 Kazuyuki Sato
Kazuyuki Sato Takahiro Higuchi
Takahiro Higuchi- 1Department for the Psychology of Human Movement and Sport, Friedrich Schiller University Jena, Jena, Germany
- 2Department of Health Promotion Science, Tokyo Metropolitan University, Tokyo, Japan
Introduction: The ability to predict collisions with moving objects declines with age, partly due to reduced sensitivity to object expansion cues. This study examined whether perceptual training specifically targeting object expansion improves collision prediction more effectively than repeated practice on an identical collision prediction task. Additionally, the study verified whether such training could be employed to improve prediction accuracy in a more realistic context, using a virtual road-crossing scenario.
Methods: Twenty older adults (71.35 ± 6.04 years; 11 females) participated. All tasks were constructed in virtual reality (VR) from a first-person perspective. Pre- and post-evaluation sessions comprised three tasks: a) an interception task assessing collision prediction ability, b) a target-approach detection task assessing the sensitivity of object expansion, and c) a road-crossing task. Participants were randomly assigned to one of two training groups: (a) a time-to-contact (TTC) estimation group (TE-group) or (b) an interception task group (IC-group). For the TE-group, participants repeatedly performed a TTC estimation task within a VR environment setting to isolate object expansion cues. This was achieved by restricting other visual cues and limiting the target's motion to a head-on collision approach. In the IC-group, participants repeatedly performed the same interception task used in the evaluation session.
Results and Discussion: The TE-group showed significant improvement in collision prediction compared to the IC-group, indicating that training focused on the perception of object expansion was more effective than simple repetition of its evaluation task. However, neither sensitivity to object expansion nor the accuracy of road-crossing decisions improved significantly, suggesting that other factors may have contributed to the observed improvement.
Introduction
The ability to predict collisions is crucial for navigating complex environments while promptly avoiding collisions with moving entities such as pedestrians and vehicles. Previous studies have demonstrated that this ability declines with age, making it more difficult to accurately assess the collision risk with a moving object (1, 2). Indeed, it has been shown that driving (3) and pedestrian-related accidents (4) are more prevalent among older adults. Therefore, improving collision prediction ability may contribute to the prevention of such accidents.
Two key optical variables have been identified as being important in the context of collision prediction: “object expansion” (1, 5–10) and “bearing angle” (6, 11–16). Object expansion refers to the rate of change in an object's size on the retina, which is needed to estimate the time-to-contact (TTC) with an approaching object. For example, the faster the rate of object expansion changes, the shorter the TTC (17). The bearing angle is the horizontal angle between a moving observer and a moving object, and it is used to judge the trajectory of the object. If the observer perceives that the bearing angle remains constant while they are approaching each other, the observer can determine whether their trajectory is on a collision course with a moving object. Thus, the key point for successful collision prediction lies in accurately perceiving these two types of visual cues.
However, sensitivity to these two types of visual cues declines with age, highlighting the need for strategies to compensate for this decline. Andersen and Enriquez (1) proposed the “expansion sensitivity hypothesis,” which suggests that a reduction in the sensitivity to object expansion makes collision prediction more difficult. Their experiments showed that even when expansion was easy to perceive, older adults detected collisions less accurately than younger adults (1). François et al. (18) used a virtual reality (VR) interception task and found that older adults had difficulty maintaining a constant bearing angle while intercepting a moving object, resulting in more erratic and non-linear movement patterns (18). Their findings suggested that the sensitivity to these two types of visual cues is susceptible to aging.
Previous work from our group investigated which visual cues, i.e., object expansion or bearing angle, should be prioritized to improve collision prediction in older adults (19). Based on the affordance-based model (20, 21), which emphasizes the need to accurately perceive both visual cues for successful collision prediction, an interception task used by Steinmetz et al. (22) was implemented in a head-mounted display (HMD)-based VR environment (22). An original part of the study was to leverage the controllability of VR to apply a visual perturbation to each of these visual cues. It was expected that the perturbation would impair performance only in participants who rely on the optical variable to perform a task effectively. A comparison between older and younger adults revealed that performance declined in older adults when a perturbation was applied to the bearing angle, whereas performance remained unaffected when the object expansion was perturbed. This indicates that improving perceptual sensitivity to object expansion is essential for collision prediction in older adults.
The present study investigated whether perceptual training focused on perceiving object expansion—delivered in immersive, first-person VR without a visible self-avatar—is more effective than training that replicates the evaluation task (i.e., the interception task) in enhancing collision prediction ability in older adults. As mentioned above, the age-dependent decline in sensitivity to object expansion was identified as a primary factor underlying the deterioration of collision prediction in older adults. Similarly, previous research has shown that the ability to detect lateral motion remains relatively unaffected by age (23), supporting the rationale for focusing on object expansion in training. To focus on the perception of object expansion, the present study referred to the experimental design employed in a previous study (10), which eliminated the surrounding visual cues and presented only a target approaching from the front. This design effectively removed bearing angle information, ensuring that object expansion served as the sole visual cue for detecting potential collisions. Such visual manipulation is also suitable from a perceptual training perspective, aligning with evidence that repeated practice targeting a specific visual cue enhances perceptual sensitivity (24–26). Based on this rationale, the present study hypothesized that perceptual training specifically targeting object expansion would be more effective than repeating the interception task in improving collision prediction in older adults.
Furthermore, to evaluate the transfer of perceptual training to an everyday task, we assessed the accuracy of road-crossing decisions. Previous studies have shown that older adults tend to make more errors in road-crossing decisions (27–36), potentially reflecting reduced sensitivity to optical expansion (37). Therefore, the perceptual training that targets sensitivity to expansion cues may be of practical relevance. In the present study, a highly realistic, first-person VR road-crossing simulation allowed participants to experience traffic scenarios that closely approximate real-world conditions in a safe, controlled, and repeatable manner. Critically, stereoscopic, first-person 3D VR has been reported to enhance realism and presence and to reduce extraneous cognitive load (38, 39). It also supports the formation of accurate spatial representations during navigation (40) and is associated with faster, more precise task execution (41). These advantages enabled us to assess performance in a context that more closely resembles real-life behavior. If perceptual training is shown to transfer to ecological performance, it may represent a viable intervention for reducing collision risk in older adults during daily activities.
Methods
Participants
Twenty older adults (71.35 ± 6.04 years, 11 females) were recruited for this study. All participants provided written informed consent and received a bookstore gift card for their participation. Participants were excluded if they had a Mini–Mental State Examination (MMSE) score ≤23 (42) or if they self-reported visual disorders. Because participants were permitted to wear corrective lenses (e.g., eyeglasses or contact lenses) during testing, visual acuity was not an exclusion criterion. Although no detailed assessment for vertigo or vestibular dysfunction was conducted, no participants self-reported vertigo symptoms. Participants were monitored throughout the experiment for signs of vertigo and cybersickness (e.g., nausea, dizziness), and no symptoms were reported during or after testing. As use was restricted to the left-hand controller, participant handedness was not assessed. The Ethics Committee of Tokyo Metropolitan University approved the study protocol (Approval No. H5-13).
Apparatus
The virtual environment employed in this study was generated using the Unity cross-platform game engine (Unity Technologies, San Francisco, US) on a G-Tune E5 laptop computer (Mouse Computer Co., Ltd., Chuo-ku, Tokyo, Japan) with two NVIDIA® GeForce RTX™ 3,060 graphics cards with Max-Q design (NVIDIA, Santa Clara, CA, USA), a 2.3 GHz Core i7-12700H processor (Intel, Santa Clara, CA, USA), and 32 GB of RAM running Windows 11 (Microsoft, Redmond, WA, USA). Participants wore a head-mounted Oculus Quest 2 display (Meta Platforms, Inc., Menlo Park, CA, USA), which has an LCD resolution of 1,832 × 1,920, a refresh rate of 72–120 Hz, a 110-degree viewing angle, and controllers. The height of the viewpoint in the VR environment was 1.2 m above floor level. Only the left-handed controller was used.
Protocol and tasks
Procedure
The experimental protocol is shown in Figure 1. Participants were randomly assigned to one of two training groups: the TTC estimation group (TE-group) and the interception task group (IC-group). Of the 20 participants, 10 were assigned to the IC-group (72.8 ± 5.78 years, 5 females), and 10 were assigned to the TE-group (69.3 ± 3.91 years, 6 females). The experiment consisted of three main sessions: a pre-training evaluation session, a 60 min perceptual training session, and a post-training evaluation session. Each evaluation session comprised three tasks: (a) a target-detection task, (b) an interception task, and (c) a road-crossing task. The same interception task was used for both the evaluation and training sessions in the IC-group. All tasks were conducted in VR using an HMD. Tasks (a) and (b) were performed in an abstract VR environment with handheld-controller input, whereas task (c) was performed in a realistic road-crossing simulation in which participants moved physically within the virtual space. The HMD provided a first-person view, and the scene updated in real time with head movements via head tracking. The entire protocol required approximately 2 h and 30 min to complete. The order of tasks in both the pre- and post-evaluation sessions was counterbalanced across participants to minimize order effects.
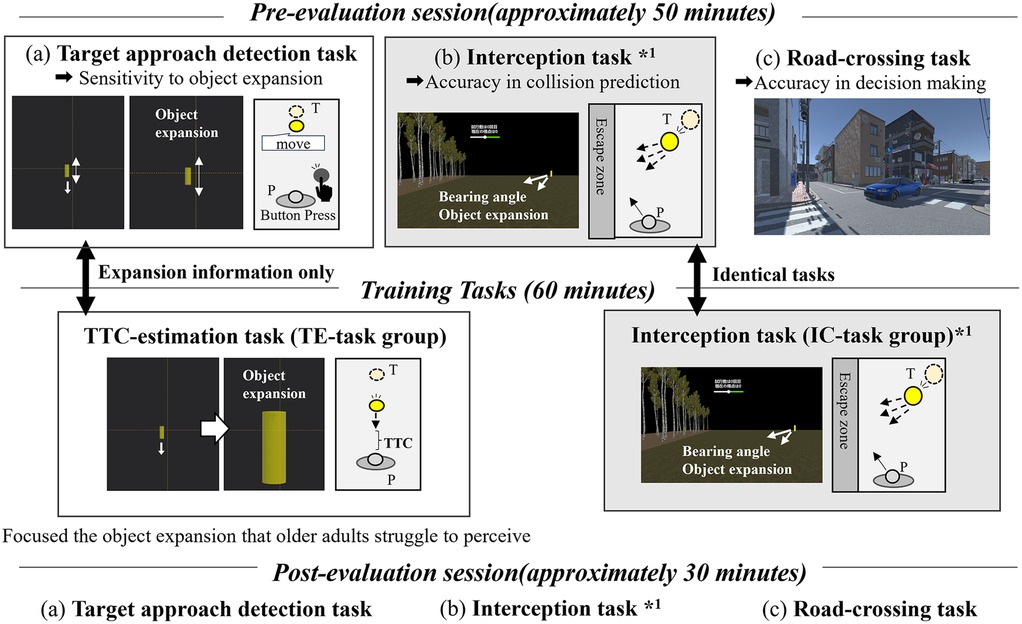
Figure 1. Experimental protocol. P: participant, T: target, TTC: time-to-contact. The evaluation sessions include (a) an interception task assessing collision prediction, (b) a target-approach detection task assessing sensitivity to object expansion, and (c) a VR road-crossing task. The same interception task was used for both the pre- and post-evaluation (*1). The pre- and post-evaluation sessions comprised identical tasks. In the target-approach detection task and the TTC estimation task, only a target approaching directly from the front was presented. In contrast, the interception task included not only the approaching target but also the surrounding environmental visual cues, and the target could move laterally to the left or right.
Evaluation tasks
Evaluation task (a): target-approach detection task
The target-approach detection task was an original task developed to evaluate the sensitivity to object expansion. In this task, participants were instructed to press a button at the moment they perceived the approach of the target, and the reaction time was measured. While seated and wearing the HMD, participants observed only a yellow cylindrical target measuring 1.6 m high and 0.4 m wide against a black background (Figure 2). Because contrast sensitivity declines with age (43–46), high-contrast visual stimuli (yellow cylinders on a black background) were employed in this study to maximize the salience of the expansion cue and minimize floor effects. By presenting only the target and restricting its trajectory to a head-on course, participants needed to rely solely on the visual expansion of the target to detect the approach of the target. Two initial target-participant distances were used: 40 m (far) and 20 m (near distance). Two target speeds were also tested: 100 cm/s (fast) and 50 cm/s (slow speed). Participants pressed a button on a controller with their left hand to indicate detection of the stationary target as it began moving toward them. If the button was pressed while the target remained stationary, a beep sound was played and the trial was considered invalid. The duration of the stationary phase varied randomly between 1 and 15 s across trials. Because the stationary phase before motion onset was widely randomized and premature presses were invalidated, we considered anticipatory response biases to be minimal and therefore did not include dedicated catch (no-motion) trials. The time from the onset of the target approach to the button press was recorded as the detection time. A shorter detection time indicates higher sensitivity to object expansion.

Figure 2. Virtual reality environment used in the target-approach detection task. (A) View presented to the participant through the head-mounted display. (B) Bird's-eye view of the scene showing the spatial arrangement of the target and participant.
Participants completed 12 trials in total: two distances (near, far) and two speeds (slow, fast), each repeated three times. The average detection time was calculated across all trials. The order of the four conditions (two distances × two speeds) was counterbalanced across participants.
Evaluation task (b): interception task
The interception task was developed based on previous studies (19, 22). Although the target used was the same as in the target-approach detection task, additional visual cues were incorporated into the virtual environment, including a ground surface and a forested area within the escape zone to strengthen optic-flow cues and the perception of self-motion (Figure 3). In this task, participants were required to decide whether to pursue the moving target in an attempt to intercept it or refrain from pursuit if they judged interception to be unfeasible before the target reached the escape zone. A scoring system used in the study of Steinmetz et al. (22) was employed (see Table 1), in which successful interception of the target resulted in point gains, while longer movement distances by the participant incurred point deductions. Participants were instructed to maximize their overall score. Upon a signal from the experimenter, the target began moving toward one of the designated escape points. The speed and direction of the target varied across trials. In approximately half of the trials, the target was programmed to be uncatchable. In these trials, the optimal decision for participants was to refrain from pursuit to avoid score deductions. During the first second after the target motion onset, participants were restricted from moving and required only to observe the target's trajectory (observation phase). At the end of this phase, a beep sound indicated the start of the response phase, during which participants could either attempt to pursue the target or give up. Participants' movement was controlled by using a joystick on the handheld controller, and the decision to give up was executed by pressing a designated button. Each participant completed 30 trials. Before the main trials, participants completed a 50-trial familiarization block to confirm task comprehension and controller proficiency. Because sensorimotor adaptation includes a fast-timescale process that rapidly stabilizes performance (e.g., reductions in movement error) over the first few dozen trials (47), fifty practice trials were deemed sufficient to achieve stable controller use. Further details regarding target speeds, movement directions, escape point positions, practice procedures, and the scoring system are provided in the Appendix 1.

Figure 3. Virtual reality environment used in the interception task. (A) View presented to the participant through the head-mounted display. (B) Bird's-eye view of the virtual scene showing the positions of the participant, target, and possible escape points.

Table 1. Trial outcomes and corresponding point values in the interception task.
In addition to the scoring system, performance was also quantified based on Signal Detection Theory (48), using hit rate, false alarm rate, sensitivity index (d′), and decision criterion (c). The hit rate was calculated as the proportion of signal-present trials in which the participant correctly identified the presence of a signal (i.e., number of hits divided by the number of signal-present trials). The false alarm rate was defined as the proportion of signal-absent trials in which the participant incorrectly responded as if a signal were present (i.e., number of false alarms divided by the total number of signal-absent trials). The sensitivity index d′ was calculated using the following formula (49):
A higher d′ value indicates greater discriminability in decision-making. For example, frequent misjudgments, such as attempting to pursue an uncatchable target (i.e., a “Go” response on a signal-absent trial) or failing to pursue a catchable target (i.e., a “No-go” response on a signal-present trial), would result in a lower d′ value.
The decision criterion (c) quantifies a participant's response bias. Whereas d′ value reflects the ability to discriminate between signal and noise, c indicates the tendency to respond conservatively or liberally to the presence of a signal. The decision criterion was calculated using the following formula:
Lower c values reflect a more liberal response bias, indicating that the participant is more likely to judge a signal as present based on limited evidence, which increases the likelihood of false alarms. In contrast, higher c values indicate a more conservative bias, making the participant less likely to respond to the presence of a signal, increasing the likelihood of misses. A c value close to zero indicates a neutral decision criterion with minimal response bias.
Evaluation task (c): VR road-crossing task
A road-crossing task was developed in a VR environment based on the experimental design of Stafford et al. (37), with the primary objective of evaluating the accuracy of participants' road-crossing decisions. The VR environment was designed to realistically replicate a typical Japanese urban street (Figure 4). In this task, participants observed the gaps between five passing vehicles and determined whether they could safely cross the road at their normal walking speed. The size of each gap was determined based on each participant's pre-measured walking speed. Gap sizes were individually adjusted so that one of the gaps was crossable, while the remaining seven gaps were non-crossable gaps. Participants needed to physically cross the virtual road at their normal walking speed while being immersed in a VR environment. Participants were allowed to increase their walking speed during crossing if a collision appeared imminent. If participants judged that the gaps were too narrow to cross safely, they were instructed to wait until the last vehicle had passed before crossing. Each participant performed a total of 15 trials.

Figure 4. (A) Virtual reality scene of a pedestrian crosswalk in a Japanese cityscape, including vehicles. (B) A participant performing the task, wearing a head-mounted display, accompanied by an experimenter to ensure safety during actual walking.
To assess decision accuracy, the percentage of trials in which participants correctly identified the crossable gap was calculated. Further details regarding the VR environment setup, vehicle speeds, inter-vehicle gap specifications, walking speed measurement procedures, and familiarization sessions are provided in the Appendix 1.
Training tasks
Training task (a): TTC estimation task (TE-group)
The TTC estimation task was developed based on a previous study (50–53). While seated and wearing the HMD, participants were instructed to estimate the time remaining until a target, approaching from the front, would arrive. Participants were required to press a button on the controller at the exact moment they judged that the TTC matched a pre-designated duration (1, 3, or 5 s), with the goal of minimizing estimation error.
The virtual environment used in this task was identical to that of the target-approach detection task (Figure 5, main task session). To ensure that participants relied solely on object expansion cues, the target approached directly from the front without any horizontal (lateral) movement. The initial distance between the participant and the target varied randomly between 40 and 80 m across trials. The target's approach speed also varied randomly across trials, ranging from 6.8–16.2 m/s (i.e., 24.48–58.32 km/h). The target began moving directly toward the participant following a verbal cue from the experimenter. Immediately after the participant pressed the button, feedback indicating the TTC estimation error was displayed on the screen. Upon confirming the feedback, the participant received a cue from the experimenter to proceed to the next trial. The three TTC conditions (1, 3, and 5 s) were randomized every 10 trials, with the designated TTC duration verbally announced before each block. The current TTC condition was also displayed at the top center of the screen throughout each trial. Participants completed multiple 60-trial blocks within an approximately 60-minute training period, with rest periods provided as needed based on individual fatigue.
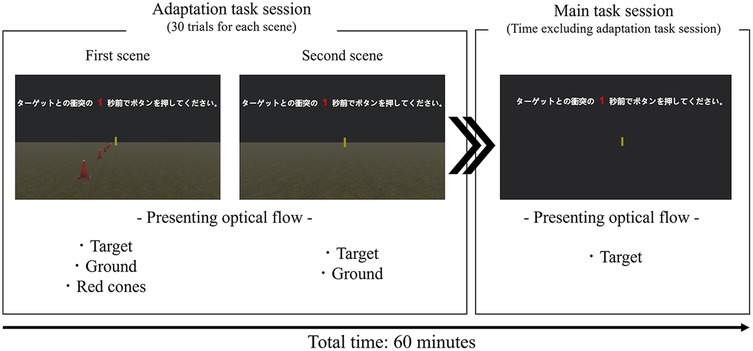
Figure 5. Virtual reality scene used in the TTC-estimation task for the TE-group. The image shows the gradual reduction of visual information (optical flow) from the adaptation task session to the main task session. The total time for the adaptation task session and the main task session was approximately 60 min.
Given concerns that detecting object expansion without background cues might be too difficult for older adults, an adaptation task session using two different scenes was performed prior to the main task session. Initiating the TTC estimation task with some additional visual cues was expected to facilitate participants' adaptation to the task (see Figure 5: Adaptation task session). In the first scene, the target was presented against a black background on a green surface. Additionally, red cones were placed every 5 meters to enhance the perception of optical flow. In the second scene, the target remained on the green surface but without the red cones, thereby emphasizing reliance on object expansion cues for TTC estimation. By gradually removing visual cues such as the red cones during the adaptation phase, a smooth transition was provided to the training environment in which the participants ultimately depended solely on object expansion. Participants completed a total of 30 trials, comprising 10 trials for each of the predetermined TTC conditions (1, 3, or 5 s).
Training task (b): interception task (IC-group)
The interception task used for training in the IC-group was identical to that employed during the evaluation phase. The visual environment, difficulty settings, and task rules were all held constant. Participants were instructed to maximize their total score over 30 trials. The current score was continuously displayed at the top of the screen during each trial. Total scores were calculated at the end of each 30-trial block, and the score was reset at the start of each new block. Participants performed multiple 30-trial blocks within an approximately 60-minute training period, with rest periods provided based on individual fatigue.
Data analysis
The dependent variables were as follows: target detection time from the target-approach detection task; score and signal detection measures (hit rate, false alarm rate, d′ value, and c) from the interception task; and decision accuracy from the road-crossing task. For each outcome variable, a two-way repeated measures ANOVA was calculated, with Session (pre, post) as the within-subjects factor and Group (TE-group, IC-group) as the between-subjects factor. In addition to p-values, we also reported partial eta squared (partial η2). All statistical analyses were conducted using IBM SPSS Statistics for Windows, version 27.0 (IBM Corp., Armonk, NY, USA), with the significance level set at p ≤ .05.
Results
Target-approach detection task
Mean detection times for each group in the pre- and post-evaluation sessions are shown in Figure 6. No significant main effects were observed for Session (F1,18 = .042, p = .840, partial η2 = .002) or Group (F1,18 = .162, p = .692, partial η2 = .009). The interaction between Session and Group was also not significant (F1,18 = .208, p = .654, partial η2 = .011).
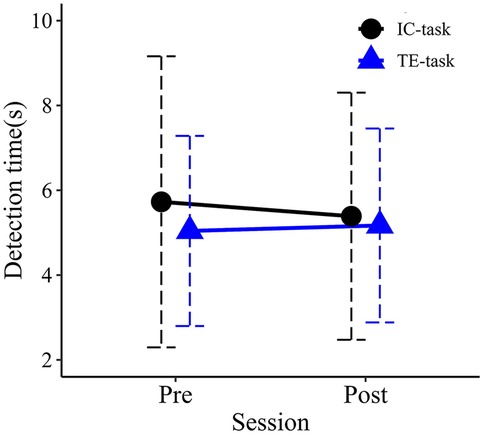
Figure 6. Mean detection times in the pre- and post-training. Error bars represent standard deviations.
Interception task
Mean performance scores for each group in the pre- and post-evaluation sessions are shown in Figure 7. An ANOVA revealed a significant main effect for Session (F1,18 = 21.693, p < .001, partial η2 = .547), with higher performance scores observed in the post-evaluation session compared to the pre-evaluation session. The main effect of Group was not significant (F1,18 = .322, p = .577, partial η2 = .018), nor was the Session × Group interaction (F1,18 = .000, p = .991, partial η2 = .000).
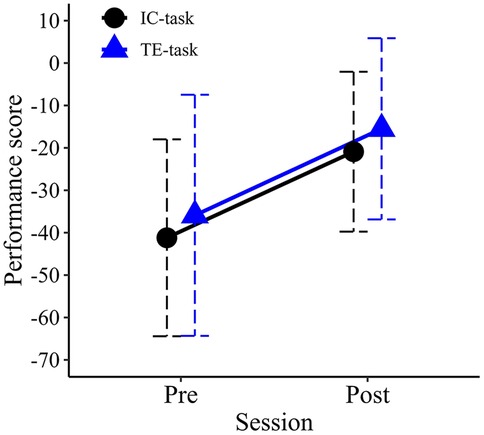
Figure 7. Mean performance scores in the pre- and post-training sessions. Error bars represent standard deviations.
Mean hit rates for each group in the pre- and post-evaluation sessions are shown in Figure 8. No significant main effects were observed for Session (F1,18 = .926, p = .349, partial η2 = .049) or Group (F1,18 = .000, p = .982, partial η2 = .000). The interaction between Session and Group was also not significant (F1,18 = 1.424, p = .248, partial η2 = .073).
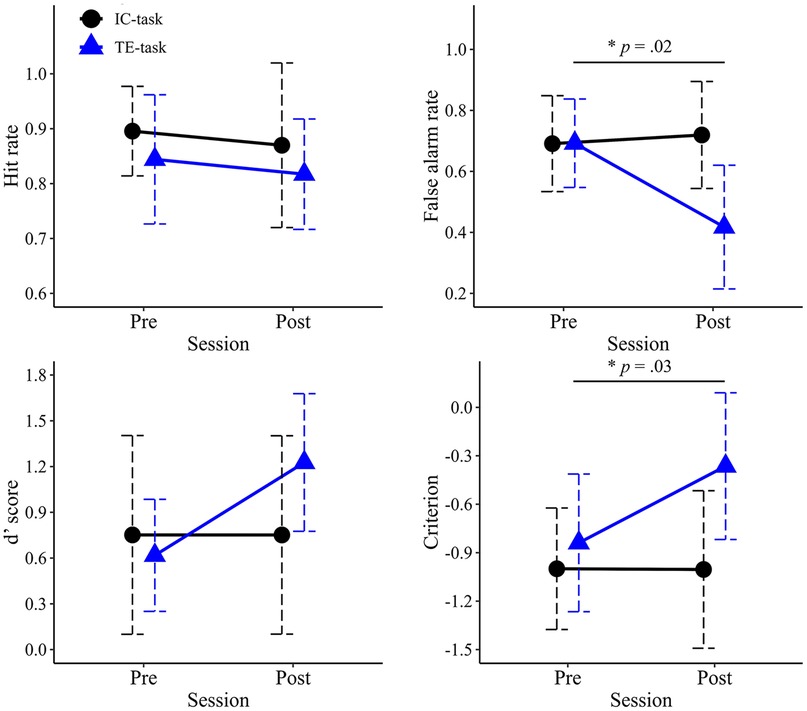
Figure 8. Mean values of signal detection theory measures in the pre- and post-training sessions. The upper left panel shows mean hit rate, the upper right shows mean false alarm rate, the lower left shows the mean d′ value, and the lower right shows the mean criterion. Error bars represent standard deviations.
Mean false-alarm rates for each group in the pre- and post-evaluation sessions are shown in Figure 8. A two-way ANOVA revealed a significant main effect of Session (F1,18 = 7.059, p = .016, partial η2 = .282), with lower false-alarm rates observed in the post-evaluation session compared to the pre-evaluation session. A significant main effect of Group was also found (F1,18 = 6.057, p = .024, partial η2 = .252), with the TE-group exhibiting significantly lower false-alarm rates than the IC-group. The interaction between Session and Group was significant (F1,18 = 10.688, p = .004, partial η2 = .373). post hoc comparisons indicated that the simple main effect of Group was significant only in the post-evaluation session (F1,18 = 6.057, p = .024, partial η2 = .252), where the TE-group demonstrated significantly lower false-alarm rates than in the IC-group.
Mean d′ values for each group in the pre- and post-evaluation sessions are shown in Figure 8. No significant main effects were observed for Session (F1,18 = 2.966, p = .102, partial η2 = .141) or Group (F1,18 = 1.036, p = .322, partial η2 = .054). The interaction between Session and Group was also not significant (F1,18 = 2.971, p = .102, partial η2 = .142).
Mean criterion values for each group in the pre- and post-evaluation sessions are shown in Figure 8. A two-way ANOVA revealed a significant main effect of Session (F1,18 = 5.775, p = .027, partial η2 = .243), with significantly higher values observed in the post-evaluation session compared to the pre-evaluation session. The main effect of Group was also significant (F1,18 = 5.565, p = .030, partial η2 = .236). The interaction between Session and Group was significant (F1,18 = 5.992, p = .025, partial η2 = .250). post hoc comparisons indicated that the simple main effect of Group was significant only at the post-evaluation session (F1,18 = 5.565, p = .030, partial η2 = .236), where the TE-group exhibited significantly higher c values than the IC-group.
Road crossing task
Mean correct rates for each group in the pre- and post-evaluation sessions are shown in Figure 9. No significant main effects were observed for Session (F1,18 = 0.022, p = .883, partial η2 = .001) or Group (F1,18 = 0.699, p = .414, partial η2 = .037). The interaction between Session and Group was also not significant (F1,18 = 0.323, p = .527, partial η2 = .018).
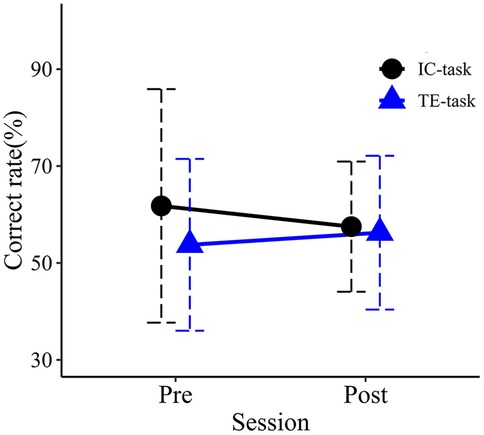
Figure 9. Mean correct rates in the pre- and post-training sessions. Error bars represent standard deviations.
Discussion
This study examined whether a TTC estimation task designed to enhance sensitivity to object expansion would be more effective in improving collision prediction ability in older adults than repeated practice of the collision prediction task (i.e., the interception task). The results showed that the TE-group exhibited significantly greater improvement in collision prediction performance compared to the IC-group. However, no improvements were observed in sensitivity to object expansion or in the accuracy of road-crossing decisions.
Several previous studies have demonstrated the effectiveness of perceptual training in older adults (54–60). For example, Andersen et al. (56) reported that training with a texture discrimination task improved visual performance in older adults, suggesting that perceptual training may positively influence functional abilities such as driving and mobility. Consistent with these positive findings, the present results indicate that even abilities that decline with age can be enhanced through perceptual training.
Although collision prediction performance and the accuracy of TTC estimation improved significantly following 60 min of training (see Figure 10), sensitivity to object expansion did not show a significant change. These findings suggest that, contrary to our initial hypothesis, the observed improvements in performance cannot be attributed to increased sensitivity to object expansion. Other factors, such as shifts in decision-making biases or the optimization of cognitive strategies, may have contributed to the improvement observed in collision prediction ability. Previous studies have shown that performance improvements in perceptual tasks can result not only from improvements in sensory processing but also from modifications in decision-making biases (25, 26, 61, 62). For example, Diaz et al. (61) demonstrated that training on a visual categorization task, where participants needed to judge whether noisy images depicted a face or a car, increased neural activity associated more with decision-making than with sensory processing. Similarly, Jones et al. (63) observed a strong correlation between performance improvement in perceptual tasks and reductions in response bias, highlighting the importance of bias control as a key element in perceptual learning (63). In this study, although sensitivity to object expansion did not improve, participants also exhibited reduced judgment bias in the interception task (i.e., improvement in c). Taken together, the observed improvement in collision prediction performance may have been rooted in learning mechanisms related to decision-making and response optimization, rather than in perceptual sensitivity improvement.
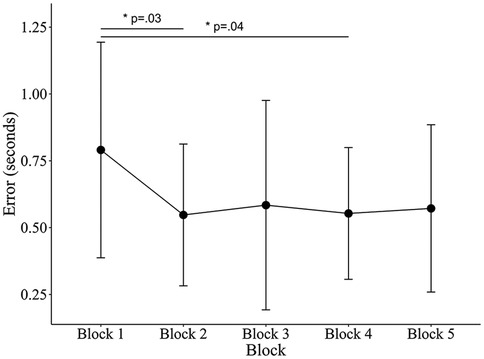
Figure 10. Mean TTC estimation errors across blocks. For each participant, total practice time was divided into five equal segments to account for individual differences in session length. Error bars represent standard deviations. Estimation errors were converted to absolute values. One-way ANOVA showed a significant effect of Block (F4, 45 = 3.18, p = .022, partial η2 = .22), indicating that Blocks 2 and 4 were lower than Block 1.
The absence of improvement in sensitivity to object expansion may be attributable to the limited duration of training. Since a previous study reported that the amount of training is not necessarily critical for learning effects (64) and another demonstrated the effectiveness of a short training session (57), the present study adopted a relatively short training duration (60 min) based on those findings. However, numerous previous studies reporting significant improvements in perceptual performance (55, 58, 65–69) employed training programs of longer duration and distributed over multiple days. It has been shown that spreading training over several days, rather than condensing it into a single session, facilitates memory consolidation during sleep and enhances learning outcomes (70). Based on these findings, future studies may benefit from implementing multi-session training protocols spread over several days while also accounting for the physical limitations of older participants. Such an approach may be more effective for enhancing perceptual sensitivity.
Although collision prediction performance improved in the interception task, no evidence of transfer was observed in the road-crossing task. In general, transfer of training is more likely when the training and real-world tasks are similar (71–74). In the present study, several factors differed among tasks, including attentional demands, situational awareness, psychological factors, and the involvement of actual locomotion. The nature of the visual information presented in the VR environment also differed substantially; for example, a single expanding target was used in the training task vs. multiple vehicles of varying sizes in the road-crossing task. These contextual mismatches may have limited the extent of transfer. Furthermore, the absence of a self-avatar in the VR road-crossing task may also have influenced the results. Presenting a self-avatar enhances presence (75) and improves spatial perception (76), providing a more ecologically valid visual environment. Moreover, because street crossing represents only one component of everyday mobility, it may be beneficial to examine generalization across other ecologically relevant locomotor tasks characterized by differing visual and motor loads.
This study has several limitations. First, we did not assess participant handedness, and all participants used the left-hand controller. Although we provided a practice session, several participants experienced difficulty with precisely controlling the joystick. Therefore, the performance scores in the interception task may have been affected, particularly among right-handed participants. Second, our methodology of using reaction times for evaluating sensitivity to object expansion can be influenced by a variety of factors other than perceptual sensitivity, including motor control, decision bias, and attentional capacity (77–79). As such, even if perceptual sensitivity to object expansion had improved slightly, it may not have been detected through reaction time alone. In addition, including catch (no-motion) trials would have revealed responses to non-events (i.e., false alarms), enabling a cleaner estimate of perceptual sensitivity independent of response bias. Future studies should include catch trials and more direct and sensitive measures, such as discrimination thresholds or neurophysiological assessments like event-related potentials [e.g., visual evoked potentials (VEPs)], to evaluate changes in sensitivity to object expansion more precisely. Third, this study measured the effects of training immediately after the post-assessment session, without examining long-term retention or real-world applicability. Future longitudinal studies are needed to determine how long the training effects persist. Fourth, the relatively small sample limits both generalizability and statistical power. Future studies should recruit larger and more demographically diverse samples. Finally, except for the road-crossing task, the VR tasks were conducted in abstract visual environments, which may limit generalizability.
Conclusion
The present study demonstrated that training with a TTC estimation task focused on object expansion effectively improved collision prediction performance in older adults. This finding suggests that age-related declines in collision prediction ability can be improved through perceptual training. However, no improvement was observed in sensitivity to object expansion, indicating that the observed enhancement in performance may be attributed to changes in decision-making processes or reductions in judgment bias rather than increased perceptual sensitivity. Furthermore, no improvement was found in road-crossing decisions, a more practical and complex task, suggesting limited transfer of learning to real-world situations. Future research should focus on developing practical training programs that can contribute to performance improvements in real-world situations.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by The Ethics Committee of Tokyo Metropolitan University (Approval No. H5-13). The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
KS: Data curation, Conceptualization, Validation, Methodology, Visualization, Investigation, Resources, Writing – review & editing, Formal analysis, Writing – original draft. TH: Supervision, Conceptualization, Project administration, Writing – review & editing, Methodology.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Andersen GJ, Enriquez A. Aging and the detection of observer and moving object collisions. Psychol Aging. (2006) 21(1):74–85. doi: 10.1037/0882-7974.21.1.74
2. Bian Z, Guindon AH, Andersen GJ. Aging and detection of collision events on curved trajectories. Accid Anal Prev. (2013) 50:926–33. doi: 10.1016/j.aap.2012.07.013
3. Pitta LSR, Quintas JL, Trindade IOA, Belchior P, Gameiro K, Gomes CM, et al. Older drivers are at increased risk of fatal crash involvement: results of a systematic review and meta-analysis. Arch Gerontol Geriatr. (2021) 95:104414. doi: 10.1016/j.archger.2021.104414
4. Wilmut K, Purcell C. Why are older adults more at risk as pedestrians? A systematic review. Hum Factors. (2022) 64(8):1269–91. doi: 10.1177/0018720821989511
5. Andersen GJ, Cisneros J, Saidpour A, Atchley P. Age-related differences in collision detection during deceleration. Psychol Aging. (2000) 15(2):241–52. doi: 10.1037//0882-7974.15.2.241
6. Andersen GJ, Kim RD. Perceptual information and attentional constraints in visual search of collision events. J Exp Psychol Hum Percept Perform. (2001) 27(5):1039–56. doi: 10.1037//0096-1523.27.5.1039
7. DeLucia PR, Braly AM, Savoy BR. Does the size-arrival effect occur with an active collision-avoidance task in an immersive 3D virtual reality environment? Hum Factors. (2023) 65(5):956–65. doi: 10.1177/00187208211031043
8. Markkula G, Uludag Z, Wilkie RM, Billington J. Accumulation of continuously time-varying sensory evidence constrains neural and behavioral responses in human collision threat detection. PLoS Comput Biol. (2021) 17(7):e1009096. doi: 10.1371/journal.pcbi.1009096
9. Rio KW, Rhea CK, Warren WH. Follow the leader: visual control of speed in pedestrian following. J Vis. (2014) 14(2):4. doi: 10.1167/14.2.4
10. Yan JJ, Lorv B, Li H, Sun HJ. Visual processing of the impending collision of a looming object: time to collision revisited. J Vis. (2011) 11(12):7. doi: 10.1167/11.12.7
11. Fajen BR, Warren WH. Visual guidance of intercepting a moving target on foot. Perception. (2004) 33(6):689–715. doi: 10.1068/p5236
12. Hardiess G, Hansmann-Roth S, Mallot HA. Gaze movements and spatial working memory in collision avoidance: a traffic intersection task. Front Behav Neurosci. (2013) 7:62. doi: 10.3389/fnbeh.2013.00062
13. Ni R, Andersen GJ. Detection of collision events on curved trajectories: optical information from invariant rate-of-bearing change. Percept Psychophys. (2008) 70(7):1314–24. doi: 10.3758/PP/70.7.1314
14. Ni R, Bian Z, Guindon A, Andersen GJ. Aging and the detection of imminent collisions under simulated fog conditions. Accid Anal Prev. (2012) 49:525–31. doi: 10.1016/j.aap.2012.03.029
15. Zhao H, Warren WH. Intercepting a moving target: on-line or model-based control? J Vis. (2017) 17(5):12. doi: 10.1167/17.5.12
16. Lenoir M, Musch E, Janssens M, Thiery E, Uyttenhove J. Intercepting moving objects during self-motion. J Mot Behav. (1999) 31(1):55–67. doi: 10.1080/00222899909601891
17. Hosking SG, Crassini B. The influence of optic expansion rates when judging the relative time to contact of familiar objects. J Vis. (2011) 11(6):20. doi: 10.1167/11.6.20
18. Francois M, Morice AH, Blouin J, Montagne G. Age-related decline in sensory processing for locomotion and interception. Neuroscience. (2011) 172:366–78. doi: 10.1016/j.neuroscience.2010.09.020
19. Sato K, Fukuhara K, Higuchi T. Age-related changes in the utilization of visual information for collision prediction: a study using an affordance-based model. Exp Aging Res. (2023) 50(5):800–16. doi: 10.1080/0361073X.2023.2278985
20. Fajen BR. Guiding locomotion in complex, dynamic environments. Front Behav Neurosci. (2013) 7:85. doi: 10.3389/fnbeh.2013.00085
21. Fajen BR. Affordance-based control of visually guided action. Ecol Psychol. (2007) 19(4):383–410. doi: 10.1080/10407410701557877
22. Steinmetz ST, Layton OW, Powell NV, Fajen BR. Affordance-based versus current-future accounts of choosing whether to pursue or abandon the chase of a moving target. J Vis. (2020) 20(3):8. doi: 10.1167/jov.20.3.8
23. Evans L, Champion RA, Rushton SK, Montaldi D, Warren PA. Detection of scene-relative object movement and optic flow parsing across the adult lifespan. J Vis. (2020) 20(9):12. doi: 10.1167/jov.20.9.12
24. Carmel D, Carrasco M. Perceptual learning and dynamic changes in primary visual cortex. Neuron. (2008) 57(6):799–801. doi: 10.1016/j.neuron.2008.03.009
25. Dosher B, Lu ZL. Visual perceptual learning and models. Annu Rev Vis Sci. (2017) 3:343–63. doi: 10.1146/annurev-vision-102016-061249
26. Sagi D. Perceptual learning in vision research. Vision Res. (2011) 51(13):1552–66. doi: 10.1016/j.visres.2010.10.019
27. Dommes A. Street-crossing workload in young and older pedestrians. Accid Anal Prev. (2019) 128:175–84. doi: 10.1016/j.aap.2019.04.018
28. Butler AA, Lord SR, Fitzpatrick RC. Perceptions of speed and risk: experimental studies of road crossing by older people. PLoS One. (2016) 11(4):e0152617. doi: 10.1371/journal.pone.0152617
29. Zivotofsky AZ, Eldror E, Mandel R, Rosenbloom T. Misjudging their own steps: why elderly people have trouble crossing the road. Hum Factors. (2012) 54(4):600–7. doi: 10.1177/0018720812447945
30. Zito GA, Cazzoli D, Scheffler L, Jager M, Muri RM, Mosimann UP, et al. Street crossing behavior in younger and older pedestrians: an eye- and head-tracking study. BMC Geriatr. (2015) 15:176. doi: 10.1186/s12877-015-0175-0
31. Dommes A, Cavallo V. The role of perceptual, cognitive, and motor abilities in street-crossing decisions of young and older pedestrians. Ophthalmic Physiol Opt. (2011) 31(3):292–301. doi: 10.1111/j.1475-1313.2011.00835.x
32. Dommes A, Cavallo V, Vienne F, Aillerie I. Age-related differences in street-crossing safety before and after training of older pedestrians. Accid Anal Prev. (2012) 44(1):42–7. doi: 10.1016/j.aap.2010.12.012
33. Oxley JA, Ihsen E, Fildes BN, Charlton JL, Day RH. Crossing roads safely: an experimental study of age differences in gap selection by pedestrians. Accid Anal Prev. (2005) 37(5):962–71. doi: 10.1016/j.aap.2005.04.017
34. Maillot P, Dommes A, Dang NT, Vienne F. Training the elderly in pedestrian safety: transfer effect between two virtual reality simulation devices. Accid Anal Prev. (2017) 99(Pt A):161–70. doi: 10.1016/j.aap.2016.11.017
35. Lobjois R, Cavallo V. The effects of aging on street-crossing behavior: from estimation to actual crossing. Accid Anal Prev. (2009) 41(2):259–67. doi: 10.1016/j.aap.2008.12.001
36. Nicholls VI, Wiener J, Meso AI, Miellet S. The impact of perceptual complexity on road crossing decisions in younger and older adults. Sci Rep. (2024) 14(1):479. doi: 10.1038/s41598-023-49456-9
37. Stafford J, Rodger M, Gomez-Jordana LI, Whyatt C, Craig CM. Developmental differences across the lifespan in the use of perceptual information to guide action-based decisions. Psychol Res. (2022) 86(1):268–83. doi: 10.1007/s00426-021-01476-8
38. Tang Q, Wang Y, Liu H, Liu Q, Jiang S. Experiencing an art education program through immersive virtual reality or iPad: examining the mediating effects of sense of presence and extraneous cognitive load on enjoyment, attention, and retention. Front Psychol. (2022) 13:957037. doi: 10.3389/fpsyg.2022.957037
39. Ros M, Debien B, Cyteval C, Molinari N, Gatto F, Lonjon N. Applying an immersive tutorial in virtual reality to learning a new technique. Neurochirurgie. (2020) 66(4):212–8. doi: 10.1016/j.neuchi.2020.05.006
40. Kuhrt D, St John NR, Bellmund JLS, Kaplan R, Doeller CF. An immersive first-person navigation task for abstract knowledge acquisition. Sci Rep. (2021) 11(1):5612. doi: 10.1038/s41598-021-84599-7
41. Ros M, Neuwirth LS, Ng S, Debien B, Molinari N, Gatto F, et al. The effects of an immersive virtual reality application in first person point-of-view (IVRA-FPV) on the learning and generalized performance of a lumbar puncture medical procedure. Educ Technol Res Dev. (2021) 69(3):1529–56. doi: 10.1007/s11423-021-10003-w
42. Folstein MF, Folstein SE, McHugh PR. “Mini-mental state”. A practical method for grading the cognitive state of patients for the clinician. J Psychiatr Res. (1975) 12(3):189–98. doi: 10.1016/0022-3956(75)90026-6
43. Crassini B, Brown B, Bowman K. Age-related changes in contrast sensitivity in central and peripheral retina. Perception. (1988) 17(3):315–32. doi: 10.1068/p170315
44. Owsley C. Aging and vision. Vision Res. (2011) 51(13):1610–22. doi: 10.1016/j.visres.2010.10.020
45. Braham Chaouche A, Silvestre D, Trognon A, Arleo A, Allard R. Age-related decline in motion contrast sensitivity due to lower absorption rate of cones and calculation efficiency. Sci Rep. (2020) 10(1):16521. doi: 10.1038/s41598-020-73322-7
46. Betts LR, Sekuler AB, Bennett PJ. The effects of aging on orientation discrimination. Vision Res. (2007) 47(13):1769–80. doi: 10.1016/j.visres.2007.02.016
47. Smith MA, Ghazizadeh A, Shadmehr R. Interacting adaptive processes with different timescales underlie short-term motor learning. PLoS Biol. (2006) 4(6):e179. doi: 10.1371/journal.pbio.0040179
48. Green DM, Swets JA. Signal Detection Theory and Psychophysics. New York: Wiley (1966). p. xi. 455 pages: illustrations p.
49. Randerath J, Frey SH. Diagnostics and training of affordance perception in healthy young adults-implications for post-stroke neurorehabilitation. Front Hum Neurosci. (2015) 9:674. doi: 10.3389/fnhum.2015.00674
50. Wessels M, Hecht H, Huisman T, Oberfeld D. Trial-by-trial feedback fails to improve the consideration of acceleration in visual time-to-collision estimation. PLoS One. (2023) 18(8):e0288206. doi: 10.1371/journal.pone.0288206
51. Pai D, Rolin R, Fooken J, Spering M. Time to contact estimation in virtual reality. J Vis. (2017) 17(10):417. doi: 10.1167/17.10.417
52. Hecht H, Brendel E, Wessels M, Bernhard C. Estimating time-to-contact when vision is impaired. Sci Rep. (2021) 11(1):21213. doi: 10.1038/s41598-021-00331-5
53. Rolin RA, Fooken J, Spering M, Pai DK. Perception of looming motion in virtual reality egocentric interception tasks. IEEE Trans Vis Comput Graph. (2019) 25(10):3042–8. doi: 10.1109/TVCG.2018.2859987
54. DeLoss DJ, Watanabe T, Andersen GJ. Optimization of perceptual learning: effects of task difficulty and external noise in older adults. Vis Res. (2014) 99:37–45. doi: 10.1016/j.visres.2013.11.003
55. Bower JD, Andersen GJ. Aging, perceptual learning, and changes in efficiency of motion processing. Vis Res. (2012) 61:144–56. doi: 10.1016/j.visres.2011.07.016
56. Andersen GJ, Ni R, Bower JD, Watanabe T. Perceptual learning, aging, and improved visual performance in early stages of visual processing. J Vis. (2010) 10(13):4. doi: 10.1167/10.13.4
57. DeLoss DJ, Bian Z, Watanabe T, Andersen GJ. Behavioral training to improve collision detection. J Vis. (2015) 15(10):2. doi: 10.1167/15.10.2
58. Bower JD, Watanabe T, Andersen GJ. Perceptual learning and aging: improved performance for low-contrast motion discrimination. Front Psychol. (2013) 4:66. doi: 10.3389/fpsyg.2013.00066
59. Berry AS, Zanto TP, Clapp WC, Hardy JL, Delahunt PB, Mahncke HW, et al. The influence of perceptual training on working memory in older adults. PLoS One. (2010) 5(7):e11537. doi: 10.1371/journal.pone.0011537
60. Erbes S, Michelson G. Stereoscopic visual perceptual learning in seniors. Geriatrics (Basel). (2021) 6(3):94. doi: 10.3390/geriatrics6030094
61. Diaz JA, Queirazza F, Philiastides MG. Perceptual learning alters post-sensory processing in human decision-making. Nat Hum Behav. (2017) 1(2):0035. doi: 10.1038/s41562-016-0035
62. Sasaki Y, Nanez JE, Watanabe T. Advances in visual perceptual learning and plasticity. Nat Rev Neurosci. (2010) 11(1):53–60. doi: 10.1038/nrn2737
63. Jones PR, Moore DR, Shub DE, Amitay S. The role of response bias in perceptual learning. J Exp Psychol Learn Mem Cogn. (2015) 41(5):1456–70. doi: 10.1037/xlm0000111
64. Song Y, Chen N, Fang F. Effects of daily training amount on visual motion perceptual learning. J Vis. (2021) 21(4):6. doi: 10.1167/jov.21.4.6
65. Gabriel GA, Harris LR, Henriques DYP, Pandi M, Campos JL. Multisensory visual-vestibular training improves visual heading estimation in younger and older adults. Front Aging Neurosci. (2022) 14:816512. doi: 10.3389/fnagi.2022.816512
66. Yotsumoto Y, Chang LH, Ni R, Pierce R, Andersen GJ, Watanabe T, et al. White matter in the older brain is more plastic than in the younger brain. Nat Commun. (2014) 5:5504. doi: 10.1038/ncomms6504
67. Legault I, Allard R, Faubert J. Healthy older observers show equivalent perceptual-cognitive training benefits to young adults for multiple object tracking. Front Psychol. (2013) 4:323. doi: 10.3389/fpsyg.2013.00323
68. Mishra J, Rolle C, Gazzaley A. Neural plasticity underlying visual perceptual learning in aging. Brain Res. (2015) 1612:140–51. doi: 10.1016/j.brainres.2014.09.009
69. Li X, Allen PA, Lien MC, Yamamoto N. Practice makes it better: a psychophysical study of visual perceptual learning and its transfer effects on aging. Psychol Aging. (2017) 32(1):16–27. doi: 10.1037/pag0000145
70. Larcombe SJ, Kennard C, Bridge H. Time course influences transfer of visual perceptual learning across spatial location. Vis Res. (2017) 135:26–33. doi: 10.1016/j.visres.2017.04.002
71. Kahalani-Hodedany R, Lev M, Sagi D, Polat U. Generalization in perceptual learning across stimuli and tasks. Sci Rep. (2024) 14(1):24546. doi: 10.1038/s41598-024-75710-9
72. Barnett SM, Ceci SJ. When and where do we apply what we learn? A taxonomy for far transfer. Psychol Bull. (2002) 128(4):612–37. doi: 10.1037/0033-2909.128.4.612
73. Yashar A, Denison RN. Feature reliability determines specificity and transfer of perceptual learning in orientation search. PLoS Comput Biol. (2017) 13(12):e1005882. doi: 10.1371/journal.pcbi.1005882
74. Harris DJ, Bird JM, Smart PA, Wilson MR, Vine SJ. A framework for the testing and validation of simulated environments in experimentation and training. Front Psychol. (2020) 11:605. doi: 10.3389/fpsyg.2020.00605
75. Halbig A, Latoschik ME. The interwoven nature of spatial presence and virtual embodiment: a comprehensive perspective. Front Virtual Real. (2025):6:1616662. doi: 10.3389/frvir.2025.1616662
76. Creem-Regehr SH, Stefanucci JK, Bodenheimer B. Perceiving distance in virtual reality: theoretical insights from contemporary technologies. Philos Trans R Soc Lond B Biol Sci. (2023) 378(1869):20210456. doi: 10.1098/rstb.2021.0456
77. Starns JJ, Ma Q. Response biases in simple decision making: faster decision making, faster response execution, or both? Psychon Bull Rev. (2018) 25(4):1535–41. doi: 10.3758/s13423-017-1358-9
78. Dmochowski JP, Norcia AM. Cortical components of reaction-time during perceptual decisions in humans. PLoS One. (2015) 10(11):e0143339. doi: 10.1371/journal.pone.0143339
79. van Ede F, de Lange FP, Maris E. Attentional cues affect accuracy and reaction time via different cognitive and neural processes. J Neurosci. (2012) 32(30):10408–12. doi: 10.1523/JNEUROSCI.1337-12.2012
Appendix 1
Details of the evaluation tasks
A Target detection task
Before the main trials of the target detection task, participants completed two types of practice sessions. First, to familiarize participants with detecting the onset of target motion and pressing the response button, three practice trials were conducted using a clearly detectable target approaching at a high speed (300 cm/s). Second, to discourage premature button responses (i.e., responding before target motion onset), participants practiced withholding their response until they could clearly detect the target's approach. In this session, the target again approached at 300 cm/s. If the button was pressed while the target remained stationary, a beep sound was emitted to indicate an error. This practice was repeated, including trials with a stationary duration of 20 s, until the participant consistently refrained from premature responses.
B Interception task
The interception task was identical to that used in our previous study, with few modifications. Due to a change in the controller specifications, movement direction was no longer determined by the orientation of the HMD, as in our previous study. Instead, in the present study, directional control was implemented using the joystick on the handheld controller. To enhance the perception of optical flow during movement, a forested area was added within the escape zone, and the background was set to black to match the visual settings of the other tasks. Aside from these modifications, all other aspects of the task remained unchanged.
As shown in Figure 3, six escape points were positioned within the escape zone at 1.2-meter intervals. The time from the start signal to the moment the target reached the escape zone, referred to as the escape time, was set to one of five values: 2.3, 2.8, 3.3, 3.8, or 4.3 s. The target's approach angle ranged from 50° to 75°, and its speed varied randomly between 2.3 and 10.9 m/s. The target's initial position was randomized within the range defined by the combinations of speed and angle. Participants always started from a fixed position: 10 meters behind and 4 meters to the right of the nearest escape point. Movement direction was determined by the joystick on the left-hand controller, and the “Give Up” response was triggered by pressing the trigger button on the back of the controller. Movement speed was also controlled by joystick tilt, ranging from 0 to 4.5 m/s. In 43.3% of the trials, the target was programmed to be uncatchable, meaning that even with an ideal reaction and trajectory, interception was not possible.
Regarding the scoring system, participants received +10 points for a successful interception, which was defined as reaching the target at a distance of 1.05 meters or less (defined as a “Catch”). If the target reached the escape zone first, then participants lost 2 points (defined as a “Miss”). In cases where participants abandoned pursuit either after initiating movement (defined as “Give-up”) or without initiating movement (defined as “No-go”), the base score was 0. In addition, participants incurred a movement cost, with 0.5 points deducted for every 0.5 meters travelled.
Before the pre-evaluation session, participants completed a practice block to ensure their full understanding of the task and establish proficient control of the left-hand controller (button press and joystick operation). Each participant was first required to successfully intercept the target in at least 10 practice trials, confirming appropriate operation of the controller. In addition, participants were also required to demonstrate an understanding of the No-go concept and verify proper use of the controller's response button by refraining from pursuing clearly uncatchable targets in 10 trials. Only after confirming that participants had adequately understood the task rules did participants complete a 30-trial preliminary block to familiarize themselves with the scoring system. The main evaluation then commenced.
C Road-crossing task
In this experiment, the time required for participants to safely cross between vehicles was estimated by calculating a “minimum crossing time” based on both the crossing distance and each participant's pre-measured walking speed. Although the total width of the road was 4.3 m, only the first 2.15 m of that space constituted the vehicle travel lane and posed a collision risk. Furthermore, an additional 0.3 m was added to account for the participant's body width, resulting in a final crossing distance of 2.45 m that is used in the calculation. The minimum crossing time was determined by dividing this 2.45 m distance by their normal walking speed. A 1.5-second safety margin was then added to this minimum crossing time. The sum of the minimum crossing time and this margin was then multiplied by vehicle speed, which was randomly set between 40 and 60 km/h. This calculation yielded the final distance defining a “crossable gap.” One of the four gaps was randomly designated as the crossable gap. In contrast, for uncrossable gaps, a randomly selected time of 0.3–0.6 s was subtracted from the participant's previously calculated minimum crossing time.
To facilitate walking in the VR environment, participants first practiced crossing a road several times in a vehicle-free setting. Following this familiarization phase, participants completed three road-crossing trials to measure their normal walking speed, which was calculated using the HMD's positional tracking data. Among the three trials, the fastest walking speed was selected and used as the basis for configuring individual gap timings in the main task. Given the potential risks associated with the road-crossing task, such as tripping, falling, or VR-induced discomfort, an experimenter accompanied each participant throughout the task to ensure their safety.
Keywords: collision prediction, perceptual training, virtual reality, object expansion, aging, interception, road-crossing
Citation: Sato K and Higuchi T (2025) Enhancing collision prediction in older adults via perceptual training in virtual reality emphasizing object expansion. Front. Sports Act. Living 7:1652911. doi: 10.3389/fspor.2025.1652911
Received: 25 June 2025; Accepted: 20 October 2025;
Published: 4 November 2025.
Edited by:
Pietro Picerno, University of Sassari, ItalyReviewed by:
Lorenz S. Neuwirth, State University of New York at Old Westbury, United StatesCristiane Kauer Brazil, Kansas State University Olathe, United States
Copyright: © 2025 Sato and Higuchi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Takahiro Higuchi, aGlndWNoaXRAdG11LmFjLmpw
†ORCID:
Kazuyuki Sato
orcid.org/0009-0003-5020-2460
Takahiro Higuchi
orcid.org/0000-0002-1989-736X