 Maliheh Eftekhari
Maliheh Eftekhari Abbas Yadollahi
Abbas Yadollahi Hamed Ahmadi
Hamed Ahmadi Abdolali Shojaeiyan
Abdolali Shojaeiyan Mahdi Ayyari1
Mahdi Ayyari1- 1Department of Horticultural Sciences, Faculty of Agriculture, Tarbiat Modares University, Tehran, Iran
- 2Bioscience and Agriculture Modeling Research Unit, College of Agriculture, Tarbiat Modares University, Tehran, Iran
High performance liquid chromatography data related to the concentrations of 12 phenolic compounds in vegetative parts, measured at four sampling times were processed for developing prediction models, based on the cultivar, grapevine organ, growth stage, total flavonoid content (TFC), total reducing capacity (TRC), and total antioxidant activity (TAA). 12 Artificial neural network (ANN) models were developed with 79 input variables and different number of neurons in the hidden layer, for the prediction of 12 phenolics. The results confirmed that the developed ANN-models (R2 = 0.90 – 0.97) outperform the stepwise regression models (R2 = 0.05 – 0.78). Moreover, the sensitivity of the model outputs against each input variable was computed by using ANN and it was revealed that the key determinant of phenolic concentration was the source organ of the grapevine. The ANN prediction technique represents a promising approach to predict targeted phenolic levels in vegetative parts of the grapevine.
Introduction
Grapevine (Vitis vinifera) as one of the most economically important fruit crops worldwide, has been extensively cultivated all over the world for fresh consumption as well as industrial processing. Both cultivation and industrial processing of grapes lead to byproducts, such as leaves and stems which have been found as the enriched resources of bioactive polyphenolic compounds (Eftekhari et al., 2017). The phenolics worth is due to their important roles in protection against degenerative diseases such as cancer and atherosclerosis, in addition to antimicrobial, anti-inflammatory, antidiabetic and skin protection, hepatoprotective, and neuroprotective activities (Nassiri-Asl and Hosseinzadeh, 2016). Extracts prepared from grapevine leaves and stems are known to be promising sources of grape polyphenols including flavonoids, phenolic acids, stilbenes and COU. These compounds have recently received considerable attention, and because of their pharmacological impacts and antioxidant activity (Xia et al., 2010) can be used as natural antioxidants in the pharmaceutical, food and cosmetic industries (Houillé et al., 2015; Torres et al., 2015).
In the standard analytical approach, the identification and quantification of phenolic compounds requires expensive and complex equipment including high performance liquid chromatography (HPLC) and expensive pure standards. An alternative approach, using simple measurements to predict the phenolic profile in each part of every grapevine cultivar at defined developmental stages offers a substitute for the use of foliar waste materials. This prediction may prevent the loss of high enriched valuable sources of phenolics. Finding the association between easier and lower cost measuring indexes such as TRC, TFC, and TAA with individual phenolics content can be a supplementary source to predict the level of important phenolics in above mentioned wastes. ANN modeling provides a way of analyzing uneven and multi-dimensional datasets arising from such data collection activities. Datasets are used by software models to construct networks.
The data set is divided into training and test data. With the large number of connections, ANN can find the key non-linear relationships between the determined input and corresponding output variables in the training dataset used to develop the model, and then apply that knowledge to new inputs from previously untested samples (Hashimoto, 1997; Guoqiang et al., 1998). Accordingly, ANN look for a mathematical formulation in the training dataset used for model development to achieve the closest result to the expected value. The ANN technique is especially helpful for complicated problems involving numerous variables with restricted knowledge of the interactions between variables and their variation (Suárez et al., 2015). Hence, considering the importance of predicting phenolic contents in agricultural wastes without expensive analyses, this study aims to evaluate and validate accuracy of the ANN technique to predict phenolics levels and composition in grapevine vegetative parts as waste material of pruning and other viticultural practices due to its capability of learning complex, non-linear relationships between the input and output.
Based on ours and other published works (Houillé et al., 2015; Torres et al., 2015; Eftekhari et al., 2017), it has been shown that the vegetative parts of grapevines, which are often waste-products in grape cultivation and production, are rich in phenolics. Their phenolic composition is determined primarily by genetic factors and the identity of the organ (leaf or stem) (Eftekhari et al., 2017), and it may change during the vine development (Teixeira et al., 2013; Eftekhari et al., 2017). Meanwhile, the influence of additional factors remains unknown, as does prediction of the phenolics profile in different organs in various time points through the vine annual growth cycle.
This study first presents and compares the stepwise regression analyses for 12 important phenolic compounds to determine the importance of each factor in determining the level of the phenolics and find the association between them. A back-propagation ANN model, which consists of cultivar, organ, sampling time, TRC, TFC and TAA was established for predicting each phenolic compound using the Matlab software. The data were obtained from HPLC for individual phenolics and spectrophotometry for TRC, TFC, and TAA. The total measurements reflected the phenolic properties of the sample; but if they have a direct relationship with individual phenolics is still a question which have been analyzed only with correlation analysis in the literature (Karacabey et al., 2012; Eftekhari et al., 2017). By training the network with specified inputs and outputs, we predict the targeted phenolics content of grape cultivars foliar parts. And then the trained network can make predictions for V. vinifera cultivars considering the same factors. Cultivar, organ, time, as well as TFC, TRC and TAA were set as input variables, while each phenolic content was set as output to separate ANN networks. Then, the best network to predict output was selected based upon an optimization procedure using a GA. Finally, for the purpose of performance comparison, the predicted results of ANN models related to 12 phenolic compounds were compared to the respective stepwise regression models. The goodness of fit of the ANN and regression models were assessed using statistical analysis.
To our knowledge, the research described here represents for the first time, the use of artificial neural network prediction technique for predicting phenolic contents in plant material. Our results provide an important contribution to this research area and industrial field. To promote the commercial consumption of these bioactive plant materials, it is important to predict the phenolic potential of these grapevine leftovers in a special cultivar and organ in a particular time.
Materials and Methods
Samples and Datasets
In a previous study (Eftekhari et al., 2017), we collected leaves and stems from 5-year-old vines of 70 Iranian native grape cultivars [Supplementary Table S1 in supplementary material of Eftekhari et al. (2017)] growing in the Research Farm of Faculty of Agriculture, University of Tehran, Karaj, Alborz, Iran (latitude 35° 50′ N, longitude 50° 58′ E and altitude 132 m) at the middle of 4 months of July to October 2015. Collected samples were extracted after oven-drying at 40°C for 72 h, using the method described by Eftekhari et al. (2012).
Extracts were analyzed for their phenolic composition: flavonoids CAT, KAE, QUE, RUT, NAR, and IQ, phenolic acids GAL, PC, OC, and MC, stilbene RES and COU.
Beginning with the measured analytical data of HPLC we used a data matrix containing the results of the samples coming from different cultivars and organs (leaves or stems) at different times (July–October), to test the capability of ANN method in modeling the targeted phenolic profiling of V. vinifera foliage in relation to cultivar, organ and harvest time. A factorial design arrangement resulted in the total 1890 data (Table 1).
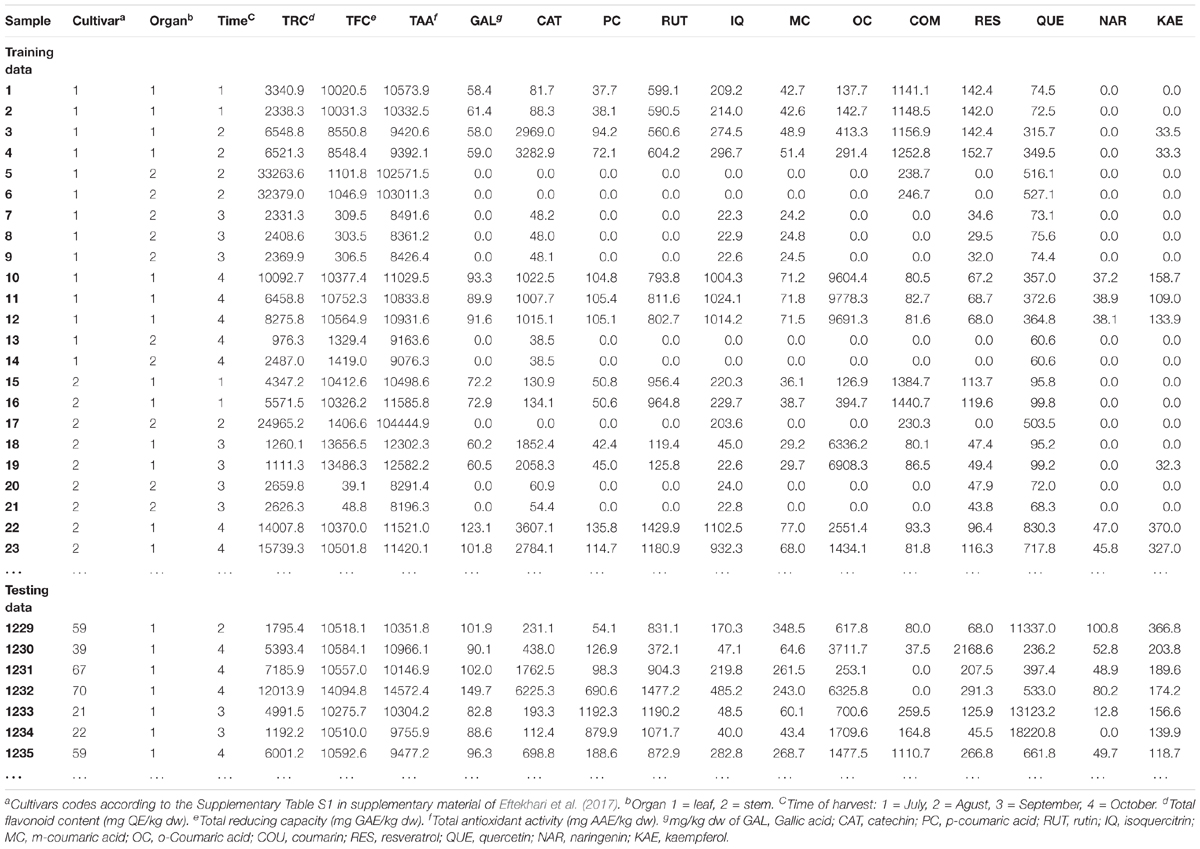
TABLE 1. Levels of variables according to the factorial arrangement of 1890 data related to phenolic compounds concentrations measured by HPLC.
Statistical Analysis and Model Development
Stepwise Regression Modeling
The popularity of regression models lie in their ease of use and interpretation. A multiple regression model with more than one explanatory variable may be written as y = b0 + biXi + … + bpXp, where y is the output variable, b the regression coefficient (i = 0, 1, 2,…, p) with b0 as the intercept, and X the input variable (i = 1, 2,…, p). When regression coefficients are attained, an equation of prediction can then be applied to forecast the continuous outputs as linear functions of independent inputs. The regression models popularity may be due to the interpretability of model parameters coefficients and simplicity of use. Here, for the prediction of phenolic composition, the forward stepwise regression models are used and the entry and stay levels of the p-values were set at 0.05 for the models. Independent variables were selected according to the maximum F-value if the associated partial correlation coefficient is zero:
where ryx(q+1).x(q) is the sample partial correlation coefficient between y and the selected (q+1) independent variable with q as the selected independ variable, the related P-value is:
Whenever P exceeds the defined α level, stopping occurs.
The stepwise regression analyses were performed on the data to test significance of the independent variables cultivar, organ, harvest time, TRC, TAA, and TFC affecting level of phenolics GAL, CAT, PC, RUT, IQ, MC, OC, COU, RES, QUE, NAR, and KAE in grapevine foliage as dependent variables. The regression analyses were performed using SAS 9.1 (SAS Institute, Cary, NC, United States).
Hybrid ANN-GA Modeling Procedure
ANN-GA procedures are adaptive having the parallel information-processing structures, which are able to make functional associations between data and to provide predominant tools for non-linear, multidimensional incorporations. Back-propagation is an optimization algorithm applied on ANNs to minimize the training error function by iteratively adjusting the weights and biases of the ANN which comprises three adjacent layers called the input, hidden and output layers which may have a number of sub-layers. Each layer consists of a certain number of neurons that needs to be optimized. ANNs are prevailing tools for estimation of unknown non-linear functions and have extensive applications in various fields (Rumelhart and McClelland, 1986; Lawrence, 1994).
In this study, the hybrid ANN-GA strategy (Mirarab et al., 2014) was used to efficiently optimize the neuron number in the hidden layer (Wang, 2005). The structure of the ANN-GA used in this paper is shown in Figure 1. We built a three-layer feed-forward ANN and applied the backpropagation algorithm to obtain the best fit to the training data because of its capacity of representing non-linear functional relationships between inputs and targets. As activation functions, we used the hyperbolic tangent sigmoid (tansig) for the hidden layer and linear (purelin) for the output layer. The Levenberg-Marquardt back-propagation training algorithm was used for minimizing the error function of the ANN (Beale et al., 2010). The fitness performance function of the GA was used to determine the optimum structure of the ANN (Figure 1). The mean square error (MSE) was used as performance function and learning was completed after 800 epochs. Three replicates of each treatment resulted in a dataset with total of 1890 observations. These data were randomly divided into two distinct groups: 65% of data lines (1228 data) for training set and, 35% (662 data) for testing set. The same set of data were used for developing 12 neural network models related to 12 phenolic compounds. Using replicates instead of mean values in ANN modeling helps to assess not only the mean, but also the range of their deviation in the model (Silva et al., 2015). The training set was used to compute all the parameters of the ANN and the testing set was used to evaluate the precision of the neural network prediction.
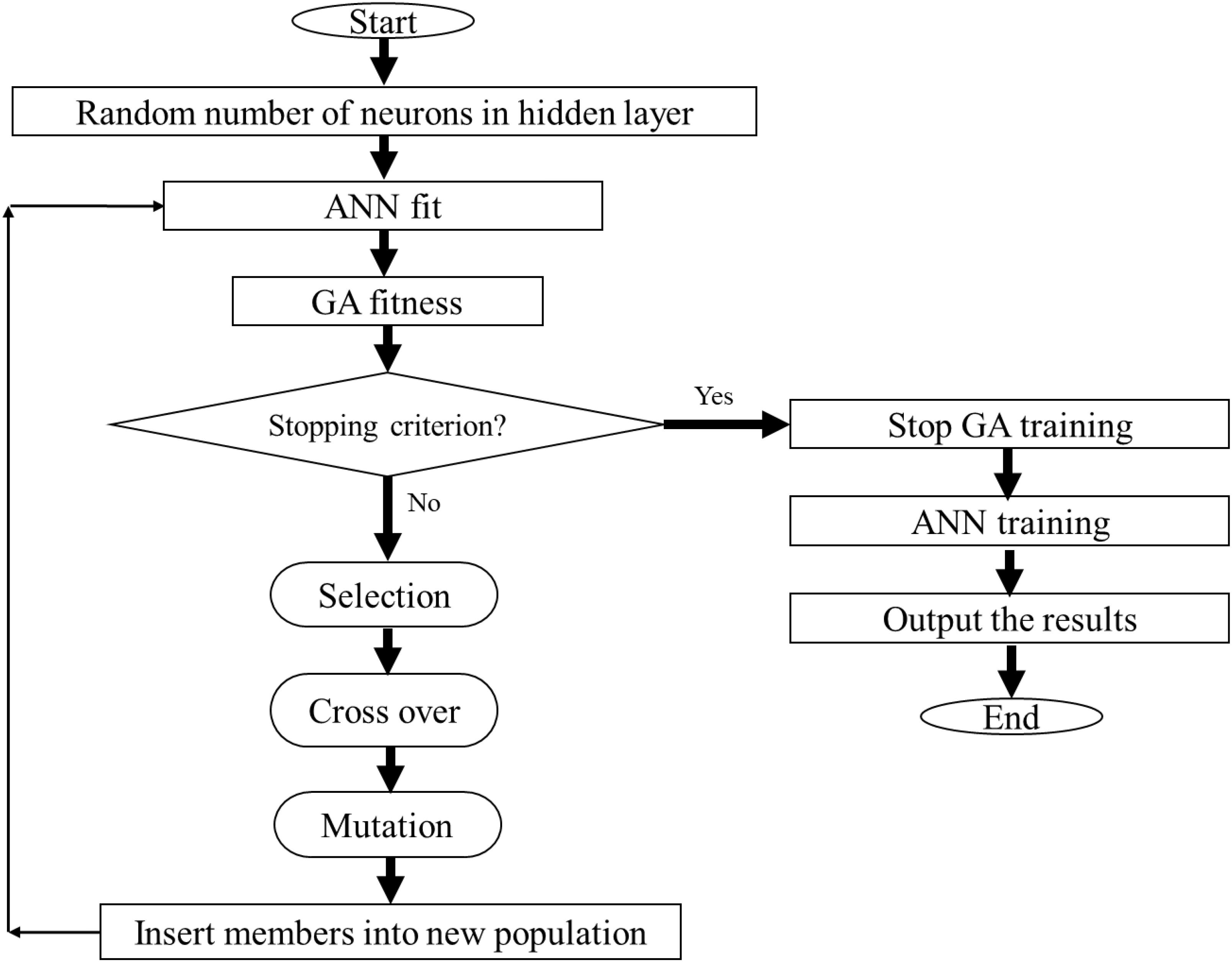
FIGURE 1. Flow chart of integrating ANN with GA for optimization of inputs combination to achieve the highest amount of each metabolite.
Furthermore, the GA was used in order to determine the optimal neuron numbers in the hidden layer (Figure 1). So, elite populations were selected for crossover using a roulette wheel selection method. An initial population of 50, generation number of 500, crossover rate of 0.85, and mutation rate of 0.01 were used to obtain the best ANN structure (Haupt and Haupt, 2004; Abramson, 2007). The stop criterion was on the basis of the MSE with the lowest level as the network performance function for the training dataset (Figure 1). To select the best ANN structures with optimum neuron number in the hidden layer, the total number of 3 to 10 neurons were used based on GA. High number of hidden neurons may cause overlearning of the neural network. On the other hand, too few hidden neurons will lead to under fitting. The generational action was frequently run to attain the number of generations.
The sensitivity analysis was performed on the developed ANN-models to find the importance of the input variable (cultivar, organ, time, TRC, TFC, and TAA) in the model for determining the content of phenolics CAT, KAE, QUE, RUT, NAR, IQ, GAL, PC, OC, MC, RES, and COU in grapevine foliar parts. The sensitivity is determined as the ratio between the error of the eliminated variable and the baseline error. It ranks the variables according to their importance and determines which variables that can be omitted and which variables that are important to keep in further analyses. The sensitivity of phenolics content against cultivar, organ, time, TRC, TFC, and TAA was determined using the criteria (Lou and Nakai, 2001; Ahmadi and Golian, 2010a,b) as follows: the variable sensitivity error (VSE) value is computed as the performance of the ANN-model where that variable is omitted, and the estimate of the variable sensitivity ratio (VSR) is then calculated as the relative ratio between the VSE and the error of an ANN-model where all variables are included. Higher VSR value shows more important variable. So, the input variables may be ranked in the order of importance on the basis of the obtained VSR value.
Matlab R2010a (Matlab R2010a, 2010) software was applied for writing mathematical code to build and evaluate the ANN-models. In fact, the developed program is a modified source code of an ANN algorithm which was previously used by (Ahmadi and Golian, 2011; Arab et al., 2016; Jamshidi et al., 2016).
Twelve models were developed separately for predicting the concentration of CAT, KAE, QUE, RUT, NAR, IQ, GAL, PC, OC, MC, RES, and COU. In order to make the model computationally more tractable, both the input and output data were normalized to the range of -1 to 1 (Beale et al., 2010; Gulati et al., 2010; Ahmadi and Golian, 2011).
For determining the accuracy of the developed ANN and regression models, the statistical parameters root mean square error (RMSE) and mean bias error (MBE) were applied in addition to R2, using the following formulas (Ahmadi et al., 2007):
where n is the number of observations in the test data, y are the values of the output in the test data, and y are values of the predicted outputs.
Results
Stepwise Regression Modeling
According to the results of the stepwise regression models (Table 2) (number of observations = 1890), organ, time and cultivar were found to differently affect the phenolics content. So that RUT and NAR concentrations are under the effect of all three factors while for GAL, m- and OCs and COU levels, cultivar is not an important factor as well as time which is not critical in determining IQ, RES and PC content. Cultivar is the only factor among three above mentioned factors which affects QUE level whereas time is important for CAT and KAE content.

TABLE 2. Stepwise regression model of cultivar, organ (leaf or stem), month (July, August, September, and October), TRC, TFC, and TAA for different measured phenolics content of V. vinifera foliara.
The amounts of TRC, TFC, and TAA showed various relationships with the content of phenolics, as well. As CAT is associated with all three measured factors but TAA is excluded about GAL and OC as well as exclusion of TFC for RUT, IQ, and COU. NAR, p- and MCs are just related to TRC while QUE and KAE are associated to TFC. RES content did not show any relationship with the last three measured factors.
ANN-GA Modeling and Sensitivity Analysis
To verify the capability of the ANN in phenolic profiling prediction, we used empirical data of our previous HPLC analyses (Eftekhari et al., 2017). Initially, we used cultivar, organ, sampling time, TRC, TFC, and TAA as input variables and each phenolic concentration as the output variable of the network, and the concentration of every phenolic compound could be predicted according to the trained network in separate models.
In order to test the performance of the developed ANN-models, the predicted and experimental datasets of training samples were compared and the results presented in Table 3 show the high ability of the ANN to produce outputs close to the experimental data. The average accuracy (R2 = 0.95) of training data is indicating that the developed network could be used for testing data in the subsequent analysis.
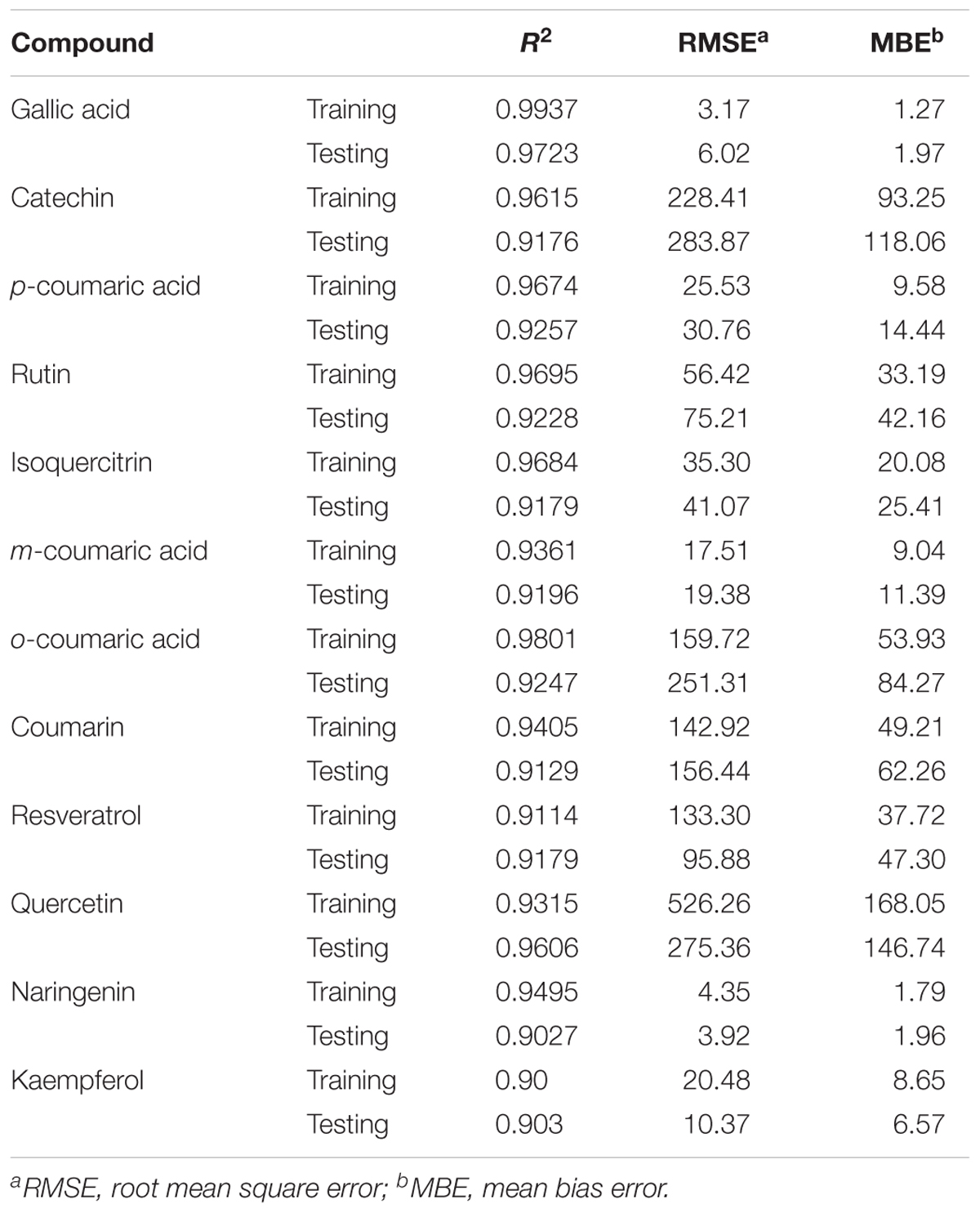
TABLE 3. Statistics and information on artificial neural network models for measured phenolics in leaf and stem extracts of V. vinifera during 4 months (training vs. testing values).
In order to evaluate the generalization capability of the model, we examined the response ability of established models to respond to the testing dataset not involved in the training process. The prediction results of the testing dataset are listed in Table 3. Clearly, a high correlation between the predicted results and targets is noticeable. The average testing accuracy (R2 = 0.92) is indicating that the developed network is efficient and feasible.
The error statistics evaluated on our developed ANN-models are highly constant for both training and test data prediction of each output (Table 3) suggesting lack of over fitting throughout the training process (Ahmadi and Golian, 2010a,b).
In order to determine the relative importance of input variables, the entire dataset was used to estimate the overall VSR for each phenolic concentration. The obtained VSR for each output variable of the models concerning 79 input variables are shown in Table 4.
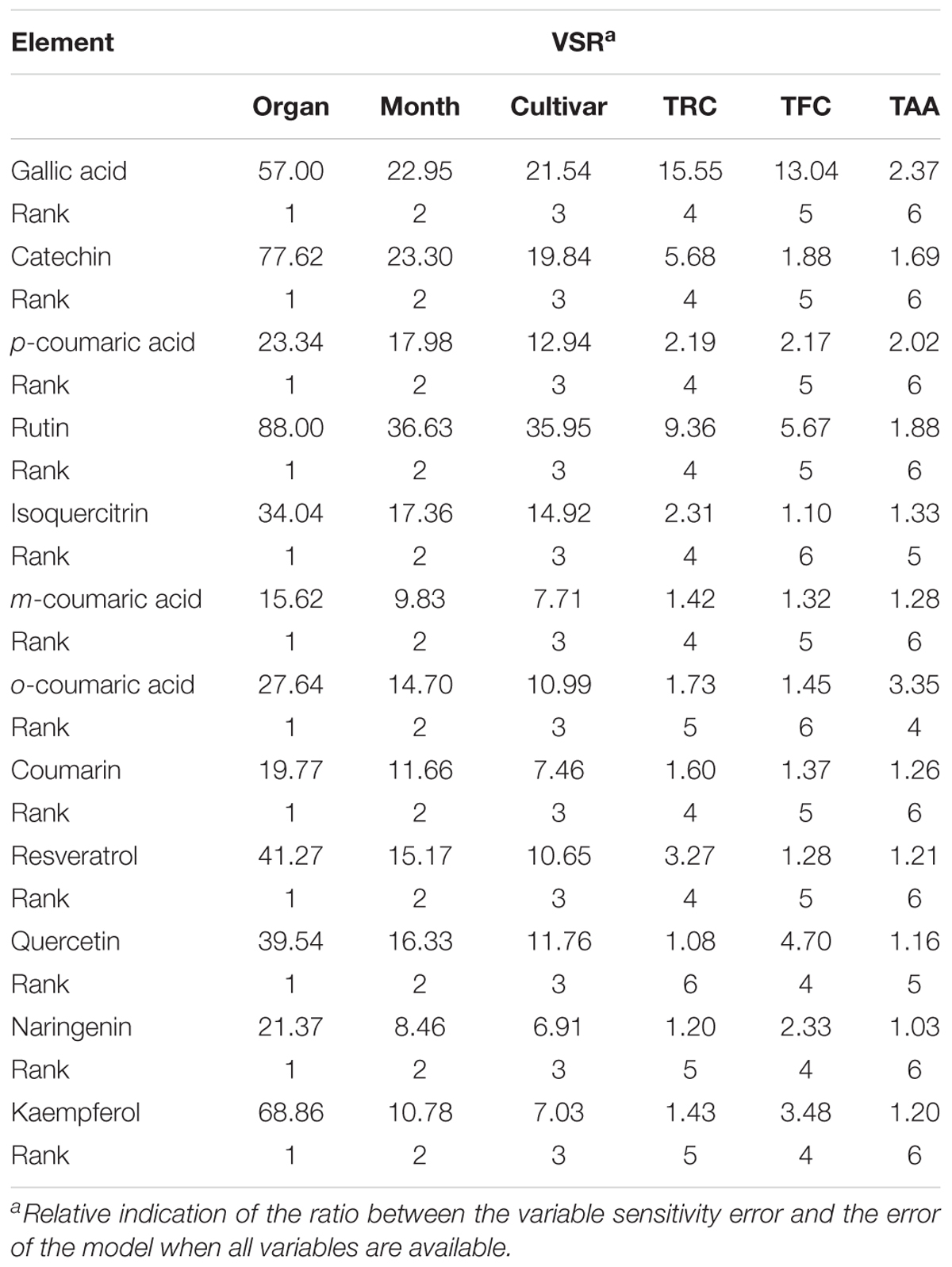
TABLE 4. Importance of evaluated factors on phenolics content of grapevine vegetative parts according to the sensitivity analysis on the developed neural network models.
The higher the VSR value, the more important is the input variable. Thus, the inputs can be ranked according to their importance in determining the outputs using VSR values (Table 4).
Among the input variables, organ had the highest values of VSR in datasets for all phenolics. According to the obtained VSR values, the order of the most important phenolics in grapevine were organ, time, cultivar, TRC, TFC, and TAA, respectively. But about the last three mentioned factors, OC was more sensitive to TAA (3.35) followed by TRC (1.73) and TFC (1.45), while QUE was more sensitive to TFC (4.70) followed by TAA (1.16) and TRC (1.08) (Table 4). The order of input sensitivity for NAR and KAE was as TFC (2.33 and 3.48), TRC (1.20 and 1.43) and TAA (1.03 and 1.20).
Comparison of ANN-GA and Stepwise Regression Models
The estimated statistical values related to the ANN-models revealed a substantially higher accuracy of prediction than for regression models, so as calculated R2 for ANN vs. regression models were: GAL = 0.97 vs. 0.78, CAT = 0.92 vs. 0.19, PC = 0.93 vs. 0.18, RUT = 0.92 vs. 0.34, IQ = 0.92 vs. 0.27, MC = 0.92 vs. 0.11, OC = 0.92 vs. 0.18, COU = 0.91 vs. 0.48, RES = 0.92 vs. 0.06, QUE = 0.96 vs. 0.05, NAR = 0.90 vs. 0.21 and KAE = 0.90 vs. 0.13 (Tables 2, 3). In order to develop an accurate prediction model, it is important to use a reliable modeling system to predict subjects.
Accuracy of ANN Prediction
Based on the train and test accuracies (Table 3), we can conclude that the use of the tansig activation function provides a rational choice for modeling non-linearities over all experiments. The number of neurons in hidden layer (Table 5) as well as close errors of training and testing subsets ensure that over-learning has not happened (Matlab R2010a, 2010). The strength of our work is that we used the same datasets (training and testing) for developing different ANN-models which confirms that the developed models are quite reliable and valid.
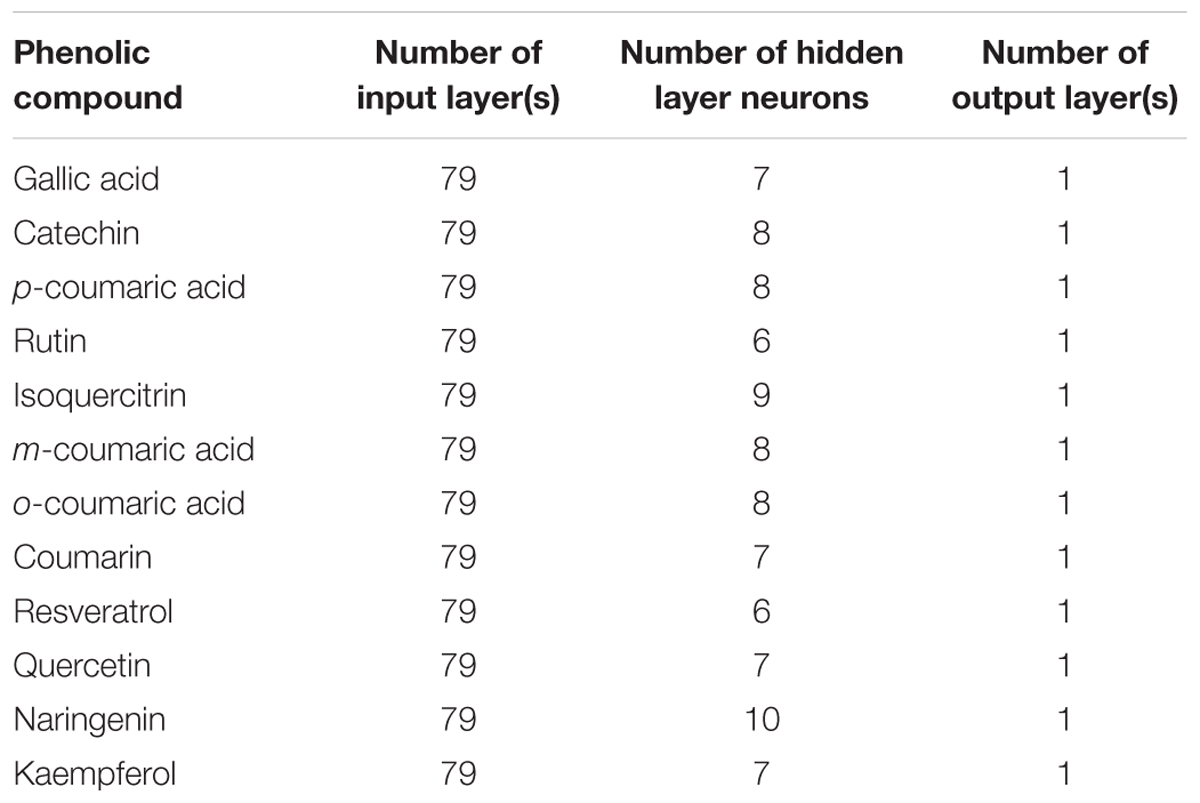
TABLE 5. Structure of artificial neural networks used to build models for prediction of phenolics concentrations.
As it was pointed out before, plant organ is of critical importance since phenolics accumulate in different organs according to the plant growth stage (Eftekhari et al., 2017) and the content of phenolic compounds is also cultivar dependent (Eftekhari et al., 2017). Predicting the amount of phenolics in different parts of the grapevine as enriched raw material for extraction and industrial applications is highly helpful and much required as knowledge of the phenolic profiles and features of the samples will assist to make a decision in the collection of the most appropriate sample for industrial scale extraction increasing the value of a potential commercial product.
Discussion
To the best of our knowledge, this study is the first to give an idea about the prediction of phenolic composition in grapevine foliage. Using the combination of ANN and GA is recommended as a promising prediction method to evaluate phenolics in different grape cultivars, organs and developmental stages. And this technique cannot only be useful for making predictions for high value bioactive compounds, but also provides new potential approaches for bio-compounds research into other plants and other environmental conditions.
The present study was conducted to predict the phenolic profiles of grapevine (V. vinifera) leaves and stems, as residues of the viticulture or winery industries, addressed to food, pharma or cosmetic industries. Previous results (Eftekhari et al., 2017) on the V. vinifera cultivars foliar parts revealed that they contain high levels of valuable phenolic compounds comparable or more than the reported levels in different parts of the fruit and winery by-products (Di Lecce et al., 2014; Ky et al., 2014). In the same study, grape cultivars were discriminated according to the phenolic compounds composition in their foliar parts during grapevine development confirming the significant impact of vine growth stage in addition to cultivar and organ on phenolics accumulation. Recent valorization studies on grape and wine industry wastes open paths to the production of bioactive compounds. Various analytical spectrophotometric techniques have been established based on different principles for the total determination of different structural groups existing in the phenolic compounds such as TFC. These determinations accompanied by the antioxidant activity are preliminary evaluation of polyphenol content due to providing valuable information about the comparative content and potential bioactivity of the sample (Cámara et al., 2010; Fontana et al., 2017).
The diverse phytochemical contents of leaves and stems (Eftekhari et al., 2017) together with the drive to reduce environmental effects on wastes has led to viticulture waste valorization initiatives including using those wastes as a source for the production of high-value bioactive chemicals such as RES.
The stepwise regression modeling and ANN performed here were used to assess the relationships between three factors of cultivar, organ and time as well as three total measured factors, i.e., TRC, TFC, and TAA with the contents of phenolics in grapevine foliar parts and the possibility of the prediction of phenolics content according to determined factors. Such mathematical relationships and predictions have not been previously reported by researchers in this area. ANN-based models were compared with stepwise regression models considering accuracy of the prediction, relative importance, and the effect of input variables on phenolics content.
Neural networks are able to learn complex relationships and generalize results from given patterns of input/output data. Therefore, ANNs are appropriate techniques for the modeling of complicated systems for which precise models or probable performances have not been found. Solving a problem using ANNs depends on the magnitude, quality and preprocessing of the training data, type, and construction of the ANN and the learning algorithm for that special case (Baykal and Yildirim, 2013).
The key privilege of ANN-model is that it is not necessary to specify a preceding proper fitting function; so, it has a complete calculation capability to estimate practically all types of non-linear functions which helps us to develop the most accurate prediction model. Based on the high accuracy of the predicted data both in the training and testing processes, we can conclude that the offered neural networks are capable of predicting the respective phenolic content in grape foliage. Despite lots of research reports on the existing correlation between TAA, TRC, or TFC with the individual phenolics in grape berries, leaves, stems, and wine (Bors et al., 1990; Rice-Evans and Miller, 1996; Torres et al., 2015; Eftekhari et al., 2017), there is still this question that which phenolic compounds have direct relationship with the mentioned total indices. As mentioned above, the sensitivity of the studied phenolics prediction models to continuous input variables, i.e., TRC, TFC, and TAA is less than three categorical inputs, i.e., cultivar, time and organ but the ANN-models were constructed considering all inputs together. In our previous work (Eftekhari et al., 2017), we concluded that the type of the phenolic compound is important in determining the antioxidant activity of an extract as it has also been stated by other researchers (Rice-Evans and Miller, 1996). Here, we can more precisely state that OC is more related to the TAA than other investigated phenolics (Table 4). The most sensitive flavonoid model to TAA is the model related to QUE which has been previously found as the most powerful flavonoid with the anti-oxidative action (Bors et al., 1990; Rice-Evans et al., 1996). And one of its glycosylated forms, i.e., IQ, as a flavonoid, was also more sensitive to TAA than TFC (Table 4).
Previous modeling studies in different research areas have also indicated substantially higher accuracy of ANN modeling technique than regression modeling (Jamshidi et al., 2016) or other modeling procedures (Moghri et al., 2015). Comparing other regression methods performances like partial least squares (PLS) with ANN using spectrum data of near-infrared (NIR) for the prediction of total anthocyanin concentration in red-grape homogenates revealed that the PLS prediction had a high error at concentration extremes while ANN provided a higher correlation (Janik et al., 2007). In order to estimate total phenol in tea, Luo et al. (2005) also used NIR with ANN rather than a linear PLS model theoretically to expand the applicable analysis range as mentioned in the wine study. Furthermore, it has been displayed that GA is an easy, precise and effective optimization method (Moghri et al., 2015) which can be useful for developing an optimized number of neurons in hidden layer of ANN for constructing prediction model of phenolics composition in grapevine foliar parts.
Neural models have been used before in order to assessment of β-carotene and lycopene concentrations in samples of food to solve the intervention of analytical techniques UV-vis and HPLC (Cámara et al., 2010) but these models have not been developed previously for modeling the effect of different factors like cultivar, time and organe on phenolics yield in plants as well as even using TAA, TRC, or TFC indices to predict the presence of phenolics to avoid using complex and expensive analytical techniques like HPLC.
Factors like altitude of the place in which grapevine is growing and the skin color of grape berry can be added as inputs to the model to achieve more extensive models and predictions. Thus, future studies are suggested to evaluate these facts in the grapevines with the aim to establish the effect on the phenolic composition of foliage.
Conclusion
Twelve ANN-models were constructed to predict targeted phenolics (GAL, CAT, PC, MC, OC, RUT, IQ, COU, RES, QUE, NAR, and KAE) levels in the grapevine foliage. Very small differences between the ANN predicted results and experimental data of the phenolic concentration confirmed the outstanding performance of the GA-ANN method. This can be attributed to the ANN capability to construct non-linear mapping of data. Sensitivity analysis of the ANN-model revealed that the organ was the most important controlling factor affecting the content of each phenolic compound, followed by sampling time, and then cultivar; however, considering the total measured indices as predictive factors, phenolics were most related to TRC, followed by TFC, and then TAA with the exception of OC, QUE, NAR and KAE which were somehow different.
These results are promising from the standpoint of the industrial exploitation of grapevine foliage wastes and can be assumed as a starting point to design future studies focused on the determination of phenolics composition in different parts of the grape including fruit, wine and wastes of industrial processing from different cultivars.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
This work was supported by Iran National Science Foundation (INSF), with funds provided by the Office of President, Vice-Presidency for Science and Technology (project 93004406).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors thank Dr. Christopher M. Ford of Adelaide University, Australia for English editing and proofreading the manuscript.
Abbreviations
ANN, artificial neural network; CAT, catechin; COU, coumarin; GA, genetic algorithm; GAL, gallic acid; IQ, isoquercitrin; KAE, kaempferol; MC, m-coumaric acid; NAR, naringenin; OC, o-coumaric acid; PC, p-coumaric acid; QUE, quercetin; RES, resveratrol; RUT, rutin; TAA, total antioxidant activity; TFC, total flavonoid content; TRC, total reducing capacity.
References
Abramson, M. A. (2007). Genetic Algorithm and Direct Search Toolbox User’s Guide. Natick, MA: MathWorks Inc.
Ahmadi, H., and Golian, A. (2010a). Growth analysis of chickens fed diets varying in the percentage of metabolizable energy provided by protein, fat, and carbohydrate through artificial neural network. Poult. Sci. 89, 173–179. doi: 10.3382/ps.2009-00125
Ahmadi, H., and Golian, A. (2010b). The integration of broiler chicken threonine responses data into neural network models. Poult. Sci. 89, 2535–2541. doi: 10.3382/ps.2010-00884
Ahmadi, H., and Golian, A. (2011). Response surface and neural network models for performance of broiler chicks fed diets varying in digestible protein and critical amino acids from 11 to 17 days of age. Poult. Sci. 90, 2085–2096. doi: 10.3382/ps.2011-01367
Ahmadi, H., Mottaghitalab, M., and Nariman-Zadeh, N. (2007). Group method of data handling-type neural network prediction of broiler performance based on dietary metabolizable energy, methionine, and lysine. J. Appl. Poult. Res. 16, 494–501. doi: 10.3382/japr.2006-00074
Arab, M. M., Yadollahi, A., Shojaeiyan, A., and Ahmadi, H. (2016). Artificial neural network genetic algorithm as powerful tool to predict and optimize in vitro proliferation mineral medium for g × n15 rootstock. Front. Plant Sci. 7:1526. doi: 10.3389/fpls.2016.01526
Baykal, H., and Yildirim, H. K. (2013). Application of artificial neural networks (ANNs) in wine technology. Crit. Rev. Food Sci. Nutr. 53, 415–421. doi: 10.1080/10408398.2010.540359
Beale, M. H., Hagan, M. T., and Demuth, H. B. (2010). Neural Network ToolboxTM User’s Guide. Natick, MA: MathWorks Inc, doi: 10.1016/j.ejor.2006.12.004
Bors, W., Heller, W., Michel, C., and Saran, M. (1990). Flavonoids as antioxidants: determination of radical-scavenging efficiencies. Methods Enzymol. 186, k343–355. doi: 10.1016/0076-6879(90)86128-I
Cámara, M., Torrecilla, J. S., Caceres, J. O., Sánchez Mata, M. C., and Fernandez-Ruiz, V. (2010). Neural network analysis of spectroscopic data of lycopene and β-carotene content in food samples compared to HPLC-UV-Vis. J. Agric. Food Chem. 58, 72–75. doi: 10.1021/jf902466x
Di Lecce, G., Arranz, S., Jáuregui, O., Tresserra-Rimbau, A., Quifer-Rada, P., and Lamuela-Raventós, R. M. (2014). Phenolic profiling of the skin, pulp and seeds of albariño grapes using hybrid quadrupole time-of-flight and triple-quadrupole mass spectrometry. Food Chem. 145, 874–882. doi: 10.1016/j.foodchem.2013.08.115
Eftekhari, M., Alizadeh, M., and Ebrahimi, P. (2012). Evaluation of the total phenolics and quercetin content of foliage in mycorrhizal grape (Vitis vinifera L.) varieties and effect of postharvest drying on quercetin yield. Ind. Crops Prod. 38, 160–165. doi: 10.1016/j.indcrop.2012.01.022
Eftekhari, M., Yadollahi, A., Ford, C. M., and Shojaeiyan, A. (2017). Chemodiversity evaluation of grape (Vitis vinifera) vegetative parts during summer and early fall. Ind. Crops Prod. 108, 267–277. doi: 10.1016/j.indcrop.2017.05.057
Fontana, A., Antoniolli, A., D’Amario Fernández, M. A., and Bottini, R. (2017). Phenolics profiling of pomace extracts from different grape varieties cultivated in Argentina. RSC Adv. 7, 29446–29457. doi: 10.1039/C7RA04681B
Gulati, T., Chakrabarti, M., Singh, A., Duvuuri, M., and Banerjee, R. (2010). Comparative study of response surface methodology, artificial neural network and genetic algorithms for optimization of soybean hydration. Food Technol. Biotechnol. 48, 11–18.
Guoqiang, Z. B., Hu, M. Y., and Patuwo, E. (1998). Forecasting with artificial neural networks: the state of the art. Int. J. Forecast. 14, 35–62. doi: 10.1016/S0169-2070(97)00044-7
Hashimoto, Y. (1997). Applications of artificial neural networks and genetic algorithms to agricultural systems. Comput. Electron. Agric. 18, 71–239. doi: 10.1016/S0168-1699(97)00020-3
Haupt, R. L., and Haupt, S. E. (2004). Practical Genetic Algorithms. Studies in Computational Intelligence. Hoboken, NJ: John Wiley & Sons Inc, doi: 10.1007/11543138_2
Houillé, B., Besseau, S., Courdavault, V., Oudin, A., Glévarec, G., Delanoue, G., et al. (2015). Biosynthetic origin of E -resveratrol accumulation in grape canes during postharvest storage. J. Agric. Food Chem. 63, 1631–1638. doi: 10.1021/jf505316a
Jamshidi, S., Yadollahi, A., Ahmadi, H., Arab, M. M., and Eftekhari, M. (2016). Predicting in vitro culture medium macro-nutrients composition for pear rootstocks using regression analysis and neural network models. Front. Plant Sci. 7:274. doi: 10.3389/fpls.2016.00274
Janik, L. J., Cozzolino, D., Dambergs, R., Cynkar, W., and Gishen, M. (2007). The prediction of total anthocyanin concentration in red-grape homogenates using visible-near-infrared spectroscopy and artificial neural networks. Anal. Chim. Acta 594, 107–118. doi: 10.1016/j.aca.2007.05.019
Karacabey, E., Mazza, G., Bayindirli, L., and Artik, N. (2012). Extraction of bioactive compounds from milled grape canes (Vitis vinifera) using a pressurized low-polarity water extractor. Food Bioproc. Technol. 5, 359–371. doi: 10.1007/s11947-009-0286-8
Ky, I., Lorrain, B., Kolbas, N., Crozier, A., and Teissedre, P. L. (2014). Wine by-products: phenolic characterization and antioxidant activity evaluation of grapes and grape pomaces from six different French grape varieties. Molecules 19, 482–506. doi: 10.3390/molecules19010482
Lawrence, J. (1994). Introduction to Neural Networks: Design, Theory, and Applications. Nevada, CA: California Scienti?c Software.
Lou, W., and Nakai, S. (2001). Artificial neural network-based predictive model for bacterial growth in a simulated medium of modified-atmosphere-packed cooked meat products. J. Agric. Food Chem. 49, 1799–1804. doi: 10.1021/jf000650m
Luo, Y. F., Guo, Z. F., Wang, C. P., Jiang, H. Y., and Han, B. Y. (2005). Studies on ANN models of determination of tea polyphenol and amylase in tea by near-infrared spectroscopy. Spectrosc. Spect. Anal. 25, 1230–1233.
Mirarab, M., Sharifi, M., Ghayyem, M. A., and Mirarab, F. (2014). Prediction of solubility of CO2 in ethanol-[EMIM][Tf2N] ionic liquid mixtures using artificial neural networks based on genetic algorithm. Fluid Phase Equilib. 371, 6–14. doi: 10.1016/j.fluid.2014.02.030
Moghri, M., Shamaee, H., Shahrajabian, H., and Ghannadzadeh, A. (2015). The effect of different parameters on mechanical properties of PA-6/clay nanocomposite through genetic algorithm and response surface methods. Int. Nano Lett. 5, 133–140. doi: 10.1007/s40089-015-0146-7
Nassiri-Asl, M., and Hosseinzadeh, H. (2016). Review of the pharmacological effects of Vitis vinifera (Grape) and its bioactive constituents: an update. Phytother. Res. 1403, 1392–1403. doi: 10.1002/ptr.5644
Rice-Evans, C. A., and Miller, N. J. (1996). Antioxidant activities of flavonoids as bioactive components of food total antioxidant potential structure-activity relationships and determinants of radical-scavenging potential. Biochem. Soc. Trans. 24, 790–795. doi: 10.1042/bst0240790
Rice-Evans, C. A., Miller, N. J., and Paganga, G. (1996). Structure-antioxidant activity relationships of flavonoids and phenolic acids. Free Radic. Biol. Med. 20, 933–956. doi: 10.1016/0891-5849(95)02227-9
Rumelhart, D. E., and McClelland, J. L. (1986). Parallel Distributed Processing. Cambridge, MA: MIT Press.
Silva, S. F., Rodrigues Anjos, C. A., Cavalcanti, R. N., and Celeghini, R. M. (2015). Evaluation of extra virgin olive oil stability by artificial neural network. Food Chem. 179, 35–43. doi: 10.1016/j.foodchem.2015.01.100
Suárez, M. H., Dopazo, G. A., López, D. L., and Espinosa, F. (2015). Identification of relevant phytochemical constituents for characterization and authentication of tomatoes by general linear model linked to automatic interaction detection (GLM-AID) and artificial neural network models (ANNs). PLoS One 10:e0128566. doi: 10.1371/journal.pone.0128566
Teixeira, A., Eiras-Dias, J., Castellarin, S. D., and Gerós, H. (2013). Berry phenolics of grapevine under challenging environments. Int. J. Mol. Sci. 14, 18711–18739. doi: 10.3390/ijms140918711
Torres, N., Goicoechea, N., and Antolin, M. C. (2015). Antioxidant properties of leaves from different accessions of grapevine (Vitis vinifera L.) Cv. Tempranillo after applying biotic and/or environmental modulator factors. Ind. Crops Prod. 76, 77–85. doi: 10.1016/j.indcrop.2015.03.093
Wang, L. (2005). A hybrid genetic algorithm-neural network strategy for simulation optimization. Appl. Math. Comput. 170, 1329–1343. doi: 10.1016/j.amc.2005.01.024
Keywords: bioactive compounds, grapevine waste, neural network, prediction, regression
Citation: Eftekhari M, Yadollahi A, Ahmadi H, Shojaeiyan A and Ayyari M (2018) Development of an Artificial Neural Network as a Tool for Predicting the Targeted Phenolic Profile of Grapevine (Vitis vinifera) Foliar Wastes. Front. Plant Sci. 9:837. doi: 10.3389/fpls.2018.00837
Received: 22 December 2017; Accepted: 30 May 2018;
Published: 19 June 2018.
Edited by:
Alfredo Pulvirenti, Università degli Studi di Catania, ItalyReviewed by:
Patrik Waldmann, Swedish University of Agricultural Sciences, SwedenGuilherme De Alencar Barreto, Federal University of Ceará, Brazil
Copyright © 2018 Eftekhari, Yadollahi, Ahmadi, Shojaeiyan and Ayyari. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Abbas Yadollahi, eWFkb2xsYWhAbW9kYXJlcy5hYy5pcg==