 Bing Jia
Bing Jia Xue Zhang
Xue Zhang Zhemin Zhu
Zhemin Zhu- 1Teacher Training Center, Beihua University, Jilin City, China
- 2China Institute of Rural Education Development, Northeast Normal University, Changchun, China
- 3School of Education Science, Beihua University, Jilin City, China
Item response models often cannot calculate true individual response probabilities because of the existence of response disturbances (such as guessing and cheating). Many studies on aberrant responses under item response theory (IRT) framework had been conducted. Some of them focused on how to reduce the effect of aberrant responses, and others focused on how to detect aberrant examinees, such as person fit analysis. The purpose of this research was to derive a generalized formula of bias with/without aberrant responses, that showed the effect of both non-aberrant and aberrant response data on the bias of capability estimation mathematically. A new evaluation criterion, named aberrant absolute bias (|ABIAS|), was proposed to detect aberrant examinees. Simulation studies and application to a real dataset were conducted to demonstrate the efficiency and the utility of |ABIAS|.
Introduction
Item response theory (IRT) is a statistical method based on an examinee's response to explain his/her ability. Thus, the classical estimate of ability in IRT is highly sensitive to response disturbance (Magis, 2014). It can return a strongly biased estimation of true underlying ability when the responses are aberrant. The aberrant responses are often strange and different than expected. In fact, a response inconsistent with expectation is said to be aberrant (Clark, 2010). There are various sources of aberrant responses. Meijer (1996) proposed seven examinee behaviors that could cause aberrant responses: sleeping, guessing, cheating, plodding, alignment errors, extreme creativity, and deficiency of sub-abilities. For example, if an examinee chose the right answer by randomly guessing on a multiple-choice item, the test score might be inflated, leading to a higher than the actual impression of the respondent.
Aberrant responses occur when the observed response patterns are incongruous with the expected ones (Meijer, 1996; Meijer et al., 1996; Meijer and Sijtsma, 2001), which may jeopardize measurement accuracy among respondents and invalidate the use of IRT. Aberrant responses had been explored in IRT literature. Under the IRT framework, aberrant responses were addressed through (i) methods based on response times (RTs), such as classical and Bayesian checks in computerized adaptive testing (CAT; van der Linden et al., 1999; van der Linden and van Krimpen-Stoop, 2003; van der Linden, 2008); (ii) methods without response times, such as person fit analysis to identify aberrant examinees (Meijer and Sijtsma, 2001; Meijer, 2003; Emons, 2009), and weight robust estimation to reduce the influence of aberrant responses on ability estimation (Wainer and Wright, 1980; Schuster and Yuan, 2011; Magis, 2014).
Under IRT framework, RTs can be used as collateral information to analyze response data with/without abnormality. For example, time pressure can sometimes cause the high ability examinee be assigned to more difficult items (Wainer and Wang, 2007). However, the application of RTs is restricted in computer environment.
Person-fit statistics which can be used in both computer and non-computer environments are designed to identify examinees with aberrant item response patterns (Karabatsos, 2003). Karabatsos (2003) compared 36 person-fit indicators under different testing conditions, and found that HT (Sijtsma, 1986) statistic, which was a non-parametric statistic, was the best indicator to detect aberrant examinees. However, the most widely used parametric person fit indicators are lz (Drasgow et al., 1985) and CUSUM-based (cumulative sum based) indicators (Meijer, 2002).
The lz is used to quantify persons' adherence to the corresponding IRT model, and large negative value of lz indicates aberrant responses (Meijer and Sijtsma, 2001; Meijer, 2003). The CUSUM-based technique (Bradlow et al., 1998; van Krimpen-Stoop and Meijer, 2000, 2001, 2002; Bradlow and Weiss, 2001; Meijer, 2002) provides information about what occurred to each item during the answering process to detect a local misfit. Meijer (2002) found that CUSUM could provide more information about local misfit than the lz index. However, if one or more of the parameters are unknown, the power of CUSUM may be unsatisfactory (Csorgo and Horvath, 1997; Chen and Gupta, 2012).
On the other hand, instead of detecting aberrant behavior, weight robust estimation can be used to reduce the bias in estimating by weighting. Wainer and Wright (1980) were first to propose a robust approach in estimating ability in IRT. Mislevy and Bock (1982), Schuster and Yuan (2011) improved Wainer and Wright's approach by introducing different smoother weight functions. The estimation effect of the new method is more accurate.
When an examinee has aberrant responses, the ability estimate based on the whole responses is not the “true” ability estimate, that is because the ability estimate, will be affected by aberrant responses (Magis, 2014). Generally speaking, if one's responses are non-aberrant, the responses will point to the “true” ability estimate. In contrast, if the responses contain some aberrant responses, the aberrant ones will point to the aberrant ability estimate. Hence, the bias of the ability estimations may variate with the ratio of aberrant responses to the whole responses. This provides a new direction to detect aberrant examinees.
In a simple way, for one examinee, suppose the first response is aberrant, and others are non-aberrant. is the estimation of ability in an exam as shown Figure 1, although it differs from the “true” estimation. The superscript “*” denotes the aberrant response.

Figure 1. Estimation of ability by MLE, in aberrant responses.
Then we can resample the responses using the bootstrap method. If we select the first item (i.e., the aberrant response), and place it into the whole responses as shown in Figure 2, n+1 responses can be obtained. The estimation of ability, is obtained using MLE. As the ratio of aberrant responses to the whole responses becomes larger, intuitively, may be farther from “true” ability estimation than , and the absolute bias of is larger than the absolute bias of .

Figure 2. Estimation of ability by MLE in aberrant responses.
However, if we resample the second item (i.e., a non-aberrant response) as shown in Figure 3, there are also n+1 responses, containing only one aberrant response (i.e., item 1*). The estimation, , is obtained by MLE. As the ratio of the aberrant responses to the whole responses is reduced, the absolute bias of may become smaller than .

Figure 3. Estimation of ability by MLE in aberrant responses.
In order to determine the above ideas, the bias formula under aberrant responses needs to be determined. Lord (1981) derived the formula of bias that had been widely used to judge the accuracy of estimation under IRT framework. However, Lord's formula based on the ideal state did not consider aberrant responses.
Following Lord's idea, this paper aims (1) to present the generalized formula of statistical bias in the maximum likelihood estimation with or without aberrant responses, (2) to present, test and illustrate the utility of the proposed evaluation criterion which depends on the statistical bias.
Statistical Bias of Aberrant Responses
In conventional IRT models, the probability of a correct item response depends on the characteristics of items and respondents. For instance, in the popular two-parameter logistic (2PL) model (Birnbaum, 1968), the probability of a correct response is in the form of
where θ is the ability of the individual, ai is the item discrimination parameter, and bi is the item difficulty parameter with i = 1,…, n, indexing items. The items are scored dichotomously, ui = 1 for a correct response and ui = 0 for an incorrect response. The examinee subscript is omitted to simplify notation throughout the paper.
The probability of a correct non-aberrant response can be expressed as
Define Qi(θ) = 1−Pi(θ), Qi = 1−Pi as the probability of an incorrect response to item i. The likelihood function is given by
Then the log likelihood function is
The maximum likelihood estimator (MLE) of ability, , is obtained by solving the non-linear equation as follows:
where , and li(θ) = uilogPi(θ) + (1−ui)logQi(θ).
Rewrite (5) as
where by definition
Thus, considered as a function of can be expanded formally in powers of , as follows:
Let . Rather than proving the convergence of the power series, let us use a closed form that is always valid:
By defining
We can obtain
When the examinee has an aberrant response on item i, denote the aberrant response as and the probability of a correct response as P. Because when the response is aberrant, we find that
Then, the Fisher information is
Set (9) equal to zero, then it can be rewritten in terms of
Take the expectation of (24) to obtain a closed form
where Exr(r = 1, 2, ⋯) is of order n−r/2 Thus, Ex is of order n−1/2. is of order n−(r+t)/2,where r, t = 1, 2, … (Lord, 1981)
Using (21) and (22)
Square (24) and take expectation, because of local independence, we can obtain
Take (26, 27) and (18) into (25) to obtain the formula of aberrant response bias
where
When the response is non-aberrant (i.e., ), and G(n) = 0, the aberrant bias degenerates to the normal bias (Warm, 1989), that is
where
For an n-item test, when s aberrant and n-s non-aberrant responses are present, the absolute bias is
Formula (32) shows how non-aberrant and aberrant responses affect estimation ability. Based on the above formula, in the following section, a new detecting method is proposed.
Aberrant Absolute Bias
Obviously, when the aberrant response occurs, the estimation of ability will drift off the “true” ability estimate and the true ability. Accordingly, when to resample a response from the dataset and re-estimate the ability, if the selected response is normal, the difference between the ability estimations can be negligible, however, selecting an aberrant response will increase the difference between the ability estimations. Hence, we can say that if the difference between two ability estimates locates in a pre-defined range, the examinee may have aberrant responses with a high probability. According to the idea above, the accuracy of the estimation for aberrant responses is affected by the ratio of aberrant responses to the whole responses.
Example
Assuming P1* = 0.25 is the probability of correct aberrant response on the first item, and Pi = 0.2 for i = 1, 2, 3…, n are the probabilities of correct non-aberrant responses. If we select the nth item (i.e., a normal response) and put it into the whole responses, we can obtain n+1 responses. Denote Pn+1 = 0.2, which means the response of the first item is aberrant, and others (2 to n+1) are not. According to Equation (28), we can obtain
where is the absolute bias of the original n items, and is the absolute bias after resample the non-aberrant response.
Formulation of the New Evaluation Criterion
Based on the above ideas, resampling aberrant responses or non-aberrant responses will result in different ability estimates. Therefore, we propose a new evaluation criterion named the aberrant absolute bias (|ABIAS|), which can be summarized as follows,
where is the estimation of ability with response pattern u(0) = (u1, u2, u3,…, un) using MLE method, and , is the estimation of ability with response u(i) = (u1, u2, u3,…, un, ui) using MLE method. To alleviate any propagation of errors from item parameter calibration, |ABIAS| have to be used with restriction on item parameters, which are constrained to be known or pre-calibrated accurately. Throughout this paper, we assume the item parameters are known.
|ABIAS| describes the deviation of expanding one response (ui, i = 1, 2, 3…n) each time from the original responses. Selecting the first response data u1 from whole responses u(0) to u(0), then u(0) turns to u(1) = (u1, u2, u3,…, un, u1). So an ability estimation can be obtained from the responses u(1) by MLE method. Then we resample ui (i = 2,…, n) from u(0) in sequence, and repeat n-1 times. Then we can obtain from u(i) = (u1, u2, u3,…, un, ui) (i = 2, …, n). Note that each estimation process only base on n+1 data.
|ABIAS| provides a new method based on bootstrap to detect aberrant examinee roughly by migration of the “true” ability estimation. The calculation of |ABIAS| is based on MLE method. It will carry out n+1 MLE operations for a n-item test. As we known, the MLE is very fast. So |ABIAS| can be used for a quick pre-screening. For example, it could help determine whether aberrant responses exist in a computer-based test before using RTs methods.
Judgment Process
The judgment process by |ABIAS| can be summarized in three steps.
Sign-Process
For a given test, as the item parameters are (assumed to be) known, drawing some abilities from U(-3, 3) and simulating the corresponding response data, then |ABIAS| of abilities from −3 to 3 can be calculated. We call this process sign-process (SP). Denote the |ABIAS| calculated in this step as |ABIAS|SP. The |ABIAS|SP are based on the assumption of non-aberrant response, which are the benchmarks for our judgment for aberrant examinees.
Measure-Process
Estimating the abilities and calculating the |ABIAS| for each examinee. We call this step measure-process (MP), and denote the |ABIAS| calculated here as |ABIAS|MP. For each examinee, |ABIAS|MP has only one value.
Compare-Process
Comparing |ABIAS|MP to |ABIAS|SP. This process is called compare-process (CP). If |ABIAS|MP falls into the range of |ABIAS|SP, the responses are determined to be non-aberrant. Otherwise, responses are aberrant.
The method based on |ABIAS| to determine whether aberrant responses exist is called the |ABIAS| method.
Simulation Studies
A large number of studies had focused on aberrant responses. Mislevy and Bock (1982) recommended Tukey's bisquare weight function (Mosteller and Tukey, 1977) to handle aberrant responses, whereas Schuster and Yuan (2011) suggested Huber-type weight function to enhance estimation effect. All these studies used the same method to generate item parameters (Donoghue and Allen, 1993; Zwick et al., 1993; Penfield, 2003; Magis, 2014). Hence, to maintain consistency with their researches, all item parameters in simulation studies were same as those in Magis (2014), as shown in Table 1.
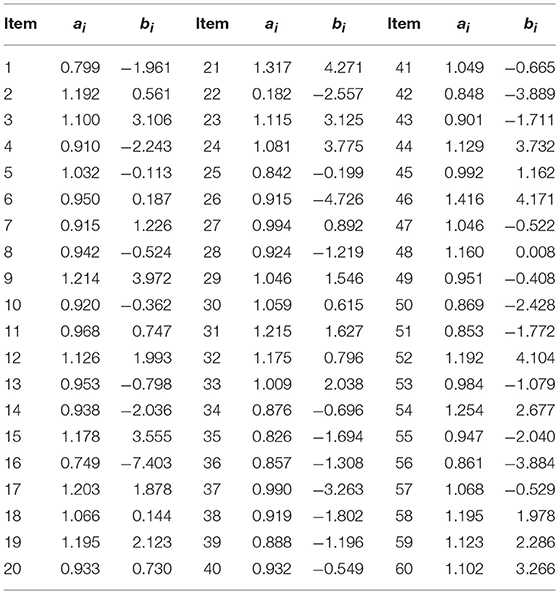
Table 1. Item discrimination ai and difficulty parameters bi in Magis (2014).
To evaluate the performance of |ABIAS| for 2PL models, two simulation studies were conducted. The manipulated factors, which were same in both studies, included 3 levels of test length (20, 40, and 60) which represented short, moderate, and long tests, and 7 levels of ability (from −3 to 3 with step 1). As the detection procedure for each examinee was independent, in this section, we focused solely on one examinee. More precisely, tests of 20 (40) items were generated by using the first 20 (40) item parameters of Table 1.
Simulation study 1 was based on the random aberrant process in three scenarios to evaluate the performance of the proposed |ABIAS| method. For the random aberrant process, if the response ui was 1, then it will be changed to 0, otherwise, it will be changed to 1. The random aberrant process do not focus on the source of aberrant responses. An additional simulation check to compare with lz was provided in Appendix (Supplementary Material).
Simulation study 2 was based on the aberrant guessing process used by Schuster and Yuan (2011) and Magis (2014). The aberrant guessing process assumed that one will answer the ith item aberrantly if the probability of the correct response is less than P#, where P# was a pre-defined cut-off value. In other words, the examinee will guess randomly when the probability of answering the item correctly was less than P#. Thus, any item response with correct response probability less than P# was replaced by an aberrant response with probability P*. P* was the pre-defined probability of the correct aberrant response in aberrant guessing process.
Step SP
In Table 2, we generated 13 intervals of abilities θ from −3 to 3 with step 0.5. Response data were generated from the 2PL model with item parameters in Table 1 under the non-aberrant assumption. MLE method was used to estimate abilities. Because of the biased property of the MLE method, considering the range of ability was more reasonable than considering the ability point. Five hundred replications were done.
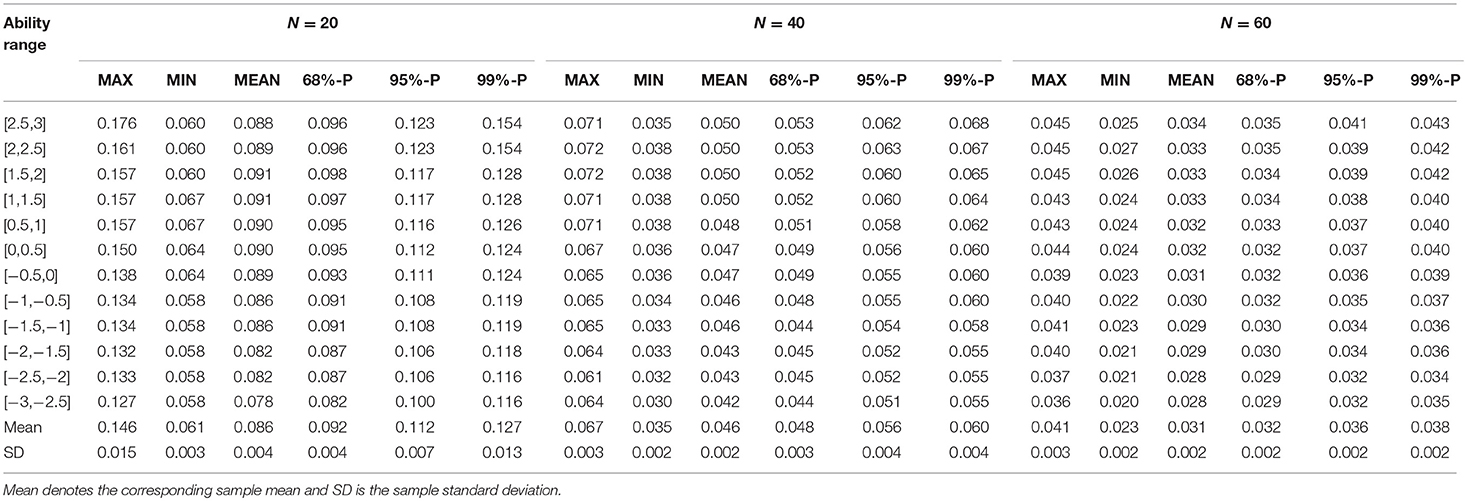
Table 2. Summary of |ABIAS|SP.
Table 2 shows the |ABIAS|SP in 3 levels of test length. MAX is the maximum value of 500 times, MIN is the minimum value, and MEAN is the mean value of 500 times. 68%-P is the value of the position of 68% in ascending order, and so are 95%-P and 99%-P. They correspond to the three standard errors of standard normal distribution. The value of |ABIAS|SP in 60-item test was smaller than that in 20- and 40-item tests. That is because the greater the item length, the higher the accuracy of ability estimation. In Table 2, the empirical standard deviations of MIN, MEAN and 68%-P were all smaller than those of MAX, 95%-P and 99%-P, that is, the stabilities of MIN, MEAN and 68%-P are better than other indices.
Empirically, |ABIAS|SP in an interval was monotonous, so we only calculated the two endpoints of each ability interval and take the smaller value as the criterion. Because the probability that the estimated value locates in the endpoints was close to 0, the intervals were set to be closed.
There are two plans in CP. If we want a more accuracy judgment, we can choose the |ABIAS|SP value (such as 68%-P, 68%-m-P, 95%-P, 95%-m-P) in the ability ranges. If we want a more quickly judgment, we can choose the mean value of indices (such as mean of 68%-P). For example, if one's |ABIAS|MP is smaller than the 68%-P of |ABIAS|SP, it can be marked as non-aberrant. What's more, Table 2 gives us different choices. If we want to have higher accuracy in detecting aberrant responses, we can use 95%-P and 95%-m-P. If we want to retain all the possible non-aberrant examinees, we can use 68%-P or 68%-m-P. This is a trade-off between detection of aberrant examinees and retention of normal examinees.
About 0.013 second of CPU time for each replication was required on a 1.60 GHz desktop using MATLAB 2016a.
Simulation Study 1
This simulation study was conducted to measure the |ABIAS| method in the random aberrant process. Under each condition, 3 levels of aberrant proportion (5, 15, and 25%) were considered, and the aberrant responses were selected randomly with the aberrant proportion. Across all the conditions, 500 replications were conducted. The results from the MP step were summarized in Tables 3–5.
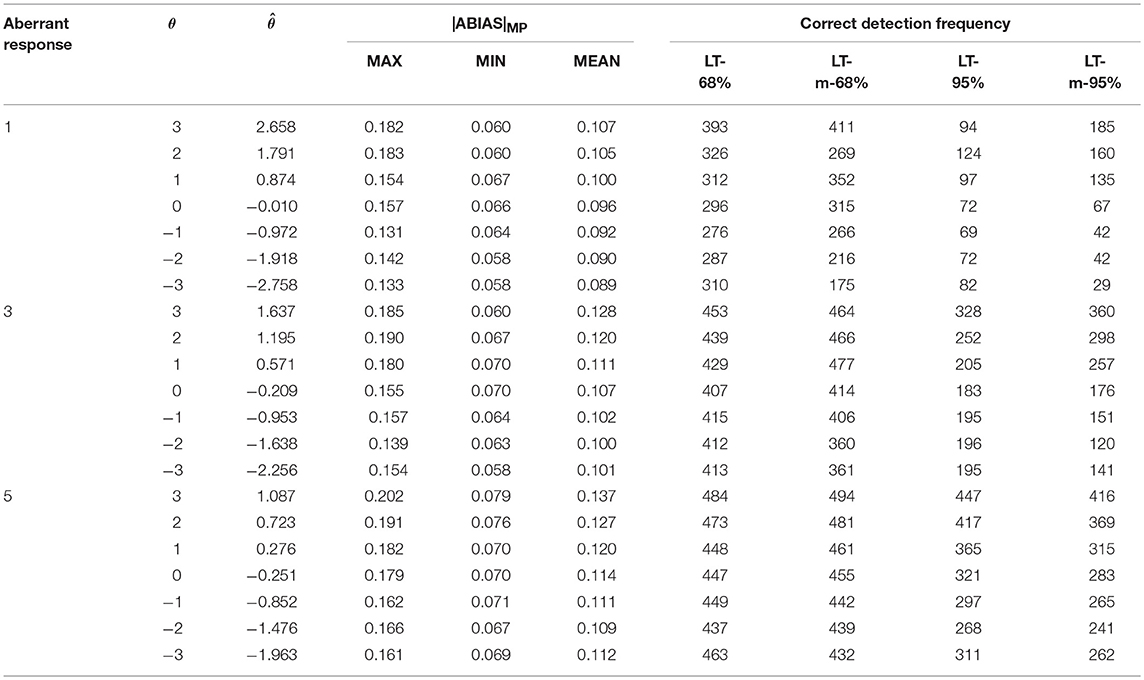
Table 3. Summary of MP and CP in random aberrant process in scenario 1.
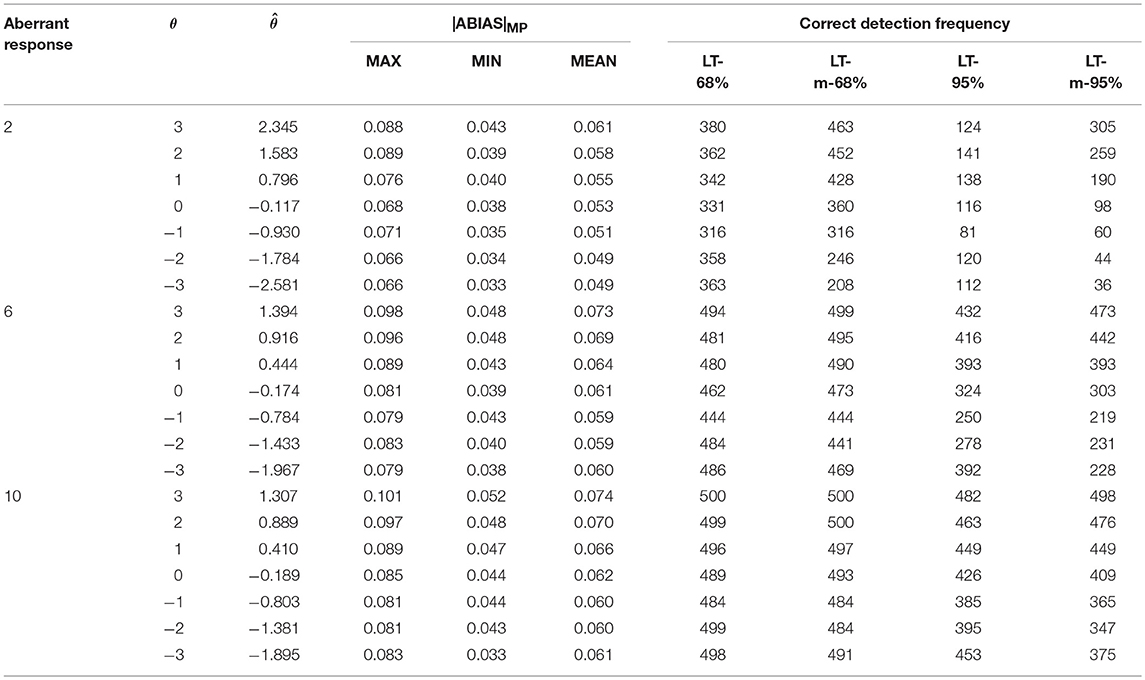
Table 4. Summary of MP and CP in random aberrant process in scenario 2.
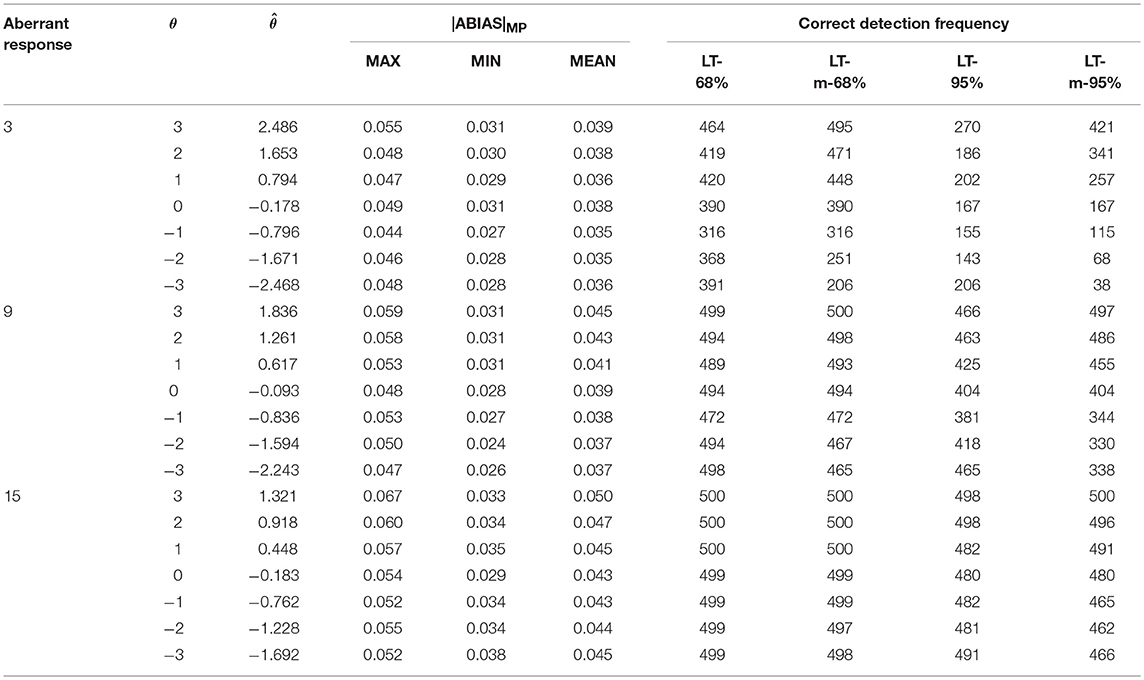
Table 5. Summary of MP and CP in random aberrant process in scenario 3.
In Tables 3–5, was the mean value of ability estimations in 500 replications. LT-68% was the number of |ABIAS|MP larger than 68% P-values in SP. LT-m-68% was the number of |ABIAS|MP larger than mean of 68% P-values in SP. LT-95% was the number of |ABIAS|MP larger than 95% P-values in SP. LT-m-95% was the number of |ABIAS|MP larger than mean of 95% P-values in SP.
Tables 3–5 indicate that the more aberrant responses, the more effective of the |ABIAS| method. Using LT-68% or LT-m-68% are better than using LT-95% or LT-m-95%. And there is few differences between LT-68% and LT-m-68%. Specifically speaking, it appears that it is better to use LT-m-68% when the estimation of ability is positive, and it is better to use LT-68% when the estimation of ability is negative. The worst case is in scenario 1, when there is only 1 random aberrant response in 20 items, the accuracy is about 40%, in other cases, the accuracy is more than 80% when we use LT-68% and LT-m-68% as the criteria in practical applications.
The MAX, MIN, and MEAN values in Tables 3–5 are all larger than those in Table 2. These observations indicate that the more aberrant responses in a test, that is, the larger the aberrant proportion, the better the performance of the |ABIAS| method in detecting aberrant responses. When the aberrant proportion is 25%, the |ABIAS| method can almost detect the existence of all aberrant examinees correctly for all replications. The accuracy of judgment increase as the absolute ability of the examinee decreases. This is because when the ability of the examinee is close to 0, correct response probability and incorrect response probability is close in many items. Hence, it will be very difficult to determine whether an aberrant response exists.
Simulation Study 2
This simulation study was designed to measure the |ABIAS| method in aberrant guessing process. The aberrant guessing process was used by Schuster and Yuan (2011) and David Magis (2014). In each scenario, test with four-choice and five-choice items were considered. That meant, the probability of correct aberrant response, P*, was 0.25 or 0.2 for a four-choice item or a five-choice item. In this simulation study, the probability of pre-defined cut-off value, P#, was set to 0.1. Hence, the correct response probability on one item, which was less than P# (i.e., 0.1), will be replaced by P* (i.e., 0.25 for four-choice item or 0.2 for five-choice item), and denoted the “updated” response on this item as the aberrant response.
Tables 6–8 show that the values of LT-68%, LT-m-68% LT-95%, LT-m-95% are larger in negative ability than these in positive ability. Because higher ability would lead to more success probabilities which is larger than P#. In fact, lower ability would likely result in aberrant responses (Schuster and Yuan, 2011; Magis, 2014). The accuracy of simulation study 2 is lower than that of study 1, because even when Pi is smaller than P# and replaced by P*, the difference between them was still small (0.25–0.1 = 0.15, and 0.2–0.1 = 0.1). Thus, response ui may not change. Nevertheless, these findings still indicate that the |ABIAS| method is effective in the aberrant guessing process. Although success is not guaranteed every time, it can also guarantee at least 50% accuracy by using LT-68% when P* is only 0.1 higher than P#. If the ability is smaller than −2, accuracy will almost be larger than 80%, making it feasible as a rough screening method.
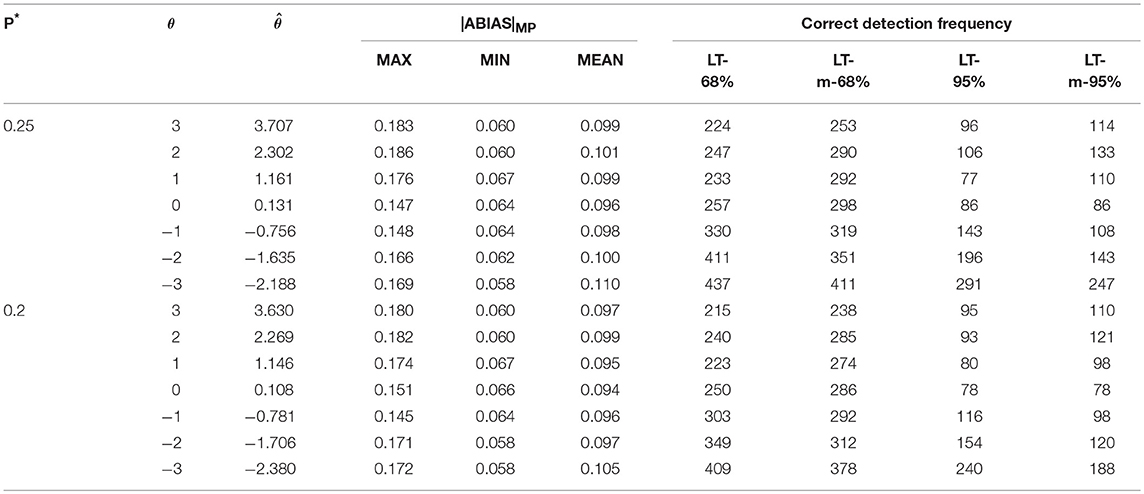
Table 6. Summary of MP and CP in aberrant guessing process in scenario 1.
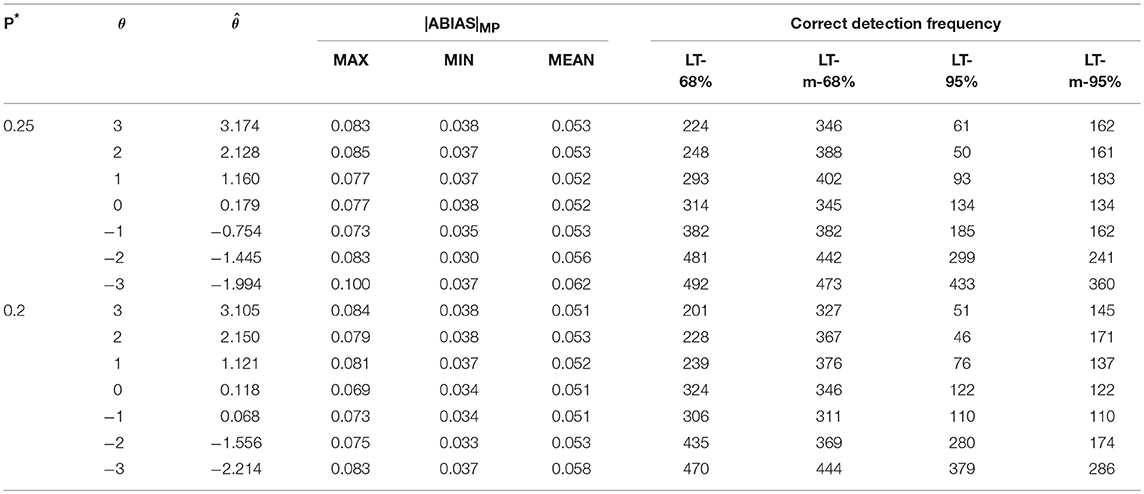
Table 7. Summary of MP and CP in aberrant guessing process in scenario 2.
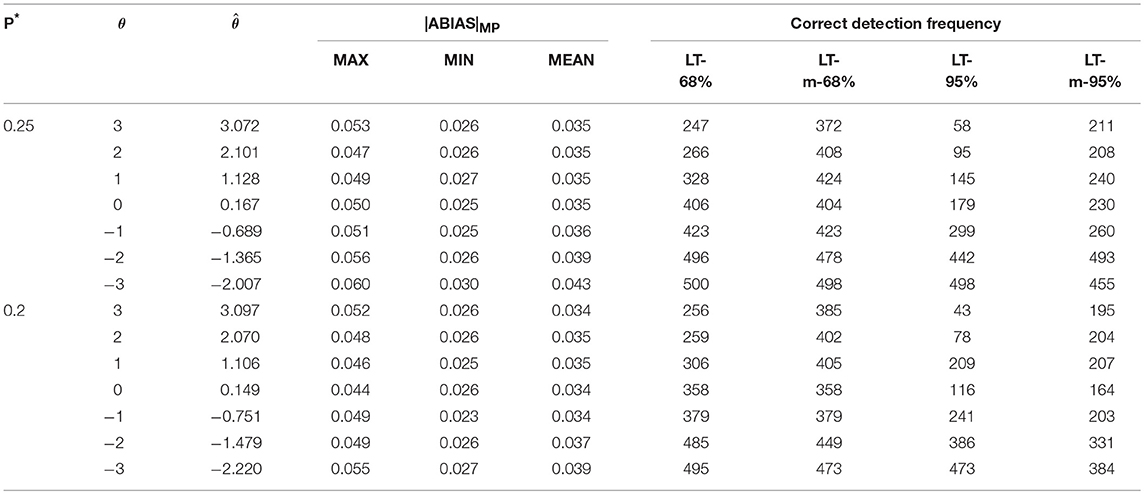
Table 8. Summary of MP and CP in aberrant guessing process in scenario 3.
The simulation studies reflect the effectiveness of the |ABIAS| method in random guessing and aberrant guessing processes. In the same aberrant proportion (aberrant responses to the whole responses) or the same probability of the correct aberrant response, the longer the test, the better the screening effect. In the same test length, the larger the aberrant proportion, the batter the screening effect. In the two aberrant processes, ability levels are all an important factor to affect the performance. We recommend LT-m-68% and LT-m-95% as the criteria for positive ability estimations, and LT-68% and LT-95% for negative ability estimations.
Application to Real Data
This example was based on a pilot study on a sample of 1,624 examinees under 170 items. The organization also flagged 41 examinees as possible cheaters from a variety of statistical analysis and an investigative process that brought in other information. The data sets were analyzed in several papers (Sinharay, 2016; Cizek and Wollack, 2017; Eckerly, 2017).
As the |ABISA| method was under the assumption that item parameters are known or pre-calibrated accurately. The item parameters were calibrated firstly by 1,583 non-aberrant examinees, and this process was called the Sign Step in simulation. And then the item parameters were used to analyze the 41 examinees who may have aberrant responses, and this is the Measure Step.
The lz index is used as a baseline. The formulation of lz is as follows,
Although lz is not perfect (Molenaar and Hoijtink, 1990, 1996), but lz is still the most popular parametric person-fit statistics. The summary of |ABIAS|SP by 2PL models was as provided in Table 9.
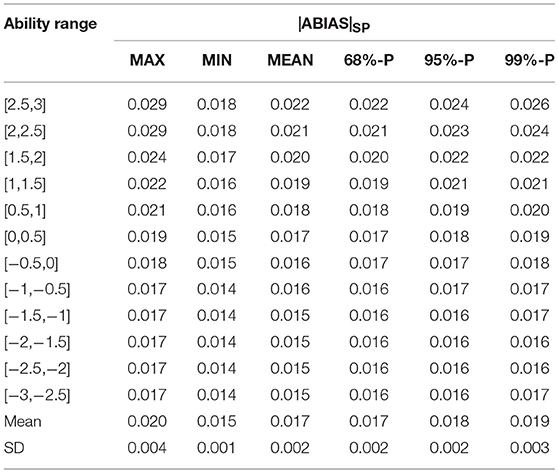
Table 9. Summary of |ABIAS|SP by 2PL model.
Table 9 indicated the |ABIAS|SP of the 2PL model. The SD of MIN and MEAN was small. The estimations and |ABIAS|MP of the 41 examinees were provided in Table 10.
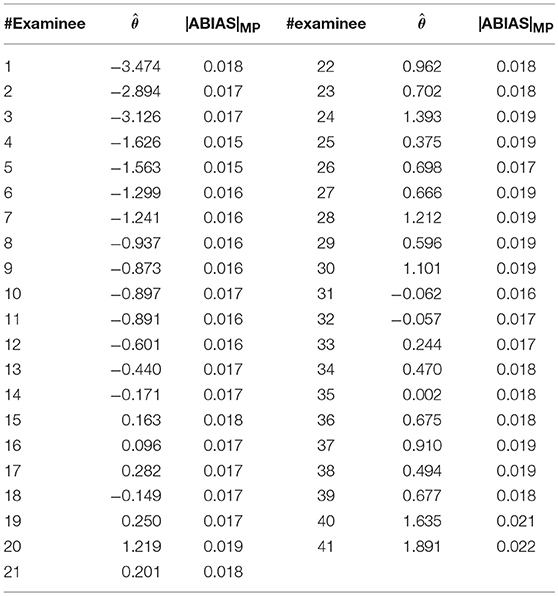
Table 10. Summary of estimation abilities and |ABIAS|MP by 2PL model.
Table 10 showed that using the |ABIAS| method, 15 aberrant examinees can be determined by 68%-P, 14 aberrant examinees by 68%-m-P, 6 aberrant examinees by 95%-P, and 12 aberrant examinees by 95%-m-P. Using the lz index, 3 aberrant examinees can be identified by 2PL model. All the results by the |ABIAS| method covered the results by lz. It appears that the |ABIAS| method outperforms lz.
Discussion and Conclusion
Aberrant responses often occurred in educational measurement. Most examinees can improve their scores by guessing when they did not know the answer, which may make it harder to obtain the “true” ability estimations. Hence, developing a simple and feasible screening method was necessary. At the very least, determining whether an examinee had aberrant responses in the test should be done. This was the main purpose of this article.
This paper followed the idea of Lord (1981) and provided a generalized formula of statistical bias in the maximum likelihood estimation with or without aberrant responses, which presented the relationship between bias and the probability of aberrant response. It was the first attempt to formulate the bias with aberrant responses, and the new bias was equivalent to the normal bias (Warm, 1989) when there were no aberrant responses in the test. The formula showed the estimation bias of aberrant responses consisted of two parts. One part came from non-aberrant responses, and the other came from aberrant responses. It was the basic of the |ABIAS| method.
In this paper, the |ABIAS| was proposed as a new indicator to identify aberrant responses according to the formula, which was fast and effective. Simulation studies showed that to a certain extent, the |ABIAS| method could judge whether an examinee had aberrant responses in a test in two different aberrant processes. The results indicated that in the random aberrant process the larger absolute ability, the better the detecting effect. In the aberrant guessing process, the smaller the ability, the better the detecting effect. Moreover, the larger the aberrant proportion, the higher the accuracy of detecting. The more items in the test, the better the detecting effect.
The new method does not rely on response times, which means that it can be used more widely. The paper-and-pencil tests can be screened by the new method and then the weight method can be used to obtain the robust estimation of examinee's ability with aberrant responses. Meanwhile, in computer-based tests, the new method can be used for screening firstly, and then the RTs can be used for the accurate search. This feature can save significant manpower and time.
In this article, the proposed detecting method is limited to unidimensional IRT models. However, as identified by Ackerman et al. (2003), many educational and psychological tests are inherently multidimensional. In multidimensional IRT (MIRT) models, the correlations between domains will affect the statistical biases of latent traits (Wang, 2015). In other words, the aberrant behavior on one item may affect the statistical biases of all the domains, rather than that of the corresponding domain. Therefore, future research should look into the application of the |ABIAS| method to detect aberrant responses under MIRT framework.
What's more, the new method could not identify which item is aberrant. In future research, we wish to construct a method based on |ABIAS| to determine which item the aberrant response occur on. This direction is a very interesting one and will have wider applications in computer-based testings.
Author Contributions
Author Contributions ZZ completed the writing of the article. XZ provided key technical support. BJ provided original thoughts and article revisions.
Funding
Funding This research is partially supported by the National Natural Science Foundation of China (Grant 11571069), Jilin Education Science Planning (GH170130), the Jilin Province Science and Technology Department (Grant 201705200054JH), and the Fundamental Research Funds for the Central Universities (Grant 2412017FZ028).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2019.00043/full#supplementary-material
References
Ackerman, T., Gierl, M. J., and Walker, C. M. (2003). Using multidimensional item response theory to evaluate educational psychological tests. Educ. Meas. Issues Pract. 22, 37–51. doi: 10.1111/j.1745-3992.2003.tb00136.x
Birnbaum, A. (1968). “Some latent trait models and their use in inferring an examinee's ability,” in Statistical Theories of Mental Test Scores, eds F. M. Lord and M. R. Novick (Reading, MA: Addison-Wesley), 397–479.
Bradlow, E., and Weiss, R. E. (2001). Outlier measures and norming methods for computerized adaptive tests. J. Educ. Behav. Stat. 26, 85–104. doi: 10.3102/10769986026001085
Bradlow, E., Weiss, R. E., and Cho, M. (1998). Bayesian detection of outliers in computerized adaptive tests. J. Am. Stat. Assoc. 93, 910–919. doi: 10.1080/01621459.1998.10473747
Chen, J., and Gupta, A. K. (2012). Parametric Statistical Change Point Analysis, 2nd Edn. Boston, MA: Birkhauser. doi: 10.1007/978-0-8176-4801-5
Cizek, G. J., and Wollack, J. A. (2017). Handbook of Detecting Cheating on Tests. Washington, DC: Routledge.
Clark, J. M. (2010). Aberrant Response Patterns as a Multidimensional Phenomenon: Using Factor-Analytic Model Comparison to Detect Cheating. Unpublished doctoral dissertation, University of Kansas, Lawrence.
Donoghue, J. R., and Allen, N. L. (1993). Thin vs. thick matching in the Mantel-Haenszel procedure for detecting DIF. J. Educ. Stat. 18, 131–154. doi: 10.2307/1165084
Drasgow, F., Levine, M. V., and Williams, E. A. (1985). Appropriateness measurement with polychotomous item response models and standardized indices. Br. J. Math. Stat. Psychol. 38, 67–86. doi: 10.1111/j.2044-8317.1985.tb00817.x
Eckerly, C. A. (2017). “Detecting item preknowledge and item compromise: Understanding the status quo,” in Handbook of Detecting Cheating on Tests, eds G. J. Cizek and J. A. Wollack (Washington, DC: Routledge), 101–123.
Emons, W. H. (2009). Detection and diagnosis of person misfit from patterns of summed polytomous item scores. Appl. Psychol. Meas. 33, 599–619. doi: 10.1177/0146621609334378
Karabatsos, G. (2003). Comparing the aberrant response detection performance of thirty six person-fit statistics. Appl. Meas. Educ. 16, 277–298. doi: 10.1207/S15324818AME1604_2
Lord, F. M. (1981). Unbiased estimators of ability parameters, of their variance, and of their parallel-forms reliability. Psychometrika 48, 233–245. doi: 10.1007/BF02294018
Magis, D. (2014). On the asymptotic standard error of a class of robust estimators of ability in dichotomous item response models. Br. J. Math. Stat. Psychol. 67, 430–450. doi: 10.1111/bmsp.12027
Meijer, R., and Sijtsma, K. (2001). Methodology review: evaluating person fit. Appl. Psychol. Meas. 25, 107–135. doi: 10.1177/01466210122031957
Meijer, R. R. (1996). Person-Fit research: an introduction. Appl. Meas. Educ. 9, 3–8. doi: 10.1207/s15324818ame0901_2
Meijer, R. R. (2002). Outlier detection in high-stakes certification testing. J. Educ. Meas. 39, 219–233. doi: 10.1111/j.1745-3984.2002.tb01175.x
Meijer, R. R. (2003). Diagnosing item score patterns on a test using item response theory-based person-fit statistics. Psychol. Methods 8, 72–87. doi: 10.1037/1082-989X.8.1.72
Meijer, R. R., Muijtjens, A. M. M., and van der Vleuten, C. P. M. (1996). Nonparametric personfit research: some theoretical issues and an empirical example. Appl. Meas. Educ. 9, 77–89. doi: 10.1207/s15324818ame0901_7
Mislevy, R. J., and Bock, R. D. (1982). Biweight estimates of latent ability. Educ. Psychol. Meas. 42, 725–737. doi: 10.1177/001316448204200302
Molenaar, I. W., and Hoijtink, H. (1990). The many null distributions of person fit indices. Psychometrika 55, 75–106. doi: 10.1007/BF02294745
Molenaar, I. W., and Hoijtink, H. (1996). Person-fit and the Rasch model, with an application to knowledge of logical quantors. Appl. Meas. Educ. 9, 27–45. doi: 10.1207/s15324818ame0901_4
Mosteller, F., and Tukey, J. (1977). Exploratory Data Analysis and Regression. Reading, MA: Addison-Wesley.
Penfield, R. D. (2003). Application of the Breslow-Day test of trend in odds ratio heterogeneity to the detection of nonuniform DIF. Alberta J. Educ. Res. 49, 231–243.
Schuster, C., and Yuan, K.-H. (2011). Robust estimation of latent ability in item response models. J. Educ. Behav. Stat. 36,720–735. doi: 10.3102/1076998610396890
Sijtsma, K. (1986). A coefficient of deviance of response patterns. Kwantitatieve Methoden 7, 131–145.
Sinharay, S. (2016). Asymptotic corrections of standardized extended caution indices. Appl. Psychol. Meas. 40, 418–433. doi: 10.1177/0146621616649963
van der Linden, W. J. (2008). Using response times for item selection in adaptive tests. J. Educ. Behav. Stat. 33, 5–20. doi: 10.3102/1076998607302626
van der Linden, W. J, Scrams, D. J., and Schnipke, D.L. (1999). Using response-time constraints to control for speededness in computerized adaptive testing. Appl. Psychol. Meas. 23, 195–210. doi: 10.1177/01466219922031329
van der Linden, W. J, and van Krimpen-Stoop, E. M. L. A. (2003). Using response times to detect aberrant response patterns in computerized adaptive testing. Psychometrika 68, 251–265. doi: 10.1007/BF02294800
van Krimpen-Stoop, E. M. L. A., and Meijer, R. R. (2000). “Detecting person misfit in adaptive testing using statistical process control techniques,” in Computerized Adaptive Testing: Theory and Practice, eds W. J. van der Linden and C. A. Glas (Dordrecht: Springer), 201–219.
van Krimpen-Stoop, E. M. L. A., and Meijer, R. R. (2001). CUSUM-based person-fit statistics for adaptive testing. J. Educ. Behav. Stat. 26, 199–217. doi: 10.3102/10769986026002199
van Krimpen-Stoop, E. M. L. A., and Meijer, R. R. (2002). Detection of person misfit in computerized adaptive tests with polytomous items. Appl. Psychol. Meas. 26, 164–180. doi: 10.1177/01421602026002004
Wainer, B., and Wang, W. (2007). Testlet Response Theory and Its Applications. New York, NY: Cambridge university press. doi: 10.1017/CBO9780511618765
Wainer, H., and Wright, B. D. (1980). Robust estimation of ability in the Rasch model. Psychometrika 45, 373–391. doi: 10.1007/BF02293910
Wang, C. (2015). On latent trait estimation in multidimensional compensatory item response models. Psychometrika 80, 428–449. doi: 10.1007/s11336-013-9399-0
Warm, T. A. (1989). Weighted likelihood estimation of ability in item response theory. Psychometrika 54, 427–450. doi: 10.1007/BF02294627
Keywords: maximum likelihood estimation, ABIAS, |ABIAS| method, aberrant response, bias
Citation: Jia B, Zhang X and Zhu Z (2019) A Short Note on Aberrant Responses Bias in Item Response Theory. Front. Psychol. 10:43. doi: 10.3389/fpsyg.2019.00043
Received: 13 September 2018; Accepted: 08 January 2019;
Published: 31 January 2019.
Edited by:
Holmes Finch, Ball State University, United StatesReviewed by:
Daniel Bolt, University of Wisconsin-Madison, United StatesSeongah Im, University of Hawaii at Manoa, United States
Copyright © 2019 Jia, Zhang and Zhu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhemin Zhu, emh1em00ODVAbmVudS5lZHUubmM=