 Yuseok Jeong1,2†
Yuseok Jeong1,2† Song Lim Kim3†
Song Lim Kim3† Thanh Tuan Thai4,5,6
Thanh Tuan Thai4,5,6 Anh Tuan Le5,7Chaewon Lee8Hyo Jun Bae1Inchan Choi1
Anh Tuan Le5,7Chaewon Lee8Hyo Jun Bae1Inchan Choi1 Sheikh Mansoor6
Sheikh Mansoor6 Yong Suk Chung6*
Yong Suk Chung6* Kyung-Hwan Kim9*
Kyung-Hwan Kim9*- 1Department of Agricultural Engineering, National Institute of Agricultural Sciences, Rural Development Administration (RDA), Jeonju, Republic of Korea
- 2School of Computer Information and Communication Engineering, Kunsan National University, Gunsan, Republic of Korea
- 3Digital Breeding Convergence Division, National Institute of Agricultural Sciences, Rural Development Administration (RDA), Jeonju, Republic of Korea
- 4Communication Multimedia Laboratory, University of Information Technology, Ho Chi Minh, Vietnam
- 5Vietnam National University, Ho Chi Minh, Vietnam
- 6Department of Plant Resources and Environment, Jeju National University, Jeju, Republic of Korea
- 7Faculty of Biology—Biotechnology, University of Science, Ho Chi Minh, Vietnam
- 8Crop Production and Physiology Research Division, National Institute of Crop and Food Science, Rural Development Administration (RDA), Wanju-Gun, Republic of Korea
- 9Supercomputing Center, National Institute of Agricultural Sciences, Rural Development Administration (RDA), Jeonju, Jeonju, Republic of Korea
Soybeans are important due to their nutritional benefits, economic role, agricultural contributions, and various industrial applications. Effective leaf detection plays a crucial role in analyzing soybean growth within precision agriculture. This study examines the influence of different labeling methods on the efficiency of artificial intelligence (AI) based soybean leaf detection. We compare a traditional general labeling technique against a new context-aware method that utilizes information about leaf length and bottom extremities. Both approaches were employed to train a YOLOv5L deep learning model using high-resolution soybean imagery. Results show that the general labeling method excelled with soybean varieties that have wider internodes and distinctly separated leaves. In contrast, the context-aware labeling method outperformed the general approach for medium soybean varieties characterized by narrower internodes and overlapping leaves. By optimizing labeling strategies, the accuracy and efficiency of AI-based soybean growth analysis can be significantly improved, particularly in high-throughput phenotyping systems. Ultimately, the findings suggest that a thoughtful approach to labeling can enhance agricultural management practices, contributing to better crop monitoring and improved yields.
Introduction
Soybean (Glycine max) is a globally important legume, serving critical roles in the food, feed, and biofuel sectors (Mansoor et al., 2024). Soybeans hold significant importance in global agriculture and nutrition due to their diverse applications and nutritional benefits. Rich in protein, soybeans are a critical food source, particularly in vegetarian and vegan diets, providing all essential amino acids necessary for human health (Messina, 1999; Kastner et al., 2021; Nair et al., 2023). Economically, soybeans are an essential crop for numerous countries, particularly the United States, Brazil, and Argentina, which are the leading producers. Soybeans’ versatility extends beyond direct consumption; they are transformed into various products such as tofu, soy milk, and soy sauce, and are also integral to animal feed, bolstering the meat and dairy industries (Klein and Luna, 2021; Toloi et al., 2021; Hamza et al., 2024). In agriculture, soybeans significantly contribute to sustainable farming practices. As legumes, they possess the unique ability to fix nitrogen in the soil through symbiotic relationships with bacteria. This natural process reduces the need for synthetic nitrogen fertilizers, improving soil fertility and health. Consequently, incorporating soybeans into crop rotations can enhance the productivity of other crops and foster more sustainable farming systems (Liu et al., 2020; Goyal et al., 2021).
Image analysis and artificial intelligence (AI) are revolutionizing soybean agriculture by enhancing crop management, improving yield prediction, and aiding in disease detection. Advanced image processing techniques, combined with machine learning algorithms, provide precise and timely information that helps farmers make informed decisions, ultimately leading to more efficient and sustainable farming practices (Redhu et al., 2022; Mesías-Ruiz et al., 2023; Sheikh et al., 2023; Jafar et al., 2024; Kashyap et al., 2024; Mansoor et al., 2024). High-resolution satellite imagery and drones equipped with multispectral cameras are increasingly used for monitoring soybean fields. These tools capture detailed images that can be analyzed to assess plant health, identify nutrient deficiencies, and detect water stress (Mansoor and Chung, 2024; Zhang et al., 2020; Olson and Anderson, 2021; Karunathilake et al., 2023). Accurate yield prediction is crucial for planning and market strategies. AI models, trained on historical yield data and environmental factors, can predict soybean yields with high accuracy. These models incorporate various data sources, including weather patterns, soil conditions, and planting density, to forecast yields (Han et al., 2020; Morales and Villalobos, 2023; von Bloh et al., 2023).
Optimizing yield and resource management in soybean production necessitates accurate monitoring and analysis of growth stages. Image analysis techniques have gained traction in soybean research, with applications such as flower and pod detection in field videos using deep learning models (Gaso et al., 2021; Vogel et al., 2021; Shammi et al., 2024). However, studies focusing on the foliate sequence, the order and timing of leaf development, remain scarce. The foliate sequence in soybeans progresses from the coleoptile to the fifth compound leaf, with the timing of leaf emergence serving as a valuable indicator of overall crop growth.
The performance of artificial intelligence (AI) models is highly dependent on the quality and relevance of input data. Effective labeling methods, tailored to the specific AI model and its purpose, are crucial for achieving optimal performance (Araújo et al., 2021; Jagatheesaperumal et al., 2021; Liang et al., 2022). Common labeling techniques include square or polygon methods for object detection, segmentation methods for object segmentation, and image-to-text or text-to-image methods for generative models (Baraheem et al., 2023). Selecting the appropriate labeling approach is essential for ensuring desirable model performance. Accurately marking the boundaries of leaves is vital, ensuring precise spatial information for models (Guo et al., 2024). For tasks like distinguishing leaves within plant canopies, instance segmentation is essential, delineating each leaf distinctly for accurate identification (Afzaal et al., 2021; Ku et al., 2023; Kwon et al., 2024). Annotating leaf landmarks supports detailed analysis like disease detection or growth stage classification (Arya et al., 2022). Adding metadata such as leaf age or health enriches datasets, aiding model generalization (Rayhana et al., 2023). Consistent labeling across datasets and annotators is critical for effective model training (Waldamichael et al., 2022).
Motivated by the above-mentioned considerations, this study investigates the application of AI for soybean leaf detection with the aim of enhancing soybean growth analysis. To achieve this, we propose a new labeling method that incorporates the growth characteristics of soybeans. This method will be compared against a General labeling method approach to evaluate its impact on the accuracy of detecting soybean leaves relative to the plant’s growth stage.
In recent years, various machine learning approaches have been explored for plant phenotyping and leaf detection. YOLO-based models have been widely applied due to their real-time detection capabilities and high performance in identifying plant organs such as fruits and leaves in crops like tomatoes and grapes (Afzaal et al., 2021; Ku et al., 2023). However, these models rely on bounding boxes, which often struggle in scenarios involving dense foliage or overlapping leaves.
To overcome these limitations, instance segmentation models like Mask R-CNN (He et al., 2017) and transformer-based object detectors such as DETR (Carion et al., 2020) and DINO (Zhang et al., 2023) have emerged. These models can distinguish object boundaries more precisely by producing pixel-level segmentation, albeit at higher computational costs.
Recent studies on plants such as Arabidopsis thaliana, strawberries, and citrus fruits have leveraged side-view high-throughput phenotyping systems to monitor growth traits over time (Sampaio et al., 2021; Xiong et al., 2021; Kwon et al., 2024). Moreover, the labeling process itself has been recognized as a significant factor influencing model performance, particularly in occluded or complex structures (Guo et al., 2024).
Despite these advancements, few studies have systematically examined how labeling strategies affect object detection performance across varying plant architectures. Therefore, this study focuses on comparing general and context-aware labeling methods for soybean leaves, considering different internode lengths, to enhance detection accuracy in high-throughput phenotyping settings.
Materials and methods
Data collection
Soybean varieties and selection criteria
Three soybean varieties were selected based on their internode length, a key indicator of growth form. Hefeng, Dawon, and Hannam were chosen to represent long, medium, and short internode varieties, respectively. This selection strategy allows us to investigate the impact of plant architecture on leaf detection performance.
Image acquisition system and data description
Soybean image data was obtained from the Crop phenomics research center of the Rural Development Administration. The center utilizes a high-throughput phenotyping system where soybean plants are placed on a conveyor belt and transported through a filming area equipped with a high-resolution camera (4,384 x 6,576 pixels). This system captures images from three different three lateral angles (0°, 120°, and 240°) for each plant, resulting in a total of six images per plant (two per day, once in the morning and once in the afternoon). The image filenames encode detailed information including the crop’s serial number (B_06_35), shooting date (2018-09-11), shooting time (14:55:07), and image equipment details (VIS_SV0). Data collection spanned a period of 22 days, from August 21st, 2018, to September 11th, 2018. A total of 5,547 images were collected, comprising 1,851 images for each variety (short, medium, and long internode). This balanced distribution across varieties ensures a statistically robust analysis of the proposed labeling method.
Data preprocessing
Region of interest extraction
The original images (4,384 x 6,576 pixels) included significant background components unrelated to the plant structure. Therefore, we implemented a custom image preprocessing pipeline in Python, which identified the central vertical axis of each plant and extracted a rectangular region of interest (ROI) around it. The segmentation was based on simple pixel intensity thresholds and geometric heuristics that isolated the vertical green structure (stem and leaves) from the white background. The extracted ROI images were resized to 2,401 × 2,951 pixels, preserving key spatial features while reducing computational overhead during model training. Figure 1 illustrates representative examples of the extracted ROI for each soybean variety.
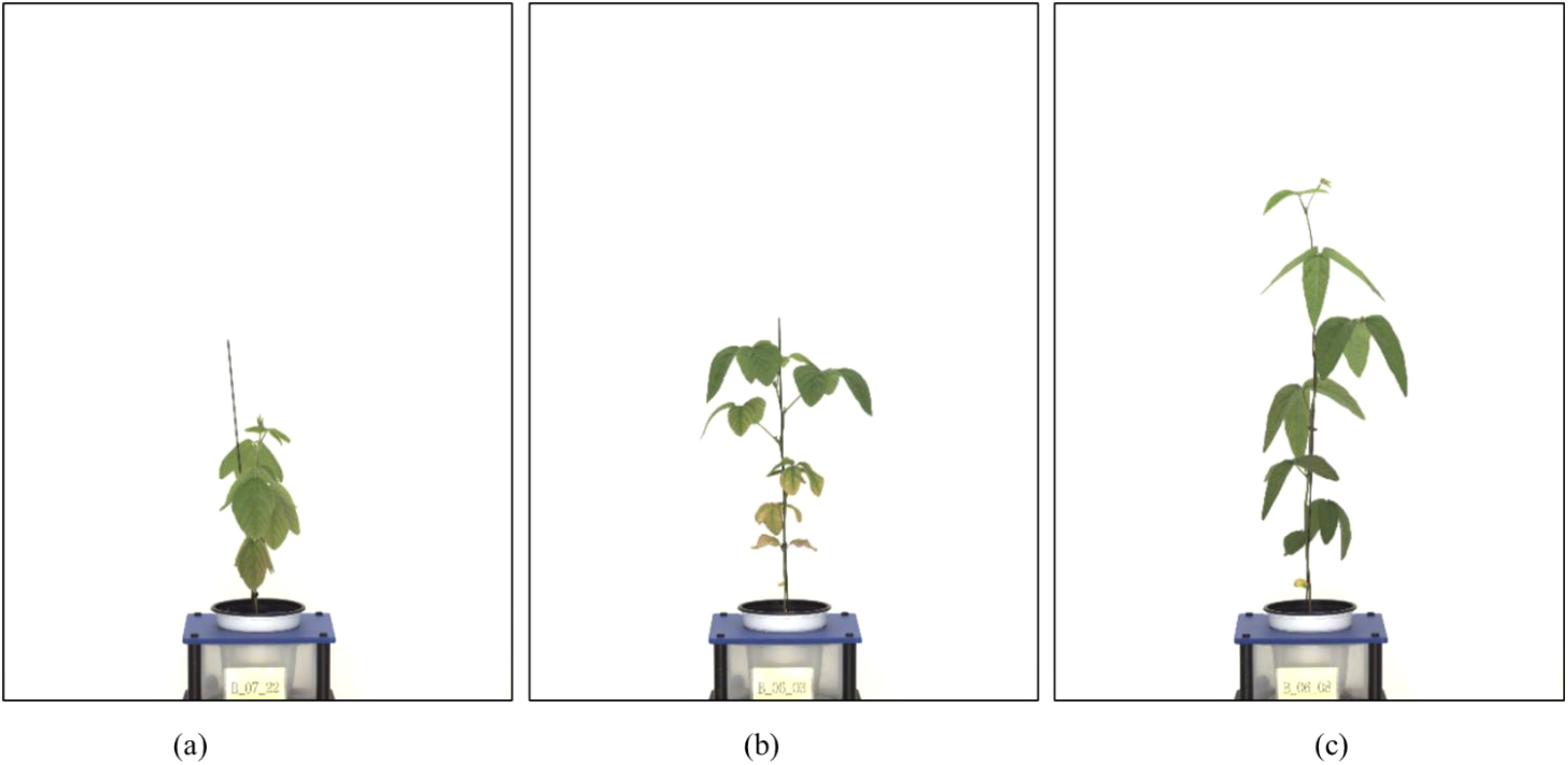
Figure 1. Examples of preprocessed soybean images (ROI extraction results). (a) Short-internode variety (Hannam), (b) Medium-internode variety (Dawon), (c) Long-internode variety (Hefeng). Each image illustrates the result of extracting a region of interest (ROI) by removing the background and focusing on the central part of the plant.
Data labeling
Data labeling was performed using the coordinate data generation program LabelImg (MIT). Two labeling strategies were compared. General Labeling Method: This approach involved drawing bounding boxes around clusters of visible leaves, treating overlapping leaves as a single object when boundaries were ambiguous. This is a commonly used strategy in many agricultural datasets, especially for high-throughput or large-scale image collections, due to its efficiency (Figure 2).
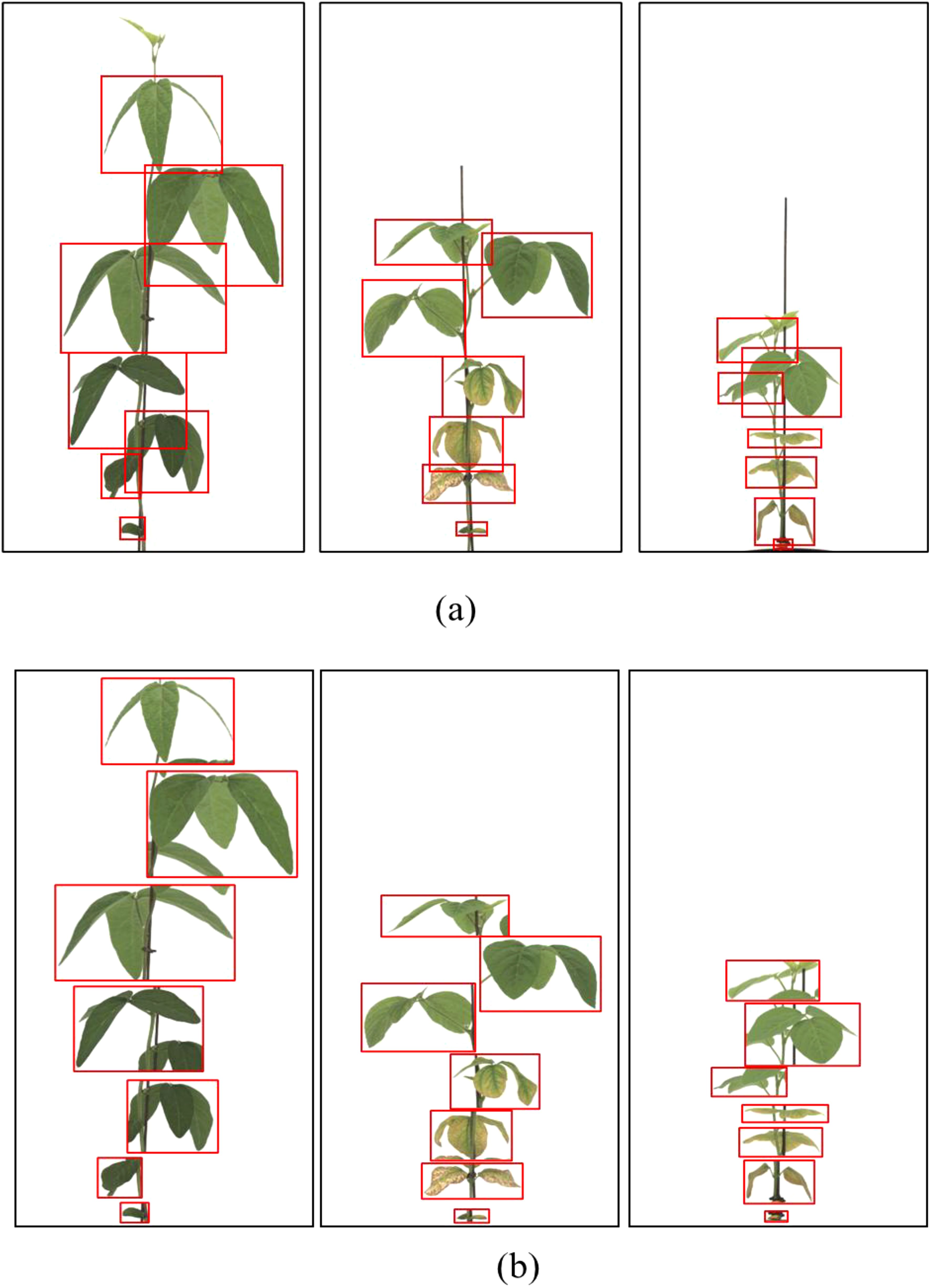
Figure 2. General labeling method (a) Bounding box annotation applied to clusters of overlapping leaves, (b) Zoomed-in view of labeled regions. Leaves are annotated collectively when boundaries are unclear, which is effective for simple plant structures but less accurate in overlapping scenarios.
Context-aware labeling method (proposed): In this method, annotators labeled each visible leaf or partial leaf individually, incorporating additional contextual cues. The vertical extent (height) of each leaf from petiole to tip. The bottom reference point (where the petiole attaches to the stem) was used to guide separation between overlapping leaves. Annotators were instructed to consider the angle of emergence, treating leaves as fully developed only if the trifoliate had horizontally unfolded. This labeling style was designed to disambiguate leaf boundaries in overlapping settings and align with known biological development stages (Szczerba et al., 2021; Vogel et al., 2021; Kaspar, 2022) (Figure 3).
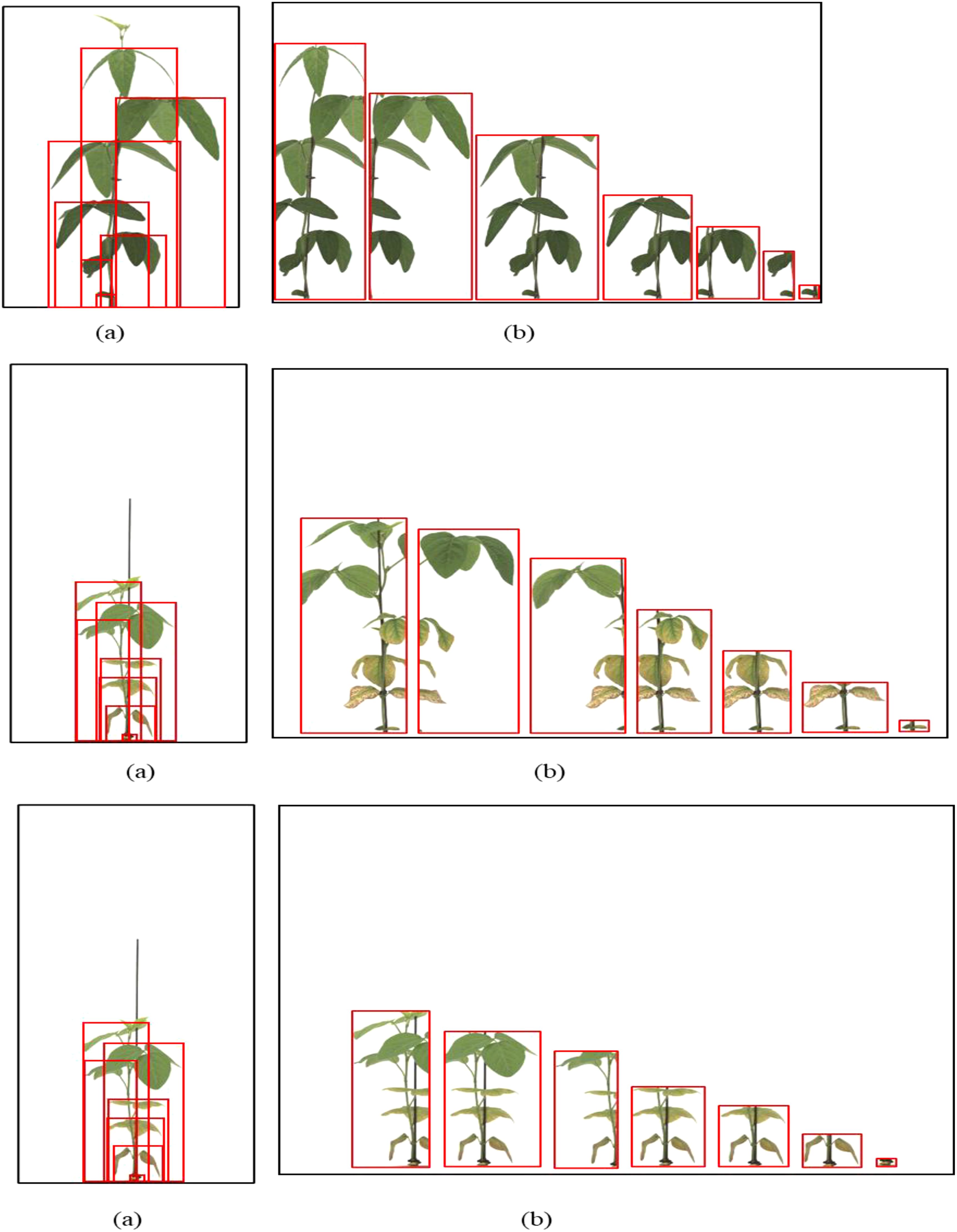
Figure 3. Proposed context-aware labeling method. (a) Individual leaf annotations incorporating lower reference points, (b) Enlarged view showing contextual labeling of overlapping leaves. Each leaf is annotated separately, considering emergence angle and attachment point, which allows for better differentiation in complex growth stages.
The labeling process required approximately 370 hours in total, emphasizing the need for future integration of semi-automated annotation systems or active learning-based labeling suggestions.
Artificial intelligence model for leaf detection
YOLOv5L was used for the model for detecting leaf objects in image data of soybean crops. YOLO divides the input image data into grid cells and detects objects when the center of an object falls within one of these cells. Each grid cell predicts bounding boxes and a confidence score for each bounding box. The confidence score indicates the model’s confidence in detection, showing both the probability that a bounding box contains an object and the accuracy of the predicted bounding box. The calculation formula for confidence is given by Equations 1, 2.
Additionally, when each grid cell contains an object, the model also computes the probability for each class. Subsequently, the process of detecting objects in the image data involves multiplying the confidence score for each bounding box by the probability for each class, and the calculation formula is as shown in Equation 3. represents the probability that the object contained in the grid cell is class i.
The most significant change in YOLOv5 is the implementation of the Backbone, previously in C language, now in PyTorch, utilizing CSP-Darknet. The Backbone functions to transform input image data into feature maps through convolutional (Conv) operations, specifically C3 operations. The Neck upsamples the feature maps to increase their size and concatenates them with other feature maps, harmonizing the extracted features from the Backbone. The Head stage performs localization and object classification. With multiple feature maps in the Neck, the model can effectively detect multiple objects from a single image data. The structure of YOLOv5L used in this paper is depicted in Figure 4.
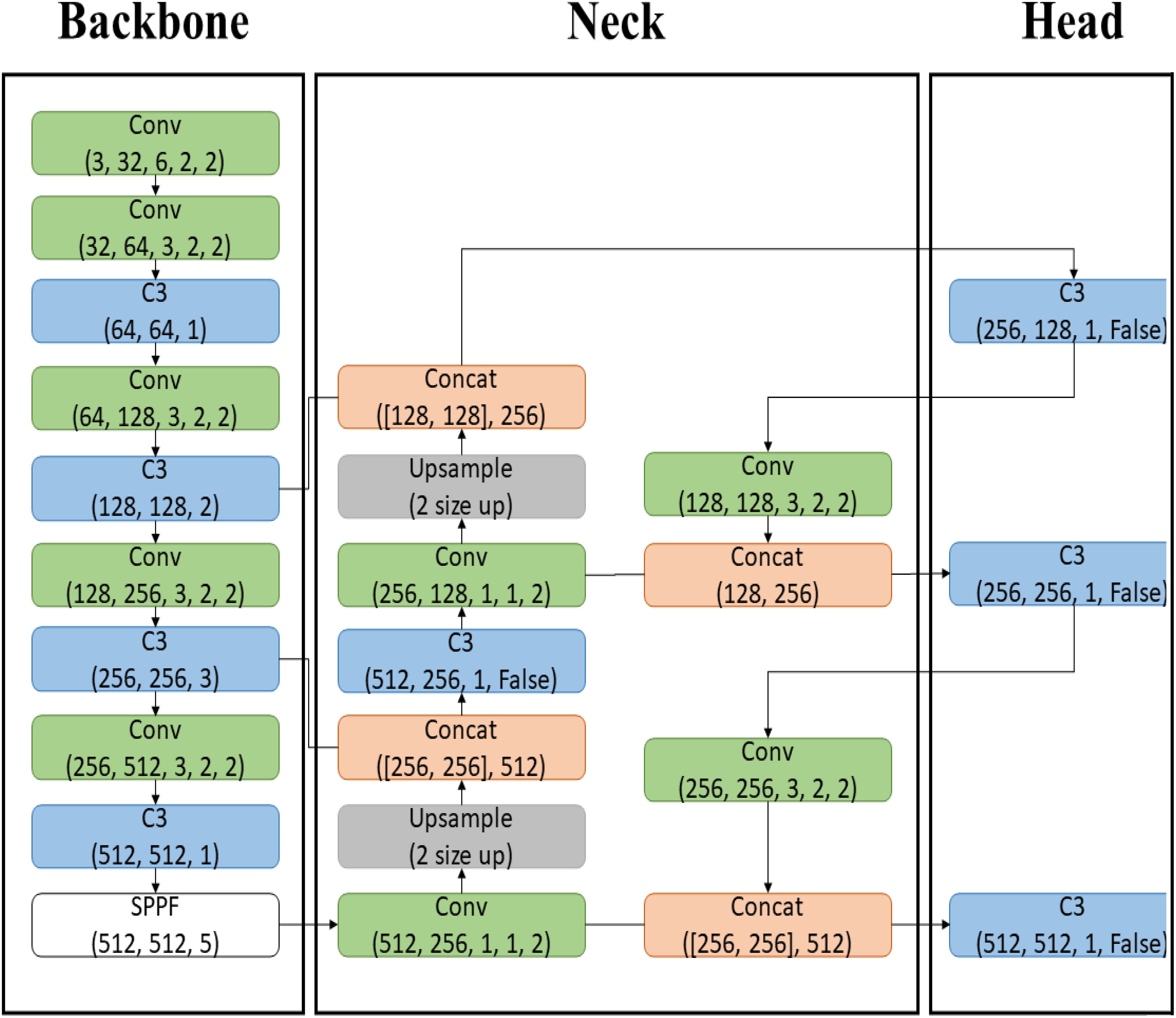
Figure 4. YOLOv5L model structure. The Backbone, implemented in PyTorch with CSP-Darknet, transforms input images into feature maps through C3 convolutional operations. The Neck upsamples and concatenates these feature maps to enhance feature extraction, while the Head stage performs object localization and classification, enabling effective multi-object detection from a single image.
Model training
To obtain an optimal artificial intelligence model, various methods, models, and parameter settings were explored. This process requires substantial time and access to the latest high-capacity equipment. However, due to modifications in simple labeling methods, the learning environment was limited for optimization through performance comparison. The learning parameters were kept consistent: Epoch 300, Batch Size 2, Image Size 1920, and Optimizer Adam. The learning environment consisted of an Intel Core i7-11700K processor, 128GB RAM, and an NVIDIA GeForce RTX 3080 TI 12GB GPU. The study used data from three soybean varieties with different internode lengths: Hannam (short internodes), Dawon (medium internodes), and Hefeng (long internodes), applying both the general labeling method and the proposed labeling method. Specifically, 1,473 images of the short variety (Hannam), 1,473 images of the medium variety (Dawon), and 1,467 images of the variety with long internodes (Hefeng) were used as learning data.
Model performance evaluation method
The performance of the object detection artificial intelligence model is evaluated using a confusion matrix that compares the predicted results with the actual values. In the confusion matrix, True Positive (TP) represents the correctly classified instances of the category of interest, while False Positive (FP) represents instances incorrectly classified as the category of interest. True Negative (TN) indicates instances correctly identified as not belonging to the category of interest, and False Negative (FN) denotes instances that were incorrectly classified as not being the category of interest. Using the values from the confusion matrix, three key measures—Accuracy, Precision, and Recall—can be calculated.
Accuracy measures the overall correctness of the model’s predictions by evaluating how well it predicts both True and False values (Equation 4). Precision measures the accuracy of the model’s positive predictions, defined as the ratio of true positive predictions to the total number of instances predicted as positive (Equation 5). Recall, also known as sensitivity, is the ratio of correctly predicted positive instances to the actual total number of positive instances, indicating how well the model identifies the category of interest (Equation 6).
Results
Performance evaluation based on labeling method and performance evaluation of variety with short internodes (Hannam)
A total of 1,473 images of the variety with short internodes (Hannam) were used for learning data. The learning environment was controlled to compare performance based on changes in the labeling method. The result graph presents data up to Epoch 300 (Figure 5).
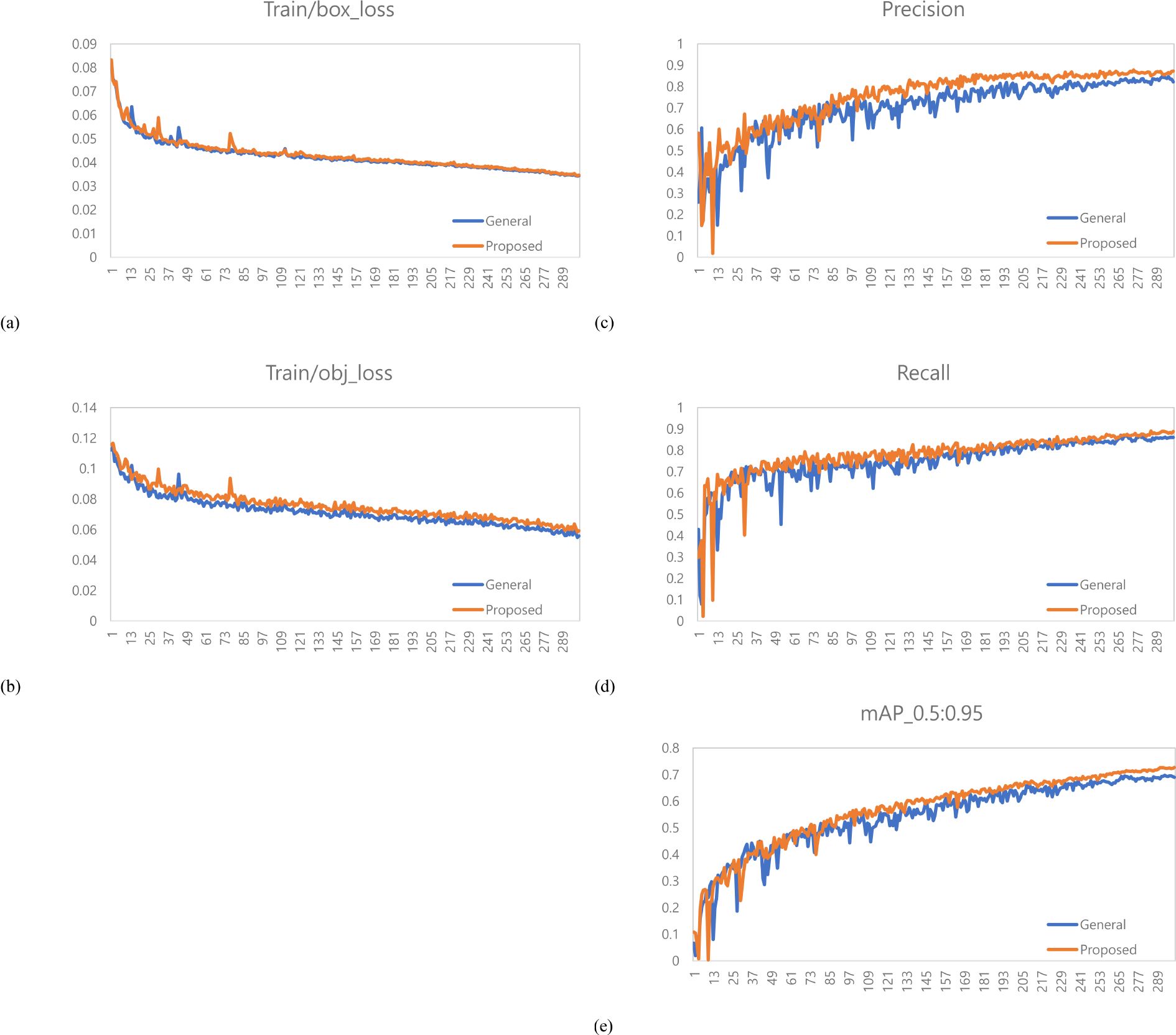
Figure 5. Training results graph for Hannam. (a) Train box loss comparison graph, (b) Train object loss comparison graph, (c) Precision comparison graph, (d) Recall comparison graph, (e) mAP_0.5:0.95 Graph.
A total of 378 images were used as validation data. Table 1 compares the performance evaluation of the general labeling method and the proposed labeling method for varieties with short internodes. The general labeling model achieved a Precision of 89.9%, Recall of 69.8%, Accuracy of 85.9%, F1 score of 78.6%, and an mAP_0.5:0.95 score of 69%. The proposed labeling model achieved a Precision of 93.3%, Recall of 74.5%, Accuracy of 88.5%, F1 score of 0.82.9%, and an mAP_0.5:0.95 score of 72.6%. For varieties with short internodes, the proposed labeling method showed improvements with increases of 3.4% in Precision, 4.7% in Recall, 2.6% in Accuracy, 4.2% in F1 score, and 3.6% in the mAP_0.5:0.95.

Table 1. Comprehensive comparison table of performance evaluation for variety with short internodes.
Both the General labeling method and Proposed labeling methods successfully detected leaf growth stages from 1st to 5th leaf during soybean growth process (Figure 6).
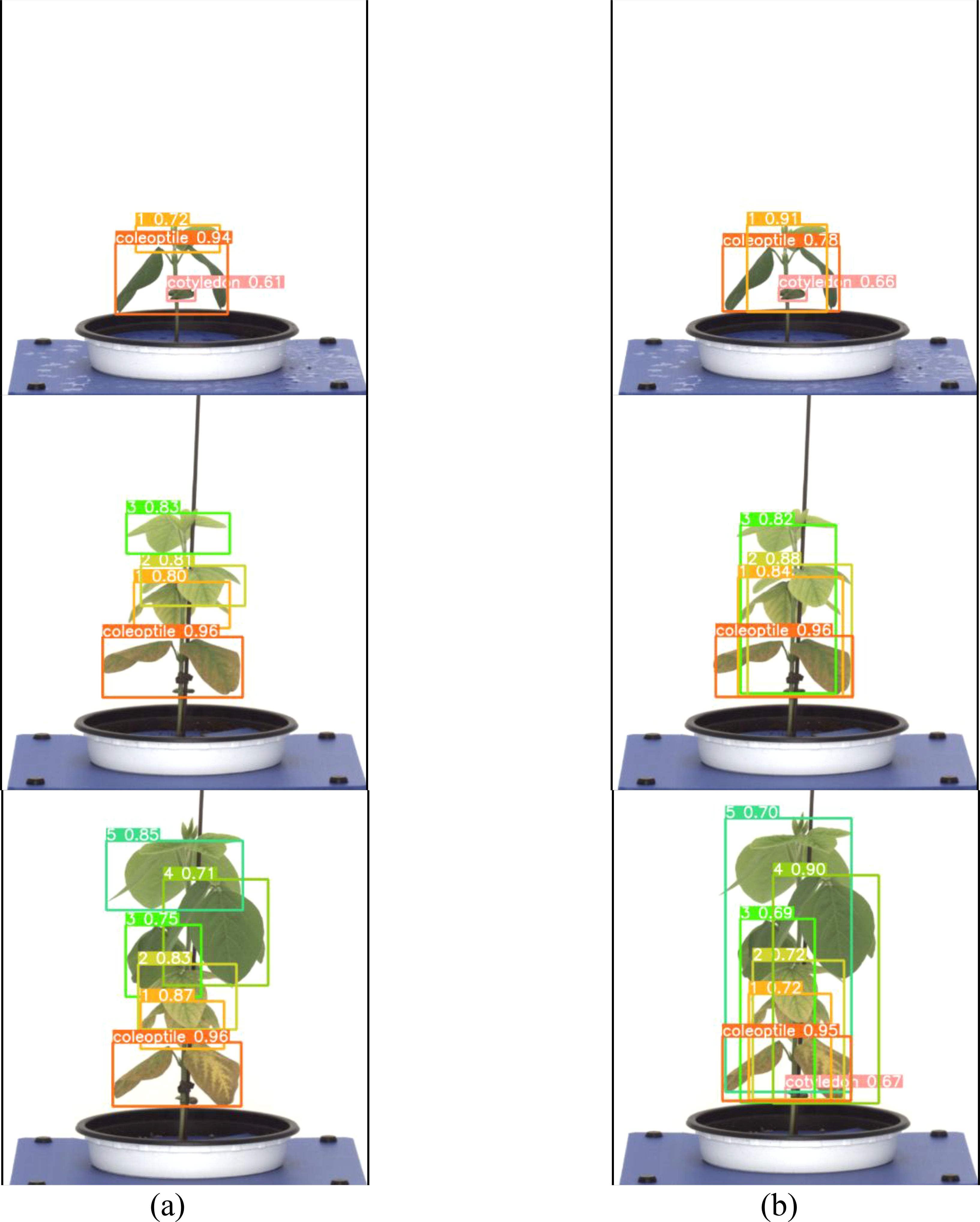
Figure 6. Results images for variety with short internodes. (a) Results with general labeling method, (b) Results with proposed labeling method.
Varieties with short internodes have short internodes, resulting in many overlapping leaves. With the general labeling method (Figure 7a), there were instances of misdetection and non-detection in overlapping leaves. However, the YOLOv5L model trained with the proposed labeling method (Figure 7b) successfully detected overlapping or obscured leaves. These overlapping features contributed to the differences in detection performance.
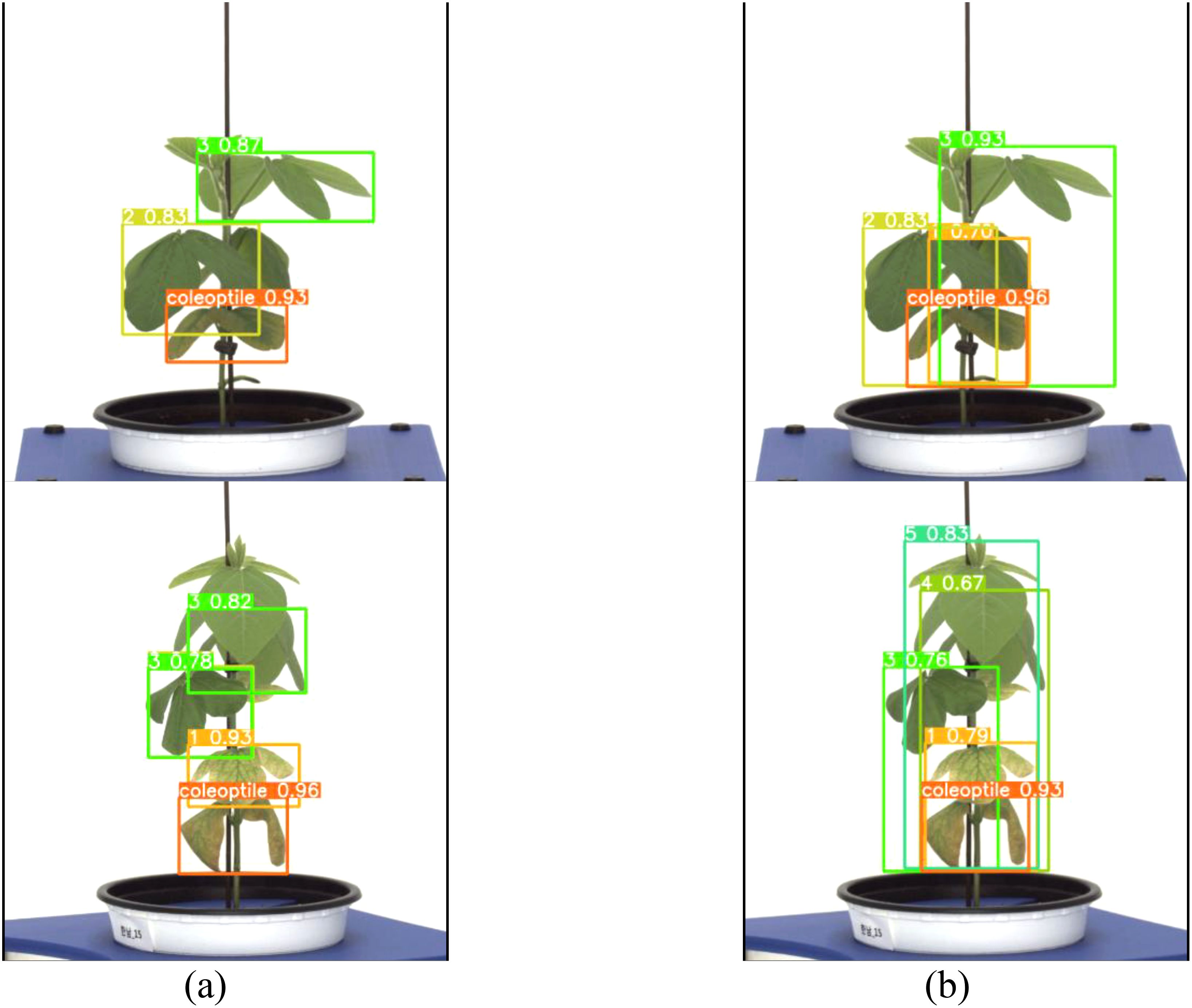
Figure 7. Comparison Images of Results for Variety with short internodes. (a) Results with General labeling Method, (b) Results with Proposed labeling method.
Performance evaluation of medium variety (Dawon)
A total of 1,473 images of varieties with intermediate growth habit (Dawon) were used as learning data. The learning environment was controlled to compare performance based on changes in the labeling method. The result graph presents data up to Epoch 300 (Figure 8).
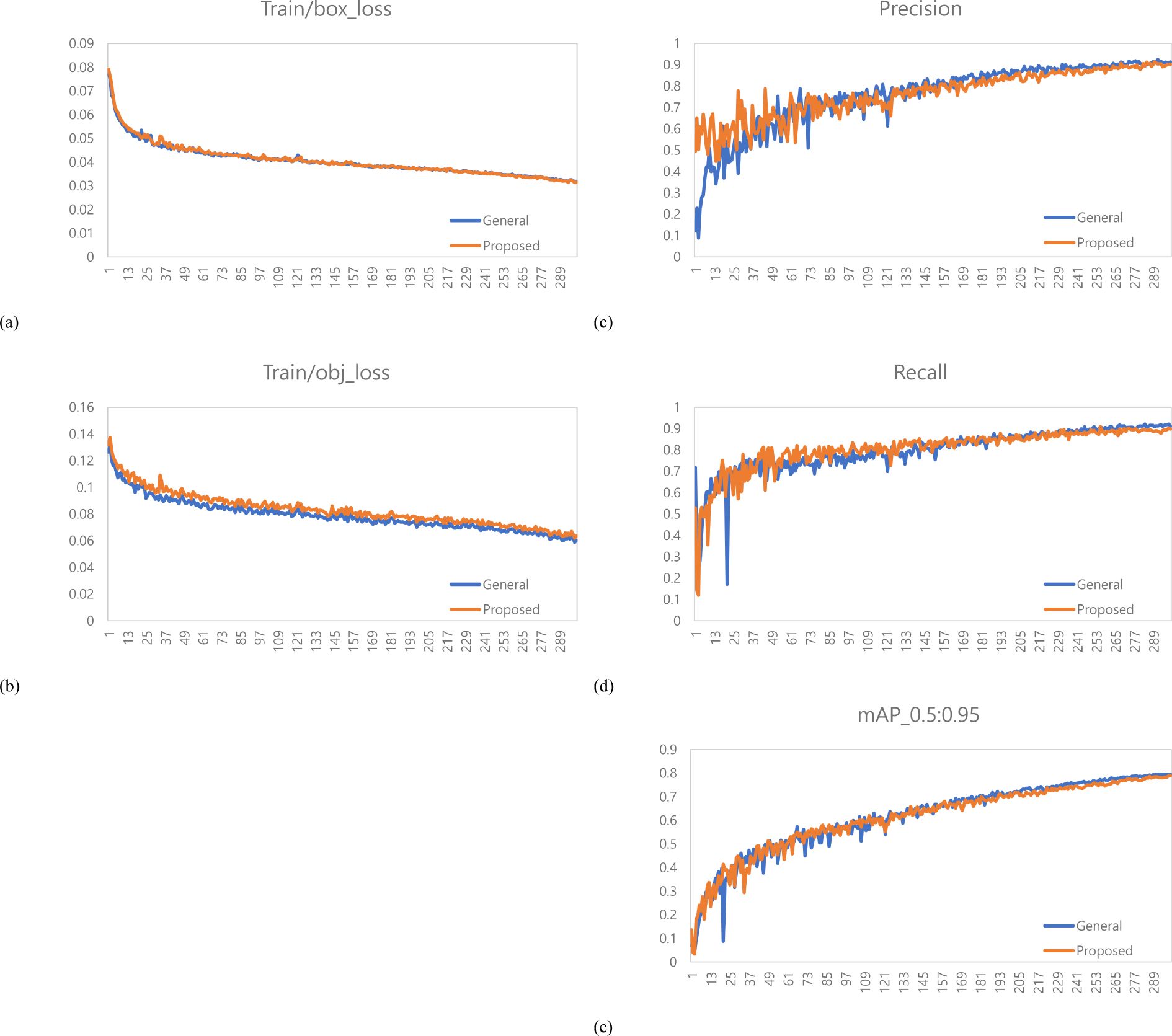
Figure 8. Training results graph for Dawon. (a) Train box loss comparison graph, (b) Train Object Loss Comparison Graph, (c) Precision Comparison Graph, (d) Recall Comparison Graph, (e) mAP_0.5:0.95 Graph.
A total of 378 images were used as validation data. Table 2 compares the performance of the general labeling method and the proposed labeling method for varieties with intermediate growth habit. The general labeling model achieved a Precision of 97.2%, Recall of 81.8%, Accuracy of 91.9%, F1 score of 88.8%, and an mAP_0.5:0.95 score of 79.5%. The proposed labeling model achieved a Precision of 96.7%, Recall of 82.9%, Accuracy of 92.2%, F1 score of 89.3%, and an mAP_0.5:0.95 score of 78.8%. For varieties with intermediate growth habit, the proposed labeling method showed improved values with a Recall increase of 1.1%, an Accuracy increase of 0.3%, and an F1 score increase of 0.5%, although Precision 0.5%, mAP_0.5:0.95 was 0.7% lower compared to the general labeling method.

Table 2. Comprehensive comparison table of performance evaluation for medium variety.
Both the general labeling method and the proposed labeling method successfully detected 1 to 5 leaves during the soybean growth process (Figure 9). Varieties with intermediate growth habit exhibit appropriate internode lengths and leaf overlap. There were no differences in the results between the general labeling method and the proposed labeling method.
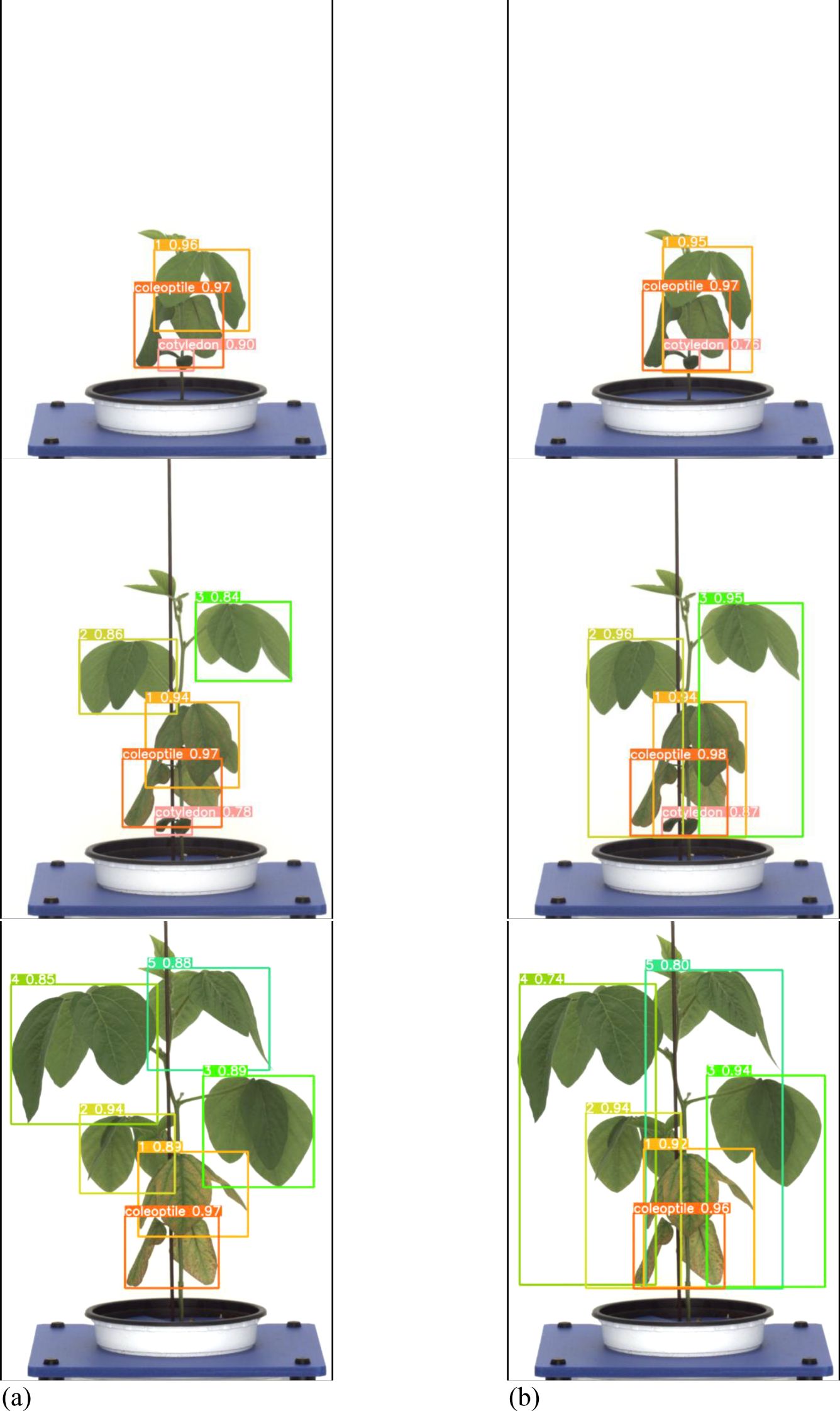
Figure 9. Results images for medium variety. (a) Results with general labeling method, (b) Results with proposed labeling method.
Performance evaluation for variety with long internodes (Hefeng)
A total of 1,467 varieties with long internodes (Hefeng) were used as learning data. The learning environment was controlled to compare performance based on changes in the labeling method. The result graph presents data up to Epoch 300 (Figure 10).
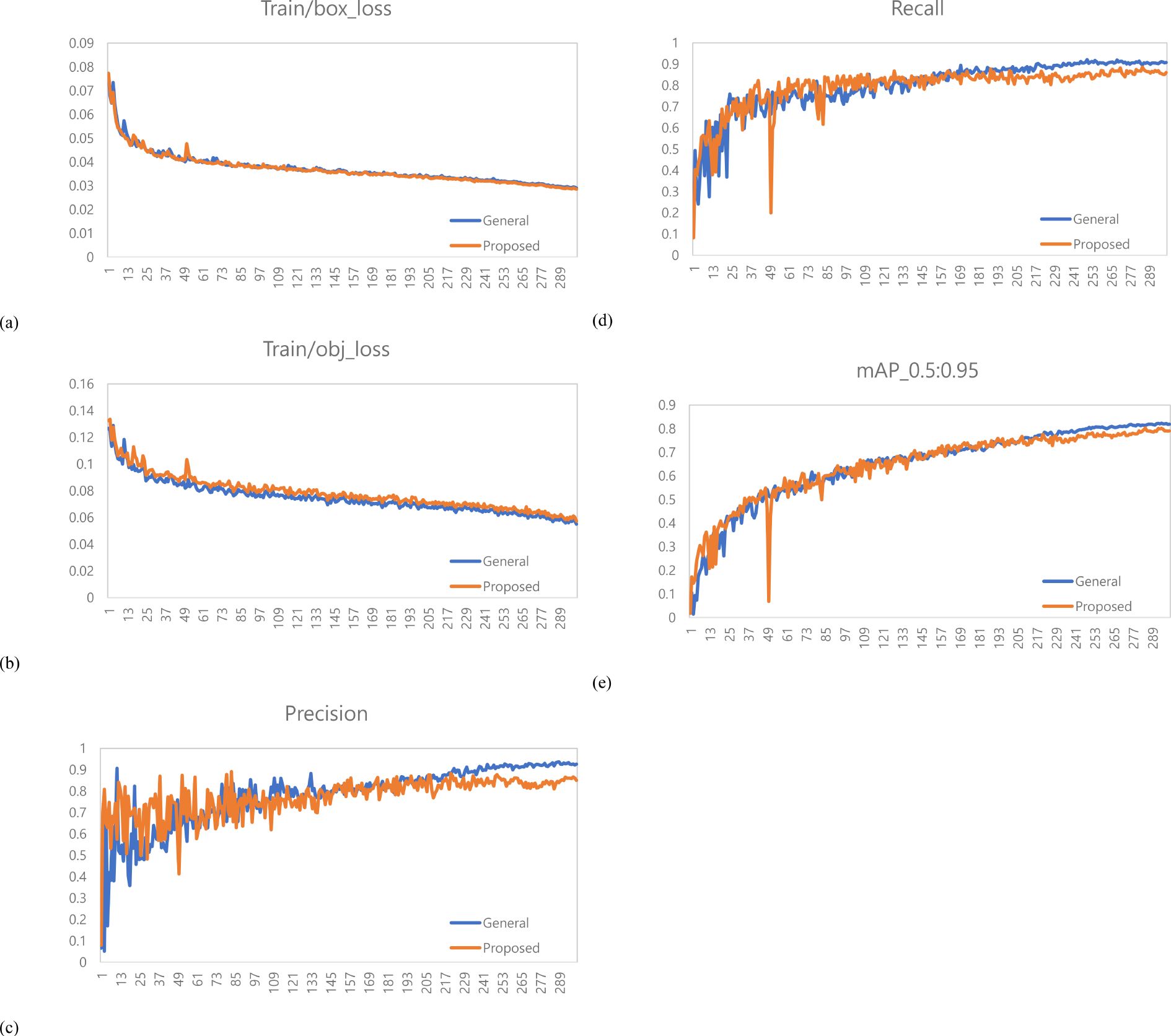
Figure 10. Training results graph for variety with long internodes. (a) Train box loss comparison graph, (b) Train object loss comparison graph, (c) Precision comparison graph, (d) Recall comparison graph, (e) mAP_0.5:0.95 Graph.
A total of 378 images were used as validation data. Table 3 presents a comparison between the general labeling method and the proposed labeling method for varieties with long internodes (Figure 11). The general labeling model achieved a precision of 97.0%, Recall of 88.4%, accuracy of 94.5%, F1 score of 92.5%, and an mAP_0.5:0.95 score of 81.8%. In contrast, the proposed labeling model achieved a precision of 92.6%, Recall of 85.8%, accuracy of 92.0%, F1 score of 89.0%, and an mAP_0.5:0.95 score of 78.9%. However, for varieties with long internodes, the general labeling method exhibited superior values with an increase in precision of 4.4%, recall of 2.6%, accuracy of 2.5%, F1 score of 3.5%, and an mAP_0.5:0.95 score of 3.1%.

Table 3. Comprehensive comparison table of performance evaluation for variety with long internodes.
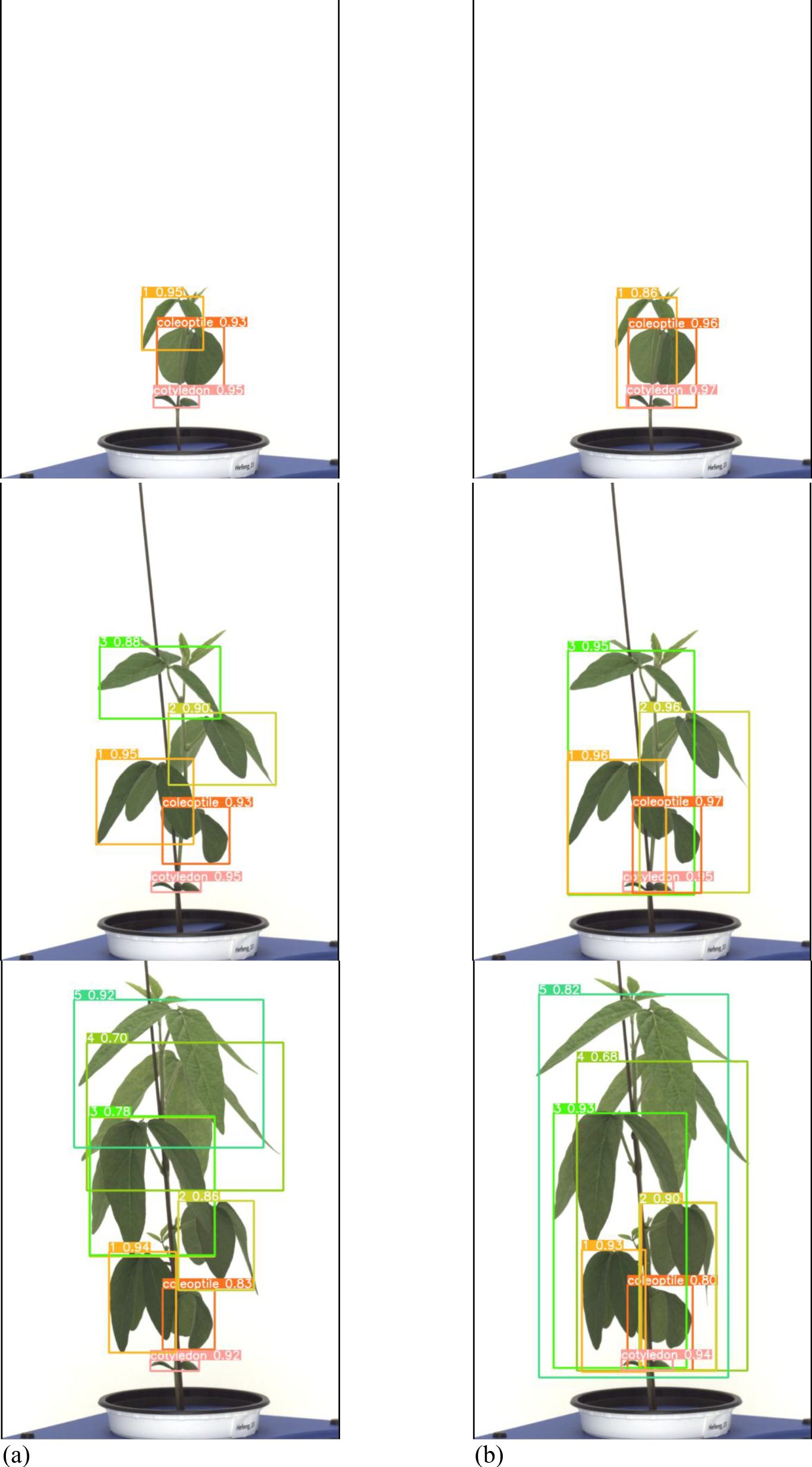
Figure 11. Results images for variety with long internodes. (a) Results with general labeling method, (b) Results with proposed labeling method.
Both the general labeling method and proposed labeling methods successfully detected leaf growth stages from 1st to 5th leaf during soybean growth process (Figure 12). In varieties with long internodes, the internodes are spacious, leading to minimal leaf overlap. With the existing method (Figure 12a), successful detection of all lobes was observed. However, in the proposed labeling method (Figure 12B), false detections were noted starting from the third lobe. This discrepancy in detection performance can be attributed to the long length of the internodes and the absence of overlapping features.
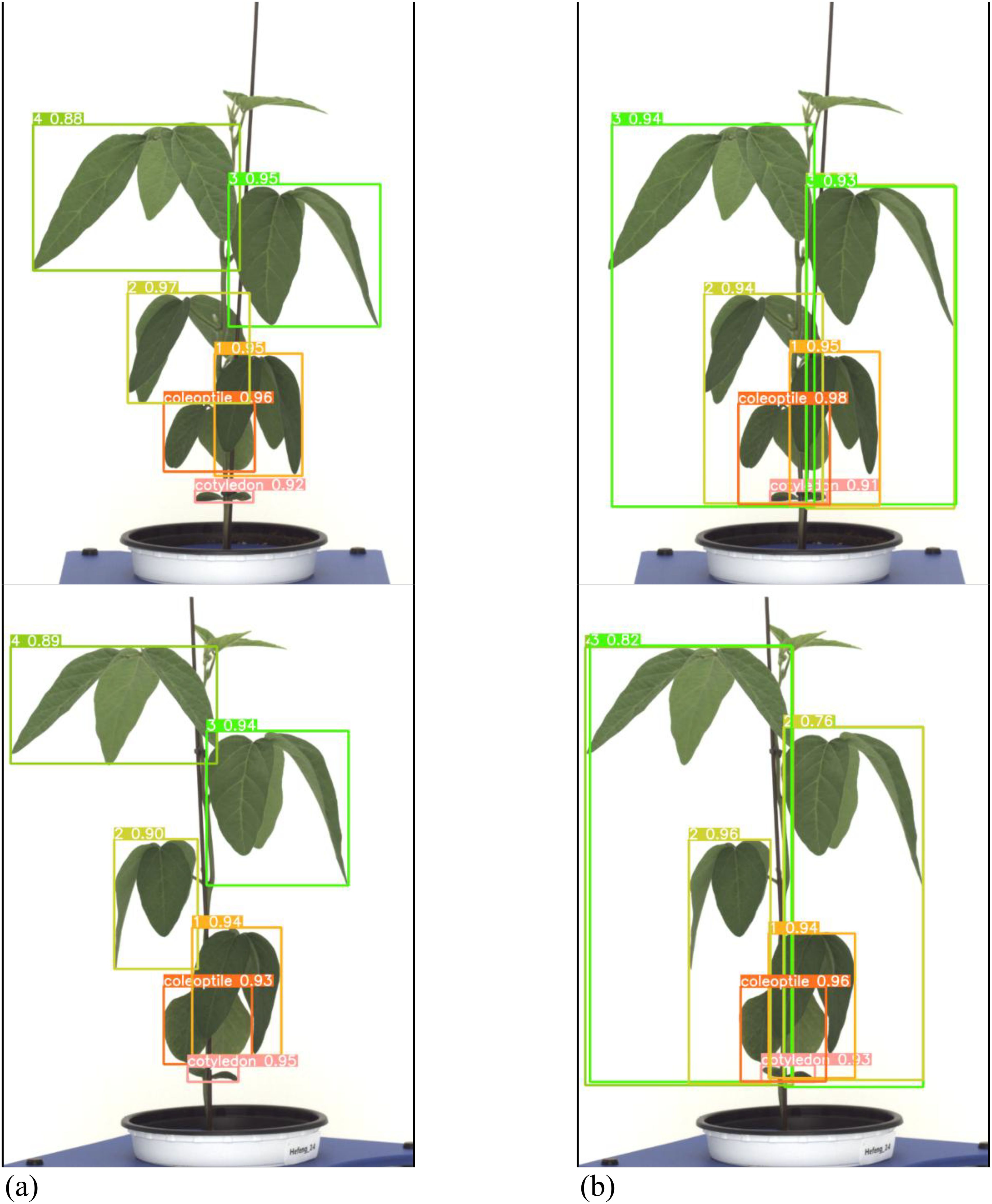
Figure 12. Comparison images of results for variety with long internodes. (a) Results with general labeling method, (b) Results with proposed labeling method.
The performance of the general labeling method improved as the leaf internodes widened, reaching its peak in varieties with long internodes. Conversely, the proposed labeling method demonstrated its highest performance in mid-nodal varieties of leaves (Figure 13).
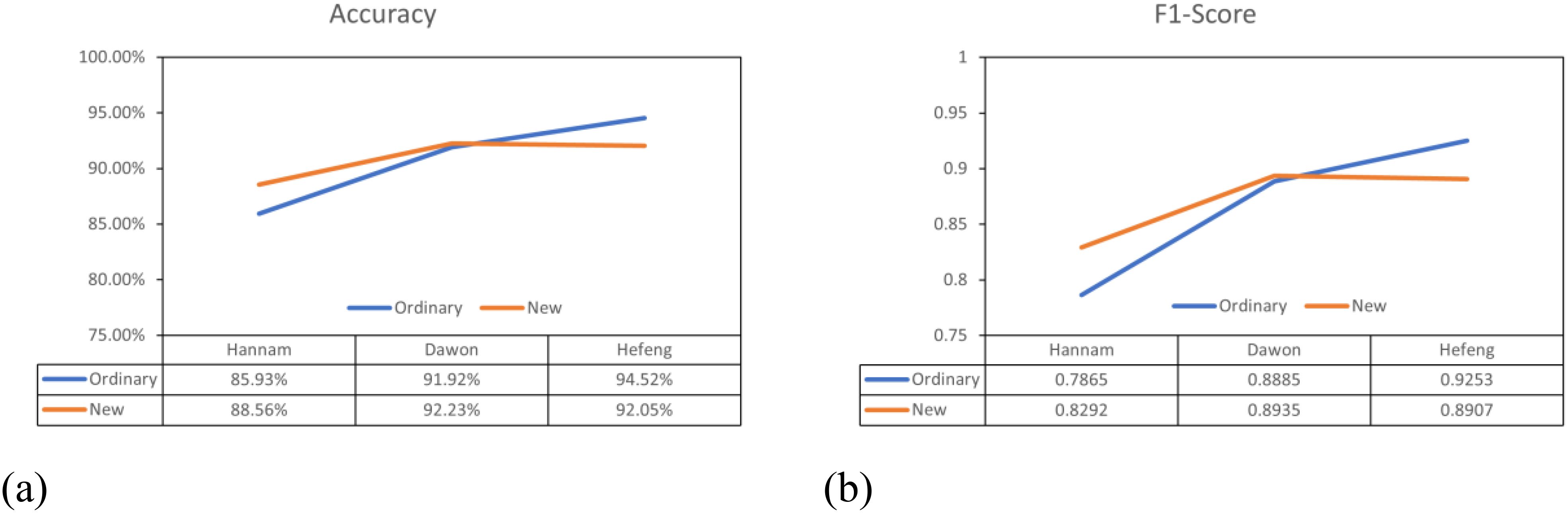
Figure 13. Overall performance comparison graphs. (a) Accuracy comparison graph, (b) F1-score comparison graph.
Discussion
Studying crop growth patterns is an important factor in predicting crop growth status and yield. Nowadays, phenotypic research in crops using cutting-edge equipment such as hyperspectral sensors, LiDAR sensors and UAVs is becoming increasingly active (Fan et al., 2021; Omia et al., 2023; Patil et al., 2024) For soybeans, research is being conducted on disease detection through leaf analysis, bioclimatic prediction based on relative maturity groups of soybeans, and growth analysis using aerial imagery (Raza et al., 2020; Zhou et al., 2020; Radočaj et al., 2021). Soybean plant architecture, the spacing between internodes significantly affects the arrangement and visibility of leaves (Wang et al., 2021; Sreekanta et al., 2024). However, there is still a lack of research that recognizes individual bean leaves growing at each stage and analyzes the growth patterns of soybeans. In soybean growth, as the internodes widen, compound leaves exist independently and distinctly. Therefore, a general labeling method proves effective. Conversely, as the internodes narrow, compound leaves tend to overlap, suggesting that a labeling method incorporating contextual overlap would be preferable to a general labeling approach. Determining the time interval between the first and second compound leaf stages offers the potential to predict subsequent leaf emergence and identify varietal growth differences. This information can further guide the selection of suitable climates and growing conditions for specific soybean varieties.
When internodes are sufficiently spaced, each compound leaf is distinct, simplifying the labeling process (Xiong et al., 2021). However, as internodes shorten and leaves overlap, more sophisticated methods that account for overlapping contexts are required to accurately label and analyze the leaves (Sampaio et al., 2021). To assess the growth of soybean crops, it is necessary to analyze the formation and deployment of soybean leaves in order to determine the trifoliate. This is because growth analysis can be conducted based on the period of trifoliate formation. When new soybean leaves are formed, the tips of the leaves point upwards and gradually unfold sideways as they develop. In the process of soybean growth analysis, the appearance of the nth trifoliate (Vn) is considered complete when the inclination of the leaves is oriented horizontally downwards. In Kaspar, 2022 (Tong et al., 2022) the vegetative stages of soybean growth are defined by the number of nodes on the main stem with fully developed leaves beginning with the unifoliolate node. The inclination and orientation of the trifoliate leaves serve as critical indicators of developmental progress and maturity (Grassini et al., 2021). Studies have also detailed that the unfolding and horizontal orientation of the leaves are significant markers in identifying the completion of specific growth stages (Herrero-Huerta et al., 2020).
We observed that the general labeling method and the proposed labeling method yielded different performance metrics for varieties with short internodes. The general labeling model achieved a precision of 89.92%, recall of 69.89%, accuracy of 85.93%, and an F1 score of 0.7865. In contrast, the proposed labeling model attained a precision of 93.36%, recall of 74.58%, accuracy of 88.56%, and an F1 score of 0.8292. For varieties with short internodes, the proposed labeling method demonstrated improvements, with increases of 3.44% in precision, 4.69% in recall, 2.93% in accuracy, and 0.0427 in the F1 score.
However, for varieties with long internodes, the general labeling method exhibited superior values with an increase in precision of 4.42%, recall of 2.63%, accuracy of 1.47%, and an F1 score of 0.0346 (Table 3). Both the general labeling method and proposed labeling methods effectively detected leaf growth stages from the 1st to the 5th leaf during the soybean growth process. In varieties with long internodes, where internodes are spacious and leaf overlap is minimal, the general labeling method (Figure 12a) successfully detected all lobes. However, the proposed labeling method (Figure 12b) encountered false detections starting from the third lobe. This discrepancy is due to the long internode and lack of overlapping features. The general labeling method’s performance improved with wider leaf internodes, peaking in varieties with long internodes, while the proposed labeling method performed best in mid-nodal varieties. Understanding the precise sequence of leaf development in soybeans enables us to more accurately predict growth stages, which is crucial for proactive planning and resource allocation (Shi et al., 2020). This precision allows for optimized irrigation and fertilizer use, ensuring that plants receive essential nutrients at critical growth phases (Shi et al., 2020; Chaffai et al., 2024).
Moreover, knowledge of the timing for specific leaf stages aids in selecting appropriate planting dates tailored to various regions and seasons. Additionally, any deviations from the expected leaf development can indicate plant stress, prompting early interventions to address nutrient deficiencies, pests, or diseases, ultimately reducing potential yield losses (Parkash and Singh, 2020; Zhou et al., 2020; Lu et al., 2021). Our investigation indicates a potential correlation between the timing of specific leaf stages and the final yield of soybeans. Utilizing data on foliate sequence enables the development of more accurate models for predicting yield, integrating crucial information about leaf development. This approach also supports the creation of robust simulations that forecast soybean growth and yield under diverse environmental conditions. By continuously monitoring foliate sequences in real-time, farmers can implement more precise and efficient agricultural practices. This allows us for tailored resource allocation, enabling targeted applications of pesticides or fungicides as needed. This approach not only minimizes waste but also reduces environmental impact, demonstrating a proactive approach to sustainable farming practices.
Conclusion
This research utilized artificial intelligence to automate the extraction, recording, and analysis of soybean growth data. To enhance the accuracy of growth analysis based on labeling methods, learning was conducted using an alternative labeling approach, considering both the general labeling method and soybean characteristics. Both the general and proposed labeling methods successfully detected compound leaves for soybean growth analysis. The general labeling method excelled in varieties with long internodes where compound leaves were distinct and independent, while the proposed labeling method outperformed in varieties with intermediate growth habit with narrow leaf internodes and extensive leaf overlap. Depending on the characteristics of the target object, superior performance can be achieved by selecting either a general labeling method for clear and independent labeling or a method that incorporates surrounding context. This approach facilitates automated analysis of soybean growth in large-scale testing systems. While the proposed labeling strategy has shown promising results in enhancing leaf detection performance, several avenues remain for future exploration. First, considering the substantial manual effort involved in generating labeled datasets, future studies could investigate semi-automated annotation approaches, such as active learning, human-in-the-loop systems, or self-supervised pretraining, to reduce annotation burden while maintaining labeling precision. Second, integrating leaf landmark detection or instance segmentation techniques would facilitate more accurate tracking of individual leaves over time, thereby enabling more precise growth stage classification and disease localization. Third, while this study was conducted under controlled indoor conditions, extending the framework to real-world field environments—with varying lighting, occlusion, and plant stress conditions—will be critical for practical deployment. Finally, the incorporation of multi-modal data (thermal, hyperspectral, or 3D LiDAR data) in combination with deep learning models may provide deeper physiological insights and improve model robustness under diverse phenotypic expressions. These directions will not only improve the generalizability of soybean phenotyping systems but also contribute to building more scalable, intelligent crop monitoring solutions for precision agriculture.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding authors.
Author contributions
YJ: Data curation, Formal analysis, Investigation, Software, Writing – original draft. SK: Data curation, Formal analysis, Investigation, Software, Validation, Writing – original draft, Writing – review & editing. TT: Data curation, Formal analysis, Investigation, Methodology, Software, Visualization, Writing – original draft, Writing – review & editing. AL: Data curation, Formal analysis, Investigation, Methodology, Software, Writing – original draft, Writing – review & editing. CL: Investigation, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. HB: Investigation, Methodology, Resources, Software, Writing – original draft, Writing – review & editing. IC: Data curation, Investigation, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. SM: Data curation, Formal analysis, Investigation, Validation, Visualization, Writing – original draft, Writing – review & editing. YC: Conceptualization, Formal analysis, Investigation, Methodology, Project administration, Resources, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. K-HK: Conceptualization, Funding acquisition, Investigation, Project administration, Resources, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was carried out with the support of the Research Program for Agricultural Sciences (PJ01486501), National Institute of Agricultural Sciences, Rural Development Administration, Republic of Korea.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Afzaal, U., Bhattarai, B., Pandeya, Y. R., and Lee, J. (2021). An instance segmentation model for strawberry diseases based on mask R-CNN. Sensors 21, 6565. doi: 10.3390/s21196565
Araújo, S. O., Peres, R. S., Barata, J., Lidon, F., and Ramalho, J. C. (2021). Characterising the agriculture 4.0 landscape—emerging trends, challenges and opportunities. Agronomy 11, 667.
Arya, S., Sandhu, K. S., Singh, J., and Kumar, S. (2022). Deep learning: As the new frontier in high-throughput plant phenotyping. Euphytica 218, 47. doi: 10.1007/s10681-022-02992-3
Baraheem, S. S., Le, T.-N., and Nguyen, T. V. (2023). Image synthesis: a review of methods, datasets, evaluation metrics, and future outlook. Artif. Intell. Rev. 56, 10813–10865. doi: 10.1007/s10462-023-10434-2
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., and Zagoruyko, S. (2020). “End-to-end object detection with transformers,” in European Conference on Computer Vision (ECCV). 213–229.
Chaffai, R., Ganesan, M., and Cherif, A. (2024). “Abiotic Stress in Plants: Challenges and Strategies for Enhancing Plant Growth and Development,” in Plant Adaptation to Abiotic Stress: From Signaling Pathways and Microbiomes to Molecular Mechanisms (Springer Nature Singapore, Singapore), 1–30.
Fan, J., Zhang, Y., Wen, W., Gu, S., Lu, X., and Guo, X. (2021). The future of Internet of Things in agriculture: Plant high-throughput phenotypic platform. J. Cleaner Production 280, 123651. doi: 10.1016/j.jclepro.2020.123651
Gaso, D. V., Wit, A. d., Berger, A. G., and Kooistra, L. (2021). Predicting within-field soybean yield variability by coupling Sentinel-2 leaf area index with a crop growth model. Agric. For. meteorology 308, 108553.
Goyal, R. K., Mattoo, A. K., and Schmidt, M. A. (2021). Rhizobial–host interactions and symbiotic nitrogen fixation in legume crops toward agriculture sustainability. Front. Microbiol. 12, 669404. doi: 10.3389/fmicb.2021.669404
Grassini, P., Menza, N. C. L., Edreira, J. I.R., Monzón, J. P., Tenorio, F. A., and Specht, J. E. (2021). “Soybean,” in Crop physiology case histories for major crops (New York, United States: Academic Press), 282–319.
Guo, X., Li, Q., Morrison-Smith, S., Anthony, L., Zare, A., and Song, Y. (2024). “Elicitating challenges and user needs associated with annotation software for plant phenotyping,” in Proceedings of the 29th International Conference on Intelligent User Interfaces. 431–443.
Hamza, M., Basit, A. W., Shehzadi, I., Tufail, U., Hassan, A., Hussain, T., et al. (2024). Global impact of soybean production: A review. Asian J. Biochemistry Genet. Mol. Biol. 16, 12–20.
Han, J., Zhang, Z., Cao, J., Luo, Y., Zhang, L., Li, Z., et al. (2020). Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 12, 236. doi: 10.3390/rs12020236
He, K., Gkioxari, G., Dollár, P., and Girshick, R. (2017). “Mask R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2961–2969.
Herrero-Huerta, M., Rodriguez-Gonzalvez, P., and Rainey, K. M. (2020). Yield prediction by machine learning from UAS-based multi-sensor data fusion in soybean. Plant Methods 16, 1–16. doi: 10.1186/s13007-020-00620-6
Jafar, A., Bibi, N., Naqvi, R. A., Sadeghi-Niaraki, A., and Jeong, D. (2024). Revolutionizing agriculture with artificial intelligence: plant disease detection methods, applications, and their limitations. Front. Plant Sci. 15, 1356260. doi: 10.3389/fpls.2024.1356260
Jagatheesaperumal, S. K., Rahouti, M., Ahmad, K., Al-Fuqaha, A., and Guizani, M. (2021). The duo of artificial intelligence and big data for industry 4.0: Applications, techniques, challenges, and future research directions. IEEE Internet Things J. 9, 12861–12885. doi: 10.1109/JIOT.2021.3139827
Karunathilake, E. M. B. M., Le, A. T., Heo, S., Chung, Y. S., and Mansoor, S. (2023). The path to smart farming: Innovations and opportunities in precision agriculture. Agriculture 13, 1593. doi: 10.3390/agriculture13081593
Kashyap, G. S., Kamani, P., Kanojia, M., Wazir, S., Malik, K., Sehgal, V. K., et al. (2024). Revolutionizing agriculture: A comprehensive review of artificial intelligence techniques in farming. doi: 10.21203/rs.3.rs-3984385/v1
Kaspar, T. C. (2022). “Growth and development of soybean root systems,” in World Soybean Research Conference III (New York, United States: CRC Press), 841–847.
Kastner, T., Chaudhary, A., Gingrich, S., Marques, A., Persson, U.M., Bidoglio, G., et al. (2021). Global agricultural trade and land system sustainability: Implications for ecosystem carbon storage, biodiversity, and human nutrition. One Earth 4, 1425–1443. doi: 10.1016/j.oneear.2021.09.006
Klein, H. S. and Luna, F. V. (2021). The growth of the soybean frontier in South America: The case of Brazil and Argentina. Rev. Hist. Economica-Journal Iberian Latin Am. Economic History 39, 427–468.
Ku, K.-B., Mansoor, S., Han, G. D., Chung, Y. S., and Tuan, T. T. (2023). Identification of new cold tolerant Zoysia grass species using high-resolution RGB and multi-spectral imaging. Sci. Rep. 13, 13209. doi: 10.1038/s41598-023-40128-2
Kwon, S.-H., Ku, K. B., Le, A. T., Han, G. D., Park, Y., Kim, J., et al. (2024). Enhancing citrus fruit yield investigations through flight height optimization with UAV imaging. Sci. Rep. 14, 322. doi: 10.1038/s41598-023-50921-8
Liang, W., Tadesse, G. A., Ho, D., Fei-Fei, L., Zaharia, M., Zhang, C., et al. (2022). Advances, challenges and opportunities in creating data for trustworthy AI. Nat. Mach. Intell. 4, 669–677. doi: 10.1038/s42256-022-00516-1
Liu, J., Yu, X., Qin, Q., Dinkins, R. D., and Zhu, H. (2020). The impacts of domestication and breeding on nitrogen fixation symbiosis in legumes. Front. Genet. 11, 568711. doi: 10.3389/fgene.2020.00973
Lu, J., Tan, L., and Jiang, H. (2021). Review on convolutional neural network (CNN) applied to plant leaf disease classification. Agriculture 11, 707. doi: 10.3390/agriculture11080707
Mansoor, S. and Chung, Y. S. (2024). Functional phenotyping: understanding the dynamic response of plants to drought stress. Curr. Plant Biol., 100331.
Mansoor, S., Karunathilake, E. M. B. M., Tuan, T. T., and Chung, Y. S. (2024). Genomics, Phenomics, and machine learning in transforming plant research: advancements and challenges. Hortic. Plant J.
Mansoor, S., Tripathi, P., Ghimire, A., Hamid, S., Abd El-moniem, D., Chung, Y. S., et al. (2024). Comparative transcriptomic analysis of the nodulation-competent zone and inference of transcription regulatory network in silicon applied Glycine max [L.]-Merr. Roots. Plant Cell Rep. 43(7), 169. doi: 10.1007/s00299-024-03250-7
Mesías-Ruiz, G. A., Pérez-Ortiz, M., Dorado, J., Castro, A. I. D., and Peña, J. M. (2023). Boosting precision crop protection towards agriculture 5.0 via machine learning and emerging technologies: A contextual review. Front. Plant Sci. 14, 1143326.
Messina, M. J. (1999). Legumes and soybeans: overview of their nutritional profiles and health effects. Am. J. Clin. Nutr. 70, 439S–450S. doi: 10.1093/ajcn/70.3.439s
Morales, A. and Villalobos, F. J. (2023). Using machine learning for crop yield prediction in the past or the future. Front. Plant Sci. 14, 1128388. doi: 10.3389/fpls.2023.1128388
Nair, R. M., Boddepalli, V. N., Yan, M.-R., Kumar, V., Gill, B., Pan, R. S., et al. (2023). Global status of vegetable soybean. Plants 12, 609. doi: 10.3390/plants12030609
Olson, D. and Anderson, J. (2021). Review on unmanned aerial vehicles, remote sensors, imagery processing, and their applications in agriculture. Agron. J. 113, 971–992. doi: 10.1002/agj2.v113.2
Omia, E., Bae, H., Park, E., Kim, M. S., Baek, I., Kabenge, I., et al. (2023). Remote sensing in field crop monitoring: A comprehensive review of sensor systems, data analyses and recent advances. Remote Sens. 15, 354. doi: 10.3390/rs15020354
Parkash, V. and Singh, S. (2020). A review on potential plant-based water stress indicators for vegetable crops. Sustainability 12, 3945. doi: 10.3390/su12103945
Patil, S. M., Choudhary, S., Kholova, J., Chandramouli, M., and Jagarlapudi, A. (2024). “Applications of UAVs: Image-Based Plant Phenotyping,” in Digital Agriculture: A Solution for Sustainable Food and Nutritional Security (Springer International Publishing, Cham), 341–367.
Radočaj, D., Jurišić, M., Gašparović, M., Plaščak, I., and Antonić, O. (2021). Cropland suitability assessment using satellite-based biophysical vegetation properties and machine learning. Agronomy 11, 1620. doi: 10.3390/agronomy11081620
Rayhana, R., Ma, Z., Liu, Z., Xiao, G., Ruan, Y., and Sangha, J. S. (2023). A review on plant disease detection using hyperspectral imaging. IEEE Trans. AgriFood Electron. doi: 10.1109/TAFE.2023.3329849
Raza, M. M., Harding, C., Liebman, M., and Leandro, L. F. (2020). Exploring the potential of high-resolution satellite imagery for the detection of soybean sudden death syndrome. Remote Sens. 12, 1213. doi: 10.3390/rs12071213
Redhu, N. S., Thakur, Z., Yashveer, S., and Mor, P. (2022). “Artificial intelligence: a way forward for agricultural sciences,” in Bioinformatics in Agriculture (Florida, United States: Academic Press), 641–668.
Sampaio, G. S., Silva, L. A., and Marengoni, M. (2021). 3D reconstruction of non-rigid plants and sensor data fusion for agriculture phenotyping. Sensors 21, 4115. doi: 10.3390/s21124115
Shammi, S. A., Huang, Y., Feng, G., Tewolde, H., Zhang, X., Jenkins, J., et al. (2024). Application of UAV multispectral imaging to monitor soybean growth with yield prediction through machine learning. Agronomy 14, 672. doi: 10.3390/agronomy14040672
Sheikh, M., Farooq, I. Q. R. A., Ambreen, H., Pravin, K. A., Manzoor, I. K. R. A., and Chung, Y. S. (2023). Integrating artificial intelligence and high-throughput phenotyping for crop improvement. J. Integr. Agric.
Shi, Z., Huang, H., Wu, Y., Chiu, Y.-H., and Qin, S. (2020). Climate change impacts on agricultural production and crop disaster area in China. Int. J. Environ. Res. Public Health 17, 4792. doi: 10.3390/ijerph17134792
Sreekanta, S., Haaning, A., Dobbels, A., O’Neill, R., Hofstad, A., Virdi, K., et al. (2024). Variation in shoot architecture traits and their relationship to canopy coverage and light interception in soybean (Glycine max). BMC Plant Biol. 24, 194. doi: 10.1186/s12870-024-04859-2
Szczerba, A., Płażek, A., Pastuszak, J., Kopeć, P., Hornyák, M., and Dubert, F. (2021). Effect of low temperature on germination, growth, and seed yield of four soybean (Glycine max L.) cultivars. Agronomy 11, 800. doi: 10.3390/agronomy11040800
Toloi, M. N. V., Bonilla, S. H., Toloi, R. C., Silva, H. R. O., and Nääs, I. d. A. (2021). Development indicators and soybean production in Brazil. Agriculture 11, 1164. doi: 10.3390/agriculture11111164
Tong, Y.-S., Lee, T.-H., and Yen, K.-S. (2022). Deep learning for image-based plant growth monitoring: A review. Int. J. Eng. Technol. Innovation 12. doi: 10.46604/ijeti.2022.8865
Vogel, J. T., Liu, W., Olhoft, P., Crafts-Brandner, S. J., Pennycooke, J. C., and Christiansen, N. (2021). Soybean yield formation physiology–a foundation for precision breeding based improvement. Front. Plant Sci. 12, 719706. doi: 10.3389/fpls.2021.719706
von Bloh, M., Júnior, R. S. N., Wangerpohl, X., Saltık, A. O., Haller, V., Kaiser, L., et al. (2023). Machine learning for soybean yield forecasting in Brazil. Agric. For. Meteorology 341, 109670.
Waldamichael, F. G., Debelee, T. G., Schwenker, F., Ayano, Y. M., and Kebede, S. R. (2022). Machine learning in cereal crops disease detection: a review. Algorithms 15, 75. doi: 10.3390/a15030075
Wang, C., Du, Y. M., Zhang, J. X., Ren, J. T., He, P., Wei, T., et al. (2021). Effects of exposure of the leaf abaxial surface to direct solar radiation on the leaf anatomical traits and photosynthesis of soybean (Glycine max L.) in dryland farming systems. Photosynthetica 59. doi: 10.32615/ps.2021.038
Xiong, J., Yu, D., Liu, S., Shu, L., Wang, X., and Liu, Z. (2021). A review of plant phenotypic image recognition technology based on deep learning. Electronics 10, 81. doi: 10.3390/electronics10010081
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., et al. (2023). “DINO: DETR with improved deNoising anchor boxes for end-to-end object detection,” in International Conference on Learning Representations(ICLR).
Zhang, C., Marzougui, A., and Sankaran, S. (2020). High-resolution satellite imagery applications in crop phenotyping: An overview. Comput. Electron. Agric. 175, 105584. doi: 10.1016/j.compag.2020.105584
Zhou, H., Zhou, G., He, Q., Zhou, L., Ji, Y., and Zhou, M. (2020). Environmental explanation of maize specific leaf area under varying water stress regimes. Environ. Exp. Bot. 171, 103932. doi: 10.1016/j.envexpbot.2019.103932
Keywords: deep learning, image analysis, object detection, phenotyping, crop management
Citation: Jeong Y, Kim SL, Thai TT, Le AT, Lee C, Bae HJ, Choi I, Mansoor S, Chung YS and Kim K-H (2025) Comparative analysis of adaptive and general labeling methods for soybean leaf detection. Front. Plant Sci. 16:1582303. doi: 10.3389/fpls.2025.1582303
Received: 24 February 2025; Accepted: 15 May 2025;
Published: 16 June 2025.
Edited by:
Huajian Liu, University of Adelaide, AustraliaReviewed by:
Danish Gul, Sher-e-Kashmir University of Agricultural Sciences and Technology of Kashmir, IndiaMarko Mišić, University of Belgrade, Serbia
Copyright © 2025 Jeong, Kim, Thai, Le, Lee, Bae, Choi, Mansoor, Chung and Kim. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Kyung-Hwan Kim, YmlvcGlha2ltQGtvcmVhLmty; Yong Suk Chung, eXNjaHVuZ0BqZWp1bnUuYWMua3I=
†These authors have contributed equally to this work