 Florian Schuberth
Florian Schuberth Jörg Henseler
Jörg Henseler Theo K. Dijkstra
Theo K. Dijkstra- 1Faculty of Engineering Technology, Chair of Product-Market Relations, University of Twente, Enschede, Netherlands
- 2Nova Information Management School, Universidade Nova de Lisboa, Lisbon, Portugal
- 3Faculty of Economics and Business, University of Groningen, Groningen, Netherlands
This article introduces confirmatory composite analysis (CCA) as a structural equation modeling technique that aims at testing composite models. It facilitates the operationalization and assessment of design concepts, so-called artifacts. CCA entails the same steps as confirmatory factor analysis: model specification, model identification, model estimation, and model assessment. Composite models are specified such that they consist of a set of interrelated composites, all of which emerge as linear combinations of observable variables. Researchers must ensure theoretical identification of their specified model. For the estimation of the model, several estimators are available; in particular Kettenring's extensions of canonical correlation analysis provide consistent estimates. Model assessment mainly relies on the Bollen-Stine bootstrap to assess the discrepancy between the empirical and the estimated model-implied indicator covariance matrix. A Monte Carlo simulation examines the efficacy of CCA, and demonstrates that CCA is able to detect various forms of model misspecification.
1. Introduction
Structural equation modeling with latent variables (SEM) comprises confirmatory factor analysis (CFA) and path analysis, thus combining methodological developments from different disciplines such as psychology, sociology, and economics, while covering a broad variety of traditional multivariate statistical procedures (Bollen, 1989; Muthén, 2002). It is capable of expressing theoretical concepts by means of multiple observable indicators to connect them via the structural model as well as to account for measurement error. Since SEM allows for statistical testing of the estimated parameters and even entire models, it is an outstanding tool for confirmatory purposes such as for assessing construct validity (Markus and Borsboom, 2013) or for establishing measurement invariance (Van de Schoot et al., 2012). Apart from the original maximum likelihood estimator, robust versions and a number of alternative estimators were also introduced to encounter violations of the original assumptions in empirical work, such as the asymptotic distribution free (Browne, 1984) or the two-stage least squares (2SLS) estimator (Bollen, 2001). Over time, the initial model has been continuously improved upon to account for more complex theories. Consequently, SEM is able to deal with categorical (Muthén, 1984) as well as longitudinal data (Little, 2013) and can be used to model non-linear relationships between the constructs (Klein and Moosbrugger, 2000).1
Researchers across many streams of science appreciate SEM's versatility as well as its ability to test common factor models. In particular, in the behavioral and social sciences, SEM enjoys wide popularity, e.g., in marketing (Bagozzi and Yi, 1988; Steenkamp and Baumgartner, 2000), psychology (MacCallum and Austin, 2000), communication science (Holbert and Stephenson, 2002), operations management (Shah and Goldstein, 2006), and information systems (Gefen et al., 2011),—to name a few. Additionally, beyond the realm of behavioral and social sciences, researchers have acknowledged the capabilities of SEM, such as in construction research (Xiong et al., 2015) or neurosciences (McIntosh and Gonzalez-Lima, 1994).
Over the last decades, the operationalization of the theoretical concept and the common factor has become more and more conflated such that hardly any distinction is made between the terms (Rigdon, 2012). Although the common factor model has demonstrated its usefulness for concepts of behavioral research such as traits and attitudes, the limitation of SEM to the factor model is unfortunate because many disciplines besides and even within social and behavioral sciences do not exclusively deal with behavioral concepts, but also with design concepts (so-called artifacts) and their interplay with behavioral concepts. For example Psychiatry: on the one hand it examines clinical relevant behavior to understand mental disorder, but on the other hand it also aims at developing mental disorder treatments (Kirmayer and Crafa, 2014). Table 1 displays further examples of disciplines investigating behavioral concepts and artifacts.
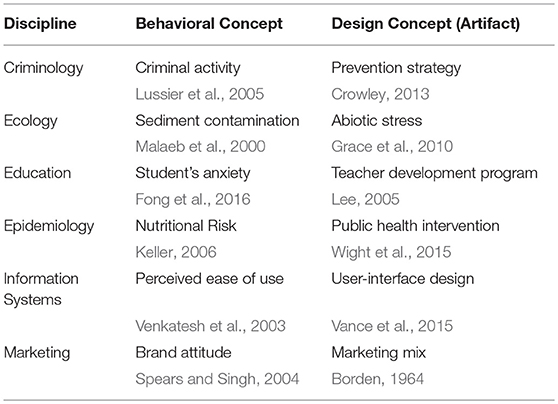
Table 1. Examples of behavioral concepts and artifacts across several disciplines.
Typically, the common factor model is used to operationalize behavioral concepts, because it is well matched with the general understanding of measurement (Sobel, 1997). It assumes that each observable indicator is a manifestation of the underlying concept that is regarded as their common cause (Reichenbach, 1956), and therefore fully explains the covariation among its indicators. However, for artifacts the idea of measurement is unrewarding as they are rather constructed to fulfill a certain purpose. To account for the constructivist character of the artifact, the composite has been recently suggested for its operationalization in SEM (Henseler, 2017). A composite is a weighted linear combination of observable indicators, and therefore in contrast to the common factor model, the indicators do not necessarily share a common cause.
At present, the validity of composite models cannot be systematically assessed. Current approaches are limited to assessing the indicators' collinearity (Diamantopoulos and Winklhofer, 2001) and their relations to other variables in the model (Bagozzi, 1994). A rigorous test of composite models in analogy to CFA does not exist so far. Not only does this situation limit the progress of composite models, it also represents an unnecessary weakness of SEM as its application is mainly limited to behavioral concepts. For this reason, we introduce confirmatory composite analysis (CCA) wherein the concept, i.e., the artifact, under investigation is modeled as a composite. In this way, we make SEM become accessible to a broader audience. We show that the composite model relaxes some of the restrictions imposed by the common factor model. However, it still provides testable constraints, which makes CCA a full-fledged method for confirmatory purposes. In general, it involves the same steps as CFA or SEM, without assuming that the underlying concept is necessarily modeled as a common factor.
While there is no exact instruction on how to apply SEM, a general consensus exists that SEM and CFA comprise at least the following four steps: model specification, model identification, model estimation, and model assessment (e.g., Schumacker and Lomax, 2009, Chap. 4). To be in line with this proceeding, the remainder of the paper is structured as follows: Section 2 introduces the composite model providing the theoretical foundation for the CCA and how the same can be specified; Section 3 considers the issue of identification in CCA and states the assumptions as being necessary to guarantee the unique solvability of the composite model; Section 4 presents one approach that can be used to estimate the model parameters in the framework of CCA; Section 5 provides a test for the overall model fit to assess how well the estimated model fits the observed data; Section 6 assesses the performance of this test in terms of a Monte Carlo simulation and presents the results; and finally, the last section discusses the results and gives an outlook for future research. A brief example on how to estimate and assess a composite model within the statistical programming environment R is provided in the Supplementary Material.
2. Specifying Composite Models
Composites have a long tradition in multivariate data analysis (Pearson, 1901). Originally, they are the outcome of dimension reduction techniques, i.e., the mapping of the data to a lower dimensional space. In this respect, they are designed to capture the most important characteristics of the data as efficiently as possible. Apart from dimension reduction, composites can serve as proxies for concepts (MacCallum and Browne, 1993). In marketing research, Fornell and Bookstein (1982) recognized that certain concepts like marketing mix or population change are not appropriately modeled by common factors and instead employed a composite to operationalize these concepts. In the recent past, more and more researchers recognized composites as a legitimate approach to operationalize concepts, e.g., in marketing science (Diamantopoulos and Winklhofer, 2001; Rossiter, 2002), business research (Diamantopoulos, 2008), environmental science (Grace and Bollen, 2008), and in design research (Henseler, 2017).
In social and behavioral sciences, concepts are often understood as ontological entities such as abilities or attitudes, which rests on the assumption that the concept of interest exists in nature, regardless of whether it is the subject of scientific examination. Researchers follow a positivist research paradigm assuming that existing concepts can be measured.
In contrast, design concepts can be conceived as artifacts, i.e., objects designed to serve explicit goal(s) (Simon, 1969). Hence, they are inextricably linked to purposefulness, i.e., teleology (Horvath, 2004; Baskerville and Pries-Heje, 2010; Møller et al., 2012). This way of thinking has its origin in constructivist epistemology. The epistemological distinction between the ontological and constructivist nature of concepts has important implications when modeling the causal relationships among the concepts and their relationships to the observable indicators.
To operationalize behavioral concepts, the common factor model is typically used. It seeks to explore whether a certain concept exists by testing if collected measures of a concept are consistent with the assumed nature of that concept. It is based on the principle of common cause (Reichenbach, 1956), and therefore assumes that all covariation within a block of indicators can be fully explained by the underlying concept. On the contrary, the composite model can be used to model artifacts as a linear combination of observable indicators. In doing so, it is more pragmatic in the sense that it examines whether a built artifact is useful at all. Figure 1 summarizes the differences between behavioral concepts and artifacts and their operationalization in SEM.
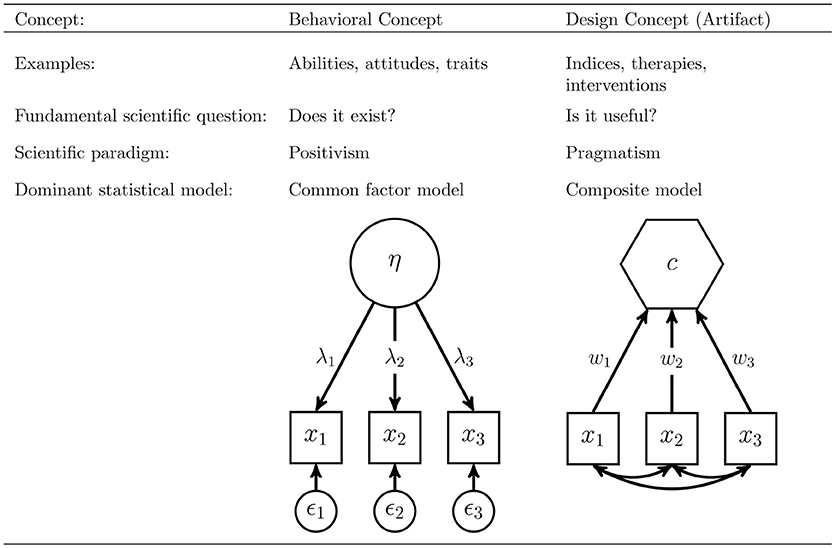
Figure 1. Two types of concepts: behavioral concepts vs. artifacts.
In the following part, we present the theoretical foundation of the composite model. Although the formal development of the composite model and the composite factor model (Henseler et al., 2014), were already laid out by Dijkstra (2013, 2015), it has not been put into a holistic framework yet. In the following, it is assumed that each artifact is modeled as a composite cj with j = 1, …, J.2 By definition, a composite is completely determined by a unique block of Kj indicators, , .
The weights of block j are included in the column vector wj of length Kj. Usually, each weight vector is scaled to ensure that the composites have unit variance (see also Section 3). Here, we assume that each indicator is connected to only one composite. The theoretical covariance matrix Σ of the indicators can be expressed as a partitioned matrix as follows:
The intra-block covariance matrix Σjj of dimension Kj × Kj is unconstrained and captures the covariation between the indicators of block j; thus, this effectively allows the indicators of one block to freely covary. Moreover, it can be shown that the indicator covariance matrix is positive-definite if and only if the following two conditions hold: (i) all intra-block covariance matrices are positive-definite, and (ii) the covariance matrix of the composite is positive-definite (Dijkstra, 2015, 2017). The covariances between the indicators of block j and l are captured in the inter-block covariance matrix Σjl, with j ≠ l of dimension Kj × Kl. However, in contrast to the intra-block covariance matrix, the inter-block covariance matrix is constrained, since by assumption, the composites carry all information between the blocks:
where equals the correlation between the composites cj and cl. The vector λj = Σjjwj of length Kj contains the composite loadings, which are defined as the covariances between the composite cj and the associated indicators xj. Equation 2 is highly reminiscent of the corresponding equation where all concepts are modeled as common factors instead of composites. In a common factor model, the vector λj captures the covariances between the indicators and its connected common factor, and ρjl represents the correlation between common factor j and l. Hence, both models show the rank-one structure for the covariance matrices between two indicator blocks.
Although the intra-block covariance matrices of the indicators Σjj are not restricted, we emphasize that the composite model is still a model from the point of view of SEM. It assumes that all information between the indicators of two different blocks is conveyed by the composite(s), and therefore, it imposes rank-one restrictions on the inter-block covariance matrices of the indicators (see Equation 2). These restrictions can be exploited for testing the overall model fit (see Section 5). It is emphasized that the weights wj producing these matrices are the same across all inter-block covariance matrices Σjl with l = 1, …, J and l ≠ j. Figure 2 illustrates an example of a composite model.
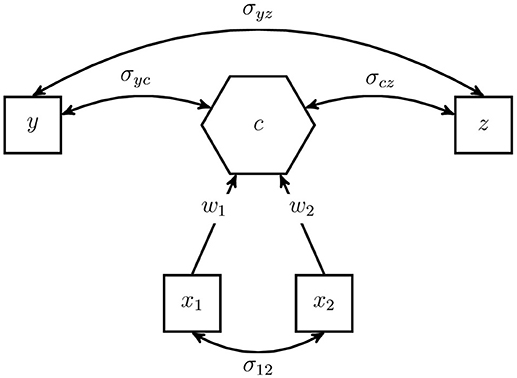
Figure 2. Example of a composite model.
The artifact under investigation is modeled as the composite c, illustrated by a hexagon, and the observable indicators are represented by squares. The unconstrained covariance σ12 between the indicators of block forming the composite is highlighted by a double-headed arrow.
The observable variables y and z do not form the composite. They are allowed to freely covary among each other as well as with the composite. For example, they can be regarded as antecedents or consequences of the modeled artifact.
To emphasize the difference between the composite model and the common factor model typically used in CFA, we depict the composite model as composite factor model (Dijkstra, 2013; Henseler et al., 2014). The composite factor model has the same model-implied indicator covariance matrix as the composite model, but the deduction of the model-implied covariances and the comparison to the common factor is more straightforward. Figure 3 shows the same model as Figure 2 but in terms of a composite factor representation.
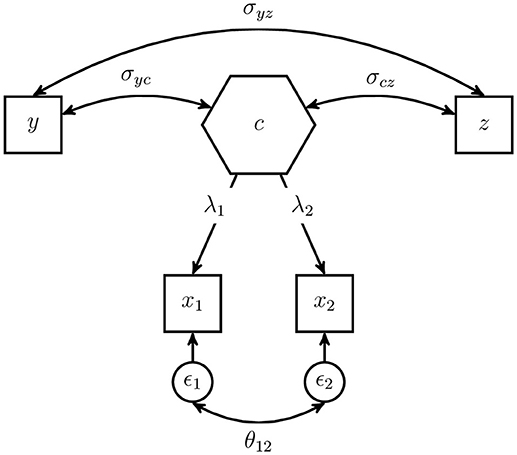
Figure 3. Example of a composite model displayed as composite factor model.
The composite loading λi, i = 1, 2 captures the covariance between the indicator xi and the composite c. In general, the error terms are included in the vector ϵ, explaining the variance of the indicators and the covariances between the indicators of one block, which are not explained by the composite factor. As the composite model does not restrict the covariances between the indicators of one block, the error terms are allowed to freely covary. The covariations among the error terms as well as their variances are captured in matrix Θ. The model-implied covariance matrix of the example composite model can be displayed as follows:
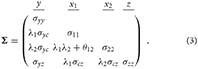
In comparison to the same model using a common factor instead of a composite, the composite model is less restrictive as it allows all error terms of one block to be correlated, which leads to a more general model (Henseler et al., 2014). In fact, the common factor model is always nested in the composite model since it uses the same restriction as the composite model; but additionally, it assumes that (some) covariances between the error terms of one block are restricted (usually to zero). Under certain conditions, it is possible to rescale the intra- and inter-block covariances of a composite model to match those of a common factor model (Dijkstra, 2013; Dijkstra and Henseler, 2015).
3. Identifying Composite Models
Like in SEM and CFA, model identification is an important issue in CCA. Since analysts can freely specify their models, it needs to be ensured that the model parameters have a unique solution (Bollen, 1989, Chap. 8). Therefore, model identification is necessary to obtain consistent parameter estimates and to reliably interpret them (Marcoulides and Chin, 2013).
In general, the following three states of model identification can be distinguished: under-identified, just-identified, and over-identified.3 An under-identified model, also known as not-identified model, offers several sets of parameters that are consistent with the model constraints, and thus, no unique solution for the model parameters exists. Therefore, only questionable conclusions can be drawn. In contrast, a just-identified model provides a unique solution for the model parameters and has the same number of free parameters as non-redundant elements of the indicator covariance matrix (degrees of freedom (df) are 0). In empirical analysis, such models cannot be used to evaluate the overall model fit since they perfectly fit the data. An over-identified model also has a unique solution; however, it provides more non-redundant elements of the indicator covariance matrix than model parameters (df > 0). This can be exploited in empirical studies for assessing the overall model fit, as these constraints should hold for a sample within the limits of sampling error if the model is valid.
A necessary condition for ensuring identification is to normalize each weight vector. In doing so, we assume that all composites are scaled to have a unit variance, .4 Besides the scaling of the composite, each composite must be connected to at least one composite or one variable not forming a composite. As a result, at least one inter-block covariance matrix Σjl, l = 1, …, J with l ≠ j satisfies the rank-one condition. Along with the normalization of the weight vectors, all model parameters can be uniquely retrieved from the indicator covariance matrix since there is a non-zero inter-block covariance matrix for every loading vector. Otherwise, if a composite ci is isolated in the nomological network, all inter-block covariances Σjl, l = 1, …, J with l ≠ j, belonging to this composite are of rank zero, and thus, the weights forming this composite cannot be uniquely retrieved. Although the non-isolation condition is required for identification, it also matches the idea of an artifact that is designed to fulfill a certain purpose. Without considering the artifact's antecedents and/or consequences, the artifact's purposefulness cannot be judged.
In the following part, we give a description on how the number of degrees of freedom is counted in case of the composite model.5 It is given by the difference between the number of non-redundant elements of the indicator population covariance matrix Σ and the number of free parameters in the model. The number of free model parameters is given by the number of covariances among the composites, the number of covariances between composites and indicators not forming a composite, the number of covariances among indicators not forming a composite, the number of non-redundant off-diagonal elements of each intra-block covariance matrix, and the number of weights. Since we fix composite variances to one, one weight of each block can be expressed by the remaining ones of this block. Hence, we regain as many degrees of freedom as fixed composite variances, i.e., as blocks in the model. Equation 4 summarizes the way of determining the number of degrees of freedom of a composite model.
To illustrate our approach to calculating the number of degrees of freedom, we consider the composite model presented in Figure 2. As described above, the model consists of four (standardized) observable variables; thus, the indicator correlation matrix has six non-redundant off-diagonal elements. The number of free model parameters is counted as follows: no correlations among the composites as the models consists of only one composite, two correlations between the composite and the observable variables not forming a composite (σyc and σcz), one correlation between the variables not forming a composite (σyz), one non-redundant off-diagonal of the intra-block correlation matrix (σ12), and two weights (w1 and w2) minus one, the number of blocks. As a result, we obtain the number of degrees of freedom as follows: df = 6−0−2−1−1−2 + 1 = 1. Once identification of the composite model is ensured, in a next step the model can be estimated.
4. Estimating Composite Models
The existing literature provides various ways of constructing composites from blocks of indicators. The most common among them are principal component analysis (PCA, Pearson, 1901), linear discriminant analysis (LDA, Fisher, 1936), and (generalized) canonical correlation analysis ((G)CCA, Hotelling, 1936; Kettenring, 1971). All these approaches seek composites that “best” explain the data and can be regarded as prescriptions for dimension reduction (Dijkstra and Henseler, 2011). Further approaches are partial least squares path modeling (PLS-PM, Wold, 1975), regularized general canonical correlation analysis (RGCCA, Tenenhaus and Tenenhaus, 2011), and generalized structural component analysis (GSCA, Hwang and Takane, 2004). The use of predefined weights is also possible.
We follow Dijkstra (2010) and apply GCCA in a first step to estimate the correlation between the composites.6 In the following part, we give a brief description of GCCA. The vector of indicators x of length K is split up into J subvectors xj, so called blocks, each of dimension (Kj × 1) with j = 1, …, J. We assume that the indicators are standardized to have means of zero and unit variances. Moreover, each indicator is connected to one composite only. Hence, the correlation matrix of the indicators can be calculated as Σ = E(xx′) and the intra-block correlation matrix as . Moreover, the correlation matrix of the composites is calculated as follows: . In general, GCCA chooses the weights to maximize the correlation between the composites. In doing so, GCCA offers the following options: sumcor, maxvar, ssqcor, minvar, and genvar.7
In the following part, we use maxvar under the constraint that each composite has a unit variance, , to estimate the weights, the composites, and the resulting composite correlations.8 In doing so, the weights are chosen to maximize the largest eigenvalue of the composite correlation matrix. Thus, the total variation of the composites is explained as well as possible by one underlying “principal component,” and the weights to form the composite cj are calculated as follows (Kettenring, 1971):
The subvector , of length J, corresponds to the largest eigenvalue of the matrix , where the matrix ΣD, of dimension J × J, is a block-diagonal matrix containing the intra-block correlation matrices Σjj, j = 1, …, J on its diagonal. To obtain the estimates of the weights, the composites, and their correlations, the population matrix Σ is replaced by its empirical counterpart S.
5. Assessing Composite Models
5.1. Tests of Overall Model Fit
In CFA and factor-based SEM, a test for overall model fit has been naturally supplied by the maximum-likelihood estimation in the form of the chi-square test (Jöreskog, 1967), while maxvar lacks in terms of such a test. In the light of this, we propose a combination of a bootstrap procedure with several distance measures to statistically test how well the assumed composite model fits to the collected data.
The existing literature provides several measures with which to assess the discrepancy between the perfect fit and the model fit. In fact, every distance measure known from CFA can be used to assess the overall fit of a composite model. They all capture the discrepancy between the sample covariance matrix S and the estimated model-implied covariance matrix of the indicators. In our study, we consider the following three distance measures: squared Euclidean distance (dL), geodesic distance (dG), and standardized root mean square residual (SRMR).
The squared Euclidean distance between the sample and the estimated model-implied covariance matrix is calculated as follows:
where K is the total number of indicators, and sij and are the elements of the sample and the estimated model-implied covariance matrix, respectively. It is obvious that the squared Euclidean distance is zero for a perfectly fitting model, .
Moreover, the geodesic distance stemming from a class of distance functions proposed by Swain (1975) can be used to measure the discrepancy between the sample and estimated model-implied covariance matrix. It is given by the following:
where φi is the i-th eigenvalue of the matrix and K is the number of indicators. The geodesic distance is zero when and only when all eigenvalues equal one, i.e., when and only when the fit is perfect.
Finally, the SRMR (Hu and Bentler, 1999) can be used to assess the overall model fit. The SRMR is calculated as follows:
where K is the number of indicators. It reflects the average discrepancy between the empirical and the estimated model-implied correlation matrix. Thus, for a perfectly fitting model, the SRMR is zero, as equals sij.
Since all distance measures considered are functions of the sample covariance matrix, a procedure proposed by Beran and Srivastava (1985) can be used to test the overall model fit: H0 : Σ = Σ(θ).9 The reference distribution of the distance measures as well as the critical values are obtained from the transformed sample data as follows:
where the data matrix x of dimension (N × K) contains the N observations of all K indicators. This transformation ensures that the new dataset satisfies the null hypothesis; i.e., the sample covariance matrix of the transformed dataset equals the estimated model-implied covariance matrix. The reference distribution of the distance measures is obtained by bootstrapping from the transformed dataset. In doing so, the estimated distance based on the original dataset can be compared to the critical value from the reference distribution (typically the empirical 95% or 99% quantile) to decide whether the null hypothesis, H0 : Σ = Σ(θ) is rejected (Bollen and Stine, 1992).
5.2. Fit Indices for Composite Models
In addition to the test of overall model fit, we provide some fit indices as measures of the overall model fit. In general, fit indices can indicate whether a model is misspecified by providing an absolute value of the misfit; however, we advise using them with caution as they are based on heuristic rules-of-thumb rather than statistical theory. Moreover, it is recommended to calculate the fit indices based on the indicator correlation matrix instead of the covariance matrix.
The standardized root mean square residual (SRMR) was already introduced as a measure of overall model fit (Henseler et al., 2014). As described above, it represents the average discrepancy between the sample and the model-implied indicator correlation matrix. Values below 0.10 and, following a more conservative view, below 0.08 indicate a good model fit (Hu and Bentler, 1998). However, these threshold values were proposed for common factor models and their usefulness for composite models needs to be investigated.
Furthermore, the normed fit index (NFI) is suggested as a measure of goodness of fit (Bentler and Bonett, 1980). It measures the relative discrepancy between the fit of the baseline model and the fit of the estimated model. In this context, a model where all indicators are assumed to be uncorrelated (the model-implied correlation matrix equals the unit matrix) can serve as a baseline model (Lohmöller, 1989, Chap. 2.4.4). To assess the fit of the baseline model and the estimated model, several measures can be used, e.g., the log likelihood function used in CFA or the geodesic distance. Values of the NFI close to one imply a good model fit. However, cut-off values still need to be determined.
Finally, we suggest considering the root mean square residual covariance of the outer residuals (RMStheta) as a further fit index (Lohmöller, 1989). It is defined as the square root of the average residual correlations. Since the indicators of one block are allowed to be freely correlated, the residual correlations within a block should be excluded and only the residual correlations across the blocks should be taken into account during its calculation. Small values close to zero for the RMStheta indicate a good model fit. However, threshold values still need to be determined.
6. A Monte Carlo Simulation
In order to assess our proposed procedure of statistically testing the overall model fit of composite models and to examine the behavior of the earlier presented discrepancy measures, we conduct a Monte Carlo simulation. In particular, we investigate the type I error rate (false positive rate) and the power, which are the most important characteristics of a statistical test. In designing the simulation, we choose a number of concepts used several times in the literature to examine the performance of fit indices and tests of overall model fit in CFA: a model containing two composites and a model containing three composites (Hu and Bentler, 1999; Heene et al., 2012). To investigate the power of the test procedure, we consider various misspecifications of these models. Figures 4 and 5 summarize the conditions investigated in our simulation study.
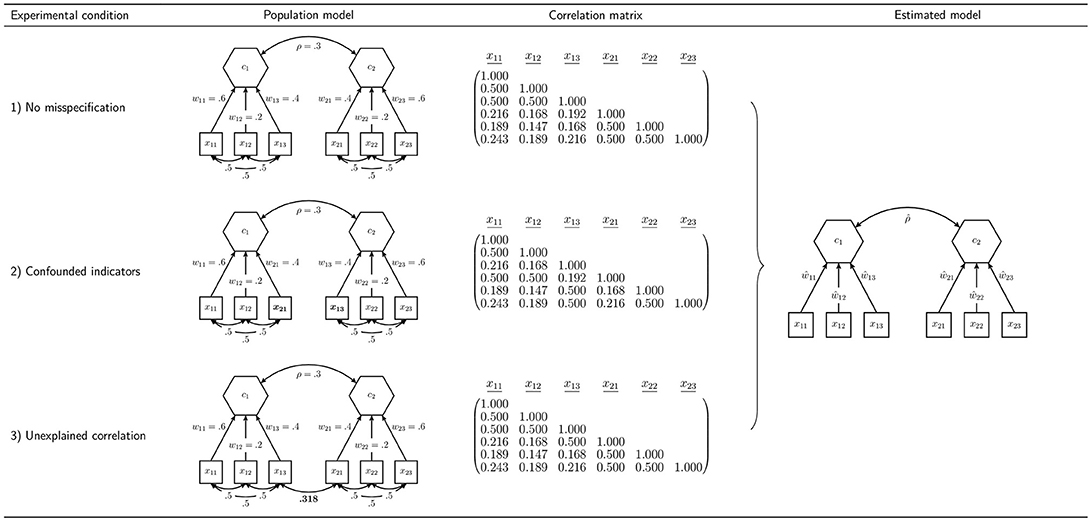
Figure 4. Simulation design for the model containing two composites.
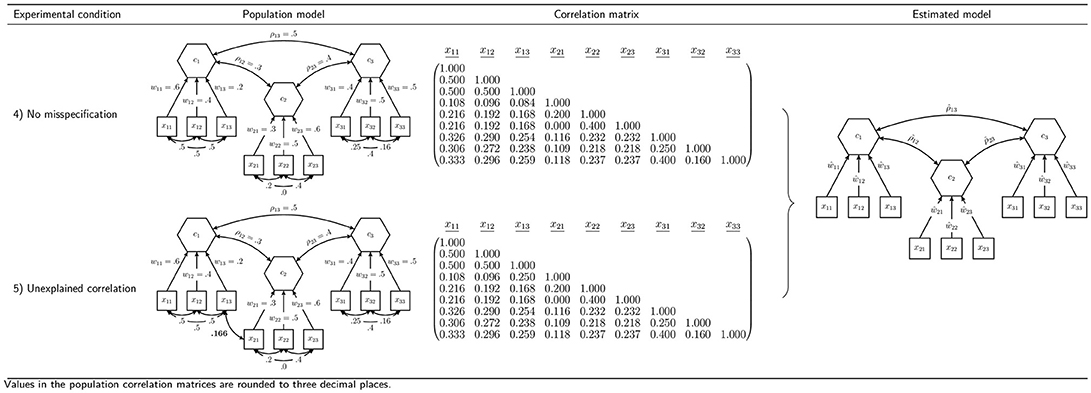
Figure 5. Simulation design for the model containing three composites.
6.1. Model Containing Two Composites
All models containing two composites are estimated using the specification illustrated in the last column of Figure 4. The indicators x11 to x13 are specified to build composite c1, while the remaining three indicators build composite c2. Moreover, the composites are allowed to freely correlate. The parameters of interest are the correlation between the two composites, and the weights, w11 to w23. As column “Population model” of Figure 4 shows, we consider three types of population models with two composites.
6.1.1. Condition 1: No Misspecification
First, in order to examine whether the rejection rates of the test procedure are close to the predefined significance level in cases in which the null hypothesis is true, a population model is considered that has the same structure as the specified model. The correlation between the two composites is set to ρ = 0.3 and the composites are formed by its connected standardized indicators as follows: with i = 1, 2, where and . All correlations between the indicators of one block are set to 0.5, which leads to the population correlation matrix given in Figure 4.
6.1.2. Condition 2: Confounded Indicators
The second condition is used to investigate whether the test procedure is capable of detecting misspecified models. It presents a situation where the researcher falsely assigns two indicators to wrong constructs. The correlation between the two composites and the weights are the same as in population model 1: ρ = 0.3, , and . However, in contrast to population model 1, the indicators x13 and x21 are interchanged. Moreover, the correlations among all indicators of one block are 0.5. The population correlation matrix of the second model is presented in Figure 4.
6.1.3. Condition 3: Unexplained Correlation
The third condition is chosen to further investigate the capabilities of the test procedure to detect misspecified models. It shows a situation where the correlation between the two indicators x13 and x21 is not fully explained by the two composites.10 As in the two previously presented population models, the two composites have a correlation of ρ = 0.3. The correlations among the indicators of one block are set to 0.5, and the weights for the construction of the composites are set to , and . The population correlation matrix of the indicators is presented in Figure 4.
6.2. Model Containing Three Composites
Furthermore, we investigate a more complex model consisting of three composites. Again, each composite is formed by three indicators, and the composites are allowed to freely covary. The column “Estimated model” of Figure 5 illustrates the specification to be estimated in case of three composites. We assume that the composites are built as follows: , , and . Again, we examine two different population models.
6.2.1. Condition 4: No Misspecification
The fourth condition is used to further investigate whether the rejection rates of the test procedure are close to the predefined significance level in cases in which the null hypothesis is true. Hence, the structure of the fourth population model matches the specified model. All composites are assumed to be freely correlated. In the population, the composite correlations are set to ρ12 = 0.3, ρ13 = 0.5, and ρ23 = 0.4. Each composite is built by three indicators using the following population weights: , , and . The indicator correlations of each block can be read from Figure 5. The indicator correlation matrix of population model 4 is given in Figure 5.
6.2.2. Condition 5: Unexplained Correlation
In the fifth condition, we investigate a situation where the correlation between two indicators is not fully explained by the underlying composites, similar to what is observed in Condition 3. Consequently, population model 5 does not match the model to be estimated and is used to investigate the power of the overall model test. It equals population model 4 with the exception that the correlation between the indicators x13 and x21 is only partly explained by the composites. Since the original correlation between these indicators is 0.084, a correlation of 0.25 presents only a weak violation. The remaining model stays untouched. The population correlation matrix is illustrated in Figure 5.
6.3. Further Simulation Conditions and Expectations
To assess the quality of the proposed test of the overall model fit, we generate 10,000 standardized samples from the multivariate normal distribution having zero means and a covariance matrix according to the respective population model. Moreover, we vary the sample size from 50 to 1,450 observations (with increments of 100) and the significance level α from 1% to 10%. To obtain the reference distribution of the discrepancy measures considered, 200 bootstrap samples are drawn from the transformed and standardized dataset. Each dataset is used in the maxvar procedure to estimate the model parameters.
All simulations are conducted in the statistical programming environment R (R Core Team, 2016). The samples are drawn from the multivariate normal distribution using the mvrnorm function of the MASS packages (Venables and Ripley, 2002). The results for the test of overall model fit are obtained by user-written functions11 and the matrixpls package (Rönkkö, 2016).
Since population models 1 and 4 fit the respective specification, we expect rejection rates close to the predefined levels of significance α. Additionally, we expect that for an increasing sample size, the predefined significance level is kept with more precision. For population model 2, 3, and 5, much larger rejection rates are expected as these population models do not match the respective specification. Moreover, we expect that the power of the test to detect misspecifications would increase along with a larger sample size. Regarding the different discrepancy measures, we have no expectations, only that the squared Euclidean distance and the SRMR should lead to identical results. For standardized datasets, the only difference is a constant factor that does not affect the order of the observations in the reference distribution and, therefore, does not affect the decision about the null hypothesis.
6.4. Results
Figure 6 illustrates the rejection rates for population model 1 i.e., no misspecification. Besides the rejection rates, the figure also depicts the 95% confidence intervals (shaded area) constructed around the rejection rates to clarify whether a rejection rate is significantly different from the predefined significance level.12
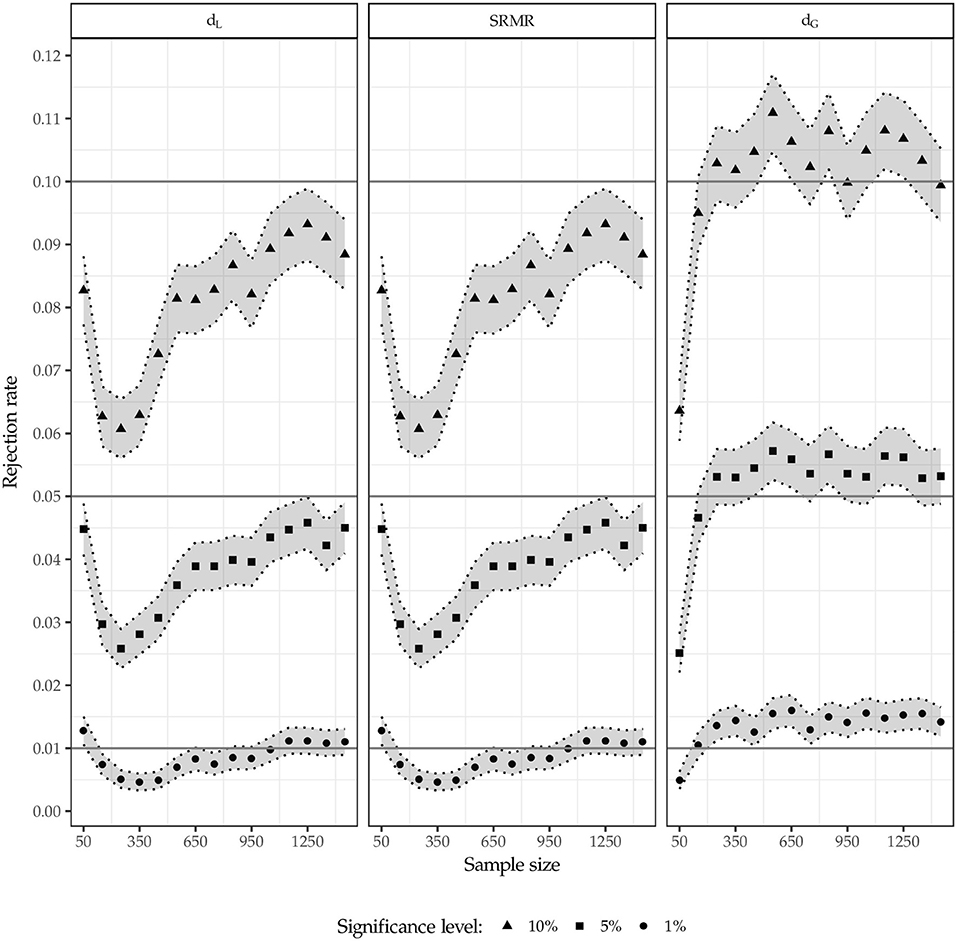
Figure 6. Rejection rates for population model 1.
First, as expected, the squared Euclidean distance (dL) as well as the SRMR lead to identical results. The test using the squared Euclidean distance and the SRMR rejects the model somewhat too rarely in case of α = 10% and α = 5% respectively; however, for an increasing sample size, the rejection rates converge to the predefined significance level without reaching it. For the 1% significance level, a similar picture is observed; however, for larger sample sizes, the significance level is retained more often compared to the larger significance levels. In contrast, the test using the geodesic distance mostly rejects the model too often for the 5% and 10% significance level. However, the obtained rejection rates are less often significantly different from the predefined significance level compared to the same situation where the SRMR or the Euclidean distance is used. In case of α = 1% and sample sizes larger than n = 100, the test using the geodesic distance rejects the model significantly too often.
Figure 7 displays the rejection rates for population models 2 and 3. The horizontal line at 80% depicts the commonly recommended power for a statistical test (Cohen, 1988). For the two cases where the specification does not match the underlying data generating process, the test using the squared Euclidean distance as well as the SRMR has more power than the test using the geodesic distance, i.e., the test using former discrepancy measures rejects the wrong model more often. For model 2 (confounded indicators) the test produces higher or equal rejection rates compared to model 3 (unexplained correlation). Furthermore, as expected, the power decreases for an increasing level of significance and increases with increasing sample sizes.
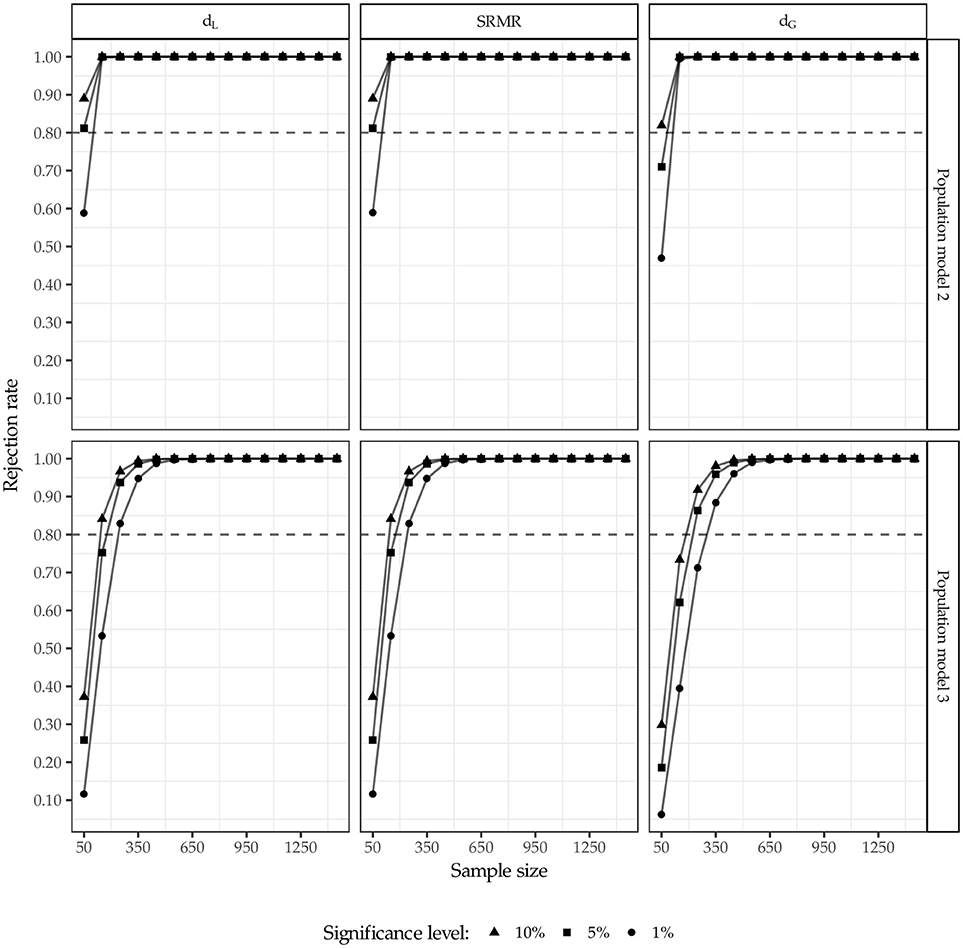
Figure 7. Rejection rates for population model 2 and 3.
Figure 8 depicts the rejection rates for population model 4 and 5. Again, the 95% confidence intervals are illustrated for population model 4 (shaded area) matching the specification estimated. Considering population model 4 which matches the estimated model, the test leads to similar results for all three discrepancy measures. However, the rejection rate of the test using the geodesic distance converges faster to the predefined significance level, i.e., for smaller sample sizes n ≥ 100. Again, among the three discrepancy measures considered, the geodesic distance performs best in terms of keeping the significance level.
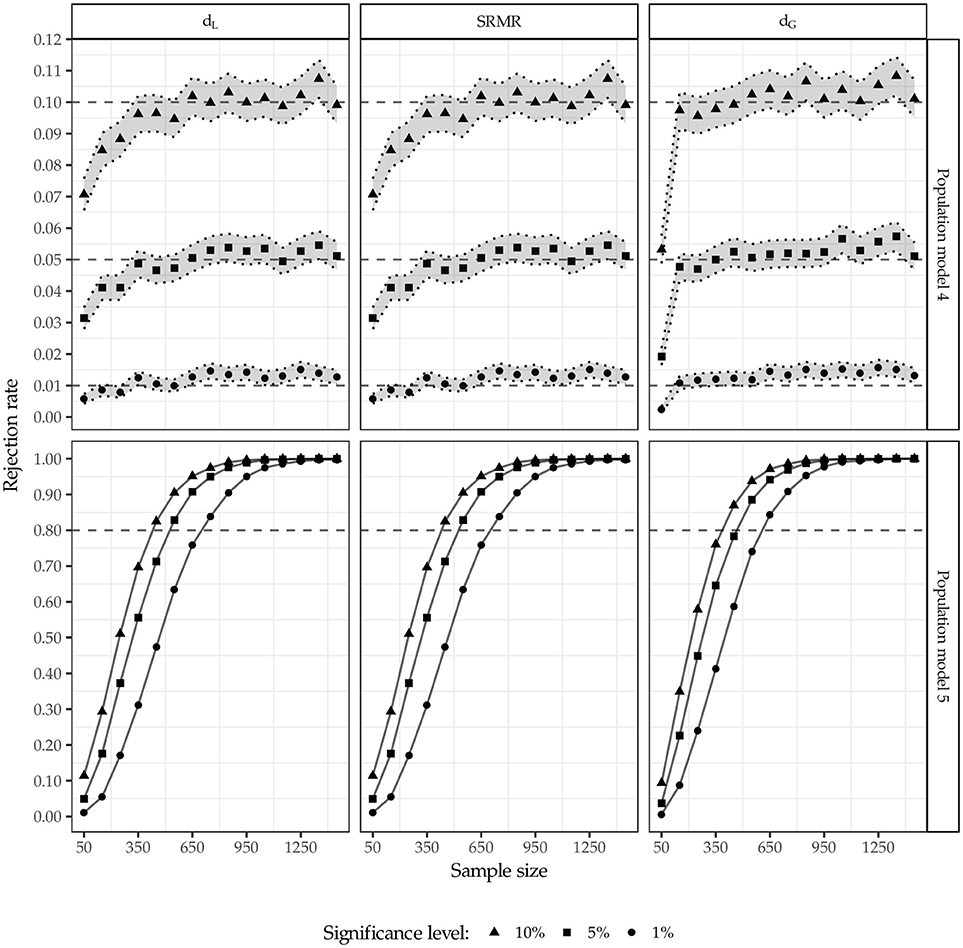
Figure 8. Rejection rates for population model 4 and 5.
As the extent of misspecification in population model 5 is minor, the test struggles to detect the model misspecification up to sample sizes n = 350, regardless of the discrepancy measure used. However, for sample sizes larger than 350 observations, the test detects the model misspecification satisfactorily. For sample sizes larger than 1,050 observations, the misspecification was identified in almost all cases regardless of the significance level and the discrepancy measure used. Again, this confirms the anticipated relationship between sample size and statistical power.
7. Discussion
We introduced the confirmatory composite analysis (CCA) as a full-fledged technique for confirmatory purposes that employs composites to model artifacts, i.e., design concepts. It overcomes current limitations in CFA and SEM and carries the spirit of CFA and SEM to research domains studying artifacts. Its application is appropriate in situations where the research goal is to examine whether an artifact is useful rather than to establish whether a certain concept exists. It follows the same steps usually applied in SEM and enables researchers to analyze a variety of situations, in particular, beyond the realm of social and behavioral sciences. Hence, CCA allows for dealing with research questions that could not be appropriately dealt with yet in the framework of CFA or more generally in SEM.
The results of the Monte Carlo simulation confirmed that CCA can be used for confirmatory purposes. They revealed that the bootstrap-based test, in combination with different discrepancy measures, can be used to statistically assess the overall model fit of the composite model. For specifications matching the population model, the rejection rates were in the acceptable range, i.e., close to the predefined significance level. Moreover, the results of the power analysis showed that the boostrap-based test can reliably detect misspecified models. However, caution is needed in case of small sample sizes where the rejection rates were low, which means that misspecified models were not reliably detected.
In future research, the usefulness of the composite model in empirical studies needs to be examined, accompanied and enhanced by simulation studies. In particular, the extensions outlined by Dijkstra (2017); to wit, interdependent systems of equations for the composites estimated by classical econometric methods (like 2SLS and three-stage least squares) warrant further analysis and scrutiny. Robustness with respect to non-normality and misspecification also appear to be relevant research topics. Additionally, devising ways to efficiently predict indicators and composites might be of particular interest (see for example the work by Shmueli et al., 2016).
Moreover, to contribute to the confirmatory character of CCA, we recommend further study of the performance and limitations of the proposed test procedure: consider more misspecifications and the ability of the test to reliably detect them, find further discrepancy measures and examine their performance, and investigate the behavior of the test under the violation of the normality assumption, similar as Nevitt and Hancock (2001) did for CFA. Finally, cut-off values for the fit indices need to be determined for CCA.
Author Contributions
FS conducted the literature review and wrote the majority of the paper (contribution: ca. 50%). JH initiated this paper and designed the simulation study (contribution: ca. 25%). TD proposed the composite model and developed the model fit test (contribution: ca. 25%).
Conflict of Interest Statement
JH acknowledges a financial interest in ADANCO and its distributor, Composite Modeling.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2018.02541/full#supplementary-material
Footnotes
1. ^For more details and a comprehensive overview, we referred to the following text books: Hayduk (1988), Bollen (1989), Marcoulides and Schumacker (2001), Raykov and Marcoulides (2006), Kline (2015), and Brown (2015).
2. ^In general, models containing common factors and composites are also conceivable but have not been considered here.
3. ^The existing literature sometimes mentions empirical (under-)identification in the context of model identification (Kenny, 1979). Since this expression refers to an issue of estimation rather than to the issue of model identification, this topic is not discussed in the following.
4. ^Another way of normalization is to fix one weight of each block to a certain value. Furthermore, we ignore trivial regularity assumptions such as weight vectors consisting of zeros only; and similarly, we ignore cases where intra-block covariance matrices are singular.
5. ^The number of degrees of freedom can be helpful at determining whether a model is identified since an identified model has a non-negative number of degrees of freedom.
6. ^GCCA builds composites in a way that they are maximally correlated.
7. ^For an overview we refer to Kettenring (1971).
8. ^In general, GCCA offers several composites (canonical variates); but in our study, we have focused only on the canonical variates of the first stage.
9. ^This procedure is known as the Bollen-Stine bootstrap (Bollen and Stine, 1992) in the factor-based SEM literature. The model must be over-identified for this test.
10. ^The model-implied correlation between the two indicators is calculated as follows, 0.8 · 0.3 · 0.8 ≠ 0.5.
11. ^These functions are provided by the contact author upon request.
12. ^The limits of the 95% confidence interval are calculated as, , where represents the rejection rate and Φ−1() is the quantile function of the standard normal distribution.
References
Bagozzi, R. P. (1994). “Structural equation models in marketing research: basic principles,” in Principles of Marketing Research eds R. P. Bagozzi (Oxford: Blackwell), 317–385.
Bagozzi, R. P., and Yi, Y. (1988). On the evaluation of structural equation models. J. Acad. Market. Sci. 16, 74–94. doi: 10.1007/BF02723327
Baskerville, R., and Pries-Heje, J. (2010). Explanatory design theory. Busin. Inform. Syst. Eng. 2, 271–282. doi: 10.1007/s12599-010-0118-4
Bentler, P. M., and Bonett, D. G. (1980). Significance tests and goodness of fit in the analysis of covariance structures. Psychol. Bull. 88, 588–606. doi: 10.1037/0033-2909.88.3.588
Beran, R., and Srivastava, M. S. (1985). Bootstrap tests and confidence regions for functions of a covariance matrix. Ann. Statist. 13, 95–115. doi: 10.1214/aos/1176346579
Bollen, K. A. (1989). Structural Equations with Latent Variables. New York, NY: John Wiley & Sons Inc.
Bollen, K. A. (2001). “Two-stage least squares and latent variable models: Simultaneous estimation and robustness to misspecifications,” in Structural Equation Modeling: Present and Future, A Festschrift in Honor of Karl Jöreskog eds R. Cudeck, S. Du Toit, and D. Sörbom (Chicago: Scientific Software International), 119–138.
Bollen, K. A., and Stine, R. A. (1992). Bootstrapping goodness-of-fit measures in structural equation models. Sociol. Methods Res. 21, 205–229. doi: 10.1177/0049124192021002004
Brown, T. A. (2015). Confirmatory Factor Analysis for Applied Research. New York, NY: Guilford Press.
Browne, M. W. (1984). Asymptotically distribution-free methods for the analysis of covariance structures. Br. J. Math. Statist. Psychol. 37, 62–83. doi: 10.1111/j.2044-8317.1984.tb00789.x
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences, 2nd Edn. Hillsdale, MI: Lawrence Erlbaum Associates.
Crowley, D. M. (2013). Building efficient crime prevention strategies. Criminol. Public Policy 12, 353–366. doi: 10.1111/1745-9133.12041
Diamantopoulos, A. (2008). Formative indicators: introduction to the special issue. J. Busin. Res. 61, 1201–1202. doi: 10.1016/j.jbusres.2008.01.008
Diamantopoulos, A., and Winklhofer, H. M. (2001). Index construction with formative indicators: an alternative to scale development. J. Market. Res. 38, 269–277. doi: 10.1509/jmkr.38.2.269.18845
Dijkstra, T. K. (2010). “Latent variables and indices: Herman Wold's basic design and partial least squares,” in Handbook of Partial Least Squares (Berlin: Springer), 23–46.
Dijkstra, T. K. (2013). “Composites as factors: Canonical variables revisited,” in Working Paper. Groningen. Available online at: https://www.rug.nl/staff/t.k.dijkstra/composites-as-factors.pdf
Dijkstra, T. K. (2015). “All-inclusive versus single block composites,” in Working Paper. Groningen. Available online at: https://www.researchgate.net/profile/Theo_Dijkstra/publication/281443431_all-inclusive_and_single_block_composites/links/55e7509208ae65b63899564f/all-inclusive-and-single-block-composites.pdf
Dijkstra, T. K. (2017). “A perfect match between a model and a mode,” in Partial Least Squares Path Modeling, eds H. Latan, and R. Noonan (Cham: Springer), 55–80.
Dijkstra, T. K., and Henseler, J. (2011). Linear indices in nonlinear structural equation models: best fitting proper indices and other composites. Qual. Quant. 45, 1505–1518. doi: 10.1007/s11135-010-9359-z
Dijkstra, T. K., and Henseler, J. (2015). Consistent and asymptotically normal PLS estimators for linear structural equations. Computat. Statist. Data Anal. 81, 10–23. doi: 10.1016/j.csda.2014.07.008
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Ann. Eugen. 7, 179–188. doi: 10.1111/j.1469-1809.1936.tb02137.x
Fong, C. J., Davis, C. W., Kim, Y., Kim, Y. W., Marriott, L., and Kim, S. (2016). Psychosocial factors and community college student success. Rev. Educ. Res. 87, 388–424. doi: 10.3102/0034654316653479
Fornell, C., and Bookstein, F. L. (1982). Two structural equation models: LISREL and PLS applied to consumer exit-voice theory. J. Market. Res. 19, 440–452. doi: 10.2307/3151718
Gefen, D., Straub, D. W., and Rigdon, E. E. (2011). An update and extension to SEM guidelines for admnistrative and social science research. MIS Quart. 35, iii–xiv. doi: 10.2307/23044042
Grace, J. B., Anderson, T. M., Olff, H., and Scheiner, S. M. (2010). On the specification of structural equation models for ecological systems. Ecol. Monogr. 80, 67–87. doi: 10.1890/09-0464.1
Grace, J. B., and Bollen, K. A. (2008). Representing general theoretical concepts in structural equation models: the role of composite variables. Environ. Ecol. Statist. 15, 191–213. doi: 10.1007/s10651-007-0047-7
Hayduk, L. A. (1988). Structural Equation Modeling With LISREL: Essentials and Advances. Baltimore, MD: John Hopkins University Press.
Heene, M., Hilbert, S., Freudenthaler, H. H., and Buehner, M. (2012). Sensitivity of SEM fit indexes with respect to violations of uncorrelated errors. Struct. Equat. Model. 19, 36–50. doi: 10.1080/10705511.2012.634710
Henseler, J. (2017). Bridging design and behavioral research with variance-based structural equation modeling. J. Advert. 46, 178–192. doi: 10.1080/00913367.2017.1281780
Henseler, J., Dijkstra, T. K., Sarstedt, M., Ringle, C. M., Diamantopoulos, A., Straub, D. W., et al. (2014). Common beliefs and reality about PLS comments on Rönkkö and Evermann (2013). Organ. Res. Methods 17, 182–209. doi: 10.1177/1094428114526928
Holbert, R. L., and Stephenson, M. T. (2002). Structural equation modeling in the communication sciences, 1995–2000. Hum. Commun. Res. 28, 531–551. doi: 10.1111/j.1468-2958.2002.tb00822.x
Horvath, I. (2004). A treatise on order in engineering design research. Res. Eng. Design 15, 155–181. doi: 10.1007/s00163-004-0052-x
Hotelling, H. (1936). Relations between two sets of variates. Biometrika 28, 321–377. doi: 10.1093/biomet/28.3-4.321
Hu, L., and Bentler, P. M. (1998). Fit indices in covariance structure modeling: sensitivity to underparameterized model misspecification. Psychol. Methods 3, 424–453. doi: 10.1037/1082-989X.3.4.424
Hu, L., and Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: conventional criteria versus new alternatives. Struc. Equat. Model. 6, 1–55. doi: 10.1080/10705519909540118
Hwang, H., and Takane, Y. (2004). Generalized structured component analysis. Psychometrika 69, 81–99. doi: 10.1007/BF02295841
Jöreskog, K. G. (1967). Some contributions to maximum likelihood factor analysis. Psychometrika 32, 443–482. doi: 10.1007/BF02289658
Keller, H. (2006). The SCREEN I (seniors in the community: risk evaluation for eating and nutrition) index adequately represents nutritional risk. J. Clin. Epidemiol. 59, 836–841. doi: 10.1016/j.jclinepi.2005.06.013
Kettenring, J. R. (1971). Canonical analysis of several sets of variables. Biometrika 58, 433–451. doi: 10.1093/biomet/58.3.433
Kirmayer, L. J., and Crafa, D. (2014). What kind of science for psychiatry? Front. Hum. Neurosci. 8:435. doi: 10.3389/fnhum.2014.00435
Klein, A., and Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the LMS method. Psychometrika 65, 457–474. doi: 10.1007/BF02296338
Kline, R. B. (2015). Principles and Practice of Structural Equation Modeling. New York, NY: Guilford Press.
Lee, H.-J. (2005). Developing a professional development program model based on teachers' needs. Profess. Educ. 27, 39–49.
Lohmöller, J.-B. (1989). Latent Variable Path Modeling with Partial Least Squares. Heidelberg: Physica.
Lussier, P., LeBlanc, M., and Proulx, J. (2005). The generality of criminal behavior: a confirmatory factor analysis of the criminal activity of sex offenders in adulthood. J. Crim. Just. 33, 177–189. doi: 10.1016/j.jcrimjus.2004.12.009
MacCallum, R. C., and Austin, J. T. (2000). Applications of structural equation modeling in psychological research. Ann. Rev. Psychol. 51, 201–226. doi: 10.1146/annurev.psych.51.1.201
MacCallum, R. C., and Browne, M. W. (1993). The use of causal indicators in covariance structure models: Some practical issues. Psychol. Bull. 114, 533–541. doi: 10.1037/0033-2909.114.3.533
Malaeb, Z. A., Summers, J. K., and Pugesek, B. H. (2000). Using structural equation modeling to investigate relationships among ecological variables. Environ. Ecol. Statist. 7, 93–111. doi: 10.1023/A:1009662930292
Marcoulides, G. A., and Chin, W. W. (2013). “You write, but others read: common methodological misunderstandings in PLS and related methods,” in New Perspectives in Partial Least Squares and Related Methods, eds H. Abdi, V. E. Vinzi, G. Russolillo, and L. Trinchera (New York, NY: Springer), 31–64.
Marcoulides, G. A., and Schumacker, R. E. editors (2001). New Developments and Techniques in Structural Equation Modeling. Mahwah, NJ: Lawrence Erlbaum Associates.
Markus, K. A., and Borsboom, D. (2013). Frontiers of Test Validity Theory: Measurement, Causation, and Meaning. New York, NY: Routledge.
McIntosh, A., and Gonzalez-Lima, F. (1994). Structural equation modeling and its application to network analysis in functional brain imaging. Hum. Brain Mapp. 2, 2–22.
Møller, C., Brandt, C. J., and Carugati, A. (2012). “Deliberately by design, or? Enterprise architecture transformation at Arla Foods,” in Advances in Enterprise Information Systems II, eds C. Møller, and S. Chaudhry (Boca Raton, FL: CRC Press), 91–104.
Muthén, B. O. (1984). A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika 49, 115–132.
Muthén, B. O. (2002). Beyond SEM: general latent variable modeling. Behaviormetrika 29, 81–117.doi: 10.2333/bhmk.29.81
Nevitt, J., and Hancock, G. R. (2001). Performance of bootstrapping approaches to model test statistics and parameter standard error estimation in structural equation modeling. Struc. Equat. Model. 8, 353–377. doi: 10.1207/S15328007SEM0803_2
Pearson, K. (1901). On lines and planes of closest fit to systems of points in space. Philos. Magazine 6 2, 559–572. doi: 10.1080/14786440109462720
R Core Team (2016). R: A Language and Environment for Statistical Computing. Version 3.3.1. Vienna: R Foundation for Statistical Computing.
Raykov, T., and Marcoulides, G. A. (2006). A First Course in Structural Equation Modeling, 2nd Edn. Mahaw: Lawrence Erlbaum Associates.
Rigdon, E. E. (2012). Rethinking partial least squares path modeling: in praise of simple methods. Long Range Plan. 45, 341–358. doi: 10.1016/j.lrp.2012.09.010
Rönkkö, M. (2016). matrixpls: Matrix-based Partial Least Squares Estimation. R package version 1.0.0. Available online at: https://cran.r-project.org/web/packages/matrixpls/vignettes/matrixpls-intro.pdf
Rossiter, J. R. (2002). The C-OAR-SE procedure for scale development in marketing. Int. J. Res. Market. 19, 305–335. doi: 10.1016/S0167-8116(02)00097-6
Schumacker, R. E., and Lomax, R. G. (2009). A Beginner's Guide to Structural Equation Modeling, 3rd Edn. New York, NY: Routledge.
Shah, R., and Goldstein, S. M. (2006). Use of structural equation modeling in operations management research: looking back and forward. J. Operat. Manag. 24, 148–169. doi: 10.1016/j.jom.2005.05.001
Shmueli, G., Ray, S., Estrada, J. M. V., and Chatla, S. B. (2016). The elephant in the room: Predictive performance of PLS models. J. Busin. Res. 69, 4552–4564. doi: 10.1016/j.jbusres.2016.03.049
Sobel, M. E. (1997). “Measurement, causation and local independence in latent variable models,” in Latent Variable Modeling and Applications to Causality, ed M. Berkane (New York, NY: Springer), 11–28.
Spears, N., and Singh, S. N. (2004). Measuring attitude toward the brand and purchase intentions. J. Curr. Iss. Res. Advert. 26, 53–66. doi: 10.1080/10641734.2004.10505164
Steenkamp, J.-B. E., and Baumgartner, H. (2000). On the use of structural equation models for marketing modeling. Int. J. Res. Market. 17, 195–202. doi: 10.1016/S0167-8116(00)00016-1
Swain, A. (1975). A class of factor analysis estimation procedures with common asymptotic sampling properties. Psychometrika 40, 315–335. doi: 10.1007/BF02291761
Tenenhaus, A., and Tenenhaus, M. (2011). Regularized generalized canonical correlation analysis. Psychometrika 76, 257–284. doi: 10.1007/s11336-011-9206-8
Van de Schoot, R., Lugtig, P., and Hox, J. (2012). A checklist for testing measurement invariance. Eur. J. Develop. Psychol. 9, 486–492. doi: 10.1080/17405629.2012.686740
Vance, A., Benjamin Lowry, P., and Eggett, D. (2015). Increasing accountability through user-interface design artifacts: a new approach to addressing the problem of access-policy violations. MIS Quart. 39, 345–366. doi: 10.25300/MISQ/2015/39.2.04
Venables, W. N., and Ripley, B. D. (2002). Modern Applied Statistics With S, 4th Edn. New York, NY: Springer.
Venkatesh, V., Morris, M. G., Davis, G. B., and Davis, F. D. (2003). User acceptance of information technology: toward a unified view. MIS Quart. 27:425. doi: 10.2307/30036540
Wight, D., Wimbush, E., Jepson, R., and Doi, L. (2015). Six steps in quality intervention development (6SQuID). J. Epidemiol. Commun. Health 70, 520–525. doi: 10.1136/jech-2015-205952
Wold, H. (1975). “Path models with latent variables: The NIPALS approach. in Quantitative Sociology, eds H. Blalock, A. Aganbegian, F. Borodkin, R. Boudon, and V. Capecchi (New York, NY: Academic Press), 307–357.
Keywords: artifacts, composite modeling, design research, Monte Carlo simulation study, structural equation modeling, theory testing
Citation: Schuberth F, Henseler J and Dijkstra TK (2018) Confirmatory Composite Analysis. Front. Psychol. 9:2541. doi: 10.3389/fpsyg.2018.02541
Received: 19 June 2018; Accepted: 28 November 2018;
Published: 13 December 2018.
Edited by:
Holmes Finch, Ball State University, United StatesReviewed by:
Daniel Saverio John Costa, University of Sydney, AustraliaShenghai Dai, Washington State University, United States
Copyright © 2018 Schuberth, Henseler and Dijkstra. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Florian Schuberth, Zi5zY2h1YmVydGhAdXR3ZW50ZS5ubA==