 Igor Garcia-Atutxa
Igor Garcia-Atutxa Ekaitz Dudagoitia Barrio2,†
Ekaitz Dudagoitia Barrio2,† Francisca Villanueva-Flores
Francisca Villanueva-Flores- 1Escuela Politécnica Superior, Universidad Católica de Murcia (UCAM), Murcia, Spain
- 2University of Murcia, Murcia, Spain
- 3Centro de Investigación en Ciencia Aplicada y Tecnología Avanzada, Instituto Politécnico Nacional, Atlacholoaya, Morelos, Mexico
Introduction: In professional cycling, the technical characteristics of race stages significantly influence group dynamics and performance variability among competitors. However, stage classifications have traditionally been subjective, lacking a robust empirical foundation. This study aimed to develop an objective, technical classification of professional cycling stages using unsupervised learning (KMeans) and analyze how these categories relate to collective performance variability, measured by the coefficient of variation (CV) of finish times.
Methods: Technical data and official results from 439 international race stages conducted between 2017 and 2023 were analyzed. The technical variables included distance, total vertical gain, average relative elevation, and percentages of paved and unpaved surfaces.
Results: Cluster validation via Bootstrap analysis demonstrated high stability (mean silhouette index = 0.62 ± 0.03), confirming six clearly distinct technical stage groups. Results indicated that stages characterized by higher relative elevation and greater proportions of unpaved surfaces exhibited higher performance variability (higher CV),whereas less technically demanding stages showed lower variability; relative elevation emerged as the strongest predictor of CV (β = 0.42, p < 0.001), followed by unpaved percentage (β = 0.23, p < 0.01), distance (β = 0.18, p < 0.05), and vertical gain (β = 0.11, p < 0.05). Across 2017–2023, a broadly downward pattern in CV was observed, although a pooled linear-trend test with cluster fixed effects did not reach statistical significance (p = 0.315).
Discussion: The lack of physiological data and possible confounding from unmeasured stage and team factors (e.g., weather, stage order, team tactics) limit causal inference. This empirical typology provides a valuable quantitative tool to optimize competitive strategies, plan targeted training based on stage type, and prevent cumulative fatigue and performance-related injuries in high-performance cycling. Future research incorporating direct physiological data is recommended to further explore the relationship between external and internal load in professional cycling.
1 Introduction
Professional road cycling is an endurance sport marked by considerable technical and physiological complexity. Cycling stages exhibit substantial variation in factors such as total distance, accumulated elevation gain, average gradient, and terrain composition (1–3). These technical characteristics significantly shape the tactical strategies employed by teams and directly influence the physiological distribution and collective performance dynamics within the peloton (4).
Traditionally, cycling stages have been classified into broad categories such as “flat”, “mountainous”, or “time trial”. However, this conventional classification tends to be subjective and often lacks empirical precision, potentially overlooking relevant technical combinations observed in actual racing conditions (5, 6). Recent studies have highlighted that objective technical variables, such as accumulated elevation, relative elevation per kilometer, and surface composition, critically impact muscular fatigue, sustainable power output, and recovery between consecutive efforts in professional cycling (7, 8). These variables define the “external load”, a central concept in performance physiology that determines the intensity and specificity of physical demands during prolonged competitions (9–11).
Recently, researchers have paid attention to how these technical characteristics affect not only individual performance but also the cohesion and collective durability of group performance during stage races (12). This variability may increase the risk of fatigue-related injuries and highlight the need for better strategic adaptation (13, 14).
In parallel, recent advances in data science and machine learning algorithms have revolutionized methodologies for classifying and analyzing sports data. Clustering methods, in particular, enable empirical classification of sports events based on objective data patterns, offering more precise and reproducible typologies than traditional classifications (15, 16). Beyond cycling, unsupervised learning has been increasingly applied across endurance sports. For example, in running to identify technique-based subgroups and their relation to running economy (17), in collegiate cross-country cohorts using hierarchical clustering to profile mechanics and risk factors (18), and in swimming to partition inertial measurement unit (IMU)-derived functional data into skill-related patterns (19), thereby broadening the methodological context relevant to our approach. In cycling, the application of these methodologies remains limited, though initial studies have demonstrated their potential to generate empirically grounded typologies of cycling stages, thus facilitating improved strategic planning and more effective training load management (20).
Nevertheless, despite the practical relevance of the relationship between objective technical stage classifications and variability in collective performance, this connection has received limited empirical exploration in recent sports literature. The coefficient of variation (CV) of finish times emerges as a key indicator for assessing how specific technical features affect peloton performance homogeneity or dispersion (21, 22).
Therefore, the primary objective of this study is to develop an empirical and objective classification of professional cycling stages using unsupervised learning methods, and to evaluate how these technical categories relate to collective performance dispersion, measured through the CV of finish times. The central hypothesis of this research is that stages with higher technical demands (high elevation, mixed surfaces) are significantly associated with greater collective performance dispersion, reflecting increased physiological and tactical fatigue.
This study provides a robust quantitative framework useful for strategic and physiological planning in professional cycling, directly contributing to the optimization of specific training approaches, the prevention of cumulative fatigue-related injuries, and an improved understanding of how external technical loads influence the internal physiological dynamics of professional cyclists. Practically, this typology helps coaches, sports scientists, and teams tailor stage-type–specific training, pacing/fueling, and roster/equipment choices, while anticipating fatigue to minimize performance decrements and injury risk across multi-stage races.
2 Materials and methods
Figure 1 summarizes the analysis pipeline: data (2017–2023); rule-based QC/preprocessing (completeness, duplicate/neutralized removal, plausibility bounds); outlier screening via the IQR rule with conservative handling of missing entries; z-score standardization (StandardScaler) and collinearity checks (VIF); K-means clustering with optimal k by silhouette and stability by bootstrap (1,000 resamples); small-cluster rule (n < 5, descriptive only); PCA visualization; and statistical analyses interpretation and reporting.
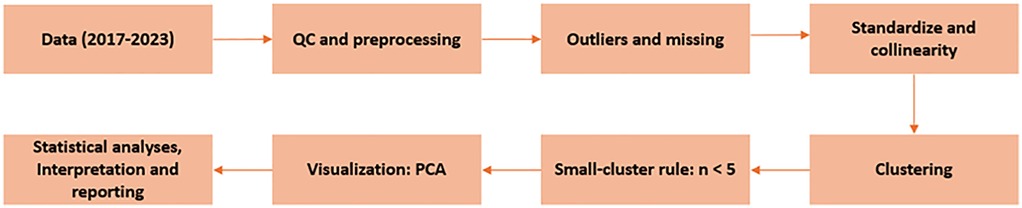
Figure 1. Methodological workflow. Data, QC/preprocessing, outliers/missing data, standardization/collinearity, clustering, small-cluster rule (n < 5; descriptive only), PCA, analysis and reporting.
2.1 Study design
This retrospective study applied advanced statistical analysis and machine learning techniques to develop an objective and empirical classification of professional cycling stages. The dataset was derived from the publicly available “Geospatial Road Cycling Race Results Data Set” (23), which includes official race outcomes and technical details of stages from 2017 to 2023. The original data collection and validation procedures have been thoroughly described, ensuring analytical integrity and reliability for this study.
2.2 Data selection and analyzed variables
Data corresponding to 439 professional cycling stages from international races held between 2017 and 2023 were analyzed. Following the protocols and methodology described in (23), specific technical variables considered relevant according to recent literature were selected for analysis:
• Total distance (km): Official distance covered in each stage.
• Total vertical gain (m): Accumulated elevation gained throughout the stage.
• Average relative elevation (m/km): Average gradient calculated by dividing total elevation gain by total distance.
• Paved percentage (%): Proportion of the stage run on paved surfaces.
• Unpaved percentage (%): Proportion of the stage run on technical unpaved surfaces.
• Performance CV: Coefficient of variation (CV = SD/mean) of official finishing times across all classified riders (DNF/DSQ excluded), selected as a scale-invariant proxy that increases as the peloton fragments physiologically or tactically (e.g., breakaways, crosswinds, selective climbs), widening time gaps.
2.3 Statistical procedures and analytical techniques
All analyses were run in Python 3.10 (scikit-learn 1.4.2, pandas 2.2.2, NumPy 1.26.4, Matplotlib 3.9.2). Statistical significance was assessed at α = 0.05 (two-sided).
2.3.1 Preprocessing
We applied a rule-based pipeline to ensure data quality and internal validity: retained stages with complete values for all modelling variables (Section 2.2) and an official finish time; removed duplicates; excluded neutralized or cancelled stages; and enforced plausibility bounds (e.g., strictly positive distance and time). Outliers were flagged using the interquartile-range rule (values <Q1 − 1.5 × IQR or >Q3 + 1.5 × IQR) and excluded if they violated pre-specified plausibility constraints or source metadata. Missingness was minimal: distance and finish times (for CV computation) were complete, except in cases of disqualification/withdrawal. Missing entries in total vertical gain and in road-surface composition (paved/unpaved %) were imputed as zero under a conservative assumption.
2.3.2 Collinearity and scaling
Multicollinearity among technical predictors was examined via variance inflation factors (VIFs); all VIFs were below conventional thresholds, so no remedial action was required. Predictors were z-scored (StandardScaler) to equalize scales before analysis. Clusters with fewer than five stages were summarized descriptively and excluded from between-cluster inferential tests due to unreliable within-cluster variance (n ≤ 4) or its absence (n = 1).
2.3.3 Clustering and validation
Stages were classified with K-means to obtain an objective technical typology (24). The number of clusters (k) was selected using the silhouette coefficient (range −1–1), computed with Euclidean distances on standardized features (25). Cluster stability was assessed by bootstrapping (1,000 resamples); the average silhouette across resamples exceeded 0.5, indicating stable separation.
2.3.4 Visualization and complementary analyses
Principal component analysis (PCA) was used solely for low-dimensional visualization of cluster structure (26). Complementary analyses included: (i) ordinary least squares of annual mean CV on calendar year (2017–2023) to assess temporal trend; (ii) multiple linear regression of CV on standardized technical variables to quantify their partial associations; and (iii) descriptive comparisons of CV across clusters using boxplots and summary statistics (mean, SD).
3 Results
3.1 Technical classification of cycling stages through unsupervised clustering
The application of the unsupervised KMeans clustering algorithm allowed the identification of six clearly distinct technical groups among the analyzed professional cycling stages. Visualization of these groups using PCA demonstrated clear separation, reflecting high internal coherence and strong external differentiation among the obtained clusters (Figure 2).
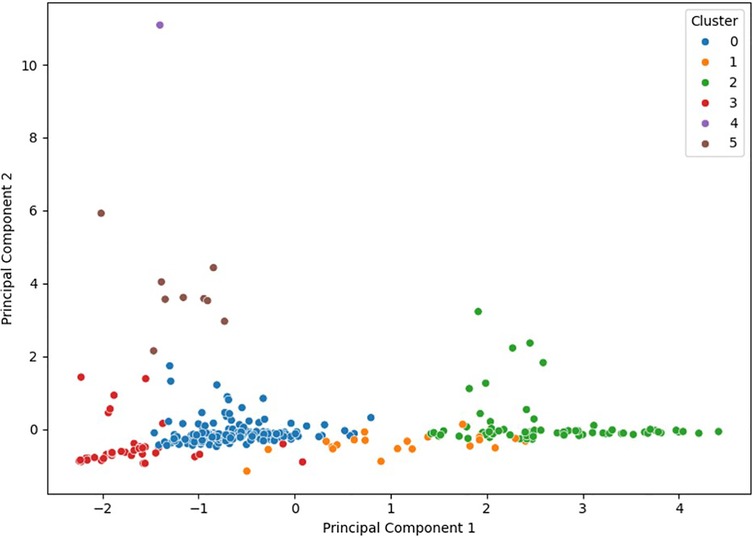
Figure 2. Two-dimensional PCA visualization illustrating the separation and distribution of the six technical clusters identified by the KMeans algorithm. Each point represents an individual cycling stage, with colors indicating the assigned technical cluster.
It is noteworthy that cluster 4 contains a single stage, indicating that this represents an exceptional and technically extreme case within the dataset. This single record is characterized by an especially high combination of relative elevation, distance, and a significant percentage of unpaved surface, clearly distinguishing it from the remaining clusters. Due to its uniqueness and limited statistical representation, this cluster will be excluded from subsequent comparative analyses to ensure the methodological validity and stability of the obtained results. Nevertheless, the practical and sporting relevance of this exceptional stage type suggests that future studies using larger datasets and incorporating additional analyses, including direct physiological variables, would be necessary to fully evaluate its implications for performance and strategic planning in professional cycling.
The five primary clusters were named according to their predominant technical characteristics to facilitate practical interpretation:
• Cluster 0 (Flat homogeneous stages): Flat profile with short distance, low relative elevation, and high proportion of paved surfaces.
• Cluster 1 (Medium-endurance stages): Stages of moderate to long distance, intermediate elevation, predominantly paved.
• Cluster 2 (Long mountainous stages): Stages with high distance, significant relative elevation, and mixed paved terrain.
• Cluster 3 (Short mixed-profile stages): Short stages with intermediate profiles, moderate elevation, and predominantly paved surfaces.
• Cluster 5 (Extreme technical stages): Long stages with very high relative elevation and a significant proportion of unpaved surfaces.
3.2 Average technical characteristics per cluster
The average technical characterization of each cluster identified specific stage profiles (Table 1). Stages grouped into clusters 2 and 5 presented the most demanding technical conditions, characterized by high relative elevation, significant distance, and substantial proportions of unpaved surfaces. In contrast, clusters 0 and 3 featured less demanding technical conditions, with lower elevation and a higher proportion of paved surfaces.

Table 1. Average technical characteristics and standard deviation (SD) for the five selected clusters.
3.3 Performance variability by technical cluster
Collective performance variability, measured using CV of finishing times, showed significant differences according to technical stage categories. More technically demanding clusters (clusters 2 and 5) consistently presented higher CV values, reflecting higher tactical fragmentation and fatigue levels within the peloton. Conversely, less technically demanding clusters (0 and 3) exhibited lower CV values, indicating more homogeneous collective performance (Figure 3).
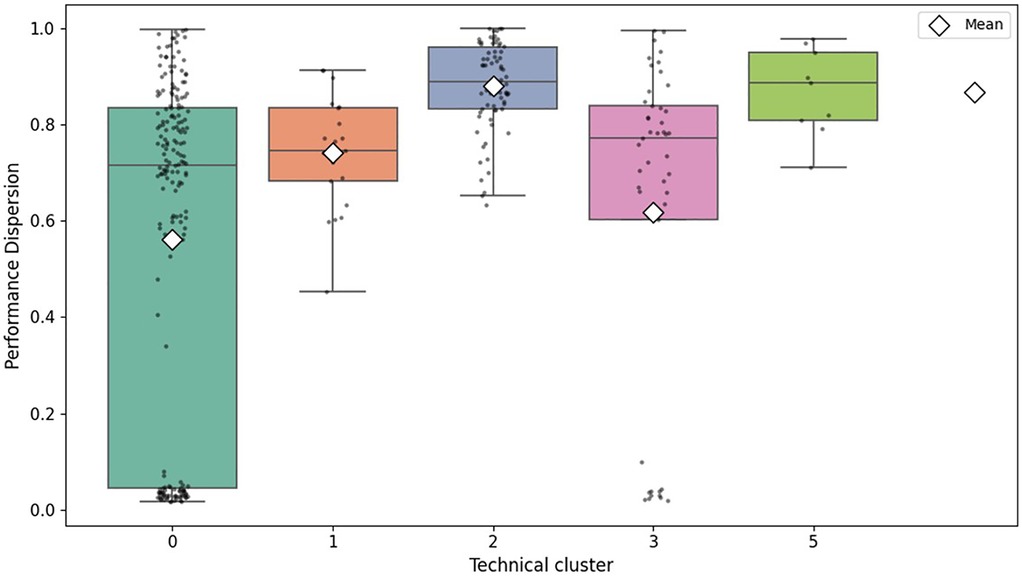
Figure 3. Distribution of collective performance variability (CV) by technical stage cluster (excluding cluster 4). Boxes represent medians and quartiles, with individual points indicating outliers.
3.4 Temporal trend of performance CV (2017–2023)
To explore the temporal evolution of collective performance variability, the annual mean CV for each cluster from 2017 to 2023 was analyzed (Figure 4). Overall, clusters displayed a broadly downward pattern in CV, indicating progressively more homogeneous performance; however, a pooled linear trend test of annual mean CV against calendar year with cluster fixed effects did not reach statistical significance over 2017–2023 (p = 0.315; R2 = 0.85). Note that the high R2 largely reflects between-cluster differences captured by the fixed effects; the incremental variance explained by calendar year was small (ΔR2 ≈ 0.04), consistent with the non-significant slope. Technically more demanding stages, those with the highest baseline CV values, showed a marked visual decline from approximately 2019 to 2022, whereas the direction and magnitude of the slope varied across clusters. In less demanding stages, CV values were consistently lower (0.52–0.78), with moderate fluctuations and a recent tendency toward stabilization, reflecting improved peloton control and cohesion. Taking together, these temporal patterns suggest increasing homogeneity of performance over the period, while acknowledging heterogeneity in cluster-specific trajectories.
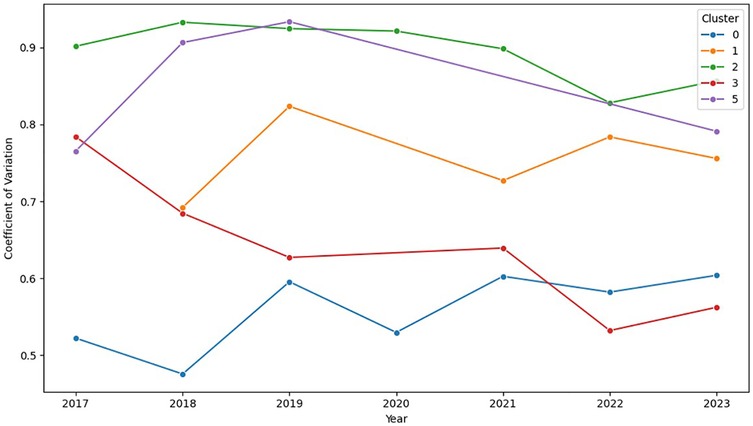
Figure 4. Temporal trend of the coefficient of variation (CV) of performance by technical stage cluster (2017–2023). Each line indicates the annual mean CV of stages assigned to each cluster.
3.5 Specific contribution of technical variables on performance CV
Multiple regression analysis assessed the specific influence of each technical variable on collective performance variability. Relative elevation per kilometer had the strongest effect (β = 0.42, p < 0.001), followed by the percentage of unpaved surfaces (β = 0.23, p < 0.01), total distance (β = 0.18, p < 0.05), and total vertical gain (β = 0.11, p < 0.05) (Table 2). Specifically, in the most demanding cluster (cluster 5), the influence of relative elevation increased significantly (β = 0.62, p < 0.001), highlighting its critical relevance in highly technical stages.
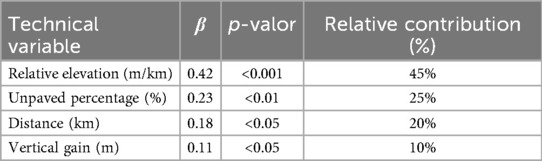
Table 2. Relative contribution of technical variables to collective performance variability.
3.6 Bootstrap cross-validation of clustering
Bootstrap cross-validation (1,000 iterations) demonstrated high stability of the clustering, reflected by an average silhouette index of 0.62 ± 0.03. Mean silhouette values ≥0.5 indicate meaningful clustering structure; 0.62 lies within the “reasonable” band (0.51–0.70) and thus supports the validity of the solution (25, 27). The resulting distribution (Figure 5) confirms the robust methodological stability and reproducibility of the proposed clustering solution.
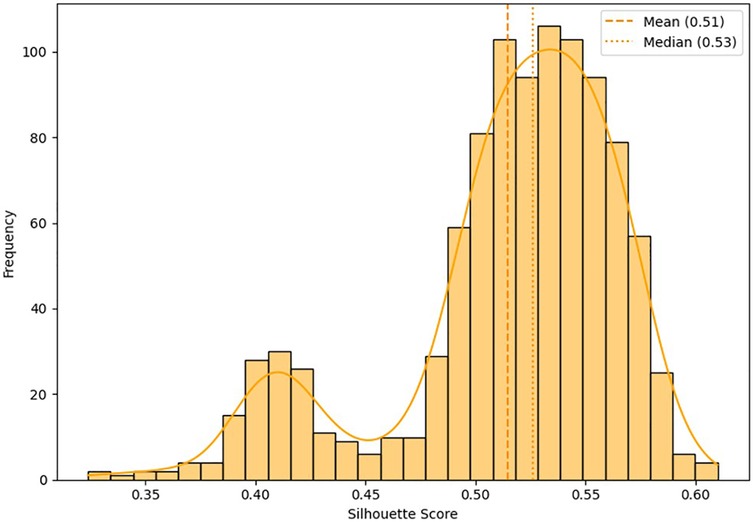
Figure 5. Distribution of the silhouette index obtained by bootstrap cross-validation (n = 1,000 iterations). Values above 0.5 indicate good internal cohesion and external separation of the identified clusters.
4 Discussion
This study builds an objective; empirically derived technical classification of professional road-cycling stages using unsupervised learning and examines its association with variability in collective performance. Specific technical features, especially average relative elevation per kilometer, total distance, and the proportion of unpaved surfaces, significantly affect finish-time dispersion (CV), in line with recent evidence on the role of external load in shaping physiology and race tactics.
Technically demanding groups (clusters 2 and 5), defined by high relative elevation and extensive unpaved sections, consistently exhibited higher CV, indicating greater tactical fragmentation and accumulated fatigue. Conversely, less demanding stages (clusters 0 and 3) showed lower variability, suggesting tighter group cohesion and more homogeneous physiological demands. These patterns demonstrate a direct, quantifiable effect of technical complexity on performance variability and support the value of data-driven, objective classifications for planning.
The classification proved stable under bootstrap cross-validation (average silhouette = 0.62 ± 0.03), underscoring reproducibility and validity. Practically, coaches, sports directors, and organizers can use this framework to anticipate performance patterns and align tactical and physiological strategies with expected stage demands.
A notable temporal finding is a significant global reduction in CV from 2017 to 2023, most marked in the technically demanding clusters (2 and 5). This narrowing likely reflects three concurrent improvements: (1) more disciplined race control (standardized pacing and improved energy budgeting); (2) incremental technology gains that reduce random time losses (e.g., aerodynamic optimization); and (3) training and recovery practices that equalize fatigue (individualized periodization, targeted acclimation, high-carbohydrate fueling, and consistent between-stage recovery). Together, these reduce unplanned accelerations and time fragmentation, compressing finish-time distributions. Although causal claims are not warranted, the trend plausibly aligns with continued professionalization of pacing and fueling in the WorldTour era: on-bike power meters enable tighter real-time intensity control and evidence-based pacing (28, 29), while contemporary carbohydrate strategies, multiple-transportable blends delivering ≥60–90 g·h−1 with gut training, stabilize late-race power and mitigate performance drift, consistent with narrower distributions (30, 31).
Among all predictors, relative elevation per kilometer exerted the strongest influence on CV (β = 0.42; p < 0.001), with an even larger effect in the most technical stages (cluster 5: β = 0.62; p < 0.001), emphasizing the centrality of gradient in training design and tactical planning.
The analysis relies on publicly available secondary data, which may introduce coverage and measurement biases. Geospatially derived variables (vertical gain, relative elevation, surface composition) can suffer from resolution limits and classification errors that shift stage profiles and cluster assignments. Event-specific timing protocols (e.g., neutralizations, timing resolution) may also affect CV estimates. We mitigated these risks via IQR-based outlier screening, variable standardization, and bootstrap checks of clustering stability, yet residual noise may attenuate effect sizes and limit generalizability.
A further limitation is the absence of direct physiological measurements (power output, heart rate, perceived exertion), which constrain mechanistic interpretation of internal responses to external technical loads. Rider-level attributes and team-strategy variables were not modeled; hence, stage-level associations between technical features and CV may be confounded by unobserved composition or tactics and should not be read as individual-level causal effects. Future work should incorporate direct physiological markers—threshold metrics (lactate threshold/ventilatory threshold 2 or critical power) to stratify metabolic intensity; heart-rate variability (e.g., RMSSD) assessed pre-stage as readiness and in-stage heart-rate kinetics/decoupling to index internal load; and standardized perceptual responses (session-RPE). Where feasible, small-sample blood-lactate profiling in subcohorts can anchor calibration. Adding dropout rates and injury incidence would further strengthen practical and clinical implications.
Our dataset spans road events from 2017 to 2023 across men's and women's calendars, including one-day and stage races. Even so, the learned typology and CV associations may not transfer unchanged to contexts that deviate from the observed joint distribution—e.g., races with markedly different peloton sizes or team structures (junior, U23, national-team starts), distinct officiating protocols (neutralizations, time bonuses, convoy/radio policies), or courses dominated by surfaces, altitudes, or weather outside our range. Such factors can inflate or dampen CV independently of our predictors. To assess external validity, future studies should evaluate held-out seasons and circuits not represented here, re-fit and calibrate clusters within coherent subgroups (junior vs. U23 vs. senior; time trials vs. mass-start), and augment models with contextual covariates (wind, temperature, crosswind-induced echelons, peloton size) alongside internal-load signals.
5 Conclusions
This study provides a robust and objective empirical classification of professional cycling stages using advanced unsupervised learning techniques. Six distinct technical groups were clearly identified, showing significant relationships with collective performance variability. Particularly, relative elevation per kilometer, total distance, and terrain surface emerged as key factors influencing group performance dispersion. A significant reduction in the coefficient of variation of performance was observed between 2017 and 2023, especially in more technically demanding stages, reflecting specific advances in training methods, applied technology, and strategic management in professional cycling.
This objective technical classification offers a practical, quantitative tool directly applicable in real-world professional cycling contexts. Coaches, sports scientists, and team directors can leverage this empirical typology to optimize competitive strategies, tailor specific training loads according to stage types, and prevent risks related to accumulated fatigue and injury. Future research integrating direct physiological measurements and additional variables on injury incidence or dropout rates will enable a deeper understanding of the physiological, tactical, and clinical dimensions of professional cycling performance.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://figshare.com/articles/dataset/Cycling_Analytics_Data_Sets/24566542.
Author contributions
IG-A: Writing – original draft, Writing – review & editing. ED: Writing – review & editing. FV-F: Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. APC support has been granted by IPN-SIP under the 2025 “Apoyos Económicos para Publicaciones” call.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Generative AI was used in the creation of this manuscript. GPT-4, developed by OpenAI, was used to assist with the grammatical correction and refinement of the manuscript's writing.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Sanders D, Heijboer M. Physical demands and power profile of different stage types within a cycling grand tour. Eur J Sport Sci. (2019) 19(6):736–44. doi: 10.1080/17461391.2018.1554706
2. Lucía A, Hoyos J, Chicharro JL. Physiology of professional road cycling. Sports Med. (2001) 31(5):325–37. doi: 10.2165/00007256-200131050-00004
3. Abbiss CR, Laursen PB. Describing and understanding pacing strategies during athletic competition. Sports Med Auckl NZ. (2008) 38(3):239–52. doi: 10.2165/00007256-200838030-00004
4. VAN Erp T, Sanders D, Lamberts RP. Maintaining power output with accumulating levels of work done is a key determinant for success in professional cycling. Med Sci Sports Exerc. (2021) 53(9):1903–10. doi: 10.1249/MSS.0000000000002656
5. Passfield L, Hopker JG, Jobson S, Friel D, Zabala M. Knowledge is power: issues of measuring training and performance in cycling. J Sports Sci. (2017) 35(14):1426–34. doi: 10.1080/02640414.2016.1215504
6. Mujika I, Padilla S. Cardiorespiratory and metabolic characteristics of detraining in humans. Med Sci Sports Exerc. (2001) 33(3):413–21. doi: 10.1097/00005768-200103000-00013
7. Valenzuela PL, Mateo-March M, Muriel X, Zabala M, Lucia A, Pallares JG, et al. Road gradient and cycling power: an observational study in male professional cyclists. J Sci Med Sport. (2022) 25(12):1017–22. doi: 10.1016/j.jsams.2022.10.001
8. Ashtiani F, Sreedhara VSM, Vahidi A, Hutchison R, Mocko G. Experimental modeling of cyclists fatigue and recovery dynamics enabling optimal pacing in a time trial. (2019). p. 5083–8.
9. Ammann L, Chmura P. Internal and external load during on-field training drills with an aim of improving the physical performance of players in professional soccer: a retrospective observational study. Front Physiol. (2023) 14. doi: 10.3389/fphys.2023.1212573
10. Li G, Shang L, Qin S, Yu H. The impact of internal and external loads on player performance in Chinese basketball association. BMC Sports Sci Med Rehabil. (2024) 16(1):194. doi: 10.1186/s13102-024-00983-6
11. Yang K. Quarterly fluctuations in external and internal loads among professional basketball players. Front Physiol. (2024) 15. doi: 10.3389/fphys.2024.1419097
12. Mateo-March M, Valenzuela PL, Muriel X, Gandia-Soriano A, Zabala M, Lucia A, et al. The record power profile of male professional cyclists: fatigue matters. Int J Sports Physiol Perform. (2022) 17(6):926–31. doi: 10.1123/ijspp.2021-0403
13. Bonato G, Goodman SPJ, Tjh L. Physiological and performance effects of live high train low altitude training for elite endurance athletes: a narrative review. Curr Res Physiol. (2023) 6:100113. doi: 10.1016/j.crphys.2023.100113
14. Turner MM. Cycling on rough roads: a model for resistance and vibration. Veh Syst Dyn. (2024) 62(10):2729–49. doi: 10.1080/00423114.2024.2304031
15. Davis J, Bransen L, Devos L, Jaspers A, Meert W, Robberechts P, et al. Methodology and evaluation in sports analytics: challenges, approaches, and lessons learned. Mach Learn. (2024) 113(9):6977–7010. doi: 10.1007/s10994-024-06585-0
16. Xia J, Wang J, Chen H, Zhuang J, Cao Z, Chen P. An unsupervised machine learning approach to evaluate sports facilities condition in primary school. PLoS One. (2022) 17(4). doi: 10.1371/journal.pone.0267009
17. Rivadulla AR, Chen X, Cazzola D, Trewartha G, Preatoni E. Clustering analysis across different speeds reveals two distinct running techniques with no differences in running economy. Sports Biomech. (2024) 11:1–24. doi: 10.1080/14763141.2024.2372608
18. Martin JA, Stiffler-Joachim MR, Wille CM, Heiderscheit BC. A hierarchical clustering approach for examining potential risk factors for bone stress injury in runners. J Biomech. (2022) 141:111136. doi: 10.1016/j.jbiomech.2022.111136
19. Bouvet A, Kolei SE, Marbac M. Investigating swimming technical skills by a double partition clustering of multivariate functional data allowing for dimension selection [Internet]. arXiv. (2023). Disponible en: http://arxiv.org/abs/2303.15812
20. Reis FJJ, Alaiti RK, Vallio CS, Hespanhol L. Artificial intelligence and machine learning approaches in sports: concepts, applications, challenges, and future perspectives. Braz J Phys Ther. (2024) 28(3):101083. doi: 10.1016/j.bjpt.2024.101083
21. Phillips KE. An Examination of the Factors Determining the Performance of Cyclists in Elite Competitions. Melbourne: Victoria University (2020).
22. Ausloos M. Shannon entropy and Herfindahl-Hirschman index as team’s performance and competitive balance indicators in cyclist multi-stage races. Entropy. (2023) 25(6):955. doi: 10.3390/e25060955
23. Janssens B, Pappalardo L, Bock JD, Bogaert M, Verstockt S. Geospatial Road Cycling Race Results Data Set. arXiv. (2024).
24. Lloyd S. Least squares quantization in PCM. IEEE Trans Inf Theory. (1982) 28(2):129–37. doi: 10.1109/TIT.1982.1056489
25. Rousseeuw PJ. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math. (1987) 20:53–65. doi: 10.1016/0377-0427(87)90125-7
26. Wold S, Esbensen K, Geladi P. Principal component analysis. Chemom Intell Lab Syst. (1987) 2(1):37–52. doi: 10.1016/0169-7439(87)80084-9
27. Kaufman L, Rousseeuw PJ. Finding Groups in Data: An Introduction to Cluster Analysis [Internet]. 1st ed. New York: Wiley (1990). Disponible en: https://onlinelibrary.wiley.com/doi/book/10.1002/9780470316801
28. Sundström D, Carlsson P, Tinnsten M. On optimization of pacing strategy in road cycling. Procedia Eng. (2013) 60:118–23. doi: 10.1016/j.proeng.2013.07.062
29. Leo P, Spragg J, Podlogar T, Lawley JS, Mujika I. Power profiling and the power-duration relationship in cycling: a narrative review. Eur J Appl Physiol. (2022) 122(2):301–16. doi: 10.1007/s00421-021-04833-y
30. Jeukendrup AE. Nutrition for endurance sports: marathon, triathlon, and road cycling. J Sports Sci. (2011) 29(Suppl 1):S91–9. doi: 10.1080/02640414.2011.610348
31. Burke LM, Hawley JA, Jeukendrup A, Morton JP, Stellingwerff T, Maughan RJ. Toward a common understanding of diet-exercise strategies to manipulate fuel availability for training and competition preparation in endurance sport. Int J Sport Nutr Exerc Metab. (2018) 28(5):451–63. doi: 10.1123/ijsnem.2018-0289
Keywords: professional cycling, unsupervised learning, clustering, performance variability, external load
Citation: Garcia-Atutxa I, Dudagoitia Barrio E and Villanueva-Flores F (2025) Technical classification of professional cycling stages using unsupervised learning: implications for performance variability. Front. Sports Act. Living 7:1661456. doi: 10.3389/fspor.2025.1661456
Received: 7 July 2025; Accepted: 22 September 2025;
Published: 15 October 2025.
Edited by:
António Miguel Monteiro, Instituto Politécnico de Bragança, PortugalReviewed by:
Pedro Forte, Higher Institute of Educational Sciences of the Douro, PortugalJosé Eduardo Teixeira, Instituto Politécnico da Guarda, Portugal
Copyright: © 2025 Garcia-Atutxa, Dudagoitia Barrio and Villanueva-Flores. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Francisca Villanueva-Flores, ZnZpbGxhbnVldmFmQGlwbi5teA==
†ORCID:
Igor Garcia-Atutxa
orcid.org/0009-0002-1551-2685
Ekaitz Dudagoitia Barrio
orcid.org/0000-0003-0990-3081
Francisca Villanueva-Flores
orcid.org/0000-0001-6092-4211