 Gianluca Calcagni
Gianluca Calcagni Ernesto Caballero-Garrido
Ernesto Caballero-Garrido Ricardo Pellón
Ricardo Pellón- 1Instituto de Estructura de la Materia, CSIC, Madrid, Spain
- 2National Association of Researchers, Twenty-First Century, Madrid, Spain
- 3Facultad de Psicología, Universidad Nacional de Educación a Distancia (UNED), Madrid, Spain
How stable and general is behavior once maximum learning is reached? To answer this question and understand post-acquisition behavior and its related individual differences, we propose a psychological principle that naturally extends associative models of Pavlovian conditioning to a dynamical oscillatory model where subjects have a greater memory capacity than usually postulated, but with greater forecast uncertainty. This results in a greater resistance to learning in the first few sessions followed by an over-optimal response peak and a sequence of progressively damped response oscillations. We detected the first peak and trough of the new learning curve in our data, but their dispersion was too large to also check the presence of oscillations with smaller amplitude. We ran an unusually long experiment with 32 rats over 3,960 trials, where we excluded habituation and other well-known phenomena as sources of variability in the subjects' performance. Using the data of this and another Pavlovian experiment by Harris et al. (2015), as an illustration of the principle we tested the theory against the basic associative single-cue Rescorla–Wagner (RW) model. We found evidence that the RW model is the best non-linear regression to data only for a minority of the subjects, while its dynamical extension can explain the almost totality of data with strong to very strong evidence. Finally, an analysis of short-scale fluctuations of individual responses showed that they are described by random white noise, in contrast with the colored-noise findings in human performance.
1. Introduction
How stable is behavior when there is nothing more to learn? Much debate has been flourished around this basic question since the earliest studies of animal conditioning (Pavlov, 1927), especially after the first efforts to make the discipline theoretically quantitative with a mathematical approach (Hull, 1943). Observations point toward an instability of the response in extended training. In the context of discrimination experiments of operant conditioning, extended training was studied in relation with behavioral contrast and the peak-shift effect. Pigeons trained for 60 days with interspersed generalization testing showed a gradual response decrease (Terrace, 1966). In an experiment lasting 64 sessions, Hearst (1971) did not observe this decrease from peak responding, sometimes called overtraining effect (as a reduction in behavioral contrast), inhibition with reinforcement, or post-peak depression (see Kimmel and Burns, 1975, for an early review and other references). Extending the training to 105–125 days, the response decrease was found to be a subject-dependent and transient effect, giving way to a greater variety of patterns characterized by apparently random response fluctuations and, in general, remarkable individual differences (Dukhayyil and Lyons, 1973). An attenuated conditioned responding with extended reinforced training has been observed also in the case of Pavlovian conditioning, where it is modulated by the context (Overmier et al., 1979; Bouton et al., 2008; Urcelay et al., 2012). Post-peak depression is a rather short-scale phenomenon usually achieved within a few sessions and not too many trials. For instance, the experiments with dogs by Overmier et al. (1979) showed response decrease on a time scale of 300 trials. In the experiments of Bouton et al. (2008), the groups of subjects received about 2 weeks of training. In the case of Urcelay et al. (2012), they were given 5–6 sessions of 5–60 trials, for a maximum of about 360 trials. For acquisition of fear conditioning, 100 pairings during 10 days are sufficient (Pickens et al., 2009). However, longer-term cases are known, such as the first documented case of inhibition with reinforcement. Pavlov (1927, Lecture XIV) reported experiments with a dog that spanned several years and that showed a progressive decrease in the conditioned response when the same type of stimuli was applied. On the other extreme of the spectrum, response fluctuations have been registered also on the very short time scale of trial by trial (Ayres et al., 1979).
The prototypical learning curve of Pavlovian conditioning in the presence of a single cue was described by Hull (1943). Estes (1950) and Bush and Mosteller (1951a) wrote down a mathematical model (somewhat implicit in Hull's discussion) in terms of response probability, but for operational reasons the latter was replaced by the association strength v by Rescorla and Wagner (1972). Due to this complicated genesis, the resulting single-cue model in terms of v has received several names: Hull, Hull–Spence, Estes, Bush–Mosteller, and single-cue Rescorla–Wagner, among others (Le Pelley, 2004; Wagner and Vogel, 2009). For brevity, we will call it Rescorla–Wagner (RW) model here.
Including RW, most conditioning models are about learning, which means that their simulation of the execution or reaction of the subject once the asymptote is reached has not been validated extensively. A classic problem consists in that, when one has learned everything, it is not convenient to keep giving attention to the stimuli of the task and there is a transition to a more automatic mode of execution. In order to explain this transition, many Pavlovian models (e.g., the Pearce and Hall model, 1980) distinguish between automatic and controlled processing. Still, this difference plays a role in the first few sessions of training and it does not address the issue of what happens after thousand of trials. Going beyond associative models, the opponent-processes theory (Solomon and Corbit, 1974) and the SOP model (Wagner, 1981) provide a partial, but not entirely comprehensive, explanation of post-peak depression and related phenomena.
These studies also highlight the parallel issue of individual differences. Individual plots are so non-smooth and erratic that any vestige of the clean, smooth learning curve of averaged data may be completely lost. When averaging, information on individuals is usually lost. This concern is not new and it was voiced already in early days of the discipline (Merrill, 1931; Sidman, 1952; Hayes, 1953) and retaken into consideration in recent years (Gallistel et al., 2004; Gallistel, 2012; Glautier, 2013; Blanco and Moris, 2018; Jaksic et al., 2018; Young, 2018; see especially Smith and Little, 2018). As Sidman (1952) pessimistically put it, “[i]ntra-organism variability may be so great as to obscure any lawful relation.” Smooth group-learning curves have even been stigmatized as an artifact, since step-like sudden acquisition has been observed in several experiments (Gallistel et al., 2004). Despite these warnings, however, averaging the data can be a useful procedure (Estes, 1956) and is still commonly employed in the great majority of publications, even those where individual responses are analyzed (Mazur and Hastie, 1978).
All this literature helps to refocus the question we proposed in the opening and to give the term “stability” two different meanings. One corresponds to intra-subject behavior stability: the variability of the individual response throughout the experiment. The other is inter-subject stability, in the sense of the range and variety of patterns that individual differences can take when the performance of experimental subjects is compared. Both intra- and inter-subject stability can refer to phenomena spanning trials (short-term stability) or sessions (long-term stability). Short-term stability usually pertains to the initial acquisition stage of conditioning, where the subjects are in the process of acquiring maximal learning but have not quite reached the asymptote of their learning curve. Long-term stability is more related to response at the asymptote. Response variations in the form of random fluctuations may be regarded both as short-term effects (they occur as gradients from one session to another) and as long-term, since they can span several sessions (or when one detects oscillation-like features with a long period).
To the best of our knowledge, the mainstream of mathematical associative models starting from RW predicts an indefinitely long asymptotic permanence of execution in the learning process, for each and any subject. Neither individual differences nor response fluctuations are considered in most analytic treatments of the theories, notwithstanding the number of exceptions to this generalized trend, some of which we have mentioned above. An inversion of this trend has been seen recently, when new models have arisen that give more importance to individual differences. The multiple-state learning model of Blanco and Moris (2018) and the MECA model of Glautier (2013) are examples. Also, Estes stimulus sampling theory (1950) is one of the earliest attempts to quantify and explain variability in learning progress, as due to fluctuations in environmental and internal factors. The issue at stake here is not just whether there exist superior ad hoc fits to averaged data than that provided by the RW model with one cue. It is already known that other types of learning curves can fare better than the exponential profile (see Equation 4 below), even at the individual level. A power-law curve (Newell and Rosenbloom, 1981) or the accumulation model (Mazur and Hastie, 1978) are two instances. Rather, here we are interested in the problem of stability in the double sense specified above, and moreover, any new model should arise as an underlying theory rather than just a tailor-made learning curve.
With the aim to study both very long-term stability and individual differences, we present the results of an experiment of Pavlovian conditioning that ran through a total of almost 4,000 trials. The first goal of this paper is to check how variable is behavior in the long-term post-acquisition phase. We do find fluctuations around the asymptote, both on a trial-by-trial and a session-by-session basis, but not statistically significant. In other words, behavior is fairly stable even when the subject is no longer learning. This provides a validation of the RW single-cue associative model even in the not-so-often explored plateau region of the learning curve, far away from initial acquisition. However, the fit of the data of individual subjects is much more unstable and one may wonder whether there exist a quantitative model accounting for this variability. Our second goal is to explore several associative models extending RW's in a most natural way, introducing a psychological principle that, in analogy with the same tool used in classical1 mechanics physics, we will call of least action. This principle states that learning processes must be described as dynamical systems, where dynamical means that there exists a quantity (the action) that must be minimized when the association strength is changed during conditioning. Through a detailed statistical and spectral analysis, we show that, despite the large fluctuations of the subjects' behavior, the RW model is still a good fit to data, except in 4 out of 15 experimental subjects. The dynamical oscillatory model (or DOM in short), based on the principle of least action and predicting resistance to learning in the first sessions, provides a better fit to the data of this 20% of the sample, according to both Bayesian and Akaike Information Criteria. Since the DOM is an extension of RW rather than a competitor, we conclude that it fits successfully 100% of the data, while the RW model accounts only for 80%. These results are strengthened when analyzing the data of Experiment 2 of Harris et al. (2015), where the RW model can fit successfully only 45% of the data and the DOM 95%. Although the existence of a learning asymptote has been questioned in the past (Gallistel et al., 2004), we find its presence to be a robust feature of all the models. The formalism we propose can be extended to the multi-cue and varying-salience cases and can account for the non-normative performance of some subjects.
The RW model may be regarded as antiquated today. Context is not fully integrated into it and few learning preparations can be viewed as single-cue because learning does not occur in a vacuum (Miller and Matzel, 1988). Furthermore, the inability of the Rescorla–Wagner model to account for recovery from extinction and other phenomena is well-known (Miller et al., 1995). Nevertheless, we believe that the novelty of the least-action principle and the ensuing dynamical proposal can be better understood and appreciated if compared with the simplest representative of the standard canon. As we will see when extending the theory to many cues, there seems to be no obstacle to apply the principle to more realistic situations.
One of the main features of this work is that traditional associative models are not extended in an ad hoc way, but by using a rigorous top-down procedure leading to a natural (in the sense of logic-based) conclusion, closer to a theory rather than a phenomenological model. To that aim, we need mathematics more advanced than those available to a large portion of the readership in psychology, but the payback offered in terms of explanation of the data may be worthwhile. In order to keep the presentation simple, we will introduce the model in a pedagogical way, confining the most rigorous parts and other dynamical models to the Supplementary Material.
The oscillations of the DOM span tens of sessions and describe individual variations in the response at large time scales. In order to study short-scale (session-by-session or even trial-by-trial) variations, we need other models and analysis tools. One such model treats short-scale fluctuations as random noise and is capable to determine whether their origin is just experimental uncertainty or some deeper, perhaps cognitive, mechanism.
The plan of the article is the following. We first review the RW associative model in section 2 and clarify whether it should be applied to individual subjects or to their average. In order to clarify the type of phenomena we would like to explore, in section 3.1, we present a 3,960-trial-long experiment, with a first analysis centered on the average learning curve, while in section 3.2 we reanalyze the original data of one of the preparations of Harris et al. (2015). Two alternative models of individual conditioning are discussed in sections 4 (a general framework where we reformulate the RW model and introduce a new model where subjects initially show resistance to learning) and Colored Stochastic Model of Individual Behavior, where we formulate a descriptive model of short-scale random fluctuations of individual responses and contrast it with the data. Final remarks are collected in section 6. The Supplementary Material is devoted to material that would disrupt the flow of the main text.
2. Single-Cue RW Model
According to the model developed by Rescorla and Wagner, the association between the conditioned stimulus (CS) and the unconditioned stimulus (US) in Pavlovian training can be measured, at the n-th trial or session, by the operational variable vn, called association strength. Usually in the literature, this is denoted with Vn, but here we use a small letter to avoid confusion with the potentials introduced below. The change Δvn: = vn − vn−1 in the strength of the association at the n-th trial is
where 0 ⩽ α ⩽ 1 is the salience of the CS, 0 ⩽ β ⩽ 1 is the salience of the US, and 0 ⩽ λ ⩽ 1 is the magnitude of the US. For convenience, we promote the trial sequence n = 1, 2, 3, … to a continuous time process described by a continuous time variable t. This approximation is valid as long as we consider many trials or sessions. In this way, we can recast Equation (1) as the first-order differential equation
where a dot denotes a derivative with respect to time, . Its general solution is
where c is a constant. The initial condition at t = 0 of this solution is v(0) = λ − c, while v(+∞) = λ. Therefore, for excitatory conditioning c = λ > 0 (Figure 1), while for extinction λ = 0 and c < 0, so that v = |c| exp(−αβt) decreases in time.
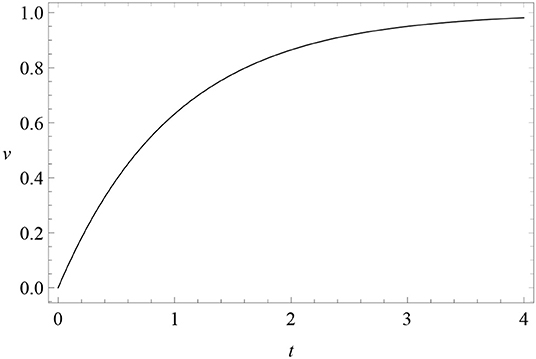
Figure 1. Learning curve: the solution (3) v(t) (vertical axis) of RW conditioning model (2) as a function of time t (horizontal axis), for c = λ = 1 and αβ = 1 (excitatory conditioning).
In this article, we will consider only excitatory conditioning and attempt, among other possibilities, to fit data with the monotonic learning curve
This theoretical curve has two free parameters: λ and the product αβ. In the experiment below, we will not be able to determine the salience of the CS and US separately.
At the risk of stating the obvious, it should be noted that there are two ways in which to interpret Equations (2) and (4). One is as an associative model for individuals, in which case v(t) is the association strength at a given time t of a given subject. If the RW model were a reliable description of reality, all subjects should obey the model with reasonable accuracy and differ in their behavior only in the value of the parameters λ, α, and β in the aforementioned equations. However, this interpretation is too restrictive and does not allow for individual differences in the learning process, something that any experimentalist would recognize as inevitable. However, if the majority of subjects obeyed the RW model, then the latter could be regarded as valid in average, in which case we will make it explicit that the association strength appearing in Equations (2) and (4) should be replaced by the average over the subjects:
As we will see in this article, the RW model is a good description of Pavlovian learning both for individuals and in average. However, we do find individual differences which can be better described by an extension of the model which we will dub “dynamical,” and which does not improve averaged data significantly. Therefore, we will strictly keep the distinction between models for individuals (v) and in average (〈v〉).
3. Two Experiments on Pavlovian Conditioning
3.1. A Long Experiment on Pavlovian Conditioning
3.1.1. Subjects and Materials
We employed 32 male Wistar Han rats, without food or water restriction, divided into two experimental groups (Group 1 and Group 2) and two control groups. The US was drops of saccharin solution at 0.1% concentration for Group 1 and at 0.2% for Group 2. One experimental subject was removed due to poor health. The US was delivered in individual conditioning boxes via a water pump activated by an electrovalve. For full details of the subjects and the materials, including a justification of the chosen saccharin concentrations (see the Supplementary Material).
All care and experimental procedures were in accordance with the Spanish Royal Decree 53/2013 regarding the protection of experimental animals and with the European Union Council Directive 2010/63. UNED bioethics committee approved the experimental protocol.
3.1.2. Experimental Design
The experiment was divided into three phases. In the first phase of pre-training, subjects were exposed to the basic functioning of the liquid dispenser in the conditioning boxes. Drops of saccharin solution of the concentration corresponding to the rat's group were delivered according to a variable-time 5 s schedule (VT-5), implemented as a uniform random distribution between 3 and 7 s with steps of 1 s. Each lick was reinforced by the delivery of another drop via a fixed-ratio schedule (FR-1). Each session of pre-training lasted 10 min and was preceded by 30 s of darkness, lasting in total 10′30″.
The second phase (training) consisted in sessions of total duration of 2,259 s (about 37′40″). After 30 s of darkness, each box was lighted and the session went through for 44 trials, ending with 10 s of inactivity. Figure 2 is a scheme of a trial for the experimental groups. An inter-trial interval (ITI) of variable length averaging 40 s, realized by a uniform random distribution between 20 and 60 s with steps of 4 s, was followed by the CS, a tone of 85 db, 600 Hz, and a fixed 10 s duration. The intensity of the tone was well above the average ambient noise inside each box (65 db). During the CS, a US consisting in one drop of saccharin solution was delivered at random intervals of 5 s (RI-5). A random-interval schedule (Millenson, 1963) establishes a fixed non-zero chance of US delivery every second. In particular, an RI-5 has a 20% chance per second to deliver one drop, hence one drop falls every 1s/0.2 = 5s in average, i.e., twice per CS. Thus, an average of 88 US per session were delivered, roughly ranging between 70 and 110 drops. Each session ended 10 s after the end of the last CS.

Figure 2. Structure of a trial for the experimental groups of our long experiment as described in the text.
The structure of the trials for control groups was the same except for the schedule of delivery of the US: an RI-25 spanning the whole duration of the trial, so that a US could equally occur during the CS and at any other moment of the trial. This corresponds to the delivery of the same amount of solution per trial as for the experimental groups: one drop every 25 s in average, 4% chance of delivery per second, average of 2 drops per trial.
The third and last phase was extinction, the only difference with respect to previous training sessions being the absence of liquid in the drinking dispensers.
3.1.3. Procedure
The subjects were distributed into four groups of eight rats: Group 1 (subjects 1-1, 1-2, …, 1-8) for a US consisting in one drop of 0.1% saccharin solution, Group 2 (subjects 2-1 to 2-8) for a US consisting in one drop of 0.2% saccharin solution and two control groups with the same concentration (Group 1C, subjects 1C-1 to 1C-8, 0.1%; Group 2C, subjects 2C-1 to 2C-8, 0.2%) but randomized US delivery as explained in the previous subsection. Although the subjects were naïve in terms of Pavlovian explicit training, their provenance from three operant experiments was counterbalanced in each group as an extra measure of precaution to minimize the effect of uncontrollable variables due to their past history.
On the first day, all subjects went through the phase of pre-training, consisting in two consecutive sessions of the pre-training described in the previous subsection. On the same day or the day after, session 1 of the training phase was run upon the subjects. The total duration of the experiment was 90 sessions, run once or twice per day with an inter-session interval ranging from a minimum of 1 h and 30 min to about 3 h and 30 min. The day after session 90, we moved all subjects through two consecutive sessions of extinction.
3.1.4. Results
To compare data with the theoretical model, one has to be careful about the identification of the association strength. In our experimental design, the US is presented simultaneously with the CS and one must account for the responses directly due to the US. However, conditioned and unconditioned licking are not easy to separate, since rats normally lick multiple times even for small volumes of water. Although it is difficult to eliminate this problem and thus to record pure conditioned responses, it is still possible to slightly reduce it and define the following index of learning. We can subtract the number of US (which varies from trial to trial and from session to session), to the total number of licks per session and we identify
Thus, whenever we talk about licks during the CS in session-by-session data, we imply that the number of unconditioned responses (responses following the delivery of an US) has been discounted. In this way, at the beginning of training animals responded only upon presentation of the US and the total number of licks is of the same order of magnitude as the number of US presented. A minor issue is that under-response generates negative values of v, but this does not correspond to inhibition. While under-response at the beginning of training means that the animal does not know that the CS predicts the US, inhibition would imply that the animal knows that the CS predicts the no-US. Since negative v's appear only in the very first sessions, this feature does not influence whatsoever the focus of our research on the rest of the data.
In trial-by-trial data, we will not subtract the number of US to the actual response by the animal. The reason is that we will be interested in these data when considering the noise component of the signal (see below for details). A randomized US delivery would produce a white noise averaging to zero and of much smaller amplitude than any other source of noise (statistical error or some intrinsic effect to be checked upon).
After determining the asymptote of learning for each subject, we normalized the data by dividing the number of licks by the estimate of λ. Normalized data have some advantage over raw ones, as explained in the Supplementary Material. For instance, with normalized data one can directly compare the fluctuations in response of different individuals. The average of normalized data is shown in Figure 3. In comparison with Figure S1, we do not notice any qualitative change in the experimental trendline. However, error bars are considerably smaller. Also, while the estimated standard deviation σ of the best fit of raw data was greater in Group 2, after normalization it is smaller: σ = 0.13 for Group 1 and σ = 0.11 for Group 2. The plots showing the data and the RW best fit of v/λ for the subjects in the experimental and control groups can be found in Figures S4–S9.
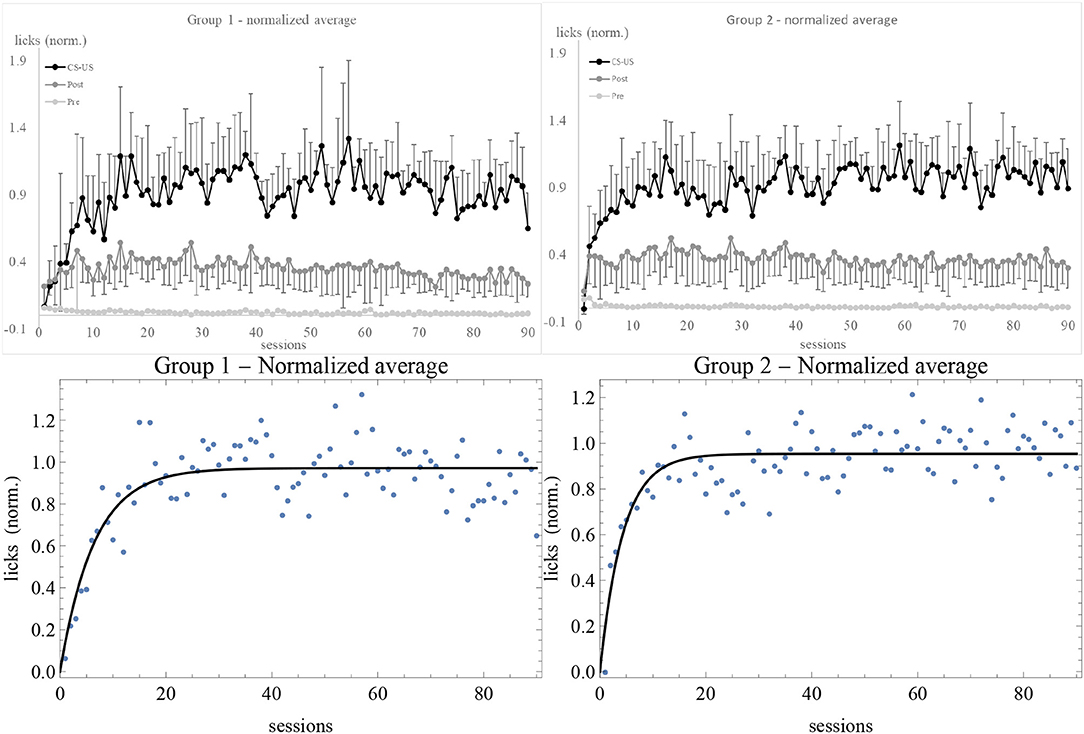
Figure 3. Average of normalized data for Group 1 (top left) and 2 (top right), together with the best fit with the RW model (bottom). Sessions are on the horizontal axis, number of licks on the vertical axis. Light gray, dark gray, and black data points (connected by lines of the same colors) are the licks in the 10 s, respectively before, during, and after the CS. The number of US has been subtracted from the during-CS licks of each individual before taking the average, and the upper and lower error bars at the 68% confidence level of CS and post-CS data are shown.
Now we are in a position to comment on the results. First of all, both the pre-CS and post-CS response in the experimental groups were much smaller than the response during the CS, respectively by a factor of 10 and of 2. At the 68% confidence level, none of the curves overlap. This means that the subjects clearly discriminated between the possibility to obtain the US during the tone and in its absence. The higher post-CS response with respect to the pre-CS is easily explained on the grounds of a natural inertia in licking that extended for a few seconds after the tone was switched off. This interpretation is confirmed by calculating Pearson's correlation coefficient for CS and post-CS licks (non-subtracted and non-normalized data) of individual subjects, which is |r| ⩾ 0.45 except in two cases (1-6 and 2-7)2. The correlation between CS and pre-CS licks is smaller, |r| < 0.38. On the other hand, the control subjects displayed about the same response level before, during, and after the CS, indicating that there was no discrimination and no acquisition of association between the CS and the US3. Moreover, the average asymptotes of learning of Groups 1 and 2 reported in the Supplementary Material before normalizing the data are significantly different: the rats did respond differentially to 0.1% and 0.2% concentrations. Finally, the data of extinction show a very quick decrease in response of experimental subjects, likely due to overtraining (Finger, 1942). The flat response of control subjects during the CS (Figure S2) reflects the absence of association. Also, control subjects showed extinction to the whole “apparatus + tone + electrovalve click” stimulus (light gray trendlines). Overall, these results indicate that simultaneous conditioning was effective and they validate the experimental design.
Let us now turn to individual response differences. Without the pretense of being exhaustive, we registered the following two pairs of patterns:
• Wildly fluctuating response (e.g., subjects 1-1, 1-4, 1-7, 2-1, 2-2, 2-5, 2-6, 1C-1, 1C-3, 1C-6, 2C-1, 2C-4). For experimental subjects, the shape of the learning curve is almost completely lost into noise.
• Less fluctuating response (e.g., subjects 1-2, 1-3, 1-5, 1-6, 2-3, 2-4, 2-7, 2-8, 1C-2, 1C-4, 1C-7, 1C-8, 2C-2, 2C-3), where strong fluctuations are less frequent. Experimental subjects follow more clearly the learning curve.
The difference between “wild” and “mild” fluctuations can be quantified by considering the estimated standard deviation of data with respect to the non-linear fit with the RW learning curve (Table 1). We took as a criterion for “wild fluctuations” variations ⩾30% of the peak response (σ ⩾ 0.30). This criterion is arbitrary (one could have taken, e.g., σ = 0.50 as a threshold) but illustrates the point. Some subjects are somewhat in between these two categories, since they showed a stable response during a long time followed by wildly fluctuating periods.
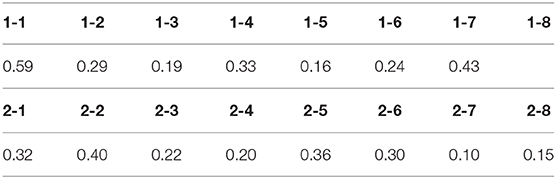
Table 1. Estimated standard deviation σ of the RW-model best fit of normalized session-by-session data.
For those subjects that showed a trend in their response, we can further recognize:
• Slow increase in response (e.g., subjects 1-2, 2-7, 1C-6, 2C-2, 2C-5, 2C-8). For experimental subjects, this is simply due to a slow learning rate, while the interpretation for control subjects is less obvious. Perhaps the unpredictability of the US was a factor increasing the response, as observed also by Kaye and Pearce (1984).
• Slow decrease in response (e.g., subjects 1-1, 1-7, 1C-1, 1C-7, 2C-7). This phenomenon is related to the presentation of the stimuli and their mutual association. This is not short-term habituation, which is a non-associative process occurring relatively quickly (only a few sessions) (Thompson, 2009; Çevik, 2014). Moreover, short-term habituation is faster for weaker stimuli, which we did not see here. However, it is not long-term habituation either, which also occurs in a relatively short time span (a few sessions, although it depends on the experiment and the subject species) before any plateau in the response (Packer and Siddle, 1987; Ornitz and Guthrie, 1989; Plaud et al., 1997). Here one might rather talk about a very long-term habituation, occurring because animals are presented with the same stimulus in all trials of all sessions.
In the next sections, we will make a more in-depth analysis of the individuals' data.
3.1.5. Discussion
Summarizing the conclusions obtained from the above results:
• The experimental design has been validated as a viable tool of generation and control of Pavlovian conditioning4. The subjects discriminated between the different chances of getting the US during the tone CS (simultaneous conditioning) with respect to when the tone was absent. The response was much higher during the CS than before or after. The definitory criterion for successful discrimination is the ratio between pre-CS and CS licking. Post-CS response, seldom discussed in the literature, was much larger than pre-CS response due to a natural inertia in the licking behavior but, still, it was much smaller than the response during the CS.
• While taking the average of raw data is useful for between-groups comparisons (absolute value of the asymptotes), error bars are reduced when considering the average of data with normalized asymptote of learning. Normalizing also the learning rate of individuals does not add much information and is a strongly model-dependent procedure.
• Although we did observe long-range (i.e, spanning several sessions) fluctuations in the average subjects response, the error bars due to individual differences are large enough to conclude that these fluctuations are not significant. The RW model (5) is a good description of the average learning curve in Pavlovian conditioning.
• The main average effects of overtraining are an extremely slow decrease of the post-CS response and a fast extinction (see Figure S10). Fast extinction points out that the response of the animals during the experiment was not driven by habit, contrary to what one might expect in long training histories (Gür et al., 2018).
We can compare our findings with those in the literature of post-peak depression or inhibition by reinforcement cited in the Introduction. In general, our subjects reached the asymptote of learning after 15–20 sessions. While gradients in response have been registered on as short a scale as trial-by-trial or session-by-session intervals, large-scale (i.e., spanning many sessions) fluctuations characterized all the plateau after acquisition. In some cases, we did see a response decrease, but much later than acquisition. Even granting that aversive conditioning may be faster than appetitive one, this leads us to believe that this decrease is a long-range phenomenon different from the post-peak depression observed in experiments employing only a few hundred CS-US pairings, in contrast with our almost four thousand trials each with an average of two CS-US pairings. The latter could be a transient phenomenon corresponding to the first fluctuation peak just after acquisition, when present. Such interpretation is corroborated by past evidence on the non-robustness of inhibition by reinforcement when extending the duration of the experiment (Dukhayyil and Lyons, 1973).
In general, observations of individual differences were not accompanied by attempts to explain them quantitatively (see however, Urcelay et al., 2012). In the following sections we want to do just that. It should be made absolutely clear that the fact that the RW model is a good fit of data does not mean that individual differences and response fluctuations are mere statistical phenomena to be treated as unwanted errors. Different subjects do respond very differently to stimuli and their response does change erratically trial after trial and session after session. The issue then is whether we can find a theoretically motivated model (not just an ad hoc fitting curve, which is not hard to concoct) better than the RW model in explaining the data, in particular, the long-range response decrease observed in some subjects (not to be confused with the post-peak depression effect in the literature, as already said above).
3.2. Experiment 2 of Harris et al. (2015)
This experiment was described in detail in Harris et al. (2015) under the heading “Experiment 2.” Here we will briefly review its characteristics. Data will be analyzed in the next section.
3.2.1. Subjects and Materials
Subjects: 16 experimentally naive male Hooded Wistar rats, 8–10 weeks of age at the start of the experiment. They had unrestricted access to water and restricted daily food rations of regular dry chow equal to 5% of the total weight of all rats in the tub, provided 30 min after the end of the daily training session.
Materials: 16 Med Associates conditioning chambers with a food magazine endowed with an infrared LED and sensor inside, to record entries by the rat. A dispenser delivering 45 mg food pellets was attached to the food magazine. Four different CSs were used: white noise (78 dB), a tone (78 dB, 2.9 kHz), a flashing light (2 Hz, 3.0 cd/m2), and a steady light (30 cd/m2).
3.2.2. Experimental Design and Procedure
For each rat, each CS was allocated to one of the following configurations (and counterbalanced across rats):
• CR10: continuous reinforcement (CS reinforced 100% of the times) with random duration of 10 s mean. Thirty sessions, 6 CR10 trials per session.
• CR30: continuous reinforcement with random duration of 30 s mean. Thirty sessions, 6 CR30 trials per session.
• PR10: partial reinforcement (CS reinforced at 33% of the times) with random duration of 10 s mean. Thirty sessions, 18 PR10 trials per session.
• PR30: partial reinforcement with random duration of 30 s mean. Thirty sessions, 18 PR30 trials per session.
Trial by trial, the CS duration varied randomly on a uniform distribution with a mean of either 10 s (2–18 s) or 30 s (2–58 s). The number of reinforced trials per session per CS was the same in all configurations and equal to 6. See Figure 4 for a scheme of the trial structure of this experiment.
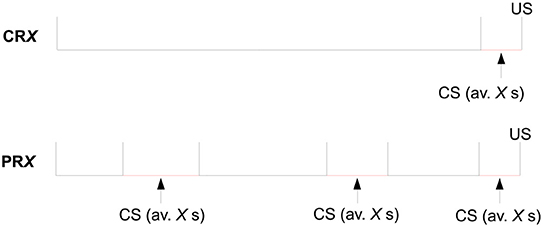
Figure 4. Structure of a trial for the four experimental groups of Experiment 2 of Harris et al. (2015), where X = 10 or 30.
Each of the 30 sessions consisted in a delayed conditioning where presentations of each of the four CSs were randomly intermixed: 6 of each of the continuously reinforced CSs and 18 of each of the partially reinforced CSs, for a total of 48 trials per session. The ITI varied randomly on a uniform distribution with a minimum of 50 s and a mean of 120 s.
The subject response was the head entry into the magazine, recorded during each CS and a 30-s pre-CS period through the interruption of a photobeam at the magazine entrance.
3.2.3. Results
We analyzed the data considering each CS configuration as completely independent of the others. Thus, we treated CR10, CR30, PR10, and PR30 as four independent groups, each undergoing 30 sessions of, respectively, 6, 6, 18, and 18 trials, for a total of, respectively, 180, 180, 540, and 540 trials.
Sessions 26–30 had seven trials each for the CR10 and CR30 CSs, rather than seven trials. The reason of the inclusion of the extra trial (which was without reinforcement) was to look at the post-CS response for at least one trial of the two CR CSs that was not contaminated by the presence of the food-pellet US. Although their impact on the results is negligible, we removed these five extra trials from the analysis.
Also, a word of caution on the analysis of the PR groups. PR subjects underwent partial reinforcement, which means that theoretical models based on continuous reinforcement (for instance, plain excitatory Rescorla–Wagner) should be applied with care, since they do not take into account the fact that the US was not presented at all trials. However, when the presentation rate is deterministic, fitting PR data entries with models of deterministically delivered continuous reinforcement will be perfectly consistent.
4. Dynamical Model of Individual Behavior
4.1. Motivation: Least-Action Principle and Fine Tuning
Thanks to its simplicity, the RW model is an ideal example where to introduce all the main ingredients of a dynamical reinterpretation of Pavlovian conditioning processes. By dynamical, we mean a very precise concept, superior to any casual use of the term in the loose sense of “evolving” or “interacting”. Namely, we postulate that any conditioning process can be described by a quantity called action and that the change of the association strength during conditioning happens in such a way that the action is minimized. Let us introduce the rationale behind this view.
As a global, externally observable phenomenon, Pavlovian learning has been described through models, such as Rescorla and Wagner (1972) and others (Mackintosh, 1975; Pearce and Hall, 1980; Wagner, 1981; Le Pelley, 2004; Wagner and Vogel, 2009). In general, the essence underlying these models appeals to psychological aspects, such as the surprisingness or novelty or predictiveness of the stimuli. However, it is not unreasonable to believe that an alternative conceptualization is possible where, despite behavioral errors by the subject, the learning process is a naturally efficient one and, so to speak, minimizes the biological adaptation effort. At a biological level, learning can be viewed as a sequence of events modifying some of the synaptic connections of the brain. This modification does not happen in a disordered way since, as associative models already highlighted, there exist laws (learning curves) applicable to statistically significant samples. Going a bit beyond the macroscopic view of traditional associative models, but without attempting a microscopic quantitative description of neural plasticity, we postulate that the brain mechanics of a subject change through learning from an initial state A to a final state B efficiently. Operationally, a most effective way to describe this minimization of effort is through the action. If we depict the learning process in time t as a path from A to B in an abstract space parameterized by the association strength v, the profile v(t) describing the evolution in the association strength minimizes the path from point v(tA) to point v(tB). A similar statement could be made about the energy spent in changing the internal state, but both are described by the same quantity, the action. The action S[v] is a function of the association strength v and it is minimized when its variation with respect to v is zero5:
This is the principle of least action. It has been applied successfully in physics and our aim now is to use it also in psychology. From physics we will get guidance about what S[v] is and this guidance will prove itself correct because it will immediately recover the RW model as a special case.
The main idea is to reinterpret the learning curve of any associative model as the trajectory of one or more small balls (pointwise particles) rolling up and down a hill (a potential). The way a particle moves along its potential is called dynamics. In the case of the RW model, there is only one particle whose trajectory is shown in Figure 1 and whose potential U(v) is depicted in Figure 5 (top). The proof of this statement, the explicit form of the action S[v] and the dynamics corresponding to multi-cue or variable-salience conditioning models are given in the Supplementary Material. In excitatory conditioning with just one cue, the particle rolls down the slope from the point v = 0 to the bottom at v = λ, where it unnaturally stops.
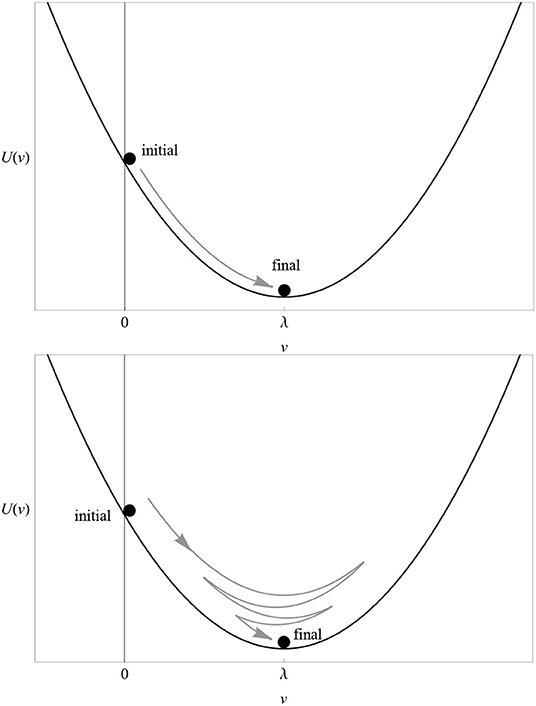
Figure 5. (Top) The potential U(v) of the RW model for λ = 1 and αβ = 1. Compare with the solution (3) in Figure 1. (Bottom) The potential U(v) of the dynamical model for λ = 1 and (αβ)2+μ2 = 1. Compare with the solution (8) in Figure 6. In both cases, the particle rolling down the potential represents the change in the associative strength. The direction of “motion” in excitatory conditioning is represented by a gray arrow.
At this point, one appreciates the first major advantage of the least-action principle. If the latter is true, then it is very hard to understand why a particle placed on the slope of the potential well would roll down and stop exactly at its bottom. The least-action principle tells us that we must fine tune the initial conditions (position and velocity) of the particle to infinite precision in order to achieve such a behavior. If some latitude in the choice of initial conditions is allowed (as it should in a natural biological setting), then in general the particle will oscillate up and down the well until reaching a final stop at the bottom, as shown in the bottom plot of Figure 5.
We decided to use tools borrowed from physics because, in the long run, they carry two major advantages. First, as said above, they allow one to modify Pavlovian models in a natural way that would result rather obscure in the traditional approach, and that can be contrasted with experiments. Second, they are the basis from which one can construct predictive theories of individual short-scale response variability, presented in the Supplementary Material. Ultimately, revisiting conditioning models as dynamical models amounts to a new paradigm of doing model-building in psychology, where qualitative reasonings leading to quantitative formulæ are replaced by a rigorous sequence of logical steps. As in any model building, arbitrariness is not removed, but it will be pinpointed and put under a higher degree of control.
4.2. Theory
The catchword is “unnatural.” The way the particle moves along its potential in the case of the RW model is very special because it reduces to the simple equation (2). When it rolls down the slope, the particle experiences some resistance (friction) from the floor, but not so much as to brake completely. This happens, by sheer coincidence, exactly at the bottom of the slope. In a more general situation, we would expect the particle to oscillate up and down the bottom, if the friction is moderate, until it reaches a complete stop (Figure 5, bottom). If we abandon the rigid setting of the RW dynamics and allow for such a scenario, much more natural from a dynamical point of view, we obtain a different trajectory, i.e., a different learning curve (see Supplementary Material):
where μ and A are constants. When μ = 0, there are no oscillations and this reduces to the RW model (4) of excitatory conditioning. When μ ≠ 0, learning is subject to a friction force with progressively damped oscillations around zero. The parameter A is the amplitude of the sine harmonics, so that when A = 0 oscillations have a pure cosine phase. The learning curve is modified as in Figure 6. This profile features oscillations of fixed frequency μ and decreasing amplitude above and below the asymptote, which we can look for in data. In particular, it predicts a first response peak above the subsequent asymptote.
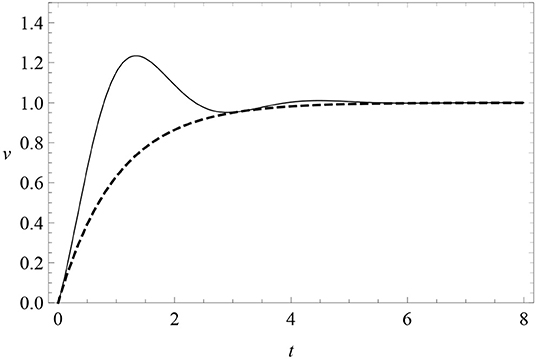
Figure 6. The learning curve (8) (solid) with periodic oscillations with μ = 2 and A = 0, compared with the RW learning curve (4) (dashed). Here λ = 1 = αβ.
Notice that v(t) is not positive definite at small times unless A is sufficiently small. To avoid this problem and to remove a free parameter from the model, we will pay special attention to the case A = 0. Data will show that the A ≠ 0 is disfavored anyway.
Reverting back to discrete time, we can recast the DOM as a law for the association strength vn at the beginning of trial (or session) n. The first and second-order derivatives and correspond, respectively, to the forward finite differences Δvn = vn − vn−1 and Δvn+1 − Δvn = vn+1 − 2vn+vn−1, so that the analog of Equation (1) is
It is easy to show that the RW model is recovered when μ = 0. In fact, (1) implies that , which is Equation (9) in the limit μ → 0. Unless μ = 0, it is not possible to write a simple incremental law as RW, and the association strength at the beginning of trial n+1 is predicted by that of the previous two trials n and n−1, instead of just the one immediately preceding as in the RW model (1). Both in the RW model and in the DOM one can predict the value vn+1 at the next trial, but while in the RW model we only need to know the present value vn, in the DOM we also need the past value vn−1. Shifting this statement one trial in the past is equivalent to say that the DOM can predict the value of the association strength not only at the next trial, but also at the next-to-next one, provided we know the present value. Conversely, shifting the last statements two trials in the future, from the present and the previous value of the association strength the DOM can retrodict the value of the association strength two trials before. In this sense, the DOM has a longer memory of past states than the RW model.
Since this feature gives valuable insight in the psychological interpretation of the DOM, let us dwell more on it. In the RW model, the main postulate is that learning (i.e., the momentum Δvn, the difference of association strength between one trial and the previous) is proportional to the prediction error (λ − vn−1). This is the incremental law (1). In the RW model, the increment Δvn is always positive, the association strength increases and the subject always “learns more” than before. However, in the DOM the association strength of the subject can also decrease in some trials, corresponding to the descending slope in the learning curve after a peak. This does not mean that the subject has “unlearned” what was previously acquired; this would be true if learning were a positive monotonic process as in the RW model. Rather, the association strength decreases only after having increased to an over-optimal point. The subjects are neither over-learning nor unlearning: they are simply trying to reach a balance between what was learned and their capacity to predict the environment.
This is reflected in the equation governing the DOM, which is more complicated than the incremental law (1) and is replaced by Equation (9). This expression relates knowledge, predictions and retrodictions of three different trials in terms of the prediction error. It is as if the animal had a better predictive algorithm than in RW in terms of how many future and past trials it can scan. In particular, Equation (9) implies that the prediction error depends mainly on the learning at the next-to-next trial and, to a lesser degree (because 1 − 2αβ < 1), on the learning at the next trial. However, with respect to RW prediction errors weigh more on learning, since the right-hand side of (9) is augmented by a factor μ2. Hence subjects can predict what is going to happen further in the future, but they do so with greater uncertainty. Or, alternatively, prediction of the subject performance at a given trial requires more information from the past, which introduces a heavier weight of the error. This is the origin of the overshooting of optimal response and the subsequent readjustments through an oscillatory pattern. We dub this justification of the DOM the errors-in-learning argument and it is perhaps the most compelling one from a psychological point of view. It makes the learning process considerably more flexible than in the RW model.
The description of learning with second-order differential or finite-difference equations (momenta) has a precedent in connectionism (Rumelhart et al., 1986), while a parallel to frictional kinematics was also established by Qian (1999). As far as we know, these ideas have never been applied to animal learning. Also, our theoretical motivations are different and strongly based on a dynamical (action-based) view of learning and behavioral processes, rather than on a simple analogy with kinematical equations.
4.3. Data Analysis: Comparison With the RW Model
In order to assess the goodness of fit of the dynamical proposal with respect to the traditional RW model, we should take into account that the first has more free parameter than RW. Having more parameters clearly gives an intrinsic flexibility in data fitting that more rigid theories do not have, and one should balance this factor against the actual capabilities of the new models to accommodate observations. This is the typical situation where comparative statistics, such as the Bayesian (or Schwarz) Information Criterion (BIC) and the Akaike Information Criterion (AIC) can be extremely useful, as advocated by Witnauer et al. (2017).
Let be the error variance of the fit, the averaged sum of squared residuals (also known as residual sum of squares or sum of squared errors), where N is the number of data, yn is the experimental datum at the n-th session and f(tn) is the value predicted by the theoretical model. (The error variance is not the estimated variance σ2 of the fits discussed above. They are related to each other by , where p is the number of free parameters of the function f). The BIC is defined as (Schwarz, 1978)
while the AIC is (Akaike, 1974)
The first term in Equations (10) and (11) quantifies the badness of the fit (the greater the error variance, the worse the fit), while the second term increase linearly with p. The BIC and AIC penalize model complexity slightly differently. For each theoretical model, one can compute the BIC and the AIC: the model with smaller criteria is to be preferred. Calling the difference Δ: = |(IC model 1) − (IC model 2)| for the Bayes or Akaike IC, one finds weak evidence if Δ < 2, positive evidence if 2 ⩽ Δ < 6, strong evidence if 6 ⩽ Δ < 10, and very strong evidence if Δ > 10 (Jeffreys, 1961; Kass and Raftery, 1995). We will use the term “moderate” to indicate cases where evidence is positive in one criterion but weak in the other.
While the RW model has two free parameters (λ and αβ), the DOM (8) has four (λ, αβ, μ, and A), which can give more flexibility with respect to the RW model but are more penalized in the Information Criteria when fitting session-by-session individual data.
We can divide the subjects in three groups: those for which the RW model is clearly favored, those for which the DOM is clearly favored, and those where the RW and dynamical oscillatory models are about equally favored by the Information Criteria.
4.3.1. Our Experiment
The results for our long experiment are summarized in Tables 2, 3.
• As one can see from the table, the RW best fit is favored for subjects 1-1, 1-2, 1-3, 1-4, 1-5, 1-6, 2-2, 2-6, and 2-7 (weak to positive evidence, 1 ⩽ Δ ⩽ 5). However, here we are not comparing two independent models but a model and its extension by one (μ) or two (μ, A) extra parameters. Therefore, we have to interpret with care the meaning of the cases where RW is favored. We can divide them in three groups:
– Five cases (subjects 1-1, 1-2, 1-4, 1-5, 2-2, and 2-7) where also the DOM with mu close to zero fits the data. It means that for these subjects the RW model and the DOM are indistinguishable. For subjects 1-1, 1-2, 1-5, 2-2, and 2-7, the estimated μ in the oscillatory best fit is compatible with zero (1-1: μ = −0.13±0.17; 1-2: μ = 10−11±107, 1-5: μ = 6±105; 2-2: μ = 10−6±104; 2-7: μ = 10−4±6). Therefore, there is no statistically significant smooth oscillation of the type (8) in their response. For subject 1-4 (weak evidence in favor of RW according to the AIC, Δ = 1), μ is non-zero at the 68% confidence level but zero at the 99% confidence level (μ = 0.45 ± 0.21).
– Two cases (subjects 1-3 and 1-6) where the DOM fails to fit data unless one imposes μ = 0 by hand. Leaving this parameter free, here μ is significantly non-zero at the 99% confidence level but is very high (1-3: μ = 12.61±0.04; 1-6: μ = 6.23±0.02), meaning that data are fitted with densely packed oscillations. We regard this as an artifact and thus discard these oscillatory fits as unviable.
– One case (subject 2-6) where the RW model is, so to speak, superior by brute force. Here μ is significantly non-zero at the 99% confidence level and is not high (μ = 0.04±0.01), but the BIC and AIC are larger than for the RW model.
From this discussion, we conclude that, of these nine cases, only one (subjects 1-3, 1-6 and 2-6) directly discards the DOM with μ ≠ 0, although with only weak to positive evidence. While in all the other cases Hull's primacy does not exclude the fact that, for these subjects, the DOM with μ close to zero is also allowed.
• The data of subjects 1-7, 2-3, 2-4, and 2-8 favor the A = 0 DOM with, respectively, very strong, moderate, strong, and moderate evidence. Restoring A as a free parameters, we get an even better fit for subject 1-7. The p-value for μ in all these cases is very small, which means that the probability to have μ ≠ 0 by statistical chance is negligible.
• The case of subjects 2-1 and 2-5 is less clear-cut and we have to look at the decimals: the A = 0 DOM (2-1: μ = 0.17±0.03; 2-5: 0.56±0.04) is slightly more favored than the RW model in the AIC for subject 2-5, and vice versa, so that we attribute one each. Since the difference is about 1% of the value of the criteria and evidence in favor or against is weak (Δ = 1), this attribution is only for the sake of the final counting.
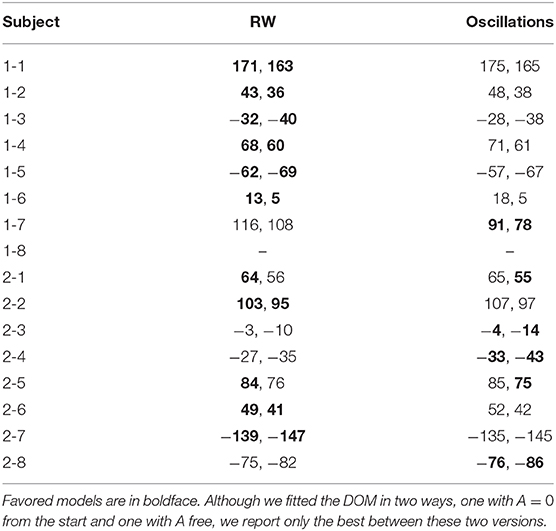
Table 2. BIC and AIC (in the format “BIC, AIC” and approximated to zero decimals) of the best fits of the session-by-session data of our long experiment with the RW model (4) and the DOM (8).

Table 3. Percentage of subjects of our long experiment following the RW model or the DOM, i.e., subjects with, respectively, zero and non-zero frequency parameter μ.
The best-fit parameter values of subjects 1-7, 2-3, 2-4, and 2-8 for the two models are given in Table 4 and the best-fit curves are shown in Figure 7. Since the favored best fits with A ≠ 0 are not particularly strong (the parameter A is always zero at the 95% confidence level), we can conclude that the model with A = 0 is sufficient to fit successfully the data of these subjects deviating from the RW behavioral trend.
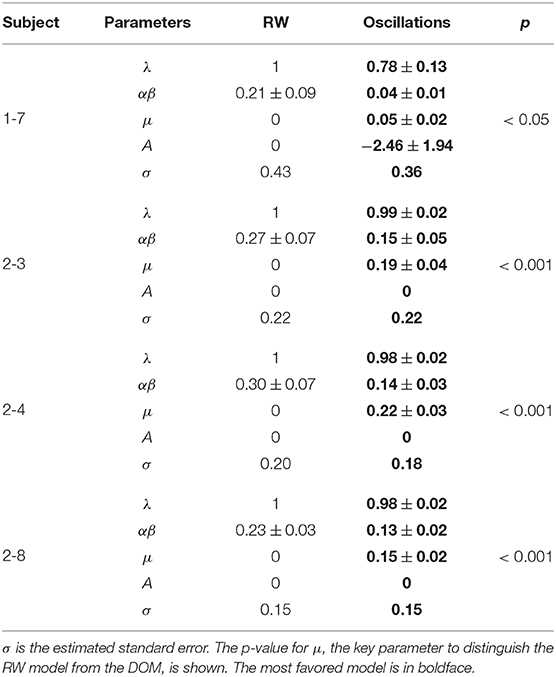
Table 4. Best-fit values of the parameters of the RW model (4) and the DOM (8) for those subjects whose data of our long experiment (normalized with respect to the RW asymptote) favor the DOM for both the BIC and the AIC (hence subject 2-5 is not shown).
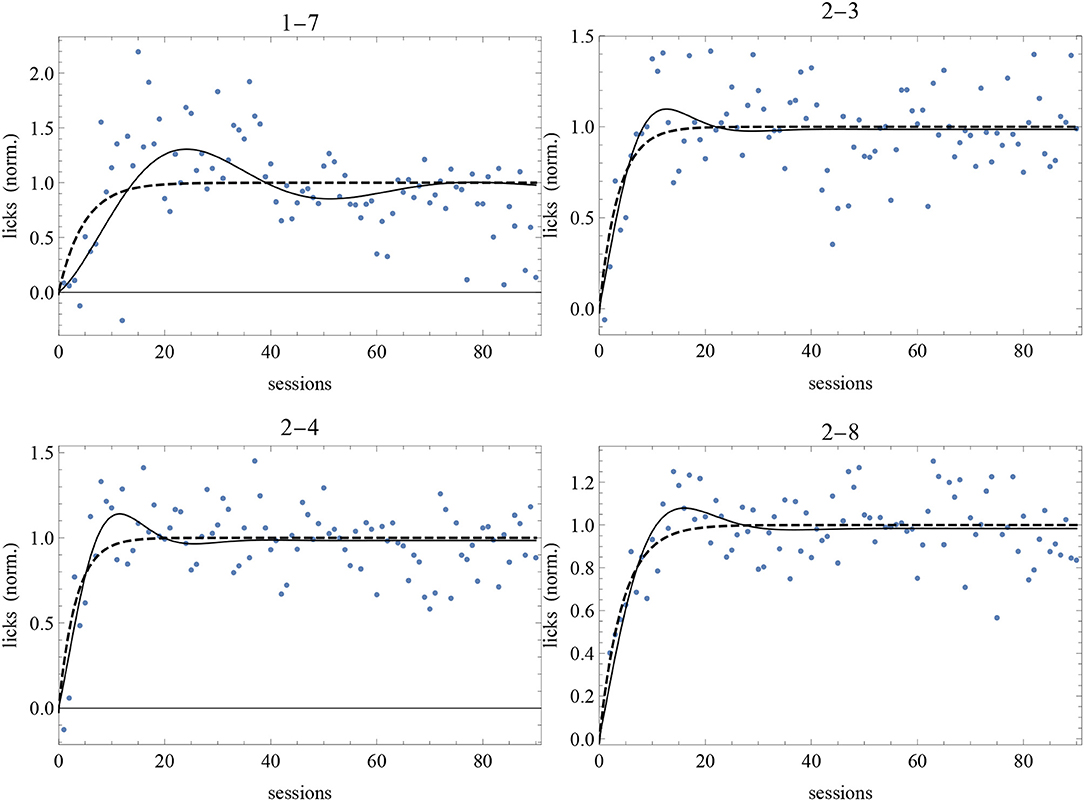
Figure 7. Best-fit of normalized data of our long experiment with the RW model (4) (dashed curve) and the DOM (8) with A = 0 with the parameter values of Table 4. Sessions are on the horizontal axis and normalized response is on the vertical axis.
4.3.2. Harris et al. (2015) Experiment 2
The BIC and AIC of the RW model and the DOM are shown in Tables 5, 6 together with the difference ΔHO = ICRW − ICoscil. Favored models are in boldface; when two models are favored in different IC, the one with strongest evidence “wins.” Oscillatory fits yielding bigger IC and those that fail to produce a non-trivial model (i.e., if μ and/or A vanish) are discarded. Trivial RW fits with vanishing αβ are reported except when also the other fits fail, in which case all cells are left blank. An example of fit is shown in Figure 8 and a summary of RW and oscillatory favored models is given in Table 7.
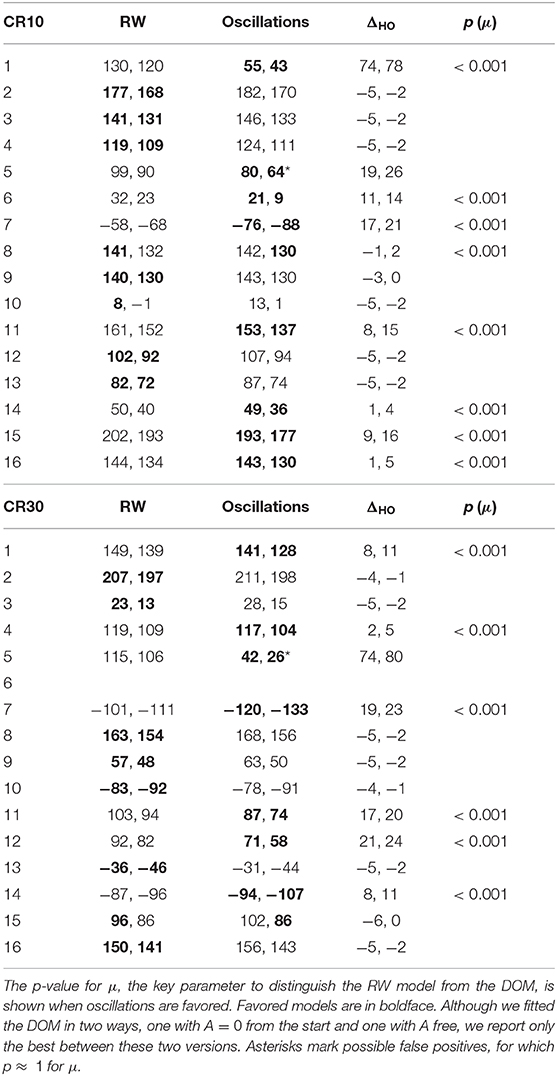
Table 5. BIC and AIC (in the format “BIC, AIC” and approximated to zero decimals) of the best fits of the trial-by-trial data of CR10 and CR30 groups in Experiment 2 of Harris et al. (2015) with the RW model (4) and the DOM (8).
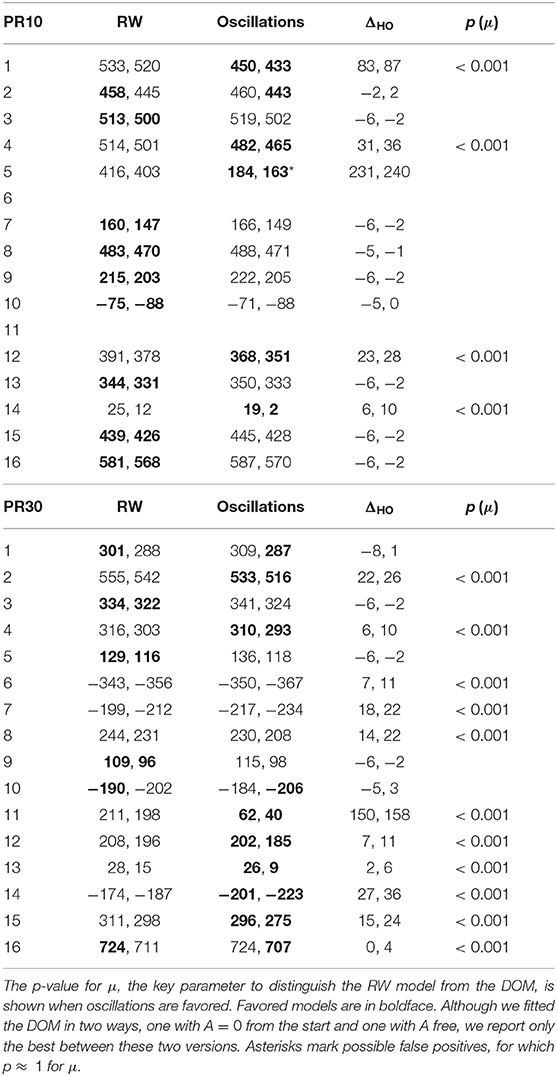
Table 6. BIC and AIC (in the format “BIC, AIC” and approximated to zero decimals) of the best fits of the trial-by-trial data of PR10 and PR30 groups in Experiment 2 of Harris et al. (2015) with the RW model (4) and the DOM (8).
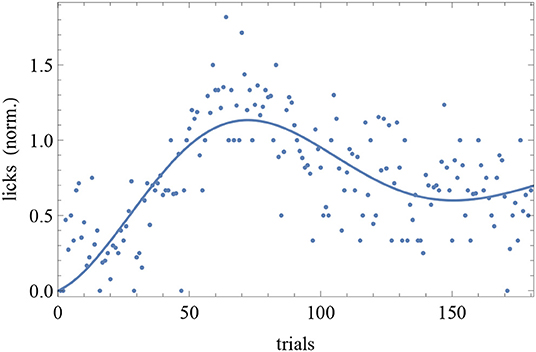
Figure 8. Trial-by-trial data of subject CR10-1 fitted with the DOM (8). Trials are on the horizontal axis and response is on the vertical axis.
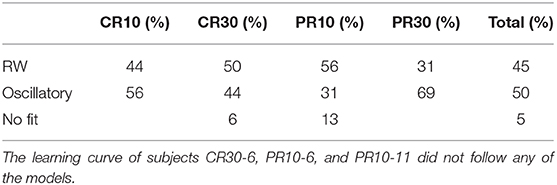
Table 7. Percentage of subjects of Experiment 2 of Harris et al. (2015) following the RW model or the DOM, i.e., subjects with, respectively, zero and non-zero frequency parameter μ.
A group comparison using Tables 5–7 shows that:
• When the RW model is favored, it is so with weak to positive evidence in CR groups and positive to strong evidence in PR groups. This increase in evidence in favor (but not in the number of favored cases) is probably due to the larger number of data points (three times as many in PR groups with respect to CR groups).
• On the other hand, the great majority of favored DOMs have very strong evidence in favor. Thus, when subjects display oscillations in their learning curve the effect is usually strong, not just tiny perturbations of the monotonic RW curve.
• Within the same type of reinforcement (continuous or partial), when extending the trial duration this percentage switches in favor of the other model, but in the opposite way of the groups with the other type of reinforcement (CR10 and PR30: majority is oscillatory; CR30 and PR10: majority is RW). This puzzling pattern may have an explanation, which we support by the data in section 2.4 of the Supplementary Material. The bottom line is that longer trials stabilize the behavior, but a partial reinforcement schedule destabilizes it, where increasing stability means fewer erratic patterns and/or more RW patterns, without being accompanied by smaller oscillations in oscillatory patterns. We will confirm this finding in Calcagni et al. (under review).
4.4. Discussion
In our long experiment, the RW model is favored (but only moderately) with the respect to the μ ≠ 0 DOM for only one out of the 15 experimental subjects; the DOM with A = 0 and μ ≠ 0 is strongly favored in two subjects and moderately favored in two more; the DOM with A = 0 and μ = 0 coincides with the RW model and is a good fit of eight more subjects; and there is no preference for either the RW model or the DOM in two more subjects. The fact that the RW model is favored (and moderately so) only in 7% of the experimental subjects with the respect to the μ ≠ 0 DOM justifies the present and future interest in the A = 0, μ ≠ 0 DOM (8).
Since RW is a subcase of the DOM, if RW is favored for a subject, then the DOM with frequency ~0 may also be a good fit, while if one of the DOMs is favored, it means that the frequency cannot be set to zero and RW is not a good fit. Since the goal is to fit as many subjects as possible with the same model, then the conclusion from our experiment (Table 3) is that, if we insist in considering the RW model as the correct description of the learning curves, then we can explain at most 67% of the data (6+4 = 10 subjects out of 15), while if we postulate the least-action principle we obtain a model that includes RW as a special case and can fit successfully 100% of the data. Also the results from Experiment 2 of Harris et al. (2015) (Table 7) leads us to conclude that the DOM provides a more powerful explanation of the data than RW, since it can account for 95% of the data against the 45% by RW. Therefore, this extension of the RW model is both natural and viable.
5. Stochastic Model of Individual Behavior
5.1. Motivation and Spectral Analysis
The DOM describes long-range modulations in the subjects' responses, where an oscillation period (a peak followed by a trough) spans tens of sessions. However, even the most cursory look at the data reveals that response variates somewhat wildly at a much shorter scale, from session to session or even from trial to trial. In this section, we will study these short-scale variations quantitatively using a spectral analysis and we will connect our results with an interesting open question in the cognitive literature: Should these fluctuations be treated as experimental error or do they have an origin in the cognitive modules of the subject? While the answer seems to be No–Yes when subjects are human, little or no attention has been drawn to the case of animals. According to our results, the answer is Yes–No: response fluctuations occurring at short time scales are indistinguishable from experimental error.
The generalized presence of large short-scale fluctuations in the response translates into an unstable inter-trial and inter-session associative strength. These fluctuations are present in Harris et al. (2015) experiments as well as in ours, even in those very few subjects with relatively small inter-session variability. Since there seems to be no qualitative change with the time scale (see Figure S18), fluctuations might be assumed to plague the performance of the subjects at any scale. This means that it is quite natural to regard these data as a time series described by a nowhere-differentiable pattern instead of a smooth learning curve. This is the motivation to replace (1) with an evolution equation for the associative strength encoding a stochastic component6.
A spectral analysis is an analysis of the frequency modes constituting the noise in data. Technically, it amounts to take the Fourier transform of the data. Intuitively, it means to count how many times a response fluctuation of a given amplitude occurs for a subject during the experiment. If data predominantly oscillate on a long time scale, then the noise dominates the small frequencies of the spectrum. On the other hand, if oscillations mainly occur on a very short time scale, then the spectrum is more noisy at large frequencies. The noise in learning data corresponds to the second case.
In essence, the variability of the response of a subject is encoded in the frequencies ω, distributed in the so-called power spectral density S(ω), obtained from the response. If the response is perfectly stable from trial to trial, then all frequencies are equally represented in S(ω) and the power spectral density is constant. If the response varies gradually as in the ideal learning curve of the RW model, then S(ω) is a smooth function. If, however, the response varies erratically from trial to trial, as in actual data, then S(ω) becomes very ragged and this raggedness is what we call noise. The basics of spectral analysis and theoretical shape of the power spectral density for the RW model without and with noise are presented in the Supplementary Material. Here we only note that noise alone is usually represented by the power spectral density
where a is a constant. When a = 0, noise is said to be white, while it is colored if a ≠ 0.
The nature of the noise source in data can be discriminated by the large-frequency region of the power spectral density. If all noise comes from statistical error, then this region is flat in the log-log plane. However, if this region is not flat and exhibits a positive or negative average slope, then it is possible that some other random noise-generating mechanism, of cognitive-behavioral origin, is in action.
5.2. Theory
The RW model with colored noise admits a straightforward mathematical treatment as a stochastic process, where vn is promoted to a random variable Vn = vn + ξn, where vn and ξn are, respectively, the deterministic and stochastic parts (see Supplementary Material).
To give ξn a psychological interpretation, we can draw inspiration from the “1/f noise” cognitive literature, where the variability in human response in memory tasks, reaction tasks, mental rotation, word naming, and so on, is characterized by a colored noise (Gilden et al., 1995; Gilden, 2001; Eke et al., 2002; Van Orden et al., 2003, 2005; Wagenmakers et al., 2004, 2005, 2012; Holden, 2005, 2013; Thornton and Gilden, 2005; Farrell et al., 2006; Kello et al., 2007, 2008; Holden et al., 2009, 2011; Stephen et al., 2009a,b; Dixon et al., 2010, 2012; Ihlen and Vereijken, 2010, 2013; Likens et al., 2015; see Kello et al., 2010; Riley and Holden, 2012, for reviews). There are three interpretations of this phenomenon. In the idiosyncratic view, this noise is regarded as the intrinsic uncertainty, possibly due to an internal estimation error, in the formation of mental representations, such as the reproduction of spatial or temporal intervals in human memory (Gilden et al., 1995). Different cognitive systems combine to accidentally generate an overall noise term (Wagenmakers et al., 2004, 2005, 2012; Farrell et al., 2006). In the nomothetic view, the stochastic component is a more fundamental mechanism where cognition emerges as a self-organizing complex dynamical system (Gilden et al., 1995; Gilden, 2001; Van Orden et al., 2003; Stephen et al., 2009a,b; Dixon et al., 2010, 2012; Ihlen and Vereijken, 2010; Riley and Holden, 2012; Holden, 2013). In particular, the colored noise is the collective expression of the metastable coordination of different cognitive and motor systems in the performance of a task (Kello et al., 2007). A third view intermediate between the idiosyncratic and the nomothetic was also considered (Likens et al., 2015).
Translating these considerations to the realm of non-human animal behavior, we can entertain the possibility (Calcagni, 2018) that, if non-white noise were detected in experiments of Pavlovian or operant conditioning, one would be observing a signal coming form the coordination of motor systems with the internal functioning of the subject's mind (either as an averaging of multiple cognitive subsystems or as an emergent collective manifestation of such coordination). We will come back to this cognitive perspective after analyzing the data.
5.3. Data Analysis: Comparison With the RW Model
Session-by-session data are a coarse-grained version of the full data set of trial points. Inevitably, this coarse graining can hide or distort stochastic signals present at all time scales. For this reason, we consider trial-by-trial data. It is not difficult to check that a similar analysis done with session-by-session data yield the same results, but with a much greater error in the fits.
Note that the fits of the oscillatory and RW models were made with session data (90 points) for our long experiment, while those for the data of Harris et al. (2015) were made with trial data (180 or 540 points). Trial data of our experiment have larger dispersion than Harris et al. (2015) trial data, while their dispersion is comparable when the former data are binned into sessions.
5.3.1. Our Experiment
The Supplementary Material includes the parameters of the RW model fitting trial-by-trial data and the power spectral density of the signal of the experimental subjects, calculated from each individual set of trial data points.
We look for a fit of the type of (12) (times a constant which plays no role here) of the region of the spectral densities dominated by the stochastic noise, typically for ω > 0.1. Fitting the power spectra from ω = 0.1 to ω = 30, we get that the parameter a is zero within the experimental uncertainty at the 1σ-level for all subjects except 1-1, 1-3, and 2-3, where a vanishes at the 2σ-level. In all cases, the best-fit value of a is very close to zero, at least in one part over one hundred. Therefore, all subjects of both groups display white noise.
Note that the spectral analysis of the noise signal occurs in a frequency region unaffected by whether the background model is RW or the oscillatory one (Equations 4 and 8).
5.3.2. Harris et al. (2015) Experiment 2
Also for this experimental set the spectral noise function fit was done from a minimal to a maximal frequency, with a given sampling rate. The maximal frequency was chosen to be 60 Hz because the time resolution of recorded data in Harris et al. (2015) was of 16.6 ms. As a lower frequency, we took 1 Hz because at frequencies lower than that the spectrum is dominated by the learning curve (i.e., the spectrum becomes a deterministic smooth curve at about ω < 0.5−1 Hz for all subjects). Including smaller frequencies would introduce artifacts. Also, trial lengths do not extend beyond a certain value (18 s for the PR CSs and 58 s for the CR CSs), which puts a limit on how low the frequency can be. A sampling rate of ω = 1/58 = 0.02 Hz for the trials of up to 58s and ω = 1/18 = 0.05 Hz for trials up to 18s was used.
The values of a of the noise best fits are all very small (see Supplementary Material) and the conclusion is that noise is white for all subjects at the 2−3σ-level. All groups show the same noise in average.
5.4. Discussion
Having checked the presence of white noise in individual subjects, we turn to the psychological interpretation of these results. From a strictly behaviorist point of view, the question of whether this noise comes from a naive sum over different cognitive systems or arises as an emergent phenomenon is immaterial. These data cannot tell us anything about either alternative. However, we observe the same noise in all subjects and this noise is white. The simplest explanation is that its origin is statistical and implies no fundamental property of the “rat mind.” If there were an underlying motor-cognitive mechanism (naive interference or emergent phenomenon) depending on the individual, on the task, and on the relevance of the stimuli for the subject and its learning history, one would see these differences in the noise trend. Although we cannot exclude this possibility, our data do not yield support to it. In particular, they exclude the cognitive function of attention as the main responsible for colored noise. In fact, the main processes involved in this Pavlovian experiment are motor and attentional, and the only source of a colored signal could come from attention alone (or its interference with motor processes; idiosyncratic view) or as an emergent phenomenon from the combination of attention and motor processes (nomothetic view). The conclusion is that higher-order cognitive functions, absent in this experiment but present in those of human response, may be the main source of colored noise.
Talking about response variability in the learning curve, Gallistel et al. (2004) conjectured that data of conditioning experiments might bear a trace of a colored noise. We do not confirm this conjecture here and, on the other hand, we also insist on the existence, at a significant confidence level, of a learning asymptote, which was questioned by the same authors.
We also stress that the cognitive-noise hypothesis is descriptive but not predictive. To the best of our knowledge, no explicit model of the “internal working of the mind” predicting the observed diversity of noise spectra has been proposed. In the Supplementary Material, we advance a quantitative theory based on quantum mechanics giving this type of prediction.
6. Conclusions
By assuming minimization of the action as a guiding principle, we have constructed a new framework of models of Pavlovian conditioning. The simplest of these models is a natural extension of Rescorla–Wagner model with one cue (RW model in short). Looking at data of two experiments, we saw that the oscillatory classical model (8) with μ ≠ 0 is favored over RW in 42% of the experimental cases. The estimated dispersion of the session-by-session individual data with respect to the theoretical curve is about the same for the RW and DOMs in all the cases where the latter is clearly favored. In all the other cases, the parameter μ is close to zero and the RW model and its extension coincide. Almost all (98%) data can be fitted successfully by the DOM, which is an extension of the RW model, while RW alone can account only for 56%. One may wonder whether this encouraging outcome was due to the presence of oscillations per se rather than for an intrinsic virtue of the new model. This is not the case, as we checked in a separate publication (Calcagni et al., under review).
At a biological level, the explanation of why μ takes different values in different subjects (for some, as we have seen, μ is close to zero) might reside in individual differences in brain configuration. Different dynamical adaptations of synaptic connections during learning would give rise to a different damping rate of the oscillations. Regardless of whether this microscopic interpretation has a basis in reality or not, the least-action principle states that learning is a naturally effective process that minimizes the internal changes in the subject. These changes are observable and can be quantified through the behavioral laws stated here.
In parallel, using individual trial-by-trial data we have checked for the presence of colored noise in the frequency spectrum of the subjects' response. We found no evidence of color and all subjects showed a flat (white) noise spectrum. It is important to stress the difference between the molecular and molar levels of analysis we considered in this paper: the spectral analysis probes response fluctuations at a much shorter time scale than learning models, such as the RW model and the DOM. While the first analysis relies on a purely stochastic pattern, the latter works on a continuum or quasi-continuum. This means, in practice, that short-scale deviations from the asymptote are pure noise, while long-range deviations have, according to evidence, an associative oscillatory nature. The DOM is not just a spurious fit to the noisea.
The origin of this white noise can be simply statistical, but we also considered two quantitative models accounting for it. One is a descriptive model implementing stochastic fluctuations in the subject's individual response; speculations about the origin of this noise may find inspiration in the “1/fα” cognitive literature, albeit in that case there is established evidence of a colored spectrum. The other model (see Supplementary Material) is not only descriptive, but also predictive, and interprets response variability as a manifestation of a process obeying the laws of quantum mechanics. We tested the predictions of the theory with data and we found agreement, although the error bars on the estimates of the “Planck” constant are too conspicuous to conclude that the model is correct.
Although data show that individual responses are far from following the textbook smooth learning curve, they do not show an “abrupt acquisition” phenomenon either, as sometimes claimed in the literature (see Gür et al., 2018, and references therein). Some subjects do show something that could be described as an abrupt acquisition, but response variability is too large throughout the experiment to make this conclusion meaningful when, to put it simply, a sharp initial rise in response is yet another random fluctuation around the ideal average curve (see Figures S4, S6). Precisely for the same reason, although it is true that traditional associative models do not predict abrupt chances in behavior, our findings do not support representational or model-based models either (Gür et al., 2018). Response variability is so fine grained that its random, nowhere-differentiable nature is, in our opinion, unquestionable. We have offered two interpretations about these behavioral fluctuations, stochastic (from cognitive noise component in the underlying model) or quantum (from a model affected by quantum uncertainties). Both cases go beyond standard associationism, but are based on it nevertheless: associative learning still is an adequate description of averaged data.
Regarding replicability and applicability, since all the models we have presented in the main text of this paper are foundational extensions of the simplest conditioning process involving simple associations between stimuli and responses, it may not be necessary to conduct ad hoc experiments to test their validity. The long-range oscillations of the dynamical model, the spectral properties of response variations, and all the main features the quantum model can be checked in any experiment, past or future, that had a sufficient number of sessions (in the case of the dynamical model) or trials (in the case of the stochastic noise and of the quantum model) and whose design induced a simple conditioning process. In general, the condition of having many sessions is much more restrictive than that of having many trials, but it is not necessary to take or make experiments as lengthy as ours. Eventually, what one is looking for is cumulative evidence, and that is achievable with enough experiments of moderate length. We made the point in this paper by reanalyzing the data of an experiment first presented by Harris et al. (2015). Moreover, our models may obtain confirmation or be ruled out by extant or future data not only about Pavlovian conditioning, but also from the operant conditioning literature. In the second case, one invokes the possibility that associative models can also describe operant behavior (Killeen and Nevin, 2018). In the first case, the generality of the construction of learning models as dynamical models and the psychological interpretation put forward in section 4.2 make us believe that they can both be extended to other Pavlovian conditioning paradigms, such as eyeblink conditioning, where the average learning pattern may differ from the RW curve. The main point is not only that recasting a learning model as a dynamical model should always be possible, but that in doing so one can discover interesting modifications dictated by the naturalness argument (absence of fine tuning), such as the introduction of a new parameter μ in the DOM case. An oscillatory behavior may or may not arise from this construction, but this is something to be checked a posteriori, not imposed by hand.
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Ethics Statement
The animal study was reviewed and approved by UNED bioethics.
Author Contributions
GC wrote the main body of the paper. EC-G and RP contributed to editing the text. All the authors participated in the execution of one of the experiments.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
GC thanks Pedro Vidal for invaluable help in writing the PASCAL programs of the pilot experiments that eventually led to the program used in this paper and Esmeralda Fuentes, Gabriela E. López-Tolsa, Ana de Paz and Valeria E. Gutiérrez-Ferre for rat-related advice. All authors thank Justin Harris for many fruitful discussions and for giving us access to the data of Harris et al. (2015), Ralph Miller for his comments and suggestions about the experimental design, Antonio Rey for his outstanding handling of the lab schedule and of technical issues, and Vanessa Roldán for her involvement in the experiment and daily lab routine through part of this project. The experiment was run at the Animal Behavior Lab, Departamento de Psicología Básica I, Facultad de Psicología, Universidad Nacional de Educación a Distancia, Madrid, Spain, and was supported by grant PSI2016-80082-P from Ministerio de Economía y Competitividad, Secretaría de Estado de Investigación, Desarrollo e Innovación, Spanish Government (RP).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.00612/full#supplementary-material
Footnotes
1. ^To avoid an otherwise inevitable confusion, in this paper we use the term “classical” always in the sense of physics, calling the traditional associative models of conditioning “Pavlovian.”
2. ^This relatively high correlation might suggest that a better indicator than (6), stripped of micro-motivational or attentional fluctuations, could be obtained if we subtract the number of post-CS licks instead of the number of US. However, as we noted before, we verified that the results of this section do not change.
3. ^The total response of control subjects in Group 1C was flat throughout the experiment: a linear fit of the total licks yields a slope −0.23 ± 0.24 and a correlation r2 = 0.01. We did register a slight positive trend in Group 2C: a linear fit of the total licks yields a slope 1.43±0.31 and a correlation r2 = 0.20. This trend was driven by subjects 2C-2, 2C-5, and 2C-8. Possibly, this means that subjects developed a liking (unrelated to any CS-US associative process) for the saccharin solution at 0.2% more pronounced that for the less concentrated solution.
4. ^It is inevitable that the procurement of saccharin in the present preparation implies licking at the bottle spout, thus establishing an operant contingency between licking and obtaining the reinforcer. Furthermore, given that the US occurred at random times within the CS, this is an ideal condition for the maintenance of superstitious licking. Despite this being correct (Killeen and Pellón, 2013; Pellón and Killeen, 2015; Pellón et al., 2018), lick suppression has been accepted as Pavlovian under an experimental paradigm similar to the current one, when the consequence is aversive or has been devalued (e.g., Jozefowiez et al., 2011). By analogy, lick enhancement might have those same characteristics as the reduction of the response, not to mention that after extended training it has been generally accepted that behavior shifts control from the consequence to the antecedent stimulus (Dickinson and Balleine, 2002), a case in which the results that will be modeled here might fall. Additionally, even if we accept that licking in the present experiment has an operant contribution to its installment, which is true, we believe that the theoretical analysis applied in the present paper is not really affected if an event stimulus is replaced by a response (see also section 6).
5. ^At the maxima and minima of a function, its first derivative vanishes.
6. ^The mathematics of stochastic processes is not a new tool in learning theories. In fact, the earliest conditioning models had an inherent element of randomness in their predictions. The classic 1950s models were cast in the language of probability theory and one considered the probability p of a given conditioned response (CR) as a function of the trial number n; see e.g., the works by Estes (1950); Estes and Burke (1953), Bush and Mosteller (1951a,b, 1953), and the reviews by Mosteller (1958) and Bower (1994). Later on, the strength of association v was regarded as a better operational variable than the probability p (Rescorla and Wagner, 1972) and the focus was shifted to ideally deterministic predictions. More recently, stochastic processes played a role in the context of neural networks and their application to robotics and artificial intelligence. In particular, a path integral can describe a learning process of a neural network as a finite-temperature stochastic process (Balakrishnan, 2000). Path integrals have also been applied to control theory and reinforcement learning (Kappen, 2007; van den Broek et al., 2008; Theodorou et al., 2010a,b, 2011; Braun et al., 2011; Theodorou, 2011; Farshidian and Buchli, 2013; Pan et al., 2014a,b). In all these cases, the problem is to minimize the cost of a learning process or of an action by an agent. Despite some remote similarities, these approaches differ from ours.
References
Akaike, H. (1974). A new look at the statistical model identification. IEEE Trans. Autom. Control 19:716. doi: 10.1109/TAC.1974.1100705
Ayres, J. J. B., Berger-Gross, P., Kohler, E. A., Mahoney, W. J., and Stone, S. (1979). Some orderly nonmonotonicities in the trial-by-trial acquisition of conditioned suppression: inhibition with reinforcement?. Anim. Learn. Behav. 7:174. doi: 10.3758/BF03209267
Balakrishnan, J. (2000). Neural network learning dynamics in a path integral framework. Eur. Phys. J. B 15:679. doi: 10.1007/s100510051172
Blanco, F., and Moris, J. (2018). Bayesian methods for addressing long-standing problems in associative learning: the case of PREE. Q. J. Exper. Psychol. 71:1844. doi: 10.1080/17470218.2017.1358292
Bouton, M., Frohardt, R., Sunsay, C., Waddell, J., and Morris, R. (2008). Contextual control of inhibition with reinforcement: adaptation and timing mechanisms. J. Exp. Psychol. Anim. Behav. Process 34:223. doi: 10.1037/0097-7403.34.2.223
Bower, G. H. (1994). A turning point in mathematical learning theory. Psychol. Rev. 101:290. doi: 10.1037/0033-295X.101.2.290
Braun, D. A., Ortega, P. A., Theodorou, E., and Schaal, S. (2011). “Path integral control and bounded rationality,” in 2011 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL) (Paris: IEEE), 202–209. doi: 10.1109/ADPRL.2011.5967366
Bush, R. R., and Mosteller, F. (1951a). A mathematical model for simple learning. Psychol. Rev. 58:313. doi: 10.1007/978-0-387-44956-2_12
Bush, R. R., and Mosteller, F. (1951b). A model for stimulus generalization and discrimination. Psychol. Rev. 58:413. doi: 10.1007/978-0-387-44956-2_13
Bush, R. R., and Mosteller, F. (1953). A stochastic model with applications to learning. Ann. Math. Stat. 24:559. doi: 10.1214/aoms/1177728914
Calcagni, G. (2018). The geometry of learning. J. Math. Psychol. 84:74. doi: 10.1016/j.jmp.2018.03.007
Çevik, M. Ö. (2014). Habituation, sensitization, and Pavlovian conditioning. Front. Integr. Neurosci. 8:13. doi: 10.3389/fnint.2014.00013
Dickinson, A., and Balleine, B. W. (2002). “The role of learning in the operation of motivational systems,” in Stevens' Handbook of Experimental Psychology. Vol. 3. Learning, Motivation and Emotion, ed C. R. Gallistel (New York, NY: Wiley), 497–533.
Dixon, J. A., Holden, J. G., Mirman, D., and Stephen, D. G. (2012). Multifractal dynamics in the emergence of cognitive structure. Topics Cogn. Sci. 4:51. doi: 10.1111/j.1756-8765.2011.01162.x
Dixon, J. A., Stephen, D. G., Boncoddo, R. A., and Anastas, J. (2010). The self-organization of cognitive structure. Psychol. Learn. Motiv. 52:343. doi: 10.1016/S0079-7421(10)52009-7
Dukhayyil, A., and Lyons, J. E. (1973). The effect of overtraining on behavioral contrast and the peak-shift. J. Exp. Anal. Behav. 20:253.
Eke, A., Herman, P., Kocsis, L., and Kozak, L. R. (2002). Fractal characterization of complexity in temporal physiological signals. Physiol. Meas. 23:R1. doi: 10.1088/0967-3334/23/1/201
Estes, W. K., and Burke, C. J. (1953). A theory of stimulus variability in learning. Psychol. Rev. 60:276.
Estes, W. K. (1950) Toward a statistical theory of learning. Psychol. Rev. 57:94. doi: 10.1037/h0058559
Estes, W. K. (1956). The problem of inference from curves based on group data. Psychol. Bull. 53:134.
Farrell, S., Wagenmakers, E.-J., and Ratcliff, R. (2006). 1/f noise in human cognition: is it ubiquitous, and what does it mean?. Psychon. Bull. Rev. 13:737. doi: 10.3758/BF03193989
Farshidian, F., and Buchli, J. (2013). Path integral stochastic optimal control for reinforcement learning (unpublished). Available online at: http://www.adrl.ethz.ch/archive/p_13_rldm_pisoc.pdf
Finger, F. W. (1942). The effect of varying conditions of reinforcement upon a simple running response. J. Exper. Psychol. 30:53.
Gallistel, C. R., Fairhurst, S., and Balsam, P. (2004). The learning curve: implications of a quantitative analysis. Proc. Nat. Acad. Sci. U.S.A. 101:13124. doi: 10.1073/pnas.0404965101
Gallistel, C. R. (2012). On the evils of group averaging: commentary on Nevin's “Resistance to extinction and behavioral momentum”. Behav. Proc. 90:98. doi: 10.1016/j.beproc.2012.02.013
Gilden, D. L., Thornton, T., and Mallon, M. W. (1995). 1/f noise in human cognition. Science 267:1837.
Gilden, D. L. (2001). Cognitive emissions of 1/f noise. Psychol. Rev. 108:33. doi: 10.1037/0033-295X.108.1.33
Glautier, S. (2013). Revisiting the learning curve (once again). Front. Psychol. 4:982. doi: 10.3389/fpsyg.2013.00982
Gür, E., Duyan, Y.A, and Balci, F. (2018). Spontaneous integration of temporal information: implications for representational/computational capacity of animals. Anim. Cogn. 21:3. doi: 10.1007/s10071-017-1137-z
Harris, J. A., Patterson, A. E., and Gharaei, S. (2015). Pavlovian conditioning and cumulative reinforcement rate. J. Exp. Psychol. Anim. Learn. Cogn. 41:137. doi: 10.1037/xan0000054
Hearst, E. (1971). Contrast and stimulus generalization following prolonged discrimination training. J. Exp. Anal. Behav. 15:355.
Holden, J. G., Choi, I., Amazeen, P. G., and Van Orden, G. (2011). Fractal 1/f dynamics suggest entanglement of measurement and human performance. J. Exp. Psychol. Hum. Percept. Perform. 37:935. doi: 10.1037/a0020991
Holden, J. G., Van Orden, G. C., and Turvey, M. T. (2009). Dispersion of response times reveals cognitive dynamics. Psychol. Rev. 116:318. doi: 10.1037/a0014849
Holden, J. G. (2005). “Gauging the fractal dimension of response times from cognitive tasks,” in Contemporary Nonlinear Methods for Behavioral Scientists: A Webbook Tutorial, eds M. A. Riley and G. C. Van Orden, 267–318.
Holden, J. G. (2013). Cognitive effects as distribution rescaling. Ecol. Psychol. 25:256. doi: 10.1080/10407413.2013.810457
Ihlen, E. A. F., and Vereijken, B. (2010). Interaction-dominant dynamics in human cognition: beyond 1/fα fluctuation. J. Exp. Psychol. Gen. 139:436. doi: 10.1037/a0019098
Ihlen, E. A. F., and Vereijken, B. (2013). Multifractal formalisms of human behavior. Hum. Mov. Sci. 32:633. doi: 10.1016/j.humov.2013.01.008
Jaksic, H., Vause, T., Frijters, J. C., and Feldman, M. (2018). A comparison of a novel application of hierarchical linear modeling and nonparametric analysis for single-subject designs. Behav. Anal. Res. Prac. 18:203. doi: 10.1037/bar0000091
Jozefowiez, J., Witnauer, J. E., and Miller, R. R. (2011). Two components of responding in Pavlovian lick suppression. Learn. Behav. 39:138. doi: 10.3758/s13420-010-0012-4
Kappen, H. J. (2007). An introduction to stochastic control theory, path integrals and reinforcement learning. AIP Conf. Proc. 887:149. doi: 10.1063/1.2709596
Kaye, H., and Pearce, J. M. (1984). The strength of the orienting response during Pavlovian conditioning. J. Exp. Psychol. Anim. Behav. Process. 10:90.
Kello, C. T., Anderson, G. G., Holden, J. G., and Van Orden, G. C. (2008). The pervasiveness of 1/f scaling in speech reflects the metastable basis of cognition. Cogn. Sci. 32:1217. doi: 10.1080/03640210801944898
Kello, C. T., Beltz, B. C., Holden, J. G., and Van Orden, G. C. (2007). The emergent coordination of cognitive function. J. Exp. Psychol. Gen. 136:551. doi: 10.1037/0096-3445.136.4.551
Kello, C. T., Brown, G. D. A., Ferrer-i-Cancho, R., Holden, J. G., Linkenkaer-Hansen, K., Rhodes, T., et al. (2010). Scaling laws in cognitive sciences. Trends Cogn. Sci. 14:223. doi: 10.1016/j.tics.2010.02.005
Killeen, P. R., and Nevin, J. A. (2018). The basis of behavioral momentum in the nonlinearity of strength. J. Exp. Anal. Behav. 109:4. doi: 10.1002/jeab.304
Killeen, P. R., and Pellón, R. (2013). Adjunctive behaviors are operants. Learn. Behav. 41:1. doi: 10.3758/s13420-012-0095-1
Kimmel, H. D., and Burns, R. A. (1975). “Adaptational aspects of conditioning,” in Handbook of Learning and Cognitive Processes, Vol. 2, ed W. K. Estes (Hillsdale, NJ: Erlbaum), 99–142.
Le Pelley, M. E. (2004). The role of associative history in models of associative learning: a selective review and a hybrid model. Q. J. Exp. Psychol. 57:193. doi: 10.1080/02724990344000141
Likens, A. D., Fine, J. M., Amazeen, E. L., and Amazeen, P. G. (2015). Experimental control of scaling behavior: what is not fractal?. Exp. Brain Res. 233:2813. doi: 10.1007/s00221-015-4351-4
Mackintosh, N. J. (1975). A theory of attention: variations in the associability of stimuli with reinforcement. Psychol. Rev. 82:276.
Mazur, J. E., and Hastie, R. (1978). Learning as accumulation: a reexamination of the learning curve. Psychol. Bull. 85:1256.
Miller, R. R., Barnet, R. C., and Grahame, N. J. (1995). Assessment of the Rescorla–Wagner model. Psychol. Bull. 117:363.
Miller, R. R., and Matzel, L. D. (1988). “The comparator hypothesis: a response rule for the expression of associations,” in The Psychology of Learning and Motivation, Vol. 2, ed G. H. Bower (Orlando, FL: Academic Press), 51–92.
Mosteller, F. (1958). Stochastic models for the learning process. Proc. Amer. Philos. Soc. 102:53. doi: 10.1007/978-0-387-44956-2_16
Newell, A., and Rosenbloom, P. S. (1981). Mechanisms of Skill Acquisition and the Law of Practice. Hillsdale, NJ: Erlbaum.
Ornitz, E. M., and Guthrie, D. (1989). Long-term habituation and sensitization of the acoustic startle response in the normal adult human. Psychophysiology 26:166.
Overmier, J. B., Payne, R. J., Brackbill, R. M., Linder, B., and Lawry, J. A. (1979). On the mechanism of the post-asymptotic CR decrement phenomenon. Acta Neurobiol. Exp. (Wars). 39:603.
Packer, J. S., and Siddle, D. A. T. (1987). The effects of signal value on short- and long-term habituation. Biol. Psychol. 24:261.
Pan, Y., Theodorou, E. A., and Kontitsis, M. (2014a). Model-based path integral stochastic control: a Bayesian nonparametric approach. arXiv 1412.3038.
Pan, Y., Theodorou, E. A., and Kontitsis, M. (2014b). Sample efficient path integral control under uncertainty. arXiv 1509.01846.
Pearce, J. M., and Hall, G. (1980). A model for Pavlovian learning: variations in the effectiveness of conditioned but not of unconditioned stimuli. Psychol. Rev. 87:532.
Pellón, R., Íbias, J., and Killeen, P. R. (2018). Delay gradients for spout-licking and magazine-entering induced by a periodic food schedule. Psychol. Rec. 68:151. doi: 10.1007/s40732-018-0275-2
Pellón, R., and Killeen, P. R. (2015). Responses compete and collaborate, shaping each other's distributions: commentary on Boakes, Patterson, Kendig, and Harris (2015). J. Exp. Psychol. Anim. Learn. Cogn. 41:444. doi: 10.1037/xan0000067
Pickens, C. L., Golden, S. A., Adams-Deutsch, T., Nair, S. G., and Shaham, Y. (2009). Long-lasting incubation of conditioned fear in rats. Biol. Psychiatry 65:881. doi: 10.1016/j.biopsych.2008.12.010
Plaud, J. J., Gaither, G. A., Amato Henderson, S., and Devitt, M. K. (1997). The long-term habituation of sexual arousal in human males: a crossover design. Psychol. Rec. 47:385.
Rescorla, R. A., and Wagner, A. R. (1972). “A theory of Pavlovian conditioning: variations in the effectiveness of reinforcement and nonreinforcement,” in Classical Conditioning II, eds A. H. Black and W. F. Prokasy (New York, NY: Appleton-Century-Crofts), 64–99.
Riley, M. A., and Holden, J. G. (2012). Dynamics of cognition. WIREs Cogn. Sci. 3:593. doi: 10.1002/wcs.1200
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). “Learning internal representations by error propagation,” in Parallel Distributed Processing, Vol. 1, eds D. E. Rumelhart and J. L. McClelland (Cambridge, MA: MIT Press), 318–362.
Smith, P. L., and Little, D. R. (2018). Small is beautiful: in defense of the small-N design. Psychon. Bull. Rev. 25:2083. doi: 10.3758/s13423-018-1451-8
Solomon, R. L., and Corbit, J. D. (1974). An opponent-process theory of motivation: I. Temporal dynamics of affect. Psychol. Rev. 81:119.
Stephen, D. G., Boncoddo, R. A., Magnuson, J. S., and Dixon, J. A. (2009a). The dynamics of insight: mathematical discovery as a phase transition. Mem. Cogn. 37:1132. doi: 10.3758/MC.37.8.1132
Stephen, D. G., Dixon, J. A., and Isenhower, R. W. (2009b). Dynamics of representational change: entropy, action, and cognition. J. Exp. Psychol. Hum. Percept. Perform. 35:1811. doi: 10.1037/a0014510
Terrace, H. S. (1966). Behavioral contrast and the peak-shift: effects of extended discrimination training. J. Exp. Anal. Behav. 9:613.
Theodorou, E, Buchli, J, and Schaal, S. (2010a). “Reinforcement learning of motor skills in high dimensions: a path integral approach,” in 2010 IEEE International Conference on Robotics and Automation (ICRA) (Anchorage, AK: IEEE), 2397–2403. doi: 10.1109/ROBOT.2010.5509336
Theodorou, E, Buchli, J, and Schaal, S. (2010b). A generalized path integral control approach to reinforcement learning. J. Mach. Learn. Res. 11:3137. Available online at: http://www.jmlr.org/papers/v11/theodorou10a.html
Theodorou, E. A. (2011). Iterative path integral stochastic optimal control: theory and applications to motor control (Ph.D. thesis), University of Southern California, Los Angeles, CA, United States.
Theodorou, E., Stulp, F., Buchli, J., and Schaal, S. (2011). An iterative path integral stochastic optimal control approach for learning robotic tasks. IFAC Proc. Vol. 44:11594. doi: 10.3182/20110828-6-IT-1002.02249
Thompson, R. F. (2009). Habituation: a history. Neurobiol. Learn. Mem. 92:127. doi: 10.1016/j.nlm.2008.07.011
Thornton, T. L., and Gilden, D. L. (2005). Provenance of correlations in psychological data. Psychon. Bull. Rev. 12:409. doi: 10.3758/BF03193785
Urcelay, G. P., Witnauer, J. E., and Miller, R. R. (2012). The dual role of the context in postpeak performance decrements resulting from extended training. Learn. Behav. 40:476. doi: 10.3758/s13420-012-0068-4
van den Broek, B., Wiegerinck, W., and Kappen, B. (2008). Graphical model inference in optimal control of stochastic multi-agent systems. J. Art. Int. Res. 32:95. doi: 10.1613/jair.2473
Van Orden, G. C., Holden, J. G., and Turvey, M. T. (2003). Self-organization of cognitive performance. J. Exp. Psychol. Gen. 132:331. doi: 10.1037/0096-3445.132.3.331
Van Orden, G. C., Holden, J. G., and Turvey, M. T. (2005). Human cognition and 1/f scaling. J. Exp. Psychol. Gen. 134:117. doi: 10.1037/0096-3445.134.1.117
Wagenmakers, E.-J., Farrell, S., and Ratcliff, R. (2004). Estimation and interpretation of 1/fα noise in human cognition. Psychon. Bull. Rev. 11:579. doi: 10.3758/BF03196615
Wagenmakers, E.-J., Farrell, S., and Ratcliff, R. (2005). Human cognition and a pile of sand: a discussion on serial correlations and self-organized criticality. J. Exp. Psychol. Gen. 135:108. doi: 10.1037/0096-3445.134.1.108
Wagenmakers, E.-J., van der Maas, H. L. J., and Farrell, S. (2012). Abstract concepts require concrete models: why cognitive scientists have not yet embraced nonlinearly coupled, dynamical, self-organized critical, synergistic, scale-free, exquisitely context-sensitive, interaction-dominant, multifractal, interdependent brain-body-niche systems. Topics Cogn. Sci. 4:87. doi: 10.1111/j.1756-8765.2011.01164.x
Wagner, A. R., and Vogel, E. H. (2009). Conditioning: theories. Encycl. Neurosci. 3:49. doi: 10.1016/B978-008045046-9.01555-2
Wagner, A. R. (1981). “SOP: a model of automatic memory processing in animal behavior,” in Information Processing in Animals: Memory Mechanisms, eds N. E. Spear and R. R. Miller (Hillsdale, NJ: Erlbaum), 5–47.
Witnauer, J. E., Hutchings, R., and Miller, R. R. (2017). Methods of comparing associative models and an application to retrospective revaluation. Behav. Proc. 144:20. doi: 10.1016/j.beproc.2017.08.004
Keywords: Pavlovian conditioning, Rescorla–Wagner model, associative models, extended training, individual differences, Bayes information criterion, 1/f noise
Citation: Calcagni G, Caballero-Garrido E and Pellón R (2020) Behavior Stability and Individual Differences in Pavlovian Extended Conditioning. Front. Psychol. 11:612. doi: 10.3389/fpsyg.2020.00612
Received: 30 October 2019; Accepted: 16 March 2020;
Published: 22 April 2020.
Edited by:
Sen Cheng, Ruhr University Bochum, GermanyReviewed by:
Maik Christopher Stüttgen, Johannes Gutenberg University Mainz, GermanyAnders Rasmussen, Erasmus Medical Center, Netherlands
Copyright © 2020 Calcagni, Caballero-Garrido and Pellón. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gianluca Calcagni, Zy5jYWxjYWduaUBjc2ljLmVz