of diary-style data,” in Handbook of Research Methods for Studying Daily Life, eds M. R. Mehl and T. S. Conner (New York, NY: The Guilford Press), 357–383.
Park, R. E., and Mitchell, B. M. (1980). Estimating the autocorrelated error model with trended data. J. Econom. 13, 185–201. doi: 10.1016/0304-4076(80)90014-7
Ramsay, J. O. (2006). “The control of behavioral input/output systems,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 176–194.
Röcke, C., Li, S.-C., and Smith, J. (2009). Intraindividual variability in positive and negative affect over 45 days: do older adults fluctuate less than young adults? Psychol. Aging 24, 863–878. doi: 10.1037/a0016276
Rovine, M. J., and Walls, T. A. (2006). “Multilevel autoregressive modeling of differences in the stability of a process,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 124–147.
Schwartz, J. E., and Stone, A. A. (2007). “The analysis of real-time momentary data: A practical guide,” in The Science of Real-Time Data Capture: Self-Reports in Health Research, eds A. Stone, S. Shiffman, A. Arienza, and L. Nebeling (New York, NY: Oxford University Press), 76–113.
Shumway, R. H., and Stoffer, D. S. (2011). Time Series Analysis and Its Applications, 3rd Edn. New York, NY: Springer.
Stone, A. A., and Shiffman, S. (1994). Ecological momentary assessment in behavioral medicine. Ann. Behav. Med. 16, 199–202.
Tompson, R. J., Mata, J., Jaeggi, S. M., Buschkuehl, M., Jonides, J., and Gotlib, I. H. (2012). The everyday emotional experience of adults with major depressive disorder: examining emotional instability, inertia, and reactivity. J. Abnorm. Psychol. 121, 819–829. doi: 10.1037/a0027978
Walls, T. A., Jung, H., and Schafer, J. L. (2006). “Multilevel models for intensive longitudinal data,” in Models for Intensive Longitudinal Data, eds T. A. Walls and J. L. Schafer (New York, NY: Oxford University Press), 3–37.
Walls, T. A., and Schafer, J. L. (Eds.). (2006). Models for Intensive Longitudinal Data. New York, NY: Oxford University Press.
Wang, L. P., Hamaker, E., and Bergeman, C. S. (2012). Investigating inter-individual differneces in short-term intra-individ ual variability. Psychol. Methods 17, 567–581. doi: 10.1037/a0029317
Keywords: multilevel model, intensive longitudinal data, heterogeneous autocorrelation, Cholesky transformation, misspecification
Citation: Jahng S and Wood PK (2017) Multilevel Models for Intensive Longitudinal Data with Heterogeneous Autoregressive Errors: The Effect of Misspecification and Correction with Cholesky Transformation. Front. Psychol. 8:262. doi: 10.3389/fpsyg.2017.00262
Received: 13 September 2016; Accepted: 10 February 2017;
Published: 24 February 2017.
Edited by:
Holmes Finch, Ball State University, USAReviewed by:
Seongah Im, University of Hawaii at Manoa, USARichard James Neufeld, Western University, Canada
Oi-Man Kwok, Texas A&M University, USA
Copyright © 2017 Jahng and Wood. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Seungmin Jahng, amFobmdzQHNra3UuZWR1