 Fei Xia
Fei Xia Xiaojun Xie
Xiaojun Xie Zongqin Wang
Zongqin Wang Shichao Jin
Shichao Jin Ke Yan
Ke Yan Zhiwei Ji
Zhiwei Ji- 1College of Artificial Intelligence, Nanjing Agricultural University, Nanjing, China
- 2Center for Data Science and Intelligent Computing, Nanjing Agricultural University, Nanjing, China
- 3Plant Phenomics Research Centre, Academy for Advanced Interdisciplinary Studies, Regional Technique Innovation Center for Wheat Production, Key Laboratory of Crop Physiology and Ecology in Southern China, Ministry of Agriculture, Nanjing Agricultural University, Nanjing, China
- 4Collaborative Innovation Centre for Modern Crop Production co-sponsored by Province and Ministry, Jiangsu Key Laboratory for Information Agriculture, Nanjing Agricultural University, Nanjing, China
- 5Department of Building, School of Design and Environment, National University of Singapore, Singapore, Singapore
Plants are often attacked by various pathogens during their growth, which may cause environmental pollution, food shortages, or economic losses in a certain area. Integration of high throughput phenomics data and computer vision (CV) provides a great opportunity to realize plant disease diagnosis in the early stage and uncover the subtype or stage patterns in the disease progression. In this study, we proposed a novel computational framework for plant disease identification and subtype discovery through a deep-embedding image-clustering strategy, Weighted Distance Metric and the t-stochastic neighbor embedding algorithm (WDM-tSNE). To verify the effectiveness, we applied our method on four public datasets of images. The results demonstrated that the newly developed tool is capable of identifying the plant disease and further uncover the underlying subtypes associated with pathogenic resistance. In summary, the current framework provides great clustering performance for the root or leave images of diseased plants with pronounced disease spots or symptoms.
Introduction
Plants are often attacked by various pathogens (e.g., bacteria, viruses, fungi, etc.) during their growth and development (Suzuki et al., 2014), resulting in abnormal physiological and morphological changes in plants. In severe cases, it may disrupt its normal growth and development and even cause large-scale disasters, such as leaf spot disease (Ozguven and Adem, 2019), powdery mildew (Lin et al., 2019), brown spot and blast diseases (Phadikar and Goswami, 2016), and gray mold (Fahrentrapp et al., 2019). The prior symptoms of these diseases include leaf discoloration, tissue deformation or necrosis, and root atrophy, etc. Plant diseases, especially crop diseases, may cause social problems such as economic losses or food shortages in a certain area (Wilkinson et al., 2011). Therefore, early diagnosis of plant diseases, especially the precise prediction of plant disease severity and drug resistance (Bock et al., 2020), will help formulate effective control strategies, thereby effectively prevent the spread of diseases and reduce economic losses (Liang et al., 2019). To solve the above problems, many researchers made great efforts on the diagnosis of plant diseases by exploring the relationship between pathogen infection and plant disease symptoms (Bass et al., 2019; Vishnoi et al., 2021). However, these studies cannot provide real-time disease diagnosis and even evolution trajectory inference and will cause delays or misjudgments in decision-making. In recent years, plant phenomics (Tardieu et al., 2017; Pasala and Pandey, 2020) was generated, which can automatically and non-destructively obtain high-throughput plant phenotyping images (Lee et al., 2018; Li et al., 2020), which makes computer-aided rapid diagnosis and real-time monitoring of plant diseases possible.
Computationally, phenomics-based plant disease diagnosis can be grouped into two categories, one is semantic feature-based models, and the other is non-sematic feature-based models (e.g., deep learning [DL] models). The first category (conventional image processing) is characterized by the features of color (Gaikwad and Musande, 2017), texture (Hossain et al., 2019; Ismail et al., 2020), and shape (Chouhan et al., 2020) extracted from the lesion area of the phenotypic images to achieve disease diagnosis and prediction. For example, Zhang et al. (2017) segmented the lesions from the leaf images and extracted the shape and color features for disease recognition in cucumber. Moreover, some researchers realized the automatic diagnosis of plant diseases through a classifier built with texture features (Hossain et al., 2019; Ismail et al., 2020). In addition, computer vision (CV) and machine learning were applied to quantify root traits in real time for precision plant breeding (Rahaman et al., 2019; Falk et al., 2020). However, the variation of plant phenomics and the dependence of prior knowledge always limit the generalization of this type of method to different plant diseases. In recent years, DL has been widely used in image classification and clustering (Hu et al., 2020; Saleem et al., 2020). The representative characterizations of DL-based models include powerful capabilities for feature extraction, low dependence on domain knowledge, and high predictive accuracy (Too et al., 2019; Lee et al., 2020). In the past few years, DL was used to analyze the phenomics of plant disease. Various convolutional neural network (CNN) models were developed as the image multi-class classifiers to distinguish different plant leaf diseases from high-throughput phenomics (Brahimi et al., 2018; Zhang et al., 2019). Furthermore, DL is also very effective for grading the severity of plants with the same disease (Verma et al., 2020). Liang et al. (2019) combined ResNet50 (Wen et al., 2020) model and Shufflenet-V2 (Ghosh et al., 2020) to build a PD2SE-Net network model, which realized the classification of plant diseases and the prediction of disease severity. Yu et al. (2006) applied VGG16 model on diseased leaf images for grading the severity of apple black rot (Wang et al., 2017). Although DL models are widely studied for plant disease diagnosis, they still face obvious challenges, such as poor generalization, unexplainable features, and high dependence on abundant training samples.
In this study, we proposed a novel image clustering method for both plant disease classification and subtype discovery. Firstly, all the original plant images were preprocessed to amplify the sample size. Secondly, we established a deep CNN to extract the features of phenotypic images. Finally, we designed a clustering strategy by integrating a Weighted Distance Metric (WDM) and the t-stochastic neighbor embedding algorithm, named “WDM-tSNE.” To validate the effectiveness, we applied the proposed method on a batch of public plant image datasets, namely, Modified National Institute of Standards and Technology (MNIST) (Deng, 2012), Aphanomyces Root Rot (ARR) in lentil (Marzougui et al., 2019), cherry powdery mildew, strawberry leaf scorch disease, and three types of tomato disease from PlantVillage dataset (Mohanty et al., 2016). The experimental results show that our method obtained high performance on plant disease classification and subtype discovery. In particular, the WDM-tSNE strategy provides better clustering accuracy than the standard tSNE.
Related Work
In this section, we briefly review the related work of plant disease diagnosis on semantic feature-based models, and non-sematic feature-based models.
Semantic Feature-Based Models
The general idea of this kind of method includes four steps: (1) image preprocessing; (2) lesion segmentation; (3) image features are defined and extracted for describing the pathology signatures of the lesion regions; and (4) the image samples are classified by using a machine-learning model (Vishnoi et al., 2021). Considering the fact that the accuracy of lesion segmentation directly affects the sample classification, many researchers used various image-segmentation strategies to achieve the extraction of the target regions, such as threshold-based segmentation methods (Tete and Kamlu, 2017), edge detection algorithms (Wang et al., 2018), and spatial clustering methods (Guan et al., 2017). After obtaining the lesion regions, researchers often define the color, texture, or shape features to characterize the disease state of each sample. Gaikwad and coworkers applied K-means to segment the lesion regions in the wheat leaf images and extracted the color features, such as color histogram (Stricker, 1994), color moments (Poonam and Jadhav, 2015), and the texture features [e.g., gray-Level co-occurrence matrix [GLCM] (Gadelmawla, 2004)] to construct a support-vector machine (SVM) model for the classification of wheat diseases (Gaikwad and Musande, 2017). Ali et al. (2017) applied Delta E (ΔE) segmentation to process the leave images of diseased potatoes and extract color and texture features based on red, green, and blue (RGB), hue, saturation, value (HSV), and local binary patterns (LBP) to implement the classification of early blight and late blight (Ismail et al., 2020). Ayyub and Manjramkar (2019) successfully classified the apple fruit diseases via a multi-class model by integrating improved sum and difference histogram (ISADH), completed local binary pattern (CLBP), and other color and texture features.
In general, this kind of method may obtain human-interpretable features and thus provide good performance on some plant diseases. However, three drawbacks exist. First, the calculation procedure of these methods is complicated. Second, these methods are highly dependent on expert knowledge. Third, they do not work well for real-time detection.
Non-sematic Feature-Based Models
In recent years, DL has promoted the development of CV, thereby providing new ideas for image analysis and automatic diagnosis of plant diseases. In particular, the CNN model has been widely studied by researchers because of its powerful image processing and feature extraction capabilities and without the prior knowledge of domain experts (Syed-Ab-Rahman et al., 2021). At present, most of the existing works applied CNN, combined with transfer learning (Too et al., 2019) to implement plant disease diagnosis. Zhang et al. (2018) used two improved CNN models, GoogleNet and Cifar10, to classify nine types of corn diseases and obtain high accuracy. To reduce the number of parameters, Rahman et al. (2020) constructed a two-stage light CNN framework Simple-CNN to identify rice diseases with high accuracy. Moreover, other researchers made great efforts to develop novel computational models for predicting the severity of plant disease. For example, José et al. (2020) used five types of CNN models (AlexNet, GoogleNet, VGG16, ResNet50, and MobileNetV2) to estimate the severity of coffee leaf biotic stress. In addition, deep learning was also widely used to identify the diseases of fruit, root, and stem. Tan et al. (2016) presented a CNN model to recognize lesion images of diseased apples, such as scab skin, black rot, scar skin, and ring spot (Wenxue Tan, 2020). Nikhitha et al. (2019) used the Inception v3 model to detect the grades of infections in fruits (e.g., apple, banana, and cherry, etc.) based on color, size, and shape of the fruit (Nikhitha et al., 2019). Tusubira et al. (2020) achieved the automated scoring for root necrosis of diseased cassava by using deep CNN with semantic segmentation, which is done by classifying the necrotized and non-necrotized pixels of cassava root cross-sections without any additional feature engineering. Compared with the first category, DL models achieve higher recognition accuracy. However, we identify three limitations. First, they require large amounts of labeled data; second, they are overly sensitive to changes in the image; and third, the non-semantic features are hard to be explained.
To address the above limitations, we proposed an efficient pipeline for both disease diagnosis and severity estimation of plants with the lesion. A DL model combined with a novel clustering strategy contributes to higher prediction accuracy and lower computational cost.
Materials and Methods
The proposed computational framework includes three steps (Figure 1) and will be explained in detail in the following subsections.
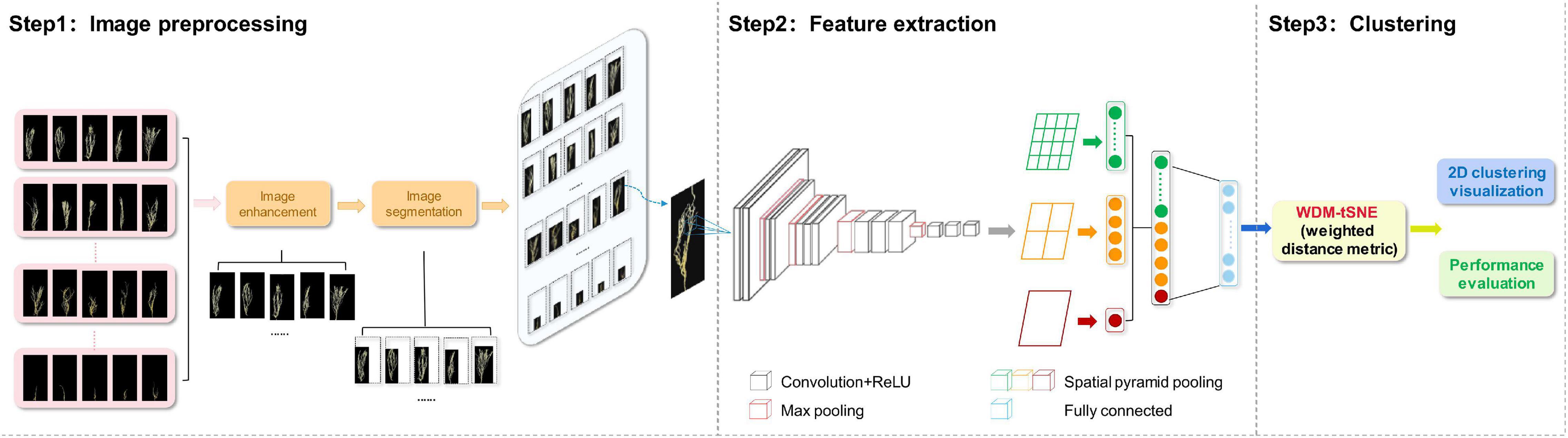
Figure 1. The flowchart of the proposed framework. ReLU, Rectified Linear Unit.
Image Preprocessing
Before extracting features, each image needs to be preprocessed, such as image enhancement and image segmentation. Image augmentation is to increase the diversity of samples (Halevy et al., 2009). we use horizontal flip (Connor Shorten, 2019) and affine transformation (Shen et al., 2019) on each image to enhance the size and quality of training datasets so that better DL models can be built. The purpose of image segmentation is to obtain areas related to plant tissues (root or leaf) from the original images. Therefore, the irrelevant region needs to be removed. In this study, we detected the relevant area by traversing all the pixels in each image and obtained the smallest circumscribed rectangle (Yu et al., 2006) of the outer contour of a plant tissue.
Feature Extraction
We developed a CNN model to extract the features from the plant images with the disease. The whole CNN model includes three layers: convolution layers, the spatial pyramid pooling (SPP) layer, and fully connected layer. The extracted high-dimensional features were further used to cluster the images with different severity levels. Figure 2 shows the details of the feature extraction process using the lentil images as an example.
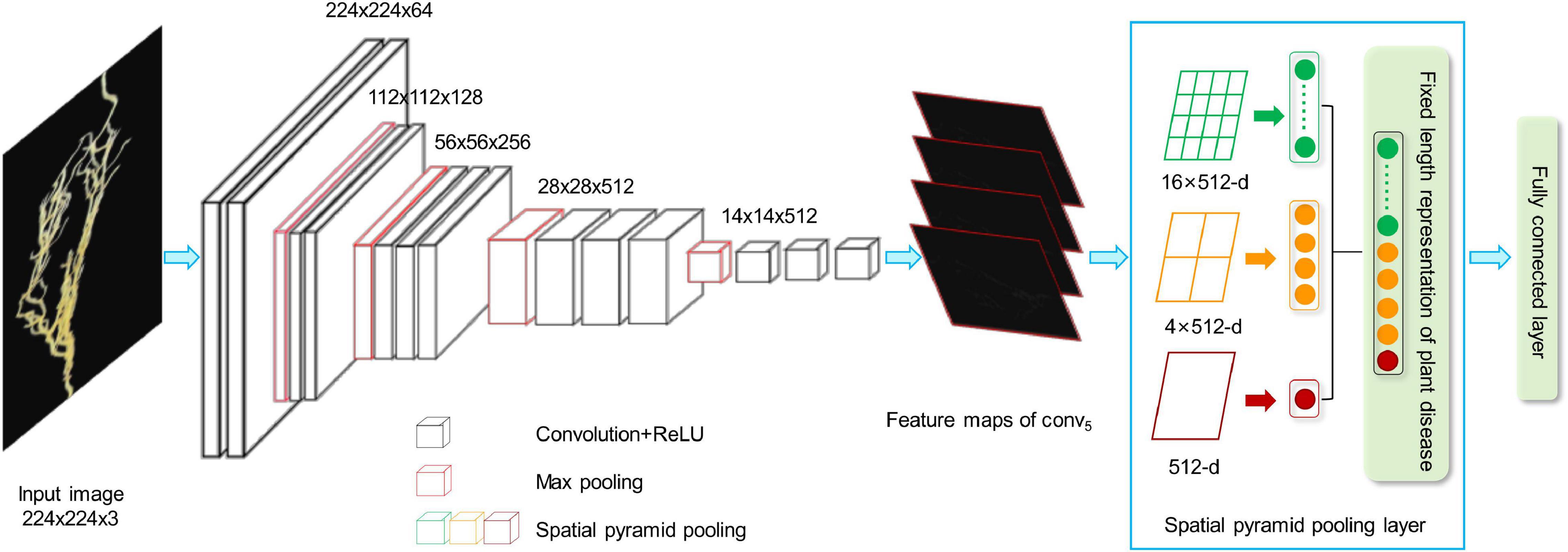
Figure 2. CNN-based network for feature extraction. ReLU, Rectified Linear Unit; CNN, convolutional neural network.
Creating the Feature Maps
As shown in Figure 2, the first step is to create the feature maps from each input image by using a series of convolutional, non-linear, and pooling. The convolutional layers can learn the low-level features, such as edges and curves, which provide the CNN with the important property of “translation invariance” (Kayhan and van Gemert, 2020). That makes it unnecessary to focus on the location of the disease on the plant roots or leaves and let alone to divide up the area of the spot. Convolution is done by applying filters to the input image data, which decreases its size (Yamashita et al., 2018). An additional operation called the Rectified Linear Unit (ReLU) (Atila and Sengür, 2021) was used after every convolution operation to generate a non-linear relationship between input and output. Finally, The pooling layer is used for secondary feature extraction, retaining the main features, reducing parameters, saving computing resources, preventing over-fitting, and improving model generalization (Suarez-Paniagua and Segura-Bedmar, 2018). Here, we define a spatial neighborhood with a 2 × 2 window and take the largest element from the rectified feature map within that window. Max pooling not only reduces the dimensionality of each feature map but also retains the most important information. Comparing with the typical VGG16 model (Qassim et al., 2018), the network structure of our model retains all the convolutional and pooling layers and the activation method, but removes three fully connected layers.
Let us say we have a plant image, and its size is 224 × 224. The representative array of this image will be 224 × 224 × 3 (3 refers to the channels of RGB). After the first operation of convolution, we obtained the feature maps as an array with 224 × 224 ×64. Passing this array through four convolutional layers, we finally obtained 512 feature maps with 14 × 14. The final output feature map (14 × 14 × 512) will be converted into one-dimensional vector.
Considering the fact that a CNN model may take time to train on large datasets, transfer learning (Pan and Yang, 2010) was considered in our study to re-use the model weights from pre-trained ImageNet (Krizhevsky et al., 2012) tasks. Here, we directly use the five convolutional layers from the entire architecture of the pre-trained the VGG16 model on ImageNet datasets.
Converting the Feature Maps to a Fixed Length Feature Vector
In this step, we convert all the two-dimensional feature maps to a single long continuous linear vector because the fully connected layer expects to receive one-dimensional inputs (Gu et al., 2018). Here, we introduce SPP (He et al., 2015) layer to remove the limitation of the fixed size of the images. The SPP layer was placed after the last convolutional layer and aggregated multi-scale features. As shown in Figure 2, each feature map (14 × 14) is divided into a lattice of n × n (n = 1,2,4) and each lattice is pooled, resulting in 21 features. This also means that the 512 feature maps of an original image are finally represented as a one-dimensional vector with a length of 10,752 (21 × 512). The output of the fully connected layer is 4,096, which means each image matrix will be converted to a feature vector with length 4,096 for clustering calculation.
Image Clustering
As mentioned above, each original image was finally represented as a 4,096 × 1 vector after the feature extraction process. The clustering of a group of original images is thus equivalent to a clustering task on a set of data points with a dimension of 4,096. Considering the fact that t-SNE is an efficient algorithm based on manifold learning for unsupervised clustering (Van der Maaten and Hinton, 2008), we designed an improved t-SNE algorithm for image clustering to classify plant diseases and graded the severity of a disease. The standard t-SNE algorithm assumes that the samples are distributed on a statistical manifold and converts the Euclidean distance between the samples into conditional probabilities to characterize the similarity between the samples (Talwalkar et al., 2008). However, the variables in the high-dimensional space often present complex non-linear relationships, and the Euclidean distance does not well reflect the real distribution of the samples, thus affecting its projection to the low-dimensional space. Within a manifold space, the Euclidean distance metrics can only represent the real distance between samples in a very small neighborhood subspace (Zhang et al., 2011).
Taken above together, we think that only the data points in the local neighborhood are applicable to the Euclidean distance, and they should be given greater weight in the conditional probability transformation. In this study, we adopted a WDM strategy to improve the t-SNE algorithm (WDM-tSNE) so that the similarity between samples can be better reflected after they are projected to a low-dimensional space. The details of WDM-tSNE are described as follows:
Firstly, we construct the distance matrix D of all the samples, where the element dij represents the distance between any two points Xi and Xj [Eq. (1)]:
All the non-zero elements dij (i≠j) are sorted in ascending order, and the distance value that ranks approximately 10% is selected as the threshold of the neighborhood relationship, denoted asθ. If dij≤θ, Xi and Xj have a neighbor relationship and weighting their distance will make them closer in the low-dimensional space. Therefore, we define a WDM strategy to adjust the distance coefficient l between any pair of samples Xi and Xj:
Under the Gaussian distribution centered on the point Xi, the conditional probability Pj|i is used to measure the similarity between Xi and Xj. In other words, Pj|imeans the probability that Xi chooses Xj as its neighbor. We thus construct conditional probability Pj|i for Xi and Xj, and the probability distribution is defined as Eq. (3):
From Eq. (3), we have Pi|i = 0. Assuming that the points Yi and Yj in the low-dimensional space are projected from Xi andXj, the similarity between the points Yi and Yj can be defined as:
According to the above description, we expect that if two points are similar in the high-dimensional space, they should be closer after being projected to the low-dimensional space. Here, we use Kullback-Leibler divergence (Van der Maaten and Hinton, 2008) to measure the difference between the above two conditional probability distributions and define the following objective function as Eq. (5):
However, the KL divergence (Kullback-Leibler divergence) is asymmetric [KL(P||Q) ≠ KL(Q||P)] (Afgani et al., 2008), which will cause the gradient calculation to be complicated. To optimize the KL divergence in SNE, t-SNE adopts symmetric SNE, that is, assuming Pj|i = Pi|j and Qj|i = Qi|j. The conditional probability pj|i can be replaced with the joint probability pij:
If Xi is an abnormal point, all the dij will be very large and may impact the calculation of Pij. Therefore, we define the joint probability distribution Pij as:
To make the points in the same cluster in the low-dimensional space more closer and the points in different clusters are more distant (Van der Maaten and Hinton, 2008), the long-tailed t-distribution is used instead of the Gaussian distribution. The joint probability of two points in the low-dimensional space can be defined as:
Therefore, Eq. (5) can be written as Eq. (9):
The formula (9) can be optimized by using the gradient descent strategy shown in formula (10):
Finally, all the point pairs of Xi and Xj in the high-dimensional space are projected to the two-dimensional space as Yi and Yj. The visualization of all the points Y can show the clustering effect of image samples.
Experimental Protocol
In this section, we introduced the experimental protocol designed for the validation of the proposed approach, such as data collection, simulation design, evaluation metric, and parameter optimization.
Data Collection
The MNIST database (Modified National Institute of Standards and Technology database) (Baldominos et al., 2019), a large database of handwritten digits, was used for data collection, which is not only used for training various image processing systems but also for testing machine-learning algorithms (Pastor-López et al., 2021). Currently, the MNIST database contains 60,000 training images and 10,000 testing images. In this study, we selected a data-subset Scikit-learn containing 1,797 8 × 8 digital images to test our proposed approach for image clustering.
PlantVillage (Barbedo, 2019) is a large, open-access image database. Currently, it stores 54,306 leaf images, associate with 26 plant diseases of 14 species (Albert et al., 2017; Brahimi et al., 2017; Ferentinos, 2018). This dataset is widely employed to test the performance of machine-learning models (Wang et al., 2017). In this study, we mainly focused on the following image sets from PlantVillage: (1) three types of leaf diseases on tomatoes (Figure 3C), such as bacterial spot of tomato (Adhikari et al., 2020), tomato leaf mold (Rivas and Thomas, 2005), and tomato yellow leaf curl virus (TYLCV) (Prasad et al., 2020); (2) cherry powdery mildew (Gupta et al., 2017; Figure 3B); (3) leaf scorch of strawberry (Dhanvantari, 1967; Figure 3A).
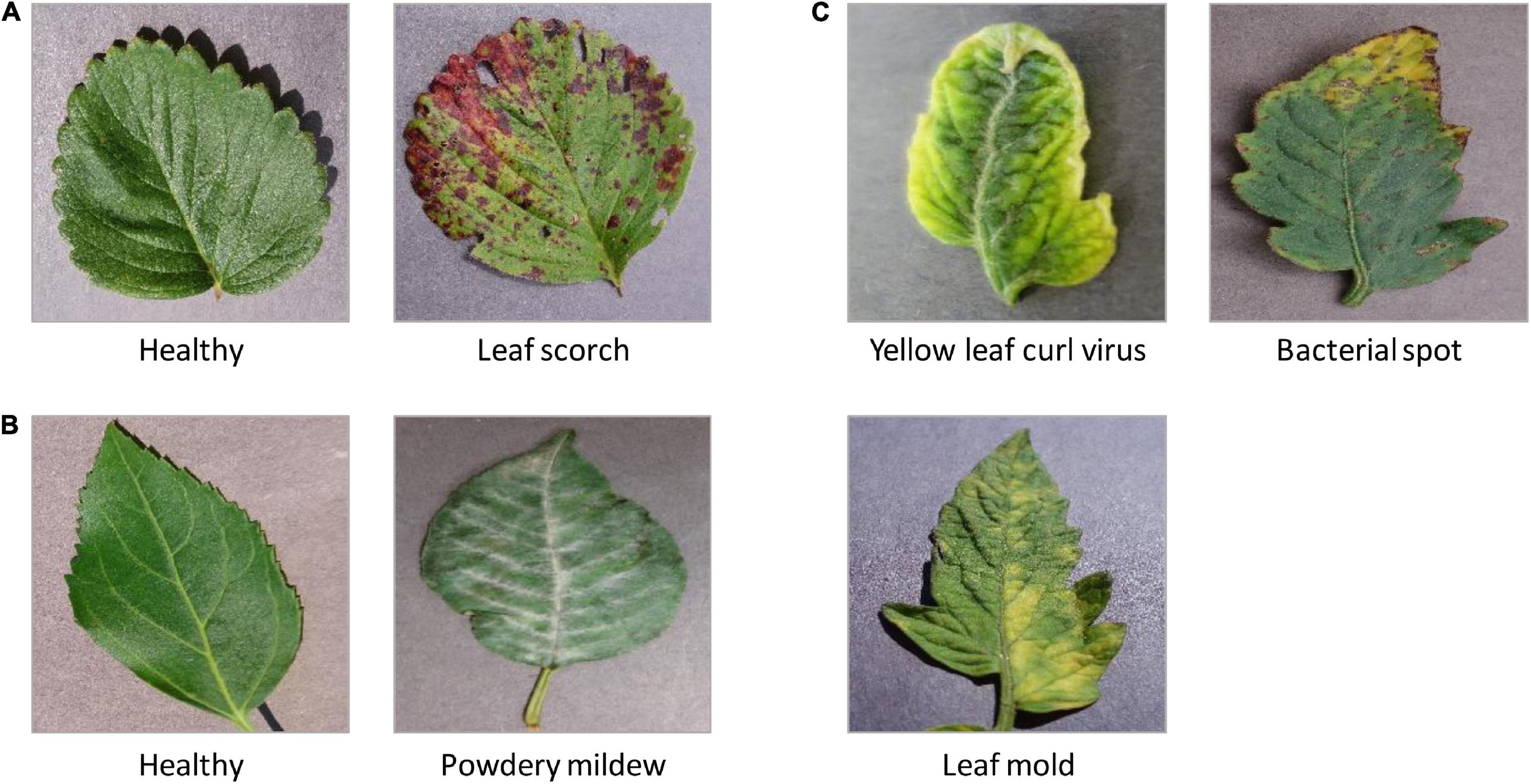
Figure 3. The representative leaf images with diseases from PlantVillage. (A) Leaf scorch of strawberry; (B) cherry powdery mildew; (C) three types of leaf diseases on tomatoes: a bacterial spot of tomato, tomato leaf mold, and tomato yellow leaf curl virus (TYLCV).
Aphanomyces Root Rot Image Dataset (Marzougui et al., 2019) contains up to 6,460 lentil images with root rot. ARR is a soil-borne disease that severely reduces lentil production. Based on the percentage of the brown discoloration area of the root and the softness of the hypocotyl (McGee et al., 2012), Marzougui et al. (2019) labeled the relative severity of all the root images using 0–5 disease scoring scale (McGee et al., 2012). For example, A score of 0 means that there are no obvious symptoms and good resistance to root rot; 1.5 means that the root has 15–25% of partial discoloration lesions; 3.5 means that the entire root has completely turned brown, and the hypocotyl has some symptoms. Eleven representative images with scores from 0 to 5 are shown in Figure 4. Furthermore, Marzougui et al. (2020) proposed three subtypes of ARR based on the visual score to evaluate the Rot severity: (1) resistant subtype with score 0–1.5; (2) partially resistant with score 2–3; (3) susceptible subtype with score 3.5–5. In this study, we selected 950 representative images of ARR for experimental simulation.

Figure 4. Aphanomyces root rot disease severity scale.
Simulation Design
Firstly, 1,797 digital images from MNIST were used to test the proposed method. Furthermore, we also compared the WDM-tSNE with the other five clustering strategies on MNIST. Secondly, a binary clustering test was further implemented on 400 strawberry and 400 cherry images to identify the diseased samples from the control. Thirdly, 300 tomato images were selected to test the clustering performance of our approach on three different diseases. Finally, we selected 950 ARR images to explore potential subtypes for the lentil invaded by Aphanomyces. We manually constructed balanced datasets and unbalanced datasets to evaluate if our approach is steady. The sample size for each dataset is presented in Supplementary File 1.
Clustering Performance Evaluation
In this study, we defined three types of metrics to assess the clustering performance. (1) Silhouette Coefficient (SC) (Dinh et al., 2019); (2) Calinski-Harabasz Index (CHI) (Łukasik et al., 2016); (3) Davies-Bouldin Index (DBI) (Vergani and Binaghi, 2018).
Silhouette Coefficient was firstly proposed by Rousseeuw (1987), which considered both the degree of cohesion and separation to measure the clustering performance. The SC value of sample j can be calculated by Eq. (11):
where Cj and Sj represent the degree of cohesion and separation, respectively. We can clearly see that good clustering means smaller Cj and larger Sj.
Calinski-Harabasz Index is defined as the ratio of the between-clusters dispersion mean and the within-cluster dispersion. A larger CHI means that the clusters themselves are tighter and the cluster-clusters are more dispersed [Eq. (12)]:
In Eq. (12), N and K are the number of samples and clusters, respectively. The variables nk and ck are the no. of points and centroid of the h-th cluster respectively, c is the global centroid.
Davies-Bouldin Index measures the average similarity between clusters [Eq. (13)].
In Eq. (13), Rij denotes the similarity between each cluster Ci and its most similar one Cj:
si denotes the average distance between each point of cluster i. dij denotes the distance between cluster centroids i and j.
Parameter Optimization
All the simulations were performed using Python with TensorFlow on Ubuntu 14.04 platform. The hardware setups are 2.30?GHz CPU and 4.00 GB RAM. CNN model is composed of 13 convolutional layers, and each layer uses a stacked 3 × 3 small convolution kernel to replace the large-size convolution kernel. After each convolutional layer, a 2 × 2 max pooling is used. In the WDM-tSNE model, the gradient descent strategy is used to optimize the cost function C [Formula (9)], and the momentum term α(t) is introduced to reduce the number of iterations (T). When the value of the cost function reaches 95% of the previous time, it indicates that the best result has been obtained, and the iteration is stopped. If T < 250, we set α(t) = 0.5; otherwise, α(t) = 0.8. The initial learning rate is set to 100, which is updated by the adaptive learning algorithm after each iteration.
Results
Validation on Modified National Institute of Standards and Technology Dataset
As a golden-standard image dataset, MNIST was firstly tested by our method. A total 1,797 digital images were imported to the CNN module and converted to a 1,797 × 64 matrix. Moreover, all the 1,797 samples in a 64-D space were then projected to 2D space by six dimensionality reduction approaches, namely, ISOMAP (Isometric Mapping), PCA (Principal Component Analysis), LLE (Locally Linear Embedding), MDS (Multidimensional Scaling), t-SNE (t-Distributed Stochastic Neighbor Embedding), and the proposed WDM-tSNE (Figure 5). From Figure 5, we found that LLE and PCA obtained the worst performance of dimensionality reduction as the 10 types of digital images in 2D space cannot be separated at all. ISOMAP and MDS work better rather than the first two, but the boundaries of inter-clusters are still blurred. In contrast, t-SNE and WDM-tSNE are significantly better than the previous four methods. Particularly, multiple evaluation metrics indicates that the WDM-tSNE strategy obtained higher clustering accuracy on MNIST superior to the standard t-SNE (Supplementary Table 1). For the geometric distribution of the samples in 2D space, WDM-tSNE can obtain better partitions of clusters (Supplementary Table 1).
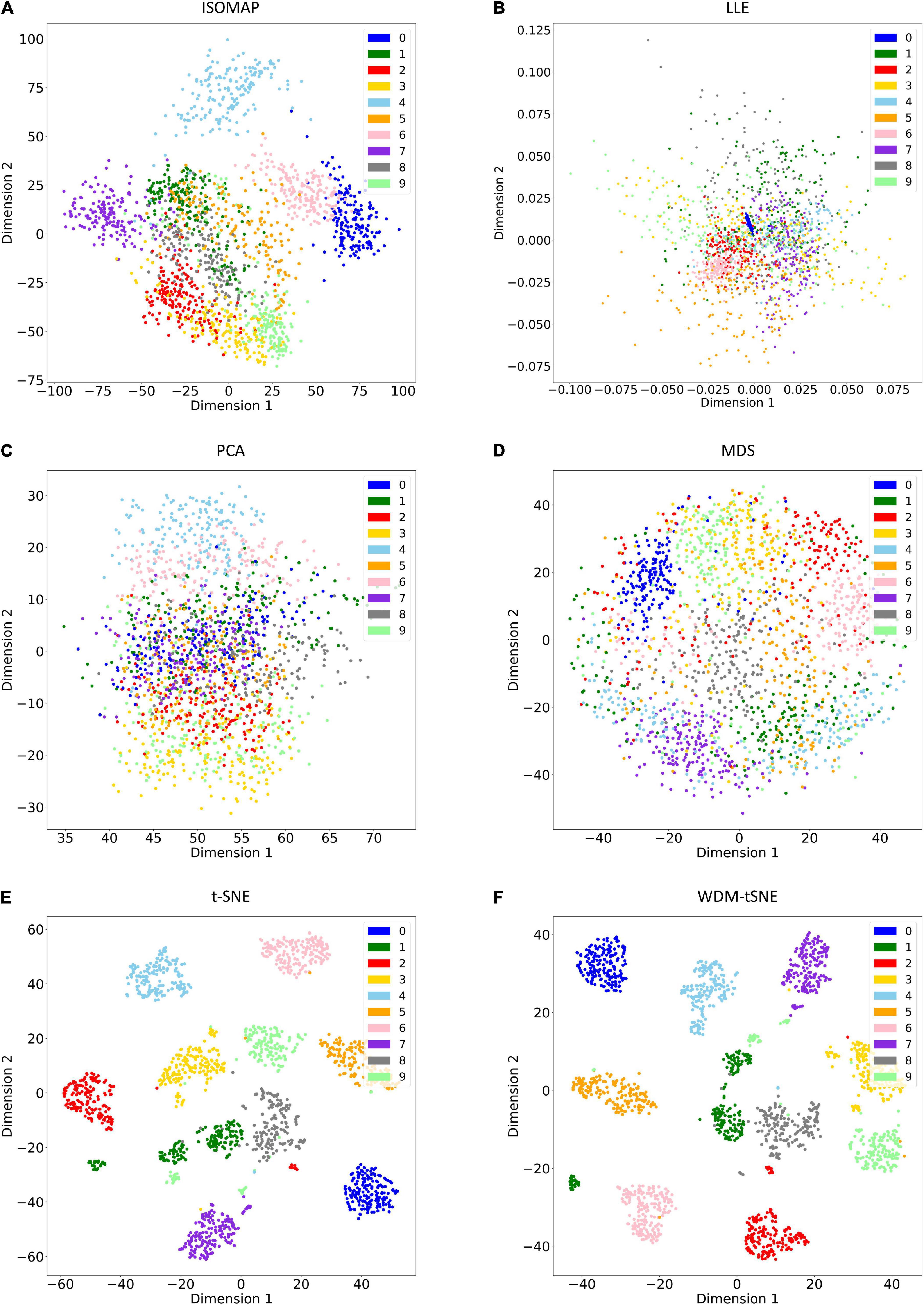
Figure 5. The plots for the MNIST dataset based on six dimensionality reduction approaches, including (A) Isomap, (B) LLE, (C) PCA, (D) MDS, (E) t-SNE, and (F) WDM-tSNE. MNIST, Modified National Institute of Standards and Technology; ISOMAP, Isometric Mapping; PCA, Principal Component Analysis; LLE, Locally Linear Embedding; MDS, Multidimensional Scaling; t-SNE, t-Distributed Stochastic Neighbor Embedding; WDM-tSNE, Weighted Distance Metric and the t-stochastic neighbor embedding algorithm.
The Proposed Model Works Well for Disease Diagnosis
We then applied our method on 400 strawberry images with leaf scorch. Figure 6 shows that the scorched leaf images can be easily identified from the healthy samples. Both balanced and unbalanced datasets revealed that the clustering performance is steady. Table 1 indicates that WDM-tSNE provides better clustering performance rather than t-SNE. Similarly, we also tested our approach on 400 cherry leaf images with powdery mildew. WCD-tSNE not only makes the samples in the same cluster more concentrated, but also guarantees the distance between different clusters is as far away as possible (Figure 7). Compared with t-SNE, WDM-tSNE has a better clustering effect (Table 2). In addition to the binary-clustering, we also tested the multi-clustering situation on the leaf images of diseased tomato. Figure 8 reveals that three distinct leaf diseases on tomatoes can be clearly identified (Table 3). Taken above together, we suggest that the proposed framework is an effective tool for identifying plant disease with high accuracy.
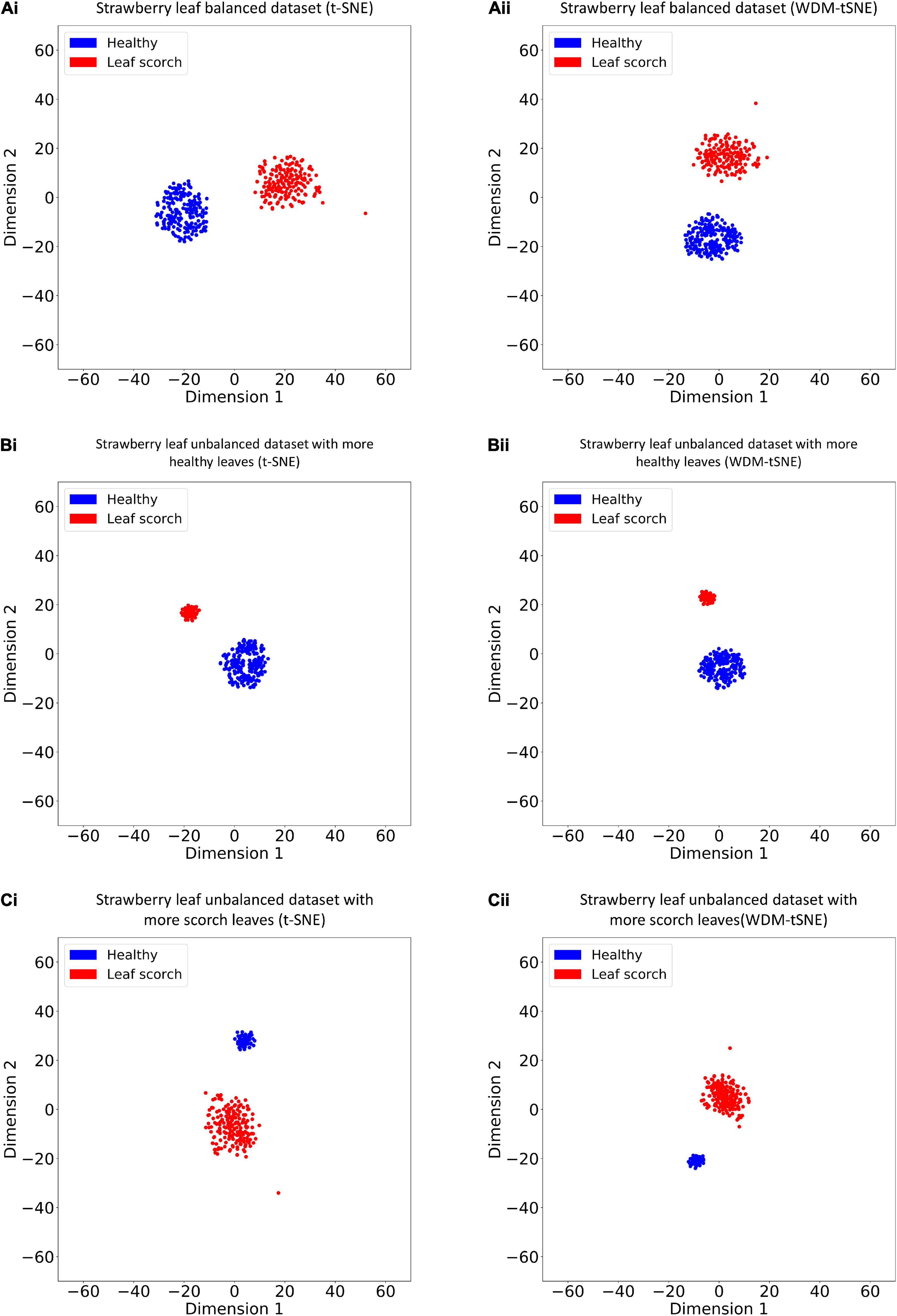
Figure 6. The plots for the (A) balanced or (B–C) unbalanced datasets of strawberry leaf scorch based on (i) t-SNE and (ii) WDM-tSNE. WDM-tSNE, Weighted Distance Metric and the t-stochastic neighbor embedding algorithm.

Table 1. The performance of WDM-tSNE on the multiple datasets of strawberry.
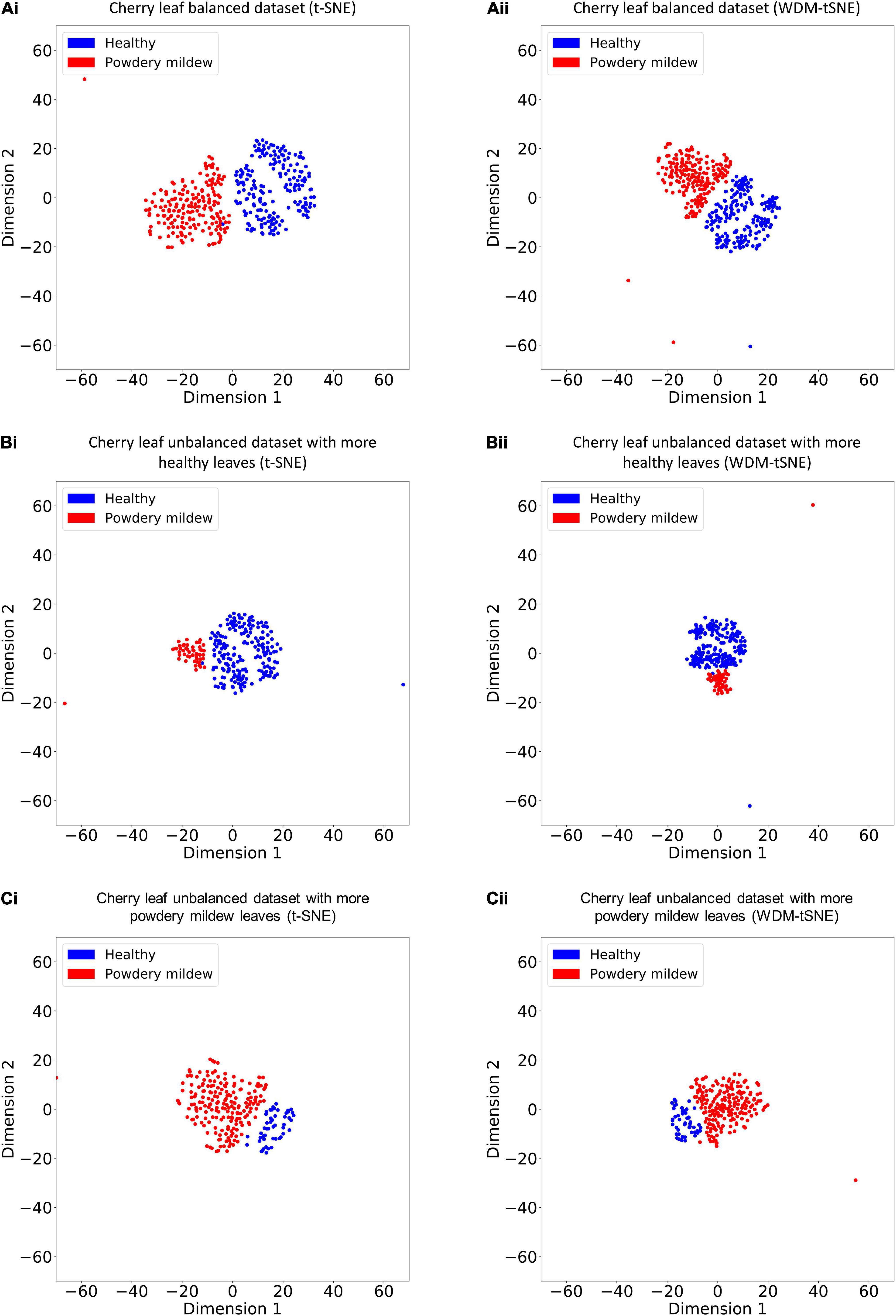
Figure 7. The plots for the (A) balanced and (B–C) unbalanced datasets of the cherry leaf with powdery mildew based on (i) t-SNE and (ii) WDM-tSNE. WDM-tSNE, Weighted Distance Metric and the t-stochastic neighbor embedding algorithm.

Table 2. The performance of WDM-tSNE on the multiple datasets of cherry.
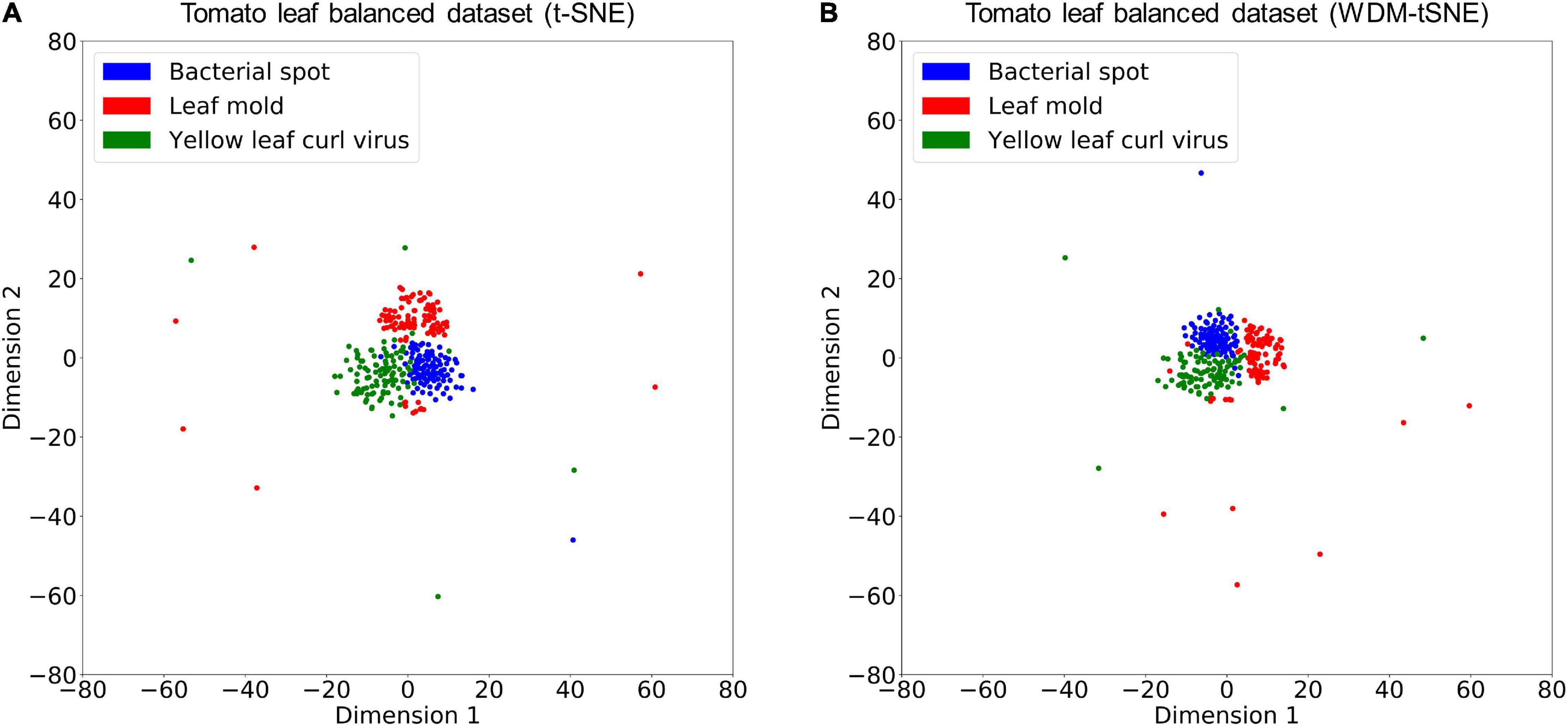
Figure 8. The plots for the balanced datasets of three tomato leaf diseases based on (A) t-SNE and (B) WDM-tSNE. WDM-tSNE, Weighted Distance Metric and the t-stochastic neighbor embedding algorithm.
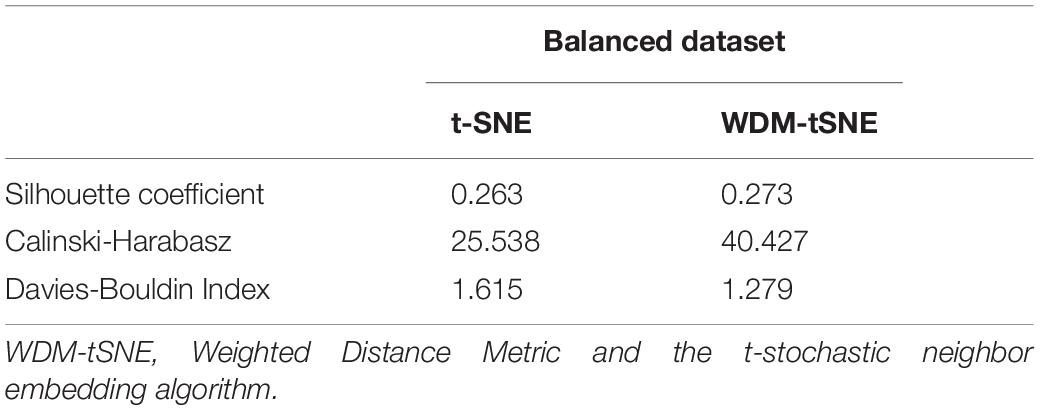
Table 3. The performance of WDM-tSNE on the dataset of tomato disease.
The Proposed Model Works Well for Subtype Discovery
Different from the experiments shown above, we further applied our model on 950 lentil root images infected by Aphanomyces euteiches to identify the underlying subtypes associate with Aphanomyces resistance. Firstly, 550 representative images (balanced dataset) of ARR with 11 rates of severity were projected to 2D space through six machine-learning approaches (Figure 9). Figures 9E,F shows that both t-SNE and WDM-tSNE can uncover the disease trajectory of all the samples from mild to severe. Secondly, we selected 550 images (50 samples for each rate) to test if WDM-tSNE has the ability to reveal the underlying subtypes of the plant samples with the same disease. Figure 10 shows that three clusters are obviously detected from balanced and unbalanced datasets. The clustering performance of WDM-tSNE is superior to t-SNE (Table 4). In the balanced dataset with 550 samples, 231 were predicted as a mild subtype with an average score of 1.93, 205 were predicted as a partially moderate subtype (average score: 2.45), and 114 were marked as a severe subtype (average score: 3.74) (Figure 11). Figure 11 also suggests that the samples with serious symptoms can be easily detected (cluster 3). However, the visual score based on the percentage of discolored lesions on the entire root system defined by Marzougui et al. may cause bias when dividing mild and moderate samples. Therefore, the data annotations based on expert knowledge are also one of the factors that affect the accuracy of the algorithm.
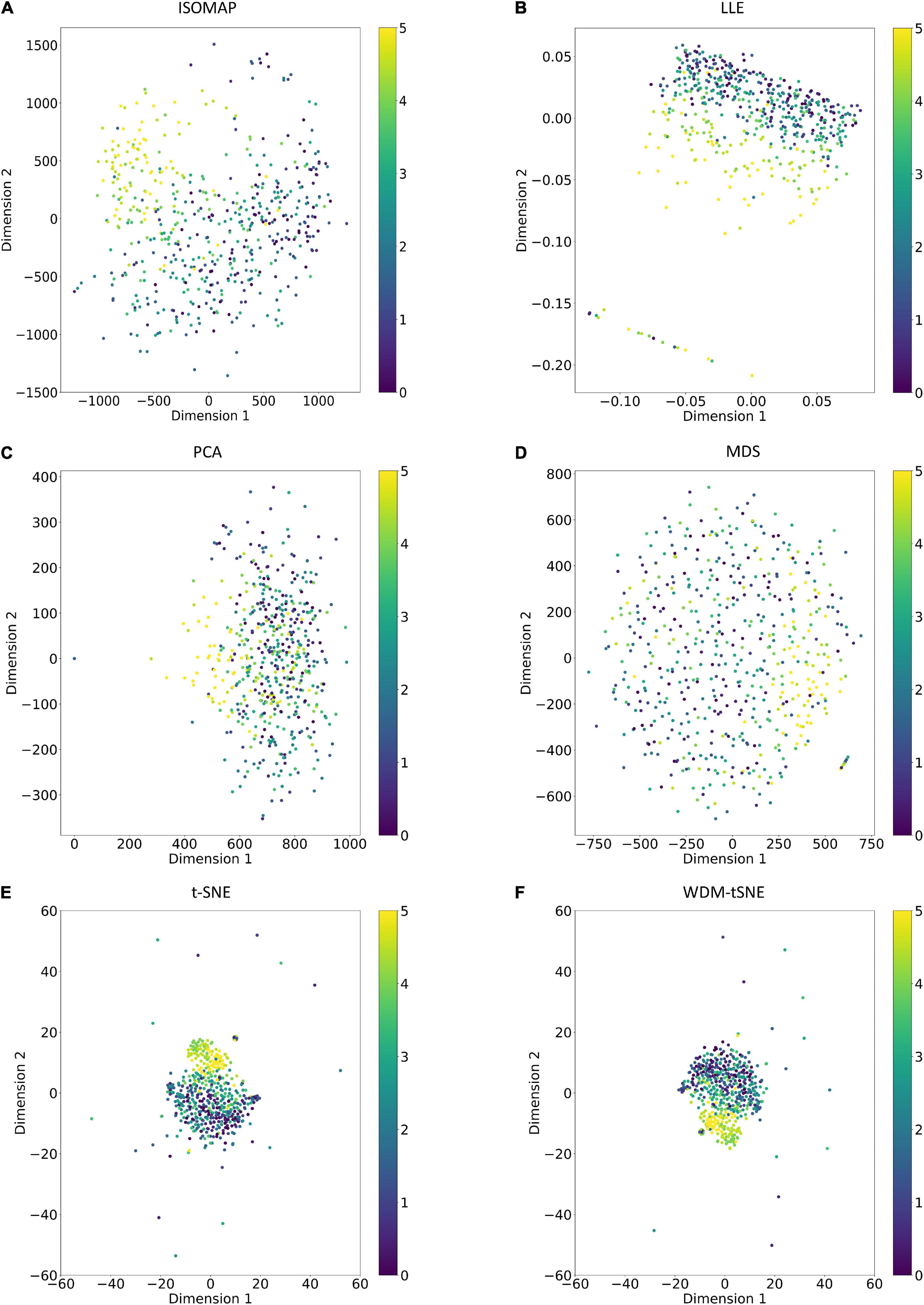
Figure 9. The plots for the balanced dataset of ARR based on six dimensionality reduction approaches, including (A) Isomap, (B) LLE, (C) PCA, (D) MDS, (E) t-SNE, and (F) WDM-tSNE. The samples with 11 rates were plotted. ARR, Aphanomyces Root Rot.
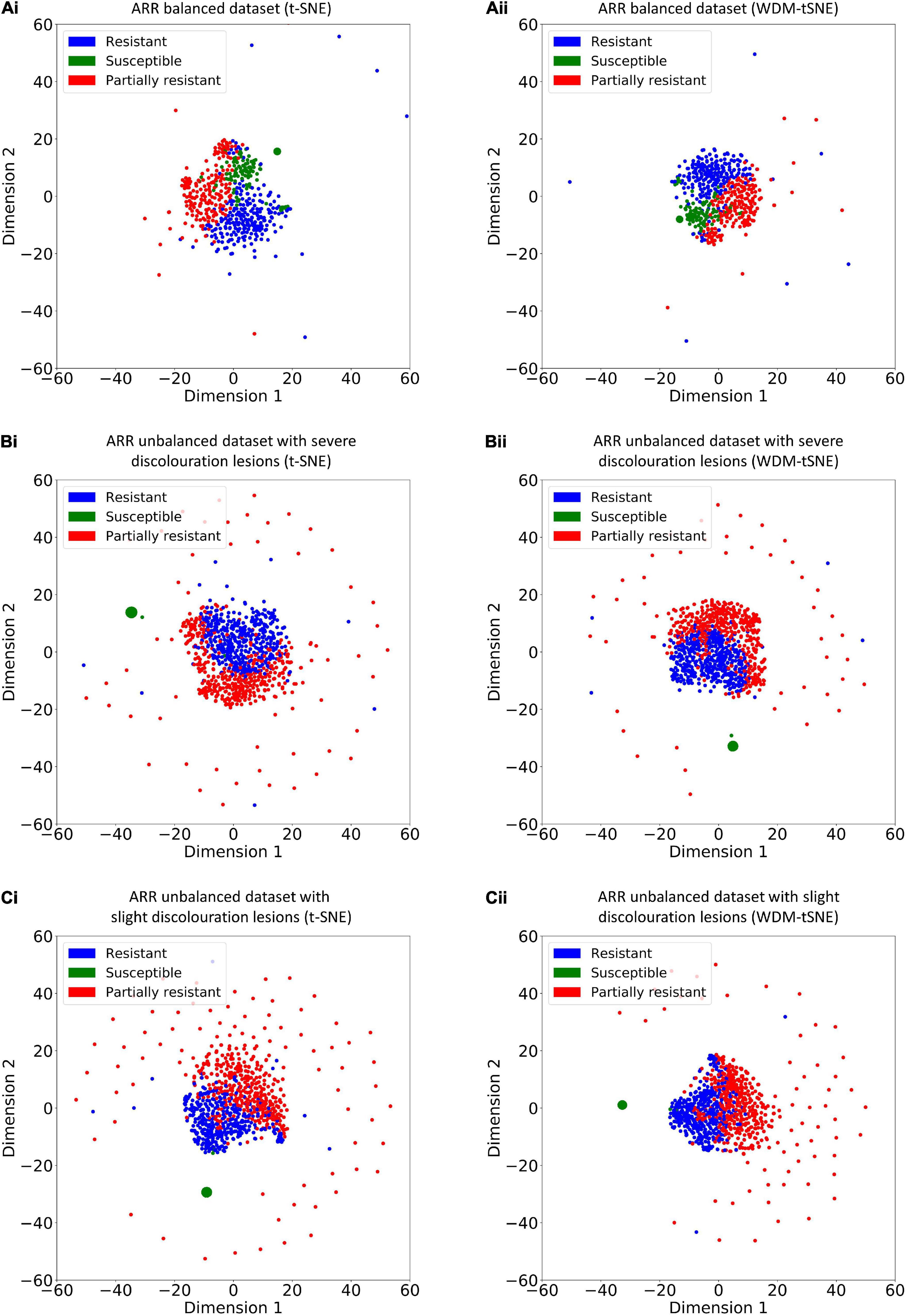
Figure 10. The plots for the (A) balanced and (B–C) unbalanced datasets of ARR are based on (i) t-SNE and (ii) WDM-tSNE. WDM-tSNE, Aphanomyces Root Rot; Weighted Distance Metric and the t-stochastic neighbor embedding algorithm; ARR, Aphanomyces Root Rot.

Table 4. The performance of WDM-tSNE on the multiple datasets of lentil.
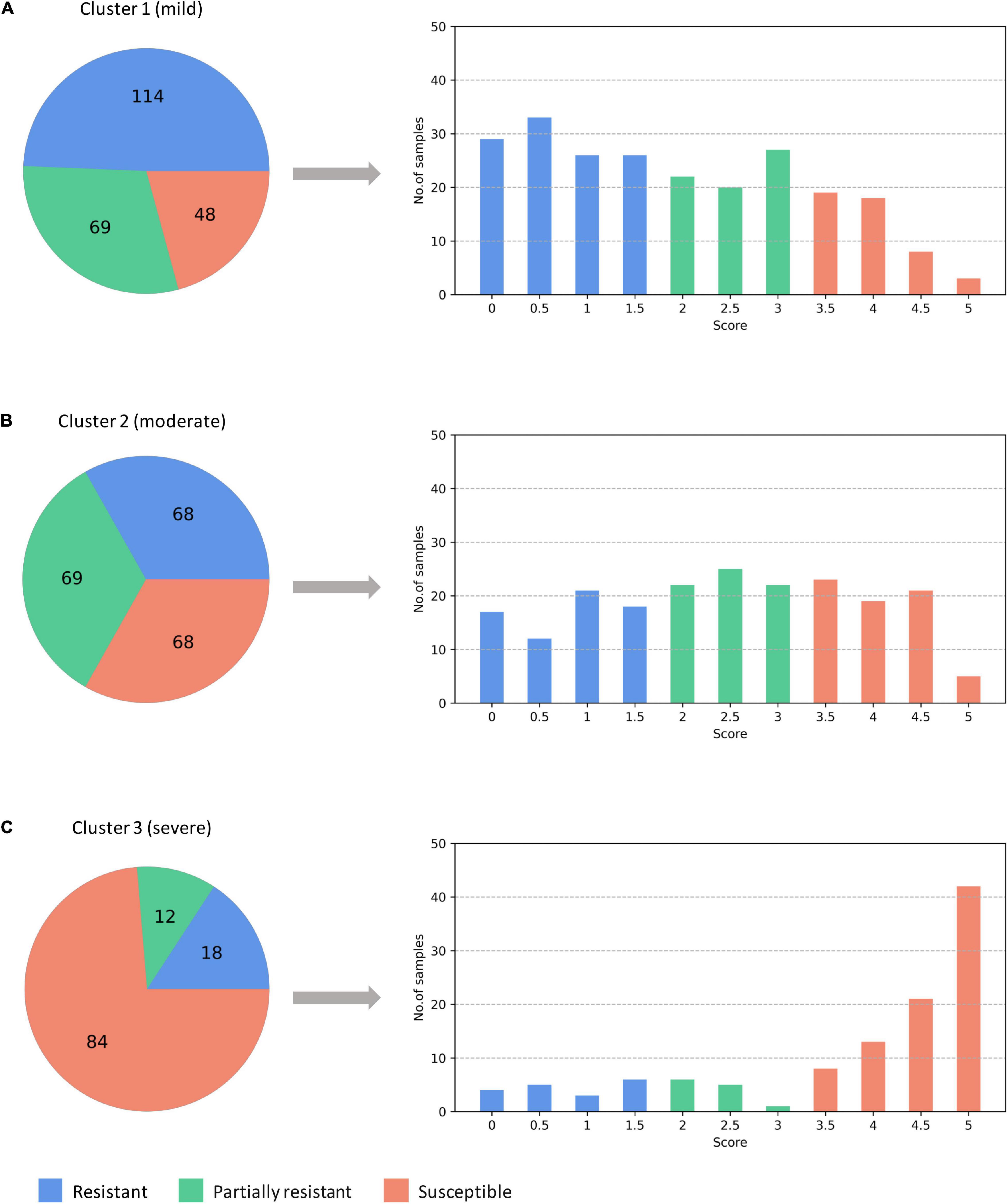
Figure 11. The predicted three subtypes of ARR: (A) mild; (B) moderate; (C) severe. The numbers denote how many samples are assigned to one of the subtypes. ARR, Aphanomyces Root Rot.
Discussion
Plant diseases are not only a threat to food security on a global scale, but also cause disastrous consequences for smallholder farmers whose livelihoods depend on healthy crops (Mohanty et al., 2016). Identifying a disease correctly when it first appears is a crucial step for efficient disease management. Various efforts have been developed to prevent the loss of the plant due to diseases. For computer-vision-based plant diseases detection, conventional image processing or manual design of features plus classifiers are often used (Tsaftaris et al., 2016). This kind of method usually makes use of the different properties of plant disease to design the imaging scheme and chooses appropriate light sources and shooting angles, which is helpful to obtain images with uniform illumination. In the real complex natural environment, plant diseases detection is faced with many challenges, such as the small differences between the lesion area and the background, low contrast, large variations in the scale of the lesion area and various types, and a lot of noise in the lesion image (Liu and Wang, 2021). In addition, over-depend on expert knowledge to manually design the features of diseased plant often limits the generalization. In recent years, DL methods are widely used in various CV tasks for plant disease diagnosis. The most challenges of DL-based strategies include small sample size problem, fine-grained identification of small-size lesions in the early stage, and the performance under the influence of illumination and occlusion (Liu and Wang, 2021).
In this study, we proposed a computational framework for both plant disease identification and severity estimation (Figure 1). Firstly, we designed a CNN network structure as a feature extractor to obtain the image features of lesion regions of a diseased plant. The input original images are not required with a fixed size, which avoid the impacts of image distortion or geometric distortion on feature extraction. Secondly, a dimension reduction strategy, WDM-tSNE, was developed for the imaging clustering tasks by improving the t-SNE with WDM. WDM-tSNE successfully realized the efficient clustering of high-dimensional samples in low-dimensional space.
To validate the effectiveness, we applied the proposed model on a bunch of plant image datasets. The experimental results revealed that our method not only identifies multiple distinct diseases of the same plant but also estimates the severity of the same disease. Figures 5, 6 indicate that our model is able to distinguish multiple diseases in a low-dimensional space. Figures 7, 8 show that the diseased samples can be easily identified from the health samples. From Figure 9, we concluded that the proposed method can be used for subtype discovery or severity estimation from the same disease (ARR). The 10-fold cross-validation on the ARR dataset revealed that our model is robust (Supplementary Table 2). Furthermore, we applied our model on three small-scale datasets for cherry, strawberry, and tomato. The sample size of each class is only 50. Our analyses show that our model works well on small-scale image datasets (Supplementary Figure 1 and Supplementary Table 3).
Considering the fact that the class imbalance may impact the clustering performance, we constructed multiple balanced and unbalanced datasets for ARR (lentil), cherry, and strawberry (Supplementary File 1). Regardless of binary-class or multi-class, WDM-tSNE shows better clustering performance than t-SNE (Tables 1–4). It indicates that the sample variation does not affect the performance of our method.
The proposed WDM-tSNE outperformed other approaches. After extracting the features from images through the CNN module, we compared the clustering performance of WDM-tSNE with the other five dimension-reduction algorithms. Figures 5, 9 proved that WDM-tSNE is not only significantly better than ISOMAP, LLE, PCA, and MDS, but also prior to tSNE.
Recent advances in genomics technologies have greatly accelerated the progress in plant science (Varshney et al., 2021). There are some studies to link phenotypic data to genomic data for discovering the responsible genes or mutations that contributed to plant disease progression (Bolger et al., 2019). Particularly, the systems biology approaches developed by integrating multi-omics data will allow us to identify potential targets and predict new therapeutic strategies (Di Silvestre et al., 2018).
There are several limitations of our current method. Firstly, the features extracted from the plant images by the CNN module are non-semantic, thus, it is hard to interpretable for disease diagnosis and management. Secondly, the current approach only focused on a single disease for each cluster of the image but did not pay attention to the images of plants suffering from multiple diseases. Thirdly, we have not applied the current model on the high-throughput phenotypic images obtained from real natural environments. Finally, we cannot guarantee the clustering performance on the image samples of diseased plants whose severity is manually labeled by different experts.
Conclusion
This paper proposes a novel computational framework for plant disease identification and subtype discovery from phenomics data. Our proposed method has achieved high accuracy and good generalization ability in all four public datasets than other deep embedding clustering of images, e.g., t-SNE, ISOMAP, etc.
Specifically, our method does not depend on prior knowledge. Moreover, the size of input images is also unlimited. As a novel embedding strategy, WDM-tSNE provides the perfect clustering performance rather than other methods. The samples in 2D space present great distributions after space embedding, which is significant to reveal the underlying patterns and trajectory of plant disease.
In the future, we will further explore the association between the environmental parameters (climate, hydrology, and soil, etc.) and plant disease evolution.
Data Availability Statement
All the raw images involved in this study can be accessed through the links: https://xf-data-bucket.oss-cn-hangzhou.aliyuncs.com/data.rar. Source code is available at GitHub: https://github.com/JakeJiUThealth/WDM1.0. The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
ZJ, FX, and XX designed the project. FX and XX analyzed the data. ZJ performed the mathematical modeling and optimization. ZJ, FX, ZW, SJ, and KY discussed the results. ZJ and FX wrote the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Science Foundation of Jiangsu Province (no. BK20211210). This work was also supported by the startup award of a new professor at Nanjing Agricultural University (no. 106/804001), and the National Science Foundation of Zhejiang Province (no. LY20F020003).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors thank Prof. Haiyan Jiang at the College of Artificial Intelligence at Nanjing Agricultural University to provide valuable discussions.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2021.789630/full#supplementary-material
Supplementary Figure 1 | The plots for the small-scale balanced datasets are based on t-SNE and WDM-tSNE. WDM-tSNE, Weighted Distance Metric and the t-stochastic neighbor embedding algorithm.
Supplementary Table 1 | Clustering performance on MNIST dataset. MNIST, Modified National Institute of Standards and Technology.
Supplementary Table 2 | A 10-fold cross-validation on the balanced dataset of ARR samples. ARR, Aphanomyces Root Rot.
Supplementary Table 3 | Clustering performance on three small-scale datasets. The sample size of each class is 50.
Supplementary File 1 | The sample assignment for each dataset involved in this study.
References
Adhikari, P., Adhikari, T. B., Louws, F. J., and Panthee, D. R. (2020). Advances and challenges in bacterial spot resistance breeding in tomato (Solanum lycopersicum L.). Int. J. Mol. Sci. 21:1734. doi: 10.3390/ijms21051734
Afgani, M., Sinanovic, S., and Haas, H. (2008). “Anomaly detection using the Kullback-Leibler divergence metric,” in Proceeding of the First International Symposium on Applied Sciences on Biomedical and Communication Technologies (IEEE), 1–5.
Albert, C., Cruz, A. L., De Bellis, L., and Ampatzidis, Y. (2017). X-FIDO: an effective application for detecting olive quick decline syndrome with deep learning and data fusion. Front. Plant Sci. 8:1741. doi: 10.3389/fpls.2017.01741
Ali, H., Lali, M. I., Nawaz, M. Z., Sharif, M., and Saleem, B. A. (2017). Symptom based automated detection of citrus diseases using color histogram and textural descriptors. Comput. Electron. Agric. 138, 92–104. doi: 10.1016/j.compag.2017.04.008
Atila, O., and Sengür, A. (2021). Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoustics 182:108260. doi: 10.1016/j.apacoust.2021.108260
Ayyub, S. R. N. M., and Manjramkar, A. (2019). “Fruit disease classification and identification using image processing,” in Proceeding of the 3rd International Conference on Computing Methodologies and Communication (ICCMC) (IEEE), 1–5.
Baldominos, A., Seaz, Y., and Isasi, P. (2019). A survey of handwritten character recognition with MNIST and EMNIST. Appl. Sci. 9:3169. doi: 10.3390/app9153169
Barbedo, J. G. (2019). Plant disease identification from individual lesions and spots using deep learning. Biosyst. Eng. 180, 96–107. doi: 10.1016/j.biosystemseng.2019.02.002
Bass, D., Stentiford, G. D., Wang, H. C., Koskella, B., and Tyler, C. R. (2019). The pathobiome in animal and plant diseases. Trends Ecol. Evol. 34, 996–1008. doi: 10.1016/j.tree.2019.07.012
Bolger, A. M., Poorter, H., Dumschott, K., Bolger, M. E., Arend, D., Osorio, S., et al. (2019). Computational aspects underlying genome to phenome analysis in plants. Plant J. 97, 182–198. doi: 10.1111/tpj.14179
Brahimi, M., Arsonovic, M., Laraba, S., Sladojevic, S., Boukhalfa, K., and Moussaoui, A. (2018). Deep learning for plant diseases: detection and saliency map visualisation. Hum. Mach. Learn. 93–117.
Brahimi, M., Boukhalfa, K., and Moussaoui, A. (2017). Deep learning for tomato diseases: classification and symptoms visualization. Appl. Artificial Intell. 31, 299–315. doi: 10.1080/08839514.2017.1315516
Chouhan, S. S., Singh, U. P., and Jain, S. (2020). Applications of computer vision in plant pathology: a survey. Arch. Comput. Methods Eng. 27, 611–632. doi: 10.1007/s11831-019-09324-0
Bock, C. H., Barbedo, J. G. A. Del Ponte, E. M., Bohnenkamp, D., and Mahlein, A.-K. (2020). From visual estimates to fully automated sensor-based measurements of plant disease severity: status and challenges for improving accuracy. Phytopathology Res. 2, 1–30. doi: 10.1186/s42483-020-00049-8
Connor Shorten, T. M. K. (2019). A survey on image data augmentation for deep learning. J. Big Data 6, 1–48.
Deng, L. (2012). The MNIST database of handwritten digit images for machine learning research. IEEE Signal Process. Magazine 29, 141–142. doi: 10.1109/msp.2012.2211477
Dhanvantari, B. N. (1967). The leaf scorch disease of strawberry (Diplocarpon earliana) and the nature of resistance to it. Can. J. Bot. 45, 1525–1543. doi: 10.1139/b67-157
Di Silvestre, D., Bergamaschi, A., Bellini, E., and Mauri, P. (2018). Large scale proteomic data and network-based systems biology approaches to explore the plant world. Proteomes 6:27. doi: 10.3390/proteomes6020027
Dinh, D. T., Fujinami, T., and Huynh, V.-N. (2019). “Estimating the optimal number of clusters in categorical data clustering by silhouette coefficient,” in International Symposium on Knowledge and Systems, eds J. Chen, V. Huynh, G. N. Nguyen, and X. Tang (Singapore: Springer), 1–17. doi: 10.1007/978-981-15-1209-4_1
Fahrentrapp, J., Ria, F., Geilhausen, M., and Panassiti, B. (2019). Detection of gray mold leaf infections prior to visual symptom appearance using a five-band multispectral sensor. Front. Plant Sci. 10:628. doi: 10.3389/fpls.2019.00628
Falk, K., Jubery, Z., Mirnezami, S. V., Parmley, K. A., Sarkar, S., Singh, A., et al. (2020). Computer vision and machine learning enabled soybean root phenotyping pipeline. Plant Methods 16, 1–19. doi: 10.1186/s13007-019-0550-5
Ferentinos, K. P. (2018). Deep learning models for plant disease detection and diagnosis. Comput. Electron. Agric. 145, 311–318. doi: 10.1016/j.compag.2018.01.009
Gadelmawla, E. S. (2004). A vision system for surface roughness characterization using the gray level co-occurrence matrix. NDT E Int. 37, 577–588. doi: 10.1016/j.ndteint.2004.03.004
Gaikwad, V. P., and Musande, V. (2017). “Wheat disease detection using image processing,” in Proceeding of the 1st International Conference on Intelligent Systems and Information Management (ICISIM) (IEEE), 1–3.
Ghosh, S., Mondal, M. J., Sen, S., Chatterjee, S., Roy, N., and Patnaik, S. (2020). “A novel approach to detect and classify fruits using ShuffleNet V2,” in Proceeding of the IEEE Applied Signal Processing Conference (ASPCON) (IEEE), 1–5.
Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., et al. (2018). Recent advances in convolutional neural networks. Pattern Recogn. 77, 354–377.
Guan, C., Yuen, K. K. F., and Chen, Q. (2017). “Towards a hybrid approach of k-means and density-based spatial clustering of applications with noise for image segmentation,” in Proceeding of the IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData) (IEEE), 396–399.
Gupta, V., Sengar, N., Dutta, M. K., Travieso, C. M., and Alonso, J. B. (2017). “Automated segmentation of powdery mildew disease from cherry leaves using image processing,” in International Conference and Workshop on Bioinspired Intelligence (IWOBI) (IEEE), 1–4. doi: 10.34133/2020/5839856
Halevy, A., Norvig, P., and Pereira, F. (2009). The unreasonable effectiveness of data. IEEE Intell. Syst. 24, 8–12.
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37, 1904–1916. doi: 10.1109/tpami.2015.2389824
Hossain, E., Hossain, F., and Rahaman, M. A. (2019). “A color and texture based approach for the detection and classification of plant leaf disease using KNN classifier,” in International Conference on Electrical, Computer and Communication Engineering (ECCE) (IEEE), 1–6.
Hu, H., Guan, Q., Chen, S., Ji, Z., and Lin, Y. (2020). Detection and recognition for life state of cell cancer using two-stage cascade CNNs. IEEE/ACM Trans. Comput. Biol. Bioinform. 17, 887–898. doi: 10.1109/TCBB.2017.2780842
Ismail, W., Attique Khan, M., Shah, S. A., and Younus, M. (2020). “An adaptive image processing model of plant disease diagnosis and quantification based on color and texture histogram,” in Proceeding of the 2nd International Conference on Computer and Information Sciences (ICCIS) (IEEE), 1–6.
José, G. M., Esgario, R. A. K., and Ventura, J. A. (2020). Deep learning for classification and severity estimation of coffee leaf biotic stress. Comput. Electron. Agric. 169:105162. doi: 10.1016/j.compag.2019.105162
Kayhan, O. S., and van Gemert, J. C. (2020). “On translation invariance in cnns: convolutional layers can exploit absolute spatial location,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (IEEE), 14274–14285.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). “ImageNet classification with deep convolutional neural networks. NIPS’12,” in Proceedings of the 25th International Conference on Neural Information Processing Systems, Vol. 1, (IEEE), 1097–1105.
Lee, S. H., Goeau, H., Bonnet, P., and Joly, A. (2020). New perspectives on plant disease characterization based on deep learning. Comput. Electron. Agric. 170:105220. doi: 10.1016/j.compag.2020.105220
Lee, U., Chang, S., Putra, G. A., Kim, H., and Kim, D. H. (2018). An automated, high-throughput plant phenotyping system using machine learning-based plant segmentation and image analysis. PLoS One 13:e0196615. doi: 10.1371/journal.pone.0196615
Li, D., Quan, C., Song, Z., Li, X., Yu, G., Li, C., et al. (2020). High-throughput plant phenotyping platform (HT3P) as a novel tool for estimating agronomic traits from the lab to the field. Front. Bioeng. Biotechnol. 8:623705. doi: 10.3389/fbioe.2020.623705
Liang, Q., Xiang, S., Hu, Y., Coppola, G., Zhang, D., Sun, W. J. C., et al. (2019). PD2SE-Net: computer-assisted plant disease diagnosis and severity estimation network. Comput. Electron. Agric. 157, 518–529.
Lin, K., Gong, L., Huang, Y., Liu, C., and Pan, J. (2019). Deep learning-based segmentation and quantification of cucumber powdery mildew using convolutional neural network. Front. Plant Sci. 10:155. doi: 10.3389/fpls.2019.00155
Liu, J., and Wang, X. (2021). Plant diseases and pests detection based on deep learning: a review. Plant Methods 17:22. doi: 10.1186/s13007-021-00722-9
Łukasik, S., Kowalski, P. A., Charytanowicz, M., and Kulczycki, P. (2016). “Clustering using flower pollination algorithm and Calinski-Harabasz index,” in Proceeding of the IEEE Congress on Evolutionary Computation (CEC) (IEEE), 1–5.
Marzougui, A., Ma, Y., McGee, R. J., Khot, L. R., and Sankaran, S. (2020). Generalized linear model with elastic net regularization and convolutional neural network for evaluating aphanomyces root rot severity in lentil. Plant Phenomics 2020:2393062. doi: 10.34133/2020/2393062
Marzougui, A., Ma, Y., Zhang, C., McGee, R. J., Coyne, C. J., Main, D., et al. (2019). Advanced imaging for quantitative evaluation of aphanomyces root rot resistance in lentil. Front. Plant Sci. 10:383. doi: 10.3389/fpls.2019.00383
McGee, R. J., Coyne, J. C., Pilet-Nayel, M. L., Moussart, A., Tivoli, B., Baranger, A., et al. (2012). Registration of pea germplasm lines partially resistant to aphanomyces root rot for breeding fresh or freezer pea and dry pea types. J. Plant Registrations 6, 203–207. doi: 10.3198/jpr2011.03.0139crg
Mohanty, S. P., Hughes, D. P., and Salathe, M. (2016). Using deep learning for image-based plant disease detection. Front. Plant Sci. 7:1419. doi: 10.3389/fpls.2016.01419
Nikhitha, M., Roopa Sri, S., and Uma Maheswari, B. (2019). “Fruit recognition and grade of disease detection using inception V3 model,” in Proceeding of the 3rd International Conference on Electronics, Communication and Aerospace Technology (ICECA) (IEEE), 1040–1043.
Ozguven, M. M., and Adem, K. (2019). Automatic detection and classification of leaf spot disease in sugar beet using deep learning algorithms. Phys. A: Stat. Mechan. Appl. 535:122537. doi: 10.1016/j.physa.2019.122537
Pan, S. J., and Yang, Q. (2010). A survey on transfer learning. IEEE Trans. Knowledge Data Eng. 22, 1345–1359.
Pasala, R., and Pandey, B. B. (2020). Plant phenomics: high-throughput technology for accelerating genomics. J. Biosci. 45:111.
Pastor-López, I., Sanz, B., Tellaeche, A., Psaila, G., Gaviriade la Puerta, J., and Bringas, P. G. (2021). Quality assessment methodology based on machine learning with small datasets: industrial castings defects. Neurocomputing 456, 622–628. doi: 10.1016/j.neucom.2020.08.094
Phadikar, S., and Goswami, J. (2016). “Vegetation indices based segmentation for automatic classification of brown spot and blast diseases of rice,” in Proceeding of the 3rd International Conference on Recent Advances in Information Technology (RAIT) (IEEE).
Poonam, S. J., and Jadhav, D. S. (2015). Video summarization using higher order color moments (VSUHCM). Proc. Comput. Sci. 45, 275–281. doi: 10.1016/j.procs.2015.03.140
Prasad, A., Sharma, N., Hari-Gowthem, G., Muthamilarasan, M., and Prasad, M. (2020). Tomato yellow leaf curl virus: impact, challenges, and management. Trends Plant Sci. 25, 897–911. doi: 10.1016/j.tplants.2020.03.015
Qassim, H., Verma, A., and Feinzimer, D. (2018). “Compressed residual-VGG16 CNN model for big data places image recognition,” in Proceeding of the IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC) (IEEE), 1–7.
Rahaman, M. M., Ahsan, M. A., and Chen, M. (2019). Data-mining techniques for image-based plant phenotypic traits identification and classification. Sci. Rep. 9:19526. doi: 10.1038/s41598-019-55609-6
Rahman, C. R., Arko, S., Ali, M. E., Khan, M. A. I., Apon, S. H., Nowrin, F., et al. (2020). Identification and recognition of rice diseases and pests using convolutional neural networks. Biosyst. Eng. 194, 112–120.
Rivas, S., and Thomas, C. M. (2005). Molecular interactions between tomato and the leaf mold pathogen Cladosporium fulvum. Annu. Rev. Phytopathol. 43, 395–436. doi: 10.1146/annurev.phyto.43.040204.140224
Rousseeuw, P. (1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65.
Saleem, M. H., Potgieter, J., and Arif, K. M. (2020). Plant disease classification: a comparative evaluation of convolutional neural networks and deep learning optimizers. Plants (Basel) 9:1319. doi: 10.3390/plants9101319
Shen, N., Li, X., Zheng, S., Zhang, L., Fu, Y., Liu, X., et al. (2019). Automated and accurate quantification of subcutaneous and visceral adipose tissue from magnetic resonance imaging based on machine learning. Magn. Reson. Imaging 64, 28–36. doi: 10.1016/j.mri.2019.04.007
Stricker, S. (1994). “The capacity of color histogram indexing,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (IEEE), 1–5.
Suarez-Paniagua, V., and Segura-Bedmar, I. (2018). Evaluation of pooling operations in convolutional architectures for drug-drug interaction extraction. BMC Bioinform. 19(Suppl. 8):209. doi: 10.1186/s12859-018-2195-1
Suzuki, N., Rivero, R. M., Shulaev, V., Blumwald, E., and Mittler, R. (2014). Abiotic and biotic stress combinations. New Phytol. 203, 32–43. doi: 10.1111/nph.12797
Syed-Ab-Rahman, S. F., Hesamian, M. H., and Prasad, M. (2021). Citrus disease detection and classification using end-to-end anchor-based deep learning model. Appl. Intell. 1–12.
Talwalkar, A., Kumar, S., and Rowley, H. (2008). “Large-scale manifold learning,” in Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition (IEEE), 1–8.
Tan, W., Zhao, C., and Wu, H. (2016). Intelligent alerting for fruit-melon lesion image based on momentum deep learning. Multimedia Tools Appl. 75, 16741–16761.
Tardieu, F., Cabrera-Bosquet, L., Pridmore, T., and Bennett, M. (2017). Plant phenomics, from sensors to knowledge. Curr. Biol. 27, R770–R783. doi: 10.1016/j.cub.2017.05.055
Tete, T. N., and Kamlu, S. (2017). “Plant disease detection using different algorithms,” in Proceedings of the Second International Conference on Research in Intelligent and Computing in Engineering (RICE), 103–106.
Too, E., Li, Y., Njuki, S., and Yingchun, L. (2019). A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 161, 272–279.
Tsaftaris, S. A., Minervini, M., and Scharr, H. (2016). Machine learning for plant phenotyping needs image processing. Trends Plant Sci. 21, 989–991. doi: 10.1016/j.tplants.2016.10.002
Tusubira, J. F., Akera, B., Nsumba, S., Nakatumba-Nabende, J., and Mwebaze, E. (2020). Scoring root necrosis in cassava using semantic segmentation. Comput. Vision Pattern Recogn. 1–10.
Van der Maaten, L., and Hinton, G. (2008). Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605.
Varshney, R. K., Bohra, A., Yu, J., Graner, A., Zhang, Q., and Sorrells, M. E. (2021). Designing future crops: genomics-assisted breeding comes of age. Trends Plant Sci 26, 631–649. doi: 10.1016/j.tplants.2021.03.010
Vergani, A. A., and Binaghi, E. (2018). “A soft davies-bouldin separation measure,” in Proceeding of the 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) (IEEE), 1–8.
Verma, S., Chug, A., and Singh, P. (2020). “Impact of hyperparameter tuning on deep learning based estimation of disease severity in grape plan,” in Recent Advances on Soft Computing and Data Mining (Cham: Springer), 161–171. doi: 10.1007/978-3-030-36056-6_16
Vishnoi, V. K., Kumar, K., and Kumar, B. (2021). Plant disease detection using computational intelligence and image processing. J. Plant Dis. Protect. 128, 19–53. doi: 10.1007/s41348-020-00368-0
Wang, G., Sun, Y., and Wang, J. (2017). Automatic image-based plant disease severity estimation using deep learning. Comput. Intell. Neurosci. 2017:2917536. doi: 10.1155/2017/2917536
Wang, Z., Wang, K., Yang, F., Pan, S., and Han, Y. (2018). Image segmentation of overlapping leaves based on Chan–Vese model and Sobel operator. Inform. Processing Agric. 5, 1–10. doi: 10.1016/j.inpa.2017.09.005
Wen, L., Li, X., and Gao, L. (2020). A transfer convolutional neural network for fault diagnosis based on ResNet-50. Neural. Comput. Appl. 32, 6111–6124. doi: 10.3934/mbe.2019165
Wenxue Tan, C. Z. H. W. (2020). Intelligent alerting for fruit-melon lesion image based on momentum deep learning. Multimed. Tools. Appl. 75, 16741–16761. doi: 10.1007/s11042-015-2940-7
Wilkinson, K., Grant, W. P., Green, L. E., Hunter, S., Jeger, M. J., Lowe, P., et al. (2011). Infectious diseases of animals and plants: an interdisciplinary approach. Philos. Trans. R Soc. Lond. B Biol. Sci. 366, 1933–1942. doi: 10.1098/rstb.2010.0415
Yamashita, R., Nishio, M., Do, R. K. G., and Togashi, K. (2018). Convolutional neural networks: an overview and application in radiology. Insights Imaging 9, 611–629. doi: 10.1007/s13244-018-0639-9
Yu, F., Chou, A., and Ko, K.-I. (2006). On the complexity of finding circumscribed rectangles and squares for a two-dimensional domain. J. Complexity 22, 803–817.
Zhang, K., Zhang, L., and Wu, Q. (2019). Identification of cherry leaf disease infected by Podosphaera pannosa via convolutional neural network. Int. J. Agric. Environ. Inform. Syst. 10, 98–110. doi: 10.4018/ijaeis.2019040105
Zhang, S., Wu, X., You, Z., and Zhang, L. (2017). Leaf image based cucumber disease recognition using sparse representation classification. Comput. Electron. Agric. 134, 135–141. doi: 10.1016/j.compag.2017.01.014
Zhang, X., Qiao, Y., Meng, F., Fan, C., and Zhang, M. J. (2018). Identification of maize leaf diseases using improved deep convolutional neural networks. IEEE Access. 6, 30370–30377. doi: 10.1109/access.2018.2844405
Keywords: plant, disease diagnosis, subtype discovery, deep learning, t-SNE, image clustering
Citation: Xia F, Xie X, Wang Z, Jin S, Yan K and Ji Z (2022) A Novel Computational Framework for Precision Diagnosis and Subtype Discovery of Plant With Lesion. Front. Plant Sci. 12:789630. doi: 10.3389/fpls.2021.789630
Received: 05 October 2021; Accepted: 03 November 2021;
Published: 03 January 2022.
Edited by:
Peng Chen, Anhui University, ChinaReviewed by:
Guangming Zhang, University of Texas Health Science Center at Houston, United StatesLisha Zhu, University of Chicago, United States
Xin Gao, Suzhou Institute of Biomedical Engineering and Technology, Chinese Academy of Sciences (CAS), China
Copyright © 2022 Xia, Xie, Wang, Jin, Yan and Ji. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhiwei Ji, Wmhpd2VpLkppQG5qYXUuZWR1LmNu
†These authors have contributed equally to this work