 Frank Gyan Okyere1,2†
Frank Gyan Okyere1,2† Daniel Cudjoe1,2†Pouria Sadeghi-Tehran1†Nicolas Virlet1†Andrew B. Riche1†
Daniel Cudjoe1,2†Pouria Sadeghi-Tehran1†Nicolas Virlet1†Andrew B. Riche1† March Castle1Latifa Greche1†Daniel Simms2†Manal Mhada3†Fady Mohareb2*†Malcolm John Hawkesford1*†
March Castle1Latifa Greche1†Daniel Simms2†Manal Mhada3†Fady Mohareb2*†Malcolm John Hawkesford1*†- 1Sustainable Soils and Crops, Rothamsted Research, Harpenden, United Kingdom
- 2School of Water, Energy and Environment, Cranfield University, Cranfield, United Kingdom
- 3AgroBioSciences Department, University of Mohammed VI Polytechnic, Ben Guerir, Morocco
Sustainable fertilizer management in precision agriculture is essential for both economic and environmental reasons. To effectively manage fertilizer input, various methods are employed to monitor and track plant nutrient status. One such method is hyperspectral imaging, which has been on the rise in recent times. It is a remote sensing tool used to monitor plant physiological changes in response to environmental conditions and nutrient availability. However, conventional hyperspectral processing mainly focuses on either the spectral or spatial information of plants. This study aims to develop a hybrid convolution neural network (CNN) capable of simultaneously extracting spatial and spectral information from quinoa and cowpea plants to identify their nutrient status at different growth stages. To achieve this, a nutrient experiment with four treatments (high and low levels of nitrogen and phosphorus) was conducted in a glasshouse. A hybrid CNN model comprising a 3D CNN (extracts joint spectral-spatial information) and a 2D CNN (for abstract spatial information extraction) was proposed. Three pre-processing techniques, including second-order derivative, standard normal variate, and linear discriminant analysis, were applied to selected regions of interest within the plant spectral hypercube. Together with the raw data, these datasets were used as inputs to train the proposed model. This was done to assess the impact of different pre-processing techniques on hyperspectral-based nutrient phenotyping. The performance of the proposed model was compared with a 3D CNN, a 2D CNN, and a Hybrid Spectral Network (HybridSN) model. Effective wavebands were selected from the best-performing dataset using a greedy stepwise-based correlation feature selection (CFS) technique. The selected wavebands were then used to retrain the models to identify the nutrient status at five selected plant growth stages. From the results, the proposed hybrid model achieved a classification accuracy of over 94% on the test dataset, demonstrating its potential for identifying nitrogen and phosphorus status in cowpea and quinoa at different growth stages.
1 Introduction
Nitrogen (N) and phosphorus (P) are two essential macronutrients that play a significant role in the normal functioning and growth of plants. They are involved in vital plant metabolic processes, such as cell division, protein formation, and photosynthesis (Siedliska et al., 2021). Plants with adequate nitrogen nutrition display green leaves, whilst nitrogen deficiency manifests as chlorosis, starting from light green and progressing to yellow and eventually brown. Phosphorus deficiency inhibits shoot growth and shows decolorized leaves, transitioning from pale green to yellow in severely affected regions (McCauley et al., 2011). When plants are insufficient in nutrients, fertilizer application is required to enrich the soil. However, the application of nitrogen and phosphorus fertilizer often relies on farmer’s experience and intuition, which may result in over- or under-application. This practice can lead to soil quality degradation, crop yield reduction, environmental pollution, and loss of biodiversity (Gao et al., 2021). Hence, accurate estimation and tracking of plant N and P status is essential to promote good agronomic practice and effective fertilizer management.
The tracking of plants’ N and P status traditionally involves visual inspection or laboratory-based chemical analysis, which can be destructive, labor intensive, and prone to error. To indirectly measure nutrient status, breeders and researchers use contact and remote sensing tools. One such tool is the SPAD (Soil Plant Analysis Development) meter, which estimates nitrogen content by measuring the light transmittance of the red (650 nm) and infrared (940nm) wavelengths through plant leaves (Uddling et al., 2007). While this technique is simple and fast, it has limitations. As a leaf contact instrument, it only captures a small area of contact (2 x 3 mm), which may not provide an accurate representation of the spatial variation of nitrogen in plants. Additionally, when these tools are used on a large scale, users may introduce errors and obtain false measurement (Hassanijalilian et al., 2020). To mitigate some of these challenges, image-based non-invasive phenotyping techniques offer a potential solution.
Image-based techniques have proven valuable in plant phenotyping, allowing for the measurement of various plant phenotypic properties such as biomass, leaf area, and plant height (Hairuddin et al., 2011). These techniques utilize images acquired from digital RGB cameras, hyperspectral and multispectral sensors, and 3D laser scanners to extract non-invasive features, trends, and patterns that demonstrate the dynamics of phenotyping traits in response to physiological and chemical changes in plants. Among these imaging sensors, digital cameras are the most widely used for plant phenotyping due to their low cost, portability, and high spatial resolution (Sadeghi-Tehran et al., 2017). However, their spectral limitations, capturing only broad spectral bands of red, green, and blue, present a major challenge. To overcome this challenge, hyperspectral imaging (HSI) has emerged as a promising technique. By combining imaging and spectroscopy, HSI allows for the acquisition of spectral and temporal information from plants, useful for estimating plant physiological parameters (Mishra et al., 2017). HSI samples the reflective areas of the electromagnetic spectrum spanning from the visible regions (400-700 nm) to the short-wave infrared regions (1100-2500 nm). This approach has been successfully applied in non-destructive phenotyping of plant leaf area index (Zhang et al., 2021), plant biomass (Ma et al., 2020), plant nutrient estimation (Ye et al., 2020), and detection of diseases and fungal infections (Siedliska et al., 2018).
HSI data are presented in a hypercube format, with the first two dimensions providing spatial information and the third dimension representing spectral information. Extracting relevant information from these hypercubes requires advanced pattern recognition algorithms, such as machine learning (ML) (Singh et al., 2016). ML algorithms learn patterns and trends from data without relying on explicit programming. In a study by Yamashita et al. (2020), ML regression models were employed to analyze differences in spectral reflectance and estimate N and chlorophyll contents in tea plants. A data-based sensitivity algorithm was applied to select the most informative spectral bands capable of estimating N and chlorophyll contents in tea leaves. The results showed that the integration of spectral data with machine learning models is a promising technique for accurate plant nutrient estimation. To further improve the application of ML models to HSI, researchers are currently exploring deep learning methods.
Deep neural networks, particularly convolutional neural networks (CNNs), have emerged as state-of-the-art machine learning techniques capable of detecting, classifying, and predicting plant phenotypes. In the context of hyperspectral imaging (HSI), CNNs have been successfully combined with HSI for various applications such as crop and weed classification (Dyrmann et al., 2016), plant seedlings classification (Nkemelu et al., 2018), and plant disease and pest detection (Sladojevic et al., 2016; Fuentes et al., 2017). Most traditional deep learning methods employed for HSI extract either spectral or spatial information separately (Hong and He, 2020). For instance, 2D-CNN models focus on spatial information, whilst 1D-CNN models primarily utilize spectral information from HSI. In Roy et al. (2020) and Mu et al. (2021), combining both the spatial (2D) and spectral information (1D) information gave better results than using only the spectral or spatial information. However, since these two are extracted separately, there is difficulty in fully utilizing all information from a hypercube simultaneously. To address this limitation and effectively utilize the structural traits of the HSI data, researchers have introduced 3D-CNN methods (Mirzaei et al., 2019; Pi et al., 2021). Indeed, 3D-CNN modeling naturally suits the spatial–spectral information of a hypercube and presents a promising approach for modeling various scenarios. For example, Al-Sarayreh et al. (2020) proposed a novel 3D-CNN model to extract combined features to classify meat using HSI imaging, while Jung et al. (2022) developed a 3D-CNN classification model for diagnosing gray mold disease in strawberries. In both studies, the models employed 3D convolutions, filters, and kernels to extract relevant spatial and spectral information from the hypercube. However, homogeneous 3D models pose difficulties in optimization due to increased parameters, resulting in lengthy computational time, over-fitting, and gradient disappearance. These challenges are attributed to the increased complexity of the models. To further understand CNN modeling using HSI data, readers are referred to Kumar et al. (2020); Paoletti et al. (2019); Huang et al. (2022); Wang et al. (2021) and Jia et al. (2021) for more details. To mitigate some of these challenges, researchers have proposed the use of hybrid CNN models, which fuse two-unit deep learning blocks together to simultaneously extract both spectral and spatial information from HSI data. For instance, Mohan and Venkatesan (2020) proposed a multiscale hybrid CNN model for hyperspectral image classification. This model extracts spatial–spectral features from different window sizes using a 3D-CNN block. The output from the 3D CNN block is concatenated and fed into a 2D CNN block for abstract spatial feature extraction. The performance of the proposed model showed satisfactory performance when compared to state-of-the-art CNN-based models. Although this method works effectively in simultaneously extracting spectral and spatial features from hypercubes, there is a considerably high number of trainable parameters, which affects the processing time.
In this study, we developed a hybrid model capable of extracting spatial and spectral information simultaneously from a hypercube with reduced computational complexities and time. The proposed model is to identify plant nutrient status (N and P) at different growth stages. Specifically, hypercube regions of interest (patches) measuring 15x15-pixels were extracted from four nutrient treatments. Different spectral transformation techniques were applied to obtain four distinct datasets. The resulting datasets were each used to train the proposed model to classify plants based on their nutrient status. Furthermore, a waveband selection method was applied to the dataset produced by the best performing dataset. The selected wavelengths were used as inputs to retrain the proposed model to identify plant nutrient status at different growth stages.
2 Materials and methods
Figure 1 is the workflow of this study. It involves the generation of the spectral library of hypercube patches to build four different datasets. These datasets were used to train four models to classify plant nutrient status. The most informative dataset was then used to retrain the models based on the selected wavebands from the full plant data (not patches) to classify plants at selected growth stages.
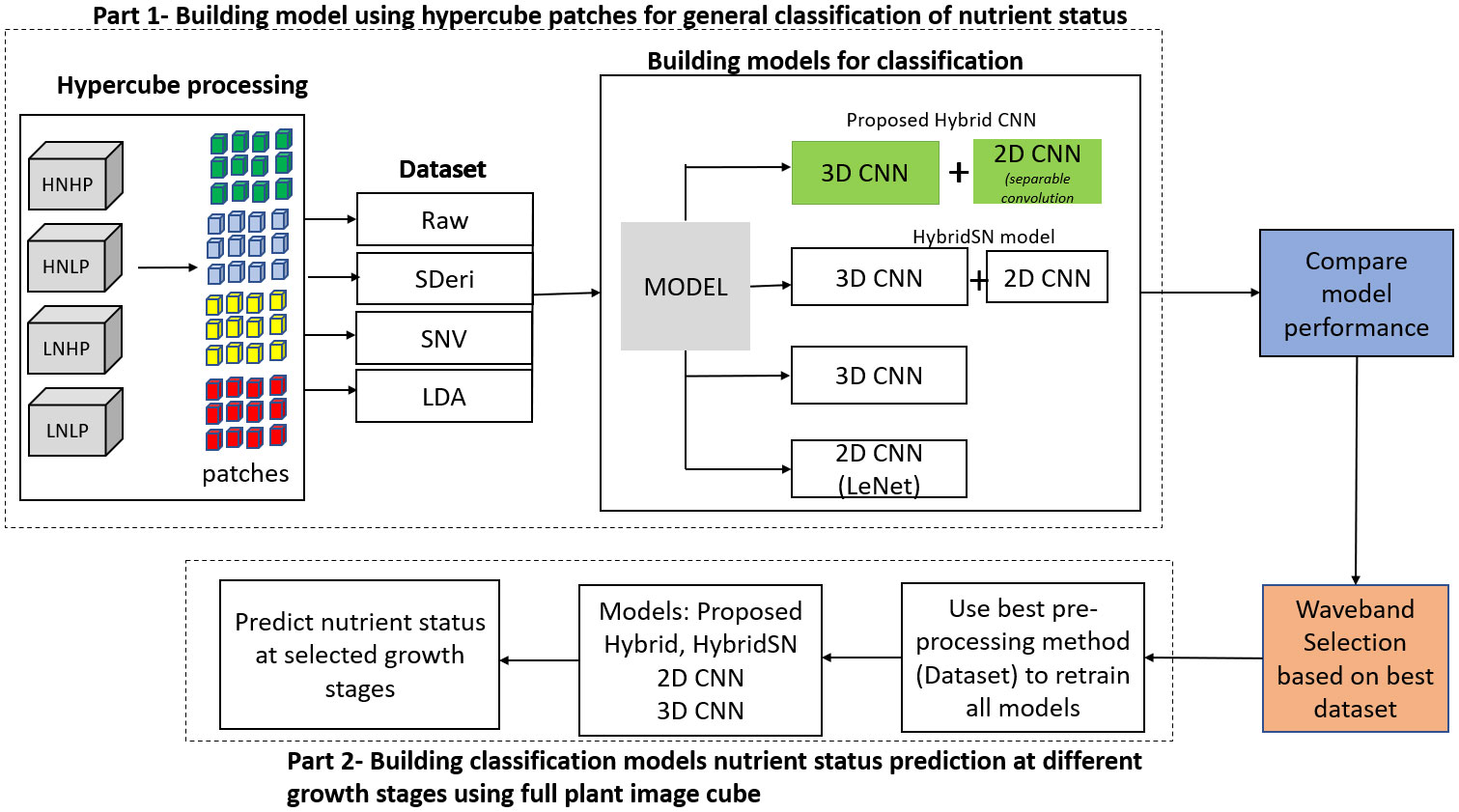
Figure 1 Workflow of the experiment.
2.1 Plant material and treatments
Vigna unguiculata (cowpea) and Chenopodium quinoa (quinoa) were cultivated in a Plant Growth Facility https://www.cranfield.ac.uk/facilities/plant-growth-facility) at Cranfield University (Cranfield, UK). The plants were grown in pots filled with compost with reconstituted nutrients. The compost was first washed with deionized water following the works of Masters-Clark et al. (2020) with some modifications. This was done by flooding one-part compost with five-part deionized water. A double-headed 0.5 µm sieve was used to drain off the soluble solution. The steps were repeated five times, ensuring the plant nutrients were depleted, and the washed compost was dried in an oven at 70°C for 72 hours. Based on the Letcombe nutrition solution (Masters-Clark et al., 2020), the required treatments were prepared as: high nitrogen high phosphorus (HNHP), high nitrogen low phosphorus (HNLP), low nitrogen high phosphorus (LNHP) and low nitrogen low phosphorus (LNLP), with five replications each for the treatments. The treatments had concentrations of 49.1 mM and 14.6 mM N for HN and LN and 13.4 mM and 3.3 mM P for HP and LP, respectively. By visual inspection, the different treatments resulted in changes in the leaf pigments, resulting in variations in the spectral characteristics during plant development. For both species, the leaves were green when the nitrogen and phosphorus levels were adequate, whilst deficiency in nitrogen was characterized by chlorosis progressing from light green to yellow to brown. Phosphorus deficiency inhibited shoot growth and decolorized leaves from a blue-green color to pale green/yellow in severely affected regions (McCauley et al., 2011).
2.2 Hyperspectral imaging system and data collection
Spectral images were collected 3.0 m above the canopy level using a Lemnatec Scanalyzer installed in the glasshouse. The Scanalyzer has a push broom hyperspectral camera (hyperspec® inspectorTM Headwall Photonic) that operates within the 390 – 2500 nm region covering the visible–near-infrared (VNIR) and short-wave infrared (SWIR) regions. The sensor collects data with a 0.7 nm step (at the VNIR region) and 6 nm step (within the SWIR region) and an FWHM (full width at half maximum) image slit of 2.5 nm. This results in a hypercube of 1015 spectral bands for the VNIR data and 275 spectral bands for the SWIR data, with a dynamic range of 16 bits. Data collection was performed twice per week throughout the full development of the plants. Five different growth stages of cowpea and quinoa, hereafter referred as growth stages I, II, III, IV, and V, were considered for this study. They represent the 19, 29, 36, 50, and 69 DAT (days after transplanting) and 13, 30, 51, 60, and 72 DAT for the cowpea and quinoa plants, respectively. Supplementary Table 1 is the description of the selected growth stages based on the BBCH system for coding the phenological growth stages of plants (Meier et al., 2009).
2.3 Pre-processing of raw spectral data
Prior to any analysis, the raw data were pre-processed to normalize the spectral data from ambient illumination and to reduce noise and other artefacts that were produced during scanning. The pre-processing steps comprised: (i) radiometric calibration to remove illumination system effect, (ii) spectral down-sampling to remove redundant wavelengths, and (iii) noise reduction.
Radiometric calibration: Hyperspectral image acquisition suffers from radiometric errors caused by illumination from varying light exposure. Radiometric correction is essential to reduce the variable illumination effect and the influence of dark current on the spectral data. During scanning, a white panel (Zenith Lite™ Ultralight Targets 95%R, Sphereoptics®) was imaged as the white reference data. Dark reference data with approximately 0% reflectance were collected in the night without any light source by completely covering the camera lens with an opaque cap (Zhu et al., 2013). The calibrated data were calculated using equation (1):
Where Ic is the calibrated data, Iraw is the raw spectral data, Rdark is the dark reference, and Rwhite is the white reference.
Down-sampling: Although the hyperspectral data contain essential plant information, the huge dataset poses computational challenges. Down-sampling helps to reduce these computational complexities and the noise generated during scanning (Sadeghi-Tehran et al., 2021). Moreover, down-sampling is conducted to map the spectral resolution to its reference target. In this study, an averaging window with a 2 nm spectral width was used to down-sample the spectral data.
Spectra smoothing and denoising: This is a common pre-processing practice that involves some numerical operations on the raw spectral data to reduce spectral noise levels. This eliminates spikes and smooths spectral curves whiles isolating essential features, which may be obscured by the presence of noise across the different wavelengths. During spectral smoothing and denoising, the original shape and features of the spectra are normally preserved. In our study, we applied the Savitzky–Golay filter (a commonly used low-pass filter), an effective and computationally fast filter, to smooth the spectra. For each data point in the spectrum, the filter selects an odd-sized window of spectral points and fits a least-square regression with a polynomial of higher order. During this operation, the data points in question are eventually replaced with the corresponding values of the fitted polynomial. We used a window of size 13- and second-degree polynomial as the optimal parameters. It should be noted that a small window size leads to the emergence of large artefacts in the smoothed spectra, whilst the larger the window size, the smaller the distinction between full and moving window processing (Rinnan et al., 2009).
Segmentation: After pre-processing, the HSI data were segmented using a selected spectral ratio combined with Otsu thresholding. To segment the VNIR dataset, 705 nm and 750 nm wavelengths were extracted to create a red-edge normalized difference vegetation index (RENDVI) image, which was then combined with automatic Otsu thresholding for segmentation. The RENDVI generally differentiates plant vegetation from non-vegetation regions. Hence, the combination with Otsu thresholding creates a binary image where the plant images are labeled as one and all other items labeled as zeros. The SWIR dataset segmentation used a similar approach, where the NDVI image was derived from wavelengths 1375 nm and 1141 nm, as proposed by Williams et al. (2017).
2.4 Data transformation
Although HSI contains important information that relates objects to its absorptance and reflectance, the measured spectra are subject to spurious signals such as multiplicative and additive effects. Hence, further pre-processing steps are applied to minimize the effect of undesirable occurrences on spectral measurement such as artifacts, particle size effects, and light scattering (Amigo, 2010). In this study, the effects of different pre-processing steps on the performance of classification models were studied by transforming the HSI data using standard normal variate (SNV), second derivative (SDeri), and linear discriminant analysis (LDA). In addition to the raw reflectance spectra, three datasets were generated from the SNV, SDeri, and LDA, respectively, to train the models.
2.4.1 Standard normal variate
SNV is a pre-processing technique aimed at limiting the multiplicative effect of scattering and particle size. It accounts for the variation in baseline shift and curvilinearity in the reflectance spectra and reduces the difference in the global intensities of the reflectance spectra (Luo et al., 2019). SNV transformation was performed on each individual spectrum, requiring no reference spectrum. The raw spectra were transformed using the SNV technique by finding the mean center of each spectrum and dividing by its standard deviation (Barnes et al., 1989), as shown in equation 2:
Where xi,jSNV is the element of the transformed spectrum, xi,j is the corresponding original element of the spectrum i at measured at wavelength j, is the mean reflectance of the uncorrected spectra i, and p is the number of variables or wavelengths in the spectrum.
It should be noted that SNV is performed independently for each pixel (has zero mean and variance equal to one). Hence, it gives an advantage over averaging methods such as MSC (Multiple-Scattering Correction), where the presence of non-plants could influence the averaging process.
2.4.2 Spectral derivatives
The spectral derivative aims to normalize the spectral differences between two continuous narrow bands and remove or suppress image artefacts that result from non-uniform illumination (Pandey et al., 2017). It increases the spectral resolution of overlapping peaks whilst accounting for the baseline correction of reflectance spectra (Perez-Sanz et al., 2017). According to Cloutis et al. (1996), the spectral derivative is sensitive to the signal-to-noise ratio (SNR), such that the higher the spectral derivative, the higher the noise and vice versa. From literature, the first and second derivatives are more effective in managing different spectral disparities and improving data modeling. In this study, we employed the second derivative (SDeri) using the Savitzky–Golay smoothing and polynomial derivative package in Python. Supplementary Figure 1 shows the hypercube of cowpea with examples of the raw, SNV, and SDeri spectral curves.
2.4.3 Linear discriminant analysis
The high spatial and spectral resolution of the data in this study posed a computational challenge to the analysis of the hypercube. Hence, it was desirable to apply a dimensionality technique to reduce the depth of the hypercube while maintaining the core informative features of the data. To do so, the hypercube defined as (w x h x λ) was rearranged into a 2-d spectral matrix (M x λ), where M is the product of w and h. A linear discriminant analysis (LDA) was applied to find the linear combination of spectral features that characterizes the different treatments. LDA is a probabilistic generalization technique that aims at projecting features in higher dimensions to lower dimensions for solving classification and regression problems (Xia et al., 2019). It reduces the size of a dataset while retaining the relevant information that discriminates the different classes. Unlike principal component analysis (PCA), which takes in only the spectral features and its variances irrespective of their classes, LDA makes use of the different class labels to maximize the differences in the classes. Supplementary Figure 2 is a scatter plot of the first and second discriminants using LDA for cowpea and quinoa. Comparing Supplementary Figures 2, 3 for LDA and PCA, respectively, it is observed that LDA performed better in separating the four classes. In the PCA, the classes were not as clearly separated, even though together the first two principal components contained over 90% of the class information.
2.5 Dataset for model training
2.5.1 Generating hypercube patches
The original HSI hypercube obtained from the Scanalyzer contained 1397 spectral dimensions (1015 and 275 for VNIR and SWIR, respectively) for each plant. Down-sampling was applied on both species, reducing the datasets to 223 (155 VNIR and 68 SWIR) spectral dimensions for further analysis. To build the classification model, an automated algorithm was created to extract hypercubes from the four datasets (raw, second derivative, LDA, and SNV data). This was done by building a spectral library of region of interest (patches) from the plant leaves. A patch (Supplementary Figure 4) is defined as a square area of size 15 x 15 pixels and has a spectral dimension with λ number of wavelengths. From a hyperspectral image (H ∈ ), n number of patches (P ∈ ) can be produced depending on the patches size required, where h x w and m x n represent the width × height dimensions of the hyperspectral image and patch hypercube, respectively, while y and k denote the spectral bands for patches and the image respectively. To produce the patches, the hypercube containing the whole plant was divided into four equal segments. A function that utilizes the patchify library in python was developed to create patches on each segment, as shown in Supplementary Figure 4. Then, 20 non-zero patches from each segment were extracted, producing 80 patches per image and resulting in 2800 patches per treatment. The patches for each species were generated from 35 (7 time points and 5 replications) hyperspectral images per treatment.
2.5.2 Developing the training dataset
Since the hyperspectral data for both species from each treatment were divided into 2800 sample patches, there was a total of 11,200 patches used for the experiment. Before extracting the hypercube patches for training the models, the original hyperspectral data were first divided into a 3:1 train–test dataset. The train dataset was further split into an 80%-20% train–validation dataset. The number of samples of the training, validation, and test set for each model is shown in Table 1. To introduce spatial variations into the dataset, the 40% of the train–validation dataset was rotated at different angles between -20° and 20°. All this was done for both species.

Table 1 The number of training, validation, and testing samples.
2.6 Developing models for spatial–spectral characterization of HSI data
2.6.1 Hybrid CNN framework hyperspectral classification
In this study, we employed a hybrid 3D-2D CNN method to model the spatial–spectral variations and interclass appearance to improve the power of accurately differentiating the N and P variations in cowpea and quinoa. The next paragraph explains the architecture and operations of the two units of the model.
3D Convolution Unit: This block employs a 3D convolution technique where the kernel slides in three dimensions convolving input data in their spatial and spectral dimensions, resulting in a 3D data output. It is made of three 3D convolution layers interspersed with layers of filters ranging from 64, 32, and 16, constituting a (3 x 3x 3), (3 x3 x 5), and (3 x 3 x 7) kernel size, respectively. In addition, the filters and the generated feature maps are all configured in a 3D format. The 3D convolution operation is given by equation (3) (Mohan and Venkatesan, 2020):
where yqrs denotes the extracted feature at position (q, r, s) and k is the kernel at dimension ijl. S is the kernel size in the spectral dimension.
2D CNN Unit: In this block, the input is convolved with 2D kernels and filters where the convolution is mathematically obtained by the sum of the dot product between the kernels and the input data. The kernel strides over the entire data to acquire the spatial information. As mentioned by Mohan and Venkatesan (2020), the 2D convolution process can be mathematically expressed as:
where Tmn is the feature extracted at position (m, n) and k is the kernel (2D) at dimension ℎ×w. This convolution operation is applied on all feature maps (l) in the receiver area summing all the values for non-linear activation.
This block has one 2D convolution layer (separable in nature), a max pooling layer, and two fully connected (FC) layers, and SoftMax layers. The separable convolution is a transformation form of conventional 2D convolution in which a single convolution is divided into two or more convolutions to get the same output. There are two steps in separable convolution: spatially and depth-wise separable convolution (Fırat et al., 2022). Spatially separable optimizes the performance of the convolution networks to help preserve the spatial information of the data, while the depth-wise convolution decreases the number of trainable weight parameters while increasing representation efficiency. To prevent the model from overfitting, a 0.5 probability dropout was used on each fully connected layer. The output is fed into a SoftMax layer. Figure 2 summarizes the hybrid CNN architecture for this study. Table 2 also shows the output dimension and number of parameters used in each layer for the hybrid model.
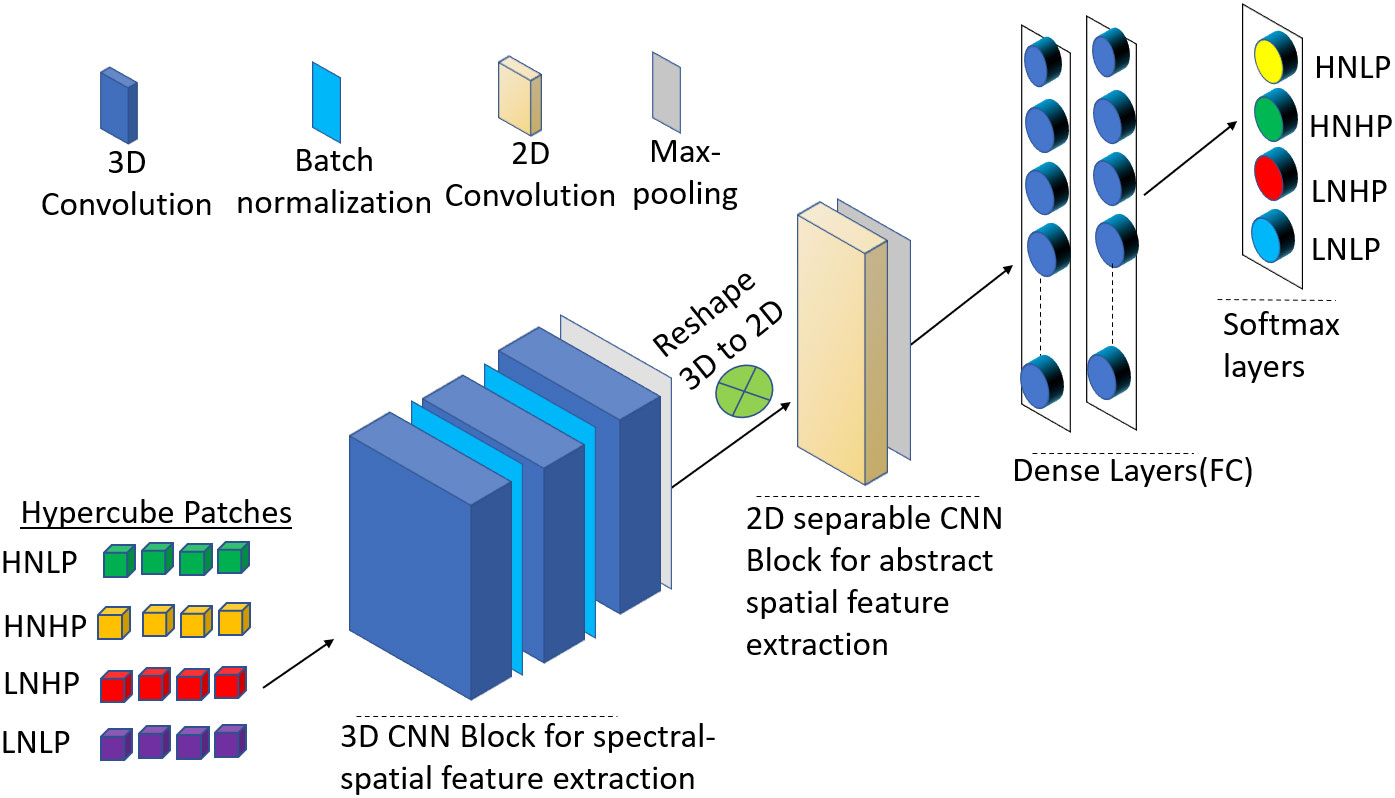
Figure 2 Schematic representation of the proposed 3D-2D-CNN framework with the full-spectrum bands as inputs.
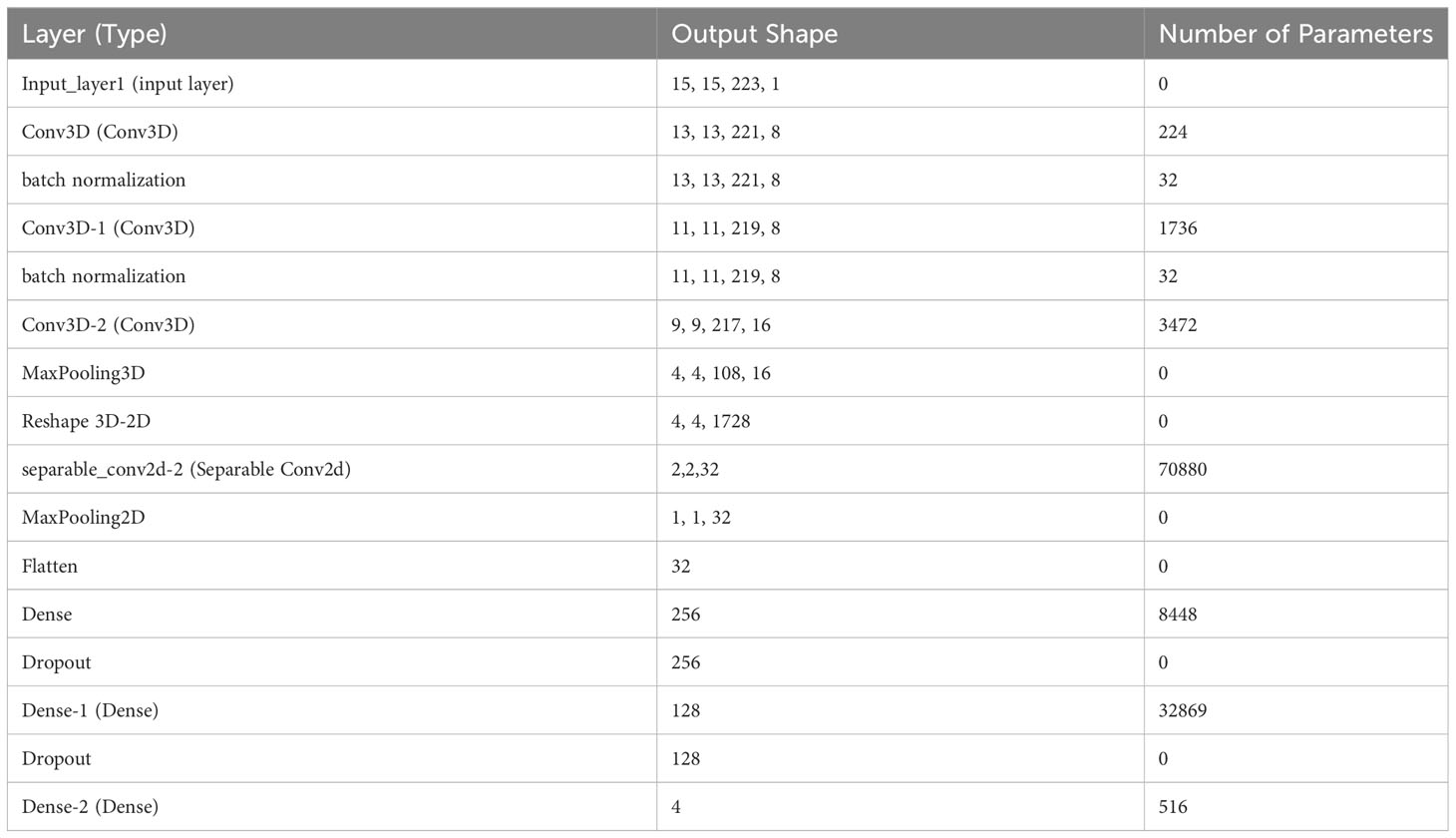
Table 2 The proposed hybrid-CNN algorithm structure.
2.6.2 Other models for comparison (3D CNN, 2D CNN, and HybridSN)
The performance of the proposed method was compared to other methods such as hybrid spectral convolution neural network (HybridSN), 3D-CNN, and 2D- CNN models. The HybridSN is a modification of the model proposed by Roy et al. (2020) for HSI classification. It is a 3D-2D CNN joint model that combines the complementary spectral–spatial information from the 3D-CNN component and abstract level information from the 2D CNN model. In this model, the first three layers are homogeneous 3D convolutions, with a 3x3x3 kernel size in the first and third layers and 3x3x5 filter kernels in the second layer. Each layer has 8, 16, and 32 filters, respectively. The output from the last layer of the 3D block is reshaped and fed into the 2D CNN block. This block is made of a classical 2D convolution with a 3 x 3 kernel size and 64 filters. The output is flattened and passed through two dense layers with Dropout. This is followed by a single SoftMax layer corresponding to the output. Supplementary Table 2 shows the detailed architecture of HybridSN used in this study.
The 3D-CNN model for hyperspectral data modeling is known for extracting spectral and spatial information simultaneously from hyperspectral data. It is especially useful when relevant information is localized in both the spatial and spectral dimension and exhibits good correlations in both domains (Nagasubramanian et al., 2019). The 3D-CNN model used in this study has four 3D convolution layers, with 3D kernel of size 3 x 3 x 3 used for the input of the first convolution layer and three kernels of sizes 3 x 3 x 5 in between the other three layers. The convolution layers are interspersed with max pooling and batch normalization layers between every two convolution layers. It uses the rectified Linear Input (ReLU) activation function for each convolution output (Glorot et al., 2011). There are two fully connected layers that follow the last convolution layer. Dropout with a 0.5 probability was performed after the first max pooling operation. The dropout process was used to prevent overfitting during training. The last fully connected layer was fed to the SoftMax layer for classification. Supplementary Table 3 is the detailed architecture of 3D CNN for the classification of nutrient status.
The 2D-CNN model is a modified version of LeNet-5 deep learning architecture introduced by LeCun et al. (1998). This model was chosen due to its simple and straightforward architecture. It is made of two convolution layers with two pooling layers interspersed between the convolutions. It also has a flattening layer, two fully connected layers, and a SoftMax layer that classifies the resulting features. The convolution layer is responsible for generating feature maps by sliding the given filters over the input data and recognizing patterns and trends. The first convolution layer has a 3 x3 kernel size, and a stride of one which outputs feature maps of sizes 11 x 11 x 6, while the second convolution layer with a 3 x3 kernel size, and a stride of one takes in 11 x11 x6 input feature maps and outputs 7 x 7x12 feature maps. The pooling layer at each end of the convolution layers is made of filters of size 2 x 2, and a stride of two which down-sampling the feature maps by calculating the average value of the patches of each feature map. The first pooling layer halves the sizes of the feature map from 11x11x 6 to 5 x 5 x 12, while the second pooling layer halves the sizes of the feature map from 11x11x 6 to 5 x 5 x 12. The fifth and sixth layers are fully connected layers with 120 feature maps of sizes 1 x 1 and 140 features maps of sizes 1 x 1, respectively. In addition, ReLU activation function is used in this architecture. Supplementary Table 4 shows the detailed architecture of the 2D-CNN model (LeNet) used in this study.
The four models were each trained with RAW, SNV, SDeri, and LDA datasets, resulting in four models for each dataset. For the validation models, a stratified 10-fold cross validation with five repeats was conducted. All the models were programmed in Python 3.8 and implemented based on TensorFlow and Karas open-source framework. The operating platform was on a PC with Intel (R) Core (TM) i7-370K U CPU with 3.50 GHz and 16 GB RAM. All the classification algorithms were established using the full spectrum (390–2500 nm), and the same parameters (window size, training sample, testing sample) were set for a fair comparison.
2.7 Optimal wavelength selection
Hyperspectral data contain a large amount of information that could be highly redundant and multi-collinear within adjacent wavelengths, resulting in computational complexities during processing and application (Hennessy et al., 2020). Feature mining methods that extract the most relevant and sensitive informative wavelengths from the spectral data are important to reduce multi-collinearity in the data and enhance model robustness. In this work, a correlation-based feature selection (CFS) method was applied to the best group of spectral data. CFS is one of the most popular data engineering methods for selecting a sensitive set of features to build a discriminative model for a specific purpose. It works on the principle that good and informative wavelengths are those that are highly correlated with a particular class but uncorrelated with each other. To use the CFS algorithm, a heuristic search algorithm was applied along with a correlation function (Pearson’s correlation) to assign high scores and select the best subset of features that had high predictive ability of the class labels with poor correlation with each other. A greedy stepwise (GS) search strategy was applied during the application of the CFS algorithms to select the space attributes of the variable subsets.
2.8 Evaluation metrics for model performance
To evaluate the performance of the proposed model against the classification models, the overall accuracy (OA), the F- Score, and the kappa coefficient (Kappa) evaluation metrics were considered. OA represents the number of correctly classified samples in the overall test samples, which is given by equation 5. The F-score evaluates the accuracy of the model on the entire dataset and is useful when there is an uneven class distribution. It is given by the expression shown in equation 6. The kappa coefficient is a statistical measure that describes the mutual information between the ground truth map and the predicted classified map. Kappa values ranges between 0 and 1, such that a coefficient of 1 means perfect agreement with predicted class and ground truth and vice versa when the coefficient is 0.
where OA is the overall accuracy, N is the number of all samples, x is the number of class labels present in the dataset, and dii is obtained from the diagonal element of the confusion matrix.
where and and TP is true positive, FN is false negative, and FP is false positive.
where Po is the probability of observed agreements and Pc is the expected agreement.
3 Results
3.1 Characteristics of spectral curves for different nutrient treatment
Figures 3 and 4 represent the average spectral curves for cowpea and quinoa, respectively, at growth stage III. For both species, although the spectral curves are similar in shape, there are visible differences between the four treatments. There is a characteristic peak in the visible spectra observed, especially for wavelengths between 550 nm and 560 nm, for both plant species. This indicates a high amount of chlorophyll absorption in this region (Siedliska et al., 2021), which shows that chlorophyll could be a responsive feature for the dynamics of N and P in both plants. The region between 600 nm and 700 nm (red band) shows a clear and continuous distinction between some variants of the experiment for both species. The low-nitrogen treatments exhibited higher reflectance in contrast to the high-nitrogen treatments, which had low reflectance in this region. HNLP had the lowest reflectance, while LNLP had the highest reflectance in cowpea. Similarly, LNLP and HNHP had the highest and lowest reflectance in the red-edge region for quinoa. This agrees with Clevers and Gitelson (2013), who demonstrated rapid change in the reflectance of the plant canopy in the red-edge region in response to high levels of nitrogen. The regions between 750 and 1100 nm (near infrared) exhibited the highest differences between the spectral curves of the two species. The HNHP had the highest reflectance in both species at above 0.62 nm and above 0.64 nm for cowpea and quinoa, respectively. This agrees with Zhai et al. (2013), who showed that reflectance of healthy plants (in this case, HNHP plants) in the NIR region has a strong correlation with the chemical and cellular architecture of plants and exhibits high reflectance. In the SWIR region, there was a characteristic drop in reflectance from 1250 to 1500 nm and a gradual rise and fall in reflectance across the spectra from 1500 to 2000 nm. Moreover, there was comparably low reflectance in the two - related treatments at 1450 nm, which agrees with Siedliska et al. (2021), who suggest that this region has a quantitative relationship between light reflectance and P treatments. From wavelengths 2000 nm to 2500 nm, there was an observable increase in reflectance for both species.

Figure 3 Average reflectance spectra for cowpea under different N and Plevels obtained at growth stage III. Each line represents the averagespectral signature for five plants from each treatment of theexperiment.
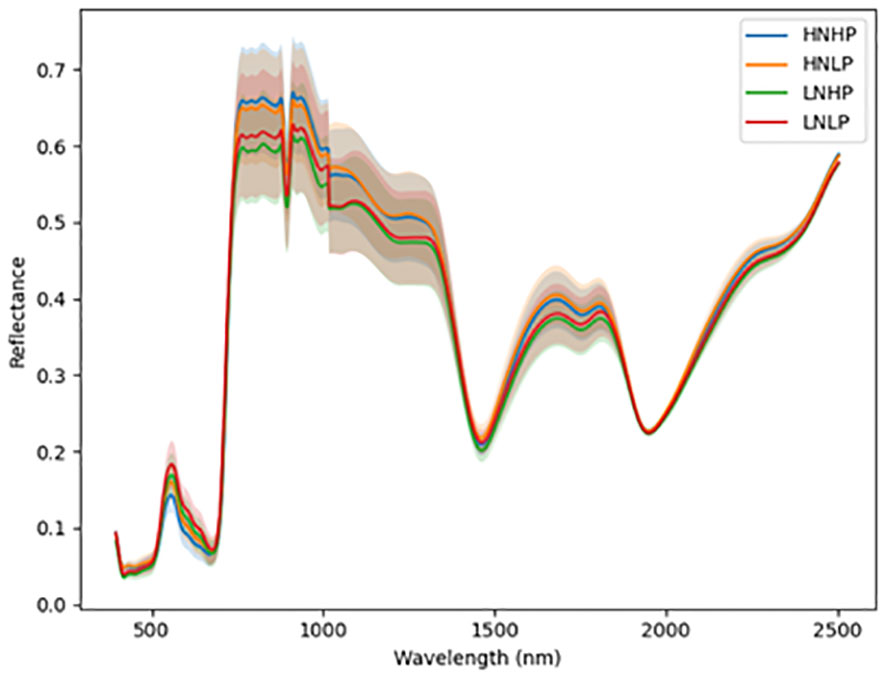
Figure 4 Average reflectance spectra for quinoa under different N and P levels obtained at growth stage III. Each line represents the averagespectral signature for five plants from each treatment of the experiment.
3.2 Model performance based on different pre-processing methods
Figures 5 and 6 are box and whisker plots summarizing the accuracy distribution scores for the different models of the two species. Tables 3, 4 summarize the performance of each model based on the evaluation metrics used in this study. From Figure 5, the pre-processing methods had an effect on the performance of the different models. SDeri datasets had higher accuracies in all four models, achieving the highest OA (99.24%), kappa (98.64%), and F-score (99.19%) for cowpea and 99.18% OA, 98.85% kappa, and 98.76% F-score for quinoa. The high OA and F-score show the good generalization capacity of the models in classifying the nutrient status. In contrast, the RAW dataset produced the lowest performance for all the models, with the hybrid CNN model achieving the highest performance for cowpea (98.39%, 98.37%, and 97.81% OA, F-score, and kappa coefficient, respectively). In quinoa, the HybridSN model achieved the best performance when trained on the raw dataset with 98.57%, 98.43% and 97.76% OA, F-score, and kappa coefficient, respectively. On the contrary, the 2DCNN model (trained with raw dataset) had the lowest performance with 92.77% OA for cowpea. Furthermore, the 2DCNN model had the lowest performance (91.15% OA) when trained with the LDA dataset for quinoa. There was a 3.58% and 1.57% reduction in accuracy performances when the hybrid model was trained with the SNV and LDA datasets, respectively, for cowpea as compared to the performance when trained with the SDeri dataset. Similarly, the proposed model decreased in performance when trained with the SNV and LDA datasets, achieving 96.32% and 91.45% OA scores, respectively, for quinoa. This suggests that the SDeri dataset had important learnable wavelengths to discriminate the treatments for both species. Although the LDA dataset had reduced training samples, all the LDA-based models displayed lower performance compared to the SDeri dataset-trained model’s performance.
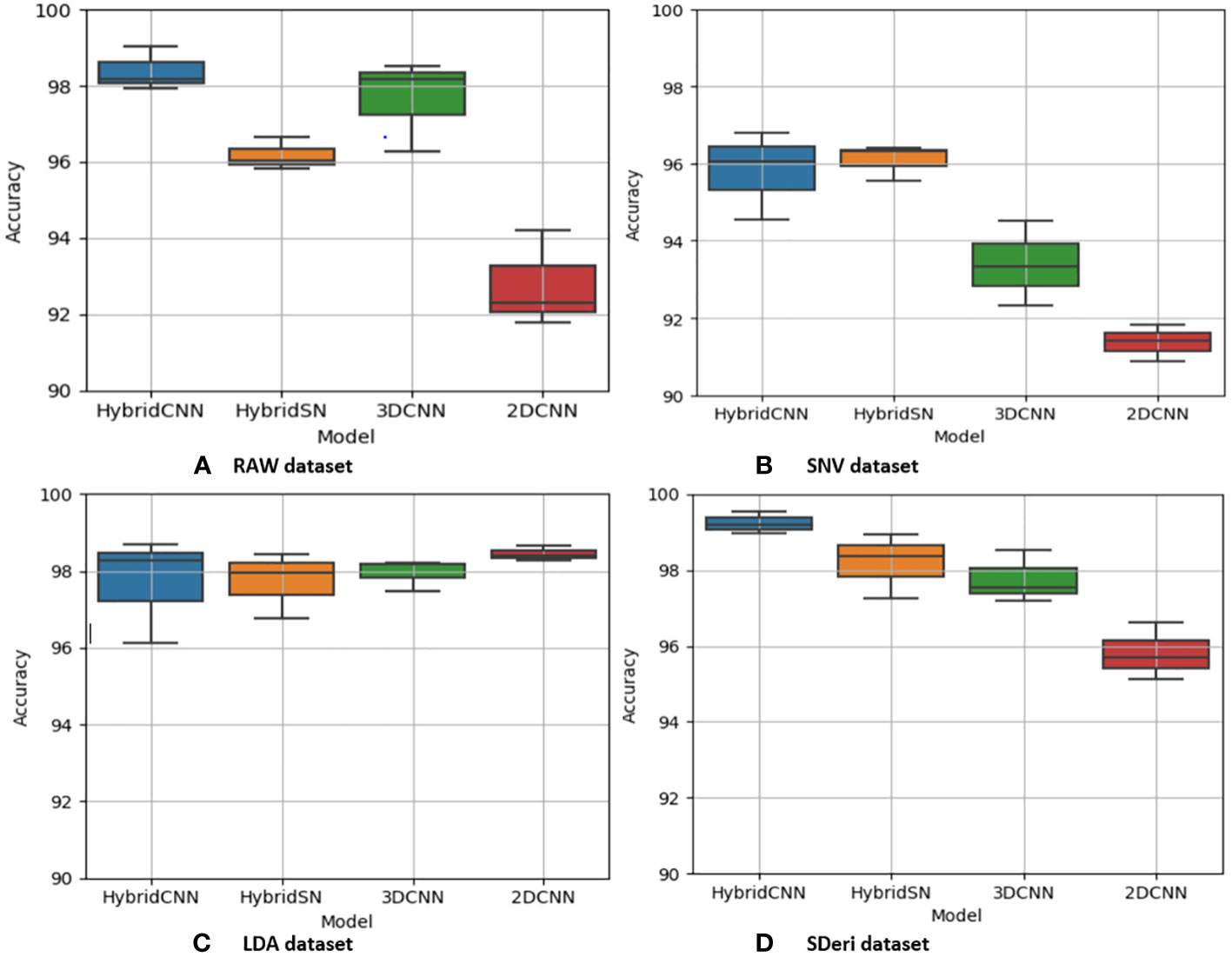
Figure 5 Box and whisker plot of classification accuracy scores for cowpea for the four models: Hybrid-CNN, 3DCNN, 2D CNN, and HybridSN. (A) Raw dataset, (B) SNV dataset, (C) LDA dataset, (D) Hybrid CNN dataset.
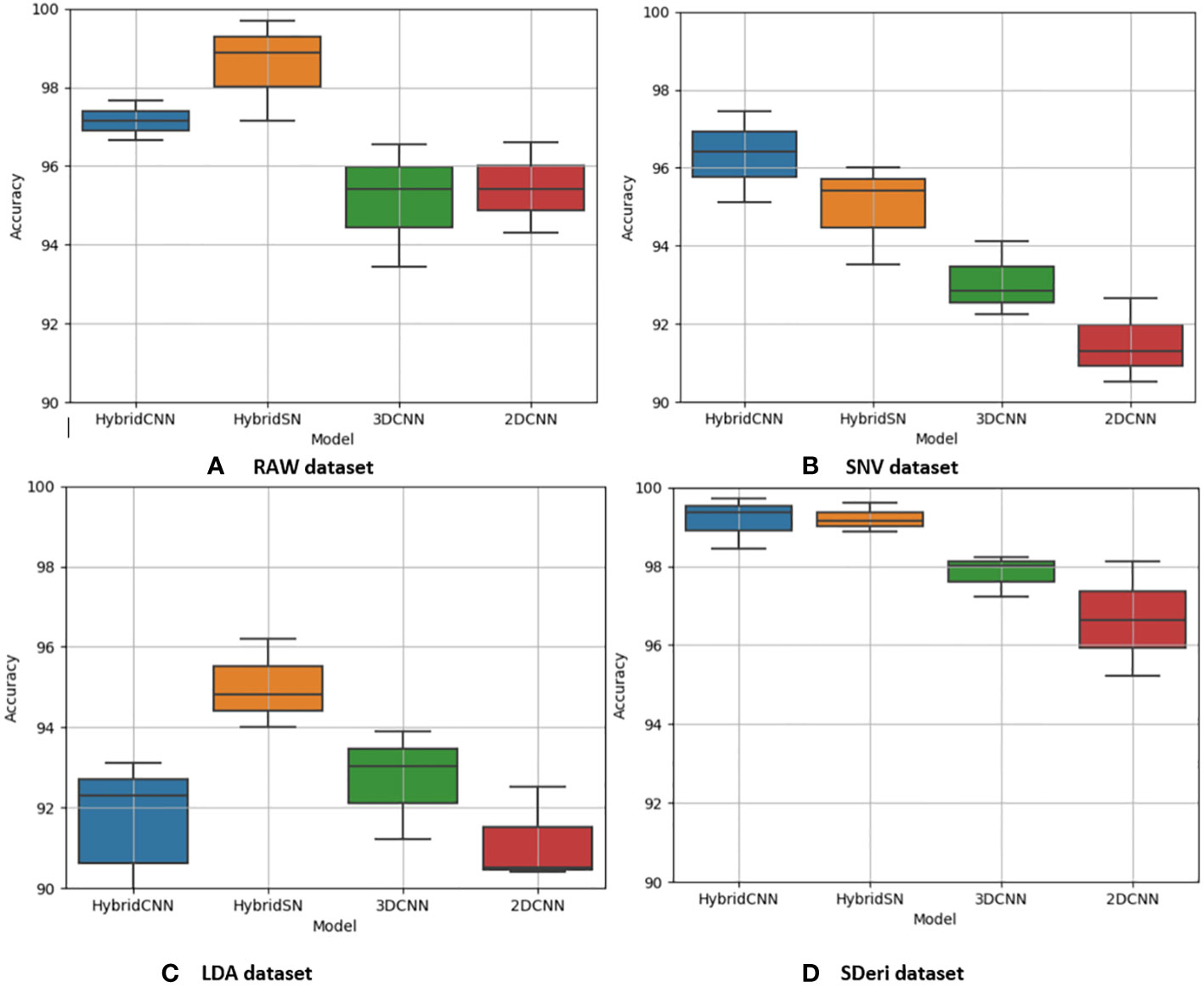
Figure 6 Box and whisker plot of classification accuracy scores for quinoa for the four algorithms: Hybrid-CNN, 3DCNN, 2D CNN, and HybridSN. (A) Raw dataset, (B) SNV dataset, (C) LDA dataset, (D) Hybrid CNN datas.
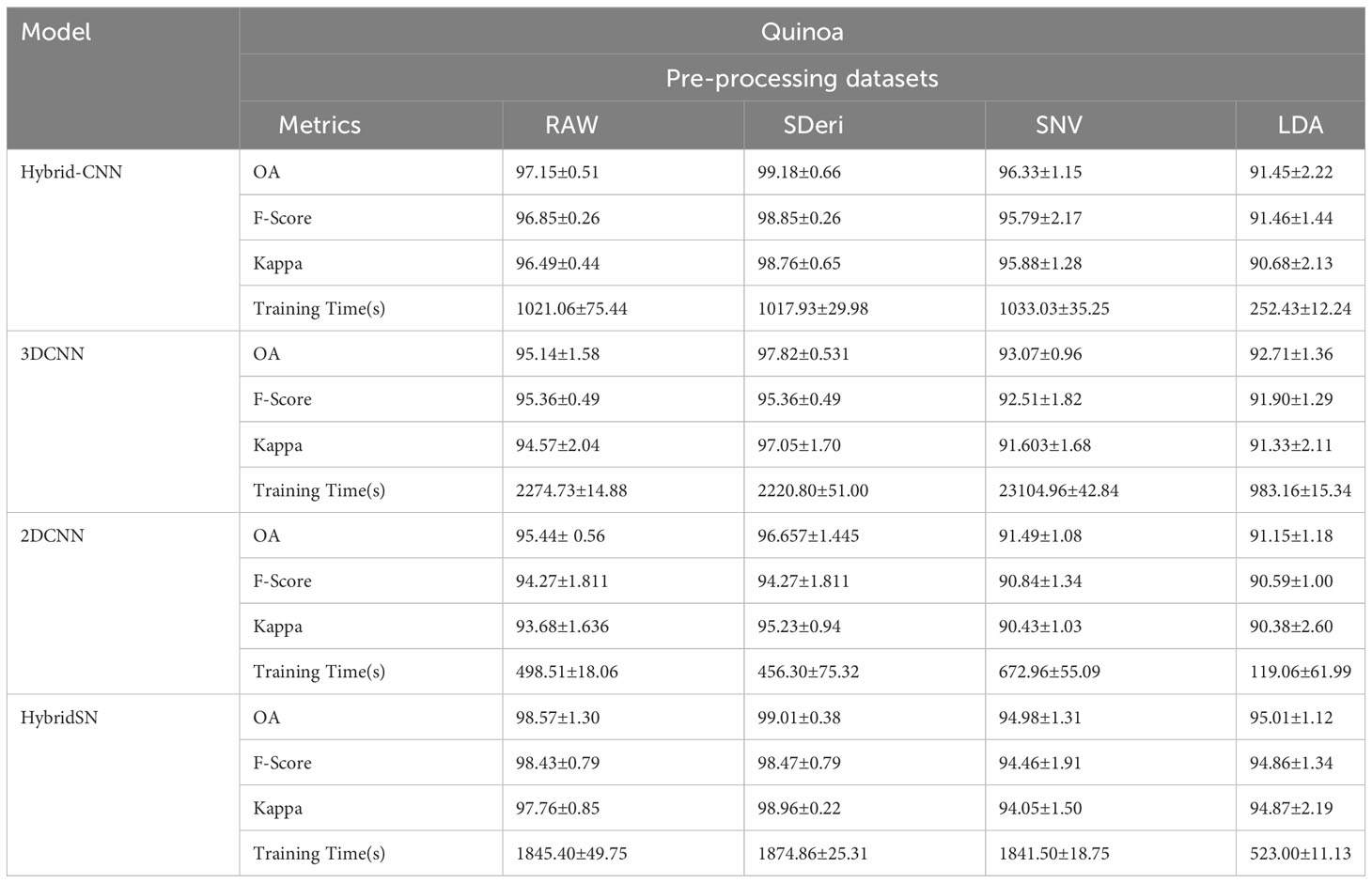
Table 3 Classification accuracy assessment and computation cost with different models and pre-processing methods for quinoa.
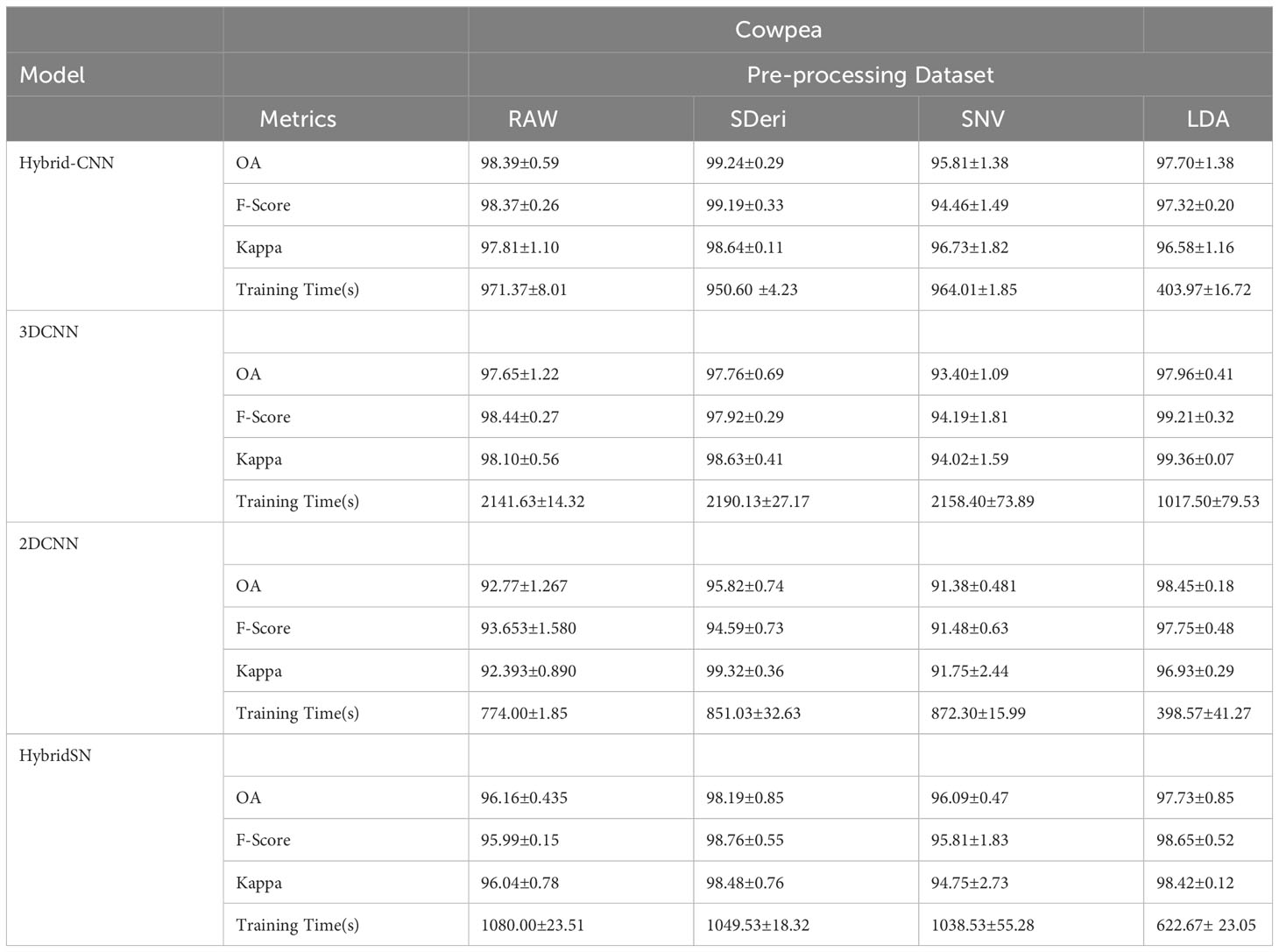
Table 4 Classification accuracy assessment and computation cost with different models and pre-processing methods for cowpea.
The proposed model for both species exhibited good performance when trained with SNV- and SDeri-transformed datasets. Although the HybridSN and 3D CNN models had good performance when trained with SDeri datasets, their training time (caused by the high number of trainable parameters) made the implementation of this model a challenge. The proposed hybrid CNN model had reduced training parameters (< 200,000 trainable parameters), subsequently affecting the computational processing time. The SDeri-trained hybrid CNN model had a processing time reduced by over 1000 s as compared to the 3DCNN-SDeri model, which had a 2141.63 processing time for cowpea. For quinoa, the SDeri-hybrid CNN model had about 54.16% reduced training time when compared to the 3D CNN model (trained with a raw dataset, which had the highest training time of over 2000 s). For both species, the HybridSN-based models had a significantly high training time irrespective of the training dataset.
3.3 Effective wavelength selection
Although the proposed model with the SDeri dataset produced the best performance in classifying plant nutrient status, the high dimensionality of the hypercube posed computational challenges. Hence, effective wavelengths that accurately distinguish between the N and P levels were selected and used to retrain the models. From Figure 7, the selected wavelengths for cowpea were localized in the blue, red-edge, near-infrared, and short-wave infrared regions (having the highest number of selected wavelengths). Sixteen (16) wavebands were selected as the most sensitive wavelengths, with three selected from the blue regions (411, 431, and 455 nm). Moreover, two were selected from the red-edge regions (683 and 691 nm), four from the near-infrared regions (791, 871, 919, and 923 nm), and seven from the SWIR regions (1438, 1450, 1461, 1485, 1508, 1602, and 1660 nm).
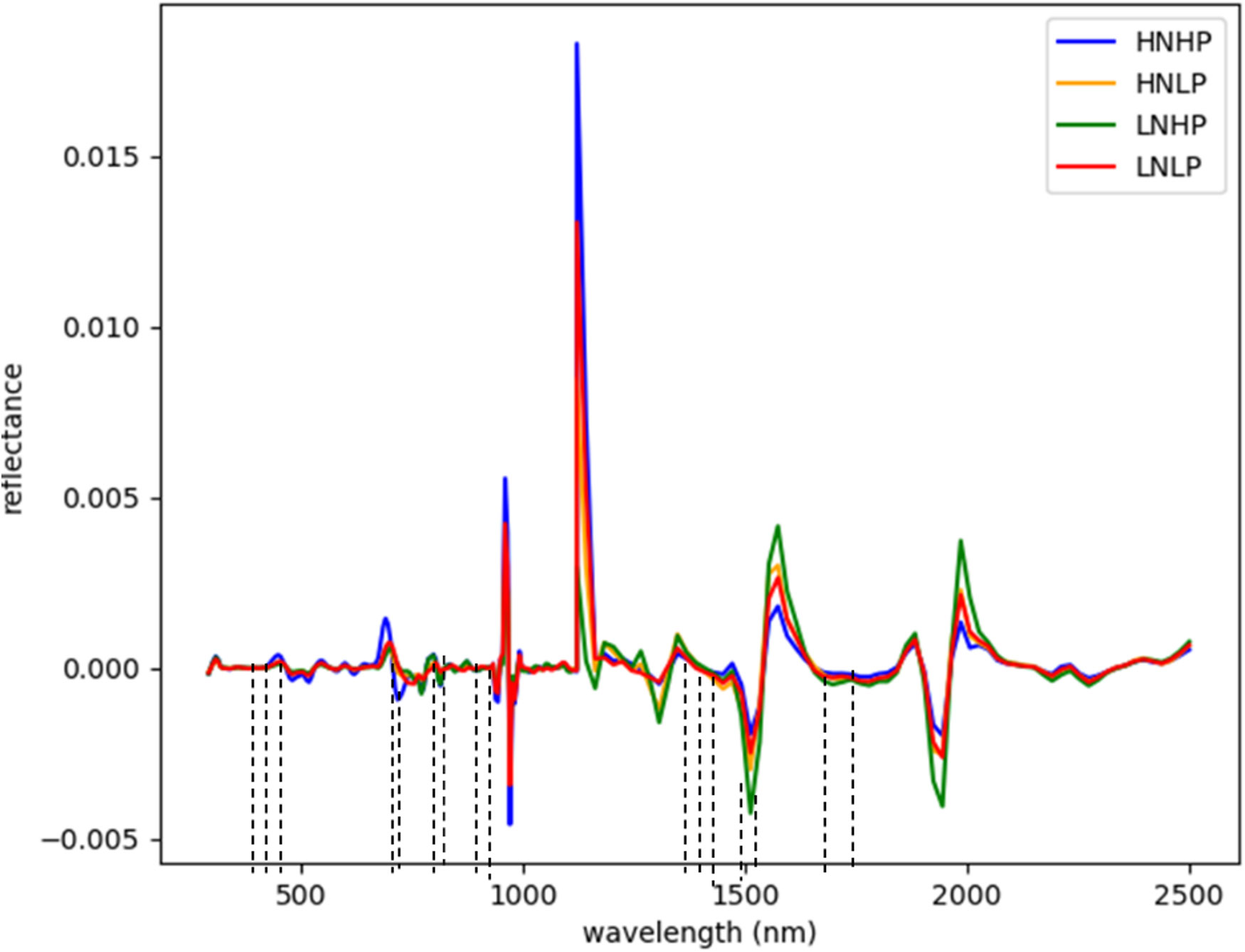
Figure 7 Selected wavebands using CFS method for cowpea; the short dash lines indicate selected band areas.
In quinoa, the wavelengths were selected within the blue, near-infrared, and SWIR regions. From Figure 8, twelve (12) wavebands were selected. These include four from the blue region (571, 575, 583, and 599 nm), one from the red spectrum (607 nm), four the near-infrared regions (723, 731, 924, and 967 nm), and three from the SWIR regions (1680 nm and 17520 nm). The differences in the selected wavebands could be due to the variability in the plant structure and the changes in the nutrient composition of the plants.
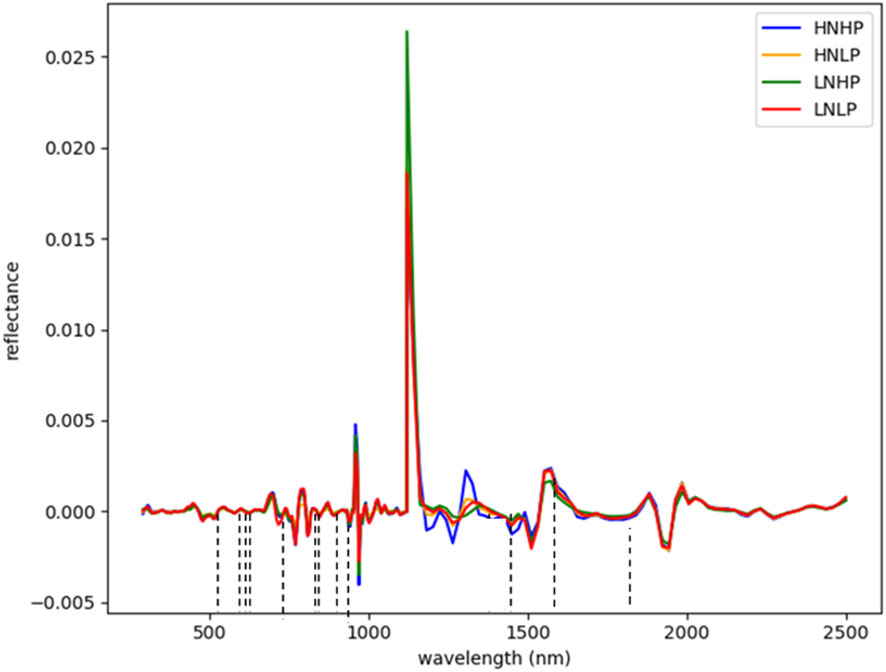
Figure 8 Selected wavebands using CFS method for quinoa; the short dash lines indicate selected band areas.
3.4 Results of discrimination analysis at different growth stages
After the waveband’s selection, the full plant (with full spatial resolution and selected spectral wavelength) in the second derivative format was used as a dataset to retrain the different models to predict the plants’ N and P statuses at different growth stages. Datasets were generated using the same approach as that in subsection 2.4.2. The training datasets were augmented to artificially enlarge the number of training images using rotation and flipping methods.
Tables 5 and 6 show the performance of the models when trained with the selected wavelengths for cowpea and quinoa, respectively. All the models performed well (with 79-100% accuracy on the test data) irrespective of the growth stage under consideration. This performance was better than that found in Siedliska et al. (2021), where a 40-100% classification accuracy rate was achieved for predicting different P levels of three plant species at five growth stages. Comparing the four models, the proposed hybrid model had the best performance, attaining above 94% and 97% test accuracy across the selected growth stages for cowpea and quinoa, respectively. The 2DCNN model had the highest misclassification, with 84.08% in cowpea at growth stage IV and 79.23% in quinoa at growth stage II in the test dataset. For each species, there were high classification errors at the early growth stages, especially in the LNHP and HNLP plants. However, as the plants developed, there were clear distinctions between the spectral signatures of the different treatments, which resulted in an increase in the classification accuracy.
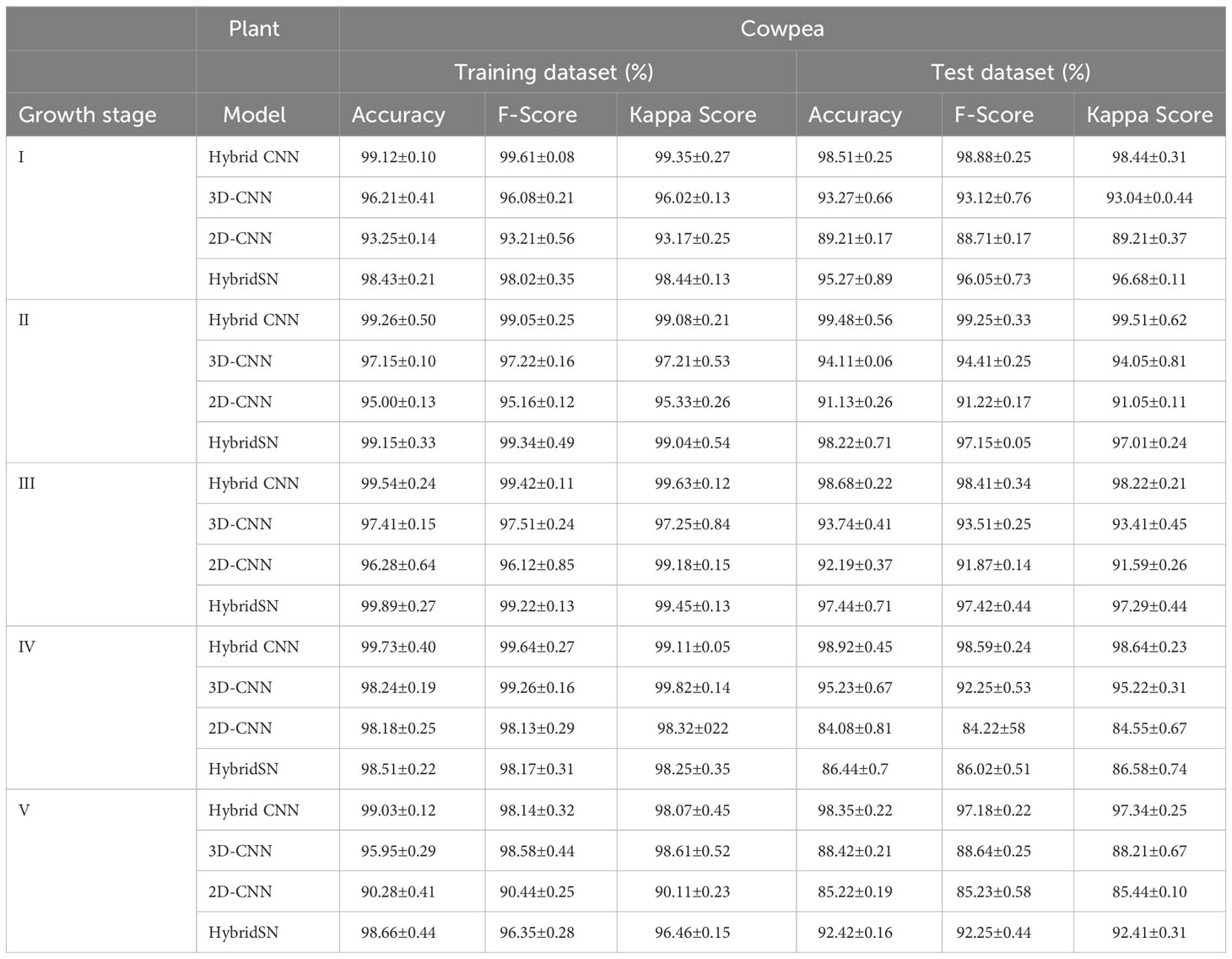
Table 5 Model performance on selected wavebands for classification of cowpea N and P levels at five growth stages.
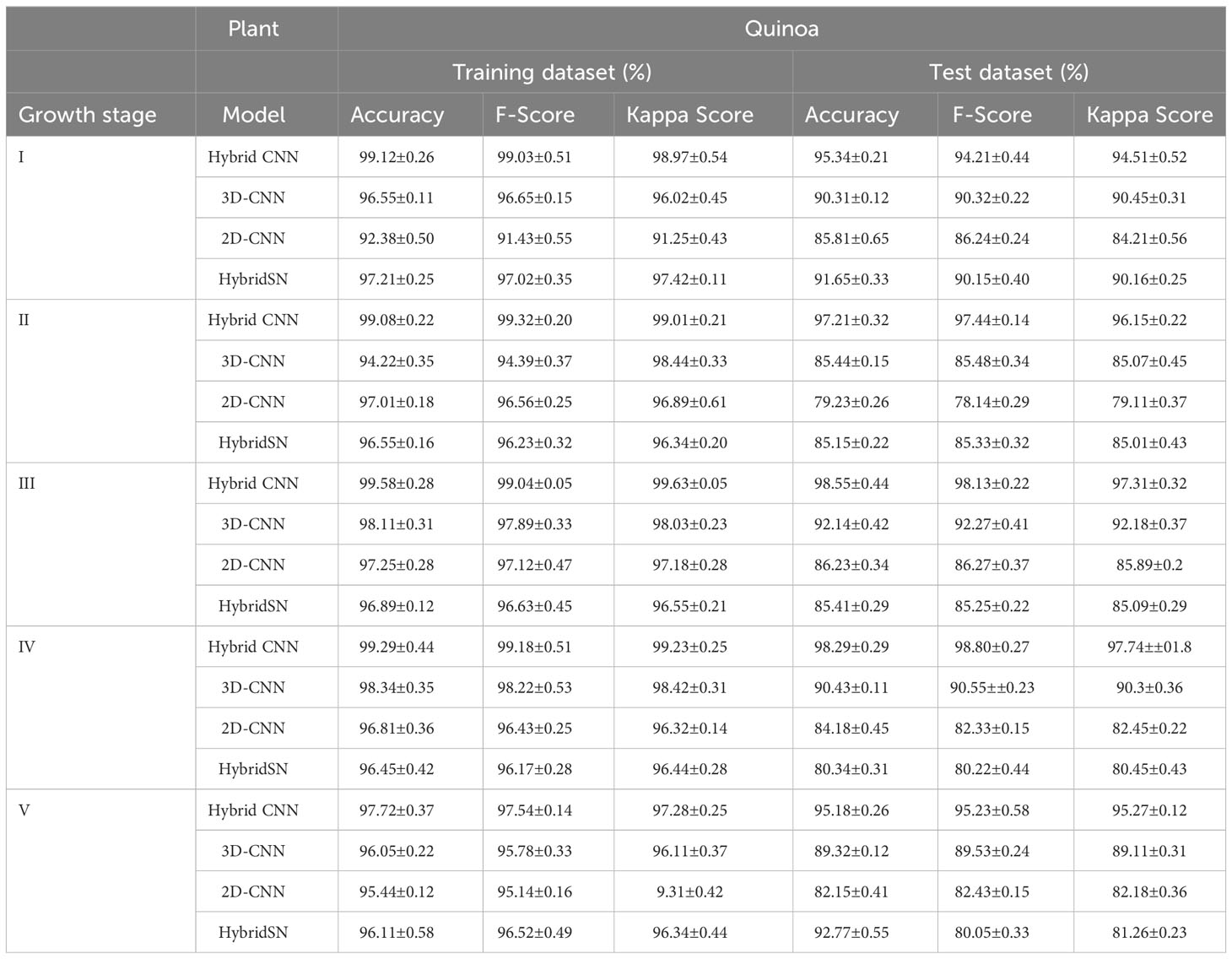
Table 6 Model performance on selected wavebands for classification of quinoa N and P levels at five growth stages.
Table 7 is the summary of the confusion matrix for the proposed model, which explains the accuracy and misclassification of the individual classes for cowpea and quinoa. For both species, the model accurately classified HNHP treatment across all the five growth stages. The model had difficulties in classifying some variants of the treatments, especially those with low phosphorus. In cowpea, HNLP (5% error) and LNHP (> 10% error) were misclassified at growth stage I. Moving to growth stage II, although a similar trend occurred, there was an improvement in the classification accuracy of LNHP (3.64% increment). In the subsequent growth stages, the model improved its performance, with > 95% at growth stages III, IV, and V. In quinoa, there was a 100% accuracy in the HNHP and HNLP classification. However, the model had lower performance in correctly classifying the LNHP treatment 92.82%. Moving across the growth spectrum, the model performance increased, achieving above 98% classification for HNHP and HNLP at growth stages IV and V.
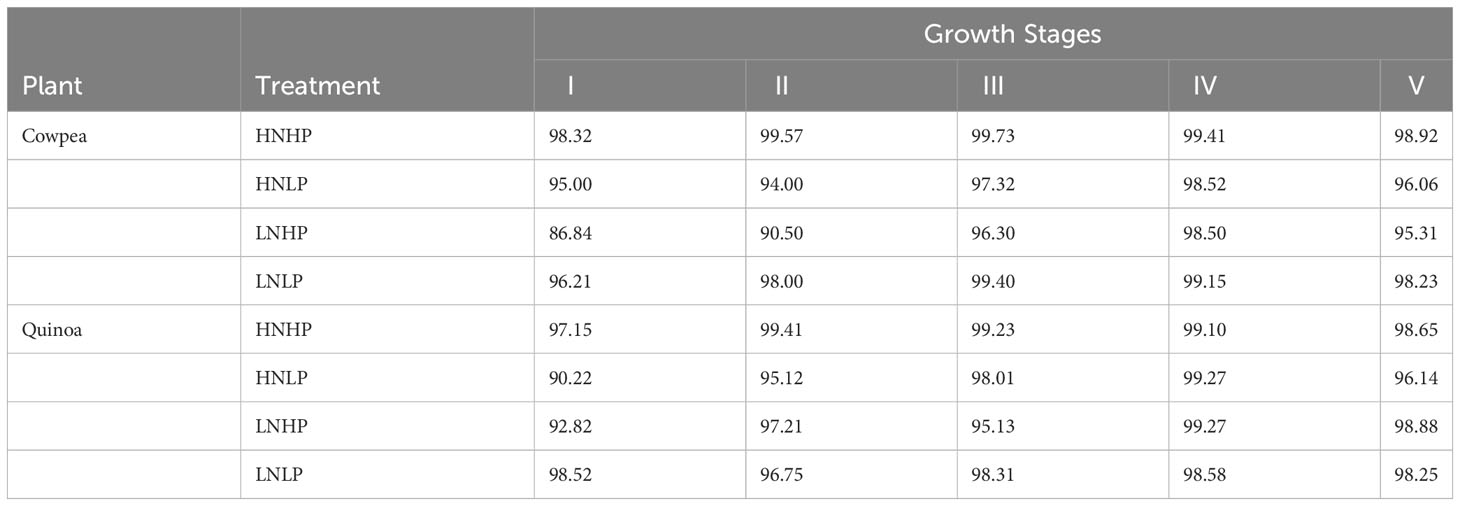
Table 7 Summary of confusion matrices created for the proposed model for nutrient status identification at five stages of plant growth.
4 Discussion
This study aimed to develop a deep learning-based HSI pipeline for classifying the N and P status in cowpea and quinoa at different growth stages. This was achieved by developing a hybrid 3D-2D CNN model to automatically learn and evaluate the spectral and spatial characteristics of the canopy components of the species. Previous studies have utilized 1D-, 2D-, and 3D-CNN models for hyperspectral image analysis. However, these models have limitations in terms of their feature extraction methods, which impact their performance. While 1D CNN extracts only spectral information and 2D CNN deals with spatial information, 3D-CNN extracts both spectral and spatial information simultaneously. Nonetheless, the complexity introduced by 3D CNN modeling can adversely affect its performance and output. Therefore, it is prudent to develop a model that combines 3D- and 2D-CNN architectures to learn features and patterns from spectral hypercube data while decreasing the computational complexities and processing time.
In this study, patches of hypercube (15 X 15 X 223) were extracted from the plant canopy with different N and P levels and used as an input to train the proposed model. Four different spectral transformation techniques were experimented to select the one with the most discriminative features for classifying plant nutrient levels. The performances of the models were compared with standard 3D-CNN, 2D-CNN, and HybridSN models (Section 3.3). As shown in Table 3 (section 3.2), the proposed method achieved an accuracy of over 94% irrespective of the pre-processing technique used. However, the models trained with the second derivative spectra (SDeri) outperformed the others. The derivative processing reduced the background signal and image artifacts, which subsequently improved the discriminating power of the dataset. The high performance of the SDeri-based models agrees with the findings of Siedliska et al. (2021) and Luo et al. (2019), who achieved similar results using derivative spectra. Additionally, although LDA achieved comparably low classification accuracy, it improved the interpretability of the spectra information by replacing the original variables with a group of discriminants while preserving their original information.
A greedy stepwise CFS technique was applied to select the most informative set of wavelengths across the various spectral bands. The selected wavebands were used to retrain the models to identify the plant nutrient status at different growth stages. The proposed method achieved the highest performance, with over 94% accuracy for both species. Although the HybridSN and 3DCNN models performed well comparably, the high training time limited their practical application. Practically, the selected wavebands can be used to develop a multispectral imaging system to predict plant nutrient status. It should also be noted that all the models experienced a decrease in accuracy when classifying nutrient status at the early growth stages, particularly for the LNHP and HNLP treatments. This decrease in accuracy can be attributed to the fact that the differences in canopy spectral properties were considerably minimal between the four treatments at the early growth stage. As a result, it became difficult for the models to accurately differentiate the nutrient statuses based on spectral information alone during these early growth stages. This is challenging because, practically, farmers and plant breeders are more interested in identifying plant nutrient status at the early growth stage for proper nutrient management. Hence, further studies are required on the dynamic response of crop canopy to subtle changes in N and P concentration at the early growth stages using hyperspectral data.
5 Conclusion
Hyperspectral data hold significant potential for monitoring nitrogen and phosphorus nutrition of quinoa and cowpea, enabling the provision of optimal conditions for development and growth. This study has proposed the use of hyperspectral imaging in tandem with a hybrid 3D-2D CNN model to identify the nutrient status of cowpea and quinoa at selected growth stages. The experiment results presented demonstrate the capability of the proposed model to accurately distinguish plant nitrogen and phosphorus levels, based on selected wavebands from the second-order derivative of the reflectance spectra. The use of separable convolutions in the 2D CNN block of the proposed model reduces the model’s complexity by reducing the number of trainable parameters. This subsequently reduces the processing time while enhancing learning efficiency, which is advantageous. These findings suggest that the proposed model could be integrated into a system for the non-invasive detection of nitrogen and phosphorus deficiencies in precision agriculture. Moreover, the success of the waveband selection process shows the potential of developing a multispectral sensor system equipped with the selected wavebands as a viable alternative to hyperspectral imaging for nutrient stress detection. These findings highlight the potential of the proposed model for the early detection and precise management of nutrient stress in cowpea and quinoa plants.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
Conceptualization, FO and DC; methodology, FO and PS-T; software, FO and PS-T; validation, MH, FM, and DS; formal analysis, FO; investigation, NV and LG; resources, MC and AR; data curation, FO and DC; writing—original draft preparation, FO; writing—review and editing, MH, NV, FM, PS-T, DS, and LG; visualization and supervision, MH and FM; project administration, MM; funding acquisition, MH. All authors contributed to the article and approved the submitted version.
Funding
This research was funded by OCP S.A. under the University of Mohammed VI Polytechnic, Rothamsted Research, and Cranfield University project (FPO4). Rothamsted Research receives grant aided support from the Biotechnology and Biological Sciences Research Council (BBSRC) through the Delivering Sustainable Wheat program (BB/X011003/1).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2023.1209500/full#supplementary-material
References
Al-Sarayreh, M., Reis, M. M., Yan, W. Q., Klette, R. (2020). Potential of deep learning and snapshot hyperspectral imaging for classification of species in meat. Food Control. 117 (January), 107332. doi: 10.1016/j.foodcont.2020.107332
Amigo, J. M. (2010). Practical issues of hyperspectral imaging analysis of solid dosage forms. Analytical. Bioanal. Chem. 398 (1), 93–109. doi: 10.1007/s00216-010-3828-z
Barnes, R. J., Dhanoa, M. S., XXXS., J. L. (1989). Standard normal variate transformation and de-trending of near-infrared diffuse reflectance spectra. Appl. Spectrosc. 43 (5), 772–777. doi: 10.1366/00037028942022
Clevers, J. G. P. W., Gitelson, A. A. (2013). Remote estimation of crop and grass chlorophyll and nitrogen content using red-edge bands on sentinel-2 and-3. Int. J. Appl. Earth Observ. Geoinform. 23 (1), 344–351. doi: 10.1016/j.jag.2012.10.008
Cloutis, E. A., Connery, D. R., Dover, F. J., Major, D. J. (1996). Airborne multi-spectral monitoring of agricultural crop status: Effect of time of year, crop type and crop condition parameter. Int. J. Remote Sens. 17 (13), 2579–2601. doi: 10.1080/01431169608949094
Dyrmann, M., Karstoft, H., Midtiby, H. S. (2016). Plant species classification using deep convolutional neural network. Biosyst. Eng. 151 (2005), 72–80. doi: 10.1016/j.biosystemseng.2016.08.024
Fırat, H., Asker, M. E., Hanbay, D. (2022). Classification of hyperspectral remote sensing images using different dimension reduction methods with 3D/2D CNN. Remote Sens. Applications.: Soc. Environ. 25, 100694. doi: 10.1016/j.rsase.2022.100694
Fuentes, A., Yoon, S., Kim, S. C., Park, D. S. (2017). A robust deep-learning-based detector for real-time tomato plant diseases and pests recognition. Sensors. (Switzerland) 17 (9), 1–21. doi: 10.3390/s17092022
Gao, Y., Song, X., Liu, K., Li, T., Zheng, W., Wang, Y., et al. (2021). Mixture of controlled-release and conventional urea fertilizer application changed soil aggregate stability, humic acid molecular composition, and maize nitrogen uptake. Sci. Total. Environ. 789, 147778. doi: 10.1016/j.scitotenv.2021.147778
Glorot, X., Bordes, A., Bengio, Y. (2011). Deep sparse rectifier neural networks. J. Mach. Learn. Res. 15, 315–323.
Hairuddin, M. A., Tahir, N. M., Shah Baki, S. R. (2011). “Representation of Elaeis Guineensis nutrition deficiency based on image processing approach,” in ICCAIE 2011 - 2011 IEEE Conference on Computer Applications and Industrial Electronics (Penang, Malaysia: Iccaie), 607–611. doi: 10.1109/ICCAIE.2011.6162206
Hassanijalilian, O., Igathinathane, C., Doetkott, C., Bajwa, S., Nowatzki, J., Haji Esmaeili, S. A. (2020). Chlorophyll estimation in soybean leaves infield with smartphone digital imaging and machine learning. Comput. Electron. Agric. 174 (April), 105433. doi: 10.1016/j.compag.2020.105433
Hennessy, A., Clarke, K., Lewis, M. (2020). Hyperspectral classification of plants: A review of waveband selection generalisability. Remote Sens. 12 (1), 1–27. doi: 10.3390/RS12010113
Hong, Z., He, Y. (2020). Rapid and nondestructive discrimination of geographical origins of longjing tea using hyperspectral imaging at two spectral ranges coupled with machine learning methods. Appl. Sci. (Switzerland) 10 (3), 1–12. doi: 10.3390/app10031173
Huang, L., Luo, R., Liu, X., Hao, X. (2022). Spectral imaging with deep learning. Light: Science and Applications 11 (1). doi: 10.1038/s41377-022-00743-6
Jia, S., Jiang, S., Lin, Z., Li, N., Xu, M., Yu, S. (2021). A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 448, 179–204. doi: 10.1016/j.neucom.2021.03.035
Jung, D. H., Kim, J., Kim, H. Y., Lee, T. S., Kim, H. S., Park, S. H. (2022). A Hyperspectral Data 3D Convolutional Neural Network Classification Model for Diagnosis of Gray Mold Disease in Strawberry Leaves. Front. Plant Sci. 13 (March). doi: 10.3389/fpls.2022.837020
Kumar, B., Dikshit, O., Gupta, A., Singh, M. K. (2020). Feature extraction for hyperspectral image classification: a review review. Int. J. Remote Sens. 41 (16), 6248–6287. doi: 10.1080/01431161.2020.1736732
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P. (1998). "Gradient based learning applied to document recognition." in Proceedings of the IEEE 86 (11), 2278–2324. doi: 10.1109/5.726791
Luo, Z., Thorp, K. R., Abdel-Haleem, H. (2019). A high-throughput quantification of resin and rubber contents in Parthenium argentatum using near-infrared (NIR) spectroscopy. Plant Methods 15 (1), 1–14. doi: 10.1186/s13007-019-0544-3
Ma, D., Maki, H., Neeno, S., Zhang, L., Wang, L., Jin, J. (2020). Application of non-linear partial least squares analysis on prediction of biomass of maize plants using hyperspectral images. Biosyst. Eng. 200, 40–54. doi: 10.1016/j.biosystemseng.2020.09.002
Masters-Clark, E., Shone, E., Paradelo, M., Hirsch, P. R., Clark, I. M., Otten, W., et al. (2020). Development of a defined compost system for the study of plant-microbe interactions. Sci. Rep. 10 (1), 1–9. doi: 10.1038/s41598-020-64249-0
McCauley, A., Jones, C., Jacobsen, J. (2011). Plant Nutrient Functions and Deficiency and Toxicity Symptoms. Nutrient. Manage. Module. 9 (9), 1–16.
Meier, U., Bleiholder, H., Buhr, L., Feller, C., Hack, H., Heß, M., et al. (2009). The BBCH system to coding the phenological growth stages of plants-history and publications. J. Für. Kulturpflanzen. 61 (2), 41–52. doi: 10.5073/JfK.2009.02.01
Mirzaei, S., Van hamme, H., Khosravani, S. (2019). Hyperspectral image classification using Non-negative Tensor Factorization and 3D Convolutional Neural Networks. Signal Processing.: Image. Commun. 76 (May), 178–185. doi: 10.1016/j.image.2019.05.004
Mishra, P., Asaari, M. S. M., Herrero-Langreo, A., Lohumi, S., Diezma, B., Scheunders, P. (2017). Close range hyperspectral imaging of plants: A review. Biosyst. Eng. 164, 49–67. doi: 10.1016/j.biosystemseng.2017.09.009
Mohan, A., Venkatesan, M. (2020). HybridCNN based hyperspectral image classification using multiscale spatiospectral features. Infrared. Phys. Technol. 108 (December 2019), 1–10. doi: 10.1016/j.infrared.2020.103326
Mu, Q., Kang, Z., Guo, Y., Chen, L., Wang, S., Zhao, Y. (2021). Hyperspectral image classification of wolfberry with different geographical origins based on three-dimensional convolutional neural network. Int. J. Food Properties. 24 (1), 1705–1721. doi: 10.1080/10942912.2021.1987457
Nagasubramanian, K., Jones, S., Singh, A. K., Sarkar, S., Singh, A., Ganapathysubramanian, B. (2019). Plant disease identification using explainable 3D deep learning on hyperspectral images. Plant Methods 15 (1), 1–10. doi: 10.1186/s13007-019-0479-8
Nkemelu, D. K., Omeiza, D., Lubalo, N. (2018). Deep Convolutional Neural Network for Plant Seedlings Classification. Available at: http://arxiv.org/abs/1811.08404.
Pandey, P., Ge, Y., Stoerger, V., Schnable, J. C. (2017). High throughput in vivo analysis of plant leaf chemical properties using hyperspectral imaging. Front. Plant Sci. 8 (August). doi: 10.3389/fpls.2017.01348
Paoletti, M. E., Haut, J. M., Plaza, J., Plaza, A. (2019). ISPRS Journal of Photogrammetry and Remote Sensing Deep learning classifiers for hyperspectral imaging: A review. ISPRS. J. Photogramm. Remote Sens. 158 (November 2018), 279–317. doi: 10.1016/j.isprsjprs.2019.09.006
Perez-Sanz, F., Navarro, P. J., Egea-Cortines, M. (2017). Plant phenomics: An overview of image acquisition technologies and image data analysis algorithms. GigaScience 6 (11), 1–18. doi: 10.1093/gigascience/gix092
Pi, W., Du, J., Bi, Y., Gao, X., Zhu, X. (2021). 3D-CNN based UAV hyperspectral imagery for grassland degradation indicator ground object classification research. Ecol. Inf. 62 (March), 101278. doi: 10.1016/j.ecoinf.2021.101278
Rinnan, Å., van den Berg, F., Engelsen, S. B. (2009). Review of the most common pre-processing techniques for near-infrared spectra. TrAC. - Trends Analytical. Chem. 28 (10), 1201–1222. doi: 10.1016/j.trac.2009.07.007
Roy, S. K., Krishna, G., Dubey, S. R., Chaudhuri, B. B. (2020). HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 17 (2), 277–281. doi: 10.1109/LGRS.2019.2918719
Sadeghi-Tehran, P., Virlet, N., Hawkesford, M. J. (2021). A neural network method for classification of sunlit and shaded components of wheat canopies in the field using high-resolution hyperspectral imagery. Remote Sens. 13 (5), 1–17. doi: 10.3390/rs13050898
Sadeghi-Tehran, P., Virlet, N., Sabermanesh, K., Hawkesford, M. J. (2017). Multi-feature machine learning model for automatic segmentation of green fractional vegetation cover for high-throughput field phenotyping. Plant Methods 13 (1), 1–17. doi: 10.1186/s13007-017-0253-8
Siedliska, A., Baranowski, P., Pastuszka-Woźniak, J., Zubik, M., Krzyszczak, J. (2021). Identification of plant leaf phosphorus content at different growth stages based on hyperspectral reflectance. BMC Plant Biol. 21 (1), 1–17. doi: 10.1186/s12870-020-02807-4
Siedliska, A., Baranowski, P., Zubik, M., Mazurek, W., Sosnowska, B. (2018). Detection of fungal infections in strawberry fruit by VNIR/SWIR hyperspectral imaging. Postharvest. Biol. Technol. 139 (February), 115–126. doi: 10.1016/j.postharvbio.2018.01.018
Singh, A., Ganapathysubramanian, B., Singh, A. K., Sarkar, S. (2016). Machine Learning for High-Throughput Stress Phenotyping in Plants. Trends Plant Sci. 21 (2), 110–124. doi: 10.1016/j.tplants.2015.10.015
Sladojevic, S., Arsenovic, M., Anderla, A., Culibrk, D., Stefanovic, D. (2016). Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Comput. Intell. Neurosci. 2016. doi: 10.1155/2016/3289801
Uddling, J., Gelang-Alfredsson, J., Piikki, K., Pleijel, H. (2007). Evaluating the relationship between leaf chlorophyll concentration and SPAD-502 chlorophyll meter readings. Photosynthesis. Res. 91 (1), 37–46. doi: 10.1007/s11120-006-9077-5
Wang, C., Liu, B., Liu, L., Zhu, Y., Hou, J., Liu, P. (2021). “A review of deep learning used in the hyperspectral image analysis for agriculture,” in Artificial Intelligence Review, vol. 54. (Springer Netherlands). doi: 10.1007/s10462-021-10018-y
Williams, D., Britten, A., McCallum, S., Jones, H., Aitkenhead, M., Karley, A., et al. (2017). A method for automatic segmentation and splitting of hyperspectral images of raspberry plants collected in field conditions. Plant Methods 13 (1), 1–12. doi: 10.1186/s13007-017-0226-y
Xia, C., Yang, S., Huang, M., Zhu, Q., Guo, Y., Qin, J. (2019). Maize seed classification using hyperspectral image coupled with multi-linear discriminant analysis. Infrared. Phys. Technol. 103 (July), 103077. doi: 10.1016/j.infrared.2019.103077
Yamashita, H., Sonobe, R., Hirono, Y., Morita, A., Ikka, T. (2020). Dissection of hyperspectral reflectance to estimate nitrogen and chlorophyll contents in tea leaves based on machine learning algorithms. Sci. Rep. 10 (1), 1–11. doi: 10.1038/s41598-020-73745-2
Ye, X., Abe, S., Zhang, S. (2020). Estimation and mapping of nitrogen content in apple trees at leaf and canopy levels using hyperspectral imaging. Precis. Agric. 21 (1), 198–225. doi: 10.1007/s11119-019-09661-x
Zhai, Y., Cui, L., Zhou, X., Gao, Y., Fei, T., Gao, W. (2013). Estimation of nitrogen, phosphorus, and potassium contents in the leaves of different plants using laboratory-based visible and near-infrared reflectance spectroscopy: Comparison of partial least-square regression and support vector machine regression met. Int. J. Remote Sens. 34 (7), 2502–2518. doi: 10.1080/01431161.2012.746484
Zhang, J., Cheng, T., Guo, W., Xu, X., Qiao, H., Xie, Y., et al. (2021). Leaf area index estimation model for UAV image hyperspectral data based on wavelength variable selection and machine learning methods. Plant Methods 17 (1), 1–14. doi: 10.1186/s13007-021-00750-5
Keywords: convolution neural network, hyperspectral imaging, plant nutrition, machine learning, spectral curves
Citation: Okyere FG, Cudjoe D, Sadeghi-Tehran P, Virlet N, Riche AB, Castle M, Greche L, Simms D, Mhada M, Mohareb F and Hawkesford MJ (2023) Modeling the spatial-spectral characteristics of plants for nutrient status identification using hyperspectral data and deep learning methods. Front. Plant Sci. 14:1209500. doi: 10.3389/fpls.2023.1209500
Received: 20 April 2023; Accepted: 05 September 2023;
Published: 16 October 2023.
Edited by:
Michiel Stock, Ghent University, BelgiumReviewed by:
Olivier Pieters, Ghent University, BelgiumYufeng Ge, University of Nebraska-Lincoln, United States
Copyright © 2023 Okyere, Cudjoe, Sadeghi-Tehran, Virlet, Riche, Castle, Greche, Simms, Mhada, Mohareb and Hawkesford. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fady Mohareb, Zi5tb2hhcmViQGNyYW5maWVsZC5hYy51aw==; Malcolm John Hawkesford, bWFsY29sbS5oYXdrZXNmb3JkQHJvdGhhbXN0ZWQuYWMudWs=
†ORCID: Frank Gyan Okyere, orcid.org/0000-0002-3341-5945
Daniel Cudjoe, orcid.org/0000-0002-4041-1176
Pouria Sedaghi-Tehran, orcid.org/0000-0003-0352-227X
Nicolas Virlet, orcid.org/0000-0001-6030-4282
Andrew B Riche, orcid.org/0000-0003-4018-6658
Latifa Greche, orcid.org/0000-0002-3977-2855
Daniel Simms, orcid.org/0000-0001-6318-4052
Manal Mhada, orcid.org/0000-0002-0690-2633
Fady Mohareb, orcid.org/0000-0002-7880-2519
Malcolm John Hawkesford, orcid.org/0000-0001-8759-3969